
CHAPTER 8
Software Development Security
This chapter presents the following:
• Common software development issues
• Software development life cycles
• Secure software development approaches
• Development/operations integration (DevOps)
• Change management
• Security of development environments
• Programming language and concepts
• Malware types and attacks
• Security of acquired software
Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live.
—John F. Woods
Software is usually developed with a strong focus on functionality, not security. In many cases, security controls are bolted on as an afterthought (if at all). To get the best of both worlds, security and functionality would have to be designed and integrated at each phase of the development life cycle. Security should be interwoven into the core of a product and provide protection at the necessary layers. This is a better approach than trying to develop a front end or wrapper that may reduce the overall functionality and leave security holes when the software has to be integrated into a production environment.
In this chapter we will cover the complex world of secure software development and the bad things that can happen when security is not interwoven into products properly.
Building Good Code
Quality can be defined as fitness for purpose. In other words, quality refers to how good or bad something is for its intended purpose. A high-quality car is good for transportation. We don’t have to worry about it breaking down, failing to protect its occupants in a crash, or being easy for a thief to steal. When we need to go somewhere, we can count on a high-quality car to get us to wherever we need to go. Similarly, we don’t have to worry about high-quality software crashing, corrupting our data under unforeseen circumstances, or being easy for someone to subvert. Sadly, many developers still think of functionality first (or only) when thinking about quality. When we look at it holistically, we see that quality is the most important concept in developing secure software.
Code reviews and interface testing, discussed in Chapter 6, are key elements in ensuring software quality. We also discussed misuse case testing, the goal of which is to identify the ways in which adversaries might try to subvert our code and then allow us to identify controls that would prevent them from doing so. So, while controls are critical to our systems’ security, they need to be considered in the context of overall software quality.
Software controls come in various flavors and have many different goals. They can control input, encryption, logic processing, number-crunching methods, interprocess communication, access, output, and interfacing with other software. Software controls should be developed with potential risks in mind, and many types of threat models and risk analyses should be invoked at different stages of development. The goals are to reduce vulnerabilities and the possibility of system compromise. The controls can be preventive, detective, or corrective. While security controls can be administrative and physical in nature, the controls used within software are usually more technical in nature.
Which specific software controls should be used depends on the software itself, its objectives, the security goals of its associated security policy, the type of data it will process, the functionality it is to carry out, and the environment in which it will be placed. If an application is purely proprietary and will run only in closed, trusted environments, fewer security controls may be needed than those required for applications that will connect businesses over the Internet and provide financial transactions. The trick is to understand the security needs of a piece of software, implement the right controls and mechanisms, thoroughly test the mechanisms and how they integrate into the application, follow structured development methodologies, and provide secure and reliable distribution methods.
Though this may all sound overwhelming, software can be developed securely. In fact, despite some catastrophic failures that occasionally show up in the news media, programmers and vendors are steadily getting better at secure development. We will walk through many of the requirements necessary to create secure software over the course of this chapter.
Where Do We Place Security?
Today, many security efforts look to solve security problems through controls such as firewalls, intrusion detection systems (IDSs), content filtering, antimalware software, vulnerability scanners, and much more. This reliance on a long laundry list of security technologies occurs mainly because our software contains many vulnerabilities. Our environments are commonly referred to as hard and crunchy on the outside and soft and chewy on the inside. This means our perimeter security is fortified and solid, but our internal environment and software are easy to exploit once access has been obtained.
In reality, the flaws within the software cause a majority of the vulnerabilities in the first place. Several reasons explain why perimeter devices are more often considered than dealing with the insecurities within the software:
• In the past, it was not considered crucial to implement security during the software development stages; thus, many programmers today do not practice these procedures.
• Most security professionals are not software developers, and thus do not have complete insight to software vulnerability issues.
• Most software developers are not security professionals and do not have security as a main focus. Functionality is usually considered more important than security.
• Software vendors are trying to get their products to market in the quickest possible time and may not take the time for proper security architecture, design, and testing steps.
• The computing community has gotten used to receiving software with flaws and then applying patches. This has become a common and seemingly acceptable practice.
• Customers cannot control the flaws in the software they purchase, so they must depend upon perimeter protection.
Finger-pointing and quick judgments are neither useful nor necessarily fair at this stage of our computing evolution. Twenty years ago, mainframes did not require much security because only a handful of people knew how to run them, users worked on computers (dumb terminals) that could not introduce malicious code to the mainframe, and environments were closed. The core protocols and computing framework were developed at a time when threats and attacks were not prevalent. Such stringent security wasn’t needed. Then, computer and software evolution took off, and the possibilities splintered into a thousand different directions. The high demand for computer technology and different types of software increased the demand for programmers, system designers, administrators, and engineers. This demand brought in a wave of people who had little experience pertaining to security. The lack of experience, the high change rate of technology, the focus on functionality, and the race to market vendors experience just to stay competitive have added problems to security measures that are not always clearly understood.
Although it is easy to blame the big software vendors for producing flawed or buggy software, this is driven by customer demand. Since at least the turn of the century, we have been demanding more and more functionality from software vendors. The software vendors have done a wonderful job in providing these perceived necessities. Only recently have customers (especially corporate ones) started to also demand security. Meeting this demand is difficult for several reasons: programmers traditionally have not been properly educated in secure coding; operating systems and applications were not built on secure architectures from the beginning; software development procedures have not been security oriented; and integrating security as an afterthought makes the process clumsier and costlier. So although software vendors should be doing a better job by providing us with more secure products, we should also understand that this is a relatively new requirement and there is much more complexity when you peek under the covers than most consumers can even comprehend.

Figure 8-1 The usual trend of software being released to the market and how security is dealt with
This chapter is an attempt to show how to address security at its source, which is at the software development level. This requires a shift from reactive to proactive actions toward security problems to ensure they do not happen in the first place, or at least happen to a smaller extent. Figure 8-1 illustrates our current way of dealing with security issues.
Different Environments Demand Different Security
Today, network and security administrators are in an overwhelming position of having to integrate different applications and computer systems to keep up with their company’s demand for expandable functionality and the new gee-whiz components that executives buy into and demand quick implementation of. This integration is further frustrated by the company’s race to provide a well-known presence on the Internet by implementing websites with the capabilities of taking online orders, storing credit card information, and setting up extranets with partners. This can quickly turn into a confusing ball of protocols, devices, interfaces, incompatibility issues, routing and switching techniques, telecommunications routines, and management procedures—all in all, a big enough headache to make an administrator buy some land in Montana and go raise goats instead.
On top of this, security is expected, required, and depended upon. When security compromises creep in, the finger-pointing starts, liability issues are tossed like hot potatoes, and people might even lose their jobs. An understanding of the environment, what is currently in it, and how it works is required so these new technologies can be implemented in a more controlled and comprehensible fashion.
The days of developing a simple web page and posting it on the Internet to illustrate your products and services are long gone. Today, the customer front end, complex middleware, and multitiered architectures must be integrated seamlessly. Networks are commonly becoming “borderless” since everything from smartphones and iPads to other mobile devices are being plugged in, and remote users are becoming more of the norm instead of the exception. As the complexity of these types of environments grows, tracking down errors and security compromises becomes an awesome task.
Environment vs. Application
Software controls can be implemented by the operating system or by the application—and usually a combination of both is used. Each approach has its strengths and weaknesses, but if they are all understood and programmed to work in a concerted manner, then many different undesirable scenarios and types of compromises can be thwarted. One downside to relying mainly on operating system controls is that although they can control a subject’s access to different objects and restrict the actions of that subject within the system, they do not necessarily restrict the subject’s actions within an application. If an application has a security vulnerability within its own programmed code, it is not always possible for the operating system to predict and control this vulnerability. An operating system is a broad environment for many applications to work within. It is unrealistic to expect the operating system to understand all the nuances of different programs and their internal mechanisms.
On the other hand, application controls and database management controls are very specific to their needs and in the security compromises they understand. Although an application might be able to protect data by allowing only certain types of input and not permitting certain users to view data kept in sensitive database fields, it cannot prevent the user from inserting bogus data into the Address Resolution Protocol (ARP) table—this is the responsibility of the operating system and its network stack. Operating system and application controls have their place and limitations. The trick is to find out where one type of control stops so the next type of control can be configured to kick into action.
Security has been mainly provided by security products and perimeter devices rather than controls built into applications. The security products can cover a wide range of applications, can be controlled by a centralized management console, and are further away from application control. However, this approach does not always provide the necessary level of granularity and does not approach compromises that can take place because of problematic coding and programming routines. Firewalls and access control mechanisms can provide a level of protection by preventing attackers from gaining access to be able to exploit known vulnerabilities, but the best protection happens at the core of the problem—proper software development and coding practices must be in place.
Functionality vs. Security
Programming code is complex—the code itself, routine interaction, global and local variables, input received from other programs, output fed to different applications, attempts to envision future user inputs, calculations, and restrictions form a long list of possible negative security consequences. Many times, trying to account for all the “what-ifs” and programming on the side of caution can reduce the overall functionality of the application. As you limit the functionality and scope of an application, the market share and potential profitability of that program could be reduced. A balancing act always exists between functionality and security, and in the development world, functionality is usually deemed the most important.
So, programmers and application architects need to find a happy medium between the necessary functionality of the program, the security requirements, and the mechanisms that should be implemented to provide this security. This can add more complexity to an already complex task.
More than one road may lead to enlightenment, but as these roads increase in number, it is hard to know if a path will eventually lead you to bliss or to fiery doom in the underworld. Many programs accept data from different parts of the program, other programs, the system itself, and user input. Each of these paths must be followed in a methodical way, and each possible scenario and input must be thought through and tested to provide a deep level of assurance. It is important that each module be capable of being tested individually and in concert with other modules. This level of understanding and testing will make the product more secure by catching flaws that could be exploited.
Implementation and Default Issues
As many people in the technology field know, out-of-the-box implementations are usually far from secure. Most security has to be configured and turned on after installation—not being aware of this can be dangerous for the inexperienced security person. The Windows operating system has received its share of criticism for lack of security, but the platform can be secured in many ways. It just comes out of the box in an insecure state because settings have to be configured to properly integrate it into different environments, and this is a friendlier way of installing the product for users. For example, if Mike is installing a new software package that continually throws messages of “Access Denied” when he is attempting to configure it to interoperate with other applications and systems, his patience might wear thin, and he might decide to hate that vendor for years to come because of the stress and confusion inflicted upon him.
Yet again, we are at a hard place for developers and architects. When a security application or device is installed, it should default to “No Access.” This means that when Laurel installs a packet-filter firewall, it should not allow any packets to pass into the network that were not specifically granted access. However, this requires Laurel to know how to configure the firewall for it to ever be useful. A fine balance exists between security, functionality, and user friendliness. If an application is extremely user friendly, it is probably not as secure. For an application to be user friendly, it usually requires a lot of extra coding for potential user errors, dialog boxes, wizards, and step-by-step instructions. This extra coding can result in bloated code that can create unforeseeable compromises. So vendors have a hard time winning, but they usually keep making money while trying.
NOTE Most operating systems nowadays ship with reasonably secure default settings, but users are still able to override the majority of these settings. This brings us closer to “default with no access,” but we still have a ways to go.
Implementation errors and misconfigurations are common items that cause many of the security issues in networked environments. Most people do not realize that various services are enabled when a system is installed. These services can provide adversaries with information and vectors that can be used during an attack. Many services provide an actual way into the environment itself. For example, NetBIOS services, which have few, if any, security controls, can be enabled to permit sharing resources in Windows environments. Other services, such as File Transfer Protocol (FTP), Trivial File Transfer Protocol (TFTP), and older versions of the Simple Network Management Protocol (SNMP), have no real safety measures in place. Some of these services (as well as others) are enabled by default, so when an administrator installs an operating system and does not check these services to properly restrict or disable them, they are available for attackers to uncover and use.
Because vendors have user friendliness and user functionality in mind, the product will usually be installed with defaults that provide no, or very little, security protection. It would be very hard for vendors to know the security levels required in all the environments the product will be installed in, so they usually do not attempt it. It is up to the person installing the product to learn how to properly configure the settings to achieve the necessary level of protection.
Another problem in implementation and security is the number of unpatched systems. Once security issues are identified, vendors develop patches or updates to address and fix these security holes. However, these often do not get installed on the systems that are vulnerable in a timely manner. The reasons for this vary: administrators may not keep up to date on the recent security vulnerabilities and necessary patches, they may not fully understand the importance of these patches, or they may be afraid the patches will cause other problems. All of these reasons are quite common, but they all have the same result—insecure systems. Many vulnerabilities that are exploited today have had patches developed and released months or years ago.
It is unfortunate that adding security (or service) patches can adversely affect other mechanisms within the system. The patches should be tested for these types of activities before they are applied to production servers and workstations to help prevent service disruptions that can affect network and employee productivity. Of course, the best way to reduce the need for patching is by developing the software properly in the first place, which is the issue to which we turn our attention next.
Software Development Life Cycle
The life cycle of software development deals with putting repeatable and predictable processes in place that help ensure functionality, cost, quality, and delivery schedule requirements are met. So instead of winging it and just starting to develop code for a project, how can we make sure we build the best software product possible?
There have been several software development life cycle (SDLC) models developed over the years, which we will cover later in this section, but the crux of each model deals with the following phases:
• Requirements gathering Determine why to create this software, what the software will do, and for whom the software will be created
• Design Deals with how the software will accomplish the goals identified, which are encapsulated into a functional design
• Development Programming software code to meet specifications laid out in the design phase and integrating that code with existing systems and/or libraries
• Testing Verifying and validating software to ensure that the software works as planned and that goals are met
• Operations and maintenance Deploying the software and then ensuring that it is properly configured, patched, and monitored
In the following sections we will cover the different phases that make up a software development life-cycle model and some specific items about each phase that are important to understand. Keep in mind that the discussion that follows covers phases that may happen repeatedly and in limited scope depending on the development methodology being used.
Project Management
Before we get into the phases of the SDLC, let’s first introduce the glue that holds them together: project management. Many developers know that good project management keeps the project moving in the right direction, allocates the necessary resources, provides the necessary leadership, and plans for the worst yet hopes for the best. Project management processes should be put into place to make sure the software development project executes each life-cycle phase properly. Project management is an important part of product development, and security management is an important part of project management.
A security plan should be drawn up at the beginning of a development project and integrated into the functional plan to ensure that security is not overlooked. The first plan is broad, covers a wide base, and refers to documented references for more detailed information. The references could include computer standards (RFCs, IEEE standards, and best practices), documents developed in previous projects, security policies, accreditation statements, incident-handling plans, and national or international guidelines. This helps ensure that the plan stays on target.
The security plan should have a lifetime of its own. It will need to be added to, subtracted from, and explained in more detail as the project continues. It is important to keep it up to date for future reference. It is always easy to lose track of actions, activities, and decisions once a large and complex project gets underway.
The security plan and project management activities may likely be audited so security-related decisions can be understood. When assurance in the product needs to be guaranteed, indicating that security was fully considered in each phase of the life cycle, the procedures, development, decisions, and activities that took place during the project will be reviewed. The documentation must accurately reflect how the product was built and how it is supposed to operate once implemented into an environment.
If a software product is being developed for a specific customer, it is common for a Statement of Work (SOW) to be developed, which describes the product and customer requirements. A detail-oriented SOW will help ensure that these requirements are properly understood and assumptions are not made.
Sticking to what is outlined in the SOW is important so that scope creep does not take place. If the scope of a project continually extends in an uncontrollable manner (creeps), the project may never end, not meet its goals, run out of funding, or all of the above. If the customer wants to modify its requirements, it is important that the SOW is updated and funding is properly reviewed.
A work breakdown structure (WBS) is a project management tool used to define and group a project’s individual work elements in an organized manner. It is a deliberate decomposition of the project into tasks and subtasks that result in clearly defined deliverables. The SDLC should be illustrated in a WBS format, so that each phase is properly addressed.
Requirements Gathering Phase
This is the phase when everyone involved attempts to understand why the project is needed and what the scope of the project entails. Either a specific customer needs a new application or a demand for the product exists in the market. During this phase, the team examines the software’s requirements and proposed functionality, engages in brainstorming sessions, and reviews obvious restrictions.
A conceptual definition of the project should be initiated and developed to ensure everyone is on the right page and that this is a proper product to develop. This phase could include evaluating products currently on the market and identifying any demands not being met by current vendors. It could also be a direct request for a specific product from a current or future customer.
As it pertains to security, the following items should be accomplished in this phase:
• Security requirements
• Security risk assessment
• Privacy risk assessment
• Risk-level acceptance
The security requirements of the product should be defined in the categories of availability, integrity, and confidentiality. What type of security is required for the software product and to what degree?
An initial security risk assessment should be carried out to identify the potential threats and their associated consequences. This process usually involves asking many, many questions to draw up the laundry list of vulnerabilities and threats, the probability of these vulnerabilities being exploited, and the outcome if one of these threats actually becomes real and a compromise takes place. The questions vary from product to product—such as its intended purpose, the expected environment it will be implemented in, the personnel involved, and the types of businesses that would purchase and use the product.
The sensitivity level of the data the software will be maintaining and processing has only increased in importance over the years. After a privacy risk assessment, a Privacy Impact Rating can be assigned, which indicates the sensitivity level of the data that will be processed or accessible. Some software vendors incorporate the following Privacy Impact Ratings in their software development assessment processes:
• P1, High Privacy Risk The feature, product, or service stores or transfers personally identifiable information (PII), monitors the user with an ongoing transfer of anonymous data, changes settings or file type associations, or installs software.
• P2, Moderate Privacy Risk The sole behavior that affects privacy in the feature, product, or service is a one-time, user-initiated anonymous data transfer (e.g., the user clicks on a link and goes out to a website).
• P3, Low Privacy Risk No behaviors exist within the feature, product, or services that affect privacy. No anonymous or personal data is transferred, no PII is stored on the machine, no settings are changed on the user’s behalf, and no software is installed.
The software vendor can develop its own Privacy Impact Ratings and their associated definitions. As of this writing there is no standardized approach to defining these rating types, but as privacy increases in importance, we might see more standardization in these ratings and associated metrics.
A clear risk-level acceptance criteria needs to be developed to make sure that mitigation efforts are prioritized. The acceptable risks will depend upon the results of the security and privacy risk assessments. The evaluated threats and vulnerabilities are used to estimate the cost/benefit ratios of the different security countermeasures. The level of each security attribute should be focused upon so a clear direction on security controls can begin to take shape and can be integrated into the design and development phases.
Design Phase
This is the phase that starts to map theory to reality. The theory encompasses all of the requirements that were identified in previous phases, and the design outlines how the product is actually going to accomplish these requirements.
The software design phase is a process used to describe the requirements and the internal behavior of the software product. It then maps the two elements to show how the internal behavior actually accomplishes the defined requirements.
Some companies skip the functional design phase, which can cause major delays down the road and redevelopment efforts because a broad vision of the product needs to be understood before looking strictly at the details.
Software requirements commonly come from three models:
• Informational model Dictates the type of information to be processed and how it will be processed
• Functional model Outlines the tasks and functions the application needs to carry out
• Behavioral model Explains the states the application will be in during and after specific transitions take place
For example, an antimalware software application may have an informational model that dictates what information is to be processed by the program, such as virus signatures, modified system files, checksums on critical files, and virus activity. It would also have a functional model that dictates that the application should be able to scan a hard drive, check e-mail for known virus signatures, monitor critical system files, and update itself. The behavioral model would indicate that when the system starts up, the antimalware software application will scan the hard drive and memory segments. The computer coming online would be the event that changes the state of the application. If a virus were found, the application would change state and deal with the virus appropriately. Each state must be accounted for to ensure that the product does not go into an insecure state and act in an unpredictable way.
The informational, functional, and behavioral model data go into the software design as requirements. What comes out of the design is the data, architectural, and procedural design, as shown in Figure 8-2.
From a security point of view, the following items should also be accomplished in this phase:
• Attack surface analysis
• Threat modeling
An attack surface is what is available to be used by an attacker against the product itself. As an analogy, if you were wearing a suit of armor and it covered only half of your body, the other half would be your vulnerable attack surface. Before you went into battle, you would want to reduce this attack surface by covering your body with as much protective armor as possible. The same can be said about software. The development team should reduce the attack surface as much as possible because the greater the attack surface of software, the more avenues for the attacker; and hence, the greater the likelihood of a successful compromise.
The aim of an attack surface analysis is to identify and reduce the amount of code and functionality accessible to untrusted users. The basic strategies of attack surface reduction are to reduce the amount of code running, reduce entry points available to untrusted users, reduce privilege levels as much as possible, and eliminate unnecessary services. Attack surface analysis is generally carried out through specialized tools to enumerate different parts of a product and aggregate their findings into a numeral value. Attack surface analyzers scrutinize files, Registry keys, memory data, session information, processes, and services details. A sample attack surface report is shown in Figure 8-3.
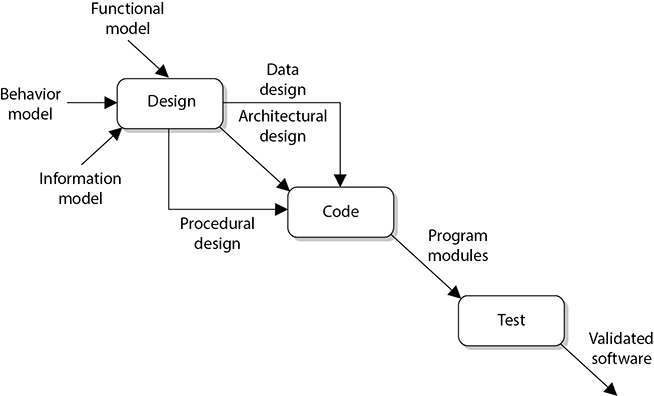
Figure 8-2 Information from three models can go into the design.

Figure 8-3 Attack surface analysis result
Threat modeling, which we covered in detail in Chapter 1 in the context of risk management, is a systematic approach used to understand how different threats could be realized and how a successful compromise could take place. As a hypothetical example, if you were responsible for ensuring that the government building in which you work is safe from terrorist attacks, you would run through scenarios that terrorists would most likely carry out so that you fully understand how to protect the facility and the people within it. You could think through how someone could bring a bomb into the building, and then you would better understand the screening activities that need to take place at each entry point. A scenario of someone running a car into the building would bring up the idea of implementing bollards around the sensitive portions of the facility. The scenario of terrorists entering sensitive locations in the facility (data center, CEO office) would help illustrate the layers of physical access controls that should be implemented. These same scenario-based exercises should take place during the design phase of software development. Just as you would think about how potential terrorists could enter and exit a facility, the design team should think through how potentially malicious activities can happen at different input and output points of the software and the types of compromises that can take place within the guts of the software itself.
It is common for software development teams to develop threat trees, as shown in Figure 8-4. The tree is a tool that allows the development team to understand all the ways specific threats can be realized; thus, it helps them understand what type of security controls should be implemented to mitigate the risks associated with each threat type. Recall that we covered threat modeling in detail in Chapter 1.
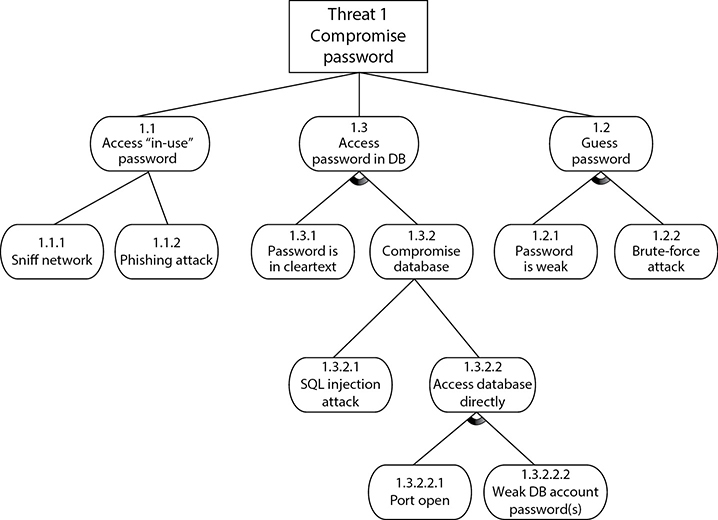
Figure 8-4 Threat tree used in threat modeling
There are many automated tools in the industry that software development teams can use to ensure that various threat types are addressed during their design stage. Figure 8-5 shows the interface to one of these types of tools. The tool describes how specific vulnerabilities could be exploited and suggests countermeasures and coding practices that should be followed to address the vulnerabilities.
The decisions made during the design phase are pivotal steps to the development phase. Software design serves as a foundation and greatly affects software quality. If good product design is not put into place in the beginning of the project, the following phases will be much more challenging.
Development Phase
This is the phase where the programmers become deeply involved. The software design that was created in the previous phase is broken down into defined deliverables, and programmers develop code to meet the deliverable requirements.
There are many computer-aided software engineering (CASE) tools that programmers can use to generate code, test software, and carry out debugging activities. When these types of activities are carried out through automated tools, development usually takes place more quickly with fewer errors.

Figure 8-5 Threat modeling tool
CASE refers to any type of software tool that allows for the automated development of software, which can come in the form of program editors, debuggers, code analyzers, version-control mechanisms, and more. These tools aid in keeping detailed records of requirements, design steps, programming activities, and testing. A CASE tool is aimed at supporting one or more software engineering tasks in the process of developing software. Many vendors can get their products to the market faster because they are “computer aided.”
In later sections we will cover different software development models and the programming languages that can be used to create software. At this point let’s take a quick peek into the abyss of “secure coding.” As stated previously, most vulnerabilities that corporations, organizations, and individuals have to worry about reside within the programming code itself. When programmers do not follow strict and secure methods of creating programming code, the effects can be widespread and the results can be devastating. But programming securely is not an easy task. The list of errors that can lead to serious vulnerabilities in software is long. To illustrate, the MITRE organization’s Common Weakness Enumeration (CWE) initiative, which it describes as “A Community-Developed List of Software Weakness Types,” collaborates with the SANS Institute to maintain a list of the top most dangerous software errors. Figure 8-6 shows the most recent CWE/SANS Top 25 Most Dangerous Software Errors list, which can be found at http://cwe.mitre.org/top25/#Listing. Although this was last updated in 2011, sadly, it is as relevant today as it was back then.
Many of these software issues are directly related to improper or faulty programming practices. Among other issues to address, the programmers need to check input lengths so buffer overflows cannot take place, inspect code to prevent the presence of covert channels, check for proper data types, make sure checkpoints cannot be bypassed by users, verify syntax, and verify checksums. Different attack scenarios should be played out to see how the code could be attacked or modified in an unauthorized fashion. Code reviews and debugging should be carried out by peer developers, and everything should be clearly documented.
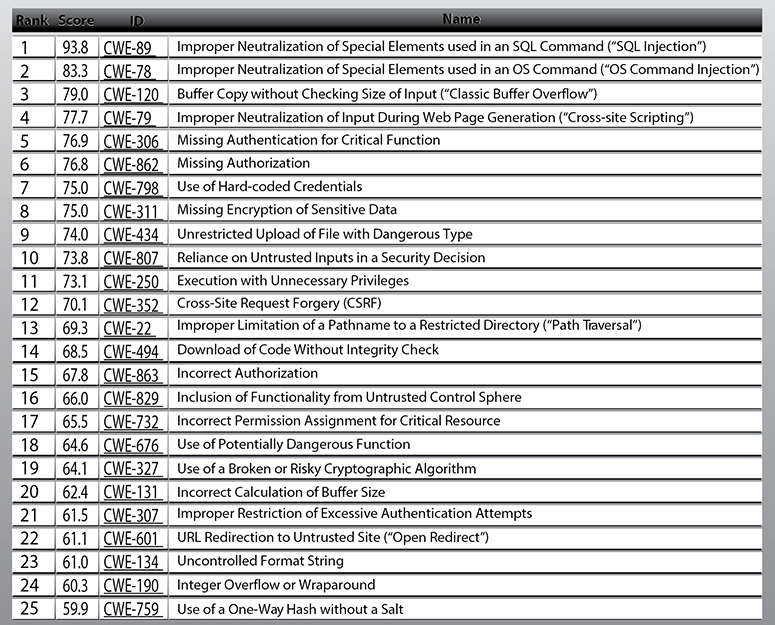
Figure 8-6 2011 CWE/SANS Top 25 Most Dangerous Software Errors list
A particularly important area of scrutiny is input validation. Though we discuss it in detail later in this chapter, it is worthwhile pointing out that improper validation of inputs leads to serious vulnerabilities. A buffer overflow is a classic example of a technique that can be used to exploit improper input validation. A buffer overflow (which is described in detail in Chapter 3) takes place when too much data is accepted as input to a specific process. The process’ memory buffer can be overflowed by shoving arbitrary data into various memory segments and inserting a carefully crafted set of malicious instructions at a specific memory address.
Buffer overflows can also lead to illicit escalation of privileges. Privilege escalation is the process of exploiting a process or configuration setting in order to gain access to resources that would normally not be available to the process or its user. For example, an attacker can compromise a regular user account and escalate its privileges in order to gain administrator or even system privileges on that computer. This type of attack usually exploits the complex interactions of user processes with device drivers and the underlying operating system. A combination of input validation and configuring the system to run with least privilege can help mitigate the threat of escalation of privileges.
Some of the most common errors (buffer overflow, injection, parameter validation) are covered later in this chapter along with organizations that provide secure software development guidelines (OWASP, DHS, MITRE). At this point we are still marching through the software development life-cycle phases, so we want to keep our focus. What is important to understand is that secure coding practices need to be integrated into the development phase of SDLC. Security has to be addressed at each phase of SDLC, with this phase being one of the most critical.
Testing Phase
Formal and informal testing should begin as soon as possible. Unit testing is concerned with ensuring the quality of individual code modules or classes. Mature developers will develop the unit tests for their modules before they even start coding, or at least in parallel with the coding. This approach is known as test-driven development and tends to result in much higher-quality code with significantly fewer vulnerabilities.
Unit tests are meant to simulate a range of inputs to which the code may be exposed. These inputs range from the mundanely expected, to the accidentally unfortunate, to the intentionally malicious. The idea is to ensure the code always behaves in an expected and secure manner. Once a module and its unit tests are finished, the unit tests are run (usually in an automated framework) on that code. The goal of this type of testing is to isolate each part of the software and show that the individual parts are correct.
Unit testing usually continues throughout the development phase. A totally different group of people should carry out the formal testing. This is an example of separation of duties. A programmer should not develop, test, and release software. The more eyes that see the code, the greater the chance that flaws will be found before the product is released.
No cookie-cutter recipe exists for security testing because the applications and products can be so diverse in functionality and security objectives. It is important to map security risks to test cases and code. Linear thinking can be followed by identifying a vulnerability, providing the necessary test scenario, performing the test, and reviewing the code for how it deals with such a vulnerability. At this phase, tests are conducted in an environment that should mirror the production environment to ensure the code does not work only in the labs.
Security attacks and penetration tests usually take place during this phase to identify any missed vulnerabilities. Functionality, performance, and penetration resistance are evaluated. All the necessary functionality required of the product should be in a checklist to ensure each function is accounted for.
Security tests should be run to test against the vulnerabilities identified earlier within the project. Buffer overflows should be attempted, interfaces should be hit with unexpected inputs, denial of service (DoS) situations should be tested, unusual user activity should take place, and if a system crashes, the product should react by reverting to a secure state. The product should be tested in various environments with different applications, configurations, and hardware platforms. A product may respond fine when installed on a clean Windows 10 installation on a stand-alone PC, but it may throw unexpected errors when installed on a laptop that is remotely connected to a network and has a virtual private network (VPN) client installed.
Testing Types
There are different types of tests the software should go through because there are different potential flaws the team should be looking for. The following are some of the most common testing approaches:
• Unit testing Testing individual components in a controlled environment where programmers validate data structure, logic, and boundary conditions
• Integration testing Verifying that components work together as outlined in design specifications
• Acceptance testing Ensuring that the code meets customer requirements
• Regression testing After a change to a system takes place, retesting to ensure functionality, performance, and protection
A well-rounded security test encompasses both manual and automatic tests. Automated tests help locate a wide range of flaws generally associated with careless or erroneous code implementations. Some automated testing environments run specific inputs in a scripted and repeatable manner. While these tests are the bread and butter of software testing, we sometimes want to simulate random and unpredictable inputs to supplement the scripted tests. A commonly used approach is to use programs known as fuzzers.
Fuzzers use complex input to impair program execution. Fuzzing is a technique used to discover flaws and vulnerabilities in software by sending large amounts of malformed, unexpected, or random data to the target program in order to trigger failures. Attackers can then manipulate these errors and flaws to inject their own code into the system and compromise its security and stability. Fuzzing tools are commonly successful at identifying buffer overflows, DoS vulnerabilities, injection weaknesses, validation flaws, and other activities that can cause software to freeze, crash, or throw unexpected errors.
A manual test is used to analyze aspects of the program that require human intuition and can usually be judged using computing techniques. Testers also try to locate design flaws. These include logical errors, where attackers may manipulate program flow by using shrewdly crafted program sequences to access greater privileges or bypass authentication mechanisms. Manual testing involves code auditing by security-centric programmers who try to modify the logical program structure using rogue inputs and reverse-engineering techniques. Manual tests simulate the live scenarios involved in real-world attacks. Some manual testing also involves the use of social engineering to analyze the human weakness that may lead to system compromise.
Dynamic analysis refers to the evaluation of a program in real time, when it is running. Dynamic analysis is commonly carried out once a program has cleared the static analysis stage and basic programming flaws have been rectified offline. It enables developers to trace subtle logical errors in the software that are likely to cause security mayhem later on. The primary advantage of this technique is that it eliminates the need to create artificial error-inducing scenarios. Dynamic analysis is also effective for compatibility testing, detecting memory leakages, and identifying dependencies, and for analyzing software without having to access the software’s actual source code.
At this stage, issues found in testing procedures are relayed to the development team in problem reports. The problems are fixed and programs retested. This is a continual process until everyone is satisfied that the product is ready for production. If there is a specific customer, the customer would run through a range of tests before formally accepting the product; if it is a generic product, beta testing can be carried out by various potential customers and agencies. Then the product is formally released to the market or customer.
NOTE Sometimes developers include lines of code in a product that will allow them to do a few keystrokes and get right into the application. This allows them to bypass any security and access controls so they can quickly access the application’s core components. This is referred to as a “back door” or “maintenance hook” and must be removed before the code goes into production.
Operations and Maintenance Phase
Once the software code is developed and properly tested, it is released so that it can be implemented within the intended production environment. The software development team’s role is not finished at this point. Newly discovered problems and vulnerabilities are commonly identified. For example, if a company developed a customized application for a specific customer, the customer could run into unforeseen issues when rolling out the product within their various networked environments. Interoperability issues might come to the surface, or some configurations may break critical functionality. The developers would need to make the necessary changes to the code, retest the code, and re-release the code.
Almost every software system will require the addition of new features over time. Frequently, these have to do with changing business processes or interoperability with other systems. Though we will cover change management later in this chapter, it is worth pointing out that the operations and development teams must work particularly closely during the operations and maintenance (O&M) phase. The operations team, which is typically the IT department, is responsible for ensuring the reliable operation of all production systems. The development team is responsible for any changes to the software in development systems up until the time they go into production. Together, the operations and development teams address the transition from development to production as well as management of the system’s configuration.
Another facet of O&M is driven by the fact that new vulnerabilities are discovered almost daily. While the developers may have carried out extensive security testing, it is close to impossible to identify all the security issues at one point and time. Zero-day vulnerabilities may be identified, coding errors may be uncovered, or the integration of the software with another piece of software may uncover security issues that have to be addressed. The development team must develop patches, hotfixes, and new releases to address these items. In all likelihood, this is where you as a CISSP will interact the most with the SDLC.
NOTE Zero-day vulnerabilities are vulnerabilities that do not currently have a resolution. If a vulnerability is identified and there is not a pre-established fix (patch, configuration, update), it is considered a zero day.
Software Development Methodologies
Several software development methodologies have emerged over the past 20 or so years. Each has its own characteristics, pros, cons, SDLC phases, and best use-case scenarios. While some methodologies include security issues in certain phases, these are not considered “security-centric development methodologies.” These are classical approaches to building and developing software. A brief discussion of some of the methodologies that have been used over the years is presented next.

EXAM TIP It is exceptionally rare to see a development methodology used in its pure form in the real world. Instead, organizations will start with a base methodology and modify it to suit their own unique environment. For purposes of the CISSP exam, however, you should focus on what differentiates each development approach.
Waterfall Methodology
The Waterfall methodology uses a linear-sequential life-cycle approach, illustrated in Figure 8-7. Each phase must be completed in its entirety before the next phase can begin. At the end of each phase, a review takes place to make sure the project is on the correct path and should continue.
In this methodology all requirements are gathered in the initial phase and there is no formal way to integrate changes as more information becomes available or requirements change. It is hard to know everything at the beginning of a project, so waiting until the whole project is complete to integrate necessary changes can be ineffective and time consuming. As an analogy, let’s say that you are planning to landscape your backyard that is one acre in size. In this scenario, you can only go to the gardening store one time to get all of your supplies. If you identify that you need more topsoil, rocks, or pipe for the sprinkler system, you have to wait and complete the whole yard before you can return to the store for extra or more suitable supplies.
This is a very rigid approach that could be useful for smaller projects that have all of the requirements fully understood, but it is a dangerous methodology for complex projects, which commonly contain many variables that affect the scope as the project continues.
V-Shaped Methodology
The V-shaped methodology was developed after the Waterfall methodology. Instead of following a flat linear approach in the software development processes, it follows steps that are laid out in a V format, as shown in Figure 8-8. This methodology emphasizes the verification and validation of the product at each phase and provides a formal method of developing testing plans as each coding phase is executed.

Figure 8-7 Waterfall methodology used for software development

Figure 8-8 V-shaped methodology
Just like the Waterfall methodology, the V-shaped methodology lays out a sequential path of execution processes. Each phase must be completed before the next phase begins. But because the V-shaped methodology requires testing throughout the development phases and not just waiting until the end of the project, it has a higher chance of success compared to the Waterfall methodology.
The V-shaped methodology is still very rigid, as is the Waterfall one. This level of rigidness does not allow for much flexibility; thus, adapting to changes is more difficult and expensive. This methodology does not allow for the handling of events concurrently, it does not integrate iterations of phases, and it does not contain risk analysis activities as later methodologies do. This methodology is best used when all requirements can be understood up front and potential scope changes are small.
Prototyping
A prototype is a sample of software code or a model that can be developed to explore a specific approach to a problem before investing expensive time and resources. A team can identify the usability and design problems while working with a prototype and adjust their approach as necessary. Within the software development industry three main prototype models have been invented and used. These are the rapid prototype, evolutionary prototype, and operational prototype.
Rapid prototyping is an approach that allows the development team to quickly create a prototype (sample) to test the validity of the current understanding of the project requirements. In a software development project, the team could quickly develop a prototype to see if their ideas are feasible and if they should move forward with their current solution. The rapid prototype approach (also called throwaway) is a “quick and dirty” method of creating a piece of code and seeing if everyone is on the right path or if another solution should be developed. The rapid prototype is not developed to be built upon, but to be discarded after serving its purposes.
When evolutionary prototypes are developed, they are built with the goal of incremental improvement. Instead of being discarded after being developed, as in the rapid prototype approach, the prototype in this model is continually improved upon until it reaches the final product stage. Feedback that is gained through each development phase is used to improve the prototype and get closer to accomplishing the customer’s needs.
The operational prototypes are an extension of the evolutionary prototype method. Both models (operational and evolutionary) improve the quality of the prototype as more data is gathered, but the operational prototype is designed to be implemented within a production environment as it is being tweaked. The operational prototype is updated as customer feedback is gathered, and the changes to the software happen within the working site.
So the rapid prototype is developed to give a quick understanding of the suggested solution, the evolutionary prototype is created and improved upon within a lab environment, and an operational prototype is developed and improved upon within a production environment.
Incremental Methodology
If a development team follows the Incremental methodology, this allows them to carry out multiple development cycles on a piece of software throughout its development stages. This would be similar to “multi-Waterfall” cycles taking place on one piece of software as it matures through the development stages. A version of the software is created in the first iteration and then it passes through each phase (requirements analysis, design, coding, testing, implementation) of the next iteration process. The software continues through the iteration of phases until a satisfactory product is produced. This methodology is illustrated in Figure 8-9.
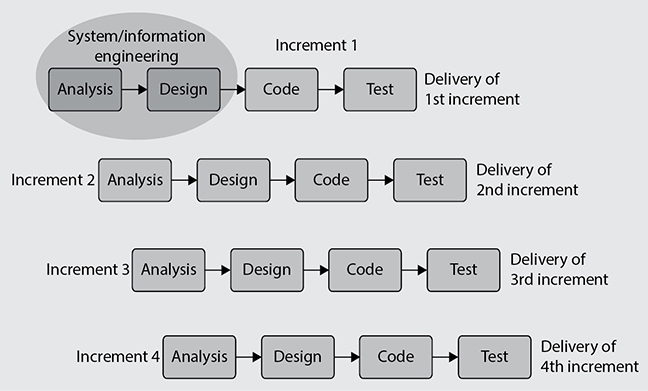
Figure 8-9 Incremental development methodology
When using the Incremental methodology, each incremental phase results in a deliverable that is an operational product. This means that a working version of the software is produced after the first iteration and that version is improved upon in each of the subsequent iterations. Some benefits to this methodology are that a working piece of software is available in early stages of development, the flexibility of the methodology allows for changes to take place, testing uncovers issues more quickly than the Waterfall methodology since testing takes place after each iteration, and each iteration is an easily manageable milestone.
Since each release delivers an operational product, the customer can respond to each build and help the development team in its improvement processes. Since the initial product is delivered more quickly compared to other methodologies, the initial product delivery costs are lower, the customer gets its functionality earlier, and the risks of critical changes being introduced are lower.
This methodology is best used when issues pertaining to risk, program complexity, funding, and functionality requirements need to be understood early in the product development cycle. If a vendor needs to get the customer some basic functionality quickly as it works on the development of the product, this can be a good methodology to follow.
Spiral Methodology
The Spiral methodology uses an iterative approach to software development and places emphasis on risk analysis. The methodology is made up of four main phases: determine objectives, risk analysis, development and test, and plan the next iteration. The development team starts with the initial requirements and goes through each of these phases, as shown in Figure 8-10. Think about starting a software development project at the center of this graphic. You have your initial understanding and requirements of the project, develop specifications that map to these requirements, carry out a risk analysis, build prototype specifications, test your specifications, build a development plan, integrate newly discovered information, use the new information to carry out a new risk analysis, create a prototype, test the prototype, integrate resulting data into the process, etc. As you gather more information about the project, you integrate it into the risk analysis process, improve your prototype, test the prototype, and add more granularity to each step until you have a completed product.
The iterative approach provided by the Spiral methodology allows new requirements to be addressed as they are uncovered. Each prototype allows for testing to take place early in the development project, and feedback based upon these tests is integrated into the following iteration of steps. The risk analysis ensures that all issues are actively reviewed and analyzed so that things do not “slip through the cracks” and the project stays on track.
In the Spiral methodology the last phase allows the customer to evaluate the product in its current state and provide feedback, which is an input value for the next spiral of activity. This is a good methodology for complex projects that have fluid requirements.
NOTE Within this methodology the angular aspect represents progress and the radius of the spirals represents cost.

Figure 8-10 Spiral methodology for software development
Rapid Application Development
The Rapid Application Development (RAD) methodology relies more on the use of rapid prototyping than on extensive upfront planning. In this methodology, the planning of how to improve the software is interleaved with the processes of developing the software, which allows for software to be developed quickly. The delivery of a workable piece of software can take place in less than half the time compared to the Waterfall methodology. The RAD methodology combines the use of prototyping and iterative development procedures with the goal of accelerating the software development process. The development process begins with creating data models and business process models to help define what the end-result software needs to accomplish. Through the use of prototyping, these data and process models are refined. These models provide input to allow for the improvement of the prototype, and the testing and evaluation of the prototype allow for the improvement of the data and process models. The goal of these steps is to combine business requirements and technical design statements, which provide the direction in the software development project.
Figure 8-11 illustrates the basic differences between traditional software development approaches and RAD. As an analogy, let’s say that the development team needs you to tell them what it is you want so that they can build it for you. You tell them that the thing you want has four wheels and an engine. They draw a picture of a two-seat convertible on a piece of paper and ask, “Is this what you want?” You say no, so they throw away that piece of paper (prototype). They ask for more information from you, and you tell them the thing must be able to seat four adults. They draw a picture of a four-seat convertible and show it to you and you tell them they are getting closer, but are still wrong. They throw away that piece of paper, and you tell them the thing must have four doors. They draw a picture of a sedan, and you nod your head in agreement. That back and forth is what is taking place in the circle portion of Figure 8-11.
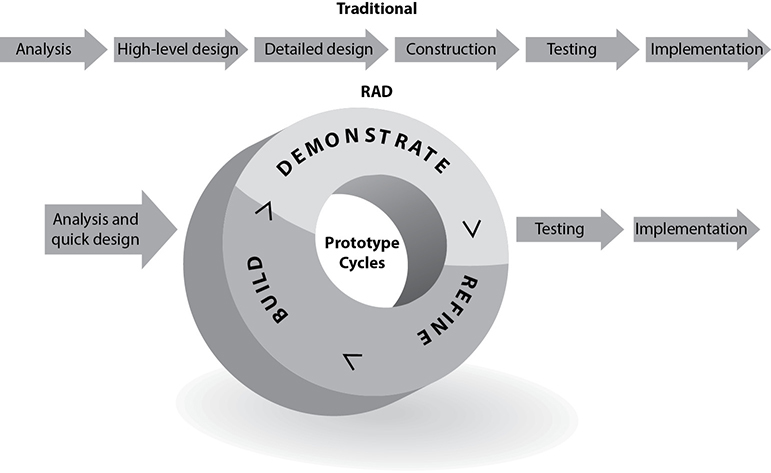
Figure 8-11 Rapid Application Development methodology
The main reason that RAD was developed was that by the time software was completely developed following other methodologies, the requirements changed and the developers had to “go back to the drawing board.” If a customer needs you to develop a software product and it takes you a year to do so, by the end of that year the customer’s needs for the software have probably advanced and changed. The RAD methodology allows for the customer to be involved during the development phases so that the end result maps to their needs in a more realistic manner.
Agile Methodologies
The industry seems to be full of software development methodologies, each trying to improve upon the deficiencies of the ones before it. Before the Agile approach to development was created, teams were following rigid process-oriented methodologies. These approaches focused more on following procedures and steps instead of potentially carrying out tasks in a more efficient manner. As an analogy, if you have ever worked within or interacted with a large government agency, you may have come across silly processes that took too long and involved too many steps. If you are a government employee and need to purchase a new chair, you might have to fill out four sets of documents that need to be approved by three other departments. You probably have to identify three different chair vendors, who have to submit a quote, which goes through the contracting office. It might take you a few months to get your new chair. The focus is to follow a protocol and rules instead of efficiency.
Many of the classical software development approaches, as in Waterfall, provide rigid processes to follow that do not allow for much flexibility and adaptability. Commonly, the software development projects that follow these approaches end up failing by not meeting schedule time release, running over budget, and/or not meeting the needs of the customer. Sometimes you need the freedom to modify steps to best meet the situation’s needs.
The Agile methodology is an umbrella term for several development methodologies. It focuses not on rigid, linear, stepwise processes, but instead on incremental and iterative development methods that promote cross-functional teamwork and continuous feedback mechanisms. This methodology is considered “lightweight” compared to the traditional methodologies that are “heavyweight,” which just means this methodology is not confined to a tunneled vision and overly structured approach. It is nimble and flexible enough to adapt to each project’s needs. The industry found out that even an exhaustive library of defined processes cannot handle every situation that could arise during a development project. So instead of investing time and resources into big upfront design analysis, this methodology focuses on small increments of functional code that are created based upon business need.
These methodologies focus on individual interaction instead of processes and tools. They emphasize developing the right software product over comprehensive and laborious documentation. They promote customer collaboration instead of contract negotiation, and abilities to respond to change instead of strictly following a plan.
A notable element of many Agile methodologies is their focus on user stories. A user story is a sentence that describes what a user wants to do and why. For instance, a user story could be “As a customer, I want to search for products so that I can buy some.” Notice the structure of the story is: As a <user role>, I want to <accomplish some goal> so that <reason for accomplishing the goal>. This method of documenting user requirements is very familiar to the customers and enables their close collaboration with the development team. Furthermore, by keeping this user focus, validation of the features is simpler because the “right system” is described up front by the users in their own words.
EXAM TIP The Agile methodologies do not use prototypes to represent the full product, but break the product down into individual features that are continuously being delivered.
Another important characteristic of the Agile methodologies is that the development team can take pieces and parts of all of the available SDLC methodologies and combine them in a manner that best meets the specific project needs. These various combinations have resulted in many methodologies that fall under the Agile umbrella.
Scrum
Scrum is one of the most widely adopted Agile methodologies in use today. It lends itself to projects of any size and complexity and is very lean and customer focused. Scrum is a methodology that acknowledges the fact that customer needs cannot be completely understood and will change over time. It focuses on team collaboration, customer involvement, and continuous delivery.
The term scrum originates from the sport of rugby. Whenever something interrupts play (e.g., a penalty or the ball goes out of bounds) and the game needs to be restarted, all players come together in an organized mob that is resolved when one team or the other gains possession of the ball, allowing the game to continue. Extending this analogy, the Scrum methodology allows the project to be reset by allowing product features to be added, changed, or removed at clearly defined points. Since the customer is intimately involved in the development process, there should be no surprises, cost overruns, or schedule delays. This allows a product to be iteratively developed and changed even as it is being built.
The change points happen at the conclusion of each sprint, a fixed-duration development interval that is usually (but not always) two weeks in length and promises delivery of a very specific set of features. These features are chosen by the team, but with a lot of input from the customer. There is a process for adding features at any time by inserting them in the feature backlog. However, these features can be considered for actual work only at the beginning of a new sprint. This shields the development team from changes during a sprint, but allows for them in between sprints.
Extreme Programming
If you take away the regularity of Scrum’s sprints and backlogs and add a lot of code reviewing, you get our next Agile methodology. Extreme Programming (XP) is a development methodology that takes code reviews (discussed in Chapter 6) to the extreme (hence the name) by having them take place continuously. These continuous reviews are accomplished using an approach called pair programming, in which one programmer dictates the code to her partner, who then types it. While this may seem inefficient, it allows two pairs of eyes to constantly examine the code as it is being typed. It turns out that this approach significantly reduces the incidence of errors and improves the overall quality of the code.
Another characteristic of XP is its reliance on test-driven development, in which the unit tests are written before the code. The programmer first writes a new unit test case, which of course fails because there is no code to satisfy it. The next step is to add just enough code to get the test to pass. Once this is done, the next test is written, which fails, and so on. The consequence is that only the minimal amount of code needed to pass the tests is developed. This extremely minimal approach reduces the incidence of errors because it weeds out complexity.
Kanban
Kanban is a production scheduling system developed by Toyota to more efficiently support just-in-time delivery. Over time, it was adopted by IT and software systems developers. In this context, the Kanban development methodology is one that stresses visual tracking of all tasks so that the team knows what to prioritize at what point in time in order to deliver the right features right on time. Kanban projects used to be very noticeable because entire walls in conference rooms would be covered in sticky notes representing the various tasks that the team was tracking. Nowadays, many Kanban teams opt for virtual walls on online systems.
The Kanban wall is usually divided vertically by production phase. Typical columns are labeled Planned, In Progress, and Done. Each sticky note can represent a user story as it moves through the development process, but more importantly, the sticky note can also be some other work that needs to be accomplished. For instance, suppose that one of the user stories is the search feature described earlier in this section. While it is being developed, the team realizes that the searches are very slow. This could result in a task being added to change the underlying data or network architecture or to upgrade hardware. This sticky note then gets added to the Planned column and starts being prioritized and tracked together with the rest of the remaining tasks. This process highlights how Kanban allows the project team to react to changing or unknown requirements, which is a common feature among all Agile methodologies.
Other Methodologies
There seems to be no shortage of SDLC and software development methodologies in the industry. The following is a quick summary of a few others that can also be used:
• Exploratory methodology A methodology that is used in instances where clearly defined project objectives have not been presented. Instead of focusing on explicit tasks, the exploratory methodology relies on covering a set of specifications likely to affect the final product’s functionality. Testing is an important part of exploratory development, as it ascertains that the current phase of the project is compliant with likely implementation scenarios.
• Joint Application Development (JAD) A methodology that uses a team approach in application development in a workshop-oriented environment. This methodology is distinguished by its inclusion of members other than coders in the team. It is common to find executive sponsors, subject matter experts, and end users spending hours or days in collaborative development workshops.
• Reuse methodology A methodology that approaches software development by using progressively developed code. Reusable programs are evolved by gradually modifying pre-existing prototypes to customer specifications. Since the reuse methodology does not require programs to be built from scratch, it drastically reduces both development cost and time.
• Cleanroom An approach that attempts to prevent errors or mistakes by following structured and formal methods of developing and testing. This approach is used for high-quality and mission-critical applications that will be put through a strict certification process.
We only covered the most commonly used methodologies in this section, but there are many more that exist. New methodologies have evolved as technology and research have advanced and various weaknesses of older approaches have been addressed. Most of the methodologies exist to meet a specific software development need, and choosing the wrong approach for a certain project could be devastating to its overall success.
Integrated Product Team
An integrated product team (IPT) is a multidisciplinary development team with representatives from many or all the stakeholder populations. The idea makes a lot of sense when you think about it. Why should programmers learn or guess the manner in which the accounting folks handle accounts payable? Why should testers and quality control personnel wait until a product is finished before examining it? Why should the marketing team wait until the project (or at least the prototype) is finished before determining how best to sell it? A comprehensive IPT includes business executives and end users and everyone in between.
The Joint Application Development (JAD) methodology, in which users join developers during extensive workshops, works well with the IPT approach. IPTs extend this concept by ensuring that the right stakeholders are represented in every phase of the development as formal team members. In addition, whereas JAD is focused on involving the user community, IPT is typically more inward facing and focuses on bringing in the business stakeholders.
An IPT is not a development methodology. Instead, it is a management technique. When project managers decide to use IPTs, they still have to select a methodology. These days, IPTs are often associated with Agile methodologies.
DevOps
Traditionally, the software development team and the IT team are two separate (and sometimes antagonistic) groups within an organization. Many problems stem from poor collaboration between these two teams during the development process. It is not rare to have the IT team berating the developers because a feature push causes the IT team to have to stay late or work on a weekend or simply drop everything they were doing in order to “fix” something that the developers “broke.” This friction makes a lot of sense when you consider that each team is incentivized by different outcomes. Developers want to push out finished code, usually under strict schedules. The IT staff, on the other hand, wants to keep the IT infrastructure operating effectively. Many project managers who have managed software development efforts will attest to having received complaints from developers that the IT team was being unreasonable and uncooperative, while the IT team was simultaneously complaining about buggy code being tossed over the fence at them at the worst possible times and causing problems on the rest of the network.
A good way to solve this friction is to have both developers and members of the operations staff (hence the term DevOps) on the software development team. DevOps is the practice of incorporating development, IT, and quality assurance (QA) staff into software development projects to align their incentives and enable frequent, efficient, and reliable releases of software products. This relationship is illustrated in Figure 8-12.
Ultimately, DevOps is about changing the culture of an organization. It has a huge positive impact on security, because in addition to QA, the IT teammates will be involved at every step of the process. Multifunctional integration allows the team to identify potential defects, vulnerabilities, and friction points early enough to resolve them proactively. This is one of the biggest selling points for DevOps. According to multiple surveys, there are a few other, perhaps more powerful benefits: DevOps increases trust within an organization and increases job satisfaction among developers, IT staff, and QA personnel. Unsurprisingly, it also improves the morale of project managers.

Figure 8-12 DevOps exists at the intersection of software development, IT, and QA.
Capability Maturity Model Integration
Capability Maturity Model Integration (CMMI) is a comprehensive, integrated set of guidelines for developing products and software. It addresses the different phases of a software development life cycle, including concept definition, requirements analysis, design, development, integration, installation, operations, and maintenance, and what should happen in each phase. It can be used to evaluate security engineering practices and identify ways to improve them. It can also be used by customers in the evaluation process of a software vendor. Ideally, software vendors would use the model to help improve their processes, and customers would use the model to assess the vendors’ practices.
CMMI describes procedures, principles, and practices that underlie software development process maturity. This model was developed to help software vendors improve their development processes by providing an evolutionary path from an ad hoc “fly by the seat of your pants” approach to a more disciplined and repeatable method that improves software quality, reduces the life cycle of development, provides better project management capabilities, allows for milestones to be created and met in a timely manner, and takes a more proactive approach than the less effective reactive approach. It provides best practices to allow an organization to develop a standardized approach to software development that can be used across many different groups. The goal is to continue to review and improve upon the processes to optimize output, increase capabilities, and provide higher-quality software at a lower cost through the implementation of continuous improvement steps.
If the company Stuff-R-Us wants a software development company, Software-R-Us, to develop an application for it, it can choose to buy into the sales hype about how wonderful Software-R-Us is, or it can ask Software-R-Us whether it has been evaluated against the CMMI model. Third-party companies evaluate software development companies to certify their product development processes. Many software companies have this evaluation done so they can use this as a selling point to attract new customers and provide confidence for their current customers.
The five maturity levels of the CMMI model are
• Initial Development process is ad hoc or even chaotic. The company does not use effective management procedures and plans. There is no assurance of consistency, and quality is unpredictable. Success is usually the result of individual heroics.
• Repeatable A formal management structure, change control, and quality assurance are in place. The company can properly repeat processes throughout each project. The company does not have formal process models defined.
• Defined Formal procedures are in place that outline and define processes carried out in each project. The organization has a way to allow for quantitative process improvement.
• Managed The company has formal processes in place to collect and analyze quantitative data, and metrics are defined and fed into the process-improvement program.
• Optimizing The company has budgeted and integrated plans for continuous process improvement.
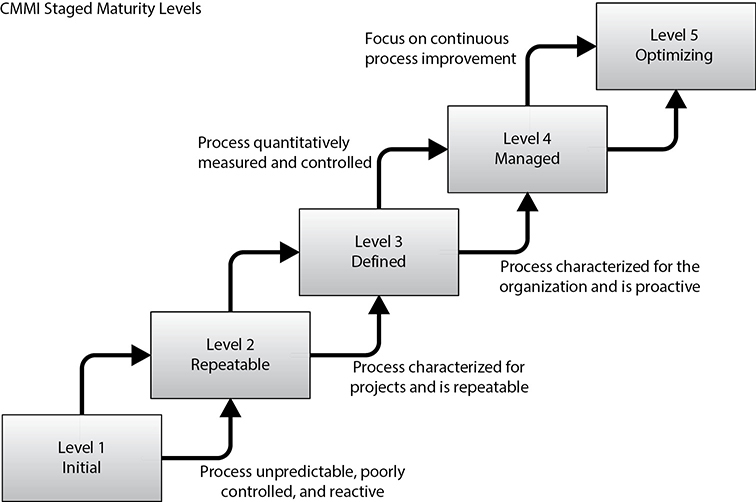
Each level builds upon the previous one. For example, a company that accomplishes a Level 5 CMMI rating must meet all the requirements outlined in Levels 1–4 along with the requirements of Level 5.
If a software development vendor is using the Prototyping methodology that was discussed earlier in this chapter, the vendor would most likely only achieve a CMMI Level 1, particularly if their practices are ad hoc, not consistent, and the level of the quality that their software products contain is questionable. If this company practiced a strict Agile SDLC methodology consistently and carried out development, testing, and documentation precisely, they would have a higher chance of obtaining a higher CMMI level.
Capability maturity models (CMMs) are used for many different purposes, software development processes being one of them. They are general models that allow for maturity-level identification and maturity improvement steps. We showed how CMM integration can be used for organizational security program improvement processes in Chapter 1.
The software industry ended up with several different CMMs, which led to confusion. CMMI was developed to bring many of these different maturity models together and allow them to be used in one framework. CMMI was developed by industry experts, government entities, and the Software Engineering Institute at Carnegie Mellon University. So CMMI has replaced CMM in the software engineering world, but you may still see CMM referred to within the industry and even on the CISSP exam. Their ultimate goals are the same, which is process improvement.
NOTE The CMMI is continually being updated and improved upon. The latest copy can be viewed at https://resources.sei.cmu.edu/library/.
Change Management
One of the key processes on which to focus for improvement involves how we deal with the inevitable changes. These can cause a lot of havoc if not managed properly and in a deliberate manner. Changes could take place for several reasons. During the development phases, a customer may alter requirements and ask that certain functionalities be added, removed, or modified. In production, changes may need to happen because of other changes in the environment, new requirements of a software product or system, or newly released patches or upgrades. These changes should be carefully analyzed, approved, and properly incorporated such that they do not affect any original functionality in an adverse way.
Change management is a systematic approach to deliberately regulating the changing nature of projects, including software development projects. It is a management process that takes into account not just the technical issues, but also resources (like people and money), project life cycle, and even organizational climate. Many times, the hardest part of managing change is not the change itself, but the effects it has in the organization. Many of us have been on the receiving end of a late-afternoon phone call in which we’re told to change our plans because of a change in a project on which we weren’t even working. An important part of change management is controlling change.
Change Control
Change control is the process of controlling the specific changes that take place during the life cycle of a system and documenting the necessary change control activities. The change must be approved, documented, and tested. Some tests may need to be rerun to ensure the change does not affect the product’s capabilities. When a programmer makes a change to source code, it should be done on the test version of the code. Under no conditions should a programmer change the code that is already in production. The changes to the code should be made and tested, and then the new code should go to the librarian. Production code should come only from the librarian and not from a programmer or directly from a test environment.
A process for dealing with changes needs to be in place at the beginning of a project so everyone knows how changes are dealt with and what is expected of each entity when a change request is made. Some projects have been doomed from the start because proper change control was not put into place and enforced. Many times in development, the customer and vendor agree on the design of the product, the requirements, and the specifications. The customer is then required to sign a contract confirming this is the agreement and that if they want any further modifications, they will have to pay the vendor for that extra work. If this is not put into place, then the customer can continually request changes, which requires the development team to put in the extra hours to provide these changes, the result of which is that the vendor loses money, the product does not meet its completion deadline, and scope creep occurs.
Other reasons exist to have change control in place. These reasons deal with organization, standard procedures, and expected results. If a product is in the last phase of development and a change request comes in, the team should know how to deal with it. Usually, the team leader must tell the project manager how much extra time will be required to complete the project if this change is incorporated and what steps need to be taken to ensure this change does not affect other components within the product. If these processes are not controlled, one part of a development team could implement the change without another part of the team being aware of it. This could break some of the other development team’s software pieces. When the pieces of the product are integrated and it is found that some pieces are incompatible, some jobs may be in jeopardy, because management never approved the change in the first place.
Change control processes should be evaluated during system audits. It is possible to overlook a problem that a change has caused in testing, so the procedures for how change control is implemented and enforced should be examined during a system audit.
The following are some necessary steps for a change control process:
1. Make a formal request for a change.
2. Analyze the request.
a. Develop the implementation strategy.
b. Calculate the costs of this implementation.
c. Review security implications.
3. Record the change request.
4. Submit the change request for approval.
5. Develop the change.
a. Recode segments of the product and add or subtract functionality.
b. Link these changes in the code to the formal change control request.
c. Submit software for testing and quality control.
d. Repeat until quality is adequate.
e. Make version changes.
6. Report results to management.
The changes to systems may require another round of certification and accreditation. If the changes to a system are significant, then the functionality and level of protection may need to be reevaluated (certified), and management would have to approve the overall system, including the new changes (accreditation).
EXAM TIP Change control is part of change management.
Security of Development Environments
By now, you should have a pretty good idea of the software development life cycle. But how do you ensure that the environments in which software is developed are secure? As you should know by now, there is no one silver bullet that will work in every case. Still, there are three major elements we should stress when it comes to security of development environments: the development platforms, the code repositories, and the software configurations.
Security of Development Platforms
Software is normally developed by a team of software engineers who may or may not use the same tools. The most important tool in their tool set is the Integrated Development Environment (IDE). An IDE allows the engineer to pull code from a repository (more on that later), edit it, test it, and then push it into the repository so the rest of the team can build on it. Depending on the programming language, target environments, and a host of other considerations, your developers may use Eclipse, Microsoft Visual Studio, Xcode, or various other applications. The software they develop will likely be tested (formally or otherwise) using development clients and servers that are supposed to represent the production platforms on which the finished software product will run. When we talk about security of the development platforms, therefore, we mean both the development endpoints and the “fake” clients and servers on which the software gets tested.
It may seem obvious, but the first step in ensuring the security of development platforms is to secure the devices on which our software engineers practice their craft. The challenge that many organizations face is that their engineers tend to be more sophisticated than the average user and will make changes to their computers that may or may not be authorized. Their principal incentive, after all, is to develop code quickly and correctly. If the configuration of their workstation gets in the way, it may find itself being modified. In order to avoid this, you should resist the temptation of giving your software engineers unfettered privileged access to their own devices. Enforcing good change management practices is critical to securing these development endpoints.
Even harder than ensuring change controls on your developers’ workstations is securely provisioning the development clients and servers that they will need for testing. Many organizations allow their developers to stand up and maintain their own development environment, which is fine provided that these devices are isolated from the production environments. It may sound like common sense, but the problem is that some organizations don’t do a good enough job at isolating development and productions systems. In principle, all it takes is to put the development nodes in an isolated virtual local area network (VLAN). In practice, the demarcation is not that cut and dry. This gets even more challenging when the team is distributed, which requires your developers (or perhaps their external collaborators) to remotely access the development hosts. The best solution is to require a VPN to connect to the isolated development network. It creates a lot of work for the operations staff but is the only way to ensure that development and production code remains separate. Another good approach is to create firewall rules that prevent any external connections to or from development servers. It should be clear by now that the provisioning of hosts on the development network should not be left to the software development team.
Security of Code Repositories
The code repository, which is typically a version control system, is the vault containing the crown jewels of any organization involved in software development. If we put on our adversarial hats for a few minutes, we could come up with all kinds of nefarious scenarios involving these repositories. Perhaps the simplest is that someone could steal our source code, which embodies not only many staff hours of work but, more significantly, our intellectual property. An adversary could also use our source code to look for vulnerabilities to exploit later, once the code is in production. Finally, adversaries could deliberately insert vulnerabilities into our software, perhaps after it has undergone all testing and is trusted, so that it can be exploited later at a time of their choosing. Clearly, securing our source code is critical.
Perhaps the most secure way of managing security for your code repositories is to implement them on an isolated (or “air-gaped”) network that includes the development, test, and QA environments. The development team would have to be on this network to do their work, and the code, once verified, could be exported to the production servers using removable storage media. We already presented this best practice in the preceding section. The challenge with this approach is that it severely limits the manner in which the development team can connect to the code. It also makes it difficult to collaborate with external parties, and for developers to work from remote or mobile locations.
A pretty good alternative would be to host the repository on the intranet, which would require developers to either be on the local network or connect to it using a VPN connection. As an added layer of security, the repositories can be configured to require the use of Secure Shell (SSH), which would ensure all traffic is encrypted even inside the intranet to mitigate the risk of sniffing. Finally, SSH can be configured to use public key infrastructure (PKI), which allows us to implement not only confidentiality and integrity, but also nonrepudiation. If you have to allow remote access to your repository, this would be a good way to go about it.
Finally, if you are operating on a limited budget or have limited security expertise in this area, you can choose one of the many web-based repository service providers and let them take care of the security for you. While this may mitigate the basic risks for small organizations, it is probably not an acceptable course of action for projects with significant investments of intellectual property.
Software Configuration Management
When changes take place to a software product during its development life cycle, a configuration management system can be put into place that allows for change control processes to take place through automation. Since deploying an insecure configuration to an otherwise secure software product makes the whole thing insecure, these settings are a critical component of securing the software development environment. A product that provides software configuration management (SCM) identifies the attributes of software at various points in time, and performs a methodical control of changes for the purpose of maintaining software integrity and traceability throughout the software development life cycle. It defines the need to track changes and provides the ability to verify that the final delivered software has all of the approved changes that are supposed to be included in the release.
During a software development project, the centralized code repositories are often kept in systems that can carry out SCM functionality, which manage and track revisions made by multiple people against a single master set. These SCM systems should provide concurrency management, versioning, and synchronization. Concurrency management deals with the issues that arise when multiple people extract the same file from a central repository and make their own individual changes. If they submit their updated files in an uncontrolled manner, the files would just write over each other and changes would be lost. Many SCM systems use algorithms to version, fork, and merge the changes as files are checked back into the repository.
Versioning deals with keeping track of file revisions, which makes it possible to “roll back” to a previous version of the file. An archive copy of every file can be made when it is checked into the repository, or every change made to a file can be saved to a transaction log. Versioning systems should also create log reports of who made changes, when they were made, and what the changes were.
Some SCM systems allow individuals to check out complete or partial copies of the repositories and work on the files as needed. They can then commit their changes back to the master repository as needed, and update their own personal copies to stay up to date with changes other people have made. This process is called synchronization.
Secure Coding
Secure coding is the process of developing software that is free from defects, particularly those that could be exploited by an adversary to cause us harm or loss. While this may not be possible in large project, it is still the standard to which we should all aspire.
Source Code Vulnerabilities
The Open Web Application Security Project (OWASP) is an organization that deals specifically with web security issues. Along with a long list of tools, articles, and resources that developers can exploit to create secure software, OWASP also has individual member meetings (chapters) throughout the world. The group provides development guidelines, testing procedures, and code review steps, but is probably best known for its OWASP Top 10 list of web application security risks that it maintains. The following is the most recent Top 10 list as of this writing, from 2017:
• A1: Injection
• A2: Broken Authentication
• A3: Sensitive Data Exposure
• A4: XML External Entities
• A5: Broken Access Control
• A6: Security Misconfiguration
• A7: Cross-Site Scripting (XSS)
• A8: Insecure Deserialization
• A9: Using Components with Known Vulnerabilities
• A10: Insufficient Logging & Monitoring
This list represents the most common vulnerabilities that reside in web-based software and are exploited most often. You can find out more information pertaining to these vulnerabilities at https://www.owasp.org/index.php/Category:OWASP_Top_Ten_Project.
Secure Coding Practices
As always seems to be the case in the technology world, we exist without standards and best practices for many years and just develop technology as the needs and desires arise. We create things in an ad hoc manner with no great overall vision of how they will integrate or interoperate. Once we create a whole bunch of things in this crazy manner, the industry has a collective thought of, “Hey, we should carry out these activities in a structured and controlled manner.” Then we have several organizations that come up with very similar standards and best practices to meet this void. Then we have too many standards and guidelines, and as the years march by the best ones usually prove their worth and the others fade in existence.
One of the organizations that consistently produces good coding standards is Carnegie Mellon University’s Software Engineering Institute (SEI). SEI’s top 10 secure coding practices are listed here along with our brief take on them:
1. Validate inputs. The most important rule of secure coding is to never ever trust your inputs.
2. Heed compiler warnings. Many developers tend to ignore compiler warnings unless they are forced to address them by either automated testing scripts or strictly enforced coding standards.
3. Architect and design for security policies. Rather than develop software in a policy vacuum, our software teams should build their systems to comply with the policies in the environment within which they’ll operate.
4. Keep it simple. Refactoring code to ensure it is as simple as possible yields huge security payoffs. This is best enforced through regular code reviews.
5. Default deny. Unless explicitly required to allow requests, our software systems should deny all.
6. Adhere to the principle of least privilege. Every process should run with the minimum set of privileges possible. If these need to be elevated, this should only happen for long enough to get the job done, then they should be dropped again.
7. Sanitize data sent to other systems. This is the other half of the first principle: though we don’t trust our inputs, we do our best to ensure our outputs can do no harm.
8. Practice defense in depth. Assume that any given layer will fail to operate securely and ensure that its neighboring layers can account for this.
9. Use effective quality assurance techniques. As we have mentioned before, quality code is free of defects and thus vulnerabilities. It may be a tall order to do this all the time, but we should set high but realistic standards.
10. Adopt a secure coding standard. Setting standards and holding people accountable enables all the other practices we’ve highlighted here.
We also have the ISO/IEC standards, covered in Chapter 1, for secure coding guidance. The ISO/IEC 27034 standard covers the following application security areas: overview and concepts (Part 1); organization normative framework (Part 2); application security management process (Part 3); protocols and application security controls data structure (Part 5); case studies (Part 6); and assurance prediction framework (Part 7). Part 4 has not been published yet. ISO/IEC 27034 is part of the ISO/IEC 27000 series, which facilitates aligning the secure software development processes with ISO/IEC’s information security management system (ISMS) model.
Programming Languages and Concepts
All software is written in some type of programming language. Programming languages have gone through several generations over time, each generation building on the next, providing richer functionality and giving the programmers more powerful tools as they evolve.
The main categories of languages are machine language, assembly language, and high-level languages. Machine language is in a format that the computer’s processor can understand and work with directly. Every processor family has its own machine code instruction set, as we covered in Chapter 3. Machine code is represented in a binary format (1 and 0) and is considered to be the most primitive form of programming language and the first generation of programming languages. Machine languages were used as the sole method of programming in the early 1950s. Early computers used only basic binary instructions because compilers and interpreters were nonexistent at the time. Programmers had to manually calculate and allot memory addresses and instructions had to be sequentially fed, as there was no concept of abstraction. Not only was programming in binary extremely time consuming, it was also highly prone to errors. (If you think about writing out thousands of 1’s and 0’s to represent what you want a computer to do, this puts this approach into perspective.) This forced programmers to keep a tight rein on their program lengths, resulting in programs that were very rudimentary.
An assembly language is considered a low-level programming language and is the symbolic representation of machine-level instructions. It is “one step above” machine language. It uses symbols (called mnemonics) to represent complicated binary codes. Programmers using assembly language could use commands like ADD, PUSH, POP, etc., instead of the binary codes (1001011010, etc.). Assembly languages use programs called assemblers, which automatically convert these assembly codes into the necessary machine-compatible binary language. To their credit, assembly languages drastically reduced programming and debugging times, introduced the concept of variables, and freed programmers from manually calculating memory addresses. But like machine code, programming in an assembly language requires extensive knowledge of a computer’s architecture. It is easier than programming in binary format, but more challenging compared to the high-level languages most programmers use today.
Programs written in assembly language are also hardware specific, so a program written for an ARM-based processor would be incompatible with Intel-based systems; thus, these types of languages are not portable.
NOTE Assembly language allows for direct control of very basic activities within a computer system, as in pushing data on a memory stack and popping data off a stack. Attackers commonly use these languages to tightly control how malicious instructions are carried out on victim systems.
The third generation of programming languages started to emerge in the early 1960s. Third-generation programming languages are known as high-level languages due to their refined programming structures. High-level languages use abstract statements. Abstraction naturalized multiple assembly language instructions into a single high-level statement, e.g., the IF – THEN – ELSE. This allowed programmers to leave low-level (system architecture) intricacies to the programming language and focus on their programming objectives. In addition, high-level languages are easier to work with compared to machine and assembly languages, as their syntax is similar to human languages. The use of mathematical operators also simplified arithmetic and logical operations. This drastically reduced program development time and allowed for more simplified debugging. This means the programs are easier to write and mistakes (bugs) are easier to identify. High-level languages are processor independent. Code written in a high-level language can be converted to machine language for different processor architectures using compilers and interpreters. When code is independent of a specific processor type, the programs are portable and can be used on many different system types.
Fourth-generation languages (very high-level languages) were designed to further enhance the natural language approach instigated within the third-generation language. Fourth-generation languages are meant to take natural language–based statements one step further. Fourth-generation programming languages focus on highly abstract algorithms that allow straightforward programming implementation in specific environments. The most remarkable aspect of fourth-generation languages is that the amount of manual coding required to perform a specific task may be ten times less than for the same task on a third-generation language. This is especially important as these languages have been developed to be used by inexpert users and not just professional programmers.
As an analogy, let’s say that you need to pass a calculus exam. You need to be very focused on memorizing the necessary formulas and applying the formulas to the correct word problems on the test. Your focus is on how calculus works, not on how the calculator you use as a tool works. If you had to understand how your calculator is moving data from one transistor to the other, how the circuitry works, and how the calculator stores and carries out its processing activities just to use it for your test, this would be overwhelming. The same is true for computer programmers. If they had to worry about how the operating system carries out memory management functions, input/output activities, and how processor-based registers are being used, it would be difficult for them to also focus on real-world problems they are trying to solve with their software. High-level languages hide all of this background complexity and take care of it for the programmer.
The early 1990s saw the conception of the fifth generation of programming languages (natural languages). These languages approach programming from a completely different perspective. Program creation does not happen through defining algorithms and function statements, but rather by defining the constraints for achieving a specified result. The goal is to create software that can solve problems by itself instead of a programmer having to develop code to deal with individual and specific problems. The applications work more like a black box—a problem goes in and a solution comes out. Just as the introduction of assembly language eliminated the need for binary-based programming, the full impact of fifth-generation programming techniques may bring to an end the traditional programming approach. The ultimate target of fifth-generation languages is to eliminate the need for programming expertise and instead use advanced knowledge-based processing and artificial intelligence.
The industry has not been able to fully achieve all the goals set out for these fifth-generation languages. The human insight of programmers is still necessary to figure out the problems that need to be solved, and the restrictions of the structure of a current computer system do not allow software to “think for itself” yet. We are getting closer to achieving artificial intelligence within our software, but we still have a long way to go.
The following lists the basic software programming language generations:
• Generation one Machine language
• Generation two Assembly language
• Generation three High-level language
• Generation four Very high-level language
• Generation five Natural language
Assemblers, Compilers, Interpreters
No matter what type or generation of programming language is used, all of the instructions and data have to end up in a binary format for the processor to understand and work with. Just like our food has to be broken down into molecules for our body to be able to process it, all code must end up in a format that is consumable for specific systems. Each programming language type goes through this transformation through the use of assemblers, compilers, or interpreters.
Assemblers are tools that convert assembly language source code into machine code. Assembly language consists of mnemonics, which are incomprehensible to processors and therefore need to be translated into operation instructions.
Compilers are tools that convert high-level language statements into the necessary machine-level format (.exe, .dll, etc.) for specific processors to understand. The compiler transforms instructions from a source language (high-level) to a target language (machine), which allows the code to be executable. A programmer may develop an application in the C++ language, but when you purchase this application you do not receive the source code; instead, you will receive the executable code that will run on your type of computer. The source code was put through a compiler, which resulted in an executable file that can run on your specific processor type.
Compilers allow developers to create software code that can be developed once in a high-level language and compiled for various platforms. So you could develop one piece of software, which is then compiled by five different compilers to allow it to be able to run on five different systems.
If a programming language is considered “interpreted,” then a tool called an interpreter does the last step of transforming high-level code to machine-level code. For example, applications that are developed to work in a .NET environment are translated into an intermediate, platform-independent format. The applications are deployed, and upon runtime the applications’ code is interpreted into processor-specific code. The goal is to improve portability. The same is true for the Java programming language. Programs written in Java have their source code compiled into an intermediate code, called bytecode. When the instructions of the application need to run, they are executed in a Java Virtual Machine (JVM). The JVM has an interpreter specific for the platform it is installed on, as illustrated in Figure 8-13. The interpreter converts the bytecode into a machine-level format for execution.
The greatest advantage of executing a program in an interpreted environment is that the platform independence and memory management functions are part of an interpreter. The major disadvantage with this approach is that the program cannot run as a stand-alone application, but requires the interpreter to be installed on the local machine.
From a security point of view, it is important to understand vulnerabilities that are inherent in specific programming languages. For example, programs written in the C language could be vulnerable to buffer overrun and format string errors. The issue is that some of the C standard software libraries do not check the length of the strings of data they manipulate by default. Consequently, if a string is obtained from an untrusted source (i.e., the Internet) and is passed to one of these library routines, parts of memory may be unintentionally overwritten with untrustworthy data—this vulnerability can potentially be used to execute arbitrary and malicious software. Some programming languages, such as Java, perform automatic garbage collection; others, such as C, require the developer to perform it manually, thus leaving opportunity for error.
Figure 8-13 Java bytecode is converted by interpreters.
Garbage collection is an automated way for software to carry out part of its memory management tasks. A garbage collector identifies blocks of memory that were once allocated but are no longer in use and deallocates the blocks and marks them as free. It also gathers scattered blocks of free memory and combines them into larger blocks. It helps provide a more stable environment and does not waste precious memory. If garbage collection does not take place properly, not only can memory be used in an inefficient manner, an attacker could carry out a denial-of-service attack specifically to artificially commit all of a system’s memory rendering it unable to function.

CAUTION Nothing in technology seems to be getting any simpler, which makes learning this stuff much harder as the years go by. Ten years ago assembly, compiled, and interpreted languages were more clear-cut and their definitions straightforward. For the most part, only scripting languages required interpreters, but as languages have evolved they have become extremely flexible to allow for greater functionality, efficiency, and portability. Many languages can have their source code compiled or interpreted depending upon the environment and user requirements.
Object-Oriented Concepts
Software development used to be done by classic input-processing-output methods. This development used an information flow model from hierarchical information structures. Data was input into a program, and the program passed the data from the beginning to end, performed logical procedures, and returned a result.
Object-oriented programming (OOP) methods perform the same functionality, but with different techniques that work in a more efficient manner. First, you need to understand the basic concepts of OOP.
OOP works with classes and objects. A real-world object, such as a table, is a member (or an instance) of a larger class of objects called “furniture.” The furniture class will have a set of attributes associated with it, and when an object is generated, it inherits these attributes. The attributes may be color, dimensions, weight, style, and cost. These attributes apply if a chair, table, or loveseat object is generated, also referred to as instantiated. Because the table is a member of the class furniture, the table inherits all attributes defined for the class (see Figure 8-14).
The programmer develops the class and all of its characteristics and attributes. The programmer does not develop each and every object, which is the beauty of this approach. As an analogy, let’s say you developed an advanced coffee maker with the goal of putting Starbucks out of business. A customer punches the available buttons on your coffee maker interface, ordering a large latte, with skim milk, vanilla and raspberry flavoring, and an extra shot of espresso, where the coffee is served at 250 degrees. Your coffee maker does all of this through automation and provides the customer with a lovely cup of coffee exactly to her liking. The next customer wants a mocha frappuccino, with whole milk, and extra foam. So the goal is to make something once (coffee maker, class), allow it to accept requests through an interface, and create various results (cups of coffee, objects) depending upon the requests submitted.
But how does the class create objects based on requests? A piece of software that is written in OOP will have a request sent to it, usually from another object. The requesting object wants a new object to carry out some type of functionality. Let’s say that object A wants object B to carry out subtraction on the numbers sent from A to B. When this request comes in, an object is built (instantiated) with all of the necessary programming code. Object B carries out the subtraction task and sends the result back to object A. It does not matter what programming language the two objects are written in; what matters is if they know how to communicate with each other. One object can communicate with another object if it knows the application programming interface (API) communication requirements. An API is the mechanism that allows objects to talk to each other. Let’s say you want to talk to Jorge, but can only do so by speaking French and can only use three phrases or less, because that is all Jorge understands. As long as you follow these rules, you can talk to Jorge. If you don’t follow these rules, you can’t talk to Jorge.
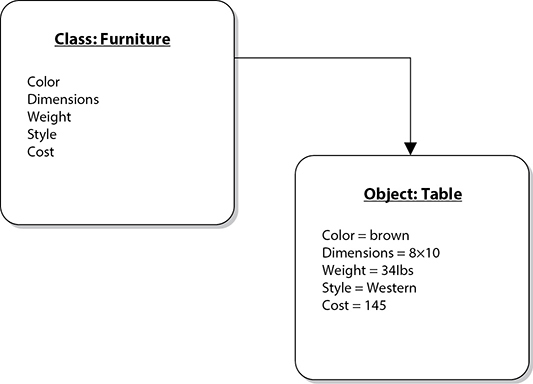
Figure 8-14 In object-oriented inheritance, each object belongs to a class and takes on the attributes of that class

TIP An object is an instance of a class.
So what’s so great about OOP? If you look at Figure 8-15, you can see the difference between OOP and non-OOP techniques. Non-OOP applications are written as monolithic entities. This means an application is just one big pile of code (sometimes called spaghetti code). If you need to change something in this pile, you would need to go through the whole program’s logic functions to figure out what your one change is going to break. If the program contains hundreds or thousands of lines of code, this is not an easy or enjoyable task. Now, if you choose to write your program in an object-oriented language, you don’t have one monolithic application, but an application that is made up of smaller components (objects). If you need to make changes or updates to some functionality in your application, you can just change the code within the class that creates the object carrying out that functionality and not worry about everything else the program actually carries out. The following breaks down the benefits of OOP:
Figure 8-15 Procedural vs. object-oriented programming
• Modularity The building blocks of software are autonomous objects, cooperating through the exchange of messages.
• Deferred commitment The internal components of an object can be redefined without changing other parts of the system.
• Reusability Classes are reused by other programs, though they may be refined through inheritance.
• Naturalness Object-oriented analysis, design, and modeling map to business needs and solutions.
Most applications have some type of functionality in common. Instead of developing the same code to carry out the same functionality for ten different applications, using OOP allows you to just create the object only once and let it be reused in other applications. This reduces development time and saves money.
Now that we’ve covered the concepts of OOP, let’s clarify the terminology used. A method is the functionality or procedure an object can carry out. An object may be constructed to accept data from a user and to reformat the request so a back-end server can understand and process it. Another object may perform a method that extracts data from a database and populates a web page with this information. Or an object may carry out a withdrawal procedure to allow the user of an ATM to extract money from her account.
The objects encapsulate the attribute values, which means this information is packaged under one name and can be reused as one entity by other objects. Objects need to be able to communicate with each other, and this happens by using messages that are sent to the receiving object’s API. If object A needs to tell object B that a user’s checking account must be reduced by $40, it sends object B a message. The message is made up of the destination, the method that needs to be performed, and the corresponding arguments. Figure 8-16 shows this example.
Messaging can happen in several ways. A given object can have a single connection (one-to-one) or multiple connections (one-to-many). It is important to map these communication paths to identify if information can flow in a way that is not intended. This will help ensure that sensitive data cannot be passed to objects of a lower security level.

Figure 8-16 Objects communicate via messages.
An object can have a shared portion and a private portion. The shared portion is the interface (API) that enables it to interact with other components. Messages enter through the interface to specify the requested operation, or method, to be performed. The private portion of an object is how it actually works and performs the requested operations. Other components need not know how each object works internally—only that it does the job requested of it. This is how data hiding is possible. The details of the processing are hidden from all other program elements outside the object. Objects communicate through well-defined interfaces; therefore, they do not need to know how each other works internally.
NOTE Data hiding is provided by encapsulation, which protects an object’s private data from outside access. No object should be allowed to, or have the need to, access another object’s internal data or processes.
These objects can grow to great numbers, so the complexity of understanding, tracking, and analyzing can get a bit overwhelming. Many times, the objects are shown in connection to a reference or pointer in documentation. Figure 8-17 shows how related objects are represented as a specific piece, or reference, in a bank ATM system. This enables analysts and developers to look at a higher level of operation and procedures without having to view each individual object and its code. Thus, this modularity provides for a more easily understood model.

Figure 8-17 Object relationships within a program
Abstraction, as discussed earlier, is the capability to suppress unnecessary details so the important, inherent properties can be examined and reviewed. It enables the separation of conceptual aspects of a system. For example, if a software architect needs to understand how data flows through the program, she would want to understand the big pieces of the program and trace the steps the data takes from first being input into the program all the way until it exits the program as output. It would be difficult to understand this concept if the small details of every piece of the program were presented. Instead, through abstraction, all the details are suppressed so the software architect can understand a crucial part of the product. It is like being able to see a forest without having to look at each and every tree.
Each object should have specifications it adheres to. This discipline provides cleaner programming and reduces programming errors and omissions. The following list is an example of what should be developed for each object:
• Object name
• Attribute descriptions
• Attribute name
• Attribute content
• Attribute data type
• External input to object
• External output from object
• Operation descriptions
• Operation name
• Operation interface description
• Operation processing description
• Performance issues
• Restrictions and limitations
• Instance connections
• Message connections
The developer creates a class that outlines these specifications. When objects are instantiated, they inherit these attributes.
Each object can be reused as stated previously, which is the beauty of OOP. This enables a more efficient use of resources and the programmer’s time. Different applications can use the same objects, which reduces redundant work, and as an application grows in functionality, objects can be easily added and integrated into the original structure.
The objects can be catalogued in a library, which provides an economical way for more than one application to call upon the objects (see Figure 8-18). The library provides an index and pointers to where the objects actually live within the system or on another system.
When applications are developed in a modular approach, like object-oriented methods, components can be reused, complexity is reduced, and parallel development can be done. These characteristics allow for fewer mistakes, easier modification, resource efficiency, and more timely coding than the classic programming languages. OOP also provides functional independence, which means each module addresses a specific subfunction of requirements and has an interface that is easily understood by other parts of the application.

Figure 8-18 Applications locate the necessary objects through a library index.
An object is encapsulated, meaning the data structure (the operation’s functionality) and the acceptable ways of accessing it are grouped into one entity. Other objects, subjects, and applications can use this object and its functionality by accessing it through controlled and standardized interfaces and sending it messages (see Figure 8-19).
Polymorphism
Polymorphism comes from the Greek, meaning “having multiple forms.” This concept usually confuses people, so let’s jump right into an example. If you develop a program in an OOP language, you can create a variable that can be used in different forms. The application will determine what form to use at the time of execution (run time). So if your variable is named USERID and you develop the object so the variable can accept either an integer or letters, this provides flexibility. This means the user ID can be accepted as a number (account number) or name (characters). If application A uses this object, it can choose to use integers for the user IDs, while application B can choose to use characters.
What confuses people about the term polymorphism is that the International Information Systems Security Certification Consortium, known as (ISC)2, commonly uses the following definition or description: “Two objects can receive the same input and have different outputs.” Clear as mud.
As a simplistic example of polymorphism, suppose three different objects receive the input “Bob.” Object A would process this input and produce the output “43-year-old white male.” Object B would receive the input “Bob” and produce the output “Husband of Sally.” Object C would produce the output “Member of User group.” Each object received the same input, but responded with a different output.
Polymorphism can also take place in the following example: Object A and Object B are created from the same parent class, but Object B is also under a subclass. Object B would have some different characteristics from Object A because of this inheritance from the parent class and the subclass. When Object A and Object B receive the same input, they would result in different outputs because only one of them inherited characteristics from the subclass.
Figure 8-19 The different components of an object and the way it works are hidden from other objects.
EXAM TIP Polymorphism takes place when different objects respond to the same command, input, or message in different ways.
Other Software Development Concepts
Regardless of the approach to software development, there are some concepts that are universal in this field. Data modeling, data structures, and the concepts of cohesion and coupling are important when developing quality software. Quality is focused on minimizing the number of errors, which in turn means the software will have fewer vulnerabilities and be more secure.
Data Modeling
Data modeling considers data independently of both the way the data is processed and the components that process the data. A data model follows an input value from beginning to end and verifies that the output is correct. OOA is an example of a structured analysis approach. If an analyst is reviewing the OOA of an application, she will make sure all relationships are set up correctly, that the inheritance flows in a predictable and usable manner, that the instances of objects are practical and provide the necessary functionality, and that the attributes of each class cover all the necessary values used by the application. When another analyst does a data model review of the same application, he will follow the data and the returned values after processing takes place. An application can have a perfect OOA structure, but when 1 + 1 is entered and it returns –3, something is wrong. This is one aspect that data modeling looks at.
Another example of data modeling deals with databases. Data modeling can be used to provide insight into the data and the relationships that govern it. A data item in one file structure, or data store, might be a pointer to another file structure or to a different data store. These pointers must actually point to the right place. Data modeling would verify this, not OOA structure analysis.
Data Structures
A data structure is a representation of the logical relationship between elements of data. It dictates the degree of association among elements, methods of access, processing alternatives, and the organization of data elements.
The structure can be simple in nature, like the scalar item, which represents a single element that can be addressed by an identifier and accessed by a single address in storage. The scalar items can be grouped in arrays, which provide access by indexes. Other data structures include hierarchical structures by using multilinked lists that contain scalar items, vectors, and possibly arrays. The hierarchical structure provides categorization and association. If a user can make a request of an application to find all computer books written on security, and that application returns a list, then this application is using a hierarchical data structure of some kind. Figure 8-20 shows simple and complex data structures.
So from a security perspective, not only do you need to understand the vulnerabilities related to a poorly architected and designed piece of software, but you need to understand the complexity issues of how the software components communicate with each other and the type of data format that is used.
Cohesion and Coupling
Cohesion reflects how many different types of tasks a module can carry out. If a module carries out only one task (i.e., subtraction) or tasks that are very similar (i.e., subtract, add, multiply), it is described as having high cohesion, which is a good thing. The higher the cohesion, the easier it is to update or modify and not affect other modules that interact with it. This also means the module is easier to reuse and maintain because it is more straightforward when compared to a module with low cohesion. An object with low cohesion carries out multiple different tasks and increases the complexity of the module, which makes it harder to maintain and reuse. So you want your objects focused, manageable, and understandable. Each object should carry out a single function or similar functions. One object should not carry out mathematical operations, graphic rendering, and cryptographic functions—these are separate functionality types and it would be confusing to keep track of this level of complexity. If you do this, you are trying to shove too much into one object. Objects should carry out modular, simplistic functions—that is the whole point of OOP.

Figure 8-20 Data structures range from very simple to very complex in nature and design.
Coupling is a measurement that indicates how much interaction one module requires to carry out its tasks. If a module has low (loose) coupling, this means the module does not need to communicate with many other modules to carry out its job. High (tight) coupling means a module depends upon many other modules to carry out its tasks. Low coupling is more desirable because the modules are easier to understand and easier to reuse, and changes can take place and not affect many modules around it. Low coupling indicates that the programmer created a well-structured module. As an analogy, a company would want its employees to be able to carry out their individual jobs with the least amount of dependencies on other workers. If Joe has to talk with five other people just to get one task done, too much complexity exists, it’s too time-consuming, and more places are created where errors can take place.
If modules are tightly coupled, the ripple effect of changing just one module can drastically affect the other modules. If they are loosely coupled, this level of complexity reduces.
An example of low coupling would be one module passing a variable value to another module. As an example of high coupling, Module A would pass a value to Module B, another value to Module C, and yet another value to Module D. Module A could not complete its tasks until Modules B, C, and D completed their tasks and returned results back to Module A.
EXAM TIP Objects should be self-contained and perform a single logical function, which is high cohesion. Objects should not drastically affect each other, which is low coupling.
The level of complexity involved with coupling and cohesion can have a direct relationship on the security level of a program. The more complex something is, the harder it is to secure. Developing “tight code” not only allows for efficiencies and effectiveness, but also reduces the software’s attack surface. Decreasing complexity where possible reduces the number of potential holes a bad guy can sneak through. As an analogy, if you were responsible for protecting a facility, it would be easier if the facility had a small number of doors, windows, and people coming in and out of it. The smaller number of variables and moving pieces would help you keep track of things and secure them.
Application Programming Interfaces
When we discussed some of the attributes of object-oriented development, we spent a bit of time on the concept of abstraction. Essentially, it is all about defining what a class or object does with no regard to how that is accomplished internally. An application programming interface (API) specifies the manner in which a software component interacts with other software components. Not only does this encourage software reuse, but it also makes the software more maintainable by localizing the changes that need to be made while eliminating (or at least reducing) cascading effects of fixes or changes.
APIs are perhaps most familiar to us in the context of software libraries. A software library is a collection of components that do specific things that are useful to many other components. For example, there are software libraries for various encryption algorithms, managing network connections, and displaying graphics. These allow software developers to work on whatever makes their program unique, while leveraging known-good code for the things that similar programs routinely do. All the programmer needs to do is understand the API for the libraries she intends to use. This reduces the amount of new code that needs to be developed, which in turn makes it easier to secure and maintain.
Besides the advantages of reduced effort and improved maintainability, APIs are oftentimes required in order to employ the underlying operating system’s functionality. Apple macOS and iOS, Google Android, and Microsoft Windows all require developers to use standard APIs for access to operating system functionality such as opening and closing files and network connections, among many others. This is also true of many disturbed computing frameworks, which is a topic we discuss next.
Distributed Computing
Many of our applications work in a client/server model, which means the smaller part (client) of the application can run on different systems and the larger piece (server) of the application runs on a single, and commonly more powerful, back-end system. The server portion carries out more functionality and has more horsepower compared to the clients. The clients will send the server requests, and the server will respond with results. Simple enough, but how do the client and server pieces actually carry out communication with each other?
A distributed object computing model needs to register the client and server components, which means to find out where they live on the network, what their names or IDs are, and what type of functionality the different components carry out. So the first step is basically, “Where are all the pieces, how do I call upon them when I need them, and what do they do?” This organization must be put in place because the coordination between the components should be controlled and monitored, and requests and results must be able to pass back and forth between the correct components.
Life might be easier if we had just one intercomponent communication architecture for developers to follow, but what fun would that be? The various architectures work a little differently from each other and are necessary to work in specific production environments. Nevertheless, they all perform the basic function of allowing components on the client and server sides to communicate with each other.
Distributed Computing Environment
Distributed Computing Environment (DCE) is a standard developed by the Open Software Foundation (OSF), also called Open Group. It is a client/server framework that is available to many vendors to use within their products. This framework illustrates how various capabilities can be integrated and shared between heterogeneous systems. DCE provides a Remote Procedure Call (RPC) service, security service, directory service, time service, and distributed file support. It was one of the first attempts at distributed computing in the industry.
DCE is a set of management services with a communications layer based on RPC. It is a layer of software that sits on the top of the network layer and provides services to the applications above it. DCE and Distributed Component Object Model (DCOM) offer much of the same functionality. DCOM, however, was developed by Microsoft and is more proprietary in nature.
DCE’s time service provides host clock synchronization and enables applications to determine sequencing and to schedule events based on this clock synchronization. This time synchronization is for applications. Users cannot access this functionality directly. The directory service enables users, servers, and resources to be contacted anywhere on the network. When the directory service is given the name, it returns the network address of the resource along with other necessary information. DCOM uses a globally unique identifier (GUID), while DCE uses a universal unique identifier (UUID). They are both used to uniquely identify users, resources, and components within an environment. DCE is illustrated in Figure 8-21.

Figure 8-21 DCE provides many services, which are all wrapped into one technology.
The RPC function collects the arguments and commands from the sending program and prepares them for transmission over the network. RPC determines the network transport protocol to be used and finds the receiving host’s address in the directory service. The thread service provides real-time priority scheduling in a multithreading environment. The security services support authentication and authorization services.
DCE was the first attempt at standardizing heterogeneous system communication through a client/server model. Though one would be hard-pressed to find it running as such on any production system, it provided many of the foundational concepts for distributed computing technologies that followed it, as in CORBA, DCOM, and J2EE, which we will cover next. Microsoft DCOM, in particular, relies extensively on DCE and RPC.
CORBA and ORBs
If we want software components to be able to communicate with each other, this means standardized interfaces and communication methods must be used. This is the only way interoperability can take place.
Common Object Request Broker Architecture (CORBA) is an open object-oriented standard architecture developed by the Object Management Group (OMG). It provides interoperability among the vast array of software, platforms, and hardware in environments today. CORBA enables applications to communicate with one another no matter where the applications are located or who developed them.
This standard defines the APIs, communication protocol, and client/server communication methods to allow heterogeneous applications written in different programming languages and run on various platforms to work together. The model defines object semantics so the external visible characteristics are standard and are viewed the same by all other objects in the environment. This standardization enables many different developers to write hundreds or thousands of components that can interact with other components in an environment without having to know how the components actually work. The developers know how to communicate with the components because the interfaces are uniform and follow the rules of the model.
In this model, clients request services from objects. The client passes the object a message that contains the name of the object, the requested operation, and any necessary parameters.
The CORBA model provides standards to build a complete distributed environment. It contains two main parts: system-oriented components (object request brokers [ORBs] and object services) and application-oriented components (application objects and common facilities). The ORB manages all communications between components and enables them to interact in a heterogeneous and distributed environment, as shown in Figure 8-22. The ORB works independently of the platforms where the objects reside, which provides greater interoperability.
ORB is the middleware that allows the client/server communication to take place between objects residing on different systems. When a client needs some type of functionality to be carried out, the ORB receives the request and is responsible for locating the necessary object for that specific task. Once the object is found, the ORB invokes a method (or operation), passes the parameters, and returns the result to the client. The client software does not need to know where the object resides or go through the trouble of finding it. That is the ORB’s job. As an analogy, when you call someone on your mobile phone, you do not have to worry about physically locating that person so your data can be passed back and forth. The mobile phones and the telecommunications network take care of that for you.
Figure 8-22 The ORB enables different components throughout a network to communicate and work with each other.
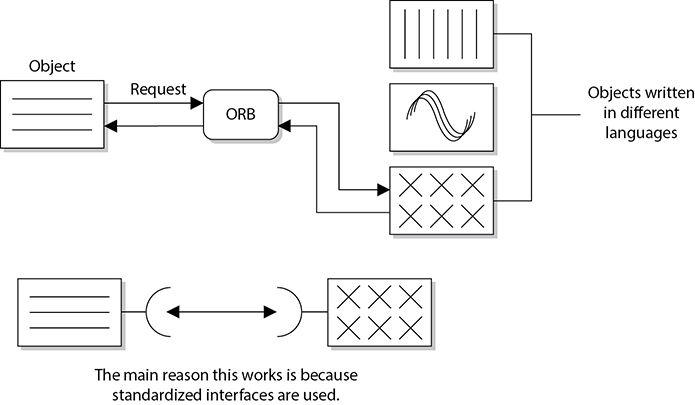
Figure 8-23 CORBA provides standard interface definitions, which offer greater interoperability in heterogeneous environments.
Software that works within the CORBA model can use objects that are written in different programming languages and that reside on different operating systems and platforms, as long as the software follows all the rules to allow for such interoperability (see Figure 8-23).
ORBs provide communications between distributed objects. If an object on a workstation must have an object on a server process data, it can make a request through the ORB, which will track down the needed object and facilitate the communication path between these two objects until the process is complete.
ORBs are mechanisms that enable objects to communicate locally or remotely. They enable objects to make requests to objects and receive responses. This happens transparently to the client and provides a type of pipeline between all corresponding objects. Using CORBA enables an application to be usable with many different types of ORBs. It provides portability for applications and tackles many of the interoperability issues that many vendors and developers run into when their products are implemented into different environments.
COM and DCOM
The Component Object Model (COM) allows for interprocess communication within one application or between applications on the same computer system. The model was created by Microsoft and outlines standardized APIs, component naming schemes, and communication standards. So if you are a developer and you want your application to be able to interact with the Windows operating system and the different applications developed for this platform, you will follow the COM outlined standards.
The Distributed Component Object Model (DCOM) supports the same model for component interaction, and also supports distributed interprocess communication (IPC). COM enables applications to use components on the same systems, while DCOM enables applications to access objects that reside in different parts of a network. So this is how the client/server-based activities are carried out by COM-based operating systems and/or applications.
Without DCOM, programmers would have to write much more complicated code to find necessary objects, set up network sockets, and incorporate the services necessary to allow communication. DCOM takes care of these issues (and more), and enables the programmer to focus on his tasks of developing the necessary functionality within his application. DCOM has a library that takes care of session handling, synchronization, buffering, fault identification and handling, and data format translation.
DCOM works as the middleware that enables distributed processing and provides developers with services that support process-to-process communications across networks (see Figure 8-24).
Other types of distributed interprocessing technologies provide similar functionality: ORB, message-oriented middleware (MOM), Open Database Connectivity (ODBC), and so on. DCOM provides ORB-like services, data connectivity services, distributed messaging services, and distributed transaction services layered over its RPC mechanism. DCOM integrates all of these functionalities into one technology that uses the same interface as COM.
Although DCOM is still in use on many systems, it has been largely replaced with the .NET framework, which is mainly used for applications that run in Windows environments. The framework has a large library that different applications can call upon. The libraries provide functions as in data access, database connectivity, network communication, etc. Programs that are written to work in this framework execute in application virtual machines, which provide memory management, exception handling, and many types of security services. A program that is written to work in this type of environment is compiled to an intermediate code type (Common Language Runtime), and then when the code is executed at run time, this happens within the application virtual machine, as illustrated in Figure 8-25.

Figure 8-24 DCOM provides communication mechanisms in a distributed environment and works in the COM architecture.

Figure 8-25 .NET Framework components
Object Linking and Embedding
Object Linking and Embedding (OLE) provides a way for objects to be shared on a local personal computer and to use COM as their foundation. OLE enables objects—such as graphics, clipart, and spreadsheets—to be embedded into documents. The capability for one program to call another program is called linking. The capability to place a piece of data inside a foreign program or document is called embedding.
OLE also allows for linking different objects and documents. For example, when Chrissy creates a document that contains a Uniform Resource Locator (URL), that URL turns blue and is underlined, indicating a user can just double-click it to be taken to the appropriate website. This is an example of linking capabilities. If Chrissy inserts a spreadsheet into her document, this is also an instance of embedding. If she needs to edit the spreadsheet, she can double-click the spreadsheet, and the operating system will open the correct environment (which might be Excel) to let her make her changes.
This technology was evolved to work on the World Wide Web and is called ActiveX, which we cover later in this chapter. The components are meant to be portable. ActiveX components can run on any platform that supports DCOM (using the COM model) or that communicates using DCOM services.
Java Platform, Enterprise Edition
Another distributed computing model is based upon the Java programming language, which is the Java Platform, Enterprise Edition (Java EE). Just as the COM and CORBA models were created to allow a modular approach to programming code with the goal of interoperability, Java EE defines a client/server model that is object oriented and platform independent.
Java EE is an enterprise Java computing platform. This means it is a framework that is used to develop enterprise software written mainly in the Java programming language. It provides APIs for networking services, fault tolerance, security, and web services for large-scale, multitiered network applications. It takes advantage of the “Write Once, Run Anywhere” capability of Java; it provides a Java-based, database-access API; and its interprocess communications are based upon CORBA. The main goal is to have a standardized method of implementing back-end code that carries out business logic for enterprise-wide applications.
The Java EE application server can handle scalability, concurrency, transactions, and various security services for the client. The goal is to allow the developers to be able to concentrate on the business logic functionality instead of the “plumbing” that is under the covers.
Service-Oriented Architecture
While many of the previously described distributed computing technologies are still in use, the industry has moved toward and integrated another approach in providing commonly needed application functionality and procedures across various environments. A service-oriented architecture (SOA) provides standardized access to the most needed services to many different applications at one time. Application functionality is separated into distinct units (services) and offered up through well-defined interfaces and data-sharing standardization. This means that individual applications do not need to possess the same redundant code and functionality. The functionality can be offered by an individual entity and then all other applications can just call upon and use the one instance. This is really the crux of all distributed computing technologies and approaches—SOA is just a more web-based approach.
As an analogy, every home does not have its own electrical power grid. A geographical area has a power grid, and all homes and offices tap into that one resource. There is a standardized method of each home accessing the power grid and obtaining the energy it needs. The same concept applies with SOA: applications access one centralized place that provides the functionality they require. A simple interface abstracts (hides) the underlying complexity, which allows for applications to call upon the services without needing to understand the service provider’s programming language or its platform implementation. For services to be able to be used (and reused) in an interoperable manner, they must be modular in nature, autonomous, loosely coupled, follow standardized service identification and categorization, and provide provisioning and delivery.
Figure 8-26 Services are located through brokers in an SOA.
The entity that will provide a service in an SOA environment sends a service-description document to a service broker. The service broker is basically a map of all the services available within a specific environment. When an application needs a specific service, it makes a call to the broker, which points the application to the necessary service provider, as shown in Figure 8-26.
Services within an SOA are usually provided through web services. A web service allows for web-based communication to happen seamlessly using web-based standards, as in Simple Object Access Protocol (SOAP), HTTP, Web Services Description Language (WSDL), Universal Description, Discovery and Integration (UDDI), and Extensible Markup Language (XML). WSDL provides a machine-readable description of the specific operations provided by the service. UDDI is an XML-based registry that lists available services. It provides a method for services to be registered by service providers and located by service consumers. UDDI provides the mechanisms to allow businesses around the world to publish their services and others to discover and use these services. When a service consumer needs to know what service is available and where it is located, it sends a message to the service broker. Through its UDDI approach, the broker can provide access to the WSDL document that describes the requirements for interacting with the requested service. The service consumer now knows how to locate the service provider and how to communicate with it. The consumer then requests and accesses the service using SOAP, which is an XML-based protocol that is used to exchange messages between a requester and provider of a web service. Figure 8-27 illustrates how these different components work together.
Web services commonly provide the functional building blocks for an SOA. New services are represented in this format using these standards, and/or existing applications are wrapped within a web service structure to allow for legacy systems to participate in SOA environments also.
There has been controversy and confusion on the distinction and similarities among SOA, mashups, Web 2.0, Software as a Service (SaaS), and cloud computing. The evolution of Web 1.0 to Web 2.0 pertains to the move from static websites that provide content and some functionality to an Internet where everyone can basically be a content provider and consumer. Through the use of Facebook, YouTube, Twitter, Flickr, and other sites, normal users can provide content to the digital world without having to understand HTML, JavaScript, web server software, and other technologies. Websites provide intricate functionality instead of just static content. The extensive manner in which information sharing, collaboration, and interaction can happen through social networking sites, blogs, wikis, hosted services, mashups, and video sharing really embodies the essence of the concept of Web 2.0. This makes for a more exciting Internet, but increased complexity for security professionals, who are responsible for understanding and securing software that maintains sensitive information.
Figure 8-27 Web services are posted and used via standard approaches.
A mashup is the combination of functionality, data, and presentation capabilities of two or more sources to provide some type of new service or functionality. Open APIs and data sources are commonly aggregated and combined to provide a more useful and powerful resource. For example, the site http://popurls.com combines the functionality of APIs provided by sites like Digg, Del.icio.us, Flickr, and YouTube to provide integrated social news.
Cloud computing is a method of providing computing as a service rather than as a physical product. It provides processing computation capabilities, storage, and software without the end user needing to know or worry about the physical location and/or configuration of the devices and software that provide this functionality. Cloud computing extends technical capabilities through a subscription-based or pay-per-use service structure. Scalable resources are consolidated and commonly used in a virtualized manner. This technology is covered more in depth in Chapter 3, but it is being presented here to illustrate the differences and similarities pertaining to the outgrowth of Internet capabilities and the use of distributed computing technologies.
Software as a Service (SaaS) is a cloud computing model that allows applications and data to be centrally hosted and accessed by thin clients, commonly web browsers. It is similar to the old centralized mainframe model, but commonly takes place over the Internet. SaaS delivers many business applications providing functionality, as in customer relationship management (CRM), enterprise resource planning (ERP), human resource management (HRM), content management (CM), and more. Most people are familiar with Salesforce.com, which was one of the first SaaS products to become available.
So DCE was the first attempt at providing client/server distributed computing capabilities and worked mainly in Unix-based environments. CORBA is a model that allows for interoperability and distributed computing for mostly non-Microsoft applications. Software that needed to work in a distributed computing environment of mostly Microsoft products first followed the DCOM model, which evolved into the .NET framework. Large enterprise-wide applications that are based upon Java can carry out distributed computing by following the Java EE model. And web-based distributed computing happens through web services and SOA frameworks. Each of these has the same basic goal, which is to allow a client application component on one computer to be able to communicate with a server application on another computer. The biggest difference between these models pertains to the environment the applications will be working within: Unix, Windows, heterogeneous, or web-based.
While distributed computing technologies allow for various systems and applications to communicate and share functionality, this can add layers of complexity when it comes to security. The client and server portions need to carry out mutual authentication to ensure that hackers do not introduce rogue applications and carry out man-in-the-middle attacks. Each communicating component needs to share similar cryptographic functionality so that the necessary encryption can take place. The integrity of the data and messages that are passed between communicating components needs to be protected. End-to-end secure transmission channels might be necessary to protect communication data. The list of security requirements can go on and on, but the point is that just getting software components to be able to communicate in a heterogeneous environment can be challenging—but securing these complex communication methods can prove to be maddening.
As a security professional, you really need to understand how software talks to other software under the covers. You can patch systems, implement access control lists (ACLs), harden operating systems, and more but still have unprotected RPC traffic taking place between applications that are totally insecure. Security has to be integrated at every level, including interprocess communication channels.
Mobile Code
Code that can be transmitted across a network, to be executed by a system or device on the other end, is called mobile code. There are many legitimate reasons to use mobile code—for example, web browser applets that may execute in the background to download additional content for the web page, such as plug-ins that allow you to view a video.
The cautions arise when a website downloads code intended to do malicious or compromising actions, especially when the recipient is unaware that the compromising activity is taking place. If a website is compromised, it can be used as a platform from which to launch attacks against anyone visiting the site and just browsing. Some of the common types of mobile code are covered in the next sections.
CAUTION Mobile code has been a regular vector for attacks for years. Except in carefully controlled environments, it should be considered risky.
Java Applets
Java is an object-oriented, platform-independent programming language. It is employed as a full-fledged programming language and is used to write complete programs and small components, called applets, which commonly run in a user’s web browser.
Other languages are compiled to object code for a specific operating system and processor. This is why a particular application may run on Windows but not on macOS. An Intel processor does not necessarily understand machine code compiled for an ARM processor, and vice versa. Java is platform independent because it creates intermediate code, bytecode, which is not processor-specific. The Java Virtual Machine (JVM) converts the bytecode to the machine code that the processor on that particular system can understand (see Figure 8-28). Let’s quickly walk through these steps:
1. A programmer creates a Java applet and runs it through a compiler.
2. The Java compiler converts the source code into bytecode (non-processor-specific).
3. The user downloads the Java applet.
4. The JVM converts the bytecode into machine-level code (processor-specific).
5. The applet runs when called upon.
Figure 8-28 The JVM interprets bytecode to machine code for that specific platform.
When an applet is executed, the JVM will create a virtual machine, which provides an environment called a sandbox. This virtual machine is an enclosed environment in which the applet carries out its activities. Applets are commonly sent over within a requested web page, which means the applet executes as soon as it arrives. It can carry out malicious activity on purpose or accidentally if the developer of the applet did not do his part correctly. So the sandbox strictly limits the applet’s access to any system resources. The JVM mediates access to system resources to ensure the applet code behaves and stays within its own sandbox. These components are illustrated in Figure 8-29.
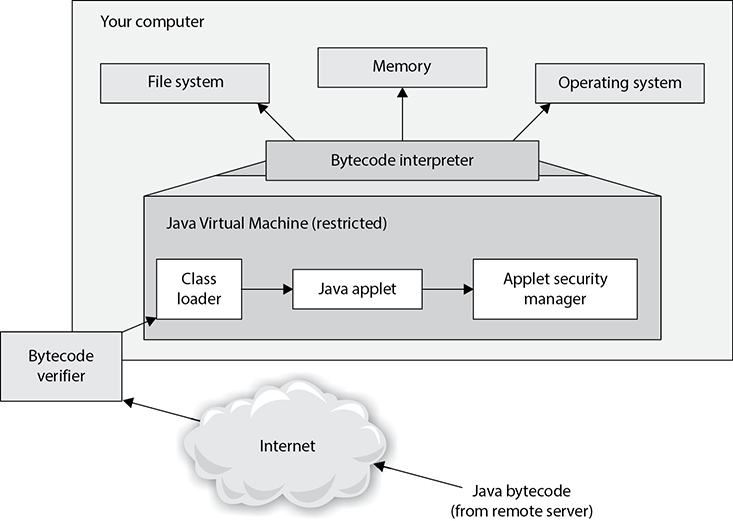
Figure 8-29 Java’s security model
NOTE The Java language itself provides protection mechanisms, such as garbage collection, memory management, validating address usage, and a component that verifies adherence to predetermined rules.
However, as with many other things in the computing world, the bad guys have figured out how to escape the confines and restrictions of the sandbox. Programmers have figured out how to write applets that enable the code to access hard drives and resources that are supposed to be protected by the Java security scheme. This code can be malicious in nature and cause destruction and mayhem to the user and her system.

ActiveX Controls
ActiveX is a Microsoft technology composed of a set of OOP technologies and tools based on COM and DCOM. A programmer uses these tools to create ActiveX controls, which are self-sufficient programs (similar to Java applets) that can be executed in the Windows environment. ActiveX controls can be reused by many applications within one system or different systems within an environment. These controls can be downloaded from websites to add extra functionality (as in providing animations for web pages), but they are also components of Windows operating systems themselves (dynamic link libraries [DLLs]) and carry out common operating system tasks.
ActiveX allow web browsers to execute other software applications within the browser that can play media files, open Portable Document Files (PDF) documents, etc. An ActiveX control can be automatically downloaded and executed by a web browser. Once downloaded, an ActiveX control in effect becomes part of the operating system. Initially ActiveX controls were intended to work on individual systems only, and hence there weren’t many security issues. Security issues started emerging only after OLE began to be used to embed ActiveX controls in web pages. The problem lay in the fact that ActiveX controls shared the privilege levels of the current user on a system, and since these controls could be built by anyone, a malicious ActiveX control would have sufficient privilege to compromise the system security and other systems connected through it. This was worsened by the fact that ActiveX controls were able to download further ActiveX components without user authentication, creating a very favorable environment for worm propagation.
ActiveX comes with a component container feature that allows multiple applications and networked computers to reuse active components. This drastically reduced the program development time. This feature too has been exploited by attackers to gain access to critical files on networked systems. Numerous patches have been released to counter reported ActiveX exploits.
ActiveX technology provides security levels and authentication settings, letting users control the security of the ActiveX components they download. Unlike Java applets, ActiveX components are downloaded to a user’s hard drive when he chooses to add the functionality the component provides. This means the ActiveX component has far greater access to the user’s system compared to Java applets.
The security-level setting of the user’s browser dictates whether an ActiveX component is downloaded automatically or whether the user is first prompted with a warning. The security level is configurable by the user via his browser controls. As the security level increases, so, too, does the browser’s sensitivity level to digitally signed and unsigned components and controls, and to the initialization of ActiveX scripts.
The main security difference between Java applets and ActiveX controls is that Java sets up a sandbox for the applet code to execute in, and this restricts the code’s access to resources within the user’s computer. ActiveX uses Authenticode technology, which relies on digital certificates and trusting certificate authorities. Although both are extremely important and highly used technologies, they have inherent flaws. Java has not been able to ensure that all code stays within the sandbox, which has caused several types of security compromises. Authenticode doesn’t necessarily provide security—in fact, it often presents annoying dialog boxes to users. Since most users do not understand this technology, they continually click OK because they don’t understand the risks involved.
NOTE Microsoft no longer supports ActiveX in its Edge web browser.