
Web Security
When it comes to the Internet and web-based applications, many security situations are unique to this area. Companies use the Internet to expose products or services to the widest possible audience; thus, they need to allow an uncontrollable number of entities on the Internet to access their web servers. In most situations companies must open up the ports related to the web-based traffic (80 and 443) on their firewalls, which are commonly used avenues for a long list of attacks.
The web-based applications themselves are somewhat mysterious to the purveyors of the Internet as well. If you want to sell your homemade pies via the Internet, you’ll typically need to display them in graphic form and allow some form of communication for questions (via e-mail or online chat). You’ll need some sort of shopping cart if you want to actually collect money for your pies, and typically you’ll have to deal with interfacing with shipping and payment processing channels. If you are a master baker, you probably aren’t a webmaster, so now you’ll have to rely on someone else to set up your website and load the appropriate applications on it. Should you develop your own PHP- or Java-based application, the benefits could be wonderful, having a customized application that would further automate your business, but the risks of developing an in-house application (especially if it’s your first time) are great if you haven’t developed the methodology, development process, quality assurance, and change control, as well as identified the risks and vulnerabilities.
The alternative to developing your own web application is using an off-the-shelf variety instead. Many commercial and free options are available for nearly every e-commerce need. These are written in a variety of languages, by a variety of entities, so now the issue is, “Whom should we trust?” Do these developers have the same processes in place that you would have used yourself? Have these applications been developed and tested with the appropriate security in mind? Will these applications introduce any vulnerabilities along with the functionality they provide? Does your webmaster understand the security implications associated with the web application he suggests you use on your site for certain functionality? These are the problems that plague not only those wanting to sell homemade pies on the Internet, but also financial institutions, auction sites, and everyone who is involved in e-commerce. With these issues in mind, let’s try to define the most glaring threats associated with web-based applications and transactions.
Specific Threats for Web Environments
The most common types of vulnerabilities, threats, and complexities are covered in the following sections, which we will explore one at a time:
• Administrative interfaces
• Authentication and access control
• Input validation
• Parameter validation
• Session management
Administrative Interfaces
Everyone wants to work from the coffee shop or at home in their pajamas. Webmasters and web developers are particularly fond of this concept. Although some systems mandate that administration be carried out from a local terminal, in most cases, there is an interface to administer the systems remotely, even over the Web. While this may be convenient to the webmaster, it also provides an entry point into the system for an unauthorized user.
Since we are talking about the Web, using a web-based administrative interface is, in most opinions, a bad idea. If we are willing to accept the risk, the administrative interface should be at least as secure as (if not more than) the web application or service we are hosting.
A bad habit that’s found even in high-security environments is hard-coding authentication credentials into the links to the management interfaces, or enabling the “remember password” option. This does make it easier on the administrator but offers up too much access to someone who stumbles across the link, regardless of their intentions.
Most commercial software and web application servers install some type of administrative console by default. Knowing this and being cognizant of the information-gathering techniques previously covered should be enough for organizations to take this threat seriously. If the management interface is not needed, it should be disabled. When custom applications are developed, the existence of management interfaces is less known, so consideration should be given to this in policy and procedures.
The simple countermeasure for this threat requires that the management interfaces be removed, but this may upset your administrators. Using a stronger authentication mechanism would be better than the standard username/password scenario. Controlling which systems are allowed to connect and administer the system is another good technique. Many systems allow specific IP addresses or network IDs to be defined that only allow administrative access from these stations.
Ultimately, the most secure management interface for a system would be one that is out-of-band, meaning a separate channel of communication is used to avoid any vulnerabilities that may exist in the environment that the system operates in. An example of out-of-band would be using a modem connected to a web server to dial in directly and configure it using a local interface, as opposed to connecting via the Internet and using a web interface. This should only be done through an encrypted channel, as in Secure Shell (SSH).
Authentication and Access Control
If you’ve used the Internet for banking, shopping, registering for classes, or working from home, you most likely logged in through a web-based application. From the consumer side or the provider side, the topic of authentication and access control is an obvious issue. Consumers want an access control mechanism that provides the security and privacy they would expect from a trusted entity, but they also don’t want to be too burdened by the process. From the service providers’ perspective, they want to provide the highest amount of security to the consumer that performance, compliance, and cost will allow. So, from both of these perspectives, typically usernames and passwords are still used to control access to most web applications.
Passwords do not provide much confidence when it comes to truly proving the identity of an entity. They are used because they are cheap, already built into existing software, and users are comfortable with using them. But passwords don’t prove conclusively that the user “jsmith” is really John Smith; they just prove that the person using the account jsmith has typed in the correct password. Systems that hold sensitive information (medical, financial, and so on) are commonly identified as targets for attackers. Mining usernames via search engines or simply using common usernames (like jsmith) and attempting to log in to these sites is very common. If you’ve ever signed up at a website for access to download a “free” document or file, what username did you use? Is it the same one you use for other sites? Maybe even the same password? Crafty attackers might be mining information via other websites that seem rather friendly, offering to evaluate your IQ and send you the results, or enter you into a sweepstakes. Remember that untrained, unaware users are an organization’s biggest threat.
Many financial organizations that provide online banking functionality have implemented multifactor authentication requirements. A user may need to provide a username, password, and then a one-time password value that was sent to their cell phone or e-mail during the authentication process.
Finally, a best practice is to exchange all authentication information (and all authenticated content) via a secure mechanism. This will typically mean to encrypt the credential and the channel of communication through Transport Layer Security (TLS). Some sites, however, still don’t use encrypted authentication mechanisms and have exposed themselves to the threat of attackers sniffing usernames and passwords.
Input Validation
Web servers are just like any other software applications; they can only carry out the functionality their instructions dictate. They are designed to process requests via a certain protocol. When a person searches on Google for the term “cissp,” the browser sends a request of the form https://www.google.com/?q=cissp using a protocol called Hypertext Transfer Protocol (HTTP). It passes the parameter “q=cissp” to the web application on the host called www in the domain google.com. A request in this form is called a Uniform Resource Locator (URL). Like many situations in our digital world, there is more than one way to request something because computers speak several different “languages”—such as binary, hexadecimal, and many encoding mechanisms—each of which is interpreted and processed by the system as valid commands. Validating that these requests are allowed is part of input validation and is usually tied to coded validation rules within the web server software. Attackers have figured out how to bypass some of these coded validation rules.
Some input validation attack examples follow:
• Path or directory traversal This attack is also known as the “dot dot slash” because it is perpetrated by inserting the characters “../” several times into a URL to back up or traverse into directories that weren’t supposed to be accessible from the Web. The command “../” at the command prompt tells the system to back up to the previous directory (i.e., “cd ../”). If a web server’s default directory is c:inetpubwww, a URL requesting http://www.website.com/scripts/../../../../../windows/system32/cmd.exe?/c+dir+c: would issue the command to back up several directories to ensure it has gone all the way to the root of the drive and then make the request to change to the operating system directory (windowssystem32) and run the cmd.exe listing the contents of the C: drive. Access to the command shell allows extensive access for the attacker.
• Unicode encoding Unicode is an industry-standard mechanism developed to represent the entire range of over 100,000 textual characters in the world as a standard coding format. Web servers support Unicode to support different character sets (for different languages), and, at one time, many web server software applications supported it by default. So, even if we told our systems to not allow the “../” directory traversal request previously mentioned, an attacker using Unicode could effectively make the same directory traversal request without using “/” but with any of the Unicode representations of that character (three exist: %c1%1c, %c0%9v, and %c0%af). That request may slip through unnoticed and be processed.
• URL encoding Ever notice a “space” that appears as “%20” in a URL in a web browser? The “%20” represents the space because spaces aren’t allowed characters in a URL. Much like the attacks using Unicode characters, attackers found that they could bypass filtering techniques and make requests by representing characters differently.
Almost every web application is going to have to accept some input. When you use the Web, you are constantly asked to input information such as usernames, passwords, and credit card information. To a web application, this input is just data that is to be processed like the rest of the code in the application. Usually, this input is used as a variable and fed into some code that will process it based on its logic instructions, such as IF [username input field]=X AND [password input field]=Y THEN Authenticate. This will function well assuming there is always correct information put into the input fields. But what if the wrong information is input? Developers have to cover all the angles. They have to assume that sometimes the wrong input will be given, and they have to handle that situation appropriately. To deal with this, a routine is usually coded in that will tell the system what to do if the input isn’t what was expected.
Client-side validation is when the input validation is done at the client before it is even sent back to the server to process. If you’ve missed a field in a web form and before clicking Submit, you immediately receive a message informing you that you’ve forgotten to fill in one of the fields, you’ve experienced client-side validation. Client-side validation is a good idea because it avoids incomplete requests being sent to the server and the server having to send back an error message to the user. The problem arises when the client-side validation is the only validation that takes place. In this situation, the server trusts that the client has done its job correctly and processes the input as if it is valid. In normal situations, accepting this input would be fine, but when an attacker can intercept the traffic between the client and server and modify it or just directly make illegitimate requests to the server without using a client, a compromise is more likely.
In an environment where input validation is weak, an attacker will try to input specific operating system commands into the input fields instead of what the system is expecting (such as the username and password) in an effort to trick the system into running the rogue commands. Remember that software can only do what it’s programmed to do, and if an attacker can get it to run a command, the software will execute the command just as it would if the command came from a legitimate application. If the web application is written to access a database, as most are, there is the threat of SQL injection, where instead of valid input, the attacker puts actual database commands into the input fields, which are then parsed and run by the application. SQL (Structured Query Language) statements can be used by attackers to bypass authentication and reveal all records in a database.
Remember that different layers of a system (see Figure 8-30) all have their own vulnerabilities that must be identified and fixed.
A similar type of attack is cross-site scripting (XSS), in which an attacker discovers and exploits a vulnerability on a website to inject malicious code into a web application. XSS attacks enable an attacker to inject their malicious code (in client-side scripting languages, such as JavaScript) into vulnerable web pages. When an unsuspecting user visits the infected page, the malicious code executes on the victim’s browser and may lead to stolen cookies, hijacked sessions, malware execution, or bypassed access control, or aid in exploiting browser vulnerabilities. There are three different XSS vulnerabilities:
• Nonpersistent XSS vulnerabilities, or reflected vulnerabilities, occur when an attacker tricks the victim into processing a URL programmed with a rogue script to steal the victim’s sensitive information (cookie, session ID, etc.). The principle behind this attack lies in exploiting the lack of proper input or output validation on dynamic websites.
• Persistent XSS vulnerabilities, also known as stored or second-order vulnerabilities, are generally targeted at websites that allow users to input data that is stored in a database or any other such location (e.g., forums, message boards, guest books, etc.). The attacker posts some text that contains some malicious JavaScript, and when other users later view the posts, their browsers render the page and execute the attacker’s JavaScript.
• DOM (Document Object Model)–based XSS vulnerabilities are also referred to as local cross-site scripting. DOM is the standard structure layout to represent HTML and XML documents in the browser. In such attacks the document components such as form fields and cookies can be referenced through JavaScript. The attacker uses the DOM environment to modify the original client-side JavaScript. This causes the victim’s browser to execute the resulting abusive JavaScript code.

Figure 8-30 Attacks can take place at many levels.
A number of applications are vulnerable to XSS attacks. The most common ones include online forums, message boards, search boxes, social networking websites, links embedded in e-mails, etc. Although cross-site attacks are primarily web application vulnerabilities, they may be used to exploit vulnerabilities in the victim’s web browser. Once the system is successfully compromised by the attackers, they may further penetrate into other systems on the network or execute scripts that may spread through the internal network.
The attacks in this section have the related issues of assuming that you can think of all the possible input values that will reach your web application, the effects that specially encoded data has on an application, and believing the input that is received is always valid. The countermeasures to many of these attacks would be to filter out all “known” malicious requests, never trust information coming from the client without first validating it, and implement a strong policy to include appropriate parameter checking in all applications.
Parameter Validation
The issue of parameter validation is akin to the issue of input validation mentioned earlier. Parameter validation is where the values that are being received by the application are validated to be within defined limits before the server application processes them within the system. The main difference between parameter validation and input validation would have to be whether the application was expecting the user to input a value as opposed to an environment variable that is defined by the application. Attacks in this area deal with manipulating values that the system would assume are beyond the client being able to configure, mainly because there isn’t a mechanism provided in the interface to do so.
In an effort to provide a rich end-user experience, web application designers have to employ mechanisms to keep track of the thousands of different web browsers that could be connected at any given time. The HTTP protocol by itself doesn’t facilitate managing the state of a user’s connection; it just connects to a server, gets whatever objects (the .htm file, graphics, and so forth) are requested in the HTML code, and then disconnects. If the browser disconnects or times out, how does the server know how to recognize this? Would you be irritated if you had to re-enter all of your information again because you spent too long looking at possible flights while booking a flight online? Since most people would, web developers employ the technique of passing a cookie to the client to help the server remember things about the state of the connection. A cookie isn’t a program, but rather just data passed and stored in memory (called a session cookie), or locally as a file (called a persistent cookie), to pass state information back to the server. An example of how cookies are employed would be a shopping cart application used on a commercial website. As you put items into your cart, they are maintained by updating a session cookie on your system. You may have noticed the “Cookies must be enabled” message that some websites issue as you enter their site.
Since accessing a session cookie in memory is usually beyond the reach of most users, most web developers didn’t think about this as a serious threat when designing their systems. It is not uncommon for web developers to enable account lockout after a certain number of unsuccessful login attempts have occurred. If a developer is using a session cookie to keep track of how many times a client has attempted to log in, there may be a vulnerability here. If an application didn’t want to allow more than three unsuccessful logins before locking a client out, the server might pass a session cookie to the client, setting a value such as “number of allowed logins = 3.” After each unsuccessful attempt, the server would tell the client to decrement the “number of allowed logins” value. When the value reaches 0, the client would be directed to a “Your account has been locked out” page.
A web proxy is a piece of software installed on a system that is designed to intercept all traffic between the local web browser and the web server. Using freely available web proxy software (such as Paros Proxy or Burp Suite), an attacker could monitor and modify any information as it travels in either direction. In the preceding example, when the server tells the client via a session cookie that the “number of allowed logins = 3,” if that information is intercepted by an attacker using one of these proxies and he changes the value to “number of allowed logins = 50000,” this would effectively allow a brute-force attack on the system if it has no other validation mechanism in place.
Using a web proxy can also exploit the use of hidden fields in web pages. As its name indicates, a hidden field is not shown in the user interface, but contains a value that is passed to the server when the web form is submitted. The exploit of using hidden values can occur when a web developer codes the prices of items on a web page as hidden values instead of referencing the items and their prices on the server. The attacker uses the web proxy to intercept the submitted information from the client and changes the value (the price) before it gets to the server. This is surprisingly easy to do and, assuming no other checks are in place, would allow the perpetrator to see the new values specified in the e-commerce shopping cart.
The countermeasure that would lessen the risk associated with these threats would be adequate parameter validation, which may include pre-validation and post-validation controls. In a client/server environment, pre-validation controls may be placed on the client side prior to submitting requests to the server. Even when these are employed, the server should perform parallel pre-validation of input prior to application submission because a client will have fewer controls than a server, and may have been compromised or bypassed.
• Pre-validation Input controls verifying data is in appropriate format and compliant with application specifications prior to submission to the application. An example of this would be form field validation, where web forms do not allow letters in a field that is expecting to receive a number (currency) value.
• Post-validation Ensuring an application’s output is consistent with expectations (that is, within predetermined constraints of reasonableness).
Session Management
As highlighted earlier, managing several thousand different clients connecting to a web-based application is a challenge. The aspect of session management requires consideration before delivering applications via the Web. The most commonly used method of managing client sessions is to assign unique session IDs to every connection. A session ID is a value sent by the client to the server with every request that uniquely identifies the client to the server or application. In the event that an attacker were able to acquire or even guess an authenticated client’s session ID and render it to the server as its own session ID, the server would be fooled and the attacker would have access to the session.
The old “never send anything in cleartext” rule certainly applies here. HTTP traffic is unencrypted by default and does nothing to combat an attacker sniffing session IDs off the wire. Because session IDs are usually passed in, and maintained, via HTTP, they should be protected in some way.
An attacker being able to predict or guess the session IDs would also be a threat in this type of environment. Using sequential session IDs for clients would be a mistake. Random session IDs of an appropriate length would counter session ID prediction. Building in some sort of timestamp or time-based validation will combat replay attacks, a simple attack in which an attacker captures the traffic from a legitimate session and replays it to authenticate his session. Finally, any cookies that are used to keep state on the connection should also be encrypted.
Web Application Security Principles
Considering their exposed nature, websites are primary targets during an attack. It is, therefore, essential for web developers to abide by the time-honored and time-tested principles to provide the maximum level of deterrence to attackers. Web application security principles are meant to govern programming practices to regulate programming styles and strategically reduce the chances of repeating known software bugs and logical flaws.
A good number of websites are exploited on the basis of vulnerabilities arising from reckless programming. With the forever growing number of websites out there, the possibility of exploiting the exploitable code is vast.
The first pillar of implementing security principles is analyzing the website architecture. The clearer and simpler a website is, the easier it is to analyze its various security aspects. Once a website has been strategically analyzed, the user-generated input fed into the website also needs to be critically scrutinized. As a rule, all input must be considered unsafe, or rogue, and ought to be sanitized before being processed. Likewise, all output generated by the system should also be filtered to ensure private or sensitive data is not being disclosed.
In addition, using encryption helps secure the input/output operations of a web application. Though encrypted data may be intercepted by malicious users, it should only be readable, or modifiable, by those with the secret key used to encrypt it.
In the event of an error, websites ought to be designed to behave in a predictable and noncompromising manner. This is also generally referred to as failing securely. Systems that fail securely display friendly error messages without revealing internal system details.
An important element in designing security functionality is keeping in perspective the human element. Though programmers may be tempted to prompt users for passwords on every mouse click, to keep security effective, web developers must maintain a state of equilibrium between functionality and security. Tedious authentication techniques usually do not stay in practice for too long. Experience has shown that the best security measures are those that are simple, intuitive, and psychologically acceptable.
A common but ineffective approach to security implementation is the use of “security through obscurity.” Security through obscurity assumes that creating overly complex or perplexing programs can reduce the chances of interventions in the software. Though obscure programs may take a tad longer to dissect, this does not guarantee protection from resolute and determined attackers. Protective measures, hence, cannot consist solely of obfuscation.
At the end, it is important to realize that the implementation of even the most beefy security techniques, without tactical considerations, will cause a website to remain as weak as its weakest link. That link could very well allow adversaries to reach the crown jewels of most organizations: their data.
Database Management
Databases have a long history of storing important intellectual property and items that are considered valuable and proprietary to companies. Because of this, they usually live in an environment of mystery to all but the database and network administrators. The less anyone knows about the databases, the better. Users generally access databases indirectly through a client interface, and their actions are restricted to ensure the confidentiality, integrity, and availability of the data held within the database and the structure of the database itself.
The risks are increasing as companies run to connect their networks to the Internet, allow remote user access, and provide more and more access to external entities. A large risk to understand is that these activities can allow indirect access to a back-end database. In the past, employees accessed customer information held in databases instead of allowing customers to access it themselves. Today, many companies allow their customers to access data in their databases through a browser. The browser makes a connection to the company’s middleware, which then connects them to the back-end database. This adds levels of complexity, and the database is accessed in new and unprecedented ways.
One example is in the banking world, where online banking is all the rage. Many financial institutions want to keep up with the times and add the services they think their customers will want. But online banking is not just another service like being able to order checks. Most banks work in closed (or semi-closed) environments, and opening their environments to the Internet is a huge undertaking. The perimeter network needs to be secured, middleware software has to be developed or purchased, and the database should be behind one or, preferably, multiple firewalls. Many times, components in the business application tier are used to extract data from the databases and process the customer requests.
Access control can be restricted by only allowing roles to interact with the database. The database administrator can define specific roles that are allowed to access the database. Each role has assigned rights and permissions, and customers and employees are then ported into these roles. Any user who is not within one of these roles is denied access. This means that if an attacker compromises the firewall and other perimeter network protection mechanisms and then is able to make requests to the database, the database is still safe if he is not in one of the predefined roles. This process streamlines access control and ensures that no users or evildoers can access the database directly, but must access it indirectly through a role account. Figure 8-31 illustrates these concepts.
Database Management Software
A database is a collection of data stored in a meaningful way that enables multiple users and applications to access, view, and modify that data as needed. Databases are managed with software that provides these types of capabilities. It also enforces access control restrictions, provides data integrity and redundancy, and sets up different procedures for data manipulation. This software is referred to as a database management system (DBMS) and is usually controlled by database administrators. Databases not only store data, but may also process data and represent it in a more usable and logical form. DBMSs interface with programs, users, and data within the database. They help us store, organize, and retrieve information effectively and efficiently.
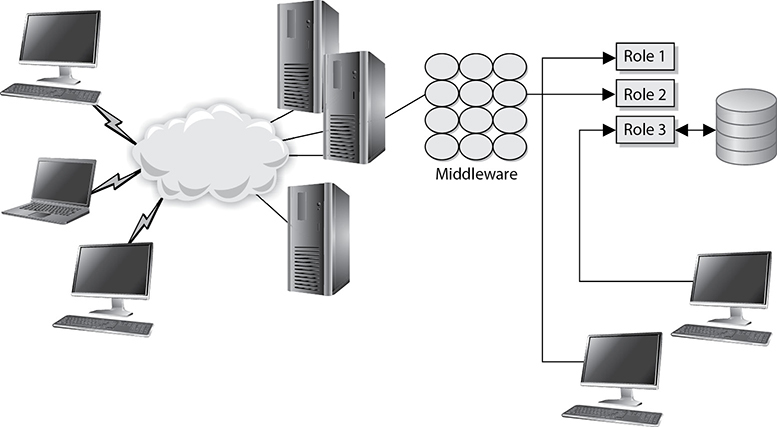
Figure 8-31 One type of database security is to employ roles.
NOTE A database management system (DBMS) is a suite of programs used to manage large sets of structured data with ad hoc query capabilities for many types of users. A DBMS can also control the security parameters of the database.
A database is the mechanism that provides structure for the data collected. The actual specifications of the structure may be different per database implementation, because different organizations or departments work with different types of data and need to perform diverse functions upon that information. There may be different workloads, relationships between the data, platforms, performance requirements, and security goals. Any type of database should have the following characteristics:
• It ensures consistency among the data held on several different servers throughout the network.
• It allows for easier backup procedures.
• It provides transaction persistence.
• It provides recovery and fault tolerance.
• It allows the sharing of data with multiple users.
• It provides security controls that implement integrity checking, access control, and the necessary level of confidentiality.
NOTE Transaction persistence means the database procedures carrying out transactions are durable and reliable. The state of the database’s security should be the same after a transaction has occurred, and the integrity of the transaction needs to be ensured.
Because the needs and requirements for databases vary, different data models can be implemented that align with different business and organizational needs.
Database Models
The database model defines the relationships between different data elements; dictates how data can be accessed; and defines acceptable operations, the type of integrity offered, and how the data is organized. A model provides a formal method of representing data in a conceptual form and provides the necessary means of manipulating the data held within the database. Databases come in several types of models, as listed next:
• Relational
• Hierarchical
• Network
• Object-oriented
• Object-relational
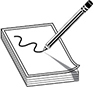
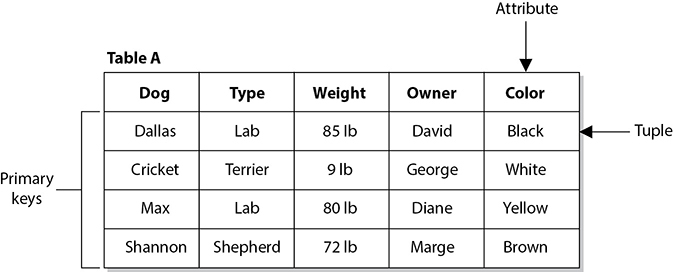
A relational database model uses attributes (columns) and tuples (rows) to contain and organize information (see Figure 8-32). The relational database model is the most widely used model today. It presents information in the form of tables. A relational database is composed of two-dimensional tables, and each table contains unique rows, columns, and cells (the intersection of a row and a column). Each cell contains only one data value that represents a specific attribute value within a given tuple. These data entities are linked by relationships. The relationships between the data entities provide the framework for organizing data. A primary key is a field that links all the data within a record to a unique value. For example, in the table in Figure 8-32, the primary keys are Product G345 and Product G978. When an application or another record refers to this primary key, it is actually referring to all the data within that given row.
A hierarchical data model (see Figure 8-33) combines records and fields that are related in a logical tree structure. The structure and relationship between the data elements are different from those in a relational database. In the hierarchical database the parents can have one child, many children, or no children. The tree structure contains branches, and each branch has a number of leaves, or data fields. These databases have well-defined, prespecified access paths, but are not as flexible in creating relationships between data elements as a relational database. Hierarchical databases are useful for mapping one-to-many relationships.
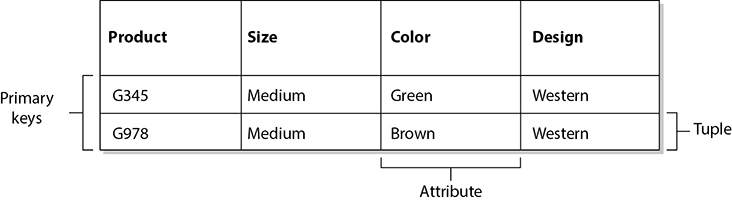
Figure 8-32 Relational databases hold data in table structures.
The hierarchical structured database is one of the first types of database model created, but is not as common as relational databases. To be able to access a certain data entity within a hierarchical database requires the knowledge of which branch to start with and which route to take through each layer until the data is reached. Unlike relational databases, it does not use indexes to search procedures, and links (relationships) cannot be created between different branches and leaves on different layers.
Figure 8-33 A hierarchical data model uses a tree structure and a parent/child relationship.
NOTE The hierarchical model is almost always employed when building indexes for relational databases. An index can be built on any attribute and allows for very fast searches of the data over that attribute.
The most commonly used implementation of the hierarchical model is in the Lightweight Directory Access Protocol (LDAP) model. This model is used in the Windows Registry structure and different file systems, but it is not commonly used in newer database products.
The network database model is built upon the hierarchical data model. Instead of being constrained by having to know how to go from one branch to another and then from one parent to a child to find a data element, the network database model allows each data element to have multiple parent and child records. This forms a redundant network-like structure instead of a strict tree structure. (The name does not indicate it is on or distributed throughout a network; it just describes the data element relationships.) Figure 8-34 shows how a network database model sets up a structure that is similar to a mesh network topology for the sake of redundancy and allows for quick retrieval of data compared to the hierarchical model.
The network database model uses the constructs of records and sets. A record contains fields, which may lay out in a hierarchical structure. Sets define the one-to-many relationships between the different records. One record can be the “owner” of any number of sets, and the same “owner” can be a member of different sets. This means that one record can be the “top dog” and have many data elements underneath it, or that record can be lower on the totem pole and be beneath a different field that is its “top dog.” This allows for a lot of flexibility in the development of relationships between data elements.

Figure 8-34 Various database models
An object-oriented database is designed to handle a variety of data types (images, audio, documents, video). An object-oriented database management system (ODBMS) is more dynamic in nature than a relational database, because objects can be created when needed and the data and procedure (called method) go with the object when it is requested. In a relational database, the application has to use its own procedures to obtain data from the database and then process the data for its needs. The relational database does not actually provide procedures, as object-oriented databases do. The object-oriented database has classes to define the attributes and procedures of its objects.
As an analogy, let’s say two different companies provide the same data to their customer bases. If you go to Company A (relational), the person behind the counter will just give you a piece of paper that contains information. Now you have to figure out what to do with that information and how to properly use it for your needs. If you go to Company B (object-oriented), the person behind the counter will give you a box. Within this box is a piece of paper with information on it, but you will also be given a couple of tools to process the data for your needs instead of you having to do it yourself. So in object-oriented databases, when your application queries for some data, what is returned is not only the data, but also the code to carry out procedures on this data.
The goal of creating this type of model was to address the limitations that relational databases encountered when large amounts of data must be stored and processed. An object-oriented database also does not depend upon SQL for interactions, so applications that are not SQL clients can work with these types of databases.
NOTE Structured Query Language (SQL) is a standard programming language used to allow clients to interact with a database. Many database products support SQL. It allows clients to carry out operations such as inserting, updating, searching, and committing data. When a client interacts with a database, it is most likely using SQL to carry out requests.
An object-relational database (ORD) or object-relational database management system (ORDBMS) is a relational database with a software front end that is written in an object-oriented programming language. Why would we create such a silly combination? Well, a relational database just holds data in static two-dimensional tables. When the data is accessed, some type of processing needs to be carried out on it—otherwise, there is really no reason to obtain the data. If we have a front end that provides the procedures (methods) that can be carried out on the data, then each and every application that accesses this database does not need to have the necessary procedures. This means that each and every application does not need to contain the procedures necessary to gain what it really wants from this database.
Different companies will have different business logic that needs to be carried out on the stored data. Allowing programmers to develop this front-end software piece allows the business logic procedures to be used by requesting applications and the data within the database. For example, if we had a relational database that contains inventory data for our company, we might want to be able to use this data for different business purposes. One application can access that database and just check the quantity of widget A products we have in stock. So a front-end object that can carry out that procedure will be created, the data will be grabbed from the database by this object, and the answer will be provided to the requesting application. We also have a need to carry out a trend analysis, which will indicate which products were moved the most from inventory to production. A different object that can carry out this type of calculation will gather the necessary data and present it to our requesting application. We have many different ways we need to view the data in that database: how many products were damaged during transportation, how fast did each vendor fulfill our supply requests, how much does it cost to ship the different products based on their weights, and so on. The data objects in Figure 8-35 contain these different business logic instructions.
Figure 8-35 The object-relational model allows objects to contain business logic and functions.
Database Programming Interfaces
Data is useless if you can’t access it and use it. Applications need to be able to obtain and interact with the information stored in databases. They also need some type of interface and communication mechanism. The following sections address some of these interface languages.
Open Database Connectivity (ODBC) An API that allows an application to communicate with a database, either locally or remotely. The application sends requests to the ODBC API. ODBC tracks down the necessary database-specific driver for the database to carry out the translation, which in turn translates the requests into the database commands that a specific database will understand.
Object Linking and Embedding Database (OLE DB) Separates data into components that run as middleware on a client or server. It provides a low-level interface to link information across different databases and provides access to data no matter where it is located or how it is formatted.
The following are some characteristics of an OLE DB:
• It’s a replacement for ODBC, extending its feature set to support a wider variety of nonrelational databases, such as object databases and spreadsheets that do not necessarily implement SQL.
• A set of COM-based interfaces provides applications with uniform access to data stored in diverse data sources (see Figure 8-36).
• Because it is COM-based, OLE DB is limited to being used by Microsoft Windows–based client tools.
• A developer accesses OLE DB services through ActiveX Data Objects (ADO).
• It allows different applications to access different types and sources of data.

Figure 8-36 OLE DB provides an interface to allow applications to communicate with different data sources.
ActiveX Data Objects (ADO) An API that allows applications to access back-end database systems. It is a set of ODBC interfaces that exposes the functionality of data sources through accessible objects. ADO uses the OLE DB interface to connect with the database, and can be developed with many different scripting languages. It is commonly used in web applications and other client/server applications. The following are some characteristics of ADO:
• It’s a high-level data access programming interface to an underlying data access technology (such as OLE DB).
• It’s a set of COM objects for accessing data sources, not just database access.
• It allows a developer to write programs that access data without knowing how the database is implemented.
• SQL commands are not required to access a database when using ADO.
Java Database Connectivity (JDBC) An API that allows a Java application to communicate with a database. The application can bridge through ODBC or directly to the database. The following are some characteristics of JDBC:
• It is an API that provides the same functionality as ODBC but is specifically designed for use by Java database applications.
• It has database-independent connectivity between the Java platform and a wide range of databases.
• It is a Java API that enables Java programs to execute SQL statements.
Relational Database Components
Like all software, databases are built with programming languages. Most database languages include a data definition language (DDL), which defines the schema; a data manipulation language (DML), which examines data and defines how the data can be manipulated within the database; a data control language (DCL), which defines the internal organization of the database; and an ad hoc query language (QL), which defines queries that enable users to access the data within the database.
Each type of database model may have many other differences, which vary from vendor to vendor. Most, however, contain the following basic core functionalities:
• Data definition language (DDL) Defines the structure and schema of the database. The structure could mean the table size, key placement, views, and data element relationship. The schema describes the type of data that will be held and manipulated, and their properties. It defines the structure of the database, access operations, and integrity procedures.
• Data manipulation language (DML) Contains all the commands that enable a user to view, manipulate, and use the database (view, add, modify, sort, and delete commands).
• Query language (QL) Enables users to make requests of the database.
• Report generator Produces printouts of data in a user-defined manner.
Data Dictionary
A data dictionary is a central collection of data element definitions, schema objects, and reference keys. The schema objects can contain tables, views, indexes, procedures, functions, and triggers. A data dictionary can contain the default values for columns, integrity information, the names of users, the privileges and roles for users, and auditing information. It is a tool used to centrally manage parts of a database by controlling data about the data (referred to as metadata) within the database. It provides a cross-reference between groups of data elements and the databases.
The database management software creates and reads the data dictionary to ascertain what schema objects exist and checks to see if specific users have the proper access rights to view them (see Figure 8-37). When users look at the database, they can be restricted by specific views. The different view settings for each user are held within the data dictionary. When new tables, new rows, or new schemas are added, the data dictionary is updated to reflect this.
Primary vs. Foreign Key
The primary key is an identifier of a row and is used for indexing in relational databases. Each row must have a unique primary key to properly represent the row as one entity. When a user makes a request to view a record, the database tracks this record by its unique primary key. If the primary key were not unique, the database would not know which record to present to the user. In the following illustration, the primary keys for Table A are the dogs’ names. Each row (tuple) provides characteristics for each dog (primary key). So when a user searches for Cricket, the characteristics of the type, weight, owner, and color will be provided.

Figure 8-37 The data dictionary is a centralized program that contains information about a database.
A primary key is different from a foreign key, although they are closely related. If an attribute in one table has a value matching the primary key in another table and there is a relationship set up between the two of them, this attribute is considered a foreign key. This foreign key is not necessarily the primary key in its current table. It only has to contain the same information that is held in another table’s primary key and be mapped to the primary key in this other table. In the following illustration, a primary key for Table A is Dallas. Because Table B has an attribute that contains the same data as this primary key and there is a relationship set up between these two keys, it is referred to as a foreign key. This is another way for the database to track relationships between the data that it houses.
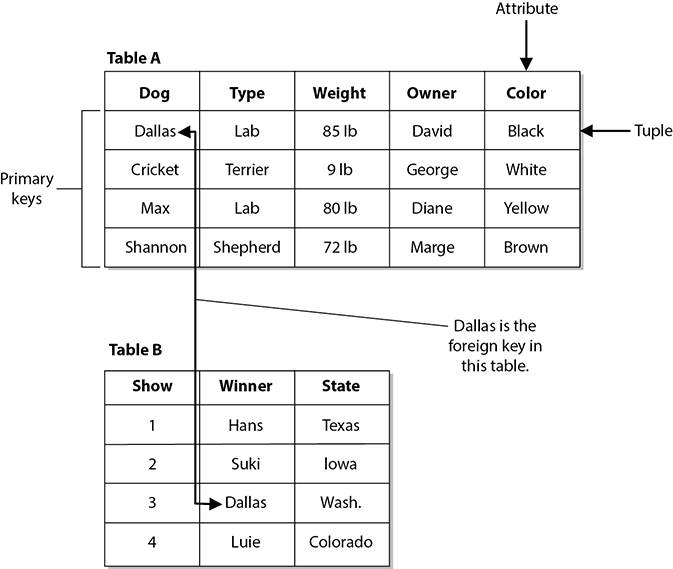
We can think of being presented with a web page that contains the data on Table B. If we want to know more about this dog named Dallas, we double-click that value and the browser presents the characteristics about Dallas that are in Table A.
This allows us to set up our databases with the relationship between the different data elements as we see fit.
Integrity
Like other resources within a network, a database can run into concurrency problems. Concurrency issues come up when there is data that will be accessed and modified at the same time by different users and/or applications. As an example of a concurrency problem, suppose that two groups use one price sheet to know how much stock to order for the next week and also to calculate the expected profit. If Dan and Elizabeth copy this price sheet from the file server to their workstations, they each have a copy of the original file. Suppose that Dan changes the stock level of computer books from 120 to 5 because his group sold 115 book in the last three days. He also uses the current prices listed in the price sheet to estimate his group’s expected profits for the next week. Elizabeth reduces the price on several computer books on her copy of the price sheet and sees that the stock level of computer books is still over 100, so she chooses not to order any more for next week for her group. Dan and Elizabeth do not communicate this different information to each other, but instead upload their copies of the price sheet to the server for everyone to view and use.
Dan copies his changes back to the file server, and then 30 seconds later Elizabeth copies her changes over Dan’s changes. So, the file only reflects Elizabeth’s changes. Because they did not synchronize their changes, they are both now using incorrect data. Dan’s profit estimates are off because he does not know that Elizabeth reduced the prices, and next week Elizabeth will have no computer books because she did not know that the stock level had dropped to five.
The same thing happens in databases. If controls are not in place, two users can access and modify the same data at the same time, which can be detrimental to a dynamic environment. To ensure that concurrency issues do not cause problems, processes can lock tables within a database, make changes, and then release the software lock. The next process that accesses the table will then have the updated information. Locking ensures that two processes do not access the same table at the same time. Pages, tables, rows, and fields can be locked to ensure that updates to data happen one at a time, which enables each process and subject to work with correct and accurate information.
Database software performs three main types of integrity services:
• A semantic integrity mechanism makes sure structural and semantic rules are enforced. These rules pertain to data types, logical values, uniqueness constraints, and operations that could adversely affect the structure of the database.
• A database has referential integrity if all foreign keys reference existing primary keys. There should be a mechanism in place that ensures no foreign key contains a reference to a primary key of a nonexistent record, or a null value.
• Entity integrity guarantees that the tuples are uniquely identified by primary key values. In the previous illustration, the primary keys are the names of the dogs, in which case, no two dogs could have the same name. For the sake of entity integrity, every tuple must contain one primary key. If it does not have a primary key, it cannot be referenced by the database.
The database must not contain unmatched foreign key values. Every foreign key refers to an existing primary key. In the example presented in the previous section, if the foreign key in Table B is Dallas, then Table A must contain a record for a dog named Dallas. If these values do not match, then their relationship is broken, and again the database cannot reference the information properly.
Other configurable operations are available to help protect the integrity of the data within a database. These operations are rollbacks, commits, savepoints, checkpoints, and two-phase commits.
The rollback is an operation that ends a current transaction and cancels the current changes to the database. These changes could have taken place to the data held within the database or a change to the schema. When a rollback operation is executed, the changes are cancelled and the database returns to its previous state. A rollback can take place if the database has some type of unexpected glitch or if outside entities disrupt its processing sequence. Instead of transmitting and posting partial or corrupt information, the database will roll back to its original state and log these errors and actions so they can be reviewed later.
The commit operation completes a transaction and executes all changes just made by the user. As its name indicates, once the commit command is executed, the changes are committed and reflected in the database. These changes can be made to data or schema information. Because these changes are committed, they are then available to all other applications and users. If a user attempts to commit a change and it cannot complete correctly, a rollback is performed. This ensures that partial changes do not take place and that data is not corrupted.
Savepoints are used to make sure that if a system failure occurs, or if an error is detected, the database can attempt to return to a point before the system crashed or hiccupped. For a conceptual example, say Dave typed, “Jeremiah was a bullfrog. He was <savepoint> a good friend of mine.” (The system inserted a savepoint.) Then a freak storm came through and rebooted the system. When Dave got back into the database client application, he might see “Jeremiah was a bullfrog. He was,” but the rest was lost. Therefore, the savepoint saved some of his work. Databases and other applications will use this technique to attempt to restore the user’s work and the state of the database after a glitch, but some glitches are just too large and invasive to overcome.
Savepoints are easy to implement within databases and applications, but a balance must be struck between too many and not enough savepoints. Having too many savepoints can degrade the performance, whereas not having enough savepoints runs the risk of losing data and decreasing user productivity because the lost data would have to be reentered. Savepoints can be initiated by a time interval, a specific action by the user, or the number of transactions or changes made to the database. For example, a database can set a savepoint for every 15 minutes, every 20 transactions completed, each time a user gets to the end of a record, or every 12 changes made to the databases.
So a savepoint restores data by enabling the user to go back in time before the system crashed or hiccupped. This can reduce frustration and help us all live in harmony.
Checkpoints are very similar to savepoints. When the database software fills up a certain amount of memory, a checkpoint is initiated, which saves the data from the memory segment to a temporary file. If a glitch is experienced, the software will try to use this information to restore the user’s working environment to its previous state.
A two-phase commit mechanism is yet another control that is used in databases to ensure the integrity of the data held within the database. Databases commonly carry out transaction processes, which means the user and the database interact at the same time. The opposite is batch processing, which means that requests for database changes are put into a queue and activated all at once—not at the exact time the user makes the request. In transactional processes, many times a transaction will require that more than one database be updated during the process. The databases need to make sure each database is properly modified, or no modification takes place at all. When a database change is submitted by the user, the different databases initially store these changes temporarily. A transaction monitor will then send out a “pre-commit” command to each database. If all the right databases respond with an acknowledgment, then the monitor sends out a “commit” command to each database. This ensures that all of the necessary information is stored in all the right places at the right time.
Database Security Issues
The two main database security issues this section addresses are aggregation and inference. Aggregation happens when a user does not have the clearance or permission to access specific information, but she does have the permission to access components of this information. She can then figure out the rest and obtain restricted information. She can learn of information from different sources and combine it to learn something she does not have the clearance to know.

EXAM TIP Aggregation is the act of combining information from separate sources. The combination of the data forms new information, which the subject does not have the necessary rights to access. The combined information has a sensitivity that is greater than that of the individual parts.
The following is a silly conceptual example. Let’s say a database administrator does not want anyone in the Users group to be able to figure out a specific sentence, so he segregates the sentence into components and restricts the Users group from accessing it, as represented in Figure 8-38. Emily, through each of three different roles she has, can access components A, C, and F. Because she is particularly bright (a Wheel of Fortune whiz), she figures out the sentence and now knows the restricted secret.
To prevent aggregation, the subject, and any application or process acting on the subject’s behalf, needs to be prevented from gaining access to the whole collection, including the independent components. The objects can be placed into containers, which are classified at a higher level to prevent access from subjects with lower-level permissions or clearances. A subject’s queries can also be tracked, and context-dependent access control can be enforced. This would keep a history of the objects that a subject has accessed and restrict an access attempt if there is an indication that an aggregation attack is under way.
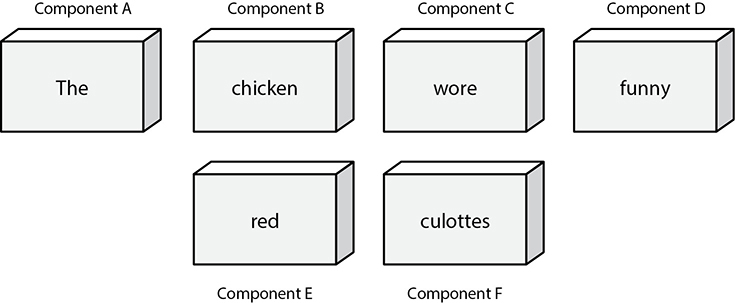
Figure 8-38 Because Emily has access to components A, C, and F, she can figure out the secret sentence through aggregation.
The other security issue is inference, which is the intended result of aggregation. The inference problem happens when a subject deduces the full story from the pieces he learned of through aggregation. This is an issue when data at a lower security level indirectly portrays data at a higher level.
EXAM TIP Inference is the ability to derive information not explicitly available.
For example, if a clerk were restricted from knowing the planned movements of troops based in a specific country, but did have access to food shipment requirements forms and tent allocation documents, he could figure out that the troops were moving to a specific place because that is where the food and tents are being shipped. The food shipment and tent allocation documents were classified as confidential, and the troop movement was classified as top secret. Because of the varying classifications, the clerk could ascertain top-secret information he was not supposed to know.
The trick is to prevent the subject, or any application or process acting on behalf of that subject, from indirectly gaining access to the inferable information. This problem is usually dealt with in the development of the database by implementing content- and context-dependent access control rules. Content-dependent access control is based on the sensitivity of the data. The more sensitive the data, the smaller the subset of individuals who can gain access to the data.
Context-dependent access control means that the software “understands” what actions should be allowed based upon the state and sequence of the request. So what does that mean? It means the software must keep track of previous access attempts by the user and understand what sequences of access steps are allowed. Content-dependent access control can go like this: “Does Julio have access to File A?” The system reviews the ACL on File A and returns with a response of “Yes, Julio can access the file, but can only read it.” In a context-dependent access control situation, it would be more like this: “Does Julio have access to File A?” The system then reviews several pieces of data: What other access attempts has Julio made? Is this request out of sequence of how a safe series of requests takes place? Does this request fall within the allowed time period of system access (8 a.m. to 5 p.m.)? If the answers to all of these questions are within a set of preconfigured parameters, Julio can access the file. If not, he is denied access.
If context-dependent access control is being used to protect against inference attacks, the database software would need to keep track of what the user is requesting. So Julio makes a request to see field 1, then field 5, then field 20, which the system allows, but once he asks to see field 15, the database does not allow this access attempt. The software must be preprogrammed (usually through a rule-based engine) as to what sequence and how much data Julio is allowed to view. If he is allowed to view more information, he may have enough data to infer something we don’t want him to know.
Obviously, content-dependent access control is not as complex as context-dependent access control because of the amount of items that needs to be processed by the system.
Some other common attempts to prevent inference attacks are cell suppression, partitioning the database, and noise and perturbation. Cell suppression is a technique used to hide specific cells that contain information that could be used in inference attacks. Partitioning a database involves dividing the database into different parts, which makes it much harder for an unauthorized individual to find connecting pieces of data that can be brought together and other information that can be deduced or uncovered. Noise and perturbation is a technique of inserting bogus information in the hopes of misdirecting an attacker or confusing the matter enough that the actual attack will not be fruitful.
Often, security is not integrated into the planning and development of a database. Security is an afterthought, and a trusted front end is developed to be used with the database instead. This approach is limited in the granularity of security and in the types of security functions that can take place.
As previously mentioned in this chapter, a common theme in security is a balance between effective security and functionality. In many cases, the more you secure something, the less functionality you have. Although this could be the desired result, it is important not to impede user productivity when security is being introduced.
Database Views
Databases can permit one group, or a specific user, to see certain information while restricting another group from viewing it altogether. This functionality happens through the use of database views, illustrated in Figure 8-39. If a database administrator wants to allow middle management members to see their departments’ profits and expenses but not show them the whole company’s profits, the DBA can implement views. Senior management would be given all views, which contain all the departments’ and the company’s profit and expense values, whereas each individual manager would only be able to view his or her department values.
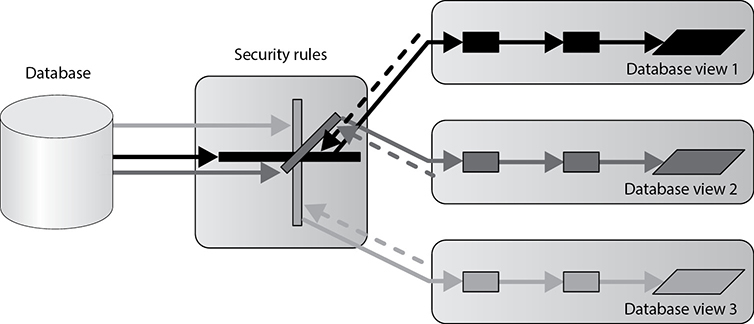
Figure 8-39 Database views are a logical type of access control.
Like operating systems, databases can employ discretionary access control (DAC) and mandatory access control (MAC), which are explained in Chapter 5. Views can be displayed according to group membership, user rights, or security labels. If a DAC system is employed, then groups and users can be granted access through views based on their identity, authentication, and authorization. If a MAC system in place, then groups and users can be granted access based on their security clearance and the data’s classification level.
Polyinstantiation
Sometimes a company does not want users at one level to access and modify data at a higher level. This type of situation can be handled in different ways. One approach denies access when a lower-level user attempts to access a higher-level object. However, this gives away information indirectly by telling the lower-level entity that something sensitive lives inside that object at that level.
Another way of dealing with this issue is polyinstantiation. This enables a table that contains multiple tuples with the same primary keys, with each instance distinguished by a security level. When this information is inserted into a database, lower-level subjects must be restricted from it. Instead of just restricting access, another set of data is created to fool the lower-level subjects into thinking the information actually means something else. For example, if a naval base has a cargo shipment of weapons going from Delaware to Ukraine via the ship Oklahoma, this type of information could be classified as top secret. Only the subjects with the security clearance of top secret and above should know this information, so a dummy file is created that states the Oklahoma is carrying a shipment from Delaware to Africa containing food, and it is given a security clearance of unclassified, as shown in Table 8-1. It will be obvious that the Oklahoma is gone, but individuals at lower security levels will think the ship is on its way to Africa, instead of Ukraine. This also makes sure no one at a lower level tries to commit the Oklahoma for any other missions. The lower-level subjects know that the Oklahoma is not available, and they will assign other ships for cargo shipments.
EXAM TIP Polyinstantiation is a process of interactively producing more detailed versions of objects by populating variables with different values or other variables. It is often used to prevent inference attacks.
In this example, polyinstantiation is used to create two versions of the same object so that lower-level subjects do not know the true information, thus stopping them from attempting to use or change that data in any way. It is a way of providing a cover story for the entities that do not have the necessary security level to know the truth. This is just one example of how polyinstantiation can be used. It is not strictly related to security, however, even though that is a common use. Whenever a copy of an object is created and populated with different data, meaning two instances of the same object have different attributes, polyinstantiation is in place.

Table 8-1 Example of Polyinstantiation to Provide a Cover Story to Subjects at Lower Security Levels
Online Transaction Processing
Online transaction processing (OLTP) is generally used when databases are clustered to provide fault tolerance and higher performance. OLTP provides mechanisms that watch for problems and deal with them appropriately when they do occur. For example, if a process stops functioning, the monitor mechanisms within OLTP can detect this and attempt to restart the process. If the process cannot be restarted, then the transaction taking place will be rolled back to ensure no data is corrupted or that only part of a transaction happens. Any erroneous or invalid transactions detected should be written to a transaction log. The transaction log also collects the activities of successful transactions. Data is written to the log before and after a transaction is carried out so a record of events exists.
The main goal of OLTP is to ensure that transactions either happen properly or don’t happen at all. Transaction processing usually means that individual indivisible operations are taking place independently. If one of the operations fails, the rest of the operations needs to be rolled back to ensure that only accurate data is entered into the database.
The set of systems involved in carrying out transactions is managed and monitored with a software OLTP product to make sure everything takes place smoothly and correctly.
OLTP can load-balance incoming requests if necessary. This means that if requests to update databases increase and the performance of one system decreases because of the large volume, OLTP can move some of these requests to other systems. This makes sure all requests are handled and that the user, or whoever is making the requests, does not have to wait a long time for the transaction to complete.
When there is more than one database, it is important they all contain the same information. Consider this scenario: Katie goes to the bank and withdraws $6,500 from her $10,000 checking account. Database A receives the request and records a new checking account balance of $3,500, but database B does not get updated. It still shows a balance of $10,000. Then, Katie makes a request to check the balance on her checking account, but that request gets sent to database B, which returns inaccurate information because the withdrawal transaction was never carried over to this database. OLTP makes sure a transaction is not complete until all databases receive and reflect this change.
OLTP records transactions as they occur (in real time), which usually updates more than one database in a distributed environment. This type of complexity can introduce many integrity threats, so the database software should implement the characteristics of what’s known as the ACID test:
• Atomicity Divides transactions into units of work and ensures that all modifications take effect or none takes effect. Either the changes are committed or the database is rolled back.
• Consistency A transaction must follow the integrity policy developed for that particular database and ensure all data is consistent in the different databases.
• Isolation Transactions execute in isolation until completed, without interacting with other transactions. The results of the modification are not available until the transaction is completed.
• Durability Once the transaction is verified as accurate on all systems, it is committed and the databases cannot be rolled back.
Data Warehousing and Data Mining
Data warehousing combines data from multiple databases or data sources into a large database for the purpose of providing more extensive information retrieval and data analysis. Data from different databases is extracted and transferred to a central data storage device called a warehouse. The data is normalized, which means redundant information is stripped out and data is formatted in the way the data warehouse expects it. This enables users to query one entity rather than accessing and querying different databases.
The data sources the warehouse is built from are used for operational purposes. A data warehouse is developed to carry out analysis. The analysis can be carried out to make business forecasting decisions and identify marketing effectiveness, business trends, and even fraudulent activities.
Data warehousing is not simply a process of mirroring data from different databases and presenting the data in one place. It provides a base of data that is then processed and presented in a more useful and understandable way. Related pieces of data are summarized and correlated before being presented to the user. Instead of having every piece of data presented, the user is given data in a more abridged form that best fits her needs.
Although this provides easier access and control, because the data warehouse is in one place, it also requires more stringent security. If an intruder were able to get into the data warehouse, he could access all of the company’s information at once.
Data mining is the process of massaging the data held in the data warehouse into more useful information. Data-mining tools are used to find an association and correlation in data to produce metadata. Metadata can show previously unseen relationships between individual subsets of information. Metadata can reveal abnormal patterns not previously apparent. A simplistic example in which data mining could be useful is in detecting insurance fraud. Suppose the information, claims, and specific habits of millions of customers are kept in a database warehouse, and a mining tool is used to look for certain patterns in claims. It might find that each time John Smith moved, he had an insurance claim two to three months following the move. He moved in 2006 and two months later had a suspicious fire, then moved in 2010 and had a motorcycle stolen three months after that, and then moved again in 2013 and had a burglar break in two months afterward. This pattern might be hard for people to manually catch because he had different insurance agents over the years, the files were just updated and not reviewed, or the files were not kept in a centralized place for agents to review.
Data mining can look at complex data and simplify it by using fuzzy logic (a set theory) and expert systems (that is, systems that use artificial intelligence) to perform the mathematical functions and look for patterns in data that are not so apparent. In many ways, the metadata is more valuable than the data it is derived from; thus, metadata must be highly protected.
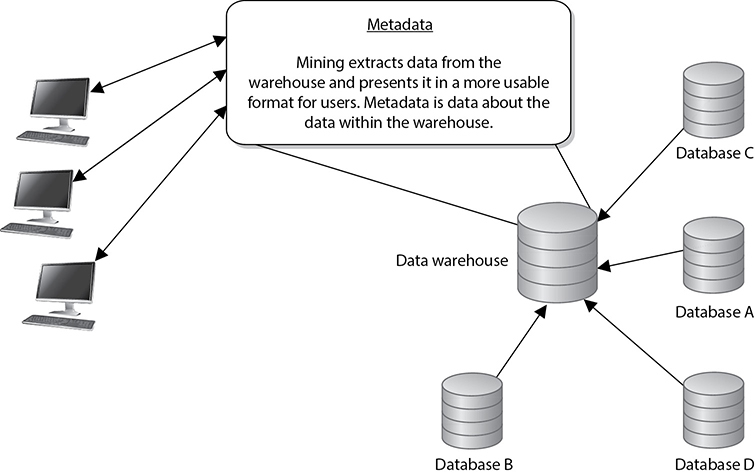
Figure 8-40 Mining tools are used to identify patterns and relationships in data warehouses.
The goal of data warehouses and data mining is to be able to extract information to gain knowledge about the activities and trends within the organization, as shown in Figure 8-40. With this knowledge, people can detect deficiencies or ways to optimize operations. For example, if we operate a retail store company, we want consumers to spend gobs of money at the stores. We can more successfully get their business if we understand customers’ purchasing habits. For example, if our data mining reveals that placing candy and other small items at the checkout stand increases purchases of those items 65 percent compared to placing them somewhere else in the store, we will place them at the checkout stand. If one store is in a more affluent neighborhood and we see a constant (or increasing) pattern of customers purchasing expensive wines there, that is where we would also sell our expensive cheeses and gourmet items. We would not place our gourmet items at another store that hardly ever sells expensive wines, and in fact we would probably stop selling expensive wines at that store.
NOTE Data mining is the process of analyzing a data warehouse using tools that look for trends, correlations, relationships, and anomalies without knowing the meaning of the data. Metadata is the result of storing data within a data warehouse and mining the data with tools. Data goes into a data warehouse and metadata comes out of that data warehouse.
So we would carry out these activities if we wanted to harness organization-wide data for comparative decision making, workflow automation, and/or competitive advantage. It is not just information aggregation; management’s goals in understanding different aspects of the company are to enhance business value and help employees work more productively.
Data mining is also known as knowledge discovery in database (KDD), and is a combination of techniques to identify valid and useful patterns. Different types of data can have various interrelationships, and the method used depends on the type of data and the patterns sought. The following are three approaches used in KDD systems to uncover these patterns:
• Classification Groups together data according to shared similarities
• Probabilistic Identifies data interdependencies and applies probabilities to their relationships
• Statistical Identifies relationships between data elements and uses rule discovery
It is important to keep an eye on the output from the KDD and look for anything suspicious that would indicate some type of internal logic problem. For example, if you wanted a report that outlines the net and gross revenues for each retail store, and instead get a report that states “Bob,” there may be an issue you need to look into.
Table 8-2 outlines the different types of systems used, depending on the requirements of the resulting data.
Big data is a term that is related to, but distinct from, data warehousing and data mining. Big data is broadly defined as very large data sets with characteristics that make them unsuitable for traditional analysis techniques. These traits are widely agreed to include heterogeneity, complexity, variability, lack of reliability, and sheer volume. Heterogeneity speaks to the diversity of both sources and structure of the data, which means that some data could be images while other data could be free text. Big data is also complex, particularly in terms of interrelationships such as the one between images that are trending on social media and news articles describing current events. By variability, we mean that some sources produce nearly constant data while other sources produce data much more sporadically or rarely. Related to this challenge is the fact that some sources of big data may be unreliable or of unknown reliability. Finally, and as if these were not enough challenges, the basic characteristic of big data is its sheer volume: enough to overwhelm most if not all of the traditional DBMSs.
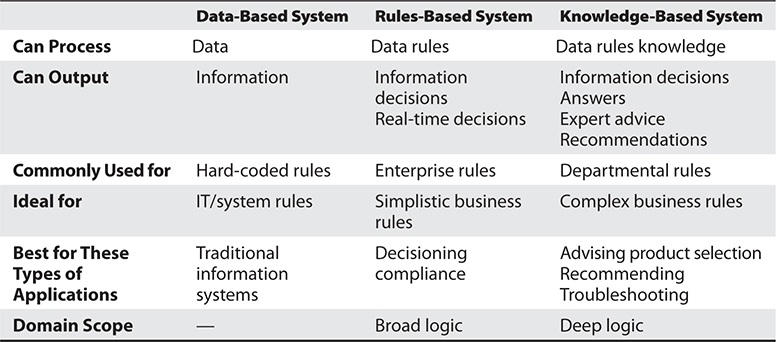
Table 8-2 Various Types of Systems Based on Capabilities
EXAM TIP Big data is stored in specialized systems like data warehouses and is exploited using approaches such as data mining. These three terms are related but distinct.
Malicious Software (Malware)
Just like good, law-abiding software developers labor day in and day out around the world to produce the software on which we’ve come to rely, so do their nefarious counterparts. These threat actors run the gamut from lone hackers to nation state operatives. Likewise, their software development approaches range from reusing (or minimally modifying) someone else’s work to sophisticated and mature development shops with formal processes. Regardless of their level of maturity, they pose a threat to our organizations and it is worth devoting some time to discuss the tools of their trade.
EXAM TIP This section on malware is not explicitly tested on the CISSP exam. We include it, as we do in other chapters, to ensure we cover the threat actor’s perspective on the topics of each domain.
Several types of malicious code, or malware, exist, such as viruses, worms, Trojan horses, and logic bombs. They usually are dormant until activated by an event the user or system initiates. They can be spread by e-mail, sharing media, sharing documents and programs, or downloading things from the Internet, or they can be purposely inserted by an attacker.
Adhering to the usual rules of not opening an e-mail attachment or clicking on a link that comes from an unknown source is one of the best ways to combat malicious code. However, recent viruses and worms have infected personal e-mail address books, so this precaution is not a sure thing to protect systems from malicious code. If an address book is infected and used during an attack, the victim gets an e-mail message that seems to have come from a person he knows. Because he knows this person, he will proceed to open the e-mail message and double-click the attachment or click on the link. And Bam! His computer is now infected and uses the e-mail client’s address book to spread the virus to all his friends and acquaintances.
There are many infection channels other than through e-mail, but it is a common one since so many people use and trust these types of messages coming into and out of their systems on a daily basis. In fact, by many estimates, upward of 95 percent of all compromises use e-mail as the principal attack vector.
Manual attacks on systems do not happen as much as they did in the past. Today hackers automate their attacks by creating a piece of malicious software (malware) that can compromise thousands of systems at one time with more precision. While malware can be designed to carry out a wide range of malicious activities, most malware is created to obtain sensitive information (credit card data, Social Security numbers, credentials, etc.), gain unauthorized access to systems, and/or carry out a profit-oriented scheme.
The proliferation of malware has a direct relationship to the large amount of profit individuals can make without much threat of being caught. The most commonly used schemes for making money through malware are as follows:
• Systems are compromised with bots and are later used in distributed denial-of-service (DDoS) attacks, spam distribution, or as part of a botnet’s command and control system.
• Ransomware encrypts some or all of the users’ files with keys that are only given to the users after they pay a ransom, typically using cryptocurrencies.
• Spyware collects personal data for the malware developer to resell to others.
• Malware redirects web traffic so that people are pointed toward a specific product for purchase.
• Malware installs key loggers, which collect sensitive financial information for the malware author to use.
• Malware is used to carry out phishing attacks, fraudulent activities, identity theft steps, and information warfare activities.
The sophistication level of malware continues to increase at a rapid pace. Years ago you just needed an antimalware product that looked for obvious signs of an infection (new files, configuration changes, system file changes, etc.), but today’s malware can bypass these simplistic detection methods.
Some malware is stored in RAM and not saved to a hard drive, which makes it harder to detect. The RAM is flushed when the system reboots, so there is hardly any evidence that it was there in the first place. Malware can be installed in a “drive-by-download” process, which means that the victim is tricked into clicking something malicious (web link, system message, pop-up window), which in turn infects his computer.
As discussed earlier, there are many web browser and web server vulnerabilities that are available through exploitation. Many websites are infected with malware, and the website owners do not know this because the malware encrypts itself, encodes itself, and carries out activities in a random fashion so that its malicious activities are not easily replicated and studied.
We will cover the main categories of malware in the following sections, but the main reasons that they are all increasing in numbers and potency are as follows:
• Many environments are homogeneous, meaning that one piece of malware will work on many or most devices.
• Everything is becoming a computer (phones, TVs, game consoles, power grids, medical devices, etc.), and thus all are capable of being compromised.
• More people and companies are storing all of their data in some digital format.
• More people and devices are connecting through various interfaces (phone apps, Facebook, websites, e-mail, texting, e-commerce, etc.).
• Many accounts are configured with too much privilege (administrative or root access).
• More people who do not understand technology are using it for sensitive purposes (online banking, e-commerce, etc.).
The digital world has provided many ways to carry out various criminal activities with a low risk of being caught.
Viruses
A virus is a small application, or string of code, that infects software. The main function of a virus is to reproduce and deliver its payload, and it requires a host application to do this. In other words, viruses cannot replicate on their own. A virus infects a file by inserting or attaching a copy of itself to the file. The virus is just the “delivery mechanism.” It can have any type of payload (deleting system files, displaying specific messages, reconfiguring systems, stealing sensitive data, installing a sniffer or back door).
A virus is a subcategory of the overall umbrella category “malware.” What makes a software component an actual virus is the fact that it can self-replicate. There are several other malware types that infect our systems and cause mayhem, but if they cannot self-replicate they do not fall into the subcategory of “virus.”
Several viruses have been released that achieved self-perpetuation by mailing themselves to every entry in a victim’s personal address book. The virus masqueraded as coming from a trusted source. The ILOVEYOU, Melissa, and Naked Wife viruses are older viruses that used the programs Outlook and Outlook Express as their host applications and were replicated when the victim chose to open the message. Several types of viruses have been developed and deployed, which we will cover next.
Macros are programs written in Visual Basic or VBScript and are generally used with Microsoft Office products. Macros automate tasks that users would otherwise have to carry out themselves. Users can define a series of activities and common tasks for the application to perform when a button is clicked, instead of doing each of those tasks individually. A macrovirus is a virus written in one of these macro languages and is platform independent. Macro viruses infect and replicate in templates and within documents. They are common because they are extremely easy to write and are used extensively in commonly used products (i.e., Microsoft Office).
Some viruses infect the boot sector (boot sector viruses) of a computer and either move data within the boot sector or overwrite the sector with new information. Some boot sector viruses have part of their code in the boot sector, which can initiate the viruses when a system boots up, and the rest of their code in sectors on the hard drive that the virus has marked off as bad. Because the sectors are marked as bad, the operating system and applications will not attempt to use those sectors; thus, they will not get overwritten.
A stealth virus hides the modifications it has made to files or boot records. This can be accomplished by monitoring system functions used to read files or sectors and forging the results. This means that when an antimalware program attempts to read an infected file or sector, the original uninfected form will be presented instead of the actual infected form. The virus can hide itself by masking the size of the file it is hidden in or actually move itself temporarily to another location while an antimalware program is carrying out its scanning process.
So a stealth virus is a virus that hides its tracks after infecting a system. Once the system is infected, the virus can make modifications to make the computer appear the same as before. The virus can show the original file size of a file it infected instead of the new, larger size to try to trick the antimalware software into thinking no changes have been made.
A polymorphic virus produces varied but operational copies of itself. This is done in the hopes of outwitting a virus scanner. Even if one or two copies are found and disabled, other copies may still remain active within the system.
The polymorphic virus can use different encryption schemes requiring different decryption routines. This would require an antimalware scan for several scan strings, one for each possible decryption method, in order to identify all copies of this type of virus.
These viruses can also vary the sequence of their instructions by including noise, or bogus instructions, with other useful instructions. They can also use a mutation engine and a random-number generator to change the sequence of their instructions in the hopes of not being detected. A polymorphic virus has the capability to change its own code, enabling the virus to have hundreds or thousands of variants. These activities can cause the virus scanner to not properly recognize the virus and to leave it alone.
A multipart virus (also called multipartite virus) has several components to it and can be distributed to different parts of the system. For example, a multipart virus might infect both the boot sector of a hard drive and executable files. By using multiple vectors it can spread more quickly than a virus using only one vector.
Meme viruses are not actual computer viruses, but types of e-mail messages that are continually forwarded around the Internet. They can be chain letters, e-mail hoax virus alerts, religious messages, or pyramid selling schemes. They are replicated by humans, not software, and can waste bandwidth and spread fear. Several e-mails have been passed around describing dangerous viruses even though the viruses weren’t real. People believed the e-mails and felt as though they were doing the right thing by passing them along to tell friends about this supposedly dangerous malware, when really the people were duped and were themselves spreading a meme virus.
Script viruses have been quite popular and damaging over the last several years. Scripts are files that are executed by an interpreter—for example, Microsoft Windows Script Host, which interprets different types of scripting languages. Websites have become more dynamic and interactive through the use of script files written in Visual Basic (VBScript) and Java (JScript) as well as other scripting languages that are embedded in HTML. When a web page that has these scripts embedded is requested by a web browser, these embedded scripts are executed, and if they are malicious, then everything just blows up. Okay, this is a tad overdramatic. The virus will carry out the payload (instructions) that the virus writer has integrated into the script, whether it is sending out copies of itself to everyone in your contact list or deleting critical files. Scripts are just another infection vector used by malware writers to carry out their evil ways.
Another type of virus, called the tunneling virus, attempts to install itself “under” the antimalware program. When the antimalware goes around doing its health check on critical files, file sizes, modification dates, and so on, it makes a request to the operating system to gather this information. Now, if the virus can put itself between the antimalware and the operating system, when the antimalware sends out a command (system call) for this type of information, the tunneling virus can intercept this call. Instead of the operating system responding to the request, the tunneling virus responds with information that indicates that everything is fine and healthy and that there is no indication of any type of infection.
So what is the difference between a stealth virus and a tunneling virus? A stealth virus is just a general term for a virus that somehow attempts to hide its actions. A stealth virus can use tunneling tactics or other tactics to hide its footprint and activities.
People in the information security industry used to know all the popular viruses and other malware types by name. For example, security professionals knew what someone was referring to when discussing the Melissa virus, ILOVEYOU virus, Code Red, SQL Slammer, Blaster, or Sasser worm. Today there are thousands of new malware variants created each day, and no one can keep up. PandaLabs reported that in the third quarter of 2017, there was a daily average of 285,000 new samples of malware.
Worms
Worms are different from viruses in that they can reproduce on their own without a host application, and are self-contained programs. As an analogy, medical viruses (e.g., the common cold) spread through human hosts. The virus can make our noses run or cause us to sneeze, which are just the virus’s way of reproducing and spreading itself. The virus is a collection of particles (DNA, RNA, proteins, lipids) and can only replicate within living cells. A virus cannot fall on the floor and just wait for someone to pass by and infect—it requires host-to-host transmission. A computer virus also requires a host, because it is not a full and self-sufficient program. A computer virus cannot make our computer sneeze, but it could make our applications share infected files, which is similar in nature.
In the nondigital world, worms are not viruses. They are invertebrate animals that can function on their own. They reproduce through some type of sexual or asexual replication process, but do not require a “host environment” of a living cell to carry out these activities. In the digital world, worms are just little programs, and like viruses they are used to transport and deliver malicious payloads. One of the most famous computer worms is Stuxnet, which targeted Siemens supervisory control and data acquisition (SCADA) software and equipment. It has a highly specialized payload that was used against Iran’s uranium enrichment infrastructures with the goal of damaging the country’s nuclear program.
Rootkit
When a system is successfully compromised, an attacker may attempt to elevate his privileges to obtain administrator- or root user–level access. Once the level of access is achieved, the attacker can upload a bundle of tools, collectively called a rootkit. The first thing that is usually installed is a back-door program, which allows the attacker to enter the system at any time without having to go through any authentication steps. The other common tools in a rootkit allow for credential capturing, sniffing, attacking other systems, and covering the attacker’s tracks.
The rootkit is just a set of tools that is placed on the compromised system for future use. Once the rootkit is loaded, the attacker can use these tools against the system or other systems it is connected to whenever he wants to.
The attacker usually replaces default system tools with new compromised tools, which share the same name. They are referred to as “Trojaned programs” because they carry out the intended functionality but do some malicious activity in the background. This is done to help ensure that the rootkit is not detected.
Most rootkits have Trojaned programs that replace these tools, because the root user could run ps or top and see there is a back-door service running, and thus detect the presence of a compromise. But when this user runs one of these Trojaned programs, the compromised tool lists all other services except the back-door process. Most rootkits also contain sniffers, so the data can be captured and reviewed by the attacker. For a sniffer to work, the system’s network interface card (NIC) must be put into promiscuous mode, which just means it can “hear” all the traffic on the network link. The default ipconfig utility allows the root user to employ a specific parameter to see whether or not the NIC is running in promiscuous mode. So, the rootkit also contains a Trojaned ipconfig program, which hides the fact that the NIC is in promiscuous mode.
Rootkits commonly include “log scrubbers,” which remove traces of the attacker’s activities from the system logs. They can also contain Trojaned programs that replace find and ls Unix utilities, so that when a user does a listing of what is in a specific directory, the rootkit will not be listed.
Some of the more powerful rootkits actually update the kernel of the system instead of just replacing individual utilities. Modifying the kernel’s code gives the attacker much more control over a system. It is also very difficult to detect kernel updates, compared to replaced utilities, because most host IDS (HIDS) products look at changes to file sizes and modification dates, which would apply to utilities and programs but not necessarily to the kernel of the operating system.
Rootkit detection can be difficult because the rootkit may be able to subvert the software that is intended to find it. Detection methods include behavioral-based methods, signature-based scanning, and memory dump analysis. Removal can be complicated, especially in cases where the rootkit resides in the kernel; reinstallation of the operating system may be the only available solution to the problem.
Rootkits and their payloads have many functions, including concealing other malware, as in password-stealing key loggers and computer viruses. A rootkit might also install software that allows the compromised system to become a zombie for specific botnets.
Rootkits can reside at the user level of an operating system, at the kernel level, in a system’s firmware, or in a hypervisor of a system using virtualization. A user-level rootkit does not have as much access or privilege compared to a kernel-level rootkit, and thus cannot carry out as much damage.
If a rootkit resides in the hypervisor of a system, it can exploit hardware virtualization features and target host operating systems. This allows the rootkit to intercept hardware calls made by the original operating system. This is not a very common type of rootkit that is deployed and used in the industry, but it is something that will probably become more popular because of the expansive use of virtualization.
Rootkits that reside in firmware are difficult to detect because software integrity checking does not usually extend down to the firmware level. If a rootkit is installed on a system’s firmware, that can allow it to load into memory before the full operating system and protection tools are loaded on the system.
Spyware and Adware
Spyware is a type of malware that is covertly installed on a target computer to gather sensitive information about a victim. The gathered data may be used for malicious activities, such as identity theft, spamming fraud, etc. Spyware can also gather information about a victim’s online browsing habits, which is then often used by spammers to send targeted advertisements. Spyware can also be used by an attacker to direct a victim’s computer to perform tasks such as installing software, changing system settings, transferring browsing history, logging keystrokes, taking screenshots, etc.
Adware is software that automatically generates (renders) advertisements. The ads can be provided through pop-ups, user interface components, or screens presented during the installation of updates of other products. The goal of adware is to generate sales revenue, not carry out malicious activities, but some adware uses invasive measures, which can cause security and privacy issues.
Botnets
A “bot” is short for “robot” and is a piece of code that carries out functionality for its master, who could be the author of this code. Bots allow for simple tasks to be carried out in an automated manner in a web-based environment. While bot software can be used for legitimate purposes (e.g., web crawling), we are going to focus on how it can be used in a malicious manner.
Bots are a type of malware and are being installed on thousands of computers even now as you’re reading this sentence. They are installed on vulnerable victim systems through infected e-mail messages, drive-by downloads, Trojan horses, and the use of shared media. Once the bot is loaded on a victim system, it usually lies dormant (zombie code) and waits for command instructions for activation purposes.
The bot can send a message to the hacker indicating that a specific system has been compromised and the system is now available to be used by the attacker as she wishes. When a hacker has a collection of these compromised systems, it is referred to as a botnet (network of bots). The hacker can use all of these systems to carry out powerful DDoS attacks or even rent these systems to spammers.
The owner of this botnet (commonly referred to as the bot herder) controls the systems remotely, usually through the Internet Relay Chat (IRC) protocol.
The common steps of the development and use of a botnet are listed next:
1. A hacker sends out malicious code that has the bot software as its payload.
2. Once installed, the bot logs into an IRC or web server that it is coded to contact. The server then acts as the controlling server of the botnet.
3. A spammer pays the hacker to use these systems and sends instructions to the controller server, which causes all of the infected systems to send out spam messages to mail servers.
Spammers use this method so their messages have a higher likelihood of getting through mail server spam filters since the sending IP addresses are those of the victims’ systems. Thus, the source IP addresses change constantly. This is how you are constantly updated on the new male enhancement solutions and ways to purchase Viagra.
Figure 8-41 illustrates the life cycle of a botnet. The botnet herder works with, or pays, hackers to develop and spread malware to infect systems that will become part of the botnet. Whoever wants to tell you about a new product they just released, carry out identity theft, conduct attacks, and so on can pay the herder to use the botnet for their purposes.
Botnets can be used for spamming, brute-force and DDoS attacks, click fraud, fast flux techniques, and the spread of illegal material. The traffic can pass over IRC or HTTP and even be tunneled through Twitter, instant messaging, and other common traffic types. The servers that send the bots instructions and manage the botnets are commonly referred to as command-and-control (C&C) servers, and they can maintain thousands or millions of computers at one time.
NOTE Fast flux is an evasion technique. Botnets can use fast flux functionality to hide the phishing and malware delivery sites they are using. One common method is to rapidly update DNS information to disguise the hosting location of the malicious websites.
Logic Bombs
A logic bomb executes a program, or string of code, when a certain set of conditions is met. For example, a network administrator may install and configure a logic bomb that is programmed to delete the company’s whole database if he is terminated.
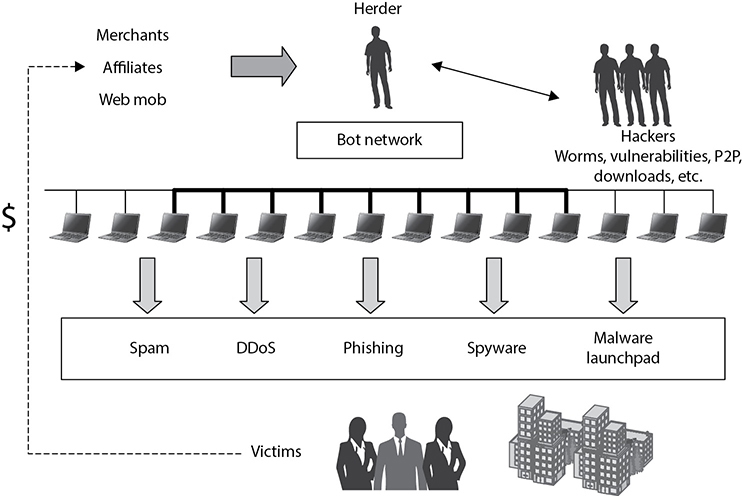
Figure 8-41 The cycle of how botnets are created, maintained, and used
The logic bomb software can have many types of triggers that activate its payload execution, as in time and date or after a user carries out a specific action. For example, many times compromised systems have logic bombs installed so that if forensics activities are carried out the logic bomb initiates and deletes all of the digital evidence. This thwarts the investigation team’s success and helps hide the attacker’s identity and methods.
Trojan Horses
A Trojan horse (oftentimes simply called a Trojan) is a program that is disguised as another program. For example, a Trojan horse can be named Notepad.exe and have the same icon as the regular Notepad program. However, when a user executes Notepad.exe, the program can delete system files. Trojan horses perform a useful functionality in addition to the malicious functionality in the background. So the Trojan horse named Notepad.exe may still run the Notepad program for the user, but in the background it will manipulate files or cause other malicious acts.
Trojan horses are so effective in part because many people would rather download a free version of a program (even from a shady site) than pay for commercial version. Users are commonly tricked into downloading some type of software from a website that is actually malicious. The Trojan horse can then set up a back door, install keystroke loggers, implement rootkits, upload files from the victim’s system, install bot software, and perform many other types of malicious acts. Trojan horses are commonly used to carry out various types of online banking fraud and identity theft activities.
Remote access Trojans (RATs) are malicious programs that run on systems and allow intruders to access and use a system remotely. They mimic the functionality of legitimate remote control programs used for remote administration, but are used for sinister purposes instead of helpful activities. They are developed to allow for stealth installation and operation, and are usually hidden in some type of mobile code, such as Java applets or ActiveX controls, that are downloaded from websites.
Several RAT programs are available to the hacker (Sakula, KjW0rm, Havex, Dark Comet, and others). Once the RAT is loaded on the victim’s system, the attacker can download or upload files, send commands, monitor user behaviors, install zombie software, activate the webcam, take screenshots, alter files, and use the compromised system as he pleases.
Creating and spreading malware used to require programming knowledge, but today people can purchase crimeware toolkits that allow them to create their own tailored malware through GUI-based tools. These toolkits provide predeveloped malicious code that can be easily customized, deployed, and automated. The kits are sold in the online underground black market and allow people with little to no technical skill to carry out cybercrime activities. These “out-of-the-box” solutions have lowered the entry barrier for cybercriminals by making sophisticated attacks easy to carry out.
The following shows the administrative interface provided by a commonly used crimeware toolkit, Spy Eye, that attackers can use to maintain and control their compromised systems.

Antimalware Software
Traditional antimalware software uses signatures to detect malicious code. Signatures, sometimes referred to as fingerprints, are created by antimalware vendors. An individual signature is a sequence of code that an antimalware vendor has extracted from the virus itself. Just like our bodies have antibodies that identify and go after a specific type of foreign material, an antimalware software package has an engine that uses these signatures to identify malware. The antimalware software scans files, e-mail messages, and other data passing through specific protocols, and then compares them to its database of signatures. When there is a match, the antimalware software carries out whatever activities it is configured to do, which can be to quarantine the file, attempt to clean the file (remove the virus), provide a warning message dialog box to the user, and/or log the event.
Signature-based detection (also called fingerprint detection) is a reasonably effective way to detect conventional malware, but there is a delayed response time to new threats. Once a virus is detected, the antimalware vendor must study it, develop and test a new signature, release the signature, and all customers must download it. If the malicious code is just sending out silly pictures to all of your friends, this delay is not so critical. If the malicious software is similar to the Slammer worm, this amount of delay can be devastating.
Since new malware is released daily, it is hard for antimalware software to keep up. The technique of using signatures means this software can only detect viruses that have been identified and where a signature is created. Since virus writers are prolific and busy beasts, and because viruses can morph, it is important that the antimalware software have other tricks up its sleeve to detect malicious code.
Another technique that almost all antimalware software products use is referred to as heuristic detection. This approach analyzes the overall structure of the malicious code, evaluates the coded instructions and logic functions, and looks at the type of data within the virus or worm. So, it collects a bunch of information about this piece of code and assesses the likelihood of it being malicious in nature. It has a type of “suspiciousness counter,” which is incremented as the program finds more potentially malicious attributes. Once a predefined threshold is met, the code is officially considered dangerous and the antimalware software jumps into action to protect the system. This allows antimalware software to detect unknown malware, instead of just relying on signatures.
As an analogy, let’s say Barney is the town cop who is employed to root out the bad guys and lock them up (quarantine). If Barney was going to use a signature method, he would compare a stack of photographs to each person he sees on the street. When he sees a match, he quickly throws the bad guy into his patrol car and drives off. If he was going to use the heuristic method, he would be watching for suspicious activity. So if someone with a ski mask was standing outside a bank, Barney would assess the likelihood of this being a bank robber against it just being a cold guy in need of some cash.

CAUTION Diskless workstations are still vulnerable to viruses, even though they do not have a hard disk and a full operating system. They can still get viruses that load and reside in memory. These systems can be rebooted remotely (remote booting) to bring the memory back to a clean state, which means the virus is “flushed” out of the system.
Some antimalware products create a simulated environment, called a virtual machine or sandbox, and allow some of the logic within the suspected code to execute in the protected environment. This allows the antimalware software to see the code in question in action, which gives it more information as to whether or not it is malicious.
NOTE The virtual machine or sandbox is also sometimes referred to as an emulation buffer. They are all the same thing—a piece of memory that is segmented and protected so that if the code is malicious, the system is protected.
Reviewing information about a piece of code is called static analysis, while allowing a portion of the code to run in a virtual machine is called dynamic analysis. They are both considered heuristic detection methods.
Now, even though all of these approaches are sophisticated and effective, they are not 100-percent effective because malware writers are crafty. It is a continual cat-and-mouse game that is carried out each and every day. The antimalware industry comes out with a new way of detecting malware, and the very next week the malware writers have a way to get around this approach. This means that antimalware vendors have to continually increase the intelligence of their products and you have to buy a new version every year.
The next phase in the antimalware software evolution is referred to as behavior blockers. Antimalware software that carries out behavior blocking actually allows the suspicious code to execute within the operating system unprotected and watches its interactions with the operating system, looking for suspicious activities. The antimalware software would be watching for the following types of actions:
• Writing to startup files or the Run keys in the Registry
• Opening, deleting, or modifying files
• Scripting e-mail messages to send executable code
• Connecting to network shares or resources
• Modifying an executable logic
• Creating or modifying macros and scripts
• Formatting a hard drive or writing to the boot sector
If the antimalware program detects some of these potentially malicious activities, it can terminate the software and provide a message to the user. The newer generation behavior blockers actually analyze sequences of these types of operations before determining the system is infected. (The first-generation behavior blockers only looked for individual actions, which resulted in a large number of false positives.) The newer generation software can intercept a dangerous piece of code and not allow it to interact with other running processes. They can also detect rootkits. In addition, some of these antimalware programs can allow the system to roll back to a state before an infection took place so the damages inflicted can be “erased.”
While it sounds like behavior blockers might bring us our well-deserved bliss and utopia, one drawback is that the malicious code must actually execute in real time; otherwise, our systems can be damaged. This type of constant monitoring also requires a high level of system resources. We just can’t seem to win.
EXAM TIP Heuristic detection and behavior blocking is considered proactive and can detect new malware, sometimes called “zero-day” attacks. Signature-based detection cannot detect new malware.
Most antimalware vendors use a blend of all of these technologies to provide as much protection as possible. The individual antimalware attack solutions are shown in Figure 8-42.
NOTE Another antimalware technique is referred to as “reputation-based protection.” An antimalware vendor collects data from many (or all) of its customers’ systems and mines that data to search for patterns to help identify good and bad files. Each file type is assigned a reputation metric value, indicating the probability of it being “good” or “bad.” These values are used by the antimalware software to help it identify “bad” (suspicious) files.
Spam Detection
We are all pretty tired of receiving e-mails that try to sell us things we don’t need. A great job working from home, a master’s degree that requires no studying, and a great sex life are all just a click away (and only $19.99!)—as promised by this continual stream of messages. These e-mails have been given the label spam, which is unsolicited junk e-mail. Along with being a nuisance, spam eats up a lot of network bandwidth and can be the source of spreading malware. Many organizations have spam filters on their mail servers, and users can configure spam rules within their e-mail clients, but just as virus writers always come up with ways to circumvent antimalware software, spammers come up with clever ways of getting around spam filters.
Detecting spam properly has become a science in itself. One technique used is called Bayesian filtering. Many moons ago, a gentleman named Thomas Bayes (a mathematician) developed a way to actually guess the probability of something being true by using math. Now what is fascinating about this is that in mathematics things are either true or they are not. This is the same in software. Software deals with 1’s and 0’s, on and off, true and false. Software does not deal with the grays (probabilities) of life too well.
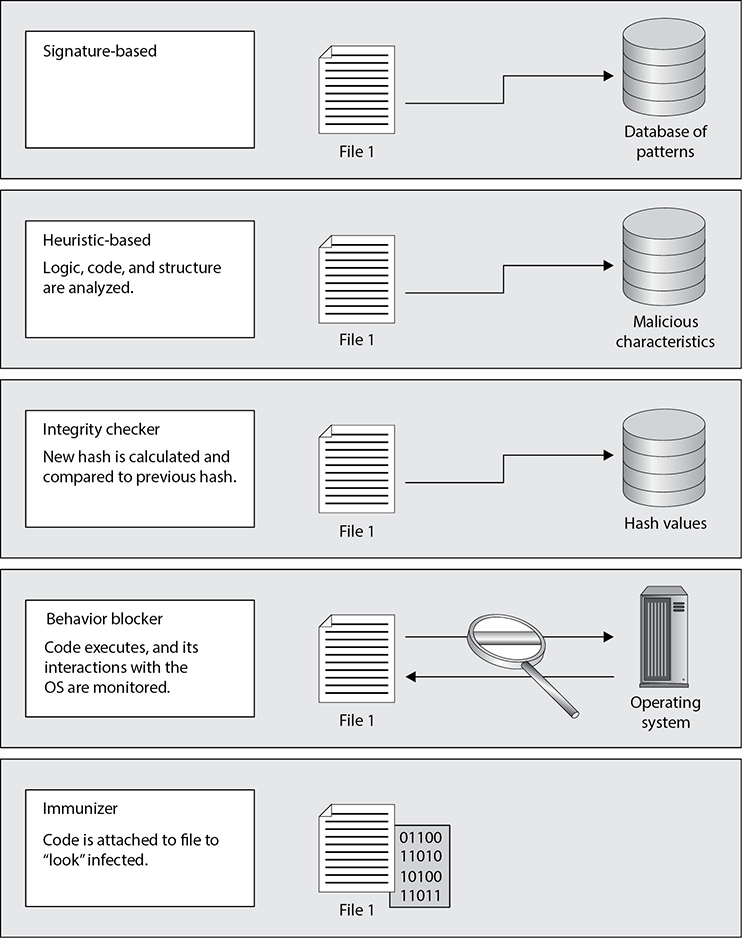
Figure 8-42 Antimalware vendors use various types of malware detection.
Bayesian logic reviews prior events to predict future events, which is basically quantifying uncertainty. Conceptually, this is not too hard to understand. If you run into a brick wall three times and fall down, you should conclude that your future attempts will result in the same painful outcomes. What is more interesting is when this logic is performed on activities that contain many more variables. For example, how does a spam filter ensure you do not receive e-mails trying to sell you Viagra, but does allow the e-mails from your friend who is obsessed with Viagra and wants to continue e-mailing you about this drug’s effects and attributes? A Bayesian filter applies statistical modeling to the words that make up an e-mail message. This means the words that make up the message have mathematical formulas performed on them to be able to fully understand their relationship to one another. The Bayesian filter carries out a frequency analysis on each word and then evaluates the message as a whole to determine whether or not it is spam.
So this filter is not just looking for “Viagra,” “manhood,” “sex,” and other words that cannot be printed in a wholesome book like this one. It is looking at how often these words are used, and in what order, to make a determination as to whether or not this message is spam. Unfortunately, spammers know how these filters work and manipulate the words in the subject line and message to try and fool the spam filter. This is why you can receive messages with misspelled words or words that use symbols instead of characters. The spammers are very dedicated to getting messages promising utopia to your e-mail box because there is big money to be made that way.
Antimalware Programs
Detecting and protecting an enterprise from the long list of malware requires more than just rolling out antimalware software. Just as with other pieces of a security program, certain administrative, physical, and technical controls must be deployed and maintained.
The organization should either have a stand-alone antimalware policy or have one incorporated into an existing security policy. It should include standards outlining what type of antimalware software and antispyware software should be installed and how they should be configured.
Antimalware information and expected user behaviors should be integrated into the security-awareness program, along with who a user should contact if she discovers a virus. A standard should cover the do’s and don’ts when it comes to malware, which are listed next:
• Every workstation, server, and mobile device should have antimalware software installed.
• An automated way of updating malware signatures should be deployed on each device.
• Users should not be able to disable antimalware software.
• A preplanned malware eradication process should be developed and a contact person designated in case of an infection.
• All external disks (USB drives and so on) should be scanned automatically.
• Backup files should be scanned.
• Antimalware policies and procedures should be reviewed annually.
• Antimalware software should provide boot malware protection.
• Antimalware scanning should happen at a gateway and on each device.
• Virus scans should be automated and scheduled. Do not rely on manual scans.
• Critical systems should be physically protected so malicious software cannot be installed locally.
NOTE Antimalware files that contain updates (new signatures) are called DAT files. It is just a data file with the file extension of .dat.
Since malware has cost organizations millions of dollars in operational costs and productivity hits, many have implemented antimalware solutions at network entry points. The scanning software can be integrated into a mail server, proxy server, or firewall. (They solutions are sometimes referred to as virus walls.) This software scans incoming traffic, looking for malware so it can be detected and stopped before entering the network. These products can scan Simple Mail Transport Protocol (SMTP), HTTP, FTP, and possibly other protocol types, but what is important to realize is that the product is only looking at one or two protocols and not all of the incoming traffic. This is the reason each server and workstation should also have antimalware software installed.
Assessing the Security of Acquired Software
Most organizations do not have the in-house capability to develop their own software systems. Their only feasible options are either to acquire standard software or to have a vendor customize a standard software system to their particular environment. In either case, software from an external source will be allowed to execute in a trusted environment. Depending on how trustworthy the source and the code are, this could have some profound implications to the security posture of the organization’s systems. As always, we need to ground our response on our risk management process.
In terms of managing the risk associated with acquired software, the essential question to ask is: How is the organization affected if this software behaves improperly? Improper behavior could be the consequence of either defects or misconfiguration. The defects can manifest themselves as computing errors (e.g., wrong results) or vulnerability to intentional attack. A related question is: What is it that we are protecting and this software could compromise? Is it PII, intellectual property, or national security information? The answers to these and other questions will dictate the required thoroughness of our approach.
In many cases, our approach to mitigating the risks of acquired software will begin with an assessment of the vendor. Characteristics that correlate to a lower risk from a given vendor’s software include the reputation of the vendor and the regularity of its patch pushes. Conversely, vendors may be riskier if they are small or new companies, if they have immature or undocumented development processes, or if their products have broad marketplace presence (meaning they are more lucrative targets to exploit developers).
A key element in assessing the security of acquired software is, rather obviously, its performance on an internal assessment. Ideally, we are able to obtain the source code from the vendor so that we can do our own code reviews, vulnerability assessments, and penetration tests. In many cases, however, this will not be possible. Our only possible assessment may be a penetration test. The catch is that we may not have the in-house capability to perform such a test. In such cases, and depending on the potential risk posed by this software, we may be well advised to hire an external party to perform an independent penetration test for us. This is likely a costly affair that would only be justifiable in cases where a successful attack against the software system would likely lead to significant losses for the organization.
Even in the most constrained case, we are still able to mitigate the risk of acquisition. If we don’t have the means to do code reviews, vulnerability assessments, or penetration tests, we can still mitigate the risk by deploying the software only in specific subnetworks, with hardened configurations, and with restrictive IDS/IPS rules monitoring its behavior. Though this approach may initially lead to constrained functionality and excessive false positives on our intrusion detection/prevention systems, we can always gradually loosen the controls as we gain assurances that the software is trustworthy. That is, after all, the bottom line for this entire chapter.
Summary
Although functionality is the first concern when developing software, adding security into the mix before the project starts and then integrating it into every step of the development process is highly beneficial. Although many companies do not view this as the most beneficial approach to software development, they are becoming convinced of it over time as more security patches and fixes must be developed and released, and as their customers continually demand more secure products.
Software development is a complex task, especially as technology changes at the speed of light, environments evolve, and more expectations are placed upon vendors who wish to be the “king of the mountain” within the software market. This complexity also makes implementing effective security more challenging. Years ago, programmers and developers did not need to consider security issues within their code, but this has not been true for a very long time. Education, experience, awareness, enforcement, and the demands of the consumers are all necessary pieces to bring more secure practices and technologies to the program code we all use.
Quick Tips
• Security should be addressed in each phase of system development. It should not be addressed only at the end of development because of the added cost, time, and effort and the lack of functionality.
• The attack surface is the collection of possible entry points for an attacker. The reduction of this surface reduces the possible ways that an attacker can exploit a system.
• Threat modeling is a systematic approach used to understand how different threats could be realized and how a successful compromise could take place.
• Computer-aided software engineering refers to any type of software that allows for the automated development of software, which can come in the form of program editors, debuggers, code analyzers, version-control mechanisms, and more. The goals are to increase development speed and productivity and reduce errors.
• Various levels of testing should be carried out during development: unit (testing individual components), integration (verifying components work together in the production environment), acceptance (ensuring code meets customer requirements), regression (testing after changes take place), static analysis (reviewing programming code), and dynamic analysis (reviewing code during execution).
• Fuzzing is the act of sending random data to the target program in order to trigger failures.
• Zero-day vulnerabilities are vulnerabilities that do not currently have a resolution or solution.
• The ISO/IEC 27034 standard covers the following items: application security overview and concepts, organization normative framework, application security management process, protocols and application security control data structure, case studies, and application security assurance prediction.
• The Open Web Application Security Project (OWASP) is an organization dedicated to helping the industry develop more secure software.
• An integrated product team (IPT) is a multidisciplinary development team with representatives from many or all the stakeholder populations.
• The CMMI model uses five maturity levels designated by the numbers 1 through 5. Each level represents the maturity level of the process quality and optimization. The levels are organized as follows: 1 = Initial, 2 = Repeatable, 3 = Defined, 4 = Managed, 5 = Optimizing.
• CMMI (Capability Maturity Model Integration) is a process improvement approach that provides organizations with the essential elements of effective processes, which will improve their performance.
• Change management is a systematic approach to deliberately regulating the changing nature of projects. Change control, which is a subpart of change management, deals with controlling specific changes to a system.
• There are several SDLC methodologies: Waterfall (sequential approach that requires each phase to complete before the next one can begin), V-shaped (emphasizes verification and validation at each phase), Prototyping (creating a sample of the code for proof-of-concept purposes), Incremental (multiple development cycles are carried out on a piece of software throughout its development stages), Spiral (iterative approach that emphases risk analysis per iteration), Rapid Application Development (combines prototyping and iterative development procedures with the goal of accelerating the software development process), and Agile (iterative and incremental development processes that encourage team-based collaboration, where flexibility and adaptability are used instead of a strict process structure).
• Software configuration management (SCM) is the task of tracking and controlling changes in the software through the use of authentication, revision control, the establishment of baselines, and auditing. It has the purpose of maintaining software integrity and traceability throughout the software development life cycle.
• Programming languages have gone through evolutionary processes. Generation one is machine language (binary format). Generation two is assembly language (which is translated by an assembler into machine code). Generation three is high-level language (which provides a level of abstraction). Generation four is a very high-level language (which provides more programming abstraction). Generation five is natural language (which is translated using artificial intelligence).
• Data modeling is a process used to define and analyze data requirements needed to support the business processes within the scope of corresponding systems and software applications.
• Object-oriented programming provides modularity, reusability, and more granular control within the programs themselves compared to classical programming languages.
• Objects are members, or instances, of classes. The classes dictate the objects’ data types, structure, and acceptable actions.
• In OOP, objects communicate with each other through messages, and a method is functionality that an object can carry out. Objects can communicate properly because they use standard interfaces.
• Polymorphism is when different objects are given the same input and react differently.
• Data and operations internal to objects are hidden from other objects, which is referred to as data hiding. Each object encapsulates its data and processes.
• Object-oriented design represents a real-world problem and modularizes the problem into cooperating objects that work together to solve the problem.
• If an object does not require much interaction with other modules, it has low coupling.
• The best programming design enables objects to be as independent and as modular as possible; therefore, the higher the cohesion and the lower the coupling, the better.
• An object request broker (ORB) manages communications between objects and enables them to interact in a heterogeneous and distributed environment.
• Common Object Request Broker Architecture (CORBA) provides a standardized way for objects within different applications, platforms, and environments to communicate. It accomplishes this by providing standards for interfaces between objects.
• Component Object Model (COM) provides an architecture for components to interact on a local system. Distributed COM (DCOM) uses the same interfaces as COM, but enables components to interact over a distributed, or networked, environment.
• Open Database Connectivity (ODBC) enables several different applications to communicate with several different types of databases by calling the required driver and passing data through that driver.
• Object linking and embedding (OLE) enables a program to call another program (linking) and permits a piece of data to be inserted inside another program or document (embedding).
• Service-oriented architecture (SOA) provides standardized access to the most needed services to many different applications at one time. Service interactions are self-contained and loosely coupled so that each interaction is independent of any other interaction.
• Java security employs a sandbox so the applet is restricted from accessing the user’s hard drive or system resources. Programmers have figured out how to write applets that escape the sandbox.
• SOAP allows programs created with different programming languages and running on different operating systems to interact without compatibility issues.
• There are three main types of cross-site scripting (XSS) attacks: nonpersistent XSS (exploiting the lack of proper input or output validation on dynamic websites), persistent XSS (attacker loads malicious code on a server that attacks visiting browsers), and DOM (attacker uses the DOM environment to modify the original client-side JavaScript).
• A database management system (DBMS) is the software that controls the access restrictions, data integrity, redundancy, and the different types of manipulation available for a database.
• A database primary key is how a specific row is located from other parts of the database in a relational database.
• A view is an access control mechanism used in databases to ensure that only authorized subjects can access sensitive information.
• A relational database uses two-dimensional tables with rows (tuples) and columns (attributes).
• A hierarchical database uses a tree-like structure to define relationships between data elements, using a parent/child relationship.
• Most databases have a data definition language (DDL), a data manipulation language (DML), a query language (QL), and a report generator.
• A data dictionary is a central repository that describes the data elements within a database and their relationships.
• Database integrity is provided by concurrency mechanisms. One concurrency control is locking, which prevents users from accessing and modifying data being used by someone else.
• Entity integrity makes sure that a row, or tuple, is uniquely identified by a primary key, and referential integrity ensures that every foreign key refers to an existing primary key.
• A rollback cancels changes and returns the database to its previous state. This takes place if there is a problem during a transaction.
• A commit statement saves all changes to the database.
• A checkpoint is used if there is a system failure or problem during a transaction. The user is then returned to the state of the last checkpoint.
• Aggregation can happen if a user does not have access to a group of elements, but has access to some of the individual elements within the group. Aggregation happens if the user combines the information of these individual elements and figures out the information of the group of data elements, which is at a higher sensitivity level.
• Inference is the capability to derive information that is not explicitly available.
• Common attempts to prevent inference attacks are partitioning the database, cell suppression, and adding noise to the database.
• Polyinstantiation is the process of allowing a table to have multiple rows with the same primary key. The different instances can be distinguished by their security levels or classifications.
• Data warehousing combines data from multiple databases and data sources.
• Data mining is the process of searching, filtering, and associating data held within a data warehouse to provide more useful information to users.
• Data-mining tools produce metadata, which can contain previously unseen relationships and patterns.
• A virus is an application that requires a host application for replication.
• Macro viruses are common because the languages used to develop macros are easy to use and they infect Microsoft Office products, which are everywhere.
• A polymorphic virus tries to escape detection by making copies of itself and modifying the code and attributes of those copies.
• A worm does not require a host application to replicate.
• A logic bomb executes a program when a predefined event takes place, or a date and time are met.
• A Trojan horse is a program that performs useful functionality apparent to the user and malicious functionally without the user knowing it.
• Botnets are networks of bots that are controlled by C&C servers and bot herders.
• Antimalware software is most effective when it is installed in every entry and end point and covered by a policy that delineates user training as well as software configuration and updating.
• Assessing the security of acquired software, in addition to internal or third-party tests, requires that we assess the reliability and maturity of the vendor.
Questions
Please remember that these questions are formatted and asked in a certain way for a reason. Keep in mind that the CISSP exam is asking questions at a conceptual level. Questions may not always have the perfect answer, and the candidate is advised against always looking for the perfect answer. Instead, the candidate should look for the best answer in the list.
1. An application is downloaded from the Internet to perform disk cleanup and to delete unnecessary temporary files. The application is also recording network login data and sending it to another party. This application is best described as which of the following?
A. A virus
B. A Trojan horse
C. A worm
D. A logic bomb
2. Which of the following best describes the term DevOps?
A. The practice of incorporating development, IT, and quality assurance (QA) staff into software development projects.
B. A multidisciplinary development team with representatives from many or all the stakeholder populations.
C. The operationalization of software development activities to support just-in-time delivery.
D. A software development methodology that relies more on the use of operational prototypes than on extensive upfront planning.
3. A system has been patched many times and has recently become infected with a dangerous virus. If antimalware software indicates that disinfecting a file may damage it, what is the correct action?
A. Disinfect the file and contact the vendor
B. Back up the data and disinfect the file
C. Replace the file with the file saved the day before
D. Restore an uninfected version of the patched file from backup media
4. What is the purpose of polyinstantiation?
A. To restrict lower-level subjects from accessing low-level information
B. To make a copy of an object and modify the attributes of the second copy
C. To create different objects that will react in different ways to the same input
D. To create different objects that will take on inheritance attributes from their class
5. Database views provide what type of security control?
A. Detective
B. Corrective
C. Preventive
D. Administrative
6. Which of the following techniques or set of techniques is used to deter database inference attacks?
A. Partitioning, cell suppression, and noise and perturbation
B. Controlling access to the data dictionary
C. Partitioning, cell suppression, and small query sets
D. Partitioning, noise and perturbation, and small query sets
7. When should security first be addressed in a project?
A. During requirements development
B. During integration testing
C. During design specifications
D. During implementation
8. An online transaction processing (OLTP) system that detects an invalid transaction should do which of the following?
A. Roll back and rewrite over original data
B. Terminate all transactions until properly addressed
C. Write a report to be reviewed
D. Checkpoint each data entry
9. Which of the following are rows and columns within relational databases?
A. Rows and tuples
B. Attributes and rows
C. Keys and views
D. Tuples and attributes
10. Databases can record transactions in real time, which usually updates more than one database in a distributed environment. This type of complexity can introduce many integrity threats, so the database software should implement the characteristics of what’s known as the ACID test. Which of the following are incorrect characteristics of the ACID test?
i. Atomicity Divides transactions into units of work and ensures that all modifications take effect or none takes effect.
ii. Consistency A transaction must follow the integrity policy developed for that particular database and ensure all data is consistent in the different databases.
iii. Isolation Transactions execute in isolation until completed, without interacting with other transactions.
iv. Durability Once the transaction is verified as inaccurate on all systems, it is committed and the databases cannot be rolled back.
A. i, ii
B. ii. iii
C. ii, iv
D. iv
11. The software development life cycle has several phases. Which of the following lists these phases in the correct order?
A. Requirements gathering, design, development, maintenance, testing, release
B. Requirements gathering, design, development, testing, operations and maintenance
C. Prototyping, build and fix, increment, test, maintenance
D. Prototyping, testing, requirements gathering, integration, testing
12. John is a manager of the application development department within his company. He needs to make sure his team is carrying out all of the correct testing types and at the right times of the development stages. Which of the following accurately describe types of software testing that should be carried out?
i. Unit testing Testing individual components in a controlled environment where programmers validate data structure, logic, and boundary conditions.
ii. Integration testing Verifying that components work together as outlined in design specifications.
iii. Acceptance testing Ensuring that the code meets customer requirements.
iv. Regression testing After a change to a system takes place, retesting to ensure functionality, performance, and protection.
A. i, ii
B. ii, iii
C. i, ii, iv
D. i, ii, iii, iv
13. Tim is a software developer for a financial institution. He develops middleware software code that carries out his company’s business logic functions. One of the applications he works with is written in the C programming language and seems to be taking up too much memory as it runs over time. Which of the following best describes what Tim should implement to rid this software of this type of problem?
A. Bounds checking
B. Garbage collector
C. Parameter checking
D. Compiling
14. Marge has to choose a software development methodology that her team should follow. The application that her team is responsible for developing is a critical application that can have few to no errors. Which of the following best describes the type of methodology her team should follow?
A. Cleanroom
B. Joint Analysis Development (JAD)
C. Rapid Application Development (RAD)
D. Reuse methodology
15. __________ is a software-testing technique that provides invalid, unexpected, or random data to the input interfaces of a program.
A. Agile testing
B. Structured testing
C. Fuzzing
D. EICAR
16. Which of the following is the second level of the Capability Maturity Model Integration?
A. Repeatable
B. Defined
C. Managed
D. Optimizing
17. One of the characteristics of object-oriented programming is deferred commitment. Which of the following is the best description for this characteristic?
A. The building blocks of software are autonomous objects, cooperating through the exchange of messages.
B. The internal components of an object can be redefined without changing other parts of the system.
C. Classes are reused by other programs, though they may be refined through inheritance.
D. Object-oriented analysis, design, and modeling map to business needs and solutions.
18. Which of the following attack types best describes what commonly takes place when you insert specially crafted and excessively long data into an input field?
A. Traversal attack
B. Unicode encoding attack
C. URL encoding attack
D. Buffer overflow attack
19. Which of the following has an incorrect attack-to-definition mapping?
A. EBJ XSS attack Content processing stages performed by the client, typically in client-side Java.
B. Nonpersistent XSS attack Improper sanitation of response from a web client.
C. Persistent XSS attack Data provided by attackers is saved on the server.
D. DOM-based XSS attack Content processing stages performed by the client, typically in client-side JavaScript.
20. John is reviewing database products. He needs a product that can manipulate a standard set of data for his company’s business logic needs. Which of the following should the necessary product implement?
A. Relational database
B. Object-relational database
C. Network database
D. Dynamic-static
21. ActiveX Data Objects (ADO) is an API that allows applications to access back-end database systems. It is a set of ODBC interfaces that exposes the functionality of data sources through accessible objects. Which of the following are incorrect characteristics of ADO?
i. It’s a low-level data access programming interface to an underlying data access technology (such as OLE DB).
ii. It’s a set of COM objects for accessing data sources, not just database access.
iii. It allows a developer to write programs that access data without knowing how the database is implemented.
iv. SQL commands are required to access a database when using ADO.
A. i, iv
B. ii, iii
C. i, ii, iii
D. i, ii, iii, iv
22. Database software performs three main types of integrity services: semantic, referential, and entity. Which of the following correctly describes one of these services?
i. A semantic integrity mechanism makes sure structural and semantic rules are enforced.
ii. A database has referential integrity if all foreign keys reference existing primary keys.
iii. Entity integrity guarantees that the tuples are uniquely identified by primary key values.
A. ii
B. ii, iii
C. i, ii, iii
D. i, ii
23. Which of the following is not very useful in assessing the security of acquired software?
A. The reliability and maturity of the vendor
B. The NIST’s National Software Reference Library
C. Third-party vulnerability assessments
D. In-house code reviews
Use the following scenario to answer Questions 24–26. Sandy has just started as the manager of software development at a new company. As she interviews her new team members, she is finding out a few things that may need to be approached differently. Programmers currently develop software code and upload it to a centralized server for backup purposes. The server software does not have versioning control capability, so sometimes the end software product contains outdated code elements. She has also discovered that many in-house business software packages follow the Common Object Request Broker Architecture, which does not necessarily allow for easy reuse of distributed web services available throughout the network. One of the team members has combined several open API functionalities within a business-oriented software package.
24. Which of the following is the best technology for Sandy’s team to implement as it pertains to the previous scenario?
A. Computer-aided software engineering tools
B. Software configuration management
C. Software development life-cycle management
D. Software engineering best practices
25. Which is the best software architecture that Sandy should introduce her team to for effective business application use?
A. Distributed component object architecture
B. Simple Object Access Protocol architecture
C. Enterprise JavaBeans architecture
D. Service-oriented architecture
26. Which best describes the approach Sandy’s team member took when creating the business-oriented software package mentioned within the scenario?
A. Software as a Service
B. Cloud computing
C. Web services
D. Mashup
27. Karen wants her team to develop software that allows her company to take advantage of and use many of the web services currently available by other companies. Which of the following best describes the components that need to be in place and what their roles are?
A. Web service provides the application functionality. Universal Description, Discovery, and Integration describes the web service’s specifications. The Web Services Description Language provides the mechanisms for web services to be posted and discovered. The Simple Object Access Protocol allows for the exchange of messages between a requester and provider of a web service.
B. Web service provides the application functionality. The Web Services Description Language describes the web service’s specifications. Universal Description, Discovery, and Integration provides the mechanisms for web services to be posted and discovered. The Simple Object Access Protocol allows for the exchange of messages between a requester and provider of a web service.
C. Web service provides the application functionality. The Web Services Description Language describes the web service’s specifications. The Simple Object Access Protocol provides the mechanisms for web services to be posted and discovered. Universal Description, Discovery, and Integration allows for the exchange of messages between a requester and provider of a web service.
D. Web service provides the application functionality. The Simple Object Access Protocol describes the web service’s specifications. Universal Description, Discovery, and Integration provides the mechanisms for web services to be posted and discovered. The Web Services Description Language allows for the exchange of messages between a requester and provider of a web service.
Use the following scenario to answer Questions 28–30. Brad is a new security administrator within a retail company. He is discovering several issues that his security team needs to address to better secure their organization overall. When reviewing different web server logs, he finds several HTTP server requests with the characters “%20” and “../”. The web server software ensures that users input the correct information within the forms that are presented to them via their web browsers. Brad identifies that the organization has a two-tier network architecture in place, which allows the web servers to directly interact with the back-end database.
28. Which of the following best describes attacks that could be taking place against this organization?
A. Cross-site scripting and certification stealing
B. URL encoding and directory traversal attacks
C. Parameter validation manipulation and session management attacks
D. Replay and password brute-force attacks
29. Which of the following functions is the web server software currently carrying out, and what is an associated security concern Brad should address?
A. Client-side validation The web server should carry out a secondary set of input validation rules on the presented data before processing it.
B. Server-side includes validation The web server should carry out a secondary set of input validation rules on the presented data before processing it.
C. Data Source Name logical naming access The web server should be carrying out a second set of reference integrity rules.
D. Data Source Name logical naming access The web server should carry out a secondary set of input validation rules on the presented data before processing it.
30. Pertaining to the network architecture described in the previous scenario, which of the following attack types should Brad be concerned with?
A. Parameter validation attack
B. Injection attack
C. Cross-site scripting
D. Database connector attack
Answers
1. B. A Trojan horse looks like an innocent and helpful program, but in the background it is carrying out some type of malicious activity unknown to the user. The Trojan horse could be corrupting files, sending the user’s password to an attacker, or attacking another computer.
2. A. DevOps is a type of integrated product team (IPT) that focuses on three communities: software development, IT operations, and quality assurance. The idea is to reduce the friction that oftentimes exists between the developers and IT staff in order to improve quality and velocity.
3. D. Some files cannot be properly sanitized by the antivirus software without destroying them or affecting their functionality. So, the administrator must replace such a file with a known uninfected file. Plus, the administrator needs to make sure he has the patched version of the file, or else he could be introducing other problems. Answer C is not the best answer because the administrator may not know the file was clean yesterday, so just restoring yesterday’s file may put him right back in the same boat.
4. B. Instantiation is what happens when an object is created from a class. Polyinstantiation is when more than one object is made and the other copy is modified to have different attributes. This can be done for several reasons. The example given in the chapter was a way to use polyinstantiation for security purposes to ensure that a lower-level subject could not access an object at a higher level.
5. C. A database view is put into place to prevent certain users from viewing specific data. This is a preventive measure, because the administrator is preventing the users from seeing data not meant for them. This is one control to prevent inference attacks.
6. A. Partitioning means to logically split the database into parts. Views then dictate which users can view specific parts. Cell suppression means that specific cells are not viewable by certain users. And noise and perturbation is when bogus information is inserted into the database to try to give potential attackers incorrect information.
7. A. The trick to this question, and any one like it, is that security should be implemented at the first possible phase of a project. Requirements are gathered and developed at the beginning of a project, which is project initiation. The other answers are steps that follow this phase, and security should be integrated right from the beginning instead of in the middle or at the end.
8. C. This can seem like a tricky question. It states that the system has detected an invalid transaction, which is most likely a user error. This error should be logged so it can be reviewed. After the review, the supervisor, or whoever makes this type of decision, will decide whether or not it was a mistake and, if so, investigate it as needed. If the system had a glitch, power fluctuation, hang-up, or any other software- or hardware-related error, it would not be an invalid transaction, and in that case the system would carry out a rollback function.
9. D. In a relational database, a row is referred to as a tuple, whereas a column is referred to as an attribute.
10. D. The following are correct characteristics of the ACID test:
• Atomicity Divides transactions into units of work and ensures that all modifications take effect or none take effect. Either the changes are committed or the database is rolled back.
• Consistency A transaction must follow the integrity policy developed for that particular database and ensure all data is consistent in the different databases.
• Isolation Transactions execute in isolation until completed, without interacting with other transactions. The results of the modification are not available until the transaction is completed.
• Durability Once the transaction is verified as accurate on all systems, it is committed and the databases cannot be rolled back.
11. B. The following outlines the common phases of the software development life cycle:
i. Requirements gathering
ii. Design
iii. Development
iv. Testing
v. Operations and maintenance
12. D. There are different types of tests the software should go through because there are different potential flaws we will be looking for. The following are some of the most common testing approaches:
• Unit testing Testing individual components in a controlled environment where programmers validate data structure, logic, and boundary conditions
• Integration testing Verifying that components work together as outlined in design specifications
• Acceptance testing Ensuring that the code meets customer requirements
• Regression testing After a change to a system takes place, retesting to ensure functionality, performance, and protection
13. B. Garbage collection is an automated way for software to carry out part of its memory management tasks. A garbage collector identifies blocks of memory that were once allocated but are no longer in use and deallocates the blocks and marks them as free. It also gathers scattered blocks of free memory and combines them into larger blocks. It helps provide a more stable environment and does not waste precious memory. Some programming languages, such as Java, perform automatic garbage collection; others, such as C, require the developer to perform it manually, thus leaving opportunity for error.
14. A. The listed software development methodologies and their definitions are as follows:
• Joint Analysis Development (JAD) A methodology that uses a team approach in application development in a workshop-oriented environment.
• Rapid Application Development (RAD) A methodology that combines the use of prototyping and iterative development procedures with the goal of accelerating the software development process.
• Reuse methodology A methodology that approaches software development by using progressively developed code. Reusable programs are evolved by gradually modifying pre-existing prototypes to customer specifications. Since the reuse methodology does not require programs to be built from scratch, it drastically reduces both development cost and time.
• Cleanroom An approach that attempts to prevent errors or mistakes by following structured and formal methods of developing and testing. This approach is used for high-quality and critical applications that will be put through a strict certification process.
15. C. Fuzz testing, or fuzzing, is a software-testing technique that provides invalid, unexpected, or random data to the input interfaces of a program. If the program fails (for example, by crashing or failing built-in code assertions), the defects can be noted.
16. A. The five levels of the Capability Maturity Integration Model are
• Initial Development process is ad hoc or even chaotic. The company does not use effective management procedures and plans. There is no assurance of consistency, and quality is unpredictable. Success is usually the result of individual heroics.
• Repeatable A formal management structure, change control, and quality assurance are in place. The company can properly repeat processes throughout each project. The company does not have formal process models defined.
• Defined Formal procedures are in place that outline and define processes carried out in each project. The organization has a way to allow for quantitative process improvement.
• Managed The company has formal processes in place to collect and analyze quantitative data, and metrics are defined and fed into the process-improvement program.
• Optimizing The company has budgeted and integrated plans for continuous process improvement.
17. B. The characteristics and their associated definitions are listed as follows:
• Modularity Autonomous objects, cooperation through exchanges of messages.
• Deferred commitment The internal components of an object can be redefined without changing other parts of the system.
• Reusability Refining classes through inheritance. Other programs using the same objects.
• Naturalness Object-oriented analysis, design, and modeling map to business needs and solutions.
18. D. The buffer overflow is probably the most notorious of input validation mistakes. A buffer is an area reserved by an application to store something in it, such as some user input. After the application receives the input, an instruction pointer points the application to do something with the input that’s been put in the buffer. A buffer overflow occurs when an application erroneously allows an invalid amount of input to be written into the buffer area, overwriting the instruction pointer in the code that tells the program what to do with the input. Once the instruction pointer is overwritten, whatever code has been placed in the buffer can then be executed, all under the security context of the application.
19. A. The nonpersistent cross-site scripting vulnerability is when the data provided by a web client, most commonly in HTTP query parameters or in HTML form submissions, is used immediately by server-side scripts to generate a page of results for that user without properly sanitizing the response. The persistent XSS vulnerability occurs when the data provided by the attacker is saved by the server and then permanently displayed on “normal” pages returned to other users in the course of regular browsing without proper HTML escaping. DOM-based vulnerabilities occur in the content processing stages performed by the client, typically in client-side JavaScript.
20. B. An object-relational database (ORD) or object-relational database management system (ORDBMS) is a relational database with a software front end that is written in an object-oriented programming language. Different companies will have different business logic that needs to be carried out on the stored data. Allowing programmers to develop this front-end software piece allows the business logic procedures to be used by requesting applications and the data within the database.
21. A. The following are correct characteristics of ADO:
• It’s a high-level data access programming interface to an underlying data access technology (such as OLE DB).
• It’s a set of COM objects for accessing data sources, not just database access.
• It allows a developer to write programs that access data without knowing how the database is implemented.
• SQL commands are not required to access a database when using ADO.
22. C. A semantic integrity mechanism makes sure structural and semantic rules are enforced. These rules pertain to data types, logical values, uniqueness constraints, and operations that could adversely affect the structure of the database. A database has referential integrity if all foreign keys reference existing primary keys. There should be a mechanism in place that ensures no foreign key contains a reference to a primary key of a nonexistent record, or a null value. Entity integrity guarantees that the tuples are uniquely identified by primary key values. For the sake of entity integrity, every tuple must contain one primary key. If it does not have a primary key, it cannot be referenced by the database.
23. B. The National Software Reference Library (NSRL) is the only term that was not addressed in this chapter. It comprises a collection of digital signatures of known, traceable software applications intended to assist in the investigation of crimes involving computers. All other three answers are part of a rigorous assessment of the security of acquired software.
24. B. Software configuration management (SCM) identifies the attributes of software at various points in time, and performs a methodical control of changes for the purpose of maintaining software integrity and traceability throughout the software development life cycle. It defines the need to track changes and provides the ability to verify that the final delivered software has all of the approved changes that are supposed to be included in the release.
25. D. A service-oriented architecture (SOA) provides standardized access to the most needed services to many different applications at one time. This approach allows for different business applications to access the current web services available within the environment.
26. D. A mashup is the combination of functionality, data, and presentation capabilities of two or more sources to provide some type of new service or functionality. Open APIs and data sources are commonly aggregated and combined to provide a more useful and powerful resource.
27. B. Web service provides the application functionality. WSDL describes the web service’s specifications. UDDI provides the mechanisms for web services to be posted and discovered. SOAP allows for the exchange of messages between a requester and provider of a web service.
28. B. The characters “%20” are encoding values that attackers commonly use in URL encoding attacks. These encoding values can be used to bypass web server filtering rules and can result in the attacker being able to gain unauthorized access to components of the web server. The characters “../” can be used by attackers in similar web server requests, which instruct the web server software to traverse directories that should be inaccessible. This is commonly referred to as a path or directory traversal attack.
29. A. Client-side validation is being carried out. This procedure ensures that the data that is inserted into the form contains valid values before being sent to the web server for processing. The web server should not just rely upon client-side validation, but should also carry out a second set of procedures to ensure that the input values are not illegal and potentially malicious.
30. B. The current architecture allows for web server software to directly communicate with a back-end database. Brad should ensure that proper database access authentication is taking place so that SQL injection attacks cannot be carried out. In a SQL injection attack the attacker sends over input values that the database carries out as commands and can allow authentication to be successfully bypassed.