
Chapter 11. Messaging
Application architectures designed around services need to build methods for communicating between these services. While REST and HTTP and JSON enable quick synchronous communication, messaging systems enable the creation of more robust asynchronous communication between services. This chapter looks at how messaging systems can be used in place of HTTP for writing data between services. It also goes over parts of the AMQP messaging standard and RabbitMQ, an open source implementation of AMQP.
What Is Messaging?
Messaging is how services communicate with each other. Traditional service-oriented architecture (SOA) approaches use HTTP as the message transport protocol and SOAP as the message format. SOAP is an XML standard for exchanging structured information between web services. When a service wants to communicate with another service, it creates a SOAP XML message and sends it over HTTP to the other web service.
Most Rails applications opt for the more modern approach of using RESTful HTTP APIs. With REST, the URLs indicate which resource is being accessed, while the message can be XML, JSON, or some other format. The example in Chapter 1, “Implementing and Consuming Your First Service,” uses a RESTful approach with JSON-formatted messages.
While communication between services often occurs in the form of HTTP-based methods, messaging in general isn’t limited to HTTP. In fact, Ruby has a built-in method of communicating between processes, which could be separate services, called Distributed Ruby (or DRb for short). Another messaging standard is the more recent BERT-RPC (http://bert-rpc.org) and its associated implementation Ernie (http://github.com/mojombo/ernie), which power GitHub. Other HTTP-based methods include XML-RPC and JSON-RPC.
Synchronous Versus Asynchronous Messaging
Messaging can occur in the form of synchronous or asynchronous communication. When talking about messaging systems in this book, synchronous messaging refers to the following scenario:
1. Client makes a request (sending a message).
2. Server receives the request.
3. Server performs whatever task the message is requesting, during which time both the client and server are blocked and waiting.
4. Server sends response back to the waiting client.
5. Client is free to continue processing.
Asynchronous messaging looks like this:
1. Client makes a request (sending a message).
2. Server receives the request.
3. Server queues the message to be processed by some other thread or process.
4. Server sends a response back to the waiting client.
5. Client is free to continue processing.
There are a few important things to note about these two different flows. First, in the synchronous model, the actual processing occurs so that a response can be sent back to the client that contains the result of that work. Second, during the synchronous processing, the client and server are tied up waiting for responses. Most servers can handle multiple clients simultaneously, but the client is waiting.
In the asynchronous model, the server doesn’t actually perform the work while the client waits. Instead, it tells someone else to process the message and instantly hands back a response to the client. The advantage is that the server can usually handle more messages per second, and the client is no longer tied up and waiting for the processing to occur. The disadvantage is that the client does not know the result of the processing. Thus, transactions are not possible in the asynchronous model of communication.
Synchronous and asynchronous can also refer to how clients or servers handle communication. Chapter 6, “Connecting to Services,” touches on this. With respect to messaging, synchronous and asynchronous refer to whether the message is processed while the client waits or whether it gets put onto a queue for processing while a response is sent back to the client.
Queues
Queues are the simple first-in, first-out (FIFO) data structure. Messages go into a queue and are pulled out of the queue in the order in which they were inserted. Using queues is the standard method for creating an asynchronous messaging system. When the messaging server gets a message, it places it on a queue for processing.
Message Formats
When building a messaging-based application, a message format must be selected. There are many different formats. SOAP was mentioned earlier as a format popular with Java-based SOA. Some APIs use XML with schemas defined by the programmer. DRb uses Ruby’s Marshal class to create its message format. BERT uses a message format pulled from the programming language Erlang.
The general goal of message formats is to serialize some object so that it can be deserialized and manipulated by the message processor. JSON offers a simple serialization standard that can be used across many languages. In addition to its ubiquity, its ease of use makes it ideal to work with. Further, the C-based Ruby libraries for working with JSON make it very fast to parse. For these reasons, this book uses JSON for all messages.
RabbitMQ and AMQP
RabbitMQ is an open source implementation of AMQP, short for Advanced Message Queuing Protocol. AMQP is an open standard for messaging middleware. There are multiple implementations of AMQP, but RabbitMQ is a mature and well-tested solution with regular improvements. The AMQP standard was developed at multiple financial firms that have very demanding messaging needs. It was designed from the ground up to be quick and flexible.
The following sections don’t cover the full AMQP spec but only the parts that are important for designing messaging-based services. The major concepts covered are queues, exchanges and bindings, and durability. A fuller description of AMQP can be found in the published spec at http://www.amqp.org/confluence/display/AMQP/AMQP+Specification.
Queues in RabbitMQ
Queues in RabbitMQ are very much like queues in other messaging systems. First, to create the queue, a call must be made from a client to the server. The call to create a queue is an idempotent operation, so it can be made many times. Once created, messages can be published to a queue, and workers can pull messages off the queue.
One area where AMQP diverges from normal server work queues is in how messages are pulled from the queue. The optimal mode of operation for reading messages from a queue is by creating a consumer. This equates to a process that reads messages from the queue. However, the process is different in AMQP in that the consumer calls out to the server and creates a subscription. Now, while the consumer is running, the server automatically pushes messages from the queue asynchronously to the process.
Exchanges and Bindings
Exchanges represent the layer of messaging that really starts to differentiate AMQP from more basic queuing systems. An exchange can be viewed as a kind of message router. Messages are published to the exchange, which forwards those messages to queues based on the exchange type and bindings. Further, each message has a routing key. This key is matched against the bindings. Queues can have multiple bindings to one or more exchanges.
Exchanges are a little different than a typical router. A router directs a packet through a system. An exchange copies messages to all queues that have bindings that match up.
With the basics out of the way, it’s time to go over the different types of exchanges. The three primary exchange types are the direct, fanout, and topic exchanges.
Direct Exchanges
The direct exchange routes messages based on a simple rule: Does the routing key of the message match exactly the routing key in the binding? Figure 11.1 shows an example of what that might look like.
Figure 11.1 A direct exchange sends messages to exact matches.
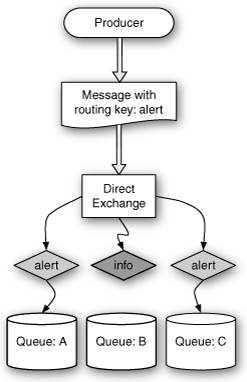
In Figure 11.1, a producer publishes a message to an exchange. Producer is the word in AMQP lingo that refers to the processes that publish messages to exchanges. The message published to the exchange has the routing key alert. The contents of the message are not important for the exchange or queue. Only the routing key and the exchange type matter.
A direct exchange looks at each queue bound to it and checks the routing key on the binding against the routing key of the message. In Figure 11.1, queues A and C are both bound to the exchange with the key alert. Copies of the message are put in each of those queues. Meanwhile, queue B does not get a copy because it is bound with the key info.
This simplified example shows how direct exchanges work when a queue has only a single binding. It’s worth remembering that queues can have multiple bindings to one or more exchanges. For example, queue A could have a binding to the direct exchange for messages with the key alert and another binding for messages with the key info. Keys are defined by the producers of messages.
Fanout Exchanges
The fanout exchange has very simple rules for how to route messages. It sends messages to every queue bound to it, regardless of the key. Thus, when a producer publishes a message to a fanout exchange, no routing key should be attached to the message. Figure 11.2 shows the operation of a fanout exchange.
Figure 11.2 A fanout exchange sends messages to all bound queues.
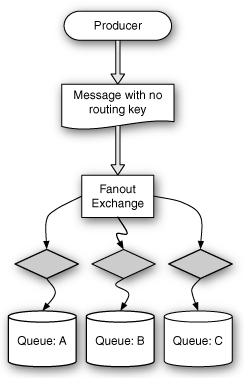
The example in Figure 11.2 shows that a message published to a fanout exchange is sent to every queue bound to that exchange. The advantage of a fanout exchange is that it is extremely fast. It doesn’t need to compare routing keys; it simply has to go through each bound queue and send the message.
Topic Exchanges
The topic exchange offers the greatest power and flexibility. Its rules for routing messages add the ability to use wildcards in bindings. To see how these wildcards are used, a more formal definition of a binding must first be created. Formally, a binding key is defined as a routing key with zero or more tokens separated by a dot (.). A token, on the other hand, is simply a string of characters.
The wildcard operators introduced by the topic exchange are # and *, and they can be used in place of tokens. The # specifies a match with zero or more tokens. The * specifies a match of exactly one token. This is a little different from regular expressions, where * specifies zero or more characters and ? specifies exactly one character.
Queues binding to a topic exchange can use this functionality or mimic the behavior of direct and fanout exchanges. To bind a queue to a topic exchange and have it behave like a direct exchange, you simply specify a binding that has exactly the key you want to match. To mimic the behavior of a fanout exchange and get every message published to the exchange, you simply bind with #, which routes every message to the bound queue. Figure 11.3 shows some examples of the message routing that topic exchanges provide.
Figure 11.3 A topic exchange sends messages based on patterns.
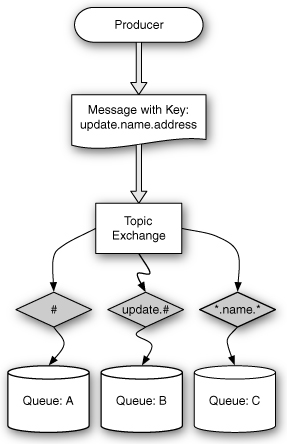
Figure 11.3 shows some possible bindings that would match against a message with the routing key update.name.address. Queue A is bound with #, which gets every message published to the exchange. Queue B is bound with update.#, which states that it wants all messages that have update as the first token. Finally, Queue C is bound with *.name.*, which states that it wants all messages that have name as the second token.
Two more interesting examples can be drawn from this type of routing key. For example, say that the first token represents an operation such as update, create, or destroy. The tokens after the first can represent the fields that were included in the operation. The message would include the old and new values of the fields in the operation. Thus, if you wanted to get messages for any modification that includes the name field, you could bind with #.name.#, which means “zero or more tokens with a name token followed by zero or more tokens.” To get messages only concerning updates to the name field, you bind with update.#.name.#.
The topic exchange is the most powerful of the three exchange types covered here. It could be used entirely in place of direct and fanout exchanges. However, the performance of direct and fanout exchanges is generally better. Which type of exchange is best depends on the setup. The smaller the number of bindings on an exchange, the less performance is an issue. As you add more bindings to an exchange, more checks must be performed for each incoming message. For this reason, it is sometimes a good idea to create multiple exchanges or one for each service that requires messaging capabilities.
Durability and Persistence
Durability refers to the ability for exchanges or queues to survive server restarts or crashes. Persistence refers to whether messages will be kept on disk and thus able to survive server restarts or crashes. In RabbitMQ, durability can be set on the queues and exchanges, while persistence can be set on the messages. In addition, consumers can be configured to tell the server that an acknowledgment for message processing is required. Which combination you want depends on the processing needs.
Durable Exchanges and Queues
Exchanges and queues that are marked as durable still exist after a restart. However, it is important to note that just because a queue is durable does not mean that the messages in the queue are also durable (or persistent). It is also worth noting that if an exchange is marked as durable, only durable queues can be bound to the exchange and vice versa.
Persistent Messages
Messages can be marked as persistent. This means that the messaging server writes a copy to disk and keeps it around until it is pushed off to a consumer. If a message is not persistent, it exists only in memory and disappears if there is a server restart before the message can be processed. Generally, persistence slows performance, so it is recommended only in situations where persistence is a requirement.
Message Acknowledgments
In AMQP, messages are pushed to consumers. These pushes generally happen asynchronously, so it is possible for a consumer to have multiple messages waiting to be processed. If the consumer process experiences a crash, the messages on the consumer can be lost. For this reason, it’s a good idea to turn on acknowledgments. To do this, the consumer tells the AMQP server that each message sent must be acknowledged. If it is not acknowledged and the consumer dies, the AMQP server pushes the message to the next available consumer.
There are many different settings in AMQP, and it can be difficult to understand them all together. When you use the messaging server to convey data that has not been saved elsewhere, it is a good idea to have durable exchanges and queues, have persistent messages, and have acknowledgments turned on. If data is being stored elsewhere and the messages can be resent after a critical server failure, a good configuration may be to have durable exchanges and queues, memory-only messages, and acknowledgments. It’s a good idea to have acknowledgments turned on at all times to guard against the possibility of a consumer having an unexpected restart or crash. The AMQP server will generally be more reliable than the consumers.
Client Libraries
In the Ruby world, there are two popular client libraries for interacting with AMQP and RabbitMQ: the AMQP Client and Bunny.
The AMQP Client
The AMQP client (http://github.com/tmm1/amqp) was written by Aman Gupta. It is an EventMachine-based client. EventMachine (http://rubyeventmachine.com/) enables asynchronous communication with the RabbitMQ server. This means that messages can be processed (in Ruby code) while messages are pushed from the server to the consumer.
This small example shows the basic usage of the AMQP library:

The call to AMQP.start starts the EventMachine reactor loop and opens a connection to the RabbitMQ server on the localhost. EventMachine is based on the reactor pattern, which processes I/O (such as network calls) asynchronously.
Once the connection is started, calls can be made to the RabbitMQ server. First, a new instance of MQ is instantiated. This is the primary interface to the API for the AMQP library. Next, a topic exchange named logger is created and set to be durable. Notice that exchanges have names. In this example, the exchange will be a place where error-logging messages are published.
After the exchange is created, a queue can be created and bound. Queues, like exchanges, also have names. In this case, the example uses a descriptive name, with the first term specifying what exchange it is primarily bound to and which messages it is processing. It is bound to the topic exchange that was just created with the key pattern some_host.*. The pattern in this logging example is that the first term represents the host name, and the second term is the process or server that is reporting a log message. Thus, this binding logs any errors from some_host.
subscribe is then called on that binding with a passed block. The block is called when messages come in from the RabbitMQ server. The block gets information including the routing key and the actual message body.
Finally, a test message is published to the logger exchange. Because the routing key matches the pattern for the subscription, the message is routed to the waiting consumer. This represents most of the basic functionality of the AMQP client library.
AMQP is a very performant library due to its use of EventMachine. However, it can be difficult to work with. This is especially true when you have a process such as a web application server that doesn’t run EventMachine (for example, Unicorn) and needs to publish to an exchange from the application. This is a very common use case. When a user request comes in that requires background processing, a message would usually be published to an exchange. So while AMQP’s performance makes it ideal for writing consumers, it is a little difficult to work with for producers that run inside a web application.
Bunny: An AMQP Client Library
Bunny (http://github.com/celldee/bunny) is a synchronous AMQP client library written by Chris Duncan. Much of the code for handling the actual AMQP protocol comes from the original AMQP client covered earlier. Due to Bunny’s synchronous nature, many users may find it easier to work with than the AMQP client. When calls are made to the RabbitMQ server, the process blocks until a response comes back. While this may sound slow, it is actually quite fast in practice due to RabbitMQ’s excellent performance. Response times are usually under a millisecond.
This Bunny example accomplishes the same things as the earlier AMQP example:

In this example, first a connection is made to the RabbitMQ server. With Bunny, a call must be made to start before any requests can be made to the server. Just as in the AMQP example, the exchange is declared, the queue is declared, the queue is bound to the exchange, and a message is published. Each of these calls is made synchronously, and the process blocks while waiting for a response from the server.
The final part of the script shows how a consumer is created. The call to subscribe blocks. Each time a message comes in, the block is called. When the block completes, an acknowledgment is sent to the server that the message has been processed. The process then blocks again until another message is pushed to the consumer, or the process calls the block with the next message if the message has already been pushed from the server to the consumer. Consumers can buffer a number of messages before the server stops pushing to them automatically.
Synchronous Reads, Asynchronous Writes
Using a flexible and powerful messaging system such as RabbitMQ along with HTTP-based services enables highly scalable architectures. The design pattern I call “synchronous reads, asynchronous writes” (SR/AW) refers to a system that routes all data writes through a messaging system while performing data reads through RESTful HTTP services. The advantages of building in this architecture are twofold. First, it is highly scalable due to the decoupling of the data store from user writes. Second, it enables event-based processing within an overall system.
HTTP-Based Reads
Data reads generally must be synchronous due to the fact that a user is waiting on a response. This also means that reads must occur quickly. The good news is that data reads are much easier to optimize than data writes. They are easily cached, which means that in a well-designed system, Ruby processes can be skipped entirely. (Caching is covered in greater detail in Chapter 8, “Load Balancing and Caching.”)
The important part of the read portion of SR/AW is that data should reside in separate services. These services can then be optimized with individual caching strategies. With good caching, it is trivial to serve a few thousand requests per second.
Messaging-Based Writes
While data reads must be synchronous, data writes often do not have the same requirement. This is ideal because writes are often much more difficult to optimize than reads, due to their need to write to disk. Routing data writes through AMQP also enables event-based processing. Briefly, this is a system that can trigger events based on changes in data. This comes in handy when replicating data across services to make fully cached data reads easy. Before we dive in to an example, there are two exchanges the write system uses that should be mentioned: the write exchange and the notify exchange.
The Write Exchange
The write exchange is a fanout exchange through which all data writes are routed. At a minimum, there must be a single consumer that pulls data off a queue bound to the exchange and writes it to a data store of some kind. This data store represents the primary responsibility holder and canonical storage of the data being written in. This consumer is in turn responsible for sending out notifications to the notify exchange.
The Notify Exchange
The notify exchange is a topic exchange that receives published events that result from writes sent through the write exchange. A good convention is to use routing keys in the following pattern: < create|update|destroy>.< field1>.< field2>.< field3>. The first token represents the operation that was performed on the data. The following tokens indicate which fields were changed by the write. The message should have the following format:

The message includes the ID of the written object and the new and old values for the fields. In the case of a previously null value, the “old” value would be omitted from the message. This section lays out the basic structure of the asynchronous writes system. The following section provides an example to help highlight a possible use of this notification system.
Receiving Notifications
In the social feed reader application, users can follow other users to get updates on their activities. This can include subscribing to a new feed, voting or commenting on an entry, or following another user. An activity service could be built that optimizes storage and reads of these different activity streams. This activity stream service would not be the primary holder of the data. It would simply act as an optimized data store for returning results for activity streams for specific users. The asynchronous writes system make the replication of the data fairly painless.
Figure 11.4 shows the full lifecycle of the asynchronous writes design. In the example, a user is following another user. The Rails application publishes a message to the user.write exchange. The message contains data with the “following” user ID and the “followed” user ID. The write exchange is a fanout, so that message has no associated routing key. The message is put into every connected queue, one of which is the queue for user data. The user data consumer is just a process running on a server that can write to the backend user data store.
Figure 11.4 The asynchronous write event cycle.
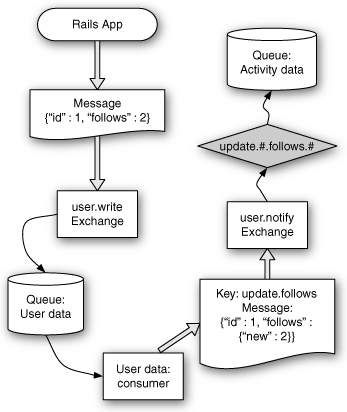
The user data consumer saves the update and sends out a notification to the user.notify exchange. Remember, the notify exchange is a topic exchange, so the message should have a routing key. In this case, the routing key shows that it was an update operation to follows. The message includes the ID of the user that was updated and the new data. This case is a little special with regard to the notification. With other types of fields, it makes sense to include the old data. However, with follows, you probably wouldn’t want to push out the full collection of IDs that a user is following each time. So this update includes only the new user.
Now it’s time for the user.notify exchange to push out these changes to all the queues that are interested. The activity service that is responsible for keeping an optimized data store for retrieving activity has a binding to listen for follows updates. It has bindings for new comments, votes, and subscriptions as well. The exchange matches the key against the binding, and the queue now has the message. The activity service can consume the message and write the activity to its data store. During normal system operation, all this would happen in under a second. However, during times of unexpected load, it can take longer, but the overall system performance would look as though it is just as responsive as during low-traffic times.
The asynchronous writes design can be particularly useful when you’re creating services that are responsible for optimizing specific portions of an application’s data. The write exchange gives a system as a whole the flexibility to manage spikes in write traffic. The notify exchange enables replication to other services to occur without requiring an update to the primary data writer. The only requirement is that the primary data owner write notification messages. Another service can bind to that exchange and pull off whatever data it is interested in.
The CAP Theorem
In 2000, Eric Brewer gave a talk on the trade-offs in designing distributed systems. He stated that the trade-offs occur between three primary design goals: consistency, availability, and partition tolerance. Brewer stated that in distributed systems, only two of these requirements can be strictly maintained. Two years later, this was proven as the CAP (consistency, availability, and partition tolerance) theorem.
Consistency refers to data consistency across replicated systems. To maintain a strongly consistent environment, all data stores must reflect the same state. Take, for example, two databases that are replicated together. To remain consistent, each must be able to replicate data writes to the other before a transaction (or a write) can be completed. A typical monolithic database such as MySQL or PostgreSQL resides on a single server and offers a strongly consistent data store.
Availability is a system’s availability to serve requests. With a single server, the availability is entirely dependent on that server. This is known as the “single point of failure” problem. With multiple servers, availability can be maintained as long as one server continues to run. However, this assumes that every server is able to serve a request. This is sometimes the case, but not always. For example, large datasets may be sharded across multiple servers. Sharding refers to splitting up the data so different portions go to different servers. If each shard contains only one server, the single point of failure still exists.
Partition tolerance is a system’s ability to tolerate breaks in network connectivity—that is, partitions in the network of distributed systems. This is important when looking at data replication. For example, consider two databases that are exact replicas of each other. They are said to be partition tolerant if connectivity between the two of them can be lost but each can continue to serve reads and writes to clients.
Together with partition tolerance, it can be seen that consistency and availability would be impossible to maintain. If a system is partition tolerant and consistent, it might not be available. Once a partition is made, writes can no longer be made to either database because the replica would be inconsistent with the database that took a write. If consistency is enforced, then neither database can take a write when a partition occurs.
Eventual Consistency
Werner Vogels, the CTO of Amazon, proposed a way around the limits of the CAP theorem, with the idea of eventual consistency. That is, it is possible to have partition tolerance and high availability if the consistency requirement is loosened from strongly consistent to eventually consistent.
A system that is eventually consistent can take data writes even when a partition is made. When a write is made to one database, data reads reflect this most recent write. Meanwhile, the replica reflects the older state of the data. When the partition is fixed and network connectivity is restored, the replica can be brought back in sync. Put more succinctly, eventual consistency is a form of weak consistency that states that if no updates are made to an object, eventually all accesses to that object will return the same value.
Designing Around Consistency
Designing a system that supports eventual consistency takes some effort on the part of an application programmer. Eventually consistent systems do not support transactions. Further, they lack the ability to lock values, which makes it hard to support uniqueness constraints and avoid write collisions.
Field Value Checking
The following scenario is an example of a write collision in an asynchronous writes system. Consider the inventory of a specific book in a store. If one customer orders a book, the count of books in inventory must be reduced by one. In a regular database system, this would mean wrapping in a transaction a read of the book stock count and updating that to the count minus one.
In an SR/AW system, you might read the inventory count and write to the messaging system the count minus one. Meanwhile, another customer could order a book before the first write has gone through. If an update is made, the system would attempt to write the count minus one again. The inventory count at this point would reflect that the system has one more book than is actually in stock.
One method of designing around the transaction/update problem is to write the previous value of the field along with the new value into the write exchange. When the writer gets the message, it can check the previous value in a regular transaction. If an error occurs, the customer can be informed or another process can attempt the operation using current data.
The specific use case of incrementing or decrementing a count by a certain number can be designed around in another way: by including an increment or decrement operator in the write. The consumer specifies the number to increment or decrement by, and the writer that gets messages from the write exchange can perform that increment or decrement in a transaction inside its own system.
Value Uniqueness
Value uniqueness is another property that is difficult to account for in an eventually consistent system. One of the most common use cases for value uniqueness is for user profile paths or user names. For example, selecting a user name for Twitter maps the user name to http://twitter.com/<username>. A couple design strategies in the SR/AW system enable name uniqueness.
The first method for enabling name uniqueness is through a form of optimistic locking. It’s not really a lock, but it is optimistic. When a user requests a user name, or some other unique value, the application can make a synchronous request to see if that name is available. If it is, the application publishes the write to the messaging system. When the message gets through the system and the writer attempts to make the write, it verifies uniqueness again. Most likely, the name is still unique. However, if a problem is encountered, the user must be notified to select a new name.
The process of requesting a name and either succeeding or failing can occur through the messaging system in under a few milliseconds. The timing is less important than designing around the possibility that there might be a failure that the user will have to be notified of. Most of the time this is successful, so it may be a strategy that works well.
The second method to enforce uniqueness is through a lock service. A synchronous HTTP-based service can be created to hand out locks. In the case of a user name, it would request a lock with the scope of a user name for the specific name requested. The lock would issue for some reasonable amount of time (such as less than 5 minutes). Once the lock has been granted, the write can go through. This ensures that no other writers can attempt to write the same name in that time frame. They are not able to obtain a lock.
Transactions
Transactions are a requirement that the asynchronous writes system does not support. The classic example for when a transaction is needed is when making a balance transfer from one account to another. Both modifications must be made within a single transaction, and the business rules usually stipulate that neither account can end the transaction with a negative amount.
One method of designing around this requirement is to implement an optimistic system. The write message should state what amount to move from one account to another. If both accounts end in a valid state, the transaction is successful. However, if one account ends up negative, the user must be notified that a failure has occurred. Note that this has to occur after the user has already left the site or has navigated on to another page. Remember that when the user made the request, the write was queued up, and a response was sent back before the actual write occurred.
The final method to deal with transactions is to bypass the asynchronous writes system for only the updates that absolutely require transactions. A synchronous service (either a database or an HTTP service) can perform the operation that requires a transaction while the user waits for the transaction to complete. This amounts to a service partition strategy where the transactions are partitioned into their own area. Meanwhile, more flexible data can be put into asynchronous writes—based services.
Data Is the API
When you design distributed systems that communicate through messaging queues such as AMQP, the data that passes through becomes a focal point. That is, every service that subscribes to updates from another service gets messages with the raw data. Field names and schema take on greater importance. The data itself becomes the API through which services interact. Specific fields can be expected to behave in a certain way. It is important when building a distributed system to document these design decisions so that they can be programmed against.
The notify exchange example earlier in the chapter shows one example of using the data as an API. The messages in the notify exchange contain the ID and the new and old values of fields. For other services and consumers to interact with this data, the messages should be consistent and known. For example, if there was no previous value (or it was null), the “old” section of the notification would be omitted for that field. The data in the notification messages takes on the importance of being the agreed-upon interface through which other services are notified of data updates.
“Data is the API” is meant to point out the importance of schemas. By nature, an API is something that should not be changed very frequently. Changes in an API force all clients dependent on it to make updates. The data that gets routed through the messaging system should be thought about with a little more care than a standard ActiveRecord model that has very flexible and quickly changing schemas.
Operations on Fields
The earlier section on designing around consistency hinted at one possibility of having the data behave as an API. An example mentions providing an increment or decrement operator. Here is an example of what a message published to the write exchange requesting an increment would look like:

The message includes only the ID of the item to be incremented and the amount of the increment. This schema has the increment as a .inc addition to the field name. The type of data being incremented is already known because it has its own AMQP exchange. Another option is to create a message that looks like this:

In this message, the operation is specified in the JSON object that is the value for the field. This method provides a little more flexibility and power (for instance, if the old field value was provided to make sure that the new value isn’t writing with stale data). This could be accomplished easily with just “old” and “new” keys and values in the object. Ultimately, neither of these situations is more correct than the other. The important thing is to choose one and remain consistent across all services and write exchanges.
Modifications to Field Operations
There are many different ways to specify field operations. One option is to turn the write exchange into a topic exchange and use the routing key to identify field operations. This method cleanly separates the actual data from the operation, but it has the limitation that only one operation can be performed per message.
More operations that might be supported are add to set, delete from set, push onto list, pop from list, queue, and dequeue. The write exchange and the data that passes through it truly becomes an API. All these can be built using whatever code and backend data store makes the most sense. The writer that gets messages from the exchange must be able to handle them, and the HTTP-based interface needs to pull from the data store. The specifics of what powers those can be improved over time.
Conclusion
Messaging provides more than a simple method for performing long-running tasks. With a highly performant messaging system, messaging can be used to achieve a number of goals. The main advantage is that messaging-based writes are able to maintain high performance under bursts of traffic and load. In addition, decoupling the client from the data store enables independent iterations on both the client and server. Finally, the notification system enables event-based processing, which makes it easy to create additional optimized data stores and services as the need arises.