
C H A P T E R 2
![]()
Taking a Crash Course in XML
Reviewing the Simple Stuff Needed to Work with SharePoint
SharePoint uses Extensible Markup Language (XML)—or, to be more specific, the Collabora tive Application Markup Language (CAML). We will spend a lot of time working with CAML, but it will be a lot easier to understand if you have the basics of XML down first.
Feel free to skip along your merry way to the next chapter if you can tell me what the difference is between an element and an attribute and when you should use one or the other.
If you have never worked with XML, either you have been living in a cave for the past ten years or you have worked very hard to avoid XML. It is time to either get you out of that cave or turn some of that avoidance effort into a learning effort.
If nothing else, I hope to show you in this chapter that XML is quite simple and that any fear you have for XML will be nothing compared to what you will face later in the book. So, take this time to relax and get some cheap knowledge that will be applicable outside of SharePoint as well.
There will be plenty of terror later. Mu-ha-ha-ha-ha....
XML: A Definition
What you see here is an XML document, albeit a rather crude and simple one:
<?xml version="1.0" encoding="utf-8" ?>
<xml>
<definition>XML is a metalanguage used to describe data</definition>
<usages>
<usage>Use XML to describe your data and to ensure you store,
transfer, and receive data in the proper format
</usage>
<usage>XML defines nothing; you must make up your own tags</usage>
<usage>Syntax is important; XML is not forgiving for minor errors.
See <![CDATA[<a href="#syntax">syntax</a>]]> for more information.
</usage>
</usages>
<acronym abbreviation="XML">Extensible Markup Language</acronym>
<syntax>
OK, I think you get the point; we'll get to syntax later.
</syntax>
</xml>
In the previous XML document, you will notice the similarities to Hypertext Markup Language (HTML), but don't let that fool you. Besides the < and > to define tags and the use of attributes to add information about the tags, there is very little commonality between the two languages.
XML is all about data and nothing else. True, you can use a derivative language called Extensible Stylesheet Language (XSL) to format the data, but XML itself cares nothing for presentation or how you use the actual data. This also means that an XML document by itself is rather pointless. You need some kind of processor to actually make use of the data.
The extensible part of the name means that you can create “dialects” of XML. As long as you adhere to the rules of XML, your dialect language is considered XML as well. The benefit is that you can use any XML editor or reader on your dialect XML files and the editor and reader will understand your document. An example of this is the CAML dialect in SharePoint or Extensible Application Markup Language (XAML) used in Windows Presentation Foundation and workflows.
The good thing about XML is that it is completely open. If you think back about a decade or two and try to remember which word processor you used to write that very important contract, you are likely to find that, even with your most trusted storage medium, the file is simply unreadable because the software used to interpret the file is gone.
XML has the shelf life of plutonium. No matter how long it takes before you need to reopen your very important file, you can always crack the file open with a text editor to extract everything you need. The original program used to author the file may have been pushing daisies for the last 20 years, but you can still get to your data.
XML Syntax
The syntax of XML resembles HTML, so if you are familiar with HTML, you should easily understand the syntax of XML as well. However, although HTML is a very loose language, XML follows strict syntax rules. In fact, XML interpreters are forbidden by the standard to attempt to interpret errors in a document.
So, to make sure that you know the rules, I'll walk you through the syntax of XML.
![]() Note The good thing about a strict language, such as XML, C#, or mathematics, is that as long as you follow the rules, you always get the same result, and you don't make mistakes. This is very unlike loose or natural languages such as English or HTML where one thing may mean something completely different to two different people or browsers.
Note The good thing about a strict language, such as XML, C#, or mathematics, is that as long as you follow the rules, you always get the same result, and you don't make mistakes. This is very unlike loose or natural languages such as English or HTML where one thing may mean something completely different to two different people or browsers.
Elements
XML consists of elements, often referred to as tags. An element looks like this:
<element></element>
Anything inside those elements is considered data. That data can comprise new elements, referred to as child elements, or it can contain literal data such as the string “Hello, world!”
Here's one example:
<element>
<childtag></childtag>
</element>
And here's another example:
<element>Hello, world!</element>
If your element does not contain any data, you can shorten the start-tag and end-tag combo. For instance, the following:
<element></element>
is exactly the same as this:
<element/>
Unlike HTML, XML is very case sensitive. In other words, the following:
<Element>
is not the same as this:
<element>
Also, unlike HTML parsers such as browsers, XML parsers are forbidden to try to fix such errors and should instead return an error to the user.
![]() Note Having an empty element such as
Note Having an empty element such as <tag/> may seem pointless, but consider how you would store NULL data in your file, and it may make more sense.
You can also have multiple and similar child elements in a tag:
<element>
<childtag>child data 1</childtag>
<childtag>child data 2</childtag>
...
<childtag>child data n</childtag>
</element>
You can use attributes, described later in the chapter, to identify each child element uniquely. Having unnumbered tags such as the previous example does have its advantages, however. Consider a simple document stored as XML:
<book>
<chapter>
<heading>Chapter 1</heading>
<paragraph>Lorem ipsum dolor sit amet, consectetuer adipiscing elit. /paragraph>
<paragraph>Maecenas porttitor congue massa.</paragraph>
<illustration>
<file>illustration1.tif</file>
<caption>Illustration 1</caption>
</illustration>
<paragraph>Fusce posuere, magna sed pulvinar ultricies, purus lectus…</paragraph>
</chapter>
</book>
If only books were that simple....
XML Declarations
XML also requires, or at least strongly encourages, you to declare the version of the XML standard. This should be considered mandatory and should be the first element in your document:
<?xml version="1.0"?>
In addition, the ?xml declaration may contain information about encoding and whether or not this document uses an external Document Type Definition (DTD):
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
![]() Note DTDs are not covered in this chapter, but we will explore a more powerful alternative for XML validation, the XML Schema language (known as XSD).
Note DTDs are not covered in this chapter, but we will explore a more powerful alternative for XML validation, the XML Schema language (known as XSD).
The reason why DTDs are not covered is that XSD is used by SharePoint to validate files. XSD is also more developer friendly and is based on XML, while DTD uses a more obscure syntax that requires a lot more explaining. This is a crash course focused on SharePoint, remember? I'm not aiming to make an XML guru out of you, at least not in this book.
This declaration must be placed on the first line and at the first character of your document (in other words, no blank spaces or lines should appear before the declaration). The declaration is referred to as the XML declaration.
Here is an example of a complete and well-formed XML document, meaning the document follows the correct XML syntax and will be read correctly by any XML interpreter:
<?xml version="1.0"?>
<element>
<childelement></childelement>
</element>
Attributes
In addition to data, your elements can contain attributes. Attributes are often used to “configure” your element, but you can use attributes to store data as well.
Attributes are added inside your start tag and contain an attribute name and value pair:
<element attributename="value"></element>
You can have multiple attributes as well; just make sure you always enclose the values with quotes (""):
<element attribute1="value1" attribute2="value2"/>
As with element names, attribute names are case sensitive. In other words, the following two elements are not the same:
<element Attribute1="value1" Attribute2="value2"></element>
<element attribute1="value1" attribute2="value2"></element>
Although this may or may not be valid XML depending on the schema, Attribute1 and attribute1 are not the same attribute.
Namespaces
Namespaces in XML ensure that multiple element names are not in conflict. If you have multiple elements with the same name but different meanings, you couldn't validate the XML document without some way to separate the similar elements.
Take a look at this example:
<book>
<author>
<name>Bj⊘rn Christoffer Thorsmæhlum Furuknap</name>
<title>Senior Solutions Architect</title>
</author>
<chapter number="1">
<title>Checking Your Gear for Departure</title>
</chapter>
</book>
Notice the two title elements. Having two title tags presents a problem in addressing the right title tag. You can solve this problem by prefixing elements that belong to a certain data group. Take a look at this improved example:
<book>
<author>
<a:name>Bj⊘rn Christoffer Thorsmæhlum Furuknap</a:name>
<a:title>Senior Solutions Architect</a:title>
</author>
<chapter number="1">
<c:title>Checking Your Gear for Departure</c:title>
</chapter>
</book>
Now, rather than just having title as the element name, you have a:title for the author title and c:title as the chapter title.
Each of the prefixes a and c is tied to a namespace. The good thing is that it's simple to define these namespaces and the connected prefix. To get a namespace and tie it to a prefix, you add an attribute to the element or an ancestor element where you intend to use the prefix:
<book xmlns:a="http://understandingsharepoint.com/userexperience/author"
xmlns:c="http://understandingsharepoint.com/userexperience/chapter">
...
</book>
The format of the namespace declaration is quite simple but can be confusing, especially since there seems to be a URL in there.
The first part, xmlns, is just to say that this is a namespace declaration. The second part, separated from xml by a colon, states which prefix you will be using. The third part is the name of the namespace and has nothing to do with the web address it resembles. You might as well have written this:
<book xmlns:a="http://Randomtext.com/Author"
xmlns:c="http://ThisIsAnotherRandomText.com/Chapter">
. . .
</book>
As long as the namespace name is a URI (or an empty string, which rarely makes sense), you should be OK.
You can add the namespace declaration to any element that is an ancestor to the element using the namespace, but you can even define the namespace on the element itself. All the following are valid declarations of namespaces for the a prefix:
<book xmlns:a="http://understandingsharepoint.com/userexperience/author">
<author><a:name>Bj⊘rn Christoffer Thorsmæhlum Furuknap</a:name></author>
</book>
<book>
<author xmlns:a="http://understandingsharepoint.com/userexperience/author">
<a:name>Bj⊘rn Christoffer Thorsmæhlum Furuknap</a:name>
</author>
</book>
<book>
<author>
<a:name xmlns:a="http://understandingsharepoint.com/userexperience/author">
Bj⊘rn Christoffer Thorsmæhlum Furuknap
</a:name>
</author>
</book>
Storing Markup in Markup
There is a problem, though. What happens if you want to store other markup, such as HTML, inside an XML document? You could translate the markup < and > into < and >, respectively, before you store the data, but that gets you only part of the way What about storing a binary file over which you have no control? A C# method function might contain < and > as comparison operators. Consider the following C# method that you might want to store:
<Method Name="IsInRange">
public bool IsInRange(int min, int max, int value)
{
if (value < max && value > min)
{
return true;
}
else
{
return false;
}
}
</Method>
Storing the method in an XML document will lead the XML parser to recognize an XML start tag, <max && min>, which is neither valid XML nor has a matching end tag. The result is that the parser will croak.
The solution comes in the form of a strangely formatted element called CDATA, short for character data. What the CDATA element does is turn off parsing of content as XML.
The format of the CDATA element is as such:
<![CDATA[content]]>
in which content is what should not be parsed as XML.
You can add line breaks, more XML, other markup, binary data, or generally whatever you like, as long as it does not contain the sequence ]]>.
To store your C# method, you would do something like this:
<Method Name="IsInRange">
<![CDATA[
public bool IsInRange(int min, int max, int value)
{
if (value < max && value > min)
{
return true;
}
else {
return false;
}
}
]]>
</Method>You may actually find yourself in the position where you need to store ]]> as part of the CDATA element. What if you wanted to store the entire Method element shown previously inside another XML element, for instance, to show as an example in a book?
To store a CDATA element inside another CDATA element, you should just split the final ]]> sequence into two CDATA elements, right before the final >:
<Example>
<![CDATA[
<Method Name="IsInRange">
<![CDATA[
public bool IsInRange(int min, int max, int value)
{
if (value < max && value > min)
{
return true;
}
else
{
return false;
}
}
]]]]><![CDATA[>]]>
</Method>
</Example>
The magic happens in the line ]]]]><![CDATA[>]]>. If you break it down, you will see that the first two characters, ]], are the beginning of the end of the inner CDATA element. Then you finish the first and outer CDATA element with the ]]> sequence before you start a completely new CDATA element to hold the final > of the inner CDATA element.
Voilà! You have a valid XML element containing another CDATA element. You might also have a headache.
Despite all these syntax rules and possibilities, you still have no way of knowing what you should put into the XML document. For that we turn to…
XML Validation
There is a difference between having a well-formed XML document and having a valid XML document. This relates to the issue of the XML schema. A schema defines how an XML document should be built—no, not which program is used to create the file but what it contains.
There are two “competing” standards for defining an XML document schema, DTD and XSD.
As I mentioned earlier, I won't be covering DTDs in this book. Simply put, I find DTDs to be more restrictive, and not in the good way, and less powerful than XSD. Also, since Share-Point uses XSD for the CAML schema, focus should be on XSD.
![]() Note Strictly speaking, you must have a DTD to have a valid XML document.
Note Strictly speaking, you must have a DTD to have a valid XML document.
XSD
An XSD file defines what you are allowed to put into your XML document. Although a schema is not required in order to have a well-formed XML document that adheres to the syntax rules of XML, having a schema means you are able to verify that the document contains what it should and in the correct amount, that is, how many times an element can or must be present. And an XML schema also enables simple data validation such as giving you a boundary for integer values or the valid values in an enumeration.
An XSD schema is just an XML file and nothing more. The XSD file uses a namespace with a prefix of XS and a name of http://www.w3.org/2001/XMLSchema. This, again, has nothing to do the web page at http://www.w3.org/2001/XMLSchema. You might begin to see the confusion here.
The XSD file defines which elements and attributes are allowed in an XML document. A good XSD file will limit the chances of making data structure mistakes in your XML document and can even limit, to some extent, errors in the data. This is accomplished by defining validation rules that are applied to elements and attributes.
The XSD schema file defines which elements are allowed at a certain level in the hierarchy and defines the actual data types that you can use. That's right—not only can you restrict a certain attribute to be a string, but you can ensure that any child elements of an element adhere to strict data formatting rules that you define.
XSD is fun, at least when you have a good schema editor and understand the basics.
The SharePoint XSD
To make heads or tails of this, we will look at how the wss.xsd file is used to validate CAML. Since we will explore a simple feature file in Chapter 3, we'll take a quick look at how a feature is defined in the wss.xsd schema.
First, using Visual Studio or any other XML editor (or even Notepad in a pinch), open the file [12]TEMPLATEXMLwss.xsd. If using Visual Studio, you will want to right-click the file and select View Code to see the gory details rather than the pretty visual rendering.
Then, scroll down to around line 683 to find these two lines:
<xs:element name="Feature" type="FeatureDefinition">
</xs:element>![]() Tip If you do not find the correct lines at the numbers I specify, search for the string. Microsoft may update these XSD files at times, so your version may be different.
Tip If you do not find the correct lines at the numbers I specify, search for the string. Microsoft may update these XSD files at times, so your version may be different.
Notice that this looks surprisingly much like XML. As I said earlier, XSD is just XML, nothing more. Now you know you can trust me.
The xs: prefix tells us that this is tied to a namespace. You can verify which namespace it is by looking at the first element in the XSD file, the element named xs:schema; there you will find the attribute xmlns:xs="http://www.w3.org/2001/XMLSchema".
The name element is the element name, go figure, and it tells the schema parser that this is an element. You can also learn from the element element that the name of the element is Feature and that it has a type of FeatureDefinition.
From this information, you can deduce that there at least is the possibility of adding an element named Feature, which should be of type FeatureDefinition from a schema file.
![]() Tip If you are familiar with creating features, element files, or site definitions using Visual Studio, you can find all the root elements of a CAML file as
Tip If you are familiar with creating features, element files, or site definitions using Visual Studio, you can find all the root elements of a CAML file as xs:element in the wss.xsd file.
But what does this really tell us? I mean, a feature is way more complex than just being a single element, right?
That is where the type comes in. In XSD, the type attribute refers to one of several data types. These data types include basic types such as strings, integers, dates, and booleans, but you can also define your very own data types.
In the Feature element, we have a type of FeatureDefinition. If you search a bit in the wss.xsd file, you'll find, at around line 654, an element beginning with this:
<xs:complexType name="FeatureDefinition">This element again uses the xs prefix but has an element name of complexType. The FeatureDefinition complex type is a data type definition that consists of several attributes and several child elements. You may recognize the attributes from our examination of features.
I'll include some of the lines here for easy reference in case you are reading this book on a bus:
<xs:complexType name="FeatureDefinition">
<xs:all>
<xs:element name="ElementManifests" type="ElementManifestReferences"
minOccurs="0" maxOccurs="1" />
<xs:element name="Properties" type="FeaturePropertyDefinitions"
minOccurs="0" maxOccurs="1" />
<xs:element name="ActivationDependencies" minOccurs="0"
maxOccurs="1" type="FeatureActivationDependencyDefinitions" />
</xs:all>
<xs:attribute name="Id" type="UniqueIdentifier" use="required" />
<xs:attribute name="Title" type="LocalizableString" />
<xs:attribute name="Description" type="LocalizableString" />
<xs:attribute name="Version" type="FeatureVersion" />
<xs:attribute name="Scope" type="FeatureScope" use="required" />
<xs:attribute name="ReceiverAssembly" type="AssemblyStrongName" />
<xs:attribute name="ReceiverClass" type="AssemblyClass" />
. . . (snipped for the sake of brevity)Each of these attributes and child elements constitutes the schema we need to validate that our feature adheres to the specification.
The outer element xs:ComplexType means we have a type that comprises other attributes and elements. You can also see the xs:all element, which says that we can include all child elements within the xs:all element.
Each of the child elements inside this xs:all element has a minOccurs attribute and a maxOccurs attribute. Although not required, these attributes define how many times a child element can occur. For the three child elements here, we can have zero or one occurrence of the element, meaning they are all optional but cannot be included more than once.
Note also that each of the child elements has a different type, defined elsewhere in the wss.xsd file. Feel free to look them up to see more examples of how XSD works.
Next we have a set of xs:attribute elements, and, you guessed it, these list which attributes are allowed in the Feature element.
If you are using an XML editor, you can connect your XML document, such as your feature.xml file, to the schema document wss.xsd to get IntelliSense support. I explained how to set this up using Visual Studio in Chapter 1.
![]() Tip There is a wonderful XSD tutorial at
Tip There is a wonderful XSD tutorial at http://www.w3schools.com/schema/ that explains far more details than I can fit here.
CAML
So, what if you want to lead the CAML to the water and make it drink? CAML is what I referred to earlier as an XML dialect. Dialects are implementations of XML and, simply put, are just a set of references and schemas to define how to create an XML document that will be used in a certain fashion. But there is more to CAML than just XML documents.
The truth is, any use of the start-tag/end-tag notation that adheres to the XML syntax rules can be considered XML. The implementation is not just limited to XML documents. In SharePoint, for instance, you would use a CAML string to retrieve data from an SPQuery object:
SPQuery query = new SPQuery();
query.Query = @"<Where><Eq><FieldRef Name='Title'/><Value Type='Text'>
My title</Value></Eq></Where>";
SPListItemCollection items = list.GetItems(query);Even though there is no XML declaration, this is XML all the same. This means you have the best of both worlds. First you have the rigidity and strong typing of an XML document, supported by a good editor. Then you can pull only the parts you need when you use XML in other forms, such as in a CAML query in an SPQuery object.
Of course, this can be a bit cumbersome. Writing the CAML by hand without validation tool support can be a nasty experience, especially for more complex queries. This is where tools come into play. Normally I do not recommend any particular tools, because I think you should find the tools you like and learn them. However, since authoring CAML can be frustrating, I'll mention a few of these tools now that we are in the desert. (Get it? Desert? Lots of CAMLs? Oh, I crack myself up.)
![]() Note We will dive into CAML details throughout the book. And I mean deep dive. Think scuba gear.
Note We will dive into CAML details throughout the book. And I mean deep dive. Think scuba gear.
CAML.net
I don't believe I am alone when I say that I hate writing HTML code by hand. Writing XML is even worse, especially if you have no IntelliSense to help you get things right. Unless you have Forrest Gump tendencies, you will have serious problems keeping track of all the elements, nesting tags, syntax, and field type references. Doing so inside a string is likely to make your head implode.
The first tool I want to mention is John Holiday's CAML.net. CAML.net is a free tool available from CodePlex. You can download it at http://www.codeplex.com/camldotnet. Feel free to mention Mr. Holiday in your prayers for his wonderful contribution to your CAML authoring sanity.
What this tool does is…let me rephrase that a bit. CAML.net is an assembly—a DLL, nothing less—that you reference in your project. When you do, you get to use the wonderful class CAML, which takes much of the pain of writing CAML code out of the equation. For example, the following:
query.Query = @"<Where><Eq><FieldRef Name='Title'/><Value Type='Text'>
My title</Value></Eq></Where7gt;";magically turns into this:
query.Query =
CAML.Where(
CAML.Eq(
CAML.FieldRef("Title"),
CAML.Value("Text", "My title")
)
);
which is a lot easier to read, not to mention easier to write.
Suddenly you have strong typing for inline CAML code, including IntelliSense support. Your days of misspelling queries or forgetting an ending tag in a complex query are over.
This is all good, but it doesn't really give you anything unless you know the CAML query in advance. As you will see in later chapters, defining views can be a bit complex. Having a tool to help us create the views would be great.
U2U CAML Query Builder Solution
U2U CAML Query Builder, or CQB for short, is a SharePoint add-in that allows you to get the CAML query of a view. The solution adds a custom action to the Actions menu on every list in your site collection. The custom action leads to an application page that contains the functionality of the solution.
![]() Note Custom actions will be covered in Chapter 5.
Note Custom actions will be covered in Chapter 5.
You define the view almost as you would define any other view in the web interface. Then CQB displays the CAML code for the view for you to use in your code.
CQB even allows you to create C# and VB .NET code for the view, including a wrapper class that you can plug into your class. Figure 2-1 shows an example of how the CQB can create CAML queries for you.
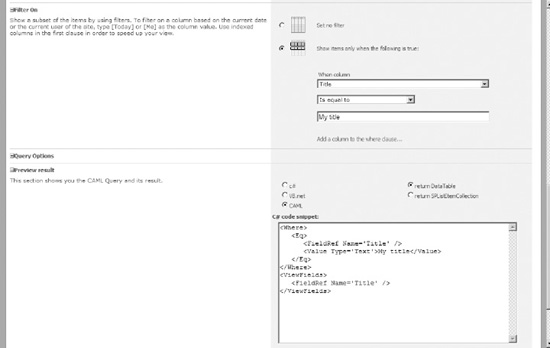
Figure 2-1. U2U CAML Query Builder query result
Going from CAML to CAML.net is trivial if you prefer to work with an object model approach.
U2U CAML Query Builder is a nagware tool, available from http://www.u2u.net. However, registration is just €10.
U2U also has a powerful Windows version of its Query Builder tool available from the same site. It's even more flexible but lacks the SharePoint integration, so I will hide behind my statement of not focusing too much on tools and instead leave the exploration to you.
XSLT
There is another technology that you might want to investigate, and I'll tell you why in a moment. Extensible Stylesheet Language Transformations (XSLT) is used to convert XML into something else. XML by itself is about as useful as square wheels, so most of the time you'll actually want XML to be something other than XML.
XSLT enters the scene and answers all our prayers. And, if you don't pray, it will still be very helpful. Basically, XSLT is an XML-based language, just like XSD, that tells an XSLT processor how to convert your XML to another language.
Now, XSLT is a somewhat complex language. First, there are two main versions, 1.0 and 2.0. Second, there are numerous XSLT processors, and each varies slightly in how they inter-pret the standards. Third, XSLT requires a different method of thinking than your regular run-of-the-mill parse-from-the-top thinking to which you might have become accustomed.
For example, XSLT relies heavily on the notion of templates to transform XML. Templates are called from anywhere in the XSLT file, whenever a certain element is matched in the XML file. This means you will need to think more like an event-driven parser.
XSLT is somewhat important to SharePoint version 3 in that the DataForm web part relies on using XSLT to transform XML from a query into HTML for display. If you want to manipulate the DataForm web part results, learning XSLT is an absolute must.
However, there is an even more important reason why you should learn XSLT. Starting with the next version of SharePoint, XSLT will replace CAML as the main rendering language for views. CAML will still be used extensively in other areas of SharePoint, but view rendering will change. And, even though the next version of SharePoint will support XSLT to a much greater extent, SharePoint 3 still relies on CAML. Chapter 7 deals with CAML as a rendering language and is thus useful if you plan on working with SharePoint 3.
If you want to learn more about XSLT, I recommend the book Beginning XSLT: From Novice to Professional by Jeni Tennison (Apress, 2005). You can also stop by http://www. understandingsharepoint.com/training for a six-part introduction course to XSLT.
</Thoughts>
Although this chapter was nowhere near a complete examination of XML, I do hope you have at least gotten a glimpse of what XML can do. And that is nothing, really, since you need to do all the hard work yourself, or at least use a decent XML parser.
However, basic knowledge of XML is vital to understanding CAML—and understand CAML you must if you are to have any chance of surviving our journey. If you have read this chapter from start to finish, you should have all the knowledge you need to both read and explore the different CAML files used later in the book.
If you want to explore XML further, I suggest picking up a copy of XML by Example (2nd Edition) by Benoit Marchal (Que, 2001), or check out the resources available at W3Schools.com. Keep in mind that although XML at the level on which we have used it so far is useful, becoming an XML guru is almost as daunting a task as learning SharePoint.