
25
Assessing the Performance of Multisensor Fusion Processes
James Llinas
CONTENTS
25.2 Test and Evaluation of the Data Fusion Process
25.2.1 Establishing the Context for Evaluation
25.2.5 The T&E Process: A Summary
25.3 Tools for Evaluation: Testbeds, Simulations, and Standard Data Sets
25.4 Relating Fusion Performance to Military Effectiveness: Measures of Merit
25.1 Introduction
In recent years, numerous prototypical systems have been developed for multisensor data fusion (DF). A paper by Hall and co-workers1 describes more than 50 such systems developed for Department of Defense (DoD) applications some 15 years ago. Such systems have become ever more sophisticated. Indeed, many of the prototypical systems summarized by Hall and co-workers1 use advanced identification techniques such as knowledge-based or expert systems, Dempster–Shafer interface techniques, adaptive neural networks, and sophisticated tracking algorithms.
Although much research has been performed to develop and apply new algorithms and techniques, much less work has been performed to formalize the techniques for determining how well such methods work or to compare alternative methods against a common problem. The issues of system performance and system effectiveness are keys to establishing, first, how well an algorithm, technique, or collection of techniques performs in a technical sense and, second, the extent to which these techniques, as part of a system, contribute to the probability of success when that system is employed on an operational mission. An important point to remember in considering the evaluation of DF processes is that those processes are either a component of a system (if they were designed-in at the beginning) or they are enhancements to a system (if they have been incorporated with the intention of performance enhancement). In other words, it is not usual that the DF processes are the system under test; DF processes are said to be designed into systems rather than being systems in their own right. What is important to understand in this sense is that the DF processes contribute some marginal or piecewise improvement to the overall system, and if the contribution of the DF process per se needs to be calculated, it must be done while holding other factors fixed. If the DF processes under examination are enhancements, it is important that such performance must be evaluated in comparison to an agreed-to baseline (e.g., without DF capability, or presumably a lesser DF capability). These points will be discussed in more detail later.
It is also important to mention that our discussion in this chapter is largely about automated DF processing (although we will make some comments about human-in-the-loop aspects later), and by and large such processes are enabled through software. Thus, it should not be surprising that remarks made herein draw on or are similar to concerns for test and evaluation (T&E) of complex software processes.
System performance at level 1, for example, focuses on establishing how well a system of sensors and DF algorithms may be utilized to achieve estimates of or inferences about location, attributes, and identity of platforms or emitters. Particular measures of performance (MOPs) may characterize a fusion system by computing one or more of the following:
Detection probability—probability of detecting entities as a function of range, signal-to-noise ratio, and so on
False alarm rate—rate at which noisy or spurious signals are incorrectly identified as valid targets
Location estimate accuracy—the accuracy with which the position of an entity is determined
Identification probability—probability of correctly identifying an entity as a target
Identification range—the range between a sensing system and target at which the probability of correct identification exceeds an established threshold
Time from transmission to detect—time delay between a signal emitted by a target (or by an active sensor) and the detection by a fusion system
Target classification accuracy—ability of a sensor suite and fusion system to correctly identify a target as a member of a general (or particular) class or category
These MOPs measure the ability of the fusion process as an information process to transform signal energy either emitted by or reflected from a target, to infer the location, attributes, or identity of the target. MOPs are often functions of several dimensional parameters used to quantify, in a single variable, a measure of operational performance.
Conversely, measures of effectiveness (MOEs) seek to provide a measure of the ability of a fusion system to assist in completion of an operational mission. MOEs may include
Target nomination rate—the rate at which the system identifies and nominates targets for consideration by weapon systems
Timeliness of information—timeline of availability of information to support command decisions
Warning time—time provided to warn a user of impending danger or enemy activity
Target leakage—percentage of enemy units or targets that evade detection
Countermeasure immunity—ability of a fusion system to avoid degradation by enemy countermeasures
At an even higher level, measures of force effectiveness (MOFEs) quantify the ability of the total military force (including the systems having DF capabilities) to complete its mission. Typical MOFEs include rates and ratios of attrition, outcomes of engagement, and functions of these variables. In the overall mission definition other factors such as cost, size of force, force composition, and so on may also be included in the MOFEs.
This chapter presents top-down, conceptual, and methodological ideas on the T&E of DF processes and systems, describes some of the tools available that are needed to support such evaluations, and discusses the range of measures of merit useful for quantification of evaluation results.
25.2 Test and Evaluation of the Data Fusion Process
Although, as has been mentioned in the preceding section, the DF process is frequently part of a larger system process (i.e., DF is often a subsystem or infrastructure process to a larger whole) and thereby would be subjected to an organized set of system-level test procedures, this section develops a stand-alone, top-level model of the T&E activity for a general DF process. This characterization is considered the proper starting point for the subsequent detailed discussions on metrics and evaluation, because it establishes a viewpoint or framework (a context) for those discussions, and also because it challenges the DF process architects to formulate a global and defendable approach to T&E.
In this discussion, it is important to understand the difference between the terms test and evaluation. One distinction (according to Webster’s Dictionary) is that testing forms a basis for evaluation. Alternately, testing is a process of conducting trials to prove or disprove a hypothesis—here, a hypothesis regarding the characteristics of a procedure within the DF process. Testing is essentially laboratory experimentation regarding the active functionality of DF procedures and, ultimately, the overall process (active meaning during their execution—not statically analyzed).
However, evaluation takes its definition from its root word: value. Evaluation is thus a process by which the value of DF procedures is determined. Value is something measured in context; it is because of this that a context must be established.
The view taken here is that the T&E activities will both be characterized as having the following components:
A philosophy that establishes or emphasizes a particular point of view for the tests and evaluations that follow. The simplest example of this notion is reflected in the so-called black box or white box viewpoints for T&E, from which either external (input/output behaviors) or internal (procedure execution behaviors) are examined (a similar concern for software processes in general, as has been noted). Another point of view revolves around the research or development goals established for the program. The philosophy establishes the high-level statement regarding context and is closely intertwined with the program goals and objectives, as discussed in Section 25.2.1.
A set of criteria according to which the quality and correctness of the T&E results or inferences will be judged.
A set of measures through which judgments on criteria can be made, and a set of metrics on which the measures depend and, importantly, which can be measured during T&E experiments.
An approach through which tests and analyses can be defined and conducted that
Are consistent with the philosophy
Produce results (measures and metrics) that can be effectively judged against the criteria
25.2.1 Establishing the Context for Evaluation
Assessments of delivered value for defense systems must be judged in light of system or program goals and objectives. In the design and development of such systems, many translations of the stated goals and objectives occur as a result of the systems engineering process, which both analyzes (decomposes) the goals into functional and performance requirements and synthesizes (reassembles) system components intended to perform in accordance with these requirements. Throughout this process, however, the program goals and objectives must be kept in view because they establish the context in which value will be judged.
Context, therefore, reflects what the program and the DF process (or system within it) are trying to achieve—that is, what the research or developmental goals (the purposes of building the system at hand) are. Such goals are typically reflected in the program name, such as a Proof of Concept program or Production Prototype program. Many recent programs involve demonstrations or experiments of some type or other, with these words reflecting in part the nature of such program goals or objectives.
Several translations must occur for the T&E activities themselves. The first of these is the translation of goals and objectives into T&E philosophies; that is, philosophies follow from statements about goals and objectives. Philosophies primarily establish points of view or perspectives for T&E that are consistent with, and can be traced to, the goals and objectives: they establish the purpose of investing in the T&E process. Philosophies also provide guidelines for the development of T&E criteria, for the definition of meaningful T&E cases and conditions, and, importantly, a sense of a satisfaction scale for test results and value judgments that guides the overall investment of precious resources in the T&E process. That is, T&E philosophies, while generally stated in nonfinancial terms, do in fact establish economic philosophies for the commitment of funds and resources to the T&E process. In today’s environment (it makes sense categorically in any case), notions of affordability must be considered for any part of the overall systems engineering approach and for system development, to include certainly the degree of investment to be made in T&E functions.
25.2.2 T&E Philosophies
Establishing a philosophy for T&E of a DF process is also tightly coupled to the establishment of what the DF process boundaries are. In general, it can be argued that the T&E of any process within a system should attempt the longest extrapolation possible in relating process behavior to program goals; that is, the evaluation should endeavor to relate process test results to program goals to the extent possible. This entails first understanding the DF process boundary, and then assessing the degree to which DF process results can be related to superordinate processes; for defense systems, this means assessing the degree to which DF results can be related to mission goals. Philosophies aside, certain acid tests should always be conducted:
Results with and without fusion (e.g., multisensor vs. single sensor or some best sensor)
Results as a function of the number of sensors or sources involved (e.g., single sensor, 2, 3, …, N sensor results for a common problem)
The last two points are associated with defining some type of baseline against which the candidate fusion process is being evaluated. In other words, these points address the question, Fusion as compared to what? If it is agreed that DF processing provides some marginal benefit, then that gain must be evaluated in comparison to the unenhanced or baseline system. That comparison also provides the basis for the cost-effectiveness trade-off in that the relative costs of the baseline and fusion-enhanced systems can be compared to the relative performance of each.
Other philosophies could be established, however, such as
Organizational: A philosophy that examines the benefits of DF products accruing to the system-owning organization and, in turn, subsequent superordinate organizations in the context of organizational purposes, goals, and objectives (no platform or mission may be involved; the benefits may accrue to an organization).
Economic: A philosophy that is explicitly focused on some sense of economic value of the DF results (weight, power, volume, and so on) or cost in a larger sense, such as the cost of weapons expended, and so on.
Informal: The class of philosophies in which DF results are measured against some human results or expectations.
Formal: The class of philosophies in which the evaluation is carried out according to appropriate formal techniques that prove or otherwise rigorously validate the program results or internal behaviors (e.g., proofs of correctness, formal logic tests, and formal evaluations of complexity).
The list is not presented as complete but as representative; further consideration would no doubt uncover many other perspectives.
25.2.3 T&E Criteria
Once having espoused one or another of the philosophies, there exists a perspective from which to select various criteria, which will collectively provide a basis for evaluation. It is important at this step to realize the exact meaning and subsequent relationships impacted by the selection of such criteria.
There should be a functionally complete hierarchy that emanates from each criterion as follows:
Criterion—a standard, rule, or test upon which a judgment or decision can be made (this is a formal dictionary definition),
which leads to the definition of
Measures—the dimensions of a criterion, that is, the factors into which a criterion can be divided
and, finally,
Metrics—those attributes of the DF process or its parameters or processing results which are considered easily and straightforwardly quantifiable or able to be defined categorically, which are relatable to the measures, and which are observable
Thus, there is, in the most general case, a functional relationship as follows:
Criterion = fct [(Measurei = fct (Metrici, Metricj…), Measurej = fct (Metrick, Metrici…), etc.]
Each metric, measure, and criterion also has a scale that must be considered. Moreover, the scales are often incongruent so that some type of normalized figure of merit approach may be necessary to integrate metrics on disparate scales and construct a unified, quantitative parameter for making judgments.
One reason to establish these relationships is to provide for traceability of the logic applied in the T&E process. Another rationale, which argues for the establishment of these relationships, is in part derived from the requirement or desire to estimate, even roughly, predicted system behaviors against which to compare actual results. Such prediction must occur at the metric level; predicted and actual metrics subsequently form the basis for comparison and evaluation. The prediction process must be functionally consistent with this hierarchy. For level 1 numeric processes, prediction of performance expectations can often be done, to a degree, on an analytical basis. (It is assumed here that in many T&E frameworks the truth state is known; this is certainly true for simulation-based experimentation but may not be true during operational tests, in which case comparisons are often done against consensus opinions of experts.) For levels 2 and 3 processes, which generally employ heuristics and relatively complex lines of reasoning, the ability to predict the metrics with acceptable accuracy must usually be developed from a sequence of exploratory experiments. Failure to do so may in fact invalidate the overall approach to the T&E process because the fundamental traceability requirement that are described in this context would be confounded.
Representative criteria focused on the DF process per se are listed below for the numerically dominated level 1 processes, and the symbolic-oriented level 2 and 3 processes.
Level 1 Criteria |
Level 2, 3 Criteria |
Accuracy |
Correctness in reasoning |
Repeatability/consistency |
Quality or relevance of decisions/advice/recommendations |
Robustness |
Intelligent behavior |
Computational complexity |
Adaptability in reasoning (robustness) |
Criteria such as computational efficiency, time-critical performance, and adaptability are applicable to all levels whereas certain criteria reflect either the largely numeric or the symbolic processes that distinguish these fusion-processing levels.
Additional conceptual and philosophical issues regarding what constitutes goodness for software of any type can, more or less, alter the complexity of the T&E issue. For example, there is the issue of reliability versus trustworthiness. Testing oriented toward measuring reliability is often classless, that is, it occurs without distinction of the type of failure encountered. Thus, reliability testing often derives an unweighted likelihood of failure, without defining the class or, perhaps more importantly, a measure of the severity of the failure. This perspective derives from a philosophy oriented to the unweighted conformance of the software with the software specifications, a common practice within the DoD and its contractors.
It can be asserted, based on the argument that exhaustive path testing is infeasible for complex software, that trustworthiness of software is a more desirable goal to achieve via the T&E process. Trustworthiness can be defined as a measure of the software’s likelihood of failing catastrophically. Thus, the characteristic of trustworthiness can be described by a function that yields the probability of occurrence for all significant levels of severe failures. This probabilistic function provides the basis for the estimation of a confidence interval for trustworthiness. The system designer/developer (or customer) can thus have a basis for assuring that the level of failures will not, within specified probabilistic limits, exceed certain levels of severity.
25.2.4 Approach to T&E
The final element of this framework is called the approach element of the T&E process. In this sense, approach means a set of activities, which are both procedural and analytical, that generates the measure results of interest (via analytical operations on the observed metrics) as well as provides the mechanics by which decisions are made based on those measures and in relation to the criteria. The approach consists of two components:
A procedure, which is a metric-gathering paradigm (it is an experimental procedure)
An experimental design, which defines (1) the test cases, (2) the standards for evaluation, and (3) the analytical framework for assessing the results.
Aspects of experimental design include the formal methods of classical, statistical experimental, design.2 Few, if any, DF research efforts in the literature have applied this type of formal strategy, presumably as a result of cost limitations. Nevertheless, there are the serious questions of sample size and confidence intervals for estimates, among others, to deal with in the formulation of any T&E program, since simple comparisons of mean values, and so on under unstructured test conditions may not have very much statistical significance in comparison to the formal requirements of a rigorous experimental design. Such DF efforts should at least recognize the risks associated with such analyses.
This latter point relates to a fundamental viewpoint taken here about the T&E of DF processes: the DF process can be considered a function that operates on random variables (the noise-corrupted measurements or other uncertain inputs, that is, those which have a statistical uncertainty) to produce estimates that are themselves random variables and therefore have a distribution. Most would agree that the inputs to the DF process are stochastic in nature (sensor observation models are almost always based on statistical models); if this is agreed, then any operation on those random variables produces random variables. It could be argued that the DF processes, separated from the sensor systems (and their noise effects), are deterministic probability calculators; in other words, processes that given the same input (the same random variable) produce the same output (the same output random variable).3 In this context, we would certainly want and expect a DF algorithm, if no other internal stochastic aspects are involved to generate the same output when given a fixed input. It could therefore be argued that some portion of the T&E process should examine such repeatability. But DeWitt3 also agrees that the proper approach for a probabilistic predictor involves stochastic methods such as those that examine the closeness of distributions. (DeWitt raises some interesting epistemological views about evaluating such processes, but, as in his report, we also do not wish to plow new ground in that area, although recognizing its importance.) Thus, we argue here for T&E techniques that somehow account for and consider the stochastic nature of the DF results when exposed to appropriately representative input, such as by employment of Monte Carlo–based experiments, analysis of variance methods, distributional closeness, and statistically designed experiments.
25.2.5 The T&E Process: A Summary
This section suggests a framework for the definition and discussion of the T&E process for the DF process and DF-enhanced systems; this framework is summarized in Figure 25.1. Much of the rationale and many of the issues raised are derived from good systems engineering concepts but are intended to sensitize DF researchers to the need for formalized T&E methods to quantify or otherwise evaluate the marginal contributions of the DF process to program/system goals. This formal framework is consistent with the formal and structured methods for the T&E of C3 systems in general—see, for example, Refs 4 and 5. In addition, since fusion processes at levels 2 and 3 typically involve the application of knowledge-based systems, further difficulties involving the T&E of such systems or processes can also complicate the approach to evaluation since, in effect, human reasoning strategies (implemented in software), not mathematical algorithms, are the subject of the tests. Improved formality of the T&E process for knowledge-based systems, using a framework similar to that proposed here, is described in Ref. 6. Little, if any, formal T&E work of this type, with statistically qualified results, appears in the DF literature. As DF procedures, algorithms, and technology mature, the issues raised here will have to be dealt with, and the development of guidelines and standards for DF process T&E undertaken. The starting point for such efforts is an integrated view of the T&E domain—the proposed process is one such view, providing a framework for discussion among DF researchers.
25.3 Tools for Evaluation: Testbeds, Simulations, and Standard Data Sets
Part of the overall T&E process just described involves the decision regarding the means for conducting the evaluation of the DF process at hand. Generally, there is a cost versus quality/fidelity trade-off in making this choice, as is depicted in Figure 25.2.7 Another characterization of the overall range of possible tools is shown in Table 25.1. Over the past several years, the defense community has built up a degree of testbed capability for studying various components of the DF process. In general, these testbeds have been associated with a particular program and its range of problems, and—except in one or two instances—the testbeds have permitted parametric-level experimentation but not algorithm-level one. That is, these testbeds, as software systems, were built from point designs for a given application wherein normal control parameters could be altered to study attendant effects, but these testbeds could not (at least easily) permit replacement of such components as a tracking algorithm. Recently, some new testbed designs are moving in this direction. One important consequence of building testbeds that permit algorithm-level test and replacement is of course that such testbeds provide a consistent basis for system evolution over time, and in principle such testbeds, in certain cases, could be shared by a community of researcher-developers. In an era of tight defense research budgets, algorithm-level shareable testbeds, it is suspected and hoped, will become the norm for the DF community. A snapshot of some representative testbeds and experimental capabilities is shown in Table 25.2. An inherent difficulty (or at least an issue) in testing DF algorithms warrants discussion because it fundamentally results from the inherent complexity of the DF process: the complexity of the DF process may make it infeasible or unaffordable to evolve, through experimentation, DF processing strategies that are optimal for other than level 1 applications. This issue depends on the philosophy with which one approaches testbed design. Consider that even in algorithmic-replaceable testbeds, the test article (a term for the algorithm under test) will be tested in the framework of the surrounding algorithms available from the testbed library. Hence, a tracking algorithm will be tested while using a separate detection algorithm, a particular strategy for track initiation, and so on. Table 25.3 shows some of the testable (replaceable) DF functions for the SDI surveillance testbed developed during the SDI program. Deciding on the granularity of the test articles (i.e., the plug-replaceable level of fidelity of algorithms to be tested) is a significant design decision for a DF testbed designer. Even if the testbed has, for example, multiple detection algorithms in its inventory, cost constraints will probably not permit combinatorial testing for optimality. The importance therefore of clearly thinking about and expressing the T&E philosophy, goals, and objectives, as described in Section 25.2, becomes evident relative to this issue. In many real-world situations, it is likely, therefore, that T&E of DF processes will espouse a satisficing philosophy, that is, be based on developing solutions that are good enough because cost and other practical constraints will likely prohibit extensive testing of wide varieties of algorithmic combinations.

FIGURE 25.1
Test and evaluation activities for the data fusion process.

FIGURE 25.2
Applicability of modeling technique. (From Przemieniecki, J.S., Am. Inst. Aero. Astro. Education Series, Washington, DC, 1990.)
TABLE 25.1
Generic Spectrum of Evaluation Tools
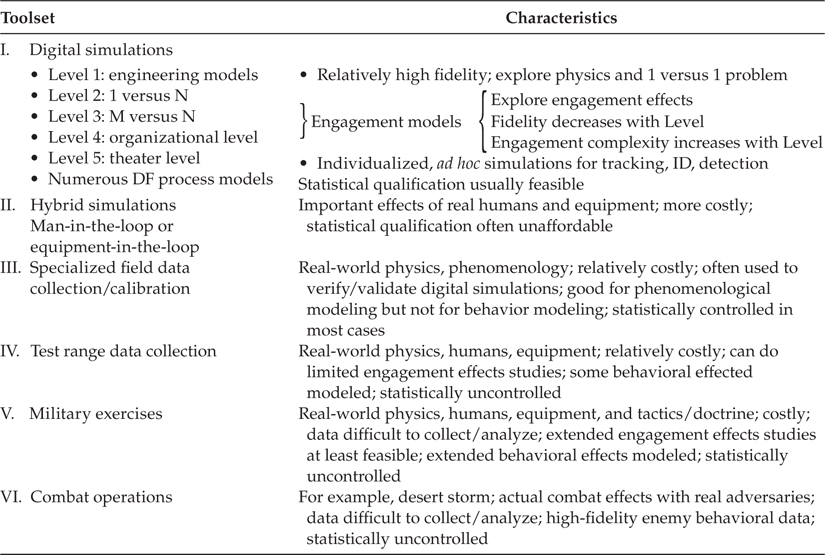
TABLE 25.2
Representative Multisensor Data Fusion Testbeds

Standardized challenge problems and associated data sets are another goal that the DF community should be seeking. To this date, very little calibrated and simultaneously collected data on targets of interest with known truth conditions exist. Some contractors have invested in the collection of such data, but those data often become proprietary. Alternatives to this situation include artificially synthesizing multisensor data from individual sensor data collected under nonstandard conditions (not easy to do in a convincing manner), or employing high-fidelity sensor and phenomenological simulators.
TABLE 25.3
SDI Surveillance Testbed: Testable Level 1 Fusion Functions

Some attempts have been made to collect such data for community-wide application. One of the earliest of such activities was the 1987 DARPA HI-CAMP experiments that collected pulse Doppler radar and long-wavelength infrared data on fairly large U.S. aircraft platforms under a limited set of observation conditions. The Army (Night Vision Laboratory) has also collected data (ground-based sensors, ground targets) for community use under a 1989 program called Multisensor Fusion Demonstration, which collected carefully ground-truthed and calibrated multisensor data for DF community use. More recently, DARPA, in combination with the Air Force Research Laboratory Sensors Directorate, made available a broad set of synthetic aperture radar (SAR) data for ground targets under a program known as MSTAR.8 However, the availability of such data to support algorithm development and DF system prototypes is extremely limited and represents a serious detriment and cost driver to the DF community.
However, similar to the DF process and its algorithms, the tool sets and data sets for supporting DF research and development are just beginning to mature. Modern designs of true testbeds permitting flexible algorithm-level test-and-replace capability for scientific experimentation are beginning to appear and are at least usable within certain subsets of the DF community; it would be encouraging to at least see plans to share such facilities on a broader basis as short-term, prioritized program needs are satisfied—that is, in the long term, these facilities should enter a national inventory. The need for data sets from real sensors and targets, even though such sensor-target pairs may be representative for only a variety of applications, is a more urgent need of the community. Programs whose focus is on algorithm development must incur redundant costs of data collection for algorithm demonstrations with real data when, in many cases, representative real data would suffice. Importantly, the availability of such data sets provides a natural framework for comparative analyses when various techniques are applied against a common or baseline problem as represented by the data. Comparative analyses set the foundation for developing deeper understanding of what methods work where, for what reasons, and for what cost.
25.4 Relating Fusion Performance to Military Effectiveness: Measures of Merit
Because sensors and fusion processes are contributors to improved information accuracy, timeliness, and content, a major objective of many fusion analyses is to determine the effect of these contributions to military effectiveness. This effectiveness must be quantified, and numerous quantifiable measures of merit can be envisioned; for conventional warfare such measures might be engagement outcomes, exchange ratios (the ratio of blue-red targets killed), total targets serviced, and so on as previously mentioned. The ability to relate DF performance to military effectiveness is difficult because of the many factors that relate improved information to improved combat effectiveness and the uncertainty in modeling them. These factors include
Cumulative effects of measurement errors that result in targeting errors
Relations between marginal improvements in data and improvements in human decision making
Effects of improved threat assessment on survivability of own forces
These factors and the hierarchy of relationships between DF performance and military effectiveness must be properly understood in order for researchers to develop measures and models that relate them. In other words, there is a large conceptual distance between the value of improved information quality, as provided by DF techniques, and its effects on military effectiveness; this large distance is what makes such evaluations difficult. The Military Operations Research Society9 has recommended a hierarchy of measures that relate performance characteristics of C3 systems (including fusion) to military effectiveness (see Table 25.4). Dimensional parameters are the typical properties or characteristics that directly define the elements of the DF system elements, such as sensors, processors, communication channels, and so on. (These are equivalent to the metrics defined in Section 25.2.) They directly describe the behavior or structure of the system and should be considered to be typical measurable specification values (bandwidth, bit-error rates, physical dimensions, and so on).
TABLE 25.4
Four Categories of Measures of Merit
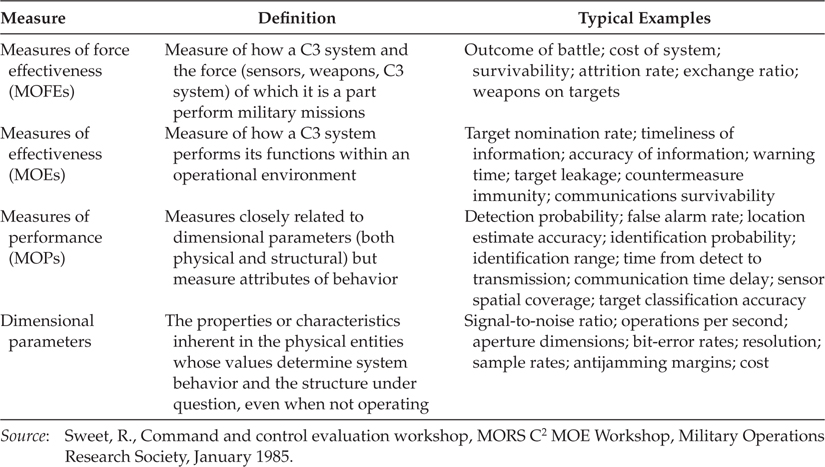
MOPs are measures that describe the important behavioral attributes of the system. MOPs are often functions of several dimensional parameters to quantify, in a single variable, a significant measure of operational performance. Intercept and detection probabilities, for example, are important MOPs that are functions of several dimensional parameters of both the sensors and the detailed signal processing operations, DF processes, and the characteristics of the targets being detected.
MOEs gauge the degree to which a system or militarily significant function was successfully performed. Typical examples, as shown in Table 25.4, are target leakage and target nomination rate.
MOFEs are the highest-level measures that quantify the ability of the total military force (including the DF system) to complete its mission. Typical MOFEs include rates and ratios of attrition, outcome of engagements, and functions of these variables. To evaluate the overall mission, factors other than outcome of the conflict (e.g., cost, size of force, composition of force) may also be included in the MOFEs.
Figure 25.3 depicts the relationship between a set of surveillance measures for a two-sensor system, showing the typical functions that relate lower-level dimensional parameters upward to higher-level measures. In this example, sensor coverage (spatial and frequency), received signal-to-noise ratios, and detection thresholds define sensor-specific detection and false alarm rate MOPs labeled measures of detection processing performance (MODPP) on the figure.
Alternately, the highest-level measures are those that relate PD (or other detection-specific parameters) to mission effectiveness. Some representative metrics are shown at the top of Figure 25.3, such as PKill, cost/kill, miss distance, and so on. These metrics could be developed using various computer models to simulate endgame activities, while driving the detection processes with actual sensor data. As mentioned earlier, there is a large conceptual distance between the lowest-level and highest-level measures. Forming the computations linking one to the other requires extensive analyses, data and parameters, simulation tools, and so on, collectively requiring possibly significant investments.
The next level down the hierarchy represents the viewpoint of studying surveillance site effectiveness; these measures are labeled measures of surveillance site effectiveness (MOSSE) in Figure 25.3. Note, too, that at this level there is a human role that can enter the evaluation; of frequent concern is the workload level to which an operator is subjected. That is, human factor-related measures enter most analyses that range over this evaluation space, adding yet other metrics and measures into the evaluation process; these are not elaborated on here, but they are recognized as important and possibly critical.
Lower levels measure the effectiveness of employing multiple sensors in generating target information (labeled measures of multisensor effectiveness [MOMSE] in Figure 25.3), the effectiveness of data combining or fusing per se (labeled measures of data fusion system performance [MODFSP]), and the effectiveness of sensor-specific detection processes (labeled MODPP), as already mentioned.
In studying the literature on surveillance and detection processes, it is interesting to see analogous varying perspectives for evaluation. Table 25.5 shows a summary of some of the works examined, where a hierarchical progression can be seen, and compares favorably with the hierarchy of Figure 25.3; the correspondence is shown in the Level in Hierarchy column in Table 25.5.
Metrics (a) and (b) in Table 25.5 reflect a surveillance system-level viewpoint; these two metrics are clearly dependent on detection process performance, and such interactive effects could be studied.10 Track purity, metric (c), a concept coined by Mori et al.,11 assesses the percentage of correctly associated measurements in a given track, and so it evaluates the association/tracking boundary (MOSSE/MOMSE of Figure 25.3). As commented in the table, this metric is not explicitly dependent on detection performance but the setting of association gates (and thus the average innovations standard deviation, which depends on PD), so a track purity-to-detection process connection is clear.

FIGURE 25.3
Hierarchical relationship among fusion measures.
TABLE 25.5
Alternative Concepts and Metrics for Evaluation

Metrics (d) and (e), the system operating characteristic (SOC) and tracker operating characteristic (TOC), developed by Bar-Shalom and co-workers,12,13 form quantitative bases for connecting track initiation, SOC, and tracker performance, TOC, with PD, and thus detection threshold strategy performance (the MOSSE/MOMSE boundary in Figure 25.3). SOC evaluates a composite track initiation logic, whereas TOC evaluates the state error covariance, each as connected to, or a function of, single-look PD.
Metric (f) is presented by Kurniawan et al.14 as a means to formulate optimum energy management or pulse management strategies for radar sensors. The work develops a semiempirical expression for the mean square error (MSE) as a function of controllable parameters (including the detection threshold), thereby establishing a framework for optimum control in the sense of MSE. For metric (g), Nagarajan et al.15 formulate a similar but more formally developed basis for sensor parameter control, employing several metrics. Relationships between the metrics and PD/threshold levels are established in both cases, so the performance of the detection strategy can be related to, among other things, MSE for the tracker process in a fashion not unlike the TOC approach. Note that these metrics evaluate the interrelationships across two hierarchical levels, relating MOSSE to MODFSP.
Metric (h), developed by Hashlamoon and Varshney16 for a distributed binary decision fusion system, is based on developing expressions for the Min (probability of error, POE) at the global (fusion) level. Employing the Blackwell theorem, this work then formulates expressions for optimum decision making (detection threshold setting) by relating Min (POE) to various statistical distance metrics (distance between H0, H1 conditional densities), which directly affect the detection process.
The lowest levels of metrics, as mentioned in the preceding paragraph, are those intimately related to the detection process. These are the standard probabilistic measures PD and Pfa and, for problems involving clutter backgrounds, the metrics that are composed of the set known as clutter filter performance measures. The latter has a standard set of IEEE definitions and has been the subject of study of the Surface Radar Group of the AES Radar Panel.17 The set is composed of
Multitarget Identification (MTI) improvement factor
Signal-to-clutter ratio improvement
Subclutter visibility
Interclutter visibility
Filter mismatch loss
Clutter visibility factor
In the context of the DF process, researchers working at level 1 have been most active in the definition and nomination of measures and metrics for evaluation. In particular, the tracking research community has offered numerous measures for evaluation of tracking, association, and assignment functions.18, 19, 20, 21 and 22 In the United States, the Automatic Target Recognizer Working Group (ATRWG), involved with level 1 classification processing, has also been active in recommending standards for various measures.23
The challenges in defining measures to have a reasonably complete set across the DF process clearly lie in the level 2–level 3 areas. To assess exactly the goodness of a situation or threat assessment is admittedly difficult but certainly not intractable; for example, analogous concepts employed for assessing the quality of images come to mind as possible candidates. A complicating factor for evaluation at these levels is that the final determinations of situations or threats typically involve human DF—that is, final interpretation of the automated DF products by a human analyst. The human is therefore the final interpreter and effecter/decision-maker in many DF systems, and understanding the interrelationship of MOEs will require understanding a group of transfer functions that characterize the translation of information about situation and threat elements into eventual engagement outcomes; one depiction of these interrelationships is shown in Figure 25.4. This figure begins, at the top, with the final product of the automated DF process; all algorithmic and symbolic processing associated with fusion has occurred by this point. That product is communicated to a human through an HCI for both levels 2 and 3 as shown. Given this cognitive interpretation (of the displayed automated results), the human must transfer this interpretation, via considerations of

FIGURE 25.4
Interrelationships between human data fusion and system and mission effectiveness.
Decision elements associated with decisions for the given mission (transfer function 1)
Considerations of the effectiveness of the C3 system, and coordination of communications aspects, to influence the power distribution of his forces on the battlefield (transfer functions 2 and 3)
The implemented decisions (via the C3 and communications systems) result in revisions to force deployment, which then (stochastically) yield an engagement outcome, and the consequent force-effectiveness measures and results. Thus, if all the aspects of human decision making are to be formally accounted for, the conceptual distance mentioned earlier is extended even further, as described in Figure 25.4.
There is yet one more, and important, aspect to think about in all this: ideally, the DF process is implemented as a dynamic (i.e., runtime dynamic) adaptive feedback process—that is, we have level 4, process refinement, at work during runtime, in some way. Such adaptation could involve adaptive sensor management, enabling some intelligent logic to dynamically improve the quality of data input, or it could involve adaptive algorithm management, enabling a logic that switches algorithms in some optimal or near-optimal way. Hence, the overall fusion process is not fixed during runtime execution, so that temporal effects need to be considered. Control theorists talk about evaluating alternative control trajectories while discussing evaluation of specific control laws that enable some type of adaptive logic or equations. DF process analysts will therefore have to think in a similar way and evaluate performance and effectiveness as a function of time. This hints at an evaluation approach that focuses on different phases of a mission and the prioritized objectives at each time-phase point or region. Combined with the stochastic aspects of fusion process evaluation, this temporal dependency only further complicates the formulation of a reasonable approach.
25.5 Summary
Developing an understanding of the relationships among these measures is a difficult problem, labeled here the interconnectivity of MOEs problem. The toolkit/testbed needed to generate, compare, and evaluate such measures can be quite broad in scope and itself represent a development challenge as described in Section 25.3.
Motivated in part by the need for continuing maturation of the DF process and the amalgam of techniques employed, and in part by expected reductions in defense research budgets, the DF community must consider strategies for the sharing of resources for research and development. A part of such resources includes standardized (i.e., with approved models) testbed environments, which will offer an economical basis not only for testing of DF techniques and algorithms, but also, importantly, a means to achieve optimality or at least properly satisfying performance of candidate methods under test. However, an important adjunct to shareable testbeds is the standardization of both the overall approach to evaluation and the family of measures involved. This chapter has attempted to offer some ideas for discussion on several of these very important matters.
References
1. Linn, R.J., Hall, D.L., and Llinas, J., A survey of multisensor data fusion systems, presented at the SPIE, Sensor Fusion Conference, In: Data Structures and Target Classification, Orlando, FL, pp. 13–29, April, 1991.
2. Villars, D.S., Statistical Design and Analysis of Experiments for Development Research, W.M.C. Brown Co., Dubuque, IA, 1951.
3. DeWitt, R.N., Principles for testing a data fusion system, PSR (Pacific-Sierra Research, Inc.) Internal Report, March 1998.
4. Anon, A., Methodology for the test and evaluation of C3I systems, Vol. 1—Methodology Description, Report 1ST-89-R-003A, prepared by Illgen Simulation Technologies, Santa Barbara, CA, May 1990.
5. International Test and Evaluation Association, Special Journal Issue on Test and Evaluation of C3IV, Vol. VIII, 2, 1987.
6. Llinas, J. et al., The test and evaluation process for knowledge-based systems, Rome Air Development Center Report RADC-TR-87-181, November 1987.
7. Przemieniecki, J.S., Introduction to mathematical methods in defense analysis, Am. Inst. Aero. Astro. Education Series, Washington, DC, 1990.
8. Bryant, M. and Garber, F., SVM classifier applied to the MSTAR public data set, Proc. SPIE, Vol. 3721, pp. 355–360, 1999.
9. Sweet, R., Command and control evaluation workshop, MORS C2 MOE Workshop, Military Operations Research Society, January 1985.
10. Summers, M.S. et al., Requirements on a fusion/tracker process of low observable vehicles, Final Report, Rome Laboratory/OCTM Contract No. F33657-82-C-0118, Order 0008, January 1986.
11. Mori, S. et al., Tracking performance evaluation: Prediction of track purity, Signal and Data Processing of Small Targets, SPIE, Vol. 1096, p. 215, 1989.
12. Bar-Shalom, Y. et al., From receiver operating characteristic to system operating characteristic: Evaluation of a large-scale surveillance system, Proc. EASCON 87, Washington, DC, October 1987.
13. Fortmann, T.E., Bar-Shalom, Y., Scheffe, M., and Gelfand, S., Detection thresholds for tracking in clutter-A connection between estimation and signal processing, IEEE Transactions on Automatic Control, Vol. 30, pp. 221–229, March 1985.
14. Kurniawan, Z. et al., Parametric optimization for an integrated radar detection and tracking system, IEEE Proc. (F), 132, 1, February 1985.
15. Nagarajan, V. et al., New approach to improved detection and tracking performance in track-while-scan-radars; Part 3: Performance prediction, optimization, and testing, IEEE Proc. (F), Communications, Radar and Signal Processing, 134, 1, pp. 89–112, February 1987.
16. Hashlamoon, W.A. and Varshney, P.K., Performance aspects of decentralized detection structures, Proc. 1989 Int. Conf. SMC, Cambridge, MA, Vol. 2, pp. 693–698, November 1989.
17. Ward, H.R., Clutter filter performance measures, Proc. 1980 Int. Radar Conf., Arlington, VA, pp. 231–239, April 1980.
18. Wiener, H.L., Willman, J.H., Kullback, J.H., and Goodman, I.R., Naval Ocean-Surveillance Correlation Handbook 1978, Naval Research Laboratory, 1978.
19. Schweiter, G.A., MOPs for the SDI tracker-correlator, Daniel H. Wagner Associates Interim Memorandum to Naval Research Laboratory, 1978.
20. Mifflin, T., Ocean-surveillance tracker-correlator measures of performance, Naval Research Laboratory Internal Memorandum, 1986.
21. Askin, K., SDI-BM tracker/correlator measures of performance, Integrated Warfare Branch Information Technology Division, April 4, 1989.
22. Belkin, B., Proposed operational measures of performance, Daniel H. Wagner Associates Internal Memorandum, August 8, 1988.
23. Anon., Target recognizer definitions and performance measures, prepared under the auspices of the Automatic Target Recognizer Working Group Data Collection Guidelines Subcommittee of the Data Base Committee, ATRWG No. 86-001, approved February 1986.