
Taking as an example the 5×5 input matrix shown earlier, a CNN is made up of an input layer consisting of 25 neurons (5×5) that has the task of acquiring the input value corresponding to each pixel and transferring it to the next layer.
In a multilayer network, the output from all of the neurons in the input layer would be connected to each neuron in the hidden layer (the fully connected layer). In CNN networks, however, the connection scheme that defines the convolutional layer that we are going to describe is significantly different. As you may be able to guess, this is the main type of layer: the use of one or more of these layers in a CNN is indispensable.
In a convolutional layer, each neuron is connected to a certain region of the input area called the receptive field. For example, using a 3×3 kernel filter, each neuron will have a bias and 9 weights (3×3) connected to a single receptive field. To effectively recognize an image, we need various different kernel filters to be applied to the same receptive field because each filter should recognize images from a different feature. The set of neurons that identifies the same feature defines a single feature map.
The following figure shows a CNN architecture in action: the 28×28 input image will be analyzed by a convolutional layer composed of a 28x28x32 feature map. The figure also shows a receptive field and a 3×3 kernel filter:
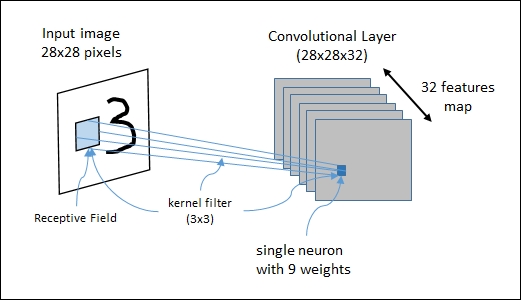
Figure 5: CNN in action
A CNN may consist of several convolution layers connected by cascade connections. The output of each convolutional layer is a set of feature maps (each generated by a single kernel filter). Each of these matrices defines a new input that will be used by the next layer.
Usually, in a CNN each neuron produces an output up to an activation threshold, which is proportional to the input and is not bounded.
CNNs also use pooling layers positioned immediately after the convolutional layers. A pooling layer divides a convolutional region into subregions. The pooling layer then selects a single representative value (max-pooling or average pooling) to reduce the computational time of subsequent layers and increase the robustness of the feature with respect to its spatial position. The last layer of a convolutional network is generally a fully connected network with a softmax activation function for the output layer. In the next few sections, the architectures of the most important CNNs will be analyzed in detail.