
9
Enabling Information and Communication Technologies
We are now at the beginning of the third part of this book, which will focus on more concrete aspects of cyber‐physical systems (CPSs) guided by the theoretical concepts presented so far; this will include data transmission and processing technologies, CPS applications, and their potential social impacts. The focus of this chapter is on the key information and communication technologies (ICTs) that afford the existence of CPSs. Instead of describing in detail the devices, protocols, algorithms, and standards, which would be hardly possible, our choice is to critically review three prominent ICT domains, namely data networks (and the Internet), advanced statistical methods for data processing, and new data storage paradigms. Specifically, we will provide an overview of the key features of the fifth generation (5G) of mobile networks and machine‐type wireless communications, the strengths and limitations of machine learning and artificial intelligence (AI), and the advantages and drawbacks of distributed ledgers like blockchains and distributed computing like federated learning. Besides those trends, a speculation of the future of ICT will be presented considering the implications of quantum computing and the Internet of Bio‐Nano Things (IoBNT).
9.1 Introduction
The technological development related to ICTs can be dated back to the years after World War II, in a specific conjuncture of the Cold War and Fordism [1]. In the 1960s, there was a great development of the cybernetics movement, firstly in the USA but also in the Soviet Union [2]. One remarkable milestone was the development of the packet switching technology, which allowed multiplexing of digital data messages and was essential to the deployment and scaling up of data networks [3]. This was the beginning of the Internet. Since the nineties, there has been a remarkable increase in deployments of wireless networks with different standards, some dedicated to voice as in the first two generations of cellular networks and others to digital data communication like the ALOHANet and then WiFi. These technologies were only possible because of the huge efforts in the research and development of digital wireless communication technologies [4, 5]. A schematic presentation of the history of telecommunication until the early two thousands can be found in [6]; more recent developments of cellular networks are presented in [7].
Currently, in the year 2021, with the already worldwide established fourth generation (4G) of mobile networks and the first deployments of 5G as well as other types of wireless networks, we are experiencing an undeniable convergence of the Internet and wireless communication including more and more applications. This is evinced, for example, by the steady growth of the Internet of Things (IoT) with protocols dedicated to machine‐type communication (MTC), virtual and augmented reality applications, and human‐type communications being mostly carried over the Internet and including not only voice but also video (including video conferences). The current discussions about what will be the sixth generation (6G) of cellular networks indicate those and other trends [8].
This is the context in which this book is written. The societal dependence of ICTs is growing at a fast pace and everywhere, even more remarkably after the mobility restrictions imposed during the COVID‐19 pandemic. They provide the infrastructure for the data and decision‐making layers that are necessary to build CPSs, as conceptualized in the previous two chapters. Note that it is possible and desirable to analyze ICT infrastructures as CPSs, and thus, our approach will consider both physical and logical relations, as well as decision‐making processes. In what follows, we will present a brief introduction of data networks with particular attention to wireless systems, mostly focusing on applications related to the IoT and the associated MTCs.
9.2 Data Networks and Wireless Communications
This section provides a brief introduction to data networks highlighting the function that wireless technologies have in their operation. The first step is to follow the framework introduced in Chapter 2, and thus, analyze a data network as a particular system (PS) whose boundaries are defined by its peculiar function (PF), also determining its conditions of existence and main components. This is presented next following the concise introduction from [Ch. 1][3].
Figure 9.1 depicts an example of a data network composed of different devices that run applications sending, requesting, and receiving data (e.g. computers, tablets, mobile phones, electricity metering), data servers (e.g. data centers and super computers, which are usually called cloud), and operational components that process data so that they can be transmitted reliably to their final destination (e.g. routers, link layer switches, modems, base stations). These elements are connected forming a decentralized network with some hubs via different physical media, namely cable (fiber‐optic and coaxial) and radio (wireless links). The proposed illustration is a simple, but yet representative, subset of the whole Internet.
In the following subsections, a schematic presentation of the Internet will be provided, briefly explaining its layered design (note that this is different from our three layers of CPSs and other layered models) and differentiating the edge and core of the network. Broadly speaking, the objective is to show how logical links between different end devices (which can be located very far away from each other) that exchange data can be physically performed with an acceptable quality of service.
9.2.1 Network Layers and Their Protocols
Data networks and the Internet are designed considering a layered architecture with respect to the services that each layer provides to the system. The advantages of this approach are fairly well described in textbooks like [3, 4]. What interests us here is that the layered approach is an effective way to organize the operation of a potentially large‐scale decentralized system, allowing elements and techniques to be included and excluded. In the following, we will provide an illustration of how the layered model works based on an example before going into the particularities of data network layers and protocols.
Figure 9.1 Illustration of a small‐scale data network.
Source: Adapted from [3].
Similar to this example, the operation of data networks and the Internet are layered based on services and functionalities that each layer provides. Particularly, the Open System Interconnection (OSI) model was proposed based on seven layers that allow decentralized data transfer, logically connecting end applications through physical (wired and/or wireless) connections. A systematic presentation of the OSI model is given in Figure 9.3.
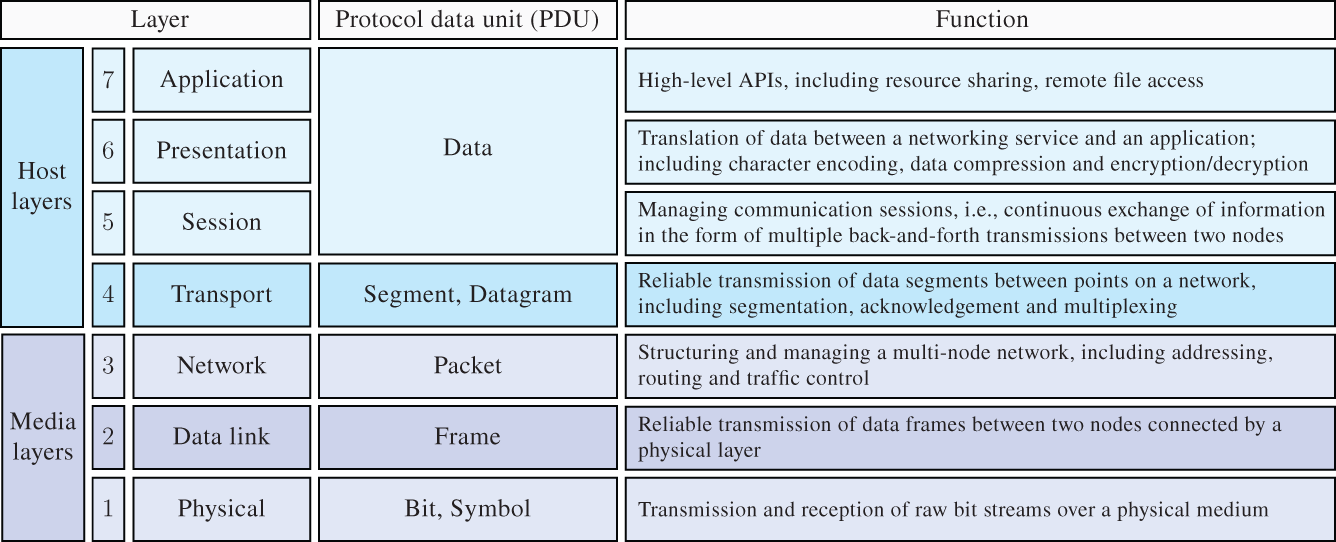
Figure 9.3 Seven layers of the OSI model.
Source: Adapted from https://en.wikipedia.org/wiki/OSI_model.
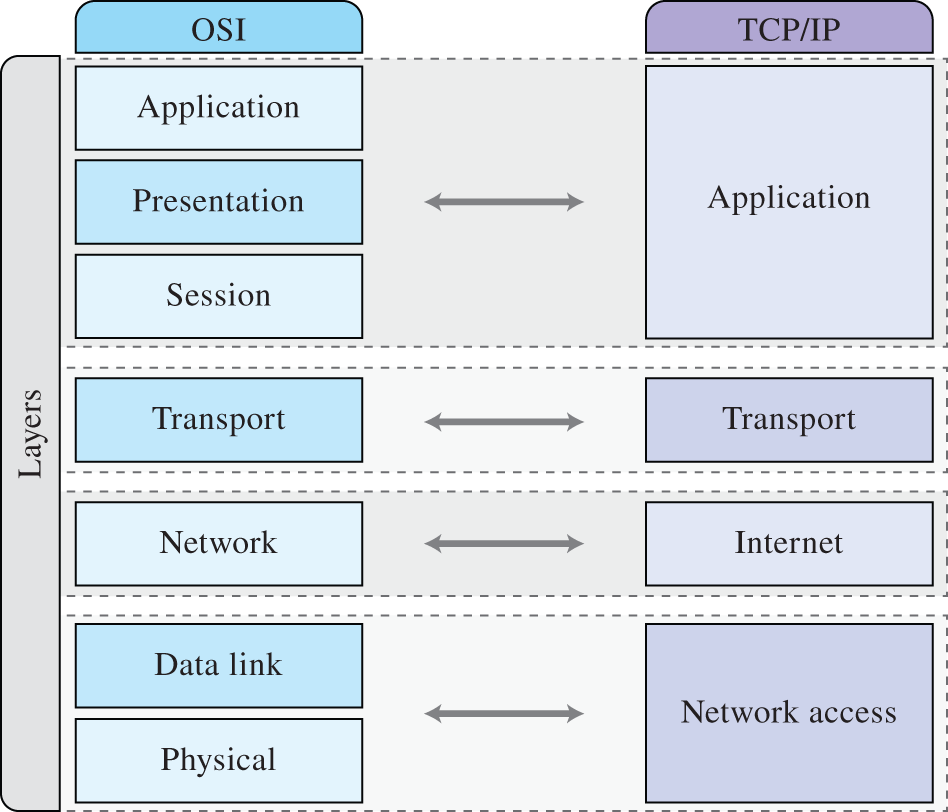
Figure 9.4 OSI reference model and the Internet protocol stack.
Source: Adapted from https://upload.wikimedia.org/wikipedia/commons/d/d7/Application_Layer.png.
{kind=link}
These seven layers constitute a reference model that guides the actual data network design and deployment, which nevertheless can be (and usually are) modified. For example, the Internet has a different layer structure than the OSI model, although a map between them is possible as illustrated in Figure 9.4. The layered model defines the protocol stack, determining the data structure and the interactions allowed at each layer. The Internet is generally constituted by the Internet Protocol (IP) related to the OSI network layer and the Transmission Control Protocol (TCP) related to the OSI transport layer.
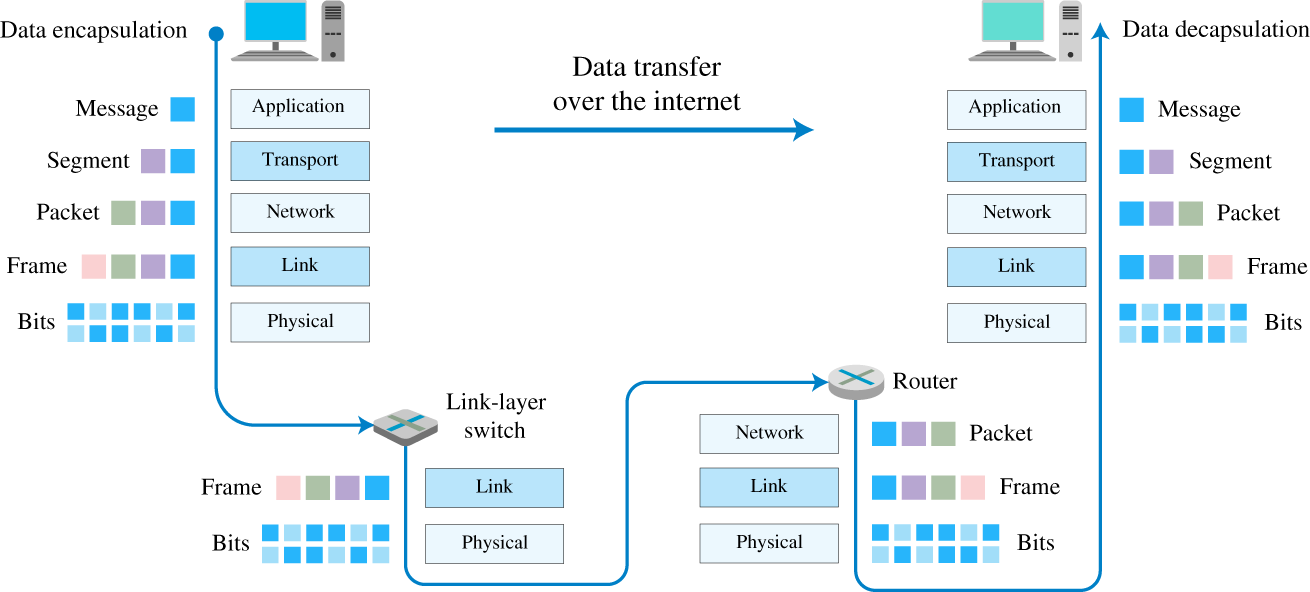
Figure 9.5 Encapsulation of a generic data transfer over the Internet.
Source: Adapted from [3].
To accomplish its peculiar function, the data network needs to logically connect two elements, namely a source of data associated with a given application and its respective destination. Examples of applications are email, instant messages, and remote monitoring of sensors. The creation of logical links through physical media requires a process of encapsulation, where at each layer a new piece of data is added to accomplish its functionality. Figure 9.5 illustrates how data are transferred over the Internet, including (i) message encapsulation at the source, (ii) physical transmissions, (iii) routing, and (iv) message decapsulation at the destination.
The operation of the data network can be analyzed from two perspectives, one physically closer to the end users (i.e. the source and destination) and the other inside the network where data are routed. The first case refers to the network edge and the second to the network core. We will discuss them in the following subsections.
9.2.2 Network: Edge and Core
In our daily lives, we constantly interact with and through data networks via devices like personal computers, smart phones, and tablets. These are denominated as end systems, which are also called hosts in the literature because of their function of hosting and running application programs. There are also other end systems such as all sorts of sensors, smart appliances, and advanced electricity meters. They constitute what we call today the IoT. All those end systems are usually called clients.
In addition, there is another class of end systems called servers that are associated with large data centers and supercomputers, whose function is to store large amounts of data and/or to perform demanding calculations. These are usually invisible pieces of hardware for the human user that enabled the cloud computing paradigm. They are generally located far away from the clients, potentially leading to a poor quality of service in terms of delay and reliability. Nowadays, in 2021, new paradigms are being developed to locate some smaller servers closer to the clients defining the edge computing paradigm, or even considering the clients as a potential source of computing power defining the fog computing paradigm. These are recent terms and their meaning might vary, although the tendency of decentralization of computing power and distributed computation is captured [9].
The network edge is composed of those end systems and applications that are physically connected to (and through) the core of the data network. Such connections happen through the access network, which is the network that exists before the first router (called edge router). There are several types of access network, including mobile networks in outdoor environments (e.g. 4G cellular systems), home networks (e.g. wireless router connected to the Internet via fiber), and corporate networks (e.g. Ethernet). They employ different physical media, either wired or wireless.
Both wired and wireless technologies have remarkably developed toward higher data rates, also improving the quality of service in terms of latency and reliability. The currently main wired technologies are twisted pair copper wire, coaxial cables, and fiber optics. The main wireless technologies employ electromagnetic waves to build radio channels allocated in the frequency (spectrum) domain. The radio channels are usually terrestrial as in cellular networks, but there are also satellite communication links including geostationary and low‐earth orbiting (LEO) satellites; underwater wireless communications, in turn, are not as widespread as the other two approaches.
The network core can be simply defined as [3] (…) the mesh of packet switches and links that interconnects the Internet's end systems. In other words, the core network function is to physically enable the logical connections between end systems and their applications. As indicated in Figure 9.5, the main elements of the network core are packet switches, namely link layer switches and routers. The function of those devices is to transfer digital data from one point of the core network to another aiming at the final destination in a decentralized manner (i.e. the end system that the message is addresses), but considering that there is no central controller to determine the optimal route (which would be nevertheless unfeasible because of the computational complexity of such a task; see Chapter 6).
The strength of the layered approach and the message encapsulation can be fully appreciated here. At the source end system, the considered application generates a message that needs to be transferred to a given destination end system. The message generated by the application layer is divided into smaller data chunks called segments, which are then combined with a transport layer header, which provides the instructions of how the original data shall be reassembled at the destination. This layer function is to construct a logical link between end systems in order to transport application layer messages from a source to a destination. TCP and User Datagram Protocol (UDP) are the Internet transport layer protocols. This step is still related to the network edge, and the data segments still require additional instructions to reach their destination through the network core.
The following steps of the data encapsulation process solve this issue. At the network layer, a new header is added to the data segments containing the details about the route to reach the final destination, forming then datagrams or data packets; the network layer protocol of the Internet is the IP. This layer is divided into a control plane related to the “global level” routes and the overall network topology (including the information needed to build routing tables) and a data plane related to forwarding from one node to another based on routing tables following the control plane policies. These two planes have traditionally been integrated into the physical router device. Currently, the trend is to consider these planes independently through software‐defined networking (SDN).
To accomplish the transmission of data packets from one node (either a host or a router) to the next one considering that there are several nodes between the source and the destination, additional specification is needed related to the specific physical communication link. A new header is added to the datagram at the link layer, then forming a frame. There are several link layer protocols like Ethernet and IEEE 802.11. Medium access protocols, error detection, and error correction are related to the link layer. The physical layer is related to how the data frame is coded to be physically transmitted as modulated digital data.
This is an extremely brief introduction to data networks, specifically to the Internet, which indicates the fundamentals of how such a system works. For interested readers, the textbook [3] offers a pedagogic introduction to the field. In the following subsection, we will turn our attention to wireless communications, specifically the novelties brought by the 5G with respect to machine‐type of traffic generated by the massive and still increasing adoption of devices connected in the Internet.
9.2.3 IoT, Machine‐Type Communications, and 5G
Wireless communications have been successfully deployed for some time and considering different end applications including localization services with satellite communications, public local Internet access with WiFi, and mobile networks for voice communication covering large areas. This last example refers to cellular systems, whose historical development is punctuated by different generations. Figure 9.6 illustrates the key differences of the existing five generations, from the first generation (1G) to the 5G that is currently being deployed worldwide.
The 1G was based on analog modulation for voice communication; it was developed to provide mobile telephone service only. The 2G implemented digital transmission techniques, also allowing Short Message Service (SMS) and relatively limited Internet connectivity. The 3G provided further improvements to guarantee Internet connectivity for mobile devices and also included services of video calling and Multimedia Messaging Service (MMS). The main focus of the 4G is on the (remarkably) improved quality of the Internet access, even allowing video stream of full high definition (full HD) video. The current 5G deployment targets not only human‐type communications and related applications, but also MTCs arising from the massive connectivity of devices and specific critical applications.
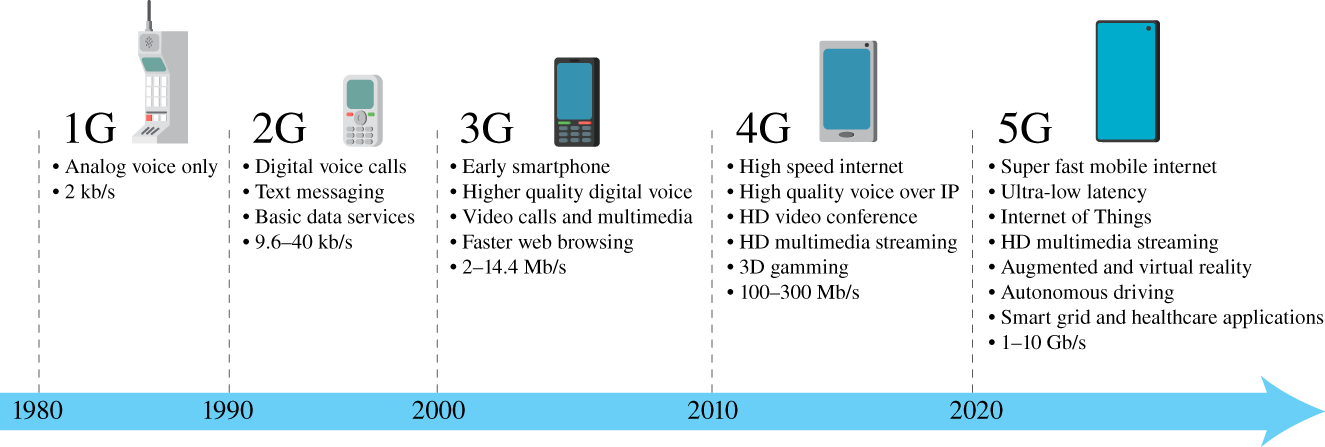
Figure 9.6 Current five generations of cellular systems in 2021.

Figure 9.7 5G applications and their requirements in terms of rate, reliability, and latency.
Figure 9.7 depicts the key 5G applications, which are mapped in three axes referring to their demand of throughput, number of communicating devices, and required performance in terms of reliability and latency. There is then a large set of applications that the 5G shall offer as a standardized wireless solution, including the coexistence of human users with their download (downlink) dominated traffic composed of relatively large messages (e.g. video stream) and machines with their upload (uplink) dominated traffic composed of short, usually periodic, timestamped messages (e.g. temperature sensors). MTCs usually refer to two extreme types of applications, namely (i) massive machine‐type communication (mMTC), where potentially millions of sensors need to transmit their data to be stored and further processed in large data centers and supercomputers, and (ii) ultrareliable low latency communications (URLLC) to be used in critical applications that are related to, for example, feedback control loops in industrial automation and self‐driving cars.
The mMTC are frequently associated with cloud computing, where the data from the machine‐type devices are first sent to cloud servers that store and process such big data that become available to be retrieved by potentially different applications. For example, temperature sensors that send the information to the cloud server of a meteorological research center, whose data can be used either by humans to verify what would be a suitable dress for the day or by a supercomputer to simulate the whether conditions.
URLLC, in turn, involve applications requiring a latency lower than 1 ms and a reliability of 99.9999%; there are also other applications with very strict latency and reliability constraints but which are not considered part of this class; for example, a communication link for the feedback control loop of a robot arm. In any case, applications with such requirements are unfeasible to be deployed by using cloud computing because of the delays related to the network core. In this case, edge computing offers a suitable alternative. Figure 9.8 illustrates the difference between these two paradigms.
There are nowadays, in 2021, huge research and development efforts to deploy 5G, considering both the radio access technologies and radio access networks (both at the network edge), as well as aspects related to the network core via software‐defined networks. A comprehensive introduction of wireless systems is provided in [4]. In the following section, we will dive into special techniques developed to process the large amount of data acquired by sensors and other devices, which today are broadly known as AI and machine learning.
9.3 Artificial Intelligence and Machine Learning
The term AI has a long history, which might be even linked with ancient myths. As the name indicates, AI should be contrasted with natural intelligence, particularly human intelligence [10]. Of course, this topic has a philosophical appeal associated with the classical questions of idealist philosophy about Freedom, Autonomy, Free Will, Liberty, and Meaning of Life. Although such metaphysical questions are still quite relevant, AI has also acquired a more scientific status closely related to the cybernetic ideas that emerged after the World War II, although the main proponent of AI as an independent research field, John MaCarthy, decided to use this name to avoid the association with Wiener's cybernetics; a brief personal note indicates the climate of the discussions [11].

Figure 9.8 Cloud vs. edge computing.
Source: Adapted from [9].
As indicated in Chapter 1, this book tries to avoid those problems by establishing the object of the proposed theory. In our understanding, the term AI is misleading and is actually based on a naive, mostly behaviorist view of what intelligence is, which was also affected by a reductionist epistemology associated with methodological individualism [12]. In this book, what one would call AI systems, or AI‐based systems, should be associated with self‐developing reflexive–active systems as presented in Chapter 7. Besides, AI is generally related to agents (artificial entities that possess both intelligence to manipulate data and ability to act and react), agent‐based models, and multiagent systems that are based on autonomous elements that sense the environment, process these data, and react. This topic is particularly covered in Chapter 6, where decision‐making and acting processes are presented.
Machine learning (ML), as a term, also has similar issues to the ones we just presented and is usually classified as a branch of AI. However, ML has a more technical flavor supported by established disciplines, such as probability, statistics, optimization, linear algebra, dynamical systems, and computer sciences. In my view, a more correct name for ML would be either data processing theory or applied data processing, although I also acknowledge that the use of analogies from other disciplines may help the technological development. Nevertheless, the aim is not to change how this field is widely known, and this book will retain the usual terminology. These first paragraphs should be read as a warning note about potential misinterpretations or transpositions that these names might lead to. In the following, the basics of ML will be presented employing the approach taken by Jung [13].
9.3.1 Machine Learning: Data, Model, and Loss Function
In [13], Alex Jung defines the three components of ML, namely data, model, and loss. Data refer to attributes of some system that can be quantified in some way that are related to features (inputs) and labels (outputs). Models refer to (computationally feasible) mathematical functions that map the feature space into a label space; models are also referred to as hypothesis space and the functions are known as predictors or classifiers. Loss function refers to the function that is employed to quantify how well a predictor or a classifier works in relation to the actual outputs. In the following, we will propose a formal example of a ML problem statement with a solution.
9.3.2 Formalizing and Solving a ML Problem
Any ML problem involves prediction or classification about a given system or process based on quantified attributes that are potentially informative data (see Chapter 4). These data are then split into two groups, namely inputs (features) and outputs (labels) of the ML problem. Before the prediction or classification, there is a training phase where, for example, known input–output pairs serve as the way to find optimal model in terms of a given loss function. In the following, we will formalize a simple ML problem.
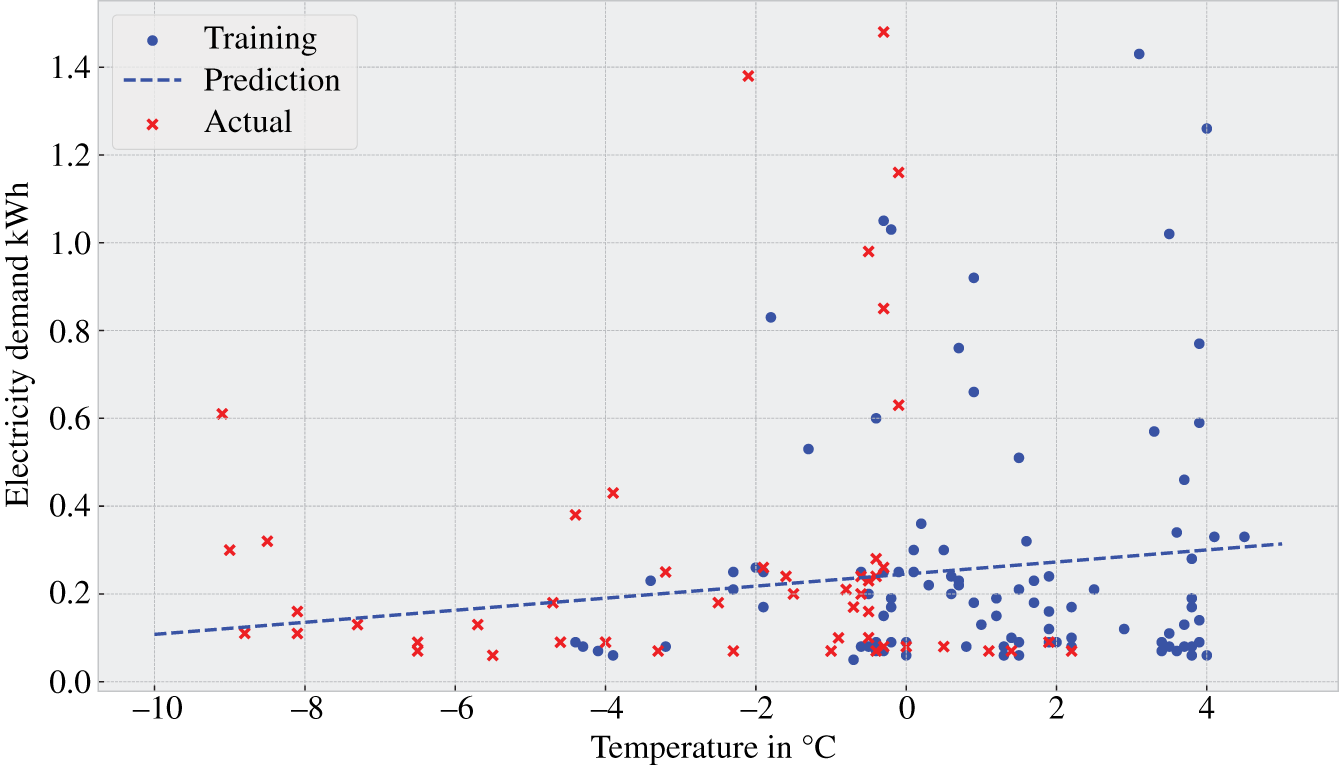
Figure 9.9 Predicting the electricity demand from air temperature based on linear regression.
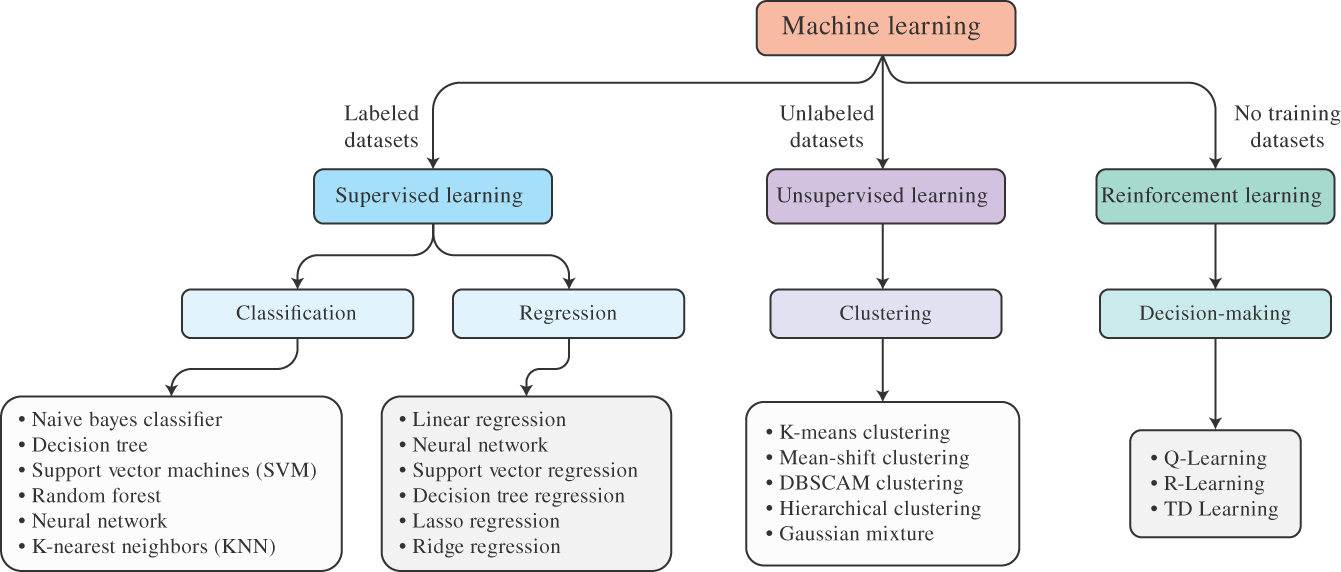
Figure 9.10 ML methods classified as a combination of data, model, and loss that are employed to solve different types of problem.
The minimization of MSE in linear equations is well established and easy to implement in software. Low dimensional datasets, linear models, and availability of labels are not the rule in ML problems, though. As mentioned in [13], there are several ML methods, which are defined by the specific combination of data, model, and loss, that better suit the system and process in hand. We will briefly discuss them next.
9.3.3 ML Methods
There are several ML methods that are employed to solve specific classification and prediction problems related to a PS or process. Such methods can be specified by a particular combination of data, model, and loss that are used to solve the ML problem. Figure 9.10 illustrates the classes of learning based on (i) the type of data available from training purposes and (ii) the type of the ML problem to be solved.
In terms of data, ML methods can be classified as supervised or unsupervised learning, the first one being related to the availability (or existence) of data about the label variables. The loss function can be based on squared error, logistic loss, or 0/1 loss. The model can be linear maps, piecewise constant, or neural networks. Each combination leads to a particular ML method, which, in turn, is suitable to perform a given computational task. For example, the case presented in the previous subsection is a supervised ML that considers a linear map model with a squared error loss function, defining a linear regression method to predict the particular value of a label for a given value of the feature.
It is also important to mention that there is another class of learning different from supervised and unsupervised ML, which is known as reinforcement learning. This method considers that a given agent needs to accomplish a predetermined goal in a trial‐and‐error fashion by indirectly learning through its interactions with the environment. The success and failure of each action in terms of the goal to be achieved is defined by a utility (or loss) function, which quantifies the level of success of each action tried by the agent. Interestingly, each action is determined by the particular model used by the agent. Reinforcement learning is then considered a third class of ML, where the model is dynamically constructed in a trial‐and‐error fashion by (indirectly) quantifying the success (failure) of an action in terms of the utility (or loss) function. For each new input data (feature), reinforcement learning methods first produce an estimated optimal model that is used to predict the respective output and the respective action. Note that the loss function can only be evaluated considering the actually selected model.
Figure 9.10 provides a good overview of ML methods and their classification, also indicating the names of some well‐known techniques. For more details, there is plenty of literature on ML methods as introduced in [13] and references therein. In the following section, we will cover another important fundamental aspect of CPS, which also involves questions related to data networks and ML methods; this refers to decentralized computing paradigms and decentralized data storage.
9.4 Decentralized Computing and Distributed Ledger Technology
While the physical and logical topology of the Internet is decentralized, the majority of applications work in a more centralized manner where more capable (hardware) elements are employed to store a massive amount of data of a huge number of individual users or to perform computationally complex calculations. This is the idea behind the concept of cloud computing. As we have mentioned in Section 9.2, other computing paradigms are emerging where elements at the network edge are employed to perform computations or to build a trustworthy database without the need of a third party that certifies transactions mediated by data. Two specific techniques – federated learning and blockchain – will be briefly described because they illustrate the typical advantages and drawbacks of decentralization. Note that these approaches are different from local storage and computation that are carried out by individual machines, such as personal computers, mobile phones, and powerful desktops. In contrast, they are designed considering a network of interacting elements that jointly constitute a specific system that performs a peculiar function.
9.4.1 Federated Learning and Decentralized Machine Learning
Consider the following scenario: several IoT devices that measure different attributes of a given system, being then connected to the Internet. This large amount of data shall be processed to train a supervised ML, whose result should be delivered back to the different IoT devices that will provide predictions to other applications. Figure 9.8 provides two possible solutions for this problem: (i) cloud computing where the ML model is trained in a supercomputer somewhere at the cloud server, or (ii) edge computing where the ML model is trained in an edge server closer to the data source (e.g. co‐located with a base station). In both cases, the end systems do not actually cooperate; they just provide the data to be processed and then receive the ML model to be used.
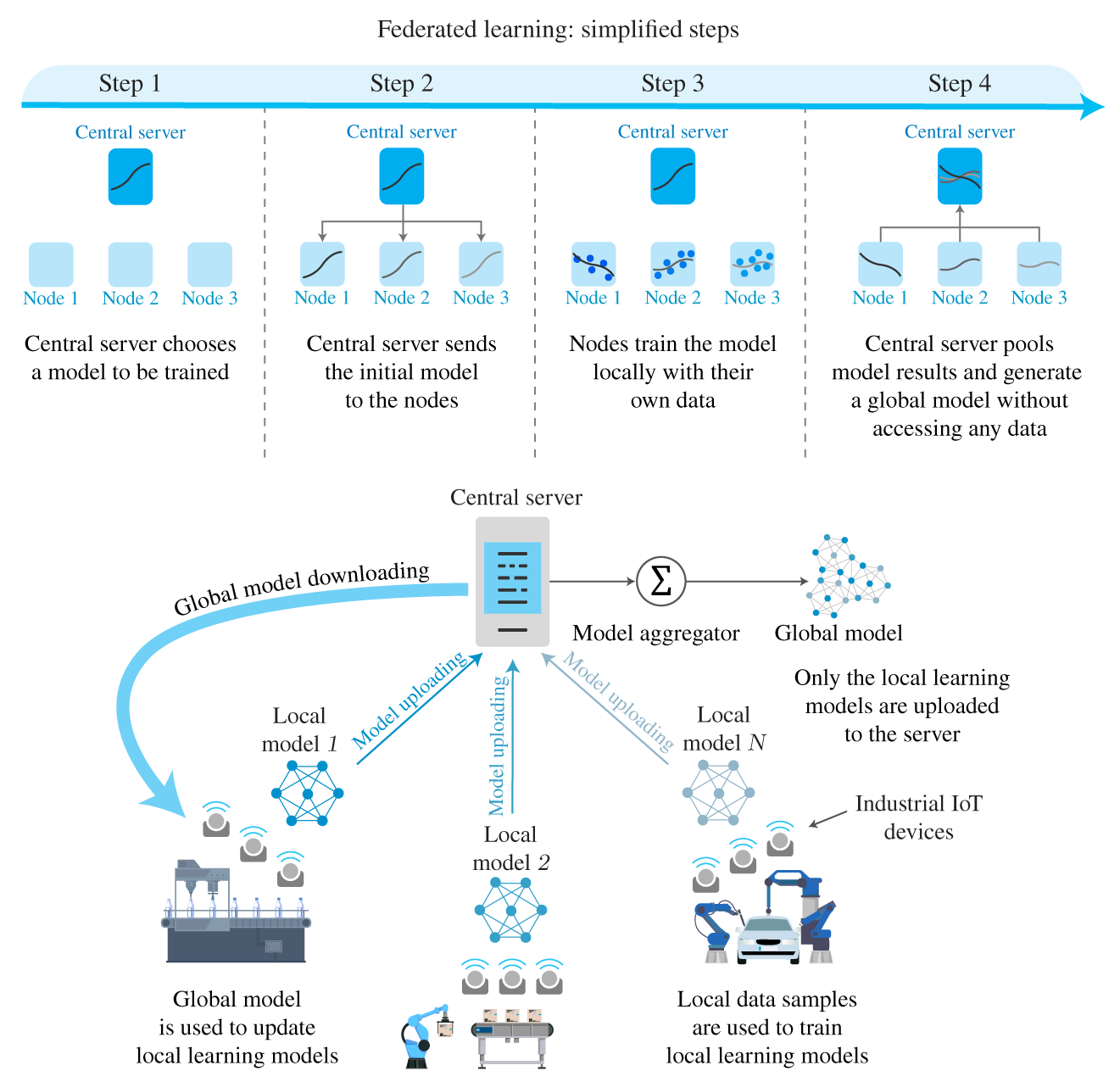
Figure 9.11 Federated learning.
Federated learning is different: a central server (either a cloud or an edge server) is used to organize the end systems to perform computations to define local models, which are then used by the central server to generate a global model to be used by the end users. Figure 9.11 depicts an example of the federated learning method. The main advantages of federated learning are [9]: less use of communication resources because less data need to be transmitted, lower communication delays if the associated central server is located at the network edge, and higher privacy guarantees because only local models are sent to the central server (not the raw data). The main drawbacks are related to the relatively small computational power of end users compared with the cloud or edge servers, and the energy required to perform computations that might be prohibitive.
The star topology employed by the federated learning may also be problematic, mainly considering a scenario where the end systems are IoT devices wirelessly connected to the data network via radio. In this scenario, other questions related to the link reliability and the coverage radio become important. A possible solution to this issue is collaborative federated learning, where different network topologies would be allowed [14]. This case would even include a more extreme case of a fully distributed, peer‐to‐peer topology.
In addition to federated learning, there are also several other methods to perform distributed machine learning, as surveyed in [15]. In particular, the most suitable choice between centralized, decentralized, or even fully distributed ML implementations depends on different aspects of the specific application and its performance requirements in terms of, for instance, accuracy and convergence time, and also of end user limitations in terms of, for instance, computational power, data storage, availability of energy, and data privacy.
9.4.2 Blockchain and Distributed Ledger Technology
The blockchain technology was first developed to guarantee the trustworthiness of the cryptocurrency bitcoin without the need of a third party. The technical solution was described in 2008 as follows [16]:
What is needed is an electronic payment system based on cryptographic proof instead of trust, allowing any two willing parties to transact directly with each other without the need for a trusted third party. Transactions that are computationally impractical to reverse would protect sellers from fraud, and routine escrow mechanisms could easily be implemented to protect buyers. In this paper, we propose a solution to the double‐spending problem using a peer‐to‐peer distributed timestamp server to generate computational proof of the chronological order of transactions. The system is secure as long as honest nodes collectively control more CPU power than any cooperating group of attacker nodes.
In this case, the function of the blockchain is to build, in a distributed way, a distributed ledger where the transaction data have their integrity verified without a central element. In a much less technical (and heavily apologetic) comment article [17], the author explains the reasons why blockchain and bitcoin are appealing:
Bitcoin's strength lies in how it approaches trust. Instead of checking the trustworthiness of each party, the system assumes that everyone behaves selfishly. No matter how greedily traders act, the blockchain retains integrity and can be trusted even if the parties cannot. Bitcoin demonstrates that banks and governments are unnecessary to ensure a financial system's reliability, security and auditability.
A more detailed discussion about the pitfalls of such a way of thinking will be provided in Chapters 10 and 11, where different applications and aspects beyond technology will be discussed. What is important to mention here is that, while distributed learning explicitly involves a certain level of cooperation between computing entities, blockchain is clear about its generalized assumption that all elements are selfish, competitive, and untrustworthy. Peers do not trust each other, neither a possible third party that would verify transactions between peers; they rather trust in the system effectiveness to perform the verification task in a distributed manner.
In technical terms, blockchain is designed to securely record transactions (or data in general) in a distributed manner by chaining blocks. Blocks corresponds to verified transactions (or data). To be accepted, a new block needs to be verified by the majority of the peers in the system based on a cryptographic hash function. Upon its acceptance, the new block is uniquely identified by a hash that links it to the previous block. In this way, the more blocks there are in the chain, the more secure is the distributed ledger in relation to tampering data. Details of the implementation can be found in [16].
Distributed ledger technology (DLT) usually refers to a generalization of blockchain (although some authors consider DLT and blockchain as synonyms). In any case, Figure 9.12 illustrates the main principles of DLT and blockchains as described above but without being restricted to its original design. The references [18] and [19] present interesting reviews of DLTs and their different design options and promising application cases beyond cryptocurrencies like bitcoin. Examples of applications are smart contracts, supply chain product tracking, and health care data.
Another important DLT application comes from IoT. The reference [20] revisits the main DLTs that are used for IoT deployments. For CPSs, DLT might be useful to guarantee the trustworthiness of sensor measurements, but this brings new challenges for the data network design because the verification process increases the network traffic, mainly at the edge with remarkable changes in the downlink [21]. As in the case of decentralized ML, the most suitable DLT design depends on tradeoffs related to, for instance, computation capabilities, issues related to data transmission and energy consumption, and individual data storage. Nevertheless, the most important task before any deployment is to actually identify whether a specific application indeed requires a DLT solution considering its main presupposition: peers do not trust each other while fully trusting the technical implementation.
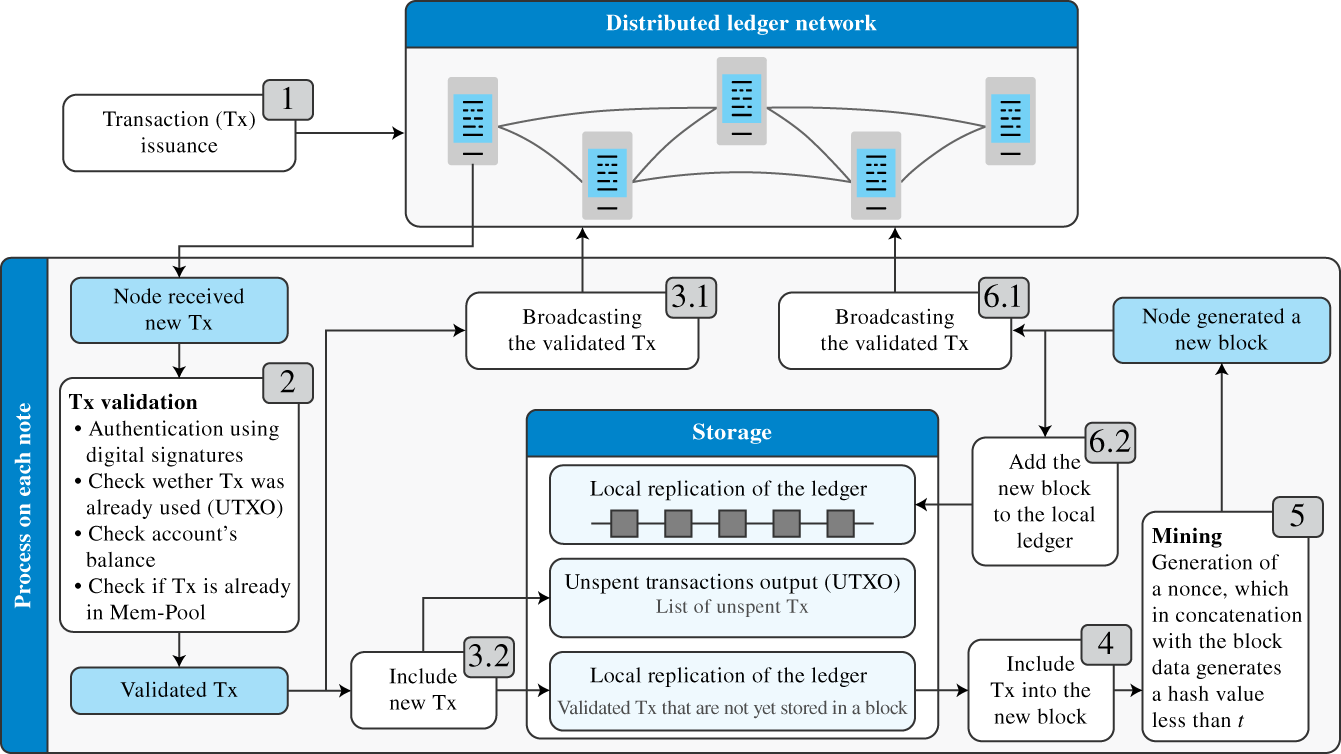
Figure 9.12 Distributed ledger technology. Source: Adapted from [19].
9.5 Future Technologies: A Look at the Unknown Future
Despite the ongoing discussions of today (2021) about what the 6G will be, which (new) applications shall be covered by the standard, and what is actually technically feasible to deploy, this section covers two paradigms that, in my view, would bring more fundamental changes in the technical domain. The first one is the Quantum Internet and the second is the IoBNT. This section ends with a brief discussion about what is coming with Moore's law.
9.5.1 Quantum Internet
Quantum computing is already a reality where computers are designed to use phenomena from quantum physics (e.g. superposition and entanglement) to process data mapped as qubits, where the states “0” and “1” of classical digital systems can be in a superposed state and be teletransported. In 2021, this technology is not yet widespread and only a few institutions have the (financial and technical) capabilities to have them. The main advantage of quantum computing is to solve at much higher speeds problems that are hard for classical computers, particularly combinatorial problems.
The Quantum Internet, in turn, does not need to be, in principle, an Internet composed of quantum computers. In a paper called Quantum internet: A vision for the road ahead [22], the authors explain the concept as follows.
The vision of a quantum internet is to fundamentally enhance internet technology by enabling quantum communication between any two points on Earth. Such a quantum internet may operate in parallel to the internet that we have today and connect quantum processors in order to achieve capabilities that are provably impossible by using only classical means.
At this stage, the authors already foresee some important applications, such as secure communications using quantum key distribution (QKD) to encrypt the message exchanges and extremely precise time synchronization. Figure 9.13 illustrates the proposed six developmental stages to construct a full‐fledged Quantum Internet. An important, sometimes not obvious, remark is that new applications, which are impossible to predict today, will surely appear throughout the development of quantum technologies. Because such large‐scale deployment is both uncertain and highly disruptive, it deserves to be mentioned here: the deployment of the Quantum Internet would have an unforeseeable impact on the data and decision layers of CPSs. An interested reader could also refer to [23] for a more detailed survey of such a new technology.
9.5.2 Internet of Bio‐Nano Things
In Chapter 3, the concept of biological information was briefly introduced to indicate the existence of (bio)chemical signals that constitute living organisms. The IoBNT has been proposed in [24] as a term to indicate how cells, which are the substrates of the Bio‐Nano Things, could be thought to have similar functionalities to IoT devices, and thus, explicit interventions could be designed accordingly. The Bio‐Nano Things would have the following functional units: controller, memory, processor, power supply, transceivers, sensors, and actuators; all mapped to specific molecules and molecular processes at the cell. The main idea of the IoBNT is to engineer molecular communications to modify the biological processes in a desired manner, which might support the development of new ways to deliver medical treatments.
Moreover, the authors of [24] aim at scenarios where the bio‐nano things are connected not only among themselves but also on the Internet. This idea would be a further extension of the already established man–machine interfaces (including brain–machine interfaces) and wearables of all kinds (e.g. smart watches and patches). What makes the IoBNT both promising and scary is the level of intrusiveness of the technology. Explicitly control molecular communications in a living body to allow coordination between cells, potentially through the Internet if suitable interfaces are developed, open up a series of possible new treatments for diseases and medical practices. On the other hand, the social impact can be fairly high; corporations and governmental institutions (including military and security agencies) will certainly find new ways to make profit and build even more direct and individualized technical solutions to analyze, profile, and control persons using their biological data. In this case, the development of the IoBNT is uncertain for technical and, above all, social and ethical reasons; nevertheless, if eventually deployed and widespread, such a technology would allow a large scale of cyber‐physical biophysical systems interacting with other CPSs.
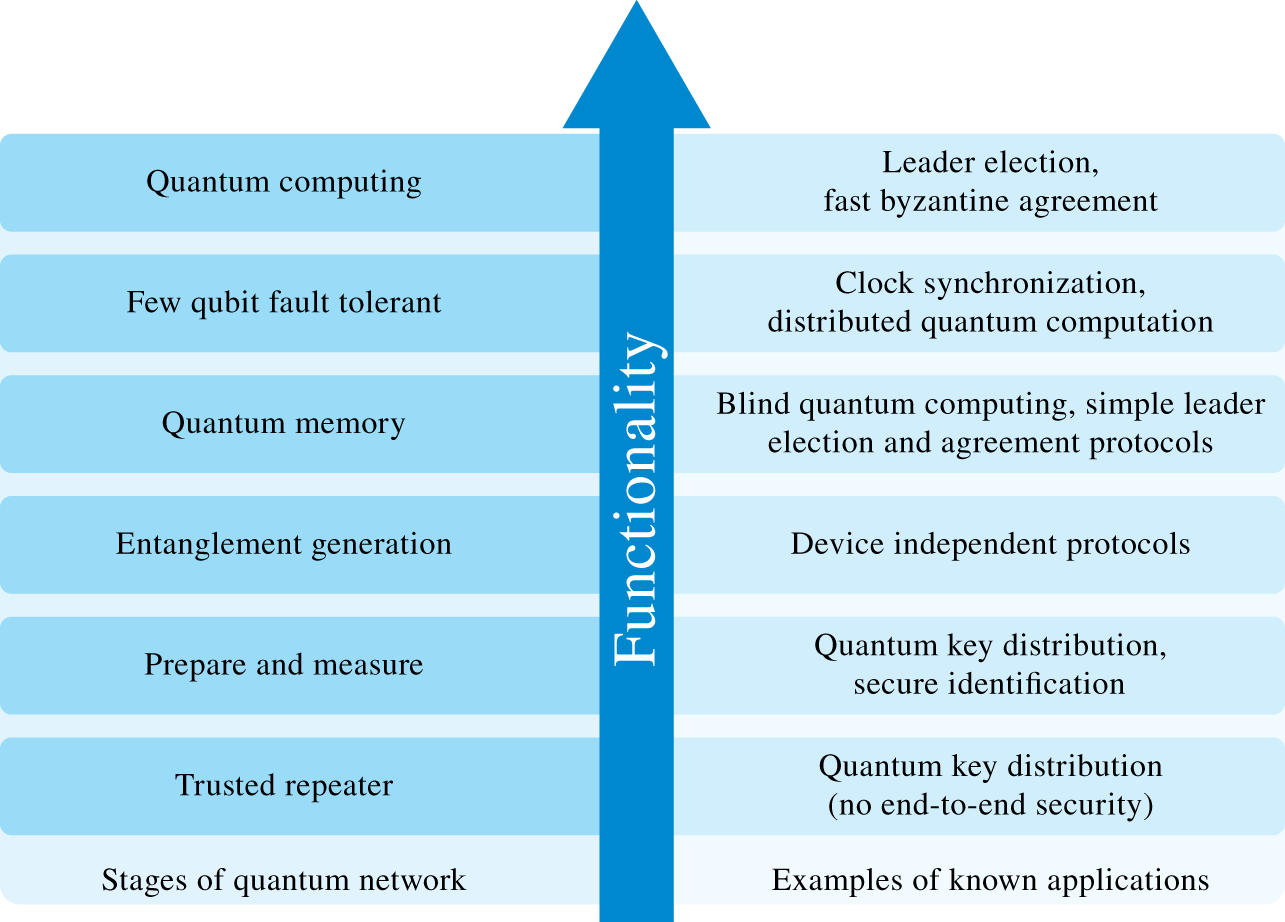
Figure 9.13 Proposed stages of the Quantum Internet development.
Source: Adapted from [22].
9.5.3 After Moore's Law
Gordon P. Moore – engineer, businessman and cofounder of one of the biggest semiconductor manufactures in the world – stated in 1975 an empirical characterization about the density of microchips pointing out that the density of transistors in integrated circuits will approximately double every two years [25]. This statement worked as a sort of self‐fulfilling prophecy or benchmark that is known as Moore's law. The miniaturization of computers is usually seen as a consequence of Moore's law. After several decades guided by such a forecast, the density of integrated circuits is now reaching its physical limits, and thus, setting an end to Moore's law. In other worlds, it seems that the gains experienced in the last fifty years, when a 2020 mobile phone is probably more powerful than a 1970 mainframe supercomputer, are over. The question that remains is: how can the huge performance gains that were predicted by Moore's law be realized in the future to come?
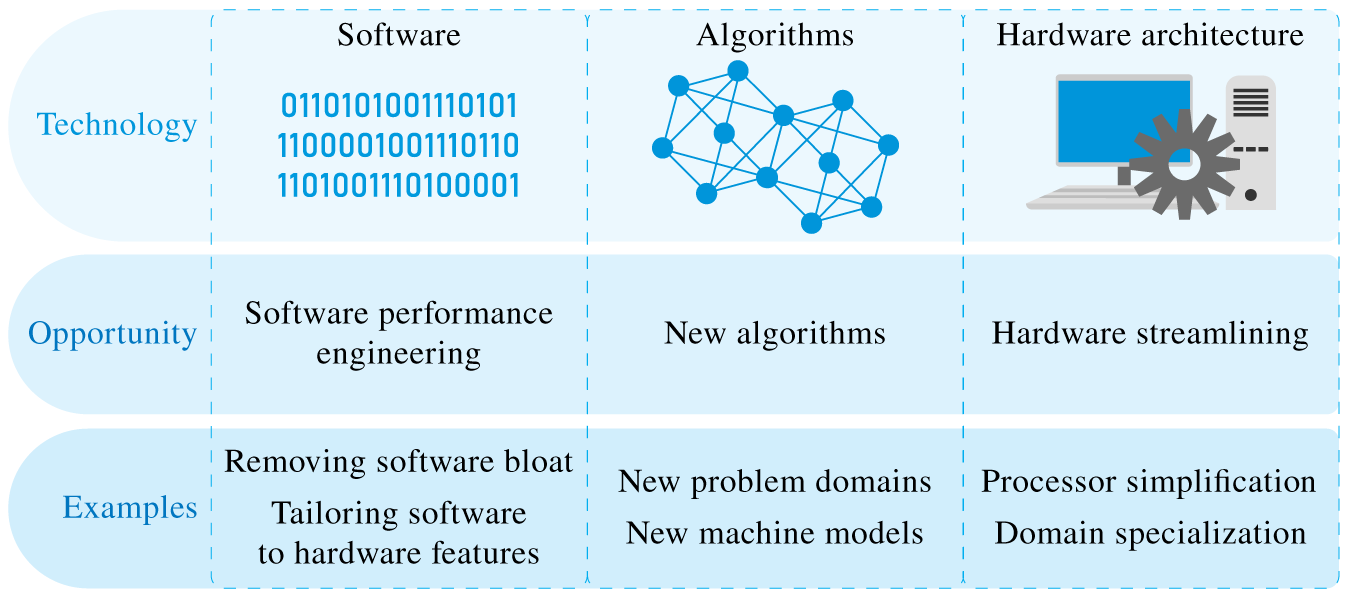
Figure 9.14 Performance gains after Moore's law.
Source: Adapted from [26].
The reference [26] provides a well‐grounded view of how to keep improving the efficiency of computers in such a new technical world. The authors' main argument is very well summarized by the title: There's plenty of room at the Top. The main idea is that, while gains at the bottom (densification of integrated circuits) is halting, many improvements can be made in software performance, algorithm design, and hardware architecture.
Figure 9.14 illustrates their view. These indications are very well grounded, also aligned with some comments presented in [15] about how specialized hardware architectures can improve the performance of distributed ML taken lessons from the parallelization of computing tasks studied by high performance computing research communities. The authors also identified potential new paradigms at the bottom, such as quantum computing, graphene chips, and neuromorphic computing, which might also be seen as potential enablers of the Quantum Internet and IoBNT. In summary, the years to come will determine what the (unwritten) long‐term future of computing (and CPSs) will be.
9.6 Summary
This chapter covered two fundamental enabling technologies for CPSs, namely data networks and AI. The focus was specifically given to the Internet‐layered architecture that can be seen as the way to physically establish logical links to transfer data and machine learning techniques to process data to be further used for prediction, classification, or decision. A very brief introduction to emerging topics like decentralized computing and distributed ledgers was also presented, because they are part of current deployment discussions of different CPSs. This chapter ended with a look at the still unclear future by discussing two different nascent technologies, Quantum Internet and IoBNT) and the future of computing after Moore's law. It is worth saying that our exposition was extremely short and oversimplified, and therefore, interested readers are invited to follow the references cited here to dive deeper into the different specialized technological domains.
Exercises
- 9.1 Random access for IoT. Most IoT devices are connected to the Internet through wireless links, which are defined by slices in the electromagnetic spectrum defined by frequencies with a given bandwidth. The use of the same frequency by two or more devices may cause destructive interference that leads to collisions and communication errors. The potentially massive number of IoT devices may lead to a situation where both centralized resource allocation is unfeasible and medium access without any contention/coordination has an overly high level of interference, which makes a successful transmission impossible.
One solution consists of using random access medium access control (MAC) protocols. There are four candidates:
- Pure ALOHA: Whenever a packet arrives at the node, it transmits.
- Slotted ALOHA: The time is slotted, and whenever a packet arrives, it is transmitted in the following time slot.
- Nonpersistent Carrier Sensing Multiple Access(CSMA): If a packet arrives, the node senses the channel; if no transmission is sensed, then the transmission starts; if a transmission is detected, the transmission is backed off for a random time when the sensing process takes place again. This process is repeated until the packet is transmitted.
- 1‐persistent CSMA: If a packet arrives, the node senses the channel; if no transmission is sensed, then the transmission starts; if a transmission is detected, the node keeps sensing until the channel becomes free when the packet is transmitted.
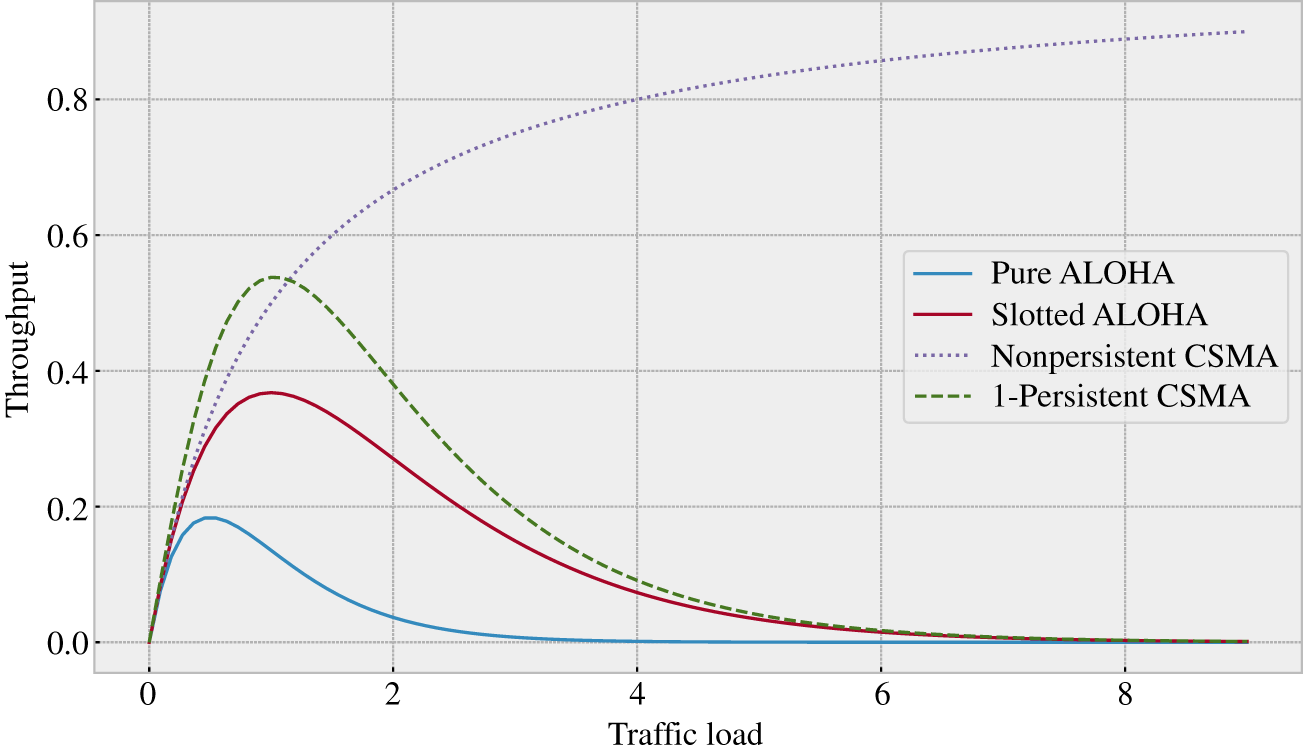
Figure 9.15 Throughput (from 0 to 1) as a function of traffic (expected packets per transmission time) for ALOHA and CSMA MAC protocols. The details of the model and equations are found in [27].
Figure 9.15 compares the performance of these four protocols in terms of throughput evaluated as the probability that a transmission is successful as a function of network traffic defined as the expected number of packets generated during the transmission time, which is considered fixed and related to data packets of the same size.
- Explain the results presented in Figure 9.15 based on the protocol description.
- CSMA outperforms ALOHA in terms of throughput, but this metric cannot capture the impact of these MAC protocols in the expected delay. Provide a qualitative comparison between CSMA and ALOHA in terms of expected delay.
- The nonpersistent and the 1‐persistent CSMA have a clear performance gap in terms of throughput, but also in terms of expected delay because in the first case every time that the channel is detected busy the transmission must wait a random time while the second case the node keeps sensing the channel until is free, but collisions may happen when more than one node is waiting to transmit. Propose a solution based on randomization that shall control the performance trade‐off between these two classes of CSMA. Hint: The solution is known as
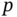 ‐persistent CSMA.
‐persistent CSMA. - Although this analysis is theoretical, those MAC protocols are indeed implemented in actual wireless networks. The master's thesis [28] provides a good overview of wireless technologies for IoT communications followed by an example of a feasibility study of different technologies for transmitting data of weather station sensors. The task is to read this more practical research work.
- 9.2 Designing a sensor network to measure air pollution. The government of a given city decided to distribute several air pollution sensors in a specific industrial region. These sensors have their energy supplied by a battery and can perform computations and store data, although their capabilities are quite limited. They are also wirelessly connected to the Internet via a 4G wireless network. Assess qualitatively the benefits and drawbacks of the following possible design solutions.
- Data processing architecture (centralized or decentralized) to construct a dynamic ML model to predict the hourly levels of pollution for the upcoming 12 hours based on the past data.
- Type of database to record new measurements considering the options of (i) one individual data storage server, (ii) a DLT where the data are stored in several desktop machines, or (iii) a DLT where the data are stored in the sensors. The server, the desktops, and the sensors are all owned by the city.
- Think about the conditions and requirements that make a centralized ML solution with DLT in desktop machines the most suitable solution.
- 9.3 Imagine the future. This task is a creative one. Write a two‐ to five‐page science fiction narrative about the future focusing on the technologies described in Section 9.5. The text can be an utopia, a dystopia, or a more realistic one.
References
- 1 Aglietta M. A Theory of Capitalist Regulation: The US Experience. vol. 28. Verso; 2000.
- 2 Gerovitch S. From Newspeak to Cyberspeak: A History of Soviet Cybernetics. MIT Press; 2004.
- 3 Kurose JF, Ross KW. Computer Networking: A Top‐Down Approach. Pearson; 2016.
- 4 Popovski P. Wireless Connectivity: An Intuitive and Fundamental Guide. John Wiley & Sons; 2020.
- 5 Madhow U. Introduction to Communication Systems. Cambridge University Press; 2014.
- 6 Huurdeman AA. The Worldwide History of Telecommunications. John Wiley & Sons; 2003.
- 7 Osseiran A, Monserrat JF, Marsch P. 5G Mobile and Wireless Communications Technology. Cambridge University Press; 2016.
- 8 Dang S, Amin O, Shihada B, Alouini MS. What should 6G be? Nature Electronics. 2020;3(1):20–29.
- 9 Narayanan A, De Sena AS, Gutierrez‐Rojas D, Melgarejo DC, Hussain HM, Ullah M, et al. Key advances in pervasive edge computing for industrial Internet of Things in 5G and beyond. IEEE Access. 2020;8:206734–206754.
- 10 Bringsjord S, Govindarajulu NS, Zalta EN, editor. Artificial Intelligence. Metaphysics Research Lab, Stanford University; 2020. https://plato.stanford.edu/archives/sum2020/entries/artificial-intelligence/.
- 11 McCarthy J. Review of the question of artificial intelligence. Annals of the History of Computing. 1988;10(3):224–229.
- 12 Heath J, Zalta EN, editor. Methodological Individualism. Metaphysics Research Lab, Stanford University; 2020. https://plato.stanford.edu/archives/sum2020/entries/methodological-individualism/.
- 13 Jung A. Machine Learning: The Basics. Springer; 2022. https://link.springer.com/book/10.1007/978-981-16-8193-6.
- 14 Chen M, Poor HV, Saad W, Cui S. Wireless communications for collaborative federated learning. IEEE Communications Magazine. 2020;58(12):48–54.
- 15 Verbraeken J, Wolting M, Katzy J, Kloppenburg J, Verbelen T, Rellermeyer JS. A survey on distributed machine learning. ACM Computing Surveys (CSUR). 2020;53(2):1–33.
- 16 Nakamoto S. Bitcoin: a peer‐to‐peer electronic cash system. Decentralized Business Review. 2008:21260. https://bitcoin.org/bitcoin.pdf.
- 17 Chapron G. The environment needs cryptogovernance. Nature News. 2017;545(7655):403.
- 18 Liu X, Farahani B, Firouzi F. Distributed ledger technology. In: Intelligent Internet of Things. Firouzi F, Chakrabarty K, and Nassif S, editor, Springer; 2020. p. 393–431. https://link.springer.com/chapter/10.1007/978-3-030-30367-9_8.
- 19 Sunyaev A. Distributed ledger technology. In: Internet Computing. Springer; 2020. p. 265–299. https://link.springer.com/chapter/10.1007/978-3-030-34957-8_9.
- 20 Wang X, Zha X, Ni W, Liu RP, Guo YJ, Niu X, et al. Survey on blockchain for Internet of Things. Computer Communications. 2019;136:10–29.
- 21 Nguyen LD, Kalor AE, Leyva‐Mayorga I, Popovski P. Trusted wireless monitoring based on distributed ledgers over NB‐IoT connectivity. IEEE Communications Magazine. 2020;58(6):77–83.
- 22 Wehner S, Elkouss D, Hanson R. Quantum internet: a vision for the road ahead. Science. 2018;362(6412).
- 23 Singh A, Dev K, Siljak H, Joshi HD, Magarini M. Quantum internet‐applications, functionalities, enabling technologies, challenges, and research directions. IEEE Communication Surveys and Tutorials. 2021;23(4):2218–2247. https://doi.org/10.1109/COMST.2021.3109944.
- 24 Akyildiz IF, Pierobon M, Balasubramaniam S, Koucheryavy Y. The internet of bio‐nano things. IEEE Communications Magazine. 2015;53(3):32–40.
- 25 Moore GE. Progress in digital integrated electronics [Technical literaiture, Copyright 1975 IEEE. Reprinted, with permission. Technical Digest. International Electron Devices Meeting, IEEE, 1975, pp. 11–13.]. IEEE Solid‐State Circuits Society Newsletter. 2006;11(3):36–37.
- 26 Leiserson CE, Thompson NC, Emer JS, Kuszmaul BC, Lampson BW, Sanchez D, et al. There's plenty of room at the top: what will drive computer performance after Moore's law? Science. 2020;368(6495):eaam9744. https://doi.org/10.1126/science.aam9744.
- 27 Kleinrock L, Tobagi F. Packet switching in radio channels: Part I‐carrier sense multiple‐access modes and their throughput‐delay characteristics. IEEE Transactions on Communications. 1975;23(12):1400–1416.
- 28 Mäki V. Feasibility evaluation of LPWAN technologies: case study for a weather station; 2021. M.Sc. thesis. Lappeenranta–Lahti University of Technology. Available at: https://lutpub.lut.fi/handle/10024/162347.