


Troubleshooting and diagnostics
This chapter provides information to start troubleshooting common problems that can occur in IBM FlashSystem environment. It describes situations that are related to IBM FlashSystem, the SAN environment, optional external storage subsystems, and hosts. It also explains how to collect the necessary problem determination data.
This chapter includes the following topics:
11.1 Starting troubleshooting
Troubleshooting is a systematic approach to solving a problem. The goal of troubleshooting or problem determination is to understand why something does not work as expected and find a resolution. Hence, the first step is to describe the problem as accurately as possible, then perform log collection from all the involved products of the solution as soon as the problem is reported. An effective problem report ideally should describe the expected behavior, the actual behavior, and, if possible, how to reproduce the behavior.
The following questions help define the problem for effective troubleshooting.
•What are the symptoms of the problem?
– What is reporting the problem?
– What are the error codes and messages?
– What is the business impact of the problem?
– Where does the problem occur?
– Is the problem specific to one or multiple hosts, one or both nodes?
– Is the current environment and configuration supported?
•When does the problem occur?
– Does the problem happen only at a certain time of day or night?
– How often does the problem happen?
– What sequence of events leads up to the time that the problem is reported?
– Does the problem happen after an environment change, such as upgrading or installing software or hardware?
•Under which conditions does the problem occur?
– Does the problem always occur when the same task is being performed?
– Does a certain sequence of events need to occur for the problem to surface?
– Do any other applications fail at the same time?
•Can the problem be reproduced?
– Can the problem be re-created on a test system?
– Are multiple users or applications encountering the same type of problem?
– Can the problem be re-created by running a single command, a set of commands, or a particular application, or a stand-alone application?
Collecting log files close to the time of the incident and providing an accurate timeline are critical for effective troubleshooting.
11.1.1 Using the GUI
IBM FlashSystem graphical user interface (GUI) is a good starting point for your troubleshooting. It has two icons at the top that can be accessed from any window of the GUI.
As shown in Figure 11-1, the first icon shows IBM FlashSystem events, such as an error or a warning, and the second icon shows suggested tasks and background tasks that are running, or that were recently completed.
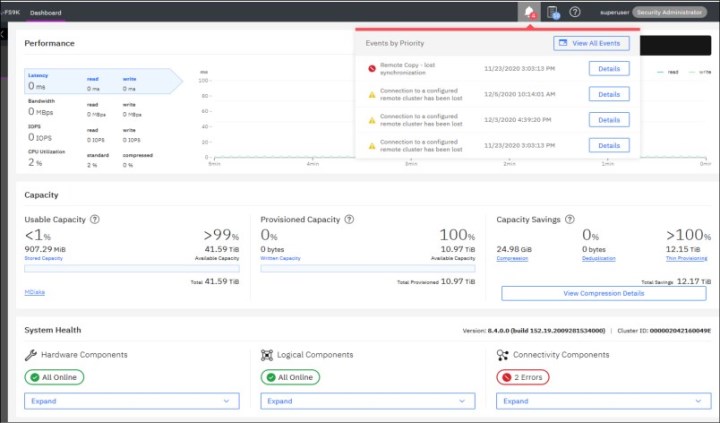
Figure 11-1 Events icon in GUI
The Dashboard provides an at-a-glance look into the condition of the system and notification of any critical issues that require immediate action. It contains sections for performance, capacity, and system health that provide an overall understanding of what is happening on the system.
Figure 11-2 shows the Dashboard window that displays the system health windows.

Figure 11-2 Dashboard showing system health
The System Health section in the bottom part of the Dashboard provides information about the health status of hardware, and logical and connectivity components.
If you click Expand in each of these categories, the status of individual components is shown (see Figure 11-3). You can also click More Details, which takes you to the window that is related to that specific component, or shows you more information about it.
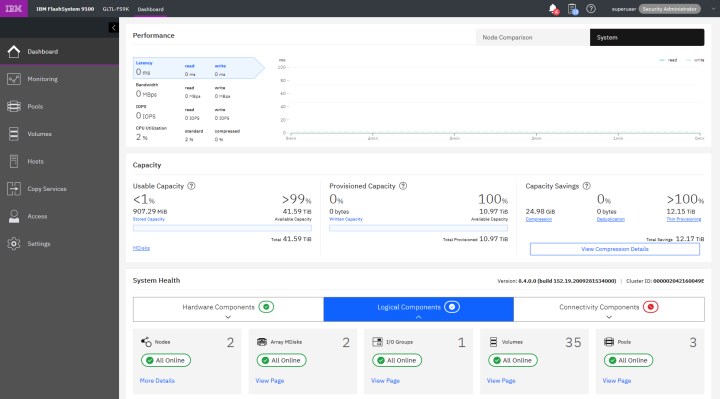
Figure 11-3 System Health expanded section in dashboard
For more information about the components in each category and IBM FlashSystem troubleshooting, see this IBM Documentation web page.
11.1.2 Recommended actions and fix procedure
The fix procedures were carefully designed to assist users to fix the problem without doing harm. When many unfixed error codes are in the event log, the management GUI provides a way to run the next recommended fix procedure. Therefore, the first step in troubleshooting is to run the fix procedures on the error codes in the event log.
These messages and codes provide reference information about configuration events and error event codes when a service action is required. The Cluster Error Code (CEC) is visible in the cluster event log; Node Error Code (NEC) is visible in node status in the service assistant GUI.
A cluster might encounter the following types of failure recoveries because of various conditions:
•Node assert (warmstart or Tier1/T1 recovery) is reported as CEC 2030.
•Cluster recovery (Tier2/T2 recovery) is reported as CEC 1001.
•System recovery (Tier3/T3 recovery) is required when all nodes of the clustered system report NEC 550/578.
•System restore (Tier4/T4 recovery) is to restore the cluster to a point where it can be used to restore from an off-cluster backup (be used by IBM Support only).
For more information about messages and codes, see this IBM Documentation web page.
The Monitoring → Events window shows information messages, warnings, and issues about the IBM FlashSystem. Therefore, this area is a good place to check the problems in the system.
Use the Recommended Actions filter to display the most important events that must be fixed.
If an important issue that must be fixed, the Run Fix button is available in the upper left with an error message that indicates which event must be fixed as soon as possible. This fix procedure assists you to resolve problems in IBM FlashSystem. It analyzes the system, provides more information about the problem, suggests actions to be taken with steps to be followed, and finally checks to see whether the problem is resolved.
Always use the fix procedures to resolve errors that are reported by the system, such as system configuration problems or hardware failures.
|
Note: IBM FlashSystem detects and reports error messages; however, many events can be triggered by external storage subsystems or the SAN.
|

Figure 11-4 Events window
|
Resolve alerts in a timely manner: When an issue or a potential issue is reported, resolve it as quickly as possible to minimize its impact and potentially avoid more serious problems with your system.
|
To obtain more information about any event, select an event in the table, and click Actions → Properties. You can also access Run Fix Procedure and properties by right-clicking an event.
More information about it is displayed in the Properties and Sense Data window for the specific event, as shown in Figure 11-5. You can review and click Run Fix to run the fix procedure.
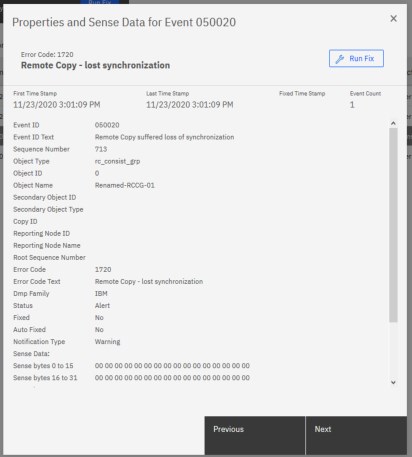
Figure 11-5 Properties and sense data for event window
|
Tip: In the Properties and Sense Data for Event window, use the Previous and Next buttons to move between events.
|
Another common practice is to use the IBM Spectrum Virtualize command-line interface (CLI) to find issues and resolve them. You also can use the CLI to perform common error recovery steps. Although the maintenance procedures perform these steps, it is sometimes faster to run these commands directly through the CLI.
Run the commands when you have the following issues:
•You experience a back-end storage issue (for example, error code 1370 or error code 1630).
•You performed maintenance on the back-end storage subsystems.
|
Important: Run the commands when any type of change that is related to the communication between IBM Spectrum Virtualize and back-end storage subsystem occurs (such as back-end storage is configured or a zoning change occurs). This process ensures that IBM Spectrum Virtualize recognizes the changes.
|
Common error-recovery involves the following IBM Spectrum Virtualize CLI commands:
•lscontroller and lsmdisk
Provides status of all controllers and MDisks.
•detectmdisk
Discovers the changes in the back-end.
•lscontroller <controller_id_or_name>
Checks the controller that was causing the issue and verifies that all the WWPNs are listed as you expect. It also checks that the path_counts are distributed evenly across the WWPNs.
•lsmdisk
Determines whether all MDisks are online.
|
Note: When an issue is resolved by using the CLI, verify that the error disappears from Monitoring → Events window. If not, make sure that the error was fixed, and if so, manually mark the error as fixed.
|
11.2 Collecting diagnostic data
Data collection and problem isolation in an IT environment are sometimes difficult tasks. In the following section, the essential steps that are needed to collect debug data to find and isolate problems in an IBM FlashSystem environment are described.
11.2.1 IBM FlashSystem data collection
When a problem occurs with an IBM FlashSystem and you must open a case with IBM support, you must provide the support packages for the device. The support packages are collected and uploaded to the IBM Support center automatically by using IBM FlashSystem, or downloading the package from the device and manually upload to IBM.
The easiest method is to automatically upload the support packages from IBM FlashSystem by using the GUI or CLI.
You can also use the new IBM Storage Insights application to upload the log data, as described in 11.6.4, “Updating a support ticket” on page 562.
Collecting data by using the GUI
Complete the following steps to collect data by using the GUI:
1. Click Settings → Support → Support Package. Both options to collect and upload support packages are available
2. To automatically the support packages, click Upload Support Package.
3. In the pop-up window, enter the IBM Salesforce case number (TS00xxxxx) and the type of support package to upload to the IBM Support center. The Snap Type 4 can be used to collect standard logs and generate a statesave on each node of the system.
The Upload Support Package window is shown in Figure 11-6.
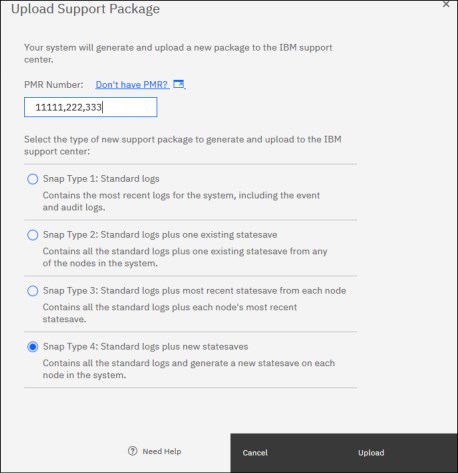
Figure 11-6 Upload Support Package window
For more information about the required support package that is most suitable to diagnose different type of issues, see this IBM Documentation web page.
Consider the following points:
•For issues that are related to interoperability with hosts or storage, use Snap Type 4.
•For critical performance issues, collect Option 1 and then, collect Snap Type 4.
•For general performance issues, collect Snap Type 4.
•For issues that are related to replication (including 1920 errors), collect Snap Type 4 from both systems.
•For issues that are related to compressed volumes, collect Snap Type 4.
•For 2030, 1196 or 1195 errors collect Snap Type 4.
•For all other issues, collect Snap Type 4.
Collecting data by using the CLI
To use the CLI to collect the same type of support packages, a livedump of the system must be generated by using the svc_livedump command. Then, the log files and newly generated dumps are uploaded by using the svc_snap command, as shown in Example 11-1 on page 528. To verify whether the support package was successfully uploaded, use the sainfo lscmdstatus command (XXXXX,YYY,ZZZ is the PMR number).
Example 11-1 The svc_livedump command
IBM_FlashSystem:FLASHPFE95:superuser>svc_livedump -nodes all -yes
Livedump - Fetching Node Configuration
Livedump - Checking for dependent vdisks
Livedump - Check Node status
Livedump - Prepare specified nodes - this may take some time...
Livedump - Prepare node 1
Livedump - Prepare node 2
Livedump - Trigger specified nodes
Livedump - Triggering livedump on node 1
Livedump - Triggering livedump on node 2
Livedump - Waiting for livedumps to complete dumping on nodes 1,2
Livedump - Waiting for livedumps to complete dumping on nodes 2
Livedump - Successfully captured livedumps on nodes 1,2
IBM_FlashSystem:FLASHPFE95:superuser>svc_snap upload pmr=TS00XXXXX gui3
Collecting data
Packaging files
Snap data collected in /dumps/snap.ABCDEFG.171128.223133.tgz
IBM_FlashSystem:FLASHPFE95:superuser>sainfo lscmdstatus
last_command satask supportupload -pmr TS00xxxxx -filename /dumps/snap.ABCDEFG.171128.223133.tgz
last_command_status CMMVC8044E Command completed successfully.
T3_status
T3_status_data
cpfiles_status Complete
cpfiles_status_data Copied 1 of 1
snap_status Complete
snap_filename /dumps/snap.ABCDEFG.171128.223133.tgz
installcanistersoftware_status
supportupload_status Complete
supportupload_status_data [PMR=TS00xxxxx] Upload complete
supportupload_progress_percent 0
supportupload_throughput_KBps 0
supportupload_filename /dumps/snap.ABCDEFG.171128.223133.tgz
downloadsoftware_status
downloadsoftware_status_data
downloadsoftware_progress_percent 0
downloadsoftware_throughput_KBps 0
downloadsoftware_size
IBM_FlashSystem:FLASHPFE95:superuser>
11.2.2 Host multipath software data collection
If a problem occurs that is related to host communication with IBM FlashSystem, collecting data from hosts and multipath software is useful.
If the systems still use SDD multipathing modules, note SDDPCM for AIX provides the sddpcmgetdata script to collect information that is used for problem determination. This script creates a .tar file in the directory with the current date and time as a part of the file name.
When you suspect an issue with SDDPCM exists, it is essential to run this script and send this .tar file to IBM Support.
SDDDSM for Windows hosts also include a utility to collect information for problem determination. The sddgetdata.bat tool creates a CAB file in the installation directory with the current date and time as part of the file name. The CAB file includes the following information:
•SystemInfo
•HKLM SYSTEMCurrentControlSet, HKLMHARDWAREDEVICEMAP, and HKLMCluster output from the registry
•SDDDSM directory contents
•HBA details
•Datapath outputs
•Pathtest trace
•SDDSRV logs
•Cluster logs
•System disks and paths
The execution and output of sddgetdata.bat tool is shown in Example 11-2.
Example 11-2 The sddgetdata.bat tool
C:Program FilesIBMSDDDSM>sddgetdata.bat
Collecting SDD trace Data
Flushing SDD kernel logs
SDD logs flushed
Collecting datapath command outputs
Collecting System Information
Collecting SDD and SDDSrv logs
Collecting Most current driver trace
Please wait for 30 secs... Writing DETAILED driver trace to trace.out
Generating a CAB file for all the Logs
sdddata_WIN-IWG6VLJN3U3_20171129_151423.cab file generated
C:Program FilesIBMSDDDSM>
For more information about diagnostics for IBM SDD, see this IBM Support web page.
11.2.3 More data collection
Data collection methods vary by storage platform, SAN switch, and operating system.
For an issue in a SAN environment when it is not clear where the problem is occurring, you might need to collect data from several devices in the SAN.
The following basic information must be collected for each type of device:
•Hosts:
– Operating system: Version and level
– HBA: Driver and firmware level
– Multipathing driver level
•SAN switches:
– Hardware model
– Software version
•Storage subsystems:
– Hardware model
– Software version
11.3 Common problems and isolation techniques
SANs, storage subsystems, and host systems can be complicated. They often consist of hundreds or thousands of disks, multiple redundant subsystem controllers, virtualization engines, and different types of SAN switches. All of these components must be configured, monitored, and managed correctly. If issues occur, administrators must know what to look for and where to look.
IBM FlashSystem features useful error logging mechanisms. It tracks its internal events and informs the user about issues in the SAN or storage subsystem. It also helps to isolate problems with the attached host systems. Therefore, by using these functions, administrators can easily locate any issue areas and take the necessary steps to fix any events.
In many cases, IBM FlashSystem and its service and maintenance features guide administrators directly, provide help, and suggest remedial action. Furthermore, IBM FlashSystem determines whether the problem still persists.
Another feature that helps administrators to isolate and identify issues that might be related to IBM FlashSystem is the ability of their nodes to maintain a database of other devices that communicate with the IBM FlashSystem device. Devices, such as hosts and optional back-end storages, are added or removed from the database as they start or stop communicating to IBM FlashSystem.
Although IBM FlashSystem node hardware and software events can be verified in the GUI or CLI, external events, such as failures in the SAN zoning configuration, hosts, and back-end storages are common. They also must have troubleshooting performed outside of IBM FlashSystem.
For example, a misconfiguration in the SAN zoning might lead to the IBM FlashSystem cluster not working correctly. This problem occurs because the IBM FlashSystem cluster nodes communicate with each other by using the Fibre Channel SAN fabrics.
In this case, check the following areas from an IBM FlashSystem perspective:
•The attached hosts. For more information, see 11.3.1, “Host problems” on page 531.
•The SAN. For more information, see 11.3.2, “SAN problems” on page 535.
•The optional attached storage subsystem. For more information, see 11.3.3, “Storage subsystem problems” on page 537.
•The local FC port masking. For more information, see 8.1.3, “Port masking” on page 368.
11.3.1 Host problems
From the host perspective, you can experience various situations that range from performance degradation to inaccessible disks. The first step in troubleshooting such issues is to check whether any potential interoperability issues exist.
Interoperability
When you experience events in the IBM FlashSystem environment, ensure that all components that comprise the storage infrastructure are interoperable. In an IBM FlashSystem environment, the IBM FlashSystem support matrix is the main source for this information. For the latest IBM FlashSystem support matrix, see IBM System Storage Interoperations Center (SSIC).
Although the latest IBM FlashSystem code level is supported to run on older host bus adapters (HBAs), storage subsystem drivers, and code levels, use the latest tested levels for best results.
After interoperability is verified, check the configuration of the host on the IBM FlashSystem side. The Hosts window in the GUI or the following CLI commands can be used to start a verification in host-related issues:
•lshost
Checks the host’s status. If the status is online, the host ports are online in both nodes of an I/O group. If the status is offline, the host ports are offline in both nodes of an I/O group. If the status is inactive, it means that the host has volumes that are mapped to it, but all of its ports did not receive Small Computer System Interface (SCSI) commands in the last 5 minutes. Also, if the status is degraded, it means at least one (but not all) of the host ports are not online in at least one node of an I/O group. Example 11-3 shows the lshost command output.
Example 11-3 lshost command
IBM_FlashSystem:FLASHPFE95:superuser>lshost
0 Win2K8 2 4 degraded
1 ESX_62_B 2 4 online
2 ESX_62_A 2 1 offline
3 Server127 2 1 degraded
•lshost <host_id_or_name>
Shows more information about a specific host. It often is used when you must identify which host port is not online in an IBM FlashSystem node. Example 11-4 shows the lshost <host_id_or_name> command output.
Example 11-4 lshost <host_id_or_name> command
IBM_FlashSystem:FLASHPFE95:superuser>lshost Win2K8
id 0
name Win2K8
port_count 2
type generic
mask 1111111111111111111111111111111111111111111111111111111111111111
iogrp_count 4
status degraded
site_id
site_name
host_cluster_id
host_cluster_name
WWPN 100000051E0F81CD
node_logged_in_count 2
state active
WWPN 100000051E0F81CC
node_logged_in_count 0
state offline
•lshostvdiskmap
Check that all volumes are mapped to the correct hosts. If a volume is not mapped correctly, create the necessary host mapping.
•lsfabric -host <host_id_or_name>
Use this command with parameter -host <host_id_or_name> to display Fibre Channel connectivity between nodes and hosts. Example 11-5 shows the lsfabric -host <host_id_or_name> command output.
Example 11-5 lsfabric -host <host_id_or_name> command
IBM_FlashSystem:FLASHPFE95:superuser>lsfabric -host Win2K8
remote_wwpn remote_nportid id node_name local_wwpn local_port local_nportid state name cluster_name type
10000090FAB386A3 502100 3 node1 5005076810120230 2 540200 inactive Win2K8 host
10000090FAB386A3 502100 1 node2 5005076810120242 2 540000 inactive Win2K8 host
To perform troubleshooting on the host side, check the following areas:
•Special software that you use
•Recent changes in the operating system (patching the operating system, an upgrade, and so on)
•Operating system version and maintenance or service pack level
•Multipathing type and driver level
•Host bus adapter model, firmware, and driver level
•Host bus adapter connectivity issues
Based on this list, the host administrator must check and correct any problems.
Hosts with higher queue depth can potentially overload shared storage ports. Therefore, it is recommended that you verify that the total of the queue depth of all hosts that are sharing a single target Fibre Channel port is limited to 2048. If any of the hosts have a queue depth of more than 128, that depth must be reviewed because queue-full conditions can lead to I/O errors and extended error recoveries.
For more information about managing hosts on IBM FlashSystem, see Chapter 8, “Configuring hosts” on page 367.
Apart from hardware-related situations, problems can exist in such areas as the operating system or the software that is used on the host. These problems normally are handled by the host administrator or the service provider of the host system. However, the multipathing driver that is installed on the host and its features can help to determine possible issues.
For example, a volume path issue is reported by SDD output on the host by using the datapath query adapter and datapath query device commands. The adapter in degraded state means that specific HBA on the server side cannot reach all the nodes in the I/O group to which the volumes are associated.
|
Note: SDDDSM and SDDPCM reached EOS. Therefore, migrate SDDDSM to MSDSM on Windows platform and SDDPCM to AIXPCM on AIX/VIOS platforms, respectively.
|
For more information, see this IBM Support web page.
Faulty paths can be caused by hardware and software problems, such as the following examples:
•Hardware:
– Faulty Small Form-factor Pluggable transceiver (SFP) on the host or SAN switch
– Faulty fiber optic cables
– Faulty HBAs
– Faulty physical SAN ports within a switch can lead to replacement of entire switch
– Contaminated SFPs/cable connectors
•Software:
– A back-level multipathing driver
– Obsolete HBA firmware or driver
– Wrong zoning
– Incorrect host-to-VDisk mapping
Based on field experience, it is recommended that you complete the following hardware checks first:
•Whether connection error indicators are lit on the host or SAN switch.
•Whether all of the parts are seated correctly. For example, cables are securely plugged in to the SFPs and the SFPs are plugged all the way into the switch port sockets.
•Ensure that fiber optic cables are not broken. If possible, swap the cables with cables that are known to work.
After the hardware check, continue to check the following aspects of software setup:
•Whether the HBA driver level and firmware level are at the preferred and supported levels.
•The multipathing driver level, and make sure that it is at the preferred and supported level.
•For link layer errors that are reported by the host or the SAN switch, which can indicate a cabling or SFP failure.
•Verify your SAN zoning configuration.
•The general SAN switch status and health for all switches in the fabric.
iSCSI/iSER configuration and performance issues
This section describes the Internet Small Computer Systems Interface (iSCSI) and iSCSI Extensions for RDMA (iSER) configuration and performance issues.
Link issues
If the Ethernet port link does not come online, check whether the SFP/cables and the port support auto-negotiation with the switch. This issue is especially true for SFPs, which support 25 G and higher because a mismatch might exist in Forward Error Correction (FEC) that might prevent a port to auto-negotiate.
Longer cables are exposed to more noise or interference (high Bit Error Ratio [BER]); therefore, they require more powerful error correction codes.
Two IEEE 802.3 FEC specifications are important. For an auto-negotiation issue, verify whether a compatibility issue exists with SFPs at both end points:
•Clause 74: Fire Code (FC-FEC) or BASE-R (BR-FEC) (16.4 dB loss specification).
•Clause 91: Reed-Solomon; that is, RS-FEC (22.4 dB loss specification)
Priority flow control
Priority flow control (PFC) is an Ethernet protocol that supports the ability to assign priorities to different types of traffic within the network. On most Data Center Bridging Capability Exchange protocol (DCBX) supported switches, verify whether Link Layer Discovery Protocol (LLDP) is enabled. The presence of a virtual local area network (VLAN) is a prerequisite for the configuration of PFC. It is recommended to set the priority tag 0 - 7.
A DCBX-enabled switch and a storage adapter exchange parameter that describe traffic classes and PFC capabilities.
In the IBM FlashSystem, Ethernet traffic is divided into the following Classes of Service based on feature use case:
•Host attachment (iSCSI/iSER)
•Back-end Storage (iSCSI)
•Node-to-node communication (Remote Direct Memory Access (RDMA) clustering)
If challenges occur as the PFC is configured, verify the following attributes to determine the issue:
•Configure IP/VLAN by using cfgportip.
•Configure class of service (COS) by using chsytsemethernet.
•Ensure that the priority tag is enabled on the switch.
•Ensure that lsportip output shows: dcbx_state, pfc_enabled_tags.
•Enhanced Transmission Selection (ETS) settings is recommended if a port is shared.
Standard network connectivity check
Verify that the required TCP/UDP ports are allowed in the network firewall. The following ports can be used for various host attachments:
• Software iSCSI requires TCP Port 3260.
• iSER/RoCE host requires 3260.
• iSER/iWRAP host requires TCP Port 860.
Verify that the IP addresses are reachable and the TCP ports are open.
iSCSI performance issues
In specific situations, the TCP/IP layer might attempt to combine several ACK responses into a single response to improve performance. However, that combination can negatively affect iSCSI read performance as the storage target waits for the response to arrive. This issue is observed when the application is single-threaded and has a low queue depth.
It is recommended to disable the TCPDelayedAck parameter on the host platforms to improve overall storage I/O performance. If the host platform does not provide a mechanism to disable TCPDelayedAck, verify whether a smaller “Max I/O Transfer Size” with more concurrency (queue depth >16) improves overall latency and bandwidth use for the specific host workload. In most Linux distributions, this Max I/O Transfer Size is controlled by the max_sectors_kb parameter with a suggested transfer size of 32 KB.
In addition, review network switch diagnostic data to evaluate packet drop or retransmission in the network. It is advisable to enable flow control or PFC to enhance the reliability of the network delivery system to avoid packet loss, which enhances storage performance.
11.3.2 SAN problems
It is not a difficult task to introduce IBM FlashSystem into your SAN environment and to use its virtualization functions. However, before you can use IBM FlashSystem in your environment, you must follow some basic rules. These rules are not complicated, but you can make mistakes that lead to accessibility issues or a reduction in the performance experienced.
Two types of SAN zones are needed to run IBM FlashSystem in your environment: A host zone and a storage zone for optional external-attached storage. In addition, you must have an IBM FlashSystem zone that contains all the IBM FlashSystem node ports of the IBM FlashSystem cluster. This IBM FlashSystem zone enables intra-cluster communication.
For more information and important points about setting up IBM FlashSystem in a SAN fabric environment, see Chapter 2, “Connecting IBM Spectrum Virtualize and IBM Storwize in storage area networks” on page 37.
Because IBM FlashSystem is a major component of the SAN and connects the host to the storage subsystem, check and monitor the SAN fabrics.
Some situations of performance degradation and buffer-to-buffer credit exhaustion can be caused by incorrect local FC port masking and remote FC port masking. To ensure healthy operation of your IBM FlashSystem, configure your local FC port masking and your remote FC port masking.
The ports that are intended to have only intra-cluster/node-to-node communication traffic must not have replication data or host or back-end data running on it. The ports that are intended to have only replication traffic must not have intra-cluster or node-to-node communication data or host or back-end data running on it.
Some situations can cause issues in the SAN fabric and SAN switches. Problems can be related to a hardware fault or to a software problem on the switch. The following hardware defects are normally the easiest problems to find:
•Switch power, fan, or cooling units
•Installed SFP modules
•Fiber optic cables
Software failures are more difficult to analyze. In most cases, you must collect data and involve IBM Support. However, before you take any other steps, check the installed code level for any known issues. Also, check whether a new code level is available that resolves the problem that you are experiencing.
The most common SAN issues often are related to zoning. For example, perhaps you chose the wrong WWPN for a host zone, such as when two IBM FlashSystem node ports must be zoned to one HBA with one port from each IBM FlashSystem node. As shown in Example 11-6, two ports are zoned that belong to the same node. Therefore, the result is that the host and its multipathing driver do not see all of the necessary paths.
Example 11-6 Incorrect WWPN zoning
zone: Senegal_Win2k3_itsosvccl1_iogrp0_Zone
50:05:07:68:10:20:37:dc
50:05:07:68:10:40:37:dc
20:00:00:e0:8b:89:cc:c2
The correct zoning must look like the zoning that is shown in Example 11-7.
Example 11-7 Correct WWPN zoning
zone: Senegal_Win2k3_itsosvccl1_iogrp0_Zone
50:05:07:68:10:40:37:e5
50:05:07:68:10:40:37:dc
20:00:00:e0:8b:89:cc:c2
The following IBM FlashSystem error codes are related to the SAN environment:
•Error 1060 - Fibre Channel ports are not operational
•Error 1220 - A remote port is excluded
A bottleneck is another common issue that is related to SAN switches. The bottleneck can be present in a port where a host, storage subsystem, or IBM Spectrum Virtualize device is connected, or in Inter-Switch Link (ISL) ports. The bottleneck can occur in some cases, such as when a device that is connected to the fabric is slow to process received frames or if a SAN switch port cannot transmit frames at a rate that is required by a device that is connected to the fabric.
These cases can slow down communication between devices in your SAN. To resolve this type of issue, refer to the SAN switch documentation or open a case with the vendor to investigate and identify what is causing the bottleneck and how fix it.
If you cannot fix the issue with these actions, use the method that is described in 11.2, “Collecting diagnostic data” on page 526, collect the SAN switch debugging data, and then, contact the vendor for assistance.
11.3.3 Storage subsystem problems
Today, various heterogeneous storage subsystems are available. All of these subsystems have different management tools, different setup strategies, and possible problem areas depending on the manufacturer. To support a stable environment, all subsystems must be correctly configured, following the respective preferred practices and with no existing issues.
Check the following areas if you experience a storage-subsystem-related issue:
•Storage subsystem configuration: Ensure that a valid configuration and preferred practices are applied to the subsystem.
•Storage subsystem node controllers: Check the health and configurable settings on the node controllers.
•Storage subsystem array: Check the state of the hardware, such as an FCM or SSD failures or enclosure alerts.
•Storage volumes: Ensure that the logical unit number (LUN) masking is correct.
•Host attachment ports: Check the status, configuration and connectivity to SAN switches.
•Layout and size of RAID arrays and LUNs: Performance and redundancy are contributing factors.
IBM FlashSystem features several CLI commands that you can use to check the status of the system and attached optional storage subsystems. Before you start a complete data collection or problem isolation on the SAN or subsystem level, use the following commands first and check the status from the IBM FlashSystem perspective:
•lsmdisk
Check that all MDisks are online (not degraded or offline).
•lsmdisk <MDisk_id_or_name>
Check several of the MDisks from each storage subsystem controller. Are they online? An example of the output from this command is shown in Example 11-8.
Example 11-8 Issuing a lsmdisk command
IBM_FlashSystem:FLASHPFE95:superuser>lsmdisk 0
id 0
name MDisk0
status online
mode array
MDisk_grp_id 0
MDisk_grp_name Pool0
capacity 198.2TB
quorum_index
block_size
controller_name
ctrl_type
ctrl_WWNN
controller_id
path_count
max_path_count
ctrl_LUN_#
UID
preferred_WWPN
active_WWPN
fast_write_state empty
raid_status online
raid_level raid6
redundancy 2
strip_size 256
spare_goal
spare_protection_min
balanced exact
tier tier0_flash
slow_write_priority latency
fabric_type
site_id
site_name
easy_tier_load
encrypt no
distributed yes
drive_class_id 0
drive_count 8
stripe_width 7
rebuild_areas_total 1
rebuild_areas_available 1
rebuild_areas_goal 1
dedupe no
preferred_iscsi_port_id
active_iscsi_port_id
replacement_date
over_provisioned yes
supports_unmap yes
provisioning_group_id 0
physical_capacity 85.87TB
physical_free_capacity 78.72TB
write_protected no
allocated_capacity 155.06TB
effective_used_capacity 16.58TB.
IBM_FlashSystem:FLASHPFE95:superuser>lsmdisk 1
id 1
name flash9h01_itsosvccl1_0
status online
mode managed
MDisk_grp_id 1
MDisk_grp_name Pool1
capacity 51.6TB
quorum_index
block_size 512
controller_name itsoflash9h01
ctrl_type 6
ctrl_WWNN 500507605E852080
controller_id 1
path_count 16
max_path_count 16
ctrl_LUN_# 0000000000000000
UID 6005076441b53004400000000000000100000000000000000000000000000000
preferred_WWPN
active_WWPN many
NOTE: lines removed for brevity
Example 11-8 on page 537 shows that for MDisk 1, the external storage controller has eight ports that are zoned to IBM FlashSystem, and IBM FlashSystem has two nodes (8 x 2= 16).
•lsvdisk
Check that all volumes are online (not degraded or offline). If the volumes are degraded, are there stopped FlashCopy jobs? Restart stopped FlashCopy jobs or seek IBM FlashSystem support guidance.
•lsfabric
Use this command with the various options, such as -controller controllerid. Also, check different parts of the IBM FlashSystem configuration to ensure that multiple paths are available from each IBM FlashSystem node port to an attached host or controller. Confirm that IBM FlashSystem node port WWPNs are also consistently connected to the optional external back-end storage.
Determining the number of paths to an external storage subsystem
By using IBM FlashSystem CLI commands, the total number of paths to an optional external storage subsystem can be determined. To determine the value of the available paths, use the following formula:
Number of MDisks x Number of FlashSystem nodes per Cluster = Number of paths
MDisk_link_count x Number of FlashSystem nodes per Cluster = Sum of path_count
Example 11-9 shows how to obtain this information by using the lscontroller <controllerid> and svcinfo lsnode commands.
Example 11-9 Output of the svcinfo lscontroller command
IBM_FlashSystem:FLASHPFE95:superuser>lscontroller 1
id 1
controller_name itsof9h01
WWNN 500507605E852080
MDisk_link_count 16
max_MDisk_link_count 16
degraded no
vendor_id IBM
product_id_low FlashSys
product_id_high tem-9840
product_revision 1430
ctrl_s/n 01106d4c0110-0000-0
allow_quorum yes
fabric_type fc
site_id
site_name
WWPN 500507605E8520B1
path_count 32
max_path_count 32
WWPN 500507605E8520A1
path_count 32
max_path_count 64
WWPN 500507605E852081
path_count 32
max_path_count 64
WWPN 500507605E852091
path_count 32
max_path_count 64
WWPN 500507605E8520B2
path_count 32
max_path_count 64
WWPN 500507605E8520A2
path_count 32
max_path_count 64
WWPN 500507605E852082
path_count 32
max_path_count 64
WWPN 500507605E852092
path_count 32
max_path_count 64
IBM_FlashSystem:FLASHPFE95:superuser>svcinfo lsnode
id name UPS_serial_number WWNN status IO_group_id IO_group_name config_node UPS_unique_id hardware iscsi_name iscsi_alias panel_name enclosure_id canister_id enclosure_serial_number site_id site_name
1 node1 500507681000000A online 0 io_grp0 no AF8 iqn.1986-03.com.ibm:2145.flashpfe95.node1 01-2 1 2 F313150
2 node2 5005076810000009 online 0 io_grp0 yes AF8 iqn.1986-03.com.ibm:2145.flashpfe95.node2 01-1 1 1 F313150
IBM_FlashSystem:FLASHPFE95:superuser>
Example 11-9 on page 539 shows that 16 MDisks are present for the external storage subsystem controller with ID 1, and two IBM FlashSystem nodes are in the cluster. In this example, the path_count is 16 x 2 = 32.
IBM FlashSystem features useful tools for finding and analyzing optional back-end storage subsystem issues because it includes a monitoring and logging mechanism.
Typical events for storage subsystem controllers include incorrect configuration, which results in a 1625 - Incorrect disk controller configuration error code. Other issues that are related to the storage subsystem include failures that point to the managed disk I/O (error code 1310), disk media (error code 1320), and error recovery procedure (error code 1370).
However, all messages do not have only one specific reason for being issued. Therefore, you must check many areas for issues, not just the storage subsystem.
To determine the root cause of a problem, complete the following steps:
1. Check the Recommended Actions window by clicking Monitoring → Events.
2. Check the attached storage subsystem for misconfigurations or failures:
a. Independent of the type of storage subsystem, first check whether the system includes any unfixed errors. Use the service or maintenance features that are provided with the storage subsystem to fix these issues.
b. Check whether the volume mapping is correct. The storage subsystem LUNs must be mapped to a host object with IBM FlashSystem ports. For more information about the IBM FlashSystem restrictions for optional back-end storage subsystems, see this IBM Support web page.
If you need to identify which of the externally attached MDisks has which corresponding LUN ID, run the IBM FlashSystem lsmdisk CLI command, as shown in Example 11-10. This command also shows to which storage subsystem a specific MDisk belongs (the controller ID).
Example 11-10 Determining the ID for the MDisk
IBM_FlashSystem:FLASHPFE95:superuser>lsmdisk
id name status mode MDisk_grp_id MDisk_grp_name capacity ctrl_LUN_# controller_name UID tier encrypt site_id site_name distributed dedupe over_provisioned supports_unmap
0 MDisk0 online array 0 Pool0 198.2TB tier0_flash no yes no yes yes
0 MDisk1 online managed 0 MDG-1 600.0GB 0000000000000000 controller0 600a0b800017423300000059469cf84500000000000000000000000000000000
2 MDisk2 online managed 0 MDG-1 70.9GB 0000000000000002 controller0 600a0b800017443100000096469cf0e800000000000000000000000000000000
3. Check the SAN environment for switch problems or zoning failures.
Make sure the zones are correctly configured, and that the zoneset is activated. The zones that allow communication between the storage subsystem and the IBM FlashSystem device must contain WWPNs of the storage subsystem and WWPNs of IBM FlashSystem.
4. Collect all support data and contact IBM Support.
Collect the support data for the involved SAN, IBM FlashSystem, or optional external storage systems as described in 11.2, “Collecting diagnostic data” on page 526.
11.3.4 Native IP replication problems
The native IP replication feature uses the following TCP/IP ports for remote cluster path discovery and data transfer:
•IP Partnership management IP communication: TCP Port 3260
•IP Partnership data path connections: TCP Port 3265
If a connectivity issue exists between the cluster in the management communication path, the cluster reports error code 2021: Partner cluster IP address unreachable. However, when a connectivity issue exists in the data path, the cluster reports error code 2020: IP Remote Copy link unavailable.
If the IP addresses are reachable and TCP ports are open, verify whether the end-to-end network supports a Maximum Transmission Unit (MTU) of 1500 bytes without packet fragmentation. When an external host-based ping utility is used to validate end-to-end MTU support, use the “do not fragment” qualifier.
Fix the network path so that traffic can flow correctly. After the connection is made, the error auto-corrects.
The network quality of service largely influences the effective bandwidth use of the dedicated link between the cluster. Bandwidth use is inversely proportional to round-trip time (RTT) and rate of packet drop or retransmission in the network.
For standard block traffic, a packet drop or retransmission of 0.5% or more can lead to unacceptable use of the available bandwidth. Work with the network team to investigate over-subscription or other quality-of-service of the link, with an objective of having the lowest possible (less than 0.1%) packet-drop percentage.
11.3.5 Remote Direct Memory Access-based clustering
RDMA technology supports zero-copy networking, which makes it possible to read data directly from the main memory of one computer and write that data directly to the main memory of another computer. This technology bypasses the CPU intervention while processing the I/O leading to lower latency and a faster rate of data transfer.
IBM FlashSystem Cluster can be formed by using RDMA-capable NICs that use RoCE or iWARP technology. Consider the following points:
•Inter-node Ethernet connectivity can be done over identical ports only; such ports must be connected within the same switching fabric.
•If the cluster is to be created without any ISL (up to 300 meters [984 feet]), deploy Independent (isolated) switches.
•If the cluster is to be created on short-distance ISL (up to 10 km [6.2 miles]), provision as many ISLs between switches as RDMA-capable cluster ports.
•For long-distance ISL (up to 100 km [62 miles]) DWDM and CWDM methods are applicable for L2 networks. Packet switched or VXLAN methods are deployed for L3 network as this equipment comes with deeper buffer “pockets”.
Following Ports must be opened in the firewall for IP-based RDMA clustering
•TCP 4791, 21451, 21452, and 21455
•UDP 4791, 21451, 21452, and 21455
The first step to review whether the node IP address is reachable and verify the required TCP/UDP ports are accessible in both directions. The following CLI output can be helpful to find the reason for connectivity error:
sainfo lsnodeipconnectivity
11.3.6 Advanced Copy services problems
Performance of a specific storage feature or overall storage subsystem is generally interlinked, meaning that a bottleneck in one software or hardware layer can propagate to other layers. Therefore, problem isolation is a critical part of performance analysis.
The first thing to check is whether any unfixed events exist that require attention. After the fix procedure is followed to correct the alerts, the next step is to check the audit log to determine whether any activity exists that can trigger the performance issue. If that information correlates, more analysis can be done to check whether that specific feature is used.
The most common root causes for performance issues are SAN congestion, configuration changes, incorrect sizing/estimation of advanced copy services (replication, FlashCopy, volume mirroring), or I/O load change, because of hardware component failure.
Remote Copy
Disturbances in the SAN or wide area network (WAN) can cause congestion and packet drop, which can affect Metro Mirror (MM) or Global Mirror (GM) traffic. Because host I/O latency depends on MM or GM I/O completion to the remote cluster, a host can experience high latency. Based on various parameters, replication can be operatively stopped to protect host.
The following conditions can affect GM/MM:
•Network congestion or fluctuation. Fix the network. Also, verify that port masking is enabled so that the congestion in replication ports does not affect clustering or host or storage ports.
•Overload of secondary/primary cluster. Monitor and throttle the host that causes the condition.
•High background copy rate, which leaves less bandwidth to replicate foreground host I/O. Adjust the background copy rate so that the link does not become oversubscribed.
•A large Global Mirror with Change Volumes (GMCV) consistency group can introduce hundreds of milliseconds of pause when the replication cycle starts. Reduce the number of relationships in a consistency group if the observed I/O pause is unacceptable.
HyperSwap
Verify that the link between the sites is stable and has enough bandwidth to replicate the peak workload. Also, check whether a volume must frequently change the replication direction from one site to other. This issue occurs when a specific volume is being written by hosts from both the sites. Evaluate if this issue can be avoided to reduce frequent direction change. Ignore it if the solution is designed consider active/active access.
If a single volume resynchronization between the sites takes a very long time, review the partnership link_bandwidth_mbits and per relationship_bandwidth_limit parameters.
FlashCopy
Consider the following points for FlashCopy troubleshooting:
•Verify that the preferred node of FlashCopy source and target volumes is the same to avoid excessive internode communications.
•High background copy rate and clean rate of FlashCopy relations can cause back-end overload.
•Port saturation or node saturation. Review if the values are correctly sized.
•Check the number of Fibre Channel relationships in any FlashCopy consistency group. The larger the number of relationships, the higher the I/O pause time (Peak I/O Latency) when the CG starts.
•If the host I/O pattern is small and random, evaluate whether reducing the FlashCopy grain size to 64 KB provides any improvement in latency compared to the default grain size of 256 KB.
Compression
Compress a volume if the data is compressible. No benefit is gained by compressing a volume where compression saving is less than 25% because that can reduce the overall performance of the Random Access Compression Engine (RACE).
If the I/O access pattern is sequential, that volume might not be a suitable candidate for RACE. Use the Comprestimator or Data Reduction Estimation Tool to size the workload.
Volume mirroring
Write-performance of the mirrored volumes is dictated by the slowest copy. Reads are served from the Copy0 of the volume (in the case of a stretched cluster topology, both the copies can serve reads, which are dictated by the host site attribute). Therefore, size the solution accordingly.
The mirroring layer maintains a bitmap copy on the quorum device; therefore, any unavailability of the quorum takes the mirroring volumes offline. Similarly, slow access to the quorum also can affect the performance of mirroring volumes.
Data reduction pools
Data reduction pools (DRPs) internally implement a log structured array (LSA), which means that writes (new or over-writes or updates) always allocate newer storage blocks. The older blocks (with invalid data) are marked for garbage collection later.
The garbage collection process is designed to defer the work as much as possible because the more it is deferred, the higher the chance of having to move only a small amount of valid data from the block to make that block available it to the free pool. However, when the pool reaches more than 85% of its allocated capacity, garbage collection must speed up and to move valid data more aggressively to make space available sooner. This issue might lead to increased latency because of increased CPU use and load on the back-end. Therefore, it is recommended to manage storage provisioning to avoid such scenarios.
Users are encouraged to pay close attention to any GUI notifications and use best practices for managing physical space. Use data reduction only at one layer (at the virtualization layer or the back-end storage or drives) because no benefit is realized by compressing and deduplicating the same data twice.
Because encrypted data cannot be compressed, data reduction must be done before the data is encrypted. Correct sizing is important to get the best of performance from data reduction; therefore, use data reduction estimation tools to evaluate system performance and space saving.
IBM FlashSystem uses the following types of data reduction techniques:
•IBM FlashSystem using the FCM NVMe drives have built-in hardware compression.
•IBM FlashSystem using industry-standard NVMe drives rely on the Spectrum Virtualize software and DRP pools to deliver data reduction.
For more information about DRPs, see Introduction and Implementation of Data Reduction Pools and Deduplication, SG24-8430.
11.3.7 Health status during upgrade
It is important to understand that during the software upgrade process, alerts that indicate the system is not healthy are reported. This issue is a normal behavior because the IBM FlashSystem node canisters go offline during this process; therefore, the system triggers these alerts.
While trying to upgrade an IBM FlashSystem, you might also receive a message, such as an error in verifying the signature of the update package.
This message does not mean that an issue exists in your system. Sometimes, this issue occurs because not enough space is available on the system to copy the file, or the package is incomplete or contains errors. In this case, open a Salesforce case with IBM Support and follow their instructions.
11.3.8 Managing physical capacity of over provisioned storage controllers
Drives and back-end controllers exist that include built-in hardware compression and other data reduction technologies that allow capacity to be provisioned over and above the available real physical capacity. Different data sets lead to different capacity savings and some data, such as encrypted data or compressed data, do not even compress. When the physical capacity savings do not match the expected or provisioned capacity, the storage can run out of physical space, which leads to a write-protected drive or array.
To avoid running out of space on the system, the usable capacity must be monitored carefully by using the GUI of the IBM FlashSystem. The IBM FlashSystem GUI is the only capacity dashboard that shows the physical capacity.
Monitoring is especially important when migrating substantial amounts of data onto the IBM FlashSystem, which typically occurs during the first part of the workload life cycle as data is on-boarded, or initially populated into the storage system.
IBM strongly encourages users to configure Call Home on the IBM FlashSystem. Call Home monitors the physical free space on the system and automatically opens a service call for systems that reach 99% of their usable capacity.
IBM Storage Insights also can monitor and report on any potential out-of-space conditions and the new Advisor function warns when the IBM FlashSystem almost at full capacity. For more information, see 11.6.5, “IBM Storage Insights Advisor” on page 564.
When IBM FlashSystem reaches an out-of-space condition, the device drops into a read-only state. An assessment of the data compression ratio and the re-planned capacity estimation should be done to determine how much outstanding storage demand might exist. This extra capacity must be prepared and presented to the host so that recovery can begin.
The approaches that can be taken to reclaim space on the IBM FlashSystem in this scenario vary by the capabilities of the system, optional external back-end controllers, the system configuration, and planned capacity overhead needs.
In general, the following options are available:
•Add capacity to the IBM FlashSystem. Customers should have a plan that allows them to add capacity to the system when needed.
•Reserve a set of space in the IBM FlashSystem that makes it “seem” fuller than it really is, and that you can free up in an emergency situation. IBM FlashSystem can create a volume that is not compressed, de-duped, or thin provisioned (a fully allocated volume). Create some of these volumes to reserve an amount of physical space. You can name (for example, “emergency buffer space”). If you are reaching the limits for physical capacity, you can delete one or more of these volumes to give yourself a temporary reprieve.
|
Important: Running out of space can be a serious situation. Recovery can be time-consuming. For this reason, it is imperative that suitable planning and monitoring be done to avoid reaching this condition.
|
Next, we describe the process for recovering from an out-of-space condition.
Reclaiming and unlocking
After you assessed and accounted for storage capacity, the first step is to contact IBM Support who can help in unlocking the read-only mode and restoring operations. The reclamation task can take a long time to run, and larger flash arrays take longer to recover than smaller ones.
Freeing up space
You can reduce the amount of used space after the IBM FlashSystem is unlocked by IBM support by using several methods.
To recover from Out of Space conditions on Standard Pools, complete the following steps:
1. Add storage to the system, if possible.
2. Migrate extents from the write-protected array to other nonwrite protected MDisks with enough extents, such as an external back-end storage array.
3. Migrate volumes with extents on the write-protected array to another pool. If possible, moving volumes from the IBM FlashSystem pool to another external pool can free up space in the IBM FlashSystem pool to allow for space reclamation.
As this volume moves into the new pool, its previously occupied flash extends are freed up (by using SCSI unmap), which then provides more free space to the IBM FlashSystem enclosure to be configured to a proper provisioning to support the compression ratio.
4. Delete dispensable volumes to free-up space. If possible, within the pool (managed disk group) on the IBM FlashSystem, delete unnecessary volumes. The IBM FlashSystem supports SCSI unmap so deleting volumes results in space reclamation benefits by using this method.
5. Bring the volumes in the pool back online by using a Directed Maintenance Procedure.
For more information about the types of recovery, see this IBM Support web page.
11.3.9 Replacing a failed flash drive
When IBM FlashSystem detects a failed NVMe drive or optional external attached flash drive, it automatically generates an error in the Events window. To replace the failed drive, always run Fix Procedure for this event in the Monitoring → Events window.
The Fix Procedure helps you to identify the enclosure and slot where the bad drive is located, and guides you to the correct steps to follow to replace it. When a flash drive fails, it is removed from the array. If a suitable spare drive is available, it is taken into the array and the rebuild process starts on this drive.
After the failed flash drive is replaced and the system detects the replacement, it reconfigures the new drive as spare. Therefore, the failed flash drive is removed from the configuration, and the new drive is used to fulfill the array membership goals of the system.
11.3.10 Recovering from common events
You can recover from several of the more common events that you might encounter. In all cases, you must read and understand the current product limitations to verify the configuration and to determine whether you must upgrade any components or install the latest fixes or patches.
To obtain support for any IBM product, see the IBM Support Homepage.
If the problem is caused by IBM Spectrum Virtualize and you cannot fix it by using the Recommended Action feature or by examining the event log, collect the IBM Spectrum Virtualize support package as described in 11.2.1, “IBM FlashSystem data collection” on page 526.
11.4 Remote Support Assistance
Remote Support Assistance (RSA) enables IBM support to access the IBM FlashSystem device to perform troubleshooting and maintenance tasks. Support assistance can be configured to support personnel work onsite only, or to access the system both onsite and remotely. Both methods use secure connections to protect data in the communication between support center and system. Also, you can audit all actions that support personnel conduct on the system.
To set up the remote support options in the GUI, select Settings → Support → Support Assistance → Reconfigure Settings, as shown in Figure 11-7.

Figure 11-7 Remote Support options
You can use local support assistance if you have security restrictions that do not allow support to connect remotely to your systems. With RSA, support personnel can work onsite and remotely by using a secure connection from the support center.
They can perform troubleshooting, upload support packages, and download software to the system with your permission. When you configure remote support assistance in the GUI, local support assistance also is enabled.
The following access types are in the remote support assistance method:
•At any time
Support center can start remote support sessions at any time.
•By permission only
Support center can start a remote support session only if permitted by an administrator. A time limit can be configured for the session.
|
Note: Systems that are purchased with a three-year warranty include Enterprise Class Support (ECS) and are entitled to IBM Support by using RSA to quickly connect and diagnose problems. However, IBM Support might choose to use this feature on non-ECS systems at their discretion; therefore, we recommend configuring and testing the connection on all systems.
|
To configure remote support assistance, the following prerequisites must be met:
•Call Home is configured with a valid email server.
•A valid service IP address is configured on each node on the system.
•If your system is behind a firewall or if you want to route traffic from multiple storage systems to the same place, a Remote Support Proxy server must be configured. Before you configure remote support assistance, the proxy server must be installed and configured separately. The IP address and the port number for the proxy server must be set up on when enabling remote support centers.
For more information about setting up the Remote Proxy Server, see this IBM Documentation web page.
•If you do not have firewall restrictions and the storage nodes are directly connected to the Internet, request your network administrator to allow connections to 129.33.206.139 and 204.146.30.139 on port 22.
•Uploading support packages and downloading software require direct connections to the Internet. A DNS server must be defined on your system for both of these functions to work. The Remote Proxy Server cannot be used to download files.
•To ensure that support packages are uploaded correctly, configure the firewall to allow connections to the following IP addresses on port 443: 129.42.56.189, 129.42.54.189, and 129.42.60.189.
•To ensure that software is downloaded correctly, configure the firewall to allow connections to the following IP addresses on port 22:
– 170.225.15.105
– 170.225.15.104
– 170.225.15.107
– 129.35.224.105
– 129.35.224.104
– 129.35.224.107
RSA can be configured by using the GUI and CLI. For more information about configuring RSA, see IBM FlashSystem 9100 Architecture, Performance, and Implementation, SG24-8425.
11.5 Call Home Connect Cloud and Health Checker feature
Formerly known as Call Home Web, the new Call Home Connect Cloud is a cloud-based version with improved features to view Call Home information on the web.
Call Home is available in several IBM systems, including IBM FlashSystem, which allows them to automatically report problems and status to IBM.
Call Home Connect Cloud provides the following information about IBM systems:
•Automated tickets
•Combined Ticket View
•Warranty and contract status
•Health check alerts and recommendations
•System connectivity heartbeat
•Recommended software levels
•Inventory
•Security bulletins
For more information about Call Home Connect Cloud (Call Home Web), see the IBM Support website.
at the IBM Support website, Call Home Web is available at My support → Call Home Web as shown in Figure 11-8.
Figure 11-8 Call Home Web
Call Home Web was replaced by the new Call Home Connect Cloud web application. The new cloud-based application provides an enhanced, live view of your assets. This view includes the status of cases, warranties, maintenance contracts, service levels, end-of-service information, and other online tools.
To allow Call Home Connect Cloud analyze data of IBM FlashSystem systems and provide useful information about them, the devices must be added to the tool. The machine type, model, and serial number are required to register the product in Call Home Web. Also, it is required that IBM FlashSystem have Call Home and inventory notification enabled and operational.
Figure 11-9 shows the Call Home Connect Cloud details window of IBM FlashSystem.

Figure 11-9 Call Home Web details window
For more information about how to set up and use Call Home Connect Cloud, see Introducing Call Home Connect Cloud.
11.5.1 Health Checker
A new feature of Call Home Connect Cloud is the Health Checker, which is a tool that runs in the IBM Cloud.
It analyzes Call Home and inventory data of systems that are registered in Call Home Connect Cloud and validates their configuration. Then, it displays alerts and provides recommendations in the Call Home Connect Cloud tool.
|
Note: Use Call Home Connect Cloud because it provides useful information about your systems. The Health Checker feature helps you to monitor the system, and operatively provides alerts and creates recommendations that are related to them.
|
Some of the functions of the IBM Call Home Connect Cloud and Health Checker were ported to IBM Storage Insights, as described in 11.6, “IBM Storage Insights” on page 551.
11.6 IBM Storage Insights
IBM Storage Insights is an important part of the monitoring and ensuring continued availability of the IBM FlashSystem.
Available at no charge, cloud-based IBM Storage Insights provides a single dashboard that gives you a clear view of all of your IBM block storage. You can make better decisions by seeing trends in performance and capacity. Storage health information enables you to focus on areas that need attention.
In addition, when IBM Support is needed, IBM Storage Insights simplifies uploading logs, speeds resolution with online configuration data, and provides an overview of open tickets all in one place.
The following features are included:
•A unified view of IBM systems provides:
– Single window to see all of your system’s characteristics
– List of all of your IBM storage inventory
– Live event feed so that you know, up to the second, what is going on with your storage, which enables you to act fast.
•IBM Storage Insight collects telemetry data and Call Home data, and provides up-to-the-second system reporting of capacity and performance.
•Overall storage monitoring:
– The overall health of the system
– The configuration to see whether it meets the best practices
– System resource management: determine whether the system is being overly taxed and provide proactive recommendations to fix it
•Storage Insights provides advanced customer service with an event filter that enables the following functions:
– The ability for you and IBM Support to view, open, and close support tickets, and track trends.
– Auto log collection capability to enable you to collect the logs and send them to IBM before support starts looking into the problem. This feature can save as much as 50% of the time to resolve the case.
In addition to the free Storage Insights, option of Storage Insights Pro is available, which is a subscription service that provides longer historical views of data, offers more reporting and optimization options, and supports IBM file and block storage with EMC VNX and VMAX.
Figure 11-10 shows the comparison of Storage Insights and Storage Insights Pro.
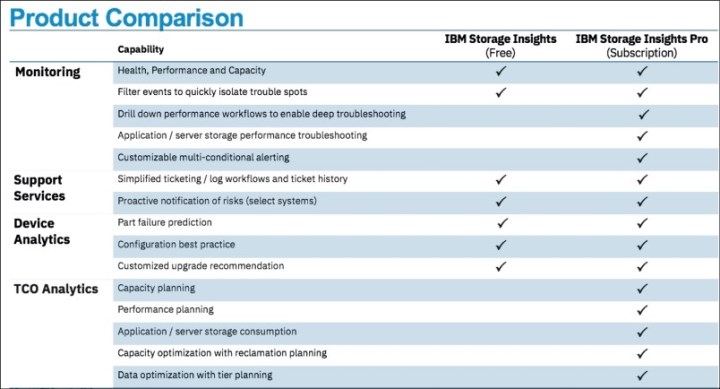
Figure 11-10 Storage Insights versus Storage Insights Pro comparison
Storage Insights provides a lightweight data collector that is deployed on a customer-supplied server. This server can be a Linux, Windows, or AIX server, or a guest in a virtual machine (for example, a VMware guest).
The data collector streams performance, capacity, asset, and configuration metadata to your IBM Cloud instance.
The metadata flows in one direction: from your data center to IBM Cloud over HTTPS. In the IBM Cloud, your metadata is protected by physical, organizational, access, and security controls. IBM Storage Insights is ISO/IEC 27001 Information Security Management certified.
Collected metadata
The following metadata about the configuration and operations of storage resources is collected:
•Name, model, firmware, and type of storage system.
•Inventory and configuration metadata for the storage system’s resources, such as volumes, pools, disks, and ports.
•Capacity values, such as capacity, unassigned space, used space, and the compression ratio.
•Performance metrics, such as read and write data rates, I/O rates, and response times.
•The application data that is stored on the storage systems cannot be accessed by the data collector
Accessing the metadata
Access to the metadata that is collected is restricted to the following users:
•The customer who owns the dashboard
•The administrators who are authorized to access the dashboard, such as the customer’s operations team
•The IBM Cloud team that is responsible for the day-to-day operation and maintenance of IBM Cloud instances
•IBM Support for investigating and closing service tickets
11.6.1 Storage Insights Customer Dashboard
Figure 11-11 shows a view of the IBM Storage Insights main dashboard and the systems that it is monitoring.

Figure 11-11 Storage Insights main dashboard
11.6.2 Customized dashboards to monitor your storage
With the latest release of IBM Storage Insights, you can customize the dashboard to show only a subset of the systems that are monitored. This feature is useful for customers that might be Cloud Service Providers (CSP) and want only a specific user to see those machines for which they are paying.
For more information about setting up the customized dashboard, see this IBM Documentation web page.
11.6.3 Creating a support ticket
The IBM Storage Insights Dashboard GUI can be used to create a support ticket for any of the systems that IBM Storage Insights reports about.
Complete the following steps:
1. In the IBM Storage Insights dashboard, choose the system for which you want to create the ticket. Then, select Actions → Create/Update Ticket (see Figure 11-12).

Figure 11-12 IBM Storage Insights Create/Update Ticket option
2. Select Create Ticket (see Figure 11-13). Several windows open in which you enter information about the machine, a problem description, and the option to upload logs.
Figure 11-13 Create ticket option
|
Note: The Permission given information box (see Figure 11-13) is an option that the customer must enable in the IBM FlashSystem GUI. For more information, see 11.4, “Remote Support Assistance” on page 547.
|
Figure 11-14 shows the ticket data collection that is done by the IBM Storage Insights application.

Figure 11-14 Collecting ticket information
3. As shown in Figure 11-15, you can add a problem description and attach other files to support the ticket, such as error logs or window captures of error messages.
Figure 11-15 Adding problem description and any other information
4. You are then prompted to set a severity level for the ticket, as shown in Figure 11-16. Severity levels range from Severity 1(for a system that is down or extreme business impact) to Severity 4 (noncritical issue).

Figure 11-16 Set severity level
A summary of the data that is used to create the ticket is shown (see Figure 11-17).

Figure 11-17 Review the ticket window
5. The final summary window (see Figure 11-18) includes the option to add logs to the ticket. When completed, click Create Ticket to create the support ticket and send it to IBM. The ticket number is created by the IBM Support system and returned to your IBM Storage Insights instance.

Figure 11-18 Final summary before ticket creation
6. Figure 11-19 shows how to view the summary of the open and closed ticket numbers for the system that is selected by using the Action menu option.

Figure 11-19 Ticket summary
11.6.4 Updating a support ticket
After a support ticket is created, the IBM Storage Insights Dashboard GUI can be used update tickets.
Complete the following steps:

Figure 11-20 IBM Storage Insights Update Ticket
2. Enter the IBM Salesforce case number and then, click Next (see Figure 11-21). The IBM Salesforce case number uses the following format:
TS000XXXXX
These details are supplied when you created the ticket or by IBM Support if the PMR was created by a problem Call Home event (assuming that Call Home is enabled).

Figure 11-21 Entering the Salesforce/PMR case number
A window opens in which you can choose the log type to upload. The window and the available options are shown in Figure 11-22 on page 564.
The following options are available:
– Type 1 - Standard logs
For general problems, including simple hardware and simple performance problems
– Type 2 - Standard logs and the most recent statesave log
– Type 3 - Standard logs and the most recent statesave log from each node
For 1195 and 1196 node errors and 2030 software restart errors
– Type 4 - Standard logs and new statesave logs
For complex performance problems, and problems with interoperability of hosts or storage systems, compressed volumes, and Remote Copy operations, including 1920 errors

Figure 11-22 Log type selection
If you are unsure about which log type to upload, contact IBM Support for guidance. The most common type to use is type 1, which is the default type. The other types are more detailed logs and for issues in order of complexity.
3. After the type of log is selected, click Next. The log collection and upload process starts. When completed, the log completion window is displayed.
11.6.5 IBM Storage Insights Advisor
IBM Storage Insights continually evolves and the latest addition is a new option from the action menu called Advisor.
IBM Storage Insights analyzes your device data to identify violations of best practice guidelines and other risks, and to provide recommendations about how to address these potential problems.
Select the system from the dashboard and then, click the Advisor option to view these recommendations. To see more information about a recommendation or to acknowledge it, double-click the recommendation.
Figure 11-23 shows the initial IBM Storage Insights Advisor menu.

Figure 11-23 IBM Storage Insights Advisor menu
Figure 11-24 shows an example of the detailed IBM Storage Insights Advisor recommendations.
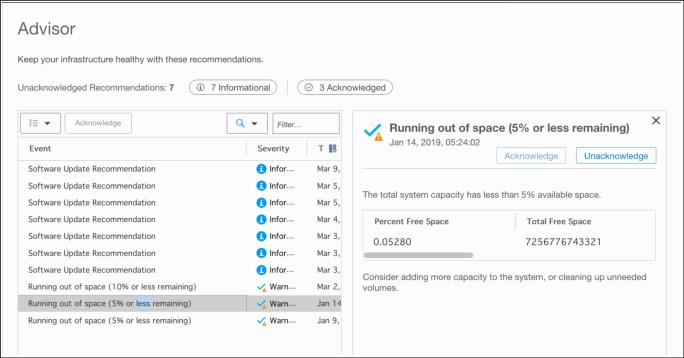
Figure 11-24 Advisor detailed summary of recommendations
As shown in Figure 11-24, the details of a Running out of space recommendation is shown the Advisor page. In this scenario, the user clicked the Warning tag to focus on only the recommendations that feature a severity of Warning.
For more information about setting and configuring the Advisor options, see this IBM Documentation web page.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.