
CHAPTER 11
Incident Response and Recovery Procedures
This chapter presents the following topics:
• E-discovery
• Data breach
• Facilitate incident detection and response
• Incident and emergency response
• Incident response support tools
• Severity of incident or breach
• Post-incident response
No matter how vigilant an organization is, security incidents will eventually occur. Organizations create incident response procedures in advance to prepare for this inevitability. Incident response is the set of procedures used to react to computer incidents. An incident is defined as anything that occurs outside the normal range. To effectively deal with computer incidents, several conditions are required. First, the concept of what’s “normal” for a system is necessary to understand. Second, the enterprise must have a set of planned responses in the form of procedures to use when the system departs from normal conditions. Without proper preparation, response, and recovery efforts, the actions necessary for incident response are unlikely to be enacted in an effective manner.
Some incidents are criminal in nature; therefore, digital forensic investigations may need to be conducted. Evidence can be highly perishable, so incident response must be efficient and precise. Incident response procedures must include requirements for who collects, preserves, and analyzes the evidence. After all evidence requirements have been met, the incident response procedures must provide a process for restoring organizational functionality back to normal.
There are many facets to incident response and recovery procedures, and you can count on this chapter to provide the necessary coverage on e-discovery, data breaches, incident detection and response, emergency response, support tools, incident severity, and post-incident responses.
E-Discovery
E-discovery is the electronic discovery of evidence. Typically, this term is associated with civil procedures. As in most aspects of enterprise operations, proper preparation is the key to success. Preparation implies policies and procedures, and these items need to be addressed before their use becomes important. E-discovery is about producing records based on a subject, an event, a person, and so on. A common e-discovery request will ask for any documents, files, e-mails (in print or electronic form) associated with, for example, a person’s name, an order number, an event that occurred, or any other strange, non-indexed reference. The key point here is “non-indexed,” because we seldom manage our records in a manner associated with the e-discovery recovery request.

EXAM TIP Incident response is the set of actions security personnel perform in response to a wide range of triggering events. These actions are vast and varied because they have to deal with a wide range of causes and consequences. Through the use of a structured framework, coupled with properly prepared processes, incident response becomes a manageable task. Without proper preparation, this task can quickly become impossible and rather expensive.
E-discovery is a task that does not scale well. In large organizations, e-discovery can pose a significant challenge. One of the driving factors behind the challenge is the 90-day clock. Most e-discovery periods are 90 days long, and failure to produce within the 90-day window can bring sanctions and penalties. The second issue becomes one of data size. In large companies with considerable quantities of information, specific information to a specific incident, order, or person, will represent a very small segment of the total information volume. Finding this information becomes a needle-in-a-haystack issue. Technology has come to the rescue in the form of specialized systems designed to assist in the archiving and indexing of e-mails, files, and other data sources. Indexing is done all the time in preparation for when it is actually needed.
Because an e-discovery request may specify information in a manner that is different from its storage, one of the challenges is in finding all the relevant records. A request for all e-mails associated with Joe Smith may include the following:
• All e-mails sent by Joe
• All e-mails received by Joe
• All e-mails that mention Joe in the e-mail itself
The first two are relatively simple with most modern mail systems. The last one is problematic—how do you find all the e-mails that mention Joe? This is where the skills of digital forensics can enter the picture.
Electronic Inventory and Asset Control
Asset management deals with the management of assets of an organization. An asset is defined as any item of value to the enterprise, including information. It is essential for a company to identify, track, classify, and assign ownership for the most important assets. The main idea behind asset management is to ensure that the assets are protected, and the assignment of responsibility to a party on an asset-by-asset basis provides a means of accountability and ownership. In the case of information-based assets, the rules are no different and, in fact, possibly even more important. In the case of a physical asset, at least someone in the organization typically has some form of physical custody of the item. In the case of electronic information, data is more of an intangible asset, making direct control over custody more challenging.
With the proliferation of mobile devices and remote workers, inventories and asset control have more ground to cover. Organizations are meeting this challenge head on with cloud-based mobile device management (MDM) products like VMware AirWatch and Microsoft Intune. MDM tools typically have the ability to perform the following tasks:
• Perform hardware and software inventories
• Deploy applications
• Update operating systems and applications
• Deploy configuration, conditional access, and compliance policies
• Perform remote wiping
• Provide endpoint protection
EXAM TIP Using GPS or cell tower tracking, organizations can track the location of lost or stolen mobile devices in order to possibly repossess them, or send remote backup and remote wipe commands to protect the organization’s data interests.
Data Retention Policies
A data retention policy dictates the systematic review, retention, and destruction of data in the enterprise. Data may not need to be stored indefinitely, and different types of data have different storage requirements. This policy should identify the requirements by data type of storage, both in terms of time and manner, as well as how data should ultimately be destroyed. Most business records have a limited business life, after which the cost of maintaining the data outweighs its usefulness. Countering this desire to eliminate undesired storage costs are the rules and regulations associated with specific data types. Contracts, billing documentation, and financial and tax records are normally prescribed to be kept for seven years after creation or last use.
The requirements of data retention are often compelled by state and federal regulations. Laws such as Sarbanes-Oxley prescribe retention periods for specific accounting information. These laws were created in response to scandals that involved the destruction of crucial records to avoid adverse legal actions. In most circumstances today, in the event that data is shown to be destroyed or otherwise not made available to legal proceedings, judges can instruct juries to consider that the data did exist and that it could be considered damaging to the withholder’s case. One of the key factors used to determine what evidence is expected in a legal case revolves around the issue of data retention. Does a firm have a policy? Does it follow this policy? Is it reasonable with respect to laws and regulations? These are all factors in determining what data is reasonable to expect in a legal case.

NOTE Data retention policies can play a key role in determining what information is expected to be produced in legal proceedings. Having a data retention policy that follows laws and regulations associated with information types, and one that is followed by the data owners, can help define what is reasonable to expect in terms of data production in a court case. Not following a retention policy (that is, not destroying data when permitted) can lead to having to produce more information in legal proceedings. Failure to uniformly follow a data retention policy can result in questions related to corruption in the case.
Data Recovery and Storage
As the saying goes, there are two types of hard drives—the dead and the dying. The storage of data on physical devices is not a foolproof operation. In some cases, devices can fail, causing errors in the structure of the data storage system and making the stored data impossible to retrieve using normal operating system methods. Data recovery is the process of recovering data from damaged, failed, corrupted, or inaccessible storage devices when it cannot be accessed using normal data access methods. Data recovery may be required due to physical damage to the storage device or logical damage to the file system that prevents it from being mounted by the host operating system. Specialized toolsets can rebuild the logical file system and, in extreme cases, can rebuild datasets from pieces recovered on damaged media. For instance, the data from a broken CD or DVD can be recovered and put on a fresh device. These are expensive and time-consuming tasks requiring special skillsets and tools and are typically not performed by most IT organizations, but rather are outsourced.
Data storage strategies, including backups to provide for recovery in the event of primary storage failure, are foundational security elements in an enterprise. Distributing storage of data across an enterprise to provide redundancy and improved local performance can enhance operations, but also can have security implications. Security requirements need to follow the data, and distributing the data means distributing the requirements as well. There is a natural separation and sharing of responsibilities when it comes to data management. Data owners are responsible for determining data requirements in terms of access, lifetime, and usage. The security team is responsible for determining the controls necessary to protect the data per the business-determined protection requirements. The IT staff is responsible for the operational implementation of the business and security requirements with respect to logical and physical systems.
As an example, the court case Oracle America v. Google required e-discovery of Google e-mails. Since organizations typically have retention and archival policies regarding corporate e-mail, Google was able to cooperate by providing all requested data.
Data Ownership and Handling
Assigning data owners and establishing responsibility for all custodial duties are key elements in managing an information asset. In most cases, these will not be performed by someone in IT because, although their responsibility may lie in activities such as backups and integrity management, the actual retention, sharing, and other decisions associated with the asset belong with the data owner. Data owners are typically department managers who make decisions on how certain data should be used and managed, whereas data custodians are the IT personnel who implement the decisions made by the data owners.
Establishing data ownership responsibilities and aligning this with the direct business impact of the information will assist in making the proper data-handling decisions. Deciding who should have access to what specific elements of data is necessary before enforcing this requirement through rules such as access control or firewall rules.
Data ownership usefully creates a single point of contact (POC) during incident response situations whenever timely advice is needed on specific data recovery efforts.
Legal Holds
The excuse of “my dog ate my homework” didn’t work with your elementary school teacher, nor will the premature destruction of potential evidence sit well with the legal system. There may come a time when an attorney compels an organization to place a legal hold on specified data types to prevent deletion. A legal hold is a process that permits organizational compliance with legal directives to preserve all digital and paper records in anticipation of possible litigation. Any data retention policies that had previously earmarked legally requested data for destruction are immediately and indefinitely suspended until all relevant litigation has concluded. To ensure compliance with legal hold requirements, an e-discovery policy is created that includes detailed requirements on the legal identification, preservation, collection, processing, review, and production of requested information. It should also include specifications on tagging data with standardized legal labels to facilitate efficient organization, discovery, and recovery of the data required by the legal hold.
As an example, an organization receives a letter from a law firm titled “Legal Hold Notice” with a description of “Do Not Destroy Stated Documents.” This letter then goes on to instruct the receiving organization to legally hold all required documents and suspend data destruction. Such records may include e-mails, writings, graphics, communications, graphs, sound, video tapes, photographs, discs, e-mails, calendars, and so forth.
NOTE To be clear, legal holds do not guarantee that data will actually be collected. Its primary objective is to ensure that required data is available should it “need” to be collected.
Data Breach
A data breach is the release of information to an unauthorized party or environment. It is also referred to as a data leak, data leakage, information disclosure, or data spill. Any loss of control over data can be considered a breach until it is determined that the data cannot be obtained by an unauthorized party. Data breaches can be the result of an accident or intentional act. Any time that sensitive or protected information is copied, transmitted, viewed, stolen, or accessed by an unauthorized party, a data breach has occurred.
Financial losses for data breaches can be in the millions, potentially hundreds of millions of dollars. For example, in November and December of 2013, 40 million Target customers had data from their credit and debit cards stolen by hackers. In response to this, Target hired a third-party forensics firm to investigate the crime. The investigation determined that the hackers stole a Target HVAC username/password, which allowed remote access to Target’s payment network. With these credentials, attackers loaded up malware on the point-of-sales (POS) terminals, which stole the financial data. It is estimated that the total cost of the Target breach was between 250 and 300 million dollars.
When data breaches have been detected, an incident response team should implement the procedures described in an incident response plan, which typically includes the following stages:
• Discover and report
• Confirm
• Investigate
• Recover
• Lessoned learned
These five stages of incident response will be covered in the “Incident Response Team” section, later in the chapter.
NOTE Many states have data breach notification laws, the most famous being California Senate Bill 1386 (SB 1386). These laws stipulate the actions an enterprise must take in the event of a data breach. These activities include actions such as reporting and the notification of affected parties. One of the best defenses against the loss of control of information is in the process of encryption. A lost backup tape set being shipped offsite could be considered a breach, because a third party could examine the information if it came into possession of the lost data. If the backup set is encrypted, then a party encountering the set cannot examine the actual data. In many states, this is sufficient to prevent triggering the data breach law.
Detection and Collection
The first step in incident response is detecting the incident. Detection may involve the examination of hardware and software alerts, surveillance cameras, various logs (such as system, application, and security logs), network traffic, error messages, and feedback from employees and customers. Also, if security baselines are in place, look for anything that indicates deviation. These initial efforts are important because detected incidents must be supported by evidence in order to substantiate a potentially worrisome and resource-intensive response process.
If the individual (or individuals) responsible for detecting the incident is not on the incident response team (IRT), they must notify the IRT at once in order for the IRT’s first responders to report immediately to the incident scene. Members of the IRT often include a representative from the security, IT, and HR departments to balance out skillsets and responsibilities. IRT members will need to be able to ask and document the answers to the following questions:
• What type of event is this?
• Is the event ongoing?
• Which people, facilities, systems, and data are potentially affected?
• Has the incident caused actual exposure/losses, or has it potentially done so?
• Is a response necessary?
Once you determine which system or systems were affected by a data breach, you should label the systems, interview all individuals with access to these systems, and leave the systems in their original power state. In other words, if it’s on, leave it on; if it’s off, leave it off.

CAUTION Evidence collection can be severely impaired if the system’s original power state is changed. Leave it “as is” until the conclusion of the incident response process.
Evidence is highly perishable; therefore, you should begin collecting it as soon as possible. Shown here is a summary of sources from where evidence can be collected:
• Smartphones
• Computers
• GPS devices
• Visited websites
• Social media
• Wearables
• Printers
• Network appliances
• IoT devices
With all the information being collected, it can be challenging to determine which evidence is important and should be preserved. At this point, the safe bet will be to keep all of it until it is more carefully analyzed. More detail on evidence collection methods will be discussed later in this chapter in the “Incident and Emergency Response” section.
After evidence has been collected, it needs to be analyzed. The manner of analysis will vary depending on whether it’s being performed by a professional computer forensic investigator or the organization’s security practitioner. In either case, the nature of the breach will need to be classified and a priority level assigned in order to ensure that the appropriate level of attention and resources are provided to the incident. Also, certain data details will need to be determined, such as any possible attacker tracks, timeline of activities, scope of compromise, and information about the attacker’s tools or techniques.
Mitigation and Response
One should consider the fact that all stored data is subject to breach or compromise. Given this assumption the question becomes, what is the best mitigation strategy to reduce the risk associated with breach or compromise? Data requires protection when in three states: in storage, in transit, and during processing. The risk from each phase of the data life cycle differs due to several factors. Time is one factor; data tends to spend more time in storage, and hence is subject to breach or compromise over longer time periods. Data spends less time in transit and processing. Quantity is a second factor. Data in storage tends to offer a greater quantity to breach or compromise than that in transit, and even less in processing. If records are being compromised while being processed, then only records being processed are subjected to risk. The last factor is access. Different protection mechanisms exist in each of the domains, and this has a direct effect on the risk associated with breach or compromise. Operating systems tend to have very tight controls to prevent cross-process data issues such as error and contamination. This plays toward security as well. The next aspect of processing risk is within process access, and a variety of attack techniques address this channel specifically. Data in transit is subject to breach or compromise from a variety of network-level attacks and vulnerabilities. Some of these are under the control of the enterprise, and some are not.
The gold standard to prevent data loss from breach or compromise is encryption. When properly employed, encryption can protect data during storage, in transit, and even during processing in some cases. Data that is encrypted no longer has direct value to an unauthorized party, for without the appropriate key there isn’t access to the data; all that is accessible are apparently random values. The purpose of encryption is not to make it impossible to obtain the data, but rather to increase the work factor involved to a level that makes obtaining the data not viable in either economic or time-based terms. Any sensitive information being sent over a network should be encrypted because the network cannot guarantee that unauthorized parties do not have access to data being transmitted across a network. For wireless networks, this is obvious, but the same issues can exist within a wired network with respect to unauthorized parties. Although HTTPS is far from perfect security, it does provide a reasonable level of protection for many Internet-based data transfers. The use of virtual private networking (VPN) technology expands this level of protection from World Wide Web–associated data transfers to the more general case of network transfer of data.
Minimize
Data minimization efforts can play a key role in both operational efficiency and security. One of the first rules associated with data is, don’t keep what you don’t need. A simple example of this is the case of spam remediation. If spam is separated from e-mail before it hits a mailbox, one can assert that it is not mail and not subject to storage, backup, or data retention issues. Because spam can comprise more than 50 percent of incoming mail, this can dramatically improve operational efficiency both in terms of speed and cost. This same principle holds true for other forms of information. When a credit card transaction is being processed, there are data elements required for the actual transaction, but once the transaction is approved, they have no further business value. Storing this information provides no business value, yet it does represent a risk in the case of a data breach. For credit card information, the rules and regulations associated with data elements are governed by contract and managed by the Payment Card Industry Data Security Specification (PCI DSS). Data storage should be governed not by what you can store, but by the business need to store. What is not stored is not subject to breach, and minimizing storage to only what is supported by business need reduces the risk and cost to the enterprise.
Minimization efforts should begin before data even hits a system, let alone before a breach occurs. During system design, the appropriate security controls are determined and deployed, with periodic audits to ensure compliance. These controls are based on the sensitivity of the information being protected. One tool that can be used to assist in the selection of controls is a data classification scheme. Not all data is equally important, nor is it equally damaging in the event of loss. Developing and deploying a data classification scheme can assist in preventative planning efforts when designing security for data elements.
Isolate
Whenever you read about wildfires, responders are always quick to point out the fire’s containment level. In other words, what percentage of the fire is surrounded by a barrier—as in no longer expected to spread? The ultimate goal is 100 percent containment. Data breaches are much like a fire in that once they occur, it is paramount that the breach be contained, or, as they say in security parlance, isolated. The method of isolation depends on the nature of the security breach. Isolation techniques may include the following:
• Disconnect affected computers.
• Disconnect affected communication device(s).
• Isolate and encrypt all mission-critical data on affected systems.
• Change passwords on affected systems.
• Quarantine affected computers into a “containment VLAN.”
CAUTION It is important to note that isolation of an issue is not a resolution but rather a step toward resolution. Once the issue is isolated, you will be able to focus on eradication of the data breach’s cause.
Recovery/Reconstitution
Recovery efforts from a data breach involve several specific elements. First, the cause of the breach needs to be determined and resolved. This is typically done through an incident response mechanism. Second, the data, if sensitive and subject to misuse, needs to be examined in the context of how it was lost, who would have access, and what business measures need to be taken to mitigate specific business damage as a result of the release. This may involve the changing of business plans if the release makes them suspect or subject to adverse impacts.
A key aspect in data breaches and many incidents is that of external communications. It is important to have a communications expert familiar with dealing with the press, with the language nuances necessary to convey the correct information and not inflame the situation. Many firms attempt to use their legal counsel for this, but generally speaking the precise language used by an attorney is not useful from a PR standpoint; therefore, a more nuanced communicator may provide a better image. In many cases of crisis management, it is not the crisis that determines the final costs but the reaction to and communication of details after the initial crisis. A recent case in point was a breach of Zappos, an online shoe vendor. Its response was so nuanced that the story turned from a breach story into a “how Zappos handled their customers” story—truly a win for the firm during the crisis.
Disclosure
After a data breach has been fully resolved, it is time to disclose all relevant data breach details to business stakeholders, which may include your immediate manager, senior management, and human resources, in addition to team leads from various departments. An incident response report form will be filled out that documents various incident information, including the following:
• Incident identification information Includes responder’s name, title, contact information, location, and time of incident
• Summary of incident Includes type of incident detected, such as DOS, malware, unauthorized access, and so on
• Notification Includes parties that were notified, such as HR, senior management, legal counsel, and public affairs
• Actions Includes detection measures, isolation measures, evidence collected, eradication measures, and recovery measures
• Follow-up Includes self-assessment of response compared to prescribed procedures, plus recommendations for future responses
Facilitate Incident Detection and Response
When a data breach occurs, the firm must be ready to respond immediately. The time to formulate plans and procedures was before the event because many factors will be driving timelines, including the business risk associated with the data loss, customer pressure, and regulatory pressure. The actions will, in most cases, be performed as part of the incident response action, but it is important to realize that breaches are separate from incidents. An incident may include a breach, but some incidents do not. By definition, any breach is an incident. Incident response teams (IRTs) are focused on the incident and follow mostly technical steps to limit the damage and return everything to a normal operating state. A data breach has an independent life of its own and may last longer than a typical incident. Part of the reason for the extended timelines involves regulatory steps and notification of customers and regulatory groups.
Detection begins with the point in time where the incident is discovered and it becomes a breach because of the nature of the incident. This is a data collection effort involving how the incident occurred, what data is known to be involved (even preliminary information), and what systems are involved. From this data, the next efforts are to identify system and data owners so that they can be notified and included in the planning of remediation and repair. Frequently this will involve personnel from the business that are directly affected and the appropriate IT staff associated with the involved systems.
Mitigation efforts are the immediate countermeasures performed, including the disconnecting of the leak. Stopping the leak while in progress can reduce the loss and risk. If personally identifiable information (PII) or personal health information (PHI) is being posted publicly, removing this public posting can reduce the temporal component of the exposure, also potentially reducing the risk. Concurrently with the mitigation efforts, the evaluation efforts can commence. Evaluation efforts include work performed to determine what has actually happened, how much has been disclosed, and what systems are at risk. This information is used to prioritize the response actions. The response stage includes the actions necessary to resolve the breach, restore the involved systems, and perform the appropriate notifications.
Internal and External
Both internal and external parties are involved in data breach issues. If external customer information is compromised, the external customers will need to be notified and, in some cases, receive assistance with respect to their risk. It is not uncommon for a firm to offer credit-monitoring services to affected external entities.
Internal entities have risks as well. If customer data is compromised, such as customer login information, the internal systems need to take this into account and manage the business expectations concerning how to address this. In some cases, it would be the disabling of an account. In others, it might be a wholesale change of login credentials.
Breaches can be the result of both internal and external actors. By convention, all access to systems is via accounts associated with internal entities. Different accounts have different levels of access associated with the business requirements of the account holder. For obvious reasons, system administrators, database administrators, and other key users have wide-sweeping access capability, making their accounts attractive targets for unauthorized use. If the account holder of one of these accounts performs unauthorized activity, the damage can be severe. It is important to more closely monitor accounts with greater levels of access to provide appropriate levels of protection.
An insider user has a couple of advantages over outside adversaries. First, they already have account access on a system. Second, in the case of power accounts, such as admin accounts, they have significant breach capability. Most importantly, the insider typically has a level of internal knowledge associated with the information necessary for exploitation. An outsider who wishes to obtain information needs to acquire access to the system via credentials as well as have an understanding of where the desired information is stored and how it can be obtained.
Criminal Actions
The primary goal behind preparing for incident response is the successful and efficient handling of the incident, including returning the system to a proper operating condition. In the case of dealing with criminal actions, additional steps may need to be taken to ensure that legal actions against the criminal are not precluded by the incident response team’s desire to return the system to a normal operating condition. Successful prosecution of a criminal will rest upon evidence that is presented in court. This evidence will be subject to challenge by the defense attorney; if any “issues” are associated with the fidelity of the data collection effort, in most cases the evidence will be suppressed or not allowed.
The best way to obtain criminal evidence is to let law enforcement collect the evidence. Any time evidence is used in legal proceedings, either criminal or civil, one of the challenges will be to the chain of custody. Because evidence can be altered or tampered with, it needs to be controlled from the time of collection until the time of use in legal proceedings. This control is in the form of a documented chain of custody that can detail where the evidence has been and who has done what with it every moment, from collection to court.
Hunt Teaming
They sometimes say in sports that the best defense is a good offense. Traditional security processes concentrate on locking down the defense. Hunt teaming takes the opposite approach of focusing on what the offense is doing. Hunt teaming is a comprehensive process of security teams seeking out any signs of attack against the organizational network. Security teams will search for signs of compromise, which may include unusual changes to audit logs, locked-out accounts, malware backdoors, changes to critical files, and slow Internet or devices—not to mention keeping an eye out for strange administrator account patterns or any signs of unapproved software and network traffic.
The key to hunt teaming is being proactive. By looking at all attack vectors for signs of malicious activities, organizations may reveal anomalies that might’ve been missed had they maintained the more typical reactionary security posture. The danger with solely relying on reactive solutions is that they block, alert, or log malicious activities after they come knocking. Although such outcomes are desirable, a more offensive approach might have eliminated the threat before it got a chance to attack. Hunt teaming converts the organization from the hunted to the hunter.
EXAM TIP Although both hunt teaming and penetration testing are considered “offensive security,” they are very different. Penetration testing involves simulating an attack against the network, whereas hunt teaming merely hunts down signs of attackers and attacks.
Behavioral Analytics
Behavioral analytics is the process of measuring and identifying how entities typically act, or behave, and later comparing these measured behaviors to future samples to potentially spot deviations. For example, if a website typically receives 1,500 hits per hour, and then increases to 2,500 hits per hour, this change of behavior could indicate either a distributed denial of service attack (DDOS) or a healthy increase in traffic levels due to increased brand awareness. Our job is not only to capture the typical and atypical behaviors, but to decide whether the causes and effects are malicious, desirable, or unremarkable.
Since networks are always changing, patience and discipline must be exercised in order to refrain from flagging every measured deviation as signs of malicious activity. Yet, don’t overlook deviations either. Hidden beneath the surface may be an attack in progress.
Heuristic Analytics
Unlike behavioral analytics, which focuses on measuring, comparing, and analyzing a set of before and after data points, heuristic analytics intelligently gathers data points from various host and network data sources within a specific environment. It then scores each of these data points relative to one another to determine if the entity is threatening, potentially threating, or not threatening in nature. Antivirus, intrusion detection systems, and intrusion prevention systems frequently utilize heuristic capabilities in order to spot zero-day or unknown attack vectors that would go unnoticed by signature-based detection measures.
Establish and Review System, Audit, and Security Logs
System administrators should enable logging on all significant systems so that data can be collected as to system performance and operation. This same data will be useful during an incident because anomalies in this data can provide evidence of abnormal activity, its source, and its cause. A basis of understanding “normal” in an enterprise system is an essential element in determining that an incident has occurred. The incident response team will need to examine data to determine what happened, what systems were affected, and the extent of the damage. One of the main sources of information will come from log files.
Enabling logging is not sufficient on its own. Log files have no value unless their contents are examined, analyzed, and acted upon. With a myriad of log files across the enterprise, an automated solution to log file collection and analysis is necessary in most enterprises. Security tools exist that permit the monitoring of large log file systems, including the automated generation of alerts based on a complex set of rules. Security information event management (SIEM) is the name of this class of device. SIEMs are database structures designed to assist the security operators in determining what systems need attention and what aspects need further investigation.
SIEM solutions are a critical component of automated security systems used in continuous monitoring, as described in Chapter 9. These systems act as a centralized hub of security information, providing the security personnel the information associated with the status of systems, controls, and security-related activity.
Incident and Emergency Response
Incident response is a term used to describe the steps an organization performs in reaction to any situation determined to be abnormal in the operation of a computer system. The causes of incidents are many—from the environment (storms), to errors on the part of users, to unauthorized actions by unauthorized users, to name a few. Although the causes may be many, the results can be organized into classes. A low-impact incident may not result in any significant risk exposure, so no action other than repairing of the broken system is needed. A moderate risk incident will require greater scrutiny and response efforts, with a high-level risk exposure incident requiring the greatest scrutiny. To manage incidents when they occur, a table of guidelines for the incident response team needs to be created to assist in determining the level.
Two major elements play a role in determining the level of response. Information criticality is the primary determinant, and this comes from the data classification effort discussed earlier and the quantity of data involved. The loss of one administrator password is less serious than the loss of all of them. The second factor involves a business decision on how this incident plays into current business operations. A series of breaches, whether minor or not, indicates a pattern that can have PR and regulatory issues.
Chain of Custody
As they say, the burden of proof is on the accuser. If a suspect of an organizational attack is brought to trial, the prosecution must prove the suspect’s guilt rather than the defense prove the suspect’s innocence. However, evidence must survive the long and perilous journey to court to be of any value to the prosecution. If there are any signs of tampering or contamination of evidence from its collection to presentation in court, it will be deemed inadmissible. As you would expect, this could destroy the prosecution’s case and allow a guilty attacker to go free. In order to prevent early dismissal of evidence, a legally defined chain of custody process must be followed by all collectors and analysts of evidence.
Chain of custody is a detailed record of evidence handling from its collection, preservation, and analysis, to presentation in court and disposal. It documents who handled the evidence, the time and date of its collection, any transfers between parties, and the reason behind the transfer. The evidence itself can be collected for many crimes, including the following:
• Computer fraud
• Network intrusion
• E-mail threats and harassment
• Software piracy
• Telecommunications fraud
• Identity theft
EXAM TIP Chain of custody can maintain many types of evidence in computer crimes, including digital data, paper effects, internal and external storage devices, photographs, e-mails, GPS tracks, captured audio/video, telephone systems, audio recorders, pagers, MP3 players, multifunction machines, and more. Be sure that any evidence you collect, transport, and analyze is following all predefined legal procedures to maximize its chances of admissibility.
Digital Forensics
Digital forensics is the application of scientific methods to electronic data systems for the purposes of gathering specific information from a system. If this information is to be relied upon, it needs to be accurate. Digital forensics began in the law enforcement realm, but civil cases and e-discovery have resulted in significant civil applications. The key to forensics is the application of a structured, step-by-step, documented process for both data collection and analysis. The admission of scientific evidence in court is governed by either the Frye Standard or, in federal court, the Daubert Standard. The majority of U.S. courts have adopted a form of Rule 702 of the Federal Rules of Evidence, which follows:
RULE 702. TESTIMONY BY EXPERT WITNESSES
A witness who is qualified as an expert by knowledge, skill, experience, training, or education may testify in the form of an opinion or otherwise if:
• The expert’s scientific, technical, or other specialized knowledge will help the trier of fact to understand the evidence or to determine a fact in issue
• The testimony is based on sufficient facts or data
• The testimony is the product of reliable principles and methods
• The expert has reliably applied the principles and methods to the facts of the case
The forensic handling of electronic evidence is not dissimilar to that of normal forensic evidence handling. The primary purpose behind the strict procedures is to prevent any alteration of the evidence that could occur as part of collection or processing. In the case of digital evidence, this is especially true, because any action performed through the operating system can result in the alteration of data on the system—potentially changing or deleting the evidence that is sought. For this reason, once a decision is made that a machine needs to be subjected to forensic analysis, it is best to use trained personnel and not just have a system administrator log on and examine the system.
The sensitivity to undetectable alteration, deletion, or creation of data makes clearly defining contents per a point in time difficult in digital systems. As described in an earlier section, a legal hold represents an order to preserve data in an unaltered state from a given point of time. For practical reasons, a litigation hold request needs to specify the range of data requested. Requesting that all data be preserved would require offline storage of the entire system and all its data, which except in the smallest of enterprises becomes time consuming and expensive.
Digital Forensics Process
To ensure the trustworthiness of digital forensics results, a repeatable process needs to be followed. The following nine steps comprise a standard digital forensics process model:
1. Identification The recognition of an incident from indicators and a determination of its type
2. Preparation The preparation of tools, techniques, search warrants, and monitoring authorizations and management support
3. Approach strategy The development of a strategy to use in order to maximize the collection of untainted evidence associated with the goal of the investigation
4. Preservation The isolation, securing, and preservation of the state of physical and digital evidence
5. Collection The recording of the physical scene and duplicate digital evidence using standardized and accepted procedures
6. Examination An in-depth systematic search of evidence relating to the goals of the investigation
7. Analysis The determination of the significance, the reconstruction of fragments of data, and the drawing of conclusions based on evidence found
8. Presentation The preparation of the summary and explanation of conclusions
9. Returning of evidence Steps to ensure both physical and digital property are returned to the proper owners
As the investigation moves through these steps, two things happen. As you progress, the quantity of data decreases and the relevancy of the retained data increases with respect to the total volume of data.
When digital evidence is being collected, it is important to use proper techniques and tools. The use of write blockers when making forensic copies, hashing and verifying hash matches, documenting, handling, as well as storing and protecting media from environmental change factors, are some of the key elements. The tools for making forensic copies (or bit-by-bit copies) are different from normal backup utilities and are important to employ correctly to get hidden partitions, slack and free space, and other artifacts. The detail necessary points to either using specially trained personnel or outsourcing the work to a forensics specialty firm.
Digital forensics is a large topic; therefore, it would be impossible to provide complete coverage of it in one section alone. However, shown next are some general best practices to consider when performing digital forensic response procedures:
• Capture the disk image.
• Capture memory contents.
• Capture network traffic/logs.
• Capture video evidence.
• Record time offset as compared to GMT time zone.
• Generate hashes.
• Create screenshots.
• Identify witnesses of evidence collection and veracity.
• Track man hours and expenses for billing and damage assessment purposes.
Privacy Policy Violations
Privacy is a separate issue from security, but it shares many traits and foundational elements. You can have security without privacy, but you really can’t have privacy without a foundation of security. Privacy is the exercise of control over what other entities know about you. In the normal course of business, there can be significant amounts of information that a user wishes to be private (not spread beyond immediate business use). Examples include financial information, medical information, plans for future events, and so on. Whenever data breaches result in privacy impact, it can kick off mandatory notification procedures to the victims. Not to mention, the failure of an organization to secure the information it has been entrusted with can lead to lawsuits, fines, government investigations, and bad publicity. All of these outcomes are negative and can lead to business impairment.
Personally identifiable information (PII) and personal health information (PHI) are two common kinds of privacy data that may be held by a firm. To ensure that this form of data is properly safeguarded, a privacy impact assessment (PIA) should be performed. The purpose of the PIA is to determine the risks associated with the collection, use, and storage of PII. The PIA should also examine whether the proper controls and safeguards are in place to protect PII from disclosure or compromise.
EXAM TIP A PIA will examine people, process, and technology factors with respect to the proper safekeeping of PII. Any time significant changes occur in systems, business operations, or people, a new PIA needs to be conducted to ensure continued protection.
Continuity of Operations
Although continuity of operations could be used in a corporate context (which negates the more contextually accurate terminology of business continuity plans and disaster recovery plans), this section will focus on its more literal government and public usage. A continuity of operations plan refers to an organization’s processes for maintaining functionality in the event of a serious event—only the organization we’re referring to here is the government.
Business continuity plans and disaster recovery plans have a reduced scope in that they focus on maintaining continuity of operations for private sector organizations—which are mostly driven by profit. Yet the government has to concern itself with public disaster recovery plans for the health and safety of its people during adverse events. For example, when hurricanes are forecasted to land at certain coastlines, state and federal government officials enact continuity of operations plans to allocate emergency resources and shelters as well as enact evacuation protocols to protect the public from the impending storm. This also includes the subsequent recovery and funding efforts following the disaster.
NOTE Continuity of operations plans are typically made up of certain components, including protecting essential functions and key personnel, providing alternate work sites, establishing communications plans, training, testing, and exercises, and protecting vital records, systems, and equipment.
Disaster Recovery
Disaster recovery involves the policies, staff, tools, and procedures to enable the timely recovery of an organization’s technological infrastructure from disruptive events. Yet, disasters seldom happen, so organizations often don’t pay much attention to them until a disaster catches them off guard. Recent acts of terrorism, hurricanes, tsunamis, and stronger compliance laws have helped create a greater sense of urgency regarding worse-case scenario planning. Disaster recovery plans are created to drive the requirements and technological implementations to successfully recover an organization from a disaster event. Disaster recovery must account for many technological areas, including the following:
• Computer emergency response plan This includes communication processes and recommended actions during computer emergencies.
• Succession plan Describes next-in-command leadership if immediate leadership is not available.
• Data Describes all important data and classifications.
• Critical services Describes all mission-critical services and the priority order in which they should be restored.
• Restoration timelines Describes recovery time objectives for various disaster events.
• Data backup/restoration plan Describes the data that is backed up, backup media and location, backup frequency, and recovery methods and timelines.
• Equipment replacement plan Describes which equipment is most needed as well as where to acquire that equipment in the event of losses.
• Public/notification management Details the process for notifying the media of adverse events that are of public interest.
Incident Response Team
Although the initial response to an incident may be done by an individual, such as a system administrator, the complete handling of an incident typically takes an entire team. An incident response team is a group of people who prepare for and respond to any emergency incident, such as a natural disaster or an interruption of business operations. A computer security incident response team is typically formed of key members that bring a wide range of skills to bear in the response effort within an organization. Incident response teams are common in corporations as well as in public service organizations.
Incident response team members ideally are trained and prepared to fulfill the roles required by the specific situation (for example, to serve as incident commander in the event of a large-scale public emergency). Incident response teams are frequently dynamically sized to the scale and nature of an incident. As the size of an incident grows, and as more resources are drawn into the event, the command of the situation may shift through several phases.
In a small-scale event, or in the case of a small firm, usually only a volunteer or ad-hoc team may exist to respond. In cases where the incident spreads beyond the local control of the incident response team, higher-level resources through industry groups and government groups exist to assist in the incident.
To function in a timely and efficient manner, ideally a team has already defined a protocol or set of actions to perform to mitigate the negative effects of most common forms of incidents.
Many models exist for the steps to perform during an incident. One model is the five-step incident response cycle shown in Figure 11-1. Here are the five key steps:

Figure 11-1 Incident response cycle
1. Discover and report Organizations should administer an incident-reporting process to make sure that potential security breaches as well as routine application problems are reported and resolved as quickly as possible. Employees should be trained on how to report system problems. Almost all incidents are first discovered by users finding abnormal conditions. The proper reporting of these observations begins the process.
2. Confirm Specialists or incident response team members review the incident report to confirm whether or not a security incident has occurred. Detailed notes should be taken and retained because they could be critically valuable for later investigation. Incidents are classified as Low, Moderate, or High, and this information is used to prioritize the initial response.
3. Investigate An incident response team composed of network, system, and application specialists should investigate the incident in detail to determine the extent of the incident and to devise a recovery plan. The composition of this team is incident specific.
4. Recover The investigation is complete and documented at this point in time. The cause of the incident has been addressed and steps are taken to return the systems and applications to operational status.
5. Lessons learned Also known as the after-action report (AAR), this is the post-mortem session designed to collect lessons learned and assign action items to correct weaknesses and to suggest ways to improve.
The key to incident response is having a plan previously established. Key individuals should be trained, and the plan needs to be tested before it is used in an incident response. A good plan lays out the following:
• What needs to be done (in a step-by-step fashion)
• Who needs to do it (and hence be trained)
• An analysis of communications and other senior management activities
Order of Volatility
The collection of electronic data can be a difficult task. In some cases, such as volatile data, there may only be one chance to collect it before it becomes lost forever. Volatile information such as the RAM can disappear in a matter of nanoseconds; therefore, data collection should occur in the order of volatility or lifetime of the data. Here is the order of volatility of digital information in a system from most-to-least volatile:
1. CPU, cache, and register contents
2. Routing tables, ARP cache, process tables, kernel statistics
3. Memory (RAM)
4. Temporary file system or swap space
5. Data on hard disk
6. Remotely logged data
7. Data stored on archival media or backups
EXAM TIP Some great tools for collecting volatile data include FTK imager, Volatility, Autopsy/Sleuth Kit, and EnCase/Digital Intelligence.
Incident Response Support Tools
When responding to a security incident, you will call upon certain software tools to gather information about the incident in order to implement appropriate mitigations. Although the following are by no means all the tools you’ll use in the industry, the CASP+ exam requires knowledge of them in particular:
• dd
• tcpdump
• nbtstat
• netstat
• nc (Netcat)
• memdump
• tshark
• foremost
dd
One of the inherent advantages of digital forensics is the simplicity of making copies of evidence. This permits analysis of the copy without affecting the original. According to its man page, dd is used for converting and copying files. It is a well-known Unix/Linux command-line tool often used in forensics for capturing raw images of files, folders, partitions, and drives. Typically, a disk-level image is made so that all data is available at one time for analysis during a data breach. The following is an example of cloning one hard drive to another:
dd if=/dev/sda of=/dev/sdb
The dd tool is capable of many operations. For more information about dd capabilities, take a look at the help file shown in Figure 11-2.

Figure 11-2 Example of dd
An enhanced version of dd was created, called dcfldd, that adds new capabilities—some of which benefit forensic operations, including the following:
• Multiple output files
• Split outputs
• Hashing on the fly
• More flexible imaging
• Displaying the progress of operations
tcpdump
The tcpdump command-line tool is commonly used on Unix/Linux operating systems to capture network packets transferred over networks. Typically, you’ll want to run it in “monitor mode” for a particular interface so that you can start capturing and displaying live network traffic, as shown in Figure 11-3.
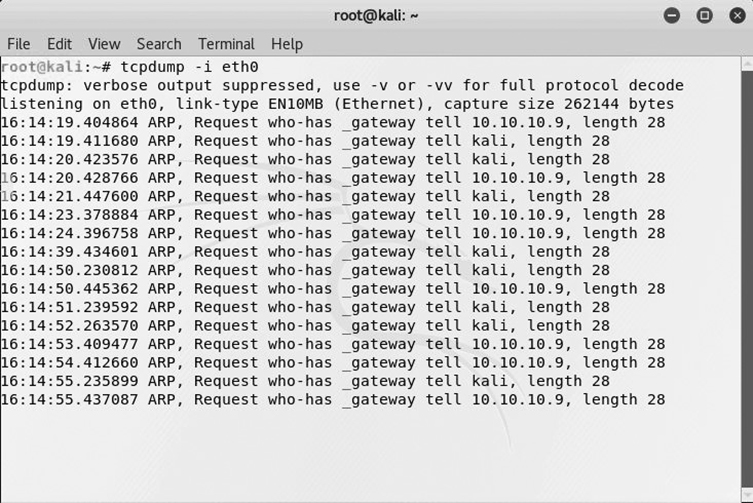
Figure 11-3 Example of tcpdump
As another example, to capture traffic from a specific port, use the following command:
tcpdump -i eth0 port 22
nbtstat
Also known as NetBIOS over TCP/IP, the nbtstat tool allows troubleshooting of NetBIOS-related issues by displaying TCP/IP connections and protocol statistics based on NetBIOS network activity. NetBIOS, which stands for Network Basic Input/Output System, is a legacy Microsoft service that permits older applications based on the NetBIOS application programming interface (API) to communicate with each other within a local area network (LAN). It was designed in the early 1980s and occupies the fifth layer of the OSI model (the Session layer). See Figure 11-4 for an example of output showing the local computer name and domain/workgroup membership.
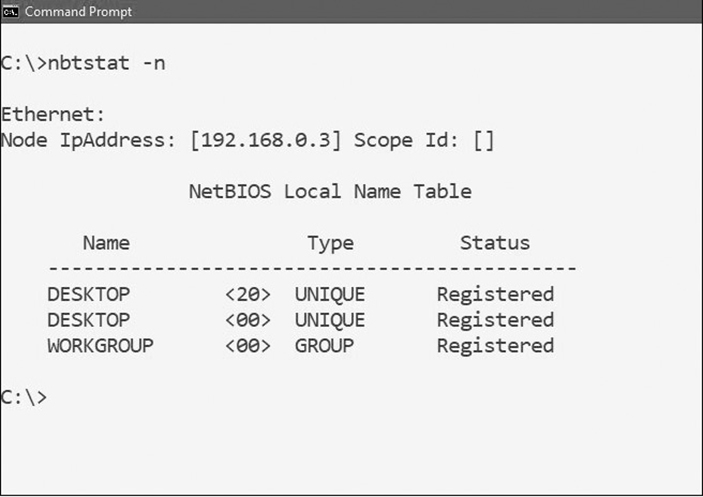
Figure 11-4 Example of nbtstat
To troubleshooting NetBIOS name resolution issues, nbtstat provides the following commands:
• nbtstat -c Lists contents of NetBIOS name cache and IP addresses
• nbtstat -n Lists locally registered NetBIOS names
• nbtstat -r Lists all names resolved by Windows Internet Naming Service (WINS) and through broadcasting
• nbtstat -R Purges and reloads the remote cache name table
• nbtstat -s Lists current NetBIOS sessions, status, and statistics
• nbtstat -S Lists sessions table with destination IP addresses
netstat
Netstat, which stands for network statistics, is a command-line tool designed to display generalized network connections and protocol statistics for the TCP/IP protocol suite. Available in Windows, Unix, Linux, and macOS operating systems, this utility can display TCP/UDP listening ports, established connections, Ethernet statistics, and routing protocol table information, and it supports many command filters. The following are some sample netstat command switches:
• netstat -a Displays all connections and listening ports
• netstat -b Displays the application/service executable file responsible for creating connections or listening ports
• netstat -e Displays Ethernet statistics
• netstat -f Displays fully qualified domain names (FQDNs) for destination addresses
• netstat -n Displays addresses and ports in numerical form
• netstat -r Displays the Windows routing table
• netstat -s Displays per-protocol stats
See Figure 11-5 for an example of netstat showing listening ports and established connections.
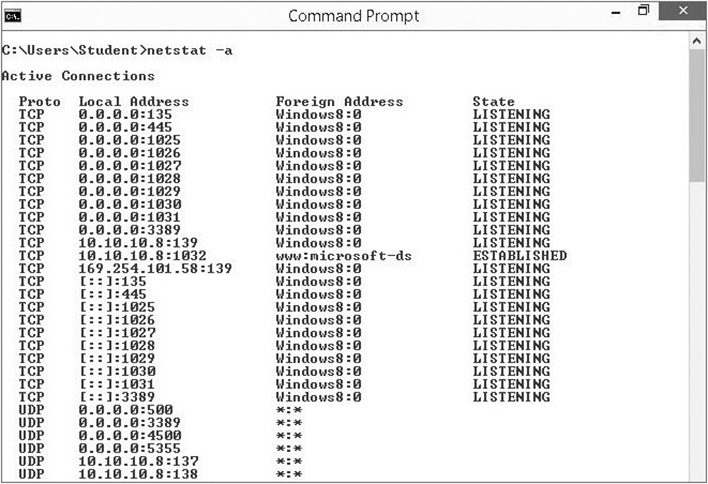
Figure 11-5 Example of netstat
nc (Netcat)
Often referred to as the “Swiss army knife” utility, nc (or netcat, as its sometimes known) is a Unix/Linux command-line tool designed to connect to or host various types of network connections with other systems. Equally capable of running in “server mode” to host connections or in “client mode” to connect to servers, nc is also capable of performing port scanning, file transfers, listening on ports, and being set up as a backdoor for remote connectivity. The following is an example of a command that demonstrates how to connect to a server called fileserver1.example.com on port 25:
nc fileserver1.example.com 25
For an example of setting up nc in listening mode for port 1234, refer to Figure 11-6.
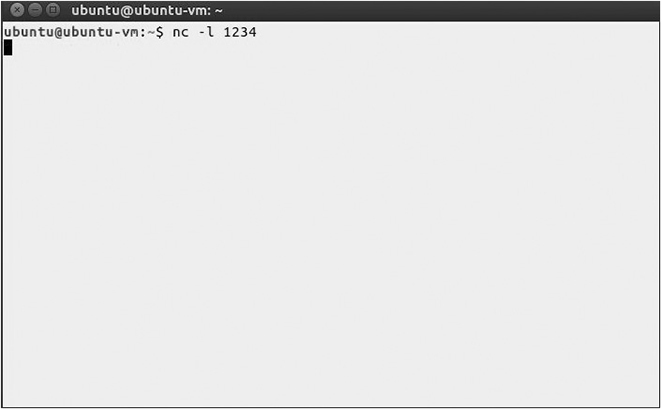
Figure 11-6 Example of nc
memdump
Evidence of data breaches is often found in physical memory—yet data residing in memory is highly volatile. Plus, data is easier to analyze when dumped from memory to a less-volatile and robust storage medium. Enter memdump, a Linux command-line tool that can dump physical and kernel memory contents to both local storage and network locations—the latter of which is the preferred method in order to prevent changing all the memory in the file system cache. The following are examples of memdump switches:
• -k Dumps kernel memory instead of physical memory
• -b Specified buffer size per memory read operation
• -d Specifies number of memory bytes to dump
• -v Enables verbose logging of memory dump

TIP A great alternative to memdump is the DumpIt utility, which is often paired with the Volatility framework for memory dump/analysis processes.
tshark
For a command-line version of Wireshark, take a look at tshark. The tshark utility is a network protocol analyzer that captures network traffic from a live network. It can also read packets that were previously captured and saved into capture files. It supports the PCAP file format, which is also supported by Wireshark and tcpdump. The following is an example of tshark capturing traffic on the eth0 interface:
tshark -i eth0
In Figure 11-7, you’ll see some sample tshark output.
Figure 11-7 Example of tshark
Foremost
Foremost is a forensic data recovery command-line tool used on Linux, primarily for law enforcement to recover deleted or corrupted data from drives. It can work on disk image files created by dd, Safeback, and EnCase, plus work with the local hard disks directly. Despite its forensics leaning, it can also be used for general data recovery operations. Using a process known as “file carving,” foremost is able to skip past the file system to recovery files and load them into memory. It can recover files from the following file systems:
• Ext3
• NTFS
• FAT file systems
• iPhone file system
Let’s say you want to recover a recently deleted JPEG file. Here is one of the commands you would type:
foremost -t jpeg -i /dev/sda1
Severity of Incident or Breach
Whenever an incident or breach occurs, organizations have to respond with an appropriate level of resources and urgency. The severity of an incident will govern how aggressively we respond, just as our earlier assessment of risks, threats, and vulnerabilities resulted in proactively implementing the very security controls aimed at preventing incidents such as these. Incidents are the price we pay for being unable to adequately mitigate those factors. To respond to an incident, we need to know what we’re dealing with in terms of the scope of the incident, its impact to the organization in terms of downtime and costs, plus the legal ramifications. This section provides coverage of each of these topics.
Scope
The scope defines the extent of an area affected or how widespread an incident or breach is. For example, is one person unable to log into the domain controller, a whole department, or the entire organization? Along with impact, scope needs to be one of the first two things understood early on in order to properly prioritize detection, escalation, mitigation, and recovery procedures. An incident that only affects one person will typically garner a comparatively abridged response, as opposed to incidents that affect dozens of workers.
Impact
Even more important than scope is the impact of an incident. Impact defines the effect of an incident on business processes. For example, an entire department is unable to log into the domain controller and therefore cannot access any company applications. The scope of the issue is one department; however, nobody in that department can work. Therefore, the incident’s impact is quite serious.
EXAM TIP If the scope of an incident increases, so does the resulting impact.
Cost
Security incidents can be very expensive, particularly when they affect mission-critical assets. Calculating the cost of incidents can be tricky due to the number of direct and indirect cost factors to consider, such as losing customer data, company downtime, and legal fees. Then there’s the cost of hiring forensic investigators, compromised trade secrets, and even the cost of damaged reputations.
The cost of incidents is also affected by the following factors:
• Industry your organization belongs to Security breaches in the medical field are the most expensive, followed by financial services and media.
• Region For economic and cost of living reasons, certain regions have an inherently more expensive data breach potential than others. The U.S. and Canada lead the way in being the most expensive regions for data breaches.
• Containment How quickly an organization responds to a breach can significantly impact the final cost of the breach.
EXAM TIP For a more accurate and efficient calculation of costs, it helps to know the value of the assets prior to a breach. Determining asset value was talked about in Chapter 3.
Downtime
Businesses are going to experience some downtime throughout the months, quarters, and years. Maintaining 100 percent availability is quite rare, with costs not typically outweighing the benefits. The trick is managing and delivering on expectations in terms of the amount of planned and unplanned downtime customers can expect during a given period of time. This is typically indicated in the organization’s service level agreement (SLA). Businesses spend a lot of money ensuring they fulfill their availability requirements because when a serious incident knocks the organization offline, it also might knock down the reputation of the business an expensive peg or two. This is why organizations must aggressively produce and reinforce business continuity plans and disaster recovery plans. For more information about downtime, see Chapter 5.
Legal Ramifications
During incidents and breaches, organizations must fear not only the customers’ wrath but also any potential legal consequences. Depending on the organization’s level of negligence, it can receive stiff fines, penalties, or in extreme cases jail time for executives. Although states have notification laws compelling organizations to notify affected customers of data breaches, many organizations suppress notifications by covering up attacks. Companies know all too well that they can do everything right in terms of security and privacy management, yet it only takes one big hack to deal a death blow to their ability to survive. The following are some other consequences experienced as a result of data breaches:
• Reduced reputation
• Reduced competitive capabilities
• Reduced customer trust
• Reduced revenue
CAUTION Compliance violations can sting. HIPAA violations can cost up to $50,000 per violation or record. GLBA can penalize financial institutions with up to five years’ imprisonment, steep fines, or both. Fines can reach $100,000 for each violation. Officers and directors can be fined up to $10,000 each.
Post-Incident Response
Just when you thought you were all done putting out the big fire, now comes the fun part—review and documentation time. This phase is important because you get an opportunity to learn from your mistakes, make decisions that can help improve your security going forward, and implement the required changes for the betterment of the organization. This section covers root-cause analysis, lessons learned, and the after-action report.
Root-Cause Analysis
Security practitioners can be called upon to resolve most security incidents to get the business back to normal. Yet, there will be times when no one knows what caused the issue in the first place. This is not a preferred outcome because central to the post-incident response process is identifying lessons learned as well as creating an after-action report to put those lessons into motion. That cannot happen if you haven’t identified the true cause of the incident. Just wiping out a virus with an antivirus tool is, more less, treatment of the symptom as opposed to curing the condition. Where did the virus come from? How did it get here? Why did it get here? Who is responsible? To help us answer those questions, and to reach that point of deeper understanding, we perform a process known as root-cause analysis.
According to NIST, root-cause analysis is “a principle-based, systems approach for the identification of underlying causes associated with a particular set of risks.” It seeks to determine—for a particular issue or problem—what the true and original source of the issue is. Let’s see this play out with an example:
1. Technician A argues that missing antivirus definitions are the cause of the user’s virus infection.
2. Technician B argues that the antivirus definitions were missing because no users or technicians thought to turn on the auto-update feature for the antivirus software.
3. Technician C argues that although these suggestions are contributing factors, they are not the root cause. The following are more appropriate root causes (because there can and usually will be more than one):
a. The lack of a security policy that defines requirements for antivirus scans and updates.
b. The lack of a procedures document that details the methods of antivirus scans, updates, and safe Internet browsing.
c. The lack of an end-user training process to raise awareness of the policy and procedures to reduce the threat of malware infections.
EXAM TIP The key to root-cause analysis is to keep asking the same question over and over: “What was the direct thing that made this happen?” This allows you to subdivide the immediate issue into its smaller pieces until you arrive at the root of it all.
Above all else, you look below the surface to cure the condition, not treat the symptom. Because, if antivirus scans aren’t being performed regularly, and definition updates aren’t kept up to date, you will continue to have malware infections even after you initially eradicate the current one. The root cause of the preceding issue wasn’t so much technical but rather managerial. Management needs to enforce security policies, ensure procedures are understood, and enact end-user training processes to ensure prevention, detection, and mitigation of the threats. Poor management was the root cause.
Lessons Learned
Root-cause analysis primarily focuses on identifying the issue source. This information is one of multiple inputs you’ll want to take into the lessons learned phase of post-incident response. Lessons learned give us an opportunity to evaluate our mistakes, our successes, assess what happened during the incident, and describe how the organization has dealt with resolving the issue. Ultimately, the goal is to identify what steps are needed in order to improve our ability to prevent, detect, and mitigate incidents going forward. To help get us there, we turn to the after-action report.
After-Action Report
We can all agree that it’s important to identify an issue’s root cause—and learn some valuable lessons along the way—but we need a vehicle to set those lessons learned into motion. Enter the after-action report. The after-action report implements the security recommendations gleaned from the lessons learned report. This will call for improvements or changes to the following areas:
• Policies, procedures, awareness
• Cybersecurity training
• Hardware/software configurations
• Security funding
• Monitoring
• Vulnerability/penetration testing
• Auditing
• Business continuity plans
• Disaster recovery plans
• Incident management
• Change management
Chapter Review
In this chapter, we covered the implementation of incident response and recovery procedures for various scenarios. The first section began with e-discovery, which describes the process of acquiring digital information for evidence purposes. To support e-discovery initiatives, we perform electronic inventories and asset control of all data to simplify indexing and searching for data when it’s legally requested. We also talked about data retention policies and the need to hold onto certain types of data for a certain number of years before it can be destroyed. We then talked about data recovery and storage techniques to ensure the availability of data during and after a loss event takes place. Data ownership was also discussed to distinguish the responsibilities between the owners, who classify data and delegate who is to provide security controls to the data, and the data custodians, who implement those security controls on the data. We then finished the section with legal holds and how they require specified data types to remain despite any content that has already aged past its data retention period.
The next section focused on data breaches. This began a dissection of incident response processes that start with the detection of the breach and the collection of data to support the existence of the breach. We then talked about analyzing the data to ensure we understand the scope and impact of the breach. We then touched on mitigation of the breach, which involves isolating the breach to a limited area, and limiting the damage it causes, as well as various mitigation techniques to ensure eradication of the threat. We then talked about recovery and reconstitution of data and systems from damage or losses, general response procedures, and disclosure of incident details to stakeholders, law enforcement, and the media.
The third section of the chapter talked about facilitating incident detection and response. Hunt teaming takes an offensive approach to detecting threats. Heuristics and behavioral analytics study the behaviors and patterns of network traffic and software functionality to detect possible or confirmed malicious activity. We then looked at reviewing system, audit, and security logs for signs of attackers knocking on the door or having already penetrated the organization’s security controls.
We then moved on to incident and emergency response measures, beginning with chain of custody and its requirements to track access, control, and movement of evidence to preserve its integrity for possible court admission. We also talked about the process of performing a forensic analysis of compromised systems. We then discussed continuity of operations planning, which involves recovering from public disaster events, and then disaster recovery, which focuses on technological recovery for private sector businesses. Incident response teams were covered to point out their roles and responsibilities for carrying out incident response plans. Finally, we finished the section talking about the order of volatility, which describes the order in which evidence should be collected before it disappears.
The next section described incident response support tools such as dd, which is a file/disk-copying tool, tcpdump for packet capturing, nbtstat for NetBIOS troubleshooting, netstat for TCP/IP connection statuses, nc for observing local and remote connections, memdump for memory dumping and analysis, tshark for a command-line version of Wireshark sniffing, and foremost, which is a tool for recovering deleted or corrupted data from drives.
The next section talked about the severity of incidents or breaches. We talked about scope, which describes how broad an issue is, and then impact, which describes the loss of business functionalities caused by the breach. Next was cost, which involves the financial damages suffered, including the cost of recovery. Then we talked about the impact and requirements of downtime, and then finally the legal ramifications that result from data breaches and incidents.
The final section of the chapter discussed post-incident responses, beginning with root-cause analysis, which seeks to understand the original cause of issues. We then talked about lessons learned, which involve gathering all information about the breach, including positives, negatives, and the need for changes to improve security in the future. We finished the chapter with a discussion of after-action reports, which take the lessons learned and apply them to the organization in order to improve security during future incidents.
Quick Tips
The following tips should serve as a brief review of the topics covered in more detail throughout the chapter.
E-Discovery
• E-discovery is the electronic discovery of evidence.
• E-discovery is about producing records based on a subject, an event, a person, and so on.
• Most e-discovery periods are 90 days long, and failure to produce in the 90-day window can bring sanctions and penalties.
• Asset management deals with the management of the assets of an organization.
• It is essential for a company to identify, track, classify, and assign ownership for its most important assets.
• A data retention policy dictates the systematic review, retention, and destruction of data in the enterprise.
• Contracts, billing documentation, and financial and tax records are normally prescribed to be kept for seven years after creation or last use.
• Data recovery is the process of recovering data from damaged, failed, corrupted, or inaccessible storage devices when it cannot be accessed using normal data access methods.
• Data storage strategies, including backups to provide for recovery in the event of primary storage failure, are foundational security elements in an enterprise.
• Assigning data owners and establishing responsibility for all custodial duties are key elements in managing an information asset.
• Data owners are typically department managers that make decisions on how certain data should be used and managed, whereas data custodians are the IT personnel who implement the decisions made by the data owners.
• A legal hold is a process that permits organizational compliance with legal directives to preserve all digital and paper records in anticipation of possible litigation.
• Any data retention policies that had previously earmarked legally requested data for destruction are immediately and indefinitely suspended until all relevant litigation has concluded.
Data Breach
• A data breach is the release of information to an unauthorized party or environment.
• Detection of breaches may involve the examination of hardware and software alerts, surveillance cameras, logs (system, application, and security), network traffic, error messages, and feedback from employees and customers.
• Evidence is highly perishable; therefore, you should begin collecting it as soon as possible.
• Data breach analysis involves classifying the breach and assigning a priority level in order to ensure that the appropriate levels of attention and resources are provided to the incident.
• The gold standard to prevent data loss from breach or compromise is encryption. When properly employed, encryption can protect data during storage, in transit, and even during processing in some cases.
• Data minimization efforts can play a key role in both operational efficiency and security. One of the first rules associated with data is “don’t keep what you don’t need.”
• Isolation involves containing the incident to a limited area to prevent spreading.
• After a data breach has been fully resolved, it is time to disclose all relevant data breach details to business stakeholders, which may include your immediate manager, senior management, and human resources, in addition to team leads from various departments.
Facilitate Incident Detection and Response
• When a data breach occurs, the firm must be ready to respond immediately.
• The time to formulate plans and procedures was before the event because many factors will be driving timelines, including the business risk associated with the data loss, customer pressure, and regulatory pressure.
• Detection begins at the point in time when the incident is discovered, and it becomes a breach because of the nature of the incident.
• Mitigation efforts are the immediate countermeasures performed.
• Both internal and external parties are involved in data breach issues.
• The primary goal behind preparing for incident response is the successful and efficient handling of the incident, including returning the system to a proper operating condition.
• The best way to obtain criminal evidence is to let law enforcement collect the evidence.
• Evidence will be subject to challenges by the defense attorney; if any “issues” are associated with the fidelity of the data collection effort, in most cases the evidence will be suppressed or not allowed.
• Hunt teaming is a comprehensive process of security teams seeking out any signs of attack against the organizational network.
• Security teams will search for signs of compromise, which may include unusual changes to audit logs, locked-out accounts, malware backdoors, changes to critical files, and slow Internet or devices—not to mention keeping an eye out for strange administrator account patterns or any signs of unapproved software and network traffic.
• The key to hunt teaming is being proactive. By looking at all attack vectors for signs of malicious activities, organizations may reveal anomalies that might’ve been missed had they maintained the more typical reactionary security posture.
• Behavioral analytics is the process of measuring and identifying how entities typically act, or behave, and later comparing these measured behaviors to future samples to potentially spot deviations.
• Heuristic analytics intelligently gathers data points from various host and network data sources within a specific environment. It then scores each of these data points relative to one another to determine if the entity is threatening, potentially threating, or not threatening in nature.
• System administrators should enable logging on all significant systems so that data can be collected as to system performance and operation.
• Enabling logging is not sufficient on its own. Log files have no value unless their contents are examined, analyzed, and acted upon.
• SIEM solutions are a critical component of automated security systems used in continuous monitoring.
Incident and Emergency Response
• Incident response is the term used to describe the steps an organization performs in reaction to any situation determined to be abnormal in the operation of a computer system.
• Chain of custody is a detailed record of evidence handling, from its collection, preservation, and analysis, to presentation in court and disposal.
• Digital forensics is the application of scientific methods to electronic data systems for the purposes of gathering specific information from a system.
• A continuity of operations plan refers to a government’s processes for maintaining functionality in the event of a serious public event.
• Business continuity plans and disaster recovery plans have a reduced scope in that they focus on maintaining continuity of operations for private sector organizations—which are mostly driven by profit. Yet the government has to concern itself with public disaster recovery plans for the health and safety of its people during adverse events.
• Disaster recovery involves the policies, staff, tools, and procedures to enable the timely recovery of an organization’s technological infrastructure from disruptive events.
• An incident response team is a group of people who prepare for and respond to any emergency incident, such as a natural disaster or an interruption of business operations.
• The order of volatility describes the order in which digital evidence should be collected before it disappears.
Incident Response Support Tools
• When responding to a security incident, you will call upon certain software tools to gather information about the incident in order to implement appropriate mitigations.
• dd is used for converting and copying files.
• The tcpdump command-line tool is commonly used on Unix/Linux operating systems to capture network packets transferred over networks.
• The nbtstat tool allows troubleshooting of NetBIOS-related issues by displaying TCP/IP connections and protocol statistics based on NetBIOS network activity.
• The netstat tool is a command-line tool designed to display generalized network connections and protocol statistics for the TCP/IP protocol suite.
• The nc tool is a Unix/Linux command-line utility designed to connect to or host various types of network connections with other systems.
• The memdump tool is a Linux command-line utility that can dump physical and kernel memory contents to both local storage and network locations.
• The tshark utility is a network protocol analyzer that captures network traffic from a live network or can read packets that were previously captured and saved into capture files.
• Foremost is a forensic data recovery command-line tool used on Linux primarily for law enforcement to recover deleted or corrupted data from drives.
Severity of Incident or Breach
• The severity of an incident will govern how aggressively you respond, just as the earlier assessment of risks, threats, and vulnerabilities resulted in proactively implementing the very security controls aimed at preventing incidents.
• The scope defines the extent of an area affected or how widespread an incident or breach is.
• Impact defines the effect of an incident on business processes.
• Calculating the cost of incidents can be tricky due to the number of direct and indirect cost factors to consider, such as losing customer data, company downtime, and legal fees. Then there’s the cost of hiring forensic investigators, compromised trade secrets, and even damaged reputation.
• Downtime involves managing and delivering on expectations in terms of the amount of planned and unplanned availability customers can expect during a given period of time.
• Legal ramifications for data breaches can involve stiff fines, penalties, or in extreme cases jail time for executives.
Post-Incident Response
• Root-cause analysis seeks to determine the root cause (or causes) of a problem.
• Lessons learned give us an opportunity to evaluate your mistakes, your successes, assess what happened during the incident, and describe how the organization has dealt with resolving the issue.
• The after-action report implements the security recommendations gleaned from the lessons learned report.
Questions
The following questions will help you measure your understanding of the material presented in this chapter. Read all the choices carefully because there might be more than one correct answer. Choose all correct answers for each question.
1. Which of the following governs the review, retention, and destruction of data in the enterprise?
A. Document retention policy
B. Data destruction policy
C. Compliance policy
D. Incident response policy
2. You are a member of a team that is going to perform a forensics capture of a desktop PC. Which is the best order of capture?
A. RAM, hard drive, DVD
B. Thumb drive, hard drive, RAM
C. Hard drive, RAM, DVD
D. Hard drive, thumb drive, RAM
3. What term is associated with the protection of forensic evidence?
A. Data analysis
B. Data retention
C. Chain of custody
D. Hashing
4. Removal of unneeded PII from a database is an example of what?
A. HIPAA compliance
B. Encryption
C. Privacy control
D. Data minimization
5. Which type of incident response team (IRT) is associated with a regional office?
A. Central IRT
B. Distributed IRT
C. Coordinating IRT
D. Outsourced IRT
6. To protect confidential data from exposure during a breach, the best solution is:
A. Hashing
B. Encryption
C. Anonymization of records
D. Mitigation
7. The use of ______ can assist in the collection and analysis of log file data to help determine the organization’s security posture.
A. PIA
B. signature analysis
C. data minimization
D. SIEM
8. An abnormal condition detected in a computer system is referred to as what?
A. Event
B. Alarm
C. Incident
D. False positive
9. Data retention times are specified by which of the following? (Select all that apply.)
A. Laws and regulations
B. Actual practice in the enterprise
C. Security policy
D. Corporate legal department
10. A web server is suspected of being compromised, and the incident response team suggests that it be fixed. What are elements associated with fixing the server? (Select all that apply.)
A. Do a directory search for changed information to see if it is compromised.
B. Make a forensic backup copy for analysis.
C. Reapply all patches to the server and then return it to service.
D. Perform a system restore from a known good copy.
11. A security incident where confidential data is copied, viewed, or stolen by an unauthorized party is a:
A. Security breach
B. PII violation
C. Data breach
D. Security failure
12. The last step of an incident response effort is:
A. Recovery
B. Assignment of blame
C. Lessons learned
D. Customer notification
13. Who is the best party to be a data owner?
A. CIO
B. Business management associated with the data
C. System administrator
D. Database administrator
14. The placing of data into groups associated with risk for the purposes of managing security is known as what?
A. Data ownership
B. Data management
C. Data retention
D. Data classification
15. A company has just migrated to a new business recordkeeping system as part of a merger. This will necessitate the repeating of what process?
A. PIA
B. PII
C. PHI
D. PCI
16. The group of people who prepare, train for, and respond to emergency incidents are referred to as which of the following?
A. Incident containment team
B. Incident response team
C. Incident investigation team
D. Incident management team
17. The salvaging of data from a damaged or corrupted secondary storage media that cannot be used in a normal access mode is an example of what?
A. Data recovery
B. Data restoration
C. Data cleansing
D. Data management
18. A set of backup tapes is lost off an overnight shipping truck and has been deemed to be unrecoverable by the shipping company. Which of the following statements is true?
A. This is a data breach.
B. This is not a data breach because the files are truly lost and are not in the hands of another party.
C. This is not a data breach because backup tapes are not truly data to outsiders.
D. This is not a data breach because the tapes are not labeled as to firm, only a code number.
19. The development of a plan to use in the collection of evidence is which step in the forensics process?
A. Preparation
B. Approach strategy
C. Collection
D. Analysis
20. In a large enterprise, e-discovery is best handled via which of the following?
A. A separate department
B. Outsourcing
C. Specialty appliances
D. Large in-house legal staff
Answers
1. A. The document retention policy (or data retention policy) governs all aspects of data/document retention.
2. A. The most volatile is RAM, which is first, followed by hard drive and DVD.
3. C. Chain of custody is associated with preserving and protecting evidence.
4. D. Not storing unneeded data is an example of data minimization.
5. B. A local independent IRT is part of a distributed IRT structure.
6. B. Data that is encrypted is not readable if lost, and although the bits may be lost, the information is not.
7. D. Security incident event management (SIEM) solutions can be programmed with alerts.
8. C. The term “incident” is used to describe any abnormal event in a system.
9. A, D. Laws and regulations (A) are one source of information; advice from the firm’s legal department (D) is another.
10. B, D. Making a forensic backup copy for analysis (B) is correct because this step is one of the first steps in an incident response, and recovery can occur by restoring from a known good image (D).
11. C. This is the definition of data breach.
12. C. The last step is a lessons learned session, where process improvements are discussed.
13. B. The best data owner is business management of the portion of the business involved in the data—it has the best visibility as to the business purpose and requirements.
14. D. Data classification is the assignment of data into different groups of security requirement levels.
15. A. A PIA (privacy impact assessment) needs to be redone after any material change in people, process, or technology.
16. B. This is the definition of an incident response team.
17. A. Data recovery is the salvaging of data from broken storage media, whether the broken aspect is either physical or logical.
18. A. A data breach is the loss of control over data, regardless of the form or cause.
19. B. The development of an approach or plan associated with strategizing the acts to be pursued is the “approach strategy” step.
20. C. Because of scale issues, specialty appliances are necessary to handle the volumes of data in the time period allotted.