
CHAPTER 14
Hashing
We start this chapter by reviewing some search algorithms from earlier chapters as a prelude to the introduction of a new search technique: hashing. The basic idea with hashing is that we perform some simple operation on an element's key to obtain an index in an array. The element is stored at that index. With an appropriate implementation, hashing allows searches (as well as insertions and removals) to be performed in constant average time. Our primary focus will be on understanding and using the HashMap class in the Java Collections Framework, but we will also consider other approaches to hashing. The application will use hashing to insert identifiers into a symbol table.
CHAPTER OBJECTIVES
- Understand how hashing works, when it should be used, and when it should not be used.
- Explain the significance of the Uniform Hashing Assumption.
- Compare the various collision handlers: chaining, offset-of-1, quotient-offset.
14.1 A Framework to Analyze Searching
Before we begin looking at hashing, we need a systematic way to analyze search methods in general. Because the search may be successful or unsuccessful, the analysis of search methods should include both possibilities. For each search method we estimate averageTimes (n), the average time—over all n elements in the collection—of a successful search. As always for average time, we make the simplifying assumption that each element in the collection is equally likely to be sought.
We will also be interested in worstTimes (n), the largest number of statements needed to successfully search for an element. That is, for a given value of n, we look at all permutations of the n elements and all possible choices of the element to be successfully sought. For each permutation and element, we determine the number of iterations (or recursive calls) to find that element. Then worstTimes (n) corresponds to the largest number of iterations attained.
We also estimate averageTimeU(n), the average time of an unsuccessful search, and worstTimeU(n). For an unsuccessful search, we assume that on average, every possible failure is equally likely. For example, in an unsuccessful search of a sequence of n elements, there are n + 1 possibilities for where the given element can occur:
before the first element in the sequence;
between the first and second elements;
between the second and third elements;
between the (n -l)st and nth elements;
after the n th element.
The next section reviews the search methods employed so far.
14.2 Review of Searching
Up to this point, we have seen three different kinds of searches: sequential search, binary search, and red-black-tree search. Let's look at each one in turn.
14.2.1 Sequential Search
A sequential search —also called a "linear search"—of a collection starts at the beginning of the collection and iterates until either the element sought is found or the end of the collection is reached. For example, the contains method in the AbstractCoiiection<E> class uses a sequential search:
/** * Determines if this AbstractCollection object contains a specified element. * The worstTime(n) is O(n). * * @param obj -the element searched for in this AbstractCollection object. * * @return true -if this AbstractionCollection object contains obj; otherwise, * return false. */ public boolean contains(Object obj) { Iterator<E> e = iterator(); // E is the type parameter for this class if (obj == null) { while (e.hasNext()) if (e.next()==null) return true ; } // if obj == null else { while (e.hasNext()) if (obj.equals(e.next())) return true ; } // obj!= null return false; } // method contains
The contains method in the ArrayList class and the containsValue method in the TreeMap class use sequential searches similar to the above.
For a successful sequential search of a collection, we assume that each of the n elements in the collection is equally likely to be sought. So the average number of loop iterations is (l + 2 + ... + n)/n, which is (n + 1)/2, and the largest possible number of loop iterations is n. We conclude that both averageTimes (n) and worstTimes (n) are linear in n.
For an unsuccessful sequential search, even if the collection happens to be ordered, we must access all n elements before concluding that the given element is not in the collection, so averageTimerU(n) and worstTimesU(n) are both linear in n. As we will see in Sections 14.2.2 and 14.2.3, ordered collections can improve on these times by employing non-sequential searches.
14.2.2 BinarySearch
Sometimes we know beforehand that the collection is sorted. For sorted collections, we can perform a binary search, so called because the size of the segment searched is repeatedly divided by two. Here, as investigated in Lab 8, is the binarySearch method from the Arrays class of the Java Collections Framework:
/** * Searches a specified array for a specified element. * The array must be sorted in ascending order according to the natural ordering * of its elements (that is, by the compareTo method); otherwise, the results are * undefined. * The worstTime(n) is O(log n). * * @param a -the array to be searched. * @param key -the element to be searched for in the array. * * @return the index of an element equal to key - if the array contains at least one * such element; otherwise, -insertion point -1, where insertion point is * the index where key would be inserted. Note that the return value is * greater than or equal to zero only if the key is found in the array. * */ public static int binarySearch (Object[ ] a, Object key) { int low = 0; int high = a.length-1; while (low <= high) { int mid =(low + high) >> 1; Comparable midVal = (Comparable)a [mid]; int cmp = midVal.compareTo(key); if (cmp < 0) low = mid + 1; else if (cmp > 0) high = mid - 1; else return mid; // key found } // while return -(low + 1); // key not found } // method binarySearch
A binary search is much faster than a sequential search. For either a successful or unsuccessful search, the number of elements to be searched is n = high + 1 - low. The while loop will continue to divide n by 2 until either key is found or high + 1 = low, that is, until n = 0. The number of loop iterations will be the number of times n can be divided by 2 until n = 0. By the Splitting Rule in Chapter 3, that number is, approximately, log2 n (also, see Example A2.2 of Appendix 2). So we get averageTimes (n) ![]() worstTimes (n)
worstTimes (n) ![]() averageTimesU (n)
averageTimesU (n) ![]() worstTimes
worstTimes ![]() averageTimes (n), which is logarithmic in n.
averageTimes (n), which is logarithmic in n.
There is also a Comparator -based version of this method; the heading is
public static <T> int binarySearch (T[ ] a, T key, Comparator<? super T> c)
For example, if words is an array of String objects ordered by the length of the string, we can utilize the ByLength class from Section 11.3 and call
System.out.println (Arrays.binarySearch (words, "misspell", new ByLength()));
14.2.3 Red-Black-Tree Search
Red-black trees were introduced in Chapter 12. One of that class's public methods, containsKey, has a one-line definition: All it does is call the private getEntry method. The getEntry method, which returns the Entry corresponding to a given key, has a definition that is similar to the definition of the binarySearch method. Here is the definition of getEntry:
final Entry<K,V> getEntry(Object key) { // Offload comparator-based version for sake of performance if (comparator != null) return getEntryUsingComparator(key); if (key == null) throw new NullPointerException(); Comparable<? super K> k = (Comparable<? super K>) key; Entry<K,V> p = root; while (p != null) { int cmp = k.compareTo(p.key); if (cmp < 0) p = p.left; else if (cmp > 0) p = p.right; else return p; } return null; }
The height of a red-black tree t is logarithmic in n, the number of elements (see Example 2.6 in Appendix 2). For an unsuccessful search, the getEntry method iterates from the root to an empty subtree. In the worst case, the empty subtree will be a distance of height(t) branches from the root, and the number of iterations will be logarithmic in n. That is, worstTimeU (n) is logarithmic in n.
The number of iterations in the average case depends on bh(root): the number of black elements in the path from the root to an element with no children or with one child. The path length from the root to such an element is certainly less than or equal to the height of the tree. As shown in Example 2.6 of Appendix 2, bh(root) ≥ height(t)/2. So the number of iterations for an unsuccessful search is between height(t)/2 and height(t). That is, averageTimesU (n) is also logarithmic in n.
For a successful search, the worst case occurs when the element sought is a leaf, and this requires only one less iteration than an unsuccessful search. That is, worstTimes (n) is logarithmic in n. It is somewhat more difficult to show that averageTimes (n) is logarithmic in n. But the strategy and result are the same as in Concept Exercise 5.7, which showed that for the recursive version of the binarySearch method, averageTimes (n) is logarithmic in n.
Section 14.3 introduces a class that allows us to break through the log n barrier for insertions, removals and searches.
14.3 The HashMap Implementation of the Map Interface
The HashMap class implements the Map interface, so you saw most of the method headings when we studied the TreeMap class in Chapter 12. The main changes have to do with the timing estimates in some of the method specifications. Basically, for the put, remove, and containsKey methods, the average number of loop iterations is constant. There are also size(), isEmpty(), clear(), toString(), entrySet(), keySet(), and valueSet() methods, whose specifications are the same as for their TreeMap counterparts.
The class heading, with "K" for key and "V" for value, is
public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable
Here is an example of the creation of a simple HashMap object. The entire map, both keys and values, is printed. Then the keys alone are printed by iterating through the map viewed as a Set object with keys as elements. Finally, the values alone are printed by iterating through the map as if it were a Collection of values.
import java.util.*; public class HashExample { public static void main (String[ ] args) { new HashExample().run(); } // method main public void run() { HashMap<String, Integer> ageMap = new HashMap<String, Integer>(); ageMap.put ("dog", 15); ageMap.put ("cat", 20); ageMap.put ("human", 75); ageMap.put ("turtle", 100); System.out.println (ageMap); for (String s : ageMap.keySet()) System.out.println (s); for (Integer i : ageMap.values()) System.out.println (i); } // method run } // class HashExample
The output will be as follows:
{cat=20, dog=15, turtle=100, human=75}
cat
dog
turtle
human
20
15
100
75
Notice that the output is not in order of increasing keys, nor in order of increasing values. (When we get to the details of the HashMap class, we'll see how the order of elements is determined.) This unsortedness is one of the few drawbacks to the HashMap class. The HashMap class is outstanding for insertions, removals, and searches, on average, but if you also need a sorted collection, you should probably use a TreeMap instead.
In trying to decide on fields for the HashMap class, you might at first be tempted to bring back a contiguous or linked design from a previous chapter. But if the elements are unordered, we will need sequential searches, and these take linear time. Even if the elements are ordered and we utilize that ordering, the best we can get is logarithmic time for searching.
The rest of this chapter is devoted to showing how, through the miracle of hashing, we can achieve searches—and insertions and removals—in constant time, on average. After we have defined what hashing is and how it works, we will spend a little time on the Java Collection Framework's implementation of the HashMap class. Then we will consider an application—hashing identifiers into a symbol table—before we consider alternate implementations.
14.3.1 Hashing
We have already ruled out a straightforward contiguous design, but just to ease into hashing, let's look at a contiguous design with the following two fields:
transient Entry[ ] table; // an array of entries; transient int size; // number of mappings in the HashMap object
Recall, from Chapter 6, that the transient modifier indicates that the field will not be saved during serialization. Appendix 1 includes a discussion of serialization.
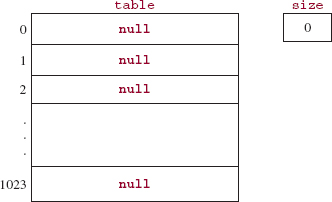
We first present a simple example and then move on to something more realistic. Suppose that the array is constructed to hold 1024 mappings, that is, 1024 key&value pairs. The key is (a reference to) an Integer object that contains a three-digit int for a person's ID. The value will be a String holding a person's name, but the values are irrelevant to this discussion, so they will be ignored. We start by calling a constructor that initializes the table length to 1024:
HashMap<Integer, String> persons = new HashMap<Integer, String>(1024);
At this point, we have the state shown in Figure 14.1.
FIGURE 14.1 The design representation of an empty HashMap object (simplified design)
At what index should we store the element with key 251? An obvious choice is index 251. The advantages are several:
- The element can be directly inserted into the array without accessing any other elements.
- Subsequent searches for the element require accessing only location 251.
- The element can be removed directly, without first accessing other elements.
We now add three elements to this HashMap object:
persons.put (251, "Smolenski"); persons.put (118, "Schwartz"); persons.put (335, "Beh-Forrest");
Figure 14.2 shows the contents of the HashMap object. We show the int values, rather than the Integer references, for the keys of inserted elements, and the names are omitted.
So far, this is no big deal. Now, for a slightly different application, suppose that table.length is still 1024, but each element has a social-security-number as the key. We need to transform the key into an index in the array, and we want this transformation to be accomplished quickly, that is, with few loop iterations. To allow fast access, we perform a bit-wise "and" of the social security number and table.length - 1. For example, the element with a key value of 214-30-3261—the hyphens are for readability only—has a binary representation of
00001100110001100000001000011101
The binary representation of 1023 is
00000000000000000000001111111111
The result of applying the bit-wise and operator, &, to a pair of bits is 1 if both bits are 1, and otherwise 0. We get
00001100110001100000001000011101
& 00000000000000000000001111111111
00000000000000000000001000011101
The decimal value of the result is 541, and so the element whose key is 214-30-3261 is stored at index 541. Similarly, the element with a key value of 033-51-8000 would be stored at location 432.
FIGURE 14.2 The HashMap object of Figure 14.1 after three elements have been inserted. For each non-null element, all that is shown is the int corresponding to the Integer key. The value parts are omitted.

Figure 14.3 shows the resulting HashMap object after the following two insertions:
persons.put (214303261, "Albert"); persons.put (033518000, "Schranz");
You might already have noticed a potential pitfall with this scheme: two distinct keys might produce the same index. For example, 214-30-3261 and 323-56-8157 both produce the index 541. Such a phenomenon is called a collision, and the colliding keys are called synonyms. We will deal with collisions shortly. For now we simply acknowledge that the possibility of collisions always exists when the size of the key space, that is, the number of legal key values, is larger than the table capacity.
Hashing is the process of transforming a key into an index in a table. One component of this transformation is the key class's hashCode() method. The purpose of this method is to perform some easily computable operation on the key object. The key class, which may be Integer, String, FullTimeEmployee, or whatever, usually defines its own hashCode() method. Alternatively, the key class can inherit a hashCodeO method from one of its ancestors; ultimately, the Object class defines a hashCode() method.1 Here is the definition of the String class's hashCode() method:
FIGURE 14.3 A HashMap object with two elements. The key is a social security number. The value is a name, but that is irrelevant, so it is not shown

* @return a hash code value for this String object. */ public int hashCode() { int h = 0; int off = offset; // index of first character in array value char val[ ] = value; // value is the array of char that holds the String int len = count; // count holds the number of characters in the String for (int i = 0; i < len; i++) h = 31*h + val[off++]; return h; } // method hashCode
The multiplication of partial sums by 31 increases the likelihood that the int value returned will be greater than table.length, so the resulting indexes can span the entire table. For example, suppose we have
System.out.println ("graduate".hashCode());
The output will be
90004811
In the HashMap class, the hashCode() method for a key is supplemented by a static hash method whose only parameter is the int returned by the hashCode() method. The hash function scrambles that int value. In fact, the basic idea of hashing is to "make hash" out of the key. The additional scrambling is accomplished with a few right shifts and bit-wise "exclusive-or" operators (return 1 if the two bits are different, otherwise 0).
Here is the hash method:
static int hash(int h) { h = (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } // method hash
For example,
"graduate".hashCode()
returns
90004811
and hash (90004811) returns
84042326
This value is bit-wise "anded" with table.length - 1 to obtain an index in the range from 0 to table.length - 1. For example, if table.length = 1024,
84042326 & 1023
returns
598
And that is the index "graduate" hashes to. The overall strategy is
hash (key.hashCode()) & table.length - 1 key -----------------------------------------------> index
One of the requirements of the HashMap class is that table.length must be a power of 2. (This requirement is specific to the Java Collections Framework, and does not apply generally.) For example, if table.length = 1024 = 210, then the index returned by
hash (key.hashCode()) & table.length - 1
consists of the rightmost 10 bits of hash (key). Because a poor-quality hashCode() method may not adequately distinguish the rightmost bits in the keys, the additional scrambling from the bit-wise operators in the hash method is usually enough to prevent a large number of collisions from occurring. You may have noticed that, because the table size is a power of 2, the result of
key (hash.hashCode()) & table.length - 1
is the same as the result of
hash (key.hashCode()) % table.length
The advantage of the former expression is that its calculation is quite a bit faster than for the latter expression. Modular arithmetic is computationally expensive, but is commonly utilized in hashing (outside of the Java Collections Framework) because its effectiveness does not require that the table size be a power of 2.
How would you go about developing your own hashCode() method? To see how this might be done, let's develop a simple hashCode() method for the FullTimeEmployee class from Chapter 1. The method should involve the two fields—name and grossPay—because these distinguish one FullTimeEmployee object from another. We have already seen the String class's hashCode() method. All of the wrapper classes, including Double, have their own hashCode() method, so we are led to the following method:
public int hashCode() { return name.hashCode() + new Double (grossPay).hashCode(); } // method hashCode in class FullTimeEmployee
For example, if a FullTimeEmployee object has the name "Dominguez" and a gross pay of 4000.00, the value returned by the hashCode() method will be −319687574. When this hashCode() method is followed by the additional bit manipulation of the HashMap class's hash method, the result will probably appear to be quite random.
The final ingredient in hashing is the collision handler, which determines what happens when two keys hash to the same index. As you might expect, if a large number of keys hash to the same index, the performance of a hashing algorithm can be seriously degraded. Collision handling will be investigated in Section 14.3.3. But first, Section 14.3.2 reveals the major assumption of hashing: basically, that there will not be a lot of keys hashing to the same index.
14.3.2 The Uniform Hashing Assumption
For each value of key in an application, a table index is calculated as
int hash = hash (key.hashCode()),
index = hash & table.length - 1; // table.length will be a power of 2
Hashing is most efficient when the values of index are spread throughout the table. This notion is referred to as the Uniform Hashing Assumption. Probabilistically speaking, the Uniform Hashing Assumption states that the set of all possible keys is uniformly distributed over the set of all table indexes. That is, each key is equally likely to hash to any one of the table indexes.
No class's hashCode method will satisfy the Uniform Hashing Assumption for all applications, although the supplemental scrambling in the hash function makes it extremely likely (but not guaranteed) that the assumption will hold.
Even if the Uniform Hashing Assumption holds, we must still deal with the possibility of collisions. That is, two distinct keys may hash to the same index. In the HashMap class, collisions are handled by a simple but quite effective technique called "chaining". Section 14.3.3 investigates chaining, and an alternate approach to collisions is introduced in Section 14.5.
14.3.3 Chaining
To resolve collisions, we store at each table location the singly-linked list of all elements whose keys have hashed to that index in table. This design is called chained hashing because the elements in each list form a chain. We still have the table and size fields from Section 14.3.1:
/** * An array; at each index, store the singly-linked list of entries whose keys hash * to that index. * */ transient Entry[ ] table; /** * The number of mappings in this HashMap object. */ transient int size;
Each element is stored in an Entry object, and the embedded Entry class starts as follows:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; final int hash; // to avoid re-calculation Entry<K,V> next; // reference to next Entry in linked list
The final modifier mandates that the key and hash fields can be assigned to only once. A singly-linked list, instead of the LinkedList class, is used to save space: There is no header, and no previous field. The Entry class also has a four-parameter constructor to initialize each of the fields.
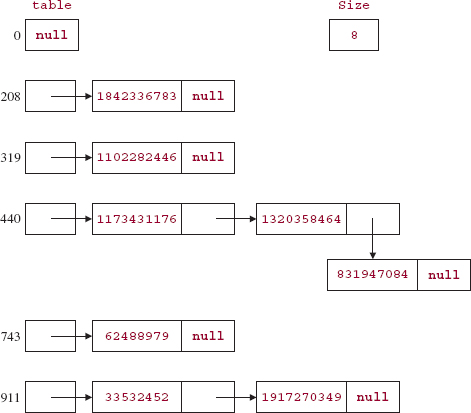
To see how chained hashing works, consider the problem just stated of storing persons with social security numbers as keys. Since each key is (a reference to) an Integer object, the hashCode() method simply returns the corresponding int, but the hash method sufficiently garbles the key that the int returned seems random. Initially, each location contains an empty list, and insertions are made at the front of the linked list. Figure 14.4 shows what we would have after inserting elements with the following Integer keys (each is shown as an int, followed by the index the key hashed to) into a table of length 1024:
| key | index |
| 62488979 | 743 |
| 831947084 | 440 |
| 1917270349 | 911 |
| 1842336783 | 208 |
| 1320358464 | 440 |
| 1102282446 | 319 |
| 1173431176 | 440 |
| 33532452 | 911 |
The keys in Figure 14.4 were "rigged" so that there would be some collisions. If the keys were chosen randomly, it is unlikely there would have been any collisions, so there would have been eight linked lists, each with a single entry. Of course, if the number of entries is large enough, there will be collisions and multi-entry lists. And that raises an interesting question: Should the table be subject to re-sizing? Suppose the initial table length is 1024. If n represents the number of entries and n can continue to increase, the average size of each linked list will be n/1024, which is linear in n. But then, for searching, inserting, and removing, worstTime(n) will be linear in n—a far cry from the constant time that was promised earlier.
FIGURE 14.4 A HashMap object into which eight elements have been inserted. For each Entry object, only the key and next fields are shown. At all indexes not shown there is a null Entry.
Given that re-sizing must be done under certain circumstances, what are those circumstances? We will re-size whenever the size of the map reaches a pre-set threshold. In the HashMap class, the default threshold is 75% of table.length. So when size is >= (int) (table.length * 0.75), the table will be re-sized. That means that the average size of each linked list will be less than one, and that is how constant average time can be achieved for inserting, deleting, and searching.
There are two additional fields relating to this discussion: loadFactor (how large can the ratio of size to table length get before resizing will occur) and threshold (how large can size get before resizing will occur). Specifically, we have2
/** * the maximum2ratio of size / table.length before re-sizing will occur * */ final float loadFactor /** * (int)(table.length * loadFactor); when size++ >= threshold, re-size table * */ int threshold;
There are three constant identifiers related to table and loadFactor:
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 16; /** * The maximum capacity, 2 to the 30thpower, used if a higher value * is implicitly specified by either of the constructors with arguments * */ static final int MAXIMUM_CAPACITY = 1 >> 30; // = 230 /** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
The value for loadFactor presents an interesting time-space tradeoff. With a low value (say, less than 1.0), searches and removals are fast, and insertions are fast until an insertion triggers a re-sizing. That insertion will require linear-in-n time and space. On the other hand, with a high value for loadFactor, searches, removals, and insertions will be slower than with a low loadFactor, but there will be fewer re-sizings. Similary, if table.length is large, there will be fewer re-sizings, but more space consumed. Ultimately, the application will dictate the need for speed (how small a load factor) and the memory available (how large a table).
Now that we have decided on the fields in the HashMap and Entry classes, we can don our developer's hat to tackle the implementation of a couple of HashMap methods: a constructor and containsKey.
14.3.4 Implementation of the HashMap Class
All of the constructors deal with the load factor and the size of the table. The fundamental constructor—the one called by the others—is the following:
/** * Constructs an empty HashMap with the specified initial * capacity and load factor. * * @param initialCapacity The initial capacity. * @param loadFactor The load factor. * @throws IllegalArgumentException if the initial capacity is negative * or the load factor is nonpositive. */ public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) // Not a Number throw new IllegalArgumentException("Illegal load factor: " + loadFactor); // Find a power of 2 >= initialCapacity int capacity = 1; while (capacity < initialCapacity) capacity <<= 1; // same as capacity = capacity << 1; this.loadFactor = loadFactor; threshold = (int)(capacity * loadFactor); table = new Entry[capacity]; init(); // allows readObject to handle subclasses of HashMap (Appendix 1, A1.2) }
This constructor is utilized, for example, in the definition of the default constructor:
/** * Constructs an empty <tt>HashMap</tt> with the default initial capacity * (16) and the default load factor (0.75). */ public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR); table = new Entry[DEFAULT_INITIAL_CAPACITY]; init(); }
We finish up this section by looking at the definition of the containsKey method. The other signature methods for a HashMap object—put, get, and remove—share the same basic strategy as containsKey: hash the key to an index in table, and then search the linked list at table [index] for a matching key. The containsKey method simply calls the getEntry method:
/** * Determines if this HashMap object contains a mapping for the * specified key. * The worstTime(n) is O(n). If the Uniform Hashing Assumption holds, * averageTime(n) is constant. * * @param key The key whose presence in this HashMap object is to be tested. * * @return true - if this map contains a mapping for the specified key. * */ public boolean containsKey(Object key) { return getEntry(key) != null ; }
Here is the definition of the getEntry method (the indexFor method simply returns hash & table.length - 1):
/** * Returns the entry associated with the specified key in the * HashMap. Returns null if the HashMap contains no mapping * for the key. */ final Entry<K,V> getEntry(Object key) { int hash = (key == null) ? 0 : hash(key.hashCode()); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
Notice that both the hash and key fields are compared. Concept Exercise 14.4 indicates why both fields are checked.
Before we leave this section on the implementation of the HashMap class, there is an important detail about insertions that deserves mention. When a re-sizing takes place, that is, when
size++ >= threshold
the table is doubled in size. But the old entries cannot simply be copied to the new table: They must be re-hashed. Why? Because the index where an entry is stored is calculated as
hash & table.length −1
When table.length changes, the index of the entry changes, so a re-hashing is required. For example,
hash ("myList") & 1023 // 1023 = 210 -1
returns 231, but
hash ("myList") & 2047 // 2047 = 211 -1
returns 1255.
After the keys have been re-hashed, subsequent calls to the containsKey method, for example, will search the linked list at the appropriate index.
In Section 14.3.5, we show that the containsKey method takes only constant time, on average.
14.3.5 Analysis of the containsKey Method
For the sake of brevity, we let n = size and m = table.length. We assume that the Uniform Hashing Assumption holds, that is, we expect the n elements to be fairly evenly distributed over the m lists. Then a successful search will examine a list that has about n/m elements3, on average. A successful, sequential search of such a list requires, approximately, n /2m loop iterations, so the average time appears to depend on both n and m. We get
averageTimes(n,m) ![]() n/2m iterations <= loadFactor / 2 < loadFactor
n/2m iterations <= loadFactor / 2 < loadFactor
The value of loadFactor is set in the HashMap object's constructor, and is fixed for the lifetime of the HashMap object. That is, averageTimes (n, m) is less than a constant. Therefore averageTimes (n, m) must be constant (in the "plain English" sense of Θ notation). In other words, the averageTime is independent of m (and even independent of n). So we conclude that averageTimes (n) is constant. Similarly, averageTimeU (n) is constant. We will avoid the subscript and simply write averageTime(n) whenever the Θ estimates are the same for both successful and unsuccessful searches. See Section 14.5 for a situation where the Θ estimates are different.
So far we have blithely ignored any discussion of worstTime. This is the Achilles' heel of hashing, just as worstTime was the vulnerable aspect of Quick Sort. The Uniform Hashing Assumption is more often a hope than a fact. If the hashCode method is inappropriate for the keys in the application, the additional scrambling in the hash function may not be enough to prevent an inordinate number of keys to hash to just a few locations, leading to linear-in-n searches. Even if the Uniform Hashing Assumption holds, we could have a worst-case scenario: the given key hashes to index, and the number of keys at table [index] is linear in n. So worstTime (n,m), for both successful and unsuccessful searches, is linear in n. The independence from m allows us to write that worstTime(n) is linear in n for both successful and unsuccessful searches for the containsKey method.
Similarly, for the get and remove methods, worstTime(n) is linear in n. What about worstTime(n, m) for the put method? In the worst case, the size of the underlying table will be at the threshold, so we will need to double the size of the table, and then iterate through all m of the linked lists (many will be empty) to re-hash the n elements into the new table. So it appears that worstTime(n, m) is Θ(n + m). But at the threshold, n/m = loadFactor (a constant), so m = n/loadFactor. Then worstTime(n,m) = worstTime(n) = Θ(n + n/loadFactor), since m is a function of n. We conclude that worstTime(n) is Θ(n), or in plain English, worstTime(n) is linear in n.
The bottom line is this: unless you are confident that the Uniform Hashing Assumption is reasonable for the key space in the application or you are not worried about linear-in-n worst time, use a TreeMap object, with its guarantee of logarithmic-in-n worst time for searching, inserting, and deleting.
The final topic in our introduction to the HashMap class is the HashIterator class.
14.3.6 The HashIterator Class
This section will clear up a mystery from when we first introduced the HashMap class: in what order are iterations performed? The answer is fairly straightforward. Starting at index table.length-1 and working down to index 0, the linked list at each index is traversed in sequential order. Starting at the back makes the continuation condition slightly more efficient: index > 0 (a constant) instead of index < table.length (a variable). In each singly-linked list, the sequential order is last-in-first-out. For example, Figure 14.5 (next page) is a repeat of the HashMap object from Figure 14.4.
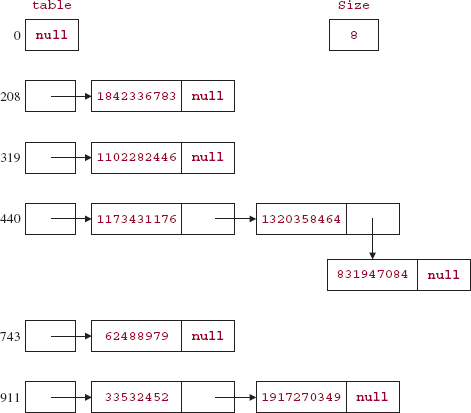
Here is the order in which the keys would appear in an iteration:
33532452 1917270349 62488979 1173431176 1320358464 831947084 1102282446 1842336783
Just as with the TreeMap class, the iteration can be by keys, by values, or by entries. For example:
for (K key : myMap.keySet()) for (V value : myMap.values()) for (Map.Entry<K, V> entry : myMap.entrySet())
Or, if the iteration might entail removals:
Iterator<K> itr1 = myMap.keySet().iterator(); Iterator<V> itr2 = myMap.values().iterator(); Iterator<Map.Entry<K, V>> itr3 = myMap.entrySet().iterator();
An iteration through a HashMap object must peruse the singly linked list at each index in the table. Even if most of those linked lists are empty, each one must be checked. The total number of loop iterations is size + table.length, and this indicates a drawback to having a very large table. If the Uniform Hashing
Assumption holds, then the time estimates for the next() method are the same as for the containsKey method in the HashMap class. In the terminology of Section 14.3.5, for example,
averageTimes(n, m) ![]() (n + m)/n = 1 + m/n = 1 + 1/loadFactor
(n + m)/n = 1 + m/n = 1 + 1/loadFactor
Since loadFactor is fixed, we conclude that averageTime(n, m) = averageTime(n) is constant for the next() method.
In the worst case, a call to the next() method will start at the end of the linked list at table [table.length - 1], with empty linked lists at indexes table.length - 2, table.length - 3, 2, 1, and a non-empty linked list at table [0]. We conclude that worstTime(n, m) is linear in m.
If you would like to have control about the order in which elements in a hash map are iterated over, Programming Exercise 14.6 will show you the way.
In Section 14.3.7, we look at the premiere application of the HashMap class: the hashing of identifiers into a symbol table by a compiler.
14.3.7 Creating a Symbol Table by Hashing
Most compilers use hashing to create a symbol table: an array that contains information about word-symbols in a program. A word-symbol can be either a reserved word or an identifier. An identifier is a name for a declared entity—such as a variable, method or class. An identifier consists of a letter, underscore or dollar sign, followed by any number of letters, digits, underscores or dollar signs. Here are some legitimate identifiers:
n tax_2010 $stack_pointer _left
The following are not legal identifiers
2010_tax // an identifier must not start with a digit time? // an identifier must not contain a ? while // an identifier must not be a reserved word
Maintaining a symbol table is a good environment for hashing: Almost all of the activity consists of retrieving a symbol-table entry, given a key. And a reasonable upper bound on the number of identifiers is the size of the program, so we can initialize the size of the symbol table to avoid re-sizing.
To avoid getting bogged down in the myriad details of symbol-table creation and maintenance, we will solve the following restricted problem: Given a file of reserved words and a program in a source file, print to a file a symbol table of word symbols, with each word symbol designated as a reserved word or identifier. One interesting feature of this project is that the input is itself a program.
The main issue is how to separate identifiers from reserved words. The list of legal reserved words4 is fixed, so we will read in a file that contains the reserved words before we read in the source file. For example, suppose the file "reserved.dat" contains the list, one per line, of reserved words in Java. And the file "Sample.java" contains the following program:
import java.io.*; public class Sample { public static void main (String[ ] args) { int i = 75; Integer top, bottom; /* all */ int z1 = 1; /* int z2 = 2; int z3 = 3; int z4 = 4; */ int z5 = 5; /* int z6 = 6;*/ String ans = "All string literals, such as this, are ignored."; char x = -x-; for (int j = 0; j < i; j++) System.out.println (i + " " + j); } // method main } // class Sample
System Test 1 (the input is boldfaced):
Please enter the path for the file that holds the reserved words: reserved.dat Please enter the path for the file that holds the source code: Sample.java Please enter the path for the file that will hold the symbol table: hasher.out
At the end of the execution of the program the file hasher.out will have:
Here is the symbol table: ans=identifier top=identifier boolean=reserved word interface=reserved word rest=reserved word for=reserved word continue=reserved word long=reserved word abstract=reserved word double=reserved word instanceof=reserved word println=identifier throws=reserved word super=reserved word throw=reserved word short=reserved word do=reserved word byte=reserved word import=reserved word if=reserved word future=reserved word package=reserved word switch=reserved word catch=reserved word return=reserved word x=identifier outer=reserved word String=identifier System=identifier z5=identifier transient=reserved word out=identifier j=identifier synchronized=reserved word else=reserved word args=identifier while=reserved word Double=identifier goto=reserved word _yes=identifier var=reserved word extends=reserved word operator=reserved word Integer=identifier case=reserved word final=reserved word Sample=identifier native=reserved word null=reserved word $name=identifier float=reserved word class=reserved word implements=reserved word private=reserved word false=reserved word main=identifier char=reserved word volatile=reserved word const=reserved word cast=reserved word bottom=identifier protected=reserved word this=reserved word static=reserved word generic=reserved word i=identifier z1=identifier void=reserved word int=reserved word byvalue=reserved word break=reserved word new=reserved word default=reserved word inner=reserved word true=reserved word public=reserved word finally=reserved word try=reserved word
We will filter out comments, string literals, and import statements. Then each line (what remains of it) will be tokenized. The delimiters will include punctuation, parentheses, and so on. For the sake of simplicity, both reserved words and identifiers will be saved in a symbol table, implemented as a HashMap object. Each key will be a word, either a reserved word or an identifier, and each value will be an indication of the word's type, either "reserved word" or "identifier".
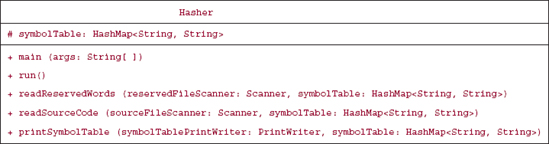
We will create a Hasher class to solve this problem. The responsibilities of the Hasher class are as follows:
- Scan the reserved words and hash each one (with "reserved word" as the value part) to the symbol table.
- Scan the lines from the source file. For each identifier in each line, post the identifier (with "identifier" as the value part) to the symbol table, unless that identifier already appears as a key in the symbol table.
- For each mapping in the symbol table, print the mapping to the output file.
14.3.7.1 Design and Testing of the Hasher Class
The responsibilities enunciated in Section 14.3.7 easily lead to method specifications. The run() method calls the following three methods (the symbolTable parameter is included for the sake of testing):
/** * Reads in the reserved words and posts them to the symbol table. * * @param reservedFileScanner - a Scanner object for the file that * contains the reserved words. * @param symbolTable - the HashMap that holds the symbol table. */ public void readReservedWords (Scanner reservedFileScanner, HashMap<String, String> symbolTable) /** * Reads the source file and posts identifiers to the symbol table. * The averageTime(n, m) is O(n), and worstTime(n, m) is O(n * n), where * n is the number of identifiers and m is the size of the symbol table. * * @param sourceFileScanner -a scanner over the source file. * contains the reserved words. * @param symbolTable - the HashMap that holds the symbol table. */ public void readSourceCode (Scanner sourceFileScanner, * HashMap<String, String> symbolTable) /** * Outputs the symbol table to a file. * The worstTime(n, m) is O(n + m), where n is the number of word symbols * and m is the size of the symbol table. * * @param symbolTablePrintWriter - a PrintWriter object for the file that * contains the symbol table. * @param symbolTable - the HashMap that holds the symbol table. */ public void printSymbolTable (PrintWriter symbolTablePrintWriter, HashMap<String, String> symbolTable)
Here is a test of ignoring string literals in the readSourceCode method:
@Test public void testIgnoreStringLiterals() throws FileNotFoundException { Scanner fileScanner = new Scanner (new File ("source.in1")); String s = hasher.readSourceCode (fileScanner); assertEquals (-1, s.indexOf ("This is a String literal.")); assertEquals (-1, s.indexOf ("Heading")); assertEquals (-1, s.indexOf ("Salaries by Department: ")); } // method testIgnoreStringLiterals
The file source.in1 consists of the following:
String front = "Heading"; String nonsense = "This is a String literal. String report = "Salaries by Department: ";
The Hasher class has two constant identifiers and one field:
protected final String IDENTIFIER = "identifier"; protected final String RESERVED_WORD = "reserved word"; protected HashMap<String, String> symbolTable;
Figure 14.6 has the class diagram for the Hasher class:
14.3.7.2 Implementation of the Hasher Class
The main method's definition is as expected. The definition of the run method is also straightforward, except for the initialization of the symbol table. To avoid the need for re-sizing, the symbol table is created with an initial capacity of the size of the source file. This number is returned by the length() method of a File object, so we first create (a reference to) such an object from the input path.
public void run() { final String RESERVED_FILE_PROMPT = " Please enter the path for the file that holds the reserved words: " final String SOURCE_FILE_PROMPT = " Please enter the path for the file that holds the source code: "; final String SYMBOL_TABLE_FILE_PROMPT = " Please enter the path for the output file that will hold the symbol table: "; Scanner keyboardScanner, reservedFileScanner = null, sourceFileScanner = null; PrintWriter symbolTablePrintWriter = null; boolean pathsOK = false; while (!pathsOK) { try { keyboardScanner = new Scanner (System.in); System.out.print (RESERVED_FILE_PROMPT); String reservedFilePath = keyboardScanner.nextLine(); reservedFileScanner = new Scanner (new File (reservedFilePath)); System.out.print (SOURCE_FILE_PROMPT); String sourceFilePath = keyboardScanner.nextLine(); File sourceFile = new File (sourceFilePath); sourceFileScanner = new Scanner (sourceFile); symbolTable = new HashMap<String, String> ((int)sourceFile.length()); System.out.print (SYMBOL_TABLE_FILE_PROMPT); String symbolTablePrintPath = keyboardScanner.nextLine(); symbolTablePrintWriter = new PrintWriter ( new FileWriter (symbolTablePrintPath)); pathsOK = true; } // try catch (Exception e) { System.out.println (e); } // catch } // while !pathsOK readReservedWords (reservedFileScanner, symbolTable); readSourceCode (sourceFileScanner, symbolTable); printSymbolTable (symbolTablePrintWriter, symbolTable); } // method run
The reservedFileScanner, sourceFileScanner, and symbolTablePrintWriter variables are initialized to null to avoid a compile-time error when they are used outside of the try block in which they are actually initialized.
The readReservedWords method loops through the file of reserved words and posts each one as a key in the symbol table; the value is the String "reserved word".
public void readReservedWords (Scanner reservedFileScanner, HashMap<String, String> symbolTable) { String reservedWord; while (true) { if (!reservedFileScanner.hasNextLine()) break; reservedWord = reservedFileScanner.nextLine(); symbolTable.put (reservedWord, RESERVED_WORD); } // while not end of file } // method readReservedWords
It is easy enough to determine if a token is the first occurrence of an identifier: It must start with a letter, and not already be in symbolTable (recall that the reserved words were posted to symbolTable earlier). The hard part of the method is filtering out comments, such as in the following:
/* all */ int z1 = 1;
/* int z2 = 2;
int z3 = 3;
int z4 = 4; */ int z5 = 5; /* int z6 = 6;*/
Here is the method definition:
public String readSourceCode (Scanner sourceFileScanner, HashMap<String, String> symbolTable) { final String DELIMITERS = "[ a-zA-Z0-9$_]+"; String line, word; int start, finish; boolean skip = false ; while (true) { if (!sourceFileScanner.hasNextLine()) break; line = sourceFileScanner.nextLine(); line = line.trim(); // Ignore lines beginning with "import". if (line.indexOf("import ") == 0) continue ; // start another iteration of this loop // Ignore string literals. while ((start = line.indexOf (""")) >= 0) { finish = line.indexOf(" "", 1 + start); while (line.charAt (finish - 1) == ' ') finish = line.indexOf (" "--, finish + 1); line = line.substring(0, start) + line.substring(finish + 1); } // while line still has a string literal // Ignore // comments if ((start = line.indexOf("//")) >= 0) line = line.substring(0, start); // Ignore any line between /* and */. if ((line.indexOf ("*/") == -1) && skip) continue ; // Remove substring up to */ if matching /* on earlier line. if ((start = line.indexOf("*/")) >= 0 && skip) { skip = false; line = line.substring (start + 2); } // first part of line a comment // Handle lines that have /*. while ((start = line.indexOf ("/*")) >= 0) if ((finish = line.indexOf("*/", start + 2)) >= 0) line = line.substring(0, start) + line.substring(finish + 2); else { line = line.substring(0, start); skip = true; } // matching */ not on this line // Tokenize line to find identifiers. Scanner lineScanner = new Scanner (line).useDelimiter (DELIMITERS); while (lineScanner.hasNext()) { word = lineScanner.next(); if (!Character.isDigit (word.charAt (0)) && !symbolTable.containsKey (word) == null) symbolTable.put (word, IDENTIFIER); } // while not at end of line } // while not end of file return symbolTable.toString(); } // method readSourceCode
Let n be the number of identifiers in the source file, and let m be the size of the source file. Because m is fixed, only n is relevant for estimating. Based on the analysis of containsKey method in Section 14.3.5, we extrapolate that each call to the HashMap methods get and put will take constant time on average, and linear-in-n time in the worst case. We conclude that for processing all n identifiers in the readSourceCode method, averageTime(n) is linear in n and worstTime(n) is quadratic in n.
Finally, the printSymbolTable method iterates through the entries in symbolTable and prints each one to the output file:
public void printSymbolTable (PrintWriter symbolTablePrintWriter, HashMap<String, String> symbolTable) { final String HEADING = "Here is the symbol table: "; symbolTablePrintWriter.println (HEADING); for (Map.Entry<String, String> entry : symbolTable.entrySet()) symbolTablePrintWriter.println (entry); } // method printSymbolTable
An iteration through a HashMap object requires n + m iterations in all cases, so worstTime(n, m) and averageTime(n, m) are both Θ(n + m). We can say, crudely, that n + m is both a lower bound and an upper bound of worstTime(n, m) and averageTime(n, m) for the printSymbolTable method.
One interesting feature of the above program is that Hasher.java itself can be the input file. The output file will then contain the symbol table of all word symbols in the Hasher class.
The word symbols in the output file are not in order. To remedy this, instead of printing out each entry, we could insert the entry into a TreeMap object, and then print out the TreeMap object, which would be in order. This sorting would take linear-logarithmic in n time; on average, that would be longer than the rest of the application.
To finish up the Java Collections Framework treatment of hashing, the next section takes a brief look at the HashSet class.
14.4 The HashSet Class
With hashing, all of the work involves the key-to-index relationship. It doesn't matter if the value associated with a key has meaning in the application or if each key is associated with the same dummy value. In the former case, we have a HashMap object and in the latter case, we have a HashSet object. The method definitions in the HashSet class are almost identical to those of the TreeSet class from Chapter 12. The major difference—besides efficiency—is that several of the constructor headings for the HashSet class involve the initial capacity and load factor.
Here is a program fragment that creates and maintains a HashSet instance in which the elements are of type String, the initial capacity is 100 and the load factor is 0.8F (that is, 0.8 as a float):
HashSet<String> names = new HashSet<String>(100, 0.8F); names.add ("Kihei"); names.add ("Kula"); names.add ("Kaanapali"); System.out.println (names.contains ("Kapalua")); // Output: false System.out.println (names.remove ("Kula") + " " + names.size()); // Output: true 2
Lab 22 covers the crucial aspect of HashMap objects and HashSet objects: their speed.
You are now prepared to do Lab 22: Timing the Hash Classes
As indicated, the Java Collections Framework's implementation of hashing uses chaining to handle collisions. Section 14.5 explores another important collision handler, one that avoids linked lists.
14.5 Open-Address Hashing (optional)
To handle collisions with chaining, the basic idea is this: when a key hashes to a given index in table, that key's entry is inserted at the front of the linked list at table [index]. Each entry contains, not only hash, key, and value fields, but a next field that points to another entry in the linked list. The total number of Entry references is equal to size + table.length. For some applications, this number may be too large.
Open addressing provides another approach to collision handling. With open addressing, each table location contains a single entry; there are no linked lists, and the total number of Entry references is equal to table.length. To insert an entry, if the entry's key hashes to an index whose entry contains a different key, the rest of the table is searched systematically until an empty—that is, "open"—location is found.
The simplest open-addressing strategy is to use an offset of 1. That is, to insert an entry whose key hashes to index j, if table [j] is empty, the entry is inserted there. Otherwise, the entry at index j + 1 is investigated, then at index j + 2, and so on until an open slot is found. Figure 14.7 shows the table created when elements with the following Integer keys are inserted:
| key | index |
| 587771904 | 754 |
| 081903292 | 919 |
| 033520048 | 212 |
| 735668100 | 919 |
| 214303261 | 212 |
| 214303495 | 212 |
| 301336785 | 80 |
| 298719753 | 529 |
In this example, table.length is 1024, but in general, we will not require that the table length be a power of two. In fact, we will see in Section 14.5.2 that we may want the table length to be a prime number.
There are a couple of minor details with open addressing:
- to ensure that an open location will be found if one is available, the table must wrap around: if the location at index table.length - 1 is not open, the next index tried is 0.
- the number of entries cannot exceed the table length, so the load factor cannot exceed 1.0. It will simplify the implementation and efficiency of the containsKey, put, and remove methods if the table always has at least one open (that is, empty) location. So we require that the load factor be strictly less than 1.0. Recall that with chaining, the load factor can exceed 1.0.
FIGURE 14.7 A table to which 8 elements have been inserted. Open addressing, with an offset of 1, handles collisions

Let's see what is involved in the design and implementation of a HashMap class with open addressing and an offset of 1. We'll have many of the same fields as in the chained-hashing design: table, size, loadFactor, and threshold. The embedded Entry class will have hash, key, and value fields, but no next field. We will focus on the containsKey, put, and remove methods: They will have to be re-defined because now there are no linked lists.
14.5.1 The remove Method
We need to consider the remove method before the containsKey and put method because the details of removing elements have a subtle impact on searches and insertions. To see what this is all about, suppose we want to remove the entry with key 033-52-0048 from the table in Figure 14.7. If we simply make that entry null, we will get the table in Figure 14.8.
Do you see the pitfall with this removal strategy? The path taken by synonyms of 033-52-0048 has been blocked. A search for the entry with key 214-30-3495 would be unsuccessful, even though there is such an entry in the table.
Instead of nulling out a removed entry, we will add another field to the Entry class:
boolean markedForRemoval;
This field is initialized to false when an entry is inserted into the table. The remove method sets this field to true. The markedForRemoval field, when true, indicates that its entry is no longer part of the hash map, but allows the offset-of-1 collision handler to continue along its path. Figure 14.9 shows a table after 8 insertions, and Figure 14.10 shows the subsequent effect of the message
FIGURE 14.8 The effect of removing the entry with key 033-52-0048 from the table in Figure 14.7 by nulling out the entry at index 212

remove (new Integer (033-52-0048))
A search for the entry with the key 214303495 would now be successful. In the definition of the remove method, a loop is executed until a null or matching entry is found. Note that an entry's key is examined only if that entry is not marked for removal.
The containsKey method loops until an empty or matching entry is found. As with the remove method, an entry's key is checked only if that entry is not marked for removal. The definition of the containsKey method is only slightly revised from the chained-hashing version. For example, here we use modular arithmetic instead of the & operator because the table length need not be a power of 2.
FIGURE 14.9 A table to which 8 elements have been inserted. Open addressing, with an offset of 1, handles collisions. In each entry, only the key and markedForRemoval fields are shown.

FIGURE 14.10 The table from Figure 14.9 after the message remove (new Integer (033520048)) has been sent

/** * Determines if this HashMap object contains a mapping for the * specified key. * The worstTime(n) is O(n). If the Uniform Hashing Assumption holds, * averageTime(n) is constant. * * @param key The key whose presence in this HashMap object is to be tested. * * @return true - if this map contains a mapping for the specified key. * */ public boolean containsKey (Object key) { Object k = maskNull (key); // use NULL_KEY if key is null int hash = hash (k); int i = indexFor (hash, table.length); Entry e = table [i]; while (e != null) { if (!e.markedForRemoval && e.hash == hash && eq (k, e.key)) return true; e = table [(++i) % table.length]; // table.length may not be a power of 2 } // while return false; } // method containsKey
With the help of the markedForRemoval field, we solved the problem of removing an element without breaking the offset-of-1 path. The put method hashes a key to an index and stores the key and value at that index if that location is unoccupied: either a null key or marked for removal.
14.5.2 Primary Clustering
There is still a disturbing feature of the offset-of-1 collision handler: all the keys that hash to a given index will probe the same path: index, index + 1, index + 2, and so on. What's worse, all keys that hash to any index in that path will follow the same path from that index on. For example, Figure 14.11 shows part of the table from Figure 14.9:
In Figure 14.11, the path traced by keys that hash to 212 is 212, 213, 214, 215, .... And the path traced by keys that hash to 213 is 213, 214, 215, .... A cluster is a sequence of non-empty locations (assume the elements at those locations are not marked for removal). With the offset-of-1 collision handler, clusters are formed by synonyms, including synonyms from different collisions. In Figure 14.11, the locations at indexes 212, 213, and 214 form a cluster. As each entry is added to a cluster, the cluster not only gets bigger, but also grows faster, because any keys that hash to that new index will follow the same path as keys already stored in the cluster. Primary clustering is the phenomenon that occurs when the collision handler allows the growth of clusters to accelerate.
FIGURE 14.11 The path traced by keys that hash to 212 overlaps the paths traced by keys that hash to 213 or 214

Clearly, the offset-of-1 collision handler is susceptible to primary clustering. The problem with primary clustering is that we get ever-longer paths that are sequentially traversed during searches, insertions, and removals. Long sequential traversals are the bane of hashing, so we should try to solve this problem.
What if we choose an offset of, say, 32 instead of 1? We would still have primary clustering: keys that hashed to index would overlap the path traced by keys that hashed to index + 32, index + 64, and so on. In fact, this could create an even bigger problem than primary clustering. For example, suppose the table size is 128 and a key hashes to index 45. Then the only locations that would be allowed in that cluster have the following indexes:
45, 77, 109, 13
Once those locations fill up, there would be no way to insert any entry whose key hashed to any one of those indexes. The reason we have this additional problem is that the offset and table size have a common factor. We can avoid this problem by making the table size a prime number, instead of a power of 2. But then we would still have primary clustering.
14.5.3 Double Hashing
We can avoid primary clustering if, instead of using the same offset for all keys, we make the offset dependent on the key. Basically, the offset will be hash/table.length. There is a problem here: hash may be negative. To remedy this, we perform a bit-wise "and" with hash and the largest positive int value, written as 0x7fffffff in hexadecimal (base 16) notation. The result is guaranteed to be non-negative. The assignment for offset is
int offset = (hash & 0x7FFFFFFF) / table.length;
And then, whether searching, inserting, or removing, replace
e = table % table.length]; // offset of 1
with
e = table [(i + offset) % table.length];
To see how this works in a simple setting (ignoring the hash method), let's insert the following keys into a table of size 19:
33 72 71 55 112 109
These keys were created, not randomly, but to illustrate that keys from different collisions, even from the same collision, do not follow the same path. Here are the relevant moduli and quotients:
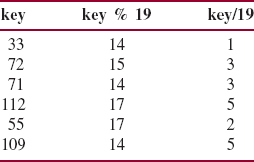
The first key, 33, is stored at index 14, and the second key, 72, is stored at index 15. The third key, 71, hashes to 14, but that location is occupied, so the index 14 is incremented by the offset 3 to yield index 17; 71 is stored at that location. The fourth key, 112, hashes to 17 (occupied); the index 17 is incremented by the offset 5. Since 22 is beyond the range of the table, we try index 22% 19, that is, 3, an unoccupied location. The key 112 is stored at index 3. The fifth key, 55, hashes to 17 (occupied) and then to (17 + 2) % 19, that is, 0, an empty location. The sixth key, 109, hashes to 14 (occupied) and then to (14 + 5) % 19, that is 0 (occupied), and then to (0 + 5) % 19, that is, 5, an unoccupied location.
Figure 14.12 shows the effect of the insertions:
FIGURE 14.12 The effect of inserting six entries into a table; the collision handler uses the hash value divided by the table size as the offset

This collision handler is known as double hashing, or the quotient-offset collision handler. There is one last problem we need to address before we get to the analysis: what happens if the offset is a multiple of the table size? For example, suppose we try to add the entry whose key is 736 to the table in Figure 14.12. We have
736 % 19 = 14
736/19 = 38
Because location 14 is occupied, the next location tried is (14 + 38) % 19, which is 14 again. To avoid this impasse, we use 1 as the offset whenever key/table.length is a multiple of table.length. This is an infrequent occurrence: it happens, on average, once in every m keys, where m = table.length. Concept Exercise 14.5 shows that if this collision handler is used and the table size is a prime number, the sequence of offsets from any key covers the whole table.
Because the table size must be a prime number, the call to the resize method—within the put method—must be changed from the offset-of-1 version:
resize (2 * table.length);
With the quotient-offset collision handler, we have
resize (nextPrime (2 * table.length));
The static method nextPrime returns the smallest prime larger than the argument.
If you undertake Programming Project 14.1, you will get to fill in the details of double hashing. If we make the Uniform Hashing Assumption, the average time for insertions, removals and searches is constant (see Collins [2003, pp 554-556]). Figure 14.13 summarizes the time estimates for successful and unsuccessful searches (that is, invocations of the containsKey method). For purposes of comparison, the information in Section 14.3.5 on chained hashing is included.
Figure 14.14 provides some specifics: the expected number of loop iterations for various ratios of n to m. For purposes of comparison, the information in Section 14.6 on chained hashing is included.
FIGURE 14.13 Estimates of average times for successful and unsuccessful calls to the containsKey method, under both chaining and double hashing. In the figure, n = number of elements inserted; m = table.length

FIGURE 14.14 Estimated average number of loop iterations for successful and unsuccessful calls to the containsKey method, under both chained hashing and double hashing. In the figure, n = number of elements inserted; m = table.length
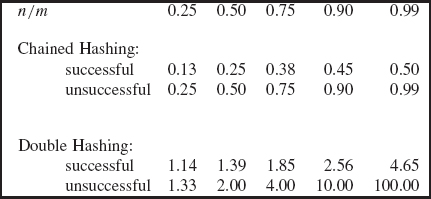
A cursory look at Figure 14.14 suggests that chained hashing is much faster than double hashing. But the figures given are mere estimates of the number of loop iterations. Run-time testing may, or may not, give a different picture. Run-time comparisons are included in Programming Project 14.1.
The main reason we looked at open-address hashing is that it is widely used; for example, some programming languages do not support linked lists. Also, open-address hashing can save space relative to chained hashing, which requires n + m references versus only m references for open-address hashing.
Even if the Uniform Hashing Assumption applies, we could still, in the worst case, get every key to hash to the same index and yield the same offset. So for the containsKey method under double hashing, worstTime^ (n, m) and worstTime^ (n, m) are linear in n.
For open addressing, we eliminated the threat of primary clustering with double hashing. Another way to avoid primary clustering is through quadratic probing: the sequence of offsets is 12,22,32,..... For details, the interested reader may consult Weiss [2002].
SUMMARY
In this chapter, we studied the Java Collections Framework's HashMap class, for which key-searches, insertions, and removals can be very fast, on average. This exceptional performance is due to hashing, the process of transforming a key into an index in a table. A hashing algorithm must include a collision handler for the possibility that two keys might hash to the same index. A widely used collision handler is chaining. With chaining, the HashMap object is represented as an array of singly linked lists. Each list contains the elements whose keys hashed to that index in the array.
Let n represent the number of elements currently in the table, and let m represent the capacity of the table. The load factor is the maximum ratio of n to m before rehashing will take place. The load factor is an upper-bound estimate of the average size of each list, assuming that the hash method scatters the keys uniformly throughout the table. With that assumption—the Uniform Hashing Assumption—the average time for successful and unsuccessful searches depends only on the ratio of n to m. The same is true for insertions and removals. If we double the table size whenever the ratio of n to m equals or exceeds the load factor, then the size of each list, on average, will be less than or equal to the load factor. This shows that with chained hashing, the average time to insert, remove, or search is constant.
A HashSet object is simply a HashMap in which each key has the same dummy value. Almost all of the HashSet methods are one-liners that invoke the corresponding HashMap method.
An alternative to chaining is open addressing. When open addressing is used to handle collisions, each location in the table consists of entries only; there are no linked lists. If a key hashes to an index at which another key already resides, the table is searched systematically until an open address, that is, empty location is found. With an offset of 1, the sequence searched if the key hashes to index, is
index, index + 1, index + 2, ..., table.length - 1, 0, 1, index - 1.
The offset-of-1 collision handler is susceptible to primary clustering: the phenomenon of having accelerating growth in the size of collision paths. Primary clustering is avoided with double hashing: the offset is the (posi-tivized) hash value divided by table.length. If the Uniform Hashing Assumption holds and the table size is prime, the average time for both successful and unsuccessful searches with double hashing is constant.
CROSSWORD PUZZLE

| ACROSS | DOWN |
| 1. An alternative to chained hashing is ______ hashing. | 2. The capacity of a HashMap object must be a ______. |
| 5. For any iteration through a HashMap object worsiTime(n, m) for the next() method is ______. | 3. The _____ Hashing Assumption states that the set of all possible keys is uniformly distributed over the set of all table indexes. |
| 7. (int)(table.length * loadFactor) | 4. The interface implemented by the TreeMap class but not by the HashMap class |
| 9. The technique for resolving collisions by storing at each table location the linked list of all elements whose keys hashed to that index in the table | 6. The process of transforming a key into a table index |
| 8. The type of the value returned by the hashCode() method |
CONCEPT EXERCISES
14.1 Why does the HashMap class use singly-linked lists instead of the LinkedList class?
14.2 Suppose you have a HashMap object, and you want to insert an element unless it is already there. How could you accomplish this?
Hint: The put method will insert the element even if it is already there (in which case, the new value will replace the old value).
14.3 For each of the following methods, estimate averageTime(n) and worstTime(n):
- making a successful call—that is, the element was found—to the contains method in the LinkedList class;
- making a successful call to the contains method in the ArrayList class;
- making a successful call to the generic algorithm binarySearch in the Arrays class; assume the elements in the array are in order.
- making a successful call to the contains method in the BinarySearchTree class;
- making a successful call to the contains method in the TreeSet class;
- making a successful call to the contains method in the HashSet class—you should make the Uniform Hashing Assumption.
14.4 This exercise helps to explain why both the hash and key fields are compared in the containsKey and put (and remove) methods of the HashMap class.
- Suppose the keys in the HashMap are from a class, Key, that overrides the Object class's equals method but does not override the Object class's hashCode method. (This is in violation of the contract for the Object class's hashCode method, namely, equal objects should have the same hash code). The Object class's hashCode method converts the Object reference to an int value. So it would be possible for a key to be constructed with a given reference, and an identical key constructed with a different reference. For example, we could have:
Key key1 = new Key ("Webucation"), key2 = new Key ("Webucation"); HashMap<Key, String> myMap = new HashMap<Key, String>(); myMap.put (key1, ""); // the value part is the empty String
If the hash fields were not compared in the containsKey and put methods, what would be returned by each of the following messages:
myMap.containsKey (key2) myMap.put (key2, "")
- In some classes, the hashCode method may return the same int value for two distinct keys. For example, in the String class, we can have two distinct String objects—even with the same characters—that have the same hash code:
String key1 = "! @"; // exclamation point, blank, at sign String key2 = " @!"; // blank, at sign, exclamation point HashMap<String, String> myMap = new HashMap<String, String>(); myMap.put (key1, ""); // the value part is the empty String System.out.println (key1.hashCode() + " " + key2.hashCode());
The output will be
32769 32769
If the key fields were not compared in the containsKey and put methods, what would be returned by each of the following messages:
myMap.containsKey (key2) myMap.put (key2, "")
14.5 Assume that p is a prime number. Use modular algebra to show that for any positive integers index and offset (with offset not a multiple of p), the following set has exactly p elements:
{(index + k * offset)%p;k = 0,1,2,..., p - 1}
14.6 Compare the space requirements for chained hashing and open-address hashing with quotient offsets. Assume that a reference occupies four bytes and a boolean value occupies one byte. Under what circumstances (size, loadFactor, table.length) will chained hashing require more space? Under what circumstances will double hashing require more space?
14.7 We noted in Chapter 12 that the term dictionary, viewed as an arbitrary collection of key-value pairs, is a synonym for map. If you were going to create a real dictionary, would you prefer to store the elements in a TreeMap object or in a HashMap object? Explain.
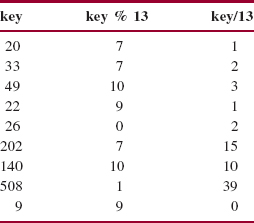
14.8 In open-addressing, with the quotient-offset collision handler, insert the following keys to a table of size 13 (ignore the hash method):
20
33
49
22
26
202
140
508
9
Here are the relevant remainders and quotients:
PROGRAMMING EXERCISES
14.1 Construct a HashMap object of the 25,000 students at Excel University. Each student's key will be that student's unique 6-digit ID. Each student's value will be that student's grade point average. Which constructor should you use and why?
14.2 Construct a HashMap object of the 25,000 students at Excel University. Each student's key will be that student's unique 6-digit ID. Each student's value will be that student's grade point average and class rank. Insert a few elements into the HashMap object. Note that the value does not consist of a single component.
14.3 Construct a HashSet object with Integer elements and an initial capacity of 2000. What is the load factor? What is the table length (Hint: It is greater than 2000)? Insert a few random Integer elements into the HashSet object.
14.4 As a programmer who uses the HashSet class, test and define test a toSortedString method:
/**
* Returns a String representation of a specified HashSet object, with the natural
* ordering,
* The worstTime(n) is O(n log n).
*
* @param hashSet -the HashSet object whose String representation, sorted, is
* to be returned.
*
* @return a String representation of hashSet, with the natural ordering.
*
*/
public static <E> String toSortedString (HashSet<E> hashSet)
Note: As a user, you cannot access any of the fields in a HashSet class.
14.5 Given the following program fragment, add the code to print out all of the keys, and then add the code to print out all of the values:
HashMap<String, Integer> ageMap = new HashMap<String, Integer>(); ageMap.put ("dog", 15); ageMap.put ("cat", 20); ageMap.put ("turtle", 100); ageMap.put ("human", 75);
14.6 The LinkedHashMap class superimposes a LinkedList object on a HashMap object, that is, there is a doubly-linked list of all of the elements in the HashMap object. For example, suppose we have
LinkedHashMap<String, Integer> ageMap =
new LinkedHashMap<String, Integer>();
ageMap.put ("dog", 15);
ageMap.put ("cat", 20);
ageMap.put ("turtle", 100);
ageMap.put ("human", 75);
System.out.println (ageMap);
The output will reflect the order in which elements were inserted, namely,
{dog=15, cat=20, turtle=100, human=75}
Revise the above code segment so that only the pets are printed, and in alphabetical order.
Programming Project 14.1: The Double Hashing Implementation of the HashMap Class
Test and develop the implementation of the HashMap class that uses double hashing—see Sections 14.5 and following. Define only a small number of methods: a default constructor, a constructor with an initial-capacity parameter, containsKey, put, and remove. The toString method is inherited from AbstractMap.
For system tests, run the Hasher program with input files Sample.java and Hasher.java itself. Use your HashMap class for Lab 22 and compare the times you get to the times you got in that lab.
Programming Project 14.2: An Integrated Web Browser and Search Engine, Part 6
At this point, your search engine created a TreeMap object in which each element was a web page: the key was a word, and the value was the number of occurrences of the word. This approach worked well for a small number of web pages, but would not scale up to the billions (even trillions) of web pages. In fact, the approach would be infeasible even if we used a HashMap object instead of a TreeMap object.
To enable searches to be completed quickly, a search engine must have a web crawler that operates all the time. The web crawler more or less randomly searches web pages and saves ("caches") the results of the searches. For example, for each possible search word, each file in which the search word occurs and the frequency of occurrences are saved. When an end-user clicks on the Search button and then enters a search string, the cached results allow for quick searches.
Initially, you will be given a file, "search.ser", that contains a search-string HashMap in serialized form (see Appendix 1 for details on serializing and de-serializing). Each key—initially—is a search word, and each value is a file-count HashMap in which the key is a file name and the value is the frequency of the search word in the file.
You will need to de-serialize the search-string HashMap. When the end-user enters a search string, there are two possibilities. If the search string already appears as a key in the search-string HashMap, the file names and counts in the file-count HashMap are put into a priority queue and Part 5 of the project takes over. If the search string does not appear as a key in the search-string HashMap, the individual words in the search string are used to search the search-string HashMap, and the combined result becomes a new entry in the search-string HashMap.
For example, suppose the universe of web pages consists of the files browser.in10, in11, in12, and in13 from Part 5 (Programming Project 13.2). The search-string HashMap starts out with keys that include "neural", "decree", and "network". If the end-user clicks on the Search button and then enters "network", the output will be
Here are the results of the old search for network: browser.in13 4 browser.in12 4 browser.in11 4 browser.in10 4
But if the end-user searches for "neural network", that string is not in the search-string HashMap. So the results from the individual words "neural" and "network" are combined, and the output will be
Here are the results of the new search for neural network: browser.in13 8 browser.in10 8 browser.in12 6 browser.in11 6
The search string "neural network" and the results will now be added to the search-string HashMap. If, later in the same run, the end-user searches for "neural network", the output will be
Here are the results of the old search for neural network: browser.in13 8 browser.in10 8 browser.in12 6 browser.in11 6
System Test 1:
(Assume the end-user searches for "neural network".)
Here are the results of the new search for neural network:
browser.in13 8 browser.in10 8 browser.in12 6 browser.in11 6
(Assume the end-user searches for "network".)
Here are the results of the old search for network:
browser.in13 4 browser.in12 4 browser.in11 4 browser.in10 4
(Assume the end-user searches for "neural network".)
Here are the results of the old search for neural network:
browser.in13 8 browser.in10 8 browser.in12 6 browser.in11 6
System Test 2:
(Assume the end-user searches for "network decree".)
Here are the results of the new search for network decree:
browser.in12 6 browser.in13 5 browser.in11 5 browser.in10 5
NOTE 1: By the end of each execution of the project, the file "search.ser" should contain the updated search-string HashMap in serialized form. For example, by the end of System Test 1, "neural network" will be one of the search strings serialized in "search.ser". You may update "search.ser" after each search.
NOTE 2: The original file search.ser is available from the ch14 directory of the book's website.
NOTE 3: If the search string does not occur in any of the files, the output should be "The search string does not occur in any of the files."
1 But the hashCode() method in the Object class will most likely return the reference itself, that is, the machine address, as an int. Then the hashCode() method applied to two equivalent objects would return different int values!
2 This definition is non-standard. In hashing terminology, load factor is simply the ratio of the number of elements in the collection to its capacity. In the Framework's HashMap and HashSet classes, load factor is the upper bound of that ratio.
3 In common hashing terminology, the load factor is simply the ratio of n to m. In the Java Collections Framework, load factor is the maximum ratio of n to m before resizing takes place.
4 Technically, true, false, and null are not reserved words. They are literals, that is, constant values for a type, just as "exhale" and 574 are literals. But we include them in with the reserved words because they cannot be used as identifiers.