
By Paul Della Maggiora, et. al.
This chapter is part of the basis for the forthcoming book Performance and Fault Management from Cisco Press.
This chapter provides a set of fault-monitoring and event-correlation guidelines, as applied to Cisco switches and routers, to help network administrators better manage their network of Cisco equipment. Switch- and router-management capabilities are first introduced, followed by more specific definitions of MIB objects, SNMP traps, and syslog messages associated with typical fault and performance conditions. These scenarios can be used to specify elements to monitor and to implement correlation rules. This chapter contains a Cisco knowledge base for Cisco switches and routers.
Also addressed is fault and event correlation for Cisco switches and routers, based on MIB objects and syslog messages. Because Cisco private MIBs are constantly evolving, some scenarios described in this chapter may not apply to your installation if these MIB objects and/or syslog messages are not supported or not applicable in your environment. The CCO Web site (http://www.cisco.com) contains a cross listing of all MIBs and syslog messages. The cross listing is organized to show the MIBs and syslog messages supported by particular platforms and by various IOS release versions.
This chapter was originally a white paper written by a group of Cisco's senior network engineers to address the concerns of customers as they migrated from router/shared hub networks to router/switched networks. They found that the network-management strategy that worked for shared networks did not scale to efficiently support and monitor switched networks.
The chapter concludes with a set of case study scenarios to assist you in switched-network management.
Within this chapter, you will find a consolidation of much information about the management of Cisco equipment for the purposes of helping end users better manage their networks, and helping network-management application vendors enhance their product offerings. It presents a set of network-monitoring and event-correlation guidelines for what the authors consider the most important conditions to monitor.
In addition to the description of the most important switch and router events to monitor within a single device, this chapter also describes a series of event-correlation scenarios to monitor across one or more devices, a VLAN or subnet, or the entire network. Cisco's event model is introduced along with a description of all possible means to gather information from a switch or router.
This chapter is written for network-management engineers who must implement network management for Cisco switches and routers. This chapter assumes the reader has a basic understanding of switching and routing theory, Simple Network Management (SNMP), and Cisco switches and routers. This chapter is also written for network-management platform and application vendors to enhance their product with specific monitoring and correlation rules for Cisco equipment.
Table 14-1 lists and explains the important terms you will find in this chapter.
Table 14-1. Network Management Terms
Other Catalyst 5000 Series acronyms can be found at the CCO Web site.
Network management is the art and science of managing network equipment such as switches, routers, hubs, and other communications equipment composing the network infrastructure.
ISO helped simplifying the partitioning of network-management activities by identifying five major areas (also known as FCAPS, for the initials of each functional area):
Fault management
Configuration management
Accounting management
Performance management
Security management
An overview of these functional areas and an introduction to networking can be found at the CCO Web site.
Although several books have been written about network management, this chapter addresses only fault- and performance-management functional areas as applied to Cisco switches and routers.
This section covers some background on how Cisco has implemented certain functions and protocols. This will be useful as background information for the material in this chapter.
A Cisco Catalyst switch is a multiport bridging device. Cisco's switching architecture depends on the concept of multilayer switching, which combines the ease of use of Layer 2 switching (bridging) within a workgroup with the stability and security of Layer 3 switching (routing) among different workgroups.
Multilayer switching is important for sustainable growth in large switched environments for several reasons:
It offers excellent throughput because it helps provide dedicated bandwidth to individual users.
It obviates the bottlenecks that simple Layer 2 switching causes when multiple 10-Mbps segments all converge at single 10-Mbps connections to servers and routers.
Because switches are multiport bridges, each port is its own separate segment or ring with 10 MB of theoretical bandwidth available, as opposed to a hub that shares a single 10 MB of capacity among its various ports.
Because each port is bridged, each port sees only broadcast, some multicast, and unicast traffic destined to or sourced from the particular port. This means that if a device connected to switch port 2 talks with a device on switch port 3, no other switch ports will see that traffic. Therefore, a network analyzer connected to switch port 4 would not see the conversation going between switch ports 2 and 3.
This section explains the various components and protocols that make up a switch.
A thorough introduction to switching basics can be found at the CCO Web site.
Switches, like routers, contain a CPU. Unlike routers, however, a switch performs most of the packet forwarding without impacting the CPU. Switching decisions are performed on the switch ASICs and, depending on the switch type, the bridging table may be stored on an ASIC as well.
Some of the operations performed by the switch's CPU include spanning tree, Telnet services, Cisco Discovery Protocol (CDP), security (such as Terminal Access Controller Access Control System [TACACS]), remote monitoring (RMON), VLAN Trunk Protocol (VTP), port aggregation, dynamic VLANs, and SNMP processing.
As such, measuring the CPU of a switch is of little importance when determining the switch's packet-forwarding performance of the switch.
Bridges/switches keep track of the ports from which they have received certain Media Access Control (MAC) addresses to isolate unicast conversations to the ports involved. The alternative is to forward all traffic, unicast and broadcast, to all switched ports, which would be excessive. This feature is traditionally done using a forwarding database (sometimes called a bridging table) and content-addressable memory (CAM) tables.
The forwarding database is usually a single centralized table or database on a bridge that contains all the MAC addresses (and their ports) the bridge has learned. It is used to forward packets to the correct ports.
The content of the CAM can be accessed using the contents rather than an address. A CAM typically exists at each physical port. In non-promiscuous mode (meaning not bridging), the CAM contains the burned-in MAC address of the network interface card (NIC), and is programmed with other addresses (like multicasts/broadcast) to which it needs to listen. Any packet that fails the CAM lookup is dropped by the NIC.
Bridges operate in promiscuous mode, which means the CAM on each port is cleared, so all MAC addresses are accepted. As the bridging table is built, the CAM is populated with destination MAC addresses of stations generating traffic on that port. In promiscuous mode, packets received on a port that have a destination MAC address that matches an entry in the CAM for that port are ignored. If MAC addresses are stored in the CAM, the MAC address is used to look up the entry, rather than a sequential search, because sequential searches are much slower. This makes the CAM quicker than the forwarding database. Many NICs have a CAM, but the Catalyst 5000 does not have CAM on Ethernet ports.
On the Catalyst 5000, the term "CAM" is used for historical reasons; no actual CAM is present. The Catalyst 5000 uses a central Enhanced Address Recognition Logic (EARL) for speed and additional functionality by combining the VLAN ID with the MAC address in the learning and lookup functions performed by the Catalyst 5000 hardware. The EARL combines the functions of the forwarding database (central complete list of MACs, VLANs, and ports) and the CAM (fast lookup using the contents of memory rather than a search). The MAC addresses are stored on an SRAM chip on the supervisor engine and do not impact memory or processor usage on the network-management processor (NMP). There is enough SRAM on the chip to store 16,000 MAC addresses.
Generally, the path of a packet through a switch is as follows:
The switch receives a packet on a particular port.
The switch looks at the destination MAC address and compares it to the entries in its forwarding database. It also records the source MAC address and the port in which it was received in the CAM/bridging table.
If the destination address was a unicast address that was recorded in the CAM/ bridging table, the switch forwards the packet out the associated destination port if it is a different port.
If the destination address was not in the bridging table or if the destination was a broadcast or multicast address, the switch forwards the packet out all ports of the switch except the one on which it was received.
All of these operations are performed without impacting the switch's CPU at all.
When bridging, Catalyst switches perform both transparent and translational bridging. Transparent bridging is the process of forwarding traffic from one port (such as Ethernet) to another common media port (such as another Ethernet port). The packet will not be modified in any form as it is taken from the receiving port and passed on to the destination port.
Translational bridging goes one step further by bridging traffic between two different media, such as from Ethernet to Fiber Distributed Data Interface (FDDI). Translational bridging requires a switch to take a received packet and "translate" it to a different media. This entails, at a minimum, the replacement of one topology's part of a packet with another. Translational switching requires extra processing time because a packet must be received, analyzed, and translated before sending the packet on to its final destination.
A VLAN is an administratively defined broadcast domain that can span multiple switches. Only end stations within the VLAN receive packets that are unicast, broadcast, or multicast (flooded). A VLAN enhances performance by limiting traffic; it allows the transmission of traffic among stations that belong to it and blocks traffic from other stations in other VLANs. VLANs can provide security barriers (firewalls) between end stations on different VLANs within the same switch.
In addition, some of the VLAN components supported on the Catalyst series include the following:
VLAN trunks—. Allow extending VLANs from one Catalyst series switch to one or more routers or other Catalyst series switches using high-speed interfaces, such as Fast Ethernet, FDDI, and Asynchronous Transfer Mode (ATM). Two trunking protocols are supported at this time: Inter-Switch Link (ISL) for Ethernet and Fast Ethernet, and 802.10 for FDDI.
Fast EtherChannel—. Allows parallel Fast Ethernet ISL trunks to split traffic among multiple trunks. By setting spanning-tree parameters on a VLAN basis, you can define which VLANs are active on a trunk and which should use the trunk as a backup if the active trunk fails.
VLAN Trunk Protocol (VTP)—. Allows VLAN naming consistency and connectivity between all devices in a management domain. When new VLANs are added to a Catalyst 5000 series switch in a management domain, the VTP automatically distributes this information to all the devices in the management domain. The VTP is transmitted on all trunk connections, including ISL, 802.10, and ATM LAN Emulation (LANE). By using multiple VTP servers through which global VLAN information is modified and maintained, you can configure redundancy in a network domain. Only a few VTP servers are required in a large network. In a small network, all devices are usually VTP servers. Catalyst 5000 Series Software Release 3.1 supports VTP version 2, an extension to VTP version 1.
When creating fault-tolerant networks, a loop-free path must exist between all nodes in the network. A spanning-tree algorithm is used to calculate the best loop-free path through a Catalyst-switched network. Spanning-tree packets are sent and received by switches in the network at regular intervals. The packets are not forwarded by the switches participating in the spanning tree, but are instead processed to determine the spanning-tree itself. The IEEE 802.1D bridge protocol, called STP, performs this function for Catalyst switches.
The Catalyst series switches can use STP on all VLANs. The STP detects and breaks loops by placing some connections in a stand-by mode, which are activated in the event of a failure. A separate STP runs within each configured VLAN, ensuring valid Layer 2 topologies throughout the network.
The supported STP states are as follows:
Disabled
Forwarding
Learning
Listening
Blocking
The state for each port is initially set by the configuration and later modified by the STP process. After the port state is set, the 802.1D bridge specification (RFC 1493) determines whether the port forwards or blocks packets.
The SPAN feature enables you to monitor traffic on any port for analysis by a network-analyzer device or RMON probe. Enhanced SPAN ( E-SPAN) enables you to monitor traffic from multiple ports with the same VLAN.
SPAN redirects traffic from an Ethernet, Fast Ethernet, FDDI port, or VLAN to an Ethernet or Fast Ethernet monitor port for analysis and troubleshooting. You can monitor a single port or VLAN using a dedicated analyzer such as a Network General Sniffer, or an RMON probe such as a Cisco SwitchProbe.
Routers are Layer 3 switching devices. Routing involves two basic activities: determination of optimal routing paths and the transport (or switching) of information groups (typically called packets) through a network. Switching is relatively straightforward. Path determination, on the other hand, can be very complex. Routing algorithms can be differentiated based on several key characteristics. First, the particular goals of the algorithm designer affect the operation of the resulting routing protocol. Second, there are various types of routing algorithms. Each algorithm has a different impact on network and router resources. Finally, routing algorithms use a variety of metrics that affect calculation of optimal routes.
A thorough overview of routing basics can be found at the CCO Web site.
Layer 3 switches combine switch and routing technology to allow traffic switching at both Layer 2 and Layer 3.
This section covers two protocols that are common to switches and routers and that help build a complete view of Layer 2 and Layer 3 devices in the network.
CDP is media and protocol independent and runs on all Cisco-manufactured equipment, including routers, bridges, access and communication servers, and switches. With CDP, network-management applications can retrieve the device type and SNMP agent address of neighboring devices. This allows applications to send SNMP queries to neighboring devices.
CDP meets a need created by the existence of lower-level, virtually transparent protocols. CDP allows network-management applications to discover Cisco devices that are neighbors of already known devices, in particular neighbors running lower-layer, transparent protocols. CDP runs on all media that support the Subnetwork Access Protocol (SNAP), including LAN and Frame Relay. CDP runs over the data link layer only, not the network layer. With CDP, two systems that support different network layer protocols can learn about each other.
Cached CDP information is available to network-management applications. Cisco devices never forward a CDP packet. When new information is received, old information is discarded. CiscoWorks for Switched Internetworks (CWSI) uses this information during network discovery.
CDP is also very useful in troubleshooting. In a network of routers only, the Address Resolution Protocol (ARP) tables, routing tables, and other information are used to discover the topology, or to confirm the connectivity of the topology that is already known. In a network of bridges, these tables aren't used; instead, a forwarding database (which is not useful to discover bridges; it's for end stations) and spanning-tree information (which may be disabled, and gives information upstream toward the root only) are used. CDP will discover all Cisco devices that are neighbors and provide information such as host name, Cisco IOS version, and management IP address.
See the CCO Web site for information on how to configure CDP in a Catalyst 5000.
RFC 1757 defines a portion of the Management Information Base (MIB) for monitoring data link layer information of remote segments, in particular, traffic characteristics and error rates.
Remote network-monitoring devices, often called monitors or probes, are instruments that exist for the purpose of managing a network. Often these remote probes are standalone devices and devote significant internal resources for the sole purpose of managing a network. An organization may employ many of these devices, one per network segment, to manage its Internet. In addition, these devices may be used for a network-management service provider to access a client network, often geographically remote.
The objects defined in the RFC are intended as an interface between an RMON agent and an RMON management application and are not intended for direct manipulation by users.
Although some users may tolerate the direct display of some of these objects, few will tolerate the complexity of manually manipulating objects to accomplish row creation. These functions should be handled by the management application. Cisco provides applications to perform these functions.
RMON, as described in RFC 1757, is implemented on Cisco Catalyst products and routers as follows:
Statistics, history, alarms, and events (of the nine RMON groups) on Ethernet segments in the 5000 or 5500 Workgroup Catalyst Switches with Software Release 2.1 and above and all 2900 Workgroup Catalyst Switches.
Statistics, history, alarms, and events (of the nine RMON groups) on Ethernet segments in the Catalyst 1900 and Catalyst 2820 Switches with Software Release 5.33 and higher.
Statistics, history, alarms, and events (of the nine RMON groups) on Ethernet segments in the 3000 Series (3000, 3100, and 3200) Workgroup Catalyst Switches.
All nine RMON groups on Ethernet segments in the 1200 Workgroup Catalyst Switch with DMP and NMP Software Version 3.1 or higher.
IOS Release 11.1 and higher supports the EtherStats, EtherHistory, Alarms, and Events MIB groups.
This section covers how industry-standard network-management protocols can be used to manage Cisco networks.
Four types of network-management protocols are available to manage Cisco equipment:
Telnet
SNMP
RMON
Syslog
Telnet (also known as CLI) allows direct login into a switch or router to have access to configuration and monitoring commands.
As defined in RFC 1157, the Simple Network Management Protocol (SNMP) is based on the concept of a SNMP Manager communicating with one or more SNMP agents, using the SNMP. SNMP Get, Get-Next, and Set operations are performed by the SNMP Manager to the agent to either retrieve or set management variables supported by the SNMP agent. Management information is usually equally available from SNMP and through Telnet. SNMP agents can notify SNMP managers by issuing SNMP traps. Traps can contain any number of management information to better qualify the trap.
Based on the SNMP technology, the remote network monitoring capabilities are supported by a dedicated RMON (remote monitoring) data-collection and monitoring engine residing in a device. Communicating—for example, setting collection rules and receiving notifications from the engine—is performed through SNMP. RMON addresses ISO Layers 1 through 3, while RMON2 addresses ISO Layers 4 and above.
The syslog protocol is used by Cisco devices to issue unsolicited notifications to a management station. Although similar in nature to SNMP traps, the syslog protocol is only used for event notification. The CISCO-SYSLOG-MIB is being implemented on Cisco devices as an alternative to issuing syslog messages, to allow any SNMP manager to receive all events through SNMP.
This section presents Cisco's conceptual event model as applied to Cisco equipment. But, first introduced are the event types available from Cisco switches and routers.
All Cisco devices generate SNMP traps to notify NMS applications of activity and error conditions. In addition, IOS-based devices generate syslog messages.
Cisco's IOS syslog logging utility is identical to the UNIX syslog utility, namely a UDP-based logging mechanism for applications and operating systems to report activity or error conditions. All routers and most switches generate syslog messages. This means that any UNIX management workstation (preferably your UNIX network-management station) can serve as the syslog server for all your Cisco equipment. Every syslog message is associated, at the time of logging, with a time stamp, a facility, a severity, and a textual description.
See the CCO Web site for a listing of all SNMP traps supported by Cisco. Cisco-supported SNMP traps can also be found in Cisco-supported MIB files.
Public and Private SNMP Traps All Cisco devices generate SNMP traps. In addition, because most Cisco devices support the standard RMON alarm and event MIB groups, additional localized polling of any MIB variables can be configured within a device to monitor for thresholds and generate SNMP traps as needed.
Syslog SNMP Traps More and more Cisco routers implement the Cisco Syslog MIB as a means to generate SNMP traps in place of, or in addition to, syslog messages. This MIB enhances Cisco device management through SNMP by adding a greater number of unsolicited messages that an NMP may receive, and therefore enhance router manageability.
To enable syslog traps on a router, use the following command:
snmp-server enable traps syslog
In addition, the following command specifies the level of messages to be sent:
logging history level
SNMPplatforms may generate their own events, or their own SNMP traps, as a result of performing remote polling of specific MIB objects and applying thresholds to these MIB objects. In addition, event-correlation engines and network-performance reporting applications may generate their own events to the NMP.
Event processing ischaracterized by the following four activities.
The basis for a comprehensive event-correlation engine is to feed it as many events as possible to get the maximum amount of filtering and correlation desired.
A high-performance event-collection engine is required to accept all events received. An event-collection engine needs to process SNMP traps and syslog messages.
Processing and reporting events must be accompanied by a comprehensive explanation of the event and how it relates to the operation of the device, and possibly of the network.
Excessive and repetitive events are known to occur and clutter a network-management system to the point where network operators shut off the feature and rely on their intuition and user complaints. Therefore, it is important to provide an effective means to reduce the number of events reported to network operators by removing repetitive messages (for example, identical messages repeated within a given time period) and to eliminate low-priority events (for example, events not deemed to require operator notification).
After events are filtered, it is still important to assess the critical nature of an event as it relates to a device or to other events. A router down event may be ignored temporarily, for example, if you know the router is restarting as a result of a software error. If the router does not come back online after 5 minutes, however, the operator should be notified immediately.
This section introduces a model to manage a high volume of traps and syslog messages and correlate them to your network; so now the information becomes practical rather than overwhelming.
The following proposed event model is a conceptual model for correlating Cisco events. It assumes syslog messages as well as SNMP traps generated either directly by the device or as a result of SNMP thresholding through the RMON alarm and event groups. All these event types serve as input into the event model.
Events are first filtered to eliminate as many events deemed of no interest as possible, as driven from a knowledge database. This operation minimizes the processing required in the subsequent phases of the event model.
Events of interest are then normalized to a common form to ease the processing in the event-correlation engine. Normalization may also involve modifying the severity of an event to more accurately reflect the priority of an event at a specific site.
The event-correlation engine is composed of several correlation conditions that may eliminate events, pass them straight through at all times, only pass them straight through if one or more other conditionsoccur within a specific time window, modify events, or create new events. Each condition is specific to a device, a type of device, or to all devices depending on the scope of the correlation rules. Correlation rules can make use of external information such as physical or logical topology to better isolate a faulty device. Correlation rules can also issue additional requests to one or more devices if they need to obtain additional information at any point in a correlation rule.
Figure 14-1 illustrates the conceptual model.
Although Figure 14-1 shows CLI commands to communicate with a device, this option is usually not needed because syslog messages and SNMP MIBs provide all information needed to manage these devices.
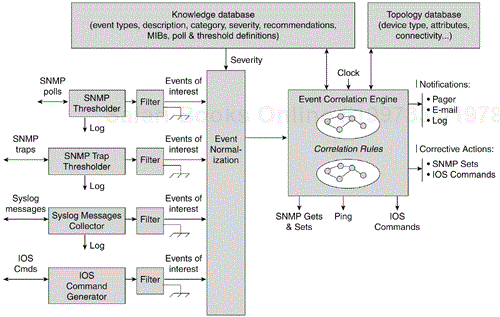
Every event-correlation system (ECS) has its own way of mapping Cisco's event model to its own implementation. Implementing the event model in a third-party correlation engine may require custom programming or scripting depending on the engine capabilities.
Table 14-2 identifies whereCisco's event model components described earlier may exist in a third-party event-correlation engine.
Table 14-2. Cisco Event Model Components
| Event Model Component | Event-Correlation Engine Mapping |
|---|---|
| Knowledge database | A relational database about all Cisco IOS syslog messages and recommendations, and Cisco SNMP traps. Would need to be populated from Cisco's existing syslog message knowledge base with additional severity mapping software/tables. |
| Topology database | This topology is usually available from the NMS platform through published APIs or an export facility. |
| SNMP thresholder | This is supported either through the platform or polling engine or through Cisco's built-in RMON alarm and event MIB groups. |
| SNMP trap collector | This is supported through the existing platform or correlation engine trap collector. |
| Syslog message collector | A custom module built to receive syslog messages and parse them appropriately. |
| IOS Command Generator | Typically a Telnet client. Can either be scripted or built in to the correlation engine. |
| Event Normalization | Every platform or engine has its own proprietary methods for normalizing an event. |
| SNMP Gets & Sets | Can either be scripted or built in to the NMS platform or correlation engine. |
| Ping (ICMP) queries | Can either be scripted or built in to the NMS platform or correlation engine. |
| IOS Commands | Typically a Telnet client. Can either be scripted or built in to the correlation engine. |
| MIBs | Cisco MIBs are available for uploading into the NMS or correlation engine and serve as the basis for the knowledge base. |
| Paging notifications | E-mail is usually supported either in the NMS platform or the correlation engine. Paging systems are usually available from third-party vendors. |
| Corrective actions | Can be invoked from within the NMS or correlation engine as a correlation rule becomes true, in an attempt to correct the faulty condition. |
Because most fault management is about detecting faults and performing root-cause analysis, less emphasis is placed on automating corrective actions in this chapter.
This section is a series of steps to follow to implement effective management of your network.
Good network-management starts with good network design. This includes the following steps:
Secure the wiring closets, and grant access in a controlled manner only. An unlocked closet is begging to be disturbed.
Document the physical network, including the network equipment and the wiring. You need to know which devices are connected to which ports of each switch and router. You then must be able to identify which cables actually connect those devices.
Define and adhere to move/add/change policies in which all network modifications are documented and planned in advance whenever possible. Physical maps and inventories should always reflect any changes.
As switches become more affordable, they are replacing hubs and media attachment units (MAUs) in the wiring closet. Typically, customers migrate from hubbed to switched networks by replacing hub ports with switch ports. Users and servers are migrated incrementally by moving a connection from the hub to a switch port.
The traditional broadcast domain or segment of Ethernet that was commonly used to monitor no longer exists. It was a shared media that any one port would give users (through an analyzer) a complete picture of what was happening for all traffic. In a switched environment the broadcast domain (VLAN) may span multiple switches, closets, and buildings. Unicast traffic and sometimes multicast traffic is segregated to only the ports that need to see it.
Traditionally, a traffic analyzer could be used to look at all traffic on a segment and determine which devices were the busiest, overloaded, underutilized, and so forth. In a switched environment, that overall picture does not exist anywhere in the network. The traffic on each port of a VLAN is different (except for ports with only one active device— the switch). Even if a SPAN port is used, it gives only a picture of what exists on a single switch, which is only part of that same VLAN, which may coexist on multiple switches.
Although the broadcast rate still imposes a limit on the growth of a VLAN (just like it did on shared media), it is only part of the picture. Because it is not practical for most of us to monitor every single switched port (to get a complete picture), we need to identify, document, and maintain only the "critical" switched ports.
A "critical" switched port is one that is vital to the success of the network's operation. Examples of critical switched-port connections include the following:
File/application servers ports
Router ports
Trunk ports
Mahogany Row ports (those executives whose ports should never go down)
Client ports (with the exception of Mahogany Row) should never be considered critical. Trying to maintain management data for that many ports can be overwhelming and overload switch resources. In addition, getting an alert whenever a user turns off her PC does not provide useful data in comparison with a warning of a trunk or router port going down in an unplanned fashion.
After the critical ports have been identified, they should be documented, physically marked, and maintained through move/add/changes. If not, network operators run the risk of reacting to ports conditions that were once critical, but are now noncritical based on an undocumented change.
The remaining keys discuss management strategies for critical ports. Setting up network availability reports by device or by critical port of a switch can provide management with an important metric for decision making.
Fault monitoring consists of availability monitoring, SNMP trap logging and processing, and syslog message logging and processing. If not already done, your network devices should be configured for SNMP access, SNMP trap generation, and syslog message generation with time stamps. Synchronize the clocks on your network devices and your network-management station (NMS) with NTP to greatly improve event-correlation capabilities.
The simplestway to monitor device availability is to check responses to a ping (ICMP) or SNMP get request. Standard NMS products monitor all the objects they manage through these simple mechanisms. Although a ping response is not a guarantee that the switch is functioning properly, the lack of such a response is a definite sign of a problem. Using an NMS with availability monitoring linked to the color of a device on a topology map is the most common example of fault monitoring.
Configure routers and switches to send their console messages to a syslog server, typically being the NMS. A Catalyst 5000 series switch can buffer the last n syslog console messages it generates by saving them in a 1-KB buffer. Although these are useful for quick reference from the command-line interface (CLI), it is recommended to log these messages to a syslog server for persistence, later reference, and correlation.
Log messages are system messages that would normally be sent out on the console port; for example: "11/4/1996,13:52:54:SYS-5: Module 3 failed configuration". Cisco routers and switches generate many different kinds of system messages.
Switch syslog messages are formatted with two parameters: the facility and severity. You must choose one of eight facilities (local0–local7), and then choose the facility based on the facilities your syslog server is already logging. It is best to choose a facility that will be dedicated to your network devices. Cisco routers choose local7 by default, which is a good choice unless there is a conflict.
You can configure the severity level of each type of message you want the switch to send. You should log a severity level of "warning" and below of each type of system message so that you do not clog up the logs with superfluous messages that do not add useful information.
Although syslog information can be used for fault management, it is not a real-time fault alert mechanism like an SNMP trap (unless you do additional work to make it behave so). Syslog information is useful for event correlation, however. Parsing the syslog files for messages correlating to a certain event can provide useful insight to the cause of the problem. You can configure the syslog server to log messages of different severities to different log files or messages of all severities to one large file. You can then use tools such as Perl to search the syslog log files for the desired information. Tools such as Cisco Resource Manager (CRM) can gather syslog information and create reports based on severity and dates. Such tools can also summarize the syslog messages to make interpreting the messages easier.
SNMP traps provide a mechanism for a device to unilaterally notify a network operator of a certain condition in real time. SNMP traps are unsolicited notifications, independent of any SNMP polling activities. The SNMP traps generated by Cisco switches and routers provide useful information on potentially harmful environmental conditions, processor status, and port status. Every device will also generate SNMP traps based on the features it supports. For example, a Cisco switch will generate SNMP spanning-tree topology changes SNMP traps when a spanning-tree configuration changes because of a trunk or switch being added or removed from the network.
Initially, it is recommended to enable the module, chassis, bridge, authentication, and port linkup/down traps. The port-level traps require enabling the port trap on the "critical" ports with this command:
set port trap module|port enable|disable
Many NMS products have trap receivers that log traps and can be configured to react to traps in fairly sophisticated ways. You can be informed of the trap through a pop-up window, an audible alarm, or an electronic page.
After documenting the network, identifying business critical switched ports, and enabling monitoring the status of your switches and routers, it is time to learn the true nature of your network by monitoring data over time and studying the traffic flows.
By collecting information for a baseline of the network, you gain an accurate picture of traffic flows through the network and have data for evaluating growth over time and estimating bottlenecks. Over time, this collection of data can serve as baseline data when determining threshold values for the next step (discussed under the heading, Define and Set Thresholds). Baselines are also valuable troubleshooting tools when you are trying to determine the cause of performance problems.
Baselining of the network is also essential because of the increasing importance of capacity planning. According to Optimal (http://www.optimal.com), 85% of new application deployments fail to meet service-level agreements. Of the several reasons for this, here are a few:
Increased network complexity
High-bandwidth multimedia applications and increased burstiness of applications
Increased use of the network for nonbusiness applications (Internet and World Wide Web traffic)
More organizations upgrading existing networks and applications rather than building new networks
Baselining is the key to capacity planning. It enables network administrators to understand their current level of capacity and performance, which is required to understand new network or application additions. Baselining should be done on at least a quarterly basis to identify capacity and trends.
First, determine what information you want to watch over time. Some examples are as follows:
CPU utilization
Memory consumption
Interface utilization
Error rate, particularly cyclic redundancy check (CRC) errors
Multicast traffic
Broadcast traffic
This information should be collected over a period of time. A 2-week period is the recommended minimum, but measurements for up to 2 months may show normal fluctuations that must be taken into account. This minimum allows the normal "rhythm" of the network traffic to be recorded. The longer the study, the higher the probability that the network's true traffic patterns will become apparent. The samples should be collected frequently enough to accurately capture traffic fluctuations, but not so frequently that the fluctuations skew the data.
After the data is collected, you can either write scripts or purchase software that will collate the data and provide "top-10" type reports to identify problem areas or areas of high activity.
Collect performance and error information from critical switch and router ports, for example, every 15 minutes over 2 weeks. After 2 weeks, analysis should reveal the baseline traffic and error rates for each critical port. These averages will be necessary for the following steps.
This baseline data can be gathered in several different ways:
Use SNMP polling to gather the necessary data. Use NMS tools to establish baseline percentages of local and cross-campus traffic, and then allocate bandwidth appropriately. There are three types of traffic patterns that should be analyzed:
Local traffic—. Traffic that remains within a small part of the network
Cross-campus traffic—. Traffic that crosses the backbone of the network, travels through a router, or both.
Campus-to-Internet traffic—. Traffic going out to the Internet from the campus and coming in to the campus from the Internet
Use tools such asTrafficDirector with built-in RMON device capabilities or RMON external probes such as SwitchProbes to gather Ethernet, Token Ring, FDDI, and ATM statistics and histories from switches and routers. Although RMON 1 monitors traffic up to Layer 3, RMON 2 probes can be used to determine baselines at the higher layers of the Open System Interconnection (OSI) model. The baselining performed in a switch environment typically takes place only at the physical and data link layers of the OSI stack.
Use the CLI via Telnet to gather the statistics. This would have to be done with scripts, such as Expect or Perl. NMS or other commercial collection applications can also be used to collect this data through SNMP.
After your network is baselined, you should have an idea of what is "normal behavior" for different segments, particularly the critical ports. The next step is to set RMON thresholds. The RMON alarm and event groups enable you to set thresholds that cause the switch to send an SNMP trap when one of those thresholds is crossed.
To control the generation of alarms, two different threshold values must be defined:
Rising-threshold values—. These cause an alarm to be generated when the value of the sampled MIB object increases until it is greater than the rising threshold.
Falling-threshold values—. These cause an alarm to be generated when the value of the sample MIB object decreases until it is less than the falling threshold.
These alarms are not generated each time a threshold is crossed. There is a built-in hysteresis mechanism to limit the number of alarms generated. Each threshold acts as a re-arming mechanism to allow the opposite threshold to alarm again. A rising threshold on port utilization is set at 40%, for example, and the falling threshold is set at 25%. If port utilization is normally around 20% and suddenly rises to 50%, and then starts fluctuating between 35% and 50%, an alarm is generated only the first time the utilization crossed the rising threshold. Any subsequent time the utilization crosses from 35% to 50%, no alarm is generated. When utilization returns to around 20%, the falling threshold is crossed once again, causing a falling threshold alarm to be generated, and the rising threshold to be re-armed. This lets you know that the situation that caused the first alarm is over. This mechanism keeps you from receiving redundant traps informing you of a condition of which you are already aware. It also informs you when the incident is over.
To generate useful alarms you have to define sensible thresholds. Unfortunately, this is not always easy to do. In general, you should set thresholds on the data you have baselined. Set one threshold that will alert you when conditions are problematic and the opposite threshold to alert you when conditions have returned to normal.
Here is a list of guidelines for identifying appropriate thresholds:
For port utilization, multicast and broadcast traffic levels use the baselines you have collected.
Error thresholds for CRC errors should be very low—as low as one per hour. You should not have to baseline CRC errors, because the error rate for Ethernet is by specifications very low. Collisions are normal, so they should be baselined and the thresholds set accordingly.
If you set the thresholds too low, many alarms will be generated. Although you want the operators to be notified of events on the network, you do not want them overwhelmed by the number of messages they receive. In addition, too many alarms can cause operators to just ignore them.
If you set the thresholds too high, the operator will not notice important events early enough or the operator will have learned about a critical situation long after the trap is generated. It makes little sense, for example, to generate a trap when link utilization reaches 98% because end users will already have experienced a serious degradation in performance before the threshold has been reached.
Over the next few weeks, continue to observe collected data. By analyzing this data and monitoring the alarm rate, you can determine the effectiveness of your configured thresholds, and adjust them accordingly.
Adjusting the threshold rates is a process that continues as the network continues to grow and network traffic increases and changes.
With the introduction of alarms and events, it is no longer necessary to actively poll for traffic statistics because the device can monitor itself through the use of RMON events and alarms. Basic fault polling, such as ICMP or SNMP polling, is still necessary because if a device fails, it is not able to advertise its own failure.
Overall, you can disable RMON history collection as you move into the baseline phase of data collection. This reduces CPU and memory consumption on the switch. However, you will probably want to continue monitoring critical switch trunk ports.
You may choose to collect further baseline data after defining your critical ports and alarm thresholds. Baseline data comes in handy if you want to study the network's growth over time and measure the performance of the switched network. Trend analysis and capacity planning come into play when actively base lining or polling your switched network.
Think carefully about the frequency with which you poll. Polling every 5 minutes for many switch ports is excessive, for example. See the sections "Network-Management Protocols" and Cisco Catalyst Switch Recommendations for specifics on what to actively monitor and poll on switches and routers, respectively, and how to gather this on-going information. SNMP polling, RMON alarms and events, and/or CLI commands can be used to gather this information.
So far, this chapter has outlined the data you need and the processes you should use to manage the switches in your network. This section provides the details of how to implement that strategy on Catalyst Series switches. Switch network management involves much more than just monitoring, SNMP polling, and MIB gathering. It needs to start from the very first switch design layout through the late deployment stages of the switched network. Several areas need to be addressed relating to managing a switched network: design and configuration recommendations, SNMP polling, SNMP traps, syslog, and RMON. See the CCO Web site for information on configuring network management in a Catalyst 5000.
Prior to the rollout of switches into the network, the following network design and configuration recommendations need to be considered.
Root bridges should be statically defined in the core distribution switches when using spanning tree. Spanning tree should be activated on all trunk ports. Optionally, you may want to activate spanning tree on end-user switch ports as well, in case a loop is mistakenly created in the network. Such a small precaution can prevent your network from grinding to a halt when a loop is created.
You can obtain the same data from a switch in a variety of ways. The method you use depends on many factors:
The size of your network
Your network-management needs
The tools you have available to collect and process this data
For very small networks, the simple CLI may suffice. For larger, more complex networks, an NMS with SNMP pollers, SNMP trap processors, and a relational database may be necessary. For most situations, it will end up being a combination of both along with some Perl and Expect scripts to fill in the gaps. The following subsections cover what data to collect, how to get that data, and then how to turn that data into useful information. The following sections describe the data you can obtain from CLI commands and specific SNMP MIB objects.
This section also covers basic fault management through SNMP traps and syslog messages.
You can collect all the performance data you need for polling and monitoring by initiating a Telnet session to the switch and issuing various CLI commands. Traffic and error statistics for each port as well as critical data on the general health of the switch are available through the CLI. Obviously, this method does not scale for large numbers of switches or for continuous monitoring of any number of switches. It is an effective tool, however, for obtaining real-time data when troubleshooting a problem. It is also a necessary tool to obtain the data that is not available via SNMP. You can use scripting languages such as Expect and Perl to obtain this data on a periodic basis or in response to the detection of some fault condition. The CLI commands to obtain specific data are covered later in this section.
The most common method for collecting performance data is to use SNMP. Through SNMP polling, you can collect RMON MIB, MIB-2, and other enterprise-specific data. This data includes traffic statistics for your critical ports. It may also include enterprise-specific data for overall switch performance, such as backplane utilization.
Commercial NMS platforms are common methods of managing a network through SNMP. Typically, you can use the polling services in such a package to periodically poll your switches for specific information and store the data in some type of database. The database may be simple flat files or a relational database management system (DBMS). Generating reports from this data may consist of importing the flat files into a spreadsheet or using the reporting utilities of the DBMS. You may also opt for creating your own SNMP tools using a scripting language such as Perl. Perl is also useful for creating reports from flat files.
Cisco TrafficDirector is an example of additional specialized management packages. They are similar to the more general NMS products mentioned previously, but they specialize in a certain type of data, such as RMON or MIB-2 traffic statistics. These packages generally produce a number of basic reports with options for customizing them for your needs.
After you have the means to gather the data, you must decide what data to poll. More than one MIB object may contain the same data. For example, the RMON etherStatsTable, the MIB-2 ifTable, and the dot3 MIB all contain objects that provide similar traffic and error statistics on Ethernet ports. Which one is better to poll? We recommend using the etherStatsTable for most polling purposes. Many commercial applications already poll the etherStatsTable for this data and have ready-made tools for processing the data and generating reports. It is also easy to take advantage of the RMON history collection features to reduce polling overhead. Note that some Catalyst Cisco IOS versions allow the setting of RMON thresholds on objects in the etherStatsTable only. Because we want to baseline objects on which we can set RMON thresholds, the etherStatsTable is a good first choice. Some traffic statistics that are useful to baseline are total traffic (etherStatsOctets), multicast traffic (etherStatsMulticastPkts), and broadcast traffic (etherStatsBroadcastPkts).
Some error statistics to monitor are error frames (etherStatsCRCAlignErrors) and perhaps Ethernet fragments and jabbers (etherStatsFragments and etherStatsJabbers). Monitoring Ethernet collisions in a switched network is usually only useful on shared segments.
For detailed definitions of the MIB objects you are polling, there is no better source than the MIB document itself. All the MIB documents Cisco devices support are available in the public MIBs area on Cisco's Web site. The "v1" and "v2" directories contain ASN.1 MIBs complete with object definitions in SNMP v1 or SNMP v2 syntax, respectively. Most NMS stations can compile these files directly into a MIB database with no modification. The "oid" and "schema" directories are provided for other NMS stations that require the MIB data in this format. The "oid" directory is also handy for finding the full object identifier (OID) of a particular object if you are writing your own scripts to collect this data. The "support_list" directory is a loose guideline for determining which objects certain devices and Cisco IOS levels support.
After your switched network is installed and configured accordingly, you need to have an NMS station set up to do SNMP polling. SNMP polling for switches is similar to SNMP polling for routers; however, the amount of and type of MIB variables polled for are different. A great number of interface or port MIB variables will not be polled using SNMP, due to the density of the ports on switches and the unknown state of switch ports directly connected to PCs or workstations that may be turned off at any time. SNMP is very useful for monitoring switch and trunk port health. User ports can be managed by relying only on SNMP link up/down traps or by using the built-in RMON capabilities. The switch MIB variables addressed in this discussion come directly from the following MIBs: RFC1213, CISCO-STACK-MIB, ETHERLIKE-MIB, and BRIDGE-MIB.
The following three polling sections are taken directly from the "Guidelines for Polling MIB Variables" as it applies to routers. The same principles can be applied to a switched environment as well, but with different MIB variables.
Before discussing what to poll for, we must first determine what the purpose of polling is. Let's say that there are three major purposes for polling devices: to determine the availability of a device (monitor polling), to determine if an error condition has occurred or is approaching (threshold polling), and to analyze data for trends or performance measurements (performance polling).
The aim of monitor polling is to detect when network changes have occurred and to generate an immediate alarm. Monitor polling is to detect "hard errors" such as a device not responding or an interface status change. Any alarm generated by monitor polling should be acted on immediately. If your network management system is monitored on a 24×7 basis, a monitor polling alarm should create a visible and audible alarm on the system, so that the operator can take immediate action. If you do not have your network management system monitored on a 24×7 basis, it is recommended that any monitor polling alarm generate an alarm to the appropriate person, possibly via pager or e-mail.
Monitor polling applications are included with most commercial SNMP platforms and SNMP-based management applications. The purpose of monitor polling applications is to analyze the data points and generate an alarm when necessary.
The aim of threshold polling is to determine when escalating error conditions are occurring and take actions before performance is severely impacted. A wide variety of problems surface originally as increased error conditions. These conditions may eventually become a "hard error," or may present themselves as phantom problems that come and go. Threshold polling is a tool to detect these problems.
To implement threshold polling, the first decision is to determine which MIB variables to poll for (MIB variables for switches follow in this section). Users who are starting out with threshold polling may start with the suggested variables that follow, and then add any other applicable MIB variables that are appropriate for their network.
After the threshold MIB variables are decided upon, you must establish baseline values for these variables. This can be done by starting a poll process on the MIB variables for a period of time (1 week, for example). You must then review the data collected. Baselining should be performed during peak traffic patterns to be most representative of unusual conditions. The more static your network is (yearly adds, moves, and changes), the less baselining you need to perform, while the more dynamic your network is (monthly adds, moves, and changes), the more baselining you need to perform. With this data in hand, determine what values would be out of specification. A rule of thumb is to set thresholds 10%–20% higher than the maximum value seen.
The threshold values for any particular MIB variable may be applied uniformly across all switches, or they could be customized for groups of switches that have similar characteristics (for example, core, distribution).
Another decision to be made is what kind of notification is appropriate for threshold violations. Threshold violations are not indications of hard errors, so immediate notification is usually not in order. Logging all threshold values and reviewing on a daily basis is usually the most appropriate means of notification. It is very important that repeated threshold violations be investigated. It can then be determined if a problem has occurred that can be corrected, or if the violations are a result of the threshold values being too low for the circumstances.
The aim of performance polling is to gather data that can be analyzed over time to determine trends and to aid in capacity planning. As with threshold polling, the determination of what MIB variables to poll for is the first consideration. Later in this section, some suggestions are made on which MIB variables would be most useful for performance polling of switches.
For performance polling, individual data points (raw data) are stored intermittently on the polling machine. Depending on what polling mechanism you are using, the data could be in either a raw format or in a relational database.
To best keep the data manageable, the raw data should periodically be aggregated, and stored in another database or file to be kept for future reporting. The raw data can be kept for a period of time for backup purposes, but eventually this data should be purged and only the aggregate data is kept. The last step in the process is to produce reports from the aggregate data that will be periodically reviewed for trending or capacity planning purposes.
To best describe this process, here's an example of a company's performance polling system:
Individual MIB variables are grouped together in a series of polling groups. Each group is polled every 5 minutes and the data is stored in a Sybase database according to the name of the poll group. Every morning at 12:01 a.m., the raw data in Sybase is aggregated into minimum, maximum, and averages for each hour and stored in another Sybase database (the user has written SQL programs to accomplish this).
Every Saturday morning at 1:00 a.m. the individual raw data points are purged from the database for the previous week. On the first day of the month, the hourly min/max/ avg data is aggregated into daily min/max/avg data and stored in another database. A series of reports are generated from both the daily and hourly data for review at the Capacity Planning meeting on the first Tuesday of the month. After the reports are produced the data from the hourly database is archived to tape.
For more detailed information on performance monitoring, see the IBM reference book (IBM Red Books) titled Monitoring Performance In Router Networks, Document GG24-4157-00.
As mentioned previously, most Catalyst switches support "mini- RMON," which consists of four basic RMON-1 groups: statistics, history, alarms, and events. For baselining purposes, the etherStats group provides a useful range of Layer 2 traffic statistics. You can use the objects in Table 14-3 to get statistics on unicast, multicast, and broadcast traffic as well as a variety of Layer 2 errors. The RMON agent on the switch can be configured to store these samples in the history group. This mechanism enables you to reduce the amount of polling without reducing the sample rate. Using RMON histories can give you more accurate baselines without substantial polling overhead. The more histories you collect, however, the more switch resources you use.
The most powerful part of RMON-1 is the thresholding mechanism provided by the alarm and event groups. RMON thresholding enables you to configure the switch to send an SNMP trap informing you of an anomalous condition. Now that you have identified all your critical ports and used SNMP polling (and maybe RMON histories) to create baselines showing normal traffic activity for those ports, you are ready to set RMON thresholds. Set the thresholds to generate an alarm when there is a large variance from the baseline for that particular port. Then, set the thresholds to notify you when the traffic returns to baseline levels for that port.
The setting of these thresholds is best done using an RMON management package. Properly creating the rows in the alarm and event tables is tedious and complex. Commercial RMON NMS packages such as TrafficDirector incorporate graphical user interfaces (GUIs), which make the setting of RMON thresholds much easier.
Although switches provide only four basic groups of RMON-1, it is important to not forget the rest of RMON-1 and RMON-2. You can get Layer 3 and higher information on your switches using the SPAN port feature and an external RMON probe such as a Cisco SwitchProbe. A SwitchProbe supports RMON-2 and can take a feed from a SPAN port to monitor full RMON data on any given port or a whole VLAN on a particular switch. You can use a SPAN port and a SwitchProbe to capture a packet stream for a particular port (using the packet capture group of RMON-1) and upload the packets for decoding to an RMON management package. You can also use the SPAN port and an external SwitchProbe to give network and application layer statistics on a particular port or VLAN. The SPAN port is SNMP-controllable via the SPAN group in the CISCO-STACK-MIB, so this process is easy to automate. TrafficDirector makes use of these features with its "roving agent" feature.
There are caveats to spanning a whole VLAN. Even if you use a 100-Mbps probe, the entire packet stream from one VLAN or even one 100-Mbps full-duplex port may exceed the bandwidth of the SPAN port. Use care to see that you are not overloading the SPAN port. If the SPAN port is running at full bandwidth continuously, chances are you are losing data.
It is important to remember that the primary function of a switch is to switch frames—not to act as a large multiport RMON probe. Therefore, as you are setting up histories and thresholds on multiple ports for every condition imaginable, keep in mind that you are stealing resources the switch could otherwise use for its primary purpose—forwarding network traffic. Also remember the critical port rule: Only poll and set thresholds on the ports which you identified as critical.
RMON memory usage is constant across all switch platforms relating to statistics, histories, alarms, and events. RMON uses what is called a "bucket" to store histories and statistics on the RMON agent (which is the switch in this case). The bucket size is defined on the RMON probe (SwitchProbe) or RMON application (TrafficDirector), and then sent to the switch to be set.
Around 450 KB of code space will be added to the NMP image to support mini-RMON (four RMON groups: statistics, history, alarms, and events). The dynamic memory requirement for RMON varies because it depends on the run-time configuration. Table 14-3 explains the run-time RMON memory usage information for each mini-RMON group.
Table 14-3. Run-Time RMON Memory Usage
| RMON Group Definition | DRAM Space Used | Notes |
|---|---|---|
| Statistics | 140 bytes per switched Ethernet/Fast Ethernet port | Per port. |
| History | 3.6 KB for 50 buckets | Each additional bucket uses 56 bytes. |
| Alarm and Event | 2.6 KB per alarm and its corresponding event entries | Per alarm per port. |
There is a single pool of DRAM for dynamic allocation. Every feature/process draws from this pool. In Catalyst 5000, Release 3.1 and later, use the show version command to see the amount of used and free DRAM. Use the preceding formulas to determine the RMON memory requirements. Saving the RMON-related configuration takes approximately the following memory:
10 KB NVRAM of space if the system total NVRAM size is 128 KB
20 KB of NVRAM space if the system total NVRAM size is 256 KB or more
The CPU impact of using RMON collection and alarms in a Cisco switch can best be described as follows:
Statistics group—Only requires CPU cycles when it's processing an SNMP get request for a port's RMON statistics; very minimal impact otherwise, because etherStats are collected in hardware.
History and alarm/event groups—Uses a few CPU cycles for each polling interval per port (that is, for every history snapshot and each alarm threshold that it must evaluate). The impact depends on the polling interval and number of ports. The CPU overhead should be minimal with a Sup2 or Sup3 (assuming less than 150 ports and polling intervals of 30 seconds or more).
Configuring syslog on the Catalyst 5000 series switches consumes 1 KB of memory (supported in software version 2.2 and higher) to save the last syslog messages generated.
Some standard MIBs assume that a particular SNMP entity contains only one instance of the MIB. Therefore, the standard MIB does not have any index that would enable users to directly access a particular instance of the MIB. In these cases, we provide community string indexing to access each instance of the standard MIB. The syntax is community string@instance number.
The Catalyst switch includes one instance of the standard BRIDGE-MIB for each VLAN in the switch, for example. If the read-only community string is "public" and the read-write community string is "private," you could use public@25 to read the BRIDGE-MIB for VLAN 25 and use private@33 to read and write the BRIDGE-MIB for VLAN 33. Only using the community string public or private will result in always accessing the BRIDGE-MIB for VLAN 1 (default behavior).
Traps sent from a MIB indexed by a community string also indicate the instance of the MIB to which it corresponds by using community string indexing. An STP newRoot trap from the BRIDGE-MIB for VLAN 25, for example, would have a community string ofpublic@25 in the trap community field, assuming the read-only community string is public.
Also note that community string indexing does not affect access to MIBs that have only one instance. Therefore, public@25 can be used to access RFC1213-MIB at the same time as the BRIDGE-MIB for VLAN 25 is being accessed.
Another example for the Catalyst switch is the SNMP-REPEATER-MIB. To access this MIB for a particular repeater in the Catalyst switch, use community string@module number/port number. If the read-only community string is public, for example, you can use public@3/1 to read the SNMP-REPEATER-MIB for the repeater attached to port 1 on module 3.
To determine the available VLANs on a given Catalyst switch, you must query the vlanTable MIB group from the CISCO-STACK-MIB using the VLAN ID as index.
Starting with Cat5xxx Release 4.1(1), the newRoot and topologyChange traps defined in the BRIDGE-MIB have the vlanIndex appended in their varBind list. This eliminates the need for SNMP platforms and applications to decode the community string within the trap. Here are two examples of the new traps supported:
Received SNMPv1 Trap: Community: public@2 Enterprise: dot1dBridge Agent-addr: 172.10.17.31 Enterprise Specific trap. Enterprise Specific trap: 2 (This is a topologyChange trap) Time Ticks: 27654316 vtpVlanIndex.1.2 = 2 (This is the VLAN number) ifName.97 = 4/2 (This is the interface index) Received SNMPv1 Trap: Community: public@3 Enterprise: dot1dBridge Agent-addr: 172.10.17.31 Enterprise Specific trap. Enterprise Specific trap: 1 (This is a newRoot trap) Time Ticks: 27651818 vtpVlanIndex.1.3 = 3 (This is the VLAN number)
For a summary of community string indexing, see the CCO Web site.
Onefrustrating issue is trying to decipher which port created a certain trap. Knowing that a trap came from ifIndex 100 does not help pinpoint the source of the trap, but knowing that the trap came from port 1/1 is very useful. We use the IF-MIB to map ifIndex to a port number. If you poll the ifXTable for ifName, you can get a correspondence between ifIndex and the actual port. If you received a trap for ifIndex 17, for example, you could poll ifName to find the port, as shown here:
$ snmpwalk robotron ifName
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.1 : DISPLAY STRING- (ascii): sc0
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.2 : DISPLAY STRING- (ascii): sl0
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.3 : DISPLAY STRING- (ascii): 1/1
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.4 : DISPLAY STRING- (ascii): 1/2
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.5 : DISPLAY STRING- (ascii): 2/1
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.6 : DISPLAY STRING- (ascii): 2/2
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.7 : DISPLAY STRING- (ascii): 2/3
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.8 : DISPLAY STRING- (ascii): 2/4
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.9 : DISPLAY STRING- (ascii): 2/5
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.10 : DISPLAY STRING- (ascii): 2/6
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.11 : DISPLAY STRING- (ascii): 2/7
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.12 : DISPLAY STRING- (ascii): 2/8
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.13 : DISPLAY STRING- (ascii): 2/9
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.14 : DISPLAY STRING- (ascii): 2/10
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.15 : DISPLAY STRING- (ascii): 2/11
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.16 : DISPLAY STRING- (ascii): 2/12
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.17 : DISPLAY STRING- (ascii): 2/13
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.18 : DISPLAY STRING- (ascii): 2/14
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.19 : DISPLAY STRING- (ascii): 2/15
ifMIB.ifMIBObjects.ifXTable.ifXEntry.ifName.20 : DISPLAY STRING- (ascii): 2/16
The output of this indicates that port 2/13 generated the trap.
Use the set snmp commands to set all SNMP parameters: community strings, RMON, and other SNMP traps. Table 14-4 explains these commands.
Table 14-4. IOS SNMP Configuration Commands
Details of all these set commands for Release 4.2 can be found on the Cisco Web site.
The common tools for fault management include logging SNMP traps (which include the RMON threshold traps) and syslog messages, and then processing the data and reacting appropriately. Most NMS packages provide a trap daemon that receives and logs SNMP traps, and then provides some mechanism for reacting to that trap. Some typical mechanisms used are pop-up messages and audible alarms on the NMS station or the execution of a paging script. More complex reactions may be to execute an Expect script that collects time-critical data to determine the state of the switch immediately following the occurrence of a fault, or perhaps trigger a packet capture from the appropriate port using an external RMON probe. Several such scenarios are described later in this chapter.
Regarding syslog messages, most (if not all) UNIX systems provide a syslog daemon. Commercial and public domain syslog daemons are also available for Win95 and WinNT systems. These daemons usually log all switch messages into a particular file. Then, a Perl script or some other reporting tool can be used to parse the log file into usable information. Cisco Resource Manager has a Syslog Analyzer, for example, which creates reports from syslog messages based on message severity levels or based on the devices generating the messages.
Most commercial NMS products understand standard basic SNMP traps (such as linkUp and linkDown traps) and RMON thresholds. But for Cisco-specific traps, you must configure the NMS to format the traps so that they are readable and recognizable. The CCO Web site contains information on formatting traps for HP OpenView Network Node Manager and Tivoli Net View in the trapd.conf file.
Cisco-specific MIBs can be found in Cisco MIBs, such as those listed in Table 14-5.
Table 14-5. List of SNMP Traps for Cisco Switches
| MIB Document | Specific Traps |
|---|---|
| CISCO-STACK-MIB | Module traps: |
| • lerAlarmOn | |
| • lerAlarmOff | |
| •moduleUp | |
| • moduleDown | |
| Chassis traps: | |
| • chassisAlarmOn | |
| • chassisAlarmOff | |
| IP permit traps | |
| • IpPermitDeniedTrap | |
| BRIDGE-MIB (RFC 1493) | STP traps |
| RFC 1157 | Authentication trap |
| CISCO-VTP-MIB | VTP traps: |
| • vtpConfigRevNumberError | |
| • vtpConfigDigestError | |
| • vtpServerDisabled | |
| • vtpMtuTooBig | |
| • vtpVlanRingNumberConfigConflict | |
| • vtpVersionOneDeviceDetected | |
| CISCO-VLAN-MEMBERSHIP-MIB | VLAN Membership Policy Server (VMPS) traps |
| SNMP-REPEATER-MIB (RFC 1516) | Repeater traps |
| IF-MIB (RFC 1573) | LinkUp and LinkDown traps for each port |
Switch resource status is information needed to validate the overall health of the switch as it pertains to traffic, system, CPU, and memory utilization.
The following variables are useful in determining the backplane utilization of the switch. The same counters are used when displaying the red traffic level indicators on the front of the supervisor card. However, these variables should not be confused with CPU or memory utilization.
The following information is available at the CCO Web site:
SysTraffic—. Traffic meter value—for example, the percentage of bandwidth utilization for the previous polling interval.
SysTrafficPeak—. Peak traffic meter value since the last time the port counters were cleared or the system started (see sysClearPortTime).
SysTrafficPeakTime—. The time (in hundredths of a second) since the peak traffic meter value occurred.
SysTrafficMeterTable—. Traffic in the system processor and on internal system buses. Only applies to Catalyst 5000 Supervisory III modules.
Use the commands described in this section as an additional method of gathering switch resource data.
This indicates supervisor queue drops, similar to input queue drops on routers, and shows traffic destined to supervisors, such as bridge protocol data units ( BPDUs). This command applies to supervisor engine 1 and 2. The main field of interest in its output is RsrcErrors:
switch 5000 (enable) show biga BIGA Registers: cstat: 00 upad : FFFF pctrl : 0000 nist : 0000 sist : 0018 hica : 0000 hicb : 0000 hicc : 00 dctrl: F5FF dstat: 0000 dctrl2: 80 npim : 00F8 thead: 101F196C ttail: 101F196C ttmph : 101F196C tptr : 104347E2 tdsc : 00000500 tlen : 0000 tqsel : 05 rhead: 101F1220 rtail: 101F1204 rtmph : 101F123C rptr : 10586C80 rdsc : 804D0000 rplen: 101F1234 rtlen : 00000000 rlen : 1600 fltr : 00FF fc : 00 Rev : 04 CFG : 02020202 BIGA Driver: Initializd: TRUE SpurusIntr: 00000000 NPIMShadow: 00F8 BIGA Receive: RxDone : FALSE First RBD : 101EF894 Last RBD : 101F1478 SoftRHead : 101F1210 SoftRTail : 101F11F4 FramesRcvd: 04572393 BytesRcvd : 589914384 QueuedRBDs: 00000256 RsrcErrors: 00000000 BIGA Transmit: First TBD : 101F1494 Last TBD : 101F1B78 SoftTHead : 101F19D4 SoftTTail : 101F19D4 Free TBDs : 00000064 No TBDs : 00000000 AcknowErrs: 00000000 HardErrors: 00000000 QueuedPkts: 00000000 XmittedPkt: 11353833 XmittedByt: 909016542 Panic : 00000000 Frag<=4Byt: 00000306
This indicates supervisor queue drops, similar to input queue drops on routers, and shows traffic destined to supervisors, such as BPDUs. This command applies to supervisor engine 3. The main field of interest in its output is RsrcErrors:
switch 5000 (enable) show inband Inband Driver: DriverPtr: A0559F20 Initializd: TRUE SpurusIntr: 00000000 RxDone: FALSE TxDMAWorking: FALSE RxRecovPtr: 00000000(-1) FPGACntl: 004F Characteristics:0000 LastISRCause: 04 Transmit: First TBD : A055E7A4(0 ) Last TBD : A055F784(0 ) TxHead : A055F5A4(112) TxTail : A055F5A4(112) AvailTBDs : 00000128 QueuedPkts: 00000000 XmittedPkt: 07626990 XmittedByt: 581073462 PanicEnd : 00000000 PanicNullP: 00000000 BufLenErrs: 00000000 Len0Errs : 00000000 Frag<=4Byt: 00000162 SpursTxInt: 00000000 No TBDs : 00000000 NullMbuf : 00000000 Receive: First RBD : A0559FA4(0 ) Last RBD : A055E780(511) RxHead : A055AE44(104) RxTail : A055AE20(103) AvailRBD : 00000512 RsrcErrors: 00000824 PanicNullP: 00000000 PanicFakeI: 00000000 FramesRcvd: 18507368 BytesRcvd : 1676456769 RuntsRcvd : 00000000 HugeRcvd : 00000000 GT64010 IntMask: F00F0000 IntCause: 0330E083 GT64010 TX DMA (CH 1): Count: 0000 Src : 0134B062 Dst : 4ff10056 NRP : 0 0000000 Cntl : 15C0 GT64010 RX DMA (CH 2): Count: 0680 Src : 4FF20000 Dst : 01c3e580 NRP : 0 0558590 Cntl : 55C0 PSI (PCI SAGE/PHOENIX Interface) FPGA: Control : 004F TxCount : 0056 RxDMACmd: 35C0 RxBufSiz: 0680 MaxPkt : 0680 IntCause: 0002 IntMask : 0003
This output shows the memory used on the NMP. This data should be collected when your initial baseline is performed. You can trend the memory usage on the switch. The "clusters" and "mbufs" fields represent two areas of working memory. The second line of output in this code shows the total number of clusters and mbufs available to the system. The third line shows how many are free at the moment the output is displayed. The fourth line shows the "low-water" mark since the switch was last booted:
switch 5000 (enable) show mbuf MBSTATS: mbufs 10224 clusters 3932 free mbufs 9946 clfree 3675 lowest free mbufs 9935 lowest clfree 3665 MALLOC STATS : Block Size Free Blocks 16 1 48 2 112 1 144 1 208 1 240 1 400 1 496 4 Largest block available : 7510096 Total Memory available : 7546400 Total Memory used : 563952
This command outputs the CPU utilization of the NMP. The last line of output represents the "idle" time. In this example, the switch CPU is 59% busy (41% idle). In that same line of output, "high" and "low" represent "water marks" since the switch was last booted. "Average" shows the amount of idle time since the last boot. The "CPU-Usage" column totals 100% (+/- rounding errors) and indicates how much of the busy CPU time was used by that process. In this example, the Kernel is using 93% of 59%, which is about 49% of the CPU capacity:
switch 5000 (enable) ps -c CPU usage information: Name CPU-Usage Invokations --------------- ------------- ------------- Kernel 93% 1 SynDiags 0% 1 SynConfig 0% 1 Earl 1% 1 THREAD 0% 1 Console 0% 1 telnetd 0% 1 cdpd 0% 1 cdpdtimer 0% 1 SptTimer 0% 1 SptBpduRx 0% 1 VtpTimer 0% 1 VtpRx 0% 1 DISL_Rx 0% 1 DISL_Timer 0% 1 sptHelper 0% 1 ..etc ..etc System Idle - Current: 41% High: 51% Low: 8% Average: 47%
This command shows the status of uptime as well as exceptions. This example displays the output from a switch crash in addition to the standard logging information. Crashes can be caused by hardware or software problems. A "Vector: 007C", as seen here, is a switch bus timeout and is very likely to be a hardware problem. Make sure all cards are properly seated. If the crash keeps occurring, you can remove modules one at a time until the problem stops. Call the TAC to get the module replaced. For software problems (Vector != 007C), call the TAC as well:
switch 5000 show log
Network Management Processor (ACTIVE NMP) Log:
Reset count: 100
Re-boot History: Mar 19 1998 16:06:10 3, Mar 11 1998 12:03:03 3
Mar 10 1998 04:34:52 3, Mar 08 1998 08:38:30 3
Mar 08 1998 08:09:51 3, Mar 08 1998 06:28:31 3
Mar 08 1998 05:33:23 3, Mar 02 1998 09:02:13 3
Feb 20 1998 05:02:35 3, Feb 20 1998 04:55:45 3
Bootrom Checksum Failures: 0 UART Failures: 0
Flash Checksum Failures: 0 Flash Program Failures: 0
Power Supply 1 Failures: 39 Power Supply 2 Failures: 1
DRAM Failures: 0
Exceptions: 9
Last Exception occurred on Feb 18 1998 17:14:18 ...
Software version = 2.3(1)
Error Msg:
PID = 0 Co_\__Ô_?
PC: 1015A3AC, Status: 2009, Vector: 007C
sp+00: 20091015 A3AC007C 00000000 00000001
sp+10: 00400000 AAAA0000 107F0008 1025EEC0
sp+20: 107FFFAC 1017563E 00000000 107FFFE8
sp+30: 10175EA0 00000000 000006C7 00000000
sp+40: 00000000 00000000 00000000 00000000
sp+50: 00000000 00000000 50000200 00000007
sp+60: 68000000 00000000 00000000 00000000
sp+70: 00000000 00000000 00000000 00000000
sp+80: 00000000 00000000 00000000 00000000
sp+90: 00000000 00000000 00000000 00000000
sp+A0: 00000000 00000000 00000000 00000000
sp+B0: 00000000 00000000 00000000 00000000
sp+C0: 00000000 00000000 00000000 00000000
sp+D0: 00000000 00000000 00000000 00000000
sp+E0: 00000000 00000000 00000000 00000000
sp+F0: 00000000 4937F8E7 00000000 00000000
D0: 00000003, D1: 00000010, D2: 00000000, D3: 00000001
D4: 0040B5C1, D5: AAAAF0E7, D6: 00000003, D7: 10800000
A0: 68000000, A1: 00000079, A2: 50000200, A3: 50000200
A4: 103FFFFC, A5: 64000000, A6: 107FFFA0, sp: 107FFF80
NVRAM log:
01. 12/29/97,07:05:17:convert_post_SAC_CiscoMIB:Nvram block 0 unconvertable: 2(1)
02. 12/29/97,07:05:17:convert_post_SAC_CiscoMIB:Nvram block 1 unconvertable: 1(0)
03. 12/29/97,07:05:17:convert_post_SAC_CiscoMIB:Nvram block 5 unconvertable: 1(0)
04. 12/29/97,07:05:17: check_block_and_log:Block 59 has been deallocated: (0x500
191D8)
05. 12/29/97,07:05:17: convert_post_SAC_CiscoMIB:Nvram block 61 unconvertable:
1(0)
Module 2 Log:
Reset Count: 2
Reset History: Thu Mar 19 1998, 16:09:04
Wed Mar 11 1998, 12:05:57
FCP Flash Checksum Failures: 0 DMP Flash Checksum Failures: 0
FCP Flash Program Failures: 0 DMP Flash Program Failures: 0
FCP DRAM Failures: 0 DMP DRAM Failures: 0
FCP SRAM Failures: 0 DMP SRAM Failures: 0
FCP Exceptions: 0 DMP Exceptions: 0
Path Test Failures: 0
Module 3 Log:
Reset Count: 2
Reset History: Thu Mar 19 1998, 16:08:18
Wed Mar 11 1998, 12:05:11
Module 4 Log:
Reset Count: 1
Reset History: Mon Mar 23 1998, 10:50:06
Module 5 Log:
Reset Count: 2
Reset History: Thu Mar 19 1998, 16:08:18
Wed Mar 11 1998, 12:05:11
Chassis and environmental status information is useful in determining the physical operational and operational state of the switch chassis and power supplies.
The SNMP MIB objects in this list should be polled if the chassisAlarmOn trap is received.
The following information is available at the CCO Web site:
chassisPs1Status—. Status of power supply number 1. If the status is not okay, the value of chassisPs1TestResult gives more detailed information about the power supply's failure condition(s).
chassisPs2Status—. Status of power supply number 2. If the status is not okay, the value of chassisPs2TestResult gives more detailed information about the power supply's failure condition(s).
chassisFanStatus—. Status of the chassis fan. If the status is not okay, the value of chassisFanTestResult gives more detailed information about the fan's failure condition(s).
chassisMinorAlarm—. The chassis minor alarm status.
chassisMajorAlarm—. The chassis major alarm status.
chassisTempAlarm—. The chassis temperature alarm status.
What is a minor and major chassis alarm? When the system LED status turns to red, a chassisMajorAlarm is generated. When the system LED status turns orange, a chassisMinorAlarm is generated. The trap generated will be a chassisAlarmOn trap. Included with the traps are variables that indicate whether the trap is from a chassisTempAlarm, a chassisMinorAlarm, or a chassisMajorAlarm. Decoding the trap indicates what kind of alarm generated the trap.
The following conditions cause a major alarm:
Any voltage failure
Simultaneous temp and fan failure
100% power supply failure (2 out of 2, or 1 out of 1)
EEPROM failure
NVRAM failure
MCP communication failure
NMP status "unknown"
The following conditions cause a minor alarm:
Temp alarm
Fan failure
Partial power-supply failure (1 out of 2)
Two power supplies of incompatible types
With either a minor or major alarm, the system status LED on the front panel turns red. This information applies to the Catalyst 5000 series switches. Other products that use the CISCO-STACK-MIB have different definitions of major and minor alarms.
This section contains samples of the output from the CLI commands that provide chassis and environmental status.
The data output by this command can be collected via SNMP as well:
switch 5000 (enable) show system
PS1-Status PS2-Status Fan-Status Temp-Alarm Sys-Status Uptime d,h:m:s Logout
---------- ---------- ---------- ---------- ---------- -------------- ---------
ok none ok off ok 14,21:20:38 20 min
PS1-Type PS2-Type Modem Baud Traffic Peak Peak-Time
---------- ---------- ------- ----- ------- ---- -------------------- -----
WS-C5008A none disable 9600 0% 0% Wed Oct 22 1997, 14:17:56
System Name System Location System Contact
------------------------ ------------------------ ------------------- -----
switch 5000
This command output displays hardware status of switch components. You must specify the module from which you want the test results:
switch 5000 show test 1
Environmental Status (. = Pass, F = Fail, U = Unknown)
PS (3.3V): . PS (12V): . PS (24V): . PS1: . PS2: .
Temperature: . Fan: .
Module 1 : 2-port 100BaseFX MM Supervisor
Network Management Processor (NMP) Status: (. = Pass, F = Fail, U = Unknown)
ROM: . Flash-EEPROM: . Ser-EEPROM: . NVRAM: . MCP Comm: .
EARL Status :
NewLearnTest: .
IndexLearnTest: .
DontForwardTest: .
MonitorTest .
DontLearn: .
FlushPacket: .
ConditionalLearn: .
EarlLearnDiscard: .
EarlTrapTest: .
LCP Diag Status for Module 1 (. = Pass, F = Fail, N = N/A)
CPU : . Sprom : . Bootcsum : . Archsum : N
RAM : . LTL : . CBL : . DPRAM : . SAMBA : N
Saints : . Pkt Bufs : . Repeater : N FLASH : N
MII Status:
Ports 1 2
-----------
N N
SAINT/SAGE Status :
Ports 1 2 3
--------------
. . .
Packet Buffer Status :
Ports 1 2 3
- -------------
. . .
Loopback Status [Reported by Module 1] :
Ports 1 2 3
--------------
. . .
Module status is the current operational status of switch modules and their components.
The SNMP MIBs in this list should be used for polling if the moduleUp or moduleDown trap is received:
The following information is available at the CCO Web site:
moduleStatus—. The operational status of the module. If the status is not okay, the value of moduleTestResult gives more information about the module's failure condition(s).
moduleAction—. This object, when read, returns one of the following results:
other(1)—Module permanently enabled
enable(3)—Module currently enabled
disable(4)—Module currently disabled
Setting this object to one of the acceptable values results in the following:
other(1)—Gives an error
reset(2)—Resets the module's control logic
enable(3)—If the module status is configurable, enables the module, else gives error
disable(4)—If the module status is configurable, disables the module, else gives error
Setting this object to any other values results in an error.
ModuleStandbyStatus—. Status of a redundant module.
This section contains samples of the output from CLI commands that provide module status.
This output can be collected via SNMP as well:
switch 5000 (enable) show module
Mod Module-Name Ports Module-Type Model Serial- Num Status
--- ------------------- ----- --------------------- --------- ------- --- -------
1 2 100BaseFX MM Supervis WS-X5006 003292389 ok
3 12 10BaseFL Ethernet WS-X5011 003140385 ok
4 12 10BaseFL Ethernet WS-X5011 003418318 ok
5 12 100BaseTX Ethernet WS-X5113 002203857 ok
Mod MAC-Address(es) Hw Fw Sw
--- ---------------------------------------- ------ ------ --------- -------
1 00-60-47-96-f2-00 thru 00-60-47-96-f5-ff 1.4 2.1 2.1(9)
3 00-60-3e-d1-86-e4 thru 00-60-3e-d1-86-ef 1.3 1.2 2.1(9)
4 00-60-3e-c9-90-54 thru 00-60-3e-c9-90-5f 1.1 1.2 2.1(9)
5 00-40-0b-d5-0e-10 thru 00-40-0b-d5-0e-1b 1.4 1.2 2.1(9)
This output shows the status of hardware self tests on the individual modules:
switch 5000 (enable) show test 4
Module 4 : 12-port 10/100BaseTX Ethernet
LCP Diag Status for Module 4 (. = Pass, F = Fail, N = N/A)
CPU : . Sprom : . Bootcsum : . Archsum : N
RAM : . LTL : . CBL : . DPRAM : N SAMBA : .
Saints : . Pkt Bufs : . Repeater : N FLASH : N
SAINT/SAGE Status :
Ports 1 2 3 4 5 6 7 8 9 10 11 12
-----------------------------------------
. . . . . . . . . . . .
Packet Buffer Status :
Ports 1 2 3 4 5 6 7 8 9 10 11 12
-----------------------------------------
. . . . . . . . . . . .
Loopback Status [Reported by Module 1] :
Ports 1 2 3 4 5 6 7 8 9 10 11 12
-----------------------------------------
. . . . . . . . . . . .
Channel Status :
Ports 1 2 3 4 5 6 7 8 9 10 11 12
-----------------------------------------
. . . . . . . . . . . .
These show commands and MIB variables enable you to determine the status of spanning tree running in the switch. Refer earlier in the chapter to the sections about spanning tree and SNMP community-based indexing.
Note
Refer to the VLANs and Community String Indexing section for usage.
The SNMP MIBs in this list should be used for polling if the newRoot or topology Change trap is received.
The following information is available at the CCO Web site:
dot1dStpTimeSinceTopologyChange—. The time (in hundredths of a second) since the last time a topology change was detected by the entity.
dot1dStpTopChanges—. The total number of topology changes detected by this bridge since the management entity was last reset or initialized.
dot1dStpDesignatedRoot—. The bridge identifier of the root of the spanning tree as determined by the Spanning-Tree Protocol as executed by this node. This value is used as the Root Identifier parameter in all configuration bridge protocol data units (PDUs) originated by this node.
dot1dStpRootCost—. The cost of the path to the root as seen from this bridge.
dot1dStpRootPort—. The port number of the port which offers the lowest-cost path from this bridge to the root bridge.
The data in this output can be collected via SNMP as well:
switch 5000 (enable) show spantree1
VLAN 1
Spanning tree enabled
Designated Root 00-60-47-96-f2-00
Designated Root Priority 32768
Designated Root Cost 0
Designated Root Port 1/0
Root Max Age 20 sec Hello Time 2 sec Forward Delay 15 sec
Bridge ID MAC ADDR 00-60-47-96-f2-00
Bridge ID Priority 32768
Bridge Max Age 20 sec Hello Time 2 sec Forward Delay 15 sec
Port Vlan Port-State Cost Priority Fast-Start
-------- ---- ------------- ----- -------- ----------
1/1 1 not-connected 10 32 disabled
1/2 1 not-connected 10 32 disabled
5/8 1 disabled 10 32 disabled
5/9 1 disabled 10 32 disabled
5/10 1 not-connected 10 32 disabled
The following MIB and show command information report the contents and status of the switch-forwarding database. Refer to the Content-Addressable Memory (CAM) Table section earlier in this chapter for more details.
To determine to which port a given MAC address is attached on a particular Catalyst switch, you must first search the dot1dTpFdbTable (1.3.6.1.2.1.17.4.3) for the MAC address and determine which bridge port is associated with that port using the object dot1dTpFdbPort (1.3.6.1.2.1.17.4.3.1.2). Remember that you may need to use community string indexing if more than one VLAN is associated with this switch.
Then, convert this bridge index to an ifIndex by using the object dot1dBasePortIfIndex (1.3.6.1.2.1.17.1.4.1.2). You can then use the ifName (1.3.6.1.2.1.31.1.1.1.1) object from the IF-MIB (RFC 1573) to get the slot number/port number of the port with which the MAC address is associated.
Note
Ethernet transparent bridging is the only media addressed here.
Note
Refer to the "VLANs and Community String Index" section for usage information.
The bridge forwarding database or "CAM table" used by the EARL is available via this MIB object:
dot1dTpFdbTable—. A table that contains information about unicast entries for which the bridge has forwarding and/or filtering information. This information is used by the transparent bridging function in determining how to propagate a received frame.
The following contains sample output from the CLI command that provides information about the CAM table.
The MIB variables and Telnet output that follows report errors on individual switch interfaces.
The following information is available at the CCO Web site:
dot3StatsAlignmentErrors—. A count of frames received on a particular interface that are not an integral number of octets in length and do not pass the FCS check.
The count represented by an instance of this object is incremented when the alignmentError status is returned by the MAC service to the logical link control (LLC) (or other MAC user). Received frames for which multiple error conditions obtain are, according to the conventions of IEEE 802.3 Layer Management, counted exclusively according to the error status presented to the LLC.
dot3StatsFCSErrors—. A count of frames received on a particular interface that are an integral number of octets in length but do not pass the FCS check.
The count represented by an instance of this object is incremented when the frameCheckError is returned by the MAC service to the LLC (or other MAC user). Received frames for which multiple error conditions obtain are, according to the conventions of IEEE 802.3 Layer Management, counted exclusively according the error status presented to the LLC.
dot3StatsSingleCollisionFrames—. A count of successfully transmitted frames on a particular interface for which transmission is inhibited by exactly one collision.
A frame that is counted by an instance of this object is also counted by the corresponding instance of either the ifOutUcastPkts, ifOutMulticastPkts, or ifOutBroadcastPkts, and is not counted by the corresponding instance of the dot3StatsMultipleCollisionFrames object.
dot3StatsMultipleCollisionFrames—. A count of successfully transmitted frames on a particular interface for which transmission is inhibited by more than one collision.
A frame that is counted by an instance of this object is also counted by the corresponding instance of either the ifOutUcastPkts, ifOutMulticastPkts, or ifOutBroadcastPkts, and is not counted by the corresponding instance of the dot3StatsSingleCollisionFrames object.
dot3StatsLateCollisions—. The number of times that a collision is detected on a particular interface later than 512 bit-times into the transmission of a packet.
Five hundred and twelve bit-times correspond to 51.2 microseconds on a 10-Mbps system. A (late) collision included in a count represented by an instance of this object is considered a (generic) collision for purposes of other collision-related statistics.
dot3StatsExcessiveCollisions—. A count of frames for which transmission on a particular interface fails because of excessive collisions.
dot3StatsCarrierSenseErrors—. The number of times that the carrier-sense condition was lost or never asserted when attempting to transmit a frame on a particular interface.
The count represented by an instance of this object is incremented (at most) once per transmission attempt, even if the carrier-sense condition fluctuates during a transmission attempt.
dot3StatsInternalMacReceiveErrors—. A count of frames for which reception on a particular interface fails because of an internal MAC sublayer receive error. A frame is only counted by an instance of this object if it is counted by the corresponding instance of either the dot3StatsFrameTooLongs object, the dot3StatsAlignmentErrors object, or the dot3StatsFCSErrors object.
The precise meaning of the count represented by an instance of this object is implementation specific. In particular, an instance of this object may represent a count of receive errors on a particular interface that are not otherwise counted.
dot3StatsInternalMacTransmitErrors—. A count of frames for which transmission on a particular interface fails because of an internal MAC sublayer transmit error. A frame is counted by an instance of this object only if it is not counted by the corresponding instance of the dot3StatsLateCollisions object, the dot3StatsExcessiveCollisions object, or the dot3StatsCarrierSenseErrors object.
The precise meaning of the count represented by instance of this object is implementation specific. In particular, an instance of this object may represent a count of transmission errors on a particular interface that are not otherwise counted.
dot3StatsFrameTooLongs—. A count of frames received on a particular interface that exceed the maximum permitted frame size.
The count represented by an instance of this object is incremented when the frameTooLong status is returned by the MAC service to the LLC (or other MAC user). Received frames for which multiple error conditions obtain are, according to the conventions of IEEE 802.3 Layer Management, counted exclusively according to the error status presented to the LLC.
The following sample output is from the CLI command that provides error counts by port.
Displays error counters on ports such as alignment error, FCS error, collision statistics, and so on:
switch 5000 (enable) show port counters
Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize
----- ---------- ---------- ---------- ---------- ---------
1/1 0 0 0 0 0
1/2 0 0 0 0 0
2/7 0 0 0 0 0
2/8 428 159 0 0 718
2/9 0 0 0 0 0
Port Single-Col Multi-Coll Late-Coll Excess-Col Carri-Sen Runts Giants
----- ---------- ---------- ---------- ---------- --------- --------- ---------
1/1 0 0 0 0 0 0 0
1/2 0 0 0 0 0 0 0
2/1 4855 479 0 0 0 0 0
2/2 775 94 0 0 0 0 0
2/3 65 6 0 0 0 0 0
2/4 69 9 0 0 0 0 0
2/5 354 36 0 0 0 0 0
2/6 0 0 0 0 0 0 0
2/7 104 14 0 0 0 0 0
2/8 0 0 0 0 0 621 -
A concern for network managers is the rate of broadcast traffic on switched ports. Because broadcast traffic is forwarded to every port on a VLAN, you can set up a "dummy" port as part of a VLAN and capture the broadcast traffic only. Then you can compare the broadcast rate to the theoretical max rate of the line.
The following are the SNMP MIBs; the information can be found on the CCO Web site:
dot1dTpPortInFrames—. The number of frames that have been received by this port from its segment. Note that a frame received on the interface corresponding to this port is counted by this object if and only if it is for a protocol being processed by the local function, including bridge management frames.
dot1dTpPortOutFrames—. The number of frames that have been transmitted by this port to its segment. Note that a frame transmitted on the interface corresponding to this port is counted by this object if and only if it is for a protocol being processed by the local bridging function, including bridge management frames.
ifInMulticastPkts—. The number of packets, delivered by this sublayer to a higher (sub-)layer, which were addressed to a multicast address at this sublayer. For a MAC layer protocol, this includes both group and functional addresses.
ifInBroadcastPkts—. The number of packets, delivered by this sublayer to a higher (sub-)layer, which were addressed to a broadcast address at this sublayer.
ifOutMulticastPkts—. The total number of packets that higher-level protocols requested be transmitted, and which were addressed to a multicast address at this sublayer, including those that were discarded or not sent. For a MAC layer protocol, this includes both group and functional addresses.
ifOutBroadcastPkts—. The total number of packets that higher-level protocols requested be transmitted, and which were addressed to a broadcast address at this sublayer, including those that were discarded or not sent.
etherStatsBroadcastPkts—. The total number of good packets received that were directed to the broadcast address. Note that this does not include multicast packets.
etherStatsMulticastPkts—. The total number of good packets received that were directed to a multicast address. Note that this number does not include packets directed to the broadcast address.
The following sample output is from the CLI command that provides MAC-level statistics.
Displays MAC-level statistics such as received/transmitted frames, received/transmitted multicast packets, and received/transmitted broadcast packets:
switch 5000 (enable) show mac
MAC Rcv-Frms Xmit-Frms Rcv-Multi Xmit-Multi Rcv-Broad Xmit-Broad
-------- ---------- ---------- ---------- ---------- ---------- ----------
1/1 0 0 0 0 0 0
1/2 0 0 0 0 0 0
2/1 7564831 3159859 93795 2982015 7375010 47356
2/2 839319 11317193 97413 2991019 1560 7417591
2/3 40744 10516768 5631 3096045 6 7419192
2/4 40989 10523185 6222 3102759 0 7419195
2/5 87858 10577397 6179 3114275 920 7418557
2/6 0 0 0 0 0 0
2/7 53448 10557561 5632 3124050 0 7419181
2/8 1646786 31124783 1645159 31124783 0 0
2/9 45666 10610469 4980 3150899 543 7418652
2/10 44872 10582388 5723 3158925 118 7417517
2/11 24269744 8525203 24269742 1104787 0 7420184
Some customers look to their switches to provide them with user or application usage information to determine service-level agreement (SLA) adherence and perhaps for user or group billing. It is recommended that you look above OSI Layer 2 for this type of information. The switches should be treated as hubs or MAUs in this situation, and you should look to higher-level protocols (which will travel over the switch) to collect this type of information.
If you are interested in how available a server is to its users, for instance, you should ping the server periodically (but not so frequently that you congest the server) and measure the response time. Assume that the switch is switching at line speeds unless data indicates that the switch is the bottleneck.
This chapter does not cover Cisco Netflow or multilayer switching.
Response-time reporting is the response measurement between two points in the network to determine delays in the network. Although most NMS can ping from a central workstation, you can also use the CISCO-PING-MIB to request Cisco routers and certain switches to ping specific devices and report on the round-trip time. You can also retrieve all Cisco neighboring devices of Cisco routers and switches by querying the CISCO-CDP-MIB.
This section, including Tables 14-6 and 14-7, identifies typical MIB variables of interest for fault and performance management and explains the most common errors encountered.
Table 14-6. Overall Switch Performance
| MIB File | MIB Objects |
|---|---|
| CISCO-STACK-MIB | SysTraffic |
| SysTrafficPeak | |
| SysTrafficPeaktime | |
| SysConfigChangeTime | |
| ChassisPs1Status | |
| ChassisPs2Status | |
| ChassisFanStatus | |
| ChassisMinorAlarm | |
| ChassisMajorAlarm | |
| ChassisTempAlarm | |
| ModuleStatus | |
| ModulePortStatus | |
| ModuleStandbyStatus |
Table 14-7. Trunk Ports and Critical Server Ports
| MIB File | MIB Objects |
|---|---|
| From the CISCO-STACK-MIB based on portIndex (cross-referenced to ifIndex through the corresponding portIfIndex field for the corresponding table instance). | PortOperStatus |
| VlanPortIslOperStatus (trunk ports only) | |
| PortAdminSpeed | |
| PortDuplex | |
| PortSpantreeFastStart | |
| From the ETHERLIKE-MIB based on ifIndex. | Dot3StatsAlignmentErrors |
| Dot3StatsFCSErrors | |
| dot3StatsSingleCollisionFrames | |
| dor3StatsMultipleCollisionFrames | |
| dot3StatsLateCollisions | |
| dot3StatsExcessiveCollisions | |
| dot3StatsInternalMacTransmitErrors | |
| dot3StatsInternalMacReceiveErrors | |
| dot3StatsDeferredTransmissions | |
| From the BRIDGE-MIB based on ifIndex. | dot1dStpPortStatus |
| dot1dStpPortForwardTransitions | |
| dot1dTpLearnedEntryDiscards | |
| From RFC1213 based on ifIndex. It is recommended to monitor rates rather than absolute values on these counters. | if.ifInDiscards |
| if.ifInErrors | |
| if.ifOutDiscards | |
| if.ifOutErrors | |
| if.ifInOctets | |
| if.ifOutOctets | |
| if.ifInUcastPkts | |
| if.ifInNUcastPkts | |
| if.ifOutUcastPkts | |
| if.fOutNUcastPkts | |
| ip.ipInRequests | |
| ip.ipInDelivers | |
| ip.ipForwDatagrams |
Alignment errors are a count of the number of frames received that don't end with an even number of octets and have a bad CRC.
When packets less than 64 bytes in length not ending on a whole byte boundary (for example, a fragments left from a collision) are received, the Catalyst will increment the runts counter and the align-err counter.
An alignment error is an indication of a cable problem or a faulty transmitter on the network equipment connected at the other end. This count should be zero or very low. When the cable is first connected, some may occur. Also, if there is a hub connected, collisions between other devices on the hub may cause this.
FCS error count is the number of frames that were transmitted and received with a bad checksum (CRC value) in the Ethernet frame. These frames are dropped and not propagated on to other ports. A small number of these errors is acceptable, but it could also be an indication of bad cables, NICs, and so on.
Runt frames are too small for an Ethernet segment.
The behavior of runts is as follows:
With packets less than 64 bytes in length (for example, fragments left from a collision) with a bad CRC, the Catalyst will increment the runts counter.
With packets less than 64 bytes in length not ending on a whole byte boundary (for example, fragments left from a collision), the Catalyst will increment the runts counter AND the align-err counter.
No FCS-err is logged with packets less than 64 bytes in length.
One case when an FCS-err is logged is when a 63-byte packet is received, and 4 bits are added for the alignment error and 4 bits added for the dribble, resulting in an incorrect packet of 64 bytes in length (see Table 14-8).
A small number of these errors is acceptable, but it could also be an indication of bad cables, NICs, and so on. In a shared Ethernet environment, runt frames are almost always caused by collisions. If runt frames occur when collisions are not high or in a switched Ethernet environment, they are the result of underruns or bad software on a network interface card. Attach a protocol analyzer to try to identify the faulty network interface card by determining the source address of the runt frames.
Table 14-8 describes which counters are incremented under certain error situations.
Table 14-8. Error Conditions Associated with Error Counters
| Packet Size (Bytes) | Errors | Port Counter Incremented |
|---|---|---|
| 66-1500 | ||
| 63 | Undersize | |
| 63 | CRC | Runts |
| 63 | align | align-err and runts |
| 63 | dribble | Undersize |
| 63 | symbol | Runts |
| 63 | CRC/align | align-err and runts |
| 63 | CRC/align/dribble | FCS-err |
| 63 | CRC/align/dribble/ symbol | FCS-err |
| 63 | align/dribble | FCS-err |
| 62 | align/dribble | Runts |
| 54 | align/dribble | Runts |
| 44 | align/dribble | Runts |
The error types are defined as follows:
The basic assumption is that a network needs to be monitored after a steady state is reached. When a subsystem (be it module configuration, port configuration, VLAN configuration, or whatever) reaches its configuration and operations steady state, additional thresholds and correlation scenarios may be enabled for that subsystem.
This section lists the MIB objects that should be monitored and what information each will provide.
For the purpose of port management, the MIB-II objects listed in Table 14-9 need to be monitored.
Table 14-9. MIB-II Objects
Several MIB objects in the CISCO-STACK MIB need to be monitored to ensure some correctness.
Table 14-10 lists the MIB objects in the system and chassis group that should be mentioned.
Table 14-10. System and Chassis MIB Objects
Table 14-11 lists the MIB objects for modules (line cards) that should be monitored.
Table 14-11. Module MIB Objects
Table 14-12 lists the MIB objects for ports that should be monitored.
Table 14-12. Port MIB Object
| MIB Object | Description | Reason to Monitor |
|---|---|---|
| portEntry.portDuplex | Indicates whether port is operating in half or full duplex. | Detect when a duplex change occurs. Detect when its value is disagree(3), which indicates a duplex mismatch. Notification may be ignored if transition was part of normal operation. |
| portEntry.portSpantreeFastStart | Indicates whether port transitions immediately to forwarding state. | Detect when this object transitions from enabled to disabled or vice versa. Notification may be ignored if transition was part of normal operation. |
| portEntry.portLinkFaultStatus | Monitor gigabit Ethernet ports. | Detect when this object transitions from a noFault status. |
| moduleEntry.modulePortStatus | Monitor module and port status. (This object offers the capability to verify all ports in the module in a single SNMP query.) | Detect when this object changes. When it changes, sort out whether it applies to the module status or a port status change. If it is a port status change, report which port changed status. Report ifOperStatus and ifAdminStatus using its corresponding portEntry.portIfIndex to index into the ifTable. |
| portEntry.portOperStatus | Monitor port failures. This function would be performed if the previous condition did not apply to all ports, but rather only to specific ports. | Detect when this object is not ok(2), assuming it is not on a Sup module in standby mode. Report ifOperStatus and ifAdminStatus using portEntry.portIfIndex to index into the ifTable. |
| portEntry.portLinkFaultStatus | Monitor gigabit links. | Detect when this object is not noFault(1) or transitions to any other state. |
Table 14-13 lists the MIB objects for trunks that should be monitored.
Table 14-13. Trunk MIB Objects
| MIB Object | Description | Reason to Monitor |
|---|---|---|
| vlanPortEntry.vlan PortIslAdminStatus | Monitor trunks are configured as trunks. | Detect when a trunk fails to operate. |
| For the ports known (assuming predefined port configuration) to be trunk ports between switches as defined by portEntry.portModuleIndex and portEntry.portIndex, read their corresponding portEntry.portIfIndex and use that value to index into the ifTable to verify their ifEntry.ifAdminStatus = up and ifEntry.ifOperStatus = up. | ||
| For those very same ports, use portModuleIndex and portIndex to index into the vlanPortEntry table to verify their vlanPortIslAdminStatus = trunking. |
Table 14-14 lists the MIB objects for VLANs that should be monitored.
Table 14-14. VLAN MIB Objects
| MIB Object | Description | Reason to Monitor |
|---|---|---|
| vlanEntry.vlanSpnTreeEnable | Monitor spanning-tree enabling per VLAN. | Detect any change in VLAN spanning-tree configuration. |
| vlanEntry.vlanPortVlan | Monitor when a port is moved to a different VLAN, for security and traffic-engineering reasons. | Monitor the VLAN membership of each port. Report vlanPortModule and vlanPort in the notification. |
| vlanEntry.vlanPortIslOperStatus | Monitor trunk ports. | For every port in trunking mode, detect when this object transitions to notTrunking mode, and vice versa. Report vlanPortModule and vlanPort in the notification. |
| vlanEntry.vlanPortOperStatus | Monitor VLAN status on ports. | Assuming this condition applies to all ports in active mode, detect when this object transitions to another state. Report the corresponding vlanPortModule and vlanPort in the notification. |
Table 14-15 lists the MIB objects for EtherChannel that should be monitored.
Table 14-15. EtherChannel MIB Objects
| MIB Object | Description | Reason to Monitor |
|---|---|---|
| portChannelEntry.portChanelPort | Monitor ports assigned to a single EtherChannel. | Detect whether ports are added or removed from an EtherChannel. Report portChannelModuleIndex, portChannelPortIndex, and portChannelIfIndex in the operator notification. |
| portChannelOperStatus | Monitor status of EtherChannel ports. | Detect status transitions. Report portChannelModuleIndex, portChannelPortIndex, and portChannelIfIndex in the operator notification. |
| portChannelNeighbourDeviceId | Monitor if the other end of the EtherChannel is modified. | Detect value changes in these objects. Report portChannelModuleIndex, portChannelPortIndex, and portChannelIfIndex in the operator notification. |
| portChannelNeighbourPortId |
Table 14-16 lists the MIB objects for the RSM that should be monitored.
Table 14-17 lists general MIB objects that should be monitored.
Table 14-17. Miscellaneous MIB Objects
| MIB Object | Description | Reason to Monitor |
|---|---|---|
| tftpHost | Monitor when new images may be loaded. | For each tftpModule that is configured in the switch, ensure that the correct combination of these three MIB objects is correct (that is, as expected). Notify operator if any inconsistencies are detected. |
| tftpFile | ||
| tftpModule | ||
| tftpResult | Monitor tftp transfers. | Detect whether this object is not successful. Inform operator if this object is inProgress. Alert operator for all other values of this object. |
| brouter scalar objects in the brouter group | Monitor brouter configuration. This group applies to FDDI. | Detect whether any changes of the brouter configuration. Applicable to FDDI interfaces only. |
| brouterPortEntry.brouterPort BridgeVlan | Monitor brouter port VLAN membership. | Detect when a port is placed in a different VLAN. Applicable to FDDI interfaces only. |
| mcastRouterEntry.mcastRouter OperStatus | Monitor multicast is enabled on router. | Detect whether any port changes status or enabled characteristics. |
| mcastEnableCgmp | ||
| mcastEnableIgmp | ||
| dnsGrp.dnsenable | Monitor DNS configuration. | Detect whether DNS transitions to a different state. Dump the dnsServerTable with the notification. |
| dnsServerEntry.dnsServerType | Monitor DNS server entries. | Detect whether any entry transitions to a different type. Generate a critical alert if an entry is removed. |
| syslogServerEntry.syslogHost Enable | Monitor switch syslog configuration. | Detect whether syslog messages are no longer sent to the correct hosts. |
| syslogServerEntry | Monitor switch syslog configuration. | Detect whether any entry is removed. |
| syslogMessageControlEntry.sys logMessageFacility | Monitor switch syslog configuration. | Detect whether any facility is logged with a lower severity (meaning more syslog messages) or higher severity (meaning fewer syslog messages). |
| syslogMessageSeverity | ||
| tacacsGrp.tacacsLogin Authentication | Monitor TACACS configuration. Only applicable if TACACS is used in the switch. | Detect any transition changes of these objects, indicating some enabled or disabled TACACS features. |
| tacacsEnableAuthentication | ||
| tacacsLocalLoginAuthentication | ||
| tacacsLocalEnableAuthentication | ||
| tacacsDirectedRequest | ||
| ipPermitEnable | Monitor whether remote Telnet is allowed into the switch. | Detect any transition change, indicating either loss of remote Telnet access, or security hole, if not part of an authorized configuration change. |
| ipPermitListEntry | Monitor allowed Telnets into the switch. | Detect whether entries are added or removed. Report the ipPermitAddress to the operator. |
| ipPermitDeniedListEntry | Monitor denied accesses into the switch. | Detect whether entries are added in this table. Report ipPermitDeniedAddress, ipPermitDeniedAccess, and ipPermitDeniedTime to the operator. |
The event-correlation scenarios in this section can be developed for a Catalyst 5000 switch.
Scenario 1—. Detect that all modules came up, as expected. This scenario requires knowing how many modules exist in the switch. Otherwise, the number of modules can be extracted from chassisGrp.chassisNumSlots.
After a switch restarts (SYS-5: system reset) or a coldStart trap is received, verify that all expected modules are back online, through SYS-5: Module x is online syslog message, where x is the module index. An alternative means to detect this situation is to process sysConfigChangeTrap traps (with varBind containing the module index). Correlate the polling and trap to avoid duplicate notifications to the operator. Include in the notification to the operator, the value of the corresponding moduleEntry, given the received module index.
An alternative is to monitor chassisSlotConfig value to detect whether the value ever changes.
Scenario 2—. Sort out minor from major power-supply faults.
Generate a minor or major notification to operator depending on whether a power-supply fault is minor or major (as per the chassisPs1Status or statusPs2Status MIB objects).
Scenario 3—. Correlate chassis alarm traps with MIB object polling for status change.
Correlate any chassisTempAlarm, chassisMinorAlarm, or chassisMajorAlarm status change with a chassisAlarmOn trap to ensure that only one notification is sent to the operator for the same problem, depending on the new value of one of these objects. Raise, escalate, or clear the alarm accordingly.
Ensure that the sysEnableChassisTraps object is set to enabled for this scenario to be working.
Scenario 4—. Monitor supervisory modules.
For all modules whose moduleType corresponds to a supervisory module (value = 23, 38 through 42, 57, 78, or 300), perform the following periodic checks. In operator notifications, include moduleName, moduleModel, moduleHwVersion, moduleFwVersion, and moduleSwVersion.
Monitor their status with moduleStatus and generate an alarm corresponding to the severity of the status field. Add the moduleTestResult in the operator notification.
Detect whether the supervisory firmware version is correct, by verifying that the moduleHwVersion, moduleFwVersion, and moduleSwVersion fields are what they are supposed to be. If the correlation engine cannot compare strings, the MIB objects moduleHwHiVersion, moduleHwLoVersion, moduleFwHiVersion, moduleFwLoVersion, moduleSwHiVersion, and moduleSwLoVersion are what they are supposed to be.
Detect when a supervisor card goes from active to standby status or vice versa by monitoring the moduleStandbyStatus object. Detect also when this object is not active or standby.
From all supervisory modules installed (as defined by moduleType), ensure that one of them is active (moduleStandbyStatus is active) and all others are in standby mode.
Scenario 5—. Monitor ports in supervisory cards.
For all modules whose moduleType corresponds to a supervisory module (value = 23, 38 through 42, 57, 78, or 300), perform the following periodic checks on the ports whose portModuleIndex (in the portTable) cross-checks with a supervisory module index (in the moduleTable). In operator notifications, include moduleName and moduleModel, moduleHwVersion, moduleFwVersion, and moduleSwVersion.
Monitor modulePortStatus (decode the octet string as specified in the MIB). Report any status change.
Verify that when a module's moduleStandbyStatus is active(2), the ports on that module have the correct status if they are used, by checking the portOperStatus field in the portTable. Note that a future Catalyst 5000 release will make ports active even on standby supervisory cards, which will affect this scenario.
Scenario 6—. Monitor port flow control.
For each port in the portTable, detect discrepancies between the following:
portAdminRxFlowControl and portOperRxFlowControl
portAdminTxFlowControl and portOperTxFlowControl
Scenario 7—. Verify links are connected to the correct port on the other switches.
Based on Cisco's CDP MIB:
Verify every port known to be trunking (given the predefined portEntry.portModuleIndex and portEntry.portIndex) on a switch is configured with CDP—for example, cdpInterfaceEntry.cdpInterfaceEnable = true where cdpInterface.cdpInterfaceIfIndex matches portEntry.portIfIndex.
For the same ports identified in the preceding step, verify cdpCacheEntry entries with the following:
cdpCacheEntry.cdpCacheIfIndex = portEntry.portIfIndex (given the pre-defined portEntry.portModuleIndex and portEntry.portIndex)
and
cdpCacheEntry.cdpCacheDeviceIndex = 1..N
The corresponding cdpCacheEntry.cdpCacheDeviceId and cdpCacheEntry.cdpCacheDevicePort are what they are expected to be.
Scenario 8—. For each VLAN in this switch, do the following:
Verify trunk ports expected to be configured in that VLAN exist. If a port exists:
Verify they are configured as ISL.
Verify the port is configured for static VLAN (assumption in this scenario).
Verify STP is enabled on the port.
Retrieve its STP state and report differences with previous known state.
Verify that ports with vlanPortEntry.vlanPortIslOperStatus set to trunking(1) have their corresponding vlanPortEntry.vlanPortIslAdminStatus set to on(1) or noNegotiate(5).
For each port in the preceding step, do the following:
Verify their vlanPortEntry.vlanPortAdminStatus is set to static.
Search the vlanTable for entries whose vlanEntry.vlanIfIndex matches the predefined module/port for trunks, and verifytheir vlanEntry.vlanSpantreeEnable = enabled(1).
Use the corresponding portEntry.portCrossIndex to index into RFC1493.dot1dStpPortEntry (where portEntry.portCrossIndex = RFC1493.dot1dStpPortEntry.dot1dStpPort) to retrieve RFC1493.dot1dStpPortEntry. dot1dStpPortState and report any state change.
This section provides information on network management for Cisco routers. See the CCO Web site for more information on monitoring the router and network and their performance.
The main objective of fault management is to detect problems and notify users as early as possible so that actions can be taken before any performance degradation occurs. This discussion first examines the functions of fault management, and then focuses on different options for implementation.
The following lists the main functions of fault management:
Monitoring network status
Problem detection and notification
Problem diagnosis and service restoration
The ability to detect problems quickly in any network is critical. Network operations personnel can rely on a graphical network map to display the operational states of critical network elements such as routers and switches. Most commercial network management can perform discovery of network devices. Each network device is represented by a graphical element on the management platform's console. Different colors on the graphical elements represent the current operational status of network devices. These network-management platforms can also receive and display events generated from network devices.
Network devices can be configured to send notifications to network-management platforms. Upon receiving the notifications, the graphical element representing the network device changes to a different color, depending on the severity of the notification received.
There are a few ways to detect faults on a network consisting of Cisco routers and switches. The most common ones are via syslog messages, SNMP/traps, and RMON. Cisco devices are capable of sending syslog messages to a syslog server. Syslog messages are system messages from routers/switches describing different conditions on a device. SNMP traps forwarded by devices are useful to notify faulty conditions, such as if an interface goes up/ down.
Not all syslog and trap messages indicate faulty conditions on a device. Some messages are informational messages and do not require any action from the user. The amount of syslog and trap messages sent by a network device can be limited by specific commands on the configuration file.
Syslog messages from routers and switches can be directed at single or multiple syslog servers. The devices can be configured to send only certain syslog messages. By limiting the amount of syslog messages to be generated by a device, a user can concentrate on specific aspects of network operations. As an example, the following syslog message will appear when an interface on a router goes down:
%LINEPROTO-5-UPDOWN: Line protocol on Interface Ethernet1, changed state to down
Syslog messages from routers and switches can be collected from any UNIX-type syslog daemon. These messages can then be viewed and reports can be generated, or actions be taken.
Cisco devices configured with SNMP can be polled for various information. In addition, the devices can send traps to a management station when specific conditions occur. By configuring network devices to send SNMP traps, conditions of interest can be detected quickly. A user can quickly determine the operational status of all interfaces in a router via SNMP, for example, without having to input the regular CLI commands. Table 14-18 contains a sample of the information returned via SNMP.
Table 14-18. Status of Network Interfaces via SNMP
| Index | Description | AdminStatus | OperStatus |
|---|---|---|---|
| 1 | Ethernet0 | Up | Up |
| 2 | Ethernet1 | Up | Up |
| 3 | FastEthernet0 | Up | Up |
| 4 | Fddi0 | Up | Up |
| 5 | Tunnel0 | Up | Down |
The CLI command to display interface status is as follows:
gateway> show interface ethernet 0 Ethernet0 is up, line protocol is up (OperStatus) Hardware is Lance, address is 0000.0c38.1669 (bia 0000.0c38.1669) Internet address is 172.16.97.1/24 MTU 1500 bytes, BW 10000 Kbit, DLY 1000 usec, rely 255/255, load 1/255 Encapsulation ARPA, loopback not set, keepalive set (10 sec) ARP type: ARPA, ARP Timeout 04:00:00 Last input 00:00:00, output 00:00:00, output hang never
In addition to standard MIBs, Cisco routers and switches support a variety of MIBs specific to Cisco devices. These specific devices enable you to gather operational data from each device. The following is a partial list of Cisco-specific MIBs:
Technology specific—. ISDN, LANE, CIP, DLSW+, Frame Relay, ATM, and so on.
Router specific—. Memory pool, chassis, CPU, flash memory, and so on.
Switch specific—. VLAN, STACK, VTP, VMPS, CDP, and so on.
Most of the MIB files also define SNMP traps. Each trap definition lists the MIB objects included in the trap PDU and the specific conditions when it is generated. Table 14-19 lists, by category, the SNMP traps defined in router MIB files.
Table 14-19. List of SNMP Traps for Cisco Routers
| MIB File | Supported Traps |
|---|---|
| Router Internals | |
| CISCO-FLASH | ciscoFlashCopyCompletionTrap |
| ciscoFlashPartitioningCompletionTrap | |
| ciscoFlashMiscOpCompletionTrap | |
| ciscoFlashDeviceChangeTrap | |
| CISCO-ACCESS-ENVMON | caemTemperatureNotification |
| CISCO-ENVMON | ciscoEnvMonShutdownNotification |
| ciscoEnvMonVoltageNotification | |
| ciscoEnvMonTemperatureNotification | |
| ciscoEnvMonFanNotification | |
| ciscoEnvMonRedundantSupplyNotification | |
| CISCO-CONFIG-MAN | ciscoConfigManEvent |
| SNA | |
| CISCO-RSRB | rsrbPeerStateChangeNotification |
| CISCO-DLSW | ciscoDlswTrapTConnPartnerReject |
| ciscoDlswTrapTConnProtViolation | |
| ciscoDlswTrapTConnUp | |
| ciscoDlswTrapTConnDown | |
| ciscoDlswTrapCircuitUp | |
| ciscoDlswTrapCircuitDown | |
| CISCO-CHANNEL | cipCardLinkFailure |
| cipCardDtrBrdLinkFailure | |
| CISCO-DSPU | newdspuPuStateChangeTrap |
| newdspuPuActivationFailureTrap | |
| newdspuLuStateChangeTrap | |
| dspuLuActivationFailureTrap | |
| dspuSapStateChangeTrap | |
| CISCO-CIPCSNA | cipCsnaOpenDuplicateSapFailure |
| cipCsnaLlc2ConnectionLimitExceeded | |
| CISCO-BSTUN | bstunPeerStateChangeNotification |
| CISCO-STUN | stunPeerStateChangeNotification |
| CISCO-SNA-LLC | llcCcStatusChange |
| CISCO-SDLLC | convSdllcPeerStateChangeNotification |
| ISDN | |
| CISCO-ISDN | demandNbrCallInformation |
| demandNbrCallDetails | |
| FRAME RELAY | |
| RFC 1315 (Frame Relay) | frDLCIStatusChange |
| X.25 | |
| RFC 1382 (X.25) | x25Restart |
| x25Reset | |
The preceding section showed how SNMP traps can provide alerts to a management station. This reactive approach is useful for informing network operators after a problem has occurred. A more proactive approach, however, would be to inform the operators before a potential problem hits the device. For example, performance will become an issue when CPU utilization on a router hits a high value. The regular approach of polling the router using SNMP to find out its utilization could miss the event depending on the polling interval. By utilizing RMON support on Cisco devices, they can be configured to monitor CPU utilization and only send an alert when a threshold is reached (that is, CPU utilization hits 90).
Figure 14-2 shows how RMON can be used to monitor CPU utilization. The device will sample the value of CPU utilization at predefined intervals. If the value hits Threshold 1, either an event can be generated to inform the user or an entry is logged in the router's retrievable RMON table. Threshold 2 is set to reactivate the monitoring when CPU utilization hits that value. RMON eliminates the regular polling from a management console, and reduces SNMP network traffic.
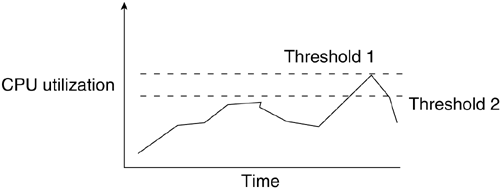
Other statistics that can be monitored using RMON include input/output drops, buffer failures, internal temperatures, number of Frame Relay BECN/FECN packets, and so on.
Events observed at the management console need to be diagnosed to determine the severity of a problem and the necessary action to correct the problem. With syslog messages, the severity and description of the problems can be determined quickly because of the message verbosity. Corrective actions can be taken after reviewing the nature of the problem.
The syslog messages in Table 14-20 have been identified as being conditions that you may want to monitor. The list is not an exhaustive list; it addresses system-related messages only. It does not address syslog messages for routing protocols and specific network interfaces such as X.25, ISDN, Frame Relay, and so on.
Table 14-20. Syslog Messages to Monitor
| Syslog Message | Description | Reason to Monitor |
|---|---|---|
| %SYS-4-SNMP_HOSTCONFIGSET : SNMP hostConfigSet request. Loading configuration from … | These messages indicate the router is loading a new configuration. | These messages may indicate a legitimate condition initiated by a network operator or a router software/ hardware problem that caused the router to reload its configuration. |
| %SYS-4-SNMP_NETCONFIGSET: SNMP netConfigSet request. Loading configuration from … | ||
| %IP-4-DUPADDR | This message indicates that the router detected a duplicate IP address. | This condition may seriously affect your network if the duplicate IP address relates to a router or server. |
| %IPRT-3-NOMEMORY | This message reports a shortage of memory in the router. | Low memory conditions are critical to monitor because they may severely affect router operations. |
| %SYS-… | These messages are system messages on router internals. | Select the messages of interest to your environment. |
Certain models of Cisco routers can perform environmental monitoring to track the voltage and temperature status. Sensors on the card periodically obtain measurements on the chassis and check whether they are within specified ranges. Warning messages are displayed on the console for out-of-range measurements.
The environmental status can be accessed via SNMP from routers supporting the following MIBs: OLD-CISCO-ENV-MIB, CISCO-ENVMON-MIB, or CISCO-ACCESS-ENVMON-MIB. Objects defined on the MIB files can return similar information provided by CLI commands.
In Table 14-21, the voltage readings are obtained from objects defined in the CISCO-ENVMON-MIB. The values returned correspond to those from the IOS CLI show environmental command. In addition to providing SNMP objects for monitoring temperature and voltage, CISCO-ENVMON-MIB and CISCO-ACCESS-ENVMON-MIB also have traps defined. These traps are sent to a management console when the measurements are out of the normal range. Refer to the Fault Management section earlier in this chapter for additional information regarding supported traps.
Table 14-21. Voltage Status Table
| Description | Value | Low | High | LastShutdown | State |
|---|---|---|---|---|---|
| +12 Voltage | 12308 | 10904 | 13384 | 12308 | Normal |
| +5 Voltage | 5171 | 4606 | 5698 | 5171 | Normal |
| 12 Voltage | -12073 | -10146 | -13859 | -12073 | Normal |
| +24 Voltage | 24247 | 20377 | 27646 | 24247 | Normal |
| 2.5 Reference | 2490 | 1250 | 3714 | 0 | Normal |
Table 14-22 lists environment-related syslog messages.
Table 14-22. Environmental Syslog Messages
| Syslog Message | Description | Reason to Monitor |
|---|---|---|
| %ENV-X, %ENVM-X, | These messages signal environmental problems with the fan and temperature inside the router. | Any of these messages may be an indication of an imminent router failure. |
| %CI-3-BLOWER, | ||
| %CI-1-BLOWSHUT, | ||
| %CI-2-ENVCRIT, | ||
| %CI-4-ENVWARN, | ||
| %SYS-1-OVERTEMP | ||
| %CI-3-PSFAIL | These messages signal system problems such as a power-supply failure. | All these messages should be considered critical. |
Performance management is a functional area that deals with various aspects of network performance. Performance of a network can be measured by taking a measurement of response time, line utilization, throughput, and so on. A baseline can be established as a comparison for subsequent performance measurements. Performance level can be measured to determine whether it is in line with the metrics defined in service-level agreements. This section briefly discusses several aspects of performance management in general. The main objective is to demonstrate how router performance measurements can be taken and viewed using SNMP.
The tasks involved in performance management are as follows:
Establishing a baseline of network performance
Defining service-level agreement and metrics
Performance monitoring and measurement
Setting thresholds and exception reporting
Analysis and tuning
Obtaining a baseline of network performance involves taking samples of network statistics over an extended period of time. The baseline data can be collected using standalone probes attached to a LAN segment or WAN link. The data is used to determine a normal traffic pattern in the network. Additional measurements on network performance can be compared against the baseline to determine whether they are within the normal pattern.
SLA involves the task of defining specific performance characteristics expected from the network. The agreement defines certain performance metrics used to measure the actual service level obtained from the network against the stated level of service in the SLA. It is a very common agreement between the provider of a service and a recipient of the service. The metrics for network performance can include response time, availability, and so on.
The performance of a network is directly linked to the operational state of devices within the network. Hardware and software components of a network device also affect its performance. Failed hardware components can cause a complete outage in the network. It is critical to monitor the operating environments of network devices such as voltage, temperature, airflow, and ensure they are operating within specifications. Software components such as buffers, memory, and so on can have a significant impact on the protocols running on the device.
A useful performance indicator on a router is its CPU utilization. By measuring CPU utilization over time, a trend can be established to determine traffic patterns. Routers running constantly at high-utilization levels can affect the overall performance of forwarding and processing packets. CLI commands exist on the router to display the CPU utilization and information on running processes. Information returned by the command on CPU load can be accessed using objects defined in the OLD-CISCO-CPU-MIB file. The following displays CPU utilization using the proper CLI command:
Router# show processes CPU utilization for five seconds: 1%/0%; one minute: 1%; five minutes: 1% PID QTy PC Runtime (ms) Invoked uSecs Stacks TTY Process 1 Mwe 6039CCC8 2203448 9944378 221 7392/9000 0 IP-EIGRP Router 2 Lst 60133594 329612 34288 9613 5760/6000 0 Check heaps 3 Cwe 6011D820 0 1 0 5648/6000 0 Pool Manager 4 Mst 6015FAA8 0 2 0 5608/6000 0 Timers
CPU utilization can be read using the MIB objects in Table 14-23.
Table 14-23. MIB Objects in OLD-CISCO-CPU-MIB for Monitoring CPU Utilization
| Objects | Description | OID |
|---|---|---|
| busyPer | CPU busy percentage in the last 5 seconds | 1.3.6.1.4.1.9.2.1.56 |
| avgBusy1 | 1-minute moving average of the CPU busy percentage | 1.3.6.1.4.1.9.2.1.57 |
| AvgBusy5 | 5-minute moving average of the CPU busy percentage | 1.3.6.1.4.1.9.2.1.58 |
The amount of main memory left on a router's processor has a significant impact on performance. Buffers are allocated from memory into different memory pools that are used by a protocol. IPX SAP packets, for example, use middle buffers in sending out packets. The following CLI commands are commonly used to monitor the memory and buffer statistics on a router:
show memory
show buffers
show interface
The values collected from CLI commands are accessible via SNMP. Cisco provides the following MIB files for obtaining the equivalent output from CLI commands: CISCO-MEMORY-POOL-MIB, OLD-CISCO-INTERFACES-MIB, and OLD-CISCO-MEMORY-MIB.
The show memory command displays memory allocation:
Router# show memory
Head Total(b) Used(b) Free(b) Lowest(b) Largest(b)
Processor 60DB19C0 119858752 1948928 117909824 117765180 117903232
Fast 60D919C0 131072 69560 61512 61512 61468
Memory allocation can be read using the MIB objects in table Table 14-24.
Table 14-24. MIB Objects in CISCO-MEMORY-POOL-MIB for Monitoring show memory Output
| Objects | Description | OID |
|---|---|---|
| CiscoMemoryPoolName | A textual name assigned to the memory pool | 1.3.6.1.4.1.9.9.48.1.1.1.2 |
| CiscoMemoryPoolUsed | The number of bytes from the memory pool that are currently in use | 1.3.6.1.4.1.9.9.48.1.1.1.5 |
| CiscoMemoryPoolFree | Indicates the number of bytes from the memory pool that are currently unused on the managed device | 1.3.6.1.4.1.9.9.48.1.1.1.6 |
| CiscoMemoryPoolLargestFree | The largest number of contiguous bytes from the memory pool that are currently unused | 1.3.6.1.4.1.9.9.48.1.1.1.7 |
Note
You can use the freemem MIB object in the CISCO-MEMORY-MIB for IOS releases prior to 11.1.
The show buffers command displays buffer allocation:
Router# show buffers Buffer elements: 499 in free list (500 max allowed) 124485689 hits, 0 misses, 0 created Public buffer pools: Small buffers, 104 bytes (total 120, permanent 120): 112 in free list (20 min, 250 max allowed) 35868550 hits, 0 misses, 0 trims, 0 created 0 failures (0 no memory) Middle buffers, 600 bytes (total 90, permanent 90): 88 in free list (10 min, 200 max allowed) 37894226 hits, 0 misses, 0 trims, 0 created 0 failures (0 no memory) Big buffers, 1524 bytes (total 90, permanent 90): 90 in free list (5 min, 300 max allowed) 1161634 hits, 0 misses, 0 trims, 0 created 0 failures (0 no memory) Large buffers, 5024 bytes (total 10, permanent 10): 10 in free list (0 min, 30 max allowed) 0 hits, 0 misses, 0 trims, 0 created 0 failures (0 no memory) Huge buffers, 18024 bytes (total 0, permanent 0): 0 in free list (0 min, 13 max allowed) 0 hits, 0 misses, 0 trims, 0 created 0 failures (0 no memory)
Buffer allocation can be read using the MIB objects in Table 14-25.
Table 14-25. MIB Objects in OLD-CISCO-MEMORY-MIB for Monitoring show buffer Output
| Objects | Description | OID |
|---|---|---|
| Buffer Elements | ||
| bufferElFree | Number of free buffer elements | 1.3.6.1.4.1.9.2.1.9 |
| bufferElMax | Maximum number of buffer elements | 1.3.6.1.4.1.9.2.1.10 |
| bufferElHit | Number of buffer element hits | 1.3.6.1.4.1.9.2.1.11 |
| bufferElMiss | Number of buffer element misses | 1.3.6.1.4.1.9.2.1.12 |
| bufferElCreate | Number of buffer element creates | 1.3.6.1.4.1.9.2.1.13 |
| Small Buffers | ||
| bufferSmSize | The size of small buffers | 1.3.6.1.4.1.9.2.1.14 |
| bufferSmTotal | Total number of small buffers | 1.3.6.1.4.1.9.2.1.15 |
| bufferSmFree | Number of free small buffers | 1.3.6.1.4.1.9.2.1.16 |
| bufferSmMax | Maximum number of small buffers | 1.3.6.1.4.1.9.2.1.17 |
| bufferSmHit | Number of small buffer hits | 1.3.6.1.4.1.9.2.1.18 |
| bufferSmMiss | Number of small buffer misses | 1.3.6.1.4.1.9.2.1.19 |
| bufferSmTrim | Number of small buffer trims | 1.3.6.1.4.1.9.2.1.20 |
| bufferSmCreate | Number of small buffer creates | 1.3.6.1.4.1.9.2.1.21 |
| Medium Buffers | ||
| bufferMdSize | The size of medium buffers | 1.3.6.1.4.1.9.2.1.22 |
| bufferMdTotal | Total number of medium buffers | 1.3.6.1.4.1.9.2.1.23 |
| bufferMdFree | Number of free medium buffers | 1.3.6.1.4.1.9.2.1.24 |
| bufferMdMax | Maximum number of medium buffers | 1.3.6.1.4.1.9.2.1.25 |
| bufferMdHit | Number of medium buffer hits | 1.3.6.1.4.1.9.2.1.26 |
| bufferMdMiss | Number of medium buffer misses | 1.3.6.1.4.1.9.2.1.27 |
| bufferMdTrim | Number of medium buffer trims | 1.3.6.1.4.1.9.2.1.28 |
| bufferMdCreate | Number of medium buffer creates | 1.3.6.1.4.1.9.2.1.29 |
| Big Buffers | ||
| bufferBgSize | The size of big buffers | 1.3.6.1.4.1.9.2.1.30 |
| bufferBgTotal | Total number of big buffers | 1.3.6.1.4.1.9.2.1.31 |
| bufferBgFree | Number of free big buffers | 1.3.6.1.4.1.9.2.1.32 |
| bufferBgMax | Maximum number of big buffers | 1.3.6.1.4.1.9.2.1.33 |
| bufferBgHit | Number of big buffer hits | 1.3.6.1.4.1.9.2.1.34 |
| bufferBgMiss | Number of big buffer misses | 1.3.6.1.4.1.9.2.1.35 |
| bufferBgTrim | Number of big buffer trims | 1.3.6.1.4.1.9.2.1.36 |
| bufferBgCreate | Number of big buffer creates | 1.3.6.1.4.1.9.2.1.37 |
| Large Buffers | ||
| bufferLgSize | The size of large buffers | 1.3.6.1.4.1.9.2.1.38 |
| bufferLgTotal | Total number of large buffers | 1.3.6.1.4.1.9.2.1.39 |
| bufferLgFree | Number of free large buffers | 1.3.6.1.4.1.9.2.1.40 |
| bufferLgMax | Maximum number of large buffers | 1.3.6.1.4.1.9.2.1.41 |
| bufferLgHit | Number of large buffer hits | 1.3.6.1.4.1.9.2.1.42 |
| bufferLgMiss | Number of large buffer misses | 1.3.6.1.4.1.9.2.1.43 |
| bufferLgTrim | Number of large buffer trims | 1.3.6.1.4.1.9.2.1.44 |
| bufferLgCreate | Number of large buffer creates | 1.3.6.1.4.1.9.2.1.45 |
| Huge Buffers | ||
| bufferHgSize | The size of huge buffers | 1.3.6.1.4.1.9.2.1.62 |
| bufferHgTotal | Total number of huge buffers | 1.3.6.1.4.1.9.2.1.63 |
| bufferHgFree | Number of free huge buffers | 1.3.6.1.4.1.9.2.1.64 |
| bufferHgMax | Maximum number of huge buffers | 1.3.6.1.4.1.9.2.1.65 |
| bufferHgHit | Number of huge buffer hits | 1.3.6.1.4.1.9.2.1.66 |
| bufferHgMiss | Number of huge buffer misses | 1.3.6.1.4.1.9.2.1.67 |
| bufferHgTrim | Number of huge buffer trims | 1.3.6.1.4.1.9.2.1.68 |
| bufferHgCreate | Number of huge buffer creates | 1.3.6.1.4.1.9.2.1.69 |
| Buffer Failures | ||
| bufferFail | Number of buffer allocation failures | 1.3.6.1.4.1.9.2.1.46 |
| bufferNoMem | Number of buffer create failures due to no free memory | 1.3.6.1.4.1.9.2.1.47 |
The show interface command displays interface statistics:
Router# show interface Ethernet0/0 is up, line protocol is up Hardware is cxBus Ethernet, address is 0010.f65f.7000 (bia 0010.f65f.7000) Internet address is 172.16.97.1/24 MTU 1500 bytes, BW 10000 Kbit, DLY 1000 usec, rely 255/255, load 1/255 Encapsulation ARPA, loopback not set, keepalive set (10 sec) ARP type: ARPA, ARP Timeout 04:00:00 Last input 00:00:01, output 00:00:01, output hang never Last clearing of "show interface" counters never Queueing strategy: fifo Output queue 0/40, 0 drops; input queue 0/75, 0 drops 5 minute input rate 0 bits/sec, 0 packets/sec 5 minute output rate 0 bits/sec, 0 packets/sec 12072853 packets input, 1379751443 bytes, 0 no buffer Received 1824605 broadcasts, 0 runts, 0 giants 0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 0 abort 0 input packets with dribble condition detected 11283674 packets output, 1218604416 bytes, 0 underruns 0 output errors, 24888 collisions, 1 interface resets 0 babbles, 0 late collision, 0 deferred 0 lost carrier, 0 no carrier 0 output buffer failures, 0 output buffers swapped out
Interface information can be read using the MIB objects in Table 14-26.
Table 14-26. MIB Objects in OLD-CISCO-INTERFACES-MIB and RFC1213 for Monitoring show interface Output
| Objects | Description | OID |
|---|---|---|
| Input Statistics | ||
| cisco.local.lifTable.locIfIn BitsSec | 5-minute exponentially decayed moving average of input bits per second | 1.3.6.1.4.1.9.2.2.1.1.6 |
| locIfInPktsSec | 5-minute exponentially decayed moving average of input packets per second | 1.3.6.1.4.1.9.2.2.1.1.7 |
| interfaces.ifTable.ifInErrors | Number of inbound packets that contained errors preventing them from being delivered them from being delivered to a high-layer protocol | 1.3.6.1.2.1.2.2.1.14 |
| interfaces.ifTable.ifOutErrors | Number of outbound packets that contained errors preventing them from being delivered them from being delivered to a high-layer protocol | 1.3.6.1.2.1.2.2.1.20 |
| ifInNUcastPkts | Number of non-unicast packets delivered to a higher-layer protocol | 1.3.6.1.2.1.2.2.1.12 |
| locIfInRunts | Number of packets input that were smaller than the allowable physicla media permitted | 1.3.6.1.4.1.9.2.2.1.1.10 |
| locIfInGiants | Number of input packets that were larger than the physical media permitted | 1.3.6.1.4.1.9.2.2.1.1.11 |
| locIfInCRC | Number of input packets that had cyclic redundancy checksum errors | 1.3.6.1.4.1.9.2.2.1.1.12 |
| locIfInOverrun | Count of input that arrived too quickly for the hardware to receive | 1.3.6.1.4.1.9.2.2.1.1.14 |
| locIfInIgnored | Number of input packets that were just ignored by this interface | 1.3.6.1.4.1.9.2.2.1.1.15 |
| locIfInAbort | Number of input packets that were aborted | 1.3.6.1.4.1.9.2.2.1.1.16 |
| locIfInputQueueDrops | Number of packets dropped because the input queue was full | 1.3.6.1.4.1.9.2.2.1.1.26 |
| Output Statistics | ||
| locIfOutBitsSec | 5-minute exponentially decayed moving average of output bits per second | 1.3.6.1.4.1.9.2.2.1.1.8 |
| locIfOutPktsSec | 5-minute exponentially decayed moving average of output packets per second | 1.3.6.1.4.1.9.2.2.1.1.9 |
| ifOutErrors | Number of outbound packets that could not be transmitted because of errors | 1.3.6.1.2.1.2.2.1.20 |
| locIfCollisions | Number of output collisions detected on this interface | 1.3.6.1.4.1.9.2.2.1.1.25 |
| locIfResets | Number of times the interface internally reset | 1.3.6.1.4.1.9.2.2.1.1.17 |
| locIfRestarts | Number of times the interface had to be completely restarted | 1.3.6.1.4.1.9.2.2.1.1.18 |
| locIfCarTrans | Number of times interface saw the carrier signal transition | 1.3.6.1.4.1.9.2.2.1.1.21 |
| locIfOutputQueueDrops | Number of packets dropped because the output queue was full | 1.3.6.1.4.1.9.2.2.1.1.27 |
Another way to look at MIB objects is to sort them by types of interfaces, as shown in Table 14-27.
Table 14-27. Table of Interface-Related MIB Objects
| Applicability | MIB Objects |
|---|---|
| All interfaces | cisco.local.lifTable.locIfInbitsSec |
| cisco.local.lifTable.locIfOutbitsSec | |
| mib-2.interfaces.ifTable.ifInErrors | |
| mib-2.interfaces.ifTable.ifOutErrors | |
| cisco.local.lifTable.locIfInputQueueDrops | |
| cisco.local.lifTable.locIfOutputQueueDrops | |
| cisco.local.lifTable.locIfInIgnored | |
| cisco.local.lifTable.locIfResets | |
| cisco.local.lifTable.locIfRestarts | |
| For serial interfaces | cisco local lifTable locIfCRC |
| cisco.local.lifTable.locIfAbort | |
| cisco.local.lifTable.locIfFrame | |
| cisco.local.lifTable.locIfCarTrans | |
| cisco.local.lifTable.locIfOverrun | |
| For Ethernet interfaces | cisco local lifTable locIfCollisions |
| cisco.local.lifTable.locIfRunts | |
| cisco.local.lifTable.locIfGiants | |
| cisco.local.lifTable.locIfFrame | |
| For Token Ring interfaces (from RFC 1231) | dot5StatsLineErrors |
| dot5StatsBurstErrors | |
| dot5StatsACErrors | |
| dot5StatsAbortTransErrors | |
| dot5StatsInternalErrors | |
| dot5StatsFrameCopiedErrors | |
| dot5StatsTokenErrors | |
| dot5StatsSoftErrors | |
| dot5StatsSignalLoss | |
| dot5StatsFreqErrors | |
| For FDDI interfaces (from RFC 1512) | snmpFddiMACLostCts |
| snmpFddiMACErrorCts |
The final tasks involved in performance management are setting thresholds, exception reporting, analysis, and tuning.
The chapter concludes with a number of network-based correlation scenarios. The section begins with an overview of scenario information and concludes with several specific scenarios.
It is assumed that all network devices are being polled either through ICMP (ping) or SNMP, or both, for basic reachability from the NMS. Whenever a device is not reachable, a DEVICE_DOWN event will be generated by the NMS to the event-correlation engine.
Most NMS support this capability.
It is assumed that the logical (that is, Layer 3) topology of the network is available to the correlation engine to understand the logical subnet connectivity and figure out whether a device is "logically" before or beyond another device from the NMS perspective.
Most NMS support this capability.
Some correlation rules require knowledge of the physical (that is, Layer 2) topology of the network to understand how switches and routers are interconnected within a subnet.
Very few NMSs support this capability.
Some event-correlation scenarios require assessing the state difference of managed objects before and after an event occurs. The event-correlation engine must maintain or have access to such state variables and have the capability to collect the new state when needed.
Thresholding also requires setting thresholds at levels representative of a customer's network. Because every network is different and displays different traffic patterns, this chapter cannot provide fixed numeric thresholds. Instead, the most representative MIB objects and events for a more proactive monitoring approach are discussed.
The event-correlation engine must allow some form of customization to tailor correlation rules for every customer. Defaults should be provided to reflect most situations.
To illustrate the event model as shown in Figure 14-1, the following conditions were identified as being the most critical conditions in a typical network of switches and routers. This study focused essentially on the Catalyst 5000 family and the 7500 router.
Simple thresholding rules involving simple cause-effect situations (such as a Counter exceeding a certain value causing operator notification) are intentionally ignored in this chapter, because they do not require any form of correlation.
Some scenarios present definitions for a simple correlation rule and an advanced correlation rule to allow for phased-in implementations. The simple correlation rule is provided as the minimal set of functionality to address the problem scenario. The advanced correlation rule presents a more extensive resolution.
Some indication of polling intervals is provided. However, every site should reevaluate these polling intervals based on their traffic patterns and equipment capacity.
A few key syslog messages need to be filtered to reduce the number of notifications to network operators. These filters need to suppress identical messages repeated within n seconds.
Selected syslog messages apply to Cisco 7500 routers and are listed in Table 14-28.
Table 14-28. Filtered Syslog Messages
| Message Type/ Description | Message Encoding |
|---|---|
| Configuration Changes Report | SYS-5-CONFIG |
| SYS-5-CONFIG_I | |
| SYS-5-CONFIG_L | |
| SYS-5-CONFIG_M | |
| SYS-5-CONFIG_NV | |
| SYS-5-CONFIG_NV_M | |
| These messages apply to 7500 routers and other IOS-based routers. The identifier after the work CONFIG specifies the origin of the configuration change. All these messages are considered identical for event correlation because operators are concerned about configuration changes, irrespective of how the changes were applied. They need to be filtered if multiple messages occur within n minutes from the same device. | |
| Recommendation: n = 5 minutes | |
| CPU Hog Report | This message applies to 7500 routers and other IOS-based routers. IOS-based routers generates a SYS-3-CPUHOG syslog message. |
| This message repeats itself if the CPU is hogged for a long time. These messages need to be filtered to eliminate duplicates within n minutes from the same router. | |
| Recommendation: n = 5 minutes |
The SNMP trap in Table 14-29 should be filtered similarly.
Table 14-29. Filtered SNMP Trap
| SNMP Trap Type/Description | Message Encoding |
|---|---|
| snmpAuthenticationFailure | This trap is defined in RFC 1213, MIB. |
| This trap indicates an attempt to access an SNMP agent with an invalid community string. | |
| If no more than three such traps are received within 5 minutes from the same device, the traps should be ignored. Otherwise, a warning notification should be sent to the network operator to alert him of a possible security attack. |
Platform: . 7500 router.
Objective: . Detect when a device reports it is shutting down (as opposed to not reaching it, which is covered in the Router/Switch Down scenario).
Symptoms: . Cisco IOS logs syslog message before (SYS-5-RELOAD) and after (SYS-5-RESTART) a device restarts.
Correlation Logic: . When the SYS-5-RELOAD message is received, the event-correlation engine must wait for a SYS-5- RESTART to arrive within n minutes and cancel the original message. If no SYS-5-RESTART message is received within n minutes, the operator should be notified of a critical alert. If the router reports a SYS-5- RESTART message within n minutes, the condition will only be logged as informational, along with the value of the whyReload MIB object.
If the router is detected as down, this information will be fed as input into the correlation rule for the router up/down problem, so that the background reachability check will not report it as down again.
Probable Cause: . Software error or operator intervention.
Actions/Resolution: . Notify operator if router does not issue a SYS-5-RESTART message within n minutes (n = time for router to reload + 1 minute).
Platform: . Catalyst 5000.
Objective: . Detect when a device reports it is being reset from the console (as opposed to not reaching it, which is covered in the Router/Switch Down scenario).
Symptoms: . Cisco IOS logs syslog message before the switch is reset from the console (SYS-5:System reset). An SNMP cold start trap and/or the IOS message (SNMP-5:Cold Start Trap) after the device restarts.
Correlation Logic: . When the SYS-5:System reset message is received, the event-correlation engine must wait for an IOS message SNMP-5:Cold Start Trap or a cold start trap to arrive within n minutes and cancel the original message. If no SNMP-5:Cold Start Trap message is received within n minutes, the operator should be notified of a critical alert. If the switch reports a SNMP-5:Cold Start Trap IOS message or cold start trap within n minutes, the condition will only be logged as informational.
If the switch is detected as down, this information will be fed as input into the correlation rule for the router/switch up/down problem, so that the background reachability check will not report it as down again.
Probable Cause: . Software error or operator intervention.
Actions/Resolution: . Notify operator if router does not issue a SNMP-5:Cold Start Trap or cold start trap message within n minutes (n = time for switch to reload + 1 minute).
Platforms: . 7500 router and other routers with BRI interfaces.
Objective: . Knowing when a link is up or down is perceived by customers as being the most important requirement. Added correlation will allow detecting normal link up/down transitions from dialup lines to more serious transitions for other links.
An interface being down can be a critical alert on a router or switch. Access routers with ISDN and ASCII links have their interfaces going up and down many times a day, however, as part of their normal activity, as dialup calls are initiated and torn down. A correlation rule should be applied to sort out the relevant link-down conditions from normal operation.
Symptoms: . LINK_3_UPDOWN syslog messages are logged.
Correlation Logic: . Two levels of correlation were identified:
Simple correlation
Advanced correlation
For simple correlation, if the string BRI is contained in the message, the message should be discarded.
For advanced correlation, if the message does not contain the string BRI, the physical topology database should be queried to determine the type of link, namely whether it is a link between two routers, a router and a switch, or router and an end-user port.
The syslog message should be further processed only if it is a link between two Cisco devices.
Probable Cause: . Link was either disconnected or broken.
Actions/Resolution: . Notify the network operator, except if the interface is that of an end user or an ASCII or BRI interface.
Platform: . Catalyst 5000 only.
Objective: . STP reconfiguration can have disastrous effects, such as some parts of the network not being accessible any longer. Upon detection of an STP reconfiguration, the event-correlation engine should ensure that the network is still functional.
Symptoms: . If you received any of the following syslog messages:
SPANTREE-6: "port [dec]/[dec] state in vlan [dec] changed to blocking."
SPANTREE-6: "port [dec]/[dec] state in vlan [dec] changed to forwarding."
Or any of the following RFC 1493 (Bridge MIB) SNMP traps:
topologyChange
newRoot
These traps contain the community string in the format community@vlanId, where vlanId is the VLAN identifier in which the spanning tree changed. For Catalyst 5000 switch Release 4.1 and higher, these traps will contain the vtpVlanIndex and ifName varBinds to provide additional information to the application processing these traps.
Correlation Logic: . Three types of correlation are possible, depending on the extent the ECS can query the network:
Simple correlation
Medium correlation
Advanced correlation
The simple STP correlation refers to ensuring that every device reporting an STP change through the means referred to earlier is monitored to ensure that it is restored to a valid state. This will be accomplished as follows, based on the Catalyst 5000 MIB.
First of all, the CISCO-STACK-MIB object sysEnableBridgeTraps should be verified to be set to enabled(1), or an alert should be raised.
The community field in the topologyChange or newRoot trap must be read and used to further interrogate the switch the trap came from. This enables you to query the specific VLAN the topology change occurred on.
First, you need to determine whether any ports were a trunk before the STP change. To do so, the list of all trunks per VLAN must be maintained and verified against the list after the STP change. A trunk port is defined as having its vlanPortIslOperStatus MIB object in the vlanPortTable of the CISCO-STACK MIB with a value of trunking(1).
Second, you need to determine which trunk ports in this VLAN had a state change by scanning the vlanPortTable for those entries with vlanPortVlan set to the VLAN ID specified in the trap.
For each of the selected ports, identify the vlanPortIslOperStatus MIB object with a value of trunking(1). For each trunk, you need to monitor its status as identified in RFC 1493. This is accomplished as follows.
Read the vlanPortIslAdminStatus object in the vlanPortTable and ensure it is not set to off(2). Otherwise, generate an alert that the port was disabled.
For each trunk port in the selected VLAN, read the corresponding vlanPortModule and vlanPort from the vlanPortTable. Use these two values of vlanPortModule and vlanPort to index into the CISCO-STACK-MIB portTable to retrieve the corresponding portIfIndex value. Use the portIfIndex to read the MIB-II ifOperStatus to determine whether the interface is still up. If not, generate an alert.
Read the portCrossIndex value in the portTable in the CISCO-STACK-MIB for the selected entry and use this value to index into the RFC 1493 dot1dStpPortTable to verify that the dot1dStpPortEnable is set to enabled(1).
Then, use the same portCrossIndex value in the portTable in the CISCO-STACK-MIB to locate the corresponding entry in the RFC 1493 dot1dStpPortTable to verify that dot1dStpPortState is either in blocking(2) or forwarding(5) mode, 2 minutes after the trap is received. Otherwise, send an alert.
Verify also that the ports that were known to be trunks before the trap occurred are still trunks (that is, that all trunks known to be valid trunks are still functioning as trunks). Otherwise, an alert should be generated. Similarly, the situation when a port was known not to be a trunk, but is found to be a trunk while processing the trap, should be reported.
Alerts should also include e-mail summarizing the discrepancies found as a result of this correlation. Whether a separate e-mail is generated for each port discrepancy or all port discrepancies associated with an STP change are accumulated in a single e-mail is implementation dependent.
Note
An alternative to processing traps would be to poll the RFC 1493 dot1dStpTopChanges MIB object to determine whether it incremented by at least one or decremented (indicating an agent reset) since the last poll.
The next correlation type is a medium correlation. An STP reconfiguration is always limited to a subnet. Assuming the event-correlation engine knows the devices in the subnet prior to the reconfiguration, a simple correlation could ensure that all these devices are still up and running (by performing a reachability test) and that these are still the same devices (by comparing the previously known and the current RFC1213-MIB sysDescr string for each device). A logical topology discovery will also be initiated to detect whether any new device was added to the network. An alternative is to rely on switches newly added to the network to generate either trap, so that the ECS can detect them.
Although not 100% perfect, this correlation rule can assist a network operator in narrowing down the scope of the error more quickly.
The final correlation type is an advanced correlation. One way to realize why an STP configuration occurred is to know ahead of time the list of devices involved in each spanning tree in the network. An STP topology can be collected by querying the dot1Stp MIB group from the RFC 1493 MIB. CWSI 1.2 and greater can also be used to display a graphical map of the STP tree over the physical topology discovered using CDP. Note that Cisco supports one spanning tree per VLAN. The VLAN ID is reported either in the syslog message or in the community string contained in the SNMP trap. If no VLAN is configured in the network, it is assumed that there is only one VLAN with a VLAN ID of 1. Therefore, the term VLAN in this section is used to represent the subnet if no VLANs are configured.
When any spanning tree in a VLAN reconfigures, the event-correlation engine can then identify which VLAN reconfigured and determine what changed in the spanning tree.
The event correlation listens for RFC 1493 (Bridge MIB) newRoot or topologyChange SNMP traps to detect when an STP reconfiguration occurs. These traps are always sent by a device whose port changed state as defined in the RFC.
If a topologyChange trap is received, the event-correlation engine can easily compile the list of devices involved in the STP reconfiguration.
If the ECS cannot adequately extract the community string from the trap and does not process syslog messages, the event-correlation rule needs to relate the trap to a VLAN by detecting which VLAN had its topology change counter increased by one. For that purpose, the CISCO-STACK vlanTable MIB group can be queried to list the VLANs configured in the switch. Using the SNMP community string to address individual VLANs (using community@vlanId), the NMS could alternately poll for the RFC 1493 dot1dStpTopChanges MIB object, which gives the number of topology changes since the device rebooted or initialized. This method would enable you to isolate which VLAN had a topology change so that further verification could be performed in that VLAN only.
Because STP reconfiguration is automatic, the event-correlation logic needs to determine the following:
The cause of the topology change
The correctness of the new STP topology
The event-correlation engine needs to determine whether a node was detected as going down prior to an STP topology change being detected. The event-correlation rule will calculate the difference between the known STP topology prior to the STP reconfiguration and the new STP configuration with the following objectives:
If a new root was defined, identify whether the previous root device is down, and whether the new root is a new device added to the network.
If a single topology change occurred, identify whether another node in the STP tree was added (for example, restarted) or removed (for example, is restarting or is not reachable at all) by rediscovering all devices involved in the VLAN.
If no device was added or removed, it would imply that a redundant link was either removed (for example, a cable was unplugged) or added.
In any of these three situations, the event-correlation engine needs to assess which ports involved in a spanning tree changed from a forwarding state to a blocking state, or from a learning to forwarding state. It also needs to correlate whether any of these ports had their RFC1213-MIB operStatus MIB object toggle from up to down, in an attempt to identify a port failure or disconnection.
The operator will be notified of the actual device and port that caused the topology change. It may be that the event correlation identifies more than one possible failure cause or device, in which case it should report all possible causes or devices to the operator.
The notion of correctness can be very complex, depending on the network characteristics.
The simplest means to determine correctness of an STP configuration is to ensure that every device in the VLAN spanning tree is reachable. Therefore, the correlation rule will trigger a reachability test to all devices known to have been members in the spanning tree prior to the reconfiguration. The correlation rule will also trigger a discovery of the new STP tree to detect whether a new device was added to the spanning tree.
The correlation engine of the device(s) involved in the reconfiguration will notify the network operator and will specify the most likely cause of the STP reconfiguration, namely:
A device was added to or removed from the subnet.
A link was added or removed between two devices.
A more difficult test is to detect which interfaces went down or up, and which would therefore have caused the STP reconfiguration, while not reporting interfaces which were known to be down before the STP topology change occurred. This correlation rule can be performed through the same mechanisms described earlier. STP discovery must include the ports involved in an STP tree with their operStatus and adminStatus as defined in the ifTable of RFC1213 MIB and compare the values of these MIB objects prior to and after an STP reconfiguration. Another way to detect whether STP reconfiguration occurred because of a down interface is to correlate it to a linkDown SNMP trap or syslog message received within seconds of a topologyChange or newRoot SNMP trap or topology change syslog message within a VLAN.
An alternative method is to monitor the dot1dStpPortForwardTransitions MIB object to detect when this object increments by one.
Probable Cause: . A device involved in the spanning tree was removed from service, failed, or was added to the network, or a link was added or removed between two switches.
Actions/Resolution: . Notify operator as specified earlier. No automatic action is expected.
Platforms: . Catalyst 5000 and 7500 router.
Objective: . Detect when a switch or router is down, without reporting the unreachable switches and routers behind it.
Based on knowledge of the topology layout, a correlation engine must identify the most likely failure from a group of unreachable nodes. Assuming Cisco manages Cisco equipment only, end-user devices'status—such as PCs and servers—will not be monitored.
Symptoms: . Several devices are not reachable at the same time.
Correlation Logic: . A logical (Layer 3) topology database can serve to detect a faulty router from a group of unreachable routers. However, a physical (for example, Layer 2) topology database is needed to detect a faulty switch from a group of unreachable switches.
Every device reported as not reachable within n minutes will be queried for RFC1213-MIB sysObjectID MIB object and use Cisco's mapping table.
Then, the event-correlation engine would either perform a simple or advanced correlation. The recommendation is n = 5 minutes.
Simple correlation involves using the existing NMS topology database.
This will work best for determining a faulty router from other routers, but will not differentiate between switches (because most NMS do not support L2 topology).
Advanced correlation allows determining a faulty switch from multiple switches in a subnet by making use of a physical-connectivity database describing how switches are interconnected. The ECS would need to first use L3 topology to identify which subnet is most likely to have a failure. Then an L2 topology database can be used to identify which switch may have failed.
Note
It is best not to connect the NMS workstation directly to a switched network because the NMS cannot isolate which switch may be "behind" other switches unless the event-correlation engine can determine which switch the NMS is connected to. This can be accomplished by querying the MAC cache tables in every switch and matching them to the MAC address of the NMS workstation. This can be a very lengthy process because there will be potentially thousands of MAC addresses to collect.
Probable Cause: . A single router or switch is down.
Actions/Resolution: . Notify operator with a single notification identifying the faulty device.
Platform: . 7500 router.
Objective: . Detect when excessive traffic causes excessive CPU load.
Network managers have only a limited understanding of the traffic flowing through their Cisco switches and routers. Detecting high traffic conditions becomes increasingly important. CPU overload conditions as reported by SYS-3-CPUHOG syslog messages will be monitored and an alert will be generated when excessive conditions are detected— conditions not related to transient traffic flows as reported by NetFlow, which may indicate a temporary overload condition.
Symptoms: . The SYS-3-CPUHOG syslog message is logged, indicating a CPU overload condition.
Correlation Logic: . Two levels of correlation were identified.
The first type of correlation is simple correlation. The event-correlation engine will 0trigger traffic statistics collection every 20 seconds for n minutes for the ifInOctets and ifOutOctets from the RFC1213 MIB ifTable. If any interface traffic utilization exceeds 40% of the link capacity (ifSpeed) for more than 50% of the collection period, the operator will be notified with a reference to the interface(s) having excessive traffic.
If the interface with excessive traffic is the same interface used for ping and SNMP reachability, it is likely that the condition will result in the device not being reachable temporarily, which would report the device as down. The device low-performance condition will be fed as input into the reachability correlation rule so that the operator is not notified twice for the same problem, or that other devices are assumed down/unreachable because this interface is overloaded (see the Router Down problem).
The low-performance condition will be deemed a minor alarm for n minutes and not reported to the network operator if it goes away within n minutes. The recommendation is n = 15 minutes.
If no performance condition exists, the lack of reachability will be treated as a critical alarm because the device is probably totally down.
The second type of correlation is advanced correlation. NetFlow can be used to perform more advanced correlation and to avoid reporting transient overloads by verifying which protocols are responsible for the high-performance impact. This is explained as follows.
The IOS command show ip cache flow will report a table of IP addresses that are communicating on which port and which device interface. The table columns are labeled SrcIPaddress, DstIPaddress, SrcP, DstP, SrcIf, and DstIf. From this information, you can determine whether CPU overload is due to excessive traffic on a given interface, and whether the traffic is transient (FTP on port 21, for example). If the traffic is identified as transient, the event-correlation engine will ignore the CPUHOP syslog message for 5 minutes for that specific session. If the CPUHOP syslog message is repeated because of the same NetFlow session, over a period of 30 minutes, the operator will be notified as a warning that an unusual NetFlow session is taking place. The IOS command export ip flow can also be used for this purpose.
If the CPUHOP syslog message occurs repeatedly for different sessions (such as 10 times per hour), the operator will be notified as an indication that the device is consistently being overloaded and should be looked at further.
Probable Cause: . The cause may be due to a transient session (such as FTP) or the router is underpowered for the traffic going through it.
Actions/Resolution: . Notify operator if performance problem persists as described earlier.
Platform: . Catalyst 5000 with redundant supervisor module.
Objective: . Detect when temperature rises and may cause a device shutdown.
Symptoms: . The Catalyst 5000 switch with a redundant supervisor module reports a syslog message: SYS-0: "Temp high Failure" or an SNMP trap: CISCO-STACK MIB chassisAlarmOn with the varBindList containing chassisTempAlarm = on(2), chassisMinorAlarm = on(2) or off(1), and chassisMajorAlarm = on(2), whenever the temperature exceeds 50° Celsius.
Correlation Logic: . If, within 5 minutes, you receive another syslog message: SYS-0: "Temp Critical Recovered" or SYS-2: "Temp high Okay" or the SNMP trap: CISCO-STACK MIB chassisAlarmOff, the alert should be cleared from the event-correlation engine.
If none of these messages or an SNMP trap is received, the alert should be fed as input into the Device Up/Down correlation rule reporting that the device is down.
Probable Cause: . The air-conditioning in the room failed or the fan failed.
Actions/Resolution: . The original error should be reported immediately as a paging notification to the network operator. If the problem clears itself, the operator should be notified again.
Platform: . 7000 router.
Objective: . Detect when temperature rises and may cause a device shutdown.
Symptoms: . Any of the following syslog messages are received:
ENV-2-TEMP
ENV-1-SHUTDOWN
ENVM-2-TEMP
ENVM-1-SHUTDOWN
The -TEMP messages will generate a major alarm; the SHUTDOWN messages will generate a critical alarm.
More granularity may be supported if the ECS can decode the actual temperature from the syslog message and apply its own thresholds and alarm severities.
The alarm would eventually have to be cleared manually by the operator.
Correlation Logic: . Pass through.
Probable Cause: . The air-conditioning in the room failed.
Actions/Resolution: . Notify operator.
This chapter provides Cisco customers with a reference to the various manageable elements of Cisco routers and Catalyst switches. From this chapter, you should have learned the elements of Catalyst switches, how to manage them, and how managing a switch differs from managing a router. The following items were covered:
An introduction to network management.
Bridging theory and implementation on Cisco switches, on Cisco routers and those technologies common to both switches and routers.
An introduction to network-management protocols, Cisco's event model, and a description of Cisco events, namely syslog messages and SNMP traps.
Keys to a successful network-management strategy.
The various aspects of switches that require management, and the appropriate techniques to manage those resources.
The various aspects of routers that require management, and the appropriate techniques to manage those resources.
Advanced monitoring and correlation scenarios within a single device or across several devices.
Details on syslog messages and reporting facilities.
Examples to set RMON thresholds.