
Edited by Atif Khan
The Border Gateway Protocol (BGP) is an interautonomous system routing protocol. The primary function of a BGP-speaking system is to exchange network reachability information with other BGP systems. This network reachability information includes the list of autonomous systems (ASs) that reachability information traverses. BGP4 provides a set of mechanisms for supporting classless interdomain routing. These mechanisms include support for advertising an IP prefix and eliminate the concept of network class within BGP. BGP4 also introduces mechanisms that allow aggregation of routes, including aggregation of AS paths. These changes provide support for the proposed supernetting scheme. This chapter describes how BGP works and how it can be used to participate in routing with other networks that run BGP. The following topics are covered:
BGP Operation
BGP Attributes
BGP Path Selection Criteria
Understanding and Defining BGP Routing Policies
This section presents fundamental information about BGP, including the following topics:
Internal BGP (IBGP)
External BGP (EBGP)
BGP and Route Maps
Advertising Networks
Routers that belong to the same AS and exchange BGP updates are said to be running internal BGP (IBGP). Routers that belong to different ASs and exchange BGP updates are said to be running external BGP (EBGP).
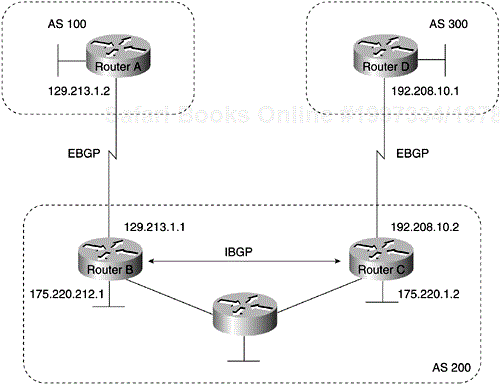
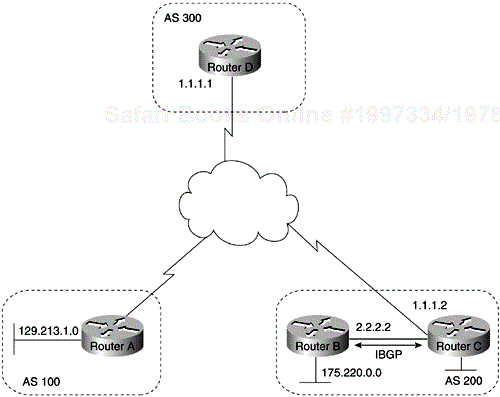
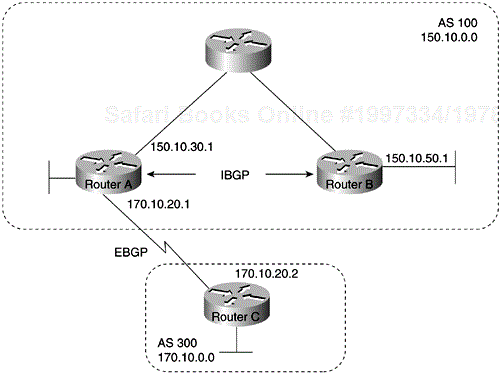
With the exception of the neighborebgp-multihop command, the commands for configuring EBGP and IBGP are the same. This chapter uses the terms EBGP and IBGP as a reminder that, for any particular context, routing updates are being exchanged between ASs (EBGP) or within an AS (IBGP). Figure 4-1 shows a network that demonstrates the difference between EBGP and IBGP.
Before it exchanges information with an external AS, BGP ensures that networks within the AS are reachable. This is done by a combination of internal BGP peering among routers within the AS and by redistributing BGP routing information to Interior Gateway Protocols (IGPs) that run within the AS, such as Enhanced Interior Gateway Routing Protocol (EIGRP), Interior Gateway Routing Protocol (IGRP), Intermediate System–to– Intermediate System (IS-IS), Routing Information Protocol (RIP), and Open Shortest Path First (OSPF).
BGP uses the Transmission Control Protocol (TCP) as its transport protocol (specifically, port 179). Any two routers that have opened a TCP connection to each other for the purpose of exchanging routing information are known as peers or neighbors. In Figure 4-1, Routers A and B are BGP peers, as are Routers B and C, and Routers C and D. The routing information consists of a series of AS numbers that describe the full path to the destination network. BGP uses this information to construct a loop-free map of ASs. Note that within an AS, BGP peers do not have to be directly connected.
BGP peers initially exchange their full BGP routing tables. Thereafter, BGP peers send incremental updates only. BGP peers also exchange keepalive messages (to ensure that the connection is up) and notification messages (in response to errors or special conditions).
Note
Routers A and B are running EBGP, and Routers B and C are running IBGP, as shown in Figure 4-1. Note that the EBGP peers are directly connected and that the IBGP peers are not. So long as there is an IGP running that allows the two neighbors to reach each other, IBGP peers do not have to be directly connected.
All BGP speakers within an AS must establish a peer relationship with one another. That is, the BGP speakers within an AS must be fully meshed logically. BGP4 provides two techniques that alleviate the requirement for a logical full mesh: confederations and route reflectors. For information about these techniques, see the sections titled Confederations and Route Reflectors later in this chapter.
AS 200 is a transit AS for AS 100 and AS 300. That is, AS 200 is used to transfer packets between AS 100 and AS 300.
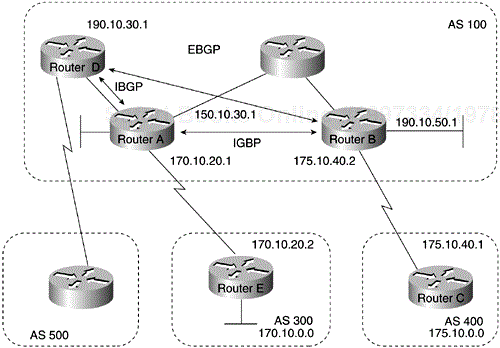
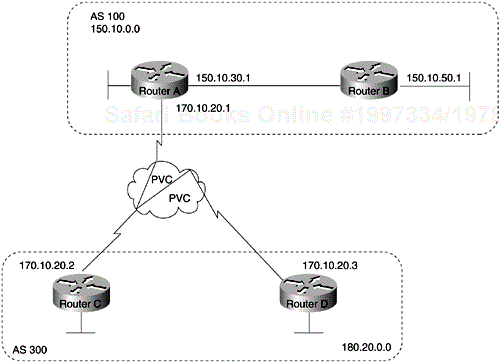
Internal BGP is the form of BGP that exchanges BGP updates within an AS. Instead of IBGP, the routes learned via EBGP could be redistributed into IGP within the AS and then redistributed again into another AS. However, IBGP is more flexible, more scalable, and provides more efficient ways of controlling the exchange of information within the AS. It also presents a consistent view of the AS to external neighbors. For example, IBGP provides ways to control the exit point from an AS. Figure 4-2 shows a topology that demonstrates IBGP.
When a BGP speaker receives an update from other BGP speakers in its own AS (that is, via IBGP), the receiving BGP speaker uses EBGP to forward the update to external BGP speakers only. This behavior of IBGP is why it is necessary for BGP speakers within an AS to be fully meshed.
In Figure 4-2, for example, if no IBGP session existed between Routers B and D, Router A would send updates from Router B to Router E, but not to Router D. If you want Router D to receive updates from Router B, Router B must be configured so that Router D is a BGP peer.
Loopback interfaces are often used by IBGP peers. The advantage of using loopback interfaces is that they eliminate a dependency that would otherwise occur when you use the IP address of a physical interface to configure BGP. Figure 4-3 shows a network in which using the loopback interface is advantageous.
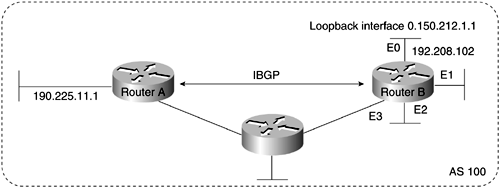
In Figure 4-3, Routers A and B are running IBGP within AS 100. If Router A were to specify the IP address of Ethernet interface 0, 1, 2, or 3 in the neighbor remote-as command, and if the specified interface were to become unavailable, Router A would not be able to establish a TCP connection with Router B. Instead, Router A specifies the IP address of the loopback interface that Router B defines. When the loopback interface is used, BGP does not have to rely on the availability of a particular interface for making TCP connections.
Note
Loopback interfaces are rarely used between EBGP peers because EBGP peers are usually directly connected and, therefore, depend on a particular physical interface for connectivity.
When two BGP speakers that are not in the same AS run BGP to exchange routing information, they are said to be runningEBGP.
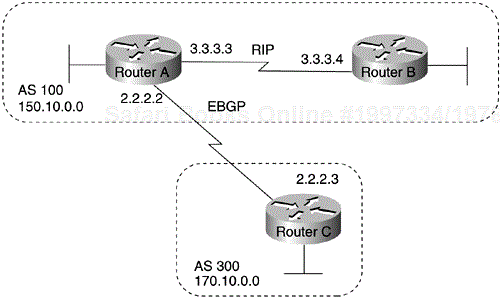
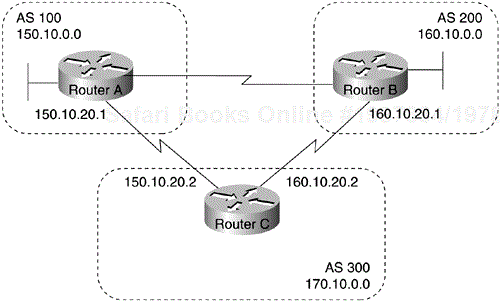
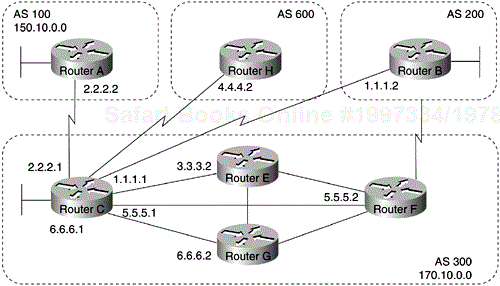
When an AS provides transit service to other ASs when there are non-BGP routers in the AS, transit traffic might be dropped if the intermediate non-BGP routers have not learned routes for that traffic via an IGP. The BGP synchronization rule states that if an AS provides transit service to another AS, BGP should not advertise a route until all the routers within the AS have learned about the route via an IGP. The topology shown in Figure 4-4 demonstrates this synchronization rule.
In Figure 4-4, Router C sends updates about network 170.10.0.0 to Router A. Routers A and B are running IBGP, so Router B receives updates about network 170.10.0.0 via IBGP. If Router B wants to reach network 170.10.0.0, it sends traffic to Router E. If Router A does not redistribute network 170.10.0.0 into an IGP, Router E has no way of knowing that network 170.10.0.0 exists and will drop the packets.
If Router B advertises to AS 400 that it can reach 170.10.0.0 before Router E learns about the network via IGP, traffic coming from Router D to Router B with a destination of 170.10.0.0 will flow to Router E and be dropped.
This situation is handled by the synchronization rule of BGP. It states that if an AS (such as AS 100 in Figure 4-4) passes traffic from one AS to another AS, BGP does not advertise a route before all routers within the AS (in this case, AS 100) have learned about the route via an IGP. In this case, Router B waits to hear about network 170.10.0.0 via an IGP before it sends an update to Router D.

In some cases, you might want to disable synchronization. Disabling synchronization allows BGP to converge more quickly, but it might result in dropped transit packets. You can disable synchronization if one of the following conditions is true:
Your AS does not pass traffic from one AS to another AS.
All the transit routers in your AS run BGP.
Route maps are used with BGP to control and modify routing information and to define the conditions by which routes are redistributed between routing domains. The format of a route map is as follows:
route-map map-tag [[permit | deny] | [sequence-number]]
The map-tagis a name that identifies the route map, and the sequence-number indicates the position that an instance of the route map is to have in relation to other instances of the same route map. (Instances are ordered sequentially.) For example, you might use the following commands to define a route map named MYMAP:
route-map MYMAP permit 10 ! First set of conditions goes here. route-map MYMAP permit 20 ! Second set of conditions goes here.
When BGP applies MYMAP to routing updates, it applies the lowest instance first (in this case, instance 10). If the first set of conditions is not met, the second instance is applied, and so on, until either a set of conditions has been met, or there are no more sets of conditions to apply.
The match and set route map configuration commands are used to define the condition portion of a route map. The match command specifies a criteria that must be matched, and the set command specifies an action that is to be taken if the routing update meets the condition defined by the match command. The following is an example of a simple route map:
route-map MYMAP permit 10 match ip address 1.1.1.1 set metric 5
When an update matches the IP address 1.1.1.1, BGP sets the metric for the update to 5, sends the update (because of the permit keyword), and breaks out of the list of route-map instances. When an update does not meet the criteria of an instance, BGP applies the next instance of the route map to the update, and so on, until an action is taken, or until there are no more route-map instances to apply. If the update does not meet any criteria, the update is not redistributed or controlled.
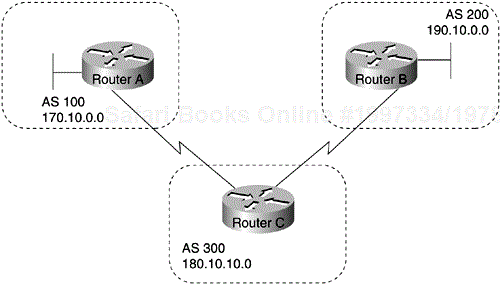
When an update meets the match criteria, and the route map specifies the deny keyword, BGP breaks out of the list of instances, and the update is not redistributed or controlled. Figure 4-5 shows a topology that demonstrates the use of route maps.
In Figure 4-5, Routers A and B run RIP with each other, and Routers A and C run BGP with each other. If you want Router A to redistribute routes from 170.10.0.0 with a metric of 2 and to redistribute all other routes with a metric of 5, use the following commands for Router A:
!Router A router rip network 3.0.0.0 network 2.0.0.0 network 150.10.0.0 passive-interface serial 0 redistribute bgp 100 route-map SETMETRIC ! router bgp 100 neighbor 2.2.2.3 remote-as 300 network 150.10.0.0 ! route-map SETMETRIC permit 10 match ip-address 1 set metric 2 ! route-map SETMETRIC permit 20 set metric 5 ! access-list 1 permit 170.10.0.0 0.0.255.255
When a route matches the IP address 170.10.0.0, it is redistributed with a metric of 2. When a route does not match the IP address 170.10.0.0, its metric is set to 5, and the route is redistributed.
Assume that on Router C you want to set to 300 the community attribute of outgoing updates for network 170.10.0.0. The following commands apply a route map to outgoing updates on Router C:
!Router C router bgp 300 network 170.10.0.0 neighbor 2.2.2.2 remote-as 100 neighbor 2.2.2.2 route-map SETCOMMUNITY out ! route-map SETCOMMUNITY permit 10 match ip address 1 set community 300 ! access-list 1 permit 0.0.0.0 255.255.255.255
Access list 1 denies any update for network 170.10.0.0 and permits updates for any other network.
A network that resides within an AS is said to originate from that network. To inform other ASs about its networks, the AS advertises them. BGP provides three ways for an AS to advertise the networks that it originates:
Redistributing static routes
Redistributing dynamic routes
Using the network command
Thissection uses the topology shown in Figure 4-6 to demonstrate how networks that originate from an AS can be advertised.
One way to advertise that a network or a subnet originates from an AS is to redistribute static routes into BGP. The only difference between advertising a static route and advertising a dynamic route is that when you redistribute a static route, BGP sets the origin attribute of updates for the route to Incomplete. (For a discussion of other values that can be assigned to the origin attribute, see the section titled Origin Attribute later in this chapter.) To configure Router C in Figure 4-6 to originate network 175.220.0.0 into BGP, use these commands:
!Router C router bgp 200 neighbor 1.1.1.1 remote-as 300 redistribute static ! ip route 175.220.0.0 0.0.255.255 null 0
The redistribute command and the static keyword cause all static routes to be redistributed into BGP. The ip route command establishes a static route for network 175.220.0.0. In theory, the specification of the null 0 interface would cause a packet destined for network 175.220.0.0 to be discarded. In practice, there will be a more specific match for the packet than 175.220.0.0, and the router will send it out the appropriate interface. Redistributing a static route is the best way to advertise a supernet because it prevents the route from flapping.
Note
Regardless of route type (static or dynamic), the redistribute command is the only way to inject BGP routes into an IGP.
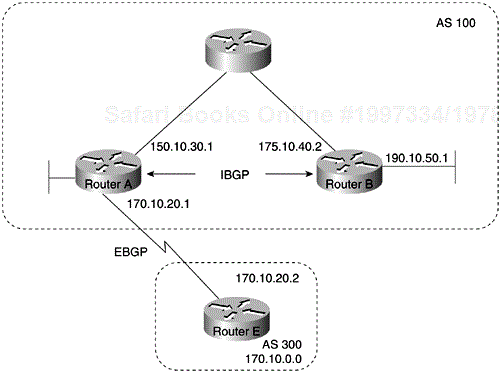
Another way to advertise networks is to redistribute dynamic routes. Typically, you redistribute IGP routes (such as Enhanced IGRP, IGRP, IS-IS, OSPF, and RIP routes) into BGP. Some of your IGP routes might have been learned from BGP, so you need to use access lists to prevent the redistribution of routes back into BGP. Assume that in Figure 4-6, Routers B and C are running IBGP, that Router C is learning 129.213.1.0 via BGP, and that Router B is redistributing 129.213.1.0 back into EIGRP. The following commands configure Router C:
!Router C router eigrp 10 network 175.220.0.0 redistribute bgp 200 redistributed connected default-metric 1000 100 250 100 1500 ! router bgp 200 neighbor 1.1.1.1 remote-as 300 neighbor 2.2.2.2 remote-as 200 neighbor 1.1.1.1 distribute-list 1 out redistribute eigrp 10 ! access-list 1 permit 175.220.0.0 0.0.255.255
The redistribute command with the eigrp keyword redistributes Enhanced IGRP routes for process ID 10 into BGP. (Normally, distributing BGP into IGP should be avoided because too many routes would be injected into the AS.) The neighbor distribute-list command applies access list 1 to outgoing advertisements to the neighbor whose IP address is 1.1.1.1 (that is, Router D). Access list 1 specifies that network 175.220.0.0 is to be advertised. All other networks, such as network 129.213.1.0, are implicitly prevented from being advertised. The access list prevents network 129.213.1.0 from being injected back into BGP as if it originated from AS 200 and allows BGP to advertise network 175.220.0.0 as originating from AS 200.
Another way to advertise networks is to use the network command. When used with BGP, the network command specifies the networks that the AS originates. (By way of contrast, when used with an IGP such as RIP, the network command identifies the interfaces on which the IGP is to run.) The network command works for networks that the router learns dynamically or that are configured as static routes. The origin attribute of routes that are injected into BGP by means of the network command is set to IGP. The following commands configure Router C to advertise network 175.220.0.0:
!Router C router bgp 200 neighbor 1.1.1.1 remote-as 300 network 175.220.0.0
The network command causes Router C to generate an entry in the BGP routing table for network 175.220.0.0. Figure 4-7 shows another topology that demonstrates the effects of the network command.
The following configurations use the network command to configure the routers shown in Figure 4-7:
!Router A router bgp 100 neighbor 150.10.20.2 remote-as 300 network 150.10.0.0 !Router B router bgp 200 neighbor 160.10.20.2 remote-as 300 network 160.10.0.0 !Router C router bgp 300 neighbor 150.10.20.1 remote-as 100 neighbor 160.10.20.1 remote-as 200 network 170.10.0.0
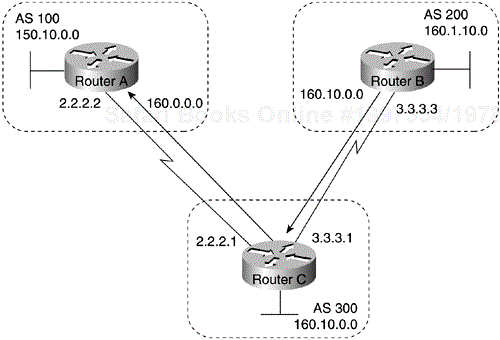
To ensure a loop-free interdomain topology, BGP does not accept updates that originated from its own AS. In Figure 4-7, for example, if Router A generates an update for network 150.10.0.0 with the origin set to AS 100 and sends it to Router C, Router C will pass the update to Router B with the origin still set to AS 100. Router B will send the update (with the origin still set to AS 100) to Router A, which will recognize that the update originated from its own AS and will ignore it.
When a BGP speaker receives updates from multiple ASs that describe different paths to the same destination, it must choose the single best path for reaching that destination. Once chosen, BGP propagates the best path to its neighbors. The decision is based on the value of attributes (such as next hop, administrative weights, local preference, the origin of the route, and path length) that the update contains and other BGP-configurable factors. This section describes the following attributes and factors that BGP uses in the decision-making process:
AS_path Attribute
Origin Attribute
Next Hop Attribute
Weight Attribute
Local Preference Attribute
Multi-Exit Discriminator Attribute
Community Attribute
Whenever an update passes through an AS, BGP prepends its AS number to the update. The AS_path attribute is the list of AS numbers that an update has traversed to reach a destination. An AS-SET is a mathematical set of all the ASs that have been traversed. Consider the network shown in Figure 4-8.
The origin attribute provides information about the origin of the route. The origin of a route can be one of three values:
IGP—. The route is interior to the originating AS. This value is set when the network command is used to inject the route into BGP. The IGP origin type is represented by the letter i in the output of the show ip bgp EXEC command.
EGP—. The route is learned via the Exterior Gateway Protocol (EGP). The EGP origin type is represented by the letter e in the output of the show ip bgp EXEC command.
Incomplete—. The origin of the route is unknown or learned in some other way. An origin of Incomplete occurs when a route is redistributed into BGP. The Incomplete origin type is represented by the question mark symbol (?) in the output of the show ip bgp EXEC command.
Figure 4-9 shows a network that demonstrates the value of the origin attribute.
The BGP next hop attribute is the IP address of the next hop that is going to be used to reach a certain destination. For EBGP, the next hop is usually the IP address of the neighbor specified by the neighbor remote-as command. (The exception is when the next hop is on a multiaccess medium, in which case the next hop could be the IP address of the router in the same subnet.) Consider the network shown in Figure 4-10.
In Figure 4-10, Router C advertises network 170.10.0.0 to Router A with a next hop attribute of 170.10.20.2, and Router A advertises network 150.10.0.0 to Router C with a next hop attribute of 170.10.20.1.
BGP specifies that the next hop of EBGP-learned routes should be carried without modification into IBGP. Because of that rule, Router A advertises 170.10.0.0 to its IBGP peer (Router B) with a next hop attribute of 170.10.20.2. As a result, according to Router B, the next hop to reach 170.10.0.0 is 170.10.20.2, rather than 150.10.30.1. For that reason, the configuration must ensure that Router B can reach 170.10.20.2 via an IGP. Otherwise, Router B will drop packets destined for 170.10.0.0 because the next hop address is inaccessible.
If Router B runs IGRP, for example, Router A should run IGRP on network 170.10.0.0. You might want to make IGRP passive on the link to Router C so that only BGP updates are exchanged.
BGP might set the value of the next hop attribute differently on multiaccess media, such as Ethernet. Consider the network shown in Figure 4-11.
In Figure 4-11, Routers C and D in AS 300 are running OSPF. Router C is running BGP with Router A. Router C can reach network 180.20.0.0 via 170.10.20.3. When Router C sends a BGP update to Router A regarding 180.20.0.0, it sets the next hop attribute to 170.10.20.3, rather than its own IP address (170.10.20.2). This is because Routers A, B, and C are in the same subnet, and it makes more sense for Router A to use Router D as the next hop instead of taking an extra hop via Router C.

In Figure 4-12, three networks are connected by a nonbroadcast media access (NBMA) cloud, such as Frame Relay.
If Routers A, C, and D use a common medium such as Frame Relay (or any NBMA cloud), Router C advertises 180.20.0.0 to Router A with a next hop of 170.10.20.3, just as it would do if the common medium were Ethernet. The problem is that Router A does not have a direct permanent virtual connection (PVC) to Router D and cannot reach the next hop, so routing will fail. To remedy this situation, use the neighbor next-hop-self command, as shown in the following configuration for Router C:
!Router C router bgp 300 neighbor 170.10.20.1 remote-as 100 neighbor 170.10.20.1 next-hop-self
The neighbor next-hop-self command causes Router C to advertise 180.20.0.0 with the next hop attribute set to 170.10.20.2.
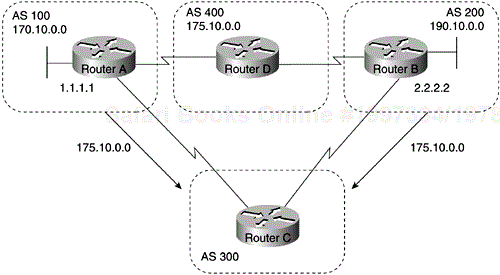
The weight attribute is a special Cisco attribute used in the path selection process when there is more than one route to the same destination. The weight attribute is local to the router on which it is assigned, and it is not propagated in routing updates. By default, the weight attribute is 32768 for paths that the router originates and zero for other paths. Routes with a higher weight are preferred when there are multiple routes to the same destination. Consider the network shown in Figure 4-13.
In Figure 4-13, Routers A and B learn about network 175.10.0.0 from AS 400, and each propagates the update to Router C. Router C has two routes for reaching 175.10.0.0 and has to decide which route to use. If, on Router C, you set the weight of the updates coming in from Router A to be higher than the updates coming in from Router B, Router C will use Router A as the next hop to reach network 175.10.0.0. There are three ways to set the weight for updates coming in from Router A:
The following commands on Router C use access lists and the value of the AS_path attribute to assign a weight to route updates:
!Router C router bgp 300 neighbor 1.1.1.1 remote-as 100 neighbor 1.1.1.1 filter-list 5 weight 2000 neighbor 2.2.2.2 remote-as 200 neighbor 2.2.2.2 filter-list 6 weight 1000 ! ip as-path access-list 5 permit ^100$ ip as-path access-list 6 permit ^200$
In this example, 2000 is assigned to the weight attribute of updates from the neighbor at IP address 1.1.1.1 that are permitted by access list 5. Access list 5 permits updates whose AS_path attribute starts with 100 (as specified by ^) and ends with 100 (as specified by $). (The ^ and $ symbols are used to form regular expressions.) This example also assigns 1000 to the weight attribute of updates from the neighbor at IP address 2.2.2.2 that are permitted by access list 6. Access list 6 permits updates whose AS_path attribute starts with 200 and ends with 200.
In effect, this configuration assigns 2000 to the weight attribute of all route updates received from AS 100 and assigns 1000 to the weight attribute of all route updates from AS 200.
The following commands on Router C use a route map to assign a weight to route updates:
!Router C router bgp 300 neighbor 1.1.1.1 remote-as 100 neighbor 1.1.1.1 route-map SETWEIGHTIN in neighbor 2.2.2.2 remote-as 200 neighbor 2.2.2.2 route-map SETWEIGHTIN in ! ip as-path access-list 5 permit ^100$ ! route-map SETWEIGHTIN permit 10 match as-path 5 set weight 2000 route-map SETWEIGHTIN permit 20 set weight 1000
This first instance of the SETWEIGHTIN route map assigns 2000 to any route update from AS 100, and the second instance of the SETWEIGHTIN route map assigns 1000 to route updates from any other AS.
The following configuration for Router C uses the neighbor weight command:
!Router C router bgp 300 neighbor 1.1.1.1 remote-as 100 neighbor 1.1.1.1 weight 2000 neighbor 2.2.2.2 remote-as 200 neighbor 2.2.2.2 weight 1000
This configuration sets the weight of all route updates from AS 100 to 2000, and the weight of all route updates coming from AS 200 to 1000. The higher weight assigned to route updates from AS 100 causes Router C to send traffic through Router A.
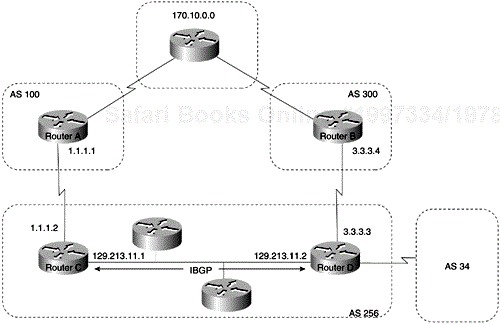
When there are multiple paths to the same destination, the local preference attribute indicates the preferred path. The path with the higher preference is preferred. (The default value of the local preference attribute is 100.) Unlike the weight attribute, which is relevant only to the local router, the local preference attribute is part of the routing update and is exchanged among routers in the same AS. The network shown in Figure 4-14 demonstrates the local preference attribute.
In Figure 4-14, AS 256 receives route updates for network 170.10.0.0 from AS 100 and AS 300. There are two ways to set local preference:
The following configurations use the bgp default local-preference command to set the local preference attribute on Routers C and D:
!Router C router bgp 256 neighbor 1.1.1.1 remote-as 100 neighbor 128.213.11.2 remote-as 256 bgp default local-preference 150 !Router D router bgp 256 neighbor 3.3.3.4 remote-as 300 neighbor 128.213.11.1 remote-as 256 bgp default local-preference 200
The configuration for Router C causes it to set the local preference of all updates from AS 300 to 150, and the configuration for Router D causes it to set the local preference for all updates from AS 100 to 200. Because local preference is exchanged within the AS, both Routers C and D determine that updates regarding network 170.10.0.0 have a higher local preference when they come from AS 300 than when they come from AS 100. As a result, all traffic in AS 256 destined for network 170.10.0.0 is sent to Router D as the exit point.
Route maps provide more flexibility than the bgp default local-preference command. When the bgp default local-preference command is used on Router D in Figure 4-14, the local preference attribute of all updates received by Router D will be set to 200, including updates from AS 34.
The following configuration uses a route map to set the local preference attribute on Router D specifically for updates regarding AS 300:
!Router D router bgp 256 neighbor 3.3.3.4 remote-as 300 route-map SETLOCALIN in neighbor 128.213.11.1 remote-as 256 ! ip as-path 7 permit ^300$ route-map SETLOCALIN permit 10 match as-path 7 set local-preference 200 ! route-map SETLOCALIN permit 20
With this configuration, the local preference attribute of any update coming from AS 300 is set to 200. Instance 20 of the SETLOCALIN route map accepts all other routes.
The multi-exit discriminator (MED) attribute is a hint to external neighbors about the preferred path into an AS when there are multiple entry points into the AS. A lower MED value is preferred over a higher MED value. The default value of the MED attribute is 0.
Note
In BGP4, MED is known as Inter-AS_Metric.
Unlike local preference, the MED attribute is exchanged between ASs, but a MED attribute that comes into an AS does not leave the AS. When an update enters the AS with a certain MED value, that value is used for decision making within the AS. When BGP sends that update to another AS, the MED is reset to 0.
Unless otherwise specified, the router compares MED attributes for paths from external neighbors that are in the same AS. If you want MED attributes from neighbors in other ASs to be compared, you must configure the bgp always-compare-med command. The network shown in Figure 4-15 demonstrates the use of the MED attribute.
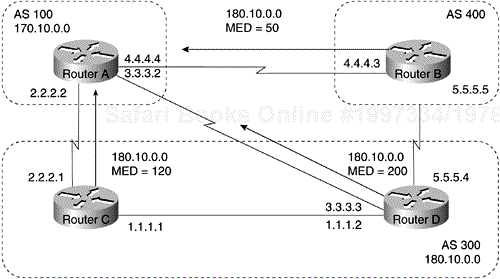
In Figure 4-15, AS 100 receives updates regarding network 180.10.0.0 from Routers B, C, and D. Routers C and D are in AS 300, and Router B is in AS 400. The following commands configure Routers A, B, C, and D:
!Router A router bgp 100 neighbor 2.2.2.1 remote-as 300 neighbor 3.3.3.3 remote-as 300 neighbor 4.4.4.3 remote-as 400 !Router B router bgp 400 neighbor 4.4.4.4 remote-as 100 neighbor 4.4.4.4 route-map SETMEDOUT out neighbor 5.5.5.4 remote-as 300 ! route-map SETMEDOUT permit 10 set metric 50 !Router C router bgp 300 neighbor 2.2.2.2 remote-as 100 neighbor 2.2.2.2 route-map SETMEDOUT out neighbor 1.1.1.2 remote-as 300 ! route-map SETMEDOUT permit 10 set metric 120 !Router D router bgp 300 neighbor 3.3.3.2 remote-as 100 neighbor 3.3.3.2 route map SETMEDOUT out neighbor 5.5.5.5 remote-as 400 neighbor 1.1.1.1 remote-as 300 route-map SETMEDOUT permit 10 set metric 200
By default, BGP compares the MED attributes of routes coming from neighbors in the same external AS (such as AS 300 in Figure 4-15). Router A can only compare the MED attribute coming from Router C (120) to the MED attribute coming from Router D (200), even though the update coming from Router B has the lowest MED value.
Router A will choose Router C as the best path for reaching network 180.10.0.0. To force Router A to include updates for network 180.10.0.0 from Router B in the comparison, use the bgp always-compare-med command, as in the following modified configuration for Router A:
!Router A router bgp 100 neighbor 2.2.2.1 remote-as 300 neighbor 3.3.3.3 remote-as 300 neighbor 4.4.4.3 remote-as 400 bgp always-compare-med
Router A will choose Router B as the best next hop for reaching network 180.10.0.0 (assuming that all other attributes are the same).
You can also set the MED attribute when you configure the redistribution of routes into BGP. On Router B you can inject the static route into BGP with a MED of 50, for example, as in the following configuration:
!Router B router bgp 400 redistribute static default-metric 50 ! ip route 160.10.0.0 255.255.0.0 null 0
The preceding configuration causes Router B to send out updates for 160.10.0.0 with a MED attribute of 50.
The community attribute provides a way of grouping destinations (called communities) to which routing decisions (such as acceptance, preference, and redistribution) can be applied. Route maps are used to set the community attribute. Table 4-1 lists a few predefined communities.
The following route maps set the value of the community attribute:
route-map COMMUNITYMAP match ip address 1 set community no-advertise ! route-map SETCOMMUNITY match as-path 1 set community 200 additive
If you specify the additive keyword, the specified community value is added to the existing value of the community attribute. Otherwise, the specified community value replaces any community value that was set previously. To send the community attribute to a neighbor, you must use the neighbor send-community command, as in the following example:
router bgp 100 neighbor 3.3.3.3 remote-as 300 neighbor 3.3.3.3 send-community neighbor 3.3.3.3 route-map setcommunity out
For examples of how the community attribute is used to filter updates, see the section titled Community Filtering later in this chapter.
BGP selects only one path as the best path. When the path is selected, BGP puts the selected path in its routing table and propagates the path to its neighbors. BGP uses the following criteria, in the order presented, to select a path for a destination:
If the path specifies a next hop that is inaccessible, drop the update.
Prefer the path with the largest weight.
If the weights are the same, prefer the path with the largest local preference.
If the local preferences are the same, prefer the path that was originated by BGP running on this router.
If no route was originated, prefer the route that has the shortest AS_path.
If all paths have the same AS_path length, prefer the path with the lowest origin type (where IGP is lower than EGP, and EGP is lower than Incomplete).
If the origin codes are the same, prefer the path with the lowest MED attribute.
If the paths have the same MED, prefer the external path over the internal path.
If the paths are still the same, prefer the path through the closest IGP neighbor.
Prefer the path with the lowest IP address, as specified by the BGP router ID.
This section describes how to understand and define BGP policies to control the flow of BGP updates. The techniques include the following:
Administrative distance
BGP filtering
BGP peer groups
CIDR and Aggregate addresses
Confederations
Route reflectors
Route flap dampening
Normally, a route could be learned via more than one protocol. Administrative distance is used to discriminate between routes learned from more than one protocol. The route with the lowest administrative distance is installed in the IP routing table. By default, BGP uses the administrative distances shown in Table 4-2.
You can control the sending and receiving of updates by using the following filtering methods:
Prefix filtering
AS_path filtering
Route map filtering
Community filtering
Each method can be used to achieve the same result—the choice of method depends on the specific network configuration.
The prefix list is implemented for the purpose of efficient route filtering (currently with only BGP). Compared to using the (extended) access list in route filtering, there are several advantages to using the prefix list:
Significant performance improvement in loading and route lookup of large lists
Support for incremental updates
More user-friendly command line interface
Several key features with the access list are preserved in the prefix list:
Configuration of either permit or deny
Order dependency—first match wins
Filtering on prefix length—both exact match and range match
However, noncontiguous masks are not supported in the prefix list.
The full syntax of a prefix list is as follows:
ip prefix-list [seq] deny|permit prefix le|ge
The following command can be used to delete a prefix list:
no ip prefix-list
seq is optional. It can be used to specify the sequence number of an entry of a prefix list.
By default, the entries of a prefix list have sequence values of 5, 10, 15, and so on. In the absence of a specified sequence value, the entry would be assigned with a sequence number of (Current_Max + 5).
If a given prefix matches multiple entries of a prefix list, the one with the smallest sequence number is considered the match.
deny or permit specifies an action taken once a match is found.
Multiple policies (exact match or range match) with different sequence numbers can be configured for the same prefix.
ge indicates greater than or equal to. le indicates less than or equal to. Both ge and le are optional. They can be used to specify the range of the prefix length to be matched for prefixes.
Exact match is assumed when neither ge nor le is specified.
The range is assumed to be from ge value to 32 if only the ge attribute is specified. The range is assumed to be from len to le value if only the le attribute is specified.
As usual, an implicit deny is assumed at the end of a prefix list.
The following are configuration examples for an exact match:
ip prefix-list aaa deny 0.0.0.0/0 ip prefix-list aaa permit 35.0.0.0/8
The following list shows configuration commands for a prefix length match:
In 192/8, accept up to /24:
ip prefix-list aaa permit 192.0.0.0/8 le 24
In 192/8, deny /25+:
ip prefix-list aaa deny 192.0.0.0/8 ge 25
In all address space, deny /0 through /7:
ip prefix-list aaa deny 0.0.0.0/0 le 7
In all address space, deny /25+:
ip prefix-list aaa deny 0.0.0.0/0 ge 25
In 10/8, deny all:
ip prefix-list aaa deny 10.0.0.0/8 le 32
In 204.70.1/24, deny /25+:
ip prefix-list aaa deny 204.70.1.0/24 ge 25
Permit all:
ip prefix-list aaa permit 0.0.0.0/0 le 32
Incremental updates are possible with prefix lists. As opposed to the normal access list where one no command will erase the whole access list, a prefix list can be modified incrementally. To change a prefix list from A to B, for example, only the difference between B and A needs to be deployed to the router.
From A:
ip prefix-list aaa deny 0.0.0.0/0 le 7ip prefix-list aaa deny 0.0.0.0/0 ge 25ip prefix-list aaa permit 35.0.0.0/8ip prefix-list aaa permit 204.70.0.0/15
To B:
ip prefix-list aaa deny 0.0.0.0/0 le 7ip prefix-list aaa deny 0.0.0.0/0 ge 25ip prefix-list aaa permit 35.0.0.0/8ip prefix-list aaa permit 198.0.0.0/8
by deploying the difference:
no ip prefix-list aaa permit 204.70.0.0/15ip prefix-list aaa permit 198.0.0.0/8
You can specify an access list on both incoming and outgoing updates based on the value of the AS_path attribute. The network shown in Figure 4-16 demonstrates the usefulness of AS_path filters:
!Router C neighbor 3.3.3.3 remote-as 200 neighbor 2.2.2.2 remote-as 100 neighbor 2.2.2.2 filter-list 1 out ! ip as-path access-list 1 deny ^200$ ip as-path access-list 1 permit .*
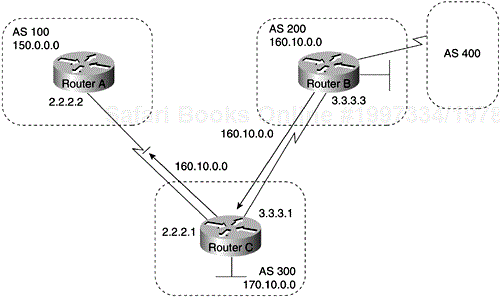
In this example, access list 1 denies any update whose AS_path attribute starts with 200 (as specified by ^) and ends with 200 (as specified by $). Because Router B sends updates about 160.10.0.0 whose AS_path attributes start with 200 and end with 200, such updates will match the access list and will be denied. By specifying that the update must also end with 200, the access list permits updates from AS 400 (whose AS_path attribute is 200, 400). If the access list specified ^200 as the regular expression, updates from AS 400 would be denied.
In the second access list statement, the period symbol (.) means any character, and the asterisk symbol (*) means a repetition of that character. Together, .* matches any value of the AS_path attribute, which in effect permits any update that has not been denied by the previous access list statement. If you want to verify that your regular expressions work as intended, use the following EXEC command:
show ip bgp regexp regular-expression
The router displays all the paths that match the specified regular expression.
The neighbor route-map command can be used to apply a route map to incoming and outgoing routes. The network shown in Figure 4-17 demonstrates using route maps to filter BGP updates.
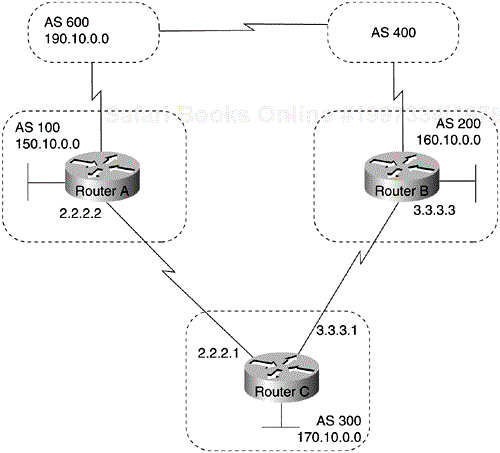
Assume that in Figure 4-17 you want Router C to learn about networks that are local to AS 200 only. (That is, you do not want Router C to learn about AS 100, AS 400, or AS 600 from AS 200.) Also, on those routes that Router C accepts from AS 200, you want the weight attribute to be set to 20. The following configuration for Router C accomplishes this goal:
!Router C router bgp 300 network 170.10.0.0 neighbor 3.3.3.3 remote-as 200 neighbor 3.3.3.3 route-map STAMP in ! route-map STAMP permit 10 match as-path 1 set weight 20 ! ip as-path access-list 1 permit ^200$
In the preceding configuration, access list 1 permits any update whose AS_path attribute begins with 200 and ends with 200 (that is, access list 1 permits updates that originate in AS 200). The weight attribute of the permitted updates is set to 20. All other updates are denied and dropped.
The network shown in Figure 4-18 demonstrates the usefulness of community filters.
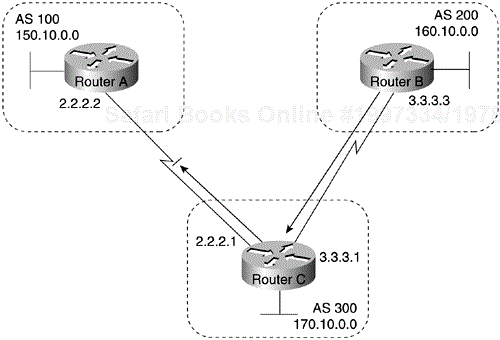
Assume that you do not want Router C to propagate routes learned from Router B to Router A. You can do this by setting the community attribute on updates that Router B sends to Router C, as in the following configuration for Router B:
!Router B router bgp 200 network 160.10.0.0 neighbor 3.3.3.1 remote-as 300 neighbor 3.3.3.1 send-community neighbor 3.3.3.1 route-map SETCOMMUNITY out ! route-map SETCOMMUNITY permit 10 match ip address 1 set community no-export ! route-map SETCOMMUNITY permit 20 ! access list 1 permit 0.0.0.0 255.255.255.255
For routes sent to the neighbor at IP address 3.3.3.1 (Router C), Router B applies the route map named SETCOMMUNITY. The SETCOMMUNITY route map sets the community attribute of any update (by means of access list 1) destined for 3.3.3.1 to no-export. The neighbor send-community command is required to include the community attribute in updates sent to the neighbor at IP address 3.3.3.1. When Router C receives the updates from Router B, it does not propagate them to Router A because the value of the community attribute is no-export.
Another way to filter updates based on the value of the community attribute is to use the ip community-list global configuration command. Assume that Router B has been configured as follows:
!Router B router bgp 200 network 160.10.0.0 neighbor 3.3.3.1 remote-as 300 neighbor 3.3.3.1 send-community neighbor 3.3.3.1 route-map SETCOMMUNITY out ! route-map SETCOMMUNITY permit 10 match ip address 2 set community 100 200 additive route-map SETCOMMUNITY permit 20 ! access list 2 permit 0.0.0.0 255.255.255.255
In the preceding configuration, Router B adds 100 and 200 to the community value of any update destined for the neighbor at IP address 3.3.3.1. To configure Router C to use the ip community-list command, set the value of the weight attribute. Based on whether the community attribute contains 100 or 200, use the following configuration:
!Router C router bgp 300 neighbor 3.3.3.3 remote-as 200 neighbor 3.3.3.3 route-map check-community in ! route-map check-community permit 10 match community 1 set weight 20 ! route-map check-community permit 20 match community 2 exact set weight 10 ! route-map check-community permit 30 match community 3 ! ip community-list 1 permit 100 ip community-list 2 permit 200 ip community-list 3 permit internet
In the preceding configuration, any route that has 100 in its community attribute matches community list 1 and has its weight set to 20. Any route whose community attribute is only 200 (by virtue of the exact keyword) matches community list 2 and has its weight set to 10. In the last community list (list 3), the use of the internet keyword permits all other updates without changing the value of an attribute. (The internet keyword specifies all routes because all routes are members of the Internet community.)
A BGP peer group is a group of BGP neighbors that share the same update policies. Update policies are usually set by route maps, distribution lists, and filter lists. Instead of defining the same policies for each individual neighbor, you define a peer group name and assign policies to the peer group.
Members of a peer group inherit all the configuration options of the peer group. Peer group members can also be configured to override configuration options if the options do not affect outgoing updates. That is, you can override options set only for incoming updates. The network shown in Figure 4-19 demonstrates the use of BGP peer groups.
The following commands configure a BGP peer group named INTERNALMAP on Router C and apply it to the other routers in AS 300:
!Router C router bgp 300 neighbor INTERNALMAP peer-group neighbor INTERNALMAP remote-as 300 neighbor INTERNALMAP route-map INTERNAL out neighbor INTERNALMAP filter-list 1 out neighbor INTERNALMAP filter-list 2 in neighbor 5.5.5.2 peer-group INTERNALMAP neighbor 6.6.6.2 peer-group INTERNALMAP neighbor 3.3.3.2 peer-group INTERNALMAP neighbor 3.3.3.2 filter-list 3 in
The preceding configuration defines the following policies for the INTERNALMAP peer group:
A route map named INTERNAL
A filter list for outgoing updates (filter list 1)
A filter list for incoming updates (filter list 2)
The configuration applies the peer group to all internal neighbors—Routers E, F, and G. The configuration also defines a filter list for incoming updates from the neighbor at IP address 3.3.3.2 (Router E). This filter list can be used only to override options that affect incoming updates.
The following commands configure a BGP peer group named EXTERNALMAP on Router C and apply it to routers in AS 100, 200, and 600:
!Router C router bgp 300 neighbor EXTERNALMAP peer-group neighbor EXTERNALMAP route-map SETMED neighbor EXTERNALMAP filter-list 1 out neighbor EXTERNALMAP filter-list 2 in neighbor 2.2.2.2 remote-as 100 neighbor 2.2.2.2 peer-group EXTERNALMAP neighbor 4.4.4.2 remote-as 600 neighbor 4.4.4.2 peer-group EXTERNALMAP neighbor 1.1.1.2 remote-as 200 neighbor 1.1.1.2 peer-group EXTERNALMAP neighbor 1.1.1.2 filter-list 3 in
In the preceding configuration, the neighbor remote-as commands are placed outside of the neighbor peer-group commands because different external ASs have to be defined. Also note that this configuration defines filter list 3, which can be used to override configuration options for incoming updates from the neighbor at IP address 1.1.1.2 (Router B).
BGP4 supports classless interdomain routing (CIDR). CIDR is a new way of looking at IP addresses that eliminates the concept of classes (Class A, Class B, and so on). Network 192.213.0.0, which is an illegal Class C network number, for example, is a legal supernet when it is represented in CIDR notation as 192.213.0.0/16. The /16 indicates that the subnet mask consists of 16 bits (counting from the left). Therefore, 192.213.0.0/16 is similar to 192.213.0.0 255.255.0.0.
CIDR makes it easy to aggregate routes. Aggregation is the process of combining several different routes in such a way that a single route can be advertised, which minimizes the size of routing tables. Consider the network shown in Figure 4-20.
In Figure 4-20, Router B in AS 200 is originating network 160.11.0.0 and advertising it to Router C in AS 300. To configure Router C to propagate the aggregate address 160.0.0.0 to Router A, use the following commands:
!Router C router bgp 300 neighbor 3.3.3.3 remote-as 200 neighbor 2.2.2.2 remote-as 100 network 160.10.0.0 aggregate-address 160.0.0.0 255.0.0.0
Theaggregate-address command advertises the prefix route (in this case, 160.0.0.0/8) and all the more-specific routes. If you want Router C to propagate the prefix route only, and you do not want it to propagate a more specific route, use the following command:
aggregate-address 160.0.0.0 255.0.0.0 summary-only
This command propagates the prefix (160.0.0.0/8) and suppresses any more-specific routes that the router may have in its BGP routing table. If you want to suppress specific routes when aggregating routes, you can define a route map and apply it to the aggregate. If, for example, you want Router C in Figure 4-20 to aggregate 160.0.0.0 and suppress the specific route 160.20.0.0, but propagate route 160.10.0.0, use the following commands:
!Router C router bgp 300 neighbor 3.3.3.3 remote-as 200 neighbor 2.2.2.2 remote-as 100 network 160.10.0.0 aggregate-address 160.0.0.0 255.0.0.0 suppress-map CHECK ! route-map CHECK permit 10 match ip address 1 ! access-list 1 deny 160.20.0.0 0.0.255.255 access-list 1 permit 0.0.0.0 255.255.255.255
If you want the router to set the value of an attribute when it propagates the aggregate route, use an attribute map, as demonstrated by the following commands:
route-map SETORIGIN permit 10 set origin igp ! aggregate-address 160.0.0.0 255.0.0.0 attribute-map SETORIGIN
Aconfederation is a technique for reducing the IBGP mesh inside the AS. Consider the network shown in Figure 4-21.
In Figure 4-21, AS 500 consists of nine BGP speakers (although there might be other routers not configured for BGP). Without confederations, BGP would require that the routers in AS 500 be fully meshed. That is, each router would need to run IBGP with each of the other eight routers, and each router would need to connect to an external AS and run EBGP, for a total of nine peers for each router.
Confederations reduce the number of peers within the AS, as shown in Figure 4-21. You use confederations to divide the AS into multiple mini-ASs and assign the mini-ASs to a confederation. Each mini-AS is fully meshed, and IBGP is run among its members. Each mini-AS has a connection to the other mini-ASs within the confederation. Even though the mini-ASs have EBGP peers to ASs within the confederation, they exchange routing updates as if they were using IBGP. That is, the next hop, MED, and local preference information is preserved. To the outside world, the confederation looks like a single AS. The following commands configure Router C:
!Router C router bgp 65050 bgp confederation identifier 500 bgp confederation peers 65060 65070 neighbor 128.213.10.1 remote-as 65050 neighbor 128.213.20.1 remote-as 65050 neighbor 128.210.11.1 remote-as 65060 neighbor 135.212.14.1 remote-as 65070 neighbor 5.5.5.5 remote-as 100
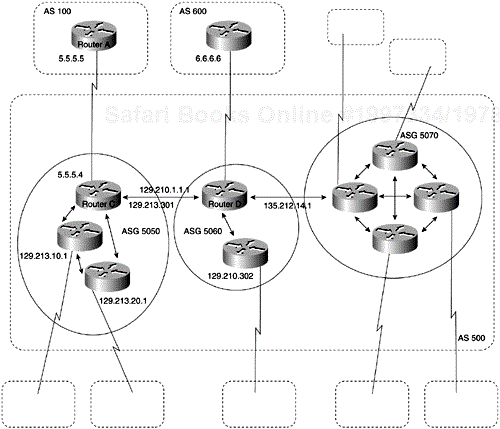
The router bgp command specifies that Router C belongs to AS 50.
The bgp confederation identifier command specifies that Router C belongs to confederation 500. The first two neighbor remote-as commands establish IBGP connections to the other two routers within AS 65050. The second two neighbor remote-as commands establish BGP connections with confederation peers 65060 and 65070. The last neighbor remote-as command establishes an EBGP connection with external AS 100. The following commands configure Router D:
!Router D router bgp 65060 bgp confederation identifier 500 bgp confederation peers 65050 65070 neighbor 129.210.30.2 remote-as 65060 neighbor 128.213.30.1 remote-as 65050 neighbor 135.212.14.1 remote-as 65070 neighbor 6.6.6.6 remote-as 600
The router bgp command specifies that Router D belongs to AS 65060. The bgp confederation identifier command specifies that Router D belongs to confederation 500.
The first neighbor remote-as command establishes an IBGP connection to the other router within AS 65060. The second two neighbor remote-as commands establish BGP connections with confederation peers 65050 and 65070. The last neighbor remote-as command establishes an EBGP connection with AS 600. The following commands configure Router A:
!Router A router bgp 100 neighbor 5.5.5.4 remote-as 500
The neighbor remote-as command establishes an EBGP connection with Router C. Router A is unaware of AS 65050, AS 65060, or AS 65070. Router A only has knowledge of AS 500.
Route reflectors are another solution for the explosion of IBGP peering within an AS. As described earlier in the section titled "Synchronization," a BGP speaker does not advertise a route learned from another IBGP speaker to a third IBGP speaker. Route reflectors ease this limitation and allow a router to advertise (reflect) IBGP-learned routes to other IBGP speakers, thereby reducing the number of IBGP peers within an AS. The network shown in Figure 4-22 demonstrates how route reflectors work.
Without a route reflector, the network shown in Figure 4-22 would require a full IBGP mesh (that is, Router A would have to be a peer of Router B). If Router C is configured as a route reflector, IBGP peering between Routers A and B is not required, because Router C will reflect updates from Router A to Router B and from Router B to Router A. To configure Router C as a route reflector, use the following commands:
!Router C router bgp 100 neighbor 1.1.1.1 remote-as 100 neighbor 1.1.1.1 route-reflector-client neighbor 2.2.2.2 remote-as 100 neighbor 2.2.2.2 route-reflector-client
The router whose configuration includes neighbor route-reflector-client commands is the route reflector. The routers identified by the neighbor route-reflector-client commands are clients of the route reflector. When considered as a whole, the route reflector and its clients are called a cluster. Other IBGP peers of the route reflector that are not clients are called nonclients.
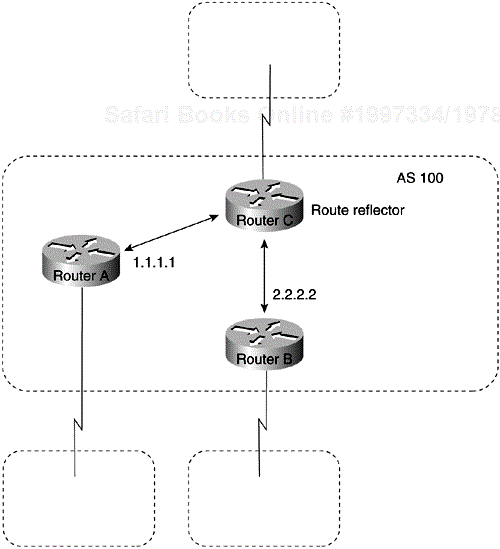
An AS can have more than one route reflector. When an AS has more than one route reflector, each route reflector treats other route reflectors as normal IBGP speakers. There can be more than one route reflector in a cluster, and there can be more than one cluster in an AS.
Route flap dampening (introduced in Cisco IOS Release 11.0) is a mechanism for minimizing the instability caused by route flapping. The following terms are used to describe route flap dampening:
Penalty—. A numeric value assigned to a route when it flaps.
Half-life time—. A configurable numeric value that describes the time required to reduce the penalty by one-half.
Suppress limit—. A numeric value that is compared with the penalty. If the penalty is greater than the suppress limit, the route is suppressed.
Suppressed—. A route that is not advertised even though it is up. A route is suppressed if the penalty is more than the suppressed limit.
Reuse limit—. A configurable numeric value that is compared with the penalty. If the penalty is less than the reuse limit, a suppressed route that is up will no longer be suppressed.
History entry—. An entry that is used to store flap information about a route that is down.
A route that is flapping receives a penalty of 1000 for each flap. When the accumulated penalty reaches a configurable limit, BGP suppresses advertisement of the route even if the route is up. The accumulated penalty is decremented by the half-life time. When the accumulated penalty is less than the reuse limit, the route is advertised again (if it is still up).
The primary function of a BGP system is to exchange network reachability information with other BGP systems. This information is used to construct a graph of AS connectivity from which routing loops are pruned and with which AS-level policy decisions are enforced. BGP provides a number of techniques for controlling the flow of BGP updates, such as route, path, and community filtering. It also provides techniques for consolidating routing information, such as CIDR aggregation, confederations, and route reflectors. BGP is a powerful tool for providing loop-free interdomain routing within and between ASs.