
![]()
CHAPTER FOURTEEN
E-SECURITY
Frameworks for Privacy and Security in E-Health Data Integration and Aggregation
Joseph Tan, Patrick Hung
III. Security and Privacy Frameworks
B. Framework for Privacy and Confidentiality
C. Privacy Legislation and Consent
A. Security and Privacy Requirements of e-HDI Services
B. Data Integrity in e-HDI Communications
C. Authentication and Authorization in e-HDI Services
V E-Health Data Aggregation Issues
A. Architecture of e-HDI Services
B. E-Security Policy for E-Health Data Integration
IX. Integrated Selective Encryption and Data Embedding for Medical Images Case
Learning Objectives
- Articulate the intent of the security process
- Understand the purpose of e-health data integration, and understand aggregation issues
- Know the differences between a security framework and a privacy and consent framework
- Characterize the security and privacy requirements of e-health data integration services and the dynamic nature of aggregation issues
- Recognize the e-security implications of using e-health data integration services for policymakers, practitioners, and researchers
- Generate a formal, rigorous e-security policy for e-health data integration, to prevent unauthorized users from accessing aggregates
Introduction
In today's era of e-health care informatics and telematics, there is a growing need for automated and integrated views of health information to guide rapidly changing health care planning activities and increasingly sophisticated health-related policy-making, as well as fulfill the information requirements of daily e-clinical care and e-patient management. Because e-health care information about individuals, groups, communities, and selected populations is mostly distributed across many different electronic databases, this information needs to be integrated in order to accomplish meaningful and intelligent decision making. This need has led to increased research on digital health data linkages and integrated views or, more formally, the theory and practice of e-health data integration (e-HDI).
Applied research in e-HDI services shows that integrated views in e-HDI can be provided in different information formats through the use of intelligent electronic health data access, analysis, and visualization tools (Lacroix, 2002). In particular, data mining and clustering techniques, which are discussed more fully in Chapter Eleven, can be used to unveil hidden patterns and complex knowledge that may have implications for future health research and health services planning, requirements, and recommendations. New developments in bioinformatics and e-diagnostic techniques are opening up enormous potential to screen for early warning signs and symptoms and to identify risk factors through accumulated and linked health data sets. Indeed, through Web interfaces, e-HDI services have already resulted in the creation of virtual communities that fill the needs of e-workers, e-providers, e-vendors, and Internet-savvy e-consumers who are also often geographically dispersed.
However, e-HDI services that link e-patients' health data sets to other sources of patient-specific data pose significant risks to the security, privacy, and confidentiality of stored patient data. These data sets often contain identifiable and sensitive information such as genetic or demographic data about individuals—for example, name, age, sex, address, phone number, employment status, family composition, and DNA profile (Quantin, Allaert, and Dusserre, 2000). Not only will disclosure of sensitive information of particular individuals potentially create personal embarrassment, but it may also, very possibly, lead to social ostracism (France, 1996).
Similarly, as e-HDI services encompass a great number of aggregates, or integrated views, the use of these aggregates for scientific research and related work will increase threats to security and privacy, especially in a cross-institutional, multiprovider environment (Moehr, 1994). Given that e-HDI services exist to aggregate the data sets in previously isolated databases for different users in a loosely coupled environment, their security must be rigorously guarded in order to ensure patient confidence (Ishikawa, 2000). At the same time, the dynamic nature of e-HDI services makes security issues challenging. Some of the most pressing security issues and privacy concerns that we have observed in e-health information management include (1) acquisition, storage, and processing of health data; (2) consent for processing and disclosure of e-health data; and (3) rights of the data subject (typically a patient about whom the data are being collected) to access and rectify his or her own health data set (France, 1996).
Earlier chapters of this text refer frequently to the need for e-security, which is essentially the design and development of frameworks for security as well as privacy, systems that safeguard against misuse or abuse of emerging e-health care applications and networks. In this chapter, we review the extant literature on security and privacy issues in order to generate appropriate security and privacy frameworks to guide future e-health care systems designers and developers. More significantly, we provide a specific treatment of security issues involved in aggregation of e-health data. In particular, we construct a formal specification for generating an e-security policy within the context of e-health data integration. We conclude the chapter with some suggestions about directions for future research in e-HDI services.
Security and Privacy Frameworks
In the last few years, a significant role of e-HDI initiatives or services has been to provide a technological platform to enable the improvement of e-health care treatment services (Grimson and others, 2001). For example, doctors who use e-HDI services to access patient medical records stored in diverse databases maintained by various health care provider groups and organizations will have a distinct advantage over those not privy to such rich patient information, which will be aggregated from diverse sources such as databases of past treatment data, medication records, and diagnostics, including digital image libraries and laboratory test reports associated with a patient. Moreover, such integrated views might be capable of being configured differently at different locations and thus be usable in varying contexts. However, this convenience does come with the cost of guarding the security, privacy, and confidentiality of the released information.
Recently, health data management that supports policymaking and high-level decisions in e-health services has been shifting its emphasis from treatment to prevention via the use of e-HDI services (Sheng and Chen, 1990). An example is the FluNet system, which aggregates worldwide information on potential threats arising from the spread of influenza-related viruses (see Chapter Five). Along these lines, e-HDI services integrate data sets from disparate health and social databases into integrated views for policymakers, practitioners, and researchers, who often use the results to conduct additional analyses. Partly owing to this development, scientific research has now become an integral part of our understanding of new strategies for management of chronic diseases such as diabetes and of patient treatment planning in specialties such as oncology (Moehr, 1994). As integrated data provide a more complete and comprehensive view of the patient care history and resulting patterns of applied treatment modalities, these can be used to guide future disease management and treatment planning.
While these developments may accelerate our knowledge of interfacing between clinical and medical sciences on the one hand and social and public health strategies on the other, and while they may help us to apply new findings to a host of health care services and treatments, there is always the danger of potential misuse, overuse, and undetected abuse of e-HDI services. Despite the inherent risk of such problems, research in the area of e-HDI security and privacy has been neglected, resulting in a significant gap in our knowledge of the issues in constructing a security policy for use when aggregating e-health data.
Our health care system has evolved on the implicit foundation of security, privacy, and confidentiality of patient records, and the emerging e-health care system and environment is bringing security and privacy issues to the fore. Indeed, the future of e-health depends on our understanding of these issues. The new security and privacy requirements confronting e-health care provider organizations and e-health data custodians are needed because of increasingly complex information technology and integrated e-technology architecture, coupled with widely distributed e-network availability (see Chapter Six).
Unfortunately, even traditional health care information systems have not been adequately audited, inviting fraud and abuse. Health care information technology has focused chiefly on administrative transactions such as laboratory results, patient registries, and traditional hospital financial information systems.
With the evolution of direct-to-digital clinical data systems, e-providers have begun to aggregate and edit data that were captured internally. This has resulted in distributed data entry (data entry from different locations) that is evolving into high-value transactions, thereby generating the “deep” trend in health care informatics. In contrast, the “wide” trend is promulgated by the movement of patient care outside the walls of the traditional inpatient environment. Not only has health care been shifting toward outpatient and ambulatory care settings, but it has also moved toward the provision of e-clinical care within an e-health care system and environment. Main-stream health care organizations are integrating modes of health care delivery in this way, regrouping themselves into highly distributed “integrated delivery networks” and e-delivery networks. These new delivery networks require applications in multiple environments in order to increase the number of access points available to users. The new networks also require a wide variety of access modalities for extracting and aggregating relevant health data sets.
Framework for Security
Before delving into the topic of security, we should first be clear about the intent of the security process. The primary challenge facing e-providers and e-health information custodians is how to handle the ubiquitous access requests from a variety of users over multiple channels who are attempting to get connected to information. Security requires that all access to information be guarded and provided only to authorized users. Thus, the challenge for e-health care managers becomes how to deploy and support increasingly complex applications across diverse environments while maintaining adequate levels of security. The essential question remains: How should the risk of releasing the information be balanced against the legitimacy of needs and the value of the released information to the user? This question is further complicated by the fact that providing some information often fuels user expectations for more information, as well as by generally increasing expectations in regard to convenient access, easy-to-use and easy-to-interpret information displays, and rapid release of information.
Today, privacy legislation in the United States (for example, the Health Insurance Portability and Accountability Act of 1996) and in Canada (for example, Bill C-6) and adoption of strong industry standards (for example, ISO 17799) have led to heightened awareness of security issues. Even so, we do not want to design systems so heavily weighted toward privacy protection requirements that they become very difficult to use, thereby defeating the purpose of making information accessible. In other words, we do not want powerful systems with rich stores of information that eventually have to be abandoned due to lack of use or usability. On the other hand, users should not be granted unrestricted access to more systems, which will only result in more user identifications and passwords to remember, let alone more potential for misuse, overuse, and abuse.
Based on our discussion, then, it seems that in planning any security application, a number of key considerations should be examined, including the following:
- Understanding the relative value of the information to the requester
- Application of available security tools to form a sound security framework
- Construction of a security policy for use when accessing aggregates
- How to evaluate compliance with the security policy and framework
The value of any particular piece of information is contingent on the need of the requester and will differ from one requester to another. Depending on what is already known, a new piece of information may or may not be valuable to a person in any particular situation. Moreover, some requesters hesitate to reveal their true intent when requesting particular information. If, for example, a patient is in need of medication, then it may be important to know the patient's medication allergies and other medications. Hence, knowing the reason why a particular piece of information is requested will go a long way toward specifying whether the requester has a legitimate claim to the information and should therefore be provided with it.
A strategy that simply encourages the implementation of a security technology system application by application is impractical and prohibitively expensive versus one in which security is managed via integrated applications. In the e-health care context, security need to entail calculated diligence in applying available tools to safeguard against potential risks. Many useful tools such as the ISO/IEC 17799 standard are available to formulate a sound security framework. The International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC) stipulate the characteristics of specialized systems for worldwide standardization. The ISO 17799 standard was published to provide an international framework for information security. The standard was not developed specifically for the health care industry; rather, the scope of the document encompasses cross-sector applications. Ten key areas that encompass a sound security framework are identified in the ISO 17799 standard. Each section provides explicitly detailed protocols that meet the security concerns associated with that area.
Of these ten areas, two stand out as most essential for security planning: (1) the formulation of a sound security policy from which security solutions can be generated and practiced and (2) compliance with the security policy and framework. Compliance monitoring ensures that all the key areas of the security framework are functioning properly. Issues of privacy and confidentiality of health information are closely related to the security of health information use and distribution.
Framework for Privacy and Confidentiality
Privacy is a basic human right, a central tenet of our free and democratic society. It is a measure of respect for personal autonomy and the dignity of the individual, and it forms the foundation of the basic rights outlined in documents such as the U.S. Constitution and the Canadian Charter of Rights and Freedoms, including freedom of speech, of association, and of choice. It is fundamental to both Canadian and U.S. societies. George Radwanski, the privacy commissioner of Canada, defines privacy as the right to control information collected about oneself, including its use and disclosure (G. Radwanski, “Patient Privacy in the Information Age,” speech given at E-Health 2001: The Future of Health Care in Canada, Toronto, 2001). Privacy, therefore, has to do with our decisions on what personal information we want to share and with whom, trusting that it will be used for the purposes for which the information was requested.
While privacy relates to one's right to prevent one's health-related information from being shared with anyone and to control what information is revealed, confidentiality refers to the responsibility of custodians and recipients of an individual's health information to use or disclose it only as authorized. These concepts differ from security—the procedures, techniques, and technology employed to protect information from accidental or malicious destruction, alteration, or access, as discussed in the previous section. In other words, security mechanisms are used to implement privacy and confidentiality policies. As e-health care gives a new dimension to the health care industry, it also brings new threats to the security, privacy, and confidentiality of patients' medical records.
Imagine, for example, that Julie, a hypothetical high-profile political science professor at a state university, has been nominated for governor of her state or province after the resignation of the former governor. Suppose that at first, her nomination is hailed statewide because of her professionally faultless record. Her manifest qualifications clearly supersede questions of partisanship politics. However, an opposition party's nominee secretly hires a hacker to delve into her medical history. Soon, information about her past medical misadventures leaks to the press. Many years ago, she had an abortion, and she has also undergone treatment for depression at some point in her life. These facts anger many of her strong supporters, who are also strong anti-abortion activists. The fallout from the information leak drives Julie back into therapy for depression, raising further doubts as to her mental stability. Results of a recent uterine biopsy raise further doubts about her overall health. Julie is eventually forced to withdraw from the governor's race.
This illustration shows how lack of proper management and security in regard to health information, particularly e-health information, can be a significant factor in the violation of an individual's rights and privacy. Legislation such as the Health Insurance Portability and Accountability Act of 1996 (HIPAA) standards play an important role in creating security solutions to prevent such security breaches; one of the primary objectives of these standards is to “guarantee security and privacy of health information.”
Obviously, Julie's case shows that personal health information is a critical area in which privacy should be enforced. Nothing is more intimate and deeply personal than one's health information. A massive amount of data has been collected over the years by trusted caregivers, and with e-health care systems, all of the data pertaining to one's physical and mental health can be conveniently housed in electronic health records. In some instances, the information will include sensitive medical information, such as the presence of a genetic predisposition to disease (for example, the breast cancer gene) or risk factors for a particular disease; history of depression or other mental illness; surgical interventions; treatment for sexually transmitted diseases; fertility status; or history of alcohol or drug abuse. Definitely, the amount of data that should be treated as strictly confidential is huge. The case of Professor Julie demonstrates how the release of this type of information can lead to significant negative personal consequences. If appropriate health information privacy is not guaranteed, the care provider–patient relationship will also be affected, possibly complicating the ethical and medical dimensions of a complex situation.
Given that it is not unusual to hear about privacy violations, particularly the inappropriate release of health information to third parties, it is easy to understand why privacy advocates have been intensely concerned about potential abuses and resulting discrimination. Dire consequences of inappropriate revelation of health information have included denial of insurance coverage, loss of job opportunities, refusal of mortgage financing, and more. Imagine how quickly these consequences would multiply in a completely wired society. The protection of e-health information privacy should therefore be of even greater concern to society than to individuals. If there were no legislated obligation for e-care providers to maintain confidentiality of health information, how frequently would fear of exposure prevent people from seeking medical attention? What would the implications be for public health issues such as HIV/AIDS and other sexually transmitted and infectious diseases?
It can be argued that individuals should have ownership of their own health information. However, once a caregiver collects the information, the organization to which the caregiver belongs almost always wants to assert some rights over the information. Consequently, privacy rules and legislation must be enforced on the premise that privacy is a right that is essential to the integrity of an individual. E-health care providers must be considered merely information custodians, not owners. Custodianship gives these providers access privileges but also a responsibility to maintain the individuals' trust. In this sense, confidentiality is the obligation of caregivers to protect personal information that is entrusted to them and includes an implicit understanding that information will not be disclosed except in limited situations. Custodians are also responsible for ensuring that the information is not misused or used for purposes other than those for which it was originally intended. This moral, ethical, and legal duty is articulated in most professional codes of conduct for example, HIPAA Information Privacy Policy and the Canadian Standards Association (CSA) Model Privacy Code. The CSA code is an adaptation of the privacy standards originally developed by the OECD. The list of fair information practices it delineates are accountability; identifying purpose; consent; limiting collection; limiting use; disclosure and retention; accuracy; safeguards; openness; individual access; and challenging compliance—that is, an individual should be able to challenge the care provider's compliance with privacy requirements.
Privacy Legislation and Consent
The importance of privacy is clear when one reviews the regulatory frameworks covering the subject on both sides of the U.S.-Canada border. The province of British Columbia, for example, has a health privacy law, the Freedom of Information and Protection of Privacy Act, which applies only to public sector organizations. In Canada, Bill C-6, or the Personal Information Protection and Electronic Documents Act, includes privacy regulations for both the public and private sectors at the national level. This legislation further mandates provinces to formulate legislation to deal with personal privacy within the private sector.
Canada's privacy commissioner sounded the alarm bell when his office discovered that a federal government department, Human Resources Development Canada (HRDC), had a linked database with information from four other departments. Even though individual health care information was not being collected, HRDC was eventually forced to inactivate and dismantle the linked database due to public pressure and increased scrutiny by the privacy commissioner. This case clearly underscores the importance that Canadians place on privacy.
In the United States, HIPAA consists of two titles: (1) HIPAA Health Insurance Reform, which protects health insurance coverage for workers and their families whenever they change or lose their jobs, and (2) HIPAA Administrative Simplification, which requires the Department of Health and Human Services (DHHS) to establish national standards for electronic health care transactions and national identifiers for providers, health plans, and employers, as well as provisions for security and privacy of health data. The Centers for Medicare and Medicaid Services were entrusted by the DHHS with the responsibility of enforcing the transaction and code set standards as part of the administrative simplification provisions.
The issue of what constitutes informed consent has been debated for years in the health care arena, but never so vigorously as in today's emerging e-health environment. When individuals enter the e-health care system, are they truly aware of how their data may be used, with or without their express or implied consent? Just what uses of the data are considered ethical or unethical? E-health care managers are challenged with these concerns on a daily basis because various stakeholders find it very tempting to access personal data for purposes other than those originally intended. Seaton (2001) states, “Consent is proving to be the greatest challenge for health informatics professionals in the whole realm of privacy….[It] is tough to define, tough to collect, tough to track, and tough to prove” (p. 28). This challenge is further complicated by the fact that many professionals are still not fully aware of the differences between security of the health information system and privacy and consent issues.
Firewalls and data encryption help to ensure the security of the system but do not offer any protection against inappropriate or malicious uses of stored information by those with access privileges. Security is more tangible than the notion of consent, which can encompass many subtle ethical dimensions; for example, a person may have a moral objection to the research for which his or her medical data were submitted, even if his or her identity is protected. Given the public's increased sensitivity about human rights and privacy, should the use of e-health information be restricted to only those purposes expressly consented to? Clearly, if the answer is yes, health care organizations will face major challenges in gathering enough data to plan and evaluate e-health care services appropriately. This rhetorical question, however, does point to operational difficulties in managing consent to disclosure of information. How can we satisfy ethical concerns about consent but also ensure that information is used for the greater good of society? An important element of any health organization's consent policy is internal education. Unfortunately, when it comes to multiple internal uses of health information, the health care system in general has not paid much attention to the issue of consent (Gostin and Hodge, 2001).
Accordingly, education on privacy and security must begin internally. Most organizations require staff to sign oaths or letters of confidentiality but do little in the way of educating employees with regard to confidentiality, privacy legislation, and consent. In fact, most employees are probably unaware of exactly where patient information resides after data have been entered into the electronic health records or on the Internet or elsewhere. Even though it may not be practical to explain every detail of the data trail to employees or e-caregivers, e-health organizations still need to ensure that their employees fully understand the issues of consent and confidentiality and how to deal with them at all stages of data collection, analysis, and release.
E-Health Data Integration
In conducting our literature survey on security, privacy, and confidentiality of health information, we found that most health informatics research focuses either on the ethical and legal dimensions or the appropriate methodological approach for guarding the security, privacy, and confidentiality of patient information, especially in services involving shared data. Little research has been conducted specifically on data aggregation with respect to issues of data confidentiality, data integrity, identity authentication, and access authorization in health informatics, particularly in the context of e-HDI services.
Security and Privacy Requirements of e-HDI Services
The literature on e-health data integration services proposes data standardization policies and both hardware and software solutions that focus on security and privacy issues in health data processing, storage, and collection, particularly for the electronic medical records (Toyoda, 1998). Consent to process and use integrated data sets would include, for example, a clear definition and a right to accept the purpose of the e-HDI service by the data subject or the patient (Moehr, 1994). In addition, there have been many discussions about the ethical right of the data subject to access and modify his or her personal medical records. For instance, a group designated “WG4” in the International Medical Informatics Association is working on the security and privacy issues of health informatics (International Medical Informatics Association, 2001). The focus of this group, while not specifically on the issues of achieving security for aggregated data in the context of e-HDI services, has been on the ethical use and distribution of electronic health and medical records among e-health practitioners and health services provider organizations.
In our discussion, the concept of aggregation issues refers to matters of security, confidentiality, and privacy that arise in the context of e-HDI services when two or more data sets are considered more sensitive together than each is separately. Take the example of an aggregate view of patient medical records at hospitals (with the data sets representing a group of employees from a particular organization) and their claims at a Medicare center which in the Australian context refers to a medical insurance organization or any other claim center. Here, the integrated view is deemed to be more sensitive than if the data sets were viewed separately because the combined data set allows the employer to know where or under what specific illnesses the majority of the claims fall and thus possibly which specific individuals or clusters of employees are most likely to be included in these claim groups. Such knowledge discovery resulting from the higher-level aggregation might allow and perhaps encourage the employer to adopt new policies to support hiring of workers falling outside certain categories or to begin outsourcing certain types of work (thereby retrenching certain categories of workers) because the aggregate data reveal a particular trend in increased medical costs for the employer.
On the basis of the preceding example and of more detailed level analyses of data aggregates, we can therefore state that it would only be ethical and acceptable to limit integration. For example, if one of the integrated data sets were to be given to a user (viewer) who is not authorized to see the sensitive data or were to be stored in a place (for example, a computer) not considered appropriate for sensitive health data, then no part of the data sets that would allow a sensitive aggregate to be formed should be included. (Data already available for the integration in question would remain available.) Otherwise, key aspects of security requirements in e-HDI services could be breached, including but not limited to data confidentiality, data integrity, identity authentication, and access authorization.
Modeling security enforcement is of paramount importance in many public, industrial, and commercial application domains, especially e-health care. Applications that require security enforcement include on-line office automation, e-government planning, e-medical diagnosis, e-mail communications, and e-networks and e-commerce systems that involve interactions between e-consumers and e-business entities (B2C applications) or between e-businesses (B2B applications). E-health data integration involves a set of heterogeneous and distributed hardware and software systems (that is, databases and networks) open to frequent sharing and exchange of e-health information and transactions. It is not surprising, then, that such data sharing activities could lead to conflicting interests or potential breaches of security measures and requirements. In any event, illegal violation of security and privacy through access of data has to be monitored, controlled, and reported meticulously. A violation is an access of systems by unauthorized users or processes. An authorized user or process circumvents or defeats the access controls of a system to obtain unauthorized access to classified information or data. The violation breaches the security policy and procedures of a system in a manner that could result in the loss or compromise of classified information or data. Thus, an e-HDI service has a set of distinct administrative domains (that is, networks and database management systems) and responsibilities that demands a complex and rigorous security policy.
If we look at e-HDI services in terms of confidentiality (Bakker, 1998), we find that first, confidentiality means that all data interchange and communications must and should only be restricted to authorized parties so that the information being entrusted to the users will not be shared with unauthorized personnel. Confidentiality focuses on preventing unauthorized disclosure of e-health data, especially identifiable and sensitive information. In other words, all access must be restricted to parties that are legally and fully authorized to have it. Prior researchers (Louwerse, 1998) have introduced the ethical need-to-know principle for restricting the accessibility of health data (Clark and Wilson, 1987). Similarly, Bobis (1994) proposes a right-to-know concept to describe levels of access that e-health practitioners should have to e-patients' medical records, which correspond to the services the e-health practitioners are providing to individual patients. In regard to methodological approach, Tsujii (1998) describes a public-key cryptosystem for e-medicine and related e-medical records that will help maintain data confidentiality and integrity in the context of secure communications.
Data Integrity in e-HDI Communications
In the context of e-health, data integrity focuses on preventing unauthorized modification of e-health data sets. In other words, data integrity is nothing more than ensuring that the data sent as part of a larger exchange are not modifiable in transit. If the data are modified or forged, those alterations or modifications should be readily identified and discarded. Obviously, the motivation for maintaining data integrity is to prevent inappropriate e-health treatment caused by corrupted e-health data. Imagine what the consequences might be if an e-physician were to view diagnostic data that have been altered. The distributed infant and maternity care system in Finland, for example, adopts a combination of secure socket layer (SSL) and Internet protocol security (IPSec) procedures to maintain data confidentiality (Kouri and Kemppainen, 2001). SSL is a protocol for transmitting information by using a private key to encrypt data that is transferred over the Internet. As both Netscape Navigator and Internet Explorer support SSL, many Web sites use SSL to obtain confidential information such as credit card numbers. IPSec is a framework of open standards for supporting network-level data confidentiality over Internet Protocol (IP) networks by using cryptographic security services as well.
Tan, Wen, and Gyires (2003) also discuss the application of public-key cryptography infrastructure (PKI) and certificates to ensure confidentiality and to verify the authenticity of mobile users in the context of e-business and e-health information exchanges and transactions (see also Chapter Six). Another interesting variation on the theme of secured data transmission is the use of “invisible” watermarks or other data hiding techniques. Chao, Hsu, and Miaou (2002), for example, discuss a data hiding technique to secure an electronic medical record transmitted over the Internet and to ensure data confidentiality, integration, and authentication. We will now consider the issue of authentication in e-HDI services, keeping in mind that many of the security properties we are discussing overlap one another.
Authentication and Authorization in e-HDI Services
Essentially, authentication in e-HDI services has to do with ensuring that the identity of a user cannot be forged or altered. Hence, authentication focuses on the verification of the identity of users of e-health data. Put simply, the identities of users of e-health data must be true and verifiable. Barber (1998) advocates the use of digital signatures in e-health services by using the RSA encryption algorithm along with the password management of traditional health information systems. In another case, a commercial clinic information system, CliniCare, uses a secure asynchronous message exchange service called Health Link to maintain confidentiality and obtain user authentication (Moehr and McDaniel, 1998).
Authorization in the e-health care context means ensuring that e-health data can be accessed only by authorized users. This is especially important for aggregated data. Kaihara (1998) describes the security issues of authorization for computerized medical records from the perspectives of intrahospital use, interhospital use, and storage. Smith and Eloff (1999) discuss a set of authorization issues that apply in the context of e-health care information systems. Malamateniou, Vassilacopoulos, and Tsanakas (1998) propose an authorization infrastructure based on a work flow system for handling virtual medical records in a loosely coupled database environment. The proposed architecture implements an automated interorganizational treatment process with a security policy for granting and revoking access privileges for e-health practitioners. The authorization architecture considers the time interval in which the operation can be performed and the location from where the operation can be performed. It means that the architecture only authorizes data access at specific locations and times that depend on what service is being rendered. For example, the data access is only authorized if the request is from the office's computer during the working hours at a company. Community health information networks (Williams, Venters, and Marwick, 2001) build access control into the design of the e-network security architecture (Please refer to Chapter Six for further details.) Sadan (2001) discusses the authorization and integrity problems that apply to sharing information between e-patients and e-health providers in the context of co-documentation and co-ownership of medical records. Although various authorization models have been proposed, aggregation issues have not been covered or considered, despite the fact that aggregation issues should have a direct impact on how authorization of users and integrated views are conceived.
Past health informatics research on communications architecture has focused on secure communication protocols. For example, Mea (2001) describes the security issues of communications in a multi-agent paradigm for e-medicine systems. Blobel (2000) proposes a security infrastructure for e-medical record systems that adopts the technologies of PKI and smart cards. In addition, Ishida and Sakamoto (1998) propose a secure communications model that consists of subdividing e-health data into fragments and forwarding encrypted fragments through multiple secure paths. However, it is not clear that this is more secure than the traditional approach of sending the medical record as a whole. Blobel and Roger-France (2001) propose a set of tools that uses unified modeling language for analysis and design of secure e-health information systems. The tools provide a layered security model with security services and mechanisms but do not consider aggregation issues.
Very little health informatics research has studied aggregation issues in order to offer a formal specification for generating a security policy for e-HDI services. The aggregation issues discussed in Lunt (1989) are based in the context of a multilevel database in which the sensitivity level of each data set is preclassified. Further, Lunt mainly focuses on the issue of quantity-based aggregation without a formal specification. A quantity-based aggregation is a collection of up to N data objects of a given type is not sensitive, but a collection of greater than N data objects is sensitive. As we have emphasized, e-HDI has to aggregate data sets from previously isolated databases without a central classification scheme. Because of this, a security policy that addresses the specific issues involved in e-HDI services is critical in order for e-HDI services to be widely accepted.
In light of the discussions we have found in the literature, we present, in the next section, some important aggregation issues in the context of a formal specification.
E-Health Data Aggregation Issues
For administrative and clinical purposes, e-medical records may often contain a combination of textual and numerical information that is similar to the data that are typically captured in relational databases. For diagnostic and other practical purposes, e-health databases should also provide graphic or pictorial information such as X-ray or endoscopy images and histopathology pictures. Typically, specific e-health data sets used in e-HDI services include not only electronic medical records but also other patient-specific data such as medical insurance claims. The implication is that an enormous range of data sets can be exposed to security threats through e-HDI services. To restrict the scope of our discussion, however, we will focus primarily on electronic medical records stored in the form of relational e-health data sets (Louwerse, 1998), which are used in most e-health databases employed within a shared network environment.
The principle of information privacy and disposition (International Medical Informatics Association, 2001) states that “All persons have a fundamental right to privacy, and hence to control over the collection, storage, access, use, communication, manipulation and disposition of data about themselves.” In an e-health system, data access should be restricted to e-health professionals only and should be based on the need-to-know principle. In other words, in principle, e-providers working with e-patients can only have access to data about the patients whom they treat. Moreover, e-health data relating to psychiatry care may be separated from those relating to home care. These separate data regarding the same patients may not be accessible to other providers in the same system—that is, different views of the patient data may be permitted based only on providers' need to know. E-health data are primarily transferred among authorized users, and the use of e-health data for research requires the consent of the individual patients concerned.
Traditional health data sets housed within hospitals are mainly governed by a set of privacy regulations that determine the aim and scope of the input of the data registration, the type of data included, the rights of data subjects, and access rights (Louwerse, 1998). Access to e-health data should be just as securely protected. Yet recent developments in e-HDI will only deepen the conflict between individual privacy concerns and the pressure for health information from nonmedical institutions (for example, insurance companies), unless a rigorous security policy framework is developed for e-HDI services (Anderson, 2000).
Architecture of e-HDI Services
Figure 14.1 shows the architecture of e-HDI services, which consists of a set of databases at N locations (for example, a hospital and a Medicare center); e-HDI middleware (typically, a powerful server that accepts the stream of requests from the e-HDI services, connects the databases from different locations, combines the requested data sets from the databases into integrated views, and makes the integrated views available to the e-HDI services); and the e-HDI services (which interface with the users' requests, send the requests to the e-HDI middleware, and send the integrated results to the users).
FIGURE 14.1. ARCHITECTURE OF E-HEALTH DATA INTEGRATION

In this scenario, the e-health data access channels are all read-only because most of the cases only involve read-only operations. An example is the Ohio cancer-related research project, which is structured as an e-HDI service to support different users in accessing specific cancer information as well as extracting integrated views on accumulated cancer data (Koroukian, Cooper, and Rimm, 2001). With this arrangement, we can see that there are two types of e-HDI users. The primary users are the e-patients and e-health service providers such as doctors and nurses. E-patients can access their own health data, communicate with e-health service providers, and even manage health insurance claims. E-health service providers use health data for a variety of purposes. For example, e-physicians may want to review an e-patient's medical records to evaluate the appropriateness of the e-consultation provided. The secondary users include policymakers, practitioners, and researchers who use the data for research, social services, public health, regulation, litigation, and commercial purposes (such as marketing and the development of new medical technology) (Anderson, 2000).
Aside from the many reasons we have discussed, another reason that security issues need to be studied and tackled seriously in e-HDI services is that the systemic use of patient-identifiable health information poses additional potential threats to the security, privacy, and confidentiality of e-patient information. For example, one published survey (Anderson, 2000) reported that in the United States, some people do not file insurance claims or see health service providers for fear that disclosure of their health information may hurt their job prospects or ability to obtain insurance coverage. Note that a user can also belong to both the primary and the secondary user groups, which may cause conflicts; for instance, a doctor can be a health service provider and an e-HDI health informatics researcher. Of course, a doctor may also be a patient. Because this section of the discussion focuses primarily on secondary e-HDI users, the term users will refer to secondary users unless otherwise specified.
Figure 14.2 shows a sample schema for e-health data integration, including the attributes of the data for each data set in the schema. Tables 14.1 to 14.4 show sample data for each data set.
In e-health data integration, each database consists of a collection of data sets. From a relational database perspective, a data set may be conceptualized as a view composed of a set of relations. Each data set represents an entity (for example, a patient) with a set of attributes (for example, the patient's name, Medicare number, and diagnosis). In addition, these data sets (such as those provided in Tables 14.1 through 14.4) can be joined to form many different sets or views of data sets, with different categories of data integrated in each view. As an illustration, the medical records with identities (that is, patient-id) “298495,” “298496,” and “298497” that are shown in Table 14.1 can be treated as a data set. An integrated view in e-health data integration is composed of a set of data sets (for example, patients and Medicare claims). Associations between data sets are represented by join-attributes (common attributes)—for example, medicare-number or patient-id—which allow the data sets to be joined to obtain an integrated view (Lunt, 1989). Table 14.5, for example, is an integrated view of the data sets from Hospital, Treatment, Pharmacy, and Medicare through the association of the major keys, namely, patient-id and medicare-number.
FIGURE 14.2. SAMPLE SCHEMA FOR E-HEALTH DATA INTEGRATION
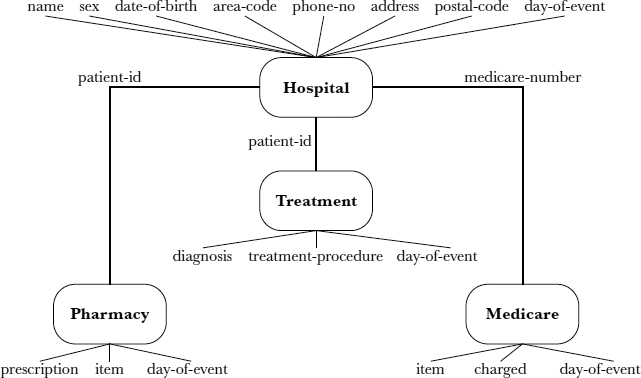
It has been suggested that to guard against possible infringement of privacy and confidentiality of patient information, the integrated view should not disclose the identity of the patients involved (Moehr, 1994). Thus identifying information (that is, medicare-number and patient-id) in Table 14.5 is hidden, to ensure anonymity. In e-health data management, anonymity means that users provided with aggregate data will not be able to access the subject's identity unless they have separately been authorized to do so (for example, because they are primary users).
Anonymity is related to security, privacy, and confidentiality; it is an important principle in e-health informatics, especially when disseminating information to secondary users. One commonly cited case example in the literature is that of the adopted child (Heinlein, 1996). The adopting parents, who are responsible for the child's medical care, have a right and a need to know the birth parents' medical histories but not their identities. When the adopted child comes of age, he or she also has those same rights and needs, but the anonymity of the birth parents may and should still be preserved in many circumstances. However, the problem of preserving patient anonymity is outside the scope of this discussion.
TABLE 14.1. SAMPLE DATA FOR HOSPITAL

TABLE 14.2. SAMPLE DATA FOR TREATMENT

TABLE 14.3. SAMPLE DATA FOR PHARMACY

TABLE 14.4. SAMPLE DATA FOR MEDICARE

An aggregation problem arises whenever some collection of data sets (that is, integrated views) is more sensitive than the individual data sets forming the aggregate. Most likely, the relations “Hospital,” “Treatment,” and “Pharmacy” would be stored on a hospital intranet. It is reasonable to assume that all these databases would be protected appropriately and robustly from most security threats. The integrated view in Table 14.5 should not cause any harm to the individual patients because their identities are hidden. However, this may not always be the case. Although the data contained in Table 14.5 are not direct identifiers, a combination of those data may somehow allow individual patients to be identified.
Generally speaking, protecting the identities of patients just by including only the nondemographic portion of the e-health data is inadequate. To appreciate how data are to be protected in the context of e-HDI security, one must understand the three layers of secrecy that are traditionally considered in e-health informatics—namely, the content layer, the description layer, and the existence layer (Smith, 1988). The content layer focuses on protecting both the actual e-health data and the association formed in e-HDI from the users. In Table 14.5, both the identities of the data subjects (that is, the individual patients) and the associations between the different data sets (that is, the join-attributes such as medicare-number and patient-id) should be hidden from the users. The description layer emphasizes hiding the e-HDI security policy from the users. This layer is more restrictive because the users do not even know which security rules are enforced in the e-HDI services. Finally and most restrictively, the existence layer concentrates on hiding the existence of any e-health data that the users have not been permitted or authorized to view. This is the most restrictive layer. Its primary purpose is to reduce security threats by keeping users completely unaware of the e-health data that have been hidden from them.
TABLE 14.5. AN INTEGRATED VIEW OF HOSPITAL, TREATMENT, PHARMACY, AND MEDICARE

Owing to the lack of research in the e-HDI domain and the need to build a firstlevel formalization of an e-HDI security policy, our goal here is to construct a first-cut yet rigorous e-security policy for e-HDI by observing different types of aggregation rules that can be formulated at the level of the content layer.
E-Security Policy for E-Health Data Integration
An e-security model for e-health data integration must support protocol-independent, declarative e-security policies. An e-security policy is a set of rules and practices that specify or regulate how a system or organization provides security services to protected electronic health resources. Accordingly, a security assertion is typically scrutinized in the context of an e-security policy.
Briefly, engineering an e-security policy begins with risk analysis and ends with a set of security assertions that is ready for integration into the e-security policy framework. In the context of e-HDI services, risk analysis identifies security threats in a particular scenario and a set of security assertions is designed in conjunction with rules and practices to regulate how sensitive information is managed and protected within such a loosely coupled execution environment. An e-security policy is often formalized or semiformalized within the context of an e-security model that provides a basis for formal analysis of security properties. In this section, our goal is to generate a set of specifications for constructing an e-security framework for e-HDI services.
Because e-health data integration involves many participants, widely diverging group interests can potentially clash (Moehr, 1994). Sheng and Chen (1990) consider the issue of conflicts in e-HDI in the context of schema integration. Aggregation problems can be avoided if conflicts of interest between users and data sets can be identified and accounted for in the e-security policy framework before the integrated view is delivered (Hung, 2002). Attempting to hide subjects' identities and related sensitive information from users of aggregate information is related to the concept of sanitization. Sanitization (Brewer and Nash, 1989) means disguising a subject's information, particularly to prevent the discovery of that subject's identity as a measure of privacy.
A first-level e-HDI security framework can be understood in terms of four types of aggregation:
- Context-dependent aggregation
- Quantity-dependent aggregation
- Time-dependent aggregation
- Functionality-dependent aggregation
We propose that users = {u1,…, un} be a set of n users and views = {v1, …, vm} be a set of m views. The value of m is then determined by ||P (data sets)|} or the power set of data sets from all databases in the e-health data integration (for example, at locations 1,…, N as shown in Figure 14.1).
Context-dependent aggregation is based on an actual value of an attribute, the association of an attribute with a specific value or a range of values, or the associations among several attributes and their values (Lunt, 1989). Further, these attributes may be associated with different data sets. In this type of aggregation, the need for conflict of interest regulation (CIR) can be represented as a binary relation in the format of first-order predicate calculus as follows:
where v ![]() views, u
views, u ![]() users, u.e refers to existing data sets at u's disposal, and s refers to sensitive information.
users, u.e refers to existing data sets at u's disposal, and s refers to sensitive information.
Simply, the statement asserted here is that if there exists CIR between the integrated view (v) and the user (u), then there may also exist an intersection between the existing data sets at the user's disposal (u.e) and the integrated view (v) and the fact that the user's existing data sets (u.e) contain sensitive information. For example, neither the users who can access the databases at the hospital (that is, “Hospital,” “Treatment,” and “Pharmacy” in Figure 14.2) nor the users who can access the databases at the Medicare center (that is, “Medicare” in Figure 14.2) should be permitted to access the integrated view shown in Table 14.5. This should not be allowed because the information available to each of the user groups on the subjects' identities may make it possible for them to use data mining techniques to infer the identities of the subjects in the integrated view (Glymour, Madigan, Pregibon, and Smyth, 1996). Although the integrated view (Table 14.5) does not contain identifying information, both user groups could identify the patients' identities with very little difficulty.
Quantity-dependent aggregation means that a collection of up to t e-health data of a given type is sensitive. In other words, if the size of the integrated view (that is, the number of records) is lower than a specific threshold (t) (Quantin, Allaert, and Dusserre, 2000), the users may also be able to identify the subjects' identities, even though the sensitive information is hidden in the integrated view. In this type of aggregation, the CIR can be represented as a binary relation in the format of first-order predicate calculus as follows:
where v ![]() views, u
views, u ![]() users, and t refers to the threshold level.
users, and t refers to the threshold level.
In this case, we have the assertion that if there exists CIR between the integrated view (v) and the user (u), then the number of records in the integrated view (v) may be less than a specific threshold (t). For example, users may be able to identify a particular patent's identity if there are less than ten patients with a specific diagnosis (for example, AIDS) in a hospital (that is, t = 10). The risk of identifying a patient decreases when the value of t increases (Quantin, Allaert, and Dusserre, 2000).
Time-dependent aggregation means that the sensitive level of an integrated view may vary with time. Certain e-health data may have a different sensitivity level during a normal period than during a crisis. For example, if a serious infectious disease such as tuberculosis is spreading in a region, the integrated view may have to include the subjects' identities in order for the policymakers and researchers to take further action. In this type of aggregation, the CIR can be extended into a binary relation with a time factor in the format of first-order predicate calculus as follows:
where v ![]() views, u
views, u ![]() users, p equals a period of time, and ext-CIR refers to a binary function to determine whether CIR exists with the time factor.
users, p equals a period of time, and ext-CIR refers to a binary function to determine whether CIR exists with the time factor.
Here, the statement provides that if CIR exists between the integrated view (v) and the user (u), then it might also imply that there exists CIR between a user (u) and a view (v) within a particular period of time (p). Furthermore, time factors should also be considered sensitive information. The integrated view in Table 14.5 hides the day-of-event information because this information may be a clue to the subject's identity; for example, an employer might be able to infer an employee's identity if the employee was on sick leave at the time the information was collected.
Functionality-dependent aggregation means that some sensitive information can be inferred via information provided by other attributes and vice versa. In this type of aggregation, the CIR can be represented as a binary relation in the format of first-order predicate calculus as follows:
where v ![]() views, u
views, u ![]() users
users ![]() is implies, (1)
is implies, (1) ![]() (2)
(2) ![]() (3)
(3) ![]() (4), v.a1, v.a2,…, v.ah refers to the set of h attributes in the integrated view, and s refers to sensitive information.
(4), v.a1, v.a2,…, v.ah refers to the set of h attributes in the integrated view, and s refers to sensitive information.
Briefly, the assertion goes like this: If there exists CIR between the integrated view (v) and the user (u), then there may exist one or more attributes in the integrated view (v) that can imply sensitive information (s). For example, users can narrow the possibilities of where a patient might live if the patient's telephone area code is presented and can narrow them even further if the postal code is also presented, even though the address may not be shown.
At this point, it is important to note that there are disjunctive relationships among the CIR rules discussed above such that (1) ![]() (2)
(2) ![]() (3)
(3) ![]() (4), meaning that more than one of the four types of aggregation can apply at the same time. These CIR rules can be used as security assertions in an e-security policy. Based on these security assertions, the e-security policy must be able to check whether there exists CIR between the users and the integrated views. Once the e-security policy, whether in part or as a whole, is violated (that is, CIR exists), the simple solution is to abort the request. However, this may not be as easy as it sounds because such an action may in turn cause other concerns, including denial of services and availability that could require a further investigation.
(4), meaning that more than one of the four types of aggregation can apply at the same time. These CIR rules can be used as security assertions in an e-security policy. Based on these security assertions, the e-security policy must be able to check whether there exists CIR between the users and the integrated views. Once the e-security policy, whether in part or as a whole, is violated (that is, CIR exists), the simple solution is to abort the request. However, this may not be as easy as it sounds because such an action may in turn cause other concerns, including denial of services and availability that could require a further investigation.
Availability focuses on preventing unauthorized withholding of e-health data or resources. Availability is especially important in e-health services because often the care provided either has to be continued or is ongoing.
In this sense, it is also necessary to control the ability of an authorized user to copy e-health data by means of implemented policies. Once a user has read e-health data of a certain sensitive level, the e-security policy must ensure that any data item written by that user in regard to that case or patient has a sensitive level at least as high as the level of the e-health data previously read because the user's knowledge of sensitive data may permeate anything he or she subsequently writes.
Conclusion
Health care information might be considered the most intimate and personal information that is systematically collected and maintained about an individual. In most countries, e-health information is classified as sensitive information. This is because electronically stored data containing sensitive information can be easily and conveniently released, and disclosing sensitive information to outsiders can cause direct or indirect damage to an individual. Although security breaches have occurred in the era of paper records, the potential harm has been multiplied by electronic databases because information can now be transferred to a large number of people within extended boundaries. Imagine now that these various databases containing sensitive information are to be integrated and the aggregate data provided to a wide variety of users, including e-health practitioners, researchers, lawyers, and business and government policymakers. How should the security, privacy, and confidentiality of patient information be protected?
The e-health paradigm shift from a traditional care model toward a shared care (multi-provider care) model is also reflected in the security framework of e-HDI services. The establishment of continuous e-care chains in covering the continuum of care will also mean sharing information by means of e-HDI services. Systems designed to support shared care will be used by many independent organizations, some of which will be virtual, and each organization's security must therefore be systematically taken into consideration and examined in great detail.
It has been demonstrated that the use of an e-security framework for e-HDI services will provide the foundation for secure yet easy-to-access shared care systems. For example, information about e-patient medication is crucial for e-medical practice. Properly implemented medication e-registry systems are rare today, and information is fragmented into several systems and organizations. E-HDI services will be invaluable both for planning e-patient treatment and for research. E-HDI services are therefore a good example of the next generation of client-centered e-health information services that will be shared among e-provider organizations. But how can we ensure adequate security so that e-HDI services can flourish for the legitimate purpose of enhancing e-patient care and treatment?
Traditionally, secrecy provisions have protected privacy in health care. In our mainstream organization-centered health care model, organizational security together with password-based access control has been considered sufficient to protect patient data in medical information systems. In e-HDI services, security issues are much more complex because they involve aggregation of data and how conflicts of interest between users and the integrated views can be reconciled. We have looked at different types of aggregation and the secrecy provisions that need to be enforced at the level of the content layer. Much more research is still needed to fully understand the potential for e-security violations in the use of e-HDI services.
We see three research directions that can build on and expand the current work. First, an e-security policy for e-health data integration is needed in order to resist both intentional and accidental security threats (Clark and Wilson, 1987). One of the classic security policies for dealing with conflict of interest regulation is “Chinese wall” security policy (Brewer and Nash, 1989). Chinese wall security policy contains a set of access control rules such that no person can ever access data (objects) on the wrong side of the security “wall.” It provides freedom of choice in the subject's initial access rights. The major objective of the Chinese wall security policy is to prevent information flows that cause conflict of interest for individual consultants in financial institutions. Webster's Dictionary defines “conflict of interest” as a conflict between the private interests and the official responsibilities of a person in a position of trust. The original application of Chinese wall security policy is illustrated as follows. Organization information is stored in datasets. Initially, each consultant has the potential to access any dataset. Once a consultant has access to a dataset of a particular organization, that consultant is not allowed access to datasets of any other competing organization. However, Chinese wall security policy is not directly applicable to e-HDI services because the policy was mainly designed for financial companies. For example, Chinese wall security policy does not involve any data integration activity. In addition, e-HDI users have different roles (for example, researchers and practitioners) that are not supported by Chinese wall security policy. Several revised Chinese wall security policies have been approved for different applications such as financial data analysis (Lin, 1990, 2000; Meadows, 1990); however, a specific version of Chinese wall security policy for e-health data integration needs to be investigated.
Second, countermeasures for e-HDI services have to be selected, implemented, and supervised in order to reduce the risks of security violations. Risk analysis is an examination of the components of risk of a particular system within a particular environment in a particular location (Smith and Eloff, 1999). Risk analysis identifies how a breach of security could affect a system and determines the seriousness of potential consequences to the health services unit (for example, a hospital or a Medicare center) (Bakker, 1998). An on-the-spot security risk factor (Hung, Karlapalem, and Gray, 1999) can be used to assess the level of risk associated with a set of subjects (users) retrieving a set of objects (integrated views). Thus, a security risk factor mechanism can be an appropriate approach for e-health data integration.
Finally, security enforcement may lead to execution failure. Availability is also an important property of security for e-HDI services. Thus, an escape mechanism may be required, by means of which emergency access could be granted, provided the user (1) has a special authorization and (2) specifies the reason for needing emergency access (Louwerse, 1998). In particular, the study of trade-offs such as breaking the access control rules (for example, conflict of interest regulation) versus resilience to execution failure is a challenge for future research to explore. Furthermore, resilience to subject (for example, data set) failures (Hung, Karlapalem, and Gray, 1999) implies the ability to complete the execution of activities even when some subjects are unavailable or have failed or when some access control rules are violated. Thus, an escape mechanism is required for e-HDI services to maintain reliable services for different users.
In real life, an e-health institution may not easily grant privileges to external users to access its e-health data unless the external users are authorized for some specific purposes such as academic studies. Referring to the privacy act in many countries, the aggregation problem has to be solved any time a user is authorized to access the e-health data with the subject's (the patient's) prior consent. In conclusion, e-security policy is an important topic in e-HDI services.
Chapter Questions
- Differentiate privacy, security, and confidentiality. Why are these terms easily confused?
- What is an e-security policy framework? What is its significance to e-health care?
- Why is it important to study data aggregation issues? Why has prior research in health informatics not focused on these important issues?
- Differentiate the security approaches used in the U.S. and Canadian health care systems. Are you aware of the approach used in any other country? How are privacy and confidentiality of patient data guarded on the basis of legislation in those countries?
- Imagine that you are a physician who has been asked to oversee John, who is unconscious and has just been admitted into the hospital after fainting in the street after his face turned red. After checking his pulse and other related symptoms, you feel very strongly that you need his medical records in order to treat John properly. John carries a smart card, and fortunately, your hospital has a smart card reader. However, the only information you can find about John or his family is a code written on a small piece of paper, which appears to be the password needed to unlock the information contained on the smart card. As a medical professional, do you check John's records (which may be encoded on his smart card, along with other private information about him) without his consent? Or do you treat him as best you can without having the essential information? Why?
References
Anderson, J. (2000). Security of the distributed electronic patient record: A case-based approach to identifying policy issues. International Journal of Medical Informatics, 60(2), 111–118.
Bakker, A. (1998). Security in perspective: Luxury or must? International Journal of Medical Informatics, 49(1), 31–37.
Barber, B. (1998). Patient data and security: An overview. International Journal of Medical Informatics, 49(1), 19–30.
Blobel, B. (2000). The European TrustHealth Project experiences with implementing a security infrastructure. International Journal of Medical Informatics, 60(2), 193–201.
Blobel, B., & Roger-France, F. (2001). A systematic approach for analysis and design of secure health information systems. International Journal of Medical Informatics, 62(1), 51–78.
Bobis, K. (1994). Implementing right to know security in the computer-based patient record. In, Proceedings of the International Phoenix Conference on Computers and Communications (pp. 156–160), Phoenix, AZ, USA.
Brewer, D., & Nash, M. (1989). The Chinese wall security policy. In Proceedings of 1990 IEEE Computer Society Symposium on Security and Privacy (pp. 206–214), Gamma Secure Systems Ltd., Camberley, Surrey, United Kingdom.
Chao, H., Hsu, C., & Miaou, S. (2002). A data-hiding technique with authentication, integration, and confidentiality for electronic patient records. IEEE Transactions on Information Technology in Biomedicine, 6(1), 46–53.
Clark, D., & Wilson, D. (1987). A comparison of commercial and military computer security policies. In, Proceedings of 1987 IEEE Symposium on Security and Privacy (pp. 184–194).
France, F. (1996). Control and use of health information: A doctor's perspective. International Journal of Biomedical Computing, 43(1–2), 19–25.
Glymour, C., Madigan, D., Pregibon, D., & Smyth, P. (1996). Statistical inference and data mining. Communications of the ACM, 39(11), 35–41.
Gostin, L., & Hodge, J. (2001). The National Centre for Health Statistics white paper: Balancing individual privacy and communal uses of health information. Retrieved from Model State Public Health Privacy Web site at www.critpath.org/msphpa/ncshdoc.htm
Grimson, J., Stephens, G., Jung, B., Grimson, W., Berry, D., & Pardon, S. (2001). Sharing health-care records over the Internet. IEEE Internet Computing, 5(3), 49–58.
Heinlein, E. (1996). Medical records security. Computers and Security, 15, 100–102.
Hung, P. (2002). Specifying conflict of interest in Web Services Endpoint Language (WSEL). ACM SIGecom Exchanges, 3.3, 1–8. Retrieved from http://www.acm.org/sigs/sigecom/exchanges/
Hung, P., Karlapalem, K., & Gray, J., III. (1999). Least privilege security in CapBasED-AMS. International Journal of Cooperative Information Systems, 8(2–3), 139–168.
International Medical Informatics Association. (2001, March). A code of ethics for health informatics professionals (HIPs). Retrieved from International Medical Informatics Association Web site at http://www.imia.org/pubdocs/Code_of_ethics.pdf
Ishida, Y., & Sakamoto, N. (1998). A secure model for communication of health care information by sub-division of information and multiplication of communication paths. International Journal of Medical Informatics, 49(1), 75–80.
Ishikawa, K. (2000, November). Health data use and protection policy; based on differences by cultural and social environment. International Journal of Medical Informatics, 60(2), 119–125.
Kaihara, S. (1998). Realisation of the computerized patient record: Relevance and unsolved problems. International Journal of Medical Informatics, 49(1), 1–8.
Koroukian, S., Cooper, G., & Rimm, A. (2001, December). The linked Ohio cancer incidence surveillance system and Medicaid files: An example of health data integration. Retrieved from the National Association of Health Data Organizations Web site at http://www.nahdo.org/meetings/16meeting/meetpres/koroukian NAHDO—Dec2001.pdf
Kouri, P., & Kemppainen, E. (2001). The implementation of security in distributed infant and maternity care. International Journal of Medical Informatics, 60(2), 211–218.
Lacroix, Z. (2002). Biological data integration: Wrapping data and tools. IEEE Transactions on Information Technology in Biomedicine, 6(2), 123–128.
Lin, T. (1990). Chinese wall security policy: An aggressive model. In, Proceedings of the Fifth Annual Computer Security Applications Conference (pp. 282–289).
Lin, T. (2000). Chinese wall security model and conflict analysis. In, Proceedings of the 24th Annual International of Computer Software and Applications Conference (COMPSAC 2000) (pp. 122–127).
Louwerse, K. (1998). The electronic patient record: The management of access. Case study: Leiden University Hospital. International Journal of Medical Informatics, 49(1), 39–44.
Lunt, T. (1989). Aggregation and inference: Facts and fallacies. In, Proceedings of the 1989 IEEE Symposium on Security and Privacy (pp. 102–109).
Malamateniou, F., Vassilacopoulos, G., & Tsanakas, P. (1998). A workflow-based approach to virtual patient record security. IEEE Transactions on Information Technology in Biomedicine, 2(3), 139–145.
Mea, V. (2001). Agents acting and moving in health care scenarios: A paradigm for telemedical collaboration. IEEE Transactions on Information Technology in Biomedicine, 5(1), 10–13.
Meadows, C. (1990). US Naval Res. Lab., Washington, DC. Extending the Brewer-Nash model to a multilevel context. In, Proceedings of 1990 IEEE Computer Society Symposium on Research in Security and Privacy (pp. 95–102). Oakland, CA, USA.
Moehr, J. (1994). Privacy and security requirements of distributed computer based patient records. International Journal of Bio-Medical Computing, 35(1), 57–64.
Moehr, J., & McDaniel, J. (1998). Adoption of security and confidentiality features in an operational community health information network: The Comox Valley experience—Case example. International Journal of Medical Informatics, 49(1), 81–87.
Quantin, C., Allaert, F., & Dusserre, L. (2000). Anonymous statistical methods versus cryptographic methods in epidemiology. International Journal of Medical Informatics, 60(2), 177–183.
Sadan, B. (2001). Patient data confidentiality and patient rights. International Journal of Medical Informatics, 62(1), 41–49.
Seaton, B. (2001). The chief privacy officer: Coming soon to a management team near you! Healthcare Information Management and Communications Canada, 15(5), 58–59.
Sheng, O., & Chen, G. (1990). Information management in hospitals: An integrating approach. In, Proceedings of Annual Phoenix Conference (pp. 296–303), Scottsdale, AZ, USA.
Smith, E., & Eloff, J. (1999). Security in health-care information systems: Current trends. International Journal of Medical Informatics, 54(1), 39–54.
Smith, G. (1988). Identifying and representing the security semantics of an application. In, Proceedings of Aerospace Computer Security Applications Conference (pp. 125–130).
Tan, J., Wen, H. J., & Gyires, T. (2003). M-commerce security: The impact of wireless application protocol (WAP) security services on e-business and e-health solutions. International Journal of M-Commerce, 1(4), 409–424.
Toyoda, K. (1998). Standardization and security for the EMR. International Journal of Medical Informatics, 48(1–3), 57–60.
Tsujii, S. (1998). Revolution of civilization and information security. International Journal of Medical Informatics, 49(1), 9–18.
Williams, M., Venters, G., & Marwick, D. (2001). Developing a regional health care information network. IEEE Transactions on Information Technology in Biomedicine, 5(2), 177–180.
Integrated Selective Encryption and Data Embedding for Medical Images Case
Qiang Cheng, Yingge Wang, Joseph Tan
This case proposes a new scheme for transmission of medical images that uses selective encryption integrated with functional data embedding. Selective encryption can speed up computation in comparison with full encryption methods using classical cryptosystems, yet it often has insufficient security or other drawbacks. The proposed new scheme embeds functional data into the image seamlessly, losslessly, and in a standards-compliant way. The selected parts of the image are encrypted efficiently. Information integration of medical images and functional data is achieved, with high levels of security and privacy. New functions may be enabled within the proposed framework. The new method has proven to yield high security and will result in significantly less computation. Experimental results demonstrate the effectiveness of the proposed scheme.
Background
The development of imaging technologies has made medical images a key component of electronic patient records. These images are often transmitted between image producers, such as radiology and pathology departments, and image requesters, such as health professionals and medical departments. With increased computing capability and broadband communications, transmission of medical images across networks will become commonplace in e-medicine and mobile medicine.
There are stringent requirements for the quality of medical images in transmission and storage. Oftentimes, especially for primary diagnosis, the medical images are not permitted to have any single-bit modification after acquisition. In e-medicine or mobile health applications, in which electronic patient and medical records are transmitted through open networks such as the Internet, insecure transmission environments expose these records to interception, impersonation, and other attacks (Schneier, 2000; Stajano, 2002). To protect the security of patient data, cryptographic methods must be applied. In general, a typical medical image is huge, which makes encryption computationally expensive or even prohibitive for small or mobile devices.
Standard cryptosystems are designed for the simplest multimedia data, plain text. For images (including image sequences), the computational complexity of these standard ciphers is high. To reduce the computational load, selective encryption methods have been proposed for multimedia data. Selective encryption enciphers only the important parts of multimedia data. The existing selective encryption methods often suffer from some drawbacks, such as insufficient security level, insignificant reduction of computational complexity, and incompatibility with existing industrial standards. Here, we propose a new scheme, integrated selective encryption and data embedding (I-SEE), to protect the security of medical images.
Data embedding methods have been proposed for multimedia copyright protection, traitor tracing, and covert data transmission. New functions can be enabled in an innocuous, seamless, and standards-compliant way. Existing data embedding methods, however, have several potential weaknesses; for example, the security of embedded data is not high, and the amount of information that can be reliably embedded usually is quite limited.
I-SEE—which integrates data embedding with selective encryption for high security, large amounts of embedded information, and moderate computational overhead—addresses these challenges. Selected parts of the image data are combined with functional data such as the patient's name, identification number, and even diagnosis. Then the composite data are encrypted. In this process, both partial image data and functional data are reversibly compressed for embedding purposes. At the receiving end, the encrypted data are first deciphered with proper cryptographic keys, and then the embedded textual data and the image parts are decompressed. The embedded data transmit important information reliably along with the images. Compared with existing selective encryption methods, our scheme achieves high levels of security with significantly reduced computational complexity and is capable of embedding a significantly high volume of textual information. I-SEE makes possible new functions such as partial availability of image contents for previewing or content-based retrieval purposes, and seamless integration of medical images with relevant associated medical data.
Rationale for I-SEE
Secure communications and storage often make use of cryptographic techniques, including standard encryption algorithms such as triple Data Encryption Standard (DES), International Data Encryption Algorithm (IDEA), Rijndael Advanced Encryption Standard (AES), and Rivest-Shamir-Adleman (RSA), which were originally designed for text (Qiao and Nahrstedt, 1998). Recently, selective encryption methods have been proposed to reduce computational requirements (Qiao and Nahrstedt, 1997; Shi, Wang, and Bhargava, 1999; Zeng and Lei, 2002; Wu and Guo, 2001). These methods apply encryption or scrambling methods (such as DES, IDEA, XOR) or permutation to parts of multimedia data in the frequency domain or spatial domain or by modifying entropy codec, a term used in image compression. Note that the entropy codec is used for image compression and decompression in the system.
The existing selective encryption methods, however, have several known weaknesses that may be potentially exploited by an attacker. For video selective ciphering, the zigzag permutation algorithm (Tang, 1996) can be cryptoanalyzed by known-plaintext or ciphertext-only attacks (Qiao and Nahrstedt, 1998). The video encryption algorithm (Qiao and Nahrstedt, 1997) encrypts every other bit of the MPEG stream and the required computation is 50 percent of full encryption, without considering the selection overhead (Wu and Guo, 2001). The real-time video encryption algorithm selects the sign bits of each macroblock and encrypts them using DES or IDEA (Shi, Wang, and Bhargava, 1999). It has been argued that encryption of sign bits and also more significant bits may still lead to information leakage (Wu and Guo, 2001). In the entropy codec design (Wu and Guo, 2001), video or image data are encrypted, using multiple Huffman coding tables and multiple state indices in the QM coder. The coding tables and state indices are known only to the encoder and decoder and thus are part of secret keys. This gives rise to inflated key size, however.
In general, these methods suffer from one or more drawbacks such as insufficient security, increase in key size, decrease in compression efficiency, or insignificant reduction of computation compared to full encryption (Qiao and Nahrstedt, 1997, 1998; Shi, Wang, and Bhargava, 1999; Zeng and Lei, 2002; Wu and Guo, 2001). Because a medical image is of little value without relevant associated data (Van de Velde and Degoulet, 2003), we propose a new scheme that seamlessly integrates the associated data into medical images and selectively encrypts the combined image data. The drawbacks of existing selective encryption are effectively addressed with the proposed algorithm; it has low computational complexity yet high levels of security. Without proper cryptographic keys, the resulting medical images are of little value due to degradation of image quality as well as the lack of relevant associated functional data. With the keys, the original medical images and associated data can be exactly reconstructed and made readily available. Compared with the original image or original textual data, the size of the data storage space resultant image decreases.
The proposed scheme exploits a reversible data embedding method (Luo, Cheng, and Tan, 2003). Data embedding, including watermarking, steganography, and fingerprinting, is an emerging technique for multimedia copyright protection, authentication, traitor tracing, and covert communication (Cox, Kilian, Leighton, and Shamoon, 1997; Cheng and Huang, 2001, 2003; Fridrich, Goljan, and Du, 2001; Cheng, Wang, and Huang, 2004). By embedding invisible secondary data into multimedia data, including images, the secondary, secret-bearing data are associated with the multimedia in a seamless and standards-compliant way.
Data embedding techniques can be roughly classified into two categories according to the characteristics of the embedding: nonreversible (lossy) or reversible (lossless). Nonreversible, or lossy, methods result in degradation in image quality that cannot be eliminated at the receiving end; in contrast, reversible, or lossless, methods yield only degradation that is removable at the receiving end. Existing reversible data embedding methods can only embed a small number of message bits, but I-SEE reversible embedding imprints a large volume of associated functional data into images.
Medical images and relevant medical data are usually separated in existing medical information systems (Van de Velde and Degoulet, 2003). Correct links or indices must be established between images and their associated data. Any incorrect or lost links lead to mistakes in medical practice. Thus, the integration of medical images with associated functional data is desirable, if it can be done securely. A large volume of data embedding can fulfill the need for medical information integration. Data embedding techniques alone, however, cannot guarantee the security of multimedia data. The embedded data must be protected with cryptographic methods.
Our novel I-SEE scheme incorporates reversible data embedding and selective encryption in order to enhance the security of images as well as integrate images with functional data. Our reversible data embedding method modifies both image data and header files. At the transmission end, functional or textual data are embedded into the medical images. The embedded, composite images are transmitted through the channel; at the receiving end, both the embedded data and the original medical images are recovered perfectly. The reversible property guarantees that the medical images have no loss in quality, and the functional data are transmitted in a covert and reliable fashion. This proposed scheme is different from both existing selective encryption and existing data embedding methods. High security and seamless association of functional data with images are achieved with moderate computational complexity. Partial availability or total obfuscation of image contents can be chosen flexibly, depending on the application or user preference.
System Framework of I-SEE
Our I-SEE system requires processing at the transmitting and receiving ends. To send the image and associated functional data, the transmitter selects some parts of an image for data embedding and encryption. These parts are reversibly compressed and padded with proper functional data, which may also be reversibly compressed. The compressed image parts together with the (compressed) functional data have the same size as the original image parts. Then, the modified parts, consisting of compressed data and embedded data, are partially encrypted. Finally, the encrypted data are put back into the original positions in the image. This modified image will be transmitted through the communication channels.
Exhibit 14.1 shows the transmission and recovery cycle of the whole process.
EXHIBIT 14.1. PROCESSING AT THE TRANSMISSION END (TOP) AND THE RECEIVING END (BOTTOM), USING THE I-SEE FRAMEWORK

At the receiving end, the encrypted parts are first deciphered with proper cryptographic keys. Then, the embedded data are extracted to obtain the associated information. The compressed image parts are reconstructed perfectly, and consequently, the original image is recovered without any modification. This recovery process is also shown in Exhibit 14.1.
System Transmitter Processing
First, the transmitter needs to select the proper parts of an image for further data embedding and encryption. The framework considered above can be easily extended to compressed images by selecting some parts of the compressed bitstream resulting from a specific codec like JPEG or JPEG2000. Considering the stringent requirement of high image quality for diagnosis purposes, we mainly focus on uncompressed medical images in this discussion. We use the effective bitplanes (those consisting of at least one nonzero bit) of the medical image as the basic parts for data embedding and encryption. Other parts of the image can be defined in other ways and similarly employed within the framework of I-SEE.
There are two different modes for using the bitplanes: selecting the most significant bitplanes (MSBs) or selecting the least significant bitplanes (LSBs) for I-SEE. Different modes can be adopted for different purposes. Because the MSBs are more significant for human perception than the LSBs, and the MSBs have similarities to the original image, while the LSBs are mostly random in appearance, different selections have different effects on the visual quality and data embedding rate. Essentially, if partial visibility of the medical images is required in content-based image retrieval applications or for preview, peer review, or research purposes, the LSBs can be employed. If the image contents need be hidden, the MSBs should be selected. The LSBs cannot be compressed much compared with the MSBs. Thus, MSBs are preferred if a higher data embedding rate is desired. One bitplane or several bitplanes together can be used, depending on the volume of the data to be embedded. The more bitplanes used, the higher the volume of functional data that can be embedded.
Next, the selected image parts are losslessly compressed. Several methods can be used for the lossless compression: JPEG-LS, JPEG, JBIG2, entropy coding such as static Huffman coding or dynamic or adaptive Lempel-Ziv (LZ) and its variants like Lempel-Ziv-Welch (LZW) (Cover and Thomas, 1991). In this case, we employ the LZW algorithm. In the LZ algorithm or its variants (Ziv and Lempel, 1978), the source sequence is sequentially parsed into strings by searching for the shortest string that has not appeared so far. Each string consists of a prefix that has occurred earlier and a last bit that is new. The string is coded by the location of the prefix and the value of the last bit. The decoding reverses the steps and recovers the source sequence without error. LZ or LZW coding is universal in the sense that it is independent of the distribution of the source—that is, given an arbitrary source, it achieves an average code word length which is asymptotically equal to the entropy rate of the source. The LZ or LZW algorithm is adaptive–that is, it does not need to learn the exact probability distribution of the source, in contrast to static algorithms like Huffman coding.
The medical images must be indexed in order to keep track of their locations and characteristics. Existing standards such as DICOM usually provide header files to collect and organize relevant patient and study demographic data. However, more electronic health record (EHR) data should be considered—for example, personal information of patients, (such as name and identification number), lab results, observations, diagnosis, and so on. These data may not always be physically associated with the images, due to the limitations of the header files or for security or privacy reasons. Merging these EPR data with corresponding medical images will facilitate information management and information integration. In doing so, the security of both the medical images and the EPR will be enhanced, and the privacy of the EPR will be better preserved; once the EPRs are directly embedded into the images, they remain unavailable even after the selective encryption is deciphered, unless the correct authorizations are provided. With the associated functional data, the performance of content-based image retrieval can be augmented, taking into account information in both image and textual modes.
Our I-SEE framework incorporates a data embedding scheme to achieve the information integration. We apply LZW coding to functional information, usually in the form of plain text, to compress it losslessly into a binary stream, then merge it into the compressed image parts. The merging can be simple concatenation or more sophisticated deterministic mixing—for example, interleaving techniques used in wireless communications to combat bursty errors or fast fading. Here, we chose a block interleaving method (Proakis, 2001). The two compressed data streams are merged such that the combined size is exactly the same as the original size of the selected image parts or multiples of the bitplane size. To this end, we pad with zeros when necessary. The method of merging and the positions of the extra zeroes will be contained in the header file—for example, using the FileMetaInformationVersion or StudyDescription field. If the number of bitplanes is changed, the corresponding fields in the header file will have to be changed correspondingly—for example, BitDepth and FileSize fields in the DICOM format. Our method of functional data embedding maintains compliance with standards because the merging of image with textual data and the modification of the header file adhere to rules or options of the standards.
After the integration of functional text and image, we encrypt the combined data. Only the modified data are encrypted, while unchanged parts are not. Standard ciphers such as triple DES, IDEA, or Rijndael AES, can be used for this purpose. To reduce complexity, we propose to employ the XOR operation for enciphering. A crypto-graphically secure random sequence controlled by a secret key can be generated efficiently (Stinson, 2000; Stajano, 2002), and the sequence, used as a one-time keypad, is XORed with the combined textual and image data. Since XOR sequence is generated using a seed, as long as the receiver has the same seed, by performing XOR again, the message can be recovered. In this case, we make use of a separate private key owned by the receiver to encrypt the secret key to the random sequence. The encrypted key to the random sequence is provided in the header file. More sophisticated off-line distributed or group key management will be designed for better security control and will be discussed in our future work. The computational complexity is proportional to the size of the selected image parts and only a fraction of what would be required for full encryption. After encryption, we put the combined data back into their original positions in the selected image parts.
It can be observed that modification of the MSBs has significant impact on the visual quality of the image, while modification of the LSBs has insignificant impact. At the same time, the volumes of data that can be embedded by using MSBs and LSBs are different. If the MSBs are used, the volume is large; if the LSBs are used, it is small. As mentioned earlier, the visual impact and volume of data embedding are important factors in selecting image parts for encryption in various applications. To quantify the volume of embedded data and visual degradation of the medical image, we define rate and distortion as follows:
The rate R of the I-SEE is defined as the average number of functional bits that can be embedded into the image per pixel; thus, its unit is bits per pixel (bpp). The rate R depends on how well the image parts can be compressed. The fundamental limit of the reversible compression is the entropy rate of the selected image parts (Cover and Thomas, 1991). If we consider bitplane or bitplanes X, the rate R has an upper bound of r − H(X), where H(X) denotes the entropy rate of the source X, and r is the number of bits per pixel for original parts X. The value of r, for example, is 1 if X is the MSB, 2 if X is the first two MSBs, and so on. If the lossless compression coder is asymptotically optimal, such as the LZ coding for an ergodic source, then the larger the size of X, the closer the rate R is to the upper bound. The MSBs are usually less random-like than the LSBs and have a smaller entropy rate than the LSBs. Thus, the MSBs yield a larger rate R than the LSBs. The distortion D of the I-SEE is measured using the peak signal-to-noise ratio. It is simply a measure of the mean squared error, which is defined as the average squared difference between the modified and the original images. The rate-distortion curve can be obtained empirically.
We conducted experiments using sixty medical images that range in size from 128 × 128 to 1024 × 1024 and in modality from computed tomography, ultrasound, and magnetic resonance imaging (MRI) to digital X-ray, digital subtraction angiography (DSA), and nuclear medicine. A range of organs were shown in these images. Because different imaging modalities have different gray scales (for example, most MRI images have 12–16 bits, while DSA images have 8–12 bits), we selected the LSBs for encryption. The motivation to select the LSBs is to obtain partial observations of medical images. The LSBs were considered consecutively. In our experiment, we considered only 8 LSBs at most. Exhibit 14.2 plots the empirically obtained rate-distortion curves using the sixty images. We plot the rate and distortion against the number of LSBs.
Note that the rate-distortion curve can also be plotted with the rate R as a function of the distortion D. Our plot clearly demonstrates an increasing trend in rate and a decreasing trend in distortion as consecutive LSBs selected for encryption are increased. If some significant bitplanes are used (or the lowest LSBs are excluded), the rate R becomes significantly higher, and the distortion D becomes lower, as explained before. Users can use the rate-distortion curve to choose a proper operational point for their I-SEE system.
EXHIBIT 14.2. RATE AND DISTORTION CURVES FOR IMAGES, BY NUMBER OF CONSECUTIVE LSBs SELECTED FOR ENCODING

System Receiver Processing
At the receiving end, the processing that was performed at the transmitting end is reversed. The receiver must possess the private key to decrypt the key that is used to generate the pseudorandom sequence. Since all processing at the transmitter is reversible, both the original image and the embedded functional data can be reconstructed simultaneously without error. The computational complexity is proportional to the size of the selected image parts.
Conclusion
We propose the integrated selective encryption and data embedding system for transmission of medical images. Functional patient and medical data are seamlessly embedded into the medical image and compressed losslessly in a way that complies with industry standards. Selected parts of the image are efficiently encrypted. Integration of medical images and functional data is achieved, and high security and privacy of data are maintained. New functions may be possible within the proposed I-SEE framework—for example, multimodal content-based image retrieval. Our future work will consider the issues in managing distributed and group keys in an I-SEE system.
Case Questions
- In what circumstances is a random-like encrypted image preferred? In what situations is partial availability of a medical image useful?
- What are the potential benefits of the integration of images with electronic patient record data?
- Application of I-SEE to medical image communications is considered in this case. Can you envision applications of I-SEE to the storage of medical images in a database? Please explain your answer.
References
Cheng, Q., & Huang, T. S. (2001, September). An additive approach to transform-domain information hiding and optimum detection structure. IEEE Transactions on Multimedia, 3(3), 273–284.
Cheng, Q., & Huang, T. S. (2003, April). Robust optimum detection of transformdomain multiplicative watermarks. IEEE Transactions on Signal Processing, 51(4), 906–924. (Special issue on signal processing for data hiding in digital media and secure content delivery).
Cheng, Q., Wang, Y., & Huang, T.S. (2004, August) Performance analysis and error exponents of asymmetric watermarking systems. Signal Processing, 84(8), 1429–1445.
Cover, T., & Thomas, J. (1991). Elements of information theory. New York: Wiley.
Cox, I. J., Kilian, J., Leighton, F. T., & Shamoon, T. (1997). Secure spread spectrum watermarking for multimedia. IEEE Transactions Image Processing, 6(12), 1673–1687.
Fridrich, J., Goljan, M., & Du, R. (2001). Invertible authentication. In, Proceedings of The International Society for Optical Engineering Photonics West Security and Watermarking of Multimedia Contents III, San Jose, California, USA, January 22–25, 2001 (Vol. 3971, pp. 197–208).
Luo, X., Cheng, Q., & Tan, J. (2003). A lossless data embedding scheme for medical images in application of e-diagnosis. In, Proceedings of the International Conference of IEEE Engineering in Medicine and Biology Society (EMBS '03), Cancun, Mexico, September 2003.
Proakis, J. G. Digital communications (4th ed.). New York: McGraw-Hill, 2001.
Qiao, L., & Nahrstedt, K. (1997). A new algorithm for MPEG video encryption. In, Proceedings of the International Conference of Imaging Science, Systems, and Technology (CISS'97), pages 21–29, Las Vegas, NV, July 1997.
Qiao, L., & Nahrstedt, K. (1998). Comparison of MPEG encryption algorithms. International Journal on Computer and Graphics, 22(3). (Special issue on data security in image communication and network.), Urbana, IL, U.S.A.
Schneier, B. (2000). Secrets and lies: Digital security in a networked world. New York: Wiley.
Shi, C., Wang, S.-Y., & Bhargava, B. (1999). MPEG video encryption in real-time using secret key cryptography, West Lafayette, IN In, Proceedings of the International Conference of Parallel and Distributed Processing Techniques and Application, Las Vegas, NV, June 1999.
Stajano, F. (2002). Security for ubiquitous computing. New York: Wiley.
Stinson, D. R. (2000). Cryptography: Theory and practice. Boca Raton, FL: CRC Press.
Tang, L. (1996). Methods for encrypting and decrypting MPEG video data efficiently. In, Proc. ACM Multimedia, Boston, November 1996 (pp. 219–230), Boston, MA.
Van de Velde, R., & Degoulet P. (2003). Clinical information systems. New York: Springer.
Wu, C.-P., & Guo, C.-C. J. (2001). Efficient multimedia encryption via entropy codec design. In, Proc. SPIE Security and Watermarking of Multimedia Content, San Jose, CA, January 2001 (Vol. 4314), San Jose, CA, USA.
Zeng, W., & Lei, L. (2002). Efficient frequency domain selective scrambling of digital video. IEEE Transactions, Multimedia.
Ziv, J., & Lempel, A. (1978). Compression of individual sequences by variable rate coding. IEEE Transactions On Information Theory, IT-24, 530–536.
The authors would like to acknowledge Kerry Taylor (CSIRO, Australia), Christine O'Keefe (CSIRO, Australia), James Gray III (RSA Security Inc., USA), Dickson K. W. Chiu (The Chinese University of Hong Kong, Hong Kong), and Mike Leung (PNM Solutions, Hong Kong) for their helpful suggestions and comments. In addition, the authors acknowledge the contributions of their past and present students, including those from the University of British Columbia, British Columbia Institute of Technology and Wayne State University, especially those who assisted with the literature review and with general research, including graphing, editing and checking references, and gathering materials presented in these chapters. Any omissions remain the responsibility of the authors. This work was supported by grants from the Office of the President of Wayne State University and other sources.
The authors thank X. Luo for his help in programming the rate and distortion curves.