
![]()
Nobody realizes that some people expend tremendous energy merely to be normal.
—Albert Camus
By now, you should have the conceptual and logical model created that covers the data requirements for your database system. As we have discussed over the previous four chapters, our design so far needn't follow any strict format or method. It didn't have to be implementable, but it did have to cover the requirements that are data related. In some cases, the initial creator of the logical model may not even be a database professional, but a client who starts the model. Changes to the logical model meant changes to the requirements of the system.
Now, we come to the most hyped topic in all relational databasedom: normalization. It is where the theory meets reality, and everything starts to pay off. We have gathered semistructured piles of data into a model in a manner that is natural to people, but we are not quite ready to start implementing. The final preimplementation step is to take the entities and attributes that have been discovered during the early modeling phases and refine them into tables for implementation in a relational database system. The process does this by removing redundancies and shaping the data in the manner that the relational engine desires to work with it. Once you are done with the process, working with the data will be more natural using the set-based language SQL.
SQL is a language designed to work with atomic values. In computer science terms, atomic means that a value cannot (or more reasonably should not) be broken down into smaller parts. Our eventual goal will be to break down the piles of data we have identified into values that are atomic, that is, broken down to the lowest form that will need to be accessed in Transact SQL (T-SQL) code.
The phrase "lowest form" can be dangerous for newbies, because one must resist the temptation to go too far. What "too far" actually means should be obvious by the end of this chapter. One analogy is to consider splitting apart hydrogen and oxygen from water. You can do that, but if you split the hydrogen atom in half, problems will occur. The same is true for columns in a database. At the correct atomic level, your T-SQL will work wonderfully with less tuning, and at the wrong level (too much or too little), you will find yourself struggling against the design.
If you are truly new at database design, you may have heard that once you learn normalization you are going to be the king biscuit database designer. Think, instead, of normalization more like the end of boot camp for young soldiers. When they get out of boot camp, they are highly trained but barely experienced. Understand the theory of how defend your nation is one thing; dodging the bullets of attacking barbarian hordes is quite a different thing.
Then too, you may have heard the term "normalization" used like a bad word by a developer and sometimes rightfully so, based on how people actually do it. The problem usually lies in the approach of the person using normalization to organize the databases, as many people think of normalization as a purely academic activity, almost as if it was a form of ritualistic sacrifice to Codd. Normalization's purpose is to shape the data to match the actual, realistic needs of the users with the cold hard facts of how the relational engine works.
Some joke that if most developers had their way, every database would have exactly one table with two columns. The table would be named "object," and the columns would be "pointer" and "blob." But this desire is usurped by a need to satisfy the customer with searched, reports, and consistent results from their data being stored.
The process of normalization is based on a set of levels, each of which achieves a level of correctness or adherence to a particular set of "rules." The rules are formally known as forms , as in the normal forms. Quite a few normal forms have been theorized and postulated, but I'll focus on the four most important, commonly known, and often applied. I'll start with First Normal Form (1NF), which eliminates data redundancy (such as a name being stored in two separate places), and continue through to Fifth Normal Form (5NF), which deals with the decomposition of ternary relationships. (One of the normal forms I'll present isn't numbered; it's named for the people who devised it.) Each level of normalization indicates an increasing degree of adherence to the recognized standards of database design. As you increase the degree of normalization of your data, you'll naturally tend to create an increasing number of tables of decreasing width (fewer columns).
![]() Note If your nerd sense is tingling because I said I would cover four normal forms and one of them is the Fifth Normal Form, you aren't wrong. One of the normal forms actually covers two other numbered forms.
Note If your nerd sense is tingling because I said I would cover four normal forms and one of them is the Fifth Normal Form, you aren't wrong. One of the normal forms actually covers two other numbered forms.
In this chapter, I will look at the different normal forms defined not so much by their numbers, but by the problems they were designed to solve. For each, I will include examples, the programming anomalies they help you avoid, and the telltale signs that your relational data is flouting that particular normal form. It might seem out of place to show programming anomalies at this point, since the early chapters of the book are specifically aligned to the preprogramming design, but it can help reconcile to the programming mind what having data in a given normal form can do to make the tables easier to work in SQL. Finally, I'll wrap up with an overview of some normalization best practices.
The process of normalization is really quite straightforward: take entities that are complex and extract simpler entities from them with the goal of ending up with entities that express fewer concepts than before. The process continues until we produce a model such that, in the implementation, every table in the database will represent one thing and every column describes that thing. This will become more apparent throughout the chapter as I work through the different normal forms.
I'll break down normalization into three general categories:
- Table and column shape
- Relationships between columns
- Multivalued and join dependencies in tables
Note that the conditions mentioned for each step should be considered for every entity you design, because each normal form is built on the precept that the lower forms have been complied with. The reality is that most designs, and even fewer implementations, do not meet any of the normal forms perfectly. Just like breaking down and having a donut on a diet doesn't mean you should stop dieting, imperfections are a part of the reality of database design. As an architect, you will strive for perfection, but it is largely impossible to achieve, if for no other reason than the fact that users' needs change frequently (and impatient project managers demand table counts and completion dates far in advance of it being realistic to make such estimates), to say the least. In Agile projects, I simply try to do the best I can to meet the demanding schedule requirements, but minimally, I try to at least document and know what the design should be because the perfect design matches the real world in a way that makes it natural to work with (if sometimes a bit tedious). Design and implementations will always be a trade off with your schedule, but the more you know about what correct is, the more likely you will be able to eventually achieve it, regardless of artificial schedule milestones.
The first step in the process of producing a normalized database is to deal with the "shape" of the data. If you ignored the rest of this book, it is minimally important to understand how the relational engine wants the data shaped. If you recall back in Chapter 1, when we covered Codd's 12 Rules, the first two are the basis for the definition of a table. The first stated that data was to be represented by values in tables, the second that you could access any piece of data in a relational database by knowing its table name, key value, and finally, column name. This set forth the requirements that
- All columns must be atomic, that is, only a single value represented in a single column in a single row of a table.
- All rows of a table must be different.
In addition, to strengthen this stance, a First Normal Form was specified to require that an atomic value would not be extended to implement arrays, or, even worse, that position-based fields having multiple values would not be allowed. Hence, First Normal Form states that:
Every row should contain the same number of values, or in other words, no arrays, subtables, or repeating groups.
This rule centers on making sure the implemented tables and columns are shaped properly for the relational languages that manipulate them (most importantly SQL). "Repeating groups" is an odd term that references having multiple values of the same type in a row, rather than splitting them into multiple rows. I will rephrase this "as rows in a table must contain the same number of values," rather than "repeating groups."
First Normal Form violations generally manifest themselves in the implemented model with data handling being far less optimal, usually because of having to decode multiple values stored where a single one should be or because of having duplicated rows that cannot be distinguished from one another. In this book, we are generally speaking of OLTP solutions, but even data warehousing databases generally follow First Normal Form in order to make queries work with the engine better. The later normal forms are less applicable because they are more concerned with redundancies in the data that make it harder to modify data, which is handled specially in data warehouse solutions.
All Columns Must Be Atomic
The goal of this requirement is that each column should represent only one value, not multiple values. This means there should be nothing like an array, no delimited lists, and no other types of multivalued columns that you could dream up represented by a single column. For example, consider a group of data like 1, 2, 3, 6, 7. This likely represents five separate values. This group of data might not actually be multiple values as far as the design is concerned, but for darn sure it needs to be looked at.
One good way to think of atomicity is to consider whether you would ever need to deal with part of a column without the other parts of the data in that same column. In the list mentioned earlier—1, 2, 3, 6, 7—if the list is always treated as a single value in SQL, it might be acceptable to store the value in a single column. However, if you might need to deal with the value 3 individually, the value is definitely not in First Normal Form. It is also important to note that even if there is not a plan to use the list elements individually, you should consider whether it is still better to store each value individually to allow for future possible usage.
One variation on atomicity is for complex datatypes. Complex datatypes can contain more than one value, as long as
- There is always the same number of values.
- The values are rarely, if ever, dealt with individually.
- The values make up some atomic thing/attribute that could not be fully expressed with a single value.
For example, consider geographic location. Two values are generally used to locate something on Earth, these being the longitude and the latitude. Most of the time, either of these, considered individually, has some (if incomplete) meaning, but taken together, they pinpoint an exact position on Earth. Implementing as a complex type can give us some ease of implementing data-protection schemes and can make using the types in formulas easier.
When it comes to test of atomicity, the test of reasonability is left up to the designer (and other designers who inherit the work later, of course), but generally speaking, the goal is that any data you ever need to deal with as a single value is modeled as its own column, so it's stored in a column of its own (for example, as a search argument or a join criterion). As an example of taking atomicity to the extreme, consider a text document with ten paragraphs. A table to store the document might easily be implemented that would require ten different rows (one for each paragraph), but there's little reason to design like that, because you'll be unlikely to deal with a paragraph as a single value in the SQL database language. Of course, if your SQL is often counting the paragraphs in documents, that approach might just be the solution you are looking for (never let anyone judge your database without knowledge of the requirements!).
As further examples, consider some of the common locations where violations of this rule of First Normal Form often can be found:
- E-mail addresses
- Names
- Telephone numbers
Each of these gives us a slightly different kind of issue with atomicity that needs to be considered when designing columns.
In an e-mail message, the e-mail address is typically stored in a format such as the following, using encoding characters to enable you to put multiple e-mail addresses in a single value:
[email protected];[email protected];[email protected]
In the data storage tier of an e-mail engine, this is the optimum format. The e-mail address columns follow a common format that allows multiple values separated by semicolons. However, if you need to store the values in a relational database, storing the data in this format is going to end up being a problem, because it represents more than one e-mail address in a single email column and leads to difficult coding in the set oriented, multirow form that SQL is good for. In Chapter 10, it will become apparent from an internal engine standpoint why this is, but here, we will look at a practical example of how this will be bothersome when working with the data in SQL.
For example, if users are allowed to have more than one e-mail address, the value of an email column might look like this: [email protected]; [email protected] . Consider too that several users in the database might use the [email protected] e-mail address (for example, if it were the family's shared e-mail account).
![]() Note In this chapter, I will use the character = to underline the key columns in a table of data, and the – character for the nonkey attributes in order to make the representation easier to read without explanation.
Note In this chapter, I will use the character = to underline the key columns in a table of data, and the – character for the nonkey attributes in order to make the representation easier to read without explanation.
Following is an example of some unnormalized data. In the following table, PersonId is the key column, while FirstName and EmailAddresses are the nonkey columns (not necessarily correct, of course as you will see.
| PersonId | FirstName | EmailAddresses |
| ======== | --------- | ------------------------------------------------ |
| 0001003 | Tay | [email protected];[email protected];[email protected] |
| 0003020 | Norma | [email protected] |
Consider the situation when one of the addresses changes. For example, we need to change all occurrences of [email protected] to [email protected] . You could execute code such as the following to update every person who references the [email protected] address:
UPDATE dbo.person
SET EmailAddress = REPLACE(EmailAddresses,'[email protected]','[email protected]')
WHERE ';' + emailAddress + ';' like '%;[email protected];%';
This code might not seem like that much trouble to write and execute, but what about the case where there is also the e-mail address [email protected] ? Our code invalidly replaces that value as well. How do you deal with that problem? Now, you have to start messing with adding semicolons to make sure the data fits just right for your search criteria so you don't get partial names. And that approach is fraught with all sorts of potential errors in making sure the format of the data stays the same. (For example, "email;"@domain.com is, in fact, a valid e-mail address based on the e-mail standard! See http://en.wikipedia.org/wiki/E-mail_address#Valid_email_addresses .) Data in the table should have meaning, not formatting. You format data for use, not for storage. It is easy to format data with the UI or even with SQL. Don't format data for storage.
Consider also if you need to count how many distinct e-mail addresses you have. With multiple e-mail addresses inline, using SQL to get this information is nearly impossible. But, you could implement the data correctly with each e-mail address represented individually in a separate row. Reformat the data as two tables, one for the Person:
| PersonId | FirstName |
| ======== | --------- |
| 0001003 | Tay |
| 0003020 | Norma |
Now, an easy query determines how many e-mail addresses there are per person:
SELECT PersonId, COUNT(*) as EmailAddressCount
FROM dbo.PersonEmailAddress
GROUP BY PersonId;
Beyond being broken down into individual rows, e-mail addresses can be broken down into two or three obvious parts based on their format. A common way to break up these values is into the following parts:
- AccountName: name1
- Domain: domain1.com
Whether storing the data as multiple parts is desirable will usually come down to whether you intend to access the individual parts separately in your code. For example, if all you'll ever do is send e-mail, a single column (with a formatting constraint!) is perfectly acceptable. However, if you need to consider what domains you have e-mail addresses stored for, then it's a completely different matter.
Finally, a domain consists of two parts: domain1 and com. So you might end up with this:
| PersonId | Name | Domain | TopLevelDomain | EmailAddress (calculated) |
| ======== | ======= | ======= | ============== | ------------------------- |
| 0001003 | tay | bull | com | [email protected] |
| 0001003 | taybull | hotmail | com | [email protected] |
| 0001003 | tbull | gmail | com | [email protected] |
| 0003020 | norma | liser | com | [email protected] |
At this point, you might be saying "What? Who would do that?" First off, I hope your user interface wouldn't force the users to enter their addresses one section at a time in either case, since parsing into multiple values is something the interface can do easily (and needs to do to at least somewhat to validate the format of the e-mail address.) Having the interface that is validating the e-mail addresses do the splitting is natural (as is having a calculated column to reconstitute the e-mail for normal usage).
The purpose of separating e-mail addresses into sections is another question. First off, you can start to be sure that all e-mail addresses are at least legally formatted. The second answer is that if you ever have to field questions like "what are the top ten services are our clients using for e-mail?" you can execute a query such as
SELECT TOP 10 Domain + '.' + TopLevelDomain as Domain, COUNT(*) as DomainCount
FROM PersonEmailAddress
GROUP BY Domain, TopLevelDomain
ORDER BY DomainCount;
Is this sort of data understanding necessary to your system? Perhaps and perhaps not. The point of this exercise is to help you understand that if you get the data broken down to the level in which you will query it, life will be easier, SQL will be easier to write, and your client will be happier?
Keep in mind, though, that you can name the column singularly and you can ask the user nicely to put in proper e-mail addresses, but if you don't protect the format, you will likely end up with your e-mail address table looking like this:
| PersonId | EmailAddress (calculated) |
| ======== | ================== |
| 0001003 | [email protected] |
| 0001003 | [email protected] |
| 0001003 | [email protected] |
| 0003020 | [email protected] |
E-mail address values are unique in this example, but clearly do not represent single e-mail addresses. Every user represented in this data will now get lies as to how many addresses are in the system, and Tay is going to get duplicate e-mails, making your company look either desperate or stupid.
Names are a fairly special case, as people in Western culture generally have three parts to their names. In a database, the name is often used in many ways: Simply first and last when greeting someone we don't know, first only when we want to sound cordial, and all three when we need to make our child realize we are actually serious.
Consider the name Rei Leigh Badezine. The first name, middle name, and last name could be stored in a single column and used. Using string parsing, you could get the first and last name if you needed it. Parsing seems simple, assuming every name is formatted just so. Add in names that have more complexity though, and parsing becomes a nightmare.
However, having multiple columns for holding names has its own set of struggles. A very common form that people tend to use is to just "keep it simple" and make one big column:
| PersonId | FullName |
| ======== | ---------------------- |
| 00202000 | R. Lee Ermey |
| 02300000 | John Ratzenberger |
| 03230021 | Javier Fernandez Pena |
This "one, big column" approach saves a lot of formatting issues for sure, but it has a lot of drawbacks as well. The problem with this approach is that is it is really hard to figure out what the first and last name are, because we have three different sorts of names formatted in the list. The best we could do is parse out the first and last parts of the names for reasonable searches (assuming no one has only one name!)
Consider you need to find the person with the name John Ratzenberger. This is easy:
SELECT FirstName, LastName
FROM Person
WHERE FullName = 'John Ratzenberger';
But what if you need to find anyone with a last name of Ratzenberger? This gets more complex, if not to code, certainly for the relational engine that works best with atomic values:
SELECT FirstName, LastName
FROM Person
WHERE FullName LIKE '%Ratzenberger';
Consider next the need of searching for someone with a middle name of Fernandez. This is where things get really muddy and very difficult to code correctly. So instead of just one big column, consider instead the following, more proper method of storing names. This time, each name-part gets its own column:
| PersonId | FirstName | MiddleName | LastName | FullName (calculated) |
| ======== | --------- | ---------- | -------- | ---------------------- |
| 00202000 | R. | Lee | Ermey | R. Lee Ermey |
| 02300000 | John | NULL | Ratzenberger | John Ratzenberger |
| 03230021 | Javier | Fernandez | Pena | Javier Fernandez Pena |
I included a calculated column that reconstitutes the name like it started and included the period after R. Lee Ermey's first name because it is an abbreviation. Names like his can be tricky, because you have to be careful as to whether or not this should be "R. Lee" as a first name or managed as two names. I would also advise you that, when creating interfaces to save names, it is almost always going to be better to provide the user with first, middle, and surname fields to fill out. Then allow the user to decide which arts of a name go into which of those columns. Leonardo Da Vinci is generally considered to have two names, not three. But Fred Da Bomb (who is an artist, just not up to Leonardo's quality), considers Da as his middle name. Allow your users to enter names as they see fit.
The prime value of doing more than having a blob of text for a name is in search performance. Instead of doing some wacky parsing on every usage and hoping everyone paid attention to the formatting, you can query by name using the following, simple, and easy to understand approach:
SELECT firstName, lastName
FROM person
WHERE firstName = 'John' AND lastName = 'Ratzenberger';
Not only does this code look a lot simpler than the code presented earlier, it works tremendously better. Because we are using the entire column value, indexing operations can be used to make searching easier. If there are only a few Johns in the database, or only a few Ratzenberger's (perhaps far more likely unless this is the database for the Ratzenberger family reunion), the optimizer can determine the best way to search.
Finally, the reality of a customer-oriented database may be that you need to store seemingly redundant information in the database to store different/customizable versions of the name, each manually created. For example, you might store versions of a person's name to be used in greeting the person (GreetingName), or to reflect the person likes to be addressed in correspondence (UsedName):
| PersonId | FirstName | MiddleName | LastName | UsedName | GreetingName |
| ======== | --------- | ---------- | -------- | ----------------- | ---------------- |
| 00202000 | R. | Lee | Ermey | R. Lee Ermey | R. Lee |
| 02300000 | John | NULL | Ratzenberger | John Ratzenberger | John |
| 03230021 | Javier | Fernandez | Pena | Javier Fernandez Pena | Javier |
Is this approach a problem with respect normalization? Not at all. The name used to talk the person might be Q-dog, and the given name Leonard. Judging the usage is not our job; our job is to model it exactly the way it needs to be. The problem is that the approach definitely is a problem for the team to manage. In the normal case, if the first name changes, the used name and greeting name probably need to change and are certainly up for review. Minimally, this is the sort of documentation you will want to provide, along with user interface assistance, to our good friends the developers.
![]() TipNames are an extremely important part of a customer system. There is at least one hotel in Chicago I would hesitate to go back to because of what they called me in a very personal sounding thank you e-mail, and when I responded that it was wrong (in my most masculine-sounding typing), they did not reply.
TipNames are an extremely important part of a customer system. There is at least one hotel in Chicago I would hesitate to go back to because of what they called me in a very personal sounding thank you e-mail, and when I responded that it was wrong (in my most masculine-sounding typing), they did not reply.
American telephone numbers are of the form 423-555-1212, plus some possible extension number. From our previous examples, you can see that several columns are probably in the telephone number value. However, complicating matters is that frequently the need exists to store more than just American telephone numbers in a database. The decision on how to handle this situation might be based on how often the users store international phone numbers, because it would be a hard task to build a table or set of tables to handle every possible phone format.
So, for an American- or Canadian-style telephone number, you can represent the standard phone number with three different columns for each of the following parts, AAA-EEE-NNNN:
- AAA (Area code): Indicates a calling area located within a state
- EEE (Exchange): Indicates a set of numbers within an area code
- NNNN (Suffix): Number used to make individual phone numbers unique
Here is where it gets tricky. If every phone number fits this format because you only permit calling to numbers in the North America, having three columns to represent each number would be a great solution. You might, too, want to include extension information. The problem is that all it takes is a single need to allow a phone number of a different format to make the pattern fail. So what do you do? Have a single column and just let anyone enter anything they want? That is the common solution, but you will all too frequently get users entering anything they want, and some stuff they will swear they didn't. Constrain values at the database level? That will make things better, but sometimes, you lose that battle because the errors you get back when you violate a CHECK constraint aren't very nice, and those people who enter the phone number in other reasonably valid formats get annoyed (of course, if the data is checked elsewhere, where does bad data come from?).
Why does it matter? Well, if a user misses a digit, you no longer will be able to call your customers to thank them or to tell them their products won't be on time. Plus, new area codes are showing up all of the time, and in some cases, phone companies split an area code and reassign certain exchanges to a new area code. The programming logic required to change part of a multipart value can be confusing. Take for example the following set of phone numbers:
PhoneNumber
============
615-555-4534
615-434-2333
The code to modify an existing area code to a new area code is pretty messy and certainly not the best performer. Usually, when an area code splits, it's for only certain exchanges. Assuming a well-maintained format of AAA-EEE-NNNN where AAA equals area code, EEE equals exchange, and NNNN equals the phone number, the code looks like this:
UPDATE dbo.PhoneNumber
SET PhoneNumber = '423' + substring(PhoneNumber,4,8)
WHERE substring(PhoneNumber,1,3) = '615'
AND substring(PhoneNumber,5,3) IN ('232','323',...,'989'),--area codes generally
--change for certain
--exchanges
This code requires perfect formatting of the phone number data to work, and unless the formatting is forced on the users, perfection is unlikely to be the case. Even a slight change, as in the following values
PhoneNumber
============
615-555-4534
615-434-2333
and you are not going to be able to deal with this data, because neither of these rows would be updated.
Changing the area code is much easier if all values are stored in single, atomic containers, as shown here:
| AreaCode | Exchange | PhoneNumber |
| ======== | ======== | =========== |
| 615 | 555 | 4534 |
| 615 | 434 | 2333 |
Now, updating the area code takes a single, easy-to-follow SQL statement, for example:
UPDATE dbo.PhoneNumber
SET AreaCode = '423'
WHERE AreaCode = '615'
AND Exchange IN ('232','323',...,'989'),
How you represent phone numbers is one of those case-by-case decisions. Using three separate values is easier for some reasons and, as a result, will be the better performer in almost all cases where you deal with only a single type of phone number. The one-value approach (with enforced formatting) has merit and will work, especially when you have to deal with multiple formats (be careful to have a key for what different formats mean and know that some countries have a variable number of digits in some positions).
You might even use a complex type to implement a phone number type. Sometimes, I use a single column with a check constraint to make sure all the dashes are in there, but I certainly prefer to have multiple columns unless the data isn't that important.
Dealing with multiple international telephone number formats complicates matters greatly, since only a few other countries use the same format as in the United States and Canada. And they all have the same sorts of telephone number concerns as we do with the massive proliferation of telephone number–oriented devices. Much like mailing addresses will be, how you model phone numbers is heavily influenced by how you will use them and especially how valuable they are to your organization. For example, a call center application might need far deeper control on the format of the numbers than would an application to provide simple phone functionality for an office. It might be legitimate to just leave it up to the user to fix numbers as they call them, rather than worry about programmability.
A solution that I have used is to have two sets of columns, with a column implemented as a calculated column that uses either the three-part number or the alternative number. Following is an example:
| AreaCode | Exchange | PhoneNumber | AlternativePhoneNumber | FullPhoneNumber (calculated) |
| -------- | -------- | ----------- | ---------------------- | ============================ |
| 615 | 555 | 4534 | NULL | 615-555-4534 |
| 615 | 434 | 2333 | NULL | 615-434-2333 |
| NULL | NULL | NULL | 01100302030324 | 01100302030324 |
Then, I write a check constraint to make sure data follows one format or the other. This approach allows the interface to present the formatted phone number but provides an override as well. The fact is, with any shape of the data concerns you have, you have to make value calls on how important the data is and whether or not values that are naturally separate should actually be broken down in your actual storage. You could go much farther with your design and have a subclass for every possible phone number format on Earth, but this is likely overkill for most systems. Just be sure to consider how likely you are to have to do searches, like on the area code or partial phone numbers, and design accordingly.
All Rows Must Contain the Same Number of Values
The First Normal Form says that every row in a table must have the same number of columns. There are two interpretations of this:
- Tables must have a fixed number of columns.
- Tables should be designed such that every row has a fixed number of values associated with it.
The first interpretation is simple and goes back to the nature of relational databases. You cannot have a table with a varying format with one row such as {Name, Address, Haircolor}, and another with a different set of columns such as {Name, Address, PhoneNumber, EyeColor}. This kind of implementation was common with record-based implementations but isn't possible with a relational database table. (Note that, internally, the storage of data in the storage engine does, in fact, look a lot like this because very little space is wasted in order to make better use of I/O channels and disk space. The goal of SQL is to make it easy to work with data and leave the hard part to other people).
The second is a more open interpretation. As an example, if you're building a table that stores a person's name and if one row has one name, all rows must have only one name. If they might have two, all rows must have precisely two (not one sometimes and certainly never three). If they may have a different number, it's inconvenient to deal with using SQL commands, which is the main reason a database is being built in an RDBMS! You must take some care with the concept of unknown values (NULLs) as well. The values aren't required, but there should always be the same number (even if the value isn't immediately known).
You can find an example of a violation of this rule of First Normal Form in tables that have several columns with the same base name suffixed (or prefixed) with a number, such as Payment1, Payment2, for example:
| CustomerId | Name | Payment1 | Payment2 | Payment3 |
| ========== | ----------------- | -------- | -------- | ---------- |
| 0000002323 | Joe's Fish Market | 100.03 | NULL | 120.23 |
| 0000230003 | Fred's Cat Shop | 200.23 | NULL | NULL |
Now, to add the next payment for Fred's, we might use some SQL code along these lines:
UPDATE dbo.Customer
SET Payment1 = CASE WHEN Payment1 IS NULL THEN 1000.00 ELSE Payment1 END
Payment2 = CASE WHEN Payment1 IS NOT NULL AND Payment2 IS NULL THEN
1000.00 ELSE Payment2 END,
Payment3 = CASE WHEN Payment1 IS NOT NULL
AND Payment2 IS NOT NULL
AND Payment3 IS NULL
THEN 1000.00 ELSE Paymen3 END
WHERE CustomerId = 0000230003;
And of course, if there were already three payments, you would not have made any changes at all. Obviously, a setup like this is far more optimized for manual modification, but our goal should be to eliminate places where people do manual tasks and get them back to doing what they do best, playing Solitaire . . . er, doing the actual business. Of course, even if the database is just used like a big spreadsheet, the preceding is not a great design. In the rare cases where there's always precisely the same number of values, then there's technically no violation of the definition of a table, or the First Normal Form. In that case, you could state a business rule that "each customer has exactly two payments." In my example though, what do you make of the fact that Payment2 is null, but Payment3 isn't? Did the customer skip a payment?
Allowing multiple values of the same type in a single row still isn't generally a good design decision, because users change their minds frequently as to how many of whatever there are. For payments, if the person paid only half of their expected payment—or some craziness that people always seem to do—what would that mean?. To overcome these sorts of problems, you should create a child table to hold the values in the repeating payment columns. Following is an example. There are two tables. The first table holds customer names. The second table holds payments by customer.
CustomerId Name
========== -----------------
0000002323 Joe's Fish Market
0000230003 Fred's Cat Shop
| CustomerId | Amount | Number | Date |
| ========== | ------ | ====== | ---------- |
| 0000002323 | 100.03 | 1 | 2011-08-01 |
| 0000002323 | 120.23 | 3 | 2011-10-04 |
| 0000230003 | 200.23 | 1 | 2011-12-01 |
The first thing to notice is that I was able to add an additional column of information about each payment with relative ease—the date each payment was made. You could also make additions to the customer payment table to indicate if payment was late, whether additional charges were assessed, whether the amount is correct, whether the principal was applied, and more. Even better, this new design also allows us to have virtually unlimited payment cardinality, whereas the previous solution had a finite number (three, to be exact) of possible configurations. The fun part is designing the structures to meet requirements that are strict enough to constrain data to good values but loose enough to allow the user to innovate within reason.
Now, with payments each having their own row, adding a payment would be as simple as adding a new row to the Payment table:
INSERT dbo.Payment (CustomerId, Amount, Number, Date)
VALUES ('000002324', $300.00, 2, '2012-01-01'),
You could calculate the payment number from previous payments, which is far easier to do using a set-based SQL statement, or the payment number could be based on something in the documentation accompanying the payment or even on when the payment is made. It really depends on your business rules. I would suggest however, if paymentNumber is simply a sequential value for display, I might not include it because it is easy to add a number to output using the ROW_NUMBER() windowing function, and maintaining such a number is usually more costly than calculating it.
Beyond allowing you to easily add data, designing row-wise clears up multiple annoyances, such as relating to the following tasks:
- Deleting a payment: Much like the update that had to determine what payment slot to fit the payment into, deleting anything other than the last payment requires shifting. For example, if you delete the payment in Payment1, then Payment2 needs to be shifted to Payment1, Payment3 to Payment2, and so on.
- Updating a payment: Say Payment1 equals 10, and Payment2 equals 10. Which one should you modify if you have to modify one of them because the amount was incorrect? Does it matter?
If your requirements really only allows three payments, it is easy enough to implement a constraint on cardinality. As I showed in Chapter 3 for data modeling, we control the number of allowable child rows using relationship cardinality. You can restrict the number of payments per customer using constraints or triggers (which will be described in more detail in Chapter 7) but whether or not you can implement something in the database is somewhat outside of this part of the database design process.
![]() CautionAnother common design uses columns such as UserDefined1, UserDefined2, . . . , UserDefinedN to allow users to store their own data that was not part of the original design. This practice is wickedly heinous for many reasons, one of them related to the proper application of First Normal Form. Second, using such column structures is directly against the essence of Codd's fourth rule involving a dynamic online catalog based on the relational model. That rule states that the database description is represented at the logical level in the same way as ordinary data so that authorized users can apply the same relational language to its interrogation that they apply to regular data.
CautionAnother common design uses columns such as UserDefined1, UserDefined2, . . . , UserDefinedN to allow users to store their own data that was not part of the original design. This practice is wickedly heinous for many reasons, one of them related to the proper application of First Normal Form. Second, using such column structures is directly against the essence of Codd's fourth rule involving a dynamic online catalog based on the relational model. That rule states that the database description is represented at the logical level in the same way as ordinary data so that authorized users can apply the same relational language to its interrogation that they apply to regular data.
Putting data into the database in more or less nameless columns requires extra knowledge about the system beyond what's included in the system catalogs (not to mention the fact that the user could use the columns for different reasons on different rows.) In Chapter 8, when I cover storing user-specified data (allowing user extensibility to your schema without changes in design), I will discuss more reasonable methods of giving users the ability to extend the schema at will.
One of the most important things you must take care of when building a database is to make sure to have keys on tables to be able to tell rows apart. Although having a completely meaningful key isn't reasonable 100 percent of the time, it usually is very possible. An example is a situation where you cannot tell the physical items apart, such as perhaps a small can of corn (or a large one, for that matter). Two cans cannot be told apart, so you might assign a value that has no meaning as part of the key, along with the things that differentiate the can from other similar objects, such as large cans of corn or small cans of spinach. You might also consider keeping just a count of the objects in a single row, depending on your needs (which will be dictated by your requirements).
Often, designers are keen to just add an artificial key value to their table, using a GUID or an integer, but as discussed in Chapter 1, adding an artificial key might technically make the table comply with the letter of the rule, but it certainly won't comply with the purpose. The purpose is that no two rows represent the same thing. An artificial key by definition has no meaning, so it won't fix the problem. You could have two rows that represent the same thing because every meaningful value has the same value, with the only difference between rows being a system-generated value. Note that I am not against using an artificial key, just that it should rarely be the only defined key. As mentioned in Chapter 1, another term for such a key is a surrogate key , so named because it is a surrogate (or a stand in) for the real key.
A common approach is to use a date and time value to differentiate between rows. If the date and time value is part of the row's logical identification, such as a calendar entry or a row that's recording/logging some event, this is not only acceptable but ideal. Conversely, simply tossing on a date and time value to force uniqueness is no better than just adding a random number or GUID on the row.
As an example of how generated values lead to confusion, consider the following subset of a table with school mascots:
MascotId Name
======== ------
1 Smokey
112 Smokey
4567 Smokey
979796 Smokey
Taken as it is presented, there is no obvious clue as to which of these rows represent the real Smokey, or if there needs to be more than one Smokey, or if the data entry person just goofed up. It could be that the school name ought to be included to produce a key, or perhaps names are supposed to be unique, or even that this table should represent the people who play the role of each mascot. It is the architect's job to make sure that the meaning is clear and that keys are enforced to prevent, or at least discourage, alternative interpretations.
Of course, the reality of life is that users will do what they must to get their job done. Take, for example, the following table of data that represents books:
| BookISBN | BookTitle | PublisherName | Author |
| ========= | ------------- | ------------- | ------- |
| 111111111 | Normalization | Apress | Louis |
| 222222222 | T-SQL | Apress | Michael |
The users go about life, entering data as needed. But when users realize that more than one author needs to be added per book, they will figure something out. What a user might figure out might look as follows:
| 444444444 | DMV Book Simple Talk Tim |
| 444444444-1 | DMV Book Simple Talk Louis |
The user has done what was needed to get by, and assuming the domain of BookISBN allows it, the approach works with no errors. However, DMV Book looks like two books with the same title. Now, your support programmers are going to have to deal with the fact that your data doesn't mean what you think it does. Ideally, at this point, you would realize that you need to add a table for authors, and you have the solution that will give you the results you want:
| BookISBN | BookTitle | PublisherName |
| ========= | ------------- | ------------- |
| 111111111 | Normalization | Apress |
| 222222222 | T-SQL | Apress |
| 333333333 | Indexing | Microsoft |
| 444444444 | DMV Book | Simple Talk |
BookISBN Author
======== =========
111111111 Louis
222222222 Michael
333333333 Kim
444444444 Tim
444444444 Louis
Now, if you need information about an author's relationship to a book (chapters written, pay rate, etc.) you can add columns to the second table without harming the current users of the system. Yes, you end up having more tables, and yes, you have to do more coding up front, but if you get the design right, it just plain works. The likelihood of discovering all data cases such as this case with multiple authors to a book before you have "completed" your design, is fairly low, so don't immediately think it is your fault. Requirements are often presented that are not fully thought through such as claiming only one author per book. Sometimes it isn't that the requirements were faulty so much as the fact that requirements change over time. In this example, it could have been that during the initial design phase the reality at the time was that the system was to support only a single author. Ever changing realities are what makes software design such a delightful task as times.
![]() CautionKey choice is one of the most important parts of your database design. Duplicated data causes tremendous and obvious issues to anyone who deals with it. It is particularly bad when you do not realize you have the problem until it is too late.
CautionKey choice is one of the most important parts of your database design. Duplicated data causes tremendous and obvious issues to anyone who deals with it. It is particularly bad when you do not realize you have the problem until it is too late.
Clues That an Existing Design Is Not in First Normal Form
When you are looking at database design to evaluate it, you can look quickly at a few basic things to see whether the data is in First Normal Form. In this section, we'll look at some of these ways to recognize whether data in a given database is already likely to be in First Normal Form. None of these clues is, by any means, a perfect test. Generally speaking, they're only clues that you can look for in data structures for places to dig deeper. Normalization is a moderately fluid set of rules somewhat based on the content and use of your data.
The following sections describe a couple of data characteristics that suggest that the data isn't in First Normal Form:
- String data containing separator-type characters
- Column names with numbers at the end
- Tables with no or poorly defined keys
This is not an exhaustive list, of course, but these are a few places to start.
String Data Containing Separator-Type Characters
Separator-type characters include commas, brackets, parentheses, semicolons, and pipe characters. These act as warning signs that the data is likely a multivalued column. Obviously, these same characters are often used in normal prose, so you need not go too far. For instance, if you're designing a solution to hold a block of text, you've probably normalized too much if you have a word table, a sentence table, and a paragraph table (if you had been considering it, give yourself three points for thinking ahead, but don't go there). In essence, this clue is basically aligned to tables that have structured, delimited lists stored in a single column rather than broken out into multiple rows.
Column Names with Numbers at the End
As noted, an obvious example would be finding tables with Child1, Child2, and similar columns, or my favorite, UserDefined1, UserDefined2, and so on. These kinds of tables are usually messy to deal with and should be considered for a new, related table. They don't have to be wrong; for example, your table might need exactly two values to always exist. In that case, it's perfectly allowable to have the numbered columns, but be careful that what's thought of as "always" is actually always. Too often, exceptions cause this solution to fail. "A person always has two forms of identification noted in fields ID1 and ID2, except when . . ." In this case, "always" doesn't mean always.
These kinds of column are a common holdover from the days of flat-file databases. Multitable/multirow data access was costly, so developers put many fields in a single file structure. Doing this in a relational database system is a waste of the power of the relational programming language.
Coordinate1 and Coordinate2 might be acceptable in cases that always require two coordinates to find a point in a two-dimensional space, never any more or never any less (though CoordinateX and CoordinateY would likely be better column names).
Tables with No or Poorly-Defined Keys
As noted in the early chapters several times, key choice is very important. Almost every database will be implemented with some primary key (though this is not a given in many cases). However, all too often the key will simply be a GUID or an identity-based value.
It might seem like I am picking on identity and GUIDs, and for good reason: I am. While I will almost always suggest you use surrogate keys in your implementations, you must be careful when using them as primary keys, and too often people use them incorrectly. Keeping row values unique is a big part of First Normal Form compliance and is something that should be high on your list of important activities.
Relationships Between Columns
The next set of normal forms to look at is concerned with the relationships between attributes in a table and, most important, the key(s) of that table. These normal forms deal with minimizing functional dependencies between the attributes. As discussed in Chapter 1, being functionally dependent implies that when running a function on one value (call it Value1), if the output of this function is always the same value (call it Value2), then Value2 is functionally dependent on Value1.
As I mention, there are three normal forms that specifically are concerned with the relationships between attributes. They are
- Second Normal Form: Each column must be a fact describing the entire primary key (and the table is in First Normal Form)
- Third Normal Form: Non-primary-key columns cannot describe other non-primary-key columns. (and the table is in Second Normal Form)
- Boyce-Codd Normal Form (BCNF) : All columns are fully dependent on a key. Every determinant is a key (and the table is in First Normal Form, not Second or Third since BCNF itself is a more strongly stated version that encompasses them both).
I am going to focus on the BCNF because it encompasses the other forms, and it is the most clear and makes the most sense based on today's typical database design patterns (specifically the use of surrogate keys and natural keys).
BCNF is named after Ray Boyce, one of the creators of SQL, and Edgar Codd, whom I introduced in the first chapter as the father of relational databases. It's a better-constructed replacement for both the Second and Third Normal Forms, and it takes the meanings of the Second and Third Normal Forms and restates them in a more general way. The BCNF is defined as follows:
- The table is already in First Normal Form.
- All columns are fully dependent on a key.
- A table is in BCNF if every determinant is a key.
Note that, to be in BCNF, you don't specifically need to be concerned with Second Normal Form or Third Normal Form. BCNF encompasses them both and changed the definition from the "primary key" to simply all defined keys. With today's almost universal de facto standard of using a surrogate key as the primary key, BCNF is a far better definition of how a properly designed database should be structured. It is my opinion that most of the time when someone says "Third Normal Form" that they are referencing something closer to BCNF.
An important part of the definition of BCNF is that "every determinant is a key." I introduced determinants back in Chapter 1, but as a quick review, consider the following table of rows, with X defined as the key:
X Y Z
=== --- ---
1 1 2
2 2 4
3 2 4
X is unique, and given the value of X, you can determine the value of Y and Z. X is the determinant for all of the rows in the table. Now, given a value of Y, you can't determine the value of X, but you seemingly can determine the value of Z. When Y = 1: Z = 2 and when Y = 2: Z = 4. Now before you pass judgment, this could be a coincidence. It is very much up to the requirements to help us decide if this determinism is incorrect. If the values of Z were arrived at by a function of Y*2, then Y would determine Z and really wouldn't need to be stored (eliminating user editable columns that are functional dependent on one another is one of the great uses of the calculated column in your SQL tables, and they manage these sorts of relationships).
When a table is in BCNF, any update to a nonkey column requires updating one and only one value. If Z is defined as Y*2, updating the Y column would require updating the Z column as well. If Y could be a key, this would be acceptable as well, but Y is not unique in the table. By discovering that Y is the determinant of Z, you have discovered that YZ should be its own independent table. So instead of the single table we had before, we have two tables that express the previous table with no invalid functional dependencies, like this:
X Y
=== ---
1 1
2 2
3 2
Y Z
=== ---
1 2
2 4
For a somewhat less abstract example, consider the following set of data, representing book information:
| BookISBN | BookTitle | PublisherName | PublisherLocation |
| ========= | ------------- | -------------- | ----------------- |
| 111111111 | Normalization | Apress | California |
| 222222222 | T-SQL | Apress | California |
| 444444444 | DMV Book | Simple Talk | England |
BookISBN is the defined key, so every one of the columns should be completely dependent on this value. The title of the book is dependent on the book ISBN, and the publisher too. The concern in this table is the PublisherLocation . A book doesn't have a publisher location, a publisher does. So if you needed to change the publisher, you would also need to change the publisher location.
To correct this situation, you need to create a separate table for publisher. Following is one approach you can take:
| BookISBN | BookTitle | PublisherName |
| ========= | ------------- | ------------- |
| 111111111 | Normalization | Apress |
| 222222222 | T-SQL | Apress |
| 444444444 | DMV Book | Simple Talk |
| Publisher | PublisherLocation | |
| =========== | ----------------- | |
| Apress | California | |
| Simple Talk | England |
Now, a change of publisher for a book requires only changing the publisher value in the Book table, and a change to publisher location requires only a single update to the Publisher table.
In the original definitions of the normal forms, we had second normal form that dealt with partial key dependencies. In BCNF, this is still a concern when you have defined composite keys (with more than one column making up the key). Most of the cases where you see a partial key dependency in an example are pretty contrived (and I will certainly not break than trend). Partial key dependencies deal with the case where you have a multicolumn key and, in turn, columns in the table that reference only part of the key.
As an example, consider a car rental database and the need to record driver information and type of cars the person will drive. Someone might (not you, certainly!) create the following:
| Driver | VehicleStyle | Height | EyeColor | ExampleModel | DesiredModelLevel |
| ====== | ============ | ------ | -------- | ------------ | ----------------- |
| Louis | CUV | 6'0" | Blue | Edge | Premium |
| Louis | Sedan | 6'0" | Blue | Fusion | Standard |
| Ted | Coupe | 5'8" | Brown | Camaro | Performance |
The key of driver plus vehicle style means that all of the columns of the table should reference both of these values. Consider the following columns:
- Height: Unless this is the height of the car, this references the driver and not car style.
- EyeColor : Clearly, this references the driver only, unless we rent Pixar car models.
- ExampleModel : This references the VehicleStyle , providing a model for the person to reference so they will know approximately what they are getting.
- DesiredModelLevel : This represents the model of vehicle that the driver wants to get. This is the only column that should be in this table.
To transform the initial one table into a proper design, we will need to split the one table into three. The first one defines the driver and just has the driver's physical characteristics:
| Driver | Height | EyeColor |
| ====== | ------ | -------- |
| Louis | 6'0" | Blue |
| Ted | 5'8" | Brown |
The second one defines the car styles and model levels the driver desires:
| Driver | VehicleStyle | DesiredModelLevel |
| ====== | ============ | ----------------- |
| Louis | CUV | Premium |
| Louis | Sedan | Standard |
| Ted | Coupe | Performance |
And finally, we need one to define the types of car styles available and to give the example model of the car:
VehicleStyle ExampleModel
============ ------------
CUV Edge
Sedan Fusion
Coupe Camaro
Note that, since the driver was repeated multiple times in the original poorly designed sample data, I ended up with only two rows for the driver as the Louis entry's data was repeated twice. It might seem like I have just made three shards of a whole, without saving much space, and ultimately will need costly joins to put everything back together. The reality is that in a real database, the driver table would be large; the table assigning drivers to car styles is very thin (has a small number of columns), and the car style table will be very small. The savings from not repeating so much data will more than overcome the overhead of doing joins on reasonably designed tables. For darn sure, the integrity of the data is much more likely to remain at a high level because every single update will only need to occur in a single place.
Third Normal Form and BCNF deal with the case where all columns need to be dependent on the entire key. (Third Normal Form specifically dealt with the primary key, but BCNF expanded it to include all defined keys.) When we have completed our design, and it is meets the standards of BCNF, every possible key is defined.
In our previous example we ended up with a driver table. That same developer, when we stopped watching, made some additions to the table to get an idea of what the driver currently drives:
| Driver | Height | EyeColor | Vehicle Owned | VehicleDoorCount | VehicleWheelCount |
| ====== | ------ | -------- | --------------- | ---------------- | ----------------- |
| Louis | 6'0" | Blue | Hatchback | 3 | 4 |
| Ted | 5'8" | Brown | Coupe | 2 | 4 |
| Rob | 6'8" | NULL | Tractor trailer | 2 | 18 |
To our trained eye, it is pretty clear almost immediately that the vehicle columns aren't quite right, but what to do? You could make a row for each vehicle, or each vehicle type, depending on how specific the need is for the usage. Since we are basically trying to gather demographic information about the user, I am going to choose vehicle type to keep things simple (and since it is a great segue to the next section). The vehicle type now gets a table of its own, and we remove from the driver table all of the vehicle pieces of information and create a key that is a coagulation of the values for the data in row:
| VehicleTypeId | VehicleType | DoorCount | WheelCount |
| ============== | --------------- | --------- | ----------- |
| 3DoorHatchback | Hatchback | 3 | 4 |
| 2DoorCoupe | Coupe | 2 | 4 |
| TractorTrailer | Tractor trailer | 2 | 18 |
And the driver table now references the vehicle type table using its key:
| Driver | VehicleTypeId | Height | EyeColor |
| ====== | -------------- | ------ | -------- |
| Louis | 3DoorHatchback | 6'0" | Blue |
| Ted | 2DoorCoupe | 5'8" | Brown |
| Rob | TractorTrailer | 6'8" | NULL |
Note that for the vehicle type table in this model, I chose to implement a smart surrogate key for simplicity, and because it is a common method that people use. A short code is concocted to give the user a bit of readability, then the additional columns are there to use in queries, particularly when you need to group or filter on some value (like if you wanted to send an offer to all drivers of three-door cars to drive a luxury car for the weekend!) It has drawbacks that are the same as the normal form we are working on if you aren't careful (the smart key has redundant data in it), so using a smart key like this is a bit dangerous. But what if we decided to use the natural key? You would end up with two tables that look like this:
| Driver | Height | EyeColor | Vehicle Owned | VehicleDoorCount |
| ======= | ------ | -------- | --------------- | ---------------- |
| Louis | 6'0" | Blue | Hatchback | 3 |
| Ted | 5'8" | Brown | Coupe | 2 |
| Rob | 6'8" | NULL | Tractor trailer | 2 |
| VehicleType | DoorCount | WheelCount |
| =============== | ========= | ---------- |
| Hatchback | 3 | 4 |
| Coupe | 2 | 4 |
| Tractor trailer | 2 | 18 |
The driver table now has almost the same columns as it had before (less the WheelCount which does not differ from a three- or five-door hatchback, for example ), referencing the existing tables columns, but it is a far more flexible solution. If you want to include additional information about given vehicle types (like towing capacity, for example), you could do it in one location and not in every single row, and users entering driver information can only use data from a given domain that is defined by the vehicle type table. Note too that the two solutions proffered are semantically equivalent in meaning but have two different solution implementations that will have an effect on implementation, but not the meaning of the data in actual usage.
Surrogate Keys Effect on Dependency
When you use a surrogate key, it is used as a stand-in for the existing key. To our previous example of driver and vehicle type, let's make one additional example table set, using a meaningless surrogate value for the vehicle type key, knowing that the natural key of the vehicle type set is VehicleType and DoorCount :
| Driver | VehicleTypeId | Height | EyeColor |
| ====== | ------------- | ------ | -------- |
| Louis | 1 | 6'0" | Blue |
| Ted | 2 | 5'8" | Brown |
| Rob | 3 | 6'8" | NULL |
| VehicleTypeId | VehicleType | DoorCount | WheelCount |
| ============= | ------------ | --------- | ---------- |
| 1 | Hatchback | 3 | 4 |
| 2 | Coupe | 2 | 4 |
| 3 | Tractor trailer | 2 | 18 |
I am going to cover key choices a bit more in Chapter 6 when I discuss uniqueness patterns, but suffice it to say that, for design and normalization purposes, using surrogates doesn't change anything except the amount of work it takes to validate the model. Everywhere the VehicleTypeId of 1 is referenced, it is taking the place of the natural key of VehicleType, DoorCount; and you must take this into consideration. The benefits of surrogates are more for programming convenience and performance but they do not take onus away from you as a designer to expand them for normalization purposes.
For an additional example involving surrogate keys, consider the case of an employee database where you have to record the driver's license of the person. We normalize the table and create a table for driver's license and we end up with the model snippet in Figure 5-1. Now, as you are figuring out whether or not the employee table is in proper BCNF, you check out the columns and you come to driversLicenseStateCode and driversLicenseNumber. Does an employee have a ? Not exactly, but a drivers license does. When columns are part of a foreign key, you have to consider the entire foreign key as a whole. So can an employee have a driver's license? Of course.
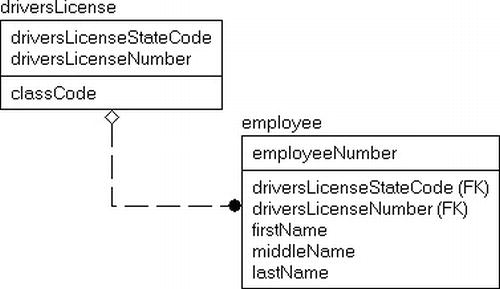
Figure 5-1. driversLicense and employee tables with natural keys
What about using surrogate keys? Well this is where the practice comes with additional cautions. In Figure 5-2, I have remodeled the table using surrogate keys for each of the tables.

Figure 5-2. driversLicense and employee tables with surrogate keys
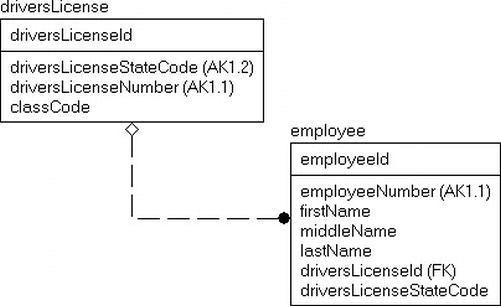
This design looks cleaner in some ways, and with the very well named columns from the natural key, it is a bit easier to see the relationships in these tables, and it is not always possible to name the various parts of the natural key as clearly as I did. In fact, the state code likely would have a domain of its own and might be named StateCode . The major con is that there is a hiding of implementation details that can lead to insidious multitable denormalizations. For example, take the following addition to the model made by designers who weren't wearing their name-brand thinking caps:
The users wanted to know the state code from the driver's license for the employer, so they added it do the employee table because it wasn't easily visible in the table. Now in essence, here is what we have in the employee table once we expand the columns from the natural key of the driversLicense table :
- employeeNumber
- firstName
- middleName
- lastName
- driversLicenseStateCode (driversLicense)
- driversLicenseNumber (driversLicense)
- driversLicenseStateCode
The state code is duplicated just to save a join to the table where it existed naturally, so the fact that we are using surrogate keys to simplify some programming tasks is not complicated by the designer's lack of knowledge (or possibly care) for why we use surrogates.
While the driversLicense example is a simplistic case that only a nonreader of this book would perpetrate, in a real model, the parent table could be five or six levels away from the child, with all tables using single key surrogates, hiding lots of natural relationships. It looks initially like the relationships are simple one-table relationships, but a surrogate key takes the place of the natural key, so in a model like in Figure 5-4, the keys are actually more complex than it appears.

Figure 5-4. Tables chained to show key migration
The full key for the Grandparent table is obvious, but the key of the Parent table is a little bit less so. Where you see the surrogate key of GrandparentId in the Parent, you need to replace it with a natural key from Grandparent. So the key to Parent is ParentName, GrandParentName. Then with child, it is the same thing, so the key becomes ChildName , ParentName , GrandparentName . This is the key you need to compare your other attributes against to make sure that it is correct.
![]() Note A lot of purists really hate surrogates because of how much they hide the interdependencies, and I would avoid them if you are unwilling to take the time to understand (and document) the models you are creating using them. As a database design book reader, unless you stumbled on this page looking for pictures of fashion models, I am going to assume this won't be an issue for you.
Note A lot of purists really hate surrogates because of how much they hide the interdependencies, and I would avoid them if you are unwilling to take the time to understand (and document) the models you are creating using them. As a database design book reader, unless you stumbled on this page looking for pictures of fashion models, I am going to assume this won't be an issue for you.
A consideration when discussing BCNF is data that is dependent on data in a different row, possibly even in a different table. A common example of this is summary data. It is an epidemic among row-by-row thinking programmers who figure that it is very costly to calculate values using set-based queries. So say, you have objects for invoice and invoice line items like the following tables of data, the first being an invoice, and the second being the line items of the invoice:
InvoiceNumber InvoiceDate InvoiceAmount
============= ----------- -------------
000000000323 2011-12-23 100
There are two issues with this data arrangement.
- InvoiceAmount is just the calculated value of SUM(Quantity * ProductPrice).
- InvoiceDate in the line item is just repeated data from Invoice.
Now, your design has become a lot more brittle, because if the invoice date changes, you will have to change all of the line items. The same is likely true for the InvoiceAmount value as well. However, it may not be so. You have to question whether or not the InvoiceAmount is a true calculation. In many cases, while the amounts actually seem like they are calculated, they may be there as a check. The value of 100 may be manually set as a check to make sure that no items are changed on the line items. The important part of this topic is that you must make sure that you store all data that is independent, regardless of how it might appear. When you hit on such natural relationships that are not implemented as dependencies, some form of external controls must be implemented, which I will talk about more in the later section titled "Denormalization".
There is one other possible problem with the data set, and that is the ProductPrice column. The question you have to consider is the life and modifiability of the data. At the instant of creating the order, the amount of the product is fetched and normally used as the price of the item. Of course, sometimes you might discount the price, or just flat change it for a good customer (or noisy one!), not to mention that prices can change. Of course, you could use the price on the order item row that is referenced. But you still might want to make changes here if need be.
The point of this work is that you have to normalize to what is actually needed, not what seems like a good idea when doing design. This kind of touch will be where you spend a good deal of time in your designs. Making sure that data that is editable is actually stored, and data that can be retrieved from a different source is not stored.
Clues That Your Database Is Not in BCNF
In the following sections, I will present a few of the flashing red lights that can tell you that your design isn't in BCNF.
- Multiple columns with the same prefix
- Repeating groups of data
- Summary data
Of course, these are only the truly obvious issues with tables, but they are very representative of the types of problems that you will frequently see in designs that haven't been done well (you know, by those people who haven't read this book!)
Multiple Columns with the Same Prefix
The situation of repeating key column prefixes is one of the dead giveaways. Going back to our earlier example table
| BookISBN | BookTitle | PublisherName | PublisherLocation |
| ========= | ------------- | ------------- | ----------------- |
| 111111111 | Normalization | Apress | California |
| 222222222 | T-SQL | Apress | California |
| 444444444 | DMV Book | Simple Talk | England |
the problem identified was in the PublisherLocation column that is functionally dependent on PublisherName . Prefixes like the "Publisher" in these two column names are a rather common tip-off, especially when designing new systems. Of course, having such an obvious prefix on columns such as Publisher% is awfully convenient, but it isn't always the case in real-life examples that weren't conjured up as an illustration.
Sometimes, rather than having a single table issue, you find that the same sort of information is strewn about the database, over multiple columns in multiple tables. For example, consider the tables in Figure 5-5.
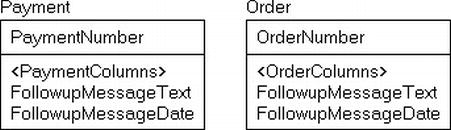
Figure 5-5. Payment and Order with errant Followup columns
The tables in Figure 5-5 are a glowing example of information that is being wasted by not having it consolidated in the same table. Most likely, you want to be reasonable with the amount of messages you send to your customers. Send too few and they forget you, too many and they get annoyed by you. By consolidating the data into a single table, it is far easier to manage. Figure 5-6 shows a better version of the design.

Figure 5-6. Payment and Order with added Followup object
More difficult to recognize are the repeating groups of data. Imagine executing multiple SELECT statements on a table, each time retrieving all rows (if possible), ordered by each of the important columns. If there's a functionally dependent column, you'll see that in form of the dependent column taking on the same value Y for a given column value X.
Take a look at some example entries for the tables we just used in previous sections:
| BookISBN | BookTitle | PublisherName | PublisherLocation |
| ========= | ------------- | ------------- | ----------------- |
| 111111111 | Normalization | Apress | California |
| 222222222 | T-SQL | Apress | California |
| 444444444 | DMV Book | Simple Talk | England |
The repeating values (Apress and California) are a clear example of something that is likely amiss. It isn't a guarantee, of course, but you can look for data such as this by careful queries. In essence, you can profile your data to identify suspicious correlations that deserve a closer look. Sometimes, even if the names are not so clearly obvious, finding ranges of data such as in the preceding example can be very valuable.
One of the most common violations of BCNF that might not seem obvious is summary data. This is where columns are added to the parent table that refer to the child rows and summarize them. Summary data has been one of the most frequently necessary evils that we've had to deal with throughout the history of the relational database server. There might be cases where calculated data needs to be stored in a table in violation of Third Normal Form, but in logical modeling, there's absolutely no place for it. Not only is summary data not functionally dependent on nonkey columns, it's dependent on columns from a different table altogether. This causes all sorts of confusion, as I'll demonstrate. Summary data should be reserved either for physical design or for implementation in reporting/data warehousing databases.
Take the example of an auto dealer, as shown in Figure 5-7. The dealer system has a table that represents all the types of automobiles it sells, and it has a table recording each automobile sale.
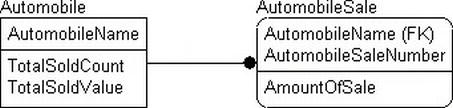
Figure 5-7. The auto dealer submodel
Summary data generally has no part in the logical model you will be creating, because the sales data is available in another table. Instead of accepting that the total number of vehicles sold and their value is available, the designer has decided to add columns in the parent table that refer to the child rows and summarize them.
Is this required for the implementation? It's unlikely, but possible, depending on performance needs. (It could be that the total values are used millions of times a day, with very infrequent changes to the data that makes up the total.) However, it's common that the complexity of the implemented system has most likely increased by an order of magnitude, because we'll have to have triggers on the AutomobileSale table that calculate these values for any change in the AutomobileSale table. If this is a highly active database with frequent rows added to the AutomobileSale table, this tends to slow the database down considerably. On the other hand, if it's an often inactive database, then there will be few rows in the child table, so the performance gains made by quickly being able to find the numbers of vehicles sold and their value will be small anyway.
The point is that in logical modeling, including summary data on the model isn't desirable, because the data modeled in the total column exists in the Sales table. What you are actually modeling is usage, not the structure of the data. Data that we identify in our logical models should be modeled to exist in only one place, and any values that could be calculated from other values shouldn't be represented on the model. This aids in keeping the integrity of the design of the data at its highest level possible.
![]() Tip One way of dealing with summary data is to use a view. An automobile view might summarize the automobile sales. In some cases, you can index the view, and the data is automatically maintained for you. The summarized data is easier to maintain using the indexed view, though it can have negative performance repercussions on modifications but positive ones on reads. Only testing your actual situation will tell, but this is not the implementation part of the book! I'll discuss indexes in some detail in Chapter 10.
Tip One way of dealing with summary data is to use a view. An automobile view might summarize the automobile sales. In some cases, you can index the view, and the data is automatically maintained for you. The summarized data is easier to maintain using the indexed view, though it can have negative performance repercussions on modifications but positive ones on reads. Only testing your actual situation will tell, but this is not the implementation part of the book! I'll discuss indexes in some detail in Chapter 10.
The last point I want to make about BCNF type issues is that you must be truly careful about the meaning of the data you are normalizing, because as you get closer and closer to the goal of one table having one meaning, almost every column will have one place where it makes sense. For example, consider the following table of data:
| CustomerId | Name | EmailAddress1 | EmailAddress2 | AllowMarketingByEmailFlag |
| =========== | ----- | --------------- | --------------- | ------------------------- |
| A0000000032 | Fred | [email protected] | [email protected] | 1 |
| A0000000033 | Sally | [email protected] | NULL | 0 |
To get this table into First Normal Form, you should immediately recognize that we need to implement a table to hold the e-mail address for the customer. The questionable attribute is the AllowMarketingByEmailFlag, which denotes whether or not we wish to market to this customer by e-mail. Is this an attribute about the e-mail address? Or the customer?
Without additional knowledge from the client, it must be assumed that the AllowMarketingByEmailFlag column applies to how we will market to the customer, so it should remain on the customer table like this:
CustomerId Name AllowMarketingByEmailFlag
=========== ----- -------------------------
A0000000032 Fred 1
A0000000033 Sally 0
CustomerId EmailAddress EmailAddressNumber
=========== --------------- ==================
A0000000032 [email protected] 1
A0000000032 [email protected] 2
A0000000033 [email protected] 1
You will also notice that I made the key of the customer e-mail address table CustomerId , EmailAddressNumber and not EmailAddress . Without further knowledge of the system, it would be impossible to know if it was acceptable to have duplication in the two columns. It really boils down to the original purpose of having multiple EmailAddress values, and you have to be careful about what the customers may have been using the values for. In a situation I recently was working on, half of the users used the latter addresses as history of old e-mail addresses and the other half as a backup e-mail for contacting the customer. For the history e-mail address values, it certainly could make sense to add start and end date values to tell when and if the address is still valid, particularly for customer relationship management systems. But at the same time, it could make sense to have only current customer information in your OLTP system and move history of to an archival or data warehouse database instead.
Finally, consider the following scenario. A client sells an electronic product that is delivered by e-mail. Sometimes, it can take weeks before the order is fulfilled and shipped. So the designer of the system created the following three table solution (less the sales order line item information about the product that was ordered):
CustomerId Name AllowMarketingByEmailFlag
=========== ---- -------------------------
A0000000032 Fred 1
CustomerId EmailAddress EmailAddressNumber
=========== --------------- ==================
A0000000032 [email protected] 1
A0000000032 [email protected] 2
SalesOrderId OrderDate ShipDate CustomerId EmailAddressNumber ShippedToEmailAddress
============ ---------- ---------- ----------- ------------------ ---------------------
1000000242 2012-01-01 2012-01-02 A0000000032 1 [email protected]
What do you figure the purpose is of the redundant e-mail address information? Is it a normalization issue? No, because although the ShippedToEmailAddress may be exactly the same as the e-mail address for the e-mail address table row with the related e-mail address number, what if the customer changed e-mail addresses and then called in to ask where you shipped the product? If you only maintained the link to the customer's current e-mail address, you wouldn't be able to know what the e-mail address was when it shipped.
The point of this section has been to think before you eliminate what seems like redundant data. Good naming standards, such as spelling out ShippedTo EmailAddress during the logical database design phase, are a definite help to make sure other developers/architects know what you have in mind for a column that you create.
So, assuming you (A) have done some work with databases before getting this deep in my book and (B) haven't been completely self-taught while living underneath 100,000 pounds of granite, you probably are wondering why this chapter on normalization didn't end a few pages back. You probably have heard that Third Normal Form (and assuming you are paying attention, BCNF) is far enough. That is often true, but not because the higher normal forms are useless or completely esoteric, but because once you have really done justice to First Normal Form and BCNF, you quite likely have it right. All of your keys are defined, and all of the nonkey columns properly reference them, but not completely. Fourth and Fifth Normal Form now focus on the relationship between key columns. If all of the natural composite key for your tables have no more than two independent key columns, you are guaranteed to be in Fourth and Fifth Normal Form if you are in BCNF as well.
Note that according to the Fourth Normal Form article in Wikipedia, there was a paper done back in 1992 by Margaret S. Wu that claimed that more than 20 percent of all databases had issues with Fourth Normal Form. And back in 1992, people actually spent time doing design, unlike today when we erect databases like a reverse implosion. However, the normal forms we will discuss in this section are truly interesting in many designs, because they center on the relationships between key columns, and both are very business-rule driven. The same table with the same columns can be a horrible mess to work with in one case, and in the next, it can be a work of art. The only way to know is to spend the time looking at the relationships.
In the next two sections, I will give an overview of Fourth and Fifth Normal Forms and what they mean to your designs. Most likely you will see some similarity to situations you have dealt with in databases before.
Fourth Normal Form: Independent Multivalued Dependencies
Fourth Normal Form deals with what are called multivalued dependencies. When we discussed dependencies in the previous sections, we discussed the case where f(x) = y, where both x and y were scalar values. For a multivalued dependency, the y value can be an array of values. So f(parent) = (child1,child2, . . . , childN) is an acceptable multivalued dependency. For a table to be in Fourth Normal Form, it needs to be in BCNF first, and then, there must not be more than one independent multivalued dependency (MVD) between the key columns.
Recall a previous example table we used:
| Driver | VehicleStyle | DesiredModelLevel |
| ====== | ============ | ----------------- |
| Louis | CUV | Premium |
| Louis | Sedan | Standard |
| Ted | Coupe | Performance |
Think about the key columns. The relationship between Driver and VehicleStyle represents a multivalued dependency for the Driver and the VehicleStyle entities. A driver such as Louis will drive either CUV or Sedan style vehicles, and Louis is the only driver to drive the CUV style. As we add more data, each vehicle style will have many drivers that choose the type as a preference. A table such as this one for DriverVehicleStyle is used frequently to resolve a many-to-many relationship between two tables, in this case, the Driver and VehicleStyle tables.
The modeling problem comes when you need to model a relationship between three entities, modeled as three columns in a key from three separate table types. As an example, consider the following table representing the assignment of a trainer to a class that is assigned to use a certain book:
| Trainer | Class | Book |
| ======= | ============== | ============================ |
| Louis | Normalization | DB Design & Implementation |
| Chuck | Normalization | DB Design & Implementation |
| Fred | Implementation | DB Design & Implementation |
| Fred | Golf | Topics for the Non-Technical |
To decide if this table is acceptable, we will look at the relationship of each column to each of the others to determine how they are related. If any two columns are not directly related to one another, there will be an issue with Fourth Normal Form with the table design. Here are the possible combinations and their relationships:
- Class and Trainer are related, and a class may have multiple trainers.
- Book and Class are related, and a book may be used for multiple classes.
- Trainer and Book are not directly related, because the rule stated that the class uses a specific book.
Hence, what we really have here are two independent types of information being represented in a single table. To deal with this, you will split the table on the column that is common to the two dependent relationships. Now, take this one table and make two tables that are equivalent:
Class Trainer
============== =======
Normalization Louis
Normalization Chuck
Implementation Fred
Golf Fred
Class Book
============== ============================
Normalization DB Design & Implementation
Implementation DB Design & Implementation
Golf Topics for the Non=Technical
Joining these two tables together on Class, you will find that you get the exact same table as before. However, if you change the book for the Normalization class, it will be changed immediately for both of the classes that are being taught by the different teachers. Note that initially it seems like we have more data because we have more rows and more tables. However, notice the redundancy in the following data from the original design:
Louis Normalization DB Design & Implementation
Chuck Normalization DB Design & Implementation
The redundancy comes from stating twice that the book DB Design & Implementation is used for the Normalization class. The new design conveys that same information with one less row of data. Once the system grows to the size of a full-blown system that has 50 Normalization classes being taught, you will have much less data, making the storage of data more efficient, possibly affording some performance benefits along with the more obvious reduction in redundant data that can get out of sync.
As an alternate situation, consider the following table of data, which might be part of the car rental system that we have used for examples before. This table defines the brand of vehicles that the driver will drive:
| Driver | VehicleStyle | VehicleBrand |
| ====== | ============= | ============ |
| Louis | Station Wagon | Ford |
| Louis | Sedan | Hyundai |
| Ted | Coupe | Chevrolet |
- Driver and VehicleStyle are related, representing the style the driver will drive.
- Driver and VehicleBrand are related, representing the brand of vehicle the driver will drive.
- VehicleStyle and VehicleBrand are related, defining the styles of vehicles the brand offers.
This table defines the types of vehicles that the driver will take. Each of the columns has a relationship to the other, so it is in Fourth Normal Form. In the next section, I will use this table again to assist in identifying Fifth Normal Form issues.
Fifth Normal Form is a general rule that breaks out any data redundancy that has not specifically been culled out by additional rules. Like Fourth Normal Form, Fifth Normal Form also deals with the relationship between key columns. Basically, the idea is that if you can break a table with three (or more) independent keys into three (or more) individual tables and be guaranteed to get the original table by joining them together, the table is not in Fifth Normal Form
Fifth Normal Form is an esoteric rule that is only occasionally violated, but it is interesting nonetheless because it does have some basis in reality and is a good exercise in understanding how to work through intercolumn dependencies between any columns. In the previous section, I presented the following table of data:
| Driver | VehicleStyle | VehicleBrand |
| ====== | ============= | ============ |
| Louis | Station Wagon | Ford |
| Louis | Sedan | Hyundai |
| Ted | Coupe | Chevrolet |
At this point, Fifth Normal Form would suggest that it's best to break down any existing ternary (or greater!) relationship into binary relationships if at all possible. To determine if breaking down tables into smaller tables will be lossless (that is, not changing the data), you have to know the requirements that were used to create the table and the data. For the relationship between Driver, VehicleStyle and VehicleBrand, if the requirements dictate that the data is that
- Louis is willing to drive any Station Wagon or Sedan from Ford or Hyundai.
- Ted is willing to drive any Coupe from Chevrolet.
Then, we can infer from this definition of the table that the following dependencies exist:
- Driver determines VehicleStyle.
- Driver determines VehicleBrand.
- VehicleBrand determines VehicleStyle.
The issue here is that if you wanted to express that Louis is now willing to drive Volvos, and that Volvo has station wagons and sedans, you would need to add least two rows:
| Driver | VehicleStyle | VehicleBrand |
| ====== | ============= | ============ |
| Louis | Station Wagon | Ford |
| Louis | Sedan | Hyundai |
| Louis | Station Wagon | Volvo |
| Louis | Sedan | Volvo |
| Ted | Coupe | Chevrolet |
In these two rows, you are expressing several different pieces of information. Volvo has Station Wagons and Sedans. Louis is willing to drive Volvos (which you have repeated multiple times). If other drivers will drive Volvos, you will have to repeat the information that Volvo has station wagons and sedans over and over.
At this point, you probably now see that ending up with tables with redundant data like in our previous example is such an unlikely mistake to make—not impossible, but not probable by any means, assuming any testing goes on with actual data in your implementation process. Once the user has to query (or worse yet, update) a million rows to express a very simple thing like the fact Volvo is now offering a sedan class automobile; changes will be made. The fix for this situation is to break the table into the following three tables, each representing the binary relationship between two of the columns of the original table:
Driver VehicleStyle
====== =============
Louis Station Wagon
Louis Sedan
Ted Coupe
Driver VehicleBrand
====== ============
Louis Ford
Louis Hyundai
Louis Volvo
Ted Chevrolet
VehicleStyle VehicleBrand
============= ============
Station Wagon Ford
Sedan Hyundai
Coupe Chevrolet
Station Wagon Volvo
Sedan Volvo
I included the additional row that says that Louis will drive Volvo vehicles and that Volvo has station wagon and sedan style vehicles. Joining these rows together will give you the table we created:
| Driver | VehicleStyle | VehicleBrand |
| ------ | ------------- | ------------ |
| Louis | Sedan | Hyundai |
| Louis | Station Wagon | Ford |
| Louis | Sedan | Volvo |
| Louis | Station Wagon | Volvo |
| Ted | Coupe | Chevrolet |
I mentioned earlier that the meaning of the table makes a large difference. An alternate interpretation of the table could be that instead of giving the users such a weak way of choosing their desired rides (maybe Volvo has the best station wagons and Ford the best sports car), the table just presented might be interpreted as
- Louis is willing to drive Ford station wagons, Hyundai sedans, and Volvo station wagons and sedans.
- Ted is willing to drive a Chevrolet coupe.
In this case, the table is in Fifth Normal Form because instead of VehicleStyle and VehicleBrand being loosely related, they are directly related and more or less to be thought of as a single value rather than two independent ones. Now the dependency is Driver to VehicleStyle plus VehicleBrand. In a well-designed system, the intersection of style and brand would have formed its own table because VehicleStyle/VehicleBrand would have been recognized as an independent object with a specific key often a surrogate key which represented a VehicleBrand that was rentable. However, in either case, the logical representation after decoding the surrogate keys would, in fact, look just like our table of Driver, VehicleStyle, and VehicleBrand.
As our final example, consider the following table of Books along with Authors and Editors:
| Book | Author | Editor |
| ====== | ====== | ======== |
| Design | Louis | Jonathan |
| Design | Jeff | Leroy |
| Golf | Louis | Steve |
| Golf | Fred | Tony |
There are two possible interpretations that would hopefully be made clear in the name of the table:
- This table is in not even in Fourth Normal Form if it represents the following:
- The Book Design has Authors Louis and Jeff and Editors Jonathan and Leroy.
- The Book Golf has Authors Louis and Fred and Editors Steve and Tony.
- Table is in Fifth Normal Form if it represents
- For the Book Design, Editor Jonathan edits Louis' work and Editor Leroy edits Jeff's work.
- For the Book Golf, Editor Steve edits Louis' work, and Editor Tony edits Fred's work.
In the first case, the author and editor are independent of each other, meaning that technically you should have a table for the Book to Author relationship and another for the Book to Editor relationship. In the second case, the author and editor are directly related. Hence, all three of the values are required to express the single thought of "for book X, editor Y edits Z's work."
![]() Note I hope the final sentence of that previous paragraph makes it clear to you what I have been trying to say, particularly "express the single thought." Every table should represent a single thing that is being modeled. This is the goal that is being pressed by each of the normal forms, particularly the Boyce Codd, Fourth, and Fifth Normal Forms. BCNF worked through nonkey dependencies to make sure the nonkey references were correct, and Fourth and Fifth Normal Forms made sure that the key identified expressed a single thought.
Note I hope the final sentence of that previous paragraph makes it clear to you what I have been trying to say, particularly "express the single thought." Every table should represent a single thing that is being modeled. This is the goal that is being pressed by each of the normal forms, particularly the Boyce Codd, Fourth, and Fifth Normal Forms. BCNF worked through nonkey dependencies to make sure the nonkey references were correct, and Fourth and Fifth Normal Forms made sure that the key identified expressed a single thought.
What can be gleaned from Fourth and Fifth Normal Forms, and indeed all the normal forms, is that when you think you can break down a table into smaller parts with different natural keys, which then have different meanings without losing the essence of the solution you are going for, then it is probably better to do so. If you can join the parts together to represent the data in the original less-broken-down form, your database will likely be better for it. Obviously, if you can't reconstruct the table from the joins, leave it as it is. In either case, be certain to test out your solution with many different permutations of data. For example, consider adding these two rows to the earlier example:
VehicleStyle VehicleBrand
============= ============
Station Wagon Volvo
Sedan Volvo
If this data does not mean what you expected, then it is wrong. For example, if as a result of adding these rows, users who just wanted Volvo sedans were getting put into station wagons, the design would not be right.
Last, the point should be reiterated that breaking down tables ought to indicate that the new tables have different meanings. If you take a table with ten nonkey columns, you could make ten tables with the same key. If all ten columns are directly related to the key of the table, then there is no need to break the table down further.
Denormalization
Denormalization is the practice of taking a properly normalized set of tables and selectively undoing some of the changes in the resulting tables made during the normalization process for performance. Bear in mind that I said "properly normalized." I'm not talking about skipping normalization and just saying the database is denormalized. Denormalization is a process that requires you to actually normalize first, and then selectively pick out data issues that you are willing to code protection for rather than using the natural ability of normalized structures to prevent data anomalies. Too often, the term "denormalization" is used as a synonym for "work of an ignorant or, worse, lazy designer."
Back in the good old days, there was a saying: "Normalize 'til it hurts; denormalize 'til it works". In the early days, hardware was a lot less powerful, and some of the dreams of using the relational engine to encapsulate away performance issues were pretty hard to achieve. In the current hardware and software reality, there only a few reasons to denormalize when normalization has been done based on requirements and user need.
Denormalization should be used primarily to improve performance in cases where normalized structures are causing overhead to the query processor and, in turn, other processes in SQL Server or to tone down some complexity to make things easier to implement. This, of course, introduces risks of introducing data anomalies or even making the data less appropriate for the relational engine. Any additional code written to deal with these anomalies needs to be duplicated in every application that uses the database, thereby increasing the likelihood of human error. The judgment call that needs to be made in this situation is whether a slightly slower (but 100 percent accurate) application is preferable to a faster application of lower accuracy.
Denormalization should not be used as a crutch to make implementing the user interfaces easier. For example, say the user interface in Figure 4.14 was fashioned for a book inventory system.
Existing graphic
Does Figure 5-8 represent a bad user interface? Not in and of itself. If the design calls for the data you see in the figure to be entered, and the client wants the design, fine. However, this requirement to see certain data on the screen together is clearly a UI design issue, not a question of database structure. Don't let user interface dictate the database structure any more than the database structures should dictate the UI. When the user figures out the problem of expecting a single author for every book, you won't have to change your design.
Figure 5-8. A possible graphical front-end to our example
![]() Note It might also be that Figure 5-8 represents the basic UI, and a button is added to the form to implement the multiple cardinality situation of more than one author in the "expert" mode, since 90 percent of all books for your client have one author.
Note It might also be that Figure 5-8 represents the basic UI, and a button is added to the form to implement the multiple cardinality situation of more than one author in the "expert" mode, since 90 percent of all books for your client have one author.
UI design and database design are seperate (yet interrelated) processes. The power of the UI comes with focusing on making the top 80 percent of use cases easier, and some processes can be left to be difficult if they are done rarely. The database can only have one way of looking at the problem, and it has to be as complicated as the most complicated case, even if that case happens just .1 percent of the time. If it is legal to have multiple authors, the database has to support that case, and the queries and reports that make use of the data must support that case as well.
It's my contention that during the modeling and implementation process, we should rarely step back from our normalized structures to performance-tune our applications proactively, that is to say, before a performance issue is actually felt/discovered.
Because this book is centered on OLTP database structures, the most important part of our design effort is to make certain that the tables we create are well formed for the relational engine and can be equated to the requirements set forth by the entities and attributes of the logical model. Once you start the process of physical storage modeling/integration (which should be analogous to performance tuning, using indexes, partitions, etc.), there might well be valid reasons to denormalize the structures, either to improve performance or to reduce implementation complexity, but neither of these pertain to the logical model that represents the world that our customers live in. You will always have fewer problems if we implement physically what is true logically. For almost all cases, I always advocate waiting until you find a compelling reason to do denormalize (such as if some part of our system is failing), before we denormalize.
There is, however, one major caveat to the "normalization at all costs" model. Whenever the read/write ratio of data approaches infinity, meaning whenever data is written just once and read very, very often, it can be advantageous to store some calculated values for easier usage. For example, consider the following scenarios:
- Balances or inventory as of a certain date: Take a look at your bank statement. At the end of every banking day, it summarizes your activity for the day and uses that value as the basis of your bank balance. The bank never goes back and makes changes to the history but instead debits or credits the account after the balance had been fixed.
- Calendar table, table of integers, or prime numbers: Certain values are fixed by definition. For example, take a table with dates in it. Storing the name of the day of the week rather than calculating it every time can be advantageous, and given a day like November 25, 2011, you can always be sure it is a Friday.
When the writes are guaranteed to be zero, denormalization can be an easy choice, but you still have to make sure that data is in sync and cannot be made out of sync. Even minimal numbers of writes can make your implementation way too complex because again, you cannot just code for the 99.9 percent case when building a noninteractive part of the system. If someone updates a value, its copies will have to be dealt with, and usually it is far easier, and not that much slower, to use a query to get the answer than it is to maintain lots of denormalized data when it is rarely used.
One suggestion that I make to people who use denormalization as a tool for tuning an application is to always include queries to verify the data. Take the following table of data we used in an earlier section:
InvoiceNumber InvoiceDate InvoiceAmount
============= ----------- -------------
000000000323 2011-12-23 100
InvoiceNumber ItemNumber Product Quantity ProductPrice OrderItemId
============= ========== ------- -------- ------------ -----------
000000000323 1 KL7R2 10 8.00 1232322
000000000323 2 RTCL3 10 2.00 1232323
If both the InvoiceAmount (the denormalized version of the summary of line item prices) are to be kept in the table, you can run a query such as the following on a regular basis during off hours to make sure that something hasn't gone wrong:
SELECT InvoiceNumber
FROM dbo.Invoice
GROUP BY InvoiceNumber, InvoiceAmount
HAVING SUM(Quantity * ProductPrice) <> InvoiceAmount
Alternatively, you can feed output from such a query into the WHERE clause of an UPDATE statement to fix the data if it isn't super important that the data is maintained perfectly on a regular basis.
Best Practices
The following are a few guiding principles that I use when normalizing a database. If you understand the fundamentals of why to normalize, these five points pretty much cover the entire process:
- Follow the rules of normalization as closely as possible: This chapter's "Summary" section summarizes these rules. These rules are optimized for use with relational database management systems, such as SQL Server. Keep in mind that SQL Server now has, and will continue to add, tools that will not necessarily be of use for normalized structures, because the goal of SQL Server is to be all things to all people. The principles of normalization are 30-plus years old and are still valid today for properly utilizing the core relational engine.
- All columns must describe the essence of what's being modeled in the table: Be certain to know what that essence or exact purpose of the table is. For example, when modeling a person, only things that describe or identify a person should be included. Anything that is not directly reflecting the essence of what the table represents is trouble waiting to happen.
- At least one key must uniquely identify what the table is modeling: Uniqueness alone isn't a sufficient criterion for being a table's only key. It isn't wrong to have a uniqueness-only key, but it shouldn't be the only key.
- Choice of primary key isn't necessarily important at this point: Keep in mind that the primary key is changeable at any time with any candidate key. I have taken a stance that only a surrogate or placeholder key is sufficient for logical modeling, because basically it represents any of the other keys (hence the name "surrogate"). This isn't a required practice; it's just a convenience that must not supplant choice of a proper key.
- Normalize as far as possible before implementation: There's little to lose by designing complex structures in the logical phase of the project; it's trivial to make changes at this stage of the process. The well-normalized structures, even if not implemented as such, will provide solid documentation on the actual "story" of the data.
Summary
In this chapter, I've presented the criteria for normalizing our databases so they'll work properly with relational database management systems. At this stage, it's pertinent to summarize quickly the nature of the main normal forms we've outlined in this and the preceding chapter; see Table 5-1.
Table 5-1. Normal Form Recap
| Form | Rules |
|---|---|
| Definition of a table | All columns must be atomic—only one value per column. All rows of a table must contain the same number of values. |
| First Normal Form | Every row should contain the same number of values, or in other words, no arrays, subtables, or repeating groups. |
| BCNF | All columns are fully dependent on a key; all columns must be a fact about a key and nothing but a key. A table is in BCNF if every determinant is a key. |
| Fourth Normal Form | The table must be in BCNF. There must not be more than one independent multivalued dependency represented by the table. |
| Fifth Normal Form | The entity must be in Fourth Normal Form. All relationships are broken down to binary relationships when the decomposition is lossless. |
Is it always necessary to go through the steps one at a time in a linear fashion? Not exactly. Once you have designed databases quite a few times, you'll usually realize when your model is not quite right, and you'll work through the list of four things that correspond to the normal forms we have covered in this chapter.
- Columns: One column, one value.
- Table/row uniqueness: Tables have independent meaning; rows are distinct from one another.
- Proper relationships between columns: Columns either are a key or describe something about the row identified by the key.
- Scrutinize dependencies: Make sure relationships between three values or tables are correct. Reduce all relationships to binary relationships if possible.
There is also one truth that I feel the need to slip into this book right now. You are not done. You are just starting the process of design with the blueprints for the implementation. The blueprints can and almost certainly will change because of any number of things. You may miss something the first time around, or you may discover a technique for modeling something that you didn't know before (hopefully from reading this book!), but don't get too happy yet. It is time to do some real work and build what you have designed (well, after an extra example and a section that kind of recaps the first chapters of the book, but then we get rolling, I promise).
Still not convinced? In the following list, consider the following list of pleasant side effects of normalization:
- Eliminating duplicated data: Any piece of data that occurs more than once in the database is an error waiting to happen. No doubt you've been beaten by this once or twice in your life: your name is stored in multiple places, then one version gets modified and the other doesn't, and suddenly, you have more than one name where before there was just one.
- Avoiding unnecessary coding: Extra programming in triggers, in stored procedures, or even in the business logic tier can be required to handle poorly structured data, and this, in turn, can impair performance significantly. Extra coding also increases the chance of introducing new bugs by causing a labyrinth of code to be needed to maintain redundant data.
- Keeping tables thin: When I refer to a "thin" table, the idea is that a relatively small number of columns are in the table. Thinner tables mean more data fits on a given page, therefore allowing the database server to retrieve more rows for a table in a single read than would otherwise be possible. This all means that there will be more tables in the system when you're finished normalizing.
- Maximizing clustered indexes: Clustered indexes order a table natively in SQL Server. Clustered indexes are special indexes in which the physical storage of the data matches the order of the indexed data, which allows for better performance of queries using that index. Each table can have only a single clustered index. The concept of clustered indexes applies to normalization in that you'll have more tables when you normalize. The increased numbers of clustered indexes increase the likelihood that joins between tables will be efficient.
The Story of the Book So Far
This is the "middle" of the process of designing a database, so I want to take a page here and recap the process we have covered:
- You've spent time gathering information, doing your best to be thorough without going Apocalypse Now on your client. You know what the client wants, and the client knows that you know what they want.
- Next, you looked for entities, attributes, business rules, and so on in this information and drew a picture, creating a model that gives an overview of the structures in a graphical manner. (The phrase "creating a model" always makes me imagine a Frankenstein Cosmetics–sponsored beauty pageant.)
- Finally, these entities were broken down and turned into relational tables such that every table relayed a single meaning. One noun equals one table, pretty much. I'll bet if it's your first time normalizing, but not your first time working with SQL, you don't exactly love the process of normalization right now.
- I don't blame you; it's a startling change of mind that takes time to get used to. I know the first time I had to create ten tables instead of one I didn't like it (all those little tables look troublesome the first few times!). Do it a few times, implement a few systems with normalized databases, and it will not only make sense, but you will feel unclean when you have to work with tables that aren't normalized.
If you're reading this book in one sitting (and I hope you aren't doing it in the bookstore without buying it), be aware that we're about to switch gears, and I don't want you to pull a muscle in your brain. We're turning away from the theory, and we're going to start doing some designs, beginning with logical designs and building SQL Server 2012 objects in reality. In all likelihood, it is probably what you thought you were getting when you first chunked down your hard-earned money for this book (or, hopefully your employer's money for a full-priced edition).
If you haven't done so, go ahead and get access to a SQL Server, such as the free SQL Server Express from Microsoft. Or download a trial copy from http://www.microsoft.com/sql/ . Everything done in this book will work on all versions of SQL Server other than the Compact Edition.
Optionally, to do some examples, you will also need the AdventureWorks2012 database installed for some of the examples, which you can get the latest version from http://msftdbprodsamples.codeplex.com/ . At the time of this writing, there is a case-sensitive and case-insensitive version. I assume that you are using the case-insensitive version. I do try my best to maintain proper casing of object names.