


Ensuring business continuity
Business continuity and continuous application availability are among the most important requirements for many organizations. Advances in virtualization, storage, and networking made enhanced business continuity possible.
Information technology solutions can now manage planned and unplanned outages, and provide the flexibility and cost efficiencies that are available from cloud-computing models.
This chapter briefly describes the HyperSwap solutions for IBM Spectrum Virtualize systems. Technical details or implementation guidelines are not presented in this chapter because they are described in separate publications.
|
Important: This book was written specifically for IBM FlashSystems products. Therefore, it does not cover Stretched Cluster and Enhanced Stretched Cluster topologies. For more information about IBM SAN Volume Controller, see IBM SAN Volume Controller Best Practices and Performance Guidelines, SG24-8502.
This book does not cover the 3-site replication solutions, which are available with the IBM Spectrum Virtualize code version 8.3.1 or later. For more information, see IBM Spectrum Virtualize 3-Site Replication, SG24-8504.
|
This chapter includes the following topics:
7.1 Business continuity with HyperSwap
The HyperSwap high-availability feature in the IBM Spectrum Virtualize and FlashSystems products enables business continuity during a hardware failure, power outage, connectivity problem, or other disasters, such as fire or flooding.
It provides highly available volumes accessible through two sites located at up to 300 kilometers (km) apart. A fully independent copy of the data is maintained at each site. When data is written by hosts at either site, both copies are synchronously updated before the write operation is completed. HyperSwap automatically optimizes itself to minimize data that is transmitted between sites, and to minimize host read and write latency.
For more information about the optimization algorithm, see 7.3, “HyperSwap Volumes” on page 364.
HyperSwap includes the following key features:
•Works with all IBM Spectrum Virtualize products except for IBM FlashSystem 5010.
•Uses intra-cluster synchronous Remote Copy (Active-Active Metro Mirror) capability, with change volumes and access I/O group technologies.
•Makes a host’s volumes accessible across two IBM Spectrum Virtualize I/O groups in a clustered system by using the Active-Active Metro Mirror relationship. The volumes are presented as a single volume to the host.
•Works with the standard multipathing drivers that are available on various host types. Additional host support is not required to access the highly available volumes.
The IBM Spectrum Virtualize HyperSwap configuration requires that at least one control enclosure is implemented in each location. Therefore, a minimum of two control enclosures for each cluster is needed to implement HyperSwap. Configurations with three or four control enclosures also are supported for the HyperSwap.
The typical IBM FlashSystems HyperSwap implementation is shown in Figure 7-1.

Figure 7-1 Typical HyperSwap configuration with IBM FlashSystem
With a copy of the data that is stored at each location, HyperSwap configurations can handle different failure scenarios.
Figure 7-2 shows how HyperSwap operates in a storage failure in one location. In this case, after the storage failure was detected in Site A, the HyperSwap function provides access to the data through the copy in the surviving site.
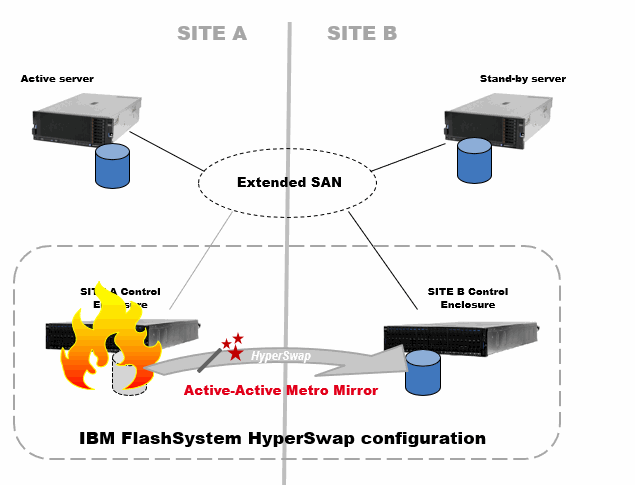
Figure 7-2 IBM FlashSystem HyperSwap in a storage failure scenario
You can lose an entire location, and access to the disks remains available at the alternate location. The use of this behavior requires clustering software at the application and server layer to fail over to a server at the alternate location and resume access to the disks.
The active-active synchronous mirroring feature, as shown in Figure 7-3, provides the capability to keep both copies of the storage in synchronization. Therefore, the loss of one location causes no disruption to the alternate location.

Figure 7-3 IBM FlashSystem HyperSwap in a site failure scenario
In addition to the active-active Metro Mirror feature, the HyperSwap feature also introduced the site awareness concept for node canisters, internal and external storage, and hosts. Finally, with the HyperSwap DR feature, you can manage rolling-disaster scenarios effectively.
7.2 Third site and IP quorum
In HyperSwap configurations, you can use a third, independent site to house a quorum device to act as the tie-breaker in case of split-brain scenarios. The quorum device can also hold a backup copy of the cluster metadata to be used in certain situations that might require a full cluster recovery.
To use a quorum disk as the quorum device, this third site must have Fibre Channel or iSCSI connectivity between an external storage system and the IBM Spectrum Virtualize cluster. Sometimes, this third site quorum disk requirement turns out to be expensive in terms of infrastructure and network costs. For this reason, a less demanding solution based on a Java application, known as the IP quorum application, is introduced with the release V7.6.
Initially, IP quorum was used only as a tie-breaker solution. However, with the release V8.2.1, it was expanded to be able to store cluster configuration metadata, fully serving as an alternative for quorum disk devices. To use an IP quorum application as the quorum device for the third site, Fibre Channel connectivity is not used. An IP quorum application can be run on any host at the third site, as shown in Figure 7-4.
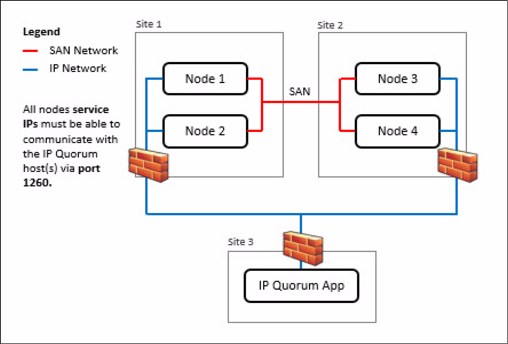
Figure 7-4 IP Quorum network layout
However, the following strict requirements must be met on the IP network when an IP quorum application is used:
•Connectivity from the servers that are running an IP quorum application to the service IP addresses of all nodes or node canisters. The network must also handle the possible security implications of exposing the service IP addresses, as this connectivity can also be used to access the service assistant interface if the IP network security is configured incorrectly.
•On each server that runs an IP quorum application, ensure that only authorized users can access the directory that contains the IP quorum application. Metadata is stored in the directory in a readable format, so ensure access to the IP quorum application and the metadata is restricted to only authorized users.
•Port 1260 is used by the IP quorum application to communicate from the hosts to all nodes or enclosures.
•The maximum round-trip delay must not exceed 80 milliseconds (ms), which means 40 ms each direction.
•If you are configuring the IP quorum application without a quorum disk for metadata, a minimum bandwidth of two megabytes per second is guaranteed for traffic between the system and the quorum application. If your system is using an IP quorum application with quorum disk for metadata, a minimum bandwidth of 64 megabytes per second is guaranteed for traffic between the system and the quorum application.
•Ensure that the directory that stores an IP quorum application with metadata contains at least 250 megabytes of available capacity.
Quorum devices are also required at Site 1 and Site 2, and can be either disk-based quorum devices or IP quorum applications. A maximum number of five IP quorum applications can be deployed.
|
Important: Do not host the quorum disk devices or IP quorum applications on storage provided by the system it is protecting, as during a tie-break situation this storage is paused for I/O.
|
For more information about IP Quorum requirements and installation, including supported Operating Systems and Java runtime environments (JREs), see this IBM Documentation web page.
For more information about quorum disk devices, see 3.5, “Quorum disks” on page 107.
|
Note: The IP Quorum configuration process has been integrated into the IBM Spectrum Virtualize GUI and can be found at Settings → Systems → IP Quorum.
|
7.2.1 Quorum modes
Quorum mode is a new configuration option that was added to the IP Quorum functionality with the release of IBM Spectrum Virtualize V8.3. By default, the IP quorum mode is set to Standard. In HyperSwap clusters, this mode can be changed to Preferred or Winner.
This configuration allows you to specify which site will resume I/O after a disruption, based on the applications that run on each site or other factors. For example, you can specify whether a selected site is the preferred for resuming I/O, or if the site automatically “wins” in tie-break scenarios.
Preferred Mode
If only one site runs critical applications, you can configure this site as preferred. During a split-brain situation, the system delays processing tie-break operations on other sites that are not specified as “preferred”. That is, the designated preferred site has a timed advantage when a split-brain situation is detected, and starts racing for the quorum device a few seconds before the non-preferred sites.
Therefore, the likelihood of reaching the quorum device first is higher. If the preferred site is damaged or cannot reach the quorum device, the other sites have the chance to win the tie breaker and continue I/O.
Winner Mode
This configuration is recommended for use when a third site is not available for a quorum device to be installed. In this case, when a split-brain situation is detected, the site configured as the winner will always be the one to continue processing I/O, regardless of the failure and its condition. The nodes at the non-winner site always loses the tie-break and stops processing I/O requests until the fault is fixed.
7.3 HyperSwap Volumes
HyperSwap Volumes is one type of volume. It consists of a Master Volume and a Master Change Volume (CV) in one system site, and an Auxiliary Volume and Auxiliary Change Volume (CV) in the other system site. An active-active synchronous mirroring relationship exists between the two sites. As with a regular Metro Mirror relationship, the active-active relationship keeps the Master Volume and Auxiliary Volume synchronized.
The relationship uses the CVs as journaling volumes during any resynchronization process. The Master CV must be in the same I/O Group as the Master Volume, and it is recommended that it is in the same pool as the Master Volume. A similar practice applies to the Auxiliary CV and the Auxiliary Volume.
For more information about the Change Volume, see “Global Mirror Change Volumes functional overview” on page 285.
The HyperSwap Volume always uses the unique identifier (UID) of the Master Volume. The HyperSwap Volume is assigned to the host by mapping only the Master Volume even though access to the Auxiliary Volume is ensured by the HyperSwap function.
Figure 7-5 shows how the HyperSwap Volume is implemented.
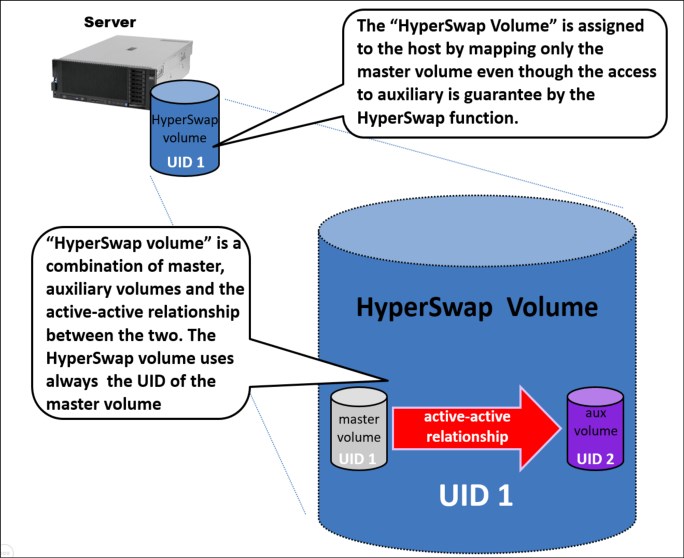
Figure 7-5 HyperSwap Volume
The active-active synchronous replication workload traverses the SAN by using the node-to-node communication. Master and Auxiliary Volumes also have a specific role of Primary or Secondary. Master or Auxiliary Volumes are Primary or Secondary based on the Metro Mirror active-active relationship direction.
Starting with the IBM Spectrum Virtualize 8.3.1 code level, reads are always done in the local copy of the volume. Write operations are always routed to the Primary copy. Therefore, hosts that access the Secondary copy for writes might experience an increased latency in the I/O operations. As a mitigation of this behavior, if sustained workload (that is, more than 75% of I/O operations for at least 20 minutes) is running over Secondary volumes, the HyperSwap function switches the direction of the active-active relationships, swapping the Secondary volume to Primary and vice versa.
|
Note: Frequent or continuous primary to secondary volume swap can lead to performance degradation. Avoid constantly switching the workload between sites at the host level.
|
7.4 Other considerations and general recommendations
Business continuity solutions implementation requires special considerations in the infrastructure and network setup. In HyperSwap topologies, the communication between the IBM Spectrum Virtualize controllers must be optimal and free of errors for best performance, as the internode messaging and cache mirroring is done across the sites. Have a dedicated private SAN for internode communication so that it is not impacted by regular SAN activities.
One other important recommendation is to review the site attribute of all the components, to make sure they are accurate. With the site awareness algorithm present in the IBM Spectrum Virtualize code, optimizations are done to reduce the cross-site workload. If this attribute is missing or not accurate, there might be an increased unnecessary cross-site traffic, which might lead to higher response time to the applications.
The HyperSwap feature requires implementing the storage network to ensure that the inter-node communication on the Fibre Channel ports on the control enclosures between the sites is on dedicated fabrics. No other traffic (hosts, back-end controllers, if any) or traffic that is unrelated to the HyperSwapped cluster can be allowed on this fabric. Two fabrics are used: one private for the inter-node communication, and one public for all other data.
A few SAN designs are available that can achieve this separation and some incorrect SAN designs can result in some potential problems that can occur with incorrect SAN design and implementation.
Find more information about design options and some common problems, see the following resources:
•This IBM Support web page.
For more information about a step-by-step configuration, see this IBM Documentation web page.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.