
Software development has problems—buggy games, blue screens of death, random crashes, programs not responding; the problems are numerous. Architects and civil engineers do not have these problems. The pyramids are doing pretty well and they are nearly 3,000 years old. Once a building is put up it tends to stay up, but humans have been putting up buildings for a lot longer than they have been writing software.
In the last few years, lots of interestingly named new software development methodologies have started to appear. These methodologies are an attempt to improve the way software is created and the final quality of the product. In this section, we’ll look at some of the more useful methodologies that you can put in your programmer’s toolkit.
Pragmatic programming is the ability to finish a program satisfactorily within a desired timeframe. This works by first understanding what is expected of the final program, then a basic bare bones version of the program is written as quickly as possible. This barely functional version is changed until it reaches the original requirements. Changes may be drastic and require rewriting of entire sections of the program, but that’s okay. The most important thing is that at all times the program is basically functional.
In the world of game development, it’s always a good idea to have something working, because then if a deadline is moved forward or a demo is required, something can be ready immediately. If you’re working alone, you have something to show people to get feedback. Feedback offers a much better idea about what will work and what won’t.
Many developers start out wanting to make a game but suddenly find that they’re writing a framework or game engine instead, and it will be useful to make any sort of game. But the developer never does make his game and falls into the framework trap, redeveloping his framework over and over, adding the latest features but never actually getting on to the game creation part.
Pragmatic programming helps you avoid the framework trap. It expressly forbids you to start working on a framework; creating a functional game is first and most important.
Pragmatic programming has two major coding principles: KISS and DRY. These are two great development tools that will improve your coding ability.
KISS stands for “Keep It Simple Stupid.” Don’t needlessly complicate your game programming.
“Hmm ... my space invaders game will be much more efficient if all the enemies and bullets are in a quadtree. So I better start building that...”
This is the wrong way to think if you want to make a game. It’s a great way to think if you want to learn about quadtrees. You have to decide which is more important to you and focus only on that. If you want to make a game, get the game functional as soon as possible, then decide if the extra complexity is needed.
DRY stands for “Don’t Repeat Yourself.”
If you start seeing snippets of code repeated all the over the place, then that code should be consolidated. The fewer places the code is repeated, the fewer places that need to be modified when making a change. Let’s take the space invader example again.
class Invader
{
...
int _health = 10;
bool _dead = false;
void OnShot()
{
_health--;
if(_health <= 0)
{
_dead = true;
}
}
...
}
class FlyingSaucer
{
...
int _health = 10;
void OnShot()
{
_health--;
if(_health <= 0)
{
_dead = true;
}
} ...
}
class Player
{
...
int _health = 10;
void OnShot()
{
_health--;
if(_health <= 0)
{
_dead = true;
}
}
...
}
In the above example, repeated code is found in all the classes. That means three different areas that need to be modified in case of change. That is more work for you, the coder; it’s also more code so it is less clear. The more code, the greater the chance for bugs to appear.
Now shields need to be added to the space invader creatures.
class Invader
{
...
int _health = 10;
bool _dead = false;
int _shieldPower = 2;
void OnShot()
{
if(_shieldPower > 0)
{
_shieldPower--;
return;
}
_health--;
if(_health <= 0)
{
_dead = true;
}
}
...
}
class FlyingSaucer
{
...
int _health = 10;
bool _dead = false;
int _shieldPower = 2;
void OnShot()
{
if(_shieldPower > 0)
{
_shieldPower--;
return;
}
_health--;
if(_health <= 0)
{
_dead = true;
}
} ...
}
class Player
{
...
int _health = 10;
bool _dead = false;
int _shieldPower = 2;
void OnShot()
{
if(_shieldPower > 0)
{
_shieldPower--;
return;
}
_health--;
if(_health <= 0)
{
_dead = true;
}
}
...
}
The above code is becoming more difficult to maintain. It could be a lot cleaner if the repeated code was refactored into a parent class.
class Spacecraft
{
int _health = 10;
bool _dead = false;
int _shieldPower = 2;
void OnShot()
{
if(_shieldPower > 0)
{
_shieldPower--;
return;
}
_health--;
if(_health <= 0)
{
_dead = true;
}
}
}
class Invader : Spacecraft
{
}
class FlyingSaucer : Spacecraft
{
}
class Player : Spacecraft
{
}
Now that the code is all in one place, it’s much easier to change in the future.
C++ does not follow the DRY principle from its very foundations. In C# there is one file that defines classes and methods: the .cs file. In C++, there is a header defining the class and all the method prototypes. A second file with a .cpp extension defines the functions again but this time with their bodies. So you have something like the following.
// Header File Player.h
class Player
{
void TeleportTo(Vector position);
};
// CPP File Player.cpp
void Player::TeleportTo(Vector position)
{
// code
}
If we want to add a return value, to report if the teleport was successful, the code must be modified in two places. That’s not DRY! In C++, the class implementation is defined in one file and the class interface in another; this code duplication is shown in the above code snippet. All but the smallest C++ programs use classes, and all classes require implementation duplication. Therefore, the DRY principle is violated by the very heart of how C++ functions. Both Java and C# were developed after C++ and both were heavily inspired by C++ (copying a large amount of the syntax and features), but they both decided to ditch header files.
You can be better than this; just remember the DRY principle.
If you’d like to know more about pragmatic programming, I recommend The Pragmatic Programmer by Andrew Hunt and David Thomas. The details are in Appendix A, “Recommended Reading.”
Source code is what you type into your editor when you’re programming. When source code is compiled, machine code is produced. The source code is for you, the human, and machine code is for the computer. The computer uses the machine code to execute a program. Source control is a program that keeps track of all the changes you make to your source code. (See Figure 3.1.)

Knowing how your code has changed and developed is not just really cool; it’s also useful. Source control gives you an unlimited numbers of “undos.” You can keep going back to previous versions of the code if you make a mistake. This is particularly useful when developing a new feature and you somehow manage to break everything. Without source control, you’d be looking forward to a painful process of trying to remember what you’d changed. With source control, you can just compare your current version with the previous version and see immediately what’s changed, as can be seen in Figure 3.2.
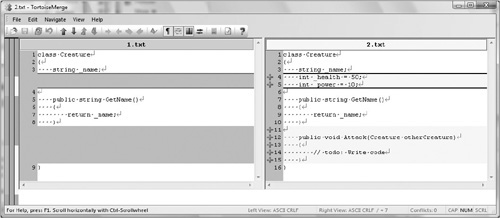
You can also revert to the previous working version of the code and lose all the broken code you added. Reverting is the process of replacing your current code files with an earlier version of those files. It’s like time travel! In the kitchen you might decide you want to cut some carrots but accidentally remove your finger. If humans had source control this would be no problem. You would just revert to the version of yourself 15 minutes ago and your finger would be back.
Source control is also great for backup. It stores all your code in one place—the source repository. This might be a local directory on your machine (c:source_ control) or it could be a server anywhere in the world accessible over the internet. If your house burns down, your source code is still safe.
Source control systems also let you create branches. This is a way to split programs into two separate versions. For instance, your chess game is going pretty well but you’re pretty sure it would be better if it had a first-person shooter mode. Adding such a mode will require a lot of code changes, and it might fail. With source control there’s no need to worry. You can create a branch. All the new code changes can be made in a new branch repository. Changes here won’t affect the main repository, called the trunk. If you fail at making ChessFPS then you can switch back to the main trunk and forget all about your failed branch. If you succeed then you can merge the branch and the trunk together again.
Source control is extremely useful for the lone developer, but one of its primary uses is allowing a team of programmers to work on the same codebase at the same time. Source control lets any programmer edit the code, and any other programmer can update and see those changes. To make a game with a group of friends, source control should certainly be used!
Hopefully, by now I’ve convinced you that source control is great and you need to use it. The code in this book uses a source control system called Subversion, but it’s a good idea to know a little about the many different source control systems.
CVS. —This is used primarily on older projects. It’s best to avoid, as Subversion has all its functionality and more.
Visual Source Safe. —Try not to use this. It is made by Microsoft, but not even Microsoft uses it internally. It has some stability issues.
Subversion. —Great free open source control with good Windows integration. My choice.
Perforce. —Used by many game companies, very good merge tools, good at handling large amounts of binary data (like images and models). Not free, or cheap.
Git. —Git is quite new and is used as source control for the Linux kernel. It’s not dependent on a central server, and it’s fast and scalable. Mostly command line based at the moment, though there are some GUI tools.
Mercurial. —A bit of a newcomer and mainly command line based, but once again there are a few GUI tools. Its goals are stated as high performance and scalability, decentralized, fully distributed collaborative development. Git and Mercurial have similar aims.
If you really want to be at the cutting edge of revision control, then look into Git or Mercurial. If you want simple and easy to use, my recommendation is Subversion.
When a programmer writes some new functionality, he’ll usually write a snippet of code to test it. Unit testing is just a clever way of gathering these little snippets of code together. Then they can be run each time the code is compiled. If suddenly a previously working test fails, it is obvious that something is broken. As the word “snippets” suggests, unit tests should be very small pieces of code that test one thing and one thing only.
In the unit-testing world, it’s very common to write the tests first and then code. This might be best illustrated with an example. Let’s say we are creating a game and a class is needed to represent the player. Players should have a health status, and when you create a player, he should have greater than zero health. Let’s write that in code form
class PlayerTests
{
bool TestPlayerIsAliveWhenBorn()
{
Player p = new Player();
if (p.Health > 0)
{
return true; // pass the test
}
return false; // fail the text
}
}
This code won’t compile yet as we haven’t even created a player class. But I think the test is pretty self-explanatory. If you create a player, he should have greater than zero health; otherwise, this test fails. Now that the test is written, let’s create the player.
class Player
{
public int Health { get; set; }
}
Now all the tests can be run using the unit-testing software. The test will fail because by default, integers are initialized to zero. To pass the test, the code must be altered.
class Player
{
public int Health { get; set; }
Player()
{
Health = 10;
}
}
Running the unit-testing software again, the test will pass. We now know this code is working under the tested condition. Let’s add two more tests.
class PlayerTests
{
bool TestPlayerIsHurtWhenHit()
{
Player p = new Player();
int oldHealth = p.Health;
p.OnHit();
if (p.Health < oldHealth)
{
return true;
}
return false;
}
bool TestPlayerIsDeadWhenHasNoHealth()
{
Player p = new Player();
p.Health = 0;
if ( p.IsDead() )
{
return true;
}
return false;
}
}
Two more tests have been added—each requiring a new player function.
class Player
{
public int Health { get; set; }
public bool IsDead()
{
return false;
}
public void OnHit()
{
}
public Player()
{
Health = 10;
}
}
The general method of unit testing is to write the test, update the code, run the test, and if it fails, modify the code until it passes the test. If the new tests are run on the updated code, they will both fail. Let’s fix that.
class Player
{
public int Health { get; set; }
public bool IsDead()
{
return Health == 0;
}
public void OnHit()
{
Health--;
}
public Player()
{
Health = 10;
}
}
Don’t worry if you’ve noticed a bug; it’s there on purpose, I promise! Run the tests and they should all pass. The code is verified, but the tests don’t exhaustively cover all the code. For instance, there is a TestPlayerIsDeadWhenHasNoHealth but not a “test the player is not dead when health is greater than 0”. I’ll leave this one as a reader exercise.
Let’s say we keep on developing in this way and get to the stage where we have a full working game. Then during testing something strange occurs; sometimes, when the player should die, he doesn’t, and after that he’s invincible. This isn’t how the game is supposed to work. All the tests are passing, so that means the bug isn’t being tested for. Doing some clever debugging, it’s discovered that the bug occurs when the player has low life, perhaps two or less units of health, and is then hit a lot of times by a number of enemies.
In unit testing, the first task is to write a test that reproduces the bug. Once this test is written, the code can be fixed and the test can confirm it. Here’s a test that covers the bug.
class PlayerTests
{
bool TestPlayerShouldBeDead()
{
Player p = new Player();
p.Health = 2; // give him low health
// Now hit him a lot, to reproduce the bug description
p.OnHit();
p.OnHit();
p.OnHit();
p.OnHit();
p.OnHit();
if ( p.IsDead() )
{
return true;
}
return false;
}
}
This test is run, and it fails. Now we’ve got a unit test that reproduces the bug. The code must now be changed to pass this test. The death function seems a good place to fix the bug.
class Player
{
bool IsDead()
{
return Health <= 0;
}
...
}
If the player has zero health or less, then he is dead. This causes all the unit tests to pass, and we’re now sure that this bug won’t crop back up without us knowing about it.
The method of writing tests, then skeleton code, and then making that code pass the test is called Test Driven Development. Developing code this way reduces bugs and you can have faith in what your code actually does. This is very important if you’re developing a big project. It also encourages classes to be quite modular and self-contained. This is because unit tests need to be small; therefore, you want to avoid having to make 50 classes and setting them all up just to run one simple test. For this reason, lots of needless coupling between classes is avoided.
The other big win on unit testing is refactoring. For instance, if the inventory system in your game needs to be massively redesigned, then with unit testing you have all the tests required to confirm you’ve replaced the system correctly.
With unit testing, you can confidently say your code is bulletproof. Unfortunately, not everything can be tested; graphics are very hard to test and you just have to assume the libraries such as OpenGL will work correctly.
The best unit-testing software for C# is called NUnit (Figure 3.3). It’s free and easy to use.
In the following chapters, we’ll download NUnit and walk through the setup. All the code in the book is unit tested, but for the sake of brevity, most unit-test code is left out of the code examples.
Writing high quality software can be difficult; it’s hard to write bug-free software and it’s hard to finish projects on time or even finish them at all. Modern programming methodologies and practices try to improve the software development process.
Pragmatic programming is the ability to finish a program satisfactorily within a desired timeframe. It is a development method that emphasizes creating a minimal version of the program as quickly as possible and then iteratively developing this program until it starts to resemble the original vision. Pragmatic programming has two main guidelines known as DRY and KISS. DRY stands for “Don’t Repeat Yourself,” and KISS stands for “Keep It Simple Stupid”; together these mean you should avoid duplicating code or functionality and you should avoid the temptation to over-complicate your programs.
Source control is used to keep your code safe and allow multiple developers to work on the same project at the same time. Unit testing is the practice of writing small tests that confirm your code is working as expected. These small tests help document how the code base should be used and are also used to catch any bugs that might be introduced when making large changes to the code. These tools and guidelines help to make software creation easier and help to make the final product more elegant and robust.