
Strategy, Scope, and Approach
Abstract
This chapter discusses strategy, scope, and approach associated to planning an enterprisewide, multi-domain Master Data Management (MDM) program. It focuses on defining the guiding principles of data governance, data stewardship, data integration, data quality management, and metadata management to create scalable approaches that will drive a successful multi-domain initiative. Discuss the importance of establishing collaboration and alignment across data governance, project management, and information technology (IT).
This chapter covers the strategy, scope, and approach associated with planning an enterprisewide, multi-domain Master Data Management (MDM) program. Although companies are increasingly recognizing the value and need for MDM, they still often struggle with being able to fully or consistently implement MDM strategies and objectives for multiple domains or subject areas. They find this so difficult because they fail to recognize the many components, functions, and services that are either required to make MDM work correctly or are created as a consequence of an integrated set of disciplines and shared data. Many companies see MDM only as a data integration discipline, which is a mistake.
This chapter sets the foundation for MDM services, components, and disciplines by defining the guiding principles of data governance, data stewardship, data integration, data quality management, and metadata management to create scalable approaches that will drive a successful multi-domain initiative. It discusses where common approaches should be applied across the data domains, while recognizing and supporting flexibility where unique requirements, priorities, and deliverables can exist within each domain. It also covers the importance of establishing collaboration and alignment across program management, data governance, business units, and information technology (IT), all supported by a strong, high-level executive sponsorship.
Defining Multi-domain MDM
A data domain reflects the organization of key business entity areas such as customers, products, vendors, partners, service providers, financial accounts, patients, employees, and sites. Master data is data most critical to a company’s operations and analytics because of how it is shared and how it interacts with and provides context to transactional data. Master data is nontransactional in nature. Multi-domain MDM is concerned with managing master data across multiple domains. While some MDM functions and disciplines can and should be leveraged across multiple domains, some of those functions and disciplines within each domain are still specific enough or have distinct business requirements, so they need very specific management and implementation. Even technology use and maturity can vary widely across domains, as will be described in more detail in Chapter 3. This fact alone directly influences how companies have to adapt their MDM practices for different domains.
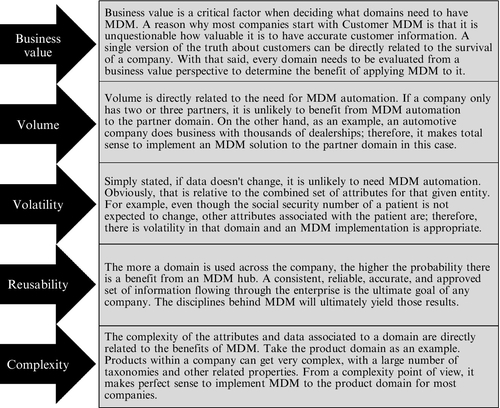
Imagine a small software company, with 10–20 employees, selling a single, very specialized application to a handful of customers using prepackaged software components from certain vendors. This company is unlikely to need MDM software or MDM automation to manage its master data. Why? It certainly knows its customers very well, and its managers have a clear understanding about what vendors they use and where to get what they need from them. They have their contacts clearly established. The multiple versions of their application can be managed by a good software configuration system. More important, chances are that they utilize a minimum set of internal software applications to maintain their operations, or even use a single cloud computing service such as Salesforce.com to support most of their IT functions. The bottom line is that the company’s volume, redundancy, and fragmentation of information are very low. Furthermore, business intelligence is simplistic. MDM automation would not add much value to this type of company.
Now imagine a large automotive finance company. This company does business with millions of prospects and customers, finances and leases millions of cars from multiple manufacturers, manages millions of financial accounts and a multitude of financial products, handles negotiations with thousands of dealerships and related contacts, maintains relationships with thousands of vendors and other firms (e.g., auction houses, appraisal companies, bankruptcy courts and trustees, and collection agencies), uses services of thousands of insurance companies, deals with thousands of attorneys representing either them or their customers when disputes occur, and hires thousands of employees. Just from these specifications, it is possible to identify a multitude of domains that such a company would have: prospects, customers, vehicles, manufacturers, financial accounts, financial products, dealers, contacts, vendors, attorneys, and employees. It is clear that the volume of information is large, and it is easy to figure out that the number of attributes and data systems maintaining all the information would probably be quite large. This company very likely can benefit from MDM because chances are that there is data redundancy and inconsistency across many data sources. But do all those domains need MDM?
There are many factors to consider when determining where to prioritize an MDM focus. Chapter 2 will detail how to identify and prioritize data domains, but let’s take a quick look at the key drivers that influence MDM decisions and priorities.
Figure 1.1 indicates the key factors that should drive the priorities and business case decisions for where MDM should be focused in a multi-domain model. However, regardless of the business case or the domain, there are key data management practices and disciplines that need to be scoped, planned for, and implemented in any MDM program. Each of the five major practices—data governance, data stewardship, data integration, data quality management, and metadata management—is important enough to be addressed by its own chapters in Part 2 of this book (Chapters 6 through 10, respectively). In addition, entity resolution, create-read-update-delete (CRUD) management, reference data management, data security, and data architecture are major topics and vital functions that also need to be covered within the overall MDM program strategy and scope. Let’s understand all these key areas before going any further.
Multi-domain MDM Strategy and Approach
Data is considered a strategic asset to a company, and it needs to be managed accordingly. Data supplies companies with the information and knowledge it needs to compete and thrive amid increasing pressure to succeed. Consequently, there is no dispute how valuable data is to a business. But the challenge is that the IT department has predominantly owned data management, and business organizations have not taken sufficient responsibility for data quality. Data is maintained within technology-enabled applications but created and changed by business processes, so any data issue requires as much of a business emphasis as it does a technical emphasis. Multi-domain MDM programs need an effective engagement and collaboration between business and IT. Collaboration is cultural, but it can be stimulated with proper organizational structure, robust communication channels, and an effective change management process.
Large companies experience huge data management challenges that emerge over the years as companies grow, constrict, acquire other companies, face new competitive challenges, transition from old system infrastructures to new platforms, and are subject to increasing requirements regarding security, information privacy, government regulations, and legal compliance. Because any of these conditions can be very disruptive, companies that can maintain a flexible and fluid dynamic between the business and IT roles will be most able to adapt quickly to address these challenges. The flexibility and adaptability needed here has to be an existing dynamic within specific roles and responsibilities and doesn’t just happen with initiating a new project or a consulting engagement.
This dynamic needs to be demonstrated by dedicated managers, data stewards, and data analysts working closely together across business and IT lines under data governance authority to address these data management challenges while also minimizing disruption to the normal operational practices. An MDM program will struggle to gain a successful foothold, where traditional business and IT dynamics create a very rigid engagement model, has a mostly reactive approach, and generally is only focused on back-end-oriented data management practices. A multi-domain MDM program needs to act as a bridging dynamic to create collaborative data management roles and responsibilities across business and IT functions. But this won’t happen overnight. MDM maturity and value grows over time.
MDM is not a project. Venturing into multi-domain MDM becomes a large exercise in Business Process Management (BPM) and Change Management. The planning and adoption of cross-functional disciplines and processes necessary for the support of MDM needs to be well orchestrated. This process can be greatly aided by leveraging a consulting partner well versed in MDM, particularly during the discovery and planning phases where capability needs, gap analysis, stakeholder assessment, and project planning deliverables need to be addressed and clearly articulated to a steering committee for review and approval.
With that said, Figure 1.2 is an example of the type of cross-domain model that must be carefully considered when creating your own model. It is also used to exemplify typical scenarios, but they must be adapted to each particular situation.
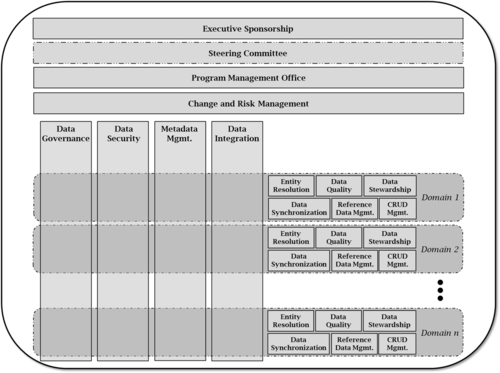
In Figure 1.2, the four boxes at the top represent the management organization functions required to support a successful multi-domain MDM model. Domains are represented by round boxes labeled “Domain 1,” “Domain 2,” and “Domain n.” Those constitute the data domains within the MDM program scope. The square boxes completely inside the rounded boxes are functions that are likely to require high specialization for a particular domain. In data synchronization, for example, one domain might require real-time synchronization among all sources, while another domain might meet business needs with nightly batch synchronization.
The vertical boxes crossing the domains represent functions that are likely to be generic and can be used by various types of master data. For example, a data governance program and charter can include scope and authority broader than just the master data focus. Similarly, data security is likely to be a cross-functional component focused on policies and management related to data access and data protection. The platform where the domain data exists is irrelevant, and data security disciplines are very reusable.
Every component will benefit from economies of scale. As MDM is applied across more domains, these functions and their associated tools and processes become more reusable or adaptable. Certain functions, such as data quality, are extremely broad. Most of the disciplines inside data quality are indeed reusable across multiple domains, but they still have domain-specific requirements for activities such as data profiling, data matching, and data cleansing.
How and Where to Start?
First, it is important to clarify there is no one-size-fits-all approach to multi-domain MDM. As indicated in Figure 1.2, there are too many factors that will differ from one company to another or within a company from one domain to another for that to be possible. A multi-domain MDM program is extremely pervasive and will affect many groups and their processes. The company culture and how well the business units interact will be key influences on the strategy and planning of a multi-domain program.
There are always questions about the best strategy and approach for initiating a multi-domain MDM program and what the main drivers are. Figure 1.3 depicts traditional approaches and drivers, but it also illustrates how a combination of approaches might be a viable option. Next is a discussion on each of them.
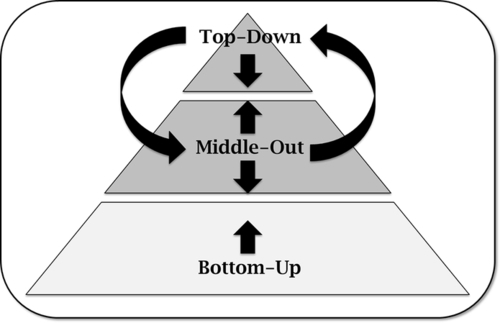
Top-Down Approach
A top-down approach is the ideal scenario. It assumes that there is an active executive steering committee overseeing the MDM program and providing consistent and visible, top-down sponsorship across the various MDM domains in scope. There are many benefits to building the executive-level engagement process as soon as possible:
• Demonstrates visibility and commitment to MDM and data governance in general.
• Some areas, such as legal, finance, human resources (HR), and compliance, may not need a full domain team structure initially (or even at all), but can still provide representation for strategic plans and tactical direction.
• Leaders associated with future domain areas are still likely to be interested in or affected by MDM decisions. Their participation in strategic decisions is important, and they can observe a working MDM and data governance model occurring with the active domains. This will help shape interest and planning for future domains.
If there is no active steering committee level, the following disadvantages can result:
• Executive leadership/sponsorship is not visible.
• Data governance may appear fragmented and/or only as an inconsistent process in some areas rather than being viewed as an enterprisewide model with an expanding plan.
• Being able to address cross-domain issues will be a more difficult and often ad hoc process if there is insufficient participation and commitment to give input when needed.
• Other business areas may not be aware of where good MDM and data governance practices exist.
Over time, one or two domains will typically command higher priority, budgets, and attention than other domains. What domain area and MDM initiatives gets the most corporate funding and highest level of attention at any given time should not be a largely dominant or limiting factor for defining and planning a multi-domain program strategy and model.
In a multi-domain plan, there will typically be leading and lagging domain scenarios. Therefore it’s important to leverage the leading cases to lay down the MDM foundation and value propositions while also planning how MDM principles and practices will be able to be applied and scale across other domains over time. If MDM is successfully executed in the leading cases, then MDM practices will become more valued and incorporated into ongoing data management strategies, therefore requiring less top-down engagement. In other words, as MDM practices mature, execution of MDM practices across multiple domains should require less top-down attention and take on more normalized processes through IT and program planning.
Middle-Out Approach
Although a top-down approach can provide the most thrust for initiating an MDM program, it may be difficult to establish or sustain a top-down approach across all domains in scope. MDM initiatives don't necessarily require a top-down model. Often, there are sufficient existing business case needs, budgets, planning processes, resources, and decision authority within an operational or analytical area to plan and drive an MDM initiative without need for top-level executive engagement. A middle-out structure is a viable option in these cases.
A middle-out approach is often triggered in cases where new business systems or analytic platforms are being funded or in progress and, through those projects, the need for MDM practices are identified and covered by the project plan. However, finding these project-driven scenarios across multiple domains can be a hit-or-miss affair and might have fixed time and budget constraints. Having a MDM program office with visibility into the company’s project planning and solution design processes can greatly enhance the ability to identify and support MDM growth opportunities from a middle-out perspective.
Bottom-Up Approach
Bottom-up is neither recommended nor likely to be a sustainable approach. Any MDM capabilities or practices stemming from localized projects and efforts are most likely to reflect one-dimensional solutions that may service the local needs well, but will not have sufficient scope or budget—for expanding the solution across other operational and organizational areas.
Movement to an enterprise model needs to be driven by executable enterprise strategies and projects acting as forcing functions to migrate localized functions. Without these enterprise drivers, there is little incentive and opportunity for localized departmental functions to move into an enterprise model. During a transition period, there may be support for both local and enterprise models until the local model is decommissioned. But generally, localized data quality and governance functions are not going to make the leap to an enterprise level unless broader factors and business strategies can enable this.
Top-Down and Middle-Out Approach
A strategy supporting a combination of top-down and middle-out can also be a realistic approach. A MDM multi-domain plan and program office should certainly look to establish the top-down approach for each domain to gain the initial momentum and sponsorship, but where top-down sponsorship is lacking for a given domain, the plan should be flexible enough to also work middle-out to recognize and promote MDM opportunities in domain areas where there are existing project opportunities that can provide fertile soil for MDM growth.
Although top-down is considered the best-practice MDM and data governance approach, history tells us that there can be significant industry swings in a company’s health, priorities, executive leadership, and employment stability. These swings will drive changes in longer-term IT and business strategies. Therefore, it’s actually prudent to build an MDM program strategy without being overly dependent on a consistent level of executive sponsorship or a fully executed enterprise architecture. A top-down and middle-out strategy will enable a more flexible approach with emphasis on aligning the MDM initiatives and priorities with the existing domain specific data management, platforms, and project roadmaps where IT investment and business process initiatives will likely be more tangible and in progress.
Multi-domain MDM Scope
Typically, an MDM program is initiated to address certain fundamental issues. Data is duplicated, fragmented, and inconsistent across multiple sources. IT systems are usually built to support a certain business function, and data is primarily maintained for that business function alone. There is very little regard to cross-business needs or systems depending on this data—aka downstream systems. Furthermore, data lacks quality because not all disparate systems and processes across the company are built with data quality in mind. Mergers and acquisitions, which bring more disparate, fragmented, and inconsistent systems from other companies into the mix, only add to the problem. Finally, volume keeps increasing at a faster pace.
The bottom line is that there are multiple sources of information with similar (but not exactly the same) data, representing a single entity. Some of that information is outdated and therefore incorrect. MDM helps by formally establishing and governing rules to define what common set of data elements should be used to match entities across multiple sources, as well as techniques to cleanse and consolidate the disparate information, and create a single version of the truth.
However, data offers a large number of challenges, and as such, there are numerous disciplines geared toward addressing their many aspects. Figure 1.4 depicts the primary multi-domain MDM functions, which are described next.
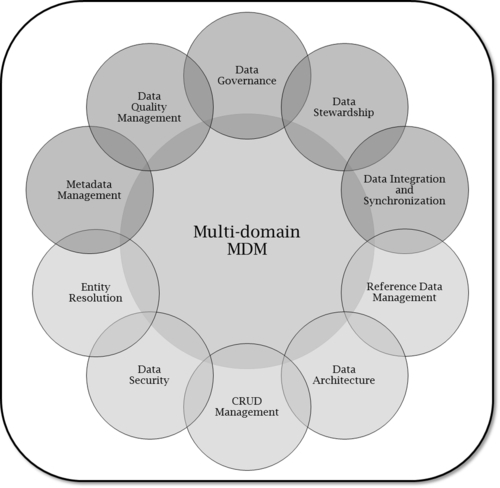
Data Governance
Data governance is the exercise of authority and control over the management of data assets. It’s important to note when planning a MDM program strategy that a data governance discipline can and should exist in a company whether it has a MDM program in place or not. As much as data governance does not require MDM, the opposite is not true, especially in an inherently complex multi-domain MDM. All the MDM functions shown in Figure 1.4 require strong data governance engagement and support in many occasions. As MDM expands into more domains and covers a larger amount of entities and master data, data governance becomes even more critical because the volume of activities, need for decisions, and prioritization of work naturally increases.
The good news is a well-established data governance program can cover many data domains and be leveraged to provide the data governance support required in the multi-domain MDM program. Even though one domain will typically have ownership of the master data associated with that domain, master data is intended to be a controlled and shared asset, often having various data creation and consuming processes across the business model. Because of this, it is important that the data governance component in a multi-domain model is prepared to support the MDM program not only for a given domain’s governance needs, but also on a cross-domain level where master data awareness, quality management, issue resolution, policies, and standards need to be addressed across applications and process areas. Data governance is the glue that holds MDM together. Without it, cross-domain MDM will not be a cohesive, sustainable program.
How to leverage data governance across multiple domains is discussed in detail in Chapter 6.
Data Stewardship
Data stewardship encompasses the tactical management and oversight of the company’s data assets. It is generally a business function facilitating the collaboration between business and IT, driving the correction of data issues, and improving the overall data management process. Their interest is in content, context, quality, and business rules surrounding the data. That’s different from the data custodianship, which is an IT function that cares about storage, safety, transportation, and support of stewardship duties.
The vast majority of data custodian activities are independent of domains since they are mostly technical and applicable to any content and context. As such, those tasks are reusable across domains. Organizations usually have a formal data administration organization that is responsible for maintaining databases, controlling access, and more. Nevertheless, these groups do need to support data stewards and their data requirements.
Data stewards gather the business’s needs and requirements related to data fitness for use and translate them into methodical steps necessary to implement data corrections and adjustments. They are also responsible for collecting and analyzing data in support of business activities. All this work performed by data stewards is specific to a given domain. Even though data analysis techniques are certainly generic, the content and context depend on the domain in question. Therefore, data stewardship functions become quite specialized.
That means that the knowledge to carry on data stewardship for customers differs from the knowledge needed to carry on data stewardship for products, financial accounts, vendors, partners, and others. That doesn’t mean there must be a separate data steward team for each domain. As stated previously, a lot of the data management techniques are quite similar and should be shared. Just keep in mind that subject matter expertise is a must and should be accounted for when planning and building a data stewardship organization.
More information about data stewardship will be given in Chapter 7.
Data Quality Management
Data Quality Management (DQM) is about employing processes, methods, and technologies to ensure the quality of the data meets specific business requirements. DQM is a very extensive function, with far-reaching results if employed consistently, continually, and reliably. Trusted data delivered in a timely manner is the ultimate goal. DQM can be reactive or preventive (aka proactive). More mature companies are capable of anticipating data issues and preparing for them. To prevent such issues, a company must create a culture of data quality. It is not only about having a data quality team. It is about encouraging quality at many levels—from a physical data model design, which is a technical function, to data entry, which is a business function.
Bad data model design will open the door for data quality issues in the future. The key is to start with a solid data architecture team and solid data design. Companies usually hire system architects to integrate their applications but fail to recognize the need for data architects. They hire data modelers, but those roles typically remain contained within their specific applications. Data architects are better prepared to understand the implications of poorly designed data models and data interfaces.
Other preventive aspects of DQM are embedded within multiple processes throughout the company. Technical and business processes must be designed and executed with data fitness in mind. Remember that it is not about data quality for its own sake. It is about fitness for use. It is about achieving the best data quality possible as required by the business. If the cost to prevent a data quality issue is higher than the cost of using bad data, you must reconsider your methods. This is by no means a green light to accept bad data. It is simply an indication to review what is being done, identify the root causes of issues, and find more efficient ways to achieve desired goals. Plus, you may not be measuring the value of your data correctly. Companies underestimate the value of good data, as well as the cost of bad data.
Nonetheless, no matter how mature a company is, there will always be a need to perform reactive data quality maintenance tasks. Again, it is about data adequacy to a business need, not perfect data. Data correction projects must have clearly established requirements, objectives, and metrics to measure success. Furthermore, every data issue has a root cause. When correcting existing data issues, make sure to identify why and how the issue occurred and implement corrective actions to prevent similar anomalies in the future.
DQM techniques are vital to many activities related to entity resolution, data governance, data stewardship, data integration and synchronization, data architecture, data security, reference data management, and CRUD management. It is a foundation to just about every MDM data component. Even though this book treats DQM as a multi-domain MDM function in itself, it is important to realize its pervasiveness across the other functions.
Besides being broad, DQM is also diverse. Techniques for designing high-quality data models are different from techniques for profiling data, which in turn are different from methods to augment information, and so on. Remember that even software designers and developers must employ proper techniques to ensure that their final product preserves high-quality information.
From a multi-domain MDM perspective, DQM will have many subjects that can be leveraged and planned for across domains and entities. But due to its diversity, some DQM subjects will still be quite specific depending on the domain being implemented. The main reason for this is that quality of information depends on business requirements, context, and subject matter expertise and its associated tools and references. For example, record linkage within entity resolution can vary widely depending on the domain being implemented. Record linkage for individuals is quite different from record linkage for products. Since data matching is the foundation for record linkage and data matching is a DQM topic, it is easy to see how specific certain DQM subjects can be for a given domain.
DQM will be covered in great detail in Chapter 8, as well as in other chapters within other disciplines as applicable.
Data Integration and Synchronization
It’s been stated already that the fundamental issue MDM addresses is the duplication, fragmentation, and inconsistency of data across multiple sources behind systems that are continuously operating in silos. Since data integration involves combining data from several sources, it becomes a required core competency in MDM programs.
There are many flavors of data integration, but they can be largely placed into either the physical or the virtual category. Physical data integration implies making a copy of the data, while virtual integration doesn’t. An enterprise data warehouse is a typical physical data integration implementation, while data federation is a technique to virtually integrate multiple data sources. In a pure sense, data migration doesn’t necessarily mean data integration because you could be moving data around without truly integrating any data. However, if data migration is in the context of an MDM program, it will certainly carry physical data integration aspects with it.
Data synchronization is the process to establish consistency among systems and ensuing continuous updates to maintain consistency. According to this definition, data synchronization presupposes an ongoing integration effort. Therefore, data synchronization is the continuing realization of a data integration activity. Because of its maintenance characteristics and associated costs and risks, data synchronization has a huge influence on the selection of an MDM architecture. This consideration will be expanded in Chapter 3, where multi-domain technologies are explored, as well as in Chapter 8, as part of a discussion of data integration.
When looking to leverage data integration and synchronization across multiple domains, it is necessary to remember the difference between their definitions: data synchronization implies ongoing data integration, while data integration in itself doesn’t have the reoccurring aspect to it. This matters because domains will have different requirements about how data is brought together, as well as how often they need to be kept in sync when data is replicated.
As with all other functions, the more mature a company becomes in one particular area, the more capable and nimble it will be to reapply related knowledge, experiences, methods, processes, and procedures in successive domains. With that said, certain aspects of data integration and data synchronization can indeed be generic for multiple domains, while others are not so much. It also depends very heavily on the type of the MDM implementation. For example, if one domain is implemented using a federated system, there is a need for initial data integration to achieve proper data linkage, but there is no need for data synchronization. There are many nuances that will be covered in a lot more detail later in this book. Generically, however, there is always a need for integration since the starting point is discrepant sources, but there may not always be a need for synchronization since a single copy might exist after data is integrated into a multi-domain MDM hub.
Metadata Management
Metadata management is likely the most overlooked data component of multi-domain MDM, data governance, and data management in general. This is largely to do with low level of maturity about how to effectively implement a metadata management program that yields short- and long-term results. The following are the main reasons why companies fail with their metadata programs:
• Unclear goals, policies, standards, or roadmaps
• Unclear who are the owners and users of the metadata
• Not setting the right priorities on what needs to be documented first
• Wasting too much time with data elements that are of little interest to consumers of metadata information
• Unsuitable technology
• Wrong personnel skills
• Underestimating the effort to maintain an up-to-date metadata repository
• Treating all metadata the same way
Most of the issues described here stem from a lack of true understanding about what metadata management is and how it is used. Metadata is briefly defined as data about data, which can be considered a bit ambiguous or vague. There are different categorizations of metadata. Some experts will separate metadata into either structural or descriptive metadata. Structural metadata is about documenting the design and specification of data structures, while descriptive metadata is about documenting the data content. Others will classify metadata into technical, business, and operational areas. Technical metadata is related to physical data structures and interfaces. Business metadata is related to a glossary of business definitions and business rules. Operational metadata is related to statistics on data movement.
The description about metadata thus far has been regarding its documentation aspect, which is obviously of huge importance. Imagine how much easier it would be to start a multi-domain MDM program if all the master data attributes were properly documented from both a technical perspective and a business perspective. That’s the ideal scenario, but it almost never happens. As said earlier, companies struggle with metadata management. They often don’t have a metadata repository solution, or if they do, it is not up to date and therefore not trustworthy. This is considering a metadata repository as an important input to an MDM program. However, there is also the importance of a metadata repository as an output of a multi-domain MDM program.
It has been stated before how MDM is about bringing data from multiple lines of business (LOBs) together, and as such, data governance is a must not only to support entity resolution, but also to manage the ongoing usage of shared master data. Business metadata becomes a critical part of supporting data governance with the appropriate channel to publish enterprise business definitions and rules for widespread understanding of shared data elements. Knowledge about information and its usage is the cornerstone to solid governance.
In addition to the documentation aspect of metadata, both as an input and as an output to a multi-domain MDM program, metadata is an important piece of some MDM architectures. Data federation requires a metadata component to virtually connect data elements from multiple sources. Therefore, depending on the technology chosen, metadata management can play an even bigger role.
Metadata management is described in more detail in Chapter 10.
Entity Resolution
Entity resolution is one of the reasons why MDM is so complex and why there aren’t many out-of-the-box technical solutions available. It is a relatively simple concept, but it is very difficult to achieve. Conceptually, the objective of entity resolution is to recognize a specific entity and properly represent it uniquely, completely, and accurately from a data point of view. Entity resolution is important because it addresses the issue of multiple versions of the truth. It encompasses processes and techniques to identify and resolve the many occurrences of an entity across many sources.
What’s an entity? This book defines entity as an object, individual, unit, place, or any other item that should be unique within a certain domain. For example, in the Customer domain, either a business or an individual with a contract could be considered an entity. In the Product domain, a single unit or a collection of parts could be considered an entity. In the Health Care Provider domain, a hospital, a doctor, or a pharmacy could be considered an entity. Not all domains will have multiple entities within them. Take the Account domain as an example. It is very possible that some companies will have only the account entity in their account domain. Even with the Customer domain, a certain company might only do business with other companies, not individuals. In those cases, the terms entity and domain are practically equivalent and could be used interchangeably.
Domains and their related entities are typically quite obvious to determine because they are key to a company’s core business. They are intrinsically nontransactional but are almost always associated with a particular transaction. For example, a person finances a vehicle with specific contract terms on a particular date, or a patient is seen by a doctor at a certain hospital on a precise day and time. Person, vehicle, contract, patient, doctor, and hospital are the entities in these two examples.
Once an entity is determined, the process to find and resolve the many occurrences and many forms of that entity across the company needs to be handled. The following is a brief description of the steps behind the entity resolution process:
1. Recognize the sources of master data: Identify what sources have master data to gather.
2. Determine what attributes to gather for a given entity: Decide what master data attributes will be in the MDM hub.
3. Define entity key attributes (identity resolution): Determine what attributes will be used to uniquely identify an entity.
4. Conduct entity matching (record linkage): Link records and attributes associated to same entity.
5. Identify the system-of-record (SOR) for each attribute: Define the best source for a given attribute or set of attributes. A SOR is the authoritative data source for a given data element or piece of information.
6. Compile business and data quality rules: Assemble a set of rules that will be used to cleanse, standardize, and survive the best information.
7. Apply business and data quality rules: Execute the rules collected previously.
8. Assemble a golden record: Create a single version of the truth for an entity (the “golden record”).
Notice that these steps are very much data oriented. Since data varies extensively from one industry to another, from one company to another, or even from one source to another within a single company, it is easy to see how difficult it is to have a one-size-fits-all solution for entity resolution. Moreover, data differs from one domain to another, which makes the process of entity resolution unique for each domain. Obviously, the entity resolution process itself is reusable, but much within those steps is domain specific, such as data classification and organization, reference data availability, entity identity, business rules, data quality rules, data fitness for use, and data ownership.
Much about entity resolution is quite specific for each entity. Other functions, on the other hand, might have more overlapping activities. Data governance, for example, has many overlapping practices and procedures across multiple domains. Therefore, the effort to govern multiple domains does not increase at the same rate as the effort to solve for entity resolution for them.
Figure 1.5 illustrates that concept. Entity resolution is unique for each domain. Therefore, the effort to execute entity resolution is expected to grow almost linearly as more domains are added. Obviously, as companies mature, they get better at entity resolution, meaning that this task does get a bit easier with time, and effort starts to flatten out. Data governance evidently matures as well, and some of the flattening is due to that. However, most of the flattening comes from leveraging existing processes, procedures, and practices established with multiple LOBs from previously implemented domains.
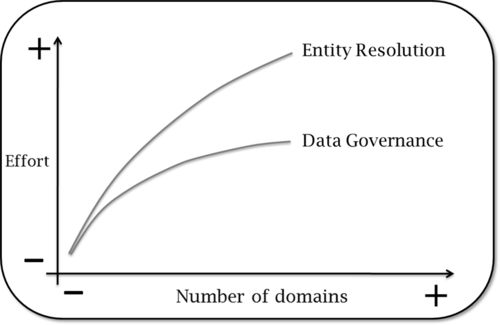
Keep Figure 1.5 in mind in relation to the other MDM functions that have been identified. Logically, the more a discipline is reused, the lesser the effort associated with it. As each component is explained, a sense regarding its reusability across multiple domains is also covered.
Entity resolution is described in more detail in Chapter 8.
Reference Data Management
Some experts use the terms reference data and master data interchangeably. In a way, all master data is reference data because it should meet the data quality standards expected from a reference. On the other hand, not all reference data is master data because, even though they are also likely to meet data quality standards, they are not necessarily directly tied to transactional processes. This book has a broader and simpler definition of reference data: It is any data that can be used to validate, classify, or categorize other data. In that regard, any data can be used as a reference, depending on its trustworthiness and context. Reference data can be simple lists, such as International Organization for Standardization (ISO) country codes or two-character U.S. standard postal code abbreviations for states. Reference data can be more complex as well, such as a vehicle catalog with make, model, year, trim, and options.
Database normalization is used fairly often to maintain reference data. It enables the creation, update, and deletion of a given data set in a single location. Therefore, it facilitates the governance and stewardship of that data. However, it is not uncommon for companies to replicate reference data as they do with master data. That means that you have challenges integrating and synchronizing reference data as well.
A vast majority of reference data is used as a lookup method to either validate an entered value or to serve as a list of possible options from where to select only the correct values. Database-driven applications normally have these lookup lists created in local tables to expedite response time. For example, you don’t want to have a web service call every time you need to create a drop-down list of valid country codes. Therefore, you should store that list as a database table that is directly accessible to that application. Since the same list might be needed in multiple applications, you end up creating tables with the same content in multiple databases. Obviously, a list of ISO country codes is relatively static. Consequently, updating multiple database tables infrequently is not such a daunting task. On the other hand, other references are less static.
Let’s take a look at a vehicle catalog as another example. There is a total of close to 50 car makes, most of them with over 10 models for a given year. Per model and year, there is a multitude of trims, colors, engine type, number of doors, transmission, manufacturer’s suggested retail price (MSRP), fuel economy, and more. Considering the catalog for new cars is updated yearly with a considerable number of changes, and manufacturers release their new cars at different schedules, one can see how dynamic this list can be. If you create a catalog of both new and used cars, the number of updates is even larger. If a company has many applications using the vehicle catalog, it makes sense to centralize this information in a single place for easier maintenance. Of course, there is always the option to obtain the vehicle catalog information via a vendor service. But in case it is necessary to create local drop-down lists for quick selection, one must use caution on how to duplicate this information internally and keep it synchronized with a possible external source.
The two examples described here are extreme, and recognizing their level of challenge can be obvious. But there are many cases in between: reference data lists that are less static or less dynamic. Recognizing the difference between these types of lists will help with the decision on how to design and maintain them. A vast majority of reference data doesn’t have the same visibility and intrinsic value as master data, which makes companies even more careless about them than they normally are with master data in terms of duplication and consistency.
In addition to static versus dynamic characteristics of reference data, there is the internal versus external aspect of it. The quantity of external reference data varies widely not only per domain, but also per industry. From example, in the Customer/Vendor/Partner domain, there is quite a bit of reference data related to companies and individuals from D&B, Acxiom, and OneSource; there is U.S. Postal Service reference data through address verification services from Vertex, DataFlux, and Trillium. Other domains can get even more specific depending on the industry. The Product domain is a good example. In the automotive industry, which is used frequently in this book, vendors such as Chrome, Kelley Blue Book, and Black Book provide reference data and services for vehicle related information validation. With that said, subject area expertise and industry experience are valuable knowledge to have when either evaluating or selecting a vendor for reference data.
Create-Read-Update-Delete (CRUD) Management
It is necessary to understand the full lifecycle of an entity to plan for its MDM implementation and ongoing maintenance. Since the ways that data records are created and used vary widely depending on the domain, it is easy to see how this aspect can be very specific for each domain being implemented and how it can influence the actual design of each one.
For example, let’s say that all vendors for a given company are created only in the enterprise resource planning (ERP) system, since that’s where they are sourced for payment information. Let’s also suppose that all other sources do not update or delete any vendor data: they simply consume what’s in ERP via a service. If that is the case, a SOR for vendor data clearly exists, and there is no fragmented or inconsistent data as all nontransactional information related to vendor comes in real time from ERP. Do you really need MDM for vendors in this example? No—you can actually use ERP as your master hub for vendor data. Even though this example is possible, it’s not what happens a good deal of the time. Other sources may create vendors as well, or they may copy some of the vendor data from ERP into a local database, change it, and augment it with what’s needed locally.
These scenarios illustrate an important aspect that will be covered in this book. A multi-domain MDM program doesn’t imply a single hub for all domains. It also doesn’t imply same integration and synchronization techniques. The data life cycle of all master attributes associated to an entity is a big driver behind fundamental decisions regarding the MDM architecture and governance of a given domain. Data governance is also affected since the who, how, and when of the data life-cycle operations are of great interest to management.
In essence, the more sources create, update, and/or delete data, the more difficult it is to keep it synchronized. In other words, the more sources only read data, the easier it is, since there is a lesser need for synchronization. Due to its technical complexity, data synchronization is intrinsically high risk and consequently very expensive to maintain.
It is repeated throughout this book that MDM is both a business and an IT issue, and that it requires constant and effective collaboration. MDM is as much a technical solution as it is a business solution. Therefore, as much as CRUD is inherently technical because you have applications and data sources collecting and propagating data, there is a business aspect to it as well. Business process requirements have a great influence on what systems are used to maintain data. Maintaining business processes streamlined and minimizing the need for CRUD in many applications will certainly simplify MDM implementation and maintenance, and consequently will lower costs and risks.
A good deal of the time, business teams will define their processes according to what systems are primarily accessible to their users. Using the vendor example presented previously, let’s say that the services team needs to modify certain attributes related to vendors. Instead of providing access for their users to ERP, which is clearly the SOR for vendors, they add a requirement to allow changes for certain attributes to be possible in CRM. That may simplify their process, but it complicates the synchronization between ERP and CRM. Balancing technical and business feasibility is a constant, and tradeoffs always have to be considered.
CRUD management is explored further when applicable when other MDM functions are discussed in this book.
Data Security
In an ever-growing reality of cyberattacks, lawsuits, stiff competition, and marketing strategies, companies must protect their data. Data security is by no means an MDM issue alone. It is a vital data management competency, and more than ever, companies must face the challenge of safeguarding their information or they could go out of business overnight. Data access control, data encryption, and data masking are just some of the subjects associated with information security.
Data security practices are quite generic and independent of domains. Companies decide what piece of information should be protected based on requirements related to privacy and confidentiality rules, government regulations, proprietary concerns, strategic directions, and other aspects. Those are not a direct consequence of an MDM implementation. What MDM brings to the picture is an increase in data sharing and data exposure across systems. Of course, the higher the data exposure, the higher the security risk.
When IT systems are operating in silos without MDM, most of the data security activities are actually simpler due to the following points:
• Access control is implemented at that particular system level. Most robust IT applications provide solid and granular capabilities to control user access, which facilitates data security management. Granted, without MDM, a single piece of information might be duplicated across many sources, which requires protecting the duplicated information in multiple places.
• The number of user groups is smaller on a system basis. Obviously, each IT system has a smaller number of users than the overall combined users of all systems.
• Data usage is more specific because each system is more specialized. Data fragmentation works in favor of security, as systems only carry data that they need.
The moment data is shared across systems, either physically or virtually, the concern increases because data now must be protected as it is transported as well as where it resides. Furthermore, as data is consolidated, more complete records are shared among more systems, which potentially increase the need to protect data in a location not in scope previously.
As it will be discussed later in this book, it is necessary during entity resolution to define what values will be used to link records from multiple sources. Care must be taken when using values that are subject to high security regulations. If those values need to be encrypted or masked, consider the impact of using them as keys to your entity.
Finally, a lot of data quality measurements and data stewardship activities might require direct database access to query raw data in bulk, which can be seen as a big security risk by many IT organizations. Consider those implications and analyze in advance how this can affect your overall multi-domain MDM and data governance design, implementation, and ongoing maintenance.
Data Architecture
IT applications are regularly replaced as they become obsolete, and data is migrated into new applications with different physical structures. An MDM data model will likely have to survive these regular application upgrades and their accompanying schemes. Very likely, MDM will have the responsibility to define the standard enterprise data model for a set of master data attributes. As such, cross-dependencies will arise, and systems that could possibly be replaced independently before now have to conform to the multi-domain MDM model as well. This increases the need for a well-designed multi-domain MDM data model to support a scalable, robust, and consequently successful program.
Furthermore, this enterprise data model will likely affect internal and even external interfaces. Carefully designing and validating the model so that it both meets current needs and is flexible enough to support future needs are not easy tasks and should not be taken lightly. A well-managed data architecture discipline needs to be in place to ensure that rigorous practices are being followed.
Companies don't carry out important IT projects without a system architect. Similarly, multi-domain MDM programs should not be performed without a data architect. A system architect is also important for MDM, as it does have many integration challenges. Those two roles need to work in tandem to assure all facets are covered.
Conclusion
Planning an enterprisewide, multi-domain MDM program offers many challenges. The right strategy and approach ultimately dictate that the proper foundation is set to fully, repeatedly, and successfully implement MDM strategies and objectives across the enterprise. This foundation is key to delivering trusted data in a timely manner to help the business gain a competitive advantage in an ever-growing, aggressive marketplace.
Data is a corporate asset. Master data, being key to business operations, require proper management. MDM is not exclusively a technology issue, but it is also a business capability. The scope of MDM is quite large as a consequence of an integrated set of components, functions, and services required for creating, maintaining, and governing critical shared data.
In a multi-domain MDM, it is important to balance when to leverage common approaches, components, functions, and services across data domains, while recognizing and supporting flexibility where unique requirements, priorities, and deliverables exist within each domain. Still, suitable business and IT collaboration lies at the core of successful implementation.