
Recognition and Learning by a Computer
In the past computers have been used mainly as tools for data processing. As the processing speed and the amount of data that can be processed by a computer have increased, we have discovered that we can use computers as more intelligent information processing tools. With this idea in mind, we can look at how a computer could be used for recognizing patterns and learning new information. This book is based on the idea that recognition and learning by a computer can be looked at as the process of generating an appropriate representation for information and transforming it into another representation using both the high speed of modern computers and their ability to process a large amount of data. In this chapter, we describe what we mean by the representation, generation, and transformation of information on a computer.
1.1 What Is Recognition by a Computer?
Many academic fields, like philosophy and psychology, use the word “recognition.” In each field it has a slightly different meaning. The literal meaning of recognition is to know again what has been known before. In computer science we use the word “recognition” to mean that a computer can recognize that the patterns of objects are ones that it has seen before. By the pattern of an object we mean any chronological or spatial data received from the object by an input device and entered into the recognition system. Although it is important to study the meaning of “recognition” in fields other than computer science, in this book we will use the computer science meaning of this word.
Suppose we have a pattern consisting of an object A and a background B as shown in Figure 1.1. In order to distinguish A from the background B in this pattern, we need to find the boundary that separates A from B. Usually, patterns such as Figure 1.1 include not only the object A and the background B but also noise (input information other than the data that are directly obtained from the object). Furthermore, the boundary may not be a continuous line. So, in order to find the boundary of A, we not only need to check the light and shading of each point on the boundary but also need to estimate the shape of the whole boundary.

If we can estimate where to find the boundary line between A and B, we can determine the region encompassed by the boundary, and, as a result, we will be able to distinguish A from B. However, we still do not know what the object A is. In order to know whether A is a glass, a vase, or a coffee cup, that is, in order to know A conceptually, we need to have some knowledge about the shape and function of a glass, a vase, and a coffee cup. Only after we look at the pattern using such knowledge will we be able to figure out that Figure 1.1 consists of a coffee cup and a wall.
This means that we need at least two kinds of algorithms in order to do recognition by computer. They are
(1) algorithms for extracting the boundary and region of a pattern, and
(2) algorithms for recognizing the original object conceptually based on knowledge of the object, its patterns, and how it is used.
In the above description of Figure 1.1, we used (1) and then (2). In other cases (2) can come before (1) or (1) and (2) can be executed alternately.
In addition to visual patterns, like that in Figure 1.1, there are many other types of patterns, such auditory or tactile, that can be recognized by a computer. This book, however, will discuss only visual patterns.
1.2 Representation and Transformation in Recognition
Frequently, a pattern is represented as a function. For example, the pattern of the coffee cup in Figure 1.1 could be represented using a pattern function whose input is coordinates of a point and whose value is the image density at each point. For visual patterns, we also call this a (visual) image function. A pattern function usually contains noise and often does not contain complete data.
Once we have estimated the boundary and region of a pattern and we have used general knowledge to recognize it conceptually, the information about this pattern will have a different structure than the original pattern function. For example, once a pattern has been recognized conceptually, it might include symbolic information describing the object such as “coffee cup” and “table” or symbols representing a relation between objects such as “the coffee cup A is on the table.” Figure 1.2 shows sample representations for a coffee cup.
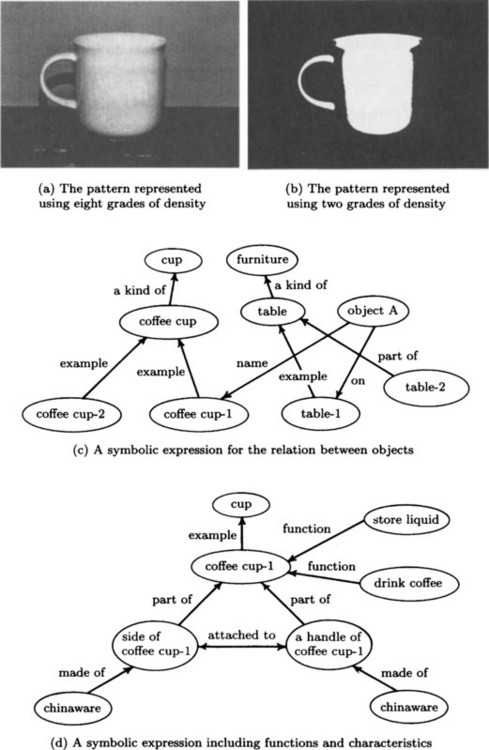
Figure 1.2 Various representations for the coffee cup shown in Figure 1.1.
As you can see, the process of pattern recognition can use many different representations including pattern functions, sets of regions divided by boundary lines, symbols describing an object, and relations among objects. These representations can be represented in a computer using many different data structures. For example, symbols and relations among symbols can be represented using graph theory (see Section 2.3). We call the data structures used to describe these representations in a computer the representation of the information.
Now we can say that the process of pattern recognition is either to create a new representation or to change one representation into another, starting from an object’s representation as a pattern function. We can also say that the purpose of pattern recognition by a computer is to generate and transform useful representations of information using the high speed and the massive data processing capability of the computer.
Based on the above, the study of pattern recognition needs to consider the following two problems:
(A) What methods of representation are available for patterns?
(B) What methods are available for transforming one representation into another?
Since the algorithms (1) and (2) mentioned earlier are for transforming representations, they belong to (B). We will describe this kind of algorithm in Chapter 3 and in more detail in Chapters 4 and 5. We will provide popular methods for representing patterns in Chapter 2.
Many possible representations can be obtained by creating and transforming the original pattern. There is often more than one transformation method possible at one time, and different orders of making these transformations may produce different results. Therefore, pattern recognition is a kind of underconstrained problem since in general we do not have enough information to decide if we have a unique solution. In order to decide on the correctness of a solution to a problem, we need to specify either the representation to be used or the method of transformation, or we need to supply some evaluation function for the solution. When we read Chapters 4 and 5, we will see that both types of specifications can be used together.
When we look at the problem of pattern recognition as the generation and transformation of representations, recognition algorithms can be divided into two parts. One part of the algorithm is the low-level information processing necessary for extracting features of a given pattern and for estimating the boundaries and regions of a pattern. The other part is the high-level algorithm for estimating, based on symbolic knowledge, what the given pattern is. (See Section 2.13 for more exact meanings of “pattern” and “symbol.”)
1.3 What Is Learning by a Computer?
Like recognition, the word “learning” is used in many fields such as psychology and education. In computer science, when a system automatically generates a new data structure or program out of an old one and thus irreversibly changes itself with some purpose for a certain amount of time, we call it machine learning. As with recognition, although it is important to study the meaning of the word “learning” as used in fields other than computer science, in this book we will use the above meaning specific to computer science.
Suppose we have objects C, D, E as in Figure 1.3 and we have the following data about C, D, E:
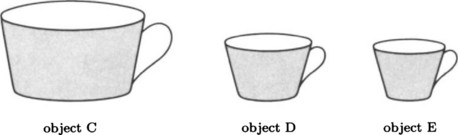

Now we suppose C, D, E are all examples of an object U. What should we imagine that the object U is? There are many ways to decide what U is. For example, since the top diameter of C, D, E is larger than the bottom diameter, we can use the notion of “the thing whose top diameter is bigger than its bottom diameter” for U. Or, we can imagine that C, D, and E are points whose top diameter and bottom diameter are their x and y coordinates (in two-dimensional Euclidean space) and consider the point where the sum of the distances from these points is smallest to be U. With this method, we can decide that the object whose top diameter is 7 cm and whose bottom diameter is 5 cm is U (see Figure 1.4). When U is determined like this, we call it a prototype of the sample group C, D, E and the samples C, D, and E are considered to be objects “similar to” U. (Generally, a prototype does not just depend on the average values.)
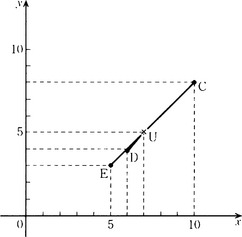
The above example illustrates the problem of creating some data that generalize some other set of data. Like pattern recognition, this is also an underconstrained problem since we are not generally given enough information to determine only one answer. In order to solve problems like this, as in pattern recognition problems, we need to specify a method for determining an answer or we need to supply some criteria for evaluating how to select methods of determining an answer. Both of these strategies are in actual use. Chapter 6 and later chapters will have many examples of using these methods.
Suppose that when we input the data C, D, and E into a computer, we get an example object U with the following characteristics:
![]()
This U is “new” data generated from the given data. Once the computer creates this prototypical U, the information it will output about U will be different from the output produced before. It can use this characteristic version of U when it needs a general representation of the samples C, D, and E. In this way we can consider the generation of U as a form of machine learning as described above.
Some readers might think that, since the procedure for determining U has been given from the outside and the computation of U is a fixed procedure, U is not new data. This is true if you mean that every step in a computation on a computer is not doing anything new. In that sense, a computer does not produce any new information.
We will call a process a machine learning process if
(1) the process is complicated and the data resulting from this process are quite different from the original data and
(2) as a result of this process, the future output of the system will be changed.
If a process satisfies only (1), we do not call it learning. For example, the process of solving a complex differential equation will not be called learning unless the computer changes the output of the system using its solution for some purpose.
This idea of learning is based on the assumption that knowing and making use of the results of a computation and learning become almost identical as the amount of the computation increases. Note that this idea assumes that the computers we are using are large enough to carry out the computations we are considering.
1.4 Representation and Transformation in Learning
In computer systems that learn, the data or programs that are part of the original system, or are added from the outside, are used to transform existing data or programs into something new. During this process, both the original data and programs and the newly created data and programs are represented in the computer by some kind of data structures.
For example, in Figure 1.3, the given data C, D, and E and the synthesized U can be thought of as pairs containing the values (top diameter, bottom diameter). In some circumstances these pairs may be represented symbolically. If the only information that a system is told about U is that “the top diameter is bigger than the bottom diameter”, then the system would use a very different abstract representation of U than it would use for the representation of the original data C, D, and E.
It is important to understand that the characteristic of allowing multiple representations is the essence of the learning process rather than simply one aspect of learning. It is this characteristic that fits the above definition of learning. In other words, we say that learning by a computer is a process of generalizing and transforming representations.
Based on the definition above, the opposite of this is not always true; that is, the process of generalization and transformation of a representation is not always “machine learning.” Remember that pattern recognition by a computer as described in Section 1.1 is also a process of generalizing and transforming representations. We see that recognition and learning by a computer, which are the main subjects of this book, are both processes of generalization and transformation of representations.
As in the case of pattern recognition, we need to consider the following two problems in the study of learning:
(A) What methods for representing information are appropriate for learning?
(B) What methods are available for transforming one representation into another?
Methods of representing information for both learning and recognition, (A), will be described in Chapter 2. Transformation algorithms, (B), will be described in Chapter 3. Algorithms for learning will be described in detail in Chapters 6–10.
1.5 Example of Recognition/Learning System
In order to have a clear picture of the problems mentioned in the previous sections, let us consider a simple example of a computer system that includes pattern recognition and learning. The content of such systems will be explained in Chapters 4, 5, and 8.
Suppose we have a pattern for a “hammer.” We input this pattern bit by bit into the pattern recognition system. This system will first extract characteristics of this pattern and will then obtain the outline shown in Figure 1.5. The system then represents the structure of the pattern, using the network as shown in Figure 1.6, by matching extracted characteristics with knowledge it has gathered on the structure of the “hammer.” We can think of this as the process of a sequence of transformations starting with the representation of the input pattern and ending with a symbolic representation using a relational network of concepts.
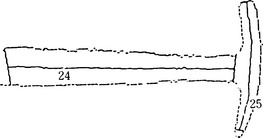
Figure 1.5 An outline of a “hammer”. (Connell and Brady, 1987)
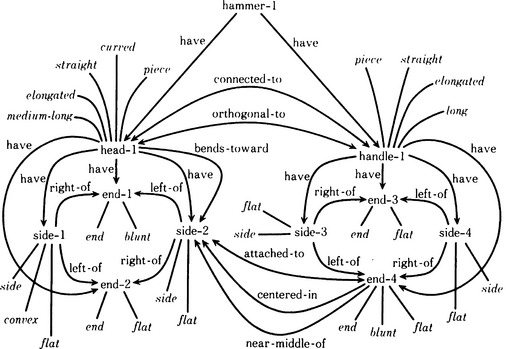
Figure 1.6 A network representation of a “hammer”. (Connell and Brady, 1987)
After the system represents some “hammer” patterns using the network, it compares the similarities between patterns. By extracting structurally identical parts of several networks, we can interpret the common parts as a representation of the “general hammer.” An example of such a representation is shown in Figure 1.7.
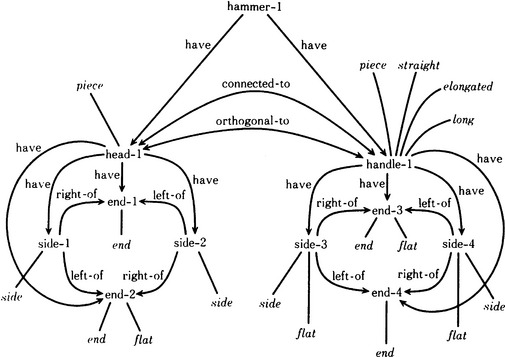
Figure 1.7 A network representation for the “general hammer”. (Connell and Brady, 1987)
We might actually construct the system so that it outputs the representation for the “general hammer” after being given several network representations of some “hammers” as inputs. This system could use the “general hammer” representation to check whether some newly input network representation actually represents a “hammer” or not. In addition, the system could update the representation of the “general hammer” every time it checks for similarity. This system could be called a learning system according to the definition of learning given in Section 1.3.
By combining a pattern recognition system and a learning system, we could design a system for judging whether a given object is a “hammer” or not. Such a system would be interesting as an existence proof for a system that combines pattern recognition and learning and as an example showing directly that recognition and learning are the process of the generalization and transformation of representations.
Summary
Chapter 1 described the nature of pattern recognition and learning by a computer.
1.1. pattern recognition and learning are areas of software science for intelligent information processing by making use of the high speed and massive data processing capability of a computer.
1.2. pattern recognition by a computer is the process of transforming a pattern function to a more structured representation of information.
1.3. Learning by a computer is the process of generating a representation of information that is suitable for accomplishing some goal.
1.4. It is possible to construct a computer system that combines pattern recognition and learning.
Exercises
1.1. Give the definition of recognition by a computer and explain the difference in meaning between recognition by a computer and “recognition” as we usually use it informally.
1.2. Give the definition of learning by a computer and explain the difference in meaning between learning by a computer and “learning” as we usually use it informally.
1.3. Explain the similarities and the differences between recognition and learning by a computer.
1.4. Suppose we have the following first-order simultaneous inequalities as an example of an underconstrained problem. In order to make the point satisfying this inequality unique, how would you change the value of the right side of (a)? Find the coordinate of such a point.