

136 4.2 IT Systems Recovery
solution, mobile sites should be designed in advance with the vendor, and
an SLA should be signed between the two parties. This is necessary because
the time required to configure the mobile site can be extensive, and without
prior coordination, the time to deliver the mobile site may exceed the sys-
tem’s allowable outage time.
4.1.1.5 Cold Site
This strategy involves the setting up of an emergency site once the crisis has
occurred. The company has a standby arrangement with a vendor to deliver
the minimum configuration urgently. This option usually enables the orga-
nization becoming operational within two to three days.
4.2 IT Systems Recovery
Recovery strategies provide a means of restoring IT operations quickly and
effectively following a service disruption. The strategies should address dis-
ruption impacts and allowable outage times identified in the BIA. Several
alternatives should be considered when developing the strategy, including
cost, allowable outage time, security, and integration with larger, organiza-
tion-level contingency plans. The selected recovery strategy should address
the potential impacts identified in the BIA and should be integrated into
the system architecture during the design and implementation phases of the
system life cycle. The strategy should include a combination of methods
that complement one another to provide recovery capability over the full
spectrum of incidents. A wide variety of recovery approaches may be con-
sidered; the appropriate choice depends on the incident, the type of system,
and its operational requirements.
4.2.1 High Availability/Fault Tolerance
There are several approaches to building fault-tolerant and high-availability
systems; however, there are certain characteristics common to any system
built with less than perfect components (which, of course, do not exist).
Namely, in order to manage a failure, there must be an alternative compo-
nent that continues to function in the presence of the failure. Thus, redun-
dancy is a fundamental prerequisite for a system that either recovers from or
masks failures. Redundancy can be provided in two very different ways,
called passive redundancy and active redundancy, each with very different
consequences. Failures in systems can be managed in two different ways,
each providing a different level of availability and very different restoration

4.2 IT Systems Recovery 137
Chapter 4
processes. The first is to recover from failures, as in passively redundant sys-
tems, and the second is to mask failures so they are invisible to the user, as
in actively redundant systems.
Availability is the assurance of sufficient bandwidth and timely access to
resources. High availability means the availability of a system has been
secured to offer very reliable assurance that the system will be online, active,
and able to respond to requests in a timely manner, and that there will be
sufficient bandwidth to accomplish requested tasks in the time required.
High availability is a form of fault tolerance, or, rather, a benefit of pro-
viding reliable fault tolerance. Fault tolerance is the ability of a network,
system, or computer to withstand a certain level of failures, faults, or prob-
lems and continue to provide reliable service. Fault tolerance is also a means
of avoiding single points of failure. A single point of failure is any system,
software or device that is mission critical to the entire environment: if that
one element fails, then the entire environment fails. Your environment
should be designed with redundancy so that there are no single points of
failures. A redundant design such as this is considered fault tolerant.
4.2.2 Backup and Recovery Processes
One of the most important aspects of planning for the majority of organi-
zations is in choosing an appropriate strategy for the backup and recovery
of the company’s IT based systems. In this section of the plan, key business
processes are matched to their supporting IT system, and an appropriate
speed of recovery strategy is chosen. This may require some research to
determine relevant costs of each strategy. It may be necessary to prepare a
Request for Proposal (RFP) for vendors to assist you in implementing the
preferred strategic approach. Consideration should also be given to the
impact severe damage to both premises and communication systems would
have, as it could also have a significant impact on the organization’s IT ser-
vices and systems.
4.2.3 Storage Solutions
It is considered good business practice to store backed-up data offsite.
Commercial data storage facilities are specially designed to archive media
and protect data from threatening elements. If using offsite storage, data is
backed up at the organization’s facility and then labeled, packed, and trans-
ported to the storage facility. If the data is required for recovery or testing
purposes, the organization contacts the storage facility requesting specific
data to be transported to the organization or to an alternate facility. Com-
138 4.2 IT Systems Recovery
mercial storage facilities often offer media transportation and response and
recovery services. Conventional backup is the method used for backing up
your organization’s various servers and shipping the tapes off to a safe offsite
or alternate location.
RAID (redundant arrays of inexpensive disks) is an extremely effective
solution for implementing redundancy on your systems. In 1987, David A.
Patterson et al. of the University of California at Berkeley published a paper
[1] that described various types of disk arrays, referred to by the acronym
RAID. The basic idea was to combine multiple small, inexpensive disk
drives into an array of drives to yield performance exceeding that of a single
large expensive drive, or SLED. Additionally, this array of drives appears to
the computer as a single logical storage unit or drive. Disk arrays can be
made fault tolerant by redundantly storing information in various ways.
The Berkeley paper defined five types of array architectures, RAID-1
through RAID-5, each providing disk fault tolerance and each offering dif-
ferent trade-offs in features and performance. In recent years, the original
five levels of RAID have been extended to include RAID-6, RAID-10,
RAID-50, and RAID-0+1. RAID solutions of an appropriate level can be
chosen based on an organization’s specific needs. In addition to these nine
redundant array architectures, it has become popular to refer to a non-
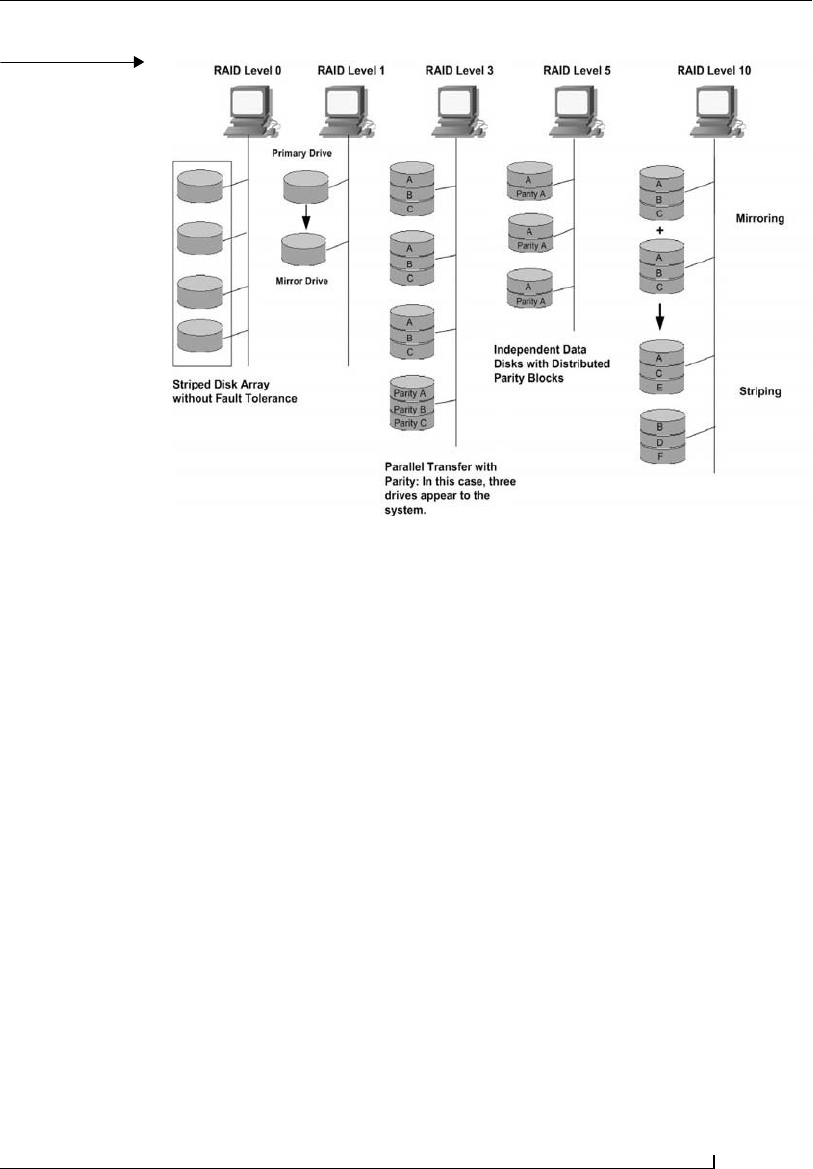
redundant array of disk drives as a RAID-0 array. The illustration in Figure
4.2 shows several of the more common RAID configurations used by busi-
nesses today.
The strategy for RAID employs two or more drives in combination for
fault tolerance and performance. RAID drives are used frequently on serv-
ers, but are rarely necessary for personal computers. Data striping is a con-
cept that is fundamental to RAID. It is a method of concatenating multiple
drives into one logical storage unit. Striping involves partitioning each
drive’s storage space into stripes that may be as small as one sector (512
bytes) or as large as several megabytes. These stripes are then interleaved in a
round-robin fashion so that the combined space is composed alternately of
stripes from each drive. In effect, the storage space of the drives is shuffled
like a deck of cards.
The original RAID was described as having five levels, with each succes-
sive level offering increased protection over the previous level. RAID-0 is
not redundant, so it does not fit the RAID model per se. In RAID-0, the
data is split across multiple drives, resulting in higher data throughput.
Since no redundant information is stored, performance is very good, but
the failure of any disk in the array results in data loss.
4.2 IT Systems Recovery 139
Chapter 4
RAID-1 provides redundancy by writing data to two or more drives.
The performance of a RAID-1 array tends to be faster on read operations
and slower on write operations compared to a single drive, but if either
drive fails, no data is lost. This is a good entry-level solution to provide for a
redundant system, since only two drives are required. Since one drive is
used to store a duplicate of the data, the cost per megabyte is high. This
process is commonly referred to as mirroring. Mirroring is a synchronous
process whereby the changes are applied on the replicated server in synchro-
nization with the primary server. This is the best method to use when the
requirement is for zero data loss. A drawback of mirroring is that it can cause
performance degradation and requires adequate bandwidth. Ideally, it
should not be used over long distances, when transaction volumes are high,
when the bandwidth available is too little, or when the network latencies
are high.
RAID-2 is intended for use with drives that do not have built-in error
detection. All SCSI (small computer system interface) drives support built-
in error detection, so this level is of little use when using SCSI drives. Each
bit of data is written to a drive using a process of error correction known as
a Hamming Error Correction Code (ECC). On a read operation, the ECC
verifies correct data or corrects single-disk errors as the need arises. This on-
the-fly data error correction process allows for an extremely high data trans-
fer rate. Entry-level cost for this solution tends to be very high. With this
Figure 4.2
Common RAID
Configurations.
140 4.2 IT Systems Recovery
solution, the transaction rate is equal to that of a single disk (with spindle
synchronization). To our knowledge, there are no commercial implementa-
tions for this solution.
RAID-3 stripes data at a byte level across several drives, with parity
stored on one drive. Byte-level striping requires hardware support for effi-
cient use. In this process, the data block is subdivided (i.e., striped) and
written on the data disks. Stripe parity is achieved on writes where parity
data is recorded on the parity disk and checked on subsequent reads.
RAID-3 requires a minimum of three drives to implement and provides a
very high read/write data transfer rate. With this solution, disk failure has
an insignificant impact on throughput. The low ratio of ECC (parity) disks
to data disks means high efficiency, but it is also a pricey solution.
RAID-4 stripes data at a block level across several drives, with parity
stored on one drive. The parity information allows recovery from the failure
of any single drive. The performance of a RAID-4 array is very good for
reads, but writes require that parity data be updated each time. This slows
small random writes in particular, though large writes or sequential writes
are fairly fast. Because only one drive in the array stores redundant data, the
cost per megabyte of a RAID-4 array can be fairly low.
RAID-5 is similar to RAID-4, but distributes parity among the drives.
This can speed small writes in multiprocessing systems, since the parity disk
does not become a bottleneck. Because parity data must be skipped on each
drive during reads, however, the performance for reads tends to be consider-
ably lower than a RAID-4 array. The cost per megabyte is about the same as
for RAID-4. RAID-5 provides striping with parity: three or more drives are
used in unison, and one drive’s worth of space is consumed with parity
information. The parity information is stored across all drives. If any one
drive of a RAID-5 volume fails, the parity information is used to rebuild
the contents of the lost drive on the fly. A new drive can replace the failed
drive, and the RAID-5 system will rebuild the contents of the lost drive
onto the replacement drive.
RAID-6 is essentially an extension of RAID-5 that allows for addi-
tional fault tolerance by using a second independent distributed parity
scheme (known as two-dimensional parity). With this approach, data is
striped on a block level across a set of drives, just like in RAID-5, and a
second set of parity is calculated and written across all the drives. RAID-6
provides extremely high data fault tolerance and can sustain multiple
simultaneous drive failures. It is considered the perfect solution for mis-
sion-critical applications.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.