
The Risk Management Process
By now you should believe that risk management is critical to the long-term security (and even success) of your organization. But how do you get this done? NIST SP 800-39 describes four interrelated components that comprise the risk management process. Let’s consider each of these components briefly now, since they will nicely frame the remainder of our discussion of risk management.
• Frame risk Risk framing defines the context within which all other risk activities take place. What are our assumptions and constraints? What are the organizational priorities? What is the risk tolerance of senior management?
• Assess risk Before we can take any action to mitigate risk, we have to assess it. This is perhaps the most critical aspect of the process, and one that we will discuss at length. If your risk assessment is spot-on, then the rest of the process becomes pretty straightforward.
• Respond to risk By now, we’ve done our homework. We know what we should, must, and can’t do (from the framing component), and we know what we’re up against in terms of threats, vulnerabilities, and attacks (from the assess component). Responding to the risk becomes a matter of matching our limited resources with our prioritized set of controls. Not only are we mitigating significant risk, but, more importantly, we can tell our bosses what risk we can’t do anything about because we’re out of resources.
• Monitor risk No matter how diligent we’ve been so far, we probably missed something. If not, then the environment likely changed (perhaps a new threat source emerged or a new system brought new vulnerabilities). In order to stay one step ahead of the bad guys, we need to continuously monitor the effectiveness of our controls against the risks for which we designed them.
You will notice that our discussion of risk so far has dealt heavily with the whole framing process. In the preceding sections, we’ve talked about the organization (top to bottom), the policies, and the team. The next step is to assess the risk, and what better way to start than by modeling the threat.
Threat Modeling
Before we can develop effective defenses, it is imperative to understand the assets that we value, as well as the threats against which we are protecting them. Though multiple definitions exist for the term, for the purposes of our discussion we define threat modeling as the process of describing feasible adverse effects on our assets caused by threat sources. That’s quite a mouthful, so let’s break it down. When we build a model of the threats we face, we want to ground them in reality, so it is important to only consider dangers that are reasonably likely to occur. To do otherwise would dilute our limited resources to the point of making us unable to properly defend ourselves.
You could argue (correctly) that threat modeling is a component task to the risk assessment that we will discuss in the next section. However, many organizations are stepping up threat intelligence efforts at an accelerated pace. Threat intelligence is becoming a resource that is used not only by the risk teams, but also by the security operations, development, and even management teams. We isolate threat modeling from the larger discussion of risk assessment here to highlight the fact that it serves more than just risk assessment efforts and allows an organization to understand what is in the realm of the probable and not just the possible.
Threat Modeling Concepts
To focus our efforts on the likely (and push aside the less likely), we need to consider what it is that we have that someone (or something) else may be able to degrade, disrupt, or destroy. As we will see shortly, inventorying and categorizing our information systems is a critical early step in the process. For the purpose of modeling the threat, we are particularly interested in the vulnerabilities inherent in our systems that could lead to the compromise of their confidentiality, integrity, or availability. We then ask the question, “Who would want to exploit this vulnerability, and why?” This leads us to a deliberate study of our potential adversaries, their motivations, and their capabilities. Finally, we determine whether a given threat source has the means to exploit one or more vulnerabilities in order to attack our assets.
Vulnerabilities
Everything built by humans is vulnerable to something. Our information systems, in particular, are riddled with vulnerabilities even in the best-defended cases. One need only read news accounts of the compromise of the highly protected and classified systems of defense contractors and even governments to see that this universal principle is true. In order to properly analyze vulnerabilities, it is useful to recall that information systems consist of information, processes, and people that are typically, but not always, interacting with computer systems. Since we discuss computer system vulnerabilities in detail in Chapter 3 (which covers domain 3, Security Architecture and Engineering), we will briefly discuss the other three components here.
Information In almost every case, the information at the core of our information systems is the most valuable asset to a potential adversary. Information within a computer information system (CIS) is represented as data. This information may be stored (data at rest), transported between parts of our system (data in motion), or actively being used by the system (data in use). In each of its three states, the information exhibits different vulnerabilities, as listed in the following examples:
• Data at rest Data is copied to a thumb drive and given to unauthorized parties by an insider, thus compromising its confidentiality.
• Data in motion Data is modified by an external actor intercepting it on the network and then relaying the altered version (known as a man-in-the-middle or MitM attack), thus compromising its integrity.
• Data in use Data is deleted by a malicious process exploiting a “time of check to time of use” (TOC/TOU) or “race condition” vulnerability, thus compromising its availability. We address this in detail in Chapter 3 (which covers domain 3, Security Architecture and Engineering).
Processes Processes are almost always instantiated in software as part of a CIS. Therefore, process vulnerabilities can be thought of as a specific kind of software vulnerability. We will address these in detail in Chapter 8 (which covers domain 8, Software Development Security). As security professionals, however, it is important that we take a broader view of the issue and think about the business processes that are implemented in our software systems.
People There are many who would consider the human the weakest link in the security chain. Whether or not you agree with this, it is important to consider the specific vulnerabilities that people present in a system. Though there are many ways to exploit the human in the loop, there are three that correspond to the bulk of the attacks, summarized briefly here:
• Social engineering This is the process of getting a person to violate a security procedure or policy, and usually involves human interaction or e-mail/text messages.
• Social networks The prevalence of social network use provides potential attackers with a wealth of information that can be leveraged directly (e.g., blackmail) or indirectly (e.g., crafting an e-mail with a link that is likely to be clicked) to exploit people.
• Passwords Weak passwords can be cracked in milliseconds using rainbow tables (discussed in Chapter 5) and are very susceptible to dictionary or brute-force attacks. Even strong passwords are vulnerable if they are reused across sites and systems.
Threats
As you identify the vulnerabilities that are inherent to your organization and its systems, it is important to also identify the sources that could attack them. The International Organization for Standardization and the International Electrotechnical Commission in their ISO/IEC standard 27000 define a threat as a “potential cause of an unwanted incident, which may result in harm to a system or organization.” While this may sound somewhat vague, it is important to include the full breadth of possibilities.
Perhaps the most obvious threat source is the malicious attacker who intentionally pokes and prods our systems looking for vulnerabilities to exploit. In the past, this was a sufficient description of this kind of threat source. Increasingly, however, organizations are interested in profiling the threat in great detail. Many organizations are implementing teams to conduct cyberthreat intelligence that allows them to individually label, track, and understand specific cybercrime groups. This capability enables these organizations to more accurately determine which attacks are likely to originate from each group based on their capabilities as well as their tactics, techniques, and procedures (TTP).
Another important threat source is the insider, who may be malicious or simply careless. The malicious insider is motivated by a number of factors, but most frequently by disgruntlement and/or financial gain. In the wake of the massive leak of classified data attributed to Edward Snowden in 2012, there’s been increased emphasis on techniques and procedures for identifying and mitigating the insider threat source. While the deliberate insider dominates the news, it is important to note that the accidental insider can be just as dangerous, particularly if they fall into one of the vulnerability classes described in the preceding section.
Finally, the nonhuman threat source can be just as important as the ones we’ve previously discussed. Hurricane Katrina in 2005 and the Tohoku earthquake and tsunami in 2011 serve as reminders that natural events can be more destructive than any human attack. They also force the information systems security professional to consider threats that fall way outside the norm. Though it is easier and in many cases cheaper to address likelier natural events such as a water main break or a fire in a facility, one should always look for opportunities to leverage countermeasures that protect against both mild and extreme events for small price differentials.
Threat Modeling Methodologies
If the vulnerability is on one end of a network and the threat source is on the other, it is the attack that ties them together. In other words, if a given threat (e.g., a disgruntled employee) wants to exploit a given vulnerability (e.g., the e-mail inbox of the company’s president), but lacks the means to do so, then an attack would likely not be feasible and this scenario would not be part of our threat model. It is not possible to determine the feasibility of an attack if we don’t know who would execute it and against which vulnerability. This shows how it is the triads formed by an existent vulnerability, a feasible attack, and a capable threat that constitute the heart of a threat model. Because there will be an awful lot of these possible triads in a typical organization, we need systematic approaches to identifying and analyzing them. This is what threat modeling methodologies give us.
Attack Trees
This methodology is based on the observation that, typically, there are multiple ways to accomplish a given objective. For example, if a disgruntled employee wanted to steal the contents of the president’s mailbox, this could be accomplished by either accessing the e-mail server, obtaining the password, or stealing the president’s laptop. Accessing the e-mail server could be accomplished by using administrative credentials or by hacking in. To get the credentials, one could use brute force or social engineering. The branches created by each decision point create what is known as an attack tree, an example of which for this scenario is shown in Figure 1-13. Each of the leaf nodes represents a specific condition that must be met in order for the parent node to be effective. For instance, to effectively obtain the mailbox credentials, the employee could have stolen a network access token. Given that the employee has met the condition of having the credentials, he would then be able to steal the contents of the president’s mailbox. A successful attack, then, is one in which the attacker traverses from a leaf node all the way to the root of the tree.
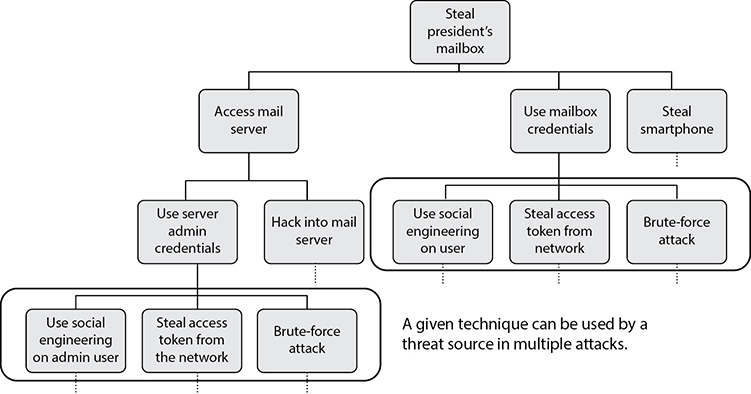
Figure 1-13 A simplified attack tree
NOTE The terms “attack chain” and “kill chain” are commonly used. They refer to a specific type of attack tree that has no branches and simply proceeds from one stage or action to the next. The attack tree is much more expressive in that it shows many ways in which an attacker can accomplish each objective.
Reduction Analysis
The generation of attack trees for an organization usually requires a large investment of resources. Each vulnerability-threat-attack triad can be described in detail using an attack tree, so you end up with as many trees as you do triads. To defeat each of the attacks you identify, you would typically need a control or countermeasure at each leaf node. Since one attack generates many leaf nodes, this has a multiplicative effect that could make it very difficult to justify the whole exercise. However, attack trees lend themselves to a methodology known as reduction analysis.
There are two aspects of reduction analysis in the context of threat modeling: one aspect is to reduce the number of attacks we have to consider, and the other is to reduce the threat posed by the attacks. The first aspect is evidenced by the commonalities in the example shown in Figure 1-13. To satisfy the conditions for logging into the mail server or the user’s mailbox, an attacker can use the exact same three techniques. This means we can reduce the number of conditions we need to mitigate by finding these commonalities. When you consider that these three sample conditions apply to a variety of other attacks, you realize that we can very quickly cull the number of conditions to a manageable number.
The second aspect of reduction analysis is the identification of ways to mitigate or negate the attacks we’ve identified. This is where the use of attack trees can really benefit us. Recall that each tree has only one root but many leaves and internal nodes. The closer you are to the root when you implement a mitigation technique, the more leaf conditions you will defeat with that one control. This allows you to easily identify the most effective techniques to protect your entire organization. These techniques are typically called controls or countermeasures.
Risk Assessment and Analysis
A risk assessment, which is really a tool for risk management, is a method of identifying vulnerabilities and threats and assessing the possible impacts to determine where to implement security controls. After parts of a risk assessment are carried out, the results are analyzed. Risk analysis is a detailed examination of the components of risk used to ensure that security is cost effective, relevant, timely, and responsive to threats. It is easy to apply too much security, not enough security, or the wrong security controls and to spend too much money in the process without attaining the necessary objectives. Risk analysis helps companies prioritize their risks and shows management the amount of resources that should be applied to protecting against those risks in a sensible manner.
NOTE The terms risk assessment and risk analysis, depending on who you ask, can mean the same thing, or one must follow the other, or one is a subpart of the other. Here, we treat risk assessment as the broader effort, which is reinforced by specific risk analysis tasks as needed. This is how you should think of it for the CISSP exam.
Risk analysis has four main goals:
• Identify assets and their value to the organization.
• Determine the likelihood that a threat exploits a vulnerability.
• Determine the business impact of these potential threats.
• Provide an economic balance between the impact of the threat and the cost of the countermeasure.
Risk analysis provides a cost/benefit comparison, which compares the annualized cost of controls to the potential cost of loss. A control, in most cases, should not be implemented unless the annualized cost of loss exceeds the annualized cost of the control itself. This means that if a facility is worth $100,000, it does not make sense to spend $150,000 trying to protect it.
It is important to figure out what you are supposed to be doing before you dig right in and start working. Anyone who has worked on a project without a properly defined scope can attest to the truth of this statement. Before an assessment is started, the team must carry out project sizing to understand what assets and threats should be evaluated. Most assessments are focused on physical security, technology security, or personnel security. Trying to assess all of them at the same time can be quite an undertaking.
One of the risk assessment team’s tasks is to create a report that details the asset valuations. Senior management should review and accept the list and make them the scope of the risk management project. If management determines at this early stage that some assets are not important, the risk assessment team should not spend additional time or resources evaluating those assets. During discussions with management, everyone involved must have a firm understanding of the value of the security AIC triad—availability, integrity, and confidentiality—and how it directly relates to business needs.
Management should outline the scope of the assessment, which most likely will be dictated by organizational compliance requirements as well as budgetary constraints. Many projects have run out of funds, and consequently stopped, because proper project sizing was not conducted at the onset of the project. Don’t let this happen to you.
A risk assessment helps integrate the security program objectives with the company’s business objectives and requirements. The more the business and security objectives are in alignment, the more successful the two will be. The assessment also helps the company draft a proper budget for a security program and its constituent security components. Once a company knows how much its assets are worth and the possible threats they are exposed to, it can make intelligent decisions about how much money to spend protecting those assets.
A risk assessment must be supported and directed by senior management if it is to be successful. Management must define the purpose and scope of the effort, appoint a team to carry out the assessment, and allocate the necessary time and funds to conduct it. It is essential for senior management to review the outcome of the risk assessment and to act on its findings. After all, what good is it to go through all the trouble of a risk assessment and not react to its findings? Unfortunately, this does happen all too often.
Risk Assessment Team
Each organization has different departments, and each department has its own functionality, resources, tasks, and quirks. For the most effective risk assessment, an organization must build a risk assessment team that includes individuals from many or all departments to ensure that all of the threats are identified and addressed. The team members may be part of management, application programmers, IT staff, systems integrators, and operational managers—indeed, any key personnel from key areas of the organization. This mix is necessary because if the team comprises only individuals from the IT department, it may not understand, for example, the types of threats the accounting department faces with data integrity issues, or how the company as a whole would be affected if the accounting department’s data files were wiped out by an accidental or intentional act. Or, as another example, the IT staff may not understand all the risks the employees in the warehouse would face if a natural disaster were to hit, or what it would mean to their productivity and how it would affect the organization overall. If the risk assessment team is unable to include members from various departments, it should, at the very least, make sure to interview people in each department so it fully understands and can quantify all threats.
The risk assessment team must also include people who understand the processes that are part of their individual departments, meaning individuals who are at the right levels of each department. This is a difficult task, since managers tend to delegate any sort of risk assessment task to lower levels within the department. However, the people who work at these lower levels may not have adequate knowledge and understanding of the processes that the risk assessment team may need to deal with.
The Value of Information and Assets
The value placed on information is relative to the parties involved, what work was required to develop it, how much it costs to maintain, what damage would result if it were lost or destroyed, what enemies would pay for it, and what liability penalties could be endured. If a company does not know the value of the information and the other assets it is trying to protect, it does not know how much money and time it should spend on protecting them. If the calculated value of your company’s secret formula is x, then the total cost of protecting it should be some value less than x. The value of the information supports security measure decisions.
The previous examples refer to assessing the value of information and protecting it, but this logic applies toward an organization’s facilities, systems, and resources. The value of the company’s facilities must be assessed, along with all printers, workstations, servers, peripheral devices, supplies, and employees. You do not know how much is in danger of being lost if you don’t know what you have and what it is worth in the first place.
Costs That Make Up the Value
An asset can have both quantitative and qualitative measurements assigned to it, but these measurements need to be derived. The actual value of an asset is determined by the importance it has to the organization as a whole. The value of an asset should reflect all identifiable costs that would arise if the asset were actually impaired. If a server cost $4,000 to purchase, this value should not be input as the value of the asset in a risk assessment. Rather, the cost of replacing or repairing it, the loss of productivity, and the value of any data that may be corrupted or lost must be accounted for to properly capture the amount the organization would lose if the server were to fail for one reason or another.
The following issues should be considered when assigning values to assets:
• Cost to acquire or develop the asset
• Cost to maintain and protect the asset
• Value of the asset to owners and users
• Value of the asset to adversaries
• Price others are willing to pay for the asset
• Cost to replace the asset if lost
• Operational and production activities affected if the asset is unavailable
• Liability issues if the asset is compromised
• Usefulness and role of the asset in the organization
Understanding the value of an asset is the first step to understanding what security mechanisms should be put in place and what funds should go toward protecting it. A very important question is how much it could cost the company to not protect the asset.
Determining the value of assets may be useful to a company for a variety of reasons, including the following:
• To perform effective cost/benefit analyses
• To select specific countermeasures and safeguards
• To determine the level of insurance coverage to purchase
• To understand what exactly is at risk
• To comply with legal and regulatory requirements
Assets may be tangible (computers, facilities, supplies) or intangible (reputation, data, intellectual property). It is usually harder to quantify the values of intangible assets, which may change over time. How do you put a monetary value on a company’s reputation? This is not always an easy question to answer, but it is important to be able to do so.
Identifying Vulnerabilities and Threats
Earlier, it was stated that the definition of a risk is the probability of a threat agent exploiting a vulnerability to cause harm to an asset and the resulting business impact. Many types of threat agents can take advantage of several types of vulnerabilities, resulting in a variety of specific threats, as outlined in Table 1-5, which represents only a sampling of the risks many organizations should address in their risk management programs.

Table 1-5 Relationship of Threats and Vulnerabilities
Other types of threats can arise in an environment that are much harder to identify than those listed in Table 1-5. These other threats have to do with application and user errors. If an application uses several complex equations to produce results, the threat can be difficult to discover and isolate if these equations are incorrect or if the application is using inputted data incorrectly. This can result in illogical processing and cascading errors as invalid results are passed on to another process. These types of problems can lie within applications’ code and are very hard to identify.
User errors, whether intentional or accidental, are easier to identify by monitoring and auditing user activities. Audits and reviews must be conducted to discover if employees are inputting values incorrectly into programs, misusing technology, or modifying data in an inappropriate manner.
Once the vulnerabilities and associated threats are identified, the ramifications of these vulnerabilities being exploited must be investigated. Risks have loss potential, meaning what the company would lose if a threat agent actually exploited a vulnerability. The loss may be corrupted data, destruction of systems and/or the facility, unauthorized disclosure of confidential information, a reduction in employee productivity, and so on. When performing a risk assessment, the team also must look at delayed loss when assessing the damages that can occur. Delayed loss is secondary in nature and takes place well after a vulnerability is exploited. Delayed loss may include damage to the company’s reputation, loss of market share, accrued late penalties, civil suits, the delayed collection of funds from customers, resources required to reimage other compromised systems, and so forth.
For example, if a company’s web servers are attacked and taken offline, the immediate damage (loss potential) could be data corruption, the man-hours necessary to place the servers back online, and the replacement of any code or components required. The company could lose revenue if it usually accepts orders and payments via its website. If it takes a full day to get the web servers fixed and back online, the company could lose a lot more sales and profits. If it takes a full week to get the web servers fixed and back online, the company could lose enough sales and profits to not be able to pay other bills and expenses. This would be a delayed loss. If the company’s customers lose confidence in it because of this activity, it could lose business for months or years. This is a more extreme case of delayed loss.
These types of issues make the process of properly quantifying losses that specific threats could cause more complex, but they must be taken into consideration to ensure reality is represented in this type of analysis.
Methodologies for Risk Assessment
The industry has different standardized methodologies when it comes to carrying out risk assessments. Each of the individual methodologies has the same basic core components (identify vulnerabilities, associate threats, calculate risk values), but each has a specific focus. As a security professional it is your responsibility to know which is the best approach for your organization and its needs.
NIST developed a guide for conducting risk assessments, which is published in SP 800-30, Revision 1. It is specific to information systems threats and how they relate to information security risks. It lays out the following steps:
1. Prepare for the assessment.
2. Conduct the assessment:
a. Identify threat sources and events.
b. Identify vulnerabilities and predisposing conditions.
c. Determine likelihood of occurrence.
d. Determine magnitude of impact.
e. Determine risk.
3. Communicate results.
4. Maintain assessment.
The NIST risk management methodology is mainly focused on computer systems and IT security issues. It does not explicitly cover larger organizational threat types, as in succession planning, environmental issues, or how security risks associate to business risks. It is a methodology that focuses on the operational components of an enterprise, not necessarily the higher strategic level.
A second type of risk assessment methodology is called FRAP, which stands for Facilitated Risk Analysis Process. The crux of this qualitative methodology is to focus only on the systems that really need assessing, to reduce costs and time obligations. It stresses prescreening activities so that the risk assessment steps are only carried out on the item(s) that needs it the most. FRAP is intended to be used to analyze one system, application, or business process at a time. Data is gathered and threats to business operations are prioritized based upon their criticality. The risk assessment team documents the controls that need to be put into place to reduce the identified risks along with action plans for control implementation efforts.
This methodology does not support the idea of calculating exploitation probability numbers or annual loss expectancy values. The criticalities of the risks are determined by the team members’ experience. The author of this methodology (Thomas Peltier) believes that trying to use mathematical formulas for the calculation of risk is too confusing and time consuming. The goal is to keep the scope of the assessment small and the assessment processes simple to allow for efficiency and cost effectiveness.
Another methodology called OCTAVE (Operationally Critical Threat, Asset, and Vulnerability Evaluation) was created by Carnegie Mellon University’s Software Engineering Institute. It is a methodology that is intended to be used in situations where people manage and direct the risk evaluation for information security within their company. This places the people who work inside the organization in the power positions as being able to make the decisions regarding what is the best approach for evaluating the security of their organization. This relies on the idea that the people working in these environments best understand what is needed and what kind of risks they are facing. The individuals who make up the risk assessment team go through rounds of facilitated workshops. The facilitator helps the team members understand the risk methodology and how to apply it to the vulnerabilities and threats identified within their specific business units. It stresses a self-directed team approach. The scope of an OCTAVE assessment is usually very wide compared to the more focused approach of FRAP. Where FRAP would be used to assess a system or application, OCTAVE would be used to assess all systems, applications, and business processes within the organization.
While NIST, FRAP, and OCTAVE methodologies focus on IT security threats and information security risks, AS/NZS ISO 31000 takes a much broader approach to risk management. This Australian and New Zealand methodology can be used to understand a company’s financial, capital, human safety, and business decisions risks. Although it can be used to analyze security risks, it was not created specifically for this purpose. This risk methodology is more focused on the health of a company from a business point of view, not security.
If we need a risk methodology that is to be integrated into our security program, we can use one that was previously mentioned within the “ISO/IEC 27000 Series” section earlier in the chapter. As a reminder, ISO/IEC 27005 is an international standard for how risk management should be carried out in the framework of an information security management system (ISMS). So where the NIST risk methodology is mainly focused on IT and operations, this methodology deals with IT and the softer security issues (documentation, personnel security, training, etc.). This methodology is to be integrated into an organizational security program that addresses all of the security threats an organization could be faced with.
Failure Modes and Effect Analysis (FMEA) is a method for determining functions, identifying functional failures, and assessing the causes of failure and their failure effects through a structured process. FMEA is commonly used in product development and operational environments. The goal is to identify where something is most likely going to break and either fix the flaws that could cause this issue or implement controls to reduce the impact of the break. For example, you might choose to carry out an FMEA on your organization’s network to identify single points of failure. These single points of failure represent vulnerabilities that could directly affect the productivity of the network as a whole. You would use this structured approach to identify these issues (vulnerabilities), assess their criticality (risk), and identify the necessary controls that should be put into place (reduce risk).
The FMEA methodology uses failure modes (how something can break or fail) and effects analysis (impact of that break or failure). The application of this process to a chronic failure enables the determination of where exactly the failure is most likely to occur. Think of it as being able to look into the future and locate areas that have the potential for failure and then applying corrective measures to them before they do become actual liabilities.
By following a specific order of steps, the best results can be maximized for an FMEA:
1. Start with a block diagram of a system or control.
2. Consider what happens if each block of the diagram fails.
3. Draw up a table in which failures are paired with their effects and an evaluation of the effects.
4. Correct the design of the system, and adjust the table until the system is not known to have unacceptable problems.
5. Have several engineers review the Failure Modes and Effect Analysis.
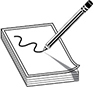
Table 1-6 is an example of how an FMEA can be carried out and documented. Although most companies will not have the resources to do this level of detailed work for every system and control, it can be carried out on critical functions and systems that can drastically affect the company.
FMEA was first developed for systems engineering. Its purpose is to examine the potential failures in products and the processes involved with them. This approach proved to be successful and has been more recently adapted for use in evaluating risk management priorities and mitigating known threat vulnerabilities.
FMEA is used in assurance risk management because of the level of detail, variables, and complexity that continues to rise as corporations understand risk at more granular levels. This methodical way of identifying potential pitfalls is coming into play more as the need for risk awareness—down to the tactical and operational levels—continues to expand.
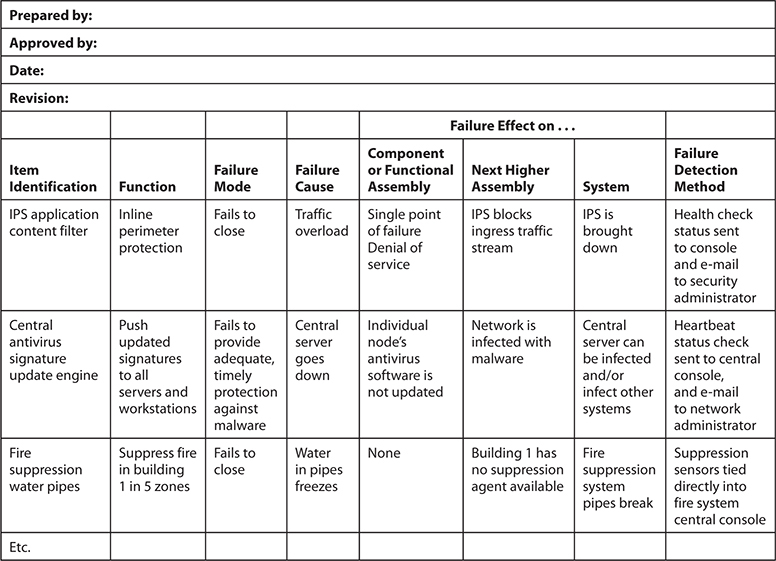
Table 1-6 How an FMEA Can Be Carried Out and Documented
While FMEA is most useful as a survey method to identify major failure modes in a given system, the method is not as useful in discovering complex failure modes that may be involved in multiple systems or subsystems. A fault tree analysis usually proves to be a more useful approach to identifying failures that can take place within more complex environments and systems. Fault trees are similar to the attack trees we discussed earlier and follow this general process. First, an undesired effect is taken as the root or top event of a tree of logic. Then, each situation that has the potential to cause that effect is added to the tree as a series of logic expressions. Fault trees are then labeled with actual numbers pertaining to failure probabilities. This is typically done by using computer programs that can calculate the failure probabilities from a fault tree.
Figure 1-14 shows a simplistic fault tree and the different logic symbols used to represent what must take place for a specific fault event to occur.
When setting up the tree, you must accurately list all the threats or faults that can occur within a system. The branches of the tree can be divided into general categories, such as physical threats, networks threats, software threats, Internet threats, and component failure threats. Then, once all possible general categories are in place, you can trim them and effectively prune the branches from the tree that won’t apply to the system in question. In general, if a system is not connected to the Internet by any means, remove that general branch from the tree.
Some of the most common software failure events that can be explored through a fault tree analysis are the following:
• False alarms
• Insufficient error handling
• Sequencing or order
• Incorrect timing outputs
• Valid but not expected outputs
Figure 1-14 Fault tree and logic components
Of course, because of the complexity of software and heterogeneous environments, this is a very small sample list.
Just in case you do not have enough risk assessment methodologies to choose from, you can also look at CRAMM (Central Computing and Telecommunications Agency Risk Analysis and Management Method), which was created by the United Kingdom, and its automated tools are sold by Siemens. It works in three distinct stages: define objectives, assess risks, and identify countermeasures. It is really not fair to call it a unique methodology, because it follows the basic structure of any risk methodology. It just has everything (questionnaires, asset dependency modeling, assessment formulas, compliancy reporting) in automated tool format.
Similar to the “Security Frameworks” section that covered things such as ISO/IEC 27000, CMMI, COBIT, COSO IC, Zachman Framework, SABSA, ITIL, NIST SP 800-53, and Six Sigma, this section on risk methodologies could at first take seem like another list of confusing standards and guidelines. Remember that the methodologies have a lot of overlapping similarities because each one has the specific goal of identifying things that could hurt the organization (vulnerabilities and threats) so that those things can be addressed (risk reduced). What make these methodologies different from each other are their unique approaches and focuses. If you need to deploy an organization-wide risk management program and integrate it into your security program, you should follow the ISO/IEC 27005 or OCTAVE methods. If you need to focus just on IT security risks during your assessment, you can follow NIST SP 800-30. If you have a limited budget and need to carry out a focused assessment on an individual system or process, you can follow the Facilitated Risk Analysis Process. If you really want to dig into the details of how a security flaw within a specific system could cause negative ramifications, you could use Failure Modes and Effect Analysis or fault tree analysis. If you need to understand your company’s business risks, then you can follow the AS/NZS ISO 31000 approach.
So up to this point, we have accomplished the following items:
• Developed a risk management policy
• Developed a risk management team
• Identified company assets to be assessed
• Calculated the value of each asset
• Identified the vulnerabilities and threats that can affect the identified assets
• Chose a risk assessment methodology that best fits our needs
The next thing we need to figure out is if our risk analysis approach should be quantitative or qualitative in nature, which we will cover in the following section.

EXAM TIP A risk assessment is used to gather data. A risk analysis examines the gathered data to produce results that can be acted upon.
Risk Analysis Approaches
The two approaches to risk analysis are quantitative and qualitative. A quantitative risk analysis is used to assign monetary and numeric values to all elements of the risk analysis process. Each element within the analysis (asset value, threat frequency, severity of vulnerability, impact damage, safeguard costs, safeguard effectiveness, uncertainty, and probability items) is quantified and entered into equations to determine total and residual risks. It is more of a scientific or mathematical approach to risk analysis compared to qualitative. A qualitative risk analysis uses a “softer” approach to the data elements of a risk analysis. It does not quantify that data, which means that it does not assign numeric values to the data so that it can be used in equations. As an example, the results of a quantitative risk analysis could be that the organization is at risk of losing $100,000 if a buffer overflow were exploited on a web server, $25,000 if a database were compromised, and $10,000 if a file server were compromised. A qualitative risk analysis would not present these findings in monetary values, but would assign ratings to the risks, as in Red, Yellow, and Green.
A quantitative analysis uses risk calculations that attempt to predict the level of monetary losses and the probability for each type of threat. Qualitative analysis does not use calculations. Instead, it is more opinion and scenario based and uses a rating system to relay the risk criticality levels.
Quantitative and qualitative approaches have their own pros and cons, and each applies more appropriately to some situations than others. Company management and the risk analysis team, and the tools they decide to use, will determine which approach is best.
In the following sections we will dig into the depths of quantitative analysis and then revisit the qualitative approach. We will then compare and contrast their attributes.
Automated Risk Analysis Methods
Collecting all the necessary data that needs to be plugged into risk analysis equations and properly interpreting the results can be overwhelming if done manually. Several automated risk analysis tools on the market can make this task much less painful and, hopefully, more accurate. The gathered data can be reused, greatly reducing the time required to perform subsequent analyses. The risk analysis team can also print reports and comprehensive graphs to present to management.
EXAM TIP Remember that vulnerability assessments are different from risk assessments. A vulnerability assessment just finds the vulnerabilities (the holes). A risk assessment calculates the probability of the vulnerabilities being exploited and the associated business impact.
The objective of these tools is to reduce the manual effort of these tasks, perform calculations quickly, estimate future expected losses, and determine the effectiveness and benefits of the security countermeasures chosen. Most automatic risk analysis products port information into a database and run several types of scenarios with different parameters to give a panoramic view of what the outcome will be if different threats come to bear. For example, after such a tool has all the necessary information inputted, it can be rerun several times with different parameters to compute the potential outcome if a large fire were to take place; the potential losses if a virus were to damage 40 percent of the data on the main file server; how much the company would lose if an attacker were to steal all the customer credit card information held in three databases; and so on. Running through the different risk possibilities gives a company a more detailed understanding of which risks are more critical than others, and thus which ones to address first.
Steps of a Quantitative Risk Analysis
Recapping the previous sections in this chapter, we have already carried out our risk assessment, which is the process of gathering data for a risk analysis. We have identified the assets that are to be assessed, associated a value to each asset, and identified the vulnerabilities and threats that could affect these assets. Now we need to carry out the risk analysis portion, which means that we need to figure out how to interpret all the data that was gathered during the assessment.
If we choose to carry out a quantitative analysis, then we are going to use mathematical equations for our data interpretation process. The most common equations used for this purpose are the single loss expectancy (SLE) and the annual loss expectancy (ALE).
The SLE is a dollar amount that is assigned to a single event that represents the company’s potential loss amount if a specific threat were to take place. The equation is laid out as follows:
Asset Value × Exposure Factor (EF) = SLE
The exposure factor (EF) represents the percentage of loss a realized threat could have on a certain asset. For example, if a data warehouse has the asset value of $150,000, it can be estimated that if a fire were to occur, 25 percent of the warehouse would be damaged, in which case the SLE would be $37,500:
Asset Value ($150,000) × Exposure Factor (25%) = $37,500
This tells us that the company could potentially lose $37,500 if a fire were to take place. But we need to know what our annual potential loss is, since we develop and use our security budgets on an annual basis. This is where the ALE equation comes into play. The ALE equation is as follows:
SLE × Annualized Rate of Occurrence (ARO) = ALE
The annualized rate of occurrence (ARO) is the value that represents the estimated frequency of a specific threat taking place within a 12-month timeframe. The range can be from 0.0 (never) to 1.0 (once a year) to greater than 1 (several times a year), and anywhere in between. For example, if the probability of a fire taking place and damaging our data warehouse is once every 10 years, the ARO value is 0.1.
So, if a fire taking place within a company’s data warehouse facility can cause $37,500 in damages, and the frequency (or ARO) of a fire taking place has an ARO value of 0.1 (indicating once in 10 years), then the ALE value is $3,750 ($37,500 × 0.1 = $3,750).
The ALE value tells the company that if it wants to put in controls to protect the asset (warehouse) from this threat (fire), it can sensibly spend $3,750 or less per year to provide the necessary level of protection. Knowing the real possibility of a threat and how much damage, in monetary terms, the threat can cause is important in determining how much should be spent to try and protect against that threat in the first place. It would not make good business sense for the company to spend more than $3,750 per year to protect itself from this threat.
Now that we have all these numbers, what do we do with them? Let’s look at the example in Table 1-7, which shows the outcome of a quantitative risk analysis. With this data, the company can make intelligent decisions on what threats must be addressed first because of the severity of the threat, the likelihood of it happening, and how much could be lost if the threat were realized. The company now also knows how much money it should spend to protect against each threat. This will result in good business decisions, instead of just buying protection here and there without a clear understanding of the big picture. Because the company has a risk of losing up to $6,500 if data is corrupted by virus infiltration, up to this amount of funds can be earmarked toward providing antivirus software and methods to ensure that a virus attack will not happen.
When carrying out a quantitative analysis, some people mistakenly think that the process is purely objective and scientific because data is being presented in numeric values. But a purely quantitative analysis is hard to achieve because there is still some subjectivity when it comes to the data. How do we know that a fire will only take place once every 10 years? How do we know that the damage from a fire will be 25 percent of the value of the asset? We don’t know these values exactly, but instead of just pulling them out of thin air, they should be based upon historical data and industry experience. In quantitative risk analysis, we can do our best to provide all the correct information, and by doing so we will come close to the risk values, but we cannot predict the future and how much the future will cost us or the company.

Table 1-7 Breaking Down How SLE and ALE Values Are Used
Results of a Quantitative Risk Analysis
The risk analysis team should have clearly defined goals. The following is a short list of what generally is expected from the results of a risk analysis:
• Monetary values assigned to assets
• Comprehensive list of all significant threats
• Probability of the occurrence rate of each threat
• Loss potential the company can endure per threat in a 12-month time span
• Recommended controls
Although this list looks short, there is usually an incredible amount of detail under each bullet item. This report will be presented to senior management, which will be concerned with possible monetary losses and the necessary costs to mitigate these risks. Although the reports should be as detailed as possible, there should be executive abstracts so senior management can quickly understand the overall findings of the analysis.
Qualitative Risk Analysis
Another method of risk analysis is qualitative, which does not assign numbers and monetary values to components and losses. Instead, qualitative methods walk through different scenarios of risk possibilities and rank the seriousness of the threats and the validity of the different possible countermeasures based on opinions. (A wide-sweeping analysis can include hundreds of scenarios.) Qualitative analysis techniques include judgment, best practices, intuition, and experience. Examples of qualitative techniques to gather data are Delphi, brainstorming, storyboarding, focus groups, surveys, questionnaires, checklists, one-on-one meetings, and interviews. The risk analysis team will determine the best technique for the threats that need to be assessed, as well as the culture of the company and individuals involved with the analysis.
The team that is performing the risk analysis gathers personnel who have experience and education on the threats being evaluated. When this group is presented with a scenario that describes threats and loss potential, each member responds with their gut feeling and experience on the likelihood of the threat and the extent of damage that may result. This group explores a scenario of each identified vulnerability and how it would be exploited. The “expert” in the group, who is most familiar with this type of threat, should review the scenario to ensure it reflects how an actual threat would be carried out. Safeguards that would diminish the damage of this threat are then evaluated, and the scenario is played out for each safeguard. The exposure possibility and loss possibility can be ranked as high, medium, or low on a scale of 1 to 5 or 1 to 10.
A common qualitative risk matrix is shown in Figure 1-15. Once the selected personnel rank the possibility of a threat happening, the loss potential, and the advantages of each safeguard, this information is compiled into a report and presented to management to help it make better decisions on how best to implement safeguards into the environment. The benefits of this type of analysis are that communication must happen among team members to rank the risks, evaluate the safeguard strengths, and identify weaknesses, and the people who know these subjects the best provide their opinions to management.
Let’s look at a simple example of a qualitative risk analysis.
The risk analysis team presents a scenario explaining the threat of a hacker accessing confidential information held on the five file servers within the company. The risk analysis team then distributes the scenario in a written format to a team of five people (the IT manager, database administrator, application programmer, system operator, and operational manager), who are also given a sheet to rank the threat’s severity, loss potential, and each safeguard’s effectiveness, with a rating of 1 to 5, 1 being the least severe, effective, or probable. Table 1-8 shows the results.
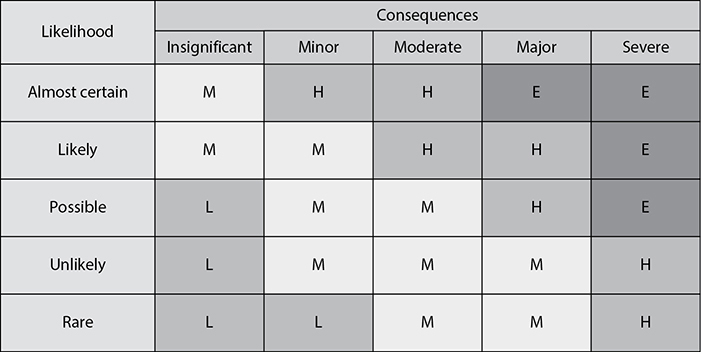
Figure 1-15 Qualitative risk matrix: likelihood vs. consequences (impact)

Table 1-8 Example of a Qualitative Analysis
This data is compiled and inserted into a report and presented to management. When management is presented with this information, it will see that its staff (or a chosen set) feels that purchasing a firewall will protect the company from this threat more than purchasing an intrusion detection system or setting up a honeypot system.
This is the result of looking at only one threat, and management will view the severity, probability, and loss potential of each threat so it knows which threats cause the greatest risk and should be addressed first.
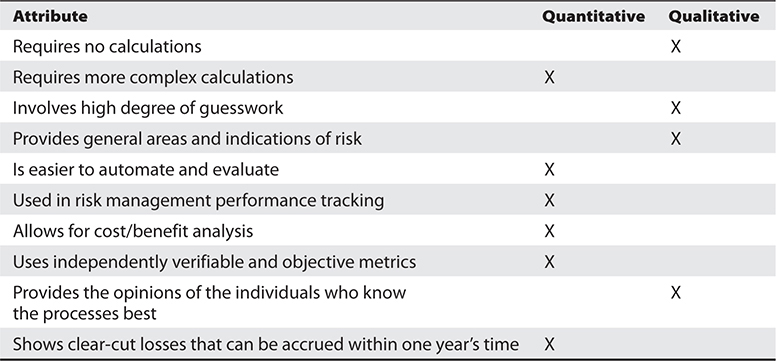
Table 1-9 Quantitative vs. Qualitative Characteristics
Quantitative vs. Qualitative
Each method has its advantages and disadvantages, some of which are outlined in Table 1-9 for purposes of comparison.
The risk analysis team, management, risk analysis tools, and culture of the company will dictate which approach—quantitative or qualitative—should be used. The goal of either method is to estimate a company’s real risk and to rank the severity of the threats so the correct countermeasures can be put into place within a practical budget.
Table 1-9 refers to some of the positive aspects of the quantitative and qualitative approaches. However, not everything is always easy. In deciding to use either a quantitative or qualitative approach, the following points might need to be considered.
Quantitative Cons:
• Calculations can be complex. Can management understand how these values were derived?
• Without automated tools, this process is extremely laborious.
• More preliminary work is needed to gather detailed information about the environment.
• Standards are not available. Each vendor has its own way of interpreting the processes and their results.
Qualitative Cons:
• The assessments and results are subjective and opinion based.
• Eliminates the opportunity to create a dollar value for cost/benefit discussions.
• Hard to develop a security budget from the results because monetary values are not used.
• Standards are not available. Each vendor has its own way of interpreting the processes and their results.
NOTE Since a purely quantitative assessment is close to impossible and a purely qualitative process does not provide enough statistical data for financial decisions, these two risk analysis approaches can be used in a hybrid approach. Quantitative evaluation can be used for tangible assets (monetary values), and a qualitative assessment can be used for intangible assets (priority values).
Protection Mechanisms
The next step is to identify the current security mechanisms and evaluate their effectiveness.
This section addresses identifying and choosing the right countermeasures for computer systems. It gives the best attributes to look for and the different cost scenarios to investigate when comparing different types of countermeasures. The end product of the analysis of choices should demonstrate why the selected control is the most advantageous to the company.
NOTE The terms control, countermeasure, safeguard, security mechanism, and protection mechanism are synonymous in the context of information systems security. We use them interchangeably.
Control Selection
A security control must make good business sense, meaning it is cost effective (its benefit outweighs its cost). This requires another type of analysis: a cost/benefit analysis. A commonly used cost/benefit calculation for a given safeguard (control) is
(ALE before implementing safeguard) – (ALE after implementing safeguard) – (annual cost of safeguard) = value of safeguard to the company
For example, if the ALE of the threat of a hacker bringing down a web server is $12,000 prior to implementing the suggested safeguard, and the ALE is $3,000 after implementing the safeguard, while the annual cost of maintenance and operation of the safeguard is $650, then the value of this safeguard to the company is $8,350 each year.
The cost of a countermeasure is more than just the amount filled out on the purchase order. The following items should be considered and evaluated when deriving the full cost of a countermeasure:
• Product costs
• Design/planning costs
• Implementation costs
• Environment modifications
• Compatibility with other countermeasures
• Maintenance requirements
• Testing requirements
• Repair, replacement, or update costs
• Operating and support costs
• Effects on productivity
• Subscription costs
• Extra man-hours for monitoring and responding to alerts
Many companies have gone through the pain of purchasing new security products without understanding that they will need the staff to maintain those products. Although tools automate tasks, many companies were not even carrying out these tasks before, so they do not save on man-hours, but many times require more hours. For example, Company A decides that to protect many of its resources, purchasing an IDS is warranted. So, the company pays $5,500 for an IDS. Is that the total cost? Nope. This software should be tested in an environment that is segmented from the production environment to uncover any unexpected activity. After this testing is complete and the security group feels it is safe to insert the IDS into its production environment, the security group must install the monitoring management software, install the sensors, and properly direct the communication paths from the sensors to the management console. The security group may also need to reconfigure the routers to redirect traffic flow, and it definitely needs to ensure that users cannot access the IDS management console. Finally, the security group should configure a database to hold all attack signatures and then run simulations.
Costs associated with an IDS alert response should most definitely be considered. Now that Company A has an IDS in place, security administrators may need additional alerting equipment such as smartphones. And then there are the time costs associated with a response to an IDS event.
Anyone who has worked in an IT group knows that some adverse reaction almost always takes place in this type of scenario. Network performance can take an unacceptable hit after installing a product if it is an inline or proactive product. Users may no longer be able to access the Unix server for some mysterious reason. The IDS vendor may not have explained that two more service patches are necessary for the whole thing to work correctly. Staff time will need to be allocated for training and to respond to all of the alerts (true or false) the new IDS sends out.
So, for example, the cost of this countermeasure could be $23,500 for the product and licenses; $2,500 for training; $3,400 for testing; $2,600 for the loss in user productivity once the product is introduced into production; and $4,000 in labor for router reconfiguration, product installation, troubleshooting, and installation of the two service patches. The real cost of this countermeasure is $36,000. If our total potential loss was calculated at $9,000, we went over budget by 300 percent when applying this countermeasure for the identified risk. Some of these costs may be hard or impossible to identify before they are incurred, but an experienced risk analyst would account for many of these possibilities.
Security Control Assessment
The risk assessment team must evaluate the security controls’ functionality and effectiveness. When selecting a security control, some attributes are more favorable than others. Table 1-10 lists and describes attributes that should be considered before purchasing and committing to a security control.

Table 1-10 Characteristics to Consider When Assessing Security Controls
Security controls can provide deterrence attributes if they are highly visible. This tells potential evildoers that adequate protection is in place and that they should move on to an easier target. Although the control may be highly visible, attackers should not be able to discover the way it works, thus enabling them to attempt to modify it, or know how to get around the protection mechanism. If users know how to disable the antivirus program that is taking up CPU cycles or know how to bypass a proxy server to get to the Internet without restrictions, they will do so.
Total Risk vs. Residual Risk
The reason a company implements countermeasures is to reduce its overall risk to an acceptable level. As stated earlier, no system or environment is 100 percent secure, which means there is always some risk left over to deal with. This is called residual risk.
Residual risk is different from total risk, which is the risk a company faces if it chooses not to implement any type of safeguard. A company may choose to take on total risk if the cost/benefit analysis results indicate this is the best course of action. For example, if there is a small likelihood that a company’s web servers can be compromised and the necessary safeguards to provide a higher level of protection cost more than the potential loss in the first place, the company will choose not to implement the safeguard, choosing to deal with the total risk.
There is an important difference between total risk and residual risk and which type of risk a company is willing to accept. The following are conceptual formulas:
threats × vulnerability × asset value = total risk (threats × vulnerability × asset value) × controls gap = residual risk
You may also see these concepts illustrated as the following:
total risk – countermeasures = residual risk
NOTE The previous formulas are not constructs you can actually plug numbers into. They are instead used to illustrate the relation of the different items that make up risk in a conceptual manner. This means no multiplication or mathematical functions actually take place. It is a means of understanding what items are involved when defining either total or residual risk.
During a risk assessment, the threats and vulnerabilities are identified. The possibility of a vulnerability being exploited is multiplied by the value of the assets being assessed, which results in the total risk. Once the controls gap (protection the control cannot provide) is factored in, the result is the residual risk. Implementing countermeasures is a way of mitigating risks. Because no company can remove all threats, there will always be some residual risk. The question is what level of risk the company is willing to accept.
Handling Risk
Once a company knows the amount of total and residual risk it is faced with, it must decide how to handle it. Risk can be dealt with in four basic ways: transfer it, avoid it, reduce it, or accept it.
Many types of insurance are available to companies to protect their assets. If a company decides the total risk is too high to gamble with, it can purchase insurance, which would transfer the risk to the insurance company.
If a company decides to terminate the activity that is introducing the risk, this is known as risk avoidance. For example, if a company allows employees to use instant messaging (IM), there are many risks surrounding this technology. The company could decide not to allow any IM activity by employees because there is not a strong enough business need for its continued use. Discontinuing this service is an example of risk avoidance.
Another approach is risk mitigation, where the risk is reduced to a level considered acceptable enough to continue conducting business. The implementation of firewalls, training, and intrusion/detection protection systems or other control types represent types of risk mitigation efforts.
The last approach is to accept the risk, which means the company understands the level of risk it is faced with, as well as the potential cost of damage, and decides to just live with it and not implement the countermeasure. Many companies will accept risk when the cost/benefit ratio indicates that the cost of the countermeasure outweighs the potential loss value.
A crucial issue with risk acceptance is understanding why this is the best approach for a specific situation. Unfortunately, today many people in organizations are accepting risk and not understanding fully what they are accepting. This usually has to do with the relative newness of risk management in the security field and the lack of education and experience in those personnel who make risk decisions. When business managers are charged with the responsibility of dealing with risk in their department, most of the time they will accept whatever risk is put in front of them because their real goals pertain to getting a project finished and out the door. They don’t want to be bogged down by this silly and irritating security stuff.
Risk acceptance should be based on several factors. For example, is the potential loss lower than the countermeasure? Can the organization deal with the “pain” that will come with accepting this risk? This second consideration is not purely a cost decision, but may entail non cost issues surrounding the decision. For example, if we accept this risk, we must add three more steps in our production process. Does that make sense for us? Or if we accept this risk, more security incidents may arise from it, and are we prepared to handle those?
The individual or group accepting risk must also understand the potential visibility of this decision. Let’s say a company has determined that it does not need to protect customers’ first names, but it does have to protect other items like Social Security numbers, account numbers, and so on. So these current activities are in compliance with the regulations and laws, but what if your customers find out you are not properly protecting their names and they associate such things with identity fraud because of their lack of education on the matter? The company may not be able to handle this potential reputation hit, even if it is doing all it is supposed to be doing. Perceptions of a company’s customer base are not always rooted in fact, but the possibility that customers will move their business to another company is a potential fact your company must comprehend.
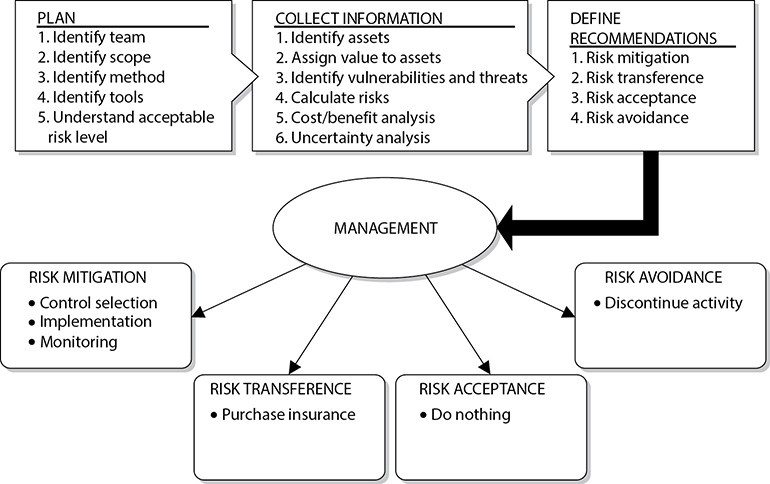
Figure 1-16 How a risk management program can be set up
Figure 1-16 shows how a risk management program can be set up, which ties together all the concepts covered in this section.
Supply Chain Risk Management
Many organizations fail to consider their supply chain when managing risk, despite the fact that it often presents a convenient and easier back door to an attacker. So what is a supply chain anyway? A supply chain is a sequence of suppliers involved in delivering some product. If your company manufactures laptops, your supply chain will include the vendor that supplies your video cards. It will also include whoever makes the integrated circuits that go on those cards as well as the supplier of the raw chemicals that are involved in that process. The supply chain also includes suppliers of services, such as the company that maintains the heating, ventilation, and air conditioning (HVAC) systems needed to keep your assembly lines running.
The various organizations that make up your supply chain will have a different outlook on security than you do. For one thing, their threat modeling will include different threats than yours. Why would a criminal looking to steal credit card information target an HVAC service provider? This is exactly what happened in 2013 when Target had over 40 million credit cards compromised. Target had done a reasonable job at securing its perimeter, but not its internal networks. The attacker, unable (or maybe just unwilling) to penetrate Target’s outer shell head-on, decided to exploit the vulnerable network of one of Target’s HVAC service providers and steal its credentials. Armed with these, the thieves were able to gain access to the point of sale terminals and, from there, the credit card information.
The basic processes you’ll need to manage risk in your supply chain are the same ones you use in the rest of your risk management program. The differences are mainly in what you look at (that is, the scope of your assessments) and what you can do about it (legally and contractually). A good resource to help integrate supply chain risk into your risk management program is NIST SP 800-161, “Supply Chain Risk Management Practices for Federal Information Systems and Organizations.”
One of the first things you’ll need to do is to create a supply chain map for your organization. This is essentially a network diagram of who supplies what to whom down to your ultimate customers. Figure 1-17 depicts a simplified systems integrator company (“Your Company”). It has a hardware components manufacturer that supplies it hardware and is, in turn, supplied by a materials producer. Your Company receives software from a developer and receives managed security from an external service provider. The hardware and software components are integrated and configured into Your Company’s product, which is then shipped to its distributor and on to its customers. In this example, the company has four suppliers on which to base its supply chain risk assessment. It is also considered a supplier to its distributor.
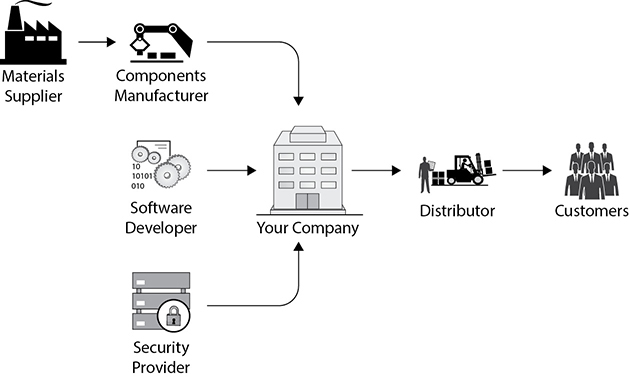
Figure 1-17 Simplified supply chain
Upstream and Downstream Suppliers
Suppliers are “upstream” from your company if they supply materials, goods, or services to your company and your company uses those in turn to provide whatever it is that it supplies to others. The core vulnerability that exists in these supply arrangements is that you could allow untrusted hardware, software, or services into your organization or products, where they could cause security problems. The Greeks used this to their advantage against the Trojans.
Conversely, your company may be upstream from others in the same supply chain. These would be your company’s downstream suppliers. While it may be tempting to think that you should be concerned only about supply chain security upstream, those who follow your company in the supply chain may have their own set of upstream requirements for your firm. Furthermore, your customers may not care that a security issue was caused by your downstream distributor; your brand name will be damaged all the same.
Hardware
One of the major supply chain risks is the addition of hardware Trojans to electronic components. A hardware Trojan is an electronic circuit that is added to an existing device in order to compromise its security or provide unauthorized functionality. Depending on the attacker’s access, these mechanisms can be inserted at any stage of the hardware development process (specification, design, fabrication, testing, assembly, or packaging). It is also possible to add them after the hardware is packaged by intercepting shipments in the supply chain. In this case, the Trojan may be noticeable if the device is opened and visually inspected. The earlier hardware Trojans are inserted, the more difficult they are to detect.
Another supply chain risk to hardware is the substitution of counterfeit components. The problems with these clones are many, but from a security perspective one of the most important is that they don’t go through the same quality controls that the real ones do. This leads to lower reliability and abnormal behavior. It could also lead to undetected hardware Trojans (perhaps inserted by the illicit manufacturers themselves). Obviously, using counterfeits could have legal implications and will definitely be a problem when you need customer support from the manufacturer.
Software
Like hardware, third-party software can be Trojaned by an adversary in your supply chain, particularly if it is custom-made for your organization. This could happen if your supplier reuses components (like libraries) developed elsewhere and to which the attacker has access. It can also be done by a malicious insider in the supplier or by a remote attacker who has gained access to the supplier’s software repositories. Failing all that, the software could be intercepted in transit to you, modified, and then sent on its way. This last approach could be made more difficult for the adversary by using code signing or hashes, but it is still possible.
Services
More organizations are outsourcing services to allow them to focus on their core business functions. Companies use hosting companies to maintain websites and e-mail servers, service providers for various telecommunication connections, disaster recovery companies for co-location capabilities, cloud computing providers for infrastructure or application services, developers for software creation, and security companies to carry out vulnerability management. It is important to realize that while you can outsource functionality, you cannot outsource risk. When your company is using these third-party service providers, your company can still be ultimately responsible if something like a data breach takes place. Let’s look at some things an organization should do to reduce its risk when it comes to outsourcing:
• Review the service provider’s security program
• Conduct onsite inspection and interviews
• Review contracts to ensure security and protection levels are agreed upon
• Ensure service level agreements are in place
• Review internal and external audit reports and third-party reviews
• Review references and communicate with former and existing customers
• Review Better Business Bureau reports
• Ensure the service provider has a business continuity plan (BCP) in place
• Implement a nondisclosure agreement (NDA)
• Understand the provider’s legal and regulatory requirements
Service outsourcing is prevalent within organizations today but is commonly forgotten about when it comes to security and compliance requirements. It may be economical to outsource certain functionalities, but if this allows security breaches to take place, it can turn out to be a very costly decision.
Service Level Agreements
A service level agreement (SLA) is a contractual agreement that states that a service provider guarantees a certain level of service. If the service is not delivered at the agreed-upon level (or better), then there are consequences (typically financial) for the service provider. SLAs provide a mechanism to mitigate some of the risk from service providers in the supply chain. For example, an Internet service provider (ISP) may sign an SLA of 99.999 percent (called five nines) uptime to the Internet backbone. That means that the ISP guarantees less than 26 seconds of downtime per month.
Risk Management Frameworks
We have covered a lot of material dealing with risk management in general and risk assessments in particular. By now, you may be asking yourself, “How does this all fit together into an actionable process?” This is where frameworks come to the rescue. The Oxford English Dictionary defines framework as a basic structure underlying a system, concept, or text. By combining this with our earlier definition of risk management, we can define a risk management framework (RMF) as a structured process that allows an organization to identify and assess risk, reduce it to an acceptable level, and ensure that it remains at that level. In essence, an RMF is a structured approach to risk management.
As you might imagine, there is no shortage of RMFs out there. What is important to you as a security professional is to ensure your organization has an RMF that works for you. That being said, there are some frameworks that have enjoyed widespread success and acceptance (see sidebar). You should at least be aware of these, and ideally adopt (and perhaps modify) one of them to fit your particular needs.
In this section, we will focus our discussion on the NIST risk management framework, SP 800-37, Revision 1, “Guide for Applying the Risk Management Framework to Federal Information Systems,” since it incorporates the most important components that you should know as a security professional. It is important to keep in mind, however, that this framework is geared toward federal government entities and may have to be modified to fit your own needs. The NIST RMF outlines the following six-step process of applying the RMF, each of which will be addressed in turn in the following sections:
1. Categorize information system.
2. Select security controls.
3. Implement security controls.
4. Assess security controls.
5. Authorize information system.
6. Monitor security controls.
Categorize Information System
The first step is to identify and categorize the information system. What does this mean? First, you have to identify what you have in terms of systems, subsystems, and boundaries. For example, if you have a customer relationship management (CRM) information system, you need to inventory its components (e.g., software, hardware), any subsystems it may include (e.g., bulk e-mailer, customer analytics), and its boundaries (e.g., interface with the corporate mail system). You also need to know how this system fits into your organization’s business process, how sensitive it is, and who owns it and the data within it. Other questions you may ask are
• How is the information system integrated into the enterprise architecture?
• What types of information are processed, stored, and transmitted by the system?
• Are there regulatory or legal requirements applicable to the information system?
• How is the system interconnected to others?
• What is the criticality of this information system to the business?
Clearly, there are many other questions you would want to ask as you categorize the system, so this list is not meant to be all-inclusive. You could use this as a starting point, but you really should have your own list of questions that you use consistently across all of your organization’s information systems. Doing so ensures that you don’t forget any important details, or that if you do, it only happens once (presuming you then add it to your list, of course). At the end of this step, you should have all the information you need in order to determine what countermeasures you can apply to manage your risk.
Select Security Controls
Recall that we already defined a security control or countermeasure as a mechanism that is put in place to mitigate (reduce) a potential risk. It then makes sense to assess our risk exposure before we select security controls for our information systems. In this step, there is an inherent assumption that you have already performed a risk assessment and have identified a number of common controls across your organization. An example of this are so-called “gold master” images that are applied to all workstations and profiles that are installed on mobile devices. These common controls ensure that the entire enterprise has a common baseline.
As you consider a new system, you have to determine if there are any risks that are specific to it or are introduced into your overall architecture by the introduction of this system. This means that you will likely conduct another risk assessment that looks at both this new system and its effects on the larger ecosystem. Having done this, you compare the results of this assessment with the common controls in your organization and determine if you need to modify any of these (i.e., create hybrid controls) or develop brand-new ones (i.e., create system-specific controls) in order to maintain the security baseline. Finally, you need to address how these new controls (if any) integrate into your continuous monitoring strategy that tells you whether or not your security is maintained over time.
Implement Security Controls
There are two key tasks in this step: implementation and documentation. The first part is very straightforward. For example, if you determined in the previous step that you need to add a rule to your intrusion prevention system to mitigate a risk, you implement that rule. Simple. The part with which many of us struggle is the documentation of this change.
The documentation is important for two obvious reasons. First, it allows everyone to understand what controls exist, where, and why. Have you ever inherited a system that is configured in a seemingly nonsensical way? You try to understand why certain parameters or rules exist but hesitate to change them because the system might fail. Likely, this was the result of either improper documentation or (even worse) a successful attack. The second reason why documentation is important is that it allows us to fully integrate the controls into the overall assessment and monitoring plan. Failing to do this invites having controls that quietly become obsolete and ineffective over time and result in undocumented risks.
Assess Security Controls
The security controls we implement are useful to our overall risk management effort only insofar as we can assess them. It is absolutely essential to our organizations to have a comprehensive plan that assesses all security controls (common, hybrid, and system-specific) with regard to the risks they are meant to address. This plan must be reviewed and approved by the appropriate official(s), and it must be exercised.
To execute an assessment plan, you will, ideally, identify an assessor who is both competent and independent from the team that implemented the controls. This person must act as an honest broker that not only assesses the effectiveness of the controls, but also ensures the documentation is appropriate for the task. For this reason, it is important to include all necessary assessment materials in the plan.
The assessment will determine whether or not the controls are effective. If they are, then the results are documented in the report so that they are available as references for the next assessment. If the controls are not effective, then the report documents the results, the remediation actions that were taken to address the shortcomings, and the outcome of the reassessment. Finally, the appropriate security plans are updated to include the findings and recommendations of the assessment.
Authorize Information System
As we already discussed, no system is ever 100 percent risk-free. At this stage in the RMF, we present the results of both our risk and controls assessments to the appropriate decision-maker in order to get approval to connect our information system into our broader architecture and operate it. This person (or group) determines whether the risk exposure is acceptable to the organization. This normally requires a review of a plan of action that addresses how the organization will deal with the remaining weaknesses and deficiencies in the information system. In many organizations this authorization is given for a set period of time, which is usually tied to the milestones in the plan of action.
Monitor Security Controls
These milestones we just mentioned are a key component of the monitoring or continuous improvement stage of the RMF. At a minimum, we must periodically look at all our controls and determine whether they are still effective. Has the threat changed its tactics, techniques, and procedures (TTPs)? Have new vulnerabilities been discovered? Has an undocumented/unapproved change to our configuration altered our risk equations? These are only some of the issues that we address through ongoing monitoring and continuous improvement.
Business Continuity and Disaster Recovery
Though we strive to drive down the risks of negative effects in our organizations, we can be sure that sooner or later an event will slip through and cause negative impacts. Ideally, the losses are contained and won’t affect the major business efforts. However, as security professionals we need to have plans in place for when the unthinkable happens. Under those extreme (and sometimes unpredictable) conditions, we need to ensure that our organizations continue to operate at some minimum acceptable threshold capacity and quickly bounce back to full productivity.
The goal of disaster recovery is to minimize the effects of a disaster or disruption. It means taking the necessary steps to ensure that the resources, personnel, and business processes are able to resume operation in a timely manner. This is different from continuity planning, which provides methods and procedures for dealing with longer-term outages and disasters. The goal of a disaster recovery plan (DRP) is to handle the disaster and its ramifications right after the disaster hits; the disaster recovery plan is usually very information technology (IT) focused.
A disaster recovery plan is carried out when everything is still in emergency mode and everyone is scrambling to get all critical systems back online. A business continuity plan (BCP) takes a broader approach to the problem. It can include getting critical systems to another environment while repair of the original facilities is under way, getting the right people to the right places during this time, and performing business in a different mode until regular conditions are back in place. It also involves dealing with customers, partners, and shareholders through different channels until everything returns to normal. So, disaster recovery deals with, “Oh my goodness, the sky is falling,” and continuity planning deals with, “Okay, the sky fell. Now, how do we stay in business until someone can put the sky back where it belongs?”

While disaster recovery and business continuity planning are directed at the development of plans, business continuity management (BCM) is the holistic management process that should cover both of them. BCM provides a framework for integrating resilience with the capability for effective responses in a manner that protects the interests of an organization’s key stakeholders. The main objective of BCM is to allow the organization to continue to perform business operations under various conditions.
Certain characteristics run through many of the chapters in this book: availability, integrity, and confidentiality. Here, we point out that integrity and confidentiality must be considered not only in everyday procedures, but also in those procedures undertaken immediately after a disaster or disruption. For instance, it may not be appropriate to leave a server that holds confidential information in one building while everyone else moves to another building. Equipment that provides secure VPN connections may be destroyed and the team might respond by focusing on enabling remote access functionality while forgetting about the needs of encryption. In most situations the company is purely focused on getting back up and running, thus focusing on functionality. If security is not integrated and implemented properly, the effects of the physical disaster can be amplified as hackers come in and steal sensitive information. Many times a company is much more vulnerable after a disaster hits, because the security services used to protect it may be unavailable or operating at a reduced capacity. Therefore, it is important that if the business has secret stuff, it stays secret.
Availability is one of the main themes behind business continuity planning, in that it ensures that the resources required to keep the business going will continue to be available to the people and systems that rely upon them. This may mean backups need to be done religiously and that redundancy needs to be factored into the architecture of the systems, networks, and operations. If communication lines are disabled or if a service is rendered unusable for any significant period of time, there must be a quick and tested way of establishing alternative communications and services. We will be diving into the many ways organizations can implement availability solutions for continuity and recovery purposes throughout this section.
When looking at business continuity planning, some companies focus mainly on backing up data and providing redundant hardware. Although these items are extremely important, they are just small pieces of the company’s overall operations pie. Hardware and computers need people to configure and operate them, and data is usually not useful unless it is accessible by other systems and possibly outside entities. Thus, a larger picture of how the various processes within a business work together needs to be understood. Planning must include getting the right people to the right places, documenting the necessary configurations, establishing alternative communications channels (voice and data), providing power, and making sure all dependencies are properly understood and taken into account.
It is also important to understand how automated tasks can be carried out manually, if necessary, and how business processes can be safely altered to keep the operation of the company going. This may be critical in ensuring the company survives the event with the least impact to its operations. Without this type of vision and planning, when a disaster hits, a company could have its backup data and redundant servers physically available at the alternative facility, but the people responsible for activating them may be standing around in a daze, not knowing where to start or how to perform in such a different environment.
Standards and Best Practices
Although no specific scientific equation must be followed to create continuity plans, certain best practices have proven themselves over time. The National Institute of Standards and Technology is responsible for developing best practices and standards as they pertain to U.S. government and military environments. It is common for NIST to document the requirements for these types of environments, and then everyone else in the industry uses NIST’s documents as guidelines. So these are “musts” for U.S. government organizations and “good to have” for other, nongovernment entities.
NIST outlines the following steps in SP 800-34, Revision 1, “Contingency Planning Guide for Federal Information Systems”:
1. Develop the continuity planning policy statement. Write a policy that provides the guidance necessary to develop a BCP and that assigns authority to the necessary roles to carry out these tasks.
2. Conduct the business impact analysis (BIA). Identify critical functions and systems and allow the organization to prioritize them based on necessity. Identify vulnerabilities and threats, and calculate risks.
3. Identify preventive controls. Once threats are recognized, identify and implement controls and countermeasures to reduce the organization’s risk level in an economical manner.
4. Create contingency strategies. Formulate methods to ensure systems and critical functions can be brought online quickly.
5. Develop an information system contingency plan. Write procedures and guidelines for how the organization can still stay functional in a crippled state.
6. Ensure plan testing, training, and exercises. Test the plan to identify deficiencies in the BCP, and conduct training to properly prepare individuals on their expected tasks.
7. Ensure plan maintenance. Put in place steps to ensure the BCP is a living document that is updated regularly.
Although the NIST SP 800-34 document deals specifically with IT contingency plans, these steps are similar when creating enterprise-wide BCPs and BCM programs.
Since BCM is so critical, it is actually addressed by other standards-based organizations, listed here:
ISO/IEC 27031:2011 Guidelines for information and communications technology readiness for business continuity. This ISO/IEC standard is a component of the overall ISO/IEC 27000 series.
ISO 22301:2012 International standard for business continuity management systems. The specification document against which organizations will seek certification. This standard replaced BS 25999-2.
Business Continuity Institute’s Good Practice Guidelines (GPG) BCM best practices, which are broken down into the following management and technical practices.
Management Practices:
• Policy and Program Management
• Embedding BCM in the Organization’s Culture
Technical Practices:
• Understanding the Organization
• Determining BCM Strategy
• Developing and Implementing a BCM Response
• Exercising, Maintaining, and Reviewing
DRI International Institute’s Professional Practices for Business Continuity Planners Best practices and framework to allow for BCM processes, which are broken down into the following sections:
• Program Initiation and Management
• Risk Evaluation and Control
• Business Impact Analysis
• Business Continuity Strategies
• Emergency Response and Operations
• Plan Implementation and Documentation
• Awareness and Training Programs
• Business Continuity Plan Exercise, Audit, and Maintenance
• Crisis Communications
• Coordination with External Agencies
Why are there so many sets of best practices and which is the best for your organization? If your organization is part of the U.S. government or a government contracting company, then you need to comply with the NIST standards. If your organization is in Europe or your company does business with other companies in Europe, then you might need to follow the BSI’s list of standard requirements. While we are not listing all of them here, there are other country-based BCM standards that your company might need to comply with if it is residing in or does business in one of those specific countries. If your organization needs to get ISO certified, then ISO/IEC 27031 and ISO 22301 are the standards to follow. While the first of these is focused on IT, the second is broader in scope and addresses the needs of the entire organization.
So some of these best practices/standards have a specific focus (DRP, BCP, government, technology), some are still evolving, and some directly compete against each other because BCM is a big and growing industry. There is a lot of overlap between them all because they all have one main focus of keeping the company in business after something bad happens. Your company’s legal and regulatory requirements commonly point toward one of these best practice standards, so find out these specifics before hitching your wagon to one specific set of practices. For example, if your company is a government contracting company that works with the U.S. government, then you follow NIST because that is the “checklist” your auditors will most likely follow and grade you against. If your company does business internationally, then following the ISO list of requirements would probably be the best bet.
Making BCM Part of the Enterprise Security Program
As we already explained, every company should have security policies, procedures, standards, and guidelines. People who are new to information security commonly think that this is one pile of documentation that addresses all issues pertaining to security, but it is more complicated than that—of course.
An enterprise security program is made up of many different disciplines. The Common Body of Knowledge (CBK) for the CISSP exam did not just fall out of the sky one day, and it was not just made up by some lonely guys sitting in a room. The CBK is broken down into the eight high-level disciplines of any enterprise security program (Security and Risk Management, Asset Security, Security Architecture and Engineering, Communication and Network Security, Identity and Access Management, Security Assessment and Testing, Security Operations, and Software Development Security). These top-tier disciplines are then broken down into supporting subcomponents. What this means is that every company actually needs to have at least eight sets of policies, standards, guidelines, and procedures—one per top-tier discipline.
We will go more in depth into what should be encapsulated in a BCP policy in a later section, but for now let’s understand why it has to be integrated into the security program as a whole. Business continuity should be a part of the security program and business decisions, as opposed to being an entity that stands off in a corner by itself. The BCM team will be responsible for putting Humpty Dumpty back together again, so it better understand all the pieces and parts that make up Humpty Dumpty before it goes falling off a wall.
Business continuity planning ought to be fully integrated into the organization as a regular management process, just like auditing or strategic planning or other “normal” processes. Instead of being considered an outsider, BCP should be “part of the team.” Further, final responsibility for BCP should belong not to the BCP team or its leader, but to a high-level executive manager, preferably a member of the executive board. This will reinforce the image and reality of continuity planning as a function seen as vital to the organizational chiefs.
By analyzing and planning for potential disruptions to the organization, the BCP team can assist such other business disciplines in their own efforts to effectively plan for and respond effectively and with resilience to emergencies. Given that the ability to respond depends on operations and management personnel throughout the organization, such capability should be developed organization-wide. It should extend throughout every location of the organization and up the employee ranks to top-tier management.
As such, the BCP program needs to be a living entity. As a company goes through changes, so should the program, thereby ensuring it stays current, usable, and effective. When properly integrated with change management processes, the program stands a much better chance of being continually updated and improved upon. Business continuity is a foundational piece of an effective security program and is critical to ensuring relevance in time of need.
A very important question to ask when first developing a BCP is why it is being developed. This may seem silly and the answer may at first appear obvious, but that is not always the case. You might think that the reason to have these plans is to deal with an unexpected disaster and to get people back to their tasks as quickly and as safely as possible, but the full story is often a bit different. Why are most companies in business? To make money and be profitable. If these are usually the main goals of businesses, then any BCP needs to be developed to help achieve and, more importantly, maintain these goals. The main reason to develop these plans in the first place is to reduce the risk of financial loss by improving the company’s ability to recover and restore operations. This encompasses the goals of mitigating the effects of the disaster.
Not all organizations are businesses that exist to make profits. Government agencies, military units, nonprofit organizations, and the like exist to provide some type of protection or service to a nation or society. While a company must create its BCP to ensure that revenue continues to come in so it can stay in business, other types of organizations must create their BCPs to make sure they can still carry out their critical tasks. Although the focus and business drivers of the organizations and companies may differ, their BCPs often will have similar constructs—which is to get their critical processes up and running.
NOTE Protecting what is most important to a company is rather difficult if what is most important is not first identified. Senior management is usually involved with this step because it has a point of view that extends beyond each functional manager’s focus area of responsibility. The company’s BCP should define the company’s critical mission and business functions. The functions must have priorities set upon them to indicate which is most crucial to a company’s survival.
As stated previously, for many companies, financial operations are most critical. As an example, an automotive company would be affected far more seriously if its credit and loan services were unavailable for a day than if, say, an assembly line went down for a day, since credit and loan services are where it generates the biggest revenues. For other organizations, customer service might be the most critical area, to ensure that order processing is not negatively affected. For example, if a company makes heart pacemakers and its physician services department is unavailable at a time when an operating room surgeon needs to contact it because of a complication, the results could be disastrous for the patient. The surgeon and the company would likely be sued, and the company would likely never be able to sell another pacemaker to that surgeon, her colleagues, or perhaps even the patient’s health maintenance organization (HMO) ever again. It would be very difficult to rebuild reputation and sales after something like that happened.
Advanced planning for emergencies covers issues that were thought of and foreseen. Many other problems may arise that are not covered in the plan; thus, flexibility in the plan is crucial. The plan is a systematic way of providing a checklist of actions that should take place right after a disaster. These actions have been thought through to help the people involved be more efficient and effective in dealing with traumatic situations.
The most critical part of establishing and maintaining a current BCP is management support. Management must be convinced of the necessity of such a plan. Therefore, a business case must be made to obtain this support. The business case may include current vulnerabilities, regulatory and legal obligations, the current status of recovery plans, and recommendations. Management is mostly concerned with cost/benefit issues, so preliminary numbers need to be gathered and potential losses estimated. A cost/benefit analysis should include shareholder, stakeholder, regulatory, and legislative impacts, as well as those on products, services, and personnel. The decision of how a company should recover is commonly a business decision and should always be treated as such.
BCP Project Components
Before everyone runs off in 2,000 different directions at one time, let’s understand what needs to be done in the project initiation phase. This is the phase in which the company really needs to figure out what it is doing and why.
Once management’s support is solidified, a business continuity coordinator must be identified. This person will be the leader for the BCP team and will oversee the development, implementation, and testing of the business continuity and disaster recovery plans. It is best if this person has good social skills, is somewhat of a politician, and has a cape, because he will need to coordinate a lot of different departments and busy individuals who have their own agendas. This person needs to have direct access to management and have the credibility and authority to carry out leadership tasks.
A leader needs a team, so a BCP committee needs to be put together. Management and the coordinator should work together to appoint specific, qualified people to be on this committee. The team must comprise people who are familiar with the different departments within the company, because each department is unique in its functionality and has distinctive risks and threats. The best plan is developed when all issues and threats are brought to the table and discussed. This cannot be done effectively with a few people who are familiar with only a couple of departments. Representatives from each department must be involved with not only the planning stages, but also the testing and implementation stages.
The committee should be made up of representatives from at least the following departments:
• Business units
• Senior management
• IT department
• Security department
• Communications department
• Legal department
If the BCP coordinator is a good management leader, she will understand that it is best to make these team members feel a sense of ownership pertaining to their tasks and roles. The people who develop the BCP should also be the ones who execute it. (If you knew that in a time of crisis you would be expected to carry out some critical tasks, you might pay more attention during the planning and testing phases.) This may entail making it very clear what the roles and responsibilities of team members are during a crisis and recovery, so that existing managers do not feel that their decision making is being overridden. The project must have proper authorization from the top.
The team must then work with the management staff to develop the ultimate goals of the plan, identify the critical parts of the business that must be dealt with first during a disaster, and ascertain the priorities of departments and tasks. Management needs to help direct the team on the scope of the project and the specific objectives.
EXAM TIP While the term “BCP” actually applies to a plan and “BCM” applies to the overall management of continuity, these terms are commonly used interchangeably.
The BCP effort has to result in a sustainable, long-term program that serves its purpose—assisting the organization in the event of a disaster. The effort must be well thought out and methodically executed. It must not be perceived as a mere “public relations” effort to make it simply appear that the organization is concerned about disaster response.
The initiation process for the BCP program might include the following:
• Setting up a budget and staff for the program before the BCP process begins. Dedicated personnel and dedicated hours are essential for executing something as labor intensive as a BCP.
• Assigning duties and responsibilities to the BCP coordinator and to representatives from all of the functional units of the organization.
• Senior management kick-off of the BCP program with a formal announcement or, better still, an organization-wide meeting to demonstrate high-level support.
• Awareness-raising activities to let employees know about the BCP program and to build internal support for it.
• Establishment of skills training for the support of the BCP effort.
• The start of data collection from throughout the organization to aid in crafting various continuity options.
• Putting into effect “quick wins” and gathering of “low-hanging fruit” to show tangible evidence of improvement in the organization’s readiness, as well as improving readiness.
After the successful execution of a BCP program, the organization should have an adequate level of response to an emergency. A desktop exercise that walks through the incident management steps that have been established should offer a scorecard of where the organization stands.
From that point, the team can hold regular progress reviews to check the accuracy of readiness levels and program costs and to see if program milestones are being met. The BCP management team then can adjust the plan to any changes in meeting cost or schedule. To assist in this, the team should choose a project management tool or method to track progress or its lack.
Scope of the Project
At first glance, it might seem as though the scope and objectives are quite clear—protect the company. But it is not that simple. The high-level organizational requirements that the BCP should address, and the resources allocated for them, must be evaluated. You want to understand the focus and direction of a business before starting on risk assessment or continuity planning. This would include the organization’s plans for growth, reorganizing, or downsizing. Other major events in an organization to consider are changes in personnel levels; relocation of facilities; new suppliers; and introduction of new products, technologies, or processes. Obtaining hard numbers or estimates for any of these areas will make things smoother for the BCP team. Of course, due to the sensitivity of some information, some of this data may not be made available to the BCP team. In such cases, the team should realize that the lack of full information may make some of its findings less than fully accurate.
Knowing how the overall organization is going to change will aid in drawing up the right contingency plans in the event of emergencies. Also, if the team identifies organizational requirements at the start and is in accord with top management on the identification and definition of such requirements, then it will be much easier to align the policy to the requirements.
Many questions must be asked. For instance, is the team supposed to develop a BCP for just one facility or for more than one facility? Is the plan supposed to cover just large potential threats (hurricanes, tornadoes, floods) or deal with smaller issues as well (loss of a communications line, power failure, Internet connection failure)? Should the plan address possible terrorist attacks and other manmade threats? What is the threat profile of the company? If the scope of the project is not properly defined, how do you know when you are done? Then there’s resources—what personnel, time allocation, and funds is management willing to commit to the BCP program overall?
NOTE Most companies outline the scope of their BCP to encompass only the larger threats. The smaller threats are then covered by independent departmental contingency plans.
A frequent objection to a BCP program is that it is unlimited in its scope when it is applied to all the functions of an organization in one fell swoop. An alternative is to break up the program into manageable pieces and to place some aspects of the organization outside the scope of the BCP. Since the scope fundamentally affects what the plan will cover, the BCP team should consider the scope from the start of the project.
Deciding whether and how to place a component of an organization outside the BCP scope can be tricky. In some cases, a product, service, or organizational component may remain within the scope, but at a reduced level of funding and activity. At other times, executives will have to decide whether to place a component outside the scope after an incident takes place—when the costs of reestablishing the component may outweigh the benefits. Senior executives, not BCP managers and planners, should make these kinds of decisions.
BCP Policy
The BCP policy supplies the framework for and governance of designing and building the BCP effort. The policy helps the organization understand the importance of BCP by outlining the BCP’s purpose. It provides an overview of the principles of the organization and those behind BCP, and the context for how the BCP team will proceed.
The contents of a policy include its scope, mission statement, principles, guidelines, and standards. The policy should draw on any existing policies if they are relevant. Note that a policy does not exist in a vacuum, but within a specific organization. Thus, in drawing up a policy, the team should examine the overall objectives and functions, including any business objectives, of the organization. The policy also should draw on standard “good practices” of similar organizations and professional standards bodies.
The BCP team produces and revises the policy, although top-tier management is actually responsible for it. A policy should be revamped as needed when the operating environment in which the organization operates changes significantly, such as a major expansion in operations or a change in location.
The process of drawing up a policy includes these steps:
1. Identify and document the components of the policy.
2. Identify and define policies of the organization that the BCP might affect.
3. Identify pertinent legislation, laws, regulations, and standards.
4. Identify “good industry practice” guidelines by consulting with industry experts.
5. Perform a gap analysis. Find out where the organization currently is in terms of continuity planning, and spell out where it wants to be at the end of the BCP process.
6. Compose a draft of the new policy.
7. Have different departments within the organization review the draft.
8. Incorporate the feedback from the departments into a revised draft.
9. Get the approval of top management on the new policy.
10. Publish a final draft, and distribute and publicize it throughout the organization.
Project Management
Sound project management processes, practices, and procedures are important for any organizational effort, and doubly so for BCP. Following accepted project management principles will help ensure effective management of the BCP process once it gets underway.
BCP projects commonly run out of funds and resources before they are fully completed. This typically occurs for one or more of the following reasons: the scope of the project is much larger than the team estimated; the BCP team members are expected to still carry out their current daily tasks along with new BCP tasks; or some other project shifts in importance and requires the attention of the BCP team members.
When technical people hear “risk management” they commonly think of security threats and technical solutions. Understanding the risk of a project must also be understood and properly planned for. If the scope of a project and the individual objectives that make up the scope are not properly defined, a lot of time and money can be easily wasted.
The individual objectives of a project must be analyzed to ensure that each is actually attainable. A part of scope analysis that may prove useful is a SWOT analysis. SWOT stands for Strengths/Weaknesses/Opportunities/Threats, and its basic tenants are as follows:
• Strengths Characteristics of the project team that give it an advantage over others
• Weaknesses Characteristics that place the team at a disadvantage relative to others
• Opportunities Elements that could contribute to the project’s success
• Threats Elements that could contribute to the project’s failure

A SWOT analysis can be carried out to ensure that the defined objectives within the scope can be accomplished and issues identified that could impede upon the necessary success and productivity required of the project as a whole.
The BCP coordinator would need to implement some good old-fashioned project management skills, as listed in Table 1-11. A project plan should be developed that has the following components:
• Objective-to-task mapping
• Resource-to-task mapping
• Workflows
• Milestones
• Deliverables
• Budget estimates
• Success factors
• Deadlines
Once the project plan is completed, it should be presented to management for written approval before any further steps are taken. It is important to ensure that no assumptions are included in the plan. It is also important that the coordinator obtain permission to use the necessary resources to move forward.
NOTE Any early planning or policy documents should include a Definition of Terms, or Terms of Reference; namely, a document that clearly defines the terminology used in the document. Clearly defining terms will avoid a great deal of confusion down the line by different groups, who might otherwise have varying definitions and assumptions about the common terms used in the continuity planning. Such a document should be treated as a formal deliverable and published early on in the process.

Table 1-11 Steps to Be Documented and Approved in Continuity Planning
Business Continuity Planning Requirements
A major requirement for anything that has such far-reaching ramifications as business continuity planning is management support, as mentioned previously. It is critical that management understand what the real threats are to the company, the consequences of those threats, and the potential loss values for each threat. Without this understanding, management may only give lip service to continuity planning, and in some cases, that is worse than not having any plans at all because of the false sense of security it creates. Without management support, the necessary resources, funds, and time will not be devoted, which could result in bad plans that, again, may instill a false sense of security. Failure of these plans usually means a failure in management understanding, vision, and due-care responsibilities.
Executives may be held responsible and liable under various laws and regulations. They could be sued by stockholders and customers if they do not practice due diligence and due care. Due diligence can be defined as doing everything within one’s power to prevent a bad thing from happening. Examples of this would be setting appropriate policies, researching the threats and incorporating them into a risk management plan, and ensuring audits happen at the right times. Due care, on the other hand, means taking the precautions that a reasonable and competent person would take in the same situation. For example, someone who ignores a security warning and clicks through to a malicious website would fail to exercise due care.
EXAM TIP Due diligence is normally associated with leaders, laws, and regulations. Due care is normally applicable to everyone and could be used to show negligence.
Executives must fulfill all of their responsibilities when it comes to disaster recovery and business continuity items. Organizations that work within specific industries have strict regulatory rules and laws that they must abide by, and these should be researched and integrated into the BCP program from the beginning. For example, banking and investment organizations must ensure that even if a disaster occurs, their customers’ confidential information will not be disclosed to unauthorized individuals or be altered or vulnerable in any way.
Disaster recovery, continuity development, and continuity planning work best in a top-down approach, not a bottom-up approach. This means that management, not the staff, should be driving the project.
Many companies are running so fast to try to keep up with a dynamic and changing business world that they may not see the immediate benefit of spending time and resources on disaster recovery issues. Those individuals who do see the value in these efforts may have a hard time convincing top management if management does not see a potential profit margin or increase in market share as a result. But if a disaster does hit and they did put in the effort to properly prepare, the result can literally be priceless. Today’s business world requires two important characteristics: the drive to produce a great product or service and get it to the market, and the insight and wisdom to know that unexpected trouble can easily find its way to your doorstep.
It is important that management set the overall goals of continuity planning, and it should help set the priorities of what should be dealt with first. Once management sets the goals and priorities, other staff members who are responsible for developing the different components of the BCP program can fill in the rest. However, management’s support does not stop there. It needs to make sure the plans and procedures developed are actually implemented. Management must make sure the plans stay updated and represent the real priorities—not simply those perceived—of a company, which change over time.
Business Impact Analysis (BIA)
Business continuity planning deals with uncertainty and chance. What is important to note here is that even though you cannot predict whether or when a disaster will happen, that doesn’t mean you can’t plan for it. Just because we are not planning for an earthquake to hit us tomorrow morning at 10 A.M. doesn’t mean we can’t plan the activities required to successfully survive when an earthquake (or a similar disaster) does hit. The point of making these plans is to try to think of all the possible disasters that could take place, estimate the potential damage and loss, categorize and prioritize the potential disasters, and develop viable alternatives in case those events do actually happen.
A business impact analysis (BIA) is considered a functional analysis, in which a team collects data through interviews and documentary sources; documents business functions, activities, and transactions; develops a hierarchy of business functions; and finally applies a classification scheme to indicate each individual function’s criticality level. But how do we determine a classification scheme based on criticality levels?
The BCP committee must identify the threats to the company and map them to the following characteristics:
• Maximum tolerable downtime and disruption for activities
• Operational disruption and productivity
• Financial considerations
• Regulatory responsibilities
• Reputation
The committee will not truly understand all business processes, the steps that must take place, or the resources and supplies these processes require. So the committee must gather this information from the people who do know—department managers and specific employees throughout the organization. The committee starts by identifying the people who will be part of the BIA data-gathering sessions. The committee needs to identify how it will collect the data from the selected employees, be it through surveys, interviews, or workshops. Next, the team needs to collect the information by actually conducting surveys, interviews, and workshops. Data points obtained as part of the information gathering will be used later during analysis. It is important that the team members ask about how different tasks—whether processes, transactions, or services, along with any relevant dependencies—get accomplished within the organization. Process flow diagrams should be built, which will be used throughout the BIA and plan development stages.
Upon completion of the data collection phase, the BCP committee needs to conduct a BIA to establish which processes, devices, or operational activities are critical. If a system stands on its own, doesn’t affect other systems, and is of low criticality, then it can be classified as a tier-two or tier-three recovery step. This means these resources will not be dealt with during the recovery stages until the most critical (tier one) resources are up and running. This analysis can be completed using a standard risk assessment as illustrated in Figure 1-18.
Risk Assessment To achieve success, the organization should systematically plan and execute a formal BCP-related risk assessment. The assessment fully takes into account the organization’s tolerance for continuity risks. The risk assessment also makes use of the data in the BIA to supply a consistent estimate of exposure.
As indicators of success, the risk assessment should identify, evaluate, and record all relevant items, which may include
• Vulnerabilities for all of the organization’s most time-sensitive resources and activities
• Threats and hazards to the organization’s most urgent resources and activities
• Measures that cut the possibility, length, or effect of a disruption on critical services and products
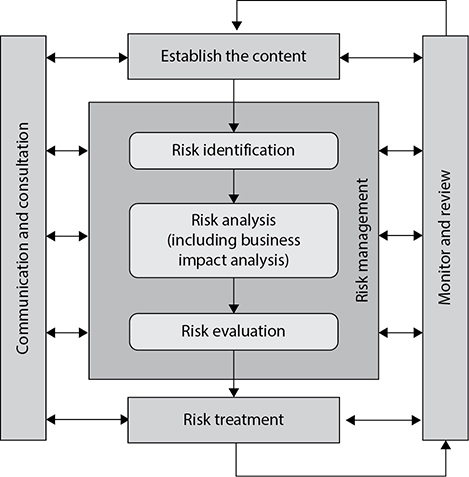
Figure 1-18 Risk assessment process
• Single points of failure; that is, concentrations of risk that threaten business continuity
• Continuity risks from concentrations of critical skills or critical shortages of skills
• Continuity risks due to outsourced vendors and suppliers
• Continuity risks that the BCP program has accepted, that are handled elsewhere, or that the BCP program does not address
Risk Assessment Evaluation and Process In a BCP setting, a risk assessment looks at the impact and likelihood of various threats that could trigger a business disruption. The tools, techniques, and methods of risk assessment include determining threats, assessing probabilities, tabulating threats, and analyzing costs and benefits.
The end goals of a risk assessment include
• Identifying and documenting single points of failure
• Making a prioritized list of threats to the particular business processes of the organization
• Putting together information for developing a management strategy for risk control and for developing action plans for addressing risks
• Documenting acceptance of identified risks, or documenting acknowledgment of risks that will not be addressed
The risk assessment is assumed to take the form of the equation Risk = Threat × Impact × Probability. However, the BIA adds the dimension of time to this equation. In other words, risk mitigation measures should be geared toward those things that might most rapidly disrupt critical business processes and commercial activities.
The main parts of a risk assessment are
• Review the existing strategies for risk management
• Construct a numerical scoring system for probabilities and impacts
• Make use of a numerical score to gauge the effect of the threat
• Estimate the probability of each threat
• Weigh each threat through the scoring system
• Calculate the risk by combining the scores of likelihood and impact of each threat
• Get the organization’s sponsor to sign off on these risk priorities
• Weigh appropriate measures
• Make sure that planned measures that alleviate risk do not heighten other risks
• Present the assessment’s findings to executive management
Threats can be manmade, natural, or technical. A manmade threat may be an arsonist, a terrorist, or a simple mistake that can have serious outcomes. Natural threats may be tornadoes, floods, hurricanes, or earthquakes. Technical threats may be data corruption, loss of power, device failure, or loss of a data communications line. It is important to identify all possible threats and estimate the probability of them happening. Some issues may not immediately come to mind when developing these plans, such as an employee strike, vandals, disgruntled employees, or hackers, but they do need to be identified. These issues are often best addressed in a group with scenario-based exercises. This ensures that if a threat becomes reality, the plan includes the ramifications on all business tasks, departments, and critical operations. The more issues that are thought of and planned for, the better prepared a company will be if and when these events take place.
The BCP committee needs to step through scenarios in which the following problems result:
• Equipment malfunction or unavailable equipment
• Unavailable utilities (HVAC, power, communications lines)
• Facility becomes unavailable
• Critical personnel become unavailable
• Vendor and service providers become unavailable
• Software and/or data corruption
The specific scenarios and damage types can vary from organization to organization.
Assigning Values to Assets Qualitative and quantitative impact information should be gathered and then properly analyzed and interpreted. The goal is to see exactly how a business will be affected by different threats. The effects can be economical, operational, or both. Upon completion of the data analysis, it should be reviewed with the most knowledgeable people within the company to ensure that the findings are appropriate and that it describes the real risks and impacts the organization faces. This will help flush out any additional data points not originally obtained and will give a fuller understanding of all the possible business impacts.
Loss criteria must be applied to the individual threats that were identified. The criteria may include the following:
• Loss in reputation and public confidence
• Loss of competitive advantages
• Increase in operational expenses
• Violations of contract agreements
• Violations of legal and regulatory requirements
• Delayed-income costs
• Loss in revenue
• Loss in productivity
These costs can be direct or indirect and must be properly accounted for.
For instance, if the BCP team is looking at the threat of a terrorist bombing, it is important to identify which business function most likely would be targeted, how all business functions could be affected, and how each bulleted item in the loss criteria would be directly or indirectly involved. The timeliness of the recovery can be critical for business processes and the company’s survival. For example, it may be acceptable to have the customer-support functionality out of commission for two days, whereas five days may leave the company in financial ruin.
After identifying the critical functions, it is necessary to find out exactly what is required for these individual business processes to take place. The resources that are required for the identified business processes are not necessarily just computer systems, but may include personnel, procedures, tasks, supplies, and vendor support. It must be understood that if one or more of these support mechanisms is not available, the critical function may be doomed. The team must determine what type of effect unavailable resources and systems will have on these critical functions.
The BIA identifies which of the company’s critical systems are needed for survival and estimates the outage time that can be tolerated by the company as a result of various unfortunate events. The outage time that can be endured by a company is referred to as the maximum tolerable downtime (MTD) or maximum period time of disruption (MPTD), which is illustrated in Figure 1-19.
The following are some MTD estimates that an organization may use. Note that these are sample estimates that will vary from organization to organization and from business unit to business unit:
• Nonessential 30 days
• Normal 7 days
• Important 72 hours
• Urgent 24 hours
• Critical Minutes to hours

Figure 1-19 Maximum period of disruption
Each business function and asset should be placed in one of these categories, depending upon how long the company can survive without it. These estimates will help the company determine what backup solutions are necessary to ensure the availability of these resources. The shorter the MTD, the higher priority of recovery for the function in question. Thus, the items classified as Urgent should be addressed before those classified as Normal.
For example, if being without a T1 communication line for three hours would cost the company $130,000, the T1 line could be considered Critical and thus the company should put in a backup T1 line from a different carrier. If a server going down and being unavailable for ten days will only cost the company $250 in revenue, this would fall into the Normal category, and thus the company may not need to have a fully redundant server waiting to be swapped out. Instead, the company may choose to count on its vendor’s service level agreement (SLA), which may promise to have it back online in eight days.
Sometimes the MTD will depend in large measure on the type of business in question. For instance, a call center—a vital link to current and prospective clients—will have a short MTD, perhaps measured in minutes instead of weeks. A common solution is to split up the calls through multiple call centers placed in differing locales. If one call center is knocked out of service, the other one can temporarily pick up the load. Manufacturing can be handled in various ways. Examples include subcontracting the making of products to an outside vendor, manufacturing at multiple sites, and warehousing an extra supply of products to fill gaps in supply in case of disruptions to normal manufacturing.
The BCP team must try to think of all possible events that might occur that could turn out to be detrimental to a company. The BCP team also must understand it cannot possibly contemplate all events, and thus protection may not be available for every scenario introduced. Being properly prepared specifically for a flood, earthquake, terrorist attack, or lightning strike is not as important as being properly prepared to respond to anything that damages or disrupts critical business functions.
All of the previously mentioned disasters could cause these results, but so could a meteor strike, a tornado, or a wing falling off a plane passing overhead. So the moral of the story is to be prepared for the loss of any or all business resources, instead of focusing on the events that could cause the loss.
EXAM TIP A BIA is performed at the beginning of business continuity planning to identify the areas that would suffer the greatest financial or operational loss in the event of a disaster or disruption. It identifies the company’s critical systems needed for survival and estimates the outage time that can be tolerated by the company as a result of a disaster or disruption.

Interdependencies
It is important to look at a company as a complex animal instead of a static two-dimensional entity. It comprises many types of equipment, people, tasks, departments, communications mechanisms, and interfaces to the outer world. The biggest challenge of true continuity planning is understanding all of these intricacies and their interrelationships. A team may develop plans to back up and restore data, implement redundant data-processing equipment, educate employees on how to carry out automated tasks manually, and obtain redundant power supplies. But if all of these components don’t know how to work together in a different, disruptive environment to get the products out the door, it might all be a waste of time.
The BCP team should carry out and address in the resulting plan the following interrelation and interdependency tasks:
• Define essential business functions and supporting departments
• Identify interdependencies between these functions and departments
• Discover all possible disruptions that could affect the mechanisms necessary to allow these departments to function together
• Identify and document potential threats that could disrupt interdepartmental communication
• Gather quantitative and qualitative information pertaining to those threats
• Provide alternative methods of restoring functionality and communication
• Provide a brief statement of rationale for each threat and corresponding information
The main goal of business continuity is to resume normal business as quickly as possible, spending the least amount of money and resources. The overall business interruption and resumption plan should cover all organizational elements, identify critical services and functions, provide alternatives for emergency operations, and integrate each departmental plan. This can be accomplished by in-house appointed employees, outside consultants, or a combination of both. A combination can bring many benefits to the company, because the consultants are experts in this field and know the necessary steps, questions to ask, and issues to look for and offer general, reasonable advice, whereas in-house employees know their company intimately and have a full understanding of how certain threats can affect operations. It is good to cover all the necessary ground, and many times a combination of consultants and employees provides just the right recipe.
Up until now, we have established management’s responsibilities as the following:
• Committing fully to the BCP
• Setting policy and goals
• Making available the necessary funds and resources
• Taking responsibility for the outcome of the development of the BCP
• Appointing a team for the process
The BCP team’s responsibilities are as follows:
• Identifying regulatory and legal requirements that must be met
• Identifying all possible vulnerabilities and threats
• Estimating the possibilities of these threats and the loss potential
• Performing a BIA
• Outlining which departments, systems, and processes must be up and running before any others
• Identifying interdependencies among departments and processes
• Developing procedures and steps in resuming business after a disaster
Several software tools are available for developing a BCP that simplify this complex process. Automation of these procedures can quicken the pace of the project and allow easier gathering of the massive amount of information entailed. This information, along with other data explained in previous sections, should be presented to senior management. Management usually wants information stated in monetary, quantitative terms, not in subjective, qualitative terms. It is one thing to know that if a tornado were to hit, the result would be really bad, but it is another to know that if a tornado were to hit and affect 65 percent of the facility, the company could be at risk of losing computing capabilities for up to 72 hours, power supply for up to 24 hours, and a full stop of operations for 76 hours, which would equate to a loss of $125,000 each day.
Personnel Security
Many facets of the responsibilities of personnel fall under management’s umbrella, and several facets have a direct correlation to the overall security of the environment.
Although society has evolved to be extremely dependent upon technology in the workplace, people are still the key ingredient to a successful company. But in security circles, people are often the weakest link. Either accidentally through mistakes or lack of training, or intentionally through fraud and malicious intent, personnel cause more serious and hard-to-detect security issues than hacker attacks, outside espionage, or equipment failure. Although the future actions of individuals cannot be predicted, it is possible to minimize the risks by implementing preventive measures. These include hiring the most qualified individuals, performing background checks, using detailed job descriptions, providing necessary training, enforcing strict access controls, and terminating individuals in a way that protects all parties involved.
Several items can be put into place to reduce the possibilities of fraud, sabotage, misuse of information, theft, and other security compromises. Separation of duties makes sure that one individual cannot complete a critical task by herself. In the movies, when a submarine captain needs to launch a nuclear torpedo to blow up the enemy and save civilization as we know it, the launch usually requires three codes to be entered into the launching mechanism by three different senior crewmembers. This is an example of separation of duties, and it ensures that the captain cannot complete such an important and terrifying task all by himself.
Separation of duties is a preventive administrative control put into place to reduce the potential of fraud. For example, an employee cannot complete a critical financial transaction by herself. She will need to have her supervisor’s written approval before the transaction can be completed.
In an organization that practices separation of duties, collusion must take place for fraud to be committed. Collusion means that at least two people are working together to cause some type of destruction or fraud. In our example, the employee and her supervisor must be participating in the fraudulent activity to make it happen.
Two variations of separation of duties are split knowledge and dual control. In both cases, two or more individuals are authorized and required to perform a duty or task. In the case of split knowledge, no one person knows or has all the details to perform a task. For example, two managers might be required to open a bank vault, with each only knowing part of the combination. In the case of dual control, two individuals are again authorized to perform a task, but both must be available and active in their participation to complete the task or mission. For example, two officers must perform an identical key-turn in a nuclear missile submarine, each out of reach of the other, to launch a missile. The control here is that no one person has the capability of launching a missile, because they cannot reach to turn both keys at the same time.
Rotation of duties (rotation of assignments) is an administrative detective control that can be put into place to uncover fraudulent activities. No one person should stay in one position for a long time because they may end up having too much control over a segment of the business. Such total control could result in fraud or the misuse of resources. Employees should be moved into different roles with the idea that they may be able to detect suspicious activity carried out by the previous employee carrying out that position. This type of control is commonly implemented in financial institutions.
Employees in sensitive areas should be forced to take their vacations, which is known as a mandatory vacation. While they are on vacation, other individuals fill their positions and thus can usually detect any fraudulent errors or activities. Two of the many ways to detect fraud or inappropriate activities would be the discovery of activity on someone’s user account while they’re supposed to be away on vacation, or if a specific problem stopped while someone was away and not active on the network. These anomalies are worthy of investigation. Employees who carry out fraudulent activities commonly do not take vacations because they do not want anyone to figure out what they are doing behind the scenes. This is why they must be forced to be away from the organization for a period of time, usually two weeks.
Hiring Practices
Depending on the position to be filled, a level of candidate screening should be done by human resources to ensure the company hires the right individual for the right job. Skills should be tested and evaluated, and the caliber and character of the individual should be examined. Joe might be the best programmer in the state, but if someone looks into his past and finds out he served prison time because he continually flashes old ladies in parks, the hiring manager might not be so eager to bring Joe into the organization.
References should be checked, military records reviewed, education verified, and, if necessary, a drug test should be administered. Many times, important personal behaviors can be concealed, and that is why hiring practices now include scenario questions, personality tests, and observations of the individual, instead of just looking at a person’s work history. When a person is hired, he is bringing his skills and whatever other baggage he carries. A company can reduce its heartache pertaining to personnel by first conducting useful and careful hiring practices.
The goal is to hire the “right person” and not just hire a person for “right now.” Employees represent an investment on the part of the organization, and by taking the time and hiring the right people for the jobs, the organization will be able to maximize their investment and achieve a better return.
A more detailed background check can reveal some interesting information. Things like unexplained gaps in employment history, the validity and actual status of professional certifications, criminal records, driving records, job titles that have been misrepresented, credit histories, unfriendly terminations, appearances on suspected terrorist watch lists, and even real reasons for having left previous jobs can all be determined through the use of background checks. This has real benefit to the employer and the organization because it serves as the first line of defense for the organization against being attacked from within. Any negative information that can be found in these areas could be indicators of potential problems that the potential employee could create for the company at a later date. Take the credit report for instance. On the surface, this may seem to be something the organization doesn’t need to know about, but if the report indicates the potential employee has a poor credit standing and a history of financial problems, it could mean you don’t want to place them in charge of the organization’s accounting, or even the petty cash.
Ultimately, the goal here is to achieve several different things at the same time by using a background check. You’re trying to mitigate risk, lower hiring costs, and also lower the turnover rate for employees. All this is being done at the same time you are trying to protect your existing customers and employees from someone gaining employment in your organization who could potentially conduct malicious and dishonest actions that could harm you, your employees, and your customers as well as the general public. In many cases, it is also harder to go back and conduct background checks after the individual has been hired and is working. This is because there will need to be a specific cause or reason for conducting this kind of investigation. If any employee moves to a position of greater security sensitivity or potential risk, a follow-up investigation should be considered.
Possible background check criteria could include
• A Social Security number trace
• A county/state criminal check
• A federal criminal check
• A sexual offender registry check
• Employment verification
• Education verification
• Professional reference verification
• An immigration check
• Professional license/certification verification
• Credit report
• Drug screening
Onboarding
Once an organization finds a good candidate, offers employment, and the candidate accepts the employment offer, it’s time to bring the candidate on board. Onboarding is the process of turning a candidate into a trusted employee who is able to perform all assigned duties. Having a structured and well-documented onboarding process not only will make the new employee feel valued and welcome, but will also ensure that your organization doesn’t forget any security tasks. Though the specific steps will vary by organization, the following are some that are pretty universal.
• The new employee attends all required security awareness training.
• The new employee must read all security policies, be given an opportunity to have any questions about the policies answered, and sign a statement indicating they understand and will comply with the policies.
• The new employee is issued all appropriate identification badges, keys, and access tokens pursuant to their assigned roles.
• The IT department creates all necessary accounts for the new employee, who signs into the systems and sets their passwords (or changes any temporary passwords).
Nondisclosure agreements (NDAs) must be developed and signed by new employees to protect the company and its sensitive information. Any conflicts of interest must be addressed, and there should be different agreements and precautions taken with temporary and contract employees.
Termination
Because terminations can happen for a variety of reasons, and terminated people have different reactions, companies should have a specific set of procedures to follow with every termination. For example:
• The employee must leave the facility immediately under the supervision of a manager or security guard.
• The employee must surrender any identification badges or keys, be asked to complete an exit interview, and return company supplies.
• That user’s accounts and passwords should be disabled or changed immediately.
These actions may seem harsh when they actually take place, but too many companies have been hurt by vengeful employees who have lashed out at the company when their positions were revoked for one reason or another. If an employee is disgruntled in any way or the termination is unfriendly, that employee’s accounts should be disabled right away, and all passwords on all systems changed.
Security Awareness Training
For an organization to achieve the desired results of its security program, it must communicate the what, how, and why of security to its employees. Security awareness training should be comprehensive, tailored for specific groups, and organization-wide. It should repeat the most important messages in different formats; be kept up to date; be entertaining, positive, and humorous; be simple to understand; and—most important—be supported by senior management. Management must allocate the resources for this activity and enforce its attendance within the organization.
The goal is for each employee to understand the importance of security to the company as a whole and to each individual. Expected responsibilities and acceptable behaviors must be clarified, and noncompliance repercussions, which could range from a warning to dismissal, must be explained before being invoked. Security awareness training is performed to modify employees’ behavior and attitude toward security. This can best be achieved through a formalized process of security awareness training.
Presenting the Training
Because security is a topic that can span many different aspects of an organization, it can be difficult to communicate the correct information to the right individuals. By using a formalized process for security awareness training, you can establish a method that will provide you with the best results for making sure security requirements are presented to the right people in an organization. This way you can make sure everyone understands what is outlined in the organization’s security program, why it is important, and how it fits into the individual’s role in the organization. The higher levels of training typically are more general and deal with broader concepts and goals, and as the training moves down to specific jobs and tasks, it becomes more situation specific as it directly applies to certain positions within the company.
A security awareness program is typically created for at least three types of audiences: management, staff, and technical employees. Each type of awareness training must be geared toward the individual audience to ensure each group understands its particular responsibilities, liabilities, and expectations. If technical security training were given to senior management, their eyes would glaze over as soon as protocols and firewalls were mentioned. On the flip side, if legal ramifications, company liability issues pertaining to protecting data, and shareholders’ expectations were discussed with the IT group, they would quickly turn to their smartphone and start tweeting, browsing the Internet, or texting their friends.
Members of management would benefit the most from a short, focused security awareness orientation that discusses corporate assets and financial gains and losses pertaining to security. They need to know how stock prices can be negatively affected by compromises, understand possible threats and their outcomes, and know why security must be integrated into the environment the same way as other business processes. Because members of management must lead the rest of the company in support of security, they must gain the right mindset about its importance.
Middle management would benefit from a more detailed explanation of the policies, procedures, standards, and guidelines and how they map to the individual departments for which each middle manager is responsible. Middle managers should be taught why their support for their specific departments is critical and what their level of responsibility is for ensuring that employees practice safe computing activities. They should also be shown how the consequences of noncompliance by individuals who report to them can affect the company as a whole and how they, as managers, may have to answer for such indiscretions.
The technical departments must receive a different presentation that aligns more to their daily tasks. They should receive a more in-depth training to discuss technical configurations, incident handling, and how to recognize different types of security compromises.
It is usually best to have each employee sign a document indicating they have heard and understand all the security topics discussed, and that they also understand the ramifications of noncompliance. This reinforces the policies’ importance to the employee and also provides evidence down the road if the employee claims they were never told of these expectations. Awareness training should happen during the hiring process and at least annually after that. Attendance of training should also be integrated into employment performance reports.
Various methods should be employed to reinforce the concepts of security awareness. Things like screen banners, employee handbooks, and even posters can be used as ways to remind employees about their duties and the necessities of good security practices.
Periodic Content Reviews
The only constant in life is change, so it should come as no surprise that after we develop the curricula and materials for security awareness training, we have to keep them up to date. It is essential that this be a deliberate process and not done in an ad hoc manner. One way to do this is to schedule refreshes at specific intervals like semi-annually or yearly and assign the task to an individual owner. This person would work with a team to review and update the plan and materials but is ultimately responsible for keeping the training up to date.
Another approach is to have content reviews be triggered by other events. For example, reviews can be required whenever any of the following occur:
• A security policy is added, changed, or discontinued
• A major incident (or pattern of smaller incidents) occurs that could’ve been avoided or mitigated through better security awareness
• A major new threat is discovered
• A major change is made to the information systems or security architecture
• An assessment of the training program shows deficiencies
Training Assessments
Many organizations treat security awareness training as a “check in the box” activity that is done simply to satisfy a requirement. The reality, however, is that effective training has both objectives (why we do it) and outcomes (what can people do after participating in it). The objectives are usually derived from senior-level policies or directives and drive the development of outcomes, which in turn drive the content and methods of delivery. For example, if the objective is reducing the incidence of successful phishing attacks, then it would be appropriate to pursue an outcome of having end users be able to detect a phishing e-mail. Both the objective and the outcome are measurable, which makes it easier to answer the question “is this working?”
We can tell if the training is having an effect on an organization’s security posture by simply measuring things before the training and then after it. Continuing the earlier example, we could keep track of the number of successful phishing attacks and see what happens to that number after the training has been conducted. This would be an assessment of the objective. We could also take trained and untrained users and test their ability to detect phishing e-mails. We would expect the trained users to fare better at this task, which would test the outcome. If we see that the number of phishing attacks remains unchanged (or worse, grows) or that the users are no better at detecting phishing e-mails after the training, then maybe the program is not effective.
When assessing a training program, it is very important to analyze the data and not jump to conclusions. In the phishing example, there are many possible explanations for the lack of improvement. Maybe the adversaries are sending more-sophisticated messages that are harder to detect. Similarly, the results could simply show that the users just don’t care and will continue to click links and open attachments until the consequences become negative enough for them. The point is to consider the root causes of the measurements when assessing the training.
Degree or Certification?
Some roles within the organization need hands-on experience and skill, meaning that the hiring manager should be looking for specific industry certifications. Some positions require more of a holistic and foundational understanding of concepts or a business background, and in those cases a degree may be required. Table 1-12 provides more information on the differences between awareness, training, and education.

Table 1-12 Aspects of Awareness, Training, and Education
Security Governance
An organization may be following many of the items laid out in this chapter: building a security program, integrating it into their business architecture, developing a risk management program, documenting the different aspects of the security program, performing data protection, and training its staff. But how does the organization know that it is doing everything correctly, and doing so on an ongoing basis? This is where security governance comes into play. Security governance is a framework that allows for the security goals of an organization to be set and expressed by senior management, communicated throughout the different levels of the organization. It grants power to the entities needed to implement and enforce security, and provides a way to verify the performance of these necessary security activities. Not only does senior management need to set the direction of security; it also needs a way to be able to view and understand how their directives are being met or not being met.
If a board of directors and CEO demand that security be integrated properly at all levels of the organization, how do they know it is really happening? Oversight mechanisms must be developed and integrated so that the people who are ultimately responsible for an organization are constantly and consistently updated on the overall health and security posture of the organization. This happens through properly defined communication channels, standardized reporting methods, and performance-based metrics.
Let’s compare two companies. Company A has an effective security governance program in place and Company B does not. Now, to the untrained eye it would seem as though Companies A and B are equal in their security practices because they both have security policies, procedures, and standards in place, the same security technology controls (firewalls, IDSs, identity management, and so on), defined security roles, and security awareness training. You may think, “Man, these two companies are on the ball and quite evolved in their security programs.” But if you look closer, you will see some critical differences (listed in Table 1-13).
Does the organization you work for look like Company A or Company B? Most organizations today have many of the pieces and parts to a security program (policies, standards, firewalls, security team, IDS, and so on), but management may not be truly involved, and security has not permeated throughout the organization. Some organizations rely just on technology and isolate all security responsibilities within the IT group. If security were just a technology issue, then this security team could properly install, configure, and maintain the products, and the company would get a gold star and pass the audit with flying colors. But that is not how the world of information security works today. It is much more than just technological solutions. Security must be utilized throughout the organization, and having several points of responsibility and accountability is critical. Security governance is a coherent system of integrated processes that helps to ensure consistent oversight, accountability, and compliance. It is a structure that we should put in place to make sure that our efforts are streamlined and effective and that nothing is being missed.

Table 1-13 Security Governance Program: A Comparison of Two Companies
Metrics
We really can’t just build a security program, call it good, and go home. We need a way to assess the effectiveness of our work, identify deficiencies, and prioritize the things that still need work. We need a way to facilitate decision making, performance improvement, and accountability through collection, analysis, and reporting of the necessary information. As the saying goes, “You can’t manage something you can’t measure.” In security there are many items that need to be measured so that performance is properly understood. We need to know how effective and efficient our security controls are, not only to make sure that assets are properly protected, but also to ensure that we are being financially responsible in our budgetary efforts.
There are different methodologies that can be followed when it comes to developing security metrics, but no matter what model is followed, some things are critical across the board. Strong management support is necessary, because while it might seem that developing ways of counting things is not overly complex, the actual implementation and use of a metric and measuring system can be quite an undertaking. The metrics have to be developed, adopted, integrated into many different existing and new processes, interpreted, and used in decision-making efforts. Management needs to be on board if this effort is going to be successful.
Another requirement is that there has to be established policies, procedures, and standards to measure against. How can you measure policy compliance when there are no policies in place? A full security program needs to be developed and matured before attempting to measure its pieces and parts.
Measurement activities need to provide quantifiable performance-based data that is repeatable, reliable, and produces results that are meaningful. Measurement will need to happen on a continuous basis, so the data collection methods must be repeatable. The same type of data must be continuously gathered and compared so that improvement or a drop in efficacy can be identified. The data collection may come from parsing system logs, incident response reports, audit findings, surveys, or risk assessments. The measurement results must also be meaningful for the intended audience. An executive will want data portrayed in a method that allows him to understand the health of the security program quickly and in terms he is used to. This can be a heat map, graph, pie chart, or scorecard. A balanced scorecard, shown in Figure 1-20, is a traditional strategic tool used for performance measurement in the business world. The goal is to present the most relevant information quickly and easily. Measurements are compared with set target values so that if performance deviates from expectations, that deviation can be conveyed in a simplistic and straightforward manner.

Figure 1-20 Balanced scorecard
If the audience for the measurement values are not executives, but instead security administrators, then the results are presented in a manner that is easiest for them to understand and use.

CAUTION It is not uncommon to see scorecards, pie charts, graphics, and dashboard results that do not map to what is really going on in the environment. Unless real data is gathered and the correct data is gathered, the resulting pie chart can illustrate a totally different story than what is really taking place. Some people spend more time making the colors in the graph look eye-pleasing than perfecting the raw data–gathering techniques. This can lead to a false sense of security and ultimately to breaches.
There are industry best practices that can be used to guide the development of a security metric and measurement system. The international standard is ISO/IEC 27004:2016, which is used to assess the effectiveness of an ISMS and the controls that make up the security program as outlined in ISO/IEC 27001. So ISO/IEC 27001 tells you how to build a security program and then ISO/IEC 27004 tells you how to measure it. The NIST SP 800-55, Revision 1 also covers performance measuring for information security, but has a U.S. government slant. The ISO standard and NIST approaches to metric development are similar, but have some differences. The ISO standard breaks individual metrics down into base measures, derived measures, and then indicator values. The NIST approach is illustrated in Figure 1-21, which breaks metrics down into implementation, effectiveness/efficiency, and impact values.
If your organization has the goal of becoming ISO/IEC 27000 certified, then you should follow ISO/IEC 27004:2016. If your organization is governmental or a government contracting company, then following the NIST standard would make more sense. What is important is consistency. For metrics to be used in a successful manner, they have to be standardized and have a direct relationship to each other. For example, if an organization used a rating system of 1–10 to measure incident response processes and a rating system of High, Medium, and Low to measure malware infection protection mechanisms, these metrics could not be integrated easily. An organization needs to establish the metric value types it will use and implement them in a standardized method across the enterprise. Measurement processes need to be thought through at a detailed level before attempting implementation. Table 1-14 illustrates a metric template that can be used to track incident response performance levels.

Figure 1-21 Security measurement processes
Table 1-14 Incident Response Measurement Template
The types of metrics that are developed need to map to the maturity level of the security program. In the beginning, simplistic items are measured (i.e., number of completed policies), and as the program matures the metrics mature and can increase in complexity (i.e., number of vulnerabilities mitigated).
The use of metrics allows an organization to truly understand the health of its security program because each activity and initiative can be measured in a quantifiable manner. The metrics are used in governing activities because this allows for the best strategic decisions to be made. The use of metrics also allows the organization to implement and follow the capability maturity model described earlier. A maturity model is used to carry out incremental improvements, and the metric results indicate what needs to be improved and to what levels. Metrics can also be used in process improvement models, as in Six Sigma and the measurements of service-level targets for ITIL. We need to know not only what to do (implement controls, build a security program), but also how well we did it and how to continuously improve.
Ethics
Ethics are based on many different issues and foundations. They can be relative to different situations and interpreted differently from individual to individual. Therefore, they are often a topic of debate. However, some ethics are less controversial than others, and these types of ethics are easier to expect of all people.
(ISC)2 requires all certified system security professionals to commit to fully supporting its Code of Ethics. If a CISSP intentionally or knowingly violates this Code of Ethics, he or she may be subject to a peer review panel, which will decide whether the certification should be revoked.
The full set of (ISC)2 Code of Ethics for the CISSP is listed on the (ISC)2 site at www.isc2.org. The following list is an overview, but each CISSP candidate should read the full version and understand the Code of Ethics before attempting this exam:
• Protect society, the common good, necessary public trust and confidence, and the infrastructure
• Act honorably, honestly, justly, responsibly, and legally
• Provide diligent and competent service to principals
• Advance and protect the profession
An interesting relationship exists between law and ethics. Most often, laws are based on ethics and are put in place to ensure that others act in an ethical way. However, laws do not apply to everything—that is when ethics should kick in. Some things may not be illegal, but that does not necessarily mean they are ethical.
Corporations should have a guide developed on computer and business ethics. This can be part of an employee handbook, used in orientation, posted, and made a part of training sessions.
Certain common ethical fallacies are used by many in the computing world to justify unethical acts. They exist because people look at issues differently and interpret (or misinterpret) rules and laws that have been put into place. The following are examples of these ethical fallacies:
• Hackers only want to learn and improve their skills. Many of them are not making a profit off of their deeds; therefore, their activities should not be seen as illegal or unethical.
• The First Amendment protects and provides the right for U.S. citizens to write viruses.
• Information should be shared freely and openly; therefore, sharing confidential information and trade secrets should be legal and ethical.
• Hacking does not actually hurt anyone.
The Computer Ethics Institute
The Computer Ethics Institute is a nonprofit organization that works to help advance technology by ethical means.
The Computer Ethics Institute has developed its own Ten Commandments of Computer Ethics:
1. Thou shalt not use a computer to harm other people.
2. Thou shalt not interfere with other people’s computer work.
3. Thou shalt not snoop around in other people’s computer files.
4. Thou shalt not use a computer to steal.
5. Thou shalt not use a computer to bear false witness.
6. Thou shalt not copy or use proprietary software for which you have not paid.
7. Thou shalt not use other people’s computer resources without authorization or proper compensation.
8. Thou shalt not appropriate other people’s intellectual output.
9. Thou shalt think about the social consequences of the program you are writing or the system you are designing.
10. Thou shalt always use a computer in ways that ensure consideration and respect for your fellow humans.
The Internet Architecture Board
The Internet Architecture Board (IAB) is the coordinating committee for Internet design, engineering, and management. It is responsible for the architectural oversight of the Internet Engineering Task Force (IETF) activities, Internet Standards Process oversight and appeal, and editor of Requests for Comments (RFCs). Figure 1-22 illustrates the IAB’s place in the hierarchy of entities that help ensure the structure and standardization of the Internet. Otherwise, the Internet would be an unusable big bowl of spaghetti and we would all still be writing letters and buying stamps.
The IAB issues ethics-related statements concerning the use of the Internet. It considers the Internet to be a resource that depends upon availability and accessibility to be useful to a wide range of people. It is mainly concerned with irresponsible acts on the Internet that could threaten its existence or negatively affect others. It sees the Internet as a great gift and works hard to protect it for all who depend upon it. The IAB sees the use of the Internet as a privilege, which should be treated as such and used with respect.
Figure 1-22 Where the Internet Architecture Board (IAB) fits
The IAB considers the following acts unethical and unacceptable behavior:
• Purposely seeking to gain unauthorized access to Internet resources
• Disrupting the intended use of the Internet
• Wasting resources (people, capacity, and computers) through purposeful actions
• Destroying the integrity of computer-based information
• Compromising the privacy of others
• Conducting Internet-wide experiments in a negligent manner
The IAB vows to work with federal agencies to take whatever actions are necessary to protect the Internet. This could be through new technologies, methods, or procedures that are intended to make the Internet more resistant to disruption. A balance exists between enhancing protection and reducing functionality. One of the Internet’s main purposes is to enable information to flow freely and not be prohibited; thus, the IAB must be logical and flexible in its approaches and in the restrictions it attempts to implement. The Internet is everyone’s tool, so everyone should work together to protect it.
NOTE RFC 1087 is called “Ethics and the Internet.” This RFC outlines the concepts pertaining to what the IAB considers unethical and unacceptable behavior.
Corporate Ethics Programs
More regulations are requiring organizations to have an ethical statement and potentially an ethical program in place. The ethical program is to serve as the “tone at the top,” which means that the executives need to ensure not only that their employees are acting ethically, but also that they themselves are following their own rules. The main goal is to ensure that the motto “succeed by any means necessary” is not the spoken or unspoken culture of a work environment. Certain structures can be put into place that provide a breeding ground for unethical behavior. If the CEO gets more in salary based on stock prices, then she may find ways to artificially inflate stock prices, which can directly hurt the investors and shareholders of the company. If managers can only be promoted based on the amount of sales they bring in, these numbers may be fudged and not represent reality. If an employee can only get a bonus if a low budget is maintained, he might be willing to take shortcuts that could hurt company customer service or product development. Although ethics seem like things that float around in the ether and make us feel good to talk about, they have to be actually implemented in the real corporate world through proper business processes and management styles.
Summary
This chapter (and its corresponding domain) is one of the longest in the book, and with good reason. It lays down the foundation on which the rest of the CISSP body of knowledge is built. Information systems security boils down to ensuring the availability, integrity, and confidentiality of our information in an environment rich in influencers. These include organizational goals, assets, laws, regulations, privacy, threats, and people. Each of these was discussed in some detail in the preceding sections. Along the way, we also covered tangible ways in which we can link security to each of the influencers. We discussed a variety of frameworks that enable our organizations to provide governance and management of business, IT, and security issues. In many cases, these frameworks are driven by legal or regulatory requirements. In other cases, they represent best practices for security. As CISSPs we must be knowledgeable of all these as we are trusted to be able to apply the right solution to any security problem.
We also took a very detailed look at the way in which we manage risk to our information systems. We know that no system is truly secure, so our job is to find the most likely and the most dangerous threat actions so that we can address them first. The process of quantifying losses and their probabilities of occurring is at the heart of risk assessments. Armed with that information, we are able to make good decisions in terms of controls, processes, and costs. Our approach is not solely focused on the human adversary, but also on any source of loss to our organizations. Most importantly, we use this information to devise ways in which to ensure we can continue business operations in the face of any reasonable threat. Figure 1-23 illustrates many of the elements that go into a complete security program.
Figure 1-23 A complete security program contains many items.
Quick Tips
• The objectives of security are to provide availability, integrity, and confidentiality protection to data and resources.
• A vulnerability is a weakness in a system that allows a threat source to compromise its security.
• A threat is the possibility that someone or something would exploit a vulnerability, either intentionally or accidentally, and cause harm to an asset.
• A risk is the probability of a threat agent exploiting a vulnerability and the loss potential from that action.
• A countermeasure, also called a safeguard or control, mitigates the risk.
• A control can be administrative, technical, or physical and can provide deterrent, preventive, detective, corrective, or recovery protection.
• A compensating control is an alternative control that is put into place because of financial or business functionality reasons.
• COBIT is a framework of control objectives and allows for IT governance.
• ISO/IEC 27001 is the standard for the establishment, implementation, control, and improvement of the information security management system.
• The ISO/IEC 27000 series were derived from BS 7799 and are international best practices on how to develop and maintain a security program.
• Enterprise architecture frameworks are used to develop architectures for specific stakeholders and present information in views.
• An information security management system (ISMS) is a coherent set of policies, processes, and systems to manage risks to information assets as outlined in ISOIEC 27001.
• Enterprise security architecture is a subset of business architecture and a way to describe current and future security processes, systems, and subunits to ensure strategic alignment.
• Blueprints are functional definitions for the integration of technology into business processes.
• Enterprise architecture frameworks are used to build individual architectures that best map to individual organizational needs and business drivers.
• Zachman Framework is an enterprise architecture framework, and SABSA is a security enterprise architecture framework.
• COSO Internal Control—Integrated Framework is a governance model used to help prevent fraud within a corporate environment.
• ITIL is a set of best practices for IT service management.
• Six Sigma is used to identify defects in processes so that the processes can be improved upon.
• CMMI is a maturity model that allows for processes to improve in an incremented and standard approach.
• Security enterprise architecture should tie in strategic alignment, business enablement, process enhancement, and security effectiveness.
• NIST SP 800-53 uses the following control categories: technical, management, and operational.
• Civil law system
• Uses prewritten rules and is not based on precedent.
• Is different from civil (tort) laws, which work under a common law system.
• Common law system
• Made up of criminal, civil, and administrative laws.
• Customary law system
• Addresses mainly personal conduct and uses regional traditions and customs as the foundations of the laws.
• Is usually mixed with another type of listed legal system rather than being the sole legal system used in a region.
• Religious law system
• Laws are derived from religious beliefs and address an individual’s religious responsibilities; commonly used in Muslim countries or regions.
• Mixed law system
• Uses two or more legal systems.
• Criminal law deals with an individual’s conduct that violates government laws developed to protect the public.
• Civil law deals with wrongs committed against individuals or companies that result in injury or damages. Civil law does not use prison time as a punishment, but usually requires financial restitution.
• Administrative, or regulatory, law covers standards of performance or conduct expected by government agencies from companies, industries, and certain officials.
• A patent grants ownership and enables that owner to legally enforce his rights to exclude others from using the invention covered by the patent.
• Copyright protects the expression of ideas rather than the ideas themselves.
• Trademarks protect words, names, product shapes, symbols, colors, or a combination of these used to identify products or a company. These items are used to distinguish products from the competitors’ products.
• Trade secrets are deemed proprietary to a company and often include information that provides a competitive edge. The information is protected as long as the owner takes the necessary protective actions.
• Crime over the Internet has brought about jurisdiction problems for law enforcement and the courts.
• Privacy laws dictate that data collected by government agencies must be collected fairly and lawfully, must be used only for the purpose for which it was collected, must only be held for a reasonable amount of time, and must be accurate and timely.
• When choosing the right safeguard to reduce a specific risk, the cost, functionality, and effectiveness must be evaluated and a cost/benefit analysis performed.
• A security policy is a statement by management dictating the role security plays in the organization.
• Procedures are detailed step-by-step actions that should be followed to achieve a certain task.
• Standards are documents that outline rules that are compulsory in nature and support the organization’s security policies.
• A baseline is a minimum level of security.
• Guidelines are recommendations and general approaches that provide advice and flexibility.
• OCTAVE is a team-oriented risk management methodology that employs workshops and is commonly used in the commercial sector.
• Security management should work from the top down (from senior management down to the staff).
• Risk can be transferred, avoided, reduced, or accepted.
• Threats × vulnerability × asset value = total risk
• (Threats × vulnerability × asset value) × controls gap = residual risk
• The main goals of risk analysis are the following: identify assets and assign values to them, identify vulnerabilities and threats, quantify the impact of potential threats, and provide an economic balance between the impact of the risk and the cost of the safeguards.
• Failure Modes and Effect Analysis (FMEA) is a method for determining functions, identifying functional failures, and assessing the causes of failure and their failure effects through a structured process.
• A fault tree analysis is a useful approach to detect failures that can take place within complex environments and systems.
• A quantitative risk analysis attempts to assign monetary values to components within the analysis.
• A purely quantitative risk analysis is not possible because qualitative items cannot be quantified with precision.
• Capturing the degree of uncertainty when carrying out a risk analysis is important, because it indicates the level of confidence the team and management should have in the resulting figures.
• Automated risk analysis tools reduce the amount of manual work involved in the analysis. They can be used to estimate future expected losses and calculate the benefits of different security measures.
• Single loss expectancy × frequency per year = annualized loss expectancy (SLE × ARO = ALE)
• Qualitative risk analysis uses judgment and intuition instead of numbers.
• Qualitative risk analysis involves people with the requisite experience and education evaluating threat scenarios and rating the probability, potential loss, and severity of each threat based on their personal experience.
• The Delphi technique is a group decision method where each group member can communicate anonymously.
• Job rotation is a detective administrative control to detect fraud.
• Mandatory vacations are a detective administrative control type that can help detect fraudulent activities.
• Separation of duties ensures no single person has total control over a critical activity or task. It is a preventive administrative control.
• Split knowledge and dual control are two aspects of separation of duties.
• Management must define the scope and purpose of security management, provide support, appoint a security team, delegate responsibility, and review the team’s findings.
• The risk management team should include individuals from different departments within the organization, not just technical personnel.
• Social engineering is a nontechnical attack carried out to manipulate a person into providing sensitive data to an unauthorized individual.
• Personally identifiable information (PII) is a collection of identity-based data that can be used in identity theft and financial fraud, and thus must be highly protected.
• A supply chain is a sequence of suppliers involved in delivering some product.
• A service level agreement (SLA) is a contractual agreement that states that a service provider guarantees a certain level of service.
• Security governance is a framework that provides oversight, accountability, and compliance.
• ISO/IEC 27004:2016 is an international standard for information security measurement management.
• NIST SP 800-55 is a standard for performance measurement for information security.
• Business continuity management (BCM) is the overarching approach to managing all aspects of BCP and DRP.
• A business continuity plan (BCP) contains strategy documents that provide detailed procedures that ensure critical business functions are maintained and that help minimize losses of life, operations, and systems.
• A BCP provides procedures for emergency responses, extended backup operations, and post-disaster recovery.
• A BCP should have an enterprise-wide reach, with individual organizational units each having its own detailed continuity and contingency plans.
• A BCP needs to prioritize critical applications and provide a sequence for efficient recovery.
• A BCP requires senior executive management support for initiating the plan and final approval.
• BCPs can quickly become outdated due to personnel turnover, reorganizations, and undocumented changes.
• Executives may be held liable if proper BCPs are not developed and used.
• Threats can be natural, manmade, or technical.
• The steps of recovery planning include initiating the project; performing business impact analyses; developing a recovery strategy; developing a recovery plan; and implementing, testing, and maintaining the plan.
• The project initiation phase involves getting management support, developing the scope of the plan, and securing funding and resources.
• The business impact analysis (BIA) is one of the most important first steps in the planning development. Qualitative and quantitative data on the business impact of a disaster need to be gathered, analyzed, interpreted, and presented to management.
• Executive commitment and support are the most critical elements in developing the BCP.
• A business case must be presented to gain executive support. This is done by explaining regulatory and legal requirements, exposing vulnerabilities, and providing solutions.
• Plans should be prepared by the people who will actually carry them out.
• The planning group should comprise representatives from all departments or organizational units.
• The BCP team should identify the individuals who will interact with external players, such as the reporters, shareholders, customers, and civic officials. Response to the disaster should be done quickly and honestly, and should be consistent with any other organizational response.
• ISO/IEC 27031:2011 describes the concepts and principles of information and communication technology (ICT) readiness for business continuity.
• ISO/IEC 22301 is the standard for business continuity management (BCM).
Questions
Please remember that these questions are formatted and asked in a certain way for a reason. Keep in mind that the CISSP exam is asking questions at a conceptual level. Questions may not always have the perfect answer, and the candidate is advised against always looking for the perfect answer. Instead, the candidate should look for the best answer in the list.
1. When can executives be charged with negligence?
A. If they follow the transborder laws
B. If they do not properly report and prosecute attackers
C. If they properly inform users that they may be monitored
D. If they do not practice due care when protecting resources
2. To better deal with computer crime, several legislative bodies have taken what steps in their strategy?
A. Expanded several privacy laws
B. Broadened the definition of property to include data
C. Required corporations to have computer crime insurance
D. Redefined transborder issues
3. Which factor is the most important item when it comes to ensuring security is successful in an organization?
A. Senior management support
B. Effective controls and implementation methods
C. Updated and relevant security policies and procedures
D. Security awareness by all employees
4. Which of the following standards would be most useful to you in ensuring your information security management system follows industry best practices?
A. NIST SP 800-53
B. Six Sigma
C. ISO/IEC 27000 series
D. COSO IC
5. Which of the following is true about data breaches?
A. They are exceptionally rare.
B. They always involve personally identifiable information (PII).
C. They may trigger legal or regulatory requirements.
D. The United States has no laws pertaining to data breaches.
6. When is it acceptable to not take action on an identified risk?
A. Never. Good security addresses and reduces all risks.
B. When political issues prevent this type of risk from being addressed.
C. When the necessary countermeasure is complex.
D. When the cost of the countermeasure outweighs the value of the asset and potential loss.
7. Which is the most valuable technique when determining if a specific security control should be implemented?
A. Risk analysis
B. Cost/benefit analysis
C. ALE results
D. Identifying the vulnerabilities and threats causing the risk
8. Which best describes the purpose of the ALE calculation?
A. Quantifies the security level of the environment
B. Estimates the loss possible for a countermeasure
C. Quantifies the cost/benefit result
D. Estimates the loss potential of a threat in a span of a year
9. How do you calculate residual risk?
A. Threats × risks × asset value
B. (Threats × asset value × vulnerability) × risks
C. SLE × frequency = ALE
D. (Threats × vulnerability × asset value) × controls gap
10. Why should the team that will perform and review the risk analysis information be made up of people in different departments?
A. To make sure the process is fair and that no one is left out.
B. It shouldn’t. It should be a small group brought in from outside the organization because otherwise the analysis is biased and unusable.
C. Because people in different departments understand the risks of their department. Thus, it ensures the data going into the analysis is as close to reality as possible.
D. Because the people in the different departments are the ones causing the risks, so they should be the ones held accountable.
11. Which best describes a quantitative risk analysis?
A. A scenario-based analysis to research different security threats
B. A method used to apply severity levels to potential loss, probability of loss, and risks
C. A method that assigns monetary values to components in the risk assessment
D. A method that is based on gut feelings and opinions
12. Why is a truly quantitative risk analysis not possible to achieve?
A. It is possible, which is why it is used.
B. It assigns severity levels. Thus, it is hard to translate into monetary values.
C. It is dealing with purely quantitative elements.
D. Quantitative measures must be applied to qualitative elements.
13. What is COBIT and where does it fit into the development of information security systems and security programs?
A. Lists of standards, procedures, and policies for security program development
B. Current version of ISO 17799
C. A framework that was developed to deter organizational internal fraud
D. Open standards for control objectives
14. What is the ISO/IEC 27799 standard?
A. A standard on how to protect personal health information
B. The new version of BS 17799
C. Definitions for the new ISO 27000 series
D. The new version of NIST SP 800-60
15. OCTAVE, NIST SP 800-30, and AS/NZS ISO 31000 are different approaches to carrying out risk management within companies and organizations. What are the differences between these methods?
A. NIST SP 800-30 and OCTAVE are corporate based, while AS/NZS is international.
B. NIST SP 800-30 is IT based, while OCTAVE and AS/NZS ISO 31000 are corporate based.
C. AS/NZS is IT based, and OCTAVE and NIST SP 800-30 are assurance based.
D. NIST SP 800-30 and AS/NZS are corporate based, while OCTAVE is international.
Use the following scenario to answer Questions 16–18. A server that houses sensitive data has been stored in an unlocked room for the last few years at Company A. The door to the room has a sign on the door that reads “Room 1.” This sign was placed on the door with the hope that people would not look for important servers in this room. Realizing this is not optimum security, the company has decided to install a reinforced lock and server cage for the server and remove the sign. The company has also hardened the server’s configuration and employed strict operating system access controls.
16. The fact that the server has been in an unlocked room marked “Room 1” for the last few years means the company was practicing which of the following?
A. Logical security
B. Risk management
C. Risk transference
D. Security through obscurity
17. The new reinforced lock and cage serve as which of the following?
A. Logical controls
B. Physical controls
C. Administrative controls
D. Compensating controls
18. The operating system access controls comprise which of the following?
A. Logical controls
B. Physical controls
C. Administrative controls
D. Compensating controls
Use the following scenario to answer Questions 19–21. A company has an e-commerce website that carries out 60 percent of its annual revenue. Under the current circumstances, the annualized loss expectancy for a website against the threat of attack is $92,000. After implementing a new application-layer firewall, the new annualized loss expectancy would be $30,000. The firewall costs $65,000 per year to implement and maintain.
19. How much does the firewall save the company in loss expenses?
A. $62,000
B. $3,000
C. $65,000
D. $30,000
20. What is the value of the firewall to the company?
A. $62,000
B. $3,000
C. –$62,000
D. –$3,000
21. Which of the following describes the company’s approach to risk management?
A. Risk transference
B. Risk avoidance
C. Risk acceptance
D. Risk mitigation
Use the following scenario to answer Questions 22–24. A small remote office for a company is valued at $800,000. It is estimated, based on historical data, that a fire is likely to occur once every ten years at a facility in this area. It is estimated that such a fire would destroy 60 percent of the facility under the current circumstances and with the current detective and preventive controls in place.
22. What is the single loss expectancy (SLE) for the facility suffering from a fire?
A. $80,000
B. $480,000
C. $320,000
D. 60%
23. What is the annualized rate of occurrence (ARO)?
A. 1
B. 10
C. .1
D. .01
24. What is the annualized loss expectancy (ALE)?
A. $480,000
B. $32,000
C. $48,000
D. .6
25. The international standards bodies ISO and IEC developed a series of standards that are used in organizations around the world to implement and maintain information security management systems. The standards were derived from the British Standard 7799, which was broken down into two main pieces. Organizations can use this series of standards as guidelines, but can also be certified against them by accredited third parties. Which of the following are incorrect mappings pertaining to the individual standards that make up the ISO/IEC 27000 series?
i. ISO/IEC 27001 outlines ISMS implementation guidelines, and ISO/IEC 27003 outlines the ISMS program’s requirements.
ii. ISO/IEC 27005 outlines the audit and certification guidance, and ISO/IEC 27002 outlines the metrics framework.
iii. ISO/IEC 27006 outlines the program implementation guidelines, and ISO/IEC 27005 outlines risk management guidelines.
iv. ISO/IEC 27001 outlines the code of practice, and ISO/IEC 27004 outlines the implementation framework.
A. i, iii
B. i, ii
C. ii, iii, iv
D. i, ii, iii, iv
26. The information security industry is made up of various best practices, standards, models, and frameworks. Some were not developed first with security in mind, but can be integrated into an organizational security program to help in its effectiveness and efficiency. It is important to know of all of these different approaches so that an organization can choose the ones that best fit its business needs and culture. Which of the following best describes the approach(es) that should be put into place if an organization wants to integrate a way to improve its security processes over a period of time?
i. Information Technology Infrastructure Library should be integrated because it allows for the mapping of IT service process management, business drivers, and security improvement.
ii. Six Sigma should be integrated because it allows for the defects of security processes to be identified and improved upon.
iii. Capability Maturity Model Integration should be integrated because it provides distinct maturity levels.
iv. The Open Group Architecture Framework should be integrated because it provides a structure for process improvement.
A. i, iii
B. ii, iii, iv
C. ii, iii
D. ii, iv
Use the following scenario to answer Questions 27–29. Todd is a new security manager and has the responsibility of implementing personnel security controls within the financial institution where he works. Todd knows that many employees do not fully understand how their actions can put the institution at risk; thus, an awareness program needs to be developed. He has determined that the bank tellers need to get a supervisory override when customers have checks over $3,500 that need to be cashed. He has also uncovered that some employees have stayed in their specific positions within the company for over three years. Todd would like to be able to investigate some of the bank’s personnel activities to see if any fraudulent activities have taken place. Todd is already ensuring that two people must use separate keys at the same time to open the bank vault.
27. Todd documents several fraud opportunities that the employees have at the financial institution so that management understands these risks and allocates the funds and resources for his suggested solutions. Which of the following best describes the control Todd should put into place to be able to carry out fraudulent investigation activity?
A. Separation of duties
B. Rotation of duties
C. Mandatory vacations
D. Split knowledge
28. If the financial institution wants to force collusion to take place for fraud to happen successfully in this situation, what should Todd put into place?
A. Separation of duties
B. Rotation of duties
C. Social engineering
D. Split knowledge
29. Todd wants to be able to prevent fraud from taking place, but he knows that some people may get around the types of controls he puts into place. In those situations he wants to be able to identify when an employee is doing something suspicious. Which of the following incorrectly describes what Todd is implementing in this scenario and what those specific controls provide?
A. Separation of duties by ensuring that a supervisor must approve the cashing of a check over $3,500. This is an administrative control that provides preventive protection for Todd’s organization.
B. Rotation of duties by ensuring that one employee only stays in one position for up to three months at a time. This is an administrative control that provides detective capabilities.
C. Security awareness training, which is a preventive administrative control that can also emphasize enforcement.
D. Dual control, which is an administrative detective control that can ensure that two employees must carry out a task simultaneously.
Use the following scenario to answer Questions 30–32. Susan has been told by her boss that she will be replacing the current security manager within her company. Her boss explained to her that operational security measures have not been carried out in a standard fashion, so some systems have proper security configurations and some do not. Her boss needs to understand how dangerous it is to have some of the systems misconfigured, along with what to do in this situation.
30. Which of the following best describes what Susan needs to ensure the operations staff creates for proper configuration standardization?
A. Dual control
B. Redundancy
C. Training
D. Baselines
31. Which of the following is the best way for Susan to illustrate to her boss the dangers of the current configuration issues?
A. Map the configurations to the compliancy requirements.
B. Compromise a system to illustrate its vulnerability.
C. Audit the systems.
D. Carry out a risk assessment.
32. Which of the following is one of the most likely solutions that Susan will come up with and present to her boss?
A. Development of standards
B. Development of training
C. Development of monitoring
D. Development of testing
33. What is one of the first steps in developing a business continuity plan?
A. Identify a backup solution.
B. Perform a simulation test.
C. Perform a business impact analysis.
D. Develop a business resumption plan.
34. The purpose of initiating emergency procedures right after a disaster takes place is to prevent loss of life and injuries, and to _______________.
A. secure the area to ensure that no looting or fraud takes place
B. mitigate further damage
C. protect evidence and clues
D. investigate the extent of the damages
35. Which of the following would you use to control the public distribution, reproduction, display, and adaptation of an original white paper written by your staff?
A. Copyright
B. Trademark
C. Patent
D. Trade secret
36. Many privacy laws dictate which of the following rules?
A. Individuals have a right to remove any data they do not want others to know.
B. Agencies do not need to ensure that the data is accurate.
C. Agencies need to allow all government agencies access to the data.
D. Agencies cannot use collected data for a purpose different from what they were collected for.
37. The term used to denote a potential cause of an unwanted incident, which may result in harm to a system or organization is
A. Vulnerability
B. Exploit
C. Threat
D. Attacker
38. A CISSP candidate signs an ethics statement prior to taking the CISSP examination. Which of the following would be a violation of the (ISC)2 Code of Ethics that could cause the candidate to lose his or her certification?
A. E-mailing information or comments about the exam to other CISSP candidates
B. Submitting comments on the questions of the exam to (ISC)2
C. Submitting comments to the board of directors regarding the test and content of the class
D. Conducting a presentation about the CISSP certification and what the certification means
39. Which of the following has an incorrect definition mapping?
i. Civil (code) law: Based on previous interpretations of laws
ii. Common law: Rule-based law, not precedent-based
iii. Customary law: Deals mainly with personal conduct and patterns of behavior
iv. Religious law: Based on religious beliefs of the region
A. i, iii
B. i, ii, iii
C. i, ii
D. iv
Answers
1. D. Executives are held to a certain standard and are expected to act responsibly when running and protecting a company. These standards and expectations equate to the due care concept under the law. Due care means to carry out activities that a reasonable person would be expected to carry out in the same situation. If an executive acts irresponsibly in any way, she can be seen as not practicing due care and be held negligent.
2. B. Many times, what is corrupted, compromised, or taken from a computer is data, so current laws have been updated to include the protection of intangible assets, as in data. Over the years, data and information have become many companies’ most valuable asset, which must be protected by the laws.
3. A. Without senior management’s support, a security program will not receive the necessary attention, funds, resources, and enforcement capabilities.
4. C. The ISO/IEC 27000 series is the only option that addresses best practices across the breadth of an ISMS. COSO IC and NIST SP 800-53 both deal with controls, which are a critical but not the only component of an ISMS.
5. C. Organizations experiencing a data breach may be required by laws or regulations to take certain actions. For instance, many countries have disclosure requirements that require notification to affected parties and/or regulatory bodies within a specific timeframe.
6. D. Companies may decide to live with specific risks they are faced with if the cost of trying to protect themselves would be greater than the potential loss if the threat were to become real. Countermeasures are usually complex to a degree, and there are almost always political issues surrounding different risks, but these are not reasons to not implement a countermeasure.
7. B. Although the other answers may seem correct, B is the best answer here. This is because a risk analysis is performed to identify risks and come up with suggested countermeasures. The ALE tells the company how much it could lose if a specific threat became real. The ALE value will go into the cost/benefit analysis, but the ALE does not address the cost of the countermeasure and the benefit of a countermeasure. All the data captured in answers A, C, and D is inserted into a cost/benefit analysis.
8. D. The ALE calculation estimates the potential loss that can affect one asset from a specific threat within a one-year time span. This value is used to figure out the amount of money that should be earmarked to protect this asset from this threat.
9. D. The equation is more conceptual than practical. It is hard to assign a number to an individual vulnerability or threat. This equation enables you to look at the potential loss of a specific asset, as well as the controls gap (what the specific countermeasure cannot protect against). What remains is the residual risk, which is what is left over after a countermeasure is implemented.
10. C. An analysis is only as good as the data that goes into it. Data pertaining to risks the company faces should be extracted from the people who understand best the business functions and environment of the company. Each department understands its own threats and resources, and may have possible solutions to specific threats that affect its part of the company.
11. C. A quantitative risk analysis assigns monetary values and percentages to the different components within the assessment. A qualitative analysis uses opinions of individuals and a rating system to gauge the severity level of different threats and the benefits of specific countermeasures.
12. D. During a risk analysis, the team is trying to properly predict the future and all the risks that future may bring. It is somewhat of a subjective exercise and requires educated guessing. It is very hard to properly predict that a flood will take place once in ten years and cost a company up to $40,000 in damages, but this is what a quantitative analysis tries to accomplish.
13. D. The Control Objectives for Information and related Technology (COBIT) is a framework developed by the Information Systems Audit and Control Association (ISACA) and the IT Governance Institute (ITGI). It defines goals for the controls that should be used to properly manage IT and ensure IT maps to business needs.
14. A. It is referred to as the health informatics, and its purpose is to provide guidance to health organizations and other holders of personal health information on how to protect such information via implementation of ISO/IEC 27002.
15. B. NIST SP 800-30, Revision 1, “Guide for Conducting Risk Assessments,” is a U.S. federal standard that is focused on IT risks. OCTAVE is a methodology to set up a risk management program within an organizational structure. AS/NZS ISO 31000 takes a much broader approach to risk management. This methodology can be used to understand a company’s financial, capital, human safety, and business decisions risks. Although it can be used to analyze security risks, it was not created specifically for this purpose.
16. D. Security through obscurity is not implementing true security controls, but rather attempting to hide the fact that an asset is vulnerable in the hope that an attacker will not notice. Security through obscurity is an approach to try and fool a potential attacker, which is a poor way of practicing security. Vulnerabilities should be identified and fixed, not hidden.
17. B. Physical controls are security mechanisms in the physical world, as in locks, fences, doors, computer cages, etc. There are three main control types, which are administrative, technical, and physical.
18. A. Logical (or technical) controls are security mechanisms, as in firewalls, encryption, software permissions, and authentication devices. They are commonly used in tandem with physical and administrative controls to provide a defense-in-depth approach to security.
19. A. $62,000 is the correct answer. The firewall reduced the annualized loss expectancy (ALE) from $92,000 to $30,000 for a savings of $62,000. The formula for ALE is single loss expectancy × annualized rate of occurrence = ALE. Subtracting the ALE value after the firewall is implemented from the value before it was implemented results in the potential loss savings this type of control provides.
20. D. –$3,000 is the correct answer. The firewall saves $62,000, but costs $65,000 per year. 62,000 – 65,000 = –3,000. The firewall actually costs the company more than the original expected loss, and thus the value to the company is a negative number. The formula for this calculation is (ALE before the control is implemented) – (ALE after the control is implemented) – (annual cost of control) = value of control.
21. D. Risk mitigation involves employing controls in an attempt to reduce either the likelihood or damage associated with an incident, or both. The four ways of dealing with risk are accept, avoid, transfer, and mitigate (reduce). A firewall is a countermeasure installed to reduce the risk of a threat.
22. B. $480,000 is the correct answer. The formula for single loss expectancy (SLE) is asset value × exposure factor (EF) = SLE. In this situation the formula would work out as asset value ($800,000) × exposure factor (60%) = $480,000. This means that the company has a potential loss value of $480,000 pertaining to this one asset (facility) and this one threat type (fire).
23. C. The annualized rate occurrence (ARO) is the frequency that a threat will most likely occur within a 12-month period. It is a value used in the ALE formula, which is SLE × ARO = ALE.
24. C. $48,000 is the correct answer. The annualized loss expectancy formula (SLE × ARO = ALE) is used to calculate the loss potential for one asset experiencing one threat in a 12-month period. The resulting ALE value helps to determine the amount that can reasonably be spent in the protection of that asset. In this situation, the company should not spend over $48,000 on protecting this asset from the threat of fire. ALE values help organizations rank the severity level of the risks they face so they know which ones to deal with first and how much to spend on each.
25. D. Unfortunately, you will run into questions on the CISSP exam that will be this confusing, so you need to be ready for them. The proper mapping for the ISO/IEC standards are as follows:
• ISO/IEC 27001 ISMS requirements
• ISO/IEC 27002 Code of practice for information security management
• ISO/IEC 27003 Guideline for ISMS implementation
• ISO/IEC 27004 Guideline for information security management measurement and metrics framework
• ISO/IEC 27005 Guideline for information security risk management
• ISO/IEC 27006 Guidance for bodies providing audit and certification of information security management systems
26. C. The best process improvement approaches provided in this list are Six Sigma and the Capability Maturity Model. The following outlines the definitions for all items in this question:
• TOGAF Model and methodology for the development of enterprise architectures developed by The Open Group
• ITIL Processes to allow for IT service management developed by the United Kingdom’s Office of Government Commerce
• Six Sigma Business management strategy that can be used to carry out process improvement
• Capability Maturity Model Integration (CMMI) Organizational development for process improvement developed by Carnegie Mellon
27. C. Mandatory vacation is an administrative detective control that allows for an organization to investigate an employee’s daily business activities to uncover any potential fraud that may be taking place. The employee should be forced to be away from the organization for a two-week period and another person should be put into that role. The idea is that the person who was rotated into that position may be able to detect suspicious activities.
28. A. Separation of duties is an administrative control that is put into place to ensure that one person cannot carry out a critical task by himself. If a person were able to carry out a critical task alone, this could put the organization at risk. Collusion is when two or more people come together to carry out fraud. So if a task was split between two people, they would have to carry out collusion (working together) to complete that one task and carry out fraud.
29. D. Dual control is an administrative preventive control. It ensures that two people must carry out a task at the same time, as in two people having separate keys when opening the vault. It is not a detective control. Notice that the question asks what Todd is not doing. Remember that on the exam you need to choose the best answer. In many situations you will not like the question or the corresponding answers on the CISSP exam, so prepare yourself. The questions can be tricky, which is one reason why the exam itself is so difficult.
30. D. The operations staff needs to know what minimum level of security is required per system within the network. This minimum level of security is referred to as a baseline. Once a baseline is set per system, then the staff has something to compare the system against to know if changes have not taken place properly, which could make the system vulnerable.
31. D. Susan needs to illustrate these vulnerabilities (misconfigured systems) in the context of risk to her boss. This means she needs to identify the specific vulnerabilities, associate threats to those vulnerabilities, and calculate their risks. This will allow her boss to understand how critical these issues are and what type of action needs to take place.
32. A. Standards need to be developed that outline proper configuration management processes and approved baseline configuration settings. Once these standards are developed and put into place, then employees can be trained on these issues and how to implement and maintain what is outlined in the standards. Systems can be tested against what is laid out in the standards, and systems can be monitored to detect if there are configurations that do not meet the requirements outlined in the standards. You will find that some CISSP questions seem subjective and their answers hard to pin down. Questions that ask what is “best” or “more likely” are common.
33. C. A business impact analysis includes identifying critical systems and functions of a company and interviewing representatives from each department. Once management’s support is solidified, a business impact analysis needs to be performed to identify the threats the company faces and the potential costs of these threats.
34. B. The main goal of disaster recovery and business continuity plans is to mitigate all risks that could be experienced by a company. Emergency procedures first need to be carried out to protect human life, and then other procedures need to be executed to reduce the damage from further threats.
35. A. A copyright fits the situation precisely. A patent could be used to protect a novel invention described in the paper, but the question did not imply that this was the case. A trade secret cannot be publicly disseminated, so it does not apply. Finally, a trademark protects only a word, symbol, sound, shape, color or combination of these.
36. D. The Federal Privacy Act of 1974 and the European Union Principles on Privacy were created to protect citizens from government agencies that collect personal data. These acts have many stipulations, including that the information can only be used for the reason for which it was collected.
37. C. The question provides the definition of a threat in ISO/IEC 27000. The term attacker (option D) could be used to describe a threat agent that is, in turn, a threat, but use of this term is much more restrictive. The best answer is a threat.
38. A. A CISSP candidate and a CISSP holder should never discuss with others what was on the exam. This degrades the usefulness of the exam to be used as a tool to test someone’s true security knowledge. If this type of activity is uncovered, the person could be stripped of their CISSP certification because this would violate the terms of the NDA upon which the candidate enters prior to taking the test. Violating an NDA is a violation of the ethics canon that requires CISSPs to act honorably, honestly, justly, responsibly and legally.
39. C. The following has the proper definition mappings:
i. Civil (code) law: Rule-based law, not precedent-based
ii. Common law: Based on previous interpretations of laws
iii. Customary law: Deals mainly with personal conduct and patterns of behavior
iv. Religious law: Based on religious beliefs of the region