
Data Integration
Abstract
This chapter covers the discipline and practice of data integration in a multi-domain model. It discusses the need to establish consistent techniques for data profiling, quality assessment, data validation, and standards when integrating data into a Master Data Management (MDM) environment. In addition, the text delves into the importance of appropriately engaging data governance teams and data stakeholder/consuming groups to help fully evaluate the requirements and impacts associated with data integration projects.
This chapter covers the discipline and practice of data integration in a multi-domain model. It discusses the need to establish consistent techniques for data profiling, quality assessment, data validation, and standards when integrating data into a Master Data Management (MDM) environment. It also covers the need to appropriately engage data governance teams and data stakeholder/consuming groups to help fully evaluate requirements and impacts associated with data integration projects. Data integration can be a very complex and time-consuming process. It can have multiple components depending on the solution implemented. For example, it might involve a one-time data migration and ongoing synchronization across multiple sources, or it might involve regular data extractions via batch or real-time interfaces, or it could be virtual data integration with ongoing metadata rule management. To be successful, data integration must be approached methodically and engage business, information technology (IT), and data governance.
Why Is Data Integration Necessary?
Multi-domain MDM solutions address an issue that most companies have: silos of master data throughout the enterprise. To resolve that problem, it is necessary to look at the data as a whole to identify duplicates, resolve inconsistencies and fragmentations, create relationships, build intelligence, control access, and consequently minimize maintenance costs and maximize governance and stewardship effectiveness. Therefore, either physically or virtually integrating data becomes a needed activity in any MDM program. In addition, if master data continue to physically reside in multiple locations, they must be maintained in a synchronized manner to truly address the MDM fundamental goal of avoiding discrepant information.
In an MDM initiative, data integration is a critical component to enable the interpretation and identification of records across multiple sources that are associated with the same entity. This process, also known as entity resolution, involves identifying the many occurrences of master data across disparate systems; cleansing, standardizing, matching, and enriching them; and finally ending up with a single version, which is often called the golden record. This record is a unique set of master data elements related to a single instance of an entity. A single instance of an entity means one person, or one company, or one patient, or one account, or one product, and so on, in spite of how many data records exist for each of them. The golden record is, in essence, the sole version of the truth for a given entity occurrence. Entity resolution can be effectively performed only when data is properly integrated. Figure 8.1 depicts the entity resolution process. Each step is described in more detail later in this chapter. The actual data integration life cycle is also described later in this chapter, but understanding the steps behind entity resolution is important to eventually connect the why, what, how, who, and when of data integration.
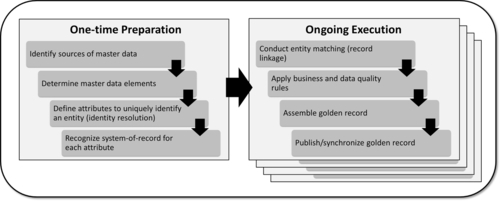
Typically, entity resolution has a one-time preparation to profile data, properly recognize sources and data elements, and define the identity attributes and system-of-record (SOR) for each data element. After preparation, ongoing execution takes place to regularly maintain linked data, apply business and data quality rules, and finally create a golden record and publish or synchronize it with consuming sources. Obviously, much of what happens as part of entity resolution also depends on the MDM style chosen. For example, with a registry style, record linkage happens virtually, while with a hybrid style, record linkage is physical and data movement is required. Therefore, it is important to understand the concepts explained here, but adjust them accordingly to your needs.
In a multi-domain environment, entity resolution is conceptually the same for the different domains, but implementation might vary quite a bit depending on requirements, data profiling analysis, sources of data, business and data quality rules, golden record survivorship rules, and publishing or synchronization of data. As such, make sure to track each domain independently, but capture the impact on the overall data model when integrating multiple domains at once.
Let’s cover each step of the entity resolution process in more detail next. Remember that entity resolution is just one part of data integration. Data integration will have additional requirements, as described later in this chapter.
Identify Sources of Master Data and Determine Master Data Elements
Chapter 2 covered defining and prioritizing master data. The first two steps related to entity resolution were explored in detail in that chapter since it is indeed very important to define and prioritize what domains and master attributes to manage. Any artifacts generated as a result of defining and prioritizing master data should be used as a starting point to the entity resolution process. Those artifacts shall be enriched with more detailed information as new findings and more data profiling lead to more relevant information.
After these two steps are completed, sources of master data and master attributes for each domain should be clearly stated. All data sources should be considered to keep any important master data from being left out. All master data elements in scope for MDM should be listed as well. Remember, as described previously in Chapter 2, not all master attributes will necessarily be in scope for the MDM hub. Recall that an MDM hub is primarily the repository for enterprise master data elements, which are generic and applicable to most lines of business (LOBs). LOB-specific information can remain distributed at each local source as applicable. To balance what is enterprise data element versus what is not is challenging. The more enterprise attributes there are, the more complete the golden record is. However, it will require more coordination, agreement, and overall governance across LOBs.
Define Attributes to Uniquely Identify an Entity (Identity Resolution)
Master elements were identified in the previous step of the process, but the question now is: What set of information from multiple sources, or even within a single source, belongs to the same entity? First, there is intersystem data duplication, where certain attributes are duplicated across sources. Second, there is intrasystem duplication, where attributes are duplicated within the same source. Third, information for the same entity is segmented across many sources, where one piece of information is in one source while another piece is in another source. Finally, there is inconsistency, with the same attribute in multiple sources, but carrying different content.
Before all those discrepancies can be resolved, it is necessary to find a way to link those entities within and across the many sources. Each system will have a uniquely generated key, but each of those keys doesn’t truly define an entity. They are simply assigned to make records unique in each system for data normalization purposes. Therefore, it is necessary to find a set of attributes that can be used to uniquely identify an entity so that proper record linkage can occur.
What data elements do you use to uniquely represent a given entity? That question has no definite answer, which complicates commercial off-the-shelf solutions. They are obviously different for each domain, but even in a given domain, they vary among industries, companies, LOBs, different regions in a global company, and within contexts in a single organization.
One of the critical goals of MDM is to enable a single version of the truth. Therefore, the definition of what attribute or attributes to use to uniquely identify an entity has to be consensual at the enterprise level. Creating this key, which usually is a combination of multiple attributes, is fundamental and will drive many future decisions. However, since each LOB might have its own definition, it becomes a challenge to come up with a single designation that meets everybody’s needs. This is certainly a business function because an entity worth mastering has a tremendous business value behind it. As discussed in Chapter 6, data governance can facilitate the process of reaching consensus among the multiple LOBs involved. There is a technical implication as well, since the chosen identity has to be practical to implement according to existing technologies.
Defining the identity of an entity is a lot more difficult than companies realize. The complication arises from trying to represent in computing terms a real-life individual, organization, object, place or thing, as well as their many contexts. Another challenge comes from having fragmented information. Normally, the key will be defined by no more than the lowest common denominator of the many attributes that are associated with that entity in its many different versions across the company.
For instance, in a health services company such as a hospital group, a Patient entity might have the following attributes in the Finance department (just a potential subset is shown in these examples):
• First Name, Last Name, Social Security Number (SSN), Data Of Birth (DOB), Address, Payment History, Health Plan Insurer, and Health Plan ID.
However, in the Care Management department, the attributes available might be the following:
• First Name, Last Name, DOB, Address, Primary Physician, Physician Type, and Treatment History.
The italic attributes in these examples are the lowest common denominator. It makes sense that the key would come from one of those elements. If an attribute that doesn’t exist in one of the systems (such as SSN in this example) is used to create a unique identity, it becomes difficult to establish the relationship between the entities in the two systems. It is obviously all right if something other than the lowest common denominator is used, though. Concluding the example, the following attributes could be used as keys:
• First Name, Last Name, and DOB
Those attributes are likely sufficient to uniquely identify a patient. But let’s take a look at the consequences surrounding this decision:
• Nicknames: For example, is Bob Smith born on 03/15/1962 the same patient as Robert Smith born on 03/15/1962?
• Name changes: For example, Mary Johnson marries, and changes her name to Mary Williams.
• Duplicate information: What if you have the same SSN associated with multiple patients with different First Name, Last Name, and DOB combinations? Is it a bad data entry, fraud, or an honest mistake by the patient?
• Different information: What if the address associated with that patient in Finance is different from the address associated with that same patient in Services? Which system is the SOR for this information?
In this example, there are one domain, two systems, and eight total attributes, and there are at least four critical questions to answer. Imagine what happens when the number of domains, systems, attributes, and business rules and processes is much larger. Complexity will certainly increase in such a scenario.
An obvious side effect of going through this exercise is controversy. Each LOB will argue that its data is better and its business rules are more important to dictate the identity of an entity. Again, data governance becomes a critical function to help facilitate the process.
Using the automotive finance industry and the vehicle domain as another example, services may maintain that a vehicle can be defined simply by its make, model, and year. But originations may determine that trim is also needed, since pricing must be done at the trim level. Another possibility is the actual key will differ depending on the stage of the process. The annual percentage rate (APR) for financing a vehicle may depend on make, model, year, and trim. However, once a vehicle is financed, a vehicle identification number (VIN) becomes available, and at that point, the VIN could become the only key needed since all other attributes can be derived from it. The actual MDM of vehicle data could be a combination of pre- and post-financing. During pre-financing, vehicle master data would be a VIN-independent catalog based on the make/model/year/trim, while during post-financing, the vehicle master data would be VIN-based and associated with account information.
Recognize SOR for Each Master Data Element
At this point, all sources of master data should have been identified. Master attributes in those sources should have been profiled and properly classified as being in or out of scope, which means whether or not to include them as part of that entity’s golden record. The next question is: What happens when the same attribute exists in multiple sources? Which one should be used? In essence, it is necessary to identify the SOR for each data element. The SOR is the authoritative data source for a given data element. Obviously, if an attribute exists in only one source, there is no dispute. On the other hand, if it exists in more than once place, that can cause controversy.
This step clearly highlights the need and consequential benefit of a data governance program. Data governance becomes critical to facilitate the resolution of the many disputes that are sure to arise when deciding which source is best for a given data element. Each LOB will say that its data is better and will want its information to take precedence. Having a mediator with overall interest at the enterprise level is vital to resolve any disputes.
The data governance Project Management Office (PMO) should lead the exercise, which culminates in a final decision on the authoritative source for each data element or piece of information. Evidently, this process of determining what data should be the trustworthy source starts by understanding the business purpose of the data, and the procedures of the LOB. Understanding the create-read-update-delete (CRUD) management steps for each data element within an LOB’s associated business processes might give a good indication about what source has the latest information and likely would be the best candidate for SOR. For example, the enterprise resource planning (ERP) system might be the only official system where vendor information should be updated, while other sources are simply consumers of that information. However, companies have a tendency to create exceptions that are never formally communicated and eventually become the norm. Let’s say that vendor information that flows from ERP to customer relationship management (CRM) might end up being updated in CRM without a properly captured business process. In this case, it is possible that CRM has the best information.
With that said, the final decision should also take into account in-depth data analysis. It cannot be stressed enough how important it is to conduct an exhaustive and systematic data profiling. Data profiling will be covered in more detail later in this chapter, as part of a discussion of the data integration life cycle. Nonetheless, it is important to note a few things about this topic at this point.
Not all data profiles are created equal. When defining in-scope attributes, it is necessary to understand the degree of completeness of a certain data element. Data completeness, which means the level of data that are missing or unusable, is indeed a fundamental characteristic and valuable for many purposes. But when identifying the SOR for a certain data element, completeness alone may not be sufficient. Other data quality dimensions, such as validity, consistency, accuracy, and timeliness, will play a bigger role. You want to use the source with the highest possible quality for each data element. Data quality dimensions are covered in detail in Chapter 9.
Data quality practices, therefore, play a fundamental role in entity resolution and MDM as an overall discipline. It is obvious that developing high-quality data suitable for use by the business should be the ultimate strategic goal for an enterprise. As a component of entity resolution, data quality must be applied tactically, both to understand the fitness for use of the existing data and to make it fit. What does that mean in this particular step? All data elements across the many sources must be evaluated fully from a quality standpoint to identify their degree of eligibility as an authoritative source. It is not sufficient to attend to each LOB, its processes, and its reasons why its data are vital to the company. Of course, there is some truth to this, but the problem is, a lot of times, the personnel in a company don’t know what they don’t know. Having real metrics backing up their statements is required.
Reference data sources become an effective and essential resource as well. Sometimes it is difficult to assess certain data-quality dimensions without using some sort of comparative method. For example, multiple data sources might have address information, and the addresses in all sources might be fairly complete, meaning that they are mostly populated. But are they valid? External references can be used to validate addresses, which can assist with deciding about what source is best.
Consistency of data across multiple sources is a great metric. First, if all sources agree on a particular related data set, this indicates that the data is up to date from an enterprise point of view. Second, if they all agree, there is no one source that is better than the other for that single piece of data. However, the fact that the information is consistent does not mean that it is accurate. It could be that it was at some point, but now it is outdated. For example, a partner may have been acquired by another company, and information about that has not been captured yet in any of the company’s systems. This situation is clearly a data-quality issue, but it is irrelevant for now since the current goal is simply to determine the best source. If they are all the same, there is no dispute. Thus, there is value in looking for consistency across multiple sources to assist in SOR identification. Consistency analysis can also establish that the formalized CRUD process is being followed.
Another important aspect when defining a SOR is to correctly group related data elements together and associate them with the same source to avoid a “Frankenstein effect.” For example, when working with a location, you shouldn’t use the Street Number and Name from one source, combined with the City and State from another source, even if they are all associated with the same patient entity. All components of an address should be from the same source to avoid a badly composed set of information. That’s why certain data elements cannot be evaluated independently. To cite another example, let’s say that a company tracks financial account–related attributes as a group, such as a set of flags related to government-required customer privacy preferences. It is possible that there is interdependency within multiple flags, depending on how they were implemented in some of the sources. If that is the case, all the flags should come from the same source. If there is a question about the quality of those flags, the issue should be addressed apart from defining the SOR.
Finally, data from a preestablished SOR will not necessarily be used in every single instance. For example, an email address might be present in multiple sources, and a certain source will have priority over another and consequently designated as the SOR. But if an email address is missing in the SOR, then the email address from another source should be used. Furthermore, besides content, it is also important to evaluate the meaning of source attributes. Some attributes might have generic names but specialized meanings. For example, an address field could contain billing address, home address, email address, and so on.
Typically, one data source is established as the SOR, and most of the time, the data from that source will trump other systems. But, in certain instances where information is not available in that location, or if data quality is better in another source, the SOR can be overridden. A priority should be established, with clear business rules when one data source should trump another for each data element. Again, data governance plays a key role in leading the effort to collect those business rules.
To summarize, this section covered the following points:
• Data governance is essential to ensure that the proper SOR is chosen with the best interest of the enterprise in mind. A suitable data governance body is the best-equipped organization to mediate disputes that are sure to arise.
• Documenting CRUD for each data element per source can assist with the determination about what sources are eligible for the SOR role. Remember to confirm the expectations with proper data analysis.
• Data quality management practices are critical to establish the truth about the quality of the existing data.
• Data profiling is the foundation of this whole process. Always keep in mind the dimensions of data quality, such as completeness, conformity, consistency, accuracy, uniqueness, integrity, and timeliness. Understanding those aspects of the data is a must.
• Reference data usage can be extremely efficient. If a data set can be properly certified against a trusted source, the level of confidence rises significantly.
• Consistency of information across multiple sources is valuable information as well. It can be used to validate the expected business process were implemented and followed accordingly.
• Group data elements appropriately. Do not combine related data elements from mixed sources. Do not mix and match separate fields from multiple sources.
• Establish one SOR for every data element or related data element. Clearly define any rules that should be followed to override the information from the SOR with the information from another source, if applicable. For example, a simple rule could be: CRM is the SOR for Customer Email data, but if email doesn’t exist in CRM for a given customer, use the information collected from recently collected marketing materials instead if it is reliable.
Conduct Entity Matching (Record Linkage)
Once the identity of an entity is properly defined, it is possible to move on to the next step, which is to use that identity to link the multiple records associated with the same entity. Remember that those records could be in multiple sources due to intersystem duplication, or within the same source due to intrasystem duplication. Record linkage is the realization of identity resolution where multiple records with the same identity are considered to belong to the same entity.
This step will reveal the level of fragmentation and inconsistency of information across sources. Once two or more records associated with the same entity are compared side by side, it will reveal what attributes exist in one source and not the other, as well as, if the attribute does exist in multiple sources, how they agree with each other. Record linkage happens either virtually or physically, depending on the MDM style chosen.
In a registry-style MDM, attributes from multiple sources are linked to each other by their identities, which are kept in the hub along with a reference back to the original system. In a transaction-style MDM, the hub becomes the new SOR. Record linkage is a one-time operation to centralize and consolidate all records into the hub. After that, records are added and modified directly into the hub and published to other sources. In a hybrid-style MDM, record linkage is applied to data that are initially migrated into the hub, and afterward, as an ongoing process, when new data are added to sources and flowed into the hub.
Apply Business and Data-Quality Rules
Data collected from multiple sources will have very different levels of quality. However, master data records will need to meet certain standards to even be considered contributors to the final golden record. Business and data-quality rule requirements should have been captured previously and applied properly to records clustered together through record linkage.
Different data domains will have distinct business rules and data-quality standards. Subject area experts from multiple organizations will need to be consulted when compiling a list of all those rules and standards. Once more, data governance is a critical element of facilitating the process and ensuring that formal steps are taken and proper approvals are issued.
Another big consideration for this step is how data stewardship will operate. Depending on the MDM style chosen, data stewardship will have certain constraints. For example, on a registry-style MDM, business and data-quality rules have to be completely automated and are applied to virtually connected data. This limits the options for data steward teams, as they cannot manually intervene during record linkage. Analysis will occur after the fact, and corrections will be done at the source or the automated logic will have to be adjusted. On a hybrid-style MDM, processes can be added to allow data stewards to manually intervene and correct data before they are added to the MDM hub and propagated to other sources.
Reference data sources should be used whenever possible to help improve the quality of the existing data. Reference data are very specific to each domain. Specialized vendors in different industries will provide a large variety of offers, along with multiple ways to technologically integrate their solutions.
Assembling a Golden Record (Survivorship)
Master data from multiple sources has been integrated, records belonging to the same entity have been matched up, and raw data from original sources have been cleansed, standardized, and enriched. Now it is time to decide which data element from each of those contributors is the best suited to survive in the golden record.
It is obviously a big challenge to automate the decision on what data source to use on each situation. We have already discussed the rules to implement when prioritizing what source to use when there is a dispute. The automation of those rules is critical, as the MDM hub will likely need to meet strict requirements related to the delivery of timely information.
Figure 8.2 depicts a potential decision-making flowchart to resolve what data to use to assemble the golden record. That logic needs to be followed for each dependent set of data attributes. Most of the time, a data element is a single attribute, but sometimes it is a set of attributes. For example, an address is a combination of several attributes: street number, street name, city, county, state, ZIP code, and country. Remember that when putting together an attribute, do not survive pieces from different sources. When surviving the address, for example, take all attributes from the same source: do not mix sources.
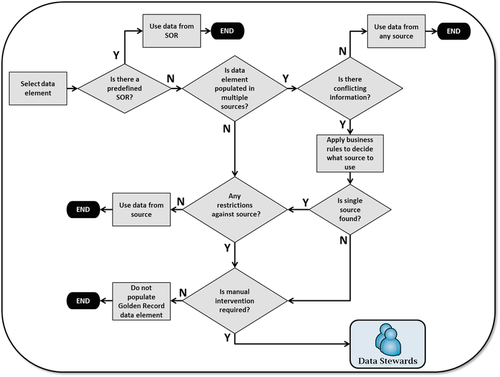
Not every domain, MDM style, or organization will allow manual intervention by data stewards during the assembly of a golden record. Most of the time, full automation is required. In those cases, a safety-net type of logic is created to decide what source or data content to use when all other conditions fail. Later, data-quality metrics can be added to check whether certain automated decisions are erroneous and need correction.
In some cases, due to the enormous volume of information, manual intervention by data stewards alone might not be effective. The concept of crowdsourcing for data stewardship can be a viable approach. Crowdsourcing is the process of obtaining content from a large group of people, each person working on a specific area but adding a small portion to the greater result. For example, salespeople could update and review the addresses of their specific customers once they are changed.
Publish and Synchronize the Golden Record
Once the golden record is created, maintained, and available in the MDM hub, it can be published or synchronized to other sources as applicable. Data is either published or synchronized depending on the MDM style. In a registry-style MDM, there is one single virtual version of master data; therefore, publication is only needed and consumed by downstream systems. In a transactional-style MDM, there are no multiple copies either: a single physical version exists, and only propagation is sufficient. In a hybrid-style MDM, some attributes are copied; consequently, synchronization is necessary.
Data Integration Life Cycle
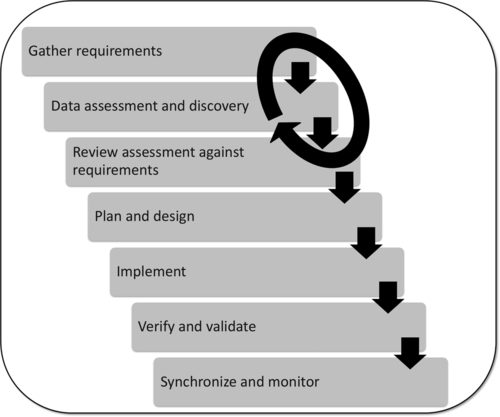
Entity resolution is just one part of data integration. Other requirements related to data integration exist in addition to what is needed for entity resolution. There are many flavors of data integration and synchronization, which depend on the multi-domain MDM style and architecture (as described in Chapter 3). However, the overall process and steps to evaluate and implement data integration in a multi-domain MDM program can be generalized. Figure 8.3 depicts the data integration life cycle, and each step is described in detail in the following sections.
Gather Requirements
The requirements for data integration are just one part of the overall requirements of a multi-domain MDM program. Nonetheless, they are critical to establish a solid technical foundation to proper support business functions, data stewardship, and data governance. All standard practices required for sound requirement analysis are obviously applicable here.
Among other things, requirement analysis involves identifying, understanding, and documenting business needs. Clearly, a multi-domain MDM program should also have a strong business focus. However, remember that there are requirements to govern and maintain the integrated information, especially when seeking high data-quality standards. Those requirements will not necessarily be spelled out by the business. Business teams automatically expect high-quality information delivered in a timely manner, but they don’t necessarily understand what it takes to achieve that. That is when solid data governance and stewardship plans are critical, and the requirements to meet those plans should be captured as early as possible because they can have a tremendous impact on the implementation of the final solution.
How is data integration in the context of MDM different from other data integration projects? Let’s dwell on this question for a moment. Companies are constantly undergoing data integration projects. A typical one is data migration (i.e., permanently moving data from one system into another when replacing obsolete applications). Another is the ongoing extraction of data from upstream systems into downstream systems, such as in a data warehouse project. Others include one-time or regular data transfers between systems, either in batch or real-time interfaces. All those integration efforts can encounter a range of challenges related to different semantics across many heterogeneous sources, which can conflict by structure, context, value, or any combination.
Different MDM styles will need different levels of data integration. Depending on the integration type selected, these requirements will include the elements that other data integration projects need; however, a multi-domain MDM program will have additional requirements as well. The reason for that is that a well-implemented MDM needs the foundation to proper govern, monitor, and act upon the data. For example, a company implementing a hybrid-style MDM will certainly need to perform a one-time data migration to initially populate the MDM hub. Furthermore, the hub will need to remain synchronized with other sources of data, but that synchronization might be affected by how data stewardship activities are structured and data quality is applied. This could change if one-way or two-way synchronization is necessary, depending on where the data is corrected.
Another consideration is if the data integration project is part of an MDM implementation, or if a particular data integration project is being leveraged to apply MDM to a new domain. We have already discussed the fact that a company may implement domains in phases. Let’s say, for example, that a company has implemented MDM to the customer domain and went through data integration specifically for that purpose. Later, the same company is going through a data migration effort to upgrade an obsolete application, and it decides to implement MDM to additional domains at the same time. That is normal, but it is important to capture the integration requirements for the MDM piece along with the other requirements that are already in place for the data conversion.
Generally, businesses will be interested mostly in functional requirements, but nonfunctional requirements play an important role in data quality and governance. Data integrity, security, availability, and interoperability are just a few of the nonfunctional requirements that are sure to strongly influence certain design decisions. In the end, remember to consider data governance, data stewardship, and data-quality requirements as well as any other standard requirements.
A multi-domain MDM hub can be implemented either as real-time or batch interfaces. This may even vary by domain within a single hub. Certain domains might have different data timeliness requirements than others. For example, consider an MDM hub hosting customer, product, and vendor data. This hub might not be the SOR for all three domains. Furthermore, the volume and frequency of data might vary for each domain. Let’s assume that the hub is the SOR for customer and vendor data, but not the product data, and that there is a high volume and frequency of customer and product data changes, but less so about vendors. Therefore, one company might decide to implement data change in real time for the customer domain because it is high-volume and the hub is the SOR for it, decide to implement product in batches because the MDM hub is not the SOR for it, and implement the vendor domain in batches due to the low volume and low frequency of changes. All these considerations are important when writing the multi-domain MDM integration requirements.
Discover and Assess Data
In any data project, requirements alone are not sufficient. Data must be analyzed to confirm or challenge any existing expectations. Much of the time, a business has a completely distorted view about the quality of the data or it completely ignores certain characteristics of the data. Therefore, data profiling is essential to provide further evidence that the requirements are solid and can indeed be met. Data profiling is important to understand how to model the MDM domains and their entities and relationships.
Figure 8.4 depicts an illustration in quadrants representing the idea that both business understanding and data profiling are necessary to minimize any risk of incorrect assumptions about the data’s fitness for use or about how the data serve the business.
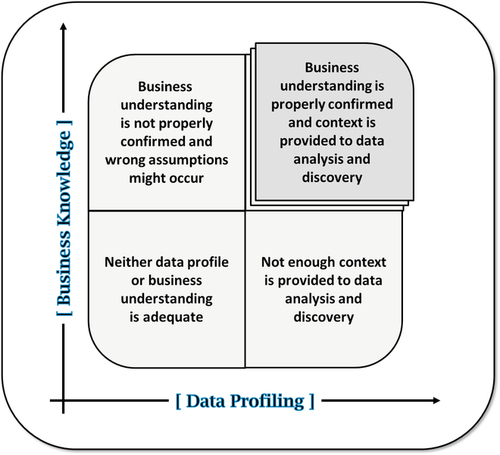
In a multi-domain MDM program, data profiling is required at multiple stages of the process. It is needed to evaluate and prioritize data domains. Business teams may have a perceived idea of what data domains are more important to apply MDM based on the value those domains bring to them, but that opinion may not necessarily be based on the data itself. For example, an auto-finance company is highly dependent on dealers. As such, the business might prioritize the Dealer domain very highly. However, an extensive data-profiling analysis might show that the existing systems do a great job maintaining dealer information through robust CRUD management, practically no data redundancy, very little inconsistency, and most important, proper fitness for use. Therefore, MDM for the Dealer domain is less important.
Once domains are properly evaluated and prioritized, data profiling is critical to determine what master data elements for given domains should be considered worth managing. Structure, content, and relationships, along with completeness, uniqueness, consistency, validity, and accuracy of information, will influence the assessment. Data profiling at this stage is also critical to confirm, dispute, and catalog enterprise metadata information. This becomes the foundation to create a sound data model to store multi-domain master data.
When data needs to be migrated or integrated into a multi-domain MDM hub, data profiling is again critical to complement this information with the current expected quality of information and business usage suitability. The MDM hub is only as good as the data in it. “Garbage in, garbage out” is a well-known saying, and the truth of it is only amplified with MDM. An enterprise multi-domain MDM hub is built to function as the ultimate reference for delivering master data to the entire company. If low-quality data from original sources is brought into the hub, the compound effect will have disastrous consequences. Previously, independent organizations had to deal only with their local data issues and had preestablished workarounds to deal with them. The moment that an MDM hub might distribute issues from one organization to another, the worse the situation will get. It is important to use data profiling to understand those issues and correct them before migrating or copying them into a centralized hub.
As part of the entity resolution process, data profiling is essential to defining what data elements to use to uniquely identify an entity, what operations are required to transform data into a minimum required standard of quality, how to cluster similar records together, and finally, how to assemble a golden record. Without data profiling, those activities could completely miss the mark by performing operations based on incorrect assumptions or incorrect enterprise metadata.
The bottom line is that data profiling is multifaceted and a lot more complex than people realize. It is easy to understand the categories and metrics of data profiling, but there are several challenges, such as the following:
• Understanding when to apply a specific technique
• Interpreting results correctly and properly adjusting subsequent steps
• Using existing metadata, if available, but utilizing profiling results to confirm or challenge current definitions
• Using profiling results to help correctly derive metadata if it does not already exist
Figure 8.5 illustrates the principle that data profiling is not a two-dimensional discipline. It is not only about applying a technique and interpreting the metrics and results. It is also about understanding where you are in a third dimension: enterprise metadata or the business’s expected meaning. Notice the word expected. Many times, what is documented or assumed is not really what is expected. Consequently, data-profiling techniques and the resulting metrics need to be revised according to actual metadata exposed by real usage of the data, not what is listed on paper. Think of it as adjusting data profiling in a three-dimensional plane.
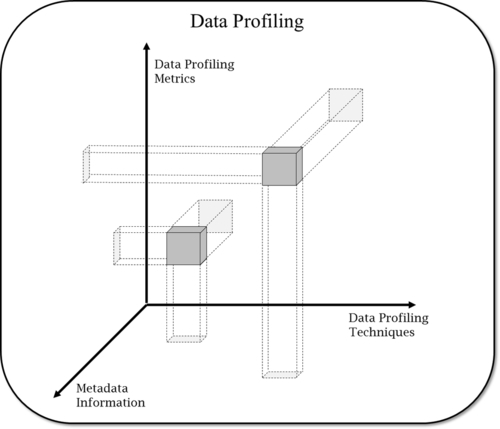
Examples of data profiling techniques include frequency distribution, pattern analysis, domain analysis, type identification, interdependency verification, redundancy analysis, primary and foreign key determination, and many other statistical measurements. A multi-domain MDM vendor solution might not necessarily include a robust data profiling functionality. It is possible to use database languages, reporting tools, or both to profile information, but specialized tools offer a greater level of sophistication and are highly recommended.
Review Assessment Against Requirements
The nature of data profiling itself is iterative. Moreover, data profiling results must be used to assess if the provided data integration requirements can be properly supported and met. Granted, requirements are mostly listed to request functionalities to attend business needs, which can be quite strict. However, using the results of the data analysis to dissect the requirements is invaluable.
As mentioned previously, business teams may have a distorted view about the data, and this misunderstanding can lead to misguided requirements. There is nothing like real data to shed light on business problems, and it is not uncommon for requirements to change completely once the supported metrics are presented. In addition, a clear understanding of the data can help you institute a much better approach to solving any issues.
Requirement gathering, data assessment, and ensuing review should happen as many times as necessary until there is high confidence that the requirements are based on a solid understanding of current state. This cyclical process is represented by the circular arrow around the first three steps shown in Figure 8.3.
Plan and Design
Once the requirements are completely validated, it is possible to move to the planning and design phase. Notice that the data profiling analysis described previously is not only useful to validate requirements, it is also extremely useful when designing the final solution.
When planning the integration of multiple domains, it is important to recognize the priority and complexity of each one of them. Certain domains will have a much higher volume of information than others. Volume is an important factor to consider because it will have a direct effect on the effort to integrate data. The higher the volume, the higher the probability that more duplication and inconsistencies exist. Therefore, integrating high-volume data into an MDM hub will be more time-consuming and present greater risk of improper entity resolution.
Data profiling results will give a good indication of the volume of information and level of data quality. Use those results to estimate how much of the integration effort can be automated and how much will require manual intervention. With data projects in general, chances are that a certain amount of data correction can be automated, while a portion of it will have to be manually fixed. It is important to categorize your data and find ways to fix each of the categories. Focus on the categories with the highest volume of data and look for automated alternatives for them.
Data stewards must be involved in the process of evaluating data profiling and data quality results and also participate in the planning. One important element is to determine how data will be improved to satisfy initial data integration. Another is to plan data quality maintenance on a regular basis during ongoing integration and synchronization. Data stewards are primarily responsible for guaranteeing that data are fit for use by the business teams. Therefore, they need to be involved in the decision process. Understanding the quality of the existing data is essential to anticipating future issues and deciding the best process to either prevent or correct them.
Obviously, data governance also needs to participate in overseeing the planning process and evaluating whether the proposed design meets existing policies, procedures, and standards. The need for additional policies, procedures, and standards will arise, depending on the level of maturity of an existing data governance program, if any. Therefore, these elements must be captured and documented properly. Data governance should also ensure that all teams are properly represented to review and approve the final design.
Depending on its style, a multi-domain MDM solution will have varying levels of impact on existing processes. More intrusive MDM styles, such as transaction and hybrid, can certainly affect existing processes deeply. More intrusive MDM styles are sure to have high demands of data integration. As such, to properly plan for highly invasive data integration projects, it is important to understand current and future business processes and communicate all changes properly.
A solid change management program should already exist as part of the overall multi-domain MDM implementation. Details related to the data integration planning and design must be added and properly communicated via channels established by the change management team. The impact of the integration on the existing business must be communicated in a timely and effective manner. Do not underestimate the need to communicate changes to both the technical and business teams for two primary purposes: to validate what is being done and to prepare for any changes caused by the actions in question.
Implement
As discussed previously, it is very common to implement a multi-domain MDM in phases. Most of the time, the phased approach is related to how data is integrated. Multiple sources are gradually integrated, multiple domains are gradually integrated, or both. There is no single recipe concerning what order or how domains and sources should be integrated. Choosing what domains and sources to integrate first are directly related to their business value, volume, volatility, reusability, and complexity.
Business value is typically the biggest driving factor. In essence, if there is enough business interest, the costs and risks associated with addressing high volume and high complexity are well justified. Reusability can be an additional factor to consider when prioritizing domains or sources to integrate. For example, if a certain domain has already been successfully integrated into an MDM hub, another domain might be easier to add if the two domains are similar enough in terms of requirements and integration logic. This reusability aspect can be used to favor the MDM of a certain domain over another. In the end, however, the key criterion is business value.
Obviously, technical aspects are highly relevant because of the cost-benefit equation. Even if there is a high business value in integrating certain sources and domains, costs and risks can be limiting factors when calculating return on investment (ROI). Integrating data will have technical challenges, as well as compliance and regulation risks. Data integration technology is more advanced for certain domains than others. The key is mostly the technology to facilitate automation. Entity resolution, which is a vital aspect of data integration, is more advanced in some subject areas than others. For example, the Customer domain is generally easier to master than the Product domain because the technology for recognizing matching entities is more mature with regard to people and company names. Therefore, mastering other domains that involve people or company names will be easier to master than domains with other taxonomies.
Except for the registry style, other MDM solutions will require data migration of master data from the original sources to the MDM hub. This migration can be done in phases, with data from distinct sources gradually introduced into the MDM hub. The main point is to identify the impact to business operations. Certain business processes may suffer if only certain data sources are migrated, while other business processes will be more affected as the number of combined sources increases. This outcome is a consequence of how much the MDM implementation will affect existing systems and accompanying processes. Needless to say, the more intrusive the MDM style and the more sources are involved, the greater the impact is.
The actual implementation of data integration hinges on proper planning and execution. But it is not only about the planning and execution of data integration; it is about planning and executing the other associated parts: data governance, data stewardship, and change management. Data governance is important to oversee the process, engage process business teams as needed, and ensure compliance to policies, procedures, and standards. Data stewards are critical because as data experts, they need to ensure that data are migrated according to business expectations, meet high quality standards, and can be properly maintained for the future. Change management is essential to communicating how data integration will affect the current state and setting proper expectations. Since projects rarely go completely as planned, it is important to keep stakeholders informed about any deviations from the original plans.
Verify and Validate
Like any other software implementation, newly developed logic must be properly tested. The challenge with data projects is to make sure to compile a comprehensive list of data scenarios, evaluate data integrity throughout their life cycles, and make maintenance as easy as possible. Usually, software testing focuses on validating functional requirements, and not necessarily other data management aspects. Granted, functional testing will require looking at many data scenarios, which are sure to test many of the aspects pertaining to data. But how the integrity of the information will be validated, how data will stay consistent with time, and how data quality is maintained are often left untested. This particular issue can cause degradation over time.
To address these issues, develop a data-driven approach. It was explained earlier in this chapter how a solid data model is fundamental to creating a scalable, high-quality, and easily maintained data system. Make sure to test those aspects of the integrated domains. This challenge increases as more domains are added. Data models become more complex when modeling relationships across multiple domains and when multiple business teams are using the master data. As data are integrated into the multi-domain MDM model, many aspects of such integration must be validated.
Verification and validation of data integration projects must be done from a technical point of view, as well as from the standpoint of business usage of data. As always, the question concerns data’s fitness for use. But data can be fit for use when they are initially migrated but become less so as time passes. If the model doesn’t preserve data integrity properly over time, or if error prevention is not a focus during data entry, data quality can easily decline and affect the data’s fitness for use. Unit, integration, and acceptance testing will not necessarily uncover those issues. Data architects, data modelers, and data stewards need to work together to test for those scenarios and methods for maintaining high-quality data.
Synchronize and Monitor
The need for data synchronization depends on the MDM style. If copies of master data are maintained at other sources as well as the MDM hub, they must be synchronized on a regular basis. Certain domains might require real-time synchronization, while others can be satisfied by batch updates. One key factor is which system is the SOR for master data in that particular domain. Remember that there are MDM styles where the MDM hub becomes the SOR for a given domain master data, while in other styles, the MDM hub is simply a system of reference.
When the MDM becomes the SOR for a particular domain, chances are that it will be required to have the most up-to-date information in real time. However, if the MDM is only a system of reference, keeping the MDM hub up to date in real time may not be required. That will depend on the systems that use the MDM hub as a reference and their underlying business processes. Therefore, updating the MDM hub with data from the actual SOR may be done every night in some situations.
Real-time interfaces are more complex than batch interfaces. Be sure to consider carefully the decision of whether they are really required, and base your deliberations on each specific domain. Obviously, a single MDM hub can be used for multiple domains. However, not all domains must follow the same synchronization scheme. Also, the MDM hub might be the SOR for one domain while serving only as a system of reference for another. Having multiple mechanisms to synchronize master data into the hub can be confusing and makes maintenance more difficult. On the other hand, requiring real-time synchronization of very low volume of data can be overkill. Make sure to balance the complexity. Having a single architecture to uniformly synchronize all domains might be desirable, but if that single architecture is real-time, two-way, and consequently complex, it might be too costly to use for low-volume, low-complex, and low-business-value domains.
In the end, despite the synchronization approach taken, the actual consistency of data across systems must be monitored and maintained. Even if a solid design is in place, certain implementations can lead to mismatches due to bugs or unforeseen circumstances. Automating a report to monitor eventual discrepancies can be a wise decision, depending on the criticality of the domain and its accuracy to business processes. Customer retention, competitive advantage, and regulatory compliance may be heavily dependent on timely, high-quality information.
Data stewards exercise a bigger role in this particular step. Ultimately, they will be responsible for keeping the data accurate and available. Prevention of data issues is the primary goal, but this may not always be possible. Therefore, establishing processes for data stewards to quickly intervene and remediate any data issues is sure to reap huge benefits. This can involve adopting a system to be used exclusively by data stewards to correct data following proper compliance, having data stewards use existing systems to update incorrect information, or a combination of both approaches. Understand whether what is offered by MDM vendors is sufficient to meet your needs. In general, MDM solutions will have a strong focus on data integration, but not necessarily the rigorous data-quality support that is necessary to detect and correct anomalies.
Entity Resolution Within the Data Integration Life Cycle
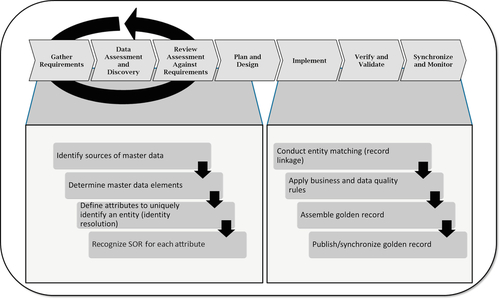
Data integration is concerned about more than entity resolution, but entity resolution is an important component. Figure 8.6 shows the entity resolution process executed within the data integration life cycle.
Conclusion
Data integration is clearly a complex exercise, with multiple details and business and technical challenges. In addition, it is not a one time-project. Certainly, the initial data integration effort will be either a one-time project or a phased approach, but synchronization and monitoring is part of an ongoing program, supported by business, IT, data governance, data stewardship, data quality, and metadata management. The data-driven nature of these types of projects requires rigorous disciplines of data management.
Notice how integrating data from multiple domains and sources will have more than just a technical impact. Business definitions previously contained within their own business functions are now spread and shared among multiple organizations due to its data-sharing nature. Data integration requires more collaboration but facilitates more formal processes to document who, where, when, and how data are created, used, modified, and deleted. Metadata management is the centerpiece to properly capturing, confirming, and disseminating data definitions, usage, and impact when changes occur. It is a fundamental practice to support correct decisions by business and technical teams, data governance, and data stewardship. Metadata should be captured throughout the data integration life cycle when fundamental decisions are taking place.
A successful data integration project requires a solid understanding of the many domains in scope, sources of master data, and quality of master data from those sources. Data profiling is a must in order to assess existing information, and data quality in general is required at many points to measure and correct data as needed during and after the initial data integration. High-quality data delivered on a timely manner is critical to business. In addition, a true measurement of the quality of the data is invaluable to support data governance and data stewardship in their strategic and tactical efforts.