
Cloud
According to Gartner, the majority of new system purchases will use IDaaS by 2021. Though IDaaS is a booming sector of the security industry, it is important to note that it is not without potential issues. First and foremost, some regulated industries may not be able to leverage IDaaS and remain compliant. This is because a critical function (i.e., IdM) is being outsourced and the service provider may not be able to comply with all the regulatory requirements. Another concern is that some of the most critical data in the enterprise is increasingly exposed once it moves out of the enterprise enclaves. Though various cloud service providers will undoubtedly be able to provide equal or better security than the client organization, it is still an important point of discussion before making the decision to go with an IDaaS solution. Finally, there is the issue of integration. Depending on the specific vendor and offering, some legacy applications may not be supported. This too needs to be discussed ahead of signing any contracts.
Integration Issues
Integration of any set of different technologies or products is typically one of the most complex and risky phases of any deployment. In order to mitigate both the complexities and risks, it is necessary to carefully characterize each product or technology as well as the systems and networks into which they will be incorporated. Regardless of whether you ultimately use an on-premise or cloud-based (or hybrid) approach, you should carefully plan how you will address connectivity, trust, testing, and federation issues. As the old carpentry adage goes, “Measure twice and cut once.”
Establishing Connectivity
A critical requirement is that we need to ensure the components are able to communicate with one another in a secure manner. The big difference between the in-house and outsourced models here is that in the former, the chokepoints are all internal to the organization’s network, while in the latter, they will also exist in the public Internet. Clearing a path for this traffic will typically mean creating new rules for firewalls and IDS/IPS. These rules must be restrictive enough to allow the IdM traffic, but nothing else, to flow between the various nodes. Depending on the systems being used, ports, protocols, and user accounts may also need to be configured in order to enable bidirectional communication.
Establishing Trust
All traffic between nodes engaged in identity services must be encrypted. (To do otherwise would defeat the whole point of this effort.) From a practical perspective, this almost certainly means that PKI in general and certificate authorities (CAs) in particular will be needed. A potential issue here is that the CAs may not be trusted by default by all the nodes. This is especially true if the enterprise has implemented its own CA internally and is deploying an outsourced service. This is easy to plan ahead of time, but could lead to some big challenges if discovered during the actual roll-out. Trust may also be needed between domains.
Incremental Testing
When dealing with complex systems, it is wise to assume that some important issue will not be covered in the plan. This is why it is important to incrementally test the integration of identity services instead of rolling out the entire system at once. Many organizations choose to roll out new services first to test accounts (i.e., not real users), then to one department or division that is used as the test case, and finally to the entire organization. For critical deployments (and one would assume that identity services would fall in this category), it is best to test as thoroughly as possible in a testbed or sandbox environment. Only then should the integration progress to real systems.
Integrating Federated Systems
Your organization may have a remarkable amount of connectivity with other organizations and individuals. You may have contractor personnel who require access to some information systems but belong to a different company’s IdM architecture. You may also have suppliers or other partners whose systems communicate directly with your own in some limited capacity. The degree to which your systems are intertwined with others is sometimes not realized until you attempt to integrate a new IdM and discover that it is somehow incompatible with the external systems. For this reason, it is imperative to take stock of every external dependency and ensure that the proposed solution is compatible and that the correct parameters are known and tested.
Access Control Mechanisms
An access control mechanism dictates how subjects access objects. It uses access control technologies and security mechanisms to enforce the rules and objectives of an access control model. There are five main types of access control models: discretionary, mandatory, role based, rule based, and attribute based. Each model type uses different methods to control how subjects access objects, and each has its own merits and limitations. The business and security goals of an organization, along with the culture of the company and the habits of conducting business, will help prescribe what access control model it should use. Some companies use one model exclusively, whereas others combine them to be able to provide the necessary level of protection.
These models are built into the core or the kernel of the different operating systems and possibly their supporting applications. Every operating system has a security kernel that enforces a reference monitor concept, which differs depending upon the type of access control model embedded into the system. For every access attempt, before a subject can communicate with an object, the security kernel reviews the rules of the access control model to determine whether the request is allowed.
The following sections explain these different models, their supporting technologies, and where they should be implemented.
Discretionary Access Control
If a user creates a file, he is the owner of that file. An identifier for this user is placed in the file header and/or in an access control matrix within the operating system. Ownership might also be granted to a specific individual. For example, a manager for a certain department might be made the owner of the files and resources within her department. A system that uses discretionary access control (DAC) enables the owner of the resource to specify which subjects can access specific resources. This model is called discretionary because the control of access is based on the discretion of the owner. Many times department managers or business unit managers are the owners of the data within their specific department. Being the owner, they can specify who should have access and who should not.
In a DAC model, access is restricted based on the authorization granted to the users. This means users are allowed to specify what type of access can occur to the objects they own. If an organization is using a DAC model, the network administrator can allow resource owners to control who has access to their files. The most common implementation of DAC is through ACLs, which are dictated and set by the owners and enforced by the operating system. This can make a user’s ability to access information dynamic versus the more static role of mandatory access control (MAC).
Most of the operating systems you may be used to dealing with are based on DAC models, such as all Windows, Linux, and macOS systems and most flavors of Unix. When you look at the properties of a file or directory and see the choices that allow you to control which users can have access to this resource and to what degree, you are witnessing an instance of ACLs enforcing a DAC model.
DACs can be applied to both the directory tree structure and the files it contains. The PC world has access permissions of No Access, Read (r), Write (w), Execute (x), Delete (d), Change (c), and Full Control. The Read attribute lets you read the file but not make changes. The Change attribute allows you to read, write, execute, and delete the file but does not let you change the ACLs or the owner of the files. Obviously, the attribute of Full Control lets you make any changes to the file and its permissions and ownership.
While DAC systems provide a lot of flexibility to the user and less administration for IT, it is also the Achilles’ heel of operating systems. Malware can install itself and work under the security context of the user. For example, if a user opens an attachment that is infected with a virus, the code can install itself in the background without the user’s being aware of this activity. This code basically inherits all the rights and permissions that the user has and can carry out all the activities the user can on the system. It can send copies of itself out to all the contacts listed in the user’s e-mail client, install a back door, attack other systems, delete files on the hard drive, and more. The user is actually giving rights to the virus to carry out its dirty deeds, because the user has very powerful discretionary rights and is considered the owner of many objects on the system. And the fact that many users are assigned local administrator or root accounts means that once malware is installed, it can do anything on a system.
As we have said before, there is a constant battle between functionality and security. To allow for the amount of functionality we demand of our operating systems today, they have to work within a DAC model—but because they work in a DAC model, extensive compromises are always possible.
While we may want to give users some freedom to indicate who can access the files that they create and other resources on their systems that they are configured to be “owners” of, we really don’t want them dictating all access decisions in environments with assets that need to be protected. We just don’t trust them that much, and we shouldn’t. In most environments user profiles are created and loaded on user workstations that indicate the level of control the user does and does not have. As a security administrator you might configure user profiles so that users cannot change the system’s time, alter system configuration files, access a command prompt, or install unapproved applications. This type of access control is referred to as nondiscretionary, meaning that access decisions are not made at the discretion of the user. Nondiscretionary access controls are put into place by an authoritative entity (usually a security administrator) with the goal of protecting the organization’s most critical assets.
Mandatory Access Control
In a mandatory access control (MAC) model, users do not have the discretion of determining who can access objects as in a DAC model. An operating system that is based upon a MAC model greatly reduces the amount of rights, permissions, and functionality a user has for security purposes. In most systems based upon the MAC model, a user cannot install software, change file permissions, add new users, etc. The system can be used by the user for very focused and specific purposes, and that is it. These systems are usually very specialized and are in place to protected highly classified data. Most people have never interacted with a MAC-based system because they are used by government-oriented agencies that maintain top-secret information.
The MAC model is much more structured and strict than the DAC model and is based on a security label system. Users are given a security clearance (secret, top secret, confidential, and so on), and data is classified in the same way. The clearance and classification data is stored in the security labels, which are bound to the specific subjects and objects. When the system makes a decision about fulfilling a request to access an object, it is based on the clearance of the subject, the classification of the object, and the security policy of the system. The rules for how subjects access objects are made by the organization’s security policy, configured by the security administrator, enforced by the operating system, and supported by security technologies.
NOTE Traditional MAC systems are based upon multilevel security policies, which outline how data at different classification levels is to be protected. Multilevel security (MLS) systems allow data at different classification levels to be accessed and interacted with by users with different clearance levels simultaneously.
Security labels are attached to all objects; thus, every file, directory, and device has its own security label with its classification information. A user may have a security clearance of secret, and the data he requests may have a security label with the classification of top secret. In this case, the user will be denied because his clearance is not equivalent or does not dominate (is not equal to or higher than) the classification of the object.

TIP The terms “security labels” and “sensitivity labels” can be used interchangeably.
Each subject and object must have an associated label with attributes at all times, because this is part of the operating system’s access-decision criteria. Each subject and object does not require a physically unique label, but can be logically associated. For example, all subjects and objects on Server 1 can share the same label of secret clearance and classification.
This type of model is used in environments where information classification and confidentiality is of utmost importance, such as military institutions, government agencies, and government contract companies. Special types of Unix systems are developed based on the MAC model. A company cannot simply choose to turn on either DAC or MAC. It has to purchase an operating system that has been specifically designed to enforce MAC rules. DAC systems do not understand security labels, classifications, or clearances, and thus cannot be used in institutions that require this type of structure for access control. A publicly released MAC system is SE Linux, developed by the NSA and Secure Computing. Trusted Solaris is a product based on the MAC model that most people are familiar with (relative to other MAC products).
While MAC systems enforce strict access control, they also provide a wide range of security, particularly dealing with malware. Malware is the bane of DAC systems. Viruses, worms, and rootkits can be installed and run as applications on DAC systems. Since users that work within a MAC system cannot install software, the operating system does not allow any type of software, including malware, to be installed while the user is logged in. But while MAC systems might seem an answer to all our security prayers, they have very limited user functionality, require a lot of administrative overhead, are very expensive, and are not user friendly. DAC systems are general-purpose computers, while MAC systems serve a very specific purpose.

EXAM TIP DAC systems are discretionary and MAC systems are considered nondiscretionary because the users cannot make access decisions based upon their own discretion (choice).
Sensitivity Labels
When the MAC model is being used, every subject and object must have a sensitivity label, also called a security label. It contains a classification and different categories. The classification indicates the sensitivity level, and the categories enforce need-to-know rules. Figure 5-19 illustrates a sensitivity label.
The classifications follow a hierarchical structure, with one level being more trusted than another. However, the categories do not follow a hierarchical scheme, because they represent compartments of information within a system. The categories can correspond to departments (UN, Information Warfare, Treasury), projects (CRM, AirportSecurity, 2018Budget), or management levels. In a military environment, the classifications could be top secret, secret, confidential, or unclassified. Each classification is more trusted than the one below it. A commercial organization might use confidential, proprietary, corporate, and sensitive. The definition of the classification is up to the organization and should make sense for the environment in which it is used.
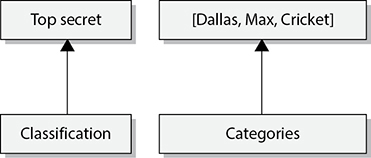
Figure 5-19 A sensitivity label is made up of a classification and categories.
The categories portion of the label enforces need-to-know rules. Just because someone has a top-secret clearance does not mean she now has access to all top-secret information. She must also have a need to know. As shown in Figure 5-19, if Cheryl has a top-secret clearance but does not have a need to know that is sufficient to access any of the listed categories (Dallas, Max, Cricket), she cannot look at this object.
EXAM TIP In MAC implementations, the system makes access decisions by comparing the subject’s clearance and need-to-know level to the object’s security label. In DAC, the system compares the subject’s identity to the ACL on the resource.
Software and hardware guards allow the exchange of data between trusted (high assurance) and less trusted (low assurance) systems and environments. For instance, if you were working on a MAC system (working in the dedicated security mode of secret) and you needed it to communicate to a MAC database (working in multilevel security mode, which goes up to top secret), the two systems would provide different levels of protection. If a system with lower assurance can directly communicate with a system of high assurance, then security vulnerabilities and compromises could be introduced. A software guard is really just a front-end product that allows interconnectivity between systems working at different security levels. Different types of guards can be used to carry out filtering, processing requests, data blocking, and data sanitization. A hardware guard can be implemented, which is a system with two NICs connecting the two systems that need to communicate with one another. Guards can be used to connect different MAC systems working in different security modes, and they can be used to connect different networks working at different security levels. In many cases, the less trusted system can send messages to the more trusted system and can only receive acknowledgments back. This is common when e-mail messages need to go from less trusted systems to more trusted classified systems.
Role-Based Access Control
A role-based access control (RBAC) model uses a centrally administrated set of controls to determine how subjects and objects interact. The access control levels can be based upon the necessary operations and tasks a user needs to carry out to fulfill her responsibilities without an organization. This type of model lets access to resources be based on the role the user holds within the company. The more traditional access control administration is based on just the DAC model, where access control is specified at the object level with ACLs. This approach is more complex because the administrator must translate an organizational authorization policy into permission when configuring ACLs. As the number of objects and users grows within an environment, users are bound to be granted unnecessary access to some objects, thus violating the least-privilege rule and increasing the risk to the company. The RBAC approach simplifies access control administration by allowing permissions to be managed in terms of user job roles.
In an RBAC model, a role is defined in terms of the operations and tasks the role will carry out, whereas a DAC model outlines which subjects can access what objects based upon the individual user identity.
Let’s say we need a research and development analyst role. We develop this role not only to allow an individual to have access to all product and testing data, but also, and more importantly, to outline the tasks and operations that the role can carry out on this data. When the analyst role makes a request to access the new testing results on the file server, in the background the operating system reviews the role’s access levels before allowing this operation to take place.
NOTE Introducing roles also introduces the difference between rights being assigned explicitly and implicitly. If rights and permissions are assigned explicitly, they are assigned directly to a specific individual. If they are assigned implicitly, they are assigned to a role or group and the user inherits those attributes.
An RBAC model is the best system for a company that has high employee turnover. If John, who is mapped to the Contractor role, leaves the company, then Chrissy, his replacement, can be easily mapped to this role. That way, the administrator does not need to continually change the ACLs on the individual objects. He only needs to create a role (Contractor), assign permissions to this role, and map the new user to this role.
As discussed in the “Identity Management” section, organizations are moving more toward role-based access models to properly control identity and provisioning activities. The formal RBAC model has several approaches to security that can be used in software and organizations.
Core RBAC
This component will be integrated in every RBAC implementation because it is the foundation of the model. Users, roles, permissions, operations, and sessions are defined and mapped according to the security policy. The core RBAC
• Has a many-to-many relationship among individual users and privileges
• Uses a session as a mapping between a user and a subset of assigned roles
• Accommodates traditional but robust group-based access control
Many users can belong to many groups with various privileges outlined for each group. When the user logs in (this is a session), the various roles and groups this user has been assigned will be available to the user at one time. If you are a member of the Accounting role, RD group, and Administrative role, when you log on, all of the permissions assigned to these various groups are available to you.
This model provides robust options because it can include other components when making access decisions, instead of just basing the decision on a credential set. The RBAC system can be configured to also include time of day, location of role, day of the week, and so on. This means other information, not just the user ID and credential, is used for access decisions.
Hierarchical RBAC
This component allows the administrator to set up an organizational RBAC model that maps to the organizational structures and functional delineations required in a specific environment. This is very useful since businesses are already set up in a personnel hierarchical structure. In most cases, the higher you are in the chain of command, the more access you will most likely have. Hierarchical RBAC
• Uses role relations in defining user membership and privilege inheritance. For example, the Nurse role can access a certain set of files, and the Lab Technician role can access another set of files. The Doctor role inherits the permissions and access rights of these two roles and has more elevated rights already assigned to the Doctor role. So hierarchical RBAC is an accumulation of rights and permissions of other roles.
• Reflects organizational structures and functional delineations.
• Supports two types of hierarchies:
• Limited hierarchies Only one level of hierarchy is allowed (Role 1 inherits from Role 2 and no other role)
• General hierarchies Allows for many levels of hierarchies (Role 1 inherits Role 2’s and Role 3’s permissions)
Hierarchies are a natural means of structuring roles to reflect an organization’s lines of authority and responsibility. Role hierarchies define an inheritance relation among roles. Different separations of duties are provided under this model:
• Static Separation of Duty (SSD) Relations through RBAC This would be used to deter fraud by constraining the combination of privileges (such as, the user cannot be a member of both the Cashier and Accounts Receivable groups).
• Dynamic Separation of Duties (DSD) Relations through RBAC This would be used to deter fraud by constraining the combination of privileges that can be activated in any session (for instance, the user cannot be in both the Cashier and Cashier Supervisor roles at the same time, but the user can be a member of both). This one is a little more confusing. It means José is a member of both the Cashier and Cashier Supervisor roles. If he logs in as a Cashier, the Supervisor role is unavailable to him during that session. If he logs in as Cashier Supervisor, the Cashier role is unavailable to him during that session.
• Role-based access control can be managed in the following ways:
• Non-RBAC Users are mapped directly to applications and no roles are used.
• Limited RBAC Users are mapped to multiple roles and mapped directly to other types of applications that do not have role-based access functionality.
• Hybrid RBAC Users are mapped to multiapplication roles with only selected rights assigned to those roles.
• Full RBAC Users are mapped to enterprise roles.
NOTE The privacy of many different types of data needs to be protected, which is why many organizations have privacy officers and privacy policies today. The current access control models (MAC, DAC, RBAC) do not lend themselves to protecting data of a given sensitivity level, but instead limit the functions that the users can carry out. For example, managers may be able to access a Privacy folder, but there needs to be more detailed access control that indicates that they can access customers’ home addresses but not Social Security numbers. This is referred to as privacy-aware RBAC.
Rule-Based Access Control
Rule-based access control uses specific rules that indicate what can and cannot happen between a subject and an object. This access control model is built on top of traditional RBAC and is thus commonly called RB-RBAC to disambiguate the otherwise overloaded RBAC acronym. It is based on the simple concept of “if X then Y” programming rules, which can be used to provide finer-grained access control to resources. Before a subject can access an object in a certain circumstance, it must meet a set of predefined rules. This can be simple and straightforward, as in, “If the user’s ID matches the unique user ID value in the provided digital certificate, then the user can gain access.” Or there could be a set of complex rules that must be met before a subject can access an object. For example, “If the user is accessing the system between Monday and Friday and between 8 a.m. and 5 p.m., and if the user’s security clearance equals or dominates the object’s classification, and if the user has the necessary need to know, then the user can access the object.”
Rule-based access control is not necessarily identity-based. The DAC model is identity-based. For example, an identity-based control would stipulate that Tom Jones can read File1 and modify File2. So when Tom attempts to access one of these files, the operating system will check his identity and compare it to the values within an ACL to see if Tom can carry out the operations he is attempting. In contrast, here is a rule-based example: A company may have a policy that dictates that e-mail attachments can only be 5MB or smaller. This rule affects all users. If rule-based was identity-based, it would mean that Sue can accept attachments of 10MB and smaller, Bob can accept attachments 2MB and smaller, and Don can only accept attachments 1MB and smaller. This would be a mess and too confusing. Rule-based access controls simplify this by setting a rule that will affect all users across the board—no matter what their identity is.
Rule-based access allows a developer to define specific and detailed situations in which a subject can or cannot access an object and what that subject can do once access is granted. Traditionally, rule-based access control has been used in MAC systems as an enforcement mechanism of the complex rules of access that MAC systems provide. Today, rule-based access is used in other types of systems and applications as well. Content filtering uses If-Then programming languages, which is a way to compare data or an activity to a long list of rules. For example, “If an e-mail message contains the word ‘Viagra,’ then disregard. If an e-mail message contains the words ‘sex’ and ‘free,’ then disregard,” and so on.
Many routers and firewalls use rules to determine which types of packets are allowed into a network and which are rejected. Rule-based access control is a type of compulsory control, because the administrator sets the rules and the users cannot modify these controls.
Attribute-Based Access Control
Attribute-based access control (ABAC) uses attributes of any part of a system to define allowable access. These attributes can belong to belong to subjects, objects, actions, or contexts. Here are some possible attributes we could use to describe our ABAC policies:
• Subjects Clearance, position title, department, years with the company, training certification on a specific platform, member of a project team, location
• Objects Classification, files pertaining to a particular project, HR records, location, security system component
• Actions Review, approve, comment, archive, configure, restart
• Context Time of day, project status (open/closed), fiscal year, ongoing audit
As you can see, ABAC provides the most granularity of any of the access control models. It would be possible, for example, to define and enforce a policy that allows only directors to comment on (but not edit) files pertaining to a project that is currently being audited. This specificity is a two-edged sword, since it can lead to an excessive number of policies that could interact with each other in ways that are difficult to predict.
Access Control Techniques and Technologies
Once an organization determines what type of access control model it is going to use, it needs to identify and refine its technologies and techniques to support that model. The following sections describe the different access controls and technologies available to support different access control models.
Constrained User Interfaces
Constrained user interfaces restrict users’ access abilities by not allowing them to request certain functions or information, or to have access to specific system resources. Three major types of constrained user interfaces exist: menus and shells, database views, and physically constrained interfaces.
When menu and shell restrictions are used, the options users are given are the commands they can execute. For example, if an administrator wants users to be able to execute only one program, that program would be the only choice available on the menu. This limits the users’ functionality. A shell is a type of virtual environment within a system. It is the users’ interface to the operating system and works as a command interpreter. If restricted shells were used, the shell would contain only the commands the administrator wants the users to be able to execute.
Many times, a database administrator will configure a database so users cannot see fields that require a level of confidentiality. Database views are mechanisms used to restrict user access to data contained in databases. If the database administrator wants managers to be able to view their employees’ work records but not their salary information, then the salary fields would not be available to these types of users. Similarly, when payroll employees look at the same database, they will be able to view the salary information but not the work history information. This example is illustrated in Figure 5-20.

Figure 5-20 Different database views of the same tables
Physically constraining a user interface can be implemented by providing only certain keys on a keypad or certain touch buttons on a screen. You see this when you get money from an ATM machine. This device has a type of operating system that can accept all kinds of commands and configuration changes, but you are physically constrained from being able to carry out these functions. You are presented with buttons that only enable you to withdraw, view your balance, or deposit funds. Period.
Remote Access Control Technologies
The following sections present some examples of centralized remote access control technologies. Each of these authentication protocols is referred to as an AAA protocol, which stands for authentication, authorization, and auditing. (Some resources have the last A stand for accounting, but it is the same functionality—just a different name.)
Depending upon the protocol, there are different ways to authenticate a user in this client/server architecture. The traditional authentication protocols are Password Authentication Protocol (PAP), Challenge Handshake Authentication Protocol (CHAP), and a newer method referred to as Extensible Authentication Protocol (EAP). Each of these authentication protocols is discussed at length in Chapter 6.
RADIUS
Remote Authentication Dial-In User Service (RADIUS) is a network protocol that provides client/server authentication and authorization, and audits remote users. A network may have access servers, a modem pool, DSL, ISDN, or a T1 line dedicated for remote users to communicate through. The access server requests the remote user’s logon credentials and passes them back to a RADIUS server, which houses the usernames and password values. The remote user is a client to the access server, and the access server is a client to the RADIUS server.
Most ISPs today use RADIUS to authenticate customers before they are allowed access to the Internet. The access server and customer’s software negotiate through a handshake procedure and agree upon an authentication protocol (PAP, CHAP, or EAP). The customer provides to the access server a username and password. This communication takes place over a Point-to-Point Protocol (PPP) connection. The access server and RADIUS server communicate over the RADIUS protocol. Once the authentication is completed properly, the customer’s system is given an IP address and connection parameters, and is allowed access to the Internet. The access server notifies the RADIUS server when the session starts and stops for billing purposes.
RADIUS is also used within corporate environments to provide road warriors and home users access to network resources. RADIUS allows companies to maintain user profiles in a central database. When a user dials in and is properly authenticated, a preconfigured profile is assigned to him to control what resources he can and cannot access. This technology allows companies to have a single administered entry point, which provides standardization in security and a simplistic way to track usage and network statistics.
RADIUS was developed by Livingston Enterprises for its network access server product series, but was then published as a set of standards (RFC 2865 and RFC 2866). This means it is an open protocol that any vendor can use and manipulate so it will work within its individual products. Because RADIUS is an open protocol, it can be used in different types of implementations. The format of configurations and user credentials can be held in LDAP servers, various databases, or text files. Figure 5-21 shows some examples of possible RADIUS implementations.
TACACS
Terminal Access Controller Access Control System (TACACS) has a very funny name. Not funny ha-ha, but funny “huh?” TACACS has been through three generations: TACACS, Extended TACACS (XTACACS), and TACACS+. TACACS combines its authentication and authorization processes; XTACACS separates authentication, authorization, and auditing processes; and TACACS+ is XTACACS with extended two-factor user authentication. TACACS uses fixed passwords for authentication, while TACACS+ allows users to employ dynamic (one-time) passwords, which provides more protection.
NOTE TACACS+ is really not a new generation of TACACS and XTACACS; it is a distinct protocol that provides similar functionality and shares the same naming scheme. Because it is a totally different protocol, it is not backward-compatible with TACACS or XTACACS.
TACACS+ provides basically the same functionality as RADIUS with a few differences in some of its characteristics. First, TACACS+ uses TCP as its transport protocol, while RADIUS uses UDP. “So what?” you may be thinking. Well, any software that is developed to use UDP as its transport protocol has to be “fatter” with intelligent code that will look out for the items that UDP will not catch. Since UDP is a connectionless protocol, it will not detect or correct transmission errors. So RADIUS must have the necessary code to detect packet corruption, long timeouts, or dropped packets. Since the developers of TACACS+ chose to use TCP, the TACACS+ software does not need to have the extra code to look for and deal with these transmission problems. TCP is a connection-oriented protocol, and that is its job and responsibility.
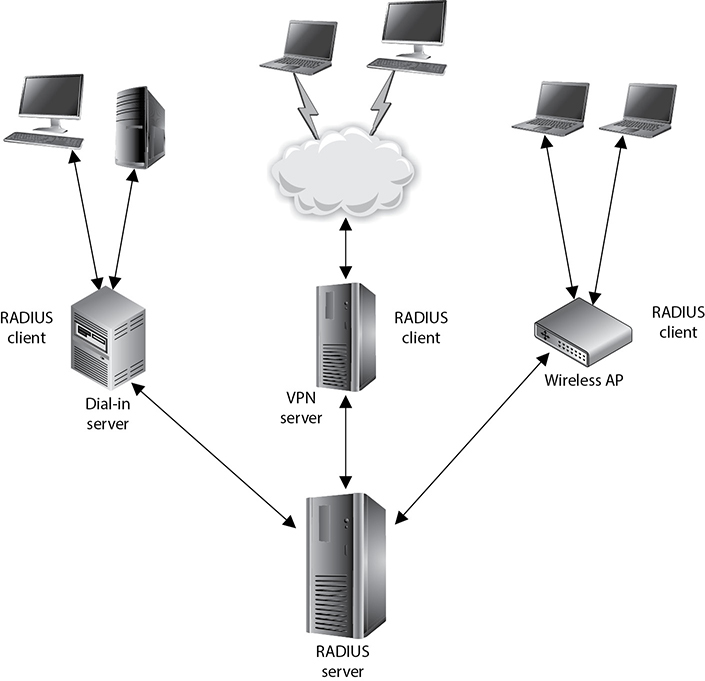
Figure 5-21 Environments can implement different RADIUS infrastructures.
RADIUS encrypts the user’s password only as it is being transmitted from the RADIUS client to the RADIUS server. Other information, as in the username, accounting, and authorized services, is passed in cleartext. This is an open invitation for attackers to capture session information for replay attacks. Vendors who integrate RADIUS into their products need to understand these weaknesses and integrate other security mechanisms to protect against these types of attacks. TACACS+ encrypts all of this data between the client and server and thus does not have the vulnerabilities inherent in the RADIUS protocol.
The RADIUS protocol combines the authentication and authorization functionality. TACACS+ uses a true authentication, authorization, and accounting/audit (AAA) architecture, which separates the authentication, authorization, and accounting functionalities. This gives a network administrator more flexibility in how remote users are authenticated. For example, if Tomika is a network administrator and has been assigned the task of setting up remote access for users, she must decide between RADIUS and TACACS+. If the current environment already authenticates all of the local users through a domain controller using Kerberos, then Tomika can configure the remote users to be authenticated in this same manner, as shown in Figure 5-22. Instead of having to maintain a remote access server database of remote user credentials and a database within Active Directory for local users, Tomika can just configure and maintain one database. The separation of authentication, authorization, and accounting functionality provides this capability. TACACS+ also enables the network administrator to define more granular user profiles, which can control the actual commands users can carry out.
Remember that RADIUS and TACACS+ are both protocols, and protocols are just agreed-upon ways of communication. When a RADIUS client communicates with a RADIUS server, it does so through the RADIUS protocol, which is really just a set of defined fields that will accept certain values. These fields are referred to as attribute-value pairs (AVPs). As an analogy, suppose Ivan sends you a piece of paper that has several different boxes drawn on it. Each box has a headline associated with it: first name, last name, hair color, shoe size. You fill in these boxes with your values and send it back to her. This is basically how protocols work; the sending system just fills in the boxes (fields) with the necessary information for the receiving system to extract and process.
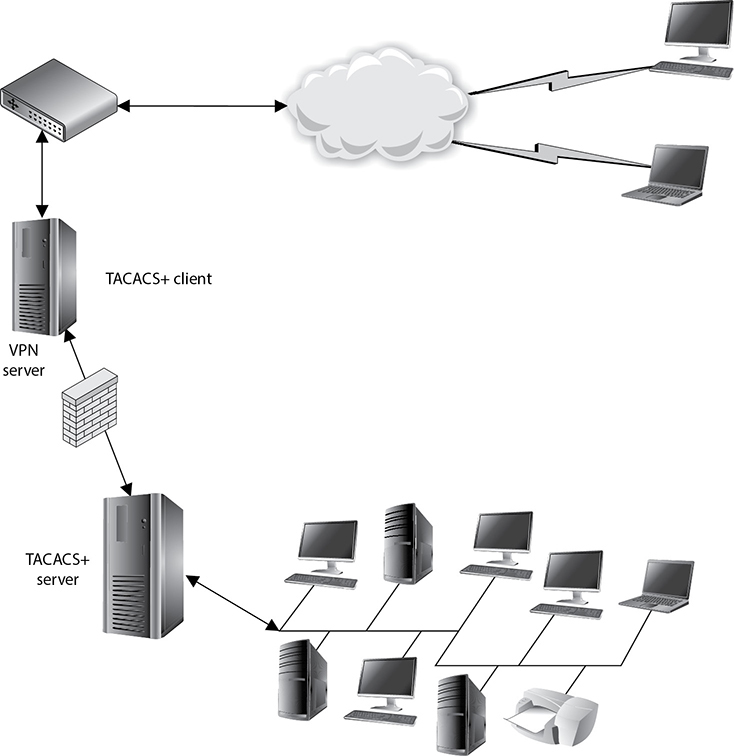
Figure 5-22 TACACS+ works in a client/server model.
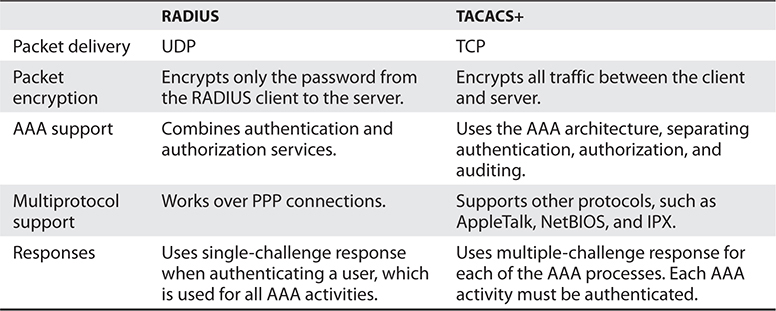
Table 5-1 Specific Differences Between These Two AAA Protocols
Since TACACS+ allows for more granular control on what users can and cannot do, TACACS+ has more AVPs, which allows the network administrator to define ACLs, filters, user privileges, and much more. Table 5-1 points out the differences between RADIUS and TACACS+.
So, RADIUS is the appropriate protocol when simplistic username/password authentication can take place and users only need an Accept or Deny for obtaining access, as in ISPs. TACACS+ is the better choice for environments that require more sophisticated authentication steps and tighter control over more complex authorization activities, as in corporate networks.
Diameter
Diameter is a protocol that has been developed to build upon the functionality of RADIUS and overcome many of its limitations. The creators of this protocol decided to call it Diameter as a play on the term RADIUS—as in the diameter is twice the radius.
Diameter is another AAA protocol that provides the same type of functionality as RADIUS and TACACS+ but also provides more flexibility and capabilities to meet the new demands of today’s complex and diverse networks. At one time, all remote communication took place over PPP and Serial Line Internet Protocol (SLIP) connections, and users authenticated themselves through PAP or CHAP. Those were simpler, happier times when our parents had to walk uphill both ways to school wearing no shoes. As with life, technology has become much more complicated, and there are more devices and protocols to choose from than ever before. Today, we want our wireless devices and smartphones to be able to authenticate themselves to our networks, and we use roaming protocols, Mobile IP, Ethernet over PPP, Voice over IP (VoIP), and other crazy stuff that the traditional AAA protocols cannot keep up with. So the smart people came up with a new AAA protocol, Diameter, that can deal with these issues and many more.
Diameter protocol consists of two portions. The first is the base protocol, which provides the secure communication among Diameter entities, feature discovery, and version negotiation. The second is the extensions, which are built on top of the base protocol to allow various technologies to use Diameter for authentication.
Up until the conception of Diameter, IETF had individual working groups who defined how VoIP, Fax over IP (FoIP), Mobile IP, and remote authentication protocols work. Defining and implementing them individually in any network can easily result in too much confusion and interoperability. It requires customers to roll out and configure several different policy servers and increases the cost with each new added service. Diameter provides a base protocol, which defines header formats, security options, commands, and AVPs. This base protocol allows for extensions to tie in other services, such as VoIP, FoIP, Mobile IP, wireless, and cell phone authentication. So Diameter can be used as an AAA protocol for all of these different uses.
As an analogy, consider a scenario in which ten people all need to get to the same hospital, which is where they all work. They all have different jobs (doctor, lab technician, nurse, janitor, and so on), but they all need to end up at the same location. So, they can either all take their own cars and their own routes to the hospital, which takes up more hospital parking space and requires the gate guard to authenticate each and every car, or they can take a bus. The bus is the common element (base protocol) to get the individuals (different services) to the same location (networked environment). Diameter provides the common AAA and security framework that different services can work within.
RADIUS and TACACS+ are client/server protocols, which means the server portion cannot send unsolicited commands to the client portion. The server portion can only speak when spoken to. Diameter is a peer-based protocol that allows either end to initiate communication. This functionality allows the Diameter server to send a message to the access server to request the user to provide another authentication credential if she is attempting to access a secure resource.
Diameter is not directly backward-compatible with RADIUS but provides an upgrade path. Diameter uses TCP and AVPs, and provides proxy server support. It has better error detection and correction functionality than RADIUS, as well as better failover properties, and thus provides better network resilience.
Diameter has the functionality and ability to provide the AAA functionality for other protocols and services because it has a large AVP set. RADIUS has 28 (256) AVPs, while Diameter has 232 (a whole bunch). Recall from earlier in the chapter that AVPs are like boxes drawn on a piece of paper that outline how two entities can communicate back and forth. So, having more AVPs allows for more functionality and services to exist and communicate between systems.
Diameter provides the AAA functionality, as listed next.
Authentication:
• PAP, CHAP, EAP
• End-to-end protection of authentication information
• Replay attack protection
Authorization:
• Redirects, secure proxies, relays, and brokers
• State reconciliation
• Unsolicited disconnect
• Reauthorization on demand
Accounting:
• Reporting, roaming operations (ROAMOPS) accounting, event monitoring
Access Control Matrix
An access control matrix is a table of subjects and objects indicating what actions individual subjects can take upon individual objects. Matrices are data structures that programmers implement as table lookups that will be used and enforced by the operating system. Table 5-2 provides an example of an access control matrix.
This type of access control is usually an attribute of DAC models. The access rights can be assigned directly to the subjects (capabilities) or to the objects (ACLs).
Capability Table
A capability table specifies the access rights a certain subject possesses pertaining to specific objects. A capability table is different from an ACL because the subject is bound to the capability table, whereas the object is bound to the ACL.

Table 5-2 Example of an Access Control Matrix
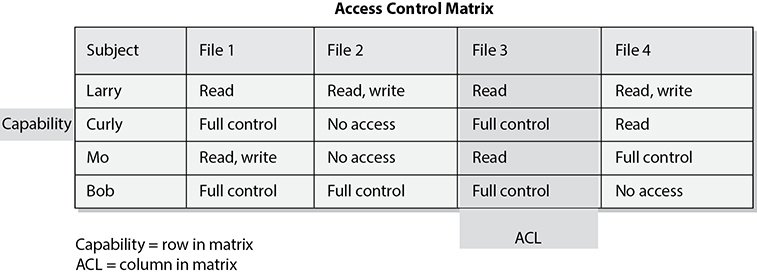
Figure 5-23 A capability table is bound to a subject, whereas an ACL is bound to an object.
The capability corresponds to the subject’s row in the access control matrix. In Table 5-2, Diane’s capabilities are File1: read and execute; File2: read, write, and execute; File3: no access. This outlines what Diane is capable of doing to each resource. An example of a capability-based system is Kerberos. In this environment, the user is given a ticket, which is his capability table. This ticket is bound to the user and dictates what objects that user can access and to what extent. The access control is based on this ticket, or capability table. Figure 5-23 shows the difference between a capability table and an ACL.
A capability can be in the form of a token, ticket, or key. When a subject presents a capability component, the operating system (or application) will review the access rights and operations outlined in the capability component and allow the subject to carry out just those functions. A capability component is a data structure that contains a unique object identifier and the access rights the subject has to that object. The object may be a file, array, memory segment, or port. Each user, process, and application in a capability system has a list of capabilities.
Access Control Lists
Access control lists (ACLs) are used in several operating systems, applications, and router configurations. They are lists of subjects that are authorized to access a specific object, and they define what level of authorization is granted. Authorization can be specific to an individual, group, or role.
ACLs map values from the access control matrix to the object. Whereas a capability corresponds to a row in the access control matrix, the ACL corresponds to a column of the matrix. The ACL for File1 in Table 5-2 is shown in Table 5-3.
Content-Dependent Access Control
As the name suggests, with content-dependent access control, access to objects is determined by the content within the object. The earlier example pertaining to database views showed how content-dependent access control can work. The content of the database fields dictates which users can see specific information within the database tables.
Content-dependent filtering is used when corporations employ e-mail filters that look for specific strings, such as “confidential,” “social security number,” “top secret,” and any other types of words the company deems suspicious. Corporations also have this in place to control web surfing—where filtering is done to look for specific words—to try to figure out whether employees are gambling or looking at pornography.

Table 5-3 The ACL for File1
Context-Dependent Access Control
Context-dependent access control differs from content-dependent access control in that it makes access decisions based on the context of a collection of information rather than on the sensitivity of the data. A system that is using context-dependent access control “reviews the situation” and then makes a decision. For example, firewalls make context-based access decisions when they collect state information on a packet before allowing it into the network. A stateful firewall understands the necessary steps of communication for specific protocols. For example, in a TCP connection, the sender sends a SYN packet, the receiver sends a SYN/ACK, and then the sender acknowledges that packet with an ACK packet. A stateful firewall understands these different steps and will not allow packets to go through that do not follow this sequence. So, if a stateful firewall receives a SYN/ACK and there was not a previous SYN packet that correlates with this connection, the firewall understands this is not right and disregards the packet. This is what stateful means—something that understands the necessary steps of a dialog session. And this is an example of context-dependent access control, where the firewall understands the context of what is going on and includes that as part of its access decision.
Some software can track a user’s access requests in sequence and make decisions based upon the previous access requests. For example, let’s say that we have a database that contains information about our military’s mission and efforts. A user might have a secret clearance and thus can access data with this level of classification. But if he accesses a data set that indicates a specific military troop location, then accesses a different data set that indicates the new location this military troop will be deployed to, and then accesses another data set that specifies the types of weapons that are being shipped to the new troop location, he might be able to figure out information that is classified as top secret, which is above his classification level. While it is okay that he knows that there is a military troop located in Kuwait, it is not okay that he knows that this troop is being deployed to Libya with fully armed drones. This is top-secret information that is outside his clearance level.
To ensure that a user cannot piece these different data sets together and figure out a secret we don’t want him to know, but still allow him access to specific data sets so he can carry out his job, we would need to implement software that can track his access requests. Each access request he makes is based upon his previous requests. So while he could access data set A, then data set B, he cannot access data sets A, B, and C.
Managing the Identity and Access Provisioning Life Cycle
Once an organization develops access control policies and determines the appropriate mechanisms, techniques, and technologies, it needs to implement procedures to ensure that identity and access are deliberately and systematically being issued to (and taken away from) users and systems. Many of us have either heard of or experienced the dismay of discovering that the credentials for someone who was fired months or years ago are still active in a domain controller. Some of us have even had to deal with that account having been used long after the individual left.
Identity and access have a life cycle that begins with provisioning of an account, goes through a series of periodic reviews to ensure the account is still necessary, and finally results in the account being deprovisioned. This is true not only for people but also for systems (such as a web server or a vulnerability scanning agent). User accounts are like keys to your office: you have to be really careful about who you give them to and know when to take them back.
Provisioning
We introduced the term provisioning earlier in this chapter when talking about authentication. Provisioning pertains to the creation of user objects or accounts. Sometimes, the term is used to describe the whole life cycle, but our focus in this section is on the first phase only, which is generating the account.
Normally, provisioning happens when a new user or system is added to an organization. For people, this is part of onboarding, which we discussed in Chapter 1. It is important to have an established process for ensuring that digital identities are issued only to the right folks. This usually involves reviews and approvals from human resources (HR) staff, the individual’s supervisor, and the IT department. The process is crucial for the rest of the life cycle because it answers the important question “Why did we provision this account?” The answer will determine whether the account remains active or is deprovisioned at some point in the future. Keep in mind that some accounts are used for long periods of time, and rationales for provisioning accounts that were obvious in the beginning may be forgotten with the passage of time and with staffing changes.
Identity and access provisioning also pertains to system accounts, which are usually associated with services and automated agents and oftentimes require privileged access. A challenge here is that most organizations have a lot of system accounts that are largely invisible on a day-to-day basis. Just as for user identity and access, the trick here is to document what accounts were created, where they were created, and why they were created.
User Access Review
Eventually, every user account (ideally) will be deprovisioned, because none of us works (or lives) forever. It may also be necessary to temporarily disable accounts, such as when a user goes on an extended leave of absence or is under some sort of adverse administrative action. The list of conditions under which an account is disabled or deprovisioned will vary by organization, but we all need to have such a list. We also need a process by which we periodically (or upon certain conditions) check every user account against that list. The purpose of these user access reviews is to ensure we don’t have any active accounts that are no longer needed.
Ideally, IT conducts reviews periodically (say, every six months), but reviews should also be triggered by certain administrative actions. A best practice is to integrate these reviews into the HR procedures because HR typically is involved in administrative actions anyway. Though it is obvious that user accounts should be disabled or deprovisioned when an employee is terminated, other situations are not as clear-cut, such as the following, and require a deliberate review by the individual’s supervisor and/or the IT department:
• Extended vacation or sabbatical
• Hospitalization
• Long-term disability (with an expected future return)
• Investigation for possible wrong-doing
• Unexpected disappearance
System Account Access Review
Just like we should do with user access, we should conduct system account access reviews both periodically and when certain conditions are met. Though HR would not be involved in these, the principle is the same: every system account eventually needs to be disabled or deprovisioned. What makes these accounts a bit trickier is that it is easy to forget they exist in the first place. It is not unusual for a service to require multiple accounts with which nobody interacts directly and yet are absolutely critical for the system. What’s worse, sometimes software updates can remove the need for legacy system accounts that are not deprovisioned as part of the updating process and remain in place as a potential vulnerability. A systematic approach to system account access review is your best way to avoid ending up with unneeded, potentially privileged accounts.
Deprovisioning
As we already said, ideally, sooner or later every account gets deprovisioned. For users, this is usually part of the termination procedures we covered in Chapter 1. For system accounts, this could happen because we got rid of a system or because some configuration change rendered an account unnecessary. Whatever the type of account or the reason for getting rid of it, it is important to document the change so we no longer track that account for reviewing purposes.
A potential challenge with deprovisioning accounts is that it could leave orphaned resources. Suppose that Jonathan is the owner of project files on a shared folder to which no one else has access. If he leaves the company and has his account deprovisioned, that shared folder would be left on the server, but nobody (except administrators) could do anything with it. Apart from being wasteful, this situation could hinder the business if those files were important later on. When deprovisioning accounts, therefore, it is important to transfer ownership of its resources to someone else.
Controlling Physical and Logical Access
Access controls can be implemented at various layers of a network and individual systems. Some controls are core components of operating systems or embedded into applications and devices, and some security controls require third-party add-on packages. Although different controls provide different functionality, they should all work together to keep the bad guys out and the good guys in, and to provide the necessary quality of protection.
Companies do not want people to be able to walk into their building arbitrarily, sit down at an employee’s computer, and access network resources. Companies also don’t want every employee to be able to access all information within the company, as in human resource records, payroll information, and trade secrets. Companies want some assurance that employees who can access confidential information will have some restrictions put upon them, making sure, say, a disgruntled employee does not have the ability to delete financial statements, tax information, and top-secret data that would put the company at risk. Several types of access controls prevent these things from happening, as discussed in the sections that follow.
Access Control Layers
Access control consists of three broad categories: administrative, technical, and physical. Each category has different access control mechanisms that can be carried out manually or automatically. All of these access control mechanisms should work in concert with each other to protect an infrastructure and its data.
Each category of access control has several components that fall within it, as listed next.
Administrative controls:
• Policy and procedures
• Personnel controls
• Supervisory structure
• Security-awareness training
• Testing
Physical controls:
• Network segregation
• Perimeter security
• Computer controls
• Work area separation
• Data backups
• Cabling
• Control zone
Technical controls:
• System access
• Network architecture
• Network access
• Encryption and protocols
• Auditing
The following sections explain each of these categories and components and how they relate to access control.
Administrative Controls
Senior management must decide what role security will play in the organization, including the security goals and objectives. These directives will dictate how all the supporting mechanisms will fall into place. Basically, senior management provides the skeleton of a security infrastructure and then appoints the proper entities to fill in the rest.
The first piece to building a security foundation within an organization is a security policy. It is management’s responsibility to construct a security policy and delegate the development of the supporting procedures, standards, and guidelines; indicate which personnel controls should be used; and specify how testing should be carried out to ensure all pieces fulfill the company’s security goals. These items are administrative controls and work at the top layer of a hierarchical access control model. (Administrative controls are examined in detail in Chapter 1, but are mentioned here briefly to show the relationship to logical and physical controls pertaining to access control.)
Personnel Controls
Personnel controls indicate how employees are expected to interact with security mechanisms and address noncompliance issues pertaining to these expectations. These controls indicate what security actions should be taken when an employee is hired, terminated, suspended, moved into another department, or promoted. Specific procedures must be developed for each situation, and many times the human resources and legal departments are involved with making these decisions.
Supervisory Structure
Management must construct a supervisory structure in which each employee has a superior to report to, and that superior is responsible for that employee’s actions. This forces management members to be responsible for employees and take a vested interest in their activities. If an employee is caught hacking into a server that holds customer credit card information, that employee and her supervisor will face the consequences. This is an administrative control that aids in fighting fraud and enforcing proper control.
Security-Awareness Training
In many organizations, management has a hard time spending money and allocating resources for items that do not seem to affect the bottom line: profitability. This is why training traditionally has been given low priority, but as computer security becomes more and more of an issue to companies, they are starting to recognize the value of security awareness training.
A company’s security depends upon technology and people, and people are usually the weakest link and cause the most security breaches and compromises. If users understand how to properly access resources, why access controls are in place, and the ramifications for not using the access controls properly, a company can reduce many types of security incidents.
Testing
All security controls, mechanisms, and procedures must be tested on a periodic basis to ensure they properly support the security policy, goals, and objectives set for them. This testing can be a drill to test reactions to a physical attack or disruption of the network, a penetration test of the firewalls and perimeter network to uncover vulnerabilities, a query to employees to gauge their knowledge, or a review of the procedures and standards to make sure they still align with implemented business or technology changes. Because change is constant and environments continually evolve, security procedures and practices should be continually tested to ensure they align with management’s expectations and stay up-to-date with each addition to the infrastructure. It is management’s responsibility to make sure these tests take place.
Physical Controls
We discussed physical security in Chapter 3, but it is important to understand that certain physical controls must support and work with administrative and technical (logical) controls to supply the right degree of access control. Examples of physical controls include having a security guard verify individuals’ identities prior to allowing them to enter a facility, erecting fences around the exterior of the facility, making sure server rooms and wiring closets are locked and protected from environmental elements (humidity, heat, and cold), and allowing only certain individuals to access work areas that contain confidential information.
Network Segregation
Network segregation can be carried out through physical and logical means. A network might be physically designed to have all computers and databases in a certain area. This area may have doors with security swipe cards that allow only individuals who have a specific clearance to access this section and these computers. Another section of the network may contain web servers, routers, and switches, and yet another network portion may have employee workstations. Each area would have the necessary physical controls to ensure that only the permitted individuals have access into and out of those sections.
Perimeter Security
Perimeter security is concerned with controlling physical access to facilities. How it is implemented depends upon the company and the security requirements of that environment. One environment may require employees to be authorized by a security guard by showing a security badge that contains a picture identification before being allowed to enter a section. Another environment may require no authentication process and let anyone and everyone into different sections. Perimeter security can also encompass closed-circuit TVs that scan the parking lots and waiting areas, fences surrounding a building, the lighting of walkways and parking areas, motion detectors, sensors, alarms, and the location and visual appearance of a building. These are examples of perimeter security mechanisms that provide physical access control by providing protection for individuals, facilities, and the components within facilities.
Computer Controls
It has been said that if an attacker can physically touch a device, then he can own it. We make the threat actors’ jobs significantly more difficult by controlling physical access to our devices and assets. Each computer can have physical controls installed and configured, such as locks on the cover so the internal parts cannot be stolen, the removal of the USB and optical drives to prevent copying of confidential information, or implementation of a protection device that reduces the electrical emissions to thwart attempts to gather information through airwaves.
Work Area Separation
Some environments might dictate that only particular individuals can access certain areas of the facility. For example, research companies might not want office personnel to be able to enter laboratories, so that they can’t disrupt or taint experiments or access test data. Most network administrators allow only network staff in the server rooms and wiring closets to reduce the possibilities of errors or sabotage attempts. In financial institutions, only certain employees can enter the vaults or other restricted areas. These examples of work area separation are physical controls used to support access control and the overall security policy of the company.
Cabling
Different types of cabling can be used to carry information throughout a network. Some cable types have sheaths that protect the data from being affected by the electrical interference of other devices that emit electrical signals. Some types of cable have protection material around each individual wire to ensure there is no crosstalk between the different wires. All cables need to be routed throughout the facility so they are not in the way of employees or exposed to any dangers like being cut, burnt, crimped, or eavesdropped upon.
Control Zone
The company facility should be split up into zones depending upon the sensitivity of the activity that takes place per zone. The front lobby could be considered a public area, the product development area could be considered top secret, and the executive offices could be considered secret. It does not matter what classifications are used, but it should be understood that some areas are more sensitive than others, which will require different access controls based on the needed protection level. The same is true of the company network. It should be segmented, and access controls should be chosen for each zone based on the criticality of devices and the sensitivity of data being processed.
Technical Controls
Technical controls regulate logical access to systems and information. They are core components of operating systems, add-on security packages, applications, network hardware devices, protocols, encryption mechanisms, and access control matrices. These controls work at different layers within a network or system and need to maintain a synergistic relationship to ensure there is no unauthorized access to resources and that the resources’ availability, integrity, and confidentiality are guaranteed. Technical controls protect the integrity and availability of resources by limiting the number of subjects that can access them and protecting the confidentiality of resources by preventing disclosure to unauthorized subjects.
System Access
Different types of controls and security mechanisms control how a computer is accessed. If an organization is using a MAC architecture, the clearance of a user is identified and compared to the resource’s classification level to verify that this user can access the requested object. If an organization is using a DAC architecture, the operating system checks to see if a user has been granted permission to access this resource. The sensitivity of data, clearance level of users, and users’ rights and permissions are used as logical controls to control access to a resource.
Many types of technical controls enable a user to access a system and the resources within that system. A technical control may be a username and password combination, a Kerberos implementation, biometrics, public key infrastructure (PKI), RADIUS, TACACS+, or authentication using a smart card through a reader connected to a system. These technologies verify the user is who he says he is by using different types of authentication methods. Once a user is properly authenticated, he can be authorized and allowed access to network resources. These technologies are addressed in further detail in future chapters, but for now understand that system access is a type of technical control that can enforce access control objectives.
Network Architecture
The architecture of a network can be constructed and enforced through several logical controls to provide segregation and protection of an environment. Whereas a network can be segregated physically by walls and location, it can also be segregated logically through IP address ranges and subnets and by controlling the communication flow between the segments. Often, it is important to control how one segment of a network communicates with another segment.
Figure 5-24 shows an example of how an organization may segregate its network and determine how network segments can communicate. This example shows that the organization does not want the internal network and the demilitarized zone (DMZ) to have open and unrestricted communication paths. There is usually no reason for internal users to have direct access to the systems in the DMZ, and cutting off this type of communication reduces the possibilities of internal attacks on those systems. Also, if an attack comes from the Internet and successfully compromises a system on the DMZ, the attacker must not be able to easily access the internal network, which this type of logical segregation protects against.
This example also shows how the management segment can communicate with all other network segments, but those segments cannot communicate in return. The segmentation is implemented because the management consoles that control the firewalls and IDSs reside in the management segment, and there is no reason for users, other than the administrator, to have access to these computers.
A network can be segregated physically and logically. This type of segregation and restriction is accomplished through logical controls.
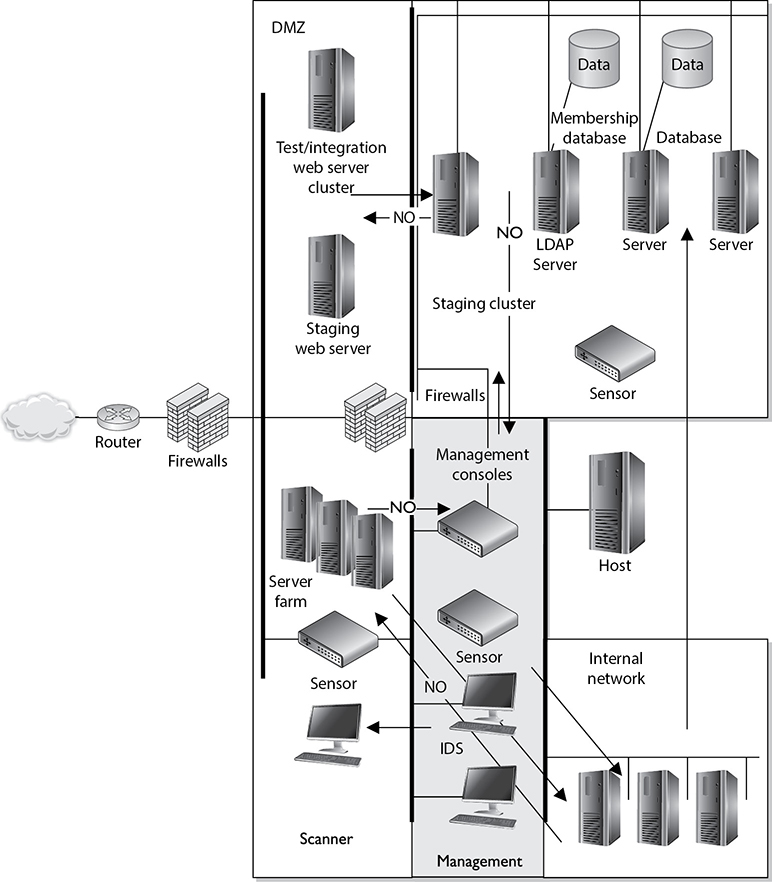
Figure 5-24 Technical network segmentation controls how different network segments communicate.
Network Access
Systems have logical controls that dictate who can and cannot access them and what those individuals can do once they are authenticated. This is also true for networks. Routers, switches, firewalls, and gateways all work as technical controls to enforce access restriction into and out of a network and access to the different segments within the network. If an attacker from the Internet wants to gain access to a specific computer, chances are she will have to hack through a firewall, router, and a switch just to be able to start an attack on a specific computer that resides within the internal network. Each device has its own logical controls that make decisions about what entities can access them and what type of actions they can carry out.
Access to different network segments should be granular in nature. Routers and firewalls can be used to ensure that only certain types of traffic get through to each segment.
Encryption and Protocols
Encryption and protocols control logical access to information by protecting it as it passes throughout a network and resides on computers. They ensure that the information is received by the correct entity and that it is not modified during transmission. These logical controls can preserve the confidentiality and integrity of data and enforce specific paths for communication to take place. (Chapter 3 discusses cryptography and encryption mechanisms.)
Auditing
Auditing tools are technical controls that track activity within a network, on a network device, or on a specific computer. Even though auditing is not an activity that will deny an entity access to a network or computer, it will track activities so a network administrator can understand the types of access that took place, identify a security breach, or warn the administrator of suspicious activity. This information can be used to point out weaknesses of other technical controls and help the administrator understand where changes must be made to preserve the necessary security level within the environment.
NOTE What is important to understand is that there are administrative, technical, and physical controls that work toward providing access control, and you should know several examples of each for the exam.
Access Control Practices
We have gone over how users are identified, authenticated, and authorized and how their actions are audited. These are necessary parts of a healthy and safe network environment. You also want to take steps to ensure there are no unnecessary open doors and that the environment stays at the same security level you have worked so hard to achieve. This means you need to implement good access control practices. Not keeping up with daily or monthly tasks usually causes the most vulnerabilities in an environment. It is hard to put out all the network fires, fight the political battles, fulfill all the users’ needs, and still keep up with small maintenance tasks. However, many companies have found that not doing these small tasks caused them the greatest heartache of all.
The following is a list of tasks that must be done on a regular basis to ensure security stays at a satisfactory level:
• Deny access to systems to undefined users or anonymous accounts.
• Limit and monitor the usage of administrator and other powerful accounts.
• Suspend or delay access capability after a specific number of unsuccessful logon attempts.
• Remove obsolete user accounts as soon as the user leaves the company.
• Suspend inactive accounts after 30 to 60 days.
• Enforce strict access criteria.
• Enforce the need-to-know and least-privilege practices.
• Disable unneeded system features, services, and ports.
• Replace default password settings on accounts.
• Limit and monitor global access rules.
• Remove redundant resource rules from accounts and group memberships.
• Remove redundant user IDs, accounts, and role-based accounts from resource access lists.
• Enforce password rotation.
• Enforce password requirements (length, contents, lifetime, distribution, storage, and transmission).
• Audit system and user events and actions, and review reports periodically.
• Protect audit logs.
Even if all of these countermeasures are in place and properly monitored, data can still be lost in an unauthorized manner in other ways. The next section looks at these issues and their corresponding countermeasures.
Unauthorized Disclosure of Information
Several things can make information available to others for whom it is not intended, which can bring about unfavorable results. Sometimes this is done intentionally; other times, unintentionally. Information can be disclosed unintentionally when one falls prey to attacks that specialize in causing this disclosure. These attacks include social engineering, covert channels, malicious code, and electrical airwave sniffing. Information can be disclosed accidentally through object reuse methods, which are explained next.
Object Reuse
Object reuse issues pertain to reassigning to a subject media that previously contained one or more objects. Huh? This means before someone uses a hard drive, USB drive, or tape, it should be cleared of any residual information still on it. This concept also applies to objects reused by computer processes, such as memory locations, variables, and registers. Any sensitive information that may be left by a process should be securely cleared before allowing another process the opportunity to access the object. This ensures that information not intended for this individual or any other subject is not disclosed. Many times, USB drives are exchanged casually in a work environment. What if a supervisor lent a USB drive to an employee without erasing it and it contained confidential employee performance reports and salary raises forecasted for the next year? This could prove to be a bad decision and may turn into a morale issue if the information was passed around. Formatting a disk or deleting files only removes the pointers to the files; it does not remove the actual files. This information will still be on the disk and available until the operating system needs that space and overwrites those files. So, for media that holds confidential information, more extreme methods should be taken to ensure the files are actually gone, not just their pointers.
Sensitive data should be classified (secret, top secret, confidential, unclassified, and so on) by the data owners. How the data is stored and accessed should also be strictly controlled and audited by software controls. However, the task does not end there. Before allowing someone to use previously used media, it should be erased or degaussed. (This responsibility usually falls on the operations department.) If media holds sensitive information and cannot be purged, steps should be created describing how to properly destroy it so no one else can obtain this information.
TIP Sometimes hackers actually configure a sector on a hard drive so it is marked as bad and unusable to an operating system but is actually fine and may hold malicious data. The operating system will not write information to this sector because it thinks it is corrupted. This is a form of data hiding. Some boot-sector virus routines are capable of putting the main part of their code (payload) into a specific sector of the hard drive, overwriting any data that may have been there, and then protecting it as a bad block.
Emanation Security
All electronic devices emit electrical signals. These signals can hold important information, and if an attacker buys the right equipment and positions himself in the right place, he could capture this information from the airwaves and access data transmissions as if he had a tap directly on the network wire.
Several incidents have occurred in which intruders have purchased inexpensive equipment and used it to intercept electrical emissions as they radiated from a computer. This equipment can reproduce data streams and display the data on the intruder’s monitor, enabling the intruder to learn of covert operations, find out military strategies, and uncover and exploit confidential information. This is not just stuff found in spy novels. It really happens. So, the proper countermeasures have been devised.
TEMPEST TEMPEST started out as a study carried out by the DoD and then turned into a standard that outlines how to develop countermeasures that control spurious electrical signals emitted by electrical equipment. Special shielding is used on equipment to suppress the signals as they are radiated from devices. TEMPEST equipment is implemented to prevent intruders from picking up information through the airwaves with listening devices. This type of equipment must meet specific standards to be rated as providing TEMPEST shielding protection. TEMPEST refers to standardized technology that suppresses signal emanations with shielding material. Vendors who manufacture this type of equipment must be certified to this standard.
The devices (monitors, computers, printers, and so on) have an outer metal coating, referred to as a Faraday cage. This is made of metal with the necessary depth to ensure only a certain amount of radiation is released. In devices that are TEMPEST rated, other components are also modified, especially the power supply, to help reduce the amount of electricity used.
Even allowable limits of emission levels can radiate and still be considered safe. The approved products must ensure only this level of emissions is allowed to escape the devices. This type of protection is usually needed only in military institutions, although other highly secured environments do utilize this kind of safeguard.
Many military organizations are concerned with stray radio frequencies emitted by computers and other electronic equipment because an attacker may be able to pick them up, reconstruct them, and give away secrets meant to stay secret.
TEMPEST technology is complex, cumbersome, and expensive, and therefore only used in highly sensitive areas that really need this high level of protection.
Two alternatives to TEMPEST exist: use white noise or use a control zone concept, both of which are explained next.
NOTE TEMPEST is the name of a program, and now a standard, that was developed in the late 1950s by the U.S. and British governments to deal with electrical and electromagnetic radiation emitted from electrical equipment, mainly computers. This type of equipment is usually used by intelligence, military, government, and law enforcement agencies, and the selling of such items is under constant scrutiny.
White Noise A countermeasure used to keep intruders from extracting information from electrical transmissions is white noise, a uniform spectrum of random electrical signals. It is distributed over the full spectrum so the bandwidth is constant and an intruder is not able to decipher real information from random noise or random information.
Control Zone Another alternative to using TEMPEST equipment is to use the zone concept, which was addressed earlier in this chapter. Some facilities use material in their walls to contain electrical signals, which acts like a large Faraday cage. This prevents intruders from being able to access information emitted via electrical signals from network devices. This control zone creates a type of security perimeter and is constructed to protect against unauthorized access to data or the compromise of sensitive information.
Access Control Monitoring
Access control monitoring is a method of keeping track of who attempts to access specific company resources. It is an important detective mechanism, and different technologies exist that can fill this need. It is not enough to invest in antivirus and firewall solutions. Companies are finding that monitoring their own internal network has become a way of life.
Intrusion Detection Systems
Intrusion detection systems (IDSs) are different from traditional firewall products because they are designed to detect a security breach. Intrusion detection is the process of detecting an unauthorized use of, or attack upon, a computer, network, or telecommunications infrastructure. IDSs are designed to aid in mitigating the damage that can be caused by hacking or by breaking into sensitive computer and network systems. The basic intent of the IDS tool is to spot something suspicious happening on the network and sound an alarm by flashing a message on a network manager’s screen, or possibly sending an e-mail or even reconfiguring a firewall’s ACL setting. The IDS tools can look for sequences of data bits that might indicate a questionable action or event, or monitor system log and activity recording files. The event does not need to be an intrusion to sound the alarm—any kind of “non-normal” behavior may do the trick.
Although different types of IDS products are available, they all have three common components: sensors, analyzers, and administrator interfaces. The sensors collect traffic and user activity data and send it to an analyzer, which looks for suspicious activity. If the analyzer detects an activity it is programmed to deem as fishy, it sends an alert to the administrator’s interface.
IDSs come in two main types: network-based, which monitor network communications, and host-based, which can analyze the activity within a particular computer system.
IDSs can be configured to watch for attacks, parse audit logs, terminate a connection, alert an administrator as attacks are happening, expose a hacker’s techniques, illustrate which vulnerabilities need to be addressed, and possibly help track down individual hackers.
Network-Based IDSs
A network-based IDS (NIDS) uses sensors, which are either host computers with the necessary software installed or dedicated appliances—each with its network interface card (NIC) in promiscuous mode. Normally, NICs watch for traffic that has the address of its host system, broadcasts, and sometimes multicast traffic. The NIC driver copies the data from the transmission medium and sends it up the network protocol stack for processing. When a NIC is put into promiscuous mode, the NIC driver captures all traffic, makes a copy of all packets, and then passes one copy to the TCP stack and one copy to an analyzer to look for specific types of patterns.
A NIDS monitors network traffic and cannot “see” the activity going on inside a computer itself. To monitor the activities within a computer system, a company would need to implement a host-based IDS.
Host-Based IDSs
A host-based IDS (HIDS) can be installed on individual workstations and/or servers to watch for inappropriate or anomalous activity. HIDSs are usually used to make sure users do not delete system files, reconfigure important settings, or put the system at risk in any other way. So, whereas the NIDS understands and monitors the network traffic, a HIDS’s universe is limited to the computer itself. A HIDS does not understand or review network traffic, and a NIDS does not “look in” and monitor a system’s activity. Each has its own job and stays out of the other’s way.
In most environments, HIDS products are installed only on critical servers, not on every system on the network, because of the resource overhead and the administration nightmare that such an installation would cause.
Just to make life a little more confusing, HIDS and NIDS can be one of the types, as listed next.
Signature-based:
• Pattern matching
• Stateful matching
Anomaly-based:
• Statistical anomaly–based
• Protocol anomaly–based
• Traffic anomaly–based
• Rule- or heuristic-based
Knowledge- or Signature-Based Intrusion Detection
Knowledge is accumulated by the IDS vendors about specific attacks and how they are carried out. Models of how the attacks are carried out are developed and called signatures. Each identified attack has a signature, which is used to detect an attack in progress or determine if one has occurred within the network. Any action that is not recognized as an attack is considered acceptable.
NOTE Signature-based is also known as pattern matching.
An example of a signature is a packet that has the same source IP address and destination IP address. All packets should have different source and destination IP addresses, and if they have the same address, this means a Land attack is under way. In a Land attack, a hacker modifies the packet header so that when a receiving system responds to the sender, it is responding to its own address. Now that seems as though it should be benign enough, but vulnerable systems just do not have the programming code to know what to do in this situation, so they freeze or reboot. Once this type of attack was discovered, the signature-based IDS vendors wrote a signature that looks specifically for packets that contain the same source and destination address.
Signature-based IDSs are the most popular IDS products today, and their effectiveness depends upon regularly updating the software with new signatures, as with antivirus software. This type of IDS is weak against new types of attacks because it can recognize only the ones that have been previously identified and have had signatures written for them. Attacks or viruses discovered in production environments are referred to as being “in the wild.”
State-Based IDSs
Before delving too deep into how a state-based IDS works, you need to understand what the state of a system or application actually is. Every change that an operating system experiences (user logs on, user opens application, application communicates to another application, user inputs data, and so on) is considered a state transition. In a very technical sense, all operating systems and applications are just lines and lines of instructions written to carry out functions on data. The instructions have empty variables, which is where the data is held. So when you use the calculator program and type in 5, an empty variable is instantly populated with this value. By entering that value, you change the state of the application. When applications communicate with each other, they populate empty variables provided in each application’s instruction set. So, a state transition is when a variable’s value changes, which usually happens continuously within every system.
Specific state changes (activities) take place with specific types of attacks. If an attacker will carry out a remote buffer overflow, then the following state changes will occur:
1. The remote user connects to the system.
2. The remote user sends data to an application (the data exceeds the allocated buffer for this empty variable).
3. The data is executed and overwrites the buffer and possibly other memory segments.
4. A malicious code executes.
So, state is a snapshot of an operating system’s values in volatile, semipermanent, and permanent memory locations. In a state-based IDS, the initial state is the state prior to the execution of an attack, and the compromised state is the state after successful penetration. The IDS has rules that outline which state transition sequences should sound an alarm. The activity that takes place between the initial and compromised state is what the state-based IDS looks for, and it sends an alert if any of the state-transition sequences match its preconfigured rules.
This type of IDS scans for attack signatures in the context of a stream of activity instead of just looking at individual packets. It can only identify known attacks and requires frequent updates of its signatures.
Statistical Anomaly–Based IDS
A statistical anomaly–based IDS is a behavioral-based system. Behavioral-based IDS products do not use predefined signatures, but rather are put in a learning mode to build a profile of an environment’s “normal” activities. This profile is built by continually sampling the environment’s activities. The longer the IDS is put in a learning mode, in most instances, the more accurate a profile it will build and the better protection it will provide. After this profile is built, all future traffic and activities are compared to it. The same type of sampling that was used to build the profile takes place, so the same type of data is being compared. Anything that does not match the profile is seen as an attack, in response to which the IDS sends an alert. With the use of complex statistical algorithms, the IDS looks for anomalies in the network traffic or user activity. Each packet is given an anomaly score, which indicates its degree of irregularity. If the score is higher than the established threshold of “normal” behavior, then the preconfigured action will take place.
The benefit of using a statistical anomaly–based IDS is that it can react to new attacks. It can detect “zero-day” attacks, which means an attack is new to the world and no signature or fix has been developed yet. These products are also capable of detecting the “low and slow” attacks, in which the attacker is trying to stay under the radar by sending packets little by little over a long period of time. The IDS should be able to detect these types of attacks because they are different enough from the contrasted profile.
Now for the bad news. Since the only thing that is “normal” about a network is that it is constantly changing, developing the correct profile that will not provide an overwhelming number of false positives can be difficult. Many IT staff members know all too well this dance of chasing down alerts that end up being benign traffic or activity. In fact, some environments end up turning off their IDS because of the amount of time these activities take up. (Proper education on tuning and configuration will reduce the number of false positives.)
If an attacker detects there is an IDS on a network, she will then try to detect the type of IDS it is so she can properly circumvent it. With a behavioral-based IDS, the attacker could attempt to integrate her activities into the behavior pattern of the network traffic. That way, her activities are seen as “normal” by the IDS and thus go undetected. It is a good idea to ensure no attack activity is under way when the IDS is in learning mode. If this takes place, the IDS will never alert you of this type of attack in the future because it sees this traffic as typical of the environment.
If a corporation decides to use a statistical anomaly–based IDS, it must ensure that the staff members who are implementing and maintaining it understand protocols and packet analysis. Because this type of an IDS sends generic alerts, compared to other types of IDSs, it is up to the network engineer to figure out what the actual issue is. For example, a signature-based IDS reports the type of attack that has been identified, while a rule-based IDS identifies the actual rule the packet does not comply with. In a statistical anomaly–based IDS, all the product really understands is that something “abnormal” has happened, which just means the event does not match the profile.
NOTE IDS and some antimalware products are said to have “heuristic” capabilities. The term heuristic means to create new information from different data sources. The IDS gathers different “clues” from the network or system and calculates the probability an attack is taking place. If the probability hits a set threshold, then the alarm sounds.
Determining the proper thresholds for statistically significant deviations is really the key for the successful use of a behavioral-based IDS. If the threshold is set too low, nonintrusive activities are considered attacks (false positives). If the threshold is set too high, some malicious activities won’t be identified (false negatives).
Once an IDS discovers an attack, several things can happen, depending upon the capabilities of the IDS and the policy assigned to it. The IDS can send an alert to a console to tell the right individuals an attack is being carried out, send an e-mail or text to the individual assigned to respond to such activities, kill the connection of the detected attack, or reconfigure a router or firewall to try to stop any further similar attacks. A modifiable response condition might include anything from blocking a specific IP address to redirecting or blocking a certain type of activity.
Protocol Anomaly–Based IDS
A statistical anomaly–based IDS can use protocol anomaly–based filters. These types of IDSs have specific knowledge of each protocol they will monitor. A protocol anomaly pertains to the format and behavior of a protocol. The IDS builds a model (or profile) of each protocol’s “normal” usage. Keep in mind, however, that protocols have theoretical usage, as outlined in their corresponding RFCs, and real-world usage, which refers to the fact that vendors seem to always “color outside the boxes” and don’t strictly follow the RFCs in their protocol development and implementation. So, most profiles of individual protocols are a mix between the official and real-world versions of the protocol and its usage. When the IDS is activated, it looks for anomalies that do not match the profiles built for the individual protocols.
Although several vulnerabilities within operating systems and applications are available to be exploited, many more successful attacks take place by exploiting vulnerabilities in the protocols themselves. At the OSI data link layer, the Address Resolution Protocol (ARP) does not have any protection against ARP attacks where bogus data is inserted into its table. At the network layer, the Internet Control Message Protocol (ICMP) can be used in a Loki attack to move data from one place to another, when this protocol was designed to only be used to send status information—not user data. IP headers can be easily modified for spoofed attacks. At the transport layer, TCP packets can be injected into the connection between two systems for a session hijacking attack.
NOTE When an attacker compromises a computer and loads a back door on the system, he will need to have a way to communicate to this computer through this back door and stay “under the radar” of the network firewall and IDS. Hackers have figured out that a small amount of code can be inserted into an ICMP packet, which is then interpreted by the back-door software loaded on a compromised system. Security devices are usually not configured to monitor this type of traffic because ICMP is a protocol that is supposed to be used just to send status information—not commands to a compromised system.
Because every packet formation and delivery involves many protocols, and because more attack vectors exist in the protocols than in the software itself, it is a good idea to integrate protocol anomaly–based filters in any network behavioral-based IDS.
Traffic Anomaly–Based IDS
Most behavioral-based IDSs have traffic anomaly–based filters, which detect changes in traffic patterns, as in DoS attacks or a new service that appears on the network. Once a profile is built that captures the baselines of an environment’s ordinary traffic, all future traffic patterns are compared to that profile. As with all filters, the thresholds are tunable to adjust the sensitivity and to reduce the number of false positives and false negatives. Since this is a type of statistical anomaly–based IDS, it can detect unknown attacks.
Rule-Based IDS
A rule-based IDS takes a different approach than a signature-based or statistical anomaly–
based system. A signature-based IDS is very straightforward. For example, if a signature-
based IDS detects a packet that has all of its TCP header flags with the bit value of 1, it knows that an Xmas attack is under way—so it sends an alert. A statistical anomaly–based IDS is also straightforward. For example, if Bob has logged on to his computer at 6 a.m. and the profile indicates this is abnormal, the IDS sends an alert, because this is seen as an activity that needs to be investigated. Rule-based intrusion detection gets a little trickier, depending upon the complexity of the rules used.
Rule-based intrusion detection is commonly associated with the use of an expert system. An expert system is made up of a knowledge base, inference engine, and rule-based programming. Knowledge is represented as rules, and the data to be analyzed is referred to as facts. The knowledge of the system is written in rule-based programming (IF situation THEN action). These rules are applied to the facts, the data that comes in from a sensor, or a system that is being monitored. For example, in scenario 1 the IDS pulls data from a system’s audit log and stores it temporarily in its fact database, as illustrated in Figure 5-25. Then, the preconfigured rules are applied to this data to indicate whether anything suspicious is taking place. In our scenario, the rule states “IF a root user creates File1 AND creates File2 SUCH THAT they are in the same directory THEN there is a call to Administrative Tool1 TRIGGER send alert.” This rule has been defined such that if a root user creates two files in the same directory and then makes a call to a specific administrative tool, an alert should be sent.
It is the inference engine that provides some artificial intelligence into this process. An inference engine can infer new information from provided data by using inference rules. To understand what inferring means in the first place, let’s look at the following:
Socrates is a man.
All men are mortals.
Thus, we can infer that Socrates is mortal. If you are asking, “What does this have to do with a hill of beans?” just hold on to your hat—here we go.
Figure 5-25 Rule-based IDS and expert system components
Regular programming languages deal with the “black and white” of life. The answer is either yes or no, not maybe this or maybe that. Although computers can carry out complex computations at a much faster rate than humans, they have a harder time guessing, or inferring, answers because they are very structured. The fifth-generation programming languages (artificial intelligence languages) are capable of dealing with the grayer areas of life and can attempt to infer the right solution from the provided data.
So, in a rule-based IDS founded on an expert system, the IDS gathers data from a sensor or log, and the inference engine uses its preprogrammed rules on it. If the characteristics of the rules are met, an alert or solution is provided.
IDS Sensors
Network-based IDSs use sensors for monitoring purposes. A sensor, which works as an analysis engine, is placed on the network segment the IDS is responsible for monitoring. The sensor receives raw data from an event generator, as shown in Figure 5-26, and compares it to a signature database, profile, or model, depending upon the type of IDS. If there is some type of a match, which indicates suspicious activity, the sensor works with the response module to determine what type of activity must take place (alerting through instant messaging, paging, or by e-mail; carrying out firewall reconfiguration; and so on). The sensor’s role is to filter received data, discard irrelevant information, and detect suspicious activity.
A monitoring console monitors all sensors and supplies the network staff with an overview of the activities of all the sensors in the network. These are the components that enable network-based intrusion detection to actually work. Sensor placement is a critical part of configuring an effective IDS. An organization can place a sensor outside of the firewall to detect attacks and place a sensor inside the firewall (in the perimeter network) to detect actual intrusions. Sensors should also be placed in highly sensitive areas, DMZs, and on extranets. Figure 5-27 shows the sensors reporting their findings to the central console.
The IDS can be centralized, as firewall products that have IDS functionality integrated within them, or distributed, with multiple sensors throughout the network.

Figure 5-26 The basic architecture of a NIDS
Network Traffic
If the network traffic volume exceeds the IDS system’s threshold, attacks may go unnoticed. Each vendor’s IDS product has its own threshold, and you should know and understand that threshold before you purchase and implement the IDS.
In very high-traffic environments, multiple sensors should be in place to ensure all packets are investigated. If necessary to optimize network bandwidth and speed, different sensors can be set up to analyze each packet for different signatures. That way, the analysis load can be broken up over different points.
Intrusion Prevention Systems
In the industry, there is constant frustration with the inability of existing products to stop the bad guys from accessing and manipulating corporate assets. This has created a market demand for vendors to get creative and come up with new, innovative technologies and new products for companies to purchase, implement, and still be frustrated with.

Figure 5-27 Sensors must be placed in each network segment to be monitored by the IDS.
The next evolution in the IDS arena was the intrusion prevention system (IPS). The traditional IDS only detects that something bad may be taking place and sends an alert. The goal of an IPS is to detect this activity and not allow the traffic to gain access to the target in the first place, as shown in Figure 5-28. So, an IPS is a preventive and proactive technology, whereas an IDS is a detective and after-the-fact technology.
IPS products can be host-based or network-based, just as IDS products. IPS technology can be “content-based,” meaning that it makes decisions pertaining to what is malicious and what is not based upon protocol analysis or signature matching capabilities. An IPS technology can also use a rate-based metric, which focuses on the volume of traffic. The volume of network traffic increases in case of a flood attack (denial of service) or when excessive system scans take place. IPS rate-based metrics can also be set to identify traffic flow anomalies, which could detect the “slow and low” stealth attack types that attempt to “stay under the radar.”
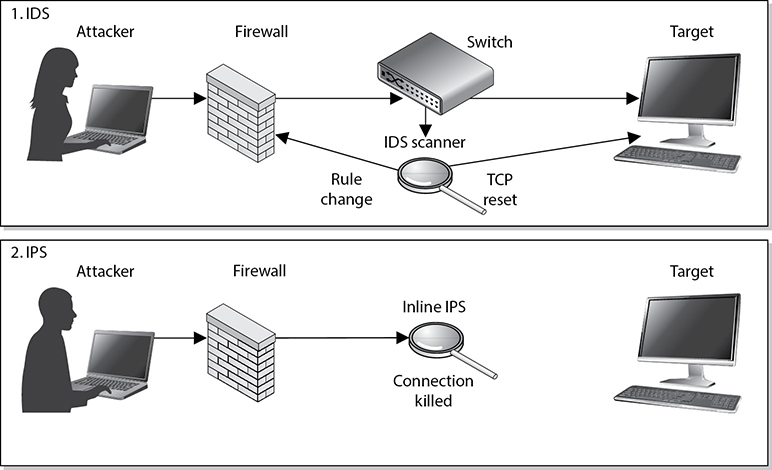
Figure 5-28 IDS vs. IPS architecture
Honeypot
A honeypot is a computer set up as a sacrificial lamb on the network. The system is not locked down and has open ports and services enabled. This is to entice a would-be attacker to this computer instead of attacking authentic production systems on a network. The honeypot contains no real company information, and thus will not be at risk if and when it is attacked.
This enables the administrator to know when certain types of attacks are happening so he can fortify the environment and perhaps track down the attacker. The longer the hacker stays at the honeypot, the more information will be disclosed about her techniques.
It is important to draw a line between enticement and entrapment when implementing a honeypot system. Legal and liability issues surround each. If the system only has open ports and services that an attacker might want to take advantage of, this would be an example of enticement. If the system has a web page indicating the user can download files, and once the user does this the administrator charges this user with trespassing, it would be entrapment. Entrapment is where the intruder is induced or tricked into committing a crime. Entrapment is illegal and cannot be used when charging an individual with hacking or unauthorized activity.
NOTE You should always check with your legal counsel before setting up a honeypot, as there may be liability issues that could pose risk to you or your organization.
Network Sniffers
A packet or network sniffer is a general term for programs or devices able to examine traffic on a LAN segment. Traffic that is being transferred over a network medium is transmitted as electrical signals encoded in binary representation. The sniffer has to have a protocol-analysis capability to recognize the different protocol values to properly interpret their meaning.
The sniffer has to have access to a network adapter that works in promiscuous mode and a driver that captures the data. This data can be overwhelming, so it must be properly filtered. The filtered data is stored in a buffer, and this information is displayed to a user and/or captured in logs. Some utilities have sniffer and packet-modification capabilities, which is how some types of spoofing and man-in-the-middle attacks are carried out.
EXAM TIP Sniffers are dangerous and very hard to detect, and their activities are difficult to audit.
Network sniffers are used by the people in the white hats (administrators and security professionals) usually to try and track down a recent problem with the network. But the guys in the black hats (attackers and crackers) can use them to learn about what type of data is passed over a specific network segment and to modify data in an unauthorized manner. Black hats usually use sniffers to obtain credentials as they pass over the network medium.
EXAM TIP A sniffer is just a tool that can capture network traffic. If it has the capability of understanding and interpreting individual protocols and their associated data, this type of tool is referred to as a protocol analyzer.
Threats to Access Control
As a majority of security professionals know, there is more risk and a higher probability of an attacker causing mayhem from within an organization than from outside it. However, many people within organizations do not know this fact because they only hear stories about the outside attackers who defaced a web server or circumvented a firewall to access confidential information.
An attacker from the outside can enter through remote access entry points, enter through firewalls and web servers, physically break in, carry out social engineering attacks, or exploit a partner communication path (extranet, vendor connection, and so on). An insider has legitimate reasons for using the systems and resources, but can misuse his privileges and launch an actual attack also. The danger of insiders is that they have already been given a wide range of access that a hacker would have to work hard to obtain; they probably have intimate knowledge of the environment; and, generally, they are trusted. We have discussed many different types of access control mechanisms that work to keep the outsiders outside and restrict insiders’ abilities to a minimum and audit their actions. Now we will look at some specific attacks commonly carried out in environments today by insiders or outsiders.
EXAM TIP (ISC)2 dropped access control attacks from this domain in the April 2018 update. However, we feel it is important to briefly cover some of the more common adversarial techniques for completeness. You should not expect your exam to include the material covered in this final part of the chapter.
Dictionary Attack
Several programs can enable an attacker (or proactive administrator) to identify user credentials. This type of program is fed lists (dictionaries) of commonly used words or combinations of characters, and then compares these values to capture passwords. In other words, the program hashes the dictionary words and compares the resulting message digest with the system password file that also stores its passwords in a one-way hashed format. If the hashed values match, it means a password has just been uncovered. Once the right combination of characters is identified, the attacker can use this password to authenticate herself as a legitimate user. Because many systems have a threshold that dictates how many failed logon attempts are acceptable, the same type of activity can happen to a captured password file. The dictionary-attack program hashes the combination of characters and compares it to the hashed entries in the password file. If a match is found, the program has uncovered a password.
The dictionaries come with the password-cracking programs, and extra dictionaries can be found on several sites on the Internet.

CAUTION Passwords should never be transmitted or stored in cleartext. Most operating systems and applications put the passwords through hashing algorithms, which result in hash values, also referred to as message digest values.
Countermeasures
To properly protect an environment against dictionary and other password attacks, the following practices should be followed:
• Do not allow passwords to be sent in cleartext.
• Encrypt the passwords with encryption algorithms or hashing functions.
• Employ one-time password tokens.
• Use hard-to-guess passwords.
• Rotate passwords frequently.
• Employ an IDS to detect suspicious behavior.
• Use dictionary-cracking tools to find weak passwords chosen by users.
• Use special characters, numbers, and upper- and lowercase letters within the password.
• Protect password files.
Brute-Force Attacks
Several types of brute-force attacks can be implemented, but each continually tries different inputs to achieve a predefined goal. Brute force is defined as “trying every possible combination until the correct one is identified.” So in a brute-force password attack, the software tool will see if the first letter is an “a” and continue through the alphabet until that single value is uncovered. Then the tool moves on to the second value, and so on.
The most effective way to uncover passwords is through a hybrid attack, which combines a dictionary attack and a brute-force attack. If a dictionary tool has found that a user’s password starts with Dallas, then the brute-force tool will try Dallas1, Dallas01, Dallasa1, and so on until a successful logon credential is uncovered. (A brute-force attack is also known as an exhaustive attack.)
These attacks are also used in war dialing efforts, in which the war dialer inserts a long list of phone numbers into a war-dialing program in hopes of finding a modem that can be exploited to gain unauthorized access. A program is used to dial many phone numbers and weed out the numbers used for voice calls and fax machine services. The attacker usually ends up with a handful of numbers he can now try to exploit to gain access into a system or network.
So, a brute-force attack perpetuates a specific activity with different input parameters until the goal is achieved.
Countermeasures
For phone brute-force attacks, auditing and monitoring of this type of activity should be in place to uncover patterns that could indicate a war-dialing attack:
• Perform brute-force attacks to find weaknesses and hanging modems.
• Make sure only necessary phone numbers are made public.
• Provide stringent access control methods that would make brute-force attacks less successful.
• Monitor and audit for such activity.
• Employ an IDS to watch for suspicious activity.
• Set lockout thresholds.
Spoofing at Logon
An attacker can use a program that presents to the user a fake logon screen, which often tricks the user into attempting to log on. The user is asked for a username and password, which are stored for the attacker to access at a later time. The user does not know this is not his usual logon screen because they look exactly the same. A fake error message can appear, indicating that the user mistyped his credentials. At this point, the fake logon program exits and hands control over to the operating system, which prompts the user for a username and password. The user assumes he mistyped his information and doesn’t give it a second thought, but an attacker now knows the user’s credentials.
Phishing and Pharming
Phishing is a type of social engineering with the goal of obtaining personal information, credentials, credit card number, or financial data. The attackers lure, or fish, for sensitive data through various different methods.
The term phishing was coined in 1996 when hackers started stealing America Online (AOL) passwords. The hackers would pose as AOL staff members and send messages to victims asking them for their passwords in order to verify correct billing information or verify information about the AOL accounts. Once the password was provided, the hacker authenticated as that victim and used his e-mail account for criminal purposes, as in spamming, pornography, and so on.
Although phishing has been around since the 1990s, many people did not fully become aware of it until mid-2003 when these types of attacks spiked. Phishers created convincing e-mails requesting potential victims to click a link to update their bank account information.
Victims click these links and are presented with a form requesting bank account numbers, Social Security numbers, credentials, and other types of data that can be used in identity theft crimes. These types of phishing e-mail scams have increased dramatically in recent years with some phishers masquerading as large banking companies, PayPal, eBay, Amazon.com, and other well-known Internet entities.
Phishers also create websites that look very similar to legitimate sites and lure victims to them through e-mail messages and other websites to gain the same type of information. Some sites require the victims to provide their Social Security numbers, date of birth, and mother’s maiden name for authentication purposes before they can update their account information.
The nefarious websites not only have the look and feel of the legitimate website, but attackers would provide URLs with domain names that look very similar to the legitimate site’s address. For example, www.amazon.com might become www.amzaon.com. Or use a specially placed @ symbol. For example, [email protected] would actually take the victim to the website notmsn.com and provide the username of www.msn.com to this website. The username www.msn.com would not be a valid username for notmsn.com, so the victim would just be shown the home page of notmsn.com. Now, notmsn.com is a nefarious site and created to look and feel just like www.msn.com. The victim feels comfortable he is at a legitimate site and logs on with his credentials.
Some JavaScript commands are even designed to show the victim an incorrect web address. So let’s say Bob is a suspicious and vigilant kind of a guy. Before he inputs his username and password to authenticate and gain access to his online bank account, he always checks the URL values in the address bar of his browser. Even though he closely inspects it to make sure he is not getting duped, there could be a JavaScript replacing the URL www.evilandwilltakeallyourmoney.com with www.citibank.com so he thinks things are safe and life is good.
NOTE There have been fixes to the previously mentioned attack dealing with URLs, but it is important to know that attackers will continually come up with new ways of carrying out these attacks. Just knowing about phishing doesn’t mean you can properly detect or prevent it. As a security professional, you must keep up with the new and tricky strategies deployed by attackers.
Some attacks use pop-up forms when a victim is at a legitimate site. So if you were at your bank’s actual website and a pop-up window appeared asking you for some sensitive information, this probably wouldn’t worry you since you were communicating with your actual bank’s website. You may believe the window came from your bank’s web server, so you fill it out as instructed. Unfortunately, this pop-up window could be from another source entirely, and your data could be placed right in the attacker’s hands, not your bank’s.
With this personal information, phishers can create new accounts in the victim’s name, gain authorized access to bank accounts, and make illegal credit card purchases or obtain cash advances.
As more people have become aware of these types of attacks and grown wary of clicking embedded links in e-mail messages, phishers have varied their attack methods. For instance, they began sending e-mails that indicate to the user that they have won a prize or that there is a problem with a financial account. The e-mail instructs the person to call a number, which has an automated voice asking the victim to type in their credit card number or Social Security number for authentication purposes.
As phishing attacks increase and more people have become victims of fraud, financial institutions have been implementing two-factor authentication for online transactions. To meet this need, some banks provided their customers with token devices that created one-time passwords. Countering, phishers set up fake websites that looked like the financial institution, duping victims into typing their one-time passwords. The websites would then send these credentials to the actual bank website, authenticate as this user, and gain access to their account.
A similar type of attack is called pharming, which redirects a victim to a seemingly legitimate, yet fake, website. In this type of attack, the attacker carries out something called DNS poisoning, in which a DNS server resolves a hostname into an incorrect IP address. When you type www.logicalsecurity.com into the address bar of your web browser, your computer really has no idea what this data is. So an internal request is made to review your TCP/IP network setting, which contains the IP address of the DNS server your computer is supposed to use. Your system then sends a request to this DNS server basically asking, “Do you have the IP address for www.logicalsecurity.com?” The DNS server reviews its resource records and, if it has one with this information in it, sends the IP address for the server that is hosting www.logicalsecurity.com to your computer. Your browser then shows the home page of this website you requested.
Now, what if an attacker poisoned this DNS server so the resource record has the wrong information? When you type in www.logicalsecurity.com and your system sends a request to the DNS server, the DNS server will send your system the IP address that it has recorded, not knowing it is incorrect. So instead of going to www.logicalsecurity.com, you are sent to www.weownyou.com.
So, let’s say the victim types in a web address of www.nicebank.com, as illustrated in Figure 5-29. The victim’s system sends a request to a poisoned DNS server, which points the victim to a different website. This different website looks and feels just like the requested website, so the user enters his username and password and may even be presented with web pages that look legitimate.
The benefit of a pharming attack to the attacker is that it can affect a large number of victims without the need to send out e-mails, and the victims usually fall for this more easily since they are requesting to go to a website themselves.
Countermeasures to phishing attacks include the following:
• Be skeptical of e-mails indicating you must make changes to your accounts, or warnings stating an account will be terminated if you don’t perform some online activity.
• Call the legitimate company to find out if this is a fraudulent message.
• Review the address bar to see if the domain name is correct.
• When submitting any type of financial information or credential data, a TLS connection should be set up, which may be indicated in the address bar (https://) or as a closed-padlock icon in the browser.
• Do not click an HTML link within an e-mail. Type the URL out manually instead.
• Do not accept e-mail in HTML format.

Figure 5-29 Pharming has been a common attack over the last several years.
Summary
Access controls are security features that are usually considered the first line of defense in asset protection. They are used to dictate how subjects access objects, and their main goal is to protect the objects from unauthorized access. These controls can be administrative, physical, or technical in nature and should be applied in a layered approach, ensuring that an intruder would have to compromise more than one countermeasure to access critical assets.
Access control defines how users should be identified, authenticated, and authorized. These issues are carried out differently in different access control models and technologies, and it is up to the organization to determine which best fits its business and security needs.
Access control needs to be integrated into the core of operating systems through the use of DAC, MAC, RBAC, RB-RBAC, and ABAC models. It needs to be embedded into applications, network devices, and protocols and enforced in the physical world through the use of security zones, network segmentation, locked doors, and security guards. Security is all about keeping the bad guys out, and unfortunately there are many different types of “doorways” they can exploit to get access to our most critical assets.
Quick Tips
• Access is a flow of information between a subject and an object.
• A subject is an active entity that requests access to an object, which is a passive entity.
• A subject can be a user, program, or process.
• Some security mechanisms that provide confidentiality are encryption, logical and physical access control, transmission protocols, database views, and controlled traffic flow.
• Identity management (IdM) solutions include directories, web access management, password management, legacy single sign-on, account management, and profile update.
• Password synchronization reduces the complexity of keeping up with different passwords for different systems.
• Self-service password reset reduces help-desk call volumes by allowing users to reset their own passwords.
• Assisted password reset reduces the resolution process for password issues for the help-desk department.
• IdM directories contain all resource information, users’ attributes, authorization profiles, roles, and possibly access control policies so other IdM applications have one centralized resource from which to gather this information.
• An automated workflow component is common in account management products that provide IdM solutions.
• User provisioning refers to the creation, maintenance, and deactivation of user objects and attributes as they exist in one or more systems, directories, or applications.
• User access reviews ensure there are no active accounts that are no longer needed.
• The HR database is usually considered the authoritative source for user identities because that is where each user’s identity is first developed and properly maintained.
• There are five main access control models: discretionary, mandatory, role based, rule based, and attribute based.
• Discretionary access control (DAC) enables data owners to dictate what subjects have access to the files and resources they own.
• The mandatory access control (MAC) model uses a security label system. Users have clearances, and resources have security labels that contain data classifications. MAC systems compare these two attributes to determine access control capabilities.
• Role-based access control (RBAC) is based on the user’s role and responsibilities (tasks) within the company.
• Rule-based RBAC (RB-RBAC) builds on RBAC by adding Boolean logic in the form of rules or policies that further restrict access.
• Attribute-based access control (ABAC) is based on attributes of any component of the system. It is the most granular of the access control models.
• Three main types of constrained user interface measurements exist: menus and shells, database views, and physically constrained interfaces.
• Access control lists are bound to objects and indicate what subjects can use them.
• A capability table is bound to a subject and lists what objects it can access.
• Some examples of remote access control technologies are RADIUS, TACACS+, and Diameter.
• Examples of administrative controls are a security policy, personnel controls, supervisory structure, security awareness training, and testing.
• Examples of physical controls are network segregation, perimeter security, computer controls, work area separation, and cable.
• Examples of technical controls are system access, network architecture, network access, encryption and protocols, and auditing.
• For a subject to be able to access a resource, it must be identified, authenticated, and authorized, and should be held accountable for its actions.
• Authentication can be accomplished by biometrics, a password, a passphrase, a cognitive password, a one-time password, or a token.
• A Type I error in biometrics means the system rejected an authorized individual, and a Type II error means an imposter was authenticated.
• A memory card cannot process information, but a smart card can through the use of integrated circuits and processors.
• Least-privilege and need-to-know principles limit users’ rights to only what is needed to perform tasks of their job.
• Single sign-on capabilities can be accomplished through Kerberos, domains, and thin clients.
• The Kerberos user receives a ticket granting ticket (TGT), which allows him to request access to resources through the ticket granting service (TGS). The TGS generates a new ticket with the session keys.
• Keystroke monitoring is a type of auditing that tracks each keystroke made by a user.
• Object reuse can unintentionally disclose information by assigning media to a subject before it is properly erased.
• Just removing pointers to files (deleting file, formatting hard drive) is not always enough protection for proper object reuse.
• Information can be obtained via electrical signals in airwaves. The ways to combat this type of intrusion are TEMPEST, white noise, and control zones.
• User authentication is accomplished by what someone knows, is, or has.
• One-time password-generating token devices can use synchronous (time, event) or asynchronous (challenge-based) methods.
• Strong authentication requires two of the three user authentication attributes (what someone knows, is, or has).
• The following are weaknesses of Kerberos: the KDC is a single point of failure; it is susceptible to password guessing; session and secret keys are locally stored; KDC needs to always be available; and there must be management of secret keys.
• Phishing is a type of social engineering with the goal of obtaining personal information, credentials, credit card numbers, or financial data.
• A race condition is possible when two or more processes use a shared resource and the access steps could take place out of sequence.
• Mutual authentication is when two entities must authenticate to each other before sending data back and forth. Also referred to as two-way authentication.
• A directory service is a software component that stores, organizes, and provides access to resources, which are listed in a directory (listing) of resources. Individual resources are assigned names within a namespace.
• A cookie is data that is held permanently on a hard drive in the format of a text file or held temporarily in memory. It can be used to store browsing habits, authentication data, or protocol state information.
• A federated identity is a portable identity, and its associated entitlements, that can be used across business boundaries without the need to synchronize or consolidate directory information.
• Extensible Markup Language (XML) is a set of rules for encoding documents in machine-readable form to allow for interoperability between various web-based technologies.
• Service Provisioning Markup Language (SPML) is an XML-based framework being developed by OASIS for exchanging user, resource, and service provisioning information between cooperating organizations.
• Extensible Access Control Markup Language (XACML), which is both a declarative access control policy language implemented in XML and a processing model, describes how to interpret security policies.
• Replay attack is a form of network attack in which a valid data transmission is maliciously or fraudulently repeated with the goal of obtaining unauthorized access.
• Clipping level is a threshold value. Once a threshold value is passed, the activity is considered to be an event that is logged, investigated, or both.
• A rainbow table is a set of precomputed hash values that represents password combinations. Rainbow tables are used in password attack processes and usually produce results more quickly than dictionary or brute-force attacks.
• Cognitive passwords are fact- or opinion-based information used to verify an individual’s identity.
• Smart cards can require physical interaction with a reader (contact) or no physical interaction with the reader (contactless architectures). Two contactless architectures are combi (one chip) and hybrid (two chips).
• A side channel attack is carried out by gathering data pertaining to how something works and using that data to attack it or crack it, as in differential power analysis or electromagnetic analysis.
• Authorization creep takes place when a user gains too much access rights and permissions over time.
• Security information and event management implements data mining and analysis functionality to be carried out on centralized logs for situational awareness capabilities.
• Intrusion detection systems are either host or network based and provide behavioral (statistical) or signature (knowledge) types of functionality.
• Phishing is a type of social engineering attack. If it is crafted for a specific individual, it is called spear-phishing. If a DNS server is poisoned and points users to a malicious website, this is referred to as pharming.
• A web portal is commonly made up of portlets, which are pluggable user interface software components that present information and services from other systems.
• The Service Provisioning Markup Language (SPML) allows for the automation of user management (account creation, amendments, revocation) and access entitlement configuration related to electronically published services across multiple provisioning systems.
• The Security Assertion Markup Language (SAML) allows for the exchange of authentication and authorization data to be shared between security domains.
• OpenID is an open standard and protocol that allows third-party authentication of a user.
• OAuth is an open standard that allows a user to grant authority to some web resource, like a contacts database, to a third party.
• OpenID Connect is an authentication layer built on the OAuth 2.0 protocol that allows transparent authentication and authorization of client resource requests.
• The Simple Object Access Protocol (SOAP) is a protocol specification for exchanging structured information in the implementation of web services and networked environments.
• Service-oriented architecture (SOA) environments allow for a suite of interoperable services to be used within multiple, separate systems from several business domains.
• Radio-frequency identification (RFID) is a technology that provides data communication through the use of radio waves.
Questions
Please remember that these questions are formatted and asked in a certain way for a reason. Keep in mind that the CISSP exam is asking questions at a conceptual level. Questions may not always have the perfect answer, and the candidate is advised against always looking for the perfect answer. Instead, the candidate should look for the best answer in the list.
1. Which of the following statements correctly describes biometric methods?
A. They are the least expensive and provide the most protection.
B. They are the most expensive and provide the least protection.
C. They are the least expensive and provide the least protection.
D. They are the most expensive and provide the most protection.
2. Which of the following statements correctly describes passwords?
A. They are the least expensive and most secure.
B. They are the most expensive and least secure.
C. They are the least expensive and least secure.
D. They are the most expensive and most secure.
3. How is a challenge/response protocol utilized with token device implementations?
A. This protocol is not used; cryptography is used.
B. An authentication service generates a challenge, and the smart token generates a response based on the challenge.
C. The token challenges the user for a username and password.
D. The token challenges the user’s password against a database of stored credentials.
4. Which access control method is considered user directed?
A. Nondiscretionary
B. Mandatory
C. Identity-based
D. Discretionary
5. Which item is not part of a Kerberos authentication implementation?
A. Message authentication code
B. Ticket granting service
C. Authentication service
D. Users, programs, and services
6. If a company has a high turnover rate, which access control structure is best?
A. Role-based
B. Decentralized
C. Rule-based
D. Discretionary
7. The process of mutual authentication involves _______________.
A. a user authenticating to a system and the system authenticating to the user
B. a user authenticating to two systems at the same time
C. a user authenticating to a server and then to a process
D. a user authenticating, receiving a ticket, and then authenticating to a service
8. In discretionary access control security, who has delegation authority to grant access to data?
A. User
B. Security officer
C. Security policy
D. Owner
9. Which could be considered a single point of failure within a single sign-on implementation?
A. Authentication server
B. User’s workstation
C. Logon credentials
D. RADIUS
10. What role does biometrics play in access control?
A. Authorization
B. Authenticity
C. Authentication
D. Accountability
11. Who or what determines if an organization is going to operate under a discretionary, mandatory, or nondiscretionary access control model?
A. Administrator
B. Security policy
C. Culture
D. Security levels
12. Which of the following best describes what role-based access control offers companies in reducing administrative burdens?
A. It allows entities closer to the resources to make decisions about who can and cannot access resources.
B. It provides a centralized approach for access control, which frees up department managers.
C. User membership in roles can be easily revoked and new ones established as job assignments dictate.
D. It enforces enterprise-wide security policies, standards, and guidelines.
13. Which of the following is the best description of directories that are used in identity management technology?
A. Most are hierarchical and follow the X.500 standard.
B. Most have a flat architecture and follow the X.400 standard.
C. Most have moved away from LDAP.
D. Many use LDAP.
14. Which of the following is not part of user provisioning?
A. Creation and deactivation of user accounts
B. Business process implementation
C. Maintenance and deactivation of user objects and attributes
D. Delegating user administration
15. What is the technology that allows a user to remember just one password?
A. Password generation
B. Password dictionaries
C. Password rainbow tables
D. Password synchronization
16. Which of the following is not considered an anomaly-based intrusion protection system?
A. Statistical anomaly–based
B. Protocol anomaly–based
C. Temporal anomaly–based
D. Traffic anomaly–based
17. This graphic covers which of the following?
A. Crossover error rate
B. Identity verification
C. Authorization rates
D. Authentication error rates
18. The diagram shown here explains which of the following concepts?

A. Crossover error rate.
B. Type III errors.
C. FAR equals FRR in systems that have a high crossover error rate.
D. Biometrics is a high acceptance technology.
19. The graphic shown here illustrates how which of the following works?
A. Rainbow tables
B. Dictionary attack
C. One-time password
D. Strong authentication
20. Which of the following has the correct term-to-definition mapping?
i. Brute-force attacks: Performed with tools that cycle through many possible character, number, and symbol combinations to uncover a password.
ii. Dictionary attacks: Files of thousands of words are compared to the user’s password until a match is found.
iii. Social engineering: An attacker falsely convinces an individual that she has the necessary authorization to access specific resources.
iv. Rainbow table: An attacker uses a table that contains all possible passwords already in a hash format.
A. i, ii
B. i, ii, iv
C. i, ii, iii, iv
D. i, ii, iii
21. George is responsible for setting and tuning the thresholds for his company’s behavior-based IDS. Which of the following outlines the possibilities of not doing this activity properly?
A. If the threshold is set too low, nonintrusive activities are considered attacks (false positives). If the threshold is set too high, malicious activities are not identified (false negatives).
B. If the threshold is set too low, nonintrusive activities are considered attacks (false negatives). If the threshold is set too high, malicious activities are not identified (false positives).
C. If the threshold is set too high, nonintrusive activities are considered attacks (false positives). If the threshold is set too low, malicious activities are not identified (false negatives).
D. If the threshold is set too high, nonintrusive activities are considered attacks (false positives). If the threshold is set too high, malicious activities are not identified (false negatives).
Use the following scenario to answer Questions 22–24. Tom is a new security manager for a retail company, which currently has an identity management system (IdM) in place. The data within the various identity stores updates more quickly than the current IdM software can keep up with, so some access decisions are made based upon obsolete information. While the IdM currently provides centralized access control of internal network assets, it is not tied into the web-based access control components that are embedded within the company’s partner portals. Tom also notices that help-desk technicians are spending too much time resetting passwords for internal employees.
22. Which of the following changes would be best for Tom’s team to implement?
A. Move from namespaces to distinguished names.
B. Move from meta-directories to virtual directories.
C. Move from RADIUS to TACACS+.
D. Move from a centralized to a decentralized control model.
23. Which of the following components should Tom make sure his team puts into place?
A. Single sign-on module
B. LDAP directory service synchronization
C. Web access management
D. X.500 database
24. Tom has been told that he has to reduce staff from the help-desk team. Which of the following technologies can help with the company’s help-desk budgetary issues?
A. Self-service password support
B. RADIUS implementation
C. Reduction of authoritative IdM sources
D. Implement a role-based access control model
Use the following scenario to answer Questions 25–27. Lenny is a new security manager for a retail company that is expanding its functionality to its partners and customers. The company’s CEO wants to allow its partners’ customers to be able to purchase items through the company’s web stores as easily as possible. The CEO also wants the company’s partners to be able to manage inventory across companies more easily. The CEO wants to be able to understand the network traffic and activities in a holistic manner, and he wants to know from Lenny what type of technology should be put into place to allow for a more proactive approach to stopping malicious traffic if it enters the network. The company is a high-profile entity constantly dealing with zero-day attacks.
25. Which of the following is the best identity management technology that Lenny should consider implementing to accomplish some of the company’s needs?
A. LDAP directories for authoritative sources
B. Digital identity provisioning
C. Active Directory
D. Federated identity
26. Lenny has a meeting with the internal software developers who are responsible for implementing the necessary functionality within the web-based system. Which of the following best describes the two items that Lenny needs to be prepared to discuss with this team?
A. Service Provisioning Markup Language and the Extensible Access Control Markup Language
B. Standard Generalized Markup Language and the Generalized Markup Language
C. Extensible Markup Language and the Hypertext Markup Language
D. Service Provisioning Markup Language and the Generalized Markup Language
27. Pertaining to the CEO’s security concerns, what should Lenny suggest the company put into place?
A. Security event management software, an intrusion prevention system, and behavior-based intrusion detection
B. Security information and event management software, an intrusion detection system, and signature-based protection
C. An intrusion prevention system, security event management software, and malware protection
D. An intrusion prevention system, security event management software, and war-dialing protection
Use the following scenario to answer Questions 28–29. Robbie is the security administrator of a company that needs to extend its remote access functionality. Employees travel around the world, but still need to be able to gain access to corporate assets such as databases, servers, and network-based devices. Also, while the company has had a VoIP telephony solution in place for two years, it has not been integrated into a centralized access control solution. Currently the network administrators have to maintain access control separately for internal resources, external entities, and VoIP end systems. Robbie has also been asked to look into some suspicious e-mails that the CIO’s secretary has been receiving, and her boss has asked her to remove some old modems that are no longer being used for remote dial-in purposes.
28. Which of the following is the best remote access technology for this situation?
A. RADIUS
B. TACACS+
C. Diameter
D. Kerberos
29. What are the two main security concerns Robbie is most likely being asked to identify and mitigate?
A. Social engineering and spear-phishing
B. War dialing and pharming
C. Spear-phishing and war dialing
D. Pharming and spear-phishing
Use the following scenario to answer Questions 30–32. Tanya is working with the company’s internal software development team. Before a user of an application can access files located on the company’s centralized server, the user must present a valid one-time password, which is generated through a challenge/response mechanism. The company needs to tighten access control for these files and reduce the number of users who can access each and every file. The company is looking to Tanya and her team for solutions to better protect the data that has been classified and deemed critical to the company’s missions. Tanya has also been asked to implement a single sign-on technology for all internal users, but she does not have the budget to implement a public key infrastructure.
30. Which of the following best describes what is currently in place?
A. Capability-based access system
B. Synchronous tokens that generate one-time passwords
C. RADIUS
D. Kerberos
31. Which of the following is one of the easiest and best solutions Tanya can consider for proper data protection?
A. Implementation of mandatory access control
B. Implementation of access control lists
C. Implementation of digital signatures
D. Implementation of multilevel security
32. Which of the following is the best single sign-on technology for this situation?
A. PKI
B. Kerberos
C. RADIUS
D. TACACS+
Use the following scenario to answer Questions 33–35. Harry is overseeing a team that has to integrate various business services provided by different company departments into one web portal for both internal employees and external partners. His company has a diverse and heterogeneous environment with different types of systems providing customer relationship management, inventory control, e-mail, and help-desk ticketing capabilities. His team needs to allow different users access to these different services in a secure manner.
33. Which of the following best describes the type of environment Harry’s team needs to set up?
A. RADIUS
B. Service-oriented architecture
C. Public key infrastructure
D. Web services
34. Which of the following best describes the types of languages and/or protocols that Harry needs to ensure are implemented?
A. Security Assertion Markup Language, Extensible Access Control Markup Language, Service Provisioning Markup Language
B. Service Provisioning Markup Language, Simple Object Access Protocol, Extensible Access Control Markup Language
C. Extensible Access Control Markup Language, Security Assertion Markup Language, Simple Object Access Protocol
D. Service Provisioning Markup Language, Security Association Markup Language
35. The company’s partners need to integrate compatible authentication functionality into their web portals to allow for interoperability across the different company boundaries. Which of the following will deal with this issue?
A. Service Provisioning Markup Language
B. Simple Object Access Protocol
C. Extensible Access Control Markup Language
D. Security Assertion Markup Language
Answers
1. D. Compared with the other available authentication mechanisms, biometric methods provide the highest level of protection and are the most expensive.
2. C. Passwords provide the least amount of protection, but are the cheapest because they do not require extra readers (as with smart cards and memory cards), do not require devices (as do biometrics), and do not require a lot of overhead in processing (as in cryptography). Passwords are the most common type of authentication method used today.
3. B. An asynchronous token device is based on challenge/response mechanisms. The authentication service sends the user a challenge value, which the user enters into the token. The token encrypts or hashes this value, and the user uses this as her one-time password.
4. D. The DAC model allows users, or data owners, the discretion of letting other users access their resources. DAC is implemented by ACLs, which the data owner can configure.
5. A. Message authentication code (MAC) is a cryptographic function and is not a key component of Kerberos. Kerberos is made up of a KDC, a realm of principals (users, services, applications, and devices), an authentication service, tickets, and a ticket granting service.
6. A. A role-based structure is easier on the administrator because she only has to create one role, assign all of the necessary rights and permissions to that role, and plug a user into that role when needed. Otherwise, she would need to assign and extract permissions and rights on all systems as each individual came and left the company.
7. A. Mutual authentication means it is happening in both directions. Instead of just the user having to authenticate to the server, the server also must authenticate to the user.
8. D. This question may seem a little confusing if you were stuck between user and owner. Only the data owner can decide who can access the resources she owns. She may or may not be a user. A user is not necessarily the owner of the resource. Only the actual owner of the resource can dictate what subjects can actually access the resource.
9. A. In a single sign-on technology, all users are authenticating to one source. If that source goes down, authentication requests cannot be processed.
10. C. Biometrics is a technology that validates an individual’s identity by reading a physical attribute. In some cases, biometrics can be used for identification, but that was not listed as an answer choice.
11. B. The security policy sets the tone for the whole security program. It dictates the level of risk that management and the company are willing to accept. This in turn dictates the type of controls and mechanisms to put in place to ensure this level of risk is not exceeded.
12. C. An administrator does not need to revoke and reassign permissions to individual users as they change jobs. Instead, the administrator assigns permissions and rights to a role, and users are plugged into those roles.
13. A. Most enterprises have some type of directory that contains information pertaining to the company’s network resources and users. Most directories follow a hierarchical database format, based on the X.500 standard, and a type of protocol, as in Lightweight Directory Access Protocol (LDAP), that allows subjects and applications to interact with the directory. Applications can request information about a particular user by making an LDAP request to the directory, and users can request information about a specific resource by using a similar request.
14. B. User provisioning refers to the creation, maintenance, and deactivation of user objects and attributes as they exist in one or more systems, directories, or applications, in response to business processes. User provisioning software may include one or more of the following components: change propagation, self-service workflow, consolidated user administration, delegated user administration, and federated change control. User objects may represent employees, contractors, vendors, partners, customers, or other recipients of a service. Services may include electronic mail, access to a database, access to a file server or mainframe, and so on.
15. D. Password synchronization technologies can allow a user to maintain just one password across multiple systems. The product will synchronize the password to other systems and applications, which happens transparently to the user.
16. C. An anomaly-based IPS is a behavioral-based system that learns the “normal” activities of an environment. The three types are listed next:
• Statistical anomaly–based Creates a profile of “normal” and compares activities to this profile
• Protocol anomaly–based Identifies protocols used outside of their common bounds
• Traffic anomaly–based Identifies unusual activity in network traffic
17. B. These steps are taken to convert the biometric input for identity verification:
i. A software application identifies specific points of data as match points.
ii. An algorithm is used to process the match points and translate that information into a numeric value.
iii. Authentication is approved or denied when the database value is compared with the end user input entered into the scanner.
18. A. This rating is stated as a percentage and represents the point at which the false rejection rate equals the false acceptance rate. This rating is the most important measurement when determining a biometric system’s accuracy.
• Type I error Rejects authorized individual
• False rejection rate (FRR)
• Type II error Accepts impostor
• False acceptance rate (FAR)
19. C. Different types of one-time passwords are used for authentication. This graphic illustrates a synchronous token device, which synchronizes with the authentication service by using time or a counter as the core piece of the authentication process.
20. C. The list has all the correct term-to-definition mappings.
21. C. If the threshold is set too high, nonintrusive activities are considered attacks (false positives). If the threshold is set too low, malicious activities are not identified (false negatives).
22. B. A meta-directory within an IdM physically contains the identity information within an identity store. It allows identity information to be pulled from various locations and be stored in one local system (identity store). The data within the identity store is updated through a replication process, which may take place weekly, daily, or hourly depending upon configuration. Virtual directories use pointers to where the identity data resides on the original system; thus, no replication processes are necessary. Virtual directories usually provide the most up-to-date identity information since they point to the original source of the data.
23. C. Web access management (WAM) is a component of most IdM products that allows for identity management of web-based activities to be integrated and managed centrally.
24. A. If help-desk staff is spending too much time with password resetting, then a technology should be implemented to reduce the amount of time paid staff is spending on this task. The more tasks that can be automated through technology, the less that has to be spent on staff. The following are password management functionalities that are included in most IdM products:
• Password synchronization Reduces the complexity of keeping up with different passwords for different systems.
• Self-service password reset Reduces help-desk call volumes by allowing users to reset their own passwords.
• Assisted password reset Reduces the resolution process for password issues for the help desk. This may include authentication with other types of authentication mechanisms (biometrics, tokens).
25. D. Federation identification allows for the company and its partners to share customer authentication information. When a customer authenticates to a partner website, that authentication information can be passed to the retail company, so when the customer visits the retail company’s website, the user has to submit less user profile information and the authentication steps the user has to go through during the purchase process could potentially be reduced. If the companies have a set trust model and share the same or similar federated identity management software and settings, this type of structure and functionality is possible.
26. A. The Service Provisioning Markup Language (SPML) allows company interfaces to pass service requests, and the receiving company provisions (allows) access to these services. Both the sending and receiving companies need to be following the XML standard, which will allow this type of interoperability to take place. When using the Extensible Access Control Markup Language (XACML), application security policies can be shared with other applications to ensure that both are following the same security rules. The developers need to integrate both of these language types to allow for their partner employees to interact with their inventory systems without having to conduct a second authentication step. The use of the languages can reduce the complexity of inventory control between the different companies.
27. A. Security event management software allows for network traffic to be viewed holistically by gathering log data centrally and analyzing it. The intrusion prevention system allows for proactive measures to be put into place to help in stopping malicious traffic from entering the network. Behavior-based intrusion detection can identify new types of attacks (zero day) compared to signature-based intrusion detection.
28. C. The Diameter protocol extends the RADIUS protocol to allow for various types of authentication to take place with a variety of different technologies (PPP, VoIP, Ethernet, etc.). It has extensive flexibility and allows for the centralized administration of access control.
29. C. Spear-phishing is a targeted social engineering attack, which is what the CIO’s secretary is most likely experiencing. War dialing is a brute-force attack against devices that use phone numbers, as in modems. If the modems can be removed, the risk of war-dialing attacks decreases.
30. A. A capability-based access control system means that the subject (user) has to present something, which outlines what it can access. The item can be a ticket, token, or key. A capability is tied to the subject for access control purposes. A synchronous token is not being used, because the scenario specifically states that a challenge esponse mechanism is being used, which indicates an asynchronous token.
31. B. Systems that provide mandatory access control (MAC) and multilevel security are very specialized, require extensive administration, are expensive, and reduce user functionality. Implementing these types of systems is not the easiest approach out of the list. Since there is no budget for a PKI, digital signatures cannot be used because they require a PKI. In most environments access control lists (ACLs) are in place and can be modified to provide tighter access control. ACLs are bound to objects and outline what operations specific subjects can carry out on them.
32. B. The scenario specifies that PKI cannot be used, so the first option is not correct. Kerberos is based upon symmetric cryptography; thus, it does not need a PKI. RADIUS and TACACS+ are remote centralized access control protocols.
33. B. A service-oriented architecture (SOA) will allow Harry’s team to create a centralized web portal and offer the various services needed by internal and external entities.
34. C. The most appropriate languages and protocols for the purpose laid out in the scenario are Extensible Access Control Markup Language, Security Assertion Markup Language, and Simple Object Access Protocol. Harry’s group is not necessarily overseeing account provisioning, so the Service Provisioning Markup Language is not necessary, and there is no language called “Security Association Markup Language.”
35. D. Security Assertion Markup Language allows the exchange of authentication and authorization data to be shared between security domains. It is one of the most commonly used approaches to allow for single sign-on capabilities within a web-based environment.