Chapter Sixteen. Modeling Management
The complexity of software is an essential property, not an accidental one. Hence descriptions of a software entity that abstract away its complexity often abstract away its essence.
Frederick P. Brooks, Jr.1
1. Frederick P. Brooks, Jr., The Mythical Man-Month: Essays on Software Engineering, Anniversary Edition (Addison-Wesley, 1995), p. 183.
One of the critical needs within all large corporations is to achieve efficient information exchange in a heterogeneous environment. The typical enterprise has hundreds of applications that serve as systems of record for information that, although developed independently and based on incompatible data models, must be shared efficiently and accurately in order to effectively support the business and create positive customer experiences.
The key issue is the scale and complexity that are not evident in smaller organizations. The problem arises when there are a large number of application interactions in a constantly changing application portfolio. If these interactions are not designed and managed effectively, they can result in production outages, poor performance, high maintenance costs, and especially a lack of business flexibility.
One of the primary methods for helping to meet integration needs is to make a complex system-of-systems easier to manage by presenting only the relevant information to different stakeholders to answer the questions they have. For this reason, abstraction and graphical visualizations are critical disciplines in an effective Lean Integration practice. Models are the primary language of integration and hence a critical dimension of an Integration Competency Center.
A model, which is an abstraction of a complex enterprise or system or other entity, is a useful and necessary tool to effectively communicate with all stakeholders, thereby helping to drive alignment across silos. We should always keep in mind the words of Brooks in the opening quote that models are not the same as the things they describe; models eliminate certain details in order to facilitate communication, but as we know from the fifth Law of Integration (Appendix B), “All details are relevant.” The models themselves are entities that have a life cycle—they need to be developed, deployed, maintained, enhanced, and eventually retired or replaced with better models. Since modeling methods (if done properly) are repeatable processes, Lean techniques can be applied to them to improve productivity and reduce cycle times. In addition, the deliverables produced by the modeling processes are enablers for a Lean Integration organization because they help to eliminate waste (such as re-creating documentation or hunting for documents in the traditional paradigm), facilitate value stream mapping (by presenting a consistent picture and language to describe cross-functional processes and data), and support automation activities (i.e., interchange modeling can be thought of as a code generator for mapping rules).
There are many dimensions to modeling. In its broadest definition a model is a pattern, plan, representation, or description designed to show the main purpose or workings of an object, system, or concept. Some of the specialized disciplines that are relevant to a Lean organization include data modeling, business process modeling, computer systems modeling, and meta-modeling. That said, these modeling disciplines are broadly practiced in the industry with well-defined methods that are generally available through books and educational programs, so it would be redundant to include them here.
The primary focus of this chapter on modeling management is to support integration needs from two perspectives:
1. Provide some prescriptive guidance around canonical data modeling (for which there are few if any good practices available in the industry)
2. Offer some guidance and rules of thumb related to our experiences in creating and sustaining enterprise models and meta-models
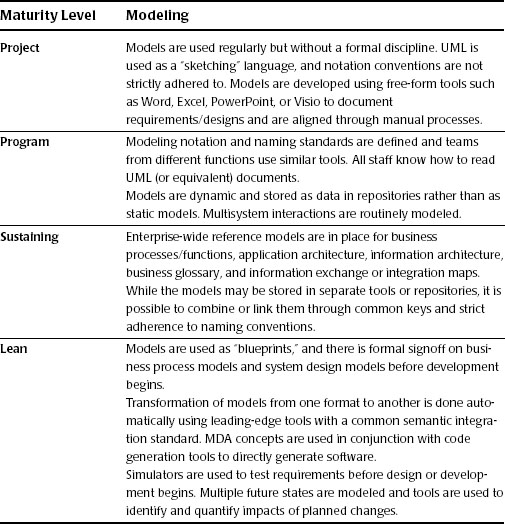
Table 16.1 provides an outline of four levels of maturity. While there is a certain amount of subjectivity around some of the definitions, nonetheless it is a useful tool for assessing your organization’s current level of maturity and for establishing a desired target maturity level.
Table 16.1 Modeling Management Maturity Model
Service-Oriented Architecture Can Create a New Hairball
SOA suggests an answer to the point-to-point integration problem through the creation of a service abstraction layer that hides the underlying data and system complexities from the builders of composite applications. Indeed, several years ago it would have been hard to find people worrying about data and integration problems during a discussion about SOA because people were worried about other problems (business/IT alignment, what ESB to use, how to monitor and manage the new system, etc.) and seemed to be under the impression that SOA would solve the data and integration problems.
Early practitioners quickly found that the data and integration problems were simply pushed down to another layer. In fact, because of the power of the new technologies to create services quickly, practitioners found that it was possible to create a new hairball in a fraction of the time it took to create the original hairball they were trying to fix. Figure 16.1 provides a visual description of how this new service layer creates a new hairball.
Figure 16.1 Services in an SOA creating a new integration hairball
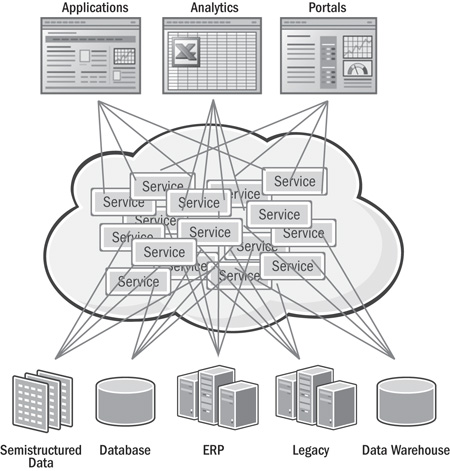
The bottom half of Figure 16.1 shows each service independently solving the problem of accessing and transforming data, typically through Java programs within the services. While the service abstraction layer certainly makes life easier for the users of the services in the top half of the figure, the producers of those services in the bottom half find that life gets worse. Because of the added layers of abstraction, it is now more difficult to determine the impact of a business or system change on the system. Additional modeling and data abstraction challenges are outlined in more detail in the next section, but the major takeaway here is that if abstraction is not added properly, with all important issues taken care of, it is best not to undertake SOA on a large scale.
So architects have begun to add a “data” service layer between the “business” service layer we see in the figure and the underlying physical systems, files, or interfaces that exist across the enterprise. Typically, this layer includes a logical, or canonical, model that attempts to model the data of the enterprise. In other words, a schema or model is presented that incorporates the critical enterprise data and relationships in a fashion that is entirely independent of the underlying applications, allowing business services to read and write these logical, canonical models using a variety of different delivery mechanisms, including Web services, SQL, XQuery, RSS, and others.
In an ideal world, this logical schema and the underlying “data services” that read and write data to the physical systems would function like a typical relational database, except that as shown in Figure 16.2, the virtual database would span whatever information systems were necessary to satisfy the user’s request. At design time, the canonical model and the necessary “read mappings” and “write mappings” that map and define the transformation rules between the logical canonical model and the underlying physical systems would provide the rules within which the optimizer would have to work. Business services or SQL requests coming into the canonical model would cause the optimizer to generate the appropriate run-time “data services” to fulfill the requests or commands.
Figure 16.2 Canonical models and data services in an SOA
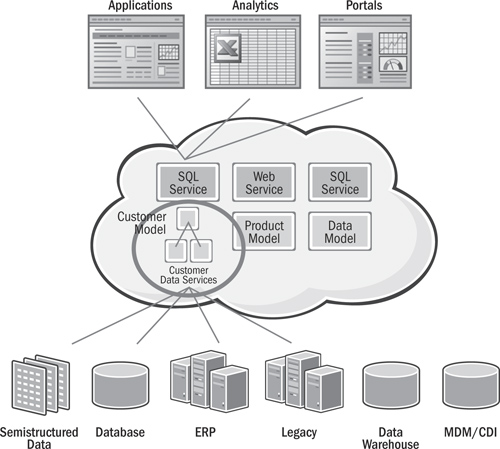
In some ways, this describes how EII products work, except that for this to be helpful in facilitating the Lean principles of mass customization and planning for change (the benefit of a canonical layer), writing data would have to be handled with the same dexterity as reading data. Furthermore, access to all types of data (complex XML, ERP, mainframe, message queues, EDI, etc.), the ability to cleanse data or perform complex transformations en route, and the ability to provision data in multiple ways and monitor the SLAs of data access would all have to be supported in a high-speed, highly available fashion. Technology to meet these demands is just now becoming available.
Creating a canonical model is an extremely difficult exercise for reasons given in the next section. Failed enterprise data modeling exercises of past decades gave the canonical model concept a bad reputation. Certainly the difficulty of canonical models should not be minimized, but if the canonical model is actionable and useful, rather than just a static point-in-time model, it can provide significant business value in achieving the agility and business/IT alignment that SOA promises.
Challenges
The challenges that are addressed in this chapter are as follows:
• Communicating data semantics
• Achieving loosely coupled systems
• Sustaining enterprise models
• Maintaining efficiency and performance at run time
Communicating Data Semantics
Semantics (the meaning of data) is a complex issue in the world of computer software and comprises four categories:
• The syntax of the data element, which includes its type, length, format, valid values, and range limits
• The definition, which includes a name, prose description, source system of record, physical location, lineage (version), and other attributes, that is typically included in a metadata repository
• The process context, including business process state, update frequencies, access methods, legal limitations, domain of valid values, and their semantic meanings or business rules
• The relationship to other data elements or structures, including meta-metadata and other business rules or policies
In ICC: An Implementation Methodology, Integration Law #4 states, “Information adapts to meet local needs.”
The Information Engineering movement of the early 1990’s was based on the incorrect notion that an enterprise can have a single consistent data model without redundancy. A more accurate way to look at information is as follows:
Information = Data + Context
This formula says that the same data across different domains may have different meanings. For example, a simple attribute such as “Current Customer” can mean something different to the Marketing, Customer Service, and Legal departments. An extreme example is Gender, which you might think could only have two states: Male or Female—one particular enterprise has defined eight different genders. The same thing happens with natural languages (the various meanings that words adopt in different communities). The ICC must embrace informational diversity, recognizing that variations exist, and use techniques to compensate for them.2
2. John Schmidt and David Lyle, Integration Competency Center: An Implementation Methodology (Informatica Corporation, 2005), p. 13.
A formal standard to communicate semantics is still a new and emerging field. The Semantic Web initiative shows promise, but it focuses primarily on human-computer interactions and not computer-computer interactions.
Achieving Loosely Coupled Systems
There is a widely held belief that canonical data models are a major enabler for loose coupling, which is an enabler for business flexibility. This is true only if the models are used properly. Improper use of canonical techniques actually couples systems more tightly and adds costs without offsetting benefits.
Conventional thinking suggests that a canonical data model, one that is independent of any specific application, is a best practice. When each application is required to produce and consume messages in this common format, components in an SOA are more loosely coupled. Here is what Gregor Hohpe has to say in his book Enterprise Integration Patterns: “The Canonical Data Model provides an additional level of indirection between applications’ individual data formats. If a new application is added to the integration solution only transformation between the Canonical Data Model has to be created, independent from the number of applications that already participate.”3
3. Gregor Hohpe, Enterprise Integration Patterns (Addison-Wesley, 2003), p. 356.
The promised benefits of canonical modeling generally include increased independence of components, so that one can change without affecting other components, and simplified interactions, because all applications use common definitions for interactions. As a result, solutions are expected to be lower in cost to develop, easier to maintain, of higher quality in operation, and quicker to adapt to changing business needs.
The reality is that loose coupling requires much more than just canonical techniques. It must be part of a broader architecture strategy and development standards and encompass some or all of the items shown in Table 16.2.4
4. Adapted from Nicolai M. Josuttis, SOA in Practice: The Art of Distributed System Design (O’Reilly Media, 2007).
Table 16.2 Loose Coupling Practices and Their Cost Implications
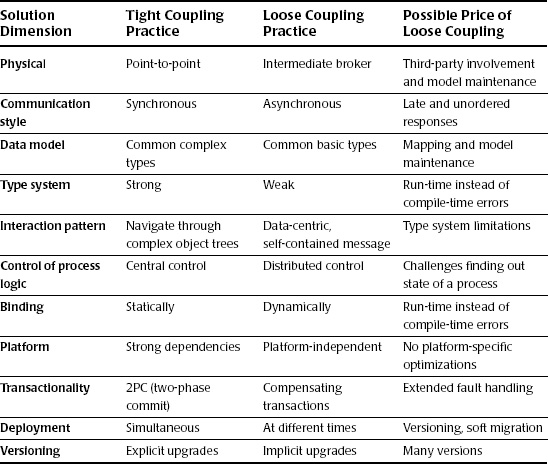
While canonical modeling can indeed provide benefits if used appropriately, there is also a cost that must be addressed. The canonical model and interchanges themselves are incremental components that must be managed and maintained. Canonical data models and interchanges require effort to define, introduce a middleware layer (either at build time or run time, depending on which techniques are used), and incur ongoing maintenance costs. These costs can exceed the benefits that the canonical models provide unless care is taken to use the techniques in the right circumstances.
Sustaining Canonical Models
Once canonical models are developed, there are a number of challenges associated with maintaining them so that they retain their value and provide ongoing benefits:
• If canonical models are not sustained, they quickly lose their value and may in fact add complexity without associated benefits.
• Canonical models are sometimes linked to industry or standard models (to some degree) and require ongoing efforts to keep them current and relevant.
• The cost to sustain canonical models can be significant (e.g., a rule of thumb is that one FTE is needed for every 1,500 attributes or 200 entities/objects).
• Since canonical models are not directly linked to specific cost-justified projects, it may be difficult to justify the cost to sustain them.
• Unstructured tools (such as Microsoft Excel) are inadequate for anything other than the simplest canonical models.
• Specialized tools for effective management of complex models can be expensive and most likely need a business case.
Maintaining Efficiency and Performance at Run Time
Canonical techniques, if used improperly, can have serious negative implications on performance and operations. Here are some of the key challenges:
• Nontransparent transformations: Canonical formats are most effective when transformations from a component’s internal data format to the canonical format are simple and direct with no semantic impedance mismatch. (But rarely are these format transformations simple.)
• Indirection at run time: While integration brokers (or ESBs) are a useful technique for loose coupling, they also add a level of indirection that complicates debugging and run-time problem resolution. The level of complexity can become almost paralyzing over time if process scenarios result in middleware calling middleware with multiple transformations in an end-to-end data flow. The benefits of loose coupling can be offset by the cost of administering the added abstraction layer over time.
• Inadequate exception handling: The beauty of a loosely coupled architecture is that components can change without impacting others. The danger is that in a large-scale distributed computing environment with many components changing dynamically, the overall system-of-systems can start to demonstrate chaotic (i.e., unexpected) behavior.
• Performance degradation: Middleware can add overhead (in comparison to point-to-point interfaces), especially if a given interaction involves multiple transformations to or from canonical formats.
Coupling and Cohesion Framework
This section represents work done by John Schmidt in several large corporate IT organizations over a five-year period. These efforts culminated in the formalization and publication of the BEST architecture while he served as the head of enterprise architecture at Wells Fargo Bank. The motivation was to provide practical “canonical” techniques and to clarify this typical IT industry buzzword—that is, an overloaded term with multiple meanings and no clear agreement on its definition. Schmidt’s contribution to the industry in this effort was twofold:
• A coupling and cohesion framework that serves as a classification scheme for comparing canonical techniques (described in this section)
• Explicit definition of three distinct and complementary canonical modeling techniques, described in more detail in the following section:
2. Canonical interchange modeling
The best architectural style in any given situation is the one that most closely addresses the functional and nonfunctional needs of the client. That said, there are two qualities that are highly desirable in any large distributed application environment: loose coupling and high cohesion. (We defined coupling and cohesion in the Wells Fargo case study at the end of Chapter 15.) These qualities fight each other. Techniques that result in loose coupling often result in low cohesion, and techniques that achieve high cohesion often result in tight coupling. An architectural style that finds an optimal balance between these two forces is the holy grail.
If we plot these two dimensions along the x- and y-axes and divide the resultant matrix in half, we end up with four quadrants as shown in Figure 16.3. The labels given to each of the four quadrants in the matrix are shorthand descriptions to characterize the kinds of solutions that are typically found in each quadrant. The architectural style of each of the quadrants is outlined here:
• Agile BPM (business process management): Components are engineered around an ME&C enterprise-wide functional domain model. When implemented using loose coupling techniques, this is the holy grail of high reliability, low cost, and flexible business process solutions.
• ERP (enterprise resource planning): This architectural style is suitable for many needs but perceived as expensive to implement and inflexible to change. It is most effective in functional domains that are relatively stable.
• EDA (event-driven architecture): Typical applications are extremely loosely coupled one-to-many publish/subscribe processes or many-to-one event correlation solutions such as fraud detection or monitoring.
• Legacy integration: This is a portfolio of coarse-grained legacy systems that were acquired without a master reference architecture and were integrated using hard-coded point-to-point interfaces. This style is not desirable but it is a pragmatic reality in many organizations.
Figure 16.3 Coupling and cohesion relationship
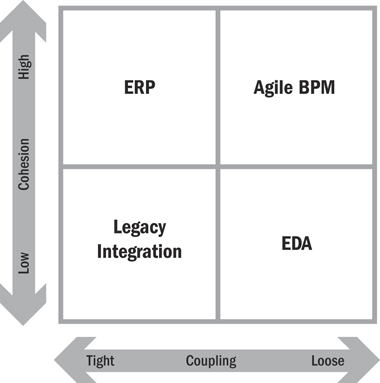
The “Agile BPM” quadrant is the most desirable, but also the hardest to achieve, and may never be fully realized since some techniques that result in high cohesion also result in tight coupling and vice versa. Furthermore, other factors such as the practical limitations related to modifying legacy systems, budget/time constraints, or infrastructure capabilities also can get in the way of achieving the nirvana environment.
Canonical Modeling Techniques
The importance of canonical data models grows as a system grows. Canonical data models reduce the number of transformations needed between systems and reduce the number of interfaces that a system supports. The need for this is usually not obvious when there are only one or two formats in an end-to-end system, but when the system reaches a critical mass in number of data formats supported (and in work required to integrate a new system, customer, or document type), having one or more canonical models becomes important.
B2B systems often grow organically over time to include systems that an organization builds or buys. For example, if a B2B system accepts 20 different inputs, passes that data to legacy systems, and generates 40 different outputs, it is apparent that unless the legacy system uses some shared canonical model, introducing a new input type requires modifications to the legacy systems, flow processes, and other areas. Put simply, if you have 20 different inputs and 40 different outputs, and all outputs can be produced from any input, you will need 800 different paths unless you take the approach of transforming all inputs to one or more canonical forms and transforming all responses from one or more forms to the 40 different outputs.
The cost of creating canonical models is that they often require design and maintenance involvement from staff on multiple teams.
This section describes three canonical techniques that can help to address the issues of data heterogeneity in an environment where application components must share information in order to provide effective business solutions:
2. Canonical interchange modeling
For a large-scale system-of-systems in a distributed computing environment, the most desirable scenario is to achieve loose coupling and high cohesion, resulting in a solution that is highly reliable, efficient, easy to maintain, and quick to adapt to changing business needs. Canonical techniques can play a significant role in achieving this ideal state.
Figure 16.4 illustrates how the three canonical techniques generally align with and enable the qualities in each of the four coupling/cohesion quadrants. There is some overlap between the techniques since there is no hard black-and-white definition of these techniques and their impact on a specific application.
Figure 16.4 Canonical techniques in relation to the coupling-cohesion framework
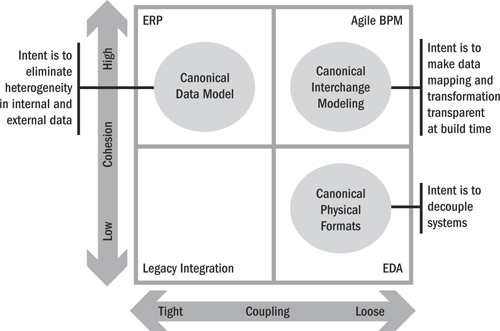
Each of the three techniques has a “sweet spot”; that is, they can be applied in a way that is extremely effective and provides significant benefits. The application of these methods to a given implementation imparts architectural qualities to the solution. This approach does not attempt to prescribe which qualities are desirable or not since that is the responsibility of the solutions architect to determine. For example, tight coupling could be a good thing or a bad thing depending on the needs and expectations of the customer. Tight coupling generally results in better response time and network performance in comparison to loose coupling, but it also can have a negative impact on the adaptability of components.
Furthermore, the three canonical approaches are generally not used in isolation; they are typically used in conjunction with other methods as part of an overall solutions methodology. As a result, it is possible to expand, shrink, or move the “sweet spot” subject to how it is used with other methods. This does not address the full spectrum of dependencies with other methods and their resultant implications, but it does attempt to identify some common pitfalls to be avoided.
When, and exactly how, to apply the canonical best practices should be a conscious, well-considered decision based on a keen understanding of the resulting implications.
Canonical Data Modeling
Canonical data modeling is a technique for developing and maintaining a logical model of the data required to support the needs of the business for a subject area. Some models may be relevant to an industry supply chain, the enterprise as a whole, or a specific line of business or organizational unit. The intent of this technique is to direct development and maintenance efforts so that the internal data structures of application systems conform to the canonical model as closely as possible.
This technique seeks to eliminate heterogeneity by aligning the internal data representation of applications with a common shared model. In an ideal scenario, there would be no need to perform any transformations at all when moving data from one component to another, but for practical reasons this is virtually impossible to achieve at an enterprise scale. Newly built components are easier to align with the common models, but legacy applications may also be aligned with the common model over time as enhancements and maintenance activities are carried out.
Common Pitfalls
• Data model bottleneck: A canonical data model is a centralization strategy that requires an adequate level of ongoing support to maintain and evolve. If the central support team is not staffed adequately, it will become a bottleneck for changes that could severely impact agility.
• Heavyweight serialized objects: There are two widely used techniques for exchanging data in a distributed computing environment: serialized objects and message transfer. The use of serialized objects can negate the positive benefits of high cohesion if they are used to pass around large, complex objects that are not stable and subject to frequent changes. The negative impacts include excessive processing capacity consumption, increased network latency, and higher project costs through extended integration test cycles.
Canonical Interchange Modeling
Canonical interchange modeling is a technique for analyzing and designing information exchanges between services that have incompatible underlying data models. This technique is particularly useful for modeling interactions between heterogeneous applications in a many-to-many scenario.
The intent of this technique is to make data mapping and transformations transparent at build time. This technique maps data from many components to a common canonical data model which thereby facilitates rapid mapping of data between individual components, since they all have a common reference model.
Common Pitfalls
• Mapping with unstructured tools: Mapping data interchanges for many enterprise business processes can be extremely complex. For example, Excel is not sophisticated enough to handle the details in environments with a large number of entities (typically over 500) and with more than two source or target applications. Without adequate metadata management tools, the level of manual effort needed to maintain the canonical models and the mappings to dependent applications in a highly dynamic environment can become a major resource drain that is not sustainable and is error-prone. Proper tools are needed for complex environments.
• Indirection at run time: Interchange modeling is a “design time” technique. Applying the same concept of an intermediate canonical format at run time results in extra overhead and a level of indirection that can significantly impact performance and reliability. The negative impacts can become even more severe when used in conjunction with a serialized object information exchange pattern, that is, large, complex objects that need to go through two (or more) conversions when being moved from application A to application B (this can become a showstopper for high-performance real-time applications when SOAP and XML are added to the equation).
Canonical Physical Format
The canonical physical format prescribes a specific run-time data format and structure for exchanging information. The prescribed generic format may be derived from the canonical data model or may simply be a standard message format that all applications are required to use for certain types of information.
The intent of this technique is to eliminate heterogeneity for data in motion by using standard data structures at run time for all information exchanges. The format is frequently independent of either the source or the target system and requires that all applications in a given interaction transform the data from their internal format to the generic format.
Common Pitfalls
• Complex common objects: Canonical physical formats are particularly useful when simple common objects are exchanged frequently between many service providers and many service consumers. Care should be taken not to use this technique for larger or more complex business objects since it tends to tightly couple systems, which can lead to longer time to market and increased maintenance costs.
• Nontransparent transformations: Canonical physical formats are most effective when the transformations from a component’s internal data format to the canonical format are simple and direct with no semantic impedance mismatch. Care should be taken to avoid semantic transformations or multiple transformations in an end-to-end service flow. While integration brokers (or ESBs) are a useful technique for loose coupling, they also add a level of indirection that can complicate debugging and run-time problem resolution. The level of complexity can become paralyzing over time if service interactions result in middleware calling middleware with multiple transformations in an end-to-end data flow.
• Inadequate exception handling: The beauty of a loosely coupled architecture is that components can change without impacting others. The danger is that in a large-scale distributed computing environment with many components changing dynamically, the overall system-of-systems can assume chaotic (unexpected) behavior. One effective counter-strategy is to ensure that every system that accepts canonical physical formats also includes a manual work queue for any inputs that it can’t interpret. The recommended approach is to make exception handling an integral part of the normal day-to-day operating procedure by pushing each message/object into a work queue for a human to review and deal with.
Navigating the Modeling Layers
The benefits of loose coupling can be undone if the cost of managing the complexity introduced by the additional layers of abstraction is not mitigated. The way to do this is to use the metadata management competency to tie everything together. Once again, one should not take the metadata framework diagram in Figure 16.5 too literally (there aren’t necessarily just four layers, and what you really want in each layer is up to you), but the important concept is the need to see, down to a data element level, how information is accessed or changed from both the business and the IT perspectives. Regarding the management of canonical models, one needs the ability to see, among other things,
• How the canonical model has changed over time
• How the canonical model accesses underlying physical data
• Who uses the different canonical models and when
Figure 16.5 Modeling management required for data services support
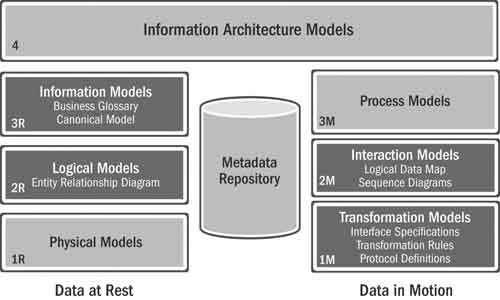
Different roles (architects, analysts, and developers) need to navigate the different layers of this model, up, down, and across, in a manner that is appropriate to their role and the questions they are trying to answer. Whether we’re talking about structural metadata, business metadata, or operational metadata, all aspects need to be tied together through relationships within the metadata repository and reported on or displayed in a way that is appropriate to the different users.
Achieving the benefits of planning for change and mass customization is more a problem of people, process, and governance than of technology. For all the talk in this chapter about metadata, virtual databases, and SOA, we recognize that business/IT alignment and business/business alignment regarding managing enterprise information is the harder problem. We address some of these issues in the next section.
Activities
Canonical models may be defined in any number of business functional or process domains at one of four levels:
1. B2B: external intercompany process and data exchange definitions
2. Enterprise: enterprise-wide data definitions (i.e., master data management programs)
3. Business unit: specific business area or functional group within the enterprise
4. System: a defined system or system-of-systems
For example, a supply chain canonical model in the mortgage industry is MISMO, which publishes an XML message architecture and a data dictionary for
• Underwriting
• Mortgage insurance applications
• Credit reporting
• Flood and title insurance
• Property appraisal
• Loan delivery
• Product and pricing
• Loan servicing
• Secondary mortgage market investor reporting
The MISMO standards are defined at the B2B level, and companies in this industry may choose to adopt these standards and participate in their evolution. Even if a company doesn’t want to take an active role, it no doubt needs to understand the standards since other companies in the supply chain will send data in these formats and may demand that they receive information according to these standards.
A company may also choose to adopt the MISMO standard at the enterprise level, possibly with some extensions or modifications to suit its internal master data management initiative. Or one business unit such as the mortgage business within a financial institution may adopt the MISMO standards as its canonical information exchange model or data dictionary—again possibly with extensions or modifications. Finally, a specific application system, or collection of systems, may select the MISMO standards as its canonical model—also with some potential changes.
In one of the more complex scenarios, a given company may need to understand and manage an external B2B canonical model, an enterprise version of the canonical format, one or more business unit versions, and one or more system versions. Furthermore, all of the models are dynamic and change from time to time, which requires careful monitoring and version control. A change at one level may also have a ripple effect and drive changes in other levels (either up or down).
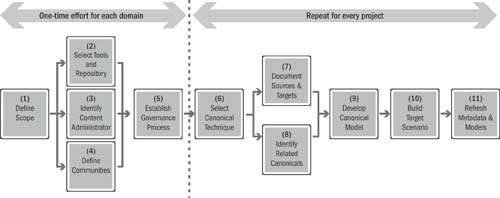
As shown in Figure 16.6, steps 1 through 5 are a one-time effort for each domain, whereas steps 6 through 11 are repeated for each project that intends to leverage the canonical models.
1. Define the scope: Determine the business motivation, functional or process domain, and level (i.e., supply chain, enterprise, business unit, or system) of the canonical modeling effort. Typical motivations include
• Custom in-house development of a family of applications
• Alignment with (and simplification of transformation with) industry or supply chain data/process models
• Real-time ICC in support of flow-through processing or business event monitoring
• Data standards in support of an SOA
2. Select the tools and repository: In small-scale or simple domains, tools such as Excel and a source code repository may be adequate. In complex environments with many groups/individuals involved, a more comprehensive structured metadata repository is likely to be needed along with a mechanism for access by a broad range of users.
3. Identify the content administrator: In small-scale or simple domains, the administration of the canonical models may be a part-time job for a data analyst, metadata administrator, process analyst, or developer. In large and complex environments, a separate administrator is often required for each level and each domain.
4. Define communities: Each level and each domain should have a defined community of stakeholders. At the core of each community are the canonical administrator, data analysts, process analysts, and developers who are directly involved in developing and maintaining the canonical model. A second layer of stakeholders consists of the individuals who need to understand and apply the canonical models. A third and final layer of stakeholders is composed of individuals such as managers, architects, program managers, and business leaders who need to understand the benefits and constraints of canonical models.
5. Establish the governance process: Define how the canonical models will develop and change over time and the roles and authority of the individuals in the defined community. This step also defines the method of communication among individuals, frequency of meetings, versioning process, publishing methods, and approval process.
6. Select the canonical technique: Each project needs to decide which of the three techniques will be used: canonical data modeling, canonical interchange modeling, or canonical physical formats. This decision is generally made by the solution architect.
7. Document sources and targets: This step involves identifying existing documentation for the systems and information exchanges involved in the project. If the documentation doesn’t exist, in most cases it must be reverse-engineered unless a given system is being retired.
8. Identify related canonicals: This step involves identifying relevant or related canonicals in other domains or at other levels that may already be defined in the enterprise. It is also often worth exploring data models of some of the large ERP systems vendors that are involved in the project, as well as researching which external industry standards may be applicable.
9. Develop the canonical model: This step involves an analysis effort, an agreement process to gain consensus across the defined community, and a documentation effort to capture the results. The canonical model may be developed either top-down, based on the expertise and understanding of domain experts; bottom-up, by rationalizing and normalizing definitions from various systems; or by adopting and tailoring existing canonical models.
10. Build the target scenario: This step is the project effort associated with leveraging the canonical model in the design, construction, or operation of the system components. Note that the canonical models may be used only at design time, in the case of canonical interchange modeling, or also at construction and run time, in the case of the other two canonical techniques.
11. Refresh the metadata and models: This is a critical step to ensure that any extensions or modifications to the canonical models that were developed during the course of the specific project are documented and captured in the repository and that other enterprise domains that may exist are aware of the changes in the event that other models may be affected as well.
Figure 16.6 Modeling management 11-step process
Summary
The key best practices are the following:
• Use canonical data models in business domains where there is a strong emphasis on building rather than buying application systems.
• Use canonical interchange modeling at build time to analyze and define information exchanges in a heterogeneous application environment.
• Use canonical physical formats at run time in many-to-many or publish/subscribe integration patterns, in particular in the context of a business event architecture.
• Plan for appropriate tools such as metadata management repositories to support architects, analysts, and developers.
• Develop a plan to maintain and evolve the canonical models as discrete enterprise components. The ongoing costs to maintain the canonical models can be significant and should be budgeted accordingly.
In summary, there are three defined canonical approaches among the five best practices, each of which has a distinct objective. Each method imparts specific qualities to the resultant implementation that can be compared using a coupling/cohesion matrix. It is the job of the architect and systems integrator to select the methods that are most appropriate in a given situation. The methods can be very effective, but they also come with a cost, so care should be taken to acquire appropriate tools and to plan for the ongoing maintenance and support of the canonical artifacts.
Case Study: European Interoperability Framework
The European Interoperability Framework for Pan-European Government Services is a useful case study and provides some context for effective practices. It defines three categories of interoperability:
1. Technical interoperability covers the technical issues of linking computer systems and services. It includes key aspects such as open interfaces, interconnection services, data integration and middleware, data presentation and exchange, accessibility, and security services.
2. Semantic interoperability is concerned with ensuring that the precise meaning of exchanged information is understandable by any other application that was not initially developed for this purpose. Semantic interoperability enables systems to combine received information with other information resources and to process it in a meaningful manner.
3. Procedural interoperability is concerned with defining business goals, modeling business processes, and bringing about the collaboration of administrations that wish to exchange information and may have different internal structures and processes. Moreover, procedural interoperability aims at addressing the requirements of the user community by making services available, easily identifiable, accessible, and user-oriented.
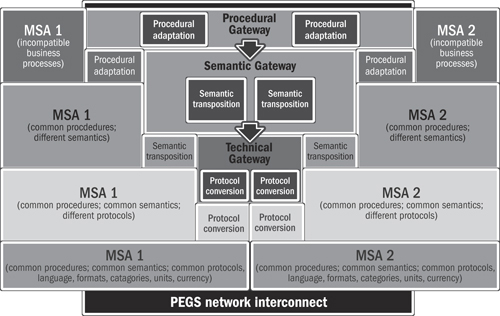
The European Interoperability Framework results in a three-layer architecture as shown in Figure 16.7:
1. Protocol conversion: Incompatible protocols, formats, or syntax requires technical conversion. That is, if you were to convert A to B and then convert B to A, you would end up with exactly what you started with. Protocol conversions are deterministic and mathematical in nature. A simple example is currency conversions or converting a two-letter state abbreviation into a numeric code based on a conversion table.
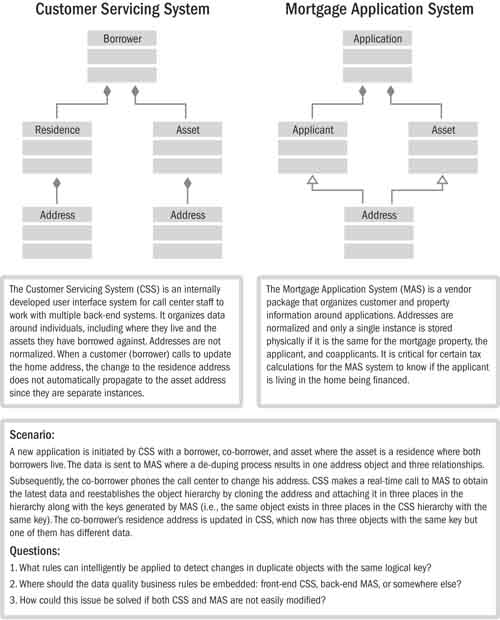
2. Semantic transposition: Incompatible data definitions require semantic transposition. This means that when you convert A to B and then B back to A, you end up with something similar but not identical. For example, if system A supports 20 product codes and system B supports only 10 product codes, some of which are aggregates, a conversion from B back to A may not give exactly the same result. Another example is relational versus hierarchical data structures. System A has a relational model where two individuals in the same household point to the same address record; this is translated into system B where the address information is duplicated for each individual. The question, then, when converting B back to A, is whether the individuals are really in the same household or are independent individuals who happen to be living at the same address.
3. Procedural adaptation: Incompatible business processes require procedural adaptation. This level of transformation deals with more complex issues where the only thing that the two entities can agree upon is the goal. For example, the process of opening a credit card account may be so different from that of opening a mortgage account that only the end point (i.e., an opened account) can have a common definition.
Figure 16.7 Graphical representation of the European Interoperability Framework
Case Study: Object-Relational Mismatch
There are sometimes very subtle differences in the meaning of data that are hidden inside the applications and the databases that control them. One such example is the object-relational impedance mismatch that is caused by encapsulation and hidden representations, data type differences, structural and integrity differences, and transactional differences.
An example scenario is shown in Figure 16.8, demonstrating how a simple difference in structure between two applications sharing data can cause problems. The scenario looks at two ways that address information commonly associated with individuals.
Figure 16.8 Semantic example of object-relational impedance mismatch