
C# is a modern object-oriented language developed by a Microsoft team led by Anders Hejlsberg. The Common Language Runtime, or CLR for short, is the virtual machine on which C# runs. Many languages run on the CLR and this means they can all be compiled and used on Windows PCs, the Xbox 360, and the Zune. The CLR is owned and developed by Microsoft, but there is also an open-source version of the CLR called Mono. Using Mono, C# programs can be run on Macs, Linux, or any other system for which Mono can be compiled.
In the game industry, we use C++, but it’s not because we want to. C++ is a sprawling language with lots of areas that can trap an unwary programmer and many areas that are simply undefined. C# is much friendlier than C++ and it’s far more fun to use for writing games.
C# was first announced in July 2000 at the Microsoft Professional Developers Conference in Orlando. At the time it was a little like the Microsoft version of Java, but it rapidly developed into something much different. C#’s most recent updates are very innovative and exciting.
Modern languages like C# and Java make programs that run on virtual machines. Older language like C++ and C make programs that run directly on the hardware of a specific machine. The hardware that runs the program is called the central processing unit, or CPU for short. This is the brain of the computer.
Modern Macs and PCs generally have an x86 CPU; the XBox 360 has a Xenon CPU; and the PS3 has a Cell CPU. All of these brains are slightly different but share the same basic purpose—to run the programs programmers write. Programs are just lists of instructions. The instructions a particular CPU understands are called machine code. Machine code for one CPU is unlikely to be understood by a different type of CPU.
Compilers take human-readable source code, written in a language like C++ or C, and compile it into machine code. For example, the PlayStation 3 C++ compiler compiles source code into machine code that can run on the Cell CPU. To run the same C++ code on the Xbox 360 Xenon CPU, it must be compiled again using the Xbox 360 C++ complier. C# doesn’t work like this. C# compiles down to an assembly language called the common intermediate language or CIL. CIL is then run on a virtual machine that generates the machine code for the particular system. In the PlayStation 3 case that would mean to run C# on the PlayStation, it would need a virtual machine that could take CIL code and output machine code that the Cell CPU understands. This difference between languages using virtual machines and languages that compile directly to machine code is shown in Figure 1.1.

C#s virtual machine, the CLR, has many advantages. The biggest advantage is you only need write the code once and it will run on every CPU that supports the CLR. It’s very hard to crash the system using C# because the system is insulated by this virtual machine. The virtual machine can catch errors before sending them to the real hardware. Also you don’t need to worry about allocating and freeing memory as this is done automatically. Programming languages can be mixed and matched provided they all compile to the CLR; languages such as F#, IronLisp, IronRuby, IronPython, and IronScheme can all be used in a single program. As a game programmer you could write your AI in a high-level, AI-friendly language and your graphics code in a more procedural C-like language.
C# is regularly updated with new functionality and improvements. Even if you have programmed in C# before you may not be aware of all the new features added to the language in recent updates.
C# version 2.0 added generics and anonymous delegates. It’s easiest to explain these new features with examples.
Generics are a way of writing code to use some general object with some general properties, rather than a specific object. Generics can be used with classes, methods, interfaces, and structs to define what data type they will use. The data types used with generic code are specified at compile time, which means the programmer no longer has to be responsible for writing test code to check that the correct data type is being used. This in turn makes the code shorter because test code doesn’t need to be written, and safer because it reduces type mismatch errors at run time. Generic code also tends to be faster because less casting between data types has to be performed.
The following code is written without the use of generics.
ArrayList _list = new ArrayList(); _list.Add(1.3); // boxing converts value type to a reference type _list.Add(1.0); //Unboxing Converts reference type to a value type. object objectAtPositionZero = _list[0]; double valueOne = (double) objectAtPositionZero; double valueTwo = (double) _list[1];
The code creates a list and adds two decimal numbers. Everything in C# is an object, including numbers. All objects in C# inherit from the object class. An ArrayList stores objects. Here, numbers have been added but the ArrayList does not know they are numbers; to the ArrayList they are just objects. Objects are the only thing it knows. When the number is passed to ArrayList.Add it is converted to an object type and added to its collection of objects.
Every time an object is taken out of the list, it must be cast back from an object to its original type. All the casts are inefficient and they clutter the code making it harder to read, which makes non-generic code unpleasant to work with. Generics fix this problem. To understand how they fix the problem, you need to understand the difference between reference types and value types.
C# has two broad categories of type, reference types and value types. Value types are the basic types such as int, float, double, bool, string, etc. Reference types are the large data structures you define yourself using the class keyword such as Player, Creature, Spaceship, etc. You can also define custom value types using the struct keyword.
// An example reference type
public class SpaceShip
{
string _name;
int _thrust;
}
//An example value type
public struct Point
{
int _x;
int _y;
}
Value types store their data directly in memory. Reference types store their data indirectly in memory. In the memory address of a reference type is another memory address to where the data is actually stored. This can be confusing at first, but once you are familiar with the concepts it’s quite simple. The differences in memory are shown in Figure 1.2.
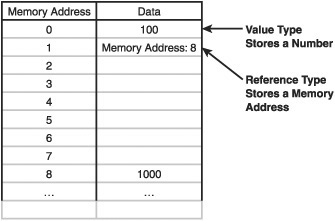
If the computer’s memory is thought of as a vast library full of bookshelves, then creating a value type is simply adding some books to the shelf. Creating a reference type is more like adding a note to the shelf that gives directions to a different part of the library where the books are stored.
Here’s an example of a value type.
int i = 100;
If we looked in memory to see where i was stored, we’d get the number 100. In our human-readable code we use the variable name i; in assembly code i is a memory address. This line of code, therefore, says put the value 100 in the next available memory address and call that memory address i.
int i = 100; int j = i; // value type so copied into i Console.WriteLine(i); // 100 Console.WriteLine(j); // 100 i = 30; Console.WriteLine(i); // 30 Console.WriteLine(j); // 100
In this example, the value type i is assigned to j, which means its data is copied. Everything stored in memory address j is now the same as whatever was in i.
The next example is similar but it uses reference types. First, a reference type needs to be created by defining a new class. All this class will do is store a number, like our own version of the int type. Our type will be called Int using a capital I to differentiate it from C#’s built-in int type.
class Int()
{
int _value;
public Int(int value)
{
_value = value;
}
public void SetValue(int value)
{
_value = value;
}
public override string ToString()
{
return _value.ToString();
}
}
Int i = new Int(100);
Int j = i; // reference type so reference copied into i
Console.WriteLine(i); // 100
Console.WriteLine(j); // 100
i.SetValue(30);
Console.WriteLine(i); // 30
Console.WriteLine(j); // 30/<- the shocking difference
Here when i changed so did j. This is because j did not have its own copy of the data; it just had the same reference to the data that i did. When the underlying data changes, it doesn’t matter if that data is accessed with i or j, the same result will always be returned.
To use the library example again, you check the library index system and it returns two shelf locations for the book you want. The first position, i, doesn’t have a book at all; it just has a small note, and when you check position j you find a similar note. Both of these notes points to a third location. If you follow either note, you will find the book you were searching for. There is only one book, but two references point to it.
Boxing is the process of taking a value type and converting it to a reference type. Unboxing is the process of converting the new reference type back to the original value type. In the first version of C#, lists of objects, even if they were all value types, had to be converted to reference types when they were added to the list. This all changed with the introduction of generics. Here’s some example code using generic functionality; compare this with the earlier example using an ArrayList.
List<float> _list = new List<float>(); _list.Add(1); _list.Add(5.6f); float valueOne = _list[0]; float valueTwo = _list[1];
This example code creates a list of floats. Floats are value types. Unlike before, the floats don’t have to boxed and unboxed by casting; instead it just works. The generic list knows the type it is storing so it doesn’t need to cast everything to an object type. This makes the code far more efficient because it’s not always swapping between types.
Generics are great for building reusable data structures like lists.
In C# a delegate is a way of passing a function as an argument to another function. This is really useful when you want to do a repetitive action to many different lists. You have one function that iterates through the list, calling a second function to operate on each list member. Here is an example.
void DoToList(List<Item> list, SomeDelegate action)
{
foreach(Item item in list)
{
action(item);
}
}
Anonymous delegates allow the function to be written straight into the DoToList function call. The function doesn’t need to be declared or predefined. Because it’s not predefined, it has no name, hence anonymous function.
// A quick way to destroy a list of items
DoToList(_itemList, delegate(Item item) { item.Destroy(); });
This example iterates through the list and applies the anonymous function to each member. The anonymous function in the example calls the Destroy method on each item. That could be pretty handy, right? But there’s one more trick to anonymous functions. Have a look at the following code.
int SumArrayOfValues(int[] array)
{
int sum = 0;
Array.ForEach(
array,
delegate(int value)
{
sum += value;
}
);
return sum;
}
This is called a closure. A delegate is created for each loop iteration, and uses the same variable, sum. The variable sum can even go out of scope, but the anonymous delegates will continue to hold a reference to it. It will become a private variable only accessible to the functions that have closed it. Closures are used heavily in functional programming languages.
The release of C# 3.0 introduced more than just a few incremental changes. The new features are extremely innovative and massively reduce the amount of boiler plate code needed. The biggest change was LINQ system.
LINQ stands for Language-Integrated Query. It’s a little like SQL (SQL, Structured Query Language, is the language used to manipulate and retrieve data from databases) for data structures. The best way to get a feel for it is to look at some examples.
Monster
{
string _name;
int _currentLevel = 1;
int _currentExperience = 0;
int _nextLevelExperience = 1000;
public Monster(string name, int currentExperience)
{
_name = name;
_currentExperience = currentExperience;
}
public string Name()
{
return _name;
}
public int CurrentExperience()
{
return _currentExperience;
}
public int NextLevelRequiredExperience()
{
return _nextLevelExperience;
}
public void LevelUp()
{
Console.WriteLine(_name + "has levelled up!");
_currentLevel++;
_currentExperience = 0;
_nextLevelExperience = _currentLevel * 1000;
}
}
List<Monster>_monsterList = new List<Monster>();
_monsterList.Add(new Monster("Ogre", 1001));
_monsterList.Add(new Monster("Skeleton", 999));
_monsterList.Add(new Monster("Giant Bat", 1004));
_monsterList.Add(new Monster("Slime", 0));
// Select monsters that are about to level up
IEnumerable<Monster> query = from m in _monsterList
where m.CurrentExperience()>
m.NextLevelRequiredExperience()
orderby m.Name() descending
select m;
foreach (Monster m in query)
{
m.LevelUp();
}
When run, this query retrieves all the monsters that can gain a level, and then orders that list by name. LINQ isn’t just used with collections; it can be used with XML and databases too. LINQ works with another new addition to C# 3.0: lambda functions.
Remember anonymous delegates? Well, lambda functions are a much more convenient way to write anonymous delegates. Here’s an example that destroys all items in a player’s inventory.
_itemList.ForEach(delegate(Item x) { x.Destroy(); });
Using the lambda functions, it can be written more concisely as follows.
_itemList.ForEach(x => x.Destroy());
Less boilerplate code is required making it easier to read.
Object initializers allow objects to be constructed in a more flexible manner, and constructors no longer need to be so verbose. Here’s an example without object initializers.
Spaceship s = new Spaceship(); s.Health = 30;
This can now be written in a more concise way.
Spaceship s = new Spaceship { Health = 30 };
This is used in some LINQ queries. Object initializers can help prevent the need to write multiple constructors that only set a few fields.
Collection initializers let you initialize lists in a pleasing way. As before, the best way to demonstrate the improvement is to show the old way.
class Orc
{
List<Item> _items = new List<Item>();
public Orc()
{
_items.Add(new Item("axe"));
_items.Add(new Item("pet_hamster"));
_items.Add(new Item("skull_helm"));
}
}
Initializing lists in this way requires a certain amount of setup code that has to be put inside the constructor or in a separate initialization method. But by using collection initializers everything can be written in a much more concise way.
class Orc
{
List<Item> _items = new List<Item>
{
new Item("axe"),
new Item("pet_hamster"),
new Item("skull_helm")
};
}
In this example case, we don’t use the constructor at all anymore; it’s done automatically when an object is created.
Using code with generics can get a little messy if there are several generic objects being initialized at the same time. Type inference can make things a little nicer.
List<List<Orc>> _orcSquads = new List<List<Orc>>();
In this code, there’s a lot of repeated typing, which means more pieces of the code to edit when changes happen. Local variable type inference can be used to help out in the following way.
var _orcSquads = new List<List<Orc>>();
The var keyword is used when you would like the compiler to work out the correct type. This is useful in our example as it reduces the amount of code that needs to be maintained. The var keyword is also used for anonymous types. Anonymous types occur when a type is created without a predefined class or struct. The syntax is similar to the collection initializer syntax.
var fullName = new { FirstName = "John", LastName = "Doe" };
The fullName object can now be used like a reference type. It has two read-only fields, FirstName and LastName. This is useful when you have a function and you really want to return two values. Both values can be combined in an anonymous type and returned. The more common use for anonymous type is when storing the data returned from LINQ queries.
C# 4.0 is the very latest release of C# and the major change is the addition of dynamic types. C# is a statically typed language. Static typing means that all the types of the various objects are known at compile time. Classes are defined with fields and methods; these fields and methods don’t change during the course of the program. In dynamic typing, objects and classes are more fluid—functions and fields can be added and taken away. IronPython and IronRuby are both dynamic languages that run on the CLR.
Dynamic objects get a new keyword: dynamic. Here’s an example of how it’s used. Imagine we had several unrelated classes that all implemented a method called GetName.
void PrintName(dynamic obj)
{
System.Console.Writeline(obj.GetName());
}
PrintName(new User("Bob")) // Bob
PrintName(new Monster("Axeface")) // Axeface
If an object is dynamic when a function is called, that function is looked up at runtime. This is called duck typing. The look-up is done using reflection, or if the object implements the interface IDynamicObject, then it calls the method GetMetaObject and the object is left to deal with it internally. Duck typing is a little slower because it takes time to determine if the function is present or not. In traditional C#, a function or field’s presence is determined once at compile time.
The following code will compile under C# 4.0.
public dynamic GetDynamicObject()
{
return new object();
}
dynamic testObj = GetDynamicObject();
testObj.ICanCallAnyFunctionILike();
The method ICanCallAnyFunctionILike probably doesn’t exist, so when the program runs and executes that section of code, it will throw an exception.
Calling any method or accessing any member of a dynamic object requires the object to do a runtime look-up to see if that member or method exists. That means if the programmer makes a typo, the error isn’t caught during compiling, only when the code is run. In C# if a method or field on a dynamic object isn’t found, the exception that’s thrown is of type RuntimeBinderException.
The dynamic keyword is useful if you intend to do a lot of dynamic scripting in your game or if you want write a function that takes advantage of duck typing, as in the PrintName example. PrintName is slower because the GetNames method must be looked up each time it is called. It may be worth taking the speed hit in certain situations, but it’s best to be aware of it.
Until version 4.0, C# had no support for optional parameters in methods. This is a standard feature of C++. Here’s how it works.
class Player
{
// Knock the player backwards
public void KnockBack(int knockBackDamage = 0)
{
// code
}
}
Player p = new Player();
p.KnockBack(); // knocks the player back and by default deals no damage
p.KnockBack(10); // knocks the player back and gives 10 damage
Optional parameters allow the programmer to give default values to the method arguments. Named arguments allow multiple optional parameters to be used in an elegant way.
enum HairColor
{
Blonde,
Brunette,
Red,
Black
}
enum Sex
{
Male,
Female
}
class Baby
{
public string Name { get; set; }
public Sex Sex { get; set; }
public HairColor HairColor { get; set; }
}
class Player
{
public Baby HaveBaby(string babyName, Sex sex = Sex.Female, HairColor
hairColor = HairColor.Black)
{
return new Baby()
{
Name = babyName,
Sex = sex,
HairColor = hairColor
};
}
}
Player player = new Player();
player.HaveBaby("Bob", Sex.Male);
player.HaveBaby("Alice");
In this example, the player class has code that allows the player to give birth. The HaveBaby method takes in a name and some other optional arguments and then returns a new baby object. The HaveBaby method requires a name to be given but the sex and hairColor arguments are optional. The next example shows how to set the hair color argument but leave the sex as the default female value.
player.HaveBaby("Jane", hairColor: HairColor.Blonde)
Named arguments provide a way to only set the arguments we want to set.
C# is a modern, garbage-collected, objected-orientated language and it’s come a long way since its debut at the July 2000 Microsoft Professional Developers Conference in Orlando. C# runs on a virtual machine called the Common Language Runtime or CLR for short. The CLR can be used to run many different languages in the same program.
C# is a living language; as time passes more functionality and features are added. There have been four major versions of C# and each has brought new and useful features. These features can often make programs easier to write and more efficient so it’s important to keep up with the changes. C# 4.0, the latest version, was released in April 2010.