
Chapter Thirteen. Metadata Management
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.
Leslie Lamport1
1. http://en.wikipedia.org/wiki/Leslie_Lamport.
In a product factory, people can touch and see the goods being manufactured. In the integration and data management world, however, humans cannot see and touch the assets directly; we can only see representations of bits and bytes on computer screens, handheld devices, or paper printouts. Data and software services are definitely real, but there must be a way of tracking these ethereal objects to make up for the fact that we cannot see or touch them directly.
Metadata provides the blueprint for data in an organization. Metadata is also the information describing the data and data processes that enable efficient factory operations and automation. The metadata management competency is possibly the single most important technical requirement behind the success and growth of Lean Integration and the Integration Factory concept. The Integration Factory is possible only with the proper management of metadata (data about data) in conjunction with appropriate technology and processes.
Metadata is conceptually simple. It is documentation about data in terms of what it means; where it is located; when its definition was changed; how it is accessed, moved, and secured; who is responsible for it; who is allowed to use it; and so on.
Analogous to the blueprints that guide the construction of a building, metadata and the models and reports that are generated can be seen as the engineering blueprints of data for an enterprise. In fact, just as there are structural, electrical, and other blueprint views of a building, so do there need to be alternative views of metadata to support the different roles and uses in the business and IT functions.
However, there are several key differences between building blueprints and metadata repositories:
1. Blueprints represent the target architecture of a building, whereas data models (to be useful beyond the initial project) must reflect the changes made in the actual construction. For practical reasons, both buildings and IT systems may deviate from the target architecture during construction, but unlike a building, which is relatively static once completed, IT systems are dynamic and constantly changing. So it is critical that the data models be constantly updated to reflect the current state of production operations.
2. Blueprints are static models representing a point-in-time snapshot, whereas data models are dynamic and at the push of a button can be regenerated based upon the contents of the metadata repository. Maintaining a repository of structured data along with tools to generate models is a different discipline from working with hand-drawn models.
By capturing metadata, the IT organization has the ability to measure, manage, and improve its operations. Capturing metadata is critical to efficiently controlling change in enterprise systems, data, and services and the relationships among them. Metadata management provides the foundation to unraveling the complexity of the hairball. When all the integration points between enterprise applications are understood, managed, and controlled, the integration hairball is transformed into an integration system. Organizations that consider data to be an important asset commonly establish dedicated teams to manage metadata in order to ensure its quality and usefulness.
The metadata management maturity table (Table 13.1) provides a rough outline for four levels of metadata maturity. While there is a certain amount of subjectivity around some of the definitions, the outline is a useful tool for assessing an organization’s current level of maturity and for establishing a desired target maturity level.
Table 13.1 Metadata Management Maturity Model
Metadata Scope for Lean Integration
The potentially limitless scope of a metadata management competency is one of the first big problems to tackle. Metadata is yet another “boiling the ocean” problem—it’s too big to tackle all at once, but if you select just a small, manageable scope, it may be too small to add value. Certainly, having a single enterprise metadata repository that contains all necessary information about all IT and business assets across the enterprise might seem like a valuable system, but many metadata initiatives collapse under this vast scope. For the purposes of Lean Integration, let us try to rein in the scope to something more manageable, achievable, and valuable.
In most IT departments, metadata is stored in proprietary repositories in many different tools such as the categories shown in Figure 13.1. The trick to making it useful for the business and IT is to pull the metadata together and determine how metadata in the different environments is related to other metadata.
Figure 13.1 Metadata dimensions
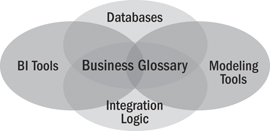
Let’s use an analogy with Google. In some ways, Google had it easy. Thanks to HTTP, HTML, and other standards, Google could create spider programs that crawl the highly homogeneous content of the World Wide Web and understand how pages are linked to each other. Google developed algorithms to score this information so that searching the content would provide highly useful results. In the metadata world of enterprise data, there are few standards yet that allow this kind of cross-vendor metadata crawling, but several companies have made good progress in starting to solve this problem, providing a way to understand and navigate the linkages between metadata objects that come from different vendors.
Once these linkages are known, it is possible to begin crawling specific threads of the integration system, allowing people to understand where business terms can be found, how those business terms map to underlying databases, how changing one item might impact others, and so on.
To support a more mature Integration Factory, the metadata management capability can be extended so that the Venn diagram in Figure 13.2 includes other outlying and related metadata.
Figure 13.2 Metadata context diagram
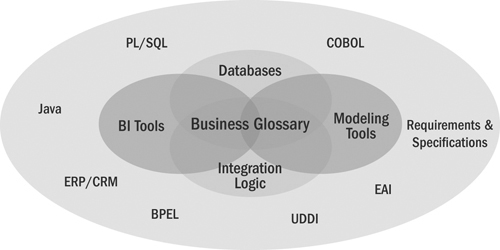
The outer ring in the figure presents additional challenges that can’t all be tackled at once, but it is helpful to set the long-term vision for relevant metadata extensions after the core has been developed. The outer ring allows for an expansion of the factory to additional areas of the metadata management capability, in the priority order of cost and benefit as seen by the customers.
Metadata Management Framework
Our goal is to achieve a level of metadata management competency that allows different roles, working together as part of a Lean Integration team, to navigate the integration system in a manner appropriate to their roles in the organization. Analysts have a different perspective from developers, for instance. Business users are interested in business terms, metrics, reports, and such. Developers are interested in this information plus technical details such as primary or secondary keys, encryption, masking, and relationships between data elements. Additionally, different roles have different tolerances for complexity and detail. Therefore, a metadata management system must incorporate the needs of the people who will be using the information, and it must be tailored to their needs.
In order to navigate the integration system effectively, “metadata visualization” techniques need to be developed to the level of maturity that “data visualization” currently enjoys.
There are several different graphical, pictorial views of metadata that help to document the hairball:
• “Data at rest”: This is our well-known phrase to describe how highly mature visualization capabilities like data models and schema diagrams help to show the way data elements, entities, and objects are related to each other.
• “Data in motion”: This graphical view of metadata describes how data changes as it moves, either virtually or physically, from its source to its destination. We overload “data in motion” to include descriptions of services, processes, and other workflow-like documentation.
In Figure 13.3, physical metadata describing “data at rest” and “data in motion” is relevant to developers and administrators. As one moves up the layers, the metadata becomes more and more relevant to the business audience. At the top level is the most abstract business documentation, which describes how a company does business, defines its terms, and so forth.
Figure 13.3 Information architecture framework
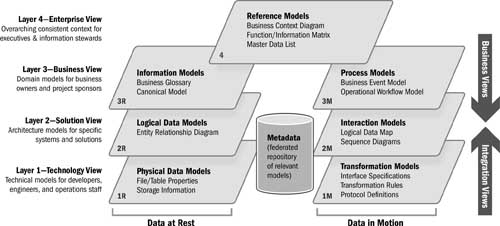
We will be using this information architecture framework as we work through the competencies in the next several chapters to discuss the relationships that bind the competencies together through metadata. While we find this framework useful, we don’t mean for this picture and its layers to be taken too literally. Concepts are missing from this diagram, and others may draw more layers or include a third dimension denoting the change in objects over time, for instance. This framework is intended to communicate the categories of metadata information and its potential to describe the complete hairball in a way that allows navigation and understanding of complex systems.
Metadata management is not just collecting the information; its value is that it allows analysts, architects, stewards, developers, and administrators to search, view, understand, change, and maintain the information that is relevant to their work. In other words, different roles should be able to quickly and easily navigate up, down, and across the stacks of the framework to understand data at rest and be able to link across to see how data is used in motion. All too often metadata projects have ended up creating a “metadata roach motel” where metadata comes in but no value comes out. In our view, to move up the maturity ladder requires giving the different roles the ability to get the information they need to do their jobs.
The framework features a four-layer architecture in which each layer focuses on a level of abstraction that is relevant to a particular category of stakeholders and the information they need:
• Layer 4—enterprise view: overarching context for information owners, governance committees, enterprise architects, and stewards
• Layer 3—business view: domain models for business owners, project sponsors, SMEs, and program managers
• Layer 2—solution view: architecture models for solution architects, designers, and analysts for specific systems and solutions
• Layer 1—technology view: technical models for developers, engineers, and operations staff
Layers 1 and 2 are typically created bottom-up (except when custom-developing applications), and layers 3 and 4 are created top-down.
Relevant information about the models is maintained in a metadata repository that is typically federated (i.e., having multiple repositories, each housing specific types of metadata models with common keys that can be used to link models to develop a consolidated view if required). Models are maintained for data at rest (i.e., data persisted and maintained by an application system) and data in motion (i.e., data exchanged and possibly transformed between applications). Sometimes the distinction is tricky, as with “view definitions” in a relational database. These definitions both define data at rest (the structure of the view name and fields as seen by someone accessing the view) as well as data in motion (the definition of the query that populates the view results that are returned).
Chapter 14 on Information Architecture provides a more complete description of all the model types.
There is an additional dimension to the diagram in Figure 13.3 that is critical to visualize. Behind all the objects implied, there is the historical knowledge of that object and how it has changed over time. For instance, to have a full view and understanding of a system, it can be useful to see the requirements documents and design specifications that were behind the original reasoning and development of systems. As discussed in Chapter 9, industry data models are purchasable to jump-start some data projects that appear at first glance to be valuable. Descriptions of data models without an understanding of the original requirements and business use cases can make it extremely challenging to figure out how to actually use these industry models.
Additionally, change histories of how metrics, services, or other objects have changed or grown over time are critical to know. Figure 13.3 should be seen only as the current-state picture for navigating the different layers of metadata and relationships between data at rest and data in motion. Keep in mind the third dimension (time) that associates the operational metadata behind the usage of objects, the original development of objects, and the continual change of those objects.
In other words, for metadata to become the active, live hypertext documentation for the integration environment, these views also need to show how IT systems and their dependencies change.
Challenges
While metadata is conceptually simple, there are a number of challenges associated with managing it in order to realize a business benefit.
Note: This competency does not focus on project challenges, but rather on challenges associated with sustaining a metadata practice in an ICC on an ongoing basis in support of either multiple projects or a broader data integration or data governance strategy.
Fully and accurately documenting the data in enterprise systems (and how data is accessed and moved) presents the following challenges:
• There are cost and risk concerns of an enterprise initiative versus a project initiative.
• Enterprise initiatives are perceived to be more costly to implement and the business case or ROI may not be clear (refer to Chapter 11, Financial Management, for guidance).
• Because of the inherent complexities associated with a cross-organizational program, enterprise initiatives are perceived as having a higher risk of failure (i.e., accomplishing a practical result).
• Robust process and information models are required but there are few generally accepted best practices. The general issues relate to
• The need for a service-centric foundation (i.e., defining IT capabilities as services)
• Logical to physical traceability
• Dependency management
• Modeling data at rest versus data in motion
• Metadata that is derived from a variety of sources and tools is often disparate, fragmented, and inconsistent and serves different purposes.
• Various types of metadata come from sources such as RDBMS, XML, mainframes, and so on.
• Descriptive (or business) metadata is used to describe the content of the metadata (e.g., zip code, bill of sale, sales data, etc.).
• Administrative (or operational) metadata is used to manage the operations of the metadata (e.g., records read, time process, etc.).
• Structural (or technical) metadata is used to describe the physical characteristics of the metadata (e.g., field name, data type, table name, table space, etc.).
• The value of metadata is largely underestimated and not necessarily a common development practice when constructing business applications.
• In general, the value of documentation on a project is not high (except for very large projects) since the scope and complexity are generally small enough that more informal methods like model sketches, whiteboards, “quick and dirty” spreadsheets, or developers simply remembering it are often quite effective and efficient in the short term.
• The following examples highlight how it is only after the project is over (or in the context of how the project impacts the broader enterprise) that the value of metadata becomes more evident:
– Metadata can help with SOX compliance initiatives.
– Metadata can provide stronger governance of when and where data is used, eliminating costly research and underestimated scope for new projects.
– Metadata can provide better process control, much as pharmaceuticals use “lot numbers” for medicines and medical devices.
– Metadata will lead to the development of best practices for data integration as a whole.
• Data governance and stewardship programs that could provide overall direction and guidance are not fully in place.
• Having well-defined data stewards or owners is extremely important to the success of the use of metadata. (Refer to Chapter 14, Information Architecture, for guidance on how to do it and Chapter 11, Financial Management, for information on how to justify a broader program.)
Table 13.2 provides a high-level summary of common objections to a governance organization like an ICC and how the metadata management best practices can address these concerns.
Table 13.2 Objection Handling with Metadata Management

Prerequisites
The primary prerequisite for the metadata management competency is to have a defined enterprise integration, data governance, SOA, Lean Integration, or similar strategy. In other words, metadata management is not an end unto itself. It should be viewed as an enabler for a broader cross-functional strategy and clearly be linked to that strategy.
A second prerequisite is to have clear ownership and accountability assigned for the metadata management activities. The accountability may be assigned to an ICC, a data warehouse team, an SOA Center of Excellence (COE), a business intelligence (BI) COE, or other similar group that is operating as a shared-services group supporting all of the applicable functional teams. The critical factor is that the assigned group has a clear enterprise-wide charter.
It is possible to leverage the metadata management practices without these prerequisites, but only in the context of a more narrowly defined scope for a single project/program or a single functional group. While a smaller scope does not offer an enterprise-wide benefit, it can be an excellent way to build expertise and begin a grassroots movement to generate awareness and interest in the broader enterprise.
Some of the other competency areas are not necessarily prerequisites, but they are often complementary practices that should be implemented in concert with a metadata management practice. The most important ones are
• Information architecture (for providing meaningful views for different stakeholders)
• Modeling management (for sustaining and evolving the models and their relationships)
• Financial management (for justifying the required infrastructure and structuring appropriate operational funding)
Industry Practices
Much has been written on metadata. Unfortunately, the most common definition thrown about, that metadata is “data about data,” oversimplifies both what metadata is and how valuable it is. We describe metadata as “information about systems, processes, and information and how they work together that describes for the business and IT what they need to know to use, trust, change, and improve those systems, processes, and information.”
Metadata elements focus upon the category of information (whether source, target, or transient), the context of data depending upon the role, the resource using the data, or the format in which the information is stored or displayed. For business intelligence usage of metadata, descriptions may also include items such as policy and security rules that relate to enterprise roles and governance issues regarding access, as well as the method for how data should be displayed (e.g., full, mask, or no display). Some of this relates to the classification of data as being for confidential, restricted, or unrestricted usage.
Our earlier book2 contains a section on Advanced Concepts in Metadata. It defines the requirements for a scalable and predictable level of metadata service across the architect/design/build/deploy/operate/manage life cycle to include
2. John Schmidt and David Lyle, Integration Competency Center: An Implementation Methodology (Informatica Corporation, 2005), p. 134.
• System-to-system data flow maps
• Detailed and searchable schemas for all data flows
• Middleware configuration management and how components interact with the integration infrastructure
A metadata system is obligated to meet these requirements. Metadata is an established practice in many larger IT organizations. It began with basic “data dictionaries” that documented the business meaning of data elements and evolved into a general inventory of data, programs, and other IT assets. It has significant overlap with IT asset management and configuration management, and there is a general lack of consensus in the IT industry on the relative scope for these disciplines. Refer to section 8.6 of ICC: An Implementation Methodology3 for further details and background.
3. Ibid.
The wide range of industry definitions highlights the fact that metadata management is still an emerging practice area. The reality is that metadata—in terms of both data about data and data about data processes—has been around for as long as the software industry has existed. In the past, metadata was an inherent element of any operational system or infrastructure. For example, a source code management system had metadata about the source code, an integration hub contained metadata about data transformations, and a messaging infrastructure contained metadata about how messages flowed from queue to queue.
The big shift in recent years is the idea that metadata should be managed as a separate and distinct entity, that is, that it has value in its own right and can benefit the enterprise if managed effectively. Furthermore, this added emphasis on metadata is based on the idea that metadata turns information into an asset that can be leveraged to generate additional business benefits for an organization. In other words, metadata is now seen as something that should be abstracted and managed independently from the underlying assets.
The idea of dealing with metadata as a separate entity has driven another major trend: the need for general-purpose metadata repositories and the need to federate or synchronize metadata across multiple domains and across a wide range of technology components. While there are some excellent tools on the market, as a general rule metadata repositories are still relatively immature. This does not mean that the tools are not useful; to the contrary, they are an essential element of a metadata management practice since it is impossible to manage a large, complex enterprise just with simple tools like spreadsheets.
As a result of the immaturity of the technology and standards, many organizations do not realize the potential benefits of a metadata strategy if they view it strictly as a technology solution. An effective strategy also requires organizational buy-in, training, and support for a wide range of stakeholders who need to update the repository, and policies and procedures to enforce and monitor usage.
Metadata Management Governance
Metadata management within a governance organization typically has scope where it relates to data functions described by the organization’s charter. This organization has two considerations with metadata management: using automated middleware tools that contain metadata, and metadata found in custom code, custom dictionaries, spreadsheets, and other tools where metadata is manually entered. The recommended practice for capturing metadata is to load it automatically. Some tools lend themselves to automatic capture, while others require a custom development approach.
Each metadata attribute can be classified as either active or passive. Active metadata attributes are crucial to the operations of a particular software or integration component. For example, a connection to a database would be considered an active metadata object. Passive metadata attributes are more focused on documentation and classification of the metadata items.
Active metadata attributes should not be migrated on a bidirectional basis without understanding the full impact of such a change. Passive metadata attributes can be migrated bidirectionally without issues.
Activities
The key activities associated with implementing and operating a metadata management capability within the context of an ICC or data governance strategy are shown in Figure 13.4. The seven-step process is described in detail in the following sections.
Figure 13.4 Metadata management implementation steps
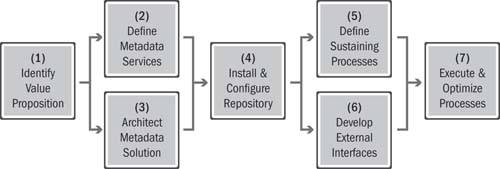
Step 1: Identify the Value Proposition
The starting point for implementing a metadata management competency is to define the purpose and business value of maintaining it. This is a critical aspect of addressing the “boiling the ocean” problem. It is expensive and time-consuming to collect and maintain metadata, so it should be done only for those elements that have a clear linkage to the defined business need.
It is particularly critical to have a clearly defined scope for the metadata management practice, including what services are offered, who the users/consumers of the services are, what the purpose of the practice is, how it is linked to the enterprise strategy, and which organizational unit is accountable.
• Metadata sponsorship needs to have an enterprise view as opposed to a project view.
• Metadata can be sponsored through a data warehouse initiative to look at information at an enterprise level.
• A shared or centralized ICC service model has an opportunity to look at things from an enterprise level.
• All data storage and movement should be incorporated so that metadata can be captured.
• Funding for a metadata initiative has to be top-down through an enterprise type of view and sponsorship.
If a business case is required to justify the cost and organizational change implications of a metadata management capability, refer to the section on Business Case Development in Chapter 11 on Financial Management.
Step 2: Define the Metadata Services
This activity accepts the output from step 1 and defines the metadata management services that will be offered to the organization. Here is a list of some commonly offered internal services:
• Project documentation: a service for project teams to capture and maintain relevant metadata in a central repository
• Compliance reporting: a service for enterprise risk and compliance officers to report on conformance to defined policies
• Data quality metrics: a service for business leaders and data stewards to track conformance to defined data quality standards
• Registration: a service for federated (distributed) repository owners to register and catalog their content in a central registry
• Synchronization and reporting: a service for business and IT management to perform ongoing production reporting of centralized or federated (distributed) metadata
• Discovery: a service for business and IT management to perform metadata search, analysis, and reporting both on a one-time basis and for special projects
• Cataloging and linking: a service for all metadata owners and consumers to maintain the system of record for the enterprise keys
There is a strong interplay between the ICC organizational model (best practices, technology standards, shared services, and central services) and the metadata services that can be offered. For example, if the ICC model is a best-practices ICC, it will not have either the resources or the mandate to actually administer and operate a metadata management office (MMO). The shared-services or central-services ICC models are best suited for an MMO, particularly since they commonly include a production control function.
A data stewardship program is strongly recommended to help with the governance issues. Data stewards are those who know their subject areas and will help define the business rules so that they can be used consistently and have a defined accountability for data quality.
Step 3: Architect the Metadata Solution
This activity, which may take place in parallel with step 2, addresses the technical and solution architecture needs of the metadata management competency. Key considerations are these:
• For consistency, metadata should be captured using automated tools. Metadata that is manually entered is neither consistent nor complete.
• Repository interface standards and supported protocols should be defined.
• The security infrastructure should be defined early to ensure flexibility in supporting different access requirements.
• Performance and scalability should be considered with an eye toward an 18- to 24-month capacity projection.
• An operational or deployment architecture is needed, especially if a high volume of changes is expected in the number and variety of future metadata sources.
• Repository tools and information exchange standards should be selected.
• Tools that don’t store metadata should be considered for replacement.
• Consider using industry standards where possible so that automatic tools can be purchased instead of homegrown.
Step 4: Install and Configure the Repository
This activity not only involves the physical installation and configuration of the repository hardware and software but also includes
• Reviewing and assessing metadata use cases
• Configuring out-of-the-box metadata access
• Determining meta-model extensions
• Inventorying metadata sources
• Defining requirements for custom interfaces
In summary, this activity is a key input for steps 5 and 6, which cannot effectively proceed without a clear definition of requirements and a development and test environment for the metadata repository.
Step 5: Define the Sustaining Processes
This activity is often one of the most complex tasks as it usually involves some amount of organization change and may impact how certain individuals perform their jobs. The specific activities will vary subject to the scope of the MMO and the details of the organizational changes that are needed. Following is a list of planning considerations:
• Metadata reports for business and technical users
• There should be several governance checkpoints linked to project deliverables, especially early in the project life cycle. Determining whether the project is on track is a manual effort unless metadata reports can be used to accurately reflect the progress of the project.
• Governance considerations
• Enforcement should occur early in the project life cycle to allow opportunity for correction.
• Production control standards include provisions for capturing metadata.
• Metadata capture should be part of each phase during project development.
• Metadata requirements should be established for any signoff of any phase of the project.
• The ICC should set guidelines and standards for what is required for each phase.
• The rationale is that once a project is close to delivery, many metadata requirements could extend the project beyond expectation.
• Enforcement of metadata standards should be tied to any production system requirements.
• Data stewardship
• A data stewardship program is recommended to help with the governance issues.
• Data stewards are those who know their subject area and will help define the business rules so that they can be used consistently.
• The ICC should set guidelines on how data stewardship is implemented and maintained.
• The ICC should set guidelines for the appropriate level of metadata required during the initial phases of metadata management.
• Data stewards should be “close to the business” in determining data needs and system requirements.
Step 6: Develop External Interfaces
This activity calls for design, development, testing, and deployment of interfaces to metadata sources within the enterprise (or external to the enterprise).
Note: All interface code should be reviewed for reuse purposes. Most rules should be stored centrally, in either a reusable object or a database table, so that they can be published for use.
Step 7: Execute and Optimize the Processes
This final activity is one that never ends (unless the original business need for metadata is eliminated). It involves
• Executing the processes defined in step 5
• Supporting an integrated engagement and fulfillment process for the services defined in step 2
• Performing ongoing process improvements
• Communicating (marketing) the results and value of the MMO to the internal stakeholders
• Looping back through steps 5 and 6 any time a significant change is made to the centralized repository or back to step 3 if a major change is planned that requires a re-architected solution