
Detection
The first and most important step in responding to an incident is to realize that you have a problem in the first place. Despite an abundance of sensors, this can be harder than it sounds for a variety of reasons. First, sophisticated adversaries may use tools and techniques that you are unable to detect (at least at first). Even if the tools or techniques are known to you, they may very well be hiding under a mound of false positives in your SIEMs. In some (improperly tuned) systems, the ratio of false positives to true positives can be ten to one (or higher). This underscores the importance of tuning your sensors and analysis platforms to reduce the rate of false positive as much as possible.
Response
Having detected the incident, the next step is to determine what the appropriate response might be. Though the instinctive reaction may be to clean up the infected workstation or add rules to your firewalls, IDS, and IPS, this well-intentioned response could lead you on an endless game of whack-a-mole or, worse yet, blind you to the adversary’s real objective. What do you know about the adversary? Who is it? What are they after? Is this tool and its use consistent with what you have already seen? Part of the early stages of a response is to figure out what information you need in order to restore security.
This is the substage of analysis, where more data is gathered (audit logs, video captures, human accounts of activities, system activities) to try and figure out the root cause of the incident. The goals are to figure out who did this, how they did it, when they did it, and why. Management must be continually kept abreast of these activities because they will be making the big decisions on how this situation is to be handled.
The group of individuals who make up the response team must have a variety of skills. They must also have a solid understanding of the systems affected by the incident, the system and application vulnerabilities, and the network and system configurations. Although formal education is important, real-world applied experience combined with proper training is key for these folks.
One of the biggest challenges the response team faces is the dynamic nature of logs. Many systems are configured to purge or overwrite their logs in a short timeframe, and time is lost the moment the incident occurs. Several hours may pass before an incident is reported or detected. Some countries are considering legislation that would require longer log file retention. However, such laws pose privacy and storage challenges.
Once you have a hypothesis about the adversary’s goals and plans, you can test it. If this particular actor is usually interested in PII on your high-net-worth clients but the incident you detected was on a (seemingly unrelated) host in the warehouse, was that an initial entry or pivot point? If so, then you may have caught them before they worked their way further along the kill chain. But what if you got your attribution wrong? How could you test for that? This chain of questions, combined with quantifiable answers from your systems, forms the basis for an effective response. To quote the famous hockey player Wayne Gretzky, we should all “skate to where the puck is going to be, not where it has been.”
NOTE It really takes a fairly mature threat intelligence capability to determine who is behind an attack (attribution), what are their typical tools, techniques, and procedures, and what might be their ultimate objective. If you do not have this capability, you may have no choice but to respond only to what you’re detecting, without regard for what they may actually be trying to do.
Mitigation
By this point in the incident response process, you should know what happened as well as what you think is likely to happen next. The next step is to mitigate or contain the damage that has been or is about to be done to your most critical assets, followed by mitigation of less important assets. Returning to the earlier PII example, a naïve response could be to take the infected system (in the warehouse) offline and preserve evidence. The problem is that if that system was simply an entry or pivot point, you may very well already be behind your adversary. Unless you look for other indicators, how would you know whether they already compromised the next system in the chain? Why bother quarantining a host that has already served its purpose (to your adversaries) when you haven’t yet taken a look at the (presumed) ultimate target?
The goal of mitigation is to prevent or reduce any further damage from this incident so that you can begin to recover and remediate. A proper mitigation strategy buys the incident response team time for a proper investigation and determination of the incident’s root cause. The mitigation strategy should be based on the category of the attack (that is, whether it was internal or external), the assets affected by the incident, and the criticality of those assets. So what kind of mitigation strategy is best? Well, it depends. Mitigation strategies can be proactive or reactive. Which is best depends on the environment and the category of the attack. In some cases, the best action might be to disconnect the affected system from the network. However, this reactive approach could cause a denial of service or limit functionality of critical systems.
When complete isolation or containment is not a viable solution, you may opt to use network segmentation to virtually isolate a system or systems. Boundary devices can also be used to stop one system from infecting another. Another reactive strategy involves reviewing and revising firewall/filtering router rule configuration. Access control lists can also be applied to minimize exposure. These mitigation strategies indicate to the attacker that his attack has been noticed and countermeasures are being implemented. But what if, in order to perform a root cause analysis, you need to keep the affected system online and not let on that you’ve noticed the attack? In this situation, you might consider installing a honeynet or honeypot to provide an area that will contain the attacker but pose minimal risk to the organization. This decision should involve legal counsel and upper management because honeynets and honeypots can introduce liability issues. Once the incident has been contained, you need to figure out what just happened by putting the available pieces together.
Reporting
Though we discuss reporting here in order to remain consistent with (ISC)2, incident reporting and documentation occurs at various stages in the response process. In many cases involving sophisticated attackers, the response team first learns of the incident because someone else reports it. Whether it is an internal user, an external client or partner, or even a three-letter government entity, this initial report becomes the start point of the entire process. In more mundane cases, we become aware that something is amiss thanks to a vigilant member of the security staff or one of the sensors deployed to detect attacks. However we learn of the incident, this first report starts what should be a continuous process of documentation.
According to NIST Special Publication 800-61, Revision 2, “Computer Security Incident Handling Guide,” the following information should be reported for each incident:
• Summary of the incident
• Indicators
• Related incidents
• Actions taken
• Chain of custody for all evidence (if applicable)
• Impact assessment
• Identity and comments of incident handlers
• Next steps to be taken
Recovery
Once the incident is mitigated, you must turn your attention to the recovery phase, in which you return all systems and information to a known-good state. It is important to gather evidence before you recover systems and information. The reason is that in many cases you won’t know that you will need legally admissible evidence until days, weeks, or even months after an incident. It pays, then, to treat each incident as if it will eventually end up in a court of justice.
Once all relevant evidence is captured, you can begin to fix all that was broken. The aim is to restore full, trustworthy functionality to the organization. For hosts that were compromised, the best practice is to simply reinstall the system from a gold master image and then restore data from the most recent backup that occurred prior to the attack. You may also have to roll back transactions and restore databases from backup systems. Once you are done, it is as if the incident never happened. Well, almost.

CAUTION An attacked or infected system should never be trusted, because you do not necessarily know all the changes that have taken place and the true extent of the damage. Some malicious code could still be hiding somewhere. Systems should be rebuilt to ensure that all of the potential bad mojo has been released by carrying out a proper exorcism.
Remediation
It is not enough to put the pieces of Humpty Dumpty back together again. You also need to ensure that the attack is never again successful. During the mitigation phase, you identified quick fixes to neutralize or reduce the effectiveness of the incident. Now, in the remediation phase, you decide which of those measures (e.g., firewall or IDS/IPS rules) need to be made permanent and which additional controls may be needed.
Another aspect of remediation is the identification of your indicators of attack (IOA) that can be used in the future to detect this attack in real time (i.e., as it is happening) as well as indicators of compromise (IOC), which tell you when an attack has been successful and your security has been compromised. Typical indicators of both attack and compromise include the following.
• Outbound traffic to a particular IP address or domain name
• Abnormal DNS query patterns
• Unusually large HTTP requests and/or responses
• DDoS traffic
• New Registry entries (in Windows systems)
At the conclusion of the remediation phase, you have a high degree of confidence that this particular attack will never again be successful against your organization. Ideally, you should share your lessons learned in the form of IOAs and IOCs with the community so that no other organization can be exploited in this manner. This kind of collaboration with partners (and even competitors) makes the adversary have to work harder.
Investigations
Whether an incident is a nondisaster, a disaster, or a catastrophe, we should treat the systems and facilities that it affects as potential crime scenes. This is because what may at first appear to have been a hardware failure, a software defect, or an accidental fire may have in fact been caused by a malicious actor targeting the organization. Even acts of nature like storms or earthquakes may provide opportunities for adversaries to victimize us. Because we are never (initially) quite sure whether an incident may have a criminal element, we should treat all incidents as if they do (until proven otherwise).
Since computer crimes are only increasing and will never really go away, it is important that all security professionals understand how computer investigations should be carried out. This includes understanding legal requirements for specific situations, the “chain of custody” for evidence, what type of evidence is admissible in court, incident response procedures, and escalation processes.
When a potential computer crime takes place, it is critical that the investigation steps are carried out properly to ensure that the evidence will be admissible to the court if things go that far and that it can stand up under the cross-examination and scrutiny that will take place. As a security professional, you should understand that an investigation is not just about potential evidence on a disk drive. The whole environment will be part of an investigation, including the people, network, connected internal and external systems, federal and state laws, management’s stance on how the investigation is to be carried out, and the skill set of whomever is carrying out the investigation. Messing up on just one of these components could make your case inadmissible or at least damage it if it is brought to court.
Computer Forensics and Proper Collection of Evidence
Forensics is a science and an art that requires specialized techniques for the recovery, authentication, and analysis of electronic data for the purposes of a digital criminal investigation. It is the coming together of computer science, information technology, and engineering with law. When discussing computer forensics with others, you might hear the terms computer forensics, network forensics, electronic data discovery, cyberforensics, and forensic computing. (ISC)2 uses digital forensics as a synonym for all of these other terms, so that’s what you’ll see on the CISSP exam. Computer forensics encompasses all domains in which evidence is in a digital or electronic form, either in storage or on the wire. At one time computer forensic results were differentiated from network and code analysis, but now this entire area is referred to as digital evidence.
The people conducting the forensic investigation must be properly skilled in this trade and know what to look for. If someone reboots the attacked system or inspects various files, this could corrupt viable evidence, change timestamps on key files, and erase footprints the criminal may have left. Most digital evidence has a short lifespan and must be collected quickly in order of volatility. In other words, the most volatile or fragile evidence should be collected first. In some situations, it is best to remove the system from the network, dump the contents of the memory, power down the system, and make a sound image of the attacked system and perform forensic analysis on this copy. Working on the copy instead of the original drive will ensure that the evidence stays unharmed on the original system in case some steps in the investigation actually corrupt or destroy data. Dumping the memory contents to a file before doing any work on the system or powering it down is a crucial step because of the information that could be stored there. This is another method of capturing fragile information. However, this creates a sticky situation: capturing RAM or conducting live analysis can introduce changes to the crime scene because various state changes and operations take place. Whatever method the forensic investigator chooses to use to collect digital evidence, that method must be documented. This is the most important aspect of evidence handling.
NOTE The forensics team needs specialized tools, an evidence collection notebook, containers, a camera, and evidence identification tags. The notebook should not be a spiral notebook but rather a notebook that is bound in a way that one can tell if pages have been removed.
Digital evidence must be handled in a careful fashion so it can be used in different courts, no matter what jurisdiction is prosecuting a suspect. Within the United States, there is the Scientific Working Group on Digital Evidence (SWGDE), which aims to ensure consistency across the forensic community. The principles developed by the SWGDE for the standardized recovery of computer-based evidence are governed by the following attributes:
• Consistency with all legal systems
• Allowance for the use of a common language
• Durability
• Ability to cross international and state boundaries
• Ability to instill confidence in the integrity of evidence
• Applicability to all forensic evidence
• Applicability at every level, including that of individual, agency, and country
The SWGDE principles are listed next:
1. When dealing with digital evidence, all of the general forensic and procedural principles must be applied.
2. Upon the seizing of digital evidence, actions taken should not change that evidence.
3. When it is necessary for a person to access original digital evidence, that person should be trained for the purpose.
4. All activity relating to the seizure, access, storage, or transfer of digital evidence must be fully documented, preserved, and available for review.
5. An individual is responsible for all actions taken with respect to digital evidence while the digital evidence is in their possession.
6. Any agency that is responsible for seizing, accessing, storing, or transferring digital evidence is responsible for compliance with these principles.
NOTE The Digital Forensic Research Workshop (DFRWS) brings together academic researchers and forensic investigators to also address a standardized process for collecting evidence, to research practitioner requirements, and to incorporate a scientific method as a tenant of digital forensic science. Learn more at www.dfrws.org.
Motive, Opportunity, and Means
Today’s computer criminals are similar to their traditional counterparts. To understand the “whys” in crime, it is necessary to understand the motive, opportunity, and means—or MOM. This is the same strategy used to determine the suspects in a traditional, noncomputer crime.
Motive is the “who” and “why” of a crime. The motive may be induced by either internal or external conditions. A person may be driven by the excitement, challenge, and adrenaline rush of committing a crime, which would be an internal condition. Examples of external conditions might include financial trouble, a sick family member, or other dire straits. Understanding the motive for a crime is an important piece in figuring out who would engage in such an activity. For example, in the past many hackers attacked big-name sites because when the sites went down, it was splashed all over the news. However, once technology advanced to the point where attacks could not bring down these sites, or once these activities were no longer so highly publicized, many individuals eventually moved on to other types of attacks.
Opportunity is the “where” and “when” of a crime. Opportunities usually arise when certain vulnerabilities or weaknesses are present. If a company does not have a firewall, hackers and attackers have all types of opportunities within that network. If a company does not perform access control, auditing, and supervision, employees may have many opportunities to embezzle funds and defraud the company. Once a crime fighter finds out why a person would want to commit a crime (motive), she will look at what could allow the criminal to be successful (opportunity).
Means pertains to the abilities a criminal would need to be successful. Suppose a crime fighter was asked to investigate a complex embezzlement that took place within a financial institution. If the suspects were three people who knew how to use a mouse, keyboard, and a word processing application, but only one of them was a programmer and system analyst, the crime fighter would realize that this person may have the means to commit this crime much more successfully than the other two individuals.
Computer Criminal Behavior
Like traditional criminals, computer criminals have a specific modus operandi (MO, pronounced “em-oh”). In other words, criminals use a distinct method of operation to carry out their crime that can be used to help identify them. The difference with computer crimes is that the investigator, obviously, must have knowledge of technology. For example, an MO for computer criminals may include the use of specific hacking tools, or targeting specific systems or networks. The method usually involves repetitive signature behaviors, such as sending e-mail messages or programming syntax. Knowledge of the criminal’s MO and signature behaviors can be useful throughout the investigative process. Law enforcement can use the information to identify other offenses by the same criminal, for example. The MO and signature behaviors can also provide information that is useful during the interview process and potentially a trial.
Psychological crime scene analysis (profiling) can also be conducted using the criminal’s MO and signature behaviors. Profiling provides insight into the thought processes of the attacker and can be used to identify the attacker or, at the very least, the tool he used to conduct the crime.
NOTE Locard’s exchange principle also applies to profiling. The principle states that a criminal leaves something behind at the crime scene and takes something with them. This principle is the foundation of criminalistics. Even in an entirely digital crime scene, Locard’s exchange principle can shed light on who the perpetrator(s) may be.
Incident Investigators
Incident investigators are a breed of their own. The good ones must be aware of suspicious or abnormal activities that others might normally ignore. This is because, due to their training and experience, they may know what is potentially going on behind some abnormal system activity, while another employee would just respond, “Oh, that just happens sometimes. We don’t know why.”
The investigator could identify suspicious activities, such as port scans, attempted SQL injections, or evidence in a log that describes a dangerous activity that took place. Identifying abnormal activities is a bit more difficult, because it is more subtle. These activities could be increased network traffic, an employee’s staying late every night, unusual requests to specific ports on a network server, and so on. On top of being observant, the investigator must understand forensic procedures, evidence collection issues, and how to analyze a situation to determine what is going on and know how to pick out the clues in system logs.
Types of Investigations
Investigations happen for very specific reasons. Maybe you suspect an employee is using your servers to mine bitcoin after hours, which in most places would be a violation of acceptable use policies. Maybe you think civil litigation is reasonably foreseeable or you uncover evidence of crime on your systems. Though the investigative process is similar regardless of the reason, it is important to differentiate the types of investigations you are likely to come across.
Administrative
An administrative investigation is one that is focused on policy violations. These represent the least impactful (to the organization) type of investigation and will likely result in administrative action if the investigation supports the allegations. For instance, violations of voluntary industry standards (such as PCI DSS) could result in an administrative investigation, particularly if the violation resulted in some loss or bad press for the organization. In the worst case, someone can get fired. Typically, however, someone is counseled not to do something again and that is that. Either way, you want to keep your human resources (HR) staff involved as you proceed.
Criminal
A seemingly administrative affair, however, can quickly get stickier. Suppose you start investigating someone for a possible policy violation and along the way discover that person was involved in what is likely criminal activity. A criminal investigation is one that is aimed at determining whether there is cause to believe beyond a reasonable doubt that someone committed a crime. The most important thing to consider is that we, as information systems security professionals, are not qualified to determine whether or not someone broke the law; that is the job of law enforcement agencies (LEAs). Our job, once we have reason to believe that a crime may have taken place, is to preserve evidence, ensure the designated people in our organizations contact the appropriate LEA, and assist them in any way that is appropriate.
Civil
Not all statutes are criminal, however, so it is possible to have an alleged violation of a law result in something other than a criminal investigation. The two likeliest ways to encounter this is regarding possible violations of civil law or government regulations. A civil investigation is typically triggered when a lawsuit is imminent or ongoing. It is similar to a criminal investigation, except that instead of working with an LEA you will probably be working with attorneys from both sides (the plaintiff is the party suing and the defendant is the one being sued). Another key difference in civil (versus criminal) investigations is that the standard of proof is much lower; instead of proving beyond a reasonable doubt, the plaintiff just has to show that the preponderance of the evidence supports the allegation.
Regulatory
Somewhere between all three (administrative, criminal, and civil investigations) lies the fourth kind you should know. A regulatory investigation is initiated by a government regulator when there is reason to believe that the organization is not in compliance. These vary significantly in scope and could look like any of the other three types of investigation depending on the severity of the allegations. As with criminal investigations, the key thing to remember is that your job is to preserve evidence and assist the regulator’s investigators as appropriate.

EXAM TIP Always treat an investigation, regardless of type, as if it would ultimately end up in a courtroom.
The Forensic Investigation Process
To ensure that forensic activities are carried out in a standardized manner and the evidence collected is admissible, it is necessary for the team to follow specific laid-out steps so that nothing is missed. Figure 7-13 illustrates the phases through a common investigation process. Each team or company may commonly come up with their own steps, but all should be essentially accomplishing the same things:
• Identification
• Preservation
• Collection
• Examination
• Analysis
• Presentation
• Decision
NOTE The principles of criminalistics are included in the forensic investigation process. They are identification of the crime scene, protection of the environment against contamination and loss of evidence, identification of evidence and potential sources of evidence, and the collection of evidence. In regard to minimizing the degree of contamination, it is important to understand that it is impossible not to change a crime scene—be it physical or digital. The key is to minimize changes and document what you did and why, and how the crime scene was affected.
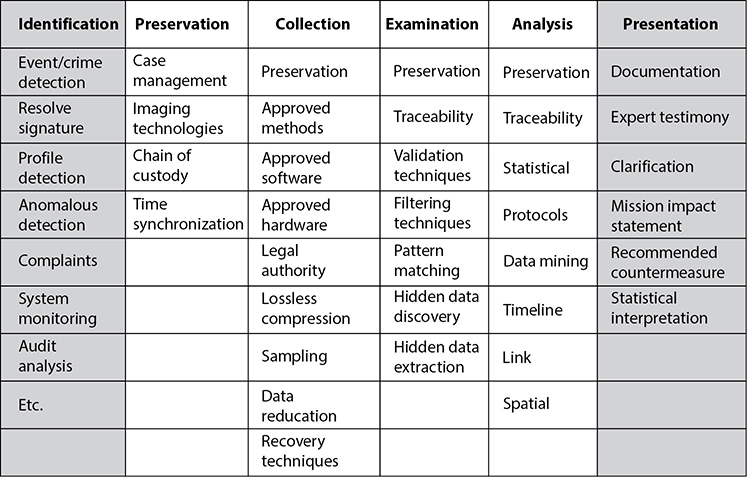
Figure 7-13 Characteristics of the different phases through an investigation process
During the examination and analysis process of a forensic investigation, it is critical that the investigator works from an image that contains all of the data from the original disk. It must be a bit-level copy, sector by sector, to capture deleted files, slack spaces, and unallocated clusters. These types of images can be created through the use of a specialized tool such as Forensic Toolkit (FTK), EnCase Forensic, or the dd Unix utility. A file copy tool does not recover all data areas of the device necessary for examination. Figure 7-14 illustrates a commonly used tool in the forensic world for evidence collection.
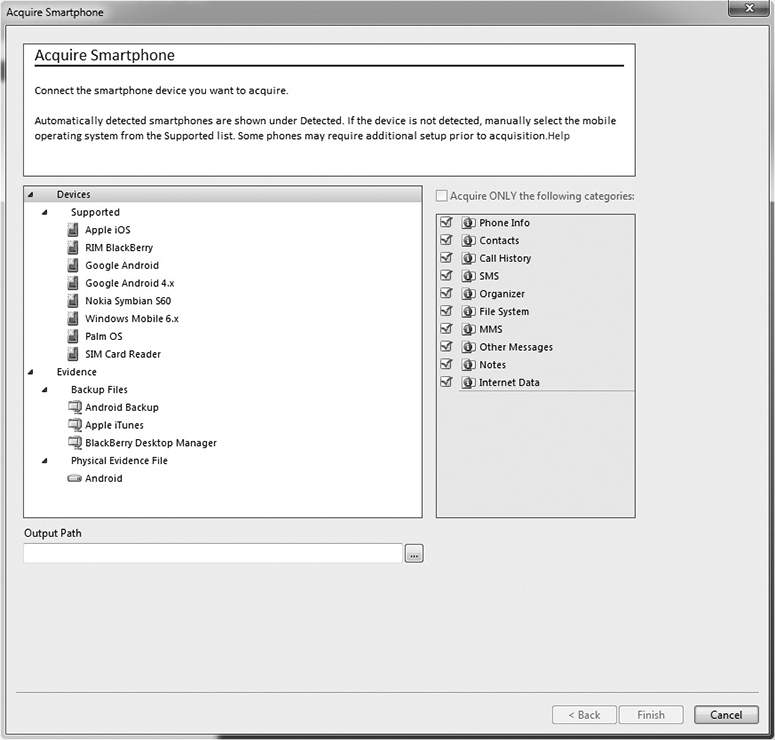
Figure 7-14 EnCase Forensic can be used to collect digital forensic data.
The original media should have two copies created: a primary image (a control copy that is stored in a library) and a working image (used for analysis and evidence collection). These should be timestamped to show when the evidence was collected.
Before creating these images, the investigator must make sure the new media has been properly purged, meaning it does not contain any residual data. Some incidents have occurred where drives that were new and right out of the box (shrink-wrapped) contained old data not purged by the vendor.
To ensure that the original image is not modified, it is important to create message digests for files and directories before and after the analysis to prove the integrity of the original image.
The investigator works from the duplicate image because it preserves the original evidence, prevents inadvertent alteration of original evidence during examination, and allows re-creation of the duplicate image if necessary. Much of the needed data is volatile and can be contained in the following:
• Registers and cache
• Process tables and ARP cache
• System memory (RAM)
• Temporary file systems
• Special disk sectors
So, great care and precision must take place to capture clues from any computer or device. Remember that digital evidence can exist in many more devices than traditional computer systems. Cell phones, USB drives, laptops, GPS devices, and memory cards can be containers of digital evidence as well.
Acquiring evidence on live systems and those using network storage further complicates matters because you cannot turn off the system in order to make a copy of the hard drive. Imagine the reaction you’d receive if you were to tell an IT manager that you need to shut down a primary database or e-mail system. It wouldn’t be favorable. So these systems and others, such as those using on-the-fly encryption, must be imaged while they are running.
When forensics teams are deployed, they should be properly equipped with all of the tools and supplies needed. The following are some of the common items in the forensics field kits:
• Documentation tools Tags, labels, and time-lined forms
• Disassembly and removal tools Antistatic bands, pliers, tweezers, screwdrivers, wire cutters, and so on
• Package and transport supplies Antistatic bags, evidence bags and tape, cable ties, and others

The next crucial piece is to keep a proper chain of custody of the evidence. Because evidence from these types of crimes can be very volatile and easily dismissed from court because of improper handling, it is important to follow very strict and organized procedures when collecting and tagging evidence in every single case—no exceptions! Furthermore, the chain of custody should follow evidence through its entire life cycle, beginning with identification and ending with its destruction, permanent archiving, or return to owner.
NOTE A chain of custody is a history that shows how evidence was collected, analyzed, transported, and preserved in order to be presented in court. Because electronic evidence can be easily modified, a clearly defined chain of custody demonstrates that the evidence is trustworthy.
When copies of data need to be made, this process must meet certain standards to ensure quality and reliability. Specialized software for this purpose can be used. The copies must be able to be independently verified and must be tamperproof.
Each piece of evidence should be marked in some way with the date, time, initials of the collector, and a case number if one has been assigned. Magnetic disk surfaces should not be marked on. The piece of evidence should then be sealed in a container, which should be marked with the same information. The container should be sealed with evidence tape, and if possible, the writing should be on the tape so a broken seal can be detected. An example of the data that should be collected and displayed on each evidence container is shown in Figure 7-15.
NOTE The chain of custody of evidence dictates that all evidence be labeled with information indicating who secured and validated it.
Wires and cables should be labeled, and a photograph of the labeled system should be taken before it is actually disassembled. Media should be write-protected if possible. Storage of media evidence should be dust free and kept at room temperature without much humidity, and, of course, the media should not be stored close to any strong magnets or magnetic fields.

Figure 7-15 Evidence container data
If possible, the crime scene should be photographed, including behind the computer if the crime involved some type of physical break-in. Documents, papers, and devices should be handled with cloth gloves and placed into containers and sealed. All storage media should be contained, even if it has been erased, because data still may be obtainable.
Because this type of evidence can be easily erased or destroyed and is complex in nature, identification, recording, collection, preservation, transportation, and interpretation are all important. After everything is properly labeled, a chain of custody log should be made of each container and an overall log should be made capturing all events.
For a crime to be successfully prosecuted, solid evidence is required. Computer forensics is the art of retrieving this evidence and preserving it in the proper ways to make it admissible in court. Without proper computer forensics, hardly any computer crimes could ever be properly and successfully presented in court.
The most common reasons for improper evidence collection are lack of an established incident response team, lack of an established incident response procedures, poorly written policy, or a broken chain of custody.
The next step is the analysis of the evidence. Forensic investigators use a scientific method that involves
• Determining the characteristics of the evidence, such as whether it’s admissible as primary or secondary evidence, as well as its source, reliability, and permanence
• Comparing evidence from different sources to determine a chronology of events
• Event reconstruction, including the recovery of deleted files and other activity on the system
This can take place in a controlled lab environment or, thanks to hardware write-blockers and forensic software, in the field. When investigators analyze evidence in a lab, they are dealing with dead forensics; that is, they are working only with static data. Live forensics, which takes place in the field, includes volatile data. If evidence is lacking, then an experienced investigator should be called in to help complete the picture.
Finally, the interpretation of the analysis should be presented to the appropriate party. This could be a judge, lawyer, CEO, or board of directors. Therefore, it is important to present the findings in a format that will be understood by a nontechnical audience. As a CISSP, you should be able to explain these findings in layman’s terms using metaphors and analogies. Of course, the findings, which are top secret or company confidential, should be disclosed only to authorized parties. This may include the legal department or any outside counsel that assisted with the investigation.
What Is Admissible in Court?
Computer logs are important in many aspects of the IT world. They are generally used to troubleshoot an issue or to try to understand the events that took place at a specific moment in time. When computer logs are to be used as evidence in court, they must be collected in the regular course of business. Most of the time, computer-related documents are considered hearsay, meaning the evidence is secondhand evidence. Hearsay evidence is not normally admissible in court unless it has firsthand evidence that can be used to prove the evidence’s accuracy, trustworthiness, and reliability, such as the testimony of a businessperson who generated the computer logs and collected them. This person must generate and collect logs as a normal part of his business activities and not just this one time for court. The value of evidence depends upon the genuineness and competence of the source.
It is important to show that the logs, and all evidence, have not been tampered with in any way, which is the reason for the chain of custody of evidence. Several tools are available that run checksums or hashing functions on the logs, which will allow the team to be alerted if something has been modified.
When evidence is being collected, one issue that can come up is the user’s expectation of privacy. If an employee is suspected of, and charged with, a computer crime, he might claim that his files on the computer he uses are personal and not available to law enforcement and the courts. This is why it is important for companies to conduct security awareness training, have employees sign documentation pertaining to the acceptable use of the company’s computers and equipment, and have legal banners pop up on every employee’s computer when they log on. These are key elements in establishing that a user has no right to privacy when he is using company equipment. The following banner is suggested by CERT Advisory:
This system is for the use of authorized users only. Individuals using this computer system without authority, or in excess of their authority, are subject to having all of their activities on this system monitored and recorded by system personnel.
In the course of monitoring an individual improperly using this system, or in the course of system maintenance, the activities of authorized users may also be monitored.
Anyone using this system expressly consents to such monitoring and is advised that if such monitoring reveals possible evidence of criminal activity, system personnel may provide the evidence of such monitoring to law enforcement officials.
This explicit warning strengthens a legal case that can be brought against an employee or intruder, because the continued use of the system after viewing this type of warning implies that the person acknowledges the security policy and gives permission to be monitored.
Evidence has its own life cycle, and it is important that the individuals involved with the investigation understand the phases of the life cycle and properly follow them.
The life cycle of evidence includes
• Collection and identification
• Storage, preservation, and transportation
• Presentation in court
• Return of the evidence to the victim or owner
Several types of evidence can be used in a trial, such as written, oral, computer generated, and visual or audio. Oral evidence is testimony of a witness. Visual or audio is usually a captured event during the crime or right after it.
It is important that evidence be relevant, complete, sufficient, and reliable to the case at hand. These four characteristics of evidence provide a foundation for a case and help ensure that the evidence is legally permissible.
For evidence to be relevant, it must have a reasonable and sensible relationship to the findings. If a judge rules that a person’s past traffic tickets cannot be brought up in a murder trial, this means the judge has ruled that the traffic tickets are not relevant to the case at hand. Therefore, the prosecuting lawyer cannot even mention them in court.
For evidence to be complete, it must present the whole truth of an issue. For the evidence to be sufficient, or believable, it must be persuasive enough to convince a reasonable person of the validity of the evidence. This means the evidence cannot be subject to personal interpretation. Sufficient evidence also means it cannot be easily doubted.
For evidence to be reliable, or accurate, it must be consistent with the facts. Evidence cannot be reliable if it is based on someone’s opinion or copies of an original document, because there is too much room for error. Reliable evidence means it is factual and not circumstantial.
NOTE Don’t dismiss the possibility that as an information security professional you will be responsible for entering evidence into court. Most tribunals, commissions, and other quasi-legal proceedings have admissibility requirements. Because these requirements can change between jurisdictions, you should seek legal counsel to better understand the specific rules for your jurisdiction.
Surveillance, Search, and Seizure
Two main types of surveillance are used when it comes to identifying computer crimes: physical surveillance and computer surveillance. Physical surveillance pertains to security cameras, security guards, and closed-circuit TV (CCTV), which may capture evidence. Physical surveillance can also be used by an undercover agent to learn about the suspect’s spending activities, family and friends, and personal habits in the hope of gathering more clues for the case.
Computer surveillance pertains to auditing events, which passively monitors events by using network sniffers, keyboard monitors, wiretaps, and line monitoring. In most jurisdictions, active monitoring may require a search warrant. In most workplace environments, to legally monitor an individual, the person must be warned ahead of time that her activities may be subject to this type of monitoring.
Search and seizure activities can get tricky depending on what is being searched for and where. For example, American citizens are protected by the Fourth Amendment against unlawful search and seizure, so law enforcement agencies must have probable cause and request a search warrant from a judge or court before conducting such a search. The actual search can take place only in the areas outlined by the warrant. The Fourth Amendment does not apply to actions by private citizens unless they are acting as police agents. So, for example, if Kristy’s boss warned all employees that the management could remove files from their computers at any time, and her boss was not a police officer or acting as a police agent, she could not successfully claim that her Fourth Amendment rights were violated. Kristy’s boss may have violated some specific privacy laws, but he did not violate Kristy’s Fourth Amendment rights.
In some circumstances, a law enforcement agent may seize evidence that is not included in the warrant, such as if the suspect tries to destroy the evidence. In other words, if there is an impending possibility that evidence might be destroyed, law enforcement may quickly seize the evidence to prevent its destruction. This is referred to as exigent circumstances, and a judge will later decide whether the seizure was proper and legal before allowing the evidence to be admitted. For example, if a police officer had a search warrant that allowed him to search a suspect’s living room but no other rooms and then he saw the suspect dumping cocaine down the toilet, the police officer could seize the cocaine even though it was in a room not covered under his search warrant.
After evidence is gathered, the chain of custody needs to be enacted and enforced to make sure the evidence’s integrity is not compromised.
A thin line exists between enticement and entrapment when it comes to capturing a suspect’s actions. Enticement is legal and ethical, whereas entrapment is neither legal nor ethical. In the world of computer crimes, a honeypot is always a good example to explain the difference between enticement and entrapment. Companies put systems in their screened subnets that either emulate services that attackers usually like to take advantage of or actually have the services enabled. The hope is that if an attacker breaks into the company’s network, she will go right to the honeypot instead of the systems that are actual production machines. The attacker will be enticed to go to the honeypot system because it has many open ports and services running and exhibits vulnerabilities that the attacker would want to exploit. The company can log the attacker’s actions and later attempt to prosecute.
The action in the preceding example is legal unless the company crosses the line to entrapment. For example, suppose a web page has a link that indicates that if an individual clicks it, she could then download thousands of MP3 files for free. However, when she clicks that link, she is taken to the honeypot system instead, and the company records all of her actions and attempts to prosecute. Entrapment does not prove that the suspect had the intent to commit a crime; it only proves she was successfully tricked.
Disaster Recovery
So far we have discussed preventing and responding to security incidents, including various types of investigations, as part of standard security operations. These are things we do day in and day out. But what happens on those rare occasions when an incident has disastrous effects? In this section, we will look at the parts of business continuity planning (BCP) and disaster recovery (DR) in which the information systems operations and security teams play a significant role. It is worth noting that BCP is much broader than the purview of security and operations, while DR is mostly in their purview.
This is a great point at which to circle back to a discussion we started in Chapter 1 on business continuity planning. Recall that we discussed the role of maximum tolerable downtime (MTD) values. In reality, basic MTD values are a good start, but are not granular enough for a company to figure out what it needs to put into place to be able to absorb the impact of a disaster. MTD values are usually “broad strokes” that do not provide enough detail to help pinpoint the actual recovery solutions that need to be purchased and implemented. For example, if the BCP team determines that the MTD value for the customer service department is 48 hours, this is not enough information to fully understand what redundant solutions or backup technology should be put into place. MTD in this example does provide a basic deadline that means if customer service is not up within 48 hours, the company may not be able to recover and everyone should start looking for new jobs.
As shown in Figure 7-16, more than just MTD metrics are needed to get production back to normal operations after a disruptive event. We will walk through each of these metric types and see how they are best used together.
The recovery time objective (RTO) is the maximum time period within which a business process must be restored to a designated service level after a disaster to avoid unacceptable consequences associated with a break in business continuity. The RTO value is smaller than the MTD value, because the MTD value represents the time after which an inability to recover significant operations will mean severe and perhaps irreparable damage to the organization’s reputation or bottom line. The RTO assumes that there is a period of acceptable downtime. This means that a company can be out of production for a certain period of time (RTO) and still get back on its feet. But if the company cannot get production up and running within the MTD window, the company is sinking too fast to properly recover.
The work recovery time (WRT) is the remainder of the overall MTD value after the RTO has passed. RTO usually deals with getting the infrastructure and systems back up and running, and WRT deals with restoring data, testing processes, and then making everything “live” for production purposes.
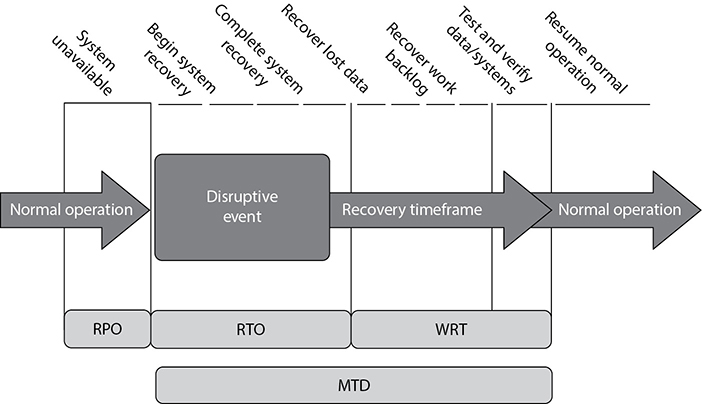
Figure 7-16 Metrics used for disaster recovery
The recovery point objective (RPO) is the acceptable amount of data loss measured in time. This value represents the earliest point in time at which data must be recovered. The higher the value of data, the more funds or other resources that can be put into place to ensure a smaller amount of data is lost in the event of a disaster. Figure 7-17 illustrates the relationship and differences between the use of RPO and RTO values.
The RTO, RPO, and WRT values are critical to understand because they will be the basic foundational metrics used when determining the type of recovery solutions a company must put into place, so let’s dig a bit deeper into them. As an example of RTO, let’s say a company has determined that if it is unable to process product order requests for 12 hours, the financial hit will be too large for it to survive. So the company develops methods to ensure that orders can be processed manually if their automated technological solutions become unavailable. But if it takes the company 24 hours to actually stand up the manual processes, the company could be in a place operationally and financially where it can never fully recover. So RTO deals with “how much time do we have to get everything up and working again?”

Figure 7-17 RPO and RTO metrics in use
Now let’s say that the same company experienced a disaster and got its manual processes up and running within two hours, so it met the RTO requirement. But just because business processes are back in place, the company still might have a critical problem. The company has to restore the data it lost during the disaster. It does no good to restore data that is a week old. The employees need to have access to the data that was being processed right before the disaster hit. If the company can only restore data that is a week old, then all the orders that were in some stage of being fulfilled over the last seven days could be lost. If the company makes an average of $25,000 per day in orders and all the order data was lost for the last seven days, this can result in a loss of $175,000 and a lot of unhappy customers. So just getting things up and running (RTO) is part of the picture. Getting the necessary data in place so that business processes are up-to-date and relevant (RPO) is just as critical.
To take things one step further, let’s say the company stood up its manual order-filling processes in two hours. It also had real-time data backup systems in place, so all of the necessary up-to-date data is restored. But no one actually tested these manual processes, everyone is confused, and orders still cannot be processed and revenue cannot be collected. This means the company met its RTO requirement and its RPO requirement, but failed its WRT requirement, and thus failed the MTD requirement. Proper business recovery means all of the individual things have to happen correctly for the overall goal to be successful.
EXAM TIP An RTO is the amount of time it takes to recover from a disaster, and an RPO is the amount of acceptable data, measured in time, that can be lost from that same event.
The actual MTD, RTO, and RPO values are derived during the business impact analysis (BIA), the purpose of which is to be able to apply criticality values to specific business functions, resources, and data types. A simplistic example is shown in Table 7-3. The company must have data restoration capabilities in place to ensure that mission-critical data is never older than one minute. The company cannot rely on something as slow as backup tape restoration, but must have a high-availability data replication solution in place. The RTO value for mission-critical data processing is two minutes or less. This means that the technology that carries out the processing functionality for this type of data cannot be down for more than two minutes. The company may choose to have a cluster technology in place that will shift the load once it notices that a server goes offline.

Table 7-3 RPO and RTO Value Relationships
In this same scenario, data that is classified as “Business” can be up to three hours old when the production environment comes back online, so a slower data replication process is acceptable. Since the RTO for business data is eight hours, the company can choose to have hot-swappable hard drives available instead of having to pay for the more complicated and expensive clustering technology.
The BCP team has to figure out what the company needs to do to actually recover the processes and services it has identified as being so important to the organization overall. In its business continuity and recovery strategy, the team closely examines the critical, agreed-upon business functions, and then evaluates the numerous recovery and backup alternatives that might be used to recover critical business operations. It is important to choose the right tactics and technologies for the recovery of each critical business process and service in order to assure that the set MTD values are met.
So what does the BCP team need to accomplish? The team needs to actually define the recovery processes, which are sets of predefined activities that will be implemented and carried out in response to a disaster. More importantly, these processes must be constantly re-evaluated and updated as necessary to ensure that the organization meets or exceeds the MTDs.
Business Process Recovery
A business process is a set of interrelated steps linked through specific decision activities to accomplish a specific task. Business processes have starting and ending points and are repeatable. The processes should encapsulate the knowledge about services, resources, and operations provided by a company. For example, when a customer requests to buy a book via an organization’s e-commerce site, a set of steps must be followed, such as these:
1. Validate that the book is available.
2. Validate where the book is located and how long it would take to ship it to the destination.
3. Provide the customer with the price and delivery date.
4. Verify the customer’s credit card information.
5. Validate and process the credit card order.
6. Send a receipt and tracking number to the customer.
7. Send the order to the book inventory location.
8. Restock inventory.
9. Send the order to accounting.
The BCP team needs to understand these different steps of the company’s most critical processes. The data is usually presented as a workflow document that contains the roles and resources needed for each process. The BCP team must understand the following about critical business processes:
• Required roles
• Required resources
• Input and output mechanisms
• Workflow steps
• Required time for completion
• Interfaces with other processes
This will allow the BCP team to identify threats and the controls to ensure the least amount of process interruption.
Recovery Site Strategies
Disruptions, in BCP terms, are of three main types: nondisasters, disasters, and catastrophes. A nondisaster is a disruption in service that has significant but limited impact on the conduct of business processes at a facility. The solution could include hardware, software, or file restoration. A disaster is an event that causes the entire facility to be unusable for a day or longer. This usually requires the use of an alternate processing facility and restoration of software and data from offsite copies. The alternate site must be available to the company until its main facility is repaired and usable. A catastrophe is a major disruption that destroys the facility altogether. This requires both a short-term solution, which would be an offsite facility, and a long-term solution, which may require rebuilding the original facility. Disasters and catastrophes are rare compared to nondisasters, thank goodness.
An organization has various recovery alternatives to choose from, such as a redundant site, outsourcing, a rented offsite installation, or a reciprocal agreement with another organization. The organization has three basic options: select a dedicated site that the organization operates itself; lease a commercial facility, such as a “hot site” that contains all the equipment and data needed to quickly restore operations; or enter into a formal agreement with another facility, such as a service bureau, to restore its operations.
In all these cases, the organization estimates the alternative’s ability to support its operations, to do it quickly, and to do it at a fair cost. It should closely query the alternative facility about such things as: How long will it take to recover from a certain incident to a certain level of operations? Will it give priority to restoring the operations of one organization over another after a disaster? What are its costs for performing various functions? What are its specifications for IT and security functions? Is the workspace big enough for the required number of employees?
An important consideration with third parties is their reliability, both in normal times and during an emergency. Their reliability can depend on considerations such as their track record, the extent and location of their supply inventory, and their access to supply and communication channels.
For larger disasters that affect the primary facility, an offsite backup facility must be accessible. Generally, contracts are established with third-party vendors to provide such services. The client pays a monthly fee to retain the right to use the facility in a time of need, and then incurs an activation fee when the facility actually has to be used. In addition, there would be a daily or hourly fee imposed for the duration of the stay. This is why subscription services for backup facilities should be considered a short-term solution, not a long-term solution.
It is important to note that most recovery site contracts do not promise to house the company in need at a specific location, but rather promise to provide what has been contracted for somewhere within the company’s locale. On, and subsequent to, September 11, 2001, many organizations with Manhattan offices were surprised when they were redirected by their backup site vendor not to sites located in New Jersey (which were already full), but rather to sites located in Boston, Chicago, or Atlanta. This adds yet another level of complexity to the recovery process, specifically the logistics of transporting people and equipment to unplanned locations.
Companies can choose from three main types of leased or rented offsite facilities:
• Hot site A facility that is leased or rented and is fully configured and ready to operate within a few hours. The only missing resources from a hot site are usually the data, which will be retrieved from a backup site, and the people who will be processing the data. The equipment and system software must absolutely be compatible with the data being restored from the main site and must not cause any negative interoperability issues. Some facilities, for a fee, store data backups close to the hot site. These sites are a good choice for a company that needs to ensure a site will be available for it as soon as possible. Most hot-site facilities support annual tests that can be done by the company to ensure the site is functioning in the necessary state of readiness.
This is the most expensive of the three types of offsite facilities. It can pose problems if a company requires proprietary or unusual hardware or software.
NOTE To attract the largest customer base, the vendor of a hot site will provide the most commonly used hardware and software products. This most likely will not include the specific customer’s proprietary or unusual hardware or software products.
• Warm site A leased or rented facility that is usually partially configured with some equipment, such as HVAC, and foundational infrastructure components, but not the actual computers. In other words, a warm site is usually a hot site without the expensive equipment such as communication equipment and servers. Staging a facility with duplicate hardware and computers configured for immediate operation is extremely expensive, so a warm site provides an alternate facility with some peripheral devices.
This is the most widely used model. It is less expensive than a hot site, and can be up and running within a reasonably acceptable time period. It may be a better choice for companies that depend upon proprietary and unusual hardware and software, because they will bring their own hardware and software with them to the site after the disaster hits. Drawbacks, however, are that much of the equipment has to be procured, delivered to, and configured at the warm site after the fact, and the annual testing available with hot-site contracts is not usually available with warm-site contracts. Thus, a company cannot be certain that it will in fact be able to return to an operating state within hours.
• Cold site A leased or rented facility that supplies the basic environment, electrical wiring, air conditioning, plumbing, and flooring, but none of the equipment or additional services. A cold site is essentially an empty data center. It may take weeks to get the site activated and ready for work. The cold site could have equipment racks and dark fiber (fiber that does not have the circuit engaged) and maybe even desks. However, it would require the receipt of equipment from the client, since it does not provide any.
The cold site is the least expensive option, but takes the most time and effort to actually get up and functioning right after a disaster, as the systems and software must be delivered, set up, and configured. Cold sites are often used as backups for call centers, manufacturing plants, and other services that can be moved lock, stock, and barrel in one shot.
After a catastrophic loss of the primary facility, some places will start their recovery in a hot or warm site, and transfer some operations over to a cold site after the latter has had time to set up.
It is important to understand that the different site types listed here are provided by service bureaus. A service bureau is a company that has additional space and capacity to provide applications and services such as call centers. A company pays a monthly subscription fee to a service bureau for this space and service. The fee can be paid for contingencies such as disasters and emergencies. You should evaluate the ability of a service bureau to provide services as you would divisions within your own organization, particularly on matters such as its ability to alter or scale its software and hardware configurations or to expand its operations to meet the needs of a contingency.
NOTE Related to a service bureau is a contingency company; its purpose is to supply services and materials temporarily to an organization that is experiencing an emergency. For example, a contingent supplier might provide raw materials such as heating fuel or backup telecommunication services. In considering contingent suppliers, the BCP team should think through considerations such as the level of services and materials a supplier can provide, how quickly a supplier can ramp up to supply them, and whether the supplier shares similar communication paths and supply chains as the affected organization.
Most companies use warm sites, which have some devices such as disk drives, tape drives, and controllers, but very little else. These companies usually cannot afford a hot site, and the extra downtime would not be considered detrimental. A warm site can provide a longer-term solution than a hot site. Companies that decide to go with a cold site must be able to be out of operation for a week or two. The cold site usually includes power, raised flooring, climate control, and wiring.
The following provides a quick overview of the differences between offsite facilities.
Hot Site Advantages:
• Ready within hours for operation
• Highly available
• Usually used for short-term solutions, but available for longer stays
• Annual testing available
Hot Site Disadvantages:
• Very expensive
• Limited on hardware and software choices
Warm and Cold Site Advantages:
• Less expensive
• Available for longer timeframes because of the reduced costs
• Practical for proprietary hardware or software use
Warm and Cold Site Disadvantages:
• Operational testing not usually available
• Resources for operations not immediately available
Backup tapes or other media should be tested periodically on the equipment kept at the hot site to make sure the media is readable by those systems. If a warm site is used, the tapes should be brought to the original site and tested on those systems. The reason for the difference is that when a company uses a hot site, it depends on the systems located at the hot site; therefore, the media needs to be readable by those systems. If a company depends on a warm site, it will most likely bring its original equipment with it, so the media needs to be readable by the company’s systems.
The BCP team may recognize the danger of the primary backup facility not being available when needed, which could require a tertiary site. This is a secondary backup site, just in case the primary backup site is unavailable. The secondary backup site is sometimes referred to as a “backup to the backup.” This is basically plan B if plan A does not work out.
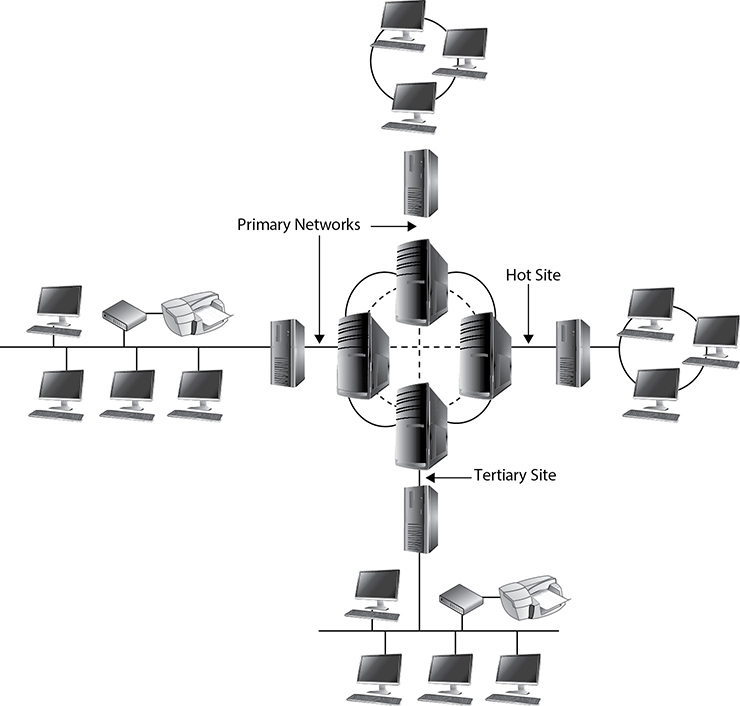
Reciprocal Agreements
Another approach to alternate offsite facilities is to establish a reciprocal agreement with another company, usually one in a similar field or that has similar technological infrastructure. This means that company A agrees to allow company B to use its facilities if company B is hit by a disaster, and vice versa. This is a cheaper way to go than the other offsite choices, but it is not always the best choice. Most environments are maxed out pertaining to the use of facility space, resources, and computing capability. To allow another company to come in and work out of the same shop could prove to be detrimental to both companies. Whether it can assist the other company while tending effectively to its own business is an open question. The stress of two companies working in the same environment could cause tremendous levels of tension. If it did work out, it would only provide a short-term solution. Configuration management could be a nightmare. Does the other company upgrade to new technology and retire old systems and software? If not, one company’s systems may become incompatible with that of the other company.
If you allow another company to move into your facility and work from there, you may have a solid feeling about your friend, the CEO, but what about all of her employees, whom you do not know? The mixing of operations could introduce many security issues. Now you have a new subset of people who may need to have privileged and direct access to your resources in the shared environment. This other company could be your competitor in the business world, so many of the employees may see you and your company more as a threat than one that is offering a helping hand in need. Close attention needs to be paid when assigning these other people access rights and permissions to your critical assets and resources, if they need access at all. Careful testing is recommended to see if one company or the other can handle the extra loads.
Reciprocal agreements have been known to work well in specific businesses, such as newspaper printing. These businesses require very specific technology and equipment that will not be available through any subscription service. These agreements follow a “you scratch my back and I’ll scratch yours” mentality. For most other organizations, reciprocal agreements are generally, at best, a secondary option for disaster protection. The other issue to consider is that these agreements are not enforceable. This means that although company A said company B could use its facility when needed, when the need arises, company A legally does not have to fulfill this promise. However, there are still many companies who do opt for this solution either because of the appeal of low cost or, as noted earlier, because it may be the only viable solution in some cases.
Important issues need to be addressed before a disaster hits if a company decides to participate in a reciprocal agreement with another company:
• How long will the facility be available to the company in need?
• How much assistance will the staff supply in integrating the two environments and ongoing support?
• How quickly can the company in need move into the facility?
• What are the issues pertaining to interoperability?
• How many of the resources will be available to the company in need?
• How will differences and conflicts be addressed?
• How does change control and configuration management take place?
• How often can drills and testing take place?
• How can critical assets of both companies be properly protected?
A variation on a reciprocal agreement is a consortium, or mutual aid agreement. In this case, more than two organizations agree to help one another in case of an emergency. Adding multiple organizations to the mix, as you might imagine, can make things even more complicated. The same concerns that apply with reciprocal agreements apply here, but even more so. Organizations entering into such agreements need to formally and legally write out their mutual responsibilities in advance. Interested parties, including the legal and IT departments, should carefully scrutinize such accords before the organization signs onto them.
Redundant Sites
Some companies choose to have redundant sites, or mirrored sites, meaning one site is equipped and configured exactly like the primary site, which serves as a redundant environment. The business-processing capabilities between the two sites can be completely synchronized. These sites are owned by the company and are mirrors of the original production environment. A redundant site has clear advantages: it has full availability, is ready to go at a moment’s notice, and is under the organization’s complete control. This is, however, one of the most expensive backup facility options, because a full environment must be maintained even though it usually is not used for regular production activities until after a disaster takes place that triggers the relocation of services to the redundant site. But “expensive” is relative here. If the company would lose a million dollars if it were out of business for just a few hours, the loss potential would override the cost of this option. Many organizations are subjected to regulations that dictate they must have redundant sites in place, so expense is not a matter of choice in these situations.
EXAM TIP A hot site is a subscription service. A redundant site, in contrast, is a site owned and maintained by the company, meaning the company does not pay anyone else for the site. A redundant site might be “hot” in nature, meaning it is ready for production quickly. However, the CISSP exam differentiates between a hot site (a subscription service) and a redundant site (owned by the company).
Another type of facility-backup option is a rolling hot site, or mobile hot site, where the back of a large truck or a trailer is turned into a data processing or working area. This is a portable, self-contained data facility. The trailer has the necessary power, telecommunications, and systems to do some or all of the processing right away. The trailer can be brought to the company’s parking lot or another location. Obviously, the trailer has to be driven over to the new site, the data has to be retrieved, and the necessary personnel have to be put into place.
Another, similar solution is a prefabricated building that can be easily and quickly put together. Military organizations and large insurance companies typically have rolling hot sites or trucks preloaded with equipment because they often need the flexibility to quickly relocate some or all of their processing facilities to different locations around the world depending on where the need arises.
Another option for organizations is to have multiple processing sites. An organization may have ten different facilities throughout the world, which are connected with specific technologies that could move all data processing from one facility to another in a matter of seconds when an interruption is detected. This technology can be implemented within the organization or from one facility to a third-party facility. Certain service providers provide this type of functionality to their customers. So if a company’s data processing is interrupted, all or some of the processing can be moved to the service provider’s servers.
It is best if a company is aware of all available options for hardware and facility backups to ensure it makes the best decision for its specific business and critical needs.
Supply and Technology Recovery
The BCP should also include backup solutions for the following:
• Network and computer equipment
• Voice and data communications resources
• Human resources
• Transportation of equipment and personnel
• Environment issues (HVAC)
• Data and personnel security issues
• Supplies (paper, forms, cabling, and so on)
• Documentation
The organization’s current technical environment must be understood. This means the planners have to know the intimate details of the network, communications technologies, computers, network equipment, and software requirements that are necessary to get the critical functions up and running. What is surprising to some people is that many organizations do not totally understand how their network is configured and how it actually works, because the network may have been established 10 to 15 years ago and has kept growing and changing under different administrators and personnel. New devices are added, new computers are added, new software packages are added, Voice over Internet Protocol (VoIP) may have been integrated, and the DMZ may have been split up into three DMZs, with an extranet for the company’s partners. Maybe the company bought and merged with another company and network. Over ten years, a number of technology refreshes most likely have taken place, and the individuals who are maintaining the environment now likely are not the same people who built it ten years ago. Many IT departments experience extensive employee turnover every five years. And most organizational network schematics are notoriously out of date because everyone is busy with their current tasks (or will come up with new tasks just to get out of having to update the schematic).
So the BCP team has to make sure that if the networked environment is partially or totally destroyed, the recovery team has the knowledge and skill to properly rebuild it.
NOTE Many organizations have moved to VoIP, which means that if the network goes down, network and voice capability are unavailable. The team should address the possible need of redundant voice systems.
The BCP team needs to take into account several things that are commonly overlooked, such as hardware replacements, software products, documentation, environmental needs, and human resources.
Hardware Backups
The BCP needs to identify the equipment required to keep the critical functions up and running. This may include servers, user workstations, routers, switches, tape backup devices, and more. The needed inventory may seem simple enough, but as they say, the devil is in the details. If the recovery team is planning to use images to rebuild newly purchased servers and workstations because the original ones were destroyed, for example, will the images work on the new computers? Using images instead of building systems from scratch can be a time-saving task, unless the team finds out that the replacement equipment is a newer version and thus the images cannot be used. The BCP should plan for the recovery team to use the company’s current images, but also have a manual process of how to build each critical system from scratch with the necessary configurations.
The BCP also needs to be based on accurate estimates of how long it will take for new equipment to arrive. For example, if the organization has identified Dell as its equipment replacement supplier, how long will it take this vendor to send 20 servers and 30 workstations to the offsite facility? After a disaster hits, the company could be in its offsite facility only to find that its equipment will take three weeks to be delivered. So, the SLA for the identified vendors needs to be investigated to make sure the company is not further damaged by delays. Once the parameters of the SLA are understood, the team must make a decision between depending upon the vendor and purchasing redundant systems and storing them as backups in case the primary equipment is destroyed.
As described earlier, when potential company risks are identified, it is better to take preventive steps to reduce the potential damage. After the calculation of the MTD values, the team will know how long the company can be without a specific device. This data should be used to make the decision on whether the company should depend on the vendor’s SLA or make readily available a hot-swappable redundant system. If the company will lose $50,000 per hour if a particular server goes down, then the team should elect to implement redundant systems and technology.
If an organization is using any legacy computers and hardware and a disaster hits tomorrow, where would it find replacements for this legacy equipment? The team should identify legacy devices and understand the risk the organization is facing if replacements are unavailable. This finding has caused many companies to move from legacy systems to commercial off-the-shelf (COTS) products to ensure that replacement is possible.
NOTE Different types of backup tape technologies can be used (digital linear tape, digital audio tape, advanced intelligent tape). The team needs to make sure it knows the type of technology that is used by the company and identify the necessary vendor in case the tape-reading device needs to be replaced.
Software Backups
Most companies’ IT departments have their array of software disks and licensing information here or there—or possibly in one centralized location. If the facility were destroyed and the IT department’s current environment had to be rebuilt, how would it gain access to these software packages? The BCP team should make sure to have an inventory of the necessary software required for mission-critical functions and have backup copies at an offsite facility. Hardware is usually not worth much to a company without the software required to run on it. The software that needs to be backed up can be in the form of applications, utilities, databases, and operating systems. The continuity plan must have provisions to back up and protect these items along with hardware and data.
The BCP team should make sure there are at least two copies of the company’s operating system software and critical applications. One copy should be stored onsite and the other copy should be stored at a secure offsite location. These copies should be tested periodically and re-created when new versions are rolled out.
It is common for organizations to work with software developers to create customized software programs. For example, in the banking world, individual financial institutions need software that will allow their bank tellers to interact with accounts, hold account information in databases and mainframes, provide online banking, carry out data replication, and perform a thousand other types of bank-like functionalities. This specialized type of software is developed and available through a handful of software vendors that specialize in this market. When bank A purchases this type of software for all of its branches, the software has to be specially customized for its environment and needs. Once this banking software is installed, the whole organization depends upon it for its minute-by-minute activities.
When bank A receives the specialized and customized banking software from the software vendor, bank A does not receive the source code. Instead, the software vendor provides bank A with a compiled version. Now, what if this software vendor goes out of business because of a disaster or bankruptcy? Then bank A will require a new vendor to maintain and update this banking software; thus, the new vendor will need access to the source code.
The protection mechanism that bank A should implement is called software escrow, in which a third party holds the source code, backups of the compiled code, manuals, and other supporting materials. A contract between the software vendor, customer, and third party outlines who can do what, and when, with the source code. This contract usually states that the customer can have access to the source code only if and when the vendor goes out of business, is unable to carry out stated responsibilities, or is in breach of the original contract. If any of these activities takes place, then the customer is protected because it can still gain access to the source code and other materials through the third-party escrow agent.
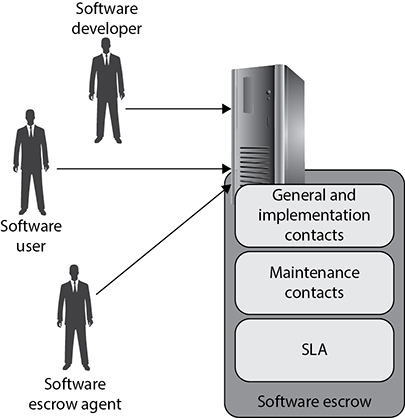
Many companies have been crippled by not implementing software escrow. Such a company would have paid a software vendor to develop specialized software, and when the software vendor went belly up, the customer did not have access to the code that its whole company ran on.
Backup Storage Strategies
Data has become one of the most critical assets to nearly all organizations. It may include financial spreadsheets, blueprints on new products, customer information, product inventory, trade secrets, and more. In Chapter 1, we stepped through risk analysis procedures and, in Chapter 2, data classification. The BCP team should not be responsible for setting up and maintaining the company’s data classification procedures, but the team should recognize that the company is at risk if it does not have these procedures in place. This should be seen as a vulnerability that is reported to management. Management would need to establish another group of individuals who would identify the company’s data, define a loss criterion, and establish the classification structure and processes.
The BCP team’s responsibility is to provide solutions to protect this data and identify ways to restore it after a disaster. In this section, we look at different ways data can be protected and restored when needed.
Data usually changes more often than hardware and software, so these backup or archival procedures must happen on a continual basis. The data backup process must make sense and be reasonable and effective. If data in the files changes several times a day, backup procedures should happen a few times a day or nightly to ensure all the changes are captured and kept. If data is changed once a month, backing up data every night is a waste of time and resources. Backing up a file and its corresponding changes is usually more desirable than having multiple copies of that one file. Online backup technologies usually record the changes to a file in a transaction log, which is separate from the original file.

The operations team is responsible for defining which data gets backed up and how often. These backups can be full, differential, or incremental, and are usually used in some type of combination with each other. Most files are not altered every day, so, to save time and resources, it is best to devise a backup plan that does not continually back up data that has not been modified. So, how do we know which data has changed and needs to be backed up without having to look at every file’s modification date? This is accomplished by an archive bit. Operating systems’ file systems keep track of what files have been modified by setting an archive bit. If a file is modified or created, the file system sets the archive bit to 1. Backup software has been created to review this bit setting when making its determination on what gets backed up and what does not.
The first step is to do a full backup, which is just what it sounds like—all data is backed up and saved to some type of storage media. During a full backup, the archive bit is cleared, which means that it is set to 0. A company can choose to do full backups only, in which case the restoration process is just one step, but the backup and restore processes could take a long time.
Most companies choose to combine a full backup with a differential or incremental backup. A differential process backs up the files that have been modified since the last full backup. When the data needs to be restored, the full backup is laid down first, and then the most recent differential backup is put down on top of it. The differential process does not change the archive bit value.
An incremental process backs up all the files that have changed since the last full or incremental backup and sets the archive bit to 0. When the data needs to be restored, the full backup data is laid down, and then each incremental backup is laid down on top of it in the proper order (see Figure 7-18). If a company experienced a disaster and it used the incremental process, it would first need to restore the full backup on its hard drives and lay down every incremental backup that was carried out before the disaster took place (and after the last full backup). So, if the full backup was done six months ago and the operations department carried out an incremental backup each month, the restoration team would restore the full backup and start with the older incremental backups taken since the full backup and restore each one of them until they were all restored.
Figure 7-18 Backup software steps
Which backup process is best? If a company wants the backup and restoration processes to be simplistic and straightforward, it can carry out just full backups—but this may require a lot of hard drive space and time. Although using differential and incremental backup processes is more complex, it requires fewer resources and less time. A differential backup takes more time in the backing-up phase than an incremental backup, but it also takes less time to restore than an incremental backup because carrying out restoration of a differential backup happens in two steps, whereas in an incremental backup, every incremental backup must be restored in the correct sequence.
Whatever the organization chooses, it is important to not mix differential and incremental backups. This overlap could cause files to be missed, since the incremental backup changes the archive bit and the differential backup does not.
Critical data should be backed up and stored at an onsite area and an offsite area. The onsite backup copies should be easily accessible in case of nondisasters and should provide a quick restore process so operations can return to normal. However, onsite backup copies are not enough to provide real protection. The data should also be held in an offsite facility in case of actual disasters or catastrophes. One decision that needs to be made is where the offsite location should be in reference to the main facility. The closer the offsite backup storage site is, the easier it is to access, but this can put the backup copies in danger if a large-scale disaster manages to take out the company’s main facility and the backup facility. It may be wiser to choose a backup facility farther away, which makes accessibility harder but reduces the risk. Some companies choose to have more than one backup facility: one that is close and one that is farther away.
The onsite backup information should be stored in a fire-resistant, heat-resistant, and waterproof safe. The procedures for backing up and restoring data should be easily accessible and comprehensible even to operators or administrators who are not intimately familiar with a specific system. In an emergency situation, the same guy who always does the backing up and restoring may not be around, or outsourced consultants may need to be temporarily hired in order to meet the restoration time constraints.
A backup strategy must take into account that failure can take place at any step of the process, so if there is a problem during the backup or restoration process that could corrupt the data, there should be a graceful way of backing out or reconstructing the data from the beginning.
Can we actually restore data? Backing up data is a wonderful thing in life, but making sure it can be properly restored is even better. Many organizations have developed a false sense of security based on the fact that they have a very organized and effective process of backing up their data. That sense of security can disappear in seconds when a company realizes in a time of crisis that its restore processes do not work. For example, one company had paid an offsite backup facility to use a courier to collect its weekly backup tapes and transport them to the offsite facility for safekeeping. What the company did not realize was that this courier used the subway and many times set the tapes on the ground while waiting for the subway train. A subway has many large engines that create their own magnetic field. This can have the same effect on media as large magnets, meaning that the data can be erased or corrupted. The company never tested its restore processes and eventually experienced a disaster. Much to its surprise, it found out that three years of data were corrupted and unusable.
Many other stories and experiences like this are out there. Don’t let your organization end up as an anecdote in someone else’s book because it failed to verify that its backups could be restored.
Electronic Backup Solutions
Manually backing up systems and data can be time-consuming, error-prone, and costly. Several technologies serve as automated backup alternatives. Although these technologies are usually more expensive, they are quicker and more accurate, which may be necessary for online information that changes often.
Among the many technologies and ways to back up data electronically is disk shadowing, which is very similar to data mirroring.
NOTE Disk duplexing means there is more than one disk controller. If one disk controller fails, the other is ready and available.
Disk shadowing is used to ensure the availability of data and to provide a fault-tolerant solution by duplicating hardware and maintaining more than one copy of the information. The data is dynamically created and maintained on two or more identical disks. If only disk mirroring is used, then each disk would have a corresponding mirrored disk that contains the exact same information. If shadow sets are used, the data can be stored as images on two or more disks.
Systems that need to interact with this data are connected to all the drives at the same time. All of these drives “look” like just one drive to the user. This provides transparency to the user so that when she needs to retrieve a file, she does not have to worry about which drive to go to for this process. When a user writes data to be stored on this media, the data is written to all disks in the shadow set.
Disk shadowing provides online backup storage, which can either reduce or replace the need for periodic offline manual backup operations. Another benefit to this solution is that it can boost read operation performance. Multiple paths are provided to duplicate data, and a shadow set can carry out multiple read requests in parallel.
Disk shadowing is commonly seen as an expensive solution because two or more hard drives are used to hold the exact same data. If a company has data that will fill up 100 hard drives, it must purchase and maintain at least 200 hard drives. A company would choose this solution if fault tolerance were required.
If a disk drive fails, at least one shadow set is still available. A new disk can be assigned to this set through proper configurations, and the data can be copied from the shadow set. The copying can take place offline, but this means the data is unavailable for a period of time. Most products that provide disk-shadowing functionality allow for online copying, where disks are hot swapped into the set, and can carry out the necessary copy functions without having to bring the drives offline.
Electronic vaulting and remote journaling are other solutions that companies should be aware of. Electronic vaulting makes copies of files as they are modified and periodically transmits them to an offsite backup site. The transmission does not happen in real time, but is carried out in batches. So, a company can choose to have all files that have been changed sent to the backup facility every hour, day, week, or month. The information can be stored in an offsite facility and retrieved from that facility in a short time.
This form of backup takes place in many financial institutions, so when a bank teller accepts a deposit or withdrawal, the change to the customer’s account is made locally to that branch’s database and to the remote site that maintains the backup copies of all customer records.
Electronic vaulting is a method of transferring bulk information to offsite facilities for backup purposes. Remote journaling is another method of transmitting data offsite, but this usually only includes moving the journal or transaction logs to the offsite facility, not the actual files. These logs contain the deltas (changes) that have taken place to the individual files. If and when data is corrupted and needs to be restored, the bank can retrieve these logs, which are used to rebuild the lost data. Journaling is efficient for database recovery, where only the reapplication of a series of changes to individual records is required to resynchronize the database.
EXAM TIP Remote journaling takes place in real time and transmits only the file deltas. Electronic vaulting takes place in batches and moves the entire file that has been updated.
It may be necessary to keep different versions of software and files, especially in a software development environment. The object and source code should be backed up along with libraries, patches, and fixes. The offsite facility should mirror the onsite facility, meaning it does not make sense to keep all of this data at the onsite facility and only the source code at the offsite facility. Each site should have a full set of the most current and updated information and files.
Another software backup technology we will discuss is referred to as tape vaulting. Many businesses back up their data to tapes that are then manually transferred to an offsite facility by a courier or an employee. With automatic tape vaulting, the data is sent over a serial line to a backup tape system at the offsite facility. The company that maintains the offsite facility maintains the systems and changes out tapes when necessary. Data can be quickly backed up and retrieved when necessary. This technology reduces the manual steps in the traditional tape backup procedures.
Basic vaulting of tape data sends backup tapes to an offsite location, but a manual process can be error-prone. Electronic tape vaulting transmits data over a network to tape devices located at an alternate data center. Electronic tape vaulting improves recovery speed and reduces errors, and backups can be run more frequently.
Data repositories commonly have replication capabilities, so that when changes take place to one repository (i.e., database) they are replicated to all of the other repositories within the organization. The replication can take place over telecommunication links, which allow offsite repositories to be continuously updated. If the primary repository goes down or is corrupted, the replication flow can be reversed, and the offsite repository updates and restores the primary repository. Replication can be asynchronous or synchronous. Asynchronous replication means the primary and secondary data volumes are out of sync. Synchronization may take place in seconds, hours, or days, depending upon the technology in place. With synchronous replication, the primary and secondary repositories are always in sync, which provides true real-time duplication. Figure 7-19 shows how offsite replication can take place.

Figure 7-19 Offsite data replication for data recovery purposes
The BCP team must balance the cost to recover against the cost of the disruption. The balancing point becomes the recovery time objective. Figure 7-20 illustrates the relationship between the cost of various recovery technologies and the provided recovery times.
Choosing a Software Backup Facility
A company needs to address several issues and ask specific questions when it is deciding upon a storage facility for its backup materials. The following provides a list of just some of the issues that need to be thought through before committing to a specific vendor for this service:
• Can the media be accessed in the necessary timeframe?
• Is the facility closed on weekends and holidays, and does it only operate during specific hours of the day?
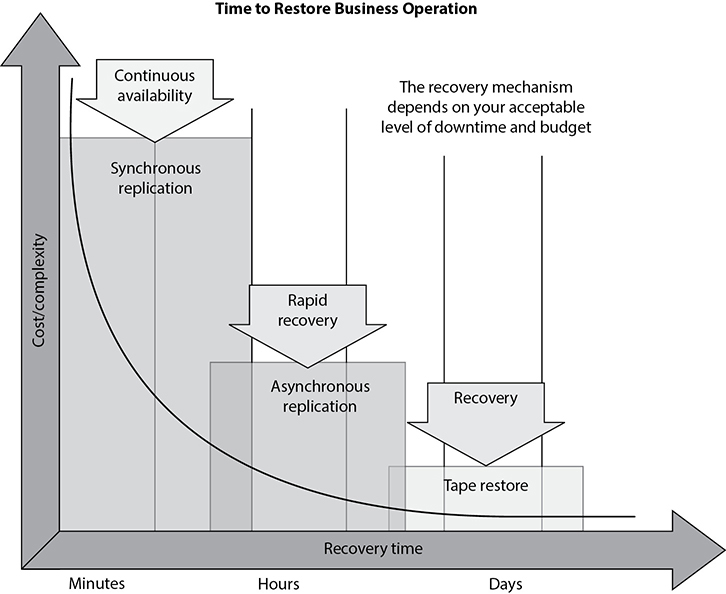
Figure 7-20 The criticality of data recovery will dictate the recovery solution.
• Are the access control mechanisms tied to an alarm and/or the police station?
• Does the facility have the capability to protect the media from a variety of threats?
• What is the availability of a bonded transport service?
• Are there any geographical environmental hazards such as floods, earthquakes, tornadoes, and so on that might affect the facility?
• Does the facility have a fire detection and suppression system?
• Does the facility provide temperature and humidity monitoring and control?
• What type of physical, administrative, and logical access controls are used?
The questions and issues that need to be addressed will vary depending on the type of company, its needs, and the requirements of a backup facility.
Documentation
Documentation seems to be a dreaded task to most people, who will find many other tasks to take on to ensure they are not the ones stuck with documenting processes and procedures. However, a company does a great and responsible job by backing up hardware and software to an offsite facility, maintaining it, and keeping everything up-to-date and current; without documentation, when a disaster hits, no one will know how to put Humpty Dumpty back together again.
Restoration of files can be challenging, but restoring a whole environment that was swept away in a flood can be overwhelming, if not impossible. Procedures need to be documented because when they are actually needed, it will most likely be a chaotic and frantic atmosphere with a demanding time schedule. The documentation may need to include information on how to install images, configure operating systems and servers, and properly install utilities and proprietary software. Other documentation could include a calling tree, which outlines who should be contacted, in what order, and who is responsible for doing the calling. The documentation must also contain contact information for specific vendors, emergency agencies, offsite facilities, and any other entity that may need to be contacted in a time of need.
Most network environments evolve over time. Software has been installed on top of other software, configurations have been altered over the years to properly work in a unique environment, and service packs and patches have been installed to fix this problem or that issue. To expect one person or a group of people to go through all of these steps during a crisis and end up with an environment that looks and behaves exactly like the original environment and in which all components work together seamlessly may be a lofty dream.
So, the dreaded task of documentation may be the saving grace one day. It is an essential piece of business, and therefore an essential piece in disaster recovery and business continuity.
It is important to make one or more roles responsible for proper documentation. As with all the items addressed in this chapter, simply saying “All documentation will be kept up to date and properly protected” is the easy part—saying and doing are two different things. Once the BCP team identifies tasks that must be done, the tasks must be assigned to individuals, and those individuals have to be accountable. If these steps are not taken, the BCP team could have wasted a lot of time and resources defining these tasks, and the company could be in grave danger if a disaster occurs.
NOTE An organization may need to solidify communications channels and relationships with government officials and emergency response groups. The goal of this activity is to solidify proper protocol in case of a city- or region-wide disaster. During the BIA phase, local authorities should be contacted so the team understands the risks of its geographical location and how to access emergency zones. If the company has to initiate its BCP, it will need to contact many of these emergency response groups during the recovery stage.
Human Resources
One of the resources commonly left out of the equation is people. A company may restore its networks and critical systems and get business functions up and running, only to realize it doesn’t know the answer to the question, “Who will take it from here?” The area of human resources is a critical component to any recovery and continuity process, and it needs to be fully thought out and integrated into the plan.
What happens if we have to move to an offsite facility that is 250 miles away? We cannot expect people to drive back and forth from home to work. Should we pay for temporary housing for the necessary employees? Do we have to pay their moving costs? Do we need to hire new employees in the area of the offsite facility? If so, what skill set do we need from them? The BCP team should go through a long succession of these types of questions.
The BCP project expands job responsibilities, descriptions, hours, and even workplaces. The project has to identify the critical personnel and subordinates who will develop the plan and execute key duties during an incident. Among the key players may be heads of BCP and DR coordination, IT systems, data and voice communications, business units, transport, logistics, security, safety, facilities, finance, auditing, legal, and public relations.
Multiple people should be trained in executing the duties and procedures spelled out in the plan so that one person can fill another’s shoes in an emergency. Clear documentation is vital in such cross-training. The HR department normally manages the availability of personnel for the continuity process.
If a large disaster takes place that affects not only the company’s facility but also surrounding areas, including housing, employees will be more worried about their families than their company. Some companies assume that employees will be ready and available to help them get back into production, when in fact they may need to be at home because they have responsibilities to their families.
Regrettably, some employees may be killed or severely injured in the disaster, and the team should have plans in place to replace employees quickly through a temporary employment agency or a job recruiter. This is an extremely unfortunate scenario to contemplate, but it is part of reality. The team that considers all threats and is responsible for identifying practical solutions needs to think through all of these issues.
Organizations should already have executive succession planning in place. This means that if someone in a senior executive position retires, leaves the company, or is killed, the organization has predetermined steps to carry out to protect the company. The loss of a senior executive could tear a hole in the company’s fabric, creating a leadership vacuum that must be filled quickly with the right individual. The line-of-succession plan defines who would step in and assume responsibility for this role. Many organizations have “deputy” roles. For example, an organization may have a deputy CIO, deputy CFO, and deputy CEO ready to take over the necessary tasks if the CIO, CFO, or CEO becomes unavailable.
Often, larger organizations also have a policy indicating that two or more of the senior staff cannot be exposed to a particular risk at the same time. For example, the CEO and president cannot travel on the same plane. If the plane were to crash and both individuals were killed, then the company could be in danger. This is why you don’t see the president of the United States and the vice president together too often. It is not because they don’t like each other and thus keep their distance from each other. It is because there is a policy indicating that to protect the United States, its top leaders cannot be under the same risk at the same time.
End-User Environment
Because the end users are usually the worker bees of a company, they must be provided a functioning environment as soon as possible after a disaster hits. This means that the BCP team must understand the current operational and technical functioning environment and examine critical pieces so they can replicate them.
The first issue pertaining to users is how they will be notified of the disaster and who will tell them where to go and when. A tree structure of managers can be developed so that once a disaster hits, the person at the top of the tree calls two managers, and they in turn call three managers, and so on until all managers are notified. Each manager would be responsible for notifying the people he is responsible for until everyone is on the same page. Then, one or two people must be in charge of coordinating the issues pertaining to users. This could mean directing them to a new facility, making sure they have the necessary resources to complete their tasks, restoring data, and being a liaison between the different groups.
In most situations, after a disaster, only a skeleton crew is put back to work. The BCP committee identified the most critical functions of the company during the analysis stage, and the employees who carry out those functions must be put back to work first. So the recovery process for the user environment should be laid out in different stages. The first stage is to get the most critical departments back online, the next stage is to get the second most important back online, and so on.
The BCP team needs to identify user requirements, such as whether users can work on stand-alone PCs or need to be connected in a network to fulfill specific tasks. For example, in a financial institution, users who work on stand-alone PCs might be able to accomplish some small tasks like filling out account forms, word processing, and accounting tasks, but they might need to be connected to a host system to update customer profiles and to interact with the database.
The BCP team also needs to identify how current automated tasks can be carried out manually if that becomes necessary. If the network is going to be down for 12 hours, could the necessary tasks be carried out through traditional pen-and-paper methods? If the Internet connection is going to be down for five hours, could the necessary communications take place through phone calls? Instead of transmitting data through the internal mail system, could couriers be used to run information back and forth? Today, we are extremely dependent upon technology, but we often take for granted that it will always be there for us to use. It is up to the BCP team to realize that technology may be unavailable for a period of time and to come up with solutions for those situations.
Availability
High availability (HA) is a combination of technologies and processes that work together to ensure that some specific thing is always up and running. The specific thing can be a database, a network, an application, a power supply, etc. Service providers have SLAs with their customers, which outline the amount of uptime they promise to provide and a turnaround time to get the item fixed if it does go down. For example, a hosting company can promise to provide 98 percent uptime for Internet connectivity. This means they are guaranteeing that at least 98 percent of the time, the Internet connection you purchase from them will be up and running. The hosting company knows that some things may take place to interrupt this service, but within your SLA with them, it promises an eight-hour turnaround time. This means if your Internet connection does go down, they will either fix it or provide you with a different connection within eight hours.
The SLA may also include one or more specifications for quality of service (QoS). Recall from Chapter 4 that QoS allows service providers to differentiate classes of service that are prioritized for different clients. During a disaster the available bandwidth on external links may be limited, so the affected organization could specify different QoS for its externally facing systems. For example, an e-commerce company could determine the minimum bandwidth to keep its web presence available to customers and specify that bit rate QoS at the expense of, say, its e-mail or VoIP traffic.
To provide this level of high availability, the hosting company has to have a long list of technologies and processes that provide redundancy, fault tolerance, and failover capabilities. Redundancy is commonly built into the network at a routing protocol level. The routing protocols are configured so if one link goes down or gets congested, then traffic is routed over a different network link. Redundant hardware can also be available so if a primary device goes down, the backup component can be swapped out and activated.
If a technology has a failover capability, this means that if there is a failure that cannot be handled through normal means, then processing is “switched over” to a working system. For example, two servers can be configured to send each other heartbeat signals every 30 seconds. If server A does not receive a heartbeat signal from server B after 40 seconds, then all processes are moved to server A so that there is no lag in operations. Also, when servers are clustered, this means that there is an overarching piece of software monitoring each server and carrying out load balancing. If one server within the cluster goes down, the clustering software stops sending it data to process so that there are no delays in processing activities.
Fault tolerance is the capability of a technology to continue to operate as expected even if something unexpected takes place (a fault). If a database experiences an unexpected glitch, it can roll back to a known-good state and continue functioning as though nothing bad happened. If a packet gets lost or corrupted during a TCP session, the TCP protocol will resend the packet so that system-to-system communication is not affected. If a disk within a RAID system gets corrupted, the system uses its parity data to rebuild the corrupted data so that operations are not affected.
Fault tolerance and resiliency are oftentimes used synonymously, though, in reality, they mean subtly different things. Fault tolerance means that when a fault happens, there’s a system in place (a backup or redundant one) to ensure services remain uninterrupted. Resiliency means that the system continues to function, albeit in a degraded fashion, when a fault is encountered. Think of it as the difference between having a spare tire for your car and having run-flat tires. The spare tire provides fault tolerance in that it lets you to recover (fairly) quickly from a flat tire and be on your way. Run-flat tires allow you to continue to drive your car (albeit slower) if you run over a nail on the road. A resilient system is fault tolerant, but a fault tolerant one may not be resilient.
Redundancy, fault tolerance, resiliency, and failover capabilities increase the reliability of a system or network, where reliability is the probability that a system performs the necessary function for a specified period under defined conditions. High reliability allows for high availability, which is a measure of its readiness. If the probability of a system performing as expected under defined conditions is low, then the availability for this system cannot be high. For a system to have the characteristic of high availability, then high reliability must be in place. Figure 7-21 illustrates where load balancing, clustering, failover devices, and replication commonly take place in a network architecture.
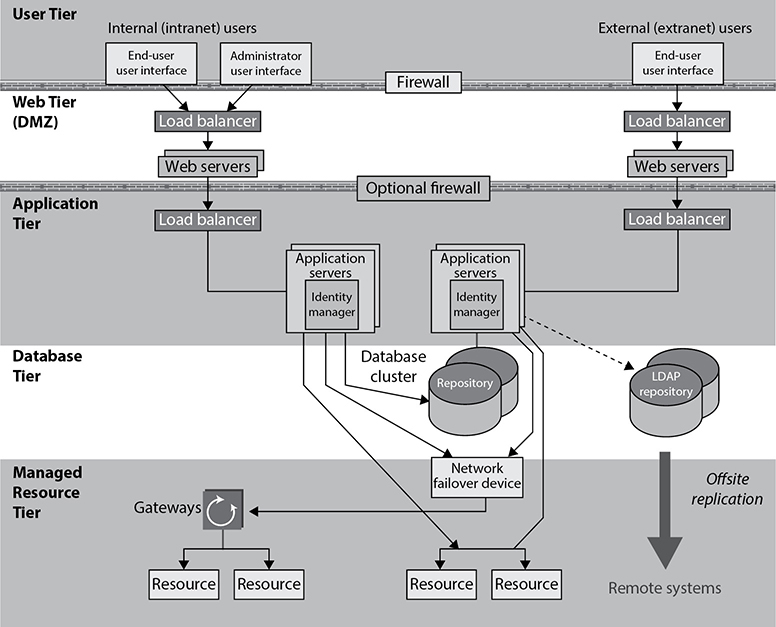
Figure 7-21 High-availability technologies
Remember that data restoration (RPO) requirements can be different from processing restoration (RTO) requirements. Data can be restored through backup tapes, electronic vaulting, synchronous or asynchronous replication, or RAID. Processing capabilities can be restored through clustering, load balancing, mirroring, redundancy, and failover technologies. If the results of the BCP team’s BIA indicate that the RPO value is two days, then the company can use tape backups. If the RPO value is one minute, then synchronous replication needs to be in place. If the BIA indicates that the RTO value is three days, then redundant hardware can be used. If the RTO value is one minute, then clustering and load balancing should be used.
HA and disaster recovery (DR) are not the same, but they have a relationship. HA technologies and processes are commonly put into place so that if a disaster does take place, either the critical functions are likelier to remain available or the delay of getting them back online and running is low.
In the industry, HA is usually thought about only in technology terms, but remember that there are many things that an organization needs to keep functioning. Availability of each of the following items must be thought through and planned:
• Facility (cold, warm, hot, redundant, rolling, reciprocal sites)
• Infrastructure (redundancy, fault tolerance)
• Storage (RAID, SAN, mirroring, disk shadowing, cloud)
• Server (clustering, load balancing)
• Data (tapes, backups, vaulting, online replication)
• Business processes
• People
NOTE Virtualization and cloud computing are covered in Chapter 3. We will not go over those technologies again in this chapter, but know that the use of these technologies has drastically increased in the realm of BCP and DRP recovery solutions.
Liability and Its Ramifications
Organizations should develop not only their preventive, detective, and corrective approaches, but also their liability and responsibility approaches. If a company has a facility that is set on fire, the arsonist is only one small piece of this tragedy. The company is responsible for providing fire detection and suppression systems, fire-resistant construction material in certain areas, alarms, exits, fire extinguishers, and backups of all the important information that could be affected by a fire. If a fire burns a company’s building to the ground and consumes all the records (customer data, inventory records, and similar information that is necessary to rebuild the business), then the company did not exercise due care (acting responsibly) to ensure it was protected from such loss (by backing up to an offsite location, for example). In this case, the employees, shareholders, customers, and everyone affected could successfully sue the company. However, if the company did everything expected of it in the previously listed respects, it could not be successfully sued for failure to practice due care.
In the context of security, due care means that a company did all it could have reasonably done, under the circumstances, to prevent security breaches, and also took reasonable steps to ensure that if a security breach did take place, proper controls or countermeasures were in place to mitigate the damages. In short, due care means that a company practiced common sense and prudent management and acted responsibly. Due diligence means that the company properly investigated all of its possible weaknesses and vulnerabilities.
Before you can figure out how to properly protect yourself, you need to find out what it is you are protecting yourself against. This is what due diligence is all about—researching and assessing the current level of vulnerabilities so the true risk level is understood. Only after these steps and assessments take place can effective controls and safeguards be identified and implemented.
Security is developed and implemented to protect an organization’s valuable resources; thus, appropriate safeguards need to be in place to protect the organization’s mission by protecting its tangible and intangible resources, reputation, employees, customers, shareholders, and legal position. Security is a means to an end and not an end itself. It is not practiced just for the sake of doing it. It should be practiced in such a way as to accomplish fully understood, planned, and attainable goals.
Senior management has an obligation to protect the company from a long list of activities that can negatively affect it, including protection from malicious code, natural disasters, privacy violations, infractions of the law, and more.
The costs and benefits of security should be evaluated in monetary and nonmonetary terms to ensure that the cost of security does not outweigh the expected benefits. Security should be proportional to potential loss estimates pertaining to the severity, likelihood, and extent of potential damage.
As the following illustration shows, there are many costs to consider when it comes to security breaches: loss of business, response activities, customer and partner notification, and detection and escalation measures. These types of costs need to be understood through due diligence exercises so that the company can practice proper due care by implementing the necessary controls to reduce the risks and these costs. Security mechanisms should be employed to reduce the frequency and severity of security-related losses. A sound security program is a smart business practice.

Senior management needs to decide upon the amount of risk it is willing to take pertaining to computer and information security, and implement security in an economical and responsible manner. (These issues are discussed in great detail in Chapter 1.) These risks do not always stop at the boundaries of the organization. Many companies work with third parties, with whom they must share sensitive data. The main company is still liable for the protection of this sensitive data that it owns, even if the data is on another company’s network. This is why more and more regulations are requiring companies to evaluate their third-party security measures.
If one of the companies does not provide the necessary level of protection and its negligence affects a partner it is working with, the affected company can sue the upstream company. For example, let’s say company A and company B have constructed an extranet. Company A does not put in controls to detect and deal with viruses. Company A gets infected with a destructive virus and it is spread to company B through the extranet. The virus corrupts critical data and causes a massive disruption to company B’s production. Therefore, company B can sue company A for being negligent. Both companies need to make sure they are doing their part to ensure that their activities, or the lack of them, will not negatively affect another company, which is referred to as downstream liability.
EXAM TIP Responsibility generally refers to the obligations and expected actions and behaviors of a particular party. An obligation may have a defined set of specific actions that are required, or a more general and open approach, which enables the party to decide how it will fulfill the particular obligation. Accountability refers to the ability to hold a party responsible for certain actions or inaction.
Each company has different requirements when it comes to its list of due care responsibilities. If these steps are not taken, the company may be charged with negligence if damage arises out of its failure to follow these steps. To prove negligence in court, the plaintiff must establish that the defendant had a legally recognized obligation, or duty, to protect the plaintiff from unreasonable risks and that the defendant’s failure to protect the plaintiff from an unreasonable risk (breach of duty) was the proximate cause of the plaintiff’s damages. Penalties for negligence can be either civil or criminal, ranging from actions resulting in compensation for the plaintiff to jail time for violation of the law.
EXAM TIP Proximate cause is an act or omission that naturally and directly produces a consequence. It is the superficial or obvious cause for an occurrence. It refers to a cause that leads directly, or in an unbroken sequence, to a particular result. It can be seen as an element of negligence in a court of law.
Liability Scenarios
The following are some sample scenarios in which a company could be held liable for negligence in its actions and responsibilities.
Personal Information
In this scenario, a company that holds medical information, Medical Information, Inc., does not have strict procedures on how patient information is disseminated or shared. A person pretending to be a physician calls Medical Information, Inc., and requests medical information on the patient Don Hammy. The receptionist does not question the caller and explains that Don Hammy has a brain tumor. A week later, Don Hammy does not receive the job he interviewed for and finds out that the employer called Medical Information, Inc., for his medical information.
So what was improper about this activity and how would liability be determined? If and when this case went to court, the following items would be introduced and addressed.
Legally recognized obligation:
• The Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule requires Medical Information, Inc., to have policies and procedures in place to protect patient information.
• The Americans with Disabilities Act (ADA) prohibits employers from making inquiries that are likely to reveal the existence of a disability before making a job offer.
Failure to conform to the required standard:
• Sensitive information was released to an unauthorized person by a Medical Information, Inc., employee.
• The employer requested information it did not have a right to.
Proximate causation and resulting injury or damage:
• The information provided by Medical Information, Inc., caused Don Hammy great emotional distress and prevented him from obtaining a specific job.
• The employer made its decision based on information it did not have a right to inquire about in the first place. The employer’s illegal acquisition and review of Don’s private medical information caused it to not hire him.
The outcome was a long legal battle, but Don Hammy ended up successfully suing both companies, recovered from his brain tumor, bought an island, and has never had to work again.
Hacker Intrusion
Suppose that a financial institution, Cheapo, Inc., buys the necessary middleware to enable it to offer online bank account transactions for its customers. It does not add any of the necessary security safeguards required for this type of transaction to take place securely over the Internet. Within the first two weeks of offering this service, 22 customers have their checking and savings accounts hacked into, with a combined loss of $439,344.09.
What was improper about this activity and how would liability be determined? If and when this case went to court, the following items would be introduced and addressed.
Legally recognized obligation:
• The Safeguards Rule in the Gramm-Leach-Bliley Act (GLBA) requires financial institutions to have information security programs that protect consumers’ personal financial information from anticipated threats and/or unauthorized access.
Failure to conform to the required standard:
• By not erecting the proper security policy and program and implementing the necessary security controls, Cheapo, Inc., broke federal regulations used to govern financial institutions.
Proximate causation and resulting injury or damage:
• The financial institution’s failure to practice due care and implement the basic requirements of online banking directly caused 22 clients to lose $439,344.09.
Eventually, a class action suit was brought against Cheapo, Inc., a majority of the customers got most of their money back, and the facility Cheapo, Inc., was using as a financial institution is now used to sell tacos.
These scenarios are simplistic and described in a light-hearted manner, but failure to implement computer and information security properly can expose a company and its board of directors to litigation and legal punishment. In cases of serious misconduct, executives are not able to hide behind the legal concept of the corporation and are held accountable individually and personally. The board of directors can shirk its responsibilities to the stockholders, customers, and employees by not ensuring that due care is practiced and that the company is not being negligent in any way.
Third-Party Risk
Most organizations outsource more business functions than they realize, and that trend is only increasing. Through the use of cloud computing, Software as a Service (SaaS) in particular, organizations are increasingly turning to third-party service providers to maintain, manage, transmit, or store company-owned information resources to improve delivery of services, gain efficiencies, and reduce cost. Information security issues should be defined and assessed before engaging a third-party service provider to host or provide a service on behalf of the organization. To ensure that adequate security controls are in place prior to finalizing any contract agreement, the organization should conduct a third-party risk assessment for all services (applications, hosting, systems, etc.) that would involve the collection, processing, transmission, or storage of sensitive data or provide critical business functionality processing.
Contractual Agreements
While often overlooked, it is critical that information security issues are addressed in many of the contracts organizations use or enter into during regular business activities. Security considerations should be taken for at least the following contracts types:
• Outsourcing agreements
• Hardware supply
• System maintenance and support
• System leasing agreements
• Consultancy service agreements
• Website development and support
• Nondisclosure and confidentiality agreements
• Information security management agreements
• Software development agreements
• Software licensing
The organization must understand its regulatory and legal requirements pertaining to the items the previous contract list involves, and security requirements must be integrated properly in the contractual clauses. Contractual agreements not only need to be created in a manner that covers regulatory, legal, and security requirements, but also must be reviewed periodically to ensure that they are still relevant and provide the necessary level of protection.
Procurement and Vendor Processes
Before purchasing any product or service, the organization’s security requirements need to be fully understood so that they can be expressed and integrated into the procurement process. Procurement is not just purchasing something, but includes the activities and processes involved with defining requirements, evaluating vendors, contract negotiation, purchasing, and receiving the needed solution.
The acquisition of a solution (system, application, or service) often includes a Request for Proposals (RFP), which is usually designed to get vendors to provide solutions to a business problem or requirement, bring structure to the procurement decision, and allow the risks and benefits of a solution to be identified clearly up-front. It is important that the RFP conveys the necessary security requirements and elicits meaningful and specific responses that describe how the vendor will meet those requirements. Federal and state legal requirements, regulation, and business contractual obligations must be thought through when constructing the requirements laid out in the RFPs.
The initial security requirements can be used to formulate questions for the RFP. The answers to the RFP can be used to evaluate vendors and refine the security requirements. The evaluation and risk assessment of vendor finalists refine the security requirements that will, in turn, be added as language to the contract or statement of work.
While procurement is an activity an organization carries out to properly identify, solicit, and select vendors for products and services, vendor management is an activity that involves developing and monitoring vendor relationships after the contracts are in place. Since organizations are extremely dependent upon their vendors and outsourcing providers, if something slips up, operations will be affected, which always drains the bottom line (profit margin) and could put the company at risk. For example, suppose your cloud computing provider downgrades its data encryption strength (from AES-256 to 3DES with a 56-bit key) so that it can meet a wider range of client requirements, but fails to inform you about the change. Next time your organization goes through a PCI DSS audit, it can be found out of compliance and your company could be fined. If your company pays a software development company to develop a specialized application, do you have a way to test the code to make sure it is providing the level of protection the developer is claiming? Or what if you set up a contract with a vendor to scan your external websites each week and you get busy with a million other things and six months down the line, the contractor just stops scanning and you are not informed. You assume it is being taken care of, but you do not have governing processes in place to make sure this is true.
A vendor management governing process needs to be set up, which includes performance metrics, SLAs, scheduled meetings, a reporting structure, and someone who is directly responsible. Your company is always responsible for its own risk. Just because it farms out some piece of its operations does not absolve it of this responsibility. The company needs to have a holistic program that defines procurement, contracting, vendor assessment, and monitoring to make sure things are continually healthy and secure.
Insurance
During the business impact analysis (BIA), discussed in Chapter 1, the team most likely uncovered several threats that the organization could not prevent. Taking on the full risk of these threats often is dangerous, which is why insurance exists. The decision of whether or not to obtain insurance for a particular threat, and how much coverage to obtain when choosing to insure, should be based on the probability of the threat becoming real and the loss potential, which was identified during the BIA. The BCP team should work with management to understand what the current coverage is, the various insurance options, and the limits of each option. The goal here is to make sure the insurance coverage fills in the gap of what the current preventive countermeasures cannot protect against. We can eat healthy, work out, and take our vitamins—but these things cannot always prevent serious health issues. We purchase medical insurance to help cover the costs of any unexpected health conditions. Organizations also need insurance to protect them from unexpected events.
Just as people are given different premiums on health and life insurance, companies are given different premiums on the type of insurance they purchase. Different types of insurance policies can be purchased by companies, cyber insurance being one of them. Cyber insurance is a new type of coverage that insures losses caused by denial-of-service attacks, malware damages, hackers, electronic theft, privacy-related lawsuits, and more. Whereas a person is asked how old he is, which previous health issues he’s had, if he smokes, and so on, to determine his health insurance premium, companies are asked questions about their security program, such as whether they have an IDS, antivirus software, firewalls, and other security measures.
A company could also choose to purchase a business interruption insurance policy. With this type of policy, if the company is out of business for a certain length of time, the insurance company will pay for specified expenses and lost earnings. Another policy that can be bought insures accounts receivable. If a company cannot collect on its accounts receivable for one reason or another, this type of coverage covers part or all of the losses and costs.
The company’s insurance should be reviewed annually because threat levels may change and the company may expand into new ventures that need to be properly covered. Purchasing insurance should not lull a company into a false sense of security, though. Insurance coverage has its limitations, and if the company does not practice due care, the insurance company may not be legally obligated to pay if a disaster hits. It is important to read and understand the fine print when it comes to insurance and to make sure you know what is expected of your company—not just what is expected from the insurance organization.
Implementing Disaster Recovery
Recovering from a disaster begins way before the event occurs. It starts by anticipating threats and developing goals that support the business’s continuity of operations. If you do not have established goals, how do you know when you are done and whether your efforts were actually successful? Goals are established so everyone knows the ultimate objectives. Establishing goals is important for any task, but especially for business continuity and disaster recovery plans. The definition of the goals helps direct the proper allocation of resources and tasks, supports the development of necessary strategies, and assists in financial justification of the plans and program overall. Once the goals are set, they provide a guide to the development of the actual plans themselves. Anyone who has been involved in large projects that entail many small, complex details knows that at times it is easy to get off track and not actually accomplish the major goals of the project. Goals are established to keep everyone on track and to ensure that the efforts pay off in the end.
Great—we have established that goals are important. But the goal could be, “Keep the company in business if an earthquake hits.” Good goal, but not overly useful without more clarity and direction. To be useful, a goal must contain certain key information, such as the following:
• Responsibility Each individual involved with recovery and continuity should have their responsibilities spelled out in writing to ensure a clear understanding in a chaotic situation. Each task should be assigned to the individual most logically situated to handle it. These individuals must know what is expected of them, which is done through training, drills, communication, and documentation. So, for example, instead of just running out of the building screaming, an individual must know that he is responsible for shutting down the servers before he can run out of the building screaming.
• Authority In times of crisis, it is important to know who is in charge. Teamwork is important in these situations, and almost every team does much better with an established and trusted leader. Such leaders must know that they are expected to step up to the plate in a time of crisis and understand what type of direction they should provide to the rest of the employees. Clear-cut authority will aid in reducing confusion and increasing cooperation.
• Priorities It is extremely important to know what is critical versus what is merely nice to have. Different departments provide different functionality for an organization. The critical departments must be singled out from the departments that provide functionality that the company can live without for a week or two. It is necessary to know which department must come online first, which second, and so on. That way, the efforts are made in the most useful, effective, and focused manner. Along with the priorities of departments, the priorities of systems, information, and programs must be established. It may be necessary to ensure that the database is up and running before working to bring the web servers online. The general priorities must be set by management with the help of the different departments and IT staff.
• Implementation and testing It is great to write down very profound ideas and develop plans, but unless they are actually carried out and tested, they may not add up to a hill of beans. Once a continuity plan is developed, it actually has to be put into action. It needs to be documented and stored in places that are easily accessible in times of crisis. The people who are assigned specific tasks need to be taught and informed how to fulfill those tasks, and dry runs must be done to walk people through different situations. The drills should take place at least once a year, and the entire program should be continually updated and improved.
NOTE Chapter 6 addresses various types of tests such as walkthrough, tabletop, simulation, parallel, and full interruption.
Studies have shown that 65 percent of businesses that lose computing capabilities for over one week are never able to recover and subsequently go out of business. Not being able to bounce back quickly or effectively by setting up shop somewhere else can make a company lose business and, more importantly, its reputation. In such a competitive world, customers have a lot of options. If one company is not prepared to bounce back after a disruption or disaster, customers may go to another vendor and stay there.
The biggest effect of an incident, especially one that is poorly managed or that was preventable, is on an organization’s reputation or brand. This can result in a considerable and even irreparable loss of trust by customers and clients. On the other hand, handling an incident well, or preventing great damage through smart, preemptive measures, can enhance the reputation of, or trust in, an organization.
The DR plan should address in detail all of the topics we have covered so far. The actual format of the plan will depend on the environment, the goals of the plan, priorities, and identified threats. After each of those items is examined and documented, the topics of the plan can be divided into the necessary categories.
Personnel
The DR coordinator needs to define several different teams that should be properly trained and available if a disaster hits. Which types of teams an organization needs depends upon the organization. The following are some examples of teams that a company may need to construct:
• Damage assessment team
• Recovery team
• Relocation team
• Restoration team
• Salvage team
• Security team
The DR coordinator should have an understanding of the needs of the company and the types of teams that need to be developed and trained. Employees should be assigned to the specific teams based on their knowledge and skill set. Each team needs to have a designated leader, who will direct the members and their activities. These team leaders will be responsible not only for ensuring that their team’s objectives are met, but also for communicating with each other to make sure each team is working in parallel phases.
The restoration team should be responsible for getting the alternate site into a working and functioning environment, and the salvage team should be responsible for starting the recovery of the original site. Both teams must know how to do many tasks, such as install operating systems, configure workstations and servers, string wire and cabling, set up the network and configure networking services, and install equipment and applications. Both teams must also know how to restore data from backup facilities. They also must know how to do so in a secure manner, one that ensures the availability, integrity, and confidentiality of the system and data.
The BCP must outline the specific teams, their responsibilities, and notification procedures. The plan must indicate the methods that should be used to contact team leaders during business hours and after business hours.
Assessment
A role, or a team, needs to be created to carry out a damage assessment once a disaster has taken place. The assessment procedures should be properly documented and include the following steps:
• Determine the cause of the disaster.
• Determine the potential for further damage.
• Identify the affected business functions and areas.
• Identify the level of functionality for the critical resources.
• Identify the resources that must be replaced immediately.
• Estimate how long it will take to bring critical functions back online.
• If it will take longer than the previously estimated MTD values to restore operations, then a disaster should be declared and the BCP should be put into action.
After this information is collected and assessed, it will indicate which teams need to be called to action and whether the BCP actually needs to be activated. The BCP coordinator and team must develop activation criteria. After the damage assessment, if one or more of the situations outlined in the criteria have taken place, then the team is moved into recovery mode.
Different organizations have different criteria because the business drivers and critical functions will vary from organization to organization. The criteria may comprise some or all of the following elements:
• Danger to human life
• Danger to state or national security
• Damage to facility
• Damage to critical systems
• Estimated value of downtime that will be experienced
Restoration
Once the damage assessment is completed and the plan is activated, various teams must be deployed, which signals the company’s entry into the restoration phase. Each team has its own tasks—for example, the facilities team prepares the offsite facility (if needed), the network team rebuilds the network and systems, and the relocation team starts organizing the staff to move into a new facility.
The restoration process needs to be well organized to get the company up and running as soon as possible. This is much easier to state in a book than to carry out in reality. This is why written procedures are critical. During the BIA, the critical functions and their resources were identified. These are the things that the teams need to work together on getting up and running first.
Templates should have been developed during the plan development stage. These templates are used by the different teams to step them through the necessary phases and to document their findings. For example, if one step could not be completed until new systems were purchased, this should be indicated on the template. If a step is partially completed, this should be documented so the team does not forget to go back and finish that step when the necessary part arrives. These templates keep the teams on task and also quickly tell the team leaders about the progress, obstacles, and potential recovery time.

TIP Examples of possible templates can be found in NIST Special Publication 800-34, Revision 1, “Contingency Planning Guide for Federal Information Systems,” which is available online at https://csrc.nist.gov/publications/detail/sp/800-34/rev-1/final.
A company is not out of an emergency state until it is back in operation at the original primary site or a new site that was constructed to replace the primary site, because the company is always vulnerable while operating in a backup facility. Many logistical issues need to be considered as to when a company must return from the alternate site to the original site. The following lists a few of these issues:
• Ensuring the safety of employees
• Ensuring an adequate environment is provided (power, facility infrastructure, water, HVAC)
• Ensuring that the necessary equipment and supplies are present and in working order
• Ensuring proper communications and connectivity methods are working
• Properly testing the new environment
Once the coordinator, management, and salvage team sign off on the readiness of the facility, the salvage team should carry out the following steps:
• Back up data from the alternate site and restore it within the new facility.
• Carefully terminate contingency operations.
• Securely transport equipment and personnel to the new facility.
The least critical functions should be moved back first, so if there are issues in network configurations or connectivity, or important steps were not carried out, the critical operations of the company are not negatively affected. Why go through the trouble of moving the most critical systems and operations to a safe and stable site, only to return them to a main site that is untested? Let the less critical departments act as the canary in the coal mine. If they survive, then move the more critical components of the company to the main site.

Communications
The purpose of the emergency communications plan that is part of the overall DR plan is to ensure everyone knows what to do at all times and that the team remains synchronized and coordinated. This all starts with the plan itself. As stated previously, copies of the DR plan need to be kept in one or more locations other than the primary site, so that if the primary site is destroyed or negatively affected, the plan is still available to the teams. It is also critical that different formats of the plan be available to the team, including both electronic and paper versions. An electronic version of the plan is not very useful if you don’t have any electricity to run a computer. In addition to having copies of the recovery documents located at their offices and homes, key individuals should have easily accessible versions of critical procedures and call tree information.
One simple way to accomplish this is to publish a call tree on cards that can be affixed to personnel badges or kept in a wallet. In an emergency situation, valuable minutes are better spent responding to an incident than looking for a document or having to wait for a laptop to power up. Of course, the call tree is only as effective as it is accurate and up-to-date, so it is imperative that it be verified periodically.
One limitation of call trees is that they are point to point, which means they’re typically good for getting the word out, but not so much for coordinating activities. Group text messages work better, but only in the context of fairly small and static groups. Many organizations have group chat solutions, but if those rely on the organization’s servers, they may be unavailable during a disaster. It is a good idea, then, to establish a communications platform that is completely independent of the organizational infrastructure. Solutions like Slack and Mattermost offer free service that is typically sufficient to keep most organizations connected in emergencies. The catch, of course, is that everyone needs to have the appropriate client installed in their personal devices and know when and how to connect.
Training
Training your team on the execution of a DR plan is critical for at least three reasons. First, it allows you to validate that the plan will actually work. If your team is doing a walk-through exercise in response to a fictitious scenario, you’ll find out very quickly whether the plan would work or not. If it doesn’t work in a training event when the stress level and stakes are low, then there is no chance it would work in a real emergency.
Another reason to train is to ensure that everyone knows what they’re supposed to do, when, where, and how. Disasters are stressful, messy affairs and key people may not be thinking clearly. It is important for them to have a familiar routine to fall back on. In a perfect world, you would train often enough for your team to develop “muscle memory” that allows them to automatically do the right things without even thinking.
Lastly, training can help establish that you are exercising due care. This could keep you out of legal trouble in the aftermath of a disaster, particularly if people end up getting hurt. A good plan and evidence of a trained workforce can go a long way to reduce liability if regulators or other investigators come knocking.
Personal Safety Concerns
The single most valuable asset for an organization, and the one that involves the highest moral and ethical standards, is its people. Our safety focus in security operations will be on our own employees, but we also need to take proper steps to ensure the safety of visitors, clients, and anyone who enters into our physical or virtual spaces. While the scope of safety is broader than information systems security, there are important contributions that we as security professionals make to this effort.
EXAM TIP Human safety almost always trumps all other concerns. If an exam question has a possible answer that focuses on safety, it is likelier to be the right one.
Emergency Management
A common tool for ensuring the safety of personnel during emergencies is the occupant emergency plan (OEP). The OEP describes the actions that facility occupants should take in order to ensure their safety during an emergency situation. This plan should address the range of emergencies from individual to facility-wide, and it should be integrated into the security operations of the organization.
Perhaps the best example of the intersection of safety and security occurs in the area of physical access control. A well-designed system of physical access controls will constrain the movement of specific individuals in and out of certain spaces. For instance, we only want authorized persons to enter the server room. But what if the server room offers the best escape route for people who would normally not be allowed in it? While we would not design a facility in which this would be the case, we sometimes end up occupying less than ideal facilities. If this were the case, what process would we implement to ensure we can get people out of the building quickly and not force them to take a circuitous route that could put them in danger, but keeps them out of the sensitive area?
Another example involves access for emergency responders. If a fire alarm is triggered in the building, how do we ensure we can evacuate all personnel while giving fire fighters access to all spaces (without requiring them to break down doors)? In this context, how do we simultaneously ensure the safety of our personnel while maintaining security of our information systems?
Lastly, many modern physical access controls require electricity. If an electronic lock does not have a battery backup, will it automatically unlock in the absence of power or will it remain in the locked state? A fail-safe device is one that will automatically move to the state that ensures safety in the event of a failure such as loss of power. Fail-safe controls, while critical to human safety, must be carefully considered because they introduce risks to the security of our information systems.
Duress
Duress is the use of threats or violence against someone in order to force them to do something they don’t want to do or otherwise wouldn’t do. Like any other threat, we need to factor in duress in our risk assessment and figure out what (if anything) to do about it. A popular example of a countermeasure for duress is the use of panic buttons by bank tellers. The button is hidden where an assailant can’t see it but where the teller can easily and discretely activate it to warn the police. A twist on this is the use of duress codes in some alarm systems. The alarm has a keypad where an authorized person can enter a secret code to deactivate it. The system can have two different codes: a regular one that disarms the alarm, and a second one that also disarms the alarm but also alerts authorities to an emergency. If someone was forcing you to disarm an alarm, you’d enter the second code and they wouldn’t be able to know that you just summoned the police.
Duress codes can also be verbal. For example, some alarm systems will have an attendant call the facility to ensure everything is fine. If someone is under duress (and perhaps on speakerphone next to the assailant) you would want a discrete way for that person to convey that they are in danger. You could set up two possible responses, like “apple pie,” which would mean you are in danger, and “sunshine,” which would mean everything is truly fine. The key is to make the duress response sound completely benign.
Another situation to consider is when an assailant forces an employee to log into their account. You could set up a duress account with a username that is very similar to the real one. Upon login, the duress account looks just like the real one, except that it doesn’t include sensitive content. The twist is that the duress password could do a range of things from activating full monitoring (like camera, keyboard, and packet logging) to quietly wiping the device in the background (useful for laptops being used away from the office). Obviously, it would also generate an alert to security personnel that the user is in danger.
Travel
Personnel safety in the workplace is one thing, but how do we protect our staff while they are traveling? Some controls we’ve covered, like duress passwords, would still work, but there are a host of other considerations we should take. The most basic one is to determine the threat landscape at the destination. Some organizations go as far as having country-specific briefings that are regularly updated and required for all staff traveling overseas. This is, obviously, a resource-intensive proposition, but there are free alternatives you can leverage. Many governments have departments or ministries that publish this information for their citizens traveling abroad. For example, the U.S. Department of State publishes travel advisories on its website for virtually any destination.
Speaking of these government entities, it is also important to know the location and contact information for the nearest embassy or consulate. In case of emergency, these offices provide a variety of important services. Depending on the threat condition at the destination, it may be a good idea to notify these offices of your own contact information, dates of travel, and where you’ll be lodging.
Hotel security starts by doing a bit of research ahead of the trip. If you’ve never stayed in a specific hotel, a few minutes of web searching will give you a good indication of whether or not it’s safe. Here are some other best practices that your organization’s staff should consider when traveling:
• Ask for a room on the second floor. It reduces the risk of random criminal activity and is still close enough to the ground to escape in case of an emergency even if you can’t use the front door.
• Ask for and keep a hotel business card on your person at all times in case you have to call the local police or embassy and provide your location in an emergency.
• Secure valuables in the in-room safe. It may not really be totally safe, but it raises the bar on would-be thieves.
• Always use the security latch on the door when in the room.
• Keep your passport with you at all times when in a foreign country. Before the trip leave a photocopy of the passport with a trusted individual at home.
Training
All these personal safety measures are good only if your organization’s staff actually knows what they are and how and when to use them. Many organizations have mandatory training events for all staff, and personal security should be part of it. Keep in mind that emergency procedures, panic codes/passwords, and travel security measures are quickly forgotten if they are not periodically reinforced.
Summary
Security operations involve keeping up with implemented solutions, keeping track of changes, properly maintaining systems, continually enforcing necessary standards, and following through with security practices and tasks. It does not do much good for a company to develop a strong password policy if, after a few months, enforcement gets lax and users can use whatever passwords they want. It is similar to working out and staying physically fit. Just because someone lifts weights and jogs for a week does not mean he can spend the rest of the year eating jelly donuts and expect to stay physically fit. Security requires discipline day in and day out, sticking to a regimen, and practicing due care.
Quick Tips
• Facilities that house systems that process sensitive information should have physical access controls to limit access to authorized personnel only.
• Clipping levels should be implemented to establish a baseline of user activity and acceptable errors.
• Separation of responsibilities and duties should be in place so that if fraud takes place, it requires collusion.
• Access to resources should be limited to authorized personnel, applications, and services and should be audited for compliance to stated policies.
• Change control and configuration management should be put in place so changes are approved, documented, tested, and properly implemented.
• Activities that involve change management include requesting a change, approving a change, documenting a change, testing a change, implementing a change, and reporting to management.
• Proper fault-tolerant mechanisms should be put in place to counter equipment failure.
• Antivirus and IDS signatures should be updated on a continual basis.
• Continuous monitoring allows organizations to maintain ongoing awareness of information security, vulnerabilities, and threats to support organizational risk management decisions.
• A whitelist is a set of known-good resources such as IP addresses, domain names, or applications. Conversely, a blacklist is a set of known-bad resources.
• A security information and event management (SIEM) system is a software platform that aggregates security information (like asset inventories) and security events (which could become incidents) and presents them in a single, consistent, and cohesive manner.
• The key aspects of operational security include resource protection, change control, hardware and software controls, trusted system recovery, separation of duties, and least privilege.
• Least privilege ensures that users, administrators, and others accessing a system have access only to the objects they absolutely require to complete their job.
• Some physical security controls may conflict with the safety of people. These issues need to be addressed; human life is always more important than protecting a facility or the assets it contains.
• Proximity identification devices can be user activated (action needs to be taken by a user) or system sensing (no action needs to be taken by the user).
• A transponder is a proximity identification device that does not require action by the user. The reader transmits signals to the device, and the device responds with an access code.
• Exterior fencing can be costly and unsightly, but can provide crowd control and help control access to the facility.
• If interior partitions do not go all the way up to the true ceiling, an intruder can remove a ceiling tile and climb over the partition into a critical portion of the facility.
• Intrusion detection devices include motion detectors, CCTVs, vibration sensors, and electromechanical devices.
• Intrusion detection devices can be penetrated, are expensive to install and monitor, require human response, and are subject to false alarms.
• CCTV enables one person to monitor a large area, but should be coupled with alerting functions to ensure proper response.
• Security guards are expensive but provide flexibility in response to security breaches and can deter intruders from attempting an attack.
• Vulnerability management is the cyclical process of identifying vulnerabilities, determining the risks they pose to the organization, and applying security controls that bring those risks to acceptable levels.
• Patch management is the process for identifying, acquiring, installing, and verifying patches for products and systems.
• Egress monitoring is the practice of tracking (and perhaps restricting) the information that is flowing out of a network.
• Offsite backup locations can supply hot, warm, or cold sites.
• A reciprocal agreement is one in which a company promises another company it can move in and share space if it experiences a disaster, and vice versa. Reciprocal agreements are very tricky to implement and may be unenforceable. However, they offer a relatively cheap offsite option and are sometimes the only choice.
• A hot site is fully configured with hardware, software, and environmental needs. It can usually be up and running in a matter of hours. It is the most expensive option, but some companies cannot be out of business longer than a day without very detrimental results.
• A warm site does not have computers, but it does have some peripheral devices, such as disk drives, controllers, and tape drives. This option is less expensive than a hot site, but takes more effort and time to become operational.
• A cold site is just a building with power, raised floors, and utilities. No devices are available. This is the cheapest of the three options, but can take weeks to get up and operational.
• Recovery time objective (RTO) is the maximum time period within which a business process must be restored to a designated service level after a disaster to avoid unacceptable consequences.
• Recovery point objective (RPO) is the acceptable amount of data loss measured in time.
• Mean time between failures (MTBF) is the predicted amount of time between inherent failures of a system during operation.
• Mean time to repair (MTTR) is the estimated amount of time it will take to get a device fixed and back into production after its failure.
• High availability refers to a system, component, or environment that is continuously operational.
• High availability for disaster recovery is often a combination of technologies and processes that include backups, redundancy, fault tolerance, clustering, and load balancing.
• Data recovery and restoration are often carried out through vaulting, backups, and replication technologies.
• When returning to the original site after a disaster, the least critical organizational units should go back first.
• COOP focuses on restoring an organization’s (usually a headquarters element) essential functions at an alternate site and performing those functions for up to 30 days before returning to normal operations. This term is commonly used by the U.S. government to denote BCP.
• An important part of the business continuity plan is to communicate its requirements and procedures to all employees.
• Business interruption insurance covers the loss of income that an organization suffers after a disaster while it is in its recovery stage.
• Due diligence means you’re identifying and analyzing risks; due care means you’re taking prudent actions day in and day out to mitigate them.
• Elements of negligence include not fulfilling a legally recognized obligation, failure to conform to a standard of care that results in injury or damage, and proximate causation.
• The primary reason for the chain of custody of evidence is to ensure that it will be admissible in court by showing it was properly controlled and handled before being presented in court.
• To be admissible in court, business records have to be made and collected in the normal course of business, not specially generated for a case in court. Business records can easily be hearsay if there is no firsthand proof of their accuracy and reliability.
• The life cycle of evidence includes the identification and collection of the evidence, and its storage, preservation, transportation, presentation in court, and return to the owner.
• Collection of computer evidence is a very complex and detail-oriented task. Only skilled people should attempt it; otherwise, evidence can be ruined forever.
• When looking for suspects, it is important to consider the motive, opportunity, and means (MOM).
• For evidence to be admissible in court, it needs to be relevant, complete, sufficient, and reliable to the case at hand.
• Evidence must be legally permissible, meaning it was seized legally and the chain of custody was not broken.
• Duress is the use of threats or violence against someone in order to force them to do something they don’t want to do or otherwise wouldn’t do.
Questions
Please remember that these questions are formatted and asked in a certain way for a reason. Keep in mind that the CISSP exam is asking questions at a conceptual level. Questions may not always have the perfect answer, and the candidate is advised against always looking for the perfect answer. Instead, the candidate should look for the best answer in the list.
1. What is the difference between due care and due diligence?
A. Due care is the continual effort to ensure that the right thing takes place, and due diligence is the continual effort to stay compliant with regulations.
B. Due care is based on the prudent person concept, whereas due diligence is not.
C. They mean the same thing.
D. Due diligence involves investigating the risks, whereas due care involves carrying out the necessary steps to mitigate these risks.
2. Why should employers make sure employees take their vacations?
A. They have a legal obligation.
B. It is part of due diligence.
C. It is a way for fraud to be uncovered.
D. To ensure the employee does not get burnt out.
3. Which of the following best describes separation of duties and job rotation?
A. Separation of duties ensures that more than one employee knows how to perform the tasks of a position, and job rotation ensures that one person cannot perform a high-risk task alone.
B. Separation of duties ensures that one person cannot perform a high-risk task alone, and job rotation can uncover fraud and ensure that more than one person knows the tasks of a position.
C. They are the same thing, but with different titles.
D. They are administrative controls that enforce access control and protect the company’s resources.
4. If a programmer is restricted from updating and modifying production code, what is this an example of?
A. Rotation of duties
B. Due diligence
C. Separation of duties
D. Controlling input values
5. Which of the following is not true about continuous monitoring?
A. It involves ad hoc processes that provide agility in responding to novel attacks.
B. Its main goal is to support organizational risk management.
C. It helps determine whether security controls remain effective.
D. It relies on carefully chosen metrics and measurements.
6. What is the difference between least privilege and need to know?
A. A user should have least privilege that restricts her need to know.
B. A user should have a security clearance to access resources, a need to know about those resources, and least privilege to give her full control of all resources.
C. A user should have a need to know to access particular resources, and least privilege should be implemented to ensure she only accesses the resources she has a need to know.
D. They are two different terms for the same issue.
7. Which of the following would not require updated documentation?
A. An antivirus signature update
B. Reconfiguration of a server
C. A change in security policy
D. The installation of a patch to a production server
8. A company needs to implement a CCTV system that will monitor a large area outside the facility. Which of the following is the correct lens combination for this?
A. A wide-angle lens and a small lens opening
B. A wide-angle lens and a large lens opening
C. A wide-angle lens and a large lens opening with a small focal length
D. A wide-angle lens and a large lens opening with a large focal length
9. Which of the following is not a true statement about CCTV lenses?
A. Lenses that have a manual iris should be used in outside monitoring.
B. Zoom lenses will carry out focus functionality automatically.
C. Depth of field increases as the size of the lens opening decreases.
D. Depth of field increases as the focal length of the lens decreases.
10. What is true about a transponder?
A. It is a card that can be read without sliding it through a card reader.
B. It is a biometric proximity device.
C. It is a card that a user swipes through a card reader to gain access to a facility.
D. It exchanges tokens with an authentication server.
11. When is a security guard the best choice for a physical access control mechanism?
A. When discriminating judgment is required
B. When intrusion detection is required
C. When the security budget is low
D. When access controls are in place
12. Which of the following is not a characteristic of an electrostatic intrusion detection system?
A. It creates an electrostatic field and monitors for a capacitance change.
B. It can be used as an intrusion detection system for large areas.
C. It produces a balance between the electric capacitance and inductance of an object.
D. It can detect if an intruder comes within a certain range of an object.
13. What is a common problem with vibration-detection devices used for perimeter security?
A. They can be defeated by emitting the right electrical signals in the protected area.
B. The power source is easily disabled.
C. They cause false alarms.
D. They interfere with computing devices.
14. Which of the following is not considered a delaying mechanism?
A. Locks
B. Defense-in-depth measures
C. Warning signs
D. Access controls
15. What are the two general types of proximity identification devices?
A. Biometric devices and access control devices
B. Swipe card devices and passive devices
C. Preset code devices and wireless devices
D. User-activated devices and system sensing devices
16. Which is not a drawback to installing intrusion detection and monitoring systems?
A. It’s expensive to install.
B. It cannot be penetrated.
C. It requires human response.
D. It’s subject to false alarms.
17. What is a cipher lock?
A. A lock that uses cryptographic keys
B. A lock that uses a type of key that cannot be reproduced
C. A lock that uses a token and perimeter reader
D. A lock that uses a keypad
18. If a cipher lock has a door delay option, what does that mean?
A. After a door is open for a specific period, the alarm goes off.
B. It can only be opened during emergency situations.
C. It has a hostage alarm capability.
D. It has supervisory override capability.
19. Which of the following best describes the difference between a warded lock and a tumbler lock?
A. A tumbler lock is more simplistic and easier to circumvent than a warded lock.
B. A tumbler lock uses an internal bolt, and a warded lock uses internal cylinders.
C. A tumbler lock has more components than a warded lock.
D. A warded lock is mainly used externally, and a tumbler lock is used internally.
20. All of the following are best practices for controlling the software that is installed and authorized to run in our systems except
A. Application whitelisting
B. Code reviews
C. Gold Masters
D. Least privilege
21. You come across an advanced piece of polymorphic malware that uses a custom communications protocol for network traffic. This protocol has a distinctive signature in its header. Which tool is best suited to mitigate this malware by preventing the packets from traversing the network?
A. Antimalware
B. Stateful firewall
C. Intrusion detection system (IDS)
D. Intrusion prevention system (IPS)
22. Which best describes a hot-site facility versus a warm- or cold-site facility?
A. A site that has disk drives, controllers, and tape drives
B. A site that has all necessary PCs, servers, and telecommunications
C. A site that has wiring, central air-conditioning, and raised flooring
D. A mobile site that can be brought to the company’s parking lot
23. Which is the best description of remote journaling?
A. Backing up bulk data to an offsite facility
B. Backing up transaction logs to an offsite facility
C. Capturing and saving transactions to two mirrored servers in-house
D. Capturing and saving transactions to different media types
24. Which of the following is something that should be required of an offsite backup facility that stores backed-up media for companies?
A. The facility should be within 10 to 15 minutes of the original facility to ensure easy access.
B. The facility should contain all necessary PCs and servers and should have raised flooring.
C. The facility should be protected by an armed guard.
D. The facility should protect against unauthorized access and entry.
25. Which of the following does not describe a reciprocal agreement?
A. The agreement is enforceable.
B. It is a cheap solution.
C. It may be able to be implemented right after a disaster.
D. It could overwhelm a current data processing site.
26. Which of the following describes a cold site?
A. Fully equipped and operational in a few hours
B. Partially equipped with data processing equipment
C. Expensive and fully configured
D. Provides environmental measures but no equipment
27. After a computer forensic investigator seizes a computer during a crime investigation, what is the next step?
A. Label and put it into a container, and then label the container
B. Dust the evidence for fingerprints
C. Make an image copy of the disks
D. Lock the evidence in the safe
28. Which of the following is a necessary characteristic of evidence for it to be admissible?
A. It must be real.
B. It must be noteworthy.
C. It must be reliable.
D. It must be important.
29. On your first day in a new job, you are invited to a meeting with attorneys representing a company for which your company provides infrastructure services. You learn that there is a major investigation underway into allegations that one of your company’s system administrators improperly accessed mailboxes belonging to this client. Based on what you know so far, which type of investigation is this likeliest to be?
A. Administrative
B. Regulatory
C. Criminal
D. Civil
Answers
1. D. Due care and due diligence are legal terms that do not just pertain to security. Due diligence involves going through the necessary steps to know what a company’s or individual’s actual risks are, whereas due care involves carrying out responsible actions to reduce those risks. These concepts correspond with the “prudent person” concept.
2. C. Many times, employees who are carrying out fraudulent activities do not take the vacation they have earned because they do not want anyone to find out what they have been doing. Forcing employees to take vacations means that someone else has to do that person’s job and can possibly uncover any misdeeds.
3. B. Rotation of duties enables a company to have more than one person trained in a position and can uncover fraudulent activities. Separation of duties is put into place to ensure that one entity cannot carry out a critical task alone.
4. C. This is just one of several examples of separation of duties. A system must be set up for proper code maintenance to take place when necessary, instead of allowing a programmer to make changes arbitrarily. These types of changes should go through a change control process and should have more entities involved than just one programmer.
5. A. Continuous monitoring is a deliberate, data-driven process supporting organizational risk management. One of the key questions it answers is: are controls still effective at mitigating risks? Continuous monitoring could potentially lead to a decision to implement specific ad hoc processes, but these would not really be part of continuous monitoring.
6. C. Users should be able to access only the resources they need to fulfill the duties of their positions. They also should only have the level of permissions and rights for those resources that are required to carry out the exact operations they need for their jobs, and no more. This second concept is more granular than the first, but they have a symbiotic relationship.
7. A. Documentation is a very important part of the change control process. If things are not properly documented, employees will forget what actually took place with each device. If the environment needs to be rebuilt, for example, it may be done incorrectly if the procedure was poorly or improperly documented. When new changes need to be implemented, the current infrastructure may not be totally understood. Continually documenting when virus signatures are updated would be overkill. The other answers contain events that certainly require documentation.
8. A. The depth of field refers to the portion of the environment that is in focus when shown on the monitor. The depth of field varies depending upon the size of the lens opening, the distance of the object being focused on, and the focal length of the lens. The depth of field increases as the size of the lens opening decreases, the subject distance increases, or the focal length of the lens decreases. So if you want to cover a large area and not focus on specific items, it is best to use a wide-angle lens and a small lens opening.
9. A. Manual iris lenses have a ring around the CCTV lens that can be manually turned and controlled. A lens that has a manual iris would be used in an area that has fixed lighting, since the iris cannot self-adjust to changes of light. An auto iris lens should be used in environments where the light changes, such as an outdoor setting. As the environment brightens, this is sensed by the iris, which automatically adjusts itself. Security personnel will configure the CCTV to have a specific fixed exposure value, which the iris is responsible for maintaining. The other answers are true.
10. A. A transponder is a type of physical access control device that does not require the user to slide a card through a reader. The reader and card communicate directly. The card and reader have a receiver, transmitter, and battery. The reader sends signals to the card to request information. The card sends the reader an access code.
11. A. Although many effective physical security mechanisms are on the market today, none can look at a situation, make a judgment about it, and decide what the next step should be. A security guard is employed when a company needs to have a countermeasure that can think and make decisions in different scenarios.
12. B. An electrostatic IDS creates an electrostatic field, which is just an electric field associated with static electric charges. The IDS creates a balanced electrostatic field between itself and the object being monitored. If an intruder comes within a certain range of the monitored object, there is capacitance change. The IDS can detect this change and sound an alarm.
13. C. This type of system is sensitive to sounds and vibrations and detects the changes in the noise level of an area it is placed within. This level of sensitivity can cause many false alarms. These devices do not emit any waves; they only listen for sounds within an area and are considered passive devices.
14. C. Every physical security program should have delaying mechanisms, which have the purpose of slowing down an intruder so security personnel can be alerted and arrive at the scene. A warning sign is a deterrence control, not a delaying control.
15. D. A user-activated device requires the user to do something: swipe the card through the reader and/or enter a code. A system sensing device recognizes the presence of the card and communicates with it without the user needing to carry out any activity.
16. B. Monitoring and intrusion detection systems are expensive, require someone to respond when they set off an alarm, and, because of their level of sensitivity, can cause several false alarms. Like any other type of technology or device, they have their own vulnerabilities that can be exploited and penetrated.
17. D. Cipher locks, also known as programmable locks, use keypads to control access into an area or facility. The lock can require a swipe card and a specific combination that’s entered into the keypad.
18. A. A security guard would want to be alerted when a door has been open for an extended period. It may be an indication that something is taking place other than a person entering or exiting the door. A security system can have a threshold set so that if the door is open past the defined time period, an alarm sounds.
19. C. The tumbler lock has more pieces and parts than a warded lock. The key fits into a cylinder, which raises the lock metal pieces to the correct height so the bolt can slide to the locked or unlocked position. A warded lock is easier to circumvent than a tumbler lock.
20. B. Code reviews are focused on finding and fixing defects in software that is undergoing development. It is not helpful in controlling which applications run on our computers.
21. D. The intrusion prevention system is the best answer because these systems can stop packets containing specific signatures. Although some antimalware software might be able to this also, this functionality is not a universal feature in this sort of solution.
22. B. A hot site is a facility that is fully equipped and properly configured so that it can be up and running within hours to get a company back into production. Answer B gives the best definition of a fully functional environment.
23. B. Remote journaling is a technology used to transmit data to an offsite facility, but this usually only includes moving the journal or transaction logs to the offsite facility, not the actual files.
24. D. This question addresses a facility that is used to store backed-up data; it is not talking about an offsite facility used for disaster recovery purposes. The facility should not be only 10 to 15 minutes away, because some types of disasters could destroy both the company’s main facility and this facility if they are that close together, in which case the company would lose all of its information. The facility should have the same security standards as the company’s security, including protection against unauthorized access.
25. A. A reciprocal agreement is not enforceable, meaning that the company that agreed to let the damaged company work out of its facility can decide not to allow this to take place. A reciprocal agreement is a better secondary backup option if the original plan falls through.
26. D. A cold site only provides environmental measures—wiring, air conditioning, raised floors—basically a shell of a building and no more.
27. C. Several steps need to be followed when gathering and extracting evidence from a scene. Once a computer has been confiscated, the first thing the computer forensics team should do is make an image of the hard drive. The team will work from this image instead of the original hard drive so that the original stays in a pristine state and the evidence on the drive is not accidentally corrupted or modified.
28. C. For evidence to be admissible, it must be relevant, complete, sufficient, and reliable to the case. For evidence to be reliable, it must be consistent with fact and must not be based on opinion or be circumstantial.
29. D. The allegations, depending on the details, could point to any of the four types of investigations. However, since you are meeting with attorneys representing this client, it is likeliest that they are considering (or taking) civil action against your company. None of the other three types of investigations would normally involve meetings with a client’s attorneys. As an aside, in this situation you would obviously want to ensure that your own company’s attorneys were present too.