
Preface
Timing is so very important in technology, as well as in our academic and professional careers. We are an extraordinarily lucky generation of programmers who have the initial opportunity to capitalize on inexpensive, generally available, massively parallel computing hardware. The impact of GPGPU (General-Purpose Graphics Processing Units) technology spans all aspects of computation, from the smallest cell phones to the largest supercomputers in the world. They are changing the commercial application landscape, scientific computing, cloud computing, computer visualization, games, and robotics and are even redefining how computer programming is taught. Teraflop (trillion floating-point operations per second) computing is now within the economic reach of most people around the world. Teenagers, students, parents, teachers, professionals, small research organizations, and large corporations can easily afford GPGPU hardware and the software development kits (SDKs) are free. NVIDIA estimates that more than 300 million of their programmable GPGPU devices have already been sold.
Programmed in CUDA (Compute Unified Device Architecture), those third of a billion NVIDIA GPUs present a tremendous market opportunity for commercial applications, and they provide a hardware base with which to redefine what is possible for scientific computing. Most importantly, CUDA and massively parallel GPGPU hardware is changing how we think about computation. No longer limited to performing one or a few operations at a time, CUDA programmers write programs that perform many tens of thousands of operations simultaneously!
This book will teach you how to think in CUDA and harness those tens of thousands of threads of execution to achieve orders-of-magnitude increased performance for your applications, be they commercial, academic, or scientific. Further, this book will explain how to utilize one or more GPGPUs within a single application, whether on a single machine or across a cluster of machines. In addition, this book will show you how to use CUDA to develop applications that can run on multicore processors, making CUDA a viable choice for all application development. No GPU required!
Not concerned with just syntax and API calls, the material in this book covers the thought behind the design of CUDA, plus the architectural reasons why GPGPU hardware can perform so spectacularly. Various guidelines and caveats will be covered so that you can write concise, readable, and maintainable code. The focus is on the latest CUDA 4.x release.
Working code is provided that can be compiled and modified because playing with and adapting code is an essential part of the learning process. The examples demonstrate how to get high-performance from the Fermi architecture (NVIDIA 20-series) of GPGPUS because the intention is not just to get code working but also to show you how to write efficient code. Those with older GPGPUs will benefit from this book, as the examples will compile and run on all CUDA-enabled GPGPUs. Where appropriate, this book will reference text from my extensive Doctor Dobb's Journal series of CUDA tutorials to highlight improvements over previous versions of CUDA and to provide insight on how to achieve good performance across multiple generations of GPGPU architectures.
Teaching materials, additional examples, and reader comments are available on the http://gpucomputing.net wiki. Any of the following URLs will access the wiki:
■ My name: http://gpucomputing.net/RobFarber.
■ The title of this book as one word: http://gpucomputing.net/CUDAapplicationdesignanddevelopment.
■ The name of my series: http://gpucomputing.net/supercomputingforthemasses.
Those who purchase the book can download the source code for the examples at http://booksite.mkp.com/9780123884268.
To accomplish these goals, the book is organized as follows:
Chapter 1. Introduces basic CUDA concepts and the tools needed to build and debug CUDA applications. Simple examples are provided that demonstrates both the thrust C++ and C runtime APIs. Three simple rules for high-performance GPU programming are introduced.
Chapter 2. Using only techniques introduced in Chapter 1, this chapter provides a complete, general-purpose machine-learning and optimization framework that can run 341 times faster than a single core of a conventional processor. Core concepts in machine learning and numerical optimization are also covered, which will be of interest to those who desire the domain knowledge as well as the ability to program GPUs.
Chapter 3. Profiling is the focus of this chapter, as it is an essential skill in high-performance programming. The CUDA profiling tools are introduced and applied to the real-world example from Chapter 2. Some surprising bottlenecks in the Thrust API are uncovered. Introductory data-mining techniques are discussed and data-mining functors for both Principle Components Analysis and Nonlinear Principle Components Analysis are provided, so this chapter should be of interest to users as well as programmers.
Chapter 4. The CUDA execution model is the topic of this chapter. Anyone who wishes to get peak performance from a GPU must understand the concepts covered in this chapter. Examples and profiling output are provided to help understand both what the GPU is doing and how to use the existing tools to see what is happening.
Chapter 5. CUDA provides several types of memory on the GPU. Each type of memory is discussed, along with the advantages and disadvantages.
Chapter 6. With over three orders-of-magnitude in performance difference between the fastest and slowest GPU memory, efficiently using memory on the GPU is the only path to high performance. This chapter discusses techniques and provides profiler output to help you understand and monitor how efficiently your applications use memory. A general functor-based example is provided to teach how to write your own generic methods like the Thrust API.
Chapter 7. GPUs provide multiple forms of parallelism, including multiple GPUs, asynchronous kernel execution, and a Unified Virtual Address (UVA) space. This chapter provides examples and profiler output to understand and utilize all forms of GPU parallelism.
Chapter 8. CUDA has matured to become a viable platform for all application development for both GPU and multicore processors. Pathways to multiple CUDA backends are discussed, and examples and profiler output to effectively run in heterogeneous multi-GPU environments are provided. CUDA libraries and how to interface CUDA and GPU computing with other high-level languages like Python, Java, R, and FORTRAN are covered.
Chapter 9. With the focus on the use of CUDA to accelerate computational tasks, it is easy to forget that GPU technology is also a splendid platform for visualization. This chapter discusses primitive restart and how it can dramatically accelerate visualization and gaming applications. A complete working example is provided that allows the reader to create and fly around in a 3D world. Profiler output is used to demonstrate why primitive restart is so fast. The teaching framework from this chapter is extended to work with live video streams in Chapter 12.
Chapter 10. To teach scalability, as well as performance, the example from Chapter 3 is extended to use MPI (Message Passing Interface). A variant of this example code has demonstrated near-linear scalability to 500 GPGPUs (with a peak of over 500,000 single-precision gigaflops) and delivered over one-third petaflop (1015 floating-point operations per second) using 60,000 x86 processing cores.
Chapter 11. No book can cover all aspects of the CUDA tidal wave. This is a survey chapter that points the way to other projects that provide free working source code for a variety of techniques, including Support Vector Machines (SVM), Multi-Dimensional Scaling (MDS), mutual information, force-directed graph layout, molecular modeling, and others. Knowledge of these projects—and how to interface with other high-level languages, as discussed in Chapter 8—will help you mature as a CUDA developer.
Chapter 12. A working real-time video streaming example for vision recognition based on the visualization framework in Chapter 9 is provided. All that is needed is an inexpensive webcam or a video file so that you too can work with real-time vision recognition. This example was designed for teaching, so it is easy to modify. Robotics, augmented reality games, and data fusion for heads-up displays are obvious extensions to the working example and technology discussion in this chapter.
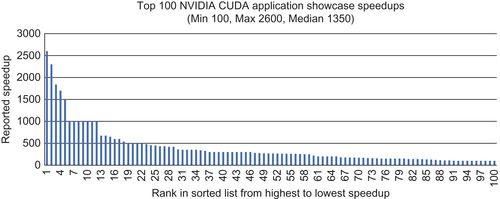
Learning to think about and program in CUDA (and GPGPUs) is a wonderful way to have fun and open new opportunities. However, performance is the ultimate reason for using GPGPU technology, and as one of my university professors used to say, “The proof of the pudding is in the tasting.”Figure 1 illustrates the performance of the top 100 applications as reported on the NVIDIA CUDA Showcase1 as of July 12, 2011. They demonstrate the wide variety of applications that GPGPU technology can accelerate by two or more orders of magnitude (100-times) over multi-core processors, as reported in the peer-reviewed scientific literature and by commercial entities. It is worth taking time to look over these showcased applications, as many of them provide freely downloadable source code and libraries.
GPGPU technology is a disruptive technology that has redefined how computation occurs. As NVIDIA notes, “from super phones to supercomputers.” This technology has arrived during a perfect storm of opportunities, as traditional multicore processors can no longer achieve significant speedups through increases in clock rate. The only way manufacturers of traditional processors can entice customers to upgrade to a new computer is to deliver speedups two to four times faster through the parallelism of dual- and quad-core processors. Multicore parallelism is disruptive, as it requires that existing software be rewritten to make use of these extra cores. Come join the cutting edge of software application development and research as the computer and research industries retool to exploit parallel hardware! Learn CUDA and join in this wonderful opportunity.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.