
9. Input and Output
This chapter describes the basics of Python input and output (I/O), including command-line options, environment variables, file I/O, Unicode, and how to serialize objects using the pickle module.
Reading Command-Line Options
When Python starts, command-line options are placed in the list sys.argv. The first element is the name of the program. Subsequent items are the options presented on the command line after the program name. The following program shows a minimal prototype of manually processing simple command-line arguments:

In this program, sys.argv[0] contains the name of the script being executed. Writing an error message to sys.stderr and raising SystemExit with a non-zero exit code as shown is standard practice for reporting usage errors in command-line tools.
Although you can manually process command options for simple scripts, use the optparse module for more complicated command-line handling. Here is a simple example:

In this example, two types of options are added. The first option, -o or --output, has a required argument. This behavior is selected by specifying action='store' in the call to p.add_option(). The second option, -d or --debug, is merely setting a Boolean flag. This is enabled by specifying action='store_true' in p.add_option(). The dest argument to p.add_option() selects an attribute name where the argument value will be stored after parsing. The p.set_defaults() method sets default values for one or more of the options. The argument names used with this method should match the destination names selected for each option. If no default value is selected, the default value is set to None.
The previous program recognizes all of the following command-line styles:

Parsing is performed using the p.parse_args() method. This method returns a 2-tuple (opts, args) where opts is an object containing the parsed option values and args is a list of items on the command line not parsed as options. Option values are retrieved using opts.dest where dest is the destination name used when adding an option. For example, the argument to the -o or --output argument is placed in opts.outfile, whereas args is a list of the remaining arguments such as ['infile1', ..., 'infileN']. The optparse module automatically provides a -h or --help option that lists the available options if requested by the user. Bad options also result in an error message.
This example only shows the simplest use of the optparse module. Further details on some of the more advanced options can be found in Chapter 19, “Operating System Services.”
Environment Variables
Environment variables are accessed in the dictionary os.environ. Here’s an example:

To modify the environment variables, set the os.environ variable. For example:
os.environ["FOO"] = "BAR"
Modifications to os.environ affect both the running program and subprocesses created by Python.
Files and File Objects
The built-in function open(name [,mode [,bufsize]]) opens and creates a file object, as shown here:
![]()
The file mode is 'r' for read, 'w' for write, or 'a' for append. These file modes assume text-mode and may implicitly perform translation of the newline character '
'. For example, on Windows, writing the character '
' actually outputs the two-character sequence '
' (and when reading the file back, '
' is translated back into a single '
' character). If you are working with binary data, append a 'b' to the file mode such as 'rb' or 'wb'. This disables newline translation and should be included if you are concerned about portability of code that processes binary data (on UNIX, it is a common mistake to omit the 'b' because there is no distinction between text and binary files). Also, because of the distinction in modes, you might see text-mode specified as 'rt', 'wt', or 'at', which more clearly expresses your intent.
A file can be opened for in-place updates by supplying a plus (+) character, such as 'r+' or 'w+'. When a file is opened for update, you can perform both input and output, as long as all output operations flush their data before any subsequent input operations. If a file is opened using 'w+' mode, its length is first truncated to zero.
If a file is opened with mode 'U' or 'rU', it provides universal newline support for reading. This feature simplifies cross-platform work by translating different newline encodings (such as '
', '
', and '
') to a standard '
' character in the strings returned by various file I/O functions. This can be useful if, for example, you are writing scripts on UNIX systems that must process text files generated by programs on Windows.
The optional bufsize parameter controls the buffering behavior of the file, where 0 is unbuffered, 1 is line buffered, and a negative number requests the system default. Any other positive number indicates the approximate buffer size in bytes that will be used.
Python 3 adds four additional parameters to the open() function, which is called as open(name [,mode [,bufsize [, encoding [, errors [, newline [, closefd]]]]]]). encoding is an encoding name such as 'utf-8' or 'ascii'. errors is the error-handling policy to use for encoding errors (see the later sections in this chapter on Unicode for more information). newline controls the behavior of universal newline mode and is set to None, '', '
', '
', or '
'. If set to None, any line ending of the form '
', '
', or '
' is translated into '
'. If set to '' (the empty string), any of these line endings are recognized as newlines, but left untranslated in the input text. If newline has any other legal value, that value is what is used to terminate lines. closefd controls whether the underlying file descriptor is actually closed when the close() method is invoked. By default, this is set to True.
Table 9.1 shows the methods supported by file objects.

The read() method returns the entire file as a string unless an optional length parameter is given specifying the maximum number of characters. The readline() method returns the next line of input, including the terminating newline; the readlines() method returns all the input lines as a list of strings. The readline() method optionally accepts a maximum line length, n. If a line longer than n characters is read, the first n characters are returned. The remaining line data is not discarded and will be returned on subsequent read operations. The readlines() method accepts a size parameter that specifies the approximate number of characters to read before stopping. The actual number of characters read may be larger than this depending on how much data has been buffered.
Both the readline() and readlines() methods are platform-aware and handle different representations of newlines properly (for example, '
' versus '
'). If the file is opened in universal newline mode ('U' or 'rU'), newlines are converted to '
'.
read() and readline() indicate end-of-file (EOF) by returning an empty string. Thus, the following code shows how you can detect an EOF condition:

A convenient way to read all lines in a file is to use iteration with a for loop. For example:
![]()
Be aware that in Python 2, the various read operations always return 8-bit strings, regardless of the file mode that was specified (text or binary). In Python 3, these operations return Unicode strings if a file has been opened in text mode and byte strings if the file is opened in binary mode.
The write() method writes a string to the file, and the writelines() method writes a list of strings to the file. write() and writelines() do not add newline characters to the output, so all output that you produce should already include all necessary formatting. These methods can write raw-byte strings to a file, but only if the file has been opened in binary mode.
Internally, each file object keeps a file pointer that stores the byte offset at which the next read or write operation will occur. The tell() method returns the current value of the file pointer as a long integer. The seek() method is used to randomly access parts of a file given an offset and a placement rule in whence. If whence is 0 (the default), seek() assumes that offset is relative to the start of the file; if whence is 1, the position is moved relative to the current position; and if whence is 2, the offset is taken from the end of the file. seek() returns the new value of the file pointer as an integer. It should be noted that the file pointer is associated with the file object returned by open() and not the file itself. The same file can be opened more than once in the same program (or in different programs). Each instance of the open file has its own file pointer that can be manipulated independently.
The fileno() method returns the integer file descriptor for a file and is sometimes used in low-level I/O operations in certain library modules. For example, the fcntl module uses the file descriptor to provide low-level file control operations on UNIX systems.
File objects also have the read-only data attributes shown in Table 9.2.
Table 9.2 File Object Attributes

Standard Input, Output, and Error
The interpreter provides three standard file objects, known as standard input, standard output, and standard error, which are available in the sys module as sys.stdin, sys.stdout, and sys.stderr, respectively. stdin is a file object corresponding to the stream of input characters supplied to the interpreter. stdout is the file object that receives output produced by print. stderr is a file that receives error messages. More often than not, stdin is mapped to the user’s keyboard, whereas stdout and stderr produce text onscreen.
The methods described in the preceding section can be used to perform raw I/O with the user. For example, the following code writes to standard output and reads a line of input from standard input:
![]()
Alternatively, the built-in function raw_input( can read a line of text from prompt)stdin and optionally print a prompt:
name = raw_input("Enter your name : ")
Lines read by raw_input() do not include the trailing newline. This is different than reading directly from sys.stdin where newlines are included in the input text. In Python 3, raw_input() has been renamed to input().
Keyboard interrupts (typically generated by Ctrl+C) result in a KeyboardInterrupt exception that can be caught using an exception handler.
If necessary, the values of sys.stdout, sys.stdin, and sys.stderr can be replaced with other file objects, in which case the print statement and input functions use the new values. Should it ever be necessary to restore the original value of sys.stdout, it should be saved first. The original values of sys.stdout, sys.stdin, and sys.stderr at interpreter startup are also available in sys._ _stdout_ _, sys._ _stdin_ _, and sys._ _stderr_ _, respectively.
Note that in some cases sys.stdin, sys.stdout, and sys.stderr may be altered by the use of an integrated development environment (IDE). For example, when Python is run under IDLE, sys.stdin is replaced with an object that behaves like a file but is really an object in the development environment. In this case, certain low-level methods, such as read() and seek(), may be unavailable.
The print Statement
Python 2 uses a special print statement to produce output on the file contained in sys.stdout. print accepts a comma-separated list of objects such as the following:
print "The values are", x, y, z
For each object, the str() function is invoked to produce an output string. These output strings are then joined and separated by a single space to produce the final output string. The output is terminated by a newline unless a trailing comma is supplied to the print statement. In this case, the next print statement will insert a space before printing more items. The output of this space is controlled by the softspace attribute of the file being used for output.
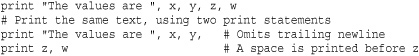
To produce formatted output, use the string-formatting operator (%) or the .format() method as described in Chapter 4, “Operators and Expressions.” Here’s an example:
![]()
You can change the destination of the print statement by adding the special >>file modifier followed by a comma, where file is a file object that allows writes. Here’s an example:

The print() Function
One of the most significant changes in Python 3 is that print is turned into a function. In Python 2.6, it is also possible to use print as a function if you include the statement from _ _future_ _ import print_function in each module where used. The print() function works almost exactly the same as the print statement described in the previous section.
To print a series of values separated by spaces, just supply them all to print() like this:
print("The values are", x, y, z)
To suppress or change the line ending, use the end=ending keyword argument. For example:
print("The values are", x, y, z, end='') # Suppress the newline
To redirect the output to a file, use the file=outfile keyword argument. For example:
print("The values are", x, y, z, file=f) # Redirect to file object f
To change the separator character between items, use the sep=sepchr keyword argument. For example:
print("The values are", x, y, z, sep=',') # Put commas between the values
Variable Interpolation in Text Output
A common problem when generating output is that of producing large text fragments containing embedded variable substitutions. Many scripting languages such as Perl and PHP allow variables to be inserted into strings using dollar-variable substitutions (that is, $name, $address, and so on). Python provides no direct equivalent of this feature, but it can be emulated using formatted I/O combined with triple-quoted strings. For example, you could write a short form letter, filling in a name, an item name, and an amount, as shown in the following example:

This produces the following output:

The format() method is a more modern alternative that cleans up some of the previous code. For example:

For certain kinds of forms, you can also use Template strings, as follows:
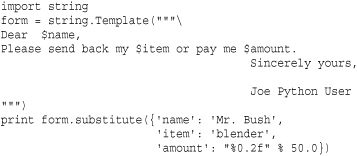
In this case, special $ variables in the string indicate substitutions. The form.substitute() method takes a dictionary of replacements and returns a new string. Although the previous approaches are simple, they aren’t always the most powerful solutions to text generation. Web frameworks and other large application frameworks tend to provide their own template string engines that support embedded control-flow, variable substitutions, file inclusion, and other advanced features.
Generating Output
Working directly with files is the I/O model most familiar to programmers. However, generator functions can also be used to emit an I/O stream as a sequence of data fragments. To do this, simply use the yield statement like you would use a write() or print statement. Here is an example:

Producing an output stream in this manner provides great flexibility because the production of the output stream is decoupled from the code that actually directs the stream to its intended destination. For example, if you wanted to route the above output to a file f, you could do this:
![]()
If, instead, you wanted to redirect the output across a socket s, you could do this:
![]()
Or, if you simply wanted to capture all of the output in a string, you could do this:
out = "".join(count)
More advanced applications can use this approach to implement their own I/O buffering. For example, a generator could be emitting small text fragments, but another function could be collecting the fragments into large buffers to create a larger, more efficient I/O operation:

For programs that are routing output to files or network connections, a generator approach can also result in a significant reduction in memory use because the entire output stream can often be generated and processed in small fragments as opposed to being first collected into one large output string or list of strings. This approach to output is sometimes seen when writing programs that interact with the Python Web Services Gateway Interface (WSGI) that’s used to communicate between components in certain web frameworks.
Unicode String Handling
A common problem associated with I/O handling is that of dealing with international characters represented as Unicode. If you have a string s of raw bytes containing an encoded representation of a Unicode string, use the s.decode([encoding [,errors]]) method to convert it into a proper Unicode string. To convert a Unicode string, u, to an encoded byte string, use the string method u.encode([encoding [, errors]]). Both of these conversion operators require the use of a special encoding name that specifies how Unicode character values are mapped to a sequence of 8-bit characters in byte strings, and vice versa. The encoding parameter is specified as a string and is one of more than a hundred different character encodings. The following values, however, are most common:

The default encoding is set in the site module and can be queried using sys.getdefaultencoding(). In many cases, the default encoding is 'ascii', which means that ASCII characters with values in the range [0x00,0x7f] are directly mapped to Unicode characters in the range [U+0000, U+007F]. However, 'utf-8' is also a very common setting. Technical details concerning common encodings appears in a later section.
When using the s.decode() method, it is always assumed that s is a string of bytes. In Python 2, this means that s is a standard string, but in Python 3, s must be a special bytes type. Similarly, the result of t.encode() is always a byte sequence. One caution if you care about portability is that these methods are a little muddled in Python 2. For instance, Python 2 strings have both decode() and encode() methods, whereas in Python 3, strings only have an encode() method and the bytes type only has a decode() method. To simplify code in Python 2, make sure you only use encode() on Unicode strings and decode() on byte strings.
When string values are being converted, a UnicodeError exception might be raised if a character that can’t be converted is encountered. For instance, if you are trying to encode a string into 'ascii' and it contains a Unicode character such as U+1F28, you will get an encoding error because this character value is too large to be represented in the ASCII character set. The errors parameter of the encode() and decode() methods determines how encoding errors are handled. It’s a string with one of the following values:

The default error handling is 'strict'.
The 'xmlcharrefreplace’ error handling policy is often a useful way to embed international characters into ASCII-encoded text on web pages. For example, if you output the Unicode string 'Jalapeu00f1o' by encoding it to ASCII with 'xmlcharrefreplace' handling, browsers will almost always correctly render the output text as “Jalapeño” and not some garbled alternative.
To keep your brain from exploding, encoded byte strings and unencoded strings should never be mixed together in expressions (for example, using + to concatenate). Python 3 prohibits this altogether, but Python 2 will silently go ahead with such operations by automatically promoting byte strings to Unicode according to the default encoding setting. This behavior is often a source of surprising results or inexplicable error messages. Thus, you should carefully try to maintain a strict separation between encoded and unencoded character data in your program.
Unicode I/O
When working with Unicode strings, it is never possible to directly write raw Unicode data to a file. This is due to the fact that Unicode characters are internally represented as multibyte integers and that writing such integers directly to an output stream causes problems related to byte ordering. For example, you would have to arbitrarily decide if the Unicode character U+HHLL is to be written in “little endian” format as the byte sequence LL HH or in “big endian” format as the byte sequence HH LL. Moreover, other tools that process Unicode would have to know which encoding you used.
Because of this problem, the external representation of Unicode strings is always done according to a specific encoding rule that precisely defines how Unicode characters are to be represented as a byte sequence. Thus, to support Unicode I/O, the encoding and decoding concepts described in the previous section are extended to files. The built-in codecs module contains a collection of functions for converting byte-oriented data to and from Unicode strings according to a variety of different data-encoding schemes.
Perhaps the most straightforward way to handle Unicode files is to use the codecs.open(filename [, mode [, encoding [, errors]]]) function, as follows:
![]()
This creates a file object that reads or writes Unicode strings. The encoding parameter specifies the underlying character encoding that will be used to translate data as it is read or written to the file. The errors parameter determines how errors are handled and is one of 'strict', 'ignore', 'replace', 'backslashreplace', or 'xmlcharrefreplace' as described in the previous section.
If you already have a file object, the codecs.EncodedFile(file, inputenc [, outputenc [, errors]]) function can be used to place an encoding wrapper around it. Here’s an example:
![]()
In this case, data read from the file will be interpreted according to the encoding supplied in inputenc. Data written to the file will be interpreted according to the encoding in inputenc and written according to the encoding in outputenc. If outputenc is omitted, it defaults to the same as inputenc. errors has the same meaning as described earlier. When putting an EncodedFile wrapper around an existing file, make sure that file is in binary mode. Otherwise, newline translation might break the encoding.
When you’re working with Unicode files, the data encoding is often embedded in the file itself. For example, XML parsers may look at the first few bytes of the string '<?xml ...>' to determine the document encoding. If the first four values are 3C 3F 78 6D ('<?xm'), the encoding is assumed to be UTF-8. If the first four values are 00 3C 00 3F or 3C 00 3F 00, the encoding is assumed to be UTF-16 big endian or UTF-16 little endian, respectively. Alternatively, a document encoding may appear in MIME headers or as an attribute of other document elements. Here’s an example:
<?xml ... encoding="ISO-8859-1" ... ?>
Similarly, Unicode files may also include special byte-order markers (BOM) that indicate properties of the character encoding. The Unicode character U+FEFF is reserved for this purpose. Typically, the marker is written as the first character in the file. Programs then read this character and look at the arrangement of the bytes to determine encoding (for example, 'xffxfe' for UTF-16-LE or 'xfexff' UTF-16-BE). Once the encoding is determined, the BOM character is discarded and the remainder of the file is processed. Unfortunately, all of this extra handling of the BOM is not something that happens behind the scenes. You often have to take care of this yourself if your application warrants it.
When the encoding is read from a document, code similar to the following can be used to turn the input file into an encoded stream:

Unicode Data Encodings
Table 9.3 lists some of the most commonly used encoders in the codecs module.
Table 9.3 Encoders in the codecs Module

The following sections describe each of the encoders in more detail.
'ascii' Encoding
In 'ascii' encoding, character values are confined to the ranges [0x00,0x7f] and [U+0000, U+007F]. Any character outside this range is invalid.
'iso-8859-1', 'latin-1' Encoding
Characters can be any 8-bit value in the ranges [0x00,0xff] and [U+0000, U+00FF]. Values in the range [0x00,0x7f] correspond to characters from the ASCII character set. Values in the range [0x80,0xff] correspond to characters from the ISO-8859-1 or extended ASCII character set. Any characters with values outside the range [0x00,0xff] result in an error.
'cp437' Encoding
This encoding is similar to 'iso-8859-1' but is the default encoding used by Python when it runs as a console application on Windows. Certain characters in the range [x80,0xff] correspond to special symbols used for rendering menus, windows, and frames in legacy DOS applications.
'cp1252' Encoding
This is an encoding that is very similar to 'iso-8859-1' used on Windows. However, this encoding defines characters in the range [0x80-0x9f] that are undefined in 'iso-8859-1' and which have different code points in Unicode.
'utf-8' Encoding
UTF-8 is a variable-length encoding that allows all Unicode characters to be represented. A single byte is used to represent ASCII characters in the range 0–127. All other characters are represented by multibyte sequences of 2 or 3 bytes. The encoding of these bytes is shown here:

For 2-byte sequences, the first byte always starts with the bit sequence 110. For 3-byte sequences, the first byte starts with the bit sequence 1110. All subsequent data bytes in multibyte sequences start with the bit sequence 10.
In full generality, the UTF-8 format allows for multibyte sequences of up to 6 bytes. In Python, 4-byte UTF-8 sequences are used to encode a pair of Unicode characters known as a surrogate pair. Both characters have values in the range [U+D800, U+DFFF] and are combined to encode a 20-bit character value. The surrogate encoding is as follows: The 4-byte sequence 11110nnn 10nnnnnn 10nmmmm 10mmmmm is encoded as the pair U+D800 + N, U+DC00 + M, where N is the upper 10 bits and M is the lower 10 bits of the 20-bit character encoded in the 4-byte UTF-8 sequence. Five- and 6-byte UTF-8 sequences (denoted by starting bit sequences of 111110 and 1111110, respectively) are used to encode character values up to 32 bits in length. These values are not supported by Python and currently result in a UnicodeError exception if they appear in an encoded data stream.
UTF-8 encoding has a number of useful properties that allow it to be used by older software. First, the standard ASCII characters are represented in their standard encoding. This means that a UTF-8–encoded ASCII string is indistinguishable from a traditional ASCII string. Second, UTF-8 doesn’t introduce embedded NULL bytes for multibyte character sequences. Therefore, existing software based on the C library and programs that expect NULL-terminated 8-bit strings will work with UTF-8 strings. Finally, UTF-8 encoding preserves the lexicographic ordering of strings. That is, if a and b are Unicode strings and a < b, then a < b also holds when a and b are converted to UTF-8. Therefore, sorting algorithms and other ordering algorithms written for 8-bit strings will also work for UTF-8.
'utf-16', 'utf-16-be', and 'utf-16-le' Encoding
UTF-16 is a variable-length 16-bit encoding in which Unicode characters are written as 16-bit values. Unless a byte ordering is specified, big endian encoding is assumed. In addition, a byte-order marker of U+FEFF can be used to explicitly specify the byte ordering in a UTF-16 data stream. In big endian encoding, U+FEFF is the Unicode character for a zero-width nonbreaking space, whereas the reversed value U+FFFE is an illegal Unicode character. Thus, the encoder can use the byte sequence FE FF or FF FE to determine the byte ordering of a data stream. When reading Unicode data, Python removes the byte-order markers from the final Unicode string.
'utf-16-be' encoding explicitly selects UTF-16 big endian encoding. 'utf-16-le' encoding explicitly selects UTF-16 little ending encoding.
Although there are extensions to UTF-16 to support character values greater than 16 bits, none of these extensions are currently supported.
'unicode-escape' and 'raw-unicode-escape' Encoding
These encoding methods are used to convert Unicode strings to the same format as used in Python Unicode string literals and Unicode raw string literals. Here’s an example:
![]()
Unicode Character Properties
In addition to performing I/O, programs that use Unicode may need to test Unicode characters for various properties such as capitalization, numbers, and whitespace. The unicodedata module provides access to a database of character properties. General character properties can be obtained with the unicodedata.category(c) function. For example, unicodedata.category(u"A") returns 'Lu', signifying that the character is an uppercase letter.
Another tricky problem with Unicode strings is that there might be multiple representations of the same Unicode string. For example, the character U+00F1 (ñ), might be fully composed as a single character U+00F1 or decomposed into a multicharacter sequence U+006e U+0303 (n, ~). If consistent processing of Unicode strings is an issue, use the unicodedata.normalize() function to ensure a consistent character representation. For example, unicodedata.normalize('NFC', s) will make sure that all characters in s are fully composed and not represented as a sequence of combining characters.
Further details about the Unicode character database and the unicodedata module can be found in Chapter 16, “Strings and Text Handling.”
Object Persistence and the pickle Module
Finally, it’s often necessary to save and restore the contents of an object to a file. One approach to this problem is to write a pair of functions that simply read and write data from a file in a special format. An alternative approach is to use the pickle and shelve modules.
The pickle module serializes an object into a stream of bytes that can be written to a file and later restored. The interface to pickle is simple, consisting of a dump() and load() operation. For example, the following code writes an object to a file:

To restore the object, you can use the following code:

A sequence of objects can be saved by issuing a series of dump() operations one after the other. To restore these objects, simply use a similar sequence of load() operations.
The shelve module is similar to pickle but saves objects in a dictionary-like database:

Although the object created by shelve looks like a dictionary, it also has restrictions. First, the keys must be strings. Second, the values stored in a shelf must be compatible with pickle. Most Python objects will work, but special-purpose objects such as files and network connections maintain an internal state that cannot be saved and restored in this manner.
The data format used by pickle is specific to Python. However, the format has evolved several times over Python versions. The choice of protocol can be selected using an optional protocol parameter to the pickle dump(obj, file, protocol) operation. By default, protocol 0 is used. This is the oldest pickle data format that stores objects in a format understood by virtually all Python versions. However, this format is also incompatible with many of Python’s more modern features of user-defined classes such as slots. Protocol 1 and 2 use a more efficient binary data representation. To use these alternative protocols, you would perform operations such as the following:

It is not necessary to specify the protocol when restoring an object using load(). The underlying protocol is encoded into the file itself.
Similarly, a shelve can be opened to save Python objects using an alternative pickle protocol like this:
![]()
It is not normally necessary for user-defined objects to do anything extra to work with pickle or shelve. However, the special methods _ _getstate_ _() and _ _setstate_ _() can be used to assist the pickling process. The _ _getstate_ _() method, if defined, will be called to create a value representing the state of an object. The value returned by _ _getstate_ _() should typically be a string, tuple, list, or dictionary. The _ _setstate_ _() method receives this value during unpickling and should restore the state of an object from it. Here is an example that shows how these methods could be used with an object involving an underlying network connection. Although the actual connection can’t be pickled, the object saves enough information to reestablish it when it’s unpickled later:

Because the data format used by pickle is Python-specific, you would not use this feature as a means for exchanging data between applications written in different programming languages. Moreover, due to security concerns, programs should not process pickled data from untrusted sources (a knowledgeable attacker can manipulate the pickle data format to execute arbitrary system commands during unpickling).
The pickle and shelve modules have many more customization features and advanced usage options. For more details, consult Chapter 13, “Python Runtime Services.”