
Chapter 4. Internal Ranking Factors
Internal ranking factors are things you control directly (as part of your site) that can affect your rank in the SERPs. There are two types of internal ranking factors: on-page ranking factors (things you can do in a particular web page, such as providing appropriate keywords) and on-site ranking factors (things you can do to your website as a whole).
How can you take into consideration hundreds of different ranking factors? You can’t. The key is to home in on 20 or so of the most important known factors—those that have stood the test of time and produced results consistently. Knowing what to optimize can make SEO a lot easier. Instead of listening to Internet hype, website owners should rely on provable facts.
This chapter sets the stage for what is to come in Chapter 13. Its ultimate goal is to take out the guesswork and really focus on what makes search engines tick, as well as to identify the key internal ranking factors you should consider when optimizing your site. I wrote a Perl script that speaks directly to these factors by performing detailed statistical analysis. This tool or one of its variants should be a component in your SEO toolkit. The idea is to analytically prove what works for different search engines.
The last section of this chapter, Putting It All Together, contains the information you need to run a script that creates a comprehensive HTML ranking report. We show pertinent excerpts from this report throughout the chapter, so please refer to the script listing for further clarification if necessary. Further study of the script is recommended.
Analyzing SERPs
The abundance of myths, speculations, and theories in the SEO community makes it hard to focus on what’s really relevant when it comes to ranking in the SERPs. To quantify the importance of different ranking factors, my Perl script analyzes and proves some of the theories. The rankingfactors.pl script appears in full in Appendix A.
The basic idea is to analyze the top results from the top search engines. Given a search term, the script collects the results from the major search engines, downloads those pages, and analyzes them to see why they got the rankings they did. The rest of our discussion in this chapter depends pretty heavily on the use of this script. Also note that we already discussed some of these ranking factors in some detail in previous chapters.
On-Page Ranking Factors
Many on-page ranking factors are related to the use of keywords. We’ll cover those first, and then we’ll cover some other factors that are not directly related to keywords.
Keywords in the <title> Tag
Your page titles will show up in the SERPs, so make them concise and relevant. The World Wide Web Consortium (W3C) provides the following recommendations for HTML titles:
Authors should use the TITLE element to identify the contents of a document. Since users often consult documents out of context, authors should provide context-rich titles. Thus, instead of a title such as “Introduction”, which doesn’t provide much contextual background, authors should supply a title such as “Introduction to Medieval Bee-Keeping” instead.
One of the most critical on-page factors, the <title> tag is not to be dismissed.
Search engines tend to use the <title> tag text as search results
titles. All pages should have unique page titles. All page titles
should be crafted wisely, using the most important keywords found in
the page copy.
The page title should contain specific keyword phrases to describe the page. Using a company name in the page title by itself can prove ineffective if it is not accompanied by additional text that briefly describes the product, service, or topic being discussed.
Titles in search results
Titles in search results have a maximum length. A long title will not hurt your site, but it may not appear in its entirety in the search results. If you have to use longer page titles, from a usability perspective ensure that the part of the title that could show up in search results contains relevant keywords. The last thing you want is for your keywords to get cut off in the search results. Don’t be afraid to change your HTML page titles. Here are some good examples that are concise and to the point:
<title>Unity St. Pizza - Best Pizza in Boston - 1-800-242-0242 - Order Online</title> <title>Java Tutorial - Programming - TechnologyFirmABC.com </title>
In the case of known brand names such as O’Reilly, HTML titles may not be as big a concern due to the probable bias by some search engines, such as Google.
The next set of examples shows poorer-quality page titles:
<title>http://bestbostonpizza.com</titles> <title>Best Pizza in Town, Town's best pizza, Excellent Pizza</title> <title> The purpose of this article is not to debate the right or wrong of third parties utilizing search engine records to probe into the activities of others. There are those in the United States and other countries that believe that giving up privacy for the purpose of prosecuting a handful of crimes is not justified. Then there are those who gladly hand over privacy for a perceived sense of security. </title> <title>Make Money! Make Money Now! Great way to Make Money! </title>
In the first example, the fictional website is using its URL as the page title. Although the actual URL contains keywords, it is not very helpful in terms of telling searchers what the page is really about.
The second example seems to be alternating between different keywords that mean the same thing. This could be interpreted as search engine spam. It does not read well to web visitors.
The third example is a really long page title. The first part of the text contains many stop words. Most of this text is unlikely to show up in search results.
The last sample title uses many poison words that could flag this page as suspicious.
Finally, the following titles are the worst kind:
<title></title> <title>Default Title</title> <title>Document 1</title> <html><body>...</body></html>
Pages using no titles or default titles as generated by various HTML programs are useless and can be detrimental to your site’s visibility.
Title keywords in the page copy
Titles need to be relevant to the page copy. You need to ensure that most, if not all,
of the words found in the <title> tag can also be found in the
page itself. Of course, some pages will be exempt from this rule,
but this should be the goal for any page. Figure 4-1 shows the script output for the keyword
o’reilly book.
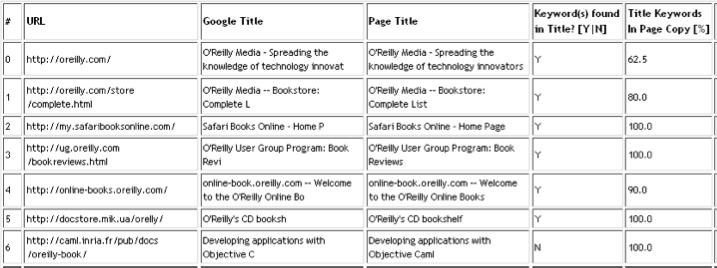
The column labeled “Google Title” in Figure 4-1 represents the title found in Google’s SERPs, and the column labeled “Page Title” represents the actual page title found in the HTML. The “Keyword(s) found in Title? [Y|N]” column states whether the keyword is found in the HTML title. The column labeled “Title Keywords in Page Copy [%]” lists the percentage of words found in the page title that are also found in the page copy.
Keywords in the Page URL
Keywords in a page URL are useful—and not just for SEO. Many of the newer CMSs, blog sites, and news sites allow for URL rewriting techniques to make their URLs stand out by using keywords in the URLs. The keywords I am referring to here are those found after the base domain name. Figure 4-2 shows an example.

Figure 4-2 shows a search result for the keyword blue suede shoes. From a usability perspective, Google also highlights in bold the words matching the search query keywords, which makes this result stand out further.
Optimizing URLs can sometimes make them very long and hard to remember. This drawback is offset by the benefit of their perceived relevance when displayed in search results.
Keywords in the Page Copy
When I talk about keywords in the page copy, I mean the number of times a particular keyword or keywords occur in the body of a document. Before optimizing your keywords, do the necessary research and figure out what people are searching for in the particular topic you are writing about.
Use tools such as Google AdWords to obtain keyword suggestions as well as to check what your competitors are using. You may want to target no more than two or three keywords per page.
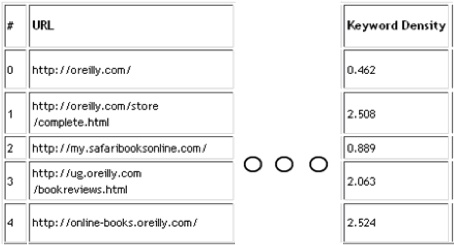
High keyword densities may be viewed with more suspicion. Typically, keyword densities range between 0.2% and 4%. This does not mean your site will be penalized if your keyword density is 10%, nor does it mean your page will not rank if your keyword density is less than 0.2%.
Figure 4-3 shows the keyword density for the top search results on Google for the keyword o’reilly book.
Keywords in the <meta> Description Tag
The text in the <meta>
description tag is not visible on the page itself, but is often
displayed in search results. This should be enough of an imperative to
fully optimize this tag. Here is the format of a <meta> description tag:
<meta name="description" content="Optimized Description with Important Keywords. This text can be a short paragraph. Use important page copy keywords in this description.">
Here are some examples of good <meta> description tags:
<meta name="description" content="Learn how to develop web applications with ASP. Learn ASP programming quickly with our three- part tutorial." /> <meta name="description" content="CompanyXYZSEO.com are experts in Organic SEO. Performance-based guarantee with low cost SEO entry packages for small businesses and the enterprise. Based out of San Franciso, CA." /> <meta name="description" content="O'Reilly Media spreads the knowledgeof technology innovators through its books, online services, magazines,and conferences.Since 1978, O'Reilly has been a chronicler and catalyst of leading-edge development, homing in on the technology trends that really matter and spurring their adoption by amplifying 'faint signals' from the alpha geeks who are creating the future. An active participant in the technology community, the company has a long history of advocacy, meme-making, and evangelism." />
The first two examples are straight-to-the-point, one- or two-line descriptions. The third (long) example is from O’Reilly’s main website. Notice the highlighted sentence. This is the part that Google is using in its SERP, while the rest is ignored.
Here are some examples of bad <meta> description tags:
<meta name="description" content="seo,organic seo, seo consultant, small business seo, small business search engine optimization consultant, small business search engine optimization" /> <html><body>...</body></html>
The first example employs confusing keywords and <meta> description tags. This sort of
description was meant for search engines only, not human visitors. The
second example illustrates the lost opportunity of not including any
<meta> description
tags.
Unless you are an established brand, make sure to include
<meta> description tags for
all pages. Don’t get lazy and reuse the same text for every page.
Every page needs to have its own unique <meta> description tag. Figure 4-4 shows the report segment
pertinent to <meta>
description tags. Search keywords tend to be found in <meta> description tags.

Search engine alternative to <meta> description tags
There is one “curveball” when it comes to <meta> description tags: search
engines will sometimes opt to ignore them in favor of the
description used at Dmoz.org or in the Yahoo! Directory (if you have a
listing there).
To help webmasters control this scenario, new meta tag
variations were created to force search engines to use the <meta> description tag instead of
the description found in the directory listings. Here are examples
that detail ways to block either Dmoz.org or Yahoo! Directory
descriptions:
<!-- Tells Yahoo! to not use Yahoo! Directory description --> <meta name="robots" content="noydir" /> <!-- Tells search engines to not use ODP description --> <meta name="robots" content="noodp" /> <!-- Tells search engines to not use either of the two directories --> <meta name="robots" content="noodp,noydir" />
If you wish to target only specific spiders, you can do the following:
<meta name="googlebot" content="noodp"> <!-- Note: Only Yahoo! uses Yahoo! Directory --> <meta name="slurp" CONTENT="noydir"> <meta name="msnbot" CONTENT="noodp">
Keywords in the Heading Tags
Make proper use of your H1 heading tags. Webmasters have used multiple H1 tags in the belief that search engines give those tags priority. The problem with this and similar techniques is that search engines are not stupid and will adapt very quickly to counterattack less scrupulous techniques such as this. Use H1 tags where and when they are appropriate.
The final HTML report, as produced by the script, contains two columns: “Header Tags” and “Header Tag Keywords.” The first column uses the following format:
Format: [H1]|[H2]|[H3]|[H4]|[H5]|[H6] Example: 1|40|100|0|0|0|
The preceding example is of a page using a single H1 tag, 40 H2 tags, and 100 H3 tags. The second column uses the following format:
Format: [Y|N]|[Y|N]|[Y|N]|[Y|N]|[Y|N]|[Y|N]| Example: Y|Y|Y|N|N|N
This example signifies the existence of keywords in H1, H2, and H3 tags.
Keyword Proximity
Keyword proximity refers to how close two or more keywords are to each other in page copy. Whenever possible, avoid using stop words to break up your important keywords. Here is an example:
We sellgreen iPodsat a discounted rate. We sell discountediPodsin various colors including white,greenand blue.
In this case, the keyword green iPods have
better keyword proximity in sentence one than they do in sentence two.
In terms of keyword proximity, you must consider all text—whether it
is part of the page copy, <title> tag, or <meta> tags—if you want to be included
in search results. Here is an example of how this information would be
rendered in the final HTML report:
14|17|21|154|157|161|212|223|236|244|247|655|658|662|1078|1081|1085| 1107|1150|1151|1183|1188|1377|1506|1712|1721|1726|
This list represents sample output of the (relative) keyword locations within a given page.
Keyword Prominence
Keyword prominence refers to relative keyword positions with respect to the start of the HTML page. Common agreement within the SEO community is that the earlier your keywords are found within the physical HTML file, the better.
The keyword prominence factor increases in importance as the document size increases. If your page is very large, ensure that your most important keywords are close to the beginning of the page.
Of course, your keywords should also appear throughout the page. It is not uncommon for Google and other search engines to pick up a phrase in the middle of your document and then place it within your search result. Keyword prominence is usually easy to achieve with semantic HTML pages. Minimize the use of inline JavaScript and CSS, and keep those in separate documents.
Aside from page copy, keyword prominence is also applicable to
your <title> and
<meta> tags, as your keywords
should appear in these tags, as we already discussed. Here is some
sample output that I obtained after running my script for one of the
page copies and for the keyword o’reilly
book:
*************************0*1********************** *****1******************************************** ************************************************** **********************************0*1************* ****************************1********************* ************************************************** ************************************************** ************************************************** ********************1**************************0*1 ************************************************** ***0*1******************************************** ************************************************** ************************************************** ******0***********1******************************* ************************************************** ************************************************** *0*******************************1**************** **************************************************
In this case, 0 signifies the relative position of the keyword o’reilly and 1 signifies the relative position of the keyword book.
All other words are signified by the star (*) character. For single keywords, you would
see only 0s. For multiword phrases, you would see 0, 1, 2, and so
forth. In other words, 0 is the first keyword, 1 is the second
keyword, and so on.
With this mapping, it is easy to see where your keywords are in the context of the whole page. Note that the keyword map shown does not represent the actual web page layout as seen in a web browser. It is only a serial representation of words found in each page.
Keywords in the Link Anchor Text
The link anchor text is all about keyword relevance. In general, all links should contain relevant keywords in the link anchor text. Here is the basic format:
<a href="some-link-with-keywords.html">Anchor Text with Keywords</a>
Here are some real examples:
<a href="perl-cookbook.html">The Perl Cookbook is a comprehensive collection of problems, solutions, and practical examples for anyone programming in Perl.</a> <a href="sharp-aquos-tvs.asp">AQUOS LCD TV at TorontoSharpDeals.com </a> <a href="valentine-gifts.pl">Valentine's Day Gifts & Ideas</a>
Search engines are keeping a close eye on link anchor text, thanks in part to so-called Google bombing. Google bombing is a technique people use to fool Google, by employing deceptive anchor text that is not necessarily related to the destination URL. Although Google has changed its algorithm to try to remove Google bombs, some people still succeed in creating them.
Link anchor text is important. This can become quite obvious in your web server logs when you compare search engine queries to your link anchor text. In many cases, the search engine queries and your link anchor text will be identical, or at least a very close match.
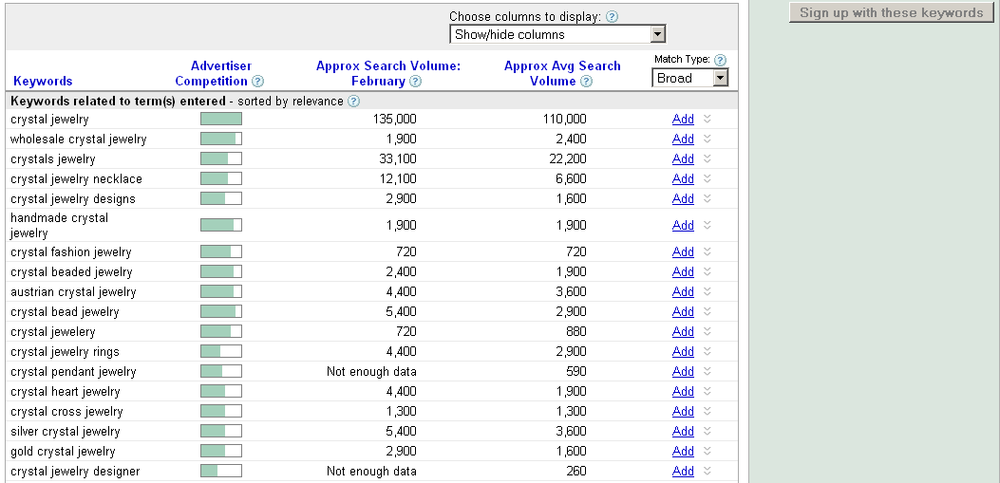
Link anchor text can be especially important with your inbound links. If you can control the anchor text of your inbound links, think carefully about what the anchor text should be. For best results, try to use a keyword suggestion tool such as the Google AdWords Keyword Tool as well as any proven (converting) keywords.
For example, let’s say you are a small online shop selling crystal jewelry. If you run a query for crystal jewelry in the AdWords Keyword Tool, you’ll get the results shown in Figure 4-5. Leverage these suggestions, if you can, when performing your link-building work.
The point is to try to use many different variations of anchor text, not just one. Search engines may get suspicious if your site starts to attain too many inbound links with the same anchor text too fast. It is best to have as many variations as possible, as this way your site will be getting hits for many different combinations of keywords.
Also note that you should be creating your link anchor text for your visitors, not just for the search engines; that is, your links should look natural, with no excessive keyword stuffing. Make sure you use the most popular anchor text phrases (on the most popular authoritative sites), as those inbound links will hold the greatest value.
Handle internal links in similar ways. Proper keyword selection for anchor text is important. Avoid using “Click here,” “Next page,” and “Read more” as your anchor text. Use semantically related anchor text instead.
Quality Outbound Links
Staying on focus is the underlying idea behind having quality outbound links. It is about what your web visitors want. Can you provide them with great content on your site plus any relevant links where they can find related information?
Keywords in outbound links
Using keywords in outbound links is a good idea. Figure 4-6 shows the part of the final HTML report that is pertinent to keywords found in outbound links. In this example, we see the top results from Google.

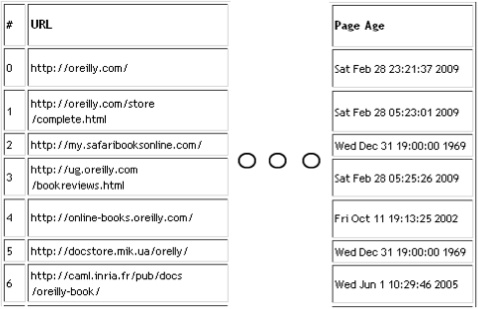
Web Page Age
For certain websites and topics, pages gain greater trust with age. This is different from the freshness boost for pages found in forums, message boards, news portals, and so forth. Note that not all web pages will return the “last modified” date. This could be an indication that the page is not to be cached. Figure 4-7 shows the “Page Age” section of our final report.
Web Page Size
There is no right or wrong answer when it comes to the perfect page size, as it obviously depends largely on what the page is about. However, your HTML should strive to be within reasonable size limits and should not contain erroneous information. To get a rough idea of the page size variable, we can use our script. Figure 4-8 shows the output section related to the page size for the keyword o’reilly book.

Calculating the optimum number of words per page
The physical web page file size can differ greatly from your page copy text. Although there are no magic numbers or rules, a general guideline is to have at least 200 words per page. Figure 4-9 illustrates this concept for the keyword o’reilly book.

On-Site Ranking Factors
So far, we have discussed ranking factors pertinent to each web page. In this section, we will cover factors that are applicable to the entire website. This includes domain name keywords, the size (or quantity) of content, linking considerations, and the freshness of pages.
Domain Name Keywords
If your domain name contains an exact (or partial) match to a search query, chances are it will show up on the first page of the SERPs—at least on Google. Google gives keyword matching domains preferential treatment.
The exception to this rule is for competitive keywords. However, the chances of acquiring a popular keyword domain are minimal, as most, if not all, dictionary words are taken, in addition to the most popular two- or three-keyword phrase combinations. This has led to the recent popularity of nonsense words as business names.
For niche keywords, you already won half the battle when you purchased your domain name. Add an index page with related keywords, and you’ll be on the first page of Google’s search results in a relatively short period of time.
You can use the following sample formats when creating your domain name:
http://www.keyword1-keyword2.com http://www.keyword1keyword2keyword3.com http://www.keyword.com http://www.keyword.somedomain.com http://keyword.basename.com
Note that the guidelines for subdomains are the same as for domains. The benefits of subdomains are multifold, but subdomains can also be viewed as search engine spam if you create too many of them. With subdomains, you can pick any name you like, as you are in control of the domain record. Table 4-1 summarizes a few other scenarios and the expected outcomes if you were to run the Perl script for certain keywords.
Keyword(s) | URL | Expected result |
new york times | No match | |
o’reilly book | Partial match | |
pragmatic programmers | No match | |
Etech | Full and partial matches |
Exact keyword matching
Exact keyword matching refers to keywords (as entered on Google) that are found in domain names. If a particular keyword or all keywords are found in a domain name, you can think of this scenario as an exact match.
Partial keyword matching
Aside from exact matching, there could be a partial match for multiword search phrases. Figure 4-10 showcases the power of having keywords as part of a domain name. This output was generated when we ran the script for the keyword o’reilly book.

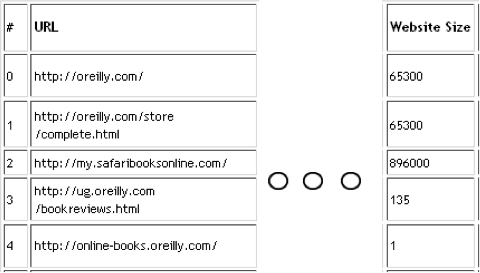
Size or Quantity of Content
When I talk about content size, I mean the amount of indexed documents on a particular site. Therefore, content size applies not only to your sites, but also to your competitors’ sites.
Estimating size of content
Although you could certainly write a web spider to crawl all
of the URLs on the Web, there is an easier way to estimate content
size. Popular search engines show this information in their search results.
To get the approximate size of a site, you can utilize Google’s site:
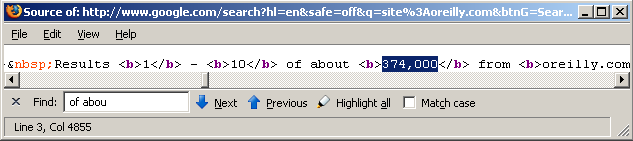
command (see Figure 4-11).

Figure 4-11 shows the approximate size of the O’Reilly website, which comprises 374,000 indexed documents at the time of this writing. You could also retrieve this data by using web scraping techniques. Looking at the HTML source of Google’s search results, you need to home in on a specific part of the HTML, as highlighted in Figure 4-12.
After running the script, it should be fairly obvious that big (good-quality) sites get better rankings—most of the time. The size of a site implies its authority. The bigger the site, the greater the site owner’s perceived authority. Of course, all of this depends on the quality of the content.
Figure 4-13 shows sample output of the final HTML report generated for the keyword o’reilly book.
Linking Considerations
The following subsections discuss things to consider when linking, including the internal link structure, pagination problems, distributed link popularity, and URL canonicalization.
Internal link architecture
Website linking architecture is important when it comes to SEO, especially when your site has many pages or is continuously growing. To create a sound linking structure for your site, you will likely need to partition your site into distinct subsections (or categories), forming a uniform (inverted) treelike structure. Sometimes creating subdomains can help in this regard. Other times, using XML Sitemaps can help showcase your most important links.
Pagination problems
Bringing inner pages to the forefront is a challenge for many
webmasters. Community sites, blogs, forums, message boards, and
other types of sites suffer from this “inner page invisibility” syndrome. If it takes more
than four clicks to get to a page, it is safe to say that this page
may not see the light of day in the SERPs. There are solutions to
pagination issues. These include pagination software reengineering,
the use of Sitemaps, and the use of the nofollow link
attribute.
Warning
Search engines don’t treat all sites in the same way. If yours is an important authority website or the site for a big respected brand, search engines will bend the rules and index your site more than they usually would, in that they will dig deeper into your sublevels—whereas if you were the owner of a new site, you would be lucky if the search engines dug down four levels when indexing your site.
Distributed internal link popularity
A true testament of a site’s performance can be viewed in terms of its distributed internal link popularity. Does your link juice dissipate quickly as soon as you leave your home page? If that’s the case, you have work to do. Sometimes you may have search engine traps that you are not aware of, and hence Google cannot see some of your pages. Check for these situations by browsing your website with a text browser or by using Google Webmaster Tools.
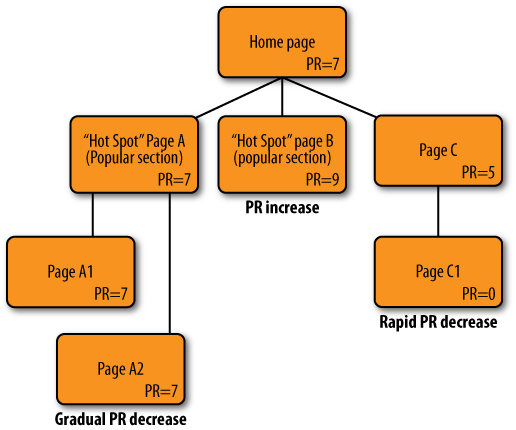
Strive to create multiple inner hotspots with gradual PageRank dissipation. Ideally, having an inner page with the same or even higher link juice as the site’s home page is desirable. One way to accomplish this is to have referral sites linking to your inner pages, and not just to your home page.
Figure 4-14 illustrates a website with three main links from its home page. The first link is just as popular as the home page, and the second link is even more popular. The third link, to Page C, has rapidly diminishing PageRank. Two clicks away from the home page, the PageRank value has gone down to zero.
URL canonicalization
The subject of URL canonicalization comes up when dealing with content duplication. The word canonicalization comes from computer science, and Wikipedia defines it as “a process for converting data that has more than one possible representation into a ‘standard’ canonical representation” (http://bit.ly/z92Dw).
In terms of SEO, this has to do with how search engines interpret the same content referenced by different link variations. For example, the following links could all point to the same physical page but be interpreted as different by the search engines:
http://somedomain.com http://somedomain.com/ http://somedomain.com/index.asp http://www.somedomain.com http://www.somedomain.com/index.html http://www.somedomain.com/Index.html http://www.somedomain.com/default.asp
Technically speaking, it is possible to serve different content for each of these URLs. So, what is the real problem of having different ways to get to the same content? It boils down to interpretation. Google and others may split your link juice across all of the different variations of URLs, hence affecting your PageRank. There are many ways to deal with canonical links.
The basic idea is to stick with one URL format throughout your website. One way to do this is to explicitly tell Google what your canonical or preferred link is via Google Webmaster Tools. Other ways include using permanent 301 redirects, custom coding, and the canonical link element in the HTML header.
Freshness of Pages
Depending on the site, your ratio of new to old pages could play a role in how search engines rank your site (or it could have no impact at all). For a news or portal site, a large ratio of new to old pages is beneficial. For sites that sell products or services that never change, this ratio might be much smaller.
For news portals, the frequency of updates will be higher when compared to other sites. Sites with fresh news tend to get a temporary ranking boost. This boost typically reaches its peek before slowly descending to few or no referrals for a particular news article.
Putting It All Together
Throughout this chapter, we referred to the HTML report produced by the rankingfactors.pl script, which you can find in Appendix A. We’ll finish the chapter by discussing how to run this script, and showing the final HTML report. We’ll also talk about the program directory structure that is required to support script execution.
Running the Script
The following fragment illustrates typical script execution:
>perl rankingfactors.pl 100 seo Starting.. ..cleanup done ..getting SERPs ..got the SERPs ..got the real titles ..finished partial title comparisons ..finished keyword title comparisons ..finished title page copy comparisons ..finished domain name exact keyword analysis ..finished domain name partial keyword analysis ..finished description META analysis ..finished header tags analysis ..finished keyword proximity analysis ..finished outbound links analysis ..finished outbound link PR analysis ..finished average page size analysis ..finished optimum number of words analysis ..finished website size analysis
In this example, we would be producing a report based on the keyword seo. We are also telling it to use the top 100 SERPs when doing the analysis. Note that you can choose between 10 and 100 top SERPs for analysis. Depending on your selection, script execution time will vary.
Final HTML Report
To see the final report, go to the report folder and open the index.html file. Your report should resemble Figure 4-15.
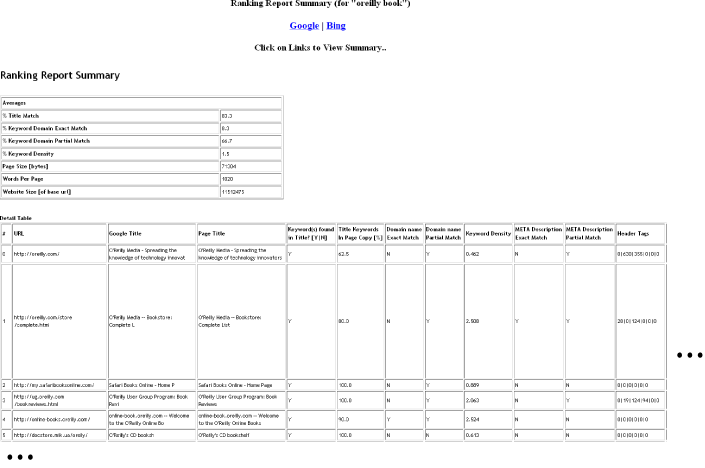
The final report contains two tables. The top table is a summary table showing several averages, including “% Title Match,” “% Keyword Domain Exact Match,” “% Keyword Domain Partial Match,” “% Keyword Density,” “Page Size [bytes],” “Words Per Page,” and “Website Size [of base url].” Immediately below the summary table is the detail table. This table is rather large and usually requires horizontal and vertical scrolling.
Report metrics summary
Table 4-2 summarizes all of the key metrics shown in the final HTML report.
Summary
With so many variables used in search engine rankings, optimizing for the most important ranking factors is paramount. Nobody has time to optimize for everything.
This chapter covered internal ranking factors. Internal ranking factors are divided into two broad categories: on-page and on-site ranking factors.
On-page ranking factors are pertinent to each page. Many on-page
ranking factors are related to keywords. This includes keywords in the
title tags, the page URL, the <meta> description tags, and the HTML
heading tags. Other on-page factors include the keyword proximity (and
prominence), the link anchor keywords, the quality of outbound links,
the page age, and the page size.
On-site ranking factors affect the entire site. These factors include the domain name keywords, the size or quantity of content, the linking architecture, and the page freshness.
We examined all of these factors in detail using a custom Perl script to help you in your SEO efforts.