Chapter Fourteen. Information Architecture
If a system is to succeed, it must satisfy a useful purpose at an affordable cost for an acceptable period of time. Architecting therefore begins with, and is responsible for maintaining, the integrity of the system’s utility or purpose.
Mark W. Maier and Eberhardt Rechtin1
1. Mark W. Maier and Eberhardt Rechtin, The Art of Systems Architecting (CRC Press, 2000), p. 10.
Information architecture is a subset of enterprise architecture, and it is the discipline that turns data into information by adding context (semantics and metadata); addressing the structural design of shared information environments; and modeling integrated views of data at conceptual, logical, and physical levels. Information architecture is an essential competency in support of enterprise data integration, process integration, and data governance strategies. Architecture and integration are complementary enterprise practices. Architecture is about differentiating the whole and transforming the business. Integration is about assembling the parts into a cohesive, holistic system. One discipline takes a top-down approach while the other is more bottom-up; both are essential.
Lean can be associated with information architecture (or IA) from two perspectives: applying Lean practices to the process of IA, or using IA practices to achieve Lean Integration. IA methodologies involve a process that, like other processes, can be subjected to Lean principles. Applying Lean practices to the process of IA can make IA more effective and efficient. This book is not about architecture per se and so we shall leave it to others or to a future date to write about how Lean can be applied to architecture processes. However, a formal IA practice is a critical ingredient for achieving the benefits of Lean Integration. Limiting variation; architecting for change and reuse; fully documenting and continually improving the appropriate technologies, best practices, and processes—these all reflect Lean principles that benefit from a mature IA practice. We will discuss IA from this perspective.
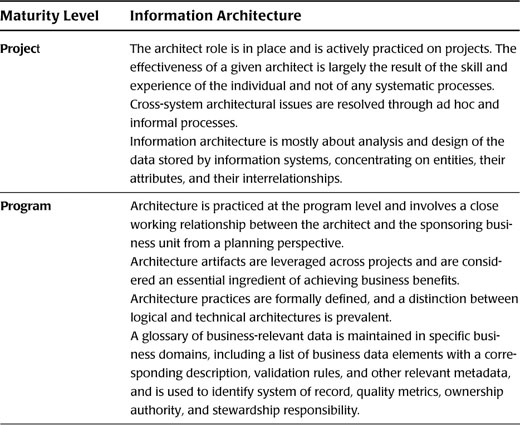
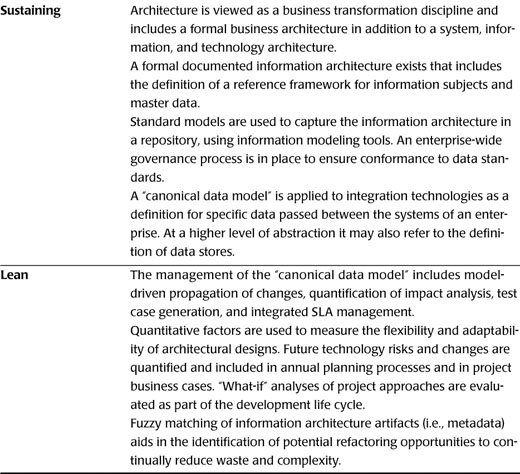
While the focus in this book is on how integration practitioners can use IA, in Table 14.1 we offer our definition of IA maturity levels, the highest level being a “Lean architecture” practice. A Lean Integration practice can work with and take advantage of IA practices at all levels, but there are limitations on what integration teams can accomplish depending on the level of IA maturity. For example, if the IA maturity is at a level where a holistic inventory of application systems is not maintained (such as at the project or program levels), it will be very difficult for the Lean Integration team to eliminate certain kinds of waste such as redundant information in applications with overlapping functionality and duplicate integration points. In this context the Lean Integration team must either take on this task directly or simply focus on other aspects of Lean, such as standard interface definitions and rapid integration development using factory techniques to support project and program efforts.
Table 14.1 Information Architecture Maturity Model
Challenges
In many organizations, there is a growing recognition that data has value not just for the group that captures it, but for the enterprise overall. This has driven the need for
• Data to be managed as a corporate asset
• Explicitly defined accountability for information, including data stewardship
• Data governance committees to facilitate cross-organizational needs
• Best practices for standard business glossaries, canonical data models, and conceptual business views, in addition to traditional logical/physical views
• Best practices for data quality
In short, data needs to be managed holistically and transparently from top to bottom in an organization. The business motivations for this growing trend include
• Application and data rationalization associated with mergers and acquisitions
• Master data management, a “single version of the truth” or a 360-degree view of customer, product, supplier, etc.
• Legacy data migrations in support of ERP or other cross-functional system implementations
• Regulatory compliance and enterprise risk management
• Operational business intelligence
• Information as a service (similar to SOA but with emphasis on data integration)
• Other needs such as supply chain optimization, customer experience improvements, or marketing effectiveness
A critical ingredient for addressing the business needs is an IA methodology that results in the following benefits:
• Helps business and IT groups work toward a common framework and road map
• Identifies redundancies
• Helps IT and the business make better-informed decisions
• Increases leverage with acquisitions and alliances
• Leverages knowledge management
• Generates cost savings by achieving alignment of capabilities
• Elevates the role of IA in business and operational planning
• Reduces risks through additional governance capabilities
While the industry trends, business needs, and business benefits paint a compelling picture of the need for and value of a mature information architecture program, there are a number of significant challenges associated with it:
• Lack of business involvement
• Creating a quantifiable business case
• Gaining consensus on data definitions
• Determining an appropriate scope
• Funding for a “new” ongoing process
• Denial that data quality is the root cause of problems
For an IA practice to be effective, it must address each of these challenges. It is therefore critical to first explore each of the challenges in more detail in order to understand how the IA practice addresses them.
Lack of Business Involvement
As a quick check, ask yourself who in your enterprise is accountable for the effective use of
• Human assets: business lines or the HR function?
• Capital assets: business lines or the finance function?
• Information assets: business lines or the IT function?
In any organization the answer to the first two is obvious: Business lines manage and make decisions regarding human and capital assets. Although this is done with the help and support of the HR and finance functions that provide expertise in their respective disciplines, it is clear that it is the business leaders who decide when to hire/fire staff and whether or not to invest capital or cut costs.
However, when it comes to information assets, a common misperception among business leaders is that IT owns the data, since IT is responsible for the operation of the application systems. IT does indeed have a role in establishing processes, policies, standards, and technologies for information management (similar to the role HR and finance have for their respective assets), but without the active involvement of senior business leaders, most data governance programs never get off the ground.
Creating a Quantifiable Business Case
Several of the key challenges related to creating a business case for top-down IA are the following:
• Fear of claiming indirect benefits
• Example: Investing in data quality technologies and a data integration program may be an enabler, but it is not the sole factor for driving an increase in revenue per customer. As a result, there is a fear of making a case for achieving business benefits that may be dependent on other factors outside the direct control of an ICC.
• Difficulty in quantifying ROI
• Few internal metrics can directly justify an ICC, SOA, or data governance strategy.
• Poor (or inconsistent) industry studies make competitive analysis difficult.
• The analysis effort required to create a quantifiable business case may itself be large enough that it requires a business case.
Cross-Functional Complexity
There are several challenges related to data integration complexity:
• Inconsistent data models from package applications and legacy systems result in massive variation in data definitions, making it unclear where to start and which to use as a reference.
• A bottom-up approach has the risk of reinforcing and codifying legacy system data and process definitions that are not applicable in the current context.
• A top-down approach has the risk of “solving problems by white-board”—that is, eliminating details that are essential for understanding root cause.
Gaining Consensus on Data Definitions
Gaining consensus on definitions for a business glossary and/or business event model is a major challenge for several reasons:
• Rivalry between organizational groups and a history of distrust and noncommunication can be barriers to collaboration.
• Transparent transformations are easy (e.g., dollars and euros), but semantic issues are difficult to resolve (e.g., system A has three genders defined but system B has five gender codes).
• The processes of different business domains may be sufficiently different that it is impossible to agree on anything other than the objective. For example, opening a credit card account may be so different from opening a mortgage account that the users see no similarity other than the end point.
• Users tend to remain steadfast in insisting that their definition is the right one (e.g., is a customer a consumer, prospect, person, or corporation?), thereby creating a barrier to collaboration.
Determining an Appropriate Scope
There are several challenges related to the scope of data analysis and governance:
• Creating data and process definitions for a medium to large organization is a “boiling the ocean” problem.
• It may not be clear where to start and what level of detail is required.
• There is a risk of becoming an “ivory tower” program (i.e., not connected with the real needs of business sponsors).
• If the effort focus is just on projects, the bigger-picture implications may be missed.
• If the effort focus is just on the big picture, it may be too theoretical and not address the needs of the projects.
• Grassroots efforts for a single functional area may provide value but pose a risk of undersizing the true effort and opportunity across the organization.
Funding for a “New” Ongoing Process
Even if the value of the IA practice and the initial investment to launch it are accepted, concerns about the ongoing costs to sustain the effort may become a showstopper:
• Enterprise models—whether they are enterprise architecture artifacts or metadata repositories—have an ongoing cost component.
• If the ongoing cost is ignored (i.e., only the initial project efforts are funded), the models will become stale and ineffective.
• If the ongoing cost is highlighted up front, the initiative may never be approved unless there is an overwhelming perceived benefit.
• There is little “good” guidance in the industry about how much effort is required to sustain these new processes.
Denial That Data Quality Is the Root Cause of Problems
A major challenge in many cases is that senior management simply does not believe that data inconsistencies are a serious concern:
• Individual business groups may not have visibility to enterprise issues such as
• Inconsistent definitions of data that make it impossible to create an enterprise view
• Redundant or duplicate information that creates inefficiencies and high costs to maintain
• Data quality issues may be “covered up” through manual efforts by front-line staff and managers and a culture of not escalating issues.
• When business leaders don’t support a data governance program led by IT, business-based data capture, maintenance, and process flaws cannot be resolved—data quality issues reappear and reinforce the negative perception of IT.
Prerequisites
The major prerequisite for creating an enterprise IA is that it be established with a clear link to a broader enterprise strategy such as an ICC, SOA, or data governance program. In other words, IA is not an end unto itself. It should be viewed as an enabler for a broader cross-functional strategy and clearly be linked to that strategy.
It is possible to leverage the IA practice without this prerequisite, but only in the context of a more narrowly defined scope of a single project/program or a single functional group. While a smaller scope does not offer an enterprise-wide benefit, it can be an excellent way to build a grassroots movement to generate awareness and interest in a broader enterprise initiative.
Activities
Information architecture is the art and science of presenting and visually depicting concept models of complex information systems in a clear and simplified format for all of the various stakeholders and roles. Three key elements are crucial in growing the maturity of IA:
• Methodology for how to create and sustain the models
• Framework for organizing various model views
• Repository for storing models and their representations
Implementing these elements requires the following activities that help lay the groundwork for a good data governance program:
• Creating various views or models (i.e., levels of abstraction) for multiple stakeholders
• Adopting a shared modeling tool and repository that support easy access to information
• Keeping the models current as the plans and environment change
• Maintaining clear definitions of data, involved applications/systems, and process flow/dependencies
• Leveraging metadata for data governance processes (i.e., inquiry, impact analysis, change management, etc.)
• Clearly defining the integration and interfaces among the various platform tools and between platform tools with other repositories and other vendor tools
Methodology
The IA methodology is described here in the context of a broader data governance methodology, as shown in Figure 14.1. We define data governance as “the policies and processes that continually work to improve and ensure the availability, accessibility, quality, consistency, auditability, and security of data in a company or institution.” Many of the activities and techniques are applicable in other contexts such as data migration programs or data rationalization in support of mergers and acquisitions. It is the task of the architect and program team to tailor the methodology for a given program or enterprise strategy or purpose.
Figure 14.1 Information architecture within a data governance methodology
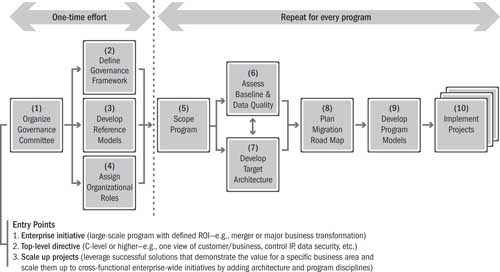
The following list provides a high-level description of the ten steps of the data governance methodology. The IA methodology described here is most closely aligned with step 3 and steps 5 through 10.
1. Organize a governance committee: Identify the business and IT leaders who will serve as the decision-making group for the enterprise, define the committee charter and business motivation for its existence, and establish its operating model. Committee members need to understand why they are there, know the boundaries of the issues to be discussed, and have an idea of how they will go about the task at hand.
2. Define the governance framework: Define the “what, who, how, and when” of the governance process, and document the data policies, integration principles, and technology standards with which all programs must comply.
3. Develop enterprise reference models: Establish top-down conceptual reference models, including a target operating blueprint, a business function/information matrix, and a business component model.
4. Assign organizational roles: Identify data owners and stewards for information domains, responsible parties/owners of shared business functions in an SOA strategy, or compliance coordinators in a data governance program.
5. Scope the program: Leverage the enterprise models to clearly define the scope of a given program, and develop a plan for the road-mapping effort. Identify the high-level milestones required to complete the program, and provide a general description of what is to take place within each of the larger milestones identified.
6. Assess the baseline and data quality: Leverage the enterprise models and the scope definition to complete a current-state architectural assessment, profile data quality, and identify the most important data as well as the business and technical opportunities.
7. Develop the target architecture: Develop a future-state data/systems/service architecture in an iterative fashion in conjunction with step 6. As additional business and technical opportunities become candidates for inclusion, the projected target architecture will also change.
8. Plan the migration road map: Develop the overall program implementation strategy and road map. From the efforts in step 5, identify and sequence the activities and deliverables within each of the larger milestones. This is a key part of the implementation strategy with the goal of developing a macro-managed road map that adheres to defined best practices. Identifying activities does not include technical tasks, which are covered in the next steps.
9. Develop program models: Create business data models and information exchange models for the defined program (i.e., logical and physical models are generally created by discrete projects within the program). The developed program models use functional specifications in conjunction with technical specifications.
10. Implement projects: This is a standard project and program management discipline with the difference that some data governance programs have no defined end. It may be necessary to loop back to step 5 periodically and/or provide input to steps 2, 3, or 4 to keep them current and relevant as needs change. As the projects are implemented, observe which aspects could have been more clearly defined and at which step an improvement should take place.
Information Architecture Models
The IA models are illustrated in Figure 14.2.
Figure 14.2 Information architecture models
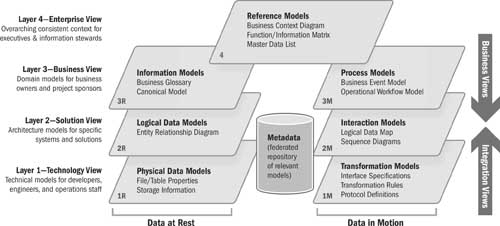
There are three reference models in the enterprise view (layer 4) of the IA framework but usually only one instance of these models for any given enterprise. These models are technology-neutral and implementation-independent.
• Business context diagram: The business context diagram for the enterprise shows key elements of organizational business units, brands, suppliers, customers, channels, regulatory agencies, and markets.
• Function/information matrix: This matrix is used to define essential operational capabilities of the business and related information subjects. The resultant matrix shows which information subjects are created by or used by the various business functions independently of how it is done. The functions and information subjects are used as a common framework to facilitate a consistent description of data at rest and data in motion in the business view models.
• Master data list: This is a list of business objects or data elements that are formally within the scope of an enterprise data governance program or master data management program.
Reference models may be purchased, developed from scratch, or adapted from vendor/industry models. A number of IT vendors and analyst firms offer various industry- or domain-specific reference models. The level of detail and usefulness of the models varies greatly. It is not in the scope of this chapter to evaluate such models, only to recognize that they exist and may be worthy of consideration.
There is a significant number of open industry standard reference models that also should be considered. For example, the Supply-Chain Operations Reference (SCOR) is a process reference model that has been developed and endorsed by the Supply Chain Council (SCC) as the cross-industry de facto standard diagnostic tool for supply chain management. Another example is the Mortgage Industry Standards Maintenance Organization (MISMO), which maintains process and information exchange definitions in the mortgage industry.
Some key advantages of buying a framework rather than developing one from scratch include these:
• Minimizing internal company politics: Since most internal groups within a company have their own terminology (i.e., domain-specific reference model), it is often a very contentious issue to rationalize differences between various internal models and decide which one to promote as the common enterprise model. A technique that is often attempted, but frequently fails, is to identify the most commonly used internal model and make it the enterprise model. This can alienate other functions that don’t agree with the model and can in the long run undermine the data governance program and cause it to fail. An effective external model, however, can serve as a “rallying point” and bring different groups from the organization together rather than pitting them against each other or forcing long, drawn-out debates.
• Avoid “paving the cow path”: The “cow path” is a metaphor for the legacy solutions that have evolved over time. An internally developed model often tends to reflect the current systems and processes (some of which may not be ideal) since there is a tendency to abstract away details from current processes. This in turn can entrench current practices, which may in fact not be ideal. An external model, almost by definition, is generic and does not include organization-specific implementation details.
• Faster development: It is generally quicker to purchase a model (and tailor it if necessary) than to develop a reference model from the ground up. The difference in time can be very significant. A rough rule of thumb is that adopting an external model takes roughly one to three months whereas developing a model can take one to three years. The reference model may involve some capital costs, but the often hidden costs of developing a reference model from scratch are much greater.
Regardless of whether you buy or build the reference models, in order for them to be effective and successful, they must have the following attributes:
• Holistic: The models must describe the entire enterprise and not just one part. Furthermore, the models must be hierarchical and support several levels of abstraction. The lowest level of the hierarchy must be mutually exclusive and comprehensive (ME&C), which means that each element in the model describes a unique and nonoverlapping portion of the enterprise while the collection of elements describes the entire enterprise. The ultimate mapping (discussed in the next chapters) to physical data may be much more complex because enterprise systems are not themselves ME&C.
Note: It is critical to resist the urge to model only a portion of the enterprise. For example, if the data governance program focus is on customer data information, it may seem easier and more practical to model only customer-related functions and data. The issue is that without the context of a holistic model, the definition of functions and data will inherently be somewhat ambiguous and therefore will be an endless source of debate and disagreement.
• Practical: It is critical to establish the right level of granularity of the enterprise models. If they are too high-level, they will be too conceptual; if they are too low-level, the task of creating the enterprise models can become a “boiling the ocean” problem and consume a huge amount of time and resources. Both extremes—too little detail or too much detail—are impractical and the root cause of failure.
Tip
There are two “secrets” to achieving the right level of granularity. First, create a hierarchy of functions and information subjects. At the highest level it is common to have in the range of five to ten functions and information subjects that describe the entire enterprise. Second, at the lowest level in the hierarchy, stop modeling when you start getting into “how” rather than “what.” A good way to recognize that you are into the realm of “how” is if you are getting into technology-specific or implementation details. A general rule of thumb is that an enterprise reference model at the greatest level of detail typically has between 100 and 200 functions and information subjects.
• Stable: Once developed, reference models should not change frequently unless the business itself changes. If the reference models did a good job separating the “what” from the “how,” a business process change should not impact the reference models; but if the organization expands its product or service offerings into new areas, either through a business transformation initiative or a merger/acquisition, the reference model should change. Examples of scenarios that would cause the reference model to change include a retail organization transforming its business by manufacturing some of its own products or a credit card company acquiring a business that originates and services securitized car and boat loans.
Reference models, once created, serve several critical roles:
1. They define the scope of selected programs and activities. The holistic and ME&C nature of the reference models allows a clear definition of what is in scope and out of scope.
2. They use a common language and framework to describe and map the current-state enterprise architecture. The reference model is particularly useful for identifying overlapping or redundant applications and data.
3. They are particularly useful for identifying opportunities for different functional groups in the enterprise to work together on common solutions.
4. They provide tremendous insight into creating target architectures that reflect sound principles of well-defined but decoupled components.
Data at Rest
The data-at-rest pieces of the IA framework in Figure 14.3 provide a series of models at different levels of abstraction and with the information that is relevant to various audiences. Collectively, these models describe data as it is persisted in business systems or in integration systems (such as data warehouses or master data repositories).
Figure 14.3 Data-at-rest models
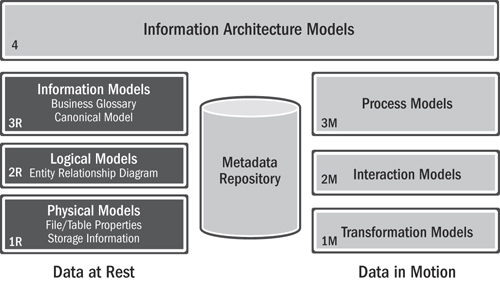
Information Models (3R)
There are two information models on the business view (layer 3) of the IA framework. These are sometimes referred to as “semantic models” since there may be separate instances for different business domains.
• Business glossary: This is a list of business data elements with a corresponding description, enterprise-level or domain-specific synonyms, validation rules, and other relevant metadata. It is used to identify the source of a record, quality metrics, ownership authority, and stewardship responsibility.
• Canonical model: This is the definition of a standard organization view of a particular information subject. Specific uses include delivering enterprise-wide business intelligence (BI) or defining a common view within an SOA. In this book we define three canonical modeling techniques, each of which serves a specific purpose: canonical data modeling, canonical physical formats, and canonical interchange modeling.
Note that while we show the canonical model at layer 3 in the framework, mature Lean Integration teams generally have canonical models at layers 2 and 4 as well. At layer 2, solution view, the canonical model represents common data definitions within the scope of two or more applications in a specific project or program. At layer 3, business view, the canonical model represents common data definitions within a business domain such as finance or marketing. At layer 4, enterprise view, the canonical model represents common data definitions or concepts across the enterprise. While not shown in the framework, it is possible to have yet another canonical model that represents common data definitions outside the enterprise as industry standard models within a supply chain.
Logical Data Models (2R)
There is one primary data model on the solution view (layer 2) of the IA framework:
• Entity relation diagram: This is an abstract and conceptual representation of data used to produce a type of conceptual schema or semantic data model of a system, often a relational database, and its requirements.
Physical Data Models (1R)
There are at least two primary physical data models on the technology view (layer 1) of the IA framework:
• File/table properties: The properties describe the structure and content of physical files, tables, interfaces, and other data objects used throughout the enterprise. These data objects could exist in relational databases, ERP or customer relationship management systems, message queues, mainframe systems, semistructured data coming from .pdf, .doc, .xls, or email files, or any other data source with a definable structure. Besides the structure and content properties, it is also crucial to track the relationships between these data objects as well as the change history of the data objects throughout the organization.
• Storage information: Particular files, tables, copybooks, message queues, or other information objects could have a single definition but have several physical instantiations throughout an organization. Keeping track of the access profiles and security characteristics as well as the storage characteristics of these objects is important for managing them.
The business glossary is implemented as a set of objects in a metadata repository to capture, navigate, and publish business terms. This model is typically implemented as custom extensions to the metadata repository rather than as Word or Excel documents (although these formats are acceptable for very simple glossaries in specific business domains).
The business glossary allows business users, data stewards, business analysts, and data analysts to create, edit, and delete business terms that describe key concepts of the business. While business terms are the main part of the model, it can also be used to describe related concepts like data stewards, synonyms, categories/classifications, rules, valid values, quality metrics, and other items.
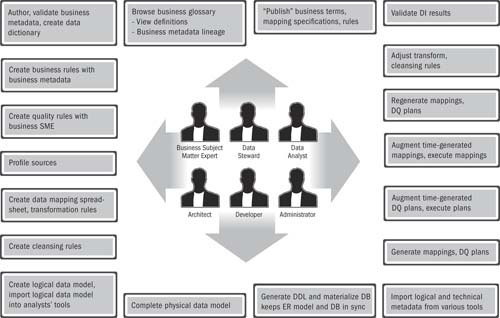
Figure 14.4 shows some of the ways that different roles either create, modify, or collaborate on parts of the IA. Many of these steps could be optional, and this is obviously not intended to be the one and only “work-flow” between these users. This picture represents some of the ways that different roles are continually working together to refine the information world for complex enterprises.
Figure 14.4 Information architecture team interactions