
This section walks through a code example that instantiates and uses a DOM parser. The DOM parser is just a utility that takes incoming XML data and creates a data structure for your application program (servlet, or whatever) to do the real work. See Figure 27-3 for the diagram form of this situation.
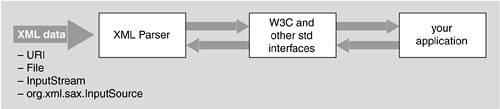
The code we show in this section is the code that is “your application” in Figure 27-3. The JAXP library has code for the other two boxes. The interface is a little more involved than simply having our class call the parser methods. This unexpected slight complication happens because the Java library implementors wanted to make absolutely sure that the installations never got locked into one particular XML parser. It's always possible to swap the parser that comes with the library for another. To retain that flexibility, we instantiate the parser object in a funny way (the Factory design pattern), which we will explain later.
The program is going to read an XML file, get it parsed, and get back the output which is a tree of Java objects that mirror and represent the XML text file. Then the program will walk the tree, printing out what it finds. We hope it will be identical with what was read. In a real application, the code would do a lot more than merely echo the data; it would process it in some fashion, extracting, comparing, summarizing. However, adding a heavyweight application would complicate the example without any benefit. So our application simply echoes what it gets. The program we are presenting here is a simplified version of an example program called DOMEcho.java that comes with the JAXP library. The general skeleton of the code is as follows.
// import statements
public class DOMEcho {
main(String[] args) {
// get a Parser from the Factory
// Parse the file, and get back a Document
// do our application code
// walk the Document, printing out nodes
echo( myDoc );
}
echo( Node n ) {
// print the data in this node
for each child of this node,
echo(child);
}
}
The first part of the program, the import statements, looks like this:
import javax.xml.parsers.*;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import org.w3c.dom.*;
import java.io.*;
That shows the JAXP and I/O packages our program will use. The next part of the program is the fancy footwork that we warned you about to obtain an instance of a parser—without mentioning the actual class name of the concrete parser we are going to use.
This is known as the Factory design pattern, and the description is coming up soon. For now, take it for granted that steps 1 and 2 give us a DOM parser instance.
public class DOMEcho {
public static void main(String[] args) throws Exception {
// Step 1: create a DocumentBuilderFactory
DocumentBuilderFactory dbf =
DocumentBuilderFactory.newInstance();
// We can set various configuration choices on dbf now
// (to ignore comments, do validation, etc)
// Step 2: create a DocumentBuilder
DocumentBuilder db = null;
try {
db = dbf.newDocumentBuilder();
} catch (ParserConfigurationException pce) {
System.err.println(pce);
System.exit(1);
}
// Step 3: parse the input file
Document doc = null;
try {
doc = db.parse(new File(args[0]));
} catch (SAXException se) {
System.err.println(se.getMessage());
System.exit(1);
} catch (IOException ioe) {
System.err.println(ioe);
System.exit(1);
}
// Step 4: echo the document
echo( doc );
}
That shows the key pieces of the main program. We will look at the code that echoes the document shortly, as it is an example of the data structure that the DOM parse hands back to your application.
When you check the javadoc HTML files for the JAXP library, you will see that the parse gives you back an object that fulfills the Document interface. Document in turn is a subclass of the more general Node interface shown in Table 27-3.
Table 27-3. Methods of org.w3c.dom.Node
|
Method |
Purpose |
|---|---|
|
|
Returns a NodeList that contains all children of this node. |
|
|
Returns a boolean signifying if the node has children or not. |
|
|
Returns the node immediately following this node, i.e., its next sibling. |
|
|
Returns an int code representing the type of the node, e.g., attribute, cdata section, comment, document, element, entity, etc. |
|
|
Returns a String representing the name of the node. For an element, this is its tag name. |
|
|
Returns a String that means different things depending on what type of Node this is. An Element that just has PCData will have a child Node of type “text” and the node value that is the element's PCData. |
|
|
Returns the parent of this node. |
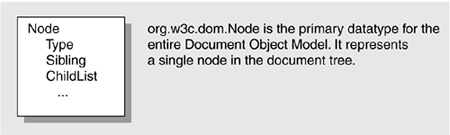
Your tree is a tree of Nodes as shown in Figure 27-5. Each element, entity, PCData, Attribute, etc., in your XML file will have a corresponding Node that represents it in the data structure handed back by the DOM parse. Node is an interface promising a dozen or so common operations: get siblings, get children, get type, get name, and so on.
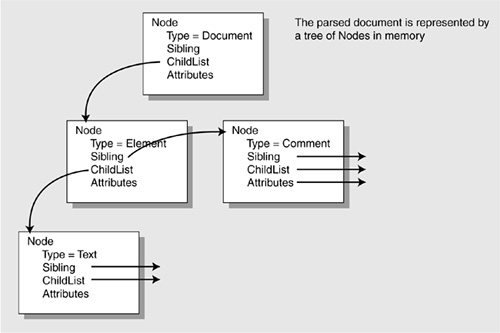
Each Node has a list of child Nodes that are the elements contained within it. There is also a field that points to a collection of attributes, if the node has attributes. When you examine the class org.w3c.dom.Node using javadoc, you will see that it has10 or 20 fields and methods allowing you to get and set data associated with the Node, as shown in Table 27-3.
You invoke these Node methods on the document value returned from the parse, as shown in the following example. Here is the remainder of the code. It does a depth-first traversal of a DOM tree and prints out what it finds. Once again, real application programs will do much more than just echo the data. We have omitted any processing of the XML data for simplicity here.
All we do here is echo the XML to prove that we have a tree that accurately reflects it.
/**
* Recursive routine to print out DOM tree nodes
*/
private void echo(Node n) {
int type = n.getNodeType();
switch (type) {
case Node.DOCUMENT_NODE:
out.print("DOC:");
break;
case Node.DOCUMENT_TYPE_NODE:
out.print("DOC_TYPE:");
break;
case Node.ELEMENT_NODE:
out.print("ELEM:");
break;
case Node.TEXT_NODE:
out.print("TEXT:");
break;
default:
out.print("OTHER NODE: " + type);
break;
}
out.print(" nodeName="" + n.getNodeName() + """);
String val = n.getNodeValue();
if (val != null) {
if ( !(val.trim().equals(""))) {
out.print(" nodeValue ""
+ n.getNodeValue() + """);
}
}
out.println();
// Print children if any
for (Node child = n.getFirstChild(); child != null;
child = child.getNextSibling()) {
echo(child);
}
}
}
The Node interface is further specialized by child interfaces that extend it. The interfaces that extend the Node interface are Attr, CDATASection, CharacterData, Comment, Document, DocumentFragment, DocumentType, Element, Entity, EntityReference, Notation, ProcessingInstruction, and Text. These sub-interfaces can do all the things that a Node can do, and have additional operations peculiar to their type that allow the getting and setting of data specific to that subtype.
As an example, the org.w3c.dom.CharacterData subinterface of Node adds a few methods to allow the inserting, deleting, and replacing of Strings. Table 27-4 lists the key methods of CharacterData. You should review Node and all its child interfaces using javadoc when you start to use XML parsers.
Table 27-4. Methods of org.w3c.dom.CharacterData
|
Method |
Purpose |
|---|---|
|
|
Returns the CharacterData of this Node. |
|
|
Appends this string onto the end of the existing character data. |
|
|
Inserts this string at the specified offset in the character data. |
|
replaceData(int offset, |
Replaces 'count' characters starting at the specified offset with the string s. |
|
|
Replaces the entire CharacterData of this node with this string. |
You will invoke these methods on any Node to modify its character data.
The Document subinterface of Node is particularly useful, having a number of methods that allow you to retrieve information about the document as a whole, e.g., get all the elements with a specified tagname. Some of the most important methods of Document are outlined in Table 27-5.
Table 27-5. Methods of org.w3c.dom.Document
|
Method |
Purpose |
|---|---|
|
|
Returns a NodeList of all the Elements with a given tag name in the order in which they are encountered in a preorder traversal of the Document tree. |
|
|
Creates an Element of the type specified. |
|
|
Returns the DTD for this document. The type of the return value is DocumentType. |
You will invoke these methods on the document value returned from the parse.
Once you have parsed an XML file, it is really easy to query it, extract from it, update it, and so on. The XML is for storing data, moving data around, sharing data with applications that haven't yet been thought of, and sharing data with others outside your own organization (e.g., an industry group or an auction site). The purpose of the parser is to rapidly convert a flat XML file into the equivalent tree data structure that your code can easily access and process.