
Developing a system is an iterative process. In each iteration, you deliver useful capabilities in terms of use cases or use-case scenarios that are tested and working. At the beginning of the project, you estimate the size of the system in terms of use cases—both application and infrastructure use cases—and in each iteration, you assess project progress according to the progress on these use cases, i.e., the degree to which they have been specified and analyzed, the degree they have been design and implemented, etc. Planning and tracking development in this way provides you with an objective assessment of the project’s status. Moreover, keeping concerns separate not only makes the system more understandable and extensible, it also provides significant savings in terms of development effort.
Managing and controlling a project with aspect orientation is quite similar to managing and controlling any other project—it is iterative. Each iteration defines a time period for the development team to achieve some demonstrable results of value. The time period can be as short as one or two weeks for small projects or as long as three months for large projects. Normally, long iteration duration is a sign that either the system is extremely complex or, more likely, the team cannot define smaller increments or get its act together to collaborate properly—it has development-process problems.
The earlier iterations in a project are driven by risks of all kinds, technical and architectural risks, business risks, process risks, and others. The later iterations are driven be completeness as the team seeks to make the system sufficiently mature for the end-user community. The gradual shift from a risk and architecture emphasis to a completeness emphasis occurs through the project life cycle and is depicted in Figure 19-1.
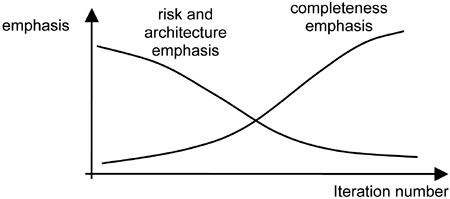
The Unified Process breaks down the project life cycle into four phases: inception, elaboration, construction, and transition.
In the inception phase, the primary goals are to set the scope of the project, reduce the business risks, and prepare an initial business case to indicate if the project is worth pursuing from a business standpoint.
In the elaboration phase, the goal is to capture most of the requirements, reduce risks further, and establish the architecture baseline—the skinny system. By the end of the elaboration phase, you can estimate the costs and schedule, and plan the construction phase in detail.
In the construction phase, the primary goal is to develop the full-fledged system.
In the transition phase, the primary goal is to ensure that the system is mature enough to be released to the end-user community.
Please remember that inception is not requirements, elaboration is not design, construction is not code, and transition is not test. In each phase, there is one or more iterations. Within each iteration, many things happen, often in parallel. You do requirements, analysis, design, implementation, test, and many other activities, and you move back and forth between them. It is useful to allocate development to a team member in terms of use-case modules because she must have freedom to move between the activities surrounding the use case.
Although some project managers like to plan an iteration in terms of activities in some form of a schedule, it is more fruitful to plan iterations in terms of results you want to achieve in that iteration and let the team coordinate itself to achieve those results. After all, achieving results is more important than meeting a schedule of activities. Certain activities, such as meetings with stakeholders, must of course be planned. However, when it comes to what the development team must do, management by results is more appropriate. This means that it is important to clarify the acceptance criteria for each target—for example, the number of use cases specified to a defined level of detail, the number of use cases designed and implemented (with test cases defined), the number of test case passed, and so on.
At the end of each iteration, some new capability will have been added to the system to demonstrate that some risks and some concerns have been resolved. This new capability is often described in terms of use cases or use-case scenarios—that is, you build a system use case by use case across iterations.
At the beginning of the project, you must systematically estimate the size and complexity of your system and determine how long the development will take. There are many software estimation techniques available, ranging from the simple to the complex. An effort estimation technique is usually in the form of:
You can compare this formula to that of driving a car:
A good estimation technique has the following characteristics:
The size estimates must be verifiable.
The productivity estimate must be tunable.
To be verifiable, the unit by which you measure the size of the project and the progress of development must correspond to what you deliver. This means that units are in terms of use cases or their derivatives, such use-case scenarios, use-case flows, use-case steps, and test cases.
To be tunable, your team productivity must be in a form that you can easily calibrate to your project. Many estimation techniques such as COCOMO [Boehm et.al. 2000], Use-Case Points [Karner 1993], and so on. use a list of parameters with values for high, low, and nominal. But a finite number of parameters is never able to capture characteristics of each project.
Another alternative to estimate team productivity is to totally ignore the use of parameters. Instead, measure what the team is actually capable of producing in each iteration. Simply get the team to work on a number of use-case scenarios for an iteration and track how much is accomplished in that iteration. This gives you a data point to estimate your team’s productivity. The data point encompasses the time that team members spend talking to each other about work, responding to emails, performing secondary duties, taking coffee breaks, dreaming about their next job, planning their vacation, and last but not least, working on delivering the use-case scenarios. It does not matter whether the developers are truthful about the use of their time because you only check the results at the end of the iteration. After observing several iterations, you have a set of historical data that is collected from your project (and not other projects) to support your productivity estimation.
At the beginning of the project, you may not have any historical basis for the team’s productivity estimates. An alternate way to estimate productivity is as follows: Choose several use cases and conduct a quick use-case analysis and design. Once you understand the complexity of the use case, you can get your team members to estimate how long each use case or its derivative might take.
As an example, you can consider a typical use-case step. The realization of a use-case step involves the submission of a request until the result is displayed to the actor. This is captured in the design realization of the Perform Transaction use case, shown in Figure 19-2.
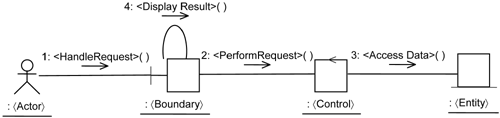
You can get a consensus from your team members on the amount of time needed for development of a use-case step, together with the use-case presentation, use-case distribution, and use-case persistence, as discussed in Chapter 15, “Separating Tests with Use-Case Test Slices.” From our experience and interaction with various project teams, this may take between one to five man days depending on the skills of the team and the complexity of the use-case step. Let’s take two and a half man days as the average. You can then count the number of use-case steps in the system for both application and infrastructure use cases. Suppose you have 10 application use cases, each with five steps in the basic flow and maybe another five steps in the alternate flow. In this case, you have about 100 use-case steps in the system. So, the development effort for the application use case alone will be 250 man days.
Suppose you have five infrastructure use cases, and each has three steps as well as three steps in the alternate flows. That’s about 30 use-case steps for the infrastructure use cases. However, your team might indicate that infrastructure use cases are technically more complex and will take twice as much effort, say, five man days. The effort required for the infrastructure use cases, therefore, will be 30 × 5 = 150 man days.
So, the total effort will be 250 + 150 = 400 man days, and if we take each man month to be 20 man days, then the effort will be approximately 20 man months. If you want the system to be delivered in five months, you need four people on the development team and one more person to play the role of a project leader, analyst, and architect. Of course, if this is a more complex project, you need more than one person to play these roles. There is a limit to how many people you can put on a project, however. You cannot put 20 people on this project and expect the project to be delivered in a month. Time must be invested to get the architecture right, and that occurs in the elaboration phase. In this five-month project, elaboration might possibly take one or two months. It is only when you have completed elaboration that it is possible to have more people on the team. Otherwise, you have some people waiting for the architecture to be stabilized and much of the work they do in the meantime will likely have to be redone.
You probably notice that we keep the estimation of application and infrastructure use cases separate. This is only possible because, if they follow the approach described in this book, they are indeed separate.
The estimation above makes two additional yet important assumptions:
You have a good idea of the system scope.
You have a good idea of the architecture you will be using.
If these assumptions are true, then your estimates will be quite credible. If not, what most project managers do is add some buffers, perhaps an additional resource, and probably more time.
In the early architectural iterations of the project, you must ensure that the assumptions are true and the estimates to develop each use-case step (application or infrastructure) are accurate. This involves observing how much the team can deliver at the end of each iteration over several iterations. At the end of the architectural iterations, you have not only an established architecture, but also a credible basis to estimate the time required to complete the remaining parts of the system.
The progress of a project usually follows an S-curve, as shown in Figure 19-3. This curve represents the accumulative number of use-case steps you complete over time. It takes an S shape because your project team normally takes time to ramp up productivity and also because of time spent on resolving critical risks early in the project. During the later part of the project, you tend to exercise more rigor, make more checks, and so on, as you attempt to get the system ready for end users. The added efforts take a toll on the team productivity and results in the S-curve.
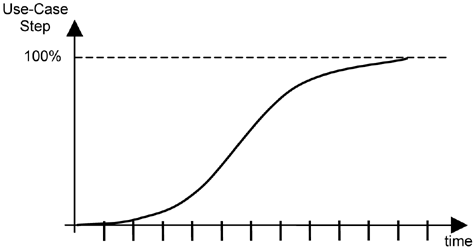
The middle part of the project is the generally the most productive. So, for example, if the project needs to be delivered in six months, you probably have, in reality, about four to five months for the bulk of the development.
Continuing with our example, there are 100 application use-case steps and 45 infrastructure use-case steps: 145 use-case steps in total. These have to be developed in about five months, and if you take each iteration to be two weeks, you have about 10 iterations for development. In each iteration, you must complete about 15 use-case steps—implemented and tested just to be on track. If you cannot keep this productivity value, your project will be delayed.
Suppose you are in the fifth iteration and you have completed 45 use-case steps. That means that you have another 100 use-case steps to go in the remaining five iterations. If you continue development at the same pace (i.e., 45/5 = 9 use-case steps per iteration), then you need 100/9 = 11 iterations more. However, you only have five left. This means that you are six iterations late! Such computation is simple and even obvious, but it does give a numerical basis about the project’s health.
Keeping track of the remaining time required is an important part of a project manager’s job. It helps you ascertain ahead of time whether you can meet the deadline and take remedial action if necessary to improve team productivity.
You have several options to improve productivity. One method, of course, is to streamline the development process and reduce unnecessary documentation effort. Another method is to add additional development resources. But this is useful only if you have an established architecture. Otherwise, you simply have more resources waiting for the architecture to be established, as previously mentioned. Another technique is to use more powerful tools to automatically generate the repetitive parts of the system. However, if such tools are not tailored or configured during elaboration, you must invest additional time just to keep them working. As a project manager, you need to decide if the expected productivity improvements outweigh the investment.
You achieve significant productivity gains with an architecture that keeps concerns separate. To justify this claim, let’s consider a system with N requirements. Let’s assume that these N requirements are independent, and the effort to develop each requirement is X. The effort required to develop the N requirements, then, is NX.
Let’s suppose the N requirements are not well separated (i.e., there has been no attempt to keep concerns separate). This means that the realization of each requirement will overlap the realization of other requirements. Let’s assume the worst case that occurs when the realization of each requirement touches the realization of N-1 requirements (i.e., every other requirement), and the effort to integrate the overlapping parts is Y. Now the effort required to develop each requirement is X + (N – 1)Y, and the effort for the entire system of N unseparated requirements is NX + N (N – 1)Y.
Figure 19-4 compares systems that are well separated (best case demanding NX effort) and unseparated (worst case demanding NX + N (N – 1)Y effort). In Figure 19-4, we have set X = 20 and Y =1; that is, the effort to realize each requirement takes 20 times more effort per integration.
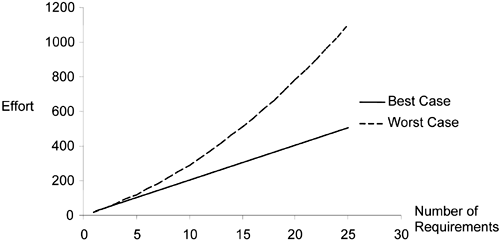
From Figure 19-4, you can see the need for better separation in a large system with a large number of requirements (i.e., N is large).
You do not need to achieve the ideal case to reap the benefits of better separation. Even by separating different kinds of concerns, such as application from infrastructure, you gain an advantage. Suppose you have 20 application and 20 infrastructure requirements: a total of 40 requirements. According to the worst-case formula NX + N(N – 1)Y, the effort is:
Suppose you have kept the application and infrastructure requirements separate so that each application requirement is separate from the other. However, the realization of each application requirement still needs to invoke each of the 20 infrastructure requirements. There is still some savings, because now the effort required per application requirements is X + 20Y, and the total effort for the whole system is 20(X + 20Y) + 20X. The last term, 20X, is the effort to realize each infrastructure requirement. After substituting X = 20 and Y = 1, the effort required for the whole system is 16,400, which is about half that of the worst case.
With the use-case slice and aspect approach, since infrastructure services are composed into the application by the aspect weaver, you no longer need to code each call to the infrastructure services; thus, the integration effort Y is reduced tremendously. Let’s assume that Y is now 0.5; the effort 20(X + 20Y ) + 20X now becomes 12,400.
From these simple calculations, you can see that there is much productivity to be gained by keeping concerns separate and leaving the development environment to compose the realization of concerns. Surely this is an incentive to apply the approach demonstrated in this book to your projects.
Software development is iterative. In each iteration, you add some useful capability. The early iterations focus on resolving risks, and the later iterations focus on completeness. You need to systematically track the progress of the project and determine if there are any delays. If there are, you must improve team productivity. By keeping concerns separate as use cases, the effort to realize each concern is reduced dramatically, and team productivity is increased.