
Chapter 8. CUDA for All GPU and CPU Applications
Software development takes time and costs money. CUDA has evolved from a solid platform to accelerate numerical computation into a platform that is appropriate for all application development. What this means is that a single source tree of CUDA code can support applications that run exclusively on conventional x86 processors, exclusively on GPU hardware, or as hybrid applications that simultaneously use all the CPU and GPU devices in a system to achieve maximal performance. The Portland Group, Inc. (PGI) native CUDA-x86 compiler is one realization of this maturation process that has made CUDA C/C++ a viable source platform for generic application development, just like C++ and Java. Unlike Java and other popular application languages, CUDA can efficiently support tens of thousands of concurrent threads of execution. CUDA also supports the conventional approach to cross-language development that uses language bindings to interface with existing languages. As with other languages, libraries simplify application development and handle commonly used methods such as linear algebra, matrix operations, and the Fast Fourier Transform (FFT). Dynamic compilation is also blurring the distinction between CUDA and other languages, as exemplified by the Copperhead project (discussed shortly), which lets Python programmers write their code entirely in Python. The Copperhead runtime then dynamically compiles the Python methods to run on CUDA-enabled hardware.
Keywords
Libraries, x86, ROI (Return on Investment), Python, R, Java, PGI (the Portland Group)
Software development takes time and costs money. CUDA has evolved from a solid platform to accelerate numerical computation into a platform that is appropriate for all application development. What this means is that a single source tree of CUDA code can support applications that run exclusively on conventional x86 processors, exclusively on GPU hardware, or as hybrid applications that simultaneously use all the CPU and GPU devices in a system to achieve maximal performance. The Portland Group, Inc. (PGI) 1 native CUDA-x86 compiler is one realization of this maturation process that has made CUDA C/C++ a viable source platform for generic application development, just like C++ and Java. Unlike Java and other popular application languages, CUDA can efficiently support tens of thousands of concurrent threads of execution. CUDA also supports the conventional approach to cross-language development that uses language bindings to interface with existing languages. As with other languages, libraries simplify application development and handle commonly used methods such as linear algebra, matrix operations, and the Fast Fourier Transform (FFT). Dynamic compilation is also blurring the distinction between CUDA and other languages, as exemplified by the Copperhead project (discussed shortly), which lets Python programmers write their code entirely in Python. The Copperhead runtime then dynamically compiles the Python methods to run on CUDA-enabled hardware.
At the end of this chapter, the reader will have a basic understanding of:
■ Tools to transparently build and run CUDA applications on non-GPU systems and GPUs manufactured by any vendor.
■ The Copperhead project, which dynamically compiles Python for CUDA execution.
■ How to incorporate CUDA with most languages, including Python, FORTRAN, R, Java, and others.
■ Important numerical libraries such as CUBLAS, CUFFT, and MAGMA.
■ How to use CUFFT concurrently on multiple GPUs.
■ CURAND and problems with naïve approaches to random number generation.
■ The effect of PCIe hardware on multi-GPU applications.
Pathways from CUDA to Multiple Hardware Backends
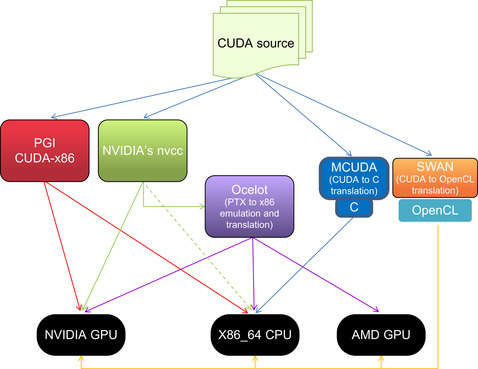
Example 8.1 illustrates the paths that are currently available to run CUDA C/C++ on x86 and GPU hardware. These are capabilities that give CUDA programmers the ability—with a single source tree—to create applications that can reach both those customers who own the third of a billion CUDA-enabled GPUs sold to date as well as the massive base of customers who already own x86-based systems. Example 8.1, “Pathway to use CUDA source code on CPUs, GPUs, and other vendor GPUs.”
 |
The PGI CUDA x86 Compiler
The concept behind native x86 compilation is to give CUDA programmers the ability—with a single source tree—to create applications that can reach most customers with a computer. When released, the PGI unified binary will greatly simplify product support and delivery as a single application binary can be shipped to customers. At runtime, the PGI unified binary will query the hardware and selectively run on any CUDA-enabled GPUs or the host multicore processor.
What distinguishes the PGI effort from source translators such as the Swan2 CUDA to OpenCL translator; the MCUDA3 CUDA to C translator; the Ocelot4 open source emulator and PTX translation project; and the ability of the NVIDIA nvcc compiler to generate both x86 and GPU based code is:
■ Speed: The PGI CUDA C/C++ compiler is a native compiler that transparently compiles CUDA to run on x86 systems even when a GPU is not present in the system. This gives the compiler the opportunity to perform x86 specific optimization to best use the multiple cores of the x86 processor as well as the SIMD parallelism in the AVX or SSE instructions within each core. (AVX is an extension of SSE to 256-bit operation.)
■ Transparency: Both NVIDIA and PGI state that even CUDA applications utilizing proprietary features of the GPU texture units will exhibit identical behavior on both x86 and GPU hardware.
■ Convenience: In 2012, the PGI compiler will be able to create a unified binary, which will simplify the software distribution process tremendously as mentioned previously. The simplicity of shipping a single binary to customers reflects the completeness of the thought behind the PGI CUDA C/C++ project.
From a planning perspective, CUDA for x86 dramatically impacts the software development decision-making process. Rather than CUDA filling the role of a niche development platform for GPU-based products, CUDA is now a platform for all product development—even for applications that are not intended to be accelerated by GPUs!
The motivation is clearly exemplified by the variety and number of projects on the NVIDIA showcase that have achieved 100 times or greater performance over commodity processors, as summarized in Figure 8.1.
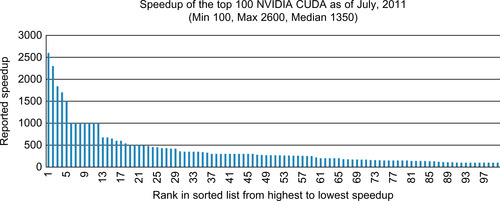
In short, the performance of applications that fail to capitalize on the parallel performance capabilities of multicore and GPU devices will plateau at or near current levels and not increase with future hardware generations. Such applications risk stagnation and a loss of competitiveness (Farber, 2010).
From a software development point of view, prudence dictates the selection of a platform that works well right now. Foresight requires picking a software framework that keeps the application running competitively on future hardware platforms without requiring a substantial rewrite or additional software investment.
Following are the top reasons to use CUDA for all application development:
■ CUDA is based on standard C and C++. Both of these languages have a solid history of application development spanning decades.
■ Applications written in CUDA and compiled with CUDA-x86 can potentially run faster on x86 platforms than code written in traditional languages through better use of parallelism and the multicore SIMD units.
■ Multicore CUDA codes will contain fewer bugs because the CUDA execution model precludes many common parallel programming errors including race conditions and deadlock.
■ CUDA will future-proof the application because CUDA was designed to scale effectively to tens of thousands of concurrent threads of execution. This benefit can save future software development dollars and allow fast penetration into new markets.
■ GPU acceleration comes for free, which opens the door for order of magnitude application acceleration on the third of a billion CUDA-enabled GPUs that have already been sold worldwide.
■ CUDA has a large base of educated developers; plus, this developer base is rapidly expanding. CUDA is currently taught at more than 450 universities and colleges worldwide. The number of institutions teaching CUDA is also rapidly expanding.
In other words, the future looks bright for literate CUDA programmers!
The PGI CUDA x86 Compiler
Using the PGI CUDA-x86 compiler is straightforward. Currently, PGI offers the compiler a free evaluation period. Just download and install it per the instructions on the PGI website. 5
Setup is straightforward and well described in the installation guide. Example 8.2, “Setting the Environment for the PGI Compilor,” contains the commands to set the environment using bash under Linux:
PGI=/opt/pgi; export PGI
MANPATH=$MANPATH:$PGI/linux86-64/11.5/man; export MANPATH
LM_LICENSE_FILE=$PGI/license.dat; export LM_LICENSE_FILE
PATH=$PGI/linux86-64/11.5/bin:$PATH; export PATH
It is quite easy to use the software. For example, copy the PGI NVIDIA SDK samples to a convenient location and build them, as in Example 8.3, “Building the PGI SDK”:
cp –r /opt/pgi/linux86-64/2011/cuda/cudaX86SDK .
cd cudaX86SDK ;
make
Example 8.4, “Output of deviceQuery When Running on a Quad-CoreCPU,” shows the output of deviceQuery on an Intel Xeon e5560:
CUDA Device Query (Runtime API) version (CUDART static linking)
There is 1 device supporting CUDA
Device 0: "DEVICE EMULATION MODE"
CUDA Driver Version:99.99
CUDA Runtime Version:99.99
CUDA Capability Major revision number:9998
CUDA Capability Minor revision number:9998
Total amount of global memory:128000000 bytes
Number of multiprocessors:1
Number of cores:0
Total amount of constant memory:1021585952 bytes
Total amount of shared memory per block:1021586048 bytes
Total number of registers available per block:1021585904
Warp size:1
Maximum number of threads per block:1021585920
Maximum sizes of each dimension of a block:32767 × 2 × 0
Maximum sizes of each dimension of a grid:1021586032 × 32767 × 1021586048
Maximum memory pitch:4206313 bytes
Texture alignment:1021585952 bytes
Clock rate:0.00 GHz
Concurrent copy and execution:Yes
Run time limit on kernels:Yes
Integrated:No
Support host page-locked memory mapping:Yes
Compute mode:Unknown
Concurrent kernel execution:Yes
Device has ECC support enabled:Yes
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 99.99, CUDA Runtime Version = 99.99, NumDevs = 1, Device = DEVICE EMULATION MODE
PASSED
Press <Enter> to Quit…
----------------------------------------------------------
Similarly, the output of bandwidthTest shows that device transfers work as expected (Example 8.5, “Output of bandwidthTest When Running on a Quad-Core CPU):
Running on…
Device 0: DEVICE EMULATION MODE
Quick Mode
Host to Device Bandwidth, 1 Device(s), Paged memory
Transfer Size (Bytes)Bandwidth(MB/s)
335544324152.5
Device to Host Bandwidth, 1 Device(s), Paged memory
Transfer Size (Bytes) Bandwidth(MB/s)
335544324257.0
Device to Device Bandwidth, 1 Device(s)
Transfer Size (Bytes)Bandwidth(MB/s)
335544328459.2
[bandwidthTest] − Test results:
PASSED
Press <Enter> to Quit…
----------------------------------------------------------
Just as with NVIDIA's nvcc compiler, it is easy to use the PGI pgCC compiler to build an executable from a CUDA source file. For example, the arrayReversal_multiblock_fast.cu code from part 3 of my Doctor Dobb's article series just compiles and runs. 6
To compile and run it under Linux, type the code in Example 8.6, “Output of arrayReversal_multiblock_fast.cu When Running on a Quad-Core CPU”:
pgCC arrayReversal_multiblock_fast.cu
./a.out
Correct!
An x86 core as an SM
In CUDA-x86, thread blocks are efficiently mapped to the processor cores. Thread-level parallelism is mapped to the SSE (Streaming SIMD Extensions) or AVX SIMD units, as shown in Figure 8.2.
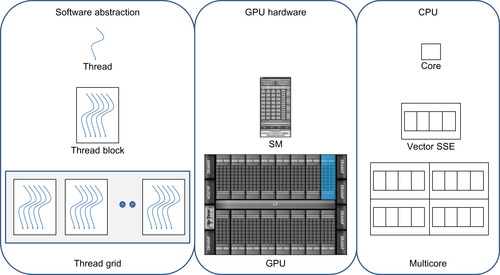
CUDA programmers should note:
■ The size of a warp will be different from the expected 32 threads per warp for a GPU. For x86 computing, a warp might be the size of the SIMD units on the x86 core (either four or eight) or one thread per warp when SIMD execution is not utilized.
■ In many cases, the PGI CUDA C compiler will remove explicit synchronization of the thread processors when the compiler can determine that it is safe to split loops where the synchronization calls occur.
■ CUDA programmers must consider data transfer times, as explicit movement of data between host and device memory and global to shared memory will still happen in CUDA-x86.
The NVIDIA NVCC Compiler
The NVIDIA nvcc compiler can generate both host- and device-based kernels. Chapter 2 utilized this capability for testing and performance analysis purposes. Though very useful, this approach requires manual effort on the part of the CUDA programmer to set up memory correctly and to call the functor appropriately.
Thrust can also transparently generate code for different backends such as x86 processors just by passing some additional command-line options to nvcc. No source code modification is required.
The following nvcc command-line demonstrated building the NVIDIA SDK Monte Carlo example to run on the host processor:
nvcc -O2 -o monte_carlo monte_carlo.cu -Xcompiler -fopenmp
-DTHRUST_DEVICE_BACKEND=THRUST_DEVICE_BACKEND_OMP -lcudart -lgomp
Timing reported on the Thrust website shows that the performance is acceptable (see Table 8.1). Be aware that Thrust is not optimized to produce the best x86 runtimes.
Ocelot
Ocelot is a popular, actively maintained package with a large user base. The website notes that Ocelot can run CUDA binaries on NVIDIA GPUS, AMD GPUs, and x86 processors at full speed without recompilation. It can be freely downloaded and is licensed under a new BSD license. A paper by Gregory Diamos, “The Design and Implementation Ocelot's7 Dynamic Binary Translator from PTX to Multi-Core x86,” is recommended reading (Diamos, 2009), as is his chapter in GPU Computing Gems (Hwu, 2011).
Ocelot's core capabilities consist of:
■ An implementation of the CUDA Runtime API.
■ A complete internal representation of PTX kernels coupled to control- and data-flow analysis procedures for analysis.
■ A functional emulator for PTX.
■ A PTX translator to multicore x86-based CPUs for efficient execution.
■ A backend to NVIDIA GPUs via the CUDA driver API.
■ Support for an extensible trace generation framework in which application behavior can be observed at instruction-level granularity.
Ocelot has three backend execution targets:
■ A PTX emulator.
■ A translator from PTX to multicore instructions.
■ A CUDA-enabled GPU.
Ocelot has been validated against more than 130 applications taken from the CUDA SDK, the UIUC Parboil benchmark, the Virginia Rodinia benchmarks (Che et al., 2009 and Che et al., 2010), the GPU-VSIPL signal and image processing library, 8 the thrust library, and several domain-specific applications. It is an exemplary tool to use in profiling and analyzing the behavior of CUDA applications that can also be used as a platform for CUDA application portability.
Swan
Swan is a freely available source-to-source translation tool that converts an existing CUDA code to use the OpenCL model. Note that the conversion process requires human intervention and is not automatic.
The authors report that the performance of a CUDA application ported to OpenCL run about 50 percent slower (Harvey & De Fabritiis, 2010). The authors attribute the performance reduction to the immaturity of the OpenCL compilers. They conclude that OpenCL is a viable platform for developing portable GPU applications but also that the more mature CUDA tools continue to provide best performance.
It is not clear how active the development effort is on the Swan project, as the most recent update was in December 2010. The current version of Swan does not support:
■ CUDA C++ templates in kernel code.
■ OpenCL Images/Samplers (analogous to Textures)—texture interpolation done in software.
■ Multiple device management in a single process.
■ Compiling kernels for the CPU.
■ CUDA device-emulation mode.
MCUDA
MCUDA is an academic effort by the IMPACT Research Group at the University of Illinois. It is available for free download. This project does not appear to be actively maintained.
The paper “MCUDA: An Efficient Implementation of CUDA Kernels for Multi-Core CPUs” is interesting reading (Stratton, Stone, & Hwu, 2008). A related paper, “FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs,” discusses translating CUDA to FPGAs (Field Programmable Gate Arrays) (Papakonstantinou et al., 2009).
Accessing CUDA from Other Languages
CUDA can be incorporated into any language that provides a mechanism for calling C or C++. To simplify this process, general-purpose interface generators have been created that will create most of the boilerplate code automatically. One of the most popular interface generators is SWIG. An alternative approach is to seamlessly integrate CUDA into the language, which is being investigated by the Copperhead Python project.
SWIG
SWIG (Simplified Wrapper and Interface Generator) is a software development tool that connects programs written in C and C++—including CUDA C/C++ applications—with a variety of high-level programming languages. SWIG is actively supported and widely used. It can be freely downloaded from the SWIG website. 9
As of the current 2.0.4 release, SWIG generates interfaces for the following languages:
■ AllegroCL
■ C# – Mono
■ C# – MS.NET
■ CFFI
■ CHICKEN
■ CLISP
■ D
■ Go language
■ Guile
■ Java
■ Lua
■ MzScheme/Racket
■ Ocaml
■ Octave
■ Perl
■ PHP
■ Python
■ R
■ Ruby
■ Tcl/Tk
Part 9 of my Doctor Dobb's Journal “Supercomputing for the Masses” tutorial series10 provides a complete working example that uses SWIG to interface a CUDA matrix operation with Python. This example can interface with other languages as well (Farber, 2008).
Copperhead
Copperhead is an early-stage research project to bring data parallelism to the Python language. It defines a small, data-parallel subset of Python that is dynamically compiled to run on parallel platforms. Right now, NVIDIA GPGPUs are the only parallel backend.
Example 8.8, “Example Copperhead Python Code,” is a simple example from the Copperhead website:
from copperhead import *
import numpy as np
@cu
def axpy(a, x, y):
return [a * xi + yi for xi, yi in zip(x, y)]
x = np.arange(100, dtype=np.float64)
y = np.arange(100, dtype=np.float64)
with places.gpu0:
gpu = axpy(2.0, x, y)
with places.here:
cpu = axpy(2.0, x, y)
Copperhead organizes computations around data parallel arrays. In this example, the Copperhead runtime intercepts the call to axpy() and compiles the function to CUDA. The runtime converts the input arguments to a type of parallel array, CuArrays, that are managed by the runtime.
The programmer specifies where the execution is to take place using the with construct shown in the previous example. Data is lazily copied to and from the execution location. Copperhead currently supports GPU execution and Python interpreter execution. Use of the Python interpreter is intended for algorithm prototyping.
EXCEL
Microsoft Excel is a widely adopted commercial spreadsheet application written and distributed by Microsoft for Windows and Mac OS. It features calculation, graphing tools, and a variety of other tools. Functionality can be programmed in Visual Basic. NVIDIA distributes the “Excel 2010 CUDA Integration Example”11 on their website, which shows how to use CUDA in Excel. This SDK example is not included in the standard SDK samples.
MATLAB
MATLAB is a commercial application developed by MathWorks. The MATLAB software allows matrix manipulation, plotting of functions and data, and a wealth of other functionality. Developers can implement algorithms and user interfaces as well as integrate MATLAB into other applications. MATLAB GPU support is available in the Parallel Computing Toolbox. It supports NVIDIA CUDA-enabled GPUs of compute 1.3 and higher. Third-party products such as those by Accelereyes provide both MATLAB access to GPU computing as well as matrix libraries for CUDA. 12
Libraries
The use of optimized libraries are often an easy way to improve the performance of an application. When porting large legacy projects, libraries may be the only real way to optimize for a new platform because code changes would require extensive validation efforts. Essentially, libraries are convenient and can greatly accelerate code development as well as application performance, but they cannot be blindly utilized. GPU-based libraries in particular require the developer to think carefully about data placement and how the library is used, or poor performance and excessive memory consumption will result.
CUBLAS
The Basic Linear Algebra Subprograms (BLAS) package is the de facto programming interface for basic linear algebra operations such as vector and matrix multiplication. NVIDIA supports this interface with their own library for the GPU called CUBLAS. The basic model by which applications use the CUBLAS library is to create matrix and vector objects in GPU memory space, fill these objects with data, call a sequence of CUBLAS functions, and return the result(s) to the host.
CUBLAS provides helper functions to create and destroy objects in GPU space and to utilize the data in these objects. CUDA programmers should note that CUBLAS uses column-major storage and 1-based indexing for maximum FORTRAN compatibility. C and C++ applications need to use macros or inline functions to facilitate access to CUBLAS created objects.
CUFFT
CUFFT is another NVIDIA supported library that provides a GPU based implementation of the FFT, a commonly used method in scientific and signal processing applications. CUFFT is modeled after FFTW, a very highly optimized and popular FFT package for general-purpose processors.
CUFFT utilizes a plan, which is a simple configuration mechanism that specifies the best “plan” of execution for a particular algorithm given a specified problem size, data type, and destination hardware platform. The advantage of this approach is that once a plan is created, it can be used for the remainder of the application lifetime. This is a commonly used programming pattern to perform runtime configuration in libraries and other high-performance portable codes. The NVIDIA CUFFT library uses this configuration model because different sizes and types of FFTs require different thread configurations and GPU resources. The simpleCUFFT example can be downloaded from the NVIDIA website. 14 It covers the basics of how to use the CUFFT library.
CUFFT also provides the method cufftPlanMany(), which creates a plan that will run multiple FFT operations at the same time. This can be both a performance boon and a memory hog.
The following test program demonstrates the use of CUFFT on one or more GPUs. It performs a 3D complex-to-complex forward and inverse in-place transform and calculates the error introduced by these transforms. Correct usage will result in a small error.
The user can specify the following runtime characteristics via the command line:
■ The number of GPUs to use. This number must be less than or equal to the number of GPUs in the system.
■ The size of each dimension.
■ The total number of FFTs to perform.
■ An optional value that specifies how many FFTs to perform on each call to CUFFT.
In addition, this test code makes use of C++ type defines. To create a double-precision executable, simply specify -D REAL=double on the nvcc command line.
General include files and constants are defined at the beginning of the example file. The preprocessor variable REAL is set to default to float if not otherwise defined during compilation. Example 8.9, “Part 1 of fft3Dtest.cu,” contains a walkthrough of the test code:
#include <iostream>
#include <cassert>
using namespace std;
#include <cuda.h>
#define CUFFT_FORWARD -1
#define CUFFT_INVERSE1
#include "thrust/host_vector.h"
#include "thrust/device_vector.h"
#include <cufft.h>
#ifndef REAL
#define REAL float
#endif
The template class DistFFT3D is defined and a number of variables are created in Example 8.10, “Part 2 of fft3Dtest.cu”:
template <typename Real>
class DistFFT3D {
protected:
int nGPU;
cudaStream_t *streams;
int nPerCall;
vector<cufftHandle> fftPlanMany;
int dim[3];
Real *h_data;
long h_data_elements;
long nfft, n2ft3d, h_memsize, nelements;
long totalFFT;
vector<Real *> d_data;
long bytesPerGPU;
The public constructor takes a vector of host data and partitions it equally across the user defined number of GPUs. These vectors are kept in the variable d_data.
For generality, an array of streams is passed to the constructor, which allows the user to queue work before and after the test. This capability is not used but is provided, in case the reader wishes to use this example in another code. It is assumed that one stream is associated with each GPU.
A vector of CUFFT handles is created in fftPlanMany() where one plan is associated with each stream. This setup implies that there will be one plan per GPU, as each stream is associated with a different GPU.
The number of multiplan FFTs is defined in the call to NperCall(). The method initFFTs() creates the handles. Similarly, a vector of device vectors is created per GPU. The pointers to device memory are held in the vector d_data. See Example 8.11, “Part 3 of fft3Dtest.cu”:
public:
DistFFT3D(int _nGPU, Real* _h_data, long _h_data_elements, int *_dim, int _nPerCall, cudaStream_t *_streams) {
nGPU= _nGPU;
h_data = _h_data;
h_data_elements = _h_data_elements;
dim[0] = _dim[0]; dim[1] = _dim[1]; dim[2] = _dim[2];
nfft = dim[0]*dim[1]*dim[2];
n2ft3d = 2*dim[0]*dim[1]*dim[2];
totalFFT = h_data_elements/n2ft3d;
set_NperCall(_nPerCall);
bytesPerGPU = nPerCall*n2ft3d*sizeof(Real);
h_memsize = h_data_elements*sizeof(Real);
assert( (totalFFT/nPerCall*bytesPerGPU) == h_memsize);
streams = _streams;
fftPlanMany = vector<cufftHandle>(nGPU);
initFFTs();
for(int i=0; i<nGPU; i++) {
Real* tmp;
cudaSetDevice(i);
if(cudaMalloc(&tmp,bytesPerGPU)) {
cerr << "Cannot allocate space on device!" << endl;
exit(1);
}
d_data.push_back(tmp);
}
}
void set_NperCall(int n) {
cerr << "Setting nPerCall " << n << endl;
nPerCall = n;
if( (nGPU * nPerCall) > totalFFT) {
cerr << "Too many nPerCall specified! max " << (totalFFT/nGPU) << endl;
exit(1);
}
}
The destructor frees the data allocated on the devices in Example 8.12, “Part 4 of fft3Dtest.cu”:
~DistFFT3D() {
for(int i=0; i < nGPU; i++){
cudaSetDevice(i);
cudaFree(d_data[i]);
}
}
Example 8.13, “Part 5 of fft3Dtest.cu,” initializes the multiplan FFTs and provides the template wrappers to correctly call the CUFFT method for float and double variable types. Note that the stream is set with cufftSetStream():
void inline initFFTs()
{
if((nPerCall*nGPU) > totalFFT) {
cerr << "nPerCall must be a multiple of totalFFT" << endl;
exit(1);
}
// Create a batched 3D plan
for(int sid=0; sid < nGPU; sid++) {
cudaSetDevice(sid);
if(sizeof(Real) == sizeof(float) ) {
cufftPlanMany(&fftPlanMany[sid], 3, dim, NULL, 1, 0, NULL, 1, 0, CUFFT_C2C,nPerCall);
} else {
cufftPlanMany(&fftPlanMany[sid], 3, dim, NULL, 1, 0, NULL, 1, 0, CUFFT_Z2Z,nPerCall);
}
if(cufftSetStream(fftPlanMany[sid],streams[sid])) {
cerr << "cufftSetStream failed!" << endl;
}
}
cudaSetDevice(0);
}
inline void _FFTerror(int ret) {
switch(ret) {
case CUFFT_SETUP_FAILED: cerr << "SETUP_FAILED" << endl; break;
case CUFFT_INVALID_PLAN: cerr << "INVALID_PLAN" << endl; break;
case CUFFT_INVALID_VALUE: cerr << "INVALID_VALUE" << endl; break;
case CUFFT_EXEC_FAILED: cerr << "EXEC_FAILED" << endl; break;
default: cerr << "UNKNOWN ret code " << ret << endl;
}
}
//template specialization to handle different data types (float,double)
inline void cinverseFFT_(cufftHandle myFFTplan, float* A, float* B ) {
int ret=cufftExecC2C(myFFTplan, (cufftComplex*)A, (cufftComplex*) B, CUFFT_INVERSE);
if(ret != CUFFT_SUCCESS) {
cerr << "C2C FFT failed! ret code " << ret << endl;
_FFTerror(ret); exit(1);
}
}
inline void cinverseFFT_(cufftHandle myFFTplan, double *A, double *B) {
int ret = cufftExecZ2Z(myFFTplan, (cufftDoubleComplex*)A, (cufftDoubleComplex*) B, CUFFT_INVERSE);
if(ret != CUFFT_SUCCESS) {
cerr << "Z2Z FFT failed! ret code " << ret << endl;
_FFTerror(ret); exit(1);
}
}
inline void cforwardFFT_(cufftHandle myFFTplan, float* A, float* B ) {
int ret = cufftExecC2C(myFFTplan, (cufftComplex*)A, (cufftComplex*) B, CUFFT_FORWARD);
if(ret != CUFFT_SUCCESS) {
cerr << "C C2C FFT failed!" << endl; _FFTerror(ret); exit(1);
}
}
inline void cforwardFFT_(cufftHandle myFFTplan, double *A, double *B) {
int ret = cufftExecZ2Z(myFFTplan, (cufftDoubleComplex*)A, (cufftDoubleComplex*) B, CUFFT_FORWARD);
if(ret != CUFFT_SUCCESS) {
cerr << "Z2Z FFT failed!" << endl; _FFTerror(ret); exit(1);
}
}
Calculate the error on the host using scaled values of the FFT results and the original host vector, as in Example 8.14, “Part 6 of fft3Dtest.cu”:
double showError(Real* h_A1)
{
double error=0.;
#pragma omp parallel for reduction (+ : error)
for(int i=0; i < h_data_elements; i++) {
h_data[i] /= (Real)nfft;
error += abs(h_data[i] − h_A1[i]);
}
return error;
}
Example 8.15, “Part 7 of fft3Dtest.cu,” performs the actual test:
void doit()
{
double startTime = omp_get_wtime();
long h_offset=0;
for(int i=0; i < totalFFT; i += nGPU*nPerCall) {
for(int j=0; j < nGPU; j++) {
cudaSetDevice(j);
cudaMemcpyAsync(d_data[j], ((char*)h_data)+h_offset, bytesPerGPU, cudaMemcpyDefault,streams[j]);
cforwardFFT_(fftPlanMany[j],d_data[j], d_data[j]);
cinverseFFT_(fftPlanMany[j],d_data[j], d_data[j]);
cudaMemcpyAsync(((char*)h_data)+h_offset, d_data[j], bytesPerGPU, cudaMemcpyDefault,streams[j]);
h_offset += bytesPerGPU;
}
}
cudaDeviceSynchronize();
cudaSetDevice(0);
double endTime = omp_get_wtime();
cout << dim[0] << " " << dim[1] << " " << dim[2]
<< " nFFT/s " << 1./(0.5*(endTime-startTime)/totalFFT)
<< " average 3D fft time " << (0.5*(endTime-startTime)/totalFFT)
<< " total " << (endTime-startTime) << endl;
}
};
The outer loop ensures that all the FFTs are performed by iterating from zero to totalFFT in steps of the number of multiplan FFT performed by all the GPUs.
The inner loop sets the device and queues:
■ The transfer of data to the device from the host. Note that the transfer with cudamemcpyAsync() is asynchronous to the host but not to the other tasks in the queue.
■ The forward and inverse FFT transforms.
■ The asynchronous transfer of data from the device back to the host.
The increment of h_offset at the end of the inner loop ensures that each GPU (and queued FFT operation) operates on different, nonoverlapping regions of host memory, so no synchronization between GPUs is required. Finally, the overall performance of this method is measured and the average number of FFTs performed per second is reported.
The main() routine parses the command line and performs some basic checks. It also creates the streams array and associates one stream per GPU.
Of particular interest is the use of pinned memory on the host for fast asynchronous data transfers between the host and devices. This memory is created with cudaHostAlloc(), using the flag cudaHostAllocPortable. The host vector is filled with recurring sequential values. See Example 8.16, “Part 8 of fft3Dtest.cu”:
main(int argc, char *argv[])
{
if(argc < 6) {
cerr << "Use nGPU dim[0] dim[1] dim[2] numberFFT [nFFT per call]" << endl;
exit(1);
}
int nPerCall = 1;
int nGPU = atoi(argv[1]);
int dim[] = { atoi(argv[2]), atoi(argv[3]), atoi(argv[4])};
int totalFFT=atoi(argv[5]);
nPerCall = totalFFT;
if( argc > 6) {
nPerCall = atoi(argv[6]);
if(totalFFT % nPerCall != 0) {
cerr << "nPerCall must be a multiple of totalFFT!" << endl;
return(1);
}
}
int systemGPUcount;
cudaGetDeviceCount(&systemGPUcount);
if(nGPU > systemGPUcount) {
cerr << "Attempting to use too many GPUs!" << endl;
return(1);
}
cerr << "nGPU = " << nGPU << endl;
cerr << "dim[0] = " << dim[0] << endl;
cerr << "dim[1] = " << dim[1] << endl;
cerr << "dim[2] = " << dim[2] << endl;
cerr << "totalFFT = " << totalFFT << endl;
cerr << "sizeof(REAL) is " << sizeof(REAL) << " bytes" << endl;
cudaStream_t streams[nGPU];
for(int sid=0; sid < nGPU; sid++) {
cudaSetDevice(sid);
if(cudaStreamCreate(&streams[sid]) != 0) {
cerr << "Stream create failed!" << endl;
}
}
cudaSetDevice(0);
long nfft = dim[0]*dim[1]*dim[2];
long n2ft3d = 2*dim[0]*dim[1]*dim[2];
long nelements = n2ft3d*totalFFT;
REAL *h_A, *h_A1;
if(cudaHostAlloc(&h_A, nelements*sizeof(REAL), cudaHostAllocPortable)
!= cudaSuccess) {
cerr << "cudaHostAlloc failed!" << endl; exit(1);
}
h_A1 = (REAL*) malloc(nelements*sizeof(REAL));
if(!h_A1) {
cerr << "malloc failed!" << endl; exit(1);
}
// fill the test data
#pragma omp parallel for
for(long i=0; i < nelements; i++) h_A1[i] = h_A[i] = i%n2ft3d;
DistFFT3D<REAL> dfft3d(nGPU, h_A, nelements, dim, nPerCall, streams);
dfft3d.doit();
double error = dfft3d.showError(h_A1);
cout << "average error per fft " << (error/nfft/totalFFT) << endl;
cudaFreeHost(h_A1);
}
This source code can be compiled with the command-line Example 8.17, “command-line to compile fft3dtest.cu”, which assumes that the file is saved in fft3dtest.cu:
nvcc -Xcompiler -fopenmp -O3 -arch sm_20 fft3Dtest.cu -lcufft
-o fft3Dtest_float
nvcc -Xcompiler -fopenmp -O3 -arch sm_20 -D REAL=double fft3Dtest.cu
-lcufft -o fft3Dtest_double
Running the test shows that the test program correctly utilizes CUFFT, as the error is small even when using single precision. For example, a 323 run that performs 128 FFT tests generates an error of 0.00225.
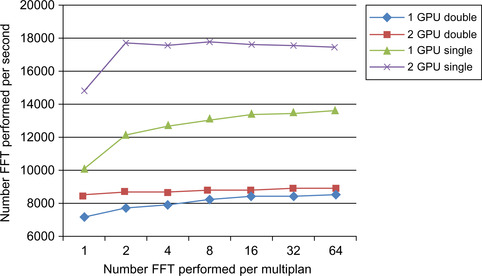
Further, there is a speedup benefit when running on two GPUs, as seen in Figure 8.3, which shows plotted results for both single- and double-precision FFTs. The second GPU appears to provide limited additional performance in the double-precision runs, probably due to doubling the amount of data that must be transferred across the PCIe bus. Performing more than a few FFTs per CUFFT call also appears to have a minimal impact on performance.
A computeprof width plot shows that the application is concurrently running on both GPUs. The following width plot was captured on a Dell Precision 7500 with two NVIDIA C2050 GPUs. 15 The original color screenshot was converted to grayscale for this book. The H2D (Host to Device) and D2H (Device to Host) transfers are noted as well as the computational kernels that implement the 3D FFT.
15Access to this machine was provided by the ICHEC (Irish Center for High-End Computing) NVIDIA CUDA Research Center.
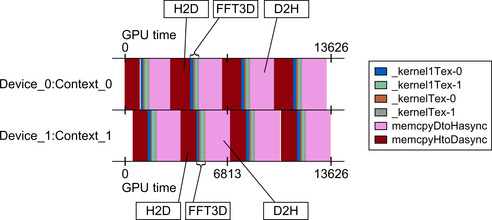
Results from the same run on an HP Z800 illustrate the importance of the PCIe hardware. Slow performance in the asynchronous transfer of data to one of the GPUs can dramatically decrease performance.
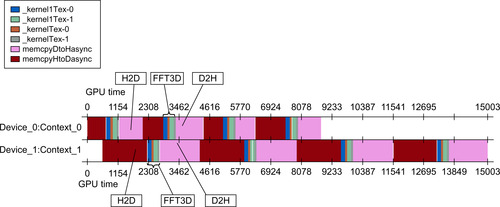
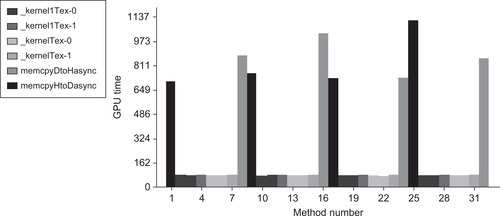
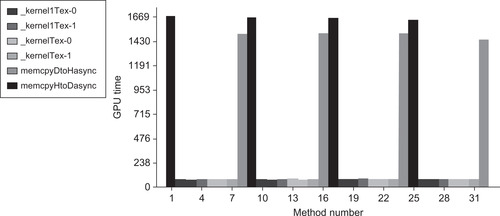
This observation is confirmed via the computeprof height plot for each GPU on the HP Z800, as there are clear differences between the two GPU devices as well as variations in the transfers performed on the device.
MAGMA
The MAGMA project aims to develop a dense linear algebra library similar to LAPACK but for heterogeneous/hybrid architectures. The initial focus is to provide a package that will concurrently run on multicore processors and a single GPU to deliver the combined performance of this hybrid environment. Later efforts will combine multiple GPUs with multiple cores.
The MAGMA team has made the conclusion that dense linear algebra (DLA), “has become a better fit for the new GPU architectures, to the point where DLA can run more efficiently on GPUs than on current, high-end homogeneous multicore-based systems” (Nath, Stanimire, & Dongerra, 2010, p. 1). According to Volkov, the current MAGMA BLAS libraries achieve up to 838 GF/s (Volkov, 2010).
The MAGMA software is freely downloadable from the University of Tennessee Innovative Computing Laboratory website. 16
phiGEMM Library
The phiGEMM library is a freely available open source library that was written by Ivan Girotto and Filippo Spiga at ICHEC. 17 It performs matrix–matrix multiplication (e.g., GEMM operations) on heterogeneous systems containing multiple GPUs and multicore processors.
The phiGEMM library extends the mapping of Fatica (Fatica, 2009) to support single-precision, double-precision, and complex matrices. The LINPACK TOP 500 benchmark HPL benchmark suite uses this mapping for a heterogeneous matrix multiply as one of the core methods to evaluate the fastest supercomputers in the world. 18 The phiGEMM library is able to deliver comparable performance to the LINPACK benchmark using a single GPU and multicore processor. As can be seen in Figure 8.8, even greater performance can be achieved using two or more GPUs.
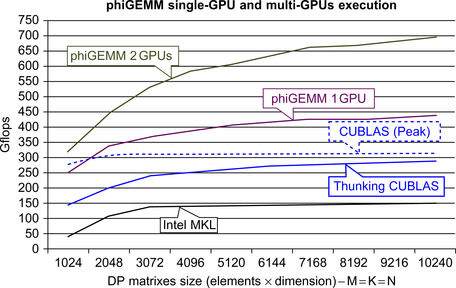 |
| Figure 8.8 |
The phiGEMM library transparently manages memory and the asynchronous data transfers amongst all the devices in the system (i.e., multiple GPUs and multicore processors). It can process matrices that are much larger than the memory capacity of a single GPU by recursively multiplying smaller submatrices. Again, the library makes this process transparent to the user. Figure 8.9 shows performance using up to four GPUs for a 15 GB matrix. The phiGEMM library is being considered for inclusion in the MAGMA library discussed earlier.
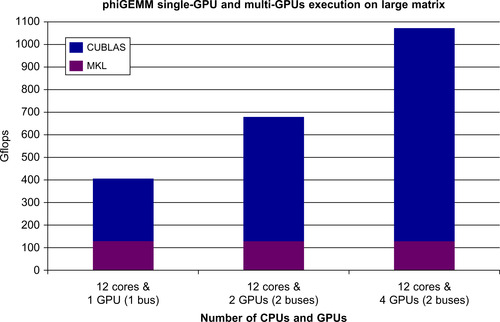
CURAND
Generating random numbers on parallel computers is challenging. The naïve approach is to have each thread supply a different seed to a common random number generation method. This approach is not guaranteed to be independent and can inadvertently introduce correlations into the “random” data (Coddington, 1997).
The CURAND library provides a simple and efficient API to generate high-quality pseudorandom and quasirandom numbers. A pseudorandom sequence of numbers satisfies most of the statistical properties of a truly random sequence but is generated by a deterministic algorithm. A quasirandom sequence of n-dimensional points is generated by a deterministic algorithm designed to fill an n-dimensional space evenly.
Application areas include:
■ Simulation: Random numbers are required to make things realistic. In the movies, computer-generated characters start and move in slightly different ways. People also arrive a airports at random intervals.
■ Sampling: For many interesting problems, it is impractical to examine all possible cases. However, random sampling can provide insight into what constitutes “typical” behavior.
■ Computer programming: Testing an algorithm with random numbers is an effective way to find problems and programmer biases.
Summary
Commercial and research projects must now have parallel applications to compete for customer and research dollars. This need translates into pressure on software development efforts to control costs while supporting a range of rapidly evolving parallel hardware platforms. CUDA has been rapidly evolving to meet this need. Unlike current programming languages, CUDA was designed to create applications that run on hundreds of parallel processing elements and manage many thousands of threads. This design makes CUDA an attractive choice compared with current development languages like C++ and Java. It also creates a demand for CUDA developers.
Projects like Copperhead are expanding the boundaries of what can be done with dynamic compilation and CUDA. Solid library support makes CUDA attractive for numerical and signal-processing applications. General interface packages like SWIG create the opportunity to add massively parallel CUDA support to many existing languages.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.