
Architecture and Technology Considerations
Abstract
This chapter provides perspective on various data architecture scenarios, as well as how and where current technologies can help support and enable a multi-domain model. It covers how to determine the capability needs and use cases for the technology solutions and explores the limitations, such that one platform (or even multiple tools) cannot address all requirements.
As stated often in this book, Master Data Management (MDM) is about people, process, technology, and methodology. The right technology is critical to success. This chapter makes no attempt to provide a comprehensive list of vendors or cover all available MDM technologies. That information, as well as product evaluations, is widely available through various websites. The primary purpose of this book is to provide general guidelines on key aspects that should be considered when planning an enterprisewide technological landscape that can sustain a scalable multi-domain MDM solution. Chapter 1 exposed the many functions and disciplines behind a complete multi-domain MDM program. The fact is that there is no single MDM solution or vendor that will provide an entire suite of applications that will provide all those moving parts—it is important to remember that. Furthermore, technology maturity varies widely across domains, as well as across the multiple activities and disciplines behind all MDM functions. This chapter addresses those issues and highlights the important aspects to contemplate when designing an effective infrastructure that truly solve your business problems.
Multi-domain MDM Technological Background
As just mentioned, there is no single product that will address all the capabilities necessary to meet multi-domain MDM needs. Even a single domain requires multiple technologies. MDM can be implemented in many different ways, depending on the problem that it is trying to solve, as well as how an eventual MDM hub will integrate with other enterprise applications. Information technology (IT) organizations typically have existing architecture and rigid processes to manage and integrate current and new enterprise applications. However, adding a multi-domain MDM to the mix is about more than just adding a new application. It is about adding a capability that will most likely affect the most important data elements across all existing systems.
From a technology perspective, no single solution on the market today can address all of them. Therefore, when evaluating multi-domain MDM products, it is necessary to understand what they offer. Most of the time, when a vendor sells an MDM product with the ability to identify and match master data, the core functionality being sold is entity resolution. Naturally, though, entity resolution presupposes some sort of data quality and data transformation activity to more effectively identify when two or more entities are truly the same. But you will not necessarily get all the data quality pieces needed to strongly support other MDM functions. For example, a product solving for entity resolution might include a deterministic fuzzy-logic algorithm to resolve the situation when two people have the same name or nickname. That is clearly a data-quality function. However, the same product may not provide other data-quality-oriented capabilities such as tools for data profiling, quality measurement, or dashboards that are essential for data analysis and data governance.
Product maturity is also another big consideration. Some vendors offer better solutions for certain domains, but not so much for others. That is not only due to product maturity, but also because certain domains are more difficult to generalize than others. Customer MDM is usually the most popular for many reasons. One is because use cases and data elements are more uniform across multiple companies when it comes to creating a product that will solve for customer MDM. Therefore, vendors have a better opportunity to create a solution that requires less customization and can be deployed more quickly and efficiently. On the other hand, product MDM is much more specific. Companies will have very unique requirements, which complicates MDM product offerings. Customer and product MDM are just two examples, but almost every company has customers and products. As other domains become even more specific, product offerings and maturity will suffer.
In addition to product value and applicability at the domain level, vendor product applicability and maturity are also issues across MDM disciplines and functions. Vendors have been slow to respond to certain data management needs. In particular, data governance and metadata management products lack sufficient maturity. Data federation has made great strides recently but still has a long way to go. Certain aspects of data integration and data quality are advanced, but there is still room for improvement. Data quality management has a very broad focus, and certain aspects of it are far more evolved than others. For example, data quality for structured data is relatively more advanced than it is for unstructured data. The integration of data quality and data governance is still at the very early stages, with product solutions still very fragmented.
Nonetheless, some vendors will offer a suite of products with functionality designed to address many data management components required to support MDM. In truth, however, these types of integrated tools all have strengths and weaknesses, with underlying design assumptions and dependencies that can make certain components fail to interoperate well with other vendor solutions. Some solutions are more mature and flexible than others, but this needs to be carefully examined.
A lot of this tendency has to do with the nature of MDM. MDM offerings do not often integrate as well with existing IT infrastructure as other applications do. Vendors must balance a solution that will address a problem and simultaneously fit an existing IT model that does not quite support what is needed to truly solve that problem. IT is typically prepared to support vertically aligned applications within distinct lines of business (LOBs). Vertically aligned applications look at a particular facet of the data to satisfy the need of a certain organization. For example, a financial department might rely solely on an enterprise resource planning (ERP) system for all its data needs. But MDM requires a horizontal view across many disparate systems to truly expose a consistent version of master data. Granted, most IT organizations will have some type of middleware technology to provide integration among systems, but using them for MDM requires customization that will add to the complexity, delivery schedule, and cost.
Therefore, companies looking for MDM solutions should not be surprised to find products that lack maturity, have insufficient functionality, and are difficult to integrate. In some cases, the only solution is to combine multiple products to cover all MDM functions, which has obvious drawbacks. In such cases, it is necessary to work with multiple vendors to create custom code to integrate products that were not naturally designed to function together. In parallel, companies need to adapt their processes and train their people to use the new product or products. With all that happening, a multi-domain MDM implementation becomes extremely difficult to achieve without proper expert guidance.
The bottom line is that evaluating technologies is a very complex task. It is best to rely on highly specialized and very experienced consultants to guide your company in this venture. Preferably, when considering a multi-domain MDM implementation, it is ideal to start with vendor-agnostic consultants with a proven track record in delivering comprehensive MDM use case analysis, planning assistance, and recommendations for how and where vendor solutions can add value. Getting objective, unbiased advice is important because that way, you’re more likely to obtain a solution that fits your specific needs.
With that said, let’s look at multi-domain MDM from an architectural point of view.
MDM Architectures and Styles
Multi-domain MDM can evolve from many different scenarios, often without a comprehensive enterprise strategy or plan. Some MDM implementations start in nonoperational environments that do not directly affect upstream applications. In these cases, it often begins as an expansion of a data warehouse or an operational data store (ODS) implementation, leveraging existing data integration capabilities but adding more formal data quality capabilities to cleanse, standardize, consolidate, and augment existing information. Those cases can be best described as analytical MDM, with its primary purpose to improve analytics, reports, and business intelligence. If a company’s business case for MDM is to increase revenue, an analytical MDM approach can be a viable option. Improved analytics will certainly help with better-informed business decisions and more precise company strategies.
Business analytics in itself is focused on improving market strategies based on increased knowledge about a company’s own data. Analytical MDM goes a step further. It establishes the opportunity to evaluate the same data, but increase internal efficiency. Data quality metrics become the foundation for data governance and data stewardship programs. It allows companies to recognize how their data lack the proper quality management rigor to meet desired outcomes. Trusted, consistent metrics provide data governance with solid information to evaluate data quality and pursue appropriate corrective actions and improvement activities with application and business process owners. Figure 3.1* depicts a typical analytical multi-domain MDM implementation.
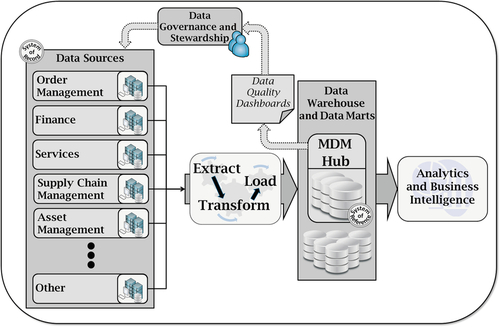
However, the analytical MDM model has only limited benefits and cannot be considered an enterprise solution. Operational systems rarely access data contained within an analytical system. From the analytical systems perspective, operational systems are upstream, read-only environments. Therefore, operational systems do not automatically benefit from data improvements or from the entity resolution in the analytical environment. Therefore, data quality improvements have to be duplicated in multiple sources, so they become scattered and inconsistent.
The concept of an operational MDM is a natural evolution. An operational MDM encompasses an MDM hub that can be directly referenced by operational sources. But an MDM hub within an operational environment can be implemented in different styles. There are many variations and different nomenclatures, but fundamentally they are
• Registry style or virtual integration (VI)
• Transaction/persistent style or single central repository architecture (SCRA)
• Hybrid style or central hub-and-spoke architecture (CHSA)
Certain MDM styles will be less intrusive than others, primarily due to architectures that vary from loose to tight coupling. A loose-coupling architecture requires less reengineering of existing systems to integrate them with a multi-domain MDM hub. Conversely, a tight-coupling architecture requires much more reengineering of the existing applications for such an integration. Therefore, a loose-coupling architecture will be much less intrusive than a tight-coupling architecture. Let’s cover each of them in more detail next, and discuss which styles are more intrusive than others. To be sure, a complete enterprise MDM solution is achieved when the results of an operational MDM is also captured at the analytical level for maximized benefits.
Registry-Style MDM
In a registry style, the MDM hub maintains only the minimum set of information necessary to identify data related to an entity and locate it at the many original data sources. In this style, the hub maintains identity information and source system keys. All other data relative to a given entity is kept at their respective sources and it’s not duplicate in the MDM hub. In essence, the hub serves to find instances of a given entity at their many sources. Notice that the hub is not truly a system of record (SOR) for an entity and its attributes. It is simply a system of reference. Figure 3.2 depicts a Registry Style Multi-domain MDM implementation.
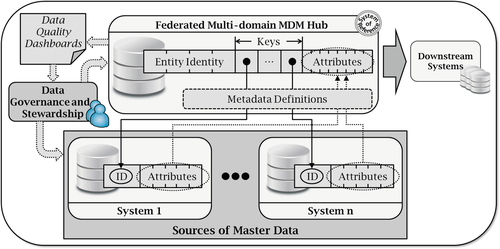
The hub does not directly update the data sources. It is a federated system that builds a master record during operation to be consumed by downstream systems. This style is not very intrusive, as it does not affect the original sources of data. However, it can suffer from performance issues due to latency as a result of dynamically collecting many attributes from multiple sources and assembling a golden record. Furthermore, if the same piece of information related to the same entity exists in multiple locations, a set of business rules must exist to clearly define a SOR or to resolve conflicts during operations.
This style has a relatively low cost and can usually be delivered quickly. It creates a solution based on loosely coupled systems, where minimal knowledge is shared across components. It is low risk since sources are left intact and act as read-only sources. The latter facilitates ongoing maintenance since it doesn’t require two-way synchronization. This style might be a good option in companies with many data sources and LOBs that are highly sensitive about ownership and changes to their data. However, if data sources are of poor quality, they won’t directly benefit from improvements and consolidation happening in the hub. This doesn’t necessarily diminish the impact of MDM; it simply points to the fact that not all source systems can accept nonapplication-centric changes.
Entity resolution is obviously a key factor in all MDM styles. But it is even more critical in the registry style because entity identification happens dynamically. Any automated matching algorithm will suffer from false positives and false negatives, and they can be higher or lower, depending on the quality of the existing data and the particular domain being mastered. Therefore, this particular style will be more effective in certain companies than others. It will also be more effective for certain domains than others, as the identity of an entity can be more straightforward for certain entities than for others.
In this style, the ability to create a robust metadata model for a particular domain is directly related to its successful outcome. Since this is a federated model and data is not copied to the hub, a metadata model must be established to dynamically represent an entity that is physically distributed in multiple places. As the attributes of that entity are physically changed or augmented at these multiple sources, their metadata representation needs to be upgraded accordingly. This factor is also more critical in some domains than others. However, not all domains must be implemented using the same MDM style, as will be discussed later in this chapter.
Transaction- or Persistent-Style MDM
In a transaction-style hub (aka a persistent hub), the MDM hub physically stores all attributes of an entity. The hub becomes a centralized single source of truth, and it is used to publish master attributes to other application systems. This style presupposes an initial loading of the hub with entity data from multiple sources. After initial loading, data are created and maintained directly in the hub and consumed by other applications, which have to be modified to use master data from the hub. This style consists of a highly coupled architecture, which is a major drawback since it is likely to require massive changes to existing applications in order to access data from the hub instead of data that is maintained locally.
Another challenge is to create a data model that satisfies all consumers of the master data in the hub. One option is to create a data model that encompasses all attributes needed by all applications. However, it is easy to see how difficult it can be to agree on a single model that can support very specific applications, created by many vendors, with clearly distinct functional requirements.
Nonetheless, this style has obvious advantages. Data is created and maintained in a single location, which increases the ability to prevent potential data issues. Remember that the most effective way to ensure data quality is through prevention. Data-quality efforts to cleanse and consolidate data after the fact can be very time consuming and have ripple effects, particularly related to risk and compliance. Data stewardship is also simpler, as there is a single location to manage information related to a domain and its entities. Finally, data synchronization is a nonfactor since multiple copies are not maintained. This is a huge advantage because data synchronization is highly risky due to its complexity and susceptibility to defects.
In summary, this style is highly intrusive and typically the most expensive and time consuming to implement. It might even be impossible to implement, depending on existing applications and their flexibility to be customized to consume data from the hub. One must consider how data will be distributed to other sources, typically through an enterprise service bus (ESB) and service-oriented architecture (SOA) due to time constraints. However, if this style is indeed achieved, ongoing maintenance is simplified when compared to other models. Data governance and stewardship will directly benefit from an authoritative source that is clearly defined, which will avoid future disputes.
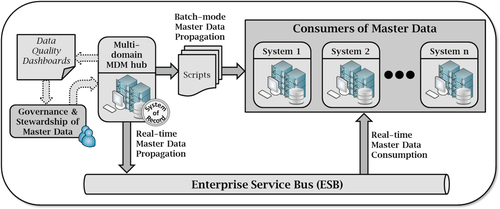
Figure 3.3 depicts a possible architecture implementing the transaction-style multi-domain MDM. Notice both real-time and batch-mode interfaces are represented, but they do not necessarily have to coexist. Nonetheless, it is not uncommon for certain sources to consume data from certain domains in batch form, while consuming data from other domains in real time. It is also possible for some sources to consume data from certain domains in real time while other sources consume the same data from the same domains in batch mode. Overall, several combinations are possible.
Hybrid-Style MDM
The hybrid model of MDM is a compromise between the registry and transaction styles. It recognizes the shortcomings of a registry model and its latency issues and the shortcomings of a transaction model and the need to modify applications to query a MDM hub for all master data. In a hybrid style, more than just identity attributes are kept in the hub. A copy of many attributes related to an entity is maintained in the hub, which speeds up queries to the hub. Also, since the information is a copy, existing systems can continue to use their own version of the data.
In this model, the hub is not the SOR since data creation and maintenance continue to happen at the original sources, and attributes replicated in the hub are kept refreshed. The MDM hub is a system of reference, integrating many sources, applying entity resolution and other data quality functions to master data, and making available a single version of the truth to consuming systems.
The hybrid MDM is loosely coupled and came into existence because tight coupling is not always practical in today’s multivendor, multiproduct IT environments that frequently use internal and external application systems. IT organizations can’t be expected to completely reengineer their existing applications, as required by the transaction-style MDM.
Although the hybrid model overcomes certain issues with the registry and transaction styles, it does have its own problems. The most glaring one is related to maintaining a copy of some attributes. Any time data is replicated, there is the risk of inconsistency. The hybrid model is popular and deployed very successfully in many setups, but if it is not implemented carefully, it can almost contradict what MDM is set to achieve. MDM is about solving issues related to having multiple copies of master data across multiple sources. Yet, the hybrid MDM does so by creating another source. Granted, in theory, it is a source setup with the capabilities to resolve conflicting information. Still, if proper precautions are not taken, it could become another source of contention.
The hybrid style shares the challenge of the transaction style with regard to creating a data model that meets the requirements of many data sources, but to a lesser extent. Since not all attributes have to reside in the hub, the hub needs to model only a minimum set of information, seen as enterprise master data attributes. Other more specific master attributes are still kept only at their original sources, supporting specific application functionalities. Those specialized attributes, although also nontransactional in nature, are considered extensions to the enterprise model. Relative to application usage, the distinction of what attributes are global and which are local can be overwhelming.
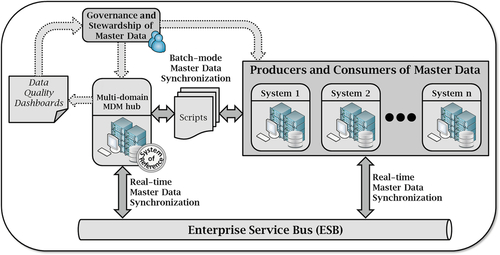
This style also presupposes an initial loading of the hub. There is a need for ongoing synchronization and its many facets, such as batch or real-time synchronization, what interfaces are bidirectional, conflicting updates from multiple sources, what attributes are affected for each source, and so on. Because original sources are kept relatively untouched, the hybrid style can be quick to deploy, but in general, it does take longer than the registry style. Figure 3.4 depicts a possible implementation of a hybrid multi-domain MDM. Notice both real-time and batch-mode interfaces are represented, but they don’t have to coexist. Nonetheless, different synchronization mechanisms or combinations thereof might exist between sources and domains.
Multi-domain MDM Technical Implementation Considerations
Before a particular style is identified for your multi-domain MDM solution, it is important to consider some fundamental aspects that are critical to making the right decision.
In very simple terms, MDM is technically about integrating master data into a data structure, creating a single version of the truth, and propagating or synchronizing this cleaner information. From a technical perspective, it is possible to say that MDM is about the following:
• Data integration
• Entity resolution
• Data synchronization or propagation
Granted, some of these items will be implemented differently depending on the MDM style chosen. But realizing that those are the actual technical components can help you evaluate vendor solutions, as well as decide which one best fits your enterprise architecture. A company will have certain cultural and operational characteristics, some of which can affect the foundational technical components. Here are some examples:
• IT infrastructure: Companies with higher capabilities in SOA and ESB are more prepared to integrate existing data and keep it synchronized in real time.
• Existing data quality: The quality of the data in existing sources will influence synchronization requirements, as well as the capabilities required to carry out entity resolution.
• Political and data ownership issues across LOBs: How willing organizations are to build an enterprise model and share ownership of the data is a strong driver to the data model behind MDM and how that model is fully integrated. In some cases, the actual definition of an entity at the organization level is different from its definition at the enterprise level due to operational idiosyncrasies.
• Business practices: Where data is created has an influence on which system is the SOR for each domain, and consequently on the MDM style itself.
• Risk and compliance factors: Certain industries and domains will be more susceptible to scrutiny by governing bodies, which can directly affect how much leeway there is to cleanse, and consequently alter, existing data.
• Global reach: Local versus global companies, and how they operate, either centralized or distributed, wields a large influence on data model designs and overall system integration.
• Data governance and stewardship models: How a company plans to execute data governance and how stewards will manage data are highly dependent on MDM styles.
These points are just some factors to consider. An enterprise and LOB balance must be found, as technical decisions will affect the business; at the same time, business practices, requirements, and company culture must be evaluated to dictate the technical implementation that best fits their needs. To be sure, it is always about solving a business problem, and in the end, any technical solution must satisfy that need. But sometimes there are multiple ways to solve the same problem, and some approaches are more suitable than others. Considering what is technically already available or what best fits an existing IT model might justify concessions on business requirements.
Let’s take a further look at the four foundational technical components mentioned previously.
Data Model
One of the reasons why it is difficult to find an existing MDM solution that fits your needs is because it is impossible to create a universal data model that will reflect every company’s business requirements. Data inside a company is very specific, both structurally and from a content point of view. Obviously, content is what makes data an asset to an organization, but structure is directly tied to business requirements. For example, some companies might use a customer-centric model while others use an account-centric model; and some companies might use the concept of a party to represent every person and company with any type of relationship with them, while other companies might model employees, individual customers, business customers, vendors, and partners completely independently.
Therefore, data normalization, cardinality, and integrity constraints are all relevant factors for both existing systems and for a newly created MDM system. Remember that MDM is integrating data from multiple sources, and in most cases, keeping it synchronized as well. Understanding how data is modeled across multiple sources and its create-read-update-delete (CRUD) management is critical to understanding how data should be modeled in MDM. Data is most likely already modeled differently within existing systems. Creating a master data model that integrates well with all those systems can be overwhelming.
The reason data models are important is that they translate business concepts into concrete technical terms. That is where the risk is. If a business concept is not clearly defined, its technical representation is flawed and further maintenance is prone to error. The challenge increases when modeling multiple domains and their relationships. Existing multi-domain MDM solutions will include a predefined physical model, but they usually allow customizations to extend their models since their existing design will not fit every company’s needs.
Vendors may or may not provide conceptual or logical models. These models can be fundamental tools for business teams, as they provide the right level of abstraction to facilitate understanding and validation, but they can also be very specific to each company and its business. Often, conceptual and logical models are never fully completed for various reasons. One major reason is the project timeline and pressure to reach the implementation phase, where the physical model is necessary. This causes the completion of conceptual and logical models to be abandoned and often leaves key business concepts or definitions incomplete, causing business-term issues to emerge later that must be resolved by data governance.
Understanding vendor-provided data models, how they can be extended and customized to support specific requirements, and how to model multiple domains and their relationships is critical to success. A data architect is needed to review and approve the data models. Remember to consider nonfunctional requirements, such as security, scalability, and performance, as well. Data models are important no matter what MDM style is chosen. What varies is just how models are rendered. In the registry style, the data model is virtual and resolved dynamically via metadata definitions. In transaction or hybrid styles, the multi-domain MDM hub is looking to encompass a large number of master data elements, and the data model needs to take that in consideration.
In addition, global companies need to consider local versus global data models and their ensuing internalization and localization requirements, as well as centralized versus distributed operations and how they can affect data model designs.
Data Integration
Data need to be integrated before a single version is created. The integration can be virtual, such as in the registry/federated MDM style, or physical, such as in the transactional or hybrid style. Physical data integration requires a data migration effort where data is copied or moved from existing systems to the MDM hub. Virtual data integration does not require data migration, but it remains necessary to define how two or more attributes from multiple systems represent the same thing.
From a multi-domain perspective, all domains will not necessarily need to be integrated in the same way. Other factors need to be considered, such as the number of sources containing master data, the quality of the data at those sources, how data needs to be synchronized and propagated, and how master entities are related to each other.
Another very important aspect when doing physical integration is the frequency of data movement. Does it need to be in real time or not? For certain companies, batches created daily are perfectly adequate to integrate data from multiple sources into an MDM hub; others might require real-time integration and harmonization of their operational data. As already stated, this requirement might vary depending on the domain being mastered. An extreme example is a large, global company implementing a distributed, multi-domain MDM with multiple hubs. For regional use, some domains are integrated in real time with local systems, and other domains are integrated in batches. For global use, a master hub is integrated with distributed hubs in batch mode.
Consider your integration requirements carefully and remember that the quality of your existing data can influence that decision as well. Profile your data fully before committing to a solution.
Entity Resolution
Obviously, the capability of a multi-domain MDM entity resolution engine is directly tied to proper vendor selection. But the less obvious element is how that capability can influence what MDM style is chosen, as well as how data stewardship practices will be conducted. The reverse is also true: How a company plans to practice data stewardship and the quality of its existing data can dictate what style and entity resolution engines work best.
Understanding the impact of false positives and false negatives is essential. False positives are distinct records, incorrectly identified as matches, while false negatives are similar records incorrectly unidentified as matches.
Let’s use some examples to clarify. In a registry-style MDM, entity resolution is happening dynamically. As such, a tool that yields either too many false positives or too many false negatives damages the overall quality of the golden record generated. But false positives and false negatives are also directly related to the quality of the existing data. If the quality of the existing data is low, a registry-style MDM should be selected only if a powerful entity resolution engine can circumvent existing issues. On the other hand, if the entity resolution engine is less powerful or appropriate for the existing level of data quality, data stewards will need to intervene to manually correct exiting data. If the correction can happen at the sources, a registry-style MDM is still acceptable. But if data stewardship needs to be centralized, either a transactional or hybrid MDM would be more appropriate.
If the quality of the existing data is relatively good, and most of the resolution can be done automatically, data stewardship intervention is less necessary. On the other hand, if existing data quality is bad, data stewardship practices need to be elevated. Those factors will influence vendor selection and MDM style. In summary, it is not only about evaluating vendors, it is also about evaluating your own data first.
Another typical point of contention is which data-matching algorithm should be used: probabilistic or deterministic. Some tools will include both, but some will have one or the other. As usual, there is no simple answer. Probabilistic methods use statistical techniques to determine the probability that two or more records are the same. Deterministic methods use rules and patterns to transform data and allow two or more similar records to match. The similarity between records depends on the algorithm used. For example, one algorithm might consider the letters y and i equivalent, making Bryan and Brian match. It is wise to conduct a proof of concept to evaluate how well a vendor algorithm will perform against your company’s data.
As expected, matching techniques and consequent false positives and false negatives are specific for each domain. That means a tool that is strong in Customer entity resolution, is not necessarily strong for Product, Account, or any other domain. Data analysis and proof of concept should be carried out on a domain basis. Remember that false positives and false negatives will never be reduced to zero. It is about finding a level that is comfortable and making sure that data is fit for usage. Some business cases will tolerate more false positives than false negatives or vice versa. Find the proper balance by analyzing your data.
Data Synchronization or Propagation
Data from the multi-domain MDM hub will certainly be consumed by multiple sources. That is the whole purpose of MDM: to serve as the single source of truth for master domain data. The more sources use data from the MDM hub, the better.
However, how data is consumed will vary depending on the MDM style. Simply stated, if multiple copies of master data exist, the data need to be synchronized. If a single version exists, either physically or virtually, data only need to be propagated. Therefore, in a registry-style MDM, since there is one single virtual version of master data, no synchronization is necessary. Data is simply consumed on demand by sources in need of trusted information. In a transactional MDM, there are no multiple copies either. A single physical version exists, and synchronization is not necessary. In a hybrid style, some attributes are copied, so synchronization is needed.
The technology for integration, synchronization, or propagation will not be included automatically as part of a vendor-provided multi-domain MDM solution. It might be necessary to acquire technology to integrate and synchronize or propagate data from a different vendor. For example, an MDM hub could be as simple as a physical data model with the logic to carry out entity resolution. To get data in and out of the hub, it might be necessary to use database tools, operating system scripts, SOA, ESB, or a combination of those.
Consider your synchronization requirements carefully. Solutions will become more complex as more systems need to remain synchronized. Minimize two-way synchronization as much as possible, as they are intricate and prone to error. Understand whether real-time synchronization is required or if batch synchronization done on a regular basis is sufficient. It is possible that these requirements will vary per domain and need to be implemented differently. When copies exist and multiple systems can potentially change data associated with the same entity, inconsistencies may arise due to latency issues. Understand what type of controls a vendor can provide to prevent these problems.
Finally, if copies of master data exist across multiple systems and proper mechanisms are indeed in place to maintain synchronized data according to the required frequency, errors still can occur. For example, chances are that data might get out of sync due to bugs or unforeseen scenarios. To address those cases, a data-quality process should be implemented to measure the consistency of master data across multiple sources. This information can be critical to helping data architects and data stewards address potential problems. Multi-domain MDM vendors will not necessarily provide out-of-the-box capabilities to measure those unexpected inconsistencies.
Technical Considerations to Other Major Functions
Up to this point, this chapter has mostly covered technologies and architecture directly related to integrating a multi-domain MDM hub into an IT infrastructure. But there are more technical considerations related to the other multi-domain MDM functions of data quality, metadata management, data governance, and data stewardship.
A lot of data-quality competencies are expected to already exist as part of a well-designed MDM hub solution. Since one of the primary functions of an MDM hub is to cleanse, standardize, and consolidate domain data, it is obviously expected that those data-quality capabilities would already be included with a vendor solution. However, data quality is needed in other areas. Data profiling, for example, is extremely important, and it cannot be stressed enough how critical it is to carefully analyze and understand existing data before an MDM solution is sought. In another example, data-quality metrics and dashboards are fundamental to data governance and stewardship activities. In the end, data-quality profiling, metrics, and improvements should be ongoing within any company looking to fully leverage data as an asset and truly adopt a data-driven mantra. With that in mind, it might be necessary to invest in additional data-quality tools to supplement what is missing from a multi-domain MDM vendor product.
Some metadata functions are included in the registry-style MDM, but that is primarily to build a data federation system to join multiple sources virtually. However, metadata management is needed in many other areas (as will be discussed in Chapter 10), and a more robust tool is highly recommended. Metadata management tools are offered either stand-alone or integrated with other data-related solutions. For example, some enterprise data warehouse (EDW) vendors might offer metadata capabilities with their data models and maintenance tools. Extract, transform, and load (ETL) vendors might also offer capabilities to automatically capture data lineage and transformations linked to their products. However, metadata management tools are also available as separate applications, agnostic to underlying vendor products, which are targets for metadata documentation. Proper decisions must consider how well the metadata solution will integrate with other technologies and processes. Keep in mind that the goal of metadata management is to be an enterprisewide practice. Carefully consider the implications of adopting a potentially specialized and localized tool that might not scale properly to the required enterprise levels of governance.
The function of data stewards is to methodically prevent and correct data issues based on business and legal requirements, data quality defect reports, and compliance with data governance policies and standards. Data stewards require great expertise in the subject matter associated with the domain they manage. In addition to business and legal requirements and data governance policies and procedures, data stewards rely heavily on data-quality reports and dashboards and glossaries defining business terms. From a technical point of view, data stewards can benefit from the following:
• Metadata tools with a comprehensive data dictionary, data lineage, data transformation rules, business rules, and a business glossary to facilitate understanding about the data and the business expectations.
• Data-quality reporting tools that can monitor and expose anomalies.
• Workflow applications to help them manage scope of work, assignments, and approval processes.
• Depending on the multi-domain MDM solution, some type of data-quality remediation tool might be included, but most of the corrections are performed using regular system applications.
• Tools that can support data corrections in bulk. The majority of data corrections are performed one by one using applications’ user interfaces. But depending on the issue, data stewards can benefit a great deal from bulk updates. Needless to say, compliance issues and other risks must be considered when performing bulk updates.
Last, but certainly not least, is data governance. From a technology support perspective, data governance shares some similarities with data stewardship regarding some underlying tools. Data governance needs metadata management tools to capture a glossary of business terms and rules, data-quality expectations, ownership, data life-cycle management, and impact analysis when changes occur. Data governance also requires substantial data-quality functions, particularly data-quality reports and dashboards. Finally, data governance needs workflow applications to facilitate tracking their work related to capturing business definitions, rules, policies, and procedures and to capturing proposed changes, required approvals, and audits.
Vendors obviously understand these dependencies. Therefore, they add functionality to their existing offerings to complement other areas. For example, a data-quality vendor might add workflow functionality that is tied to their dashboards to facilitate stewardship and governance operations; or a metadata vendor might embed approval and audit processes to its tool to enhance governance capabilities. Of course, this approach has pros and cons. An obvious advantage is that there is no need for other tools to perform new functions. One of the disadvantages is that these solutions could remain fragmented and not scale well to an enterprise level because they were just an afterthought, added to increase a vendor’s market penetration. Before you start looking for additional technology to purchase, understand what you can use in tools you already have and see if that meets your needs.
Let’s use a hypothetical example. Say that a company adopts a particular tool because it is truly the best at creating required data-quality dashboards for the business and data governance. This tool wasn’t chosen for anything other than its data-quality capabilities. Nonetheless, the vendor develops the product, adding some metadata functionality to tie business rule definitions to data elements being monitored. It also adds certain workflow functionalities to trigger email notifications when certain attributes reach undesired values. This is obviously all to the good, but from a tool perspective, data quality metrics are practically the foundation for everything else, and if the company’s data governance is still in the process of collecting business definitions and rules, obtaining approvals, and so on, the newly changed tool might not suit it. Metadata and workflow functions might be needed before the actual metric is completely defined. In this case, using this data-quality tool for anything other than data quality might not work. Using what is already available has many advantages, but be aware about how much you are willing to compromise.
Don’t analyze tools in isolation. Carefully consider options and requirements. Also, look to use what might already be available inside your own company before adding more technology.
What About Big Data?
Big data is certainly getting a lot of attention lately. But how does it relate to MDM and data governance?
Big data has the following characteristics in large scale: volume, velocity, and variety, also known as the 3 Vs. Other Vs, such as veracity and value, have been added to this list as the definition of big data continues to evolve. Social media is seen as the largest data farm out there, and it certainly meets the 3 V characteristics. Companies are increasingly looking for opportunities to tap into social media to add value to their strategies. From purchase patterns to customer complaints, the possibilities are also great. But social media is not the only source of big data. Any data meeting the 3 V characteristics should be handled as big data. For example, sensors frequently collecting information will certainly have high volume, high velocity, and potentially high variety.
Technology to efficiently handle volume, velocity, and variety is still evolving. Furthermore, the challenge is dealing not only with the 3 Vs, but also unstructured data. Big data mostly consists of unstructured data, and technology to handle unstructured data is also maturing. Nonetheless, big data is still data, and as such, it needs governance. Data governance must manage expectations, policies, and procedures regarding big data, while at the same time mediating potential opportunities created by big data projects. Data governance is highly dependent on data-quality dashboards and metadata definitions, and those will offer additional challenges. Data-quality parameters on big data might be hard to quantify, as it is very dependent on tools being able to correctly assess unstructured data against key performance indicators. In addition, unstructured data offers very little, if any, metadata information.
On the other hand, the MDM hub primarily consists of structured master data, and it is integrated from other structured or semistructured sources in the company, such as databases and spreadsheets. Granted, master data does exist in the company in unstructured or semistructured forms, such as emails, correspondence, and markup languages, but they are not the typical sources used to create an MDM hub.
Since big data is mostly unstructured, the link between master data and big data is very similar to how master data is linked to unstructured data. Master data can be used as a basis of big data analysis, such as context, search criteria, and classification. Technology is still evolving, as already stated, but one of the keys is to be able to apply certain MDM functions, such as fuzzy and probabilistic matching, to high-volume and high-velocity unstructured data.
At this point, big data is very loosely coupled to multi-domain MDM, so it is not covered in detail in this book.
Conclusion
Technology is not the only piece of the puzzle of multi-domain MDM, but it is certainly one of the most critical ones. We’ll say it again: There is no single product that will address all the necessary capabilities of multi-domain MDM. Vendor solutions have improved and continue to mature, but MDM is very specific to each company, which complicates out-of-the-box solutions. In addition, potential differences about how each master data domain needs to be handled increase the complexity of architectures and implementations.
This chapter covered general guidelines on key aspects that should be considered when planning an enterprisewide technological landscape that can sustain a scalable, multi-domain MDM solution. Adding multi-domain MDM is more than just adding applications. It is about adding capabilities that affect the most important data elements across all existing systems.
MDM technology is very complex in terms of how it affects multiple organizations across the company. Perform a thorough vendor selection process, and hire expert consultants to guide you through it.