
Chapter 14. Redundancy and Disaster Recovery
This chapter covers the following subjects:
Redundancy Planning—This section is all about ensuring your network and servers are fault tolerant. By setting up redundant power, data, servers, and even ISPs, you can avoid many disasters that could threaten the security of your organization.
Disaster Recovery Planning and Procedures—A disaster is when something happens to your network that your fault-tolerant methods cannot prevent. To help recovery after a disaster, data should be backed up, and a proper disaster recovery plan should be designed, practiced, and implemented if necessary.
This chapter covers the CompTIA Security+ SY0-201 objectives 6.1 and 6.2.
The typical definition of “redundant” means superfluous or uncalled for. However, it is not so in the IT field. Being redundant is a way of life. It is a way of enhancing your servers, network devices, and other equipment. It is a way of developing fault tolerance—the capability to continue functioning even if there is an error.
This chapter discusses how to prevent problems that might occur which could threaten the security of your servers, network equipment, and server room in general. A good network security administrator should have plenty of redundancy and fault-tolerant methods in place that can help combat threats and help avoid disaster.
However, no matter how much redundancy you implement, there is always a chance that a tragedy could arise—a disaster if you will. A disaster could be the loss of data on a server, a fire in a server room, or the catastrophic loss of access to an organization’s building. To prepare for these events, a disaster recovery plan should be designed, but with the thought in mind that redundancy and fault tolerance can defend against most “disasters.” The best admin is the one that avoids disaster and in the rare case that it does happen, has a plan in place to recovery quickly from it. This chapter also covers how to plan for disasters and discusses a plan of action for recovering swiftly.
Foundation Topics: Redundancy Planning
Most networks could do with a little more redundancy. I know...a lot of you are probably wondering why I keep repeating myself! It’s because so many customers of mine in the past, and network admins that have worked for, and with me, insist on avoiding the issue. Redundancy works—use it!
This section discusses redundant power in the form of power supplies, UPS, and backup generators. It also talks about redundant data, servers, ISPs, and sites. All these things, when planned properly, will create an environment that can withstand most failures barring total disaster.
The whole concept revolves around single points of failure. A single point of failure is an element, object, or part of a system that, if it fails, will cause the whole system to fail. By implementing redundancy, you can bypass just about any single point of failure.
There are two methods to combating single points of failure. The first is to use redundancy. If employed properly, redundancy will keep a system running with no downtime. However, this can be pricey, and we all know there is only so much IT budget to go around. So, the alternative is to make sure you have plenty of spare parts lying around. This is a good method if your network and systems are not time-critical. Installing spare parts often requires you to down the server or portion of a network. If this risk is not acceptable to an organization, you’ll have to find the cheapest redundant solutions available. Research is key, and don’t be fooled by the hype—sometimes the simplest sounding solutions are the best.
Here’s the scenario (and we will apply this to the rest of this “Redundancy Planning” section). Your server room has the following powered equipment:
• 9 servers
• 2 Microsoft domain controllers
• 1 DNS server
• 2 file servers
• 1 database server
• 2 Web servers (which second as FTP servers)
• 1 Mail server
• 5 48-port switches
• 1 master switch
• 2 CSU/DSUs
• 1 PBX
• 2 client workstations (for remote server access without having to work directly at the server), these are within the server room as well.
It appears that there is already some redundancy in place in your server room. For example, there are two domain controllers. One of them has a copy of the Active Directory and acts as a secondary DC in the case that the first one fails. There are also two web servers, one ready to take over for the other if the primary one fails. This type of redundancy is known as fail-over redundancy. The secondary system is inactive until the first one fails. Also, there are two client workstations that are used to remotely control the servers; if one fails, another one is available.
Otherwise, the rest of the servers and other pieces of equipment are one-offs; single instances in need of something to prevent failure. There are a lot of them, so we truly need to redundacize! Hey, it’s a word if IT people use it! Try to envision the various upcoming redundancy methods used with each of the items listed previously in our fictitious server room.
Redundant Power
Let’s begin with power because that is what all our devices and computers gain “sustenance” from. Power is so important—when planning for redundancy it should be at the top of your list. When considering power implications, think like an engineer; you might even need to enlist the help of a coworker who has engineering background or a third party to help plan your electrical requirements and make them a reality.
We are most interested in the server room. Smart companies will store most of their important data, settings, apps, and so on in that room. So power is critical here whereas it is not as important for client computers and other client resources. If power fails in a server room or in any one component within the server room, it could cause the network to go down, or loss of access to resources. It could also cause damage to a server or other device.
When considering power, think about it from the inside out. For example, start with individual computers, servers, and networking components. How much power does each of these things require? Make a list and tally your results. Later, this will play into the total power needed by the server room. Remember that networking devices such as IP phones, cameras, and some wireless access points are powered over Ethernet cabling, which can require additional power requirements at the Ethernet switch(s) in the server room. Think about installing redundant power supplies in some of your servers and switches. Next, ponder using UPS devices as a way of defeating short-term power loss failures. Then, move on to how many circuits you will need, total power, electrical panel requirements, and also the cleanliness of power coming in from your municipality. Finally, consider backup generators for longer term power failures.
Using proper power devices is part of a good preventative maintenance/security plan and helps to protect a computer. You need to protect against several things:
![]()
• Surges—A surge in electrical power means that there is an unexpected increase in the amount of voltage provided. This can be a small increase or a larger increase known as a spike.
• Spikes—A spike is a short transient in voltage that can be due to a short circuit, tripped circuit breaker, power outage, or lightning strike.
• Sags—An unexpected decrease in the amount of voltage provided. Typically, sags are limited in time and in the decrease in voltage. However, when voltage reduces further, a brownout could ensue.
• Brownouts—The voltage drops to such an extent that it typically causes the lights to dim and causes computers to shut off.
• Blackouts—A total loss of power for a prolonged period occurs. Another problem associated with blackouts is the spike that can occur when power is restored. In the New York area, it is common to have an increased amount of tech support calls during July; this is attributed to lightning storms! Quite often, this is due to improper protection.
• Power supply failure—Power supplies are like hard drives in two ways: One, they will fail; it’s not a matter of if, it’s a matter of when. Two, they can cause intermittent issues when they begin to fail, issues that are hard to troubleshoot. If you suspect a power supply failure then you should replace the supply. Also consider using a redundant power supply.
Some devices have specific purposes, and others can protect against more than one of these electrical issues. Let’s talk about three of them now: redundant power supplies, uninterruptible power supplies, and backup generators.
Redundant Power Supplies
A proper redundant power supply is an enclosure that contains two (or more) complete power supplies. You make one main power connection from the AC outlet to the power supply, and there is one set of wires that connect to the motherboard and devices. However, if one of the power supplies in the enclosure fails, the other takes over immediately without computer failure. These are common on servers, especially RAID boxes. They are not practical for client computers, but you might see them installed in some powerful workstations. In our scenario, we should install redundant power supplies to as many servers as possible, starting with the file servers and domain controllers. If possible, we should implement redundant power supplies for any of our switches or routers that will accept them, or consider new routers and switches that are scalable for redundant power supplies.
In some cases (pun intended), it is possible to install two completely separate power supplies so that each has a connection to an AC outlet. This will depend on your server configuration but is less common due to the amount of redundancy it requires of the devices inside the server. Either look at the specifications for your server’s case, or open it up during off hours to see if redundant power supplies are an option.
Vendors such as HP, and manufacturers such as Thermaltake, and Enlight offer redundant power supply systems for servers, and vendors such as Cisco offer redundant AC power systems for its networking devices.
This technology is great in the case that a power supply failure occurs but does not protect from scenarios when power to the computer is disrupted.
Uninterruptible Power Supplies
It should go without saying, but surge protectors are not good enough to protect power issues that might occur in your server room. A UPS is the proper device to use. An uninterruptible power supply (UPS) takes the functionality of a surge suppressor and combines that with a battery backup. So now, our server is protected not only from surges and spikes, but also from sags, brownouts, and blackouts. Most UPS devices also act as line conditioners that serve to clean up dirty power. Noise and increases/decreases in power make up dirty power. Dirty power can also be caused by too many devices using the same circuit, or because power coming from the electrical panel or from the municipal grid fluctuates, maybe because the panel or the entire grid is under/overloaded. If a line conditioning device such as a UPS doesn’t fix the problem, a quick call to your company’s electrician should result in an answer and possibly a long-term fix.
If you happen to be using a separate line conditioning device in addition to a UPS, it should be tested regularly. Line conditioning devices are always supplying power to your devices. A UPS backup battery will kick in only if a power loss occurs.
Battery backup is great, but the battery can’t last indefinitely! It is considered emergency power and typically keeps your computer system running for 5 to 30 minutes depending on the model you purchase. UPS devices today, have a USB connection so that your computer can communicate with the UPS. When there is a power outage, the UPS sends a signal to the computer telling it to shut down, suspend, or stand-by before the battery discharges completely. Most UPSs come with software that you can install that enables you to configure the computer with these options.
The more devices that connect to the UPS, the less time the battery can last if a power outage occurs; if too many devices are connected, there may be inconsistencies when the battery needs to take over. Thus many UPS manufacturers limit the amount of battery backup-protected receptacles. Connecting a laser printer to the UPS is not recommended due to the high current draw of the laser printer; and never connect a surge protector or power strip to one of the receptacles in the UPS, to protect the UPS from being overloaded.
The UPS normally has a lead-acid battery that, when discharged, requires 10 hours to 20 hours to recharge. This battery is usually shipped in a disconnected state. Before charging the device for use, you must first make sure that the leads connect. If the battery ever needs to be replaced, a red light will usually appear accompanied by a beeping sound. Beeping can also occur if power is no longer supplied to the UPS by the AC outlet.
There are varying levels of UPS devices, which incorporate different technologies. For example, the cheaper standby UPS (known as an SPS) might have a slight delay when switching from AC to battery power, possibly causing errors in the computer operating system. If a UPS is rack mounted, it will usually be a full-blown UPS (perhaps not the best choice of words!); this would be known as an “online” or “continuous” UPS—these cost in the hundreds or even thousands. If it is a smaller device that plugs into the AC outlet and lays freely about, it is probably an SPS—these cost between $25 and $100. You should realize that some care should be taken when planning the type of UPS to be used. When data is crucial, you had better plan for a quality UPS!
Just about everything in the server room should be connected to a UPS (you will most likely need several) to protect from power outages. This includes servers, monitors, switches, routers, CSU/DSUs, PBX equipment, security cameras, workstations, and monitors—really, everything in the server room!
Backup Generators
What if power to the building does fail completely? Most would consider this a disaster, and over the long term it could possibly be. However, most power outages are 5 minutes or less on the average, and most of the time a UPS can pick up the slack for these short outages, but not for the less common, longer outages that might last a few hours or days. And, a UPS powers only the devices you plug into it. If your organization is to keep functioning, it will need a backup generator to power lights, computers, phones, and security systems over short-term outages, or longer ones.
A backup generator is a part of an emergency power system used when there is an outage of regular electric grid power. Some emergency power systems might include special lighting and fuel cells, whereas larger more commercial backup generators can power portions of, or an entire building, as long as fuel is available. For our scenario we should make sure that the backup generator powers the server room at the very least.
Backup generator fuel types include gasoline, diesel, natural gas, propane, and solar. Smaller backup generators will often use gasoline, but these are not adequate for most companies. Instead, many organizations will use larger natural gas generators. Some of these generators need to be started manually, but the majority of them are known as standby generators. These are systems that will turn on automatically within seconds of a power outage. Transfer switches sense any power loss and instruct the generator to start. Standby generators may be required by code for certain types of buildings with standby lighting, or building with elevators, fire-suppression systems, and life-support equipment. You should always check company policy and your municipal guidelines before planning and implementing a backup generator system.
Backup generators can be broken into three types:
• Portable gas-engine generator—The least expensive and run on gasoline or could be solar powered. They are noisy, high maintenance, must be started manually, and usually require extension cords. They are a carbon monoxide risk and are only adequate for small operations and in mobile scenarios.
• Permanently installed generator—Much more expensive with a complex installation. These almost always run on either natural gas or propane. They are quieter and can be connected directly to the organization’s electrical panel. Usually, these are standby generators and as such require little user interaction.
• Battery-inverter generator—These are based off of lead-acid batteries, are quiet, and require little user interaction aside from an uncommon restart and change of batteries. They are well matched to environments that require a low amount of wattage or are the victims of short power outages only. Battery-inverter systems can be stored indoors, but because the batteries can release fumes, the area they are stored in should be well ventilated, such as an air conditioned server room with external exhaust. Uninterruptible power supplies fall into the battery inverter generator category.
Some of the considerations you should take into account when selecting a backup generator include the following:
• Price—As with any organizational purchase, this will have to be budgeted.
• How unit is started—Does it start automatically? Most organizations will require this.
• Uptime—How many hours will the generator stay on before needing to be refueled? This goes hand-in-hand with the next bullet.
• Power output—How many watts does the system offer? Before purchasing a backup generator, you should measure the total maximum load your organization might use by running all computers, servers, lights, and other devices simultaneously, and measure this at the main electrical panel. Alternatively, you could measure the total on paper by adding the estimated power requirements of all devices together.
• Fuel source—Does it run on natural gas, gasoline, and so on? If it is an automatically starting system, the options will probably be limited to natural gas and propane.
Some vendors that offer backup generators include Generac, Gillette, and Kohler. These devices should be monitored periodically; most companies will attempt to obtain a service contract from you, which might be wise depending on the size of your organization. We discuss service contracts and service level agreements in Chapter 15, “Policies, Procedures, and People.”
Remember that your mission-critical devices, such as servers, should constantly be drawing power from a line conditioning device. Then, if there is a power outage to the server, a UPS should kick in. (In some cases, the UPS will also act as the line conditioning device.) Finally, if necessary a backup generator will come online and feed all your critical devices with power.
Redundant Data
Now that we have power taken care of, we can move on to the heart of the matter—data. Data can fail due to file corruption and malicious intent among other things. Power failures, hard drive failures, and user error can all lead to data failure. As always, it’s the data that we are most interested in securing, so it stands to reason that the data should be redundant as well. But which data? There is so much of it! Well, generally file servers should have redundant data sets of some sorts. If an organization has the budgeting, next on the list would be databases and then web and file servers. However, in some instances these additional servers might be better off with failover systems as opposed to redundant data arrays. And certainly, the majority of client computers’ data does not constitute a reason for RAID. So we’ll concentrate on the file servers in our original scenario in the beginning of the chapter.
The best way to protect file servers’ data is to use some type of redundant array of disks. This is referred to as RAID (an acronym for redundant array of independent disks, or inexpensive disks). RAID technologies are designed to either increase the speed of reading and writing data or to create one of several types of fault tolerant volumes, or do both. From a security viewpoint, we are most interested in the fault tolerance (the capability to withstand failure) of our disks. A RAID array can be internal or external to a computer. Historically, RAID arrays were configured as SCSI chains, but nowadays you will also find SATA, eSATA, and Fibre Channel. Either way, the idea is that data is being stored on multiple disks that work with each other. The amount of disks and the way they work together will be dependent on the level of RAID. For the exam, you need to know several levels of RAID including RAID 0, RAID 1, RAID 5, RAID 6, and RAID 10. Table 14-1 describes each of these. Note that RAID 0 is the only one listed that is not fault-tolerant, so from a security perspective it is not a viable option. Nevertheless, you should know it for the exam.
Table 14-1. RAID Descriptions
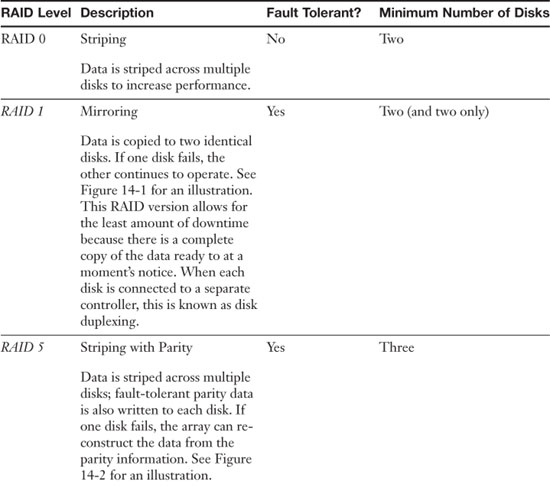

![]()
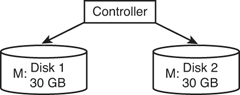
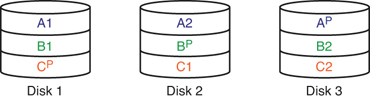
Figure 14-1 shows an illustration of RAID 1; you can see that data is written to both disks and that both disks collectively are known as the M: drive or M: volume. Figure 14-2 displays an illustration of RAID 5. In a RAID 5 array, blocks of data are distributed to the disks (A1 and A2 are a block, B1 and B2 are a block, and so on), and parity information is written for each block of data. This is written to each disk in an alternating fashion (Ap, Bp, and such) so that the parity is also distributed. If one disk fails, the parity information from the other disks will reconstruct the data. It is important to make the distinction between fault tolerance and backup. Fault tolerance means that the hard drives can continue to function (with little or no downtime) even if there is a problem with one of the drives. Backup means that we are taking the data and copying it (and possibly compressing it) to another location for archival in the event of a disaster. An example of a disaster would be if two drives in a RAID 5 array were to fail. If an organization is worried that that could happen, they should consider RAID 6, RAID 0+1, or the less common RAID 1+0.
Figure 14-1. RAID 1 Illustration
![]()
Figure 14-2. RAID 5 Illustration
![]()
Windows servers support RAID 0, 1, and 5 (and possibly 6 depending on the version) within the operating system. But most client operating systems cannot support RAID 1, 5, and 6. However, they can support hardware controllers that can create these arrays. Some motherboards have built in RAID functionality as well.
Hardware is always the better way to go when it comes to RAID. Having a separate interface that controls the RAID configuration and handling is far superior than trying to control it with software within an operating system. The hardware could be an adapter card installed inside the computer, or an external box that connects to the computer or even to the network. When it comes to RAID in a network storage scenario, you are now dealing with network attached storage (NAS). These NAS points can be combined to form a storage area network (SAN), but any type of network attached storage will cost more money to an organization.
You can classify RAID in three different ways; these classifications can help when you plan which type of RAID system to implement.
• Failure-resistant disk systems—Protect against data loss due to disk failure. An example of this would be RAID 1 Mirroring.
• Failure-tolerant disk systems—Protect against data loss due to any single component failure. An example of this would be RAID 1 mirroring with duplexing.
• Disaster-tolerant disk systems—Protect data by the creation of two independent zones, each of which provides access to stored data. An example of this would be RAID 0+1.
Of course, no matter how well you protect the data from failure, users still need to access the data, and to do so might require some redundant networking.
Redundant Networking
Network connections can fail as well. And we all know how users need to have the network up and running—or there will be heck to pay. The security of an organization can be compromised if networking connections fail. Some of the types of connections you should consider include the following:
• Server network adapter connections
• Main connections to switches and routers
• The Internet connection
So basically, when I speak of redundant networking, I’m referring to any network connection of great importance that could fail. Generally, these connections will be located in the server room.
Redundant network adapters are commonly used to decrease or eliminate server downtime in the case that one network adapter fails. However, you must consider how they will be set up. Optimally, the second network adapter will take over immediately when the first one fails, but how will this be determined? There are applications that can control multiple network adapters, or the switch that they connect to can control where data is directed in the case of a failure. Also, multiple network adapters can be part of an individual collective interface. What you decide will be dictated by company policy, budgeting, and previously installed equipment. As a rule of thumb, you should use like network adapters when implementing redundancy; check the model and the version of the particular model to be exact. When installing multiple network adapters to a server, that computer than becomes known as a multihomed machine. It is important to consider how multiple adapters (and their operating systems) will behave normally and during a failure. Microsoft has some notes about this; I left a link at the end of the chapter. In some cases, you will install multiple physical network adapters, and in others you might opt for a single card that has multiple ports such as the Intel PRO/1000 MT Dual Port Server Adapter. This is often a cheaper solution than installing multiple cards but provides a single point of failure in the form of one adapter card and one adapter card slot. In our original scenario we had domain controllers, database servers, web servers, and file servers; these would all do well with the addition of redundant network adapters.
Companies should always have at least one backup switch sitting on the shelf. If the company has only one switch, it is a desperate single point of failure. If a company has multiple switches stacked in a star-bus fashion, the whole stack can be a single point of failure unless special backup ports are used (only available on certain switches). These special ports are often fiber optic-based and are designed either for high-speed connections between switches or for redundancy. This concept should be employed at the master switch in a hierarchical star as well to avoid a complete network collapse. However, the hierarchical star is more secure than a star-bus configuration when it comes to network failure. In a hierarchical star, certain areas of the network will still function even if one switch fails. This is a form of redundant topology.
Finally, your ISP is susceptible to failure as well—as I’m sure you are well aware. Most organizations rely on just one Internet connection for their entire network. This is another example of a single point of failure. Consider secondary connections to your ISP; known as a redundant ISP. If you have a T-1 line, perhaps a BRI connection will do. Or if you have a T-3, perhaps a PRI connection would be best. At the very least, a set of dial-up connections can be used for redundancy. Some companies will install completely fault-tolerant, dual Internet connections, the second of which comes online immediately following a failure. If you use a web host for your website and/or e-mail, consider a mirror site or more than one. Basically, in a nutshell, it’s all about not being caught with your pants down. If an organization is without its Internet connection for more than a day (or hours in some cases), you know it will be the network admin and security admin that will be the first on the chopping block, most likely followed by the ISP.
Redundant Servers
Let’s take it to the next level and discuss redundant servers. When redundant network adapters and disks are not enough, you might decide to cluster multiple servers together that act as a single entity. This will be more costly and require more administration but can provide a company with low downtime and a secure feeling. Two or more servers that work with each other are a cluster.
The clustering of servers can be broken down into two types:
![]()
• Failover clusters—Otherwise known as high-availability clusters are designed so that a secondary server can take over in the case that the primary one fails, with limited or no downtime. An example of a failover cluster would be the usage of two Microsoft domain controllers. When the first domain controller fails, the secondary domain controller should be ready to go at a moment’s notice. There can be tertiary and quaternary servers and beyond as well. It all depends on how many servers you think might fail concurrently.
• Load-balancing clusters—Load balancing clusters are when multiple computers are connected together in an attempt to share resources such as CPU, RAM, and hard disks. In this way, the cluster can share CPU power, along with other resources, and balance of the CPU load among all the servers. Microsoft’s Cluster Server is an example of this (although it can also act in failover mode), enabling for parallel, high performance computing. Several third-party vendors offer clustering software for operating systems and virtual OSs as well.
Data can also be replicated back and forth between servers as it often is with database servers and web servers. This is actually a mixture of redundant data (data replication) and server clustering.
However, it doesn’t matter how many servers you install in a cluster. If they are all local, they could all be affected by certain attacks or worse yet, disasters. Enter the redundant site concept.
Redundant Sites
Well, we have implemented redundant arrays of disks, redundant network adapters, redundant power, and even redundant servers. What is left? Devising a mirror of the entire network! That’s right, a redundant site, if you will. In the case of a disaster, a redundant site can act as a safe haven for your data and users. Redundant sites are sort of a gray area between redundancy and a disaster recovery method. If you have one and need to use it, a “disaster” has probably occurred. But, the better the redundant site, the less time the organization loses, and the less it seems like a disaster and more like a failure that you have prepared for. Of course, this all depends on the type of redundant site your organization decides on.
When it comes to the types of redundant sites, I like to refer to the story of Goldilocks and the three bears’ three bowls of porridge. One was too hot, one too cold—and one just right. Most organizations will opt for the warm redundant site as opposed to the hot or cold. Let’s discuss these three now.
![]()
• Hot site—A near duplicate of the original site of the organization that can be up and running within minutes (maybe longer). Computers and phones are installed and ready to go, a simulated version of the server room stands ready, and vast majority of the data is replicated to the site on a regular basis in the event that the original site is not accessible to users for whatever reason. Hot sites are used by companies that would face financial ruin in the case that a disaster makes their main site inaccessible for a few days of even a few hours. This is the only type of redundant site that can facilitate a full recovery.
• Warm site—Will have computers, phones, and servers, but they might require some configuration before users can start working on them. The warm site will have backups of data that might need to be restored; they will probably be several days old. This is chosen the most often by organizations because it has a good amount of configuration, yet remains less inexpensive than a hot site.
• Cold site—Has tables, chairs, bathrooms, and possibly some technical setup; for example basic phone, data, and electric lines. Otherwise, a lot of configuration of computers and data restoration is necessary before the site can be properly utilized. This type of site is used only if a company can handle the stress of being nonproductive for a week or more.
Although they are redundant, these types of sites are generally known as backup sites because if they are required, a disaster has probably occurred. A good network security administrator will try to plan for, and rely on, redundancy and fault tolerance as much as possible before having to resort to disaster recovery methods.
Disaster Recovery Planning and Procedures
Regardless of how much you planned out redundancy and fault tolerance, when disaster strikes, it can be devastating. There are three things that you should be concerned with as a network security administrator when it comes to disasters—your data, your server room, and the site in general. You need to have a powerful backup plan for your data and a comprehensive disaster recovery plan as well.
Data Backup
Disaster recovery (or DR for short) is pretty simple in the case of data. If disaster strikes you better have a good data backup plan; one that fits your organization’s needs and budget. Your company might have a written policy as to what should be backed up, or you might need to decide what is best. Data can be backed up to a lot of different types of media (or to other computers), but generally the best method is tape backup.
There are three tape backup types you should be aware of for the exam. Keep in mind that this list is not the end all of backup types, but it gives a basic idea of the main types of backups used in the field. When performing any of these types of backups, the person must select what to backup. It could be a folder or an entire volume. For the sake of simplicity we will call these folders.
![]()
• Full backup—When all the contents of a folder are backed up. It can be stored on one or more tapes. If more than one is used, the restore process would require starting with the oldest tape and moving through the tapes chronologically one by one. Full backups can use a lot of space, causing a backup operator to make use of a lot of backup tapes which can be expensive. Full backups can also be time-consuming if there is a lot of data. So, quite often, incremental and differential backups are used with full backups as part of a backup plan.
• Incremental backup—Backs up only the contents of a folder that has changed since the last full backup or the last incremental backup. An incremental backup must be preceded by a full backup. Restoring the contents of a folder or volume would require a person to start with the full backup tape and then move on to each of the incremental tapes chronologically, ending with the latest incremental backup tape. Incremental backups started in the time of floppy disks when storage space and backup speed were quite limited. Some operating systems and backup systems will associate an archive bit (or archive flag) to any file that has been modified; this indicates to the backup program that it should be backed up during the next backup phase. If this is the case, the incremental backup will reset the bit after backup is complete.
• Differential backup—Backs up only the contents of a folder that has changed since the last full backup. A differential backup must be preceded by a full backup. To restore data, a person would start with the full backup tape and then move on to the differential tape. Differential backups do not reset the archive bit when backing up. This means that incremental backups will not see or know that a differential backup has occurred.
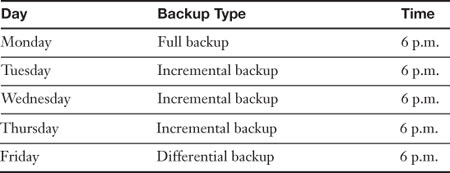
Table 14-2 shows an example of a basic one-week backup schedule using these three backup types.
Table 14-2. Example Backup Schedule
![]()
In this schedule, five backup tapes are required, one for each day. Let’s say that the backups are done at 6 p.m. daily. Often an organization might employ a sixth tape, which is a dummy tape. This tape is put in the tape drive every morning by the backup operator and is replaced with the proper daily tape at 5:30 p.m. when everyone has left the building. This prevents data theft during the day. The real tapes are kept locked up until needed. Tapes might be reused when the cycle is complete, or an organization might opt to archive certain tapes each week, for example the full and differential tapes, and use new tapes every Monday and Friday. Another option is to run a complete full backup (which might be time-consuming) over the weekend and archive that tape every Monday. As long as no data loss is reported, this is a feasible option.
Let’s say that this backup procedure was used to backup a server. Now, let’s say that the server crashed on Wednesday at 9 p.m., and the hard drive data was lost. A backup operator arriving on the scene Thursday morning would need to review any logs available to find out when the server crashed. Then, after an admin fixes the server, the backup operator would need to restore the data. This would require starting with the Monday full backup tape and continuing on to the Tuesday and Wednesday incremental backup tapes. So three tapes in total would be needed to complete the restore.
Another example would be if the backup operator needed to restore data on Monday morning due to a failure over the weekend. The backup operator would need only two backup tapes, the Monday full backup and the Friday differential backup, because the differential backup would have backed up everything since the last full backup.
Windows Server operating systems have the capability to do full backups, incrementals, and differentials, as shown in Figure 14-3. Windows refers to a full backup as “normal.” You will note that Windows also enables copy backups and daily backups.
Figure 14-3. Windows Server 2003 Backup Types
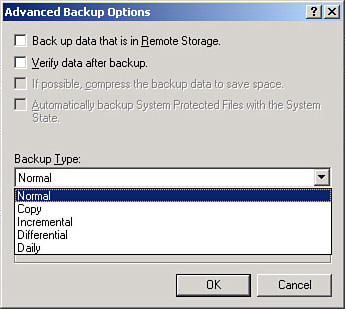
Now, the schedule we just showed in Table 14-2 is a basic backup method, also known as a backup rotation scheme. Organizations might also do something similar in a 2-week period. However, you should also be aware of a couple of other backup schemes used in the field. These might use one or more of the backup types mentioned previously.
![]()
• 10 tape rotation—This method is simple and provides easy access to data that has been backed up. It can be accomplished during a 2-week backup period, each tape is used once per day for 2 weeks. Then the entire set is recycled. Generally, this will be similar to the one-week schedule shown previously, however, the second Monday might be a differential backup instead of a full backup. And the second Friday might be a full backup, which is archived. There are several options; you would need to run some backups and see which is best for you given the amount of tapes required and time spent running the backups.
• Grandfather-father-son—This backup rotation scheme is probably the most common backup method used. When attempting to use this scheme, three sets of backup tapes must be defined—usually they are daily, weekly, and monthly, which correspond to son, father, and grandfather. Backups are rotated on a daily basis; normally the last one of the week will be graduated to father status. Weekly (father) backups are rotated on a weekly basis with the last one of the month being graduated to grandfather status. Quite often, monthly (grandfather) backups, or a copy of them, are archived offsite.
• Towers of Hanoi—This backup rotation scheme is based on the mathematics of the Towers of Hanoi puzzle. This also uses three backup sets, but they are rotated differently. Without getting into the mathematics behind it, the basic idea is that the first tape is used every 2nd day, the second tape is used every 4th day, and the third tape is used every 8th day. Table 14-3 shows an example of this. Keep in mind that this can go further; a fourth tape can be used every 16th day, and a fifth tape every 32nd day, and so on, although it gets much more complex to remember what tapes to use to backup and which order to go by when restoring. The table shows an example with three tape sets represented as set A, B, and C.
Table 14-3. Example of Towers of Hanoi 3 Tape Schedule

To avoid the rewriting of data, start on the 4th day of the cycle with tape C. This rotation scheme should be written out and perhaps calculated during the planning stage before it is implemented. Also, due to the complexity of the scheme, a restore sequence should be tested as well.
Tapes should be stored in a cool, dry area, away from sunlight, power lines, and other power sources. Most tape backup vendors will have specific guidelines as to the temperature and humidity ranges for storage, along with other storage guidelines.
Tape backup methods and tape integrity should always be tested by restoring all or part of a backup.
It’s also possible to archive data to a third-party. This could be for backup purposes or for complete file replication. Several companies offer this type of service, and you can usually select to archive data over the Internet or by courier.
Whatever your data backup method, make sure that there is some kind of archival offsite in the case of a true disaster. Optimally, this will be in a sister site in another city but regardless should be geographically distant from the main site.
DR Planning
Before we can plan for disasters, we need to define exactly what disasters are possible and list them in order starting with the most probable. Sounds a bit morbid, but it’s necessary to ensure the long-term welfare of your organization.
What could go wrong? Let’s focus in on the server room in the beginning of the chapter as our scenario. As you remember, we had nine servers, networking equipment, a PBX, and a few workstations—a pretty typical server room for a mid-sized company. Keep in mind that larger organizations will have more equipment, bigger server rooms, and more to consider when it comes to DR planning.
Disasters can be divided into two categories: natural and man-made. Some of the disasters that could render your server room inoperable include the following:
• Fire—Fire is probably the number one planned for disaster. This is partially because most municipalities will require some sort of fire suppression system, as well as the fact that most organizations’ policies will define the usage of a proper fire suppression system. You probably recall the three main types of fire extinguishers: A (for ash fires), B (for gas and other flammable liquid fires), and C (for electrical fires). Unfortunately, these and the standard sprinkler system in the rest of the building are not adequate for a server room. If there were a fire, the material from the fire extinguisher or the water from the sprinkler system would damage the equipment, making the disaster even worse! Instead, a server room should be equipped with a proper system of its own such as DuPont FM-200. This uses a large tank that stores a clean agent fire extinguishant that is sprayed from one or more nozzles in the ceiling of the server room. It can put out fires of all types in seconds. A product such as this can be used safely when people are present; however, most systems will also employ a very loud alarm that tells all personnel to leave the server room. It is wise to run through several fire suppression alarm tests and fire drills, ensuring that the alarm will sound when necessary and that personnel know what do to when the alarm sounds. We’ll talk more about fire in Chapter 15.
• Flood—The best way to avoid server room damage in the case of a flood is to locate the server room on the first floor or higher, not in a basement. There’s not much you can do about the location of a building, but if it is in a flood zone, it makes the use of a warm or hot site that much more imperative. And a server room could also be flooded by other things such as boilers. The room should not be adjacent to, or on the same floor as, a boiler room. It should also be located away from other water sources such as bathrooms and any sprinkler systems. The server room should be thought of three-dimensionally; the floors, walls, and ceiling should be analyzed and protected. Some server rooms are designed to be a room within a room and might have drainage installed as well.
• Long-term power loss—Short-term power loss should be countered by the UPS, but long-term power loss requires a backup generator and possibly a redundant site.
• Theft and malicious attack—Theft and malicious attack can also cause a disaster, if the right data is stolen. Physical security such as door locks/access systems and video cameras should be implemented to avoid this. Servers should be cable-locked to their server racks, and removable hard drives (if any are used) should have key access. Physical security is covered in more depth in Chapter 8, “Physical Security and Authentication Models.” Malicious network attacks also need to be warded off; these are covered in depth in Chapter 5, “Network Design Elements and Network Threats.”
• Loss of building—Temporary loss of the building due to gas leak, malicious attack, inaccessibility due to crime scene, or natural event will require personnel to access a redundant site. Your server room should have as much data archived as possible, and the redundant site should be warm enough to keep business running. A plan should be in place as to how data will be restored at the redundant site and how the network will be made functional.
Disaster recovery plans should include information regarding redundancy such as sites and backup but will not include information that deals with the day-to-day operations of an organization such as updating computers, patch management, monitoring and audits, and so on. It is important to include only what is necessary in a disaster recovery plan. Too much information can make it difficult to use when a disaster does strike.
Although not an exhaustive set, the following written disaster recovery policies, procedures, and information should be part of your disaster recovery plan:
• Contact information—Who you should contact if a disaster occurs and how employees will contact the organization.
• Impact determination—A procedure to determine a disaster’s full impact on the organization. This will include an evaluation of assets lost and the cost to replace those assets.
• Recovery plan—This will be based on the determination of disaster impact. This will have many permutations depending on the type of disaster. Although it is impossible to foresee every possible event, the previous list gives a good starting point. The recovery plan will include an estimated time to complete recovery and a set of steps defining the order of what will be recovered and when.
• Business continuity plan—A BCP defines how the business will continue to operate if a disaster occurs; this plan is often carried out by a team of individuals.
• Copies of agreements—Copies of any agreements with vendors of redundant sites, ISPs, building management, and so on should be stored with the DR plan.
• Disaster recovery drills and exercises—Employees should be drilled on what to do if a disaster occurs. These exercises should be written out step-by-step and should conform to safety standards.
This information should be accessible at the company site and should have a copy stored offsite as well. It might be that your organization conforms to special compliance rules; these should be consulted when designing a DR plan. Depending on the type of organization, there might be other items that go into your DR plan. We will cover these in more depth in Chapter 15.
Exam Preparation Tasks: Review Key Topics
Review the most important topics in the chapter, noted with the Key Topics icon in the outer margin of the page. Table 14-4 lists a reference of these key topics and the page numbers on which each is found.
![]()
Table 14-4. Key Topics for Chapter 14
Complete Tables and Lists from Memory
Print a copy of Appendix A, “Memory Tables,” (found on the DVD), or at least the section for this chapter, and complete the tables and lists from memory. Appendix B, “Memory Tables Answer Key,” also on the DVD, includes completed tables and lists to check your work.
Define Key Terms
Define the following key terms from this chapter, and check your answers in the glossary:
sag,
uninterruptible power supply (UPS),
disk duplexing,
Hands-On Labs
Complete the following written step-by-step scenarios. After you finish (or if you do not have adequate equipment to complete the scenario), watch the corresponding video solutions on the DVD.
If you have additional questions, feel free to post them at my website: www.davidlprowse.com in the Ask Dave forum. (Free registration is required to post on the website.)
Equipment Needed
• Windows Server 2003 with a minimum of three drives for data. These drives should be separate from the drive(s) used to store the operating system.
Lab 14-1: Backing Up Data on a Windows Server
In this lab, you will back up information on a Windows Server 2003 through the use of the built-in NTbackup program. The steps are as follows:
Step 1. Create a folder called admin. Stock it with a few files.
Step 2. Open the NTbackup program by clicking Start > Run and typing ntbackup. Deselect Wizard mode and restart the program to run it in regular mode.
Step 3. Click the Backup tab.
Step 4. Expand the + sign for the C: drive.
Step 5. Click the admin folder to view the contents.
Step 6. Checkmark the admin folder to back up all the contents within the admin folder.
Step 7. Click the Browse button to select where you will back up the data. This could be to tape, removable media, or elsewhere on the drive. For this procedure, back up to another folder on the C: drive.
Step 8. Name the backup. Consider adding the date into the filename of the backup. Then click Save.
Step 9. Click the Start Backup button. This displays the Backup Job Information window. Leave the default settings.
Step 10. Click the Advanced button.
Step 11. Select the Verify data after backup checkbox.
Step 12. Click OK.
Step 13. Click the Start Backup button.
Step 14. When the backup is complete, jot down the amount of bytes that were backed up. Next, view the report by clicking the Report button. Make sure that the data was verified within the Verified Status portion of the report.
Step 15. To represent the loss of data because of an unexpected event, go to Windows Explorer and delete the admin folder. Delete it from the Recycle Bin as well.
Step 16. Restore the deleted data from the backup file.
Step 17. Return to the NTbackup program.
Step 18. Click the Restore and Manage Media tab.
Step 19. Click the + sign next to File.
Step 20. Click the + sign for the backup that you just completed. View the contents inside the backup.
Step 21. Checkmark the backup and click the Start Restore button. Compare the amount of bytes that were restored to the amount of bytes that was originally backed up.
Step 22. Return to Windows Explorer and view your admin folder. Verify that all the contents of the folder were restored properly.
Watch the solution video in the “Hands-On Scenarios” section of the DVD.
Lab 14-2: Configuring RAID 1 and 5
In this lab, you configure RAID 1 (mirroring) and RAID 5 (striping with parity) on a Windows Server 2003. You will use the built-in software functionality to do this. The server needs to have three extra hard drives separate from the operating system drive. RAID 1 requires two individual drives; RAID 5 requires a minimum of 3, although you could use more.
The steps are as follows:
Configure a RAID 1 Mirror
Step 1. Access Disk Management within Computer Management or your MMC. The extra disks in your computer should be listed.
Step 2. Right-click the unallocated section of one of the blank disks to be used in your mirror and select New Volume.
Step 3. Click Next for the wizard.
Step 4. Click the Mirrored radio button and click Next.
Step 5. Add the disks you want to use to the Selected area by highlighting the disk(s) and clicking Add. Then click Next.
Step 6. Assign the drive letter M: for the mirror and click Next.
Step 7. In the Format Volume screen:
A. Change the name of the Volume Label to Mirror for Data.
B. Select the Perform a quick format checkbox.
C. Click Next.
If the system runs slowly, consider doing the format afterward.
Step 8. Verify the data and click Finish. That should create the mirror between the two disks (shown in a reddish color) and will begin formatting. This may take a few minutes. It should display the status Healthy when complete. Try saving data to the new mirror!
Configure a RAID 5 Mirror
Step 9. Delete the previously created mirror volume by right-clicking either of the disks in the mirror and selecting Delete.
Step 10. Confirm that you have three disks (each showing as Unallocated) available for the RAID 5 stripe set. It is recommended that you use disks of the same size; optimally they would be the same model.
Step 11. Right-click the unallocated section of one of the blank disks to be used in your mirror and select New Volume.
Step 12. Click Next for the wizard.
Step 13. Click the RAID-5 radio button and click Next.
Step 14. Add the disks you want to use to the Selected area by highlighting the disk(s) and clicking Add. (You will have to select three in total.) Then click Next.
Step 15. Assign the drive letter P: for the RAID 5 array, and click Next.
Step 16. In the Format Volume screen:
A. Change the name of the Volume Label to RAID 5 Stripe.
B. Select the Perform a quick format checkbox.
C. Click Next.
If the system runs slowly, consider doing the format afterward.
Step 17. Verify the data and click Finish. That should create the RAID 5 stripe set from the three disks (shown in a light blue color) and will begin formatting. This may take a few minutes. It should display the status Healthy when complete for each of the disks in the stripe. Try saving some data to the new array!
Watch the solution video in the “Hands-On Scenarios” section of the DVD.
View Recommended Resources
• Thermaltake redundant power supply: www.tt-server.com/Product.aspx?S=82&ID=28
• Enlight redundant power supply: http://us.enlightcorp.com/Product/Product_list_server_power.aspx
• APC enterprise-level UPS devices: www.apc.com/products/family/index.cfm?id=163
• Gillette Generators: www.gillettegenerators.com/
• Generac generators: www.generac.com/Commercial/
• Intel PRO/1000 MT Dual Port Server Adapter” www.intel.com/products/server/adapters/pro1000mt-dualport/pro1000mt-dualport-overview.htm
• Expected Behavior of Multiple Adapters on the same Network” http://support.microsoft.com/kb/175767
• Data Backup and Recovery article: http://technet.microsoft.com/en-us/library/bb727010.aspx
• DuPont FM-200 web page: www2.dupont.com/FE/en_US/products/FM200.html
Answer Review Questions
Answer the following review questions. You can find the answers at the end of this chapter.
1. Which of the following RAID versions enable the least amount of downtime?
A. RAID 0
B. RAID 1
C. RAID 4
D. RAID 5
2. Which of the following can facilitate a full recovery within minutes?
A. Warm site
B. Cold site
C. Reestablishing a mirror
D. Hot site
3. What device should be used to ensure that a server does not shut down when there is a power outage?
A. RAID 1 box
B. UPS
C. Redundant NIC
D. Hot site
4. Which of the following tape backup methods enable daily backups, weekly full backups, and monthly full backups?
A. Towers of Hanoi
B. Incremental
C. Grandfather-father-son
D. Differential
5. To prevent electrical damage to a computer and its peripherals, the computer should be connected to what?
A. Power strip
B. Power inverter
C. AC to DC converter
D. UPS
6. Which of the following would not be considered part of a disaster recovery plan?
A. Hot site
B. Patch management software
C. Backing up computers
D. Tape backup
7. Which of the following factors should you consider when evaluating assets to a company? (Select the two best answers.)
A. Its value to the company
B. Its replacement cost
C. Where they were purchased from
D. Their salvage value
8. You are using the following backup scheme. A full backup is made every Friday night at 6 p.m. Differential backups are made every other night at 6 p.m. Your database server fails on Thursday afternoon at 4 p.m. How many tapes will you need to restore the database server?
A. One
B. Two
C. Three
D. Four
9. Of the following, what is the worst place to store a backup tape?
A. Near a bundle of fiber-optic cables
B. Near a power line
C. Near a server
D. Near an LCD screen
10. Critical equipment should always be able to get power. What is the correct order of devices that your critical equipment should draw power from?
A. Generator, line conditioner, UPS battery
B. Line conditioner, UPS battery, generator
C. Generator, UPS battery, line conditioner
D. Line conditioner, generator, UPS battery
11. What is the best way to test the integrity of a company’s backed up data?
A. Conduct another backup
B. Use software to recover deleted files
C. Review written procedures
D. Restore part of the backup
12. Your company has six web servers. You are implementing load balancing. What is this an example of?
A. UPS
B. Redundant servers
C. RAID
D. Warm site
13. Your company has a T-1 connection to the Internet. Which of the following can enable your network to remain operational even if the T-1 fails?
A. Redundant network adapters
B. RAID 5
C. Redundant ISP
D. UPS
14. Which action should be taken to protect against a complete disaster in the case that a primary company’s site is permanently lost?
A. Back up all data to tape, and store those tapes at a sister site in another city.
B. Back up all data to tape, and store those tapes at a sister site across the street.
C. Back up all data to disk, and store the disk in a safe deposit box at the administrator’s home.
D. Back up all data to disk, and store the disk in a safe in the building’s basement.
15. Of the following backup types, which describes the back up of files that have changed since the last full or incremental backup?
A. Incremental
B. Differential
C. Full
D. Copy
16. Michael’s company has a single web server that is connected to three other distribution servers. What is the greatest risk involved in this scenario?
A. Fraggle attack
B. Single point of failure
C. Denial of service
D. Man-in-the-middle attack
Answers and Explanations
1. B. RAID 1 is known as mirroring. If one drive fails, the other will still function and there will be no downtime. All the rest of the answers are striping-based and therefore have downtime associated with them.
2. D. A hot site can facilitate a full recovery of communications software and equipment within minutes. Warm and cold sites cannot facilitate a full recovery but may have some of the options necessary to continue business. Reestablishing a mirror will not necessarily implement a full recovery of data communications or equipment.
3. B. An Uninterruptible Power Supply (UPS) ensures that a computer will keep running even if a power outage occurs. The amount of minutes the computer can continue in this fashion depends on the type of UPS and battery it contains. A backup generator can also be used, but it does not guarantee 100% uptime, because there might be a delay between when the power outage occurs and when the generator comes online. RAID 1 has to do with the fault tolerance of data. Redundant NICs (network adapters) are used on servers in the case that one of them fails. Hot sites are completely different places that a company can inhabit. Although the hot site can be ready in minutes, and although it may have a mirror of the server in question, they do not ensure that the original server will not shut down during a power outage.
4. C. The grandfather-father-son (GFS) backup scheme generally uses daily backups (the son), weekly backups (the father), and monthly backups (the grandfather). The Towers of Hanoi is a more complex strategy based on a puzzle. Incremental backups are simply one-time backups that back up all data that has changed since the last incremental backup. These might be used as the son in a GFS scheme. Differential backups back up everything since the last differential or full backup.
5. D. A UPS (uninterruptible power supply) protects computer equipment against surges, spikes, sags, brownouts, and blackouts. Power strips, unlike surge protectors, do not protect against surges.
6. B. Patching a system is part of the normal maintenance of a computer. In the case of a disaster to a particular computer, the computer’s OS and latest service pack would have to be reinstalled. The same would be true in the case of a disaster to a larger area, like the building. Hot sites, backing up computers, and tape backup are all components of a disaster recovery plan.
7. A and B. When evaluating assets to a company, it is important to know the replacement cost of those assets and the value of the assets to the company. If the assets were lost or stolen, the salvage value is not important, and although you may want to know where the assets were purchased from, it is not one of the best answers.
8. B. You need two tapes to restore the database server—the full backup tape made on Friday and the differential backup tape made on the following Wednesday. Only the last differential tape is needed. When restoring the database server, the technician must remember to start with the full backup tape.
9. B. Backup tapes should be kept away from power sources including power lines, CRT monitors, speakers, and so on. And the admin should keep backup tapes away from sources that might emit EMI. LCD screens, servers, and fiber optic cables have low EMI emissions.
10. B. The line conditioner is constantly serving critical equipment with clean power. It should be first and should always be on. The UPS battery should kick in only if there is a power outage. Finally, the generator should kick in only when the UPS battery is about to run out of power. Quite often, the line conditioner and UPS battery will be the same device. However, the line conditioner function will always be used, but the battery comes into play only when there is a power outage, or brownout.
11. D. The best way to test the integrity of backed up data is to restore part of that backup. Conducting another backup will tell you if the backup procedure is working properly, and if necessary after testing the integrity of the backup and after the restore a person might need to use software to recover deleted files. It’s always important to review written procedures and amend them if need be.
12. B. Load balancing is a method used when you have redundant servers. In this case, the six web servers will serve data equally to users. The UPS is an uninterruptible power supply, and RAID is the redundant array of inexpensive disks. A warm site is a secondary site that a company can use if a disaster occurs that can be up and running within a few hours or a day.
13. C. A secondary ISP enables the network to remain operational and still gain Internet access even if the T-1 connection fails. This generally means that there will be a second ISP and a secondary physical connection to the Internet. Redundant network adapters are used on servers so that the server can have a higher percentage of uptime. RAID 5 is used for redundancy of data and spreads the data over three or more disks. A UPS is used in the case of a power outage.
14. A. In the case that a building’s primary site is lost, data should be backed up to tape stored at a sister site in another city. Storing information across the street might not be good enough especially if the area has to be evacuated. Company information should never be stored at an employee’s home. And of course if the data were stored in the primary building’s basement and there were a complete disaster at the primary site, that data would also be lost.
15. A. An incremental backup backs up only the files that have changed since the last incremental or full backup. Generally it is used as a daily backup. Differential backups back up files that have changed since the last differential backup or the last full backup. A full backup backs up all files in a particular folder or drive, depending on what has been selected; this is regardless of any previous differential or incremental backups. Copies of data can be made, but they will not affect backup rotations that include incremental, differential, and full backups.
16. B. The greatest risk involved in this scenario is that the single web server is a single point of failure regardless that it is connected to three other distribution servers. If the web server goes down or is compromised, no one can access the company’s website. A Fraggle is a type of denial-of-service attack. Although denial-of-service attacks are a risk to web servers, they are not the greatest risk in this particular scenario. A company should implement as much redundancy as possible.