
APPENDIX 3
Choosing a Data Structure
A3.1 Introduction
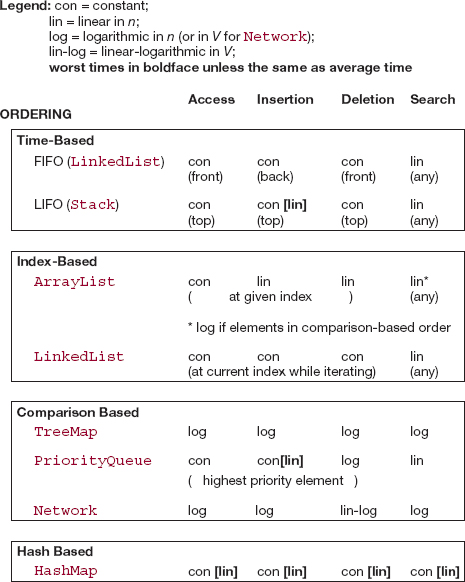
This appendix serves as a brief summary of much of the material from Chapters 6–8 and 12–15. In particular, we will categorize the eight major collection classes (ArrayList, LinkedList, Stack, Queue1, TreeMap, PriorityQueue, HashMap, Network) from those chapters in two different ways. The first classification will be by the ordering of the elements in the collection: time-based, index-based, comparison-based and hash-based. The second classification will be by the time to perform common operations on an element in the collection: access, insertion, deletion and search. For each such operation, averageTime(n) will be provided, that is, the average time (assuming each event is equally likely) to perform the operation in a collection of n elements. Whenever the estimate of averageTime(n) differs from the corresponding estimate for worstTime(n), both estimates will be given.
A3.2 Time-Based Ordering
For applications that utilize a time-based ordering, elements are removed from the collection in the same order they were inserted (First In, First Out), or in the reverse of that order (Last In, First Out). In the first case, an instance of the LinkedList class (Section 8.2.2) is appropriate, and an instance of the Stack class (Section 8.1) is called for in the second case.
For a LinkedList object, accessing the front element takes constant time, as does inserting at the back and deleting from the front. To search for a specific element in a LinkedList object, averageTime(n) is linear in n (asisworstTime(n)).
For a Stack object—implemented with an array in which the bottom of the stack is at index 0—accessing the top element takes constant time, as does popping the top element. To push an element onto the top of the stack, averageTime(n) is constant, but worstTime(n) is linear in n; the worst time occurs when the underlying array is already full before the insertion. To search for a specific element in a Stack object, averageTime(n) is linear in n (asisworstTime(n)).
A3.3 Index-Based Ordering
If the index of an element—0, 1, 2, and so on—is critical to the application, you have two choices: the ArrayList class (Section 6.2) or the LinkedList class (Section 7.3.1).
In the Java Collections Framework, the ArrayList class has an underlying array, and so accessing (or replacing) the element at a given index takes constant time in both the average and worst cases. Also, inserting or deleting at a given index entails moving the elements at higher indexes up (to make room for the insertion) or down (to close up the space of the deleted element). That is why insertion or deletion at a given index in an ArrayList object takes linear-in-n time in both the average and worst cases. Finally, searching for an element in an ArrayList object takes linear-in-n time, but only logarithmic-in-n time if the elements in the ArrayList object are in order according to a comparator.
Superficially, a LinkedList object is a pitiful choice: Both averageTime(n) and worstTime(n) are linear-in-n for accessing (or replacing) the element at a given index, as well as for inserting an element at—or deleting an element from—a given index. But LinkedList objects sparkle during an iteration: It takes only constant time to access (or replace) the "current" element, or to insert an element in front of the current element or to delete the current element. Finally, searching for an arbitrary element in a LinkedList object takes linear-in-n time.
The bottom line, as noted in Section 7.3.3 of Chapter 7, is this:
If the application entails a lot of accessing and/or replacing elements at widely varying indexes, an ArrayList object will be much faster than a LinkedList object. But if a large part of the application consists of iterating through a list and making insertions and/or removals during the iterations, a LinkedList object can be much faster than an ArrayList object.
A3.4 Comparison-Based Ordering
For many applications, the elements will be stored according to how they compare with each other. If the elements' class implements the Comparable interface, the comparisons are said to use the "natural" order. For an "unnatural" order—such as Integer elements in decreasing order, or String elements ordered by the length of the string—an implementation of the Comparator interface is appropriate. Section 11.3 of Chapter 11 has the details. In the Java Collections Framework's PriorityQueue class (Section 13.2), the focus of the comparisons is to identify the lowest valued (that is, highest priority) element. The framework's TreeMap (and TreeSet) class in Section 12.3 (and 12.5) utilizes a red-black tree to order all the elements in the collection.
A PriorityQueue object accesses the highest-priority element in constant time. Inserting an element takes constant time, on average, but worstTime(n) is linear in n: If the add (E element) method is called and the underlying array is full, that array must be resized. Removal of the highest-priority element takes logarithmic-in-n time in both the average and worst cases. The search for an arbitrary element takes linear-in-n time in both average and worst cases.
In the TreeMap class, each element is composed of a key—on which the ordering is based—and a value (the rest of the element). For both the average and worst cases, each of the following operations takes logarithmic-in-n time:
- accessing a value, given a key;
- putting a new element into the collection;
- removing an element from the collection;
- searching the collection for an element with a given key.
The Network (that is, weighted digraph) class (Section 15.6) is not part of the Java Collections Framework, but is well suited for a variety of applications, from scheduling to circuit-board wiring to analyzing web searches or social networks. In a network, the elements are called "vertices" or "nodes." The essential aspect in a network is the relationship, called an "edge" between two neighboring vertices. In the Network class, the only field is a TreeMap object in which each key is a vertex, and each value is the TreeMap object in which each key is a neighbor of the vertex, and each value is the weight of the edge connecting the vertex to the neighbor.
As you might expect, most of the usual operations have times that are similar to those of the TreeMap class. Specifically, with V representing the number of vertices and E the number of edges, the worstTime(V, E) and averageTime(V, E) are logarithmic in V for each of the following operations:
- accessing the neighbors of a given vertex;
- adding a new vertex to the network;
- searching the network for a given vertex.
In removing a vertex from a network, we must also remove all edges going to that vertex, and for this operation worstTime(V, E) and averageTime(V, E) are linear-logarithmic in V.
A3.5 Hash-Based Ordering
In some applications—such as the maintenance of a symbol table by a compiler—it is important to be able to access, insert, and search for elements in constant time on average, even if these operations might rarely take linear-in-n time. The elements need not be stored in any recognizable order, such as chronological, indexed, or comparator-based.
In the Java Collection Framework's HashMap class (Section 14.3), each element consists of a key/value pair. If the Uniform Hashing Assumption (Section 14.3.2) holds, the averageTime(n) is constant for each of the following operations:
- accessing a value, given a key;
- putting a new element into the collection;
- removing an element from the collection;
- searching the collection for an element with a given key.
Unfortunately, even if the Uniform Hashing Assumption holds, worstTime(n) is sluggish: linear-in-n for each of those four operations.
Table A3.1 encapsulates the preceding information.
A3.6 Space Considerations
The space requirements of your application may play a role in your choice of a data structure, and here are a few points worth noting. If the data structure has an underlying array (namely Stack, ArrayList, PriorityQueue, and HashMap), a too-large capacity may waste space. And a too-small capacity can entail frequent resizing, each of which takes linear-in-n time. A further complication involves the HashMap class: The time-efficiency of hashing is proportional to the unused space!
For the LinkedList classes, each entry includes previous and next fields as well as the element field, so the entry consumes three times as much space as the element itself. For a TreeMap, each entry includes left, right, parent, and color fields as well as the element field, so the entry consumes more than four times as much space as the element itself (the color field can take up just one byte).
Table A3.1 Summary of Time Estimates in Appendix 3
A3.7 The Best Data Structure?
As you can see from Table A3.1 and Section A3.6, there is no perfect data structure. Each data structure will be ideal for some applications and horrible for others. If even the possibility of linear-in-n time for the four common operations is unacceptable and space is not a factor, your best bet is the TreeMap class, whose worst times are logarithmic in n. And recall from Chapter 3 that the difference between constant time and logarithmic time is relatively small, but the difference between logarithmic time and linear time is relatively huge.
1 Implemented by LinkedList.