
Reinforcement learning (RL) is an area of machine learning that studies the science of decision-making processes, in particular trying to understand what the best way is to make decisions in a given context. The learning paradigm of RL algorithms is different from most common methodologies, such as supervised or unsupervised learning.
In RL, an agent is programmed as if he were a human being who must learn through a trial and error mechanism in order to find the best strategy to achieve the best result in terms of long-term reward.
RL has achieved incredible results within games (digital and table) and automated robot control, so it is still widely studied. In the last decade, it has been decided to add a key component to RL: neural networks.
This integration of RL and deep neural networks (DNNs), called deep reinforcement learning, has enabled Google DeepMind researchers to achieve amazing results in previously unexplored areas. In particular, in 2013, the Deep Q-Learning algorithm achieved the performance of experienced human players in the Atari games domain by taking the pixels that represented the game screen as input, placing the agent in the same situation as a human being playing a game.
Another extremely important achievement came in October 2015 when the same research lab, using the same family of algorithms, beat the European Go champion (Go is a Chinese game of great complexity), and finally beat the world champion in March 2016.
The chapter covers the following topics:
- The RL problem
- Open AI gym
- The Q-Learning algorithm
- Deep Q-Learning
RL differs greatly from supervised learning. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal). The supervised learning algorithm analyzes the training data and produces an inferred function, which can be used to map new examples.
RL does not provide an association between incoming data and the desired output values, so the learning structure is completely different. The main concept of RL is the presence of two components that interact with one another: an agent and an environment.
An RL agent learns to make decisions within an unfamiliar environment by performing a series of actions and obtaining the numerical rewards associated with them. By accumulating experience through a trial and error process, the agent learns which actions are the best to perform depending on the state it is in, defined by the environment and the set of previously performed actions. The agent has the ability to figure out what the most successful moves are by simply assessing the reward it has earned and adjusting its policy, in order to get the maximum cumulative reward over time.
The RL model is made up of the following:
-
A set of states
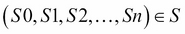 , defined by the interaction between the environment and the agent
, defined by the interaction between the environment and the agent
-
A set of possible actions (
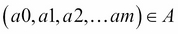 , suitably selected by the agent according to the input state
, suitably selected by the agent according to the input state
- A reward, r, associated with each interaction between the environment and the agent
- A policy mapping each state into an output action
- A set of functions called state-value functions and action-value functions that determine the value of the state of the agent at a given time and the value that the agent performs a specific action on a given moment.
An RL agent interacts with the environment at a certain time t. At each t, the agent receives a state ![]() and a reward
and a reward ![]() as input. Accordingly, the agent determines the action
as input. Accordingly, the agent determines the action ![]() to be performed, where A (st) represents the set of possible actions in a given state.
to be performed, where A (st) represents the set of possible actions in a given state.
The latter is received by the environment, which processes a new ![]() state and a new reward signal,
state and a new reward signal, ![]() , corresponding to the next agent input at time t + 1. This recursive process is the learning algorithm of the RL agent. The agent's goal is to earn as much as possible in terms of the final cumulative reward. The purpose can be achieved by using different methodologies.
, corresponding to the next agent input at time t + 1. This recursive process is the learning algorithm of the RL agent. The agent's goal is to earn as much as possible in terms of the final cumulative reward. The purpose can be achieved by using different methodologies.
During training, the agent is able to learn appropriate strategies that allow it to gain a more immediate reward or gain a greater long-term reward at the expense of immediate rewards.
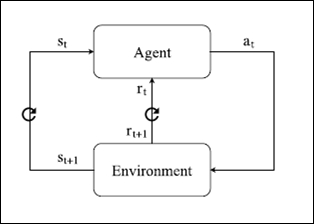
Figure 1: RL model