
7.3 Searching
Searching a list of names or numbers is another very common computer science task. There are many search algorithms, but the key in developing a search algorithm is to determine which type of candidate search process matches the particular need. The following are the two questions (parameters) that affect our search algorithm selection:
-
Is the list we are searching sorted or unsorted?
-
Are the searched list elements unique, or are there duplicate values within the list?
For simplicity, we illustrate the search process using only a unique element list. That is, our implementation assumes that there are no duplicate values. We then discuss what needs to be modified in the algorithm and corresponding Ruby implementation to support duplicate values. Given the level of programming sophistication you now possess, we forgo presenting the only slightly modified implementation that supports duplicate values and leave it as an exercise for you. Once again, we revisit the final exam grade example we used in the sections on sorting.
We now discuss two types of searches. The first is for an unsorted list called a linear search, and the second is for an ordered or sorted list; it is called a binary search.
7.3.1 Linear Search
Consider the problem of finding a number or a name, or more accurately, its position, in an unsorted list of unique elements. The simplest means to accomplish this is to visit each element in the list and check whether the element in the list matches the sought-after value. This is called a linear or sequential search since, in the worst case, the entire list must be searched in a linear fashion (one item after another). This occurs when the sought-after value either is in the last position or is absent from the list. Obviously, the average case requires searching half the list since the sought-after value can be found equally likely anywhere in the list, and the best case occurs when the sought-after value is the first element in the list. The algorithm is as follows:
-
For every element in the list, check whether the element is equal to the value to be found.
-
If the element looked for is found, then the position where the element is found is returned. Otherwise, continue to the next element in the list.
Continue the search until either the element looked for is found or the end of the list is reached.
A Ruby implementation for unique element linear search is provided in Example 7-5.
1# Code for linear search2NUM_STUDENTS=353MAX_GRADE=1004arr=Array.new(NUM_STUDENTS)5value_to_find=86i=17found=false89# Randomly put some student grades into arr10foriin(0..NUM_STUDENTS-1)11arr[i]=rand(MAX_GRADE+1)12end1314puts"Input List:"15foriin(0..NUM_STUDENTS-1)16puts"arr["+i.to_s+"] ==> "+arr[i].to_s17end18i=019# Loop over the list until it ends or we have found our value20while((i<NUM_STUDENTS)and(notfound))21# We found it :)22if(arr[i]==value_to_find)23puts"Found "+value_to_find.to_s+" at position "+i.to_s+" ofthe list."24found=true25end26i=i+127end2829# If we haven't found the value at this point, it doesn't exist in our list30if(notfound)31puts"There is no "+value_to_find.to_s+" in the list."32end
Consider now the case of an unsorted list with potentially duplicate elements. In this case, it is necessary to check each and every element in the list, since an element matching the sought-after value does not imply completion of the search process. Thus, the only difference between this algorithm and the unique element linear search algorithm is that we continue through the entire list without terminating the loop if a matching element is found.
-
In line 5, we initialize the sought-after value. Clearly the user would be prompted with some nice box to fill in, but we do not want to get distracted with user-interface issues. Ultimately the user fills in the nice box, pulls down a value list, or clicks on a radio button, and a variable such as
value_to_findwill be initialized. -
Next, a flag called
foundis set tofalseon line 7. This is used so that the search will terminate when the sought-after value is indeed found. -
In lines 10–12, the list is initialized and filled with some random values.
-
The key loop starts at line 20, where the list is traversed one item at a time. Each time, the comparison in line 22 tests to determine if the element in the array matches the sought-after value the user is trying to find. If the value matches, a message is displayed, the flag is set to
true, and the loop terminates. -
Finally, on line 30, a check is made to determine if the element was not found—in other words, is absent from the list. If this is the case, the value in the
foundflag will remainfalse. If it is stillfalseafter traversing the entire list, this means that no value in the list matched the sought-after value, and the user is notified.
7.3.2 Binary Search
Binary search operates on an ordered set of numbers. The idea is to search the list precisely how you might automatically perfectly search a phone book. A phone book is ordered from A to Z. Ideally, you initially search the halfway point in the phone book. For example, if the phone book had 99 names, ideally you would initially look at name number 50. Let’s say it starts with an M, since M is the 13th letter in the alphabet. If the name we are looking for starts with anything from A to M, for example, “Fred,” we find the halfway point between those beginning with A and those beginning with M. If, on the other hand, we are searching for a name farther down the alphabet than those names that start with M, for example, “Sam,” we find the halfway point between those beginning with M and those beginning with Z. Each time, we find the precise middle element of those elements left to be searched and repeat the process. We terminate the process once the sought-after value is found or when the remaining list of elements to search consists of only one value.
By following this process, each time we compare, we reduce half of the search space. This halving process results in a tremendous savings in terms of the number of comparisons made. A linear search must compare each element in the list; a binary search reduces the search space in half each time. Thus, 2x = n is the equation needed to determine how many comparisons (x) are needed to find a sought-after value in an n element list. Solving for x, we obtain x = log2(n).
Gem of Wisdom
Binary search is one of the finest examples of computer science helping to make software work smart instead of just working hard. A linear search of 1 million elements takes on average half a million comparisons. A binary search takes 20. That is an average savings of 499,980 comparisons! So think before you code.
Instead of an ![]() algorithm needed to find an element using a linear
search, we now have an
algorithm needed to find an element using a linear
search, we now have an ![]() search algorithm. Now, for example, consider a
sorted list with 1,048,576 elements. For a linear search, on average, we
would need to compare 524,288 elements against the sought-after value,
but we may need to perform a total of 1,048,576 comparisons.
search algorithm. Now, for example, consider a
sorted list with 1,048,576 elements. For a linear search, on average, we
would need to compare 524,288 elements against the sought-after value,
but we may need to perform a total of 1,048,576 comparisons.
In contrast, in a binary search we are guaranteed to search using
only
log2(1,048,576)
= 20 comparisons. Instead of 524,288 comparisons in the average case,
the binary search algorithm requires only 20. That is, the number of
comparisons required by the binary search algorithm is less than 0.004%
of the expected number of comparisons needed by the linear search
algorithm. As an aside, ![]() and
and ![]() are equivalent, since they differ strictly by a
constant. Hence, generally speaking, the
are equivalent, since they differ strictly by a
constant. Hence, generally speaking, the ![]() notation is preferred. Of course, binary search is
possible only if the original list is sorted. The binary search
explanation given earlier is for a unique element list only. However,
before presenting the modification needed for potential duplicate
elements, a few remarks regarding the use of binary search must be
made:
notation is preferred. Of course, binary search is
possible only if the original list is sorted. The binary search
explanation given earlier is for a unique element list only. However,
before presenting the modification needed for potential duplicate
elements, a few remarks regarding the use of binary search must be
made:
-
First, binary search assumes an ordered list. If the list is unordered, it must be sorted prior to the search, or a binary search won’t work. Sorting involves a greater time complexity than searching. Thus, if the search will occur rarely, it might not be wise to sort the list. On the other hand, searches often occur frequently and the updating of the list occurs infrequently. Thus, in such cases, always sort (order) the list and then use binary search.
-
The average- and worst-case search times for binary search are
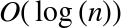 , while the average- and worst-case search times
for linear search are
, while the average- and worst-case search times
for linear search are 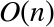 . What is interesting, however, is that unlike
for linear search, where, in practice, the worst-case search time is
double that of the average case, for binary search both times are
roughly identical in practice.
. What is interesting, however, is that unlike
for linear search, where, in practice, the worst-case search time is
double that of the average case, for binary search both times are
roughly identical in practice.
In Example 7-6, we present a Ruby implementation of unique element binary search. Note that we introduce on line 16 a built-in Ruby feature to check if a value is already present within an array and on line 22 to sort an array in place.
1# Code for binary search2NUM_STUDENTS=303MAX_GRADE=1004arr=Array.new(NUM_STUDENTS)5# The value we are looking for6value_to_find=77low=08high=NUM_STUDENTS-19middle=(low+high)/210found=false1112# Randomly put some exam grades into the array13foriin(0..NUM_STUDENTS-1)14new_value=rand(MAX_GRADE+1)15# make sure the new value is unique16while(arr.include?(new_value))17new_value=rand(MAX_GRADE+1)18end19arr[i]=new_value20end21# Sort the array (with Ruby's built-in sort)22arr.sort!2324"Input List: "25foriin(0..NUM_STUDENTS-1)26puts"arr["+i.to_s+"] ==> "+arr[i].to_s27end2829while((low<=high)and(notfound))30middle=(low+high)/231# We found it :)32ifarr[middle]==value_to_find33puts"Found grade "+value_to_find.to_s+"% at position "+middle.to_s34found=true35end3637# If the value should be lower than middle, search the lower half,38# otherwise, search the upper half39if(arr[middle]<value_to_find)40low=middle+141else42high=middle-143end44end4546if(notfound)47puts"There is no grade of "+value_to_find.to_s+"% in the list."48end
We use these features to simplify the code illustrated. Note that this type of abstraction, namely, the use of the built-in encapsulated feature, simplifies software development, increases readability, and simplifies software maintenance. Its use is paramount in practice. It should be understood that this book uses Ruby as a tool for learning concepts of computer science and basic programming, and not as an attempt to teach all the capabilities of the Ruby interpreter. See the additional reading list in Appendix A if you are interested in exploring additional built-in features of Ruby.
-
Line 9 computes the first middle range.
-
Lines 29–44 implement the key loop that keeps cutting the search space down by half.
-
Line 32 is the comparison to the sought-after value. If we find the element, we are done and we update the same
foundflag that was used for the linear search. If the value is less than the middle we update the high side of the range, and if it is greater we update the low side of the range. At the end, we verify that the sought-after value was indeed found.
As with the linear search algorithm, the modification required to support possible duplicate values is relatively minimal for the binary search algorithm. Since binary search requires an ordered list, if a sought-after value is found, then all duplicates must be adjacent to the position just found.
Thus, to find all duplicates, positions immediately preceding and following the current position are checked for as long as the sought-after value is found. That is, in succession, adjacent positions earlier and earlier in the list are checked while the stored element value equals that which is sought after, and similarly for later and later positions. Again, the implementation of this change is left as an exercise to the reader.