
CONTENTS
1.2 Selection Criterion of Duplicate Mining Methods
1.3 TV Commercial Mining for Sociological Analysis
1.3.2 Temporal Recurrence Hashing Algorithm
1.3.3 Knowledge Discovery Based on CF Mining
1.4 News Story Retrieval and Threading
1.4.3 Experimentation Evaluation
1.5 Indexing for Scaling up Video Miningi
1.5.3 Cross-Dimensional Indexing
1.6 Conclusions and Future Issues
The spread of digital multimedia content and services in the field of broadcasting and on the Internet has made multimedia data mining an important technology for transforming these sources into business intelligence for content owners, publishers, and distributors. A recent research domain known as multimedia duplicate mining (MDM) has emerged largely in response to this technological trend. The “multimedia duplicate mining” domain is based on detecting image, video, or audio copies from a test collection of multimedia resources. One very rich area of application is digital rights management, where the unauthorized or prohibited use of digital media on file-sharing networks can be detected to avoid copyright violations. The primary thesis of MDM in this application is “the media itself is the watermark,” that is, the media (image, video, or audio) contains enough unique information to be used to detect copies (Hampapur et al., 2002). The key advantage of MDM over other technologies, for example, the watermarking, is the fact that it can be introduced after copies are made and can be applied to content that is already in circulation.
Monitoring commercial films (CFs) is an important and valuable task for competitive marketing analysis, for advertising planning, and as a barometer of the advertising industry’s health in the field of market research (Li et al., 2005; Gauch and Shivadas, 2006; Herley, 2006; Berrani et al., 2008; Dohring and Lienhart, 2009; Putpuek et al., 2010; Wu and Satoh, 2011). In the field of broadcast media research, duplicate videos shared by multiple news programs imply that there are latent semantic relations between news stories. This information can be used to define the similarities between news stories; thus, it is useful for news story tracking, threading, and ranking (Duygulu et al., 2004; Zhai and Shah, 2005; Wu et al., 2008a; Wu et al., 2010). From another viewpoint, duplicate videos play a critical role in assessing the novelty and redundancy among news stories, and can help in identifying any fresh development among a huge volume of information in a limited amount of time (Wu et al., 2007a; Wu et al., 2008b). Additionally, MDM can be used to detect filler materials, for example, opening CG shots, anchor person shots, and weather charts in television, or background music in radio broadcasting (Satoh, 2002).
This chapter discusses the feasibility, techniques, and demonstrations of discovering hidden knowledge by applying MDM methods to the massive amount of multimedia content. We start by discussing the requirements and selection criteria for the duplicate mining methods in terms of the accuracy and scalability. These claims involve the sampling and description of videos, the indexing structure, and the retrieval process, which depend on the application purposes. We introduce three promising knowledge-discovery applications to show the benefits of duplicate mining. The first application (Wu and Satoh, 2011) is dedicated to fully unsupervised TV commercial mining for sociological analysis. It uses a dual-stage temporal recurrence hashing algorithm for ultra-fast detection of identical video sequences. The second application (Wu et al., 2010) focuses on news story retrieval and threading: it uses a one-to-one symmetric algorithm with a local interest point index structure to accurately detect identical news events. The third application (Poullot et al., 2008, Poullot et al., 2009) is for large-scale cross-domain video mining. It exploits any weak geometric consistencies between near-duplicate images and addresses the scalability issue of a near-duplicate search. Finally, a discussion on these techniques and applications is given.
1.2 SELECTION CRITERION OF DUPLICATE MINING METHODS
Choosing a duplicate mining method can be difficult because of the variety of methods currently available. The application provider must decide which method is best suited to their individual needs, and, of course, the type of duplicate that they want to use as the target. In this sense, the definition of a duplicate is generally subjective and, to a certain extent, does depend on the type of application being taken into consideration. The application ranges from exact duplicate mining, where no changes are allowed, to a more general definition that requires the resources to be of the same scene, but with possibly strong photometric or geometric transformations.
One direction for MDM is to mine duplicate videos or audios derived from the original resource without any or with very few transformations. This type of duplicate is known as an exact duplicate or exact copy. Typical cases include TV CFs and file footages used in news. Most existing studies on exact duplicate mining introduce the concept of fingerprint or “hash” functions. This is a signal that has been extracted from each sample of a video. It uniquely identifies the sample as genuine and cannot be decoded to get the original one, because the fingerprint is made by some of the features of the sample.
The fingerprints are computed on the sampled frames given the video dataset in order to construct a hash table, into which the frames are inserted by regarding the corresponding fingerprint as an inverted index. An important assumption made here is that identical or approximately identical frames of all the video duplicates have exactly the same fingerprint, so a hash collision occurs in the corresponding hash bucket. Based on this assumption, approximately identical frames of all the exact duplicates can be efficiently retrieved by using a collision attack process.
In most cases, the sampling rate, which defines the number of sampled frames per unit of time (usually seconds) taken from a continuous video to make a discrete fingerprint, is as dense as the allowed maximal frame frequency of the video, for example, 29.97 (NTSC) or 25 (PAL) frames per second for an MPEG-2 video. This high-density sampling can accommodate the fingerprinting errors, that is, different fingerprints derived from identical frames, and allows the detection to be precise in order to locate the boundaries of the duplicates. The description of the video, based on which the fingerprint is extracted, can be color histogram (Li et al., 2005), ordinal signature (Li et al., 2005), color moments (Gauch and Shivadas, 2006), gradient histogram (Dohring and Lienhart, 2009), luminance moments (Wu and Satoh, 2011), and acoustic signatures (Haitsma and Kalker, 2002; Cano et al., 2005). All these global descriptors have been effectively demonstrated, thanks to the limited number of transformations between the original resource and the duplicate. Therefore, most researchers attach more importance to the efficiency and scalability than the effectiveness of the exact duplicate mining methods.
Near duplicates are considered the slight alterations of videos or images issued from the same original source. In other literature, near duplicates are also known as copies. The alterations are obtained from an original using various photometric or geometric transformations, for example, cam cording, picture in picture, insertions of patterns, strong reencoding, gamma changes, decreases in quality, postproduction transformations, and so on. There is significant diversity in the nature and amplitude of the encountered transformations. Near duplicates are widespread among the current worldwide video pool. A typical example is the digital copies of copyrighted materials transferred on file-sharing networks or video-hosting services, for example, Flickr, YouTube, and so on. Two examples are shown in Figure 1.1. The transformation of the example on the left is cam-cording, and those of the right one include a change of contrast, blurring, noising, and scaling.
Near-duplicate mining is considered a more difficult case than exact duplicate mining because the videos or images can be strongly transformed. The assumption of identical or approximately identical images from among all the duplicates with exactly the same fingerprint (Section 1.2.1) becomes too weak to make when detecting near duplicates. Most existing studies on near-duplicate mining use an image distance measure instead of the fingerprinting-based hash collision attack process for finding approximately identical images. An image distance measure compares the similarities between two images in various dimensions, for example, the color, texture, and shape. Most of these studies are designed for images, but can be extended to the video (an image stream) domain by embedding the temporal consistency constraints between duplicate images in the mining process.
A general representation of the images must be chosen to compute the similarities between two images. A picture may be represented by a single global feature (e.g., color histogram, edge orientation histogram, Fourier, or Hough) or by many small local ones (e.g., SIFT, Harris, or dipoles: Gouet and Boujemaa, 2001; Lowe, 2004; Mikolajczyk et al., 2005; Joly et al., 2007). The main difference consists in the precision of the description and in the scalability of the approach, two inversely proportional parameters. Methods with global features usually have a higher efficiency than those with local ones. However, local descriptions have recently become more popular because of their superiority over the global ones in terms of their discriminative power, especially in the most difficult cases where the duplicate videos are short and strongly transformed (Law-To et al., 2007).
Given a video dataset, the local descriptors are computed on the sampled frames in order to construct a descriptor database. Most methods choose a sampling rate (e.g., one frame per second) that is much lower than the allowed maximal frame frequency of the video to ease the potentially high computation burden of the image distance measure. The descriptor database can be queried with a video or a picture, where its local features (Gouet and Boujemaa, 2001; Ke et al., 2004; Jegou et al., 2008) are used as queries, or be crossed over itself by using each of its features as a query. A set of candidates is returned for each feature query. A vote is then conducted to choose the better candidates. Some of these solutions have shown great scalability concerning the descriptor matching, but the last decision step has a prohibitive cost when performing mining. In the early 2000s, the bag of words (BoW) representation (Philbin et al., 2007; Wu et al., 2007b; Yuan et al., 2007) raised up. It was inspired from the inversed lists used in text search engines. Here, a global representation of an image is computed by using the local descriptions. A visual vocabulary is first computed on the sampled local features, by using a K-means algorithm. Then, for a given image, all its local features are quantized on this vocabulary; the resulting description is a histogram with a dimensionality equal to the vocabulary size. There are two major advantages to this approach, the compactness of the feature, and the suppression of the last decision step. It usually leads to a more scalable solution while offering good-quality results. One of the notorious disadvantages of BoW is that it ignores the spatial relationships among the patches, which is very important in image representation. Therefore, a decision process based on the spatial configuration (e.g., with RANSAC) is usually performed as well on the top candidates (Fischler and Bolles, 1981; Matas and Chum, 2005; Joly et al., 2007).

FIGURE 1.1 Two examples of near duplicates. (From NISV, Sound and Vision Video Collection 2008. With permission.)
1.3 TV COMMERCIAL MINING FOR SOCIOLOGICAL ANALYSIS
TV commercials, also known as CFs, are a form of communication intended to persuade an audience to consume or purchase a particular product or service. It is generally considered the most effective mass-market advertising format of all the different types of advertising. CF mining has recently attracted the attention of researchers. This task aims at developing techniques for detecting, localizing, and identifying CFs broadcast on different channels and in different time slots. CF removal based on CF detection and localization is an important preprocessing technique in broadcast media analysis, where CFs are usually considered to be an annoyance. In market research, monitoring CFs is an important and valuable task for competitive marketing analysis, for advertising planning, and as a barometer of the advertising industry’s health. Another promising application of CF mining is to furnish consumers with a TV CF management system, which categorizes, filters out, and recommends CFs on the basis of personalized consumer preference.
CF mining techniques can be categorized into knowledge- and repetition-based techniques. The knowledge-based ones (Albiol et al., 2004; Hua et al., 2005; Duan et al., 2006; Li et al., 2007) use the intrinsic characteristics of CF (e.g., the presence of monochrome, silence, or product frames) as prior knowledge for detecting them. Most knowledge-based techniques are efficient but not generic enough because of the data-dependent prior knowledge they use. For example, most Japanese TV stations do not use monochrome or silence frames to separate two consecutive CF sequences. Other characteristics (e.g., product frame, shot information, and motion information) normally vary with the nations and regions. Meanwhile, CF can be regarded as repetition in the stream. Some recent studies (Li et al., 2005; Gauch and Shivadas, 2006; Herley, 2006; Berrani et al., 2008; Dohring and Lienhart, 2009; Putpuek et al., 2010) have used this property to detect CFs. Conversely, repetition-based ones are unsupervised and more generic, but are a large computational burden. In some studies, the required system task is given a test collection of videos and a reference set of CFs to determine for each CF the location at which the CF occurs in the test collection. These studies are not fully unsupervised considering the construction of the reference set. In most cases, the boundaries of the CFs in the reference set are known. The increase in processing time is linear to that of the size of the test collection. A more challenging task is, when given a test collection of videos, how to determine the location, if any, at which some CF occurs. This is also the main problem that the technique introduced in this section aims to solve. Neither the reference database nor the CF boundary is provided beforehand. The system should be fully unsupervised. The algorithm needs to be much more scalable because the processing time will increase as the square of the test collection size increases.
1.3.2 TEMPORAL RECURRENCE HASHING ALGORITHM
The target is to output a set of CF clusters when given a broadcast video stream as the input. A CF cluster is a set of multiple identical CF sequences and corresponds to a specific commercial, for example, an Apple Macintosh commercial. A CF sequence, which is composed of one or more consecutive fragments, is a long and complete sequence corresponding to an instance of a commercial. A fragment, which is similar to but much shorter than a shot or subshot, is a short segment, composed of one or more consecutive and identical frames. In this study, the visual and audio features are extracted from all the frames of a broadcast video stream. Consecutive frames with identical low-level features are assembled into a fragment. An example of the fragments derived from two recurring CF sequences is shown in Figure 1.2, from where we can observe a strong temporal consistency among the pairs of recurring fragments. For instance, the temporal positions of the fragments themselves are consecutive, and the temporal intervals between each two fragments are identical to each other. This temporal consistency is exceptionally useful for distinguishing the recurring sequences from the nonduplicate ones. The CF mining task can thus be formulated into searching for recurring fragment pairs with high-temporal consistency from all the pairs of recurring fragments derived from the entire stream.
In this study, two temporal recurrence fingerprints are proposed for capturing the temporal information of each recurring fragment pair. The first fingerprint corresponds to the temporal position of the former fragment in the recurring fragment pair, the resolution of which is set to a given set of minutes so that the consecutive fragment pairs derived from two recurring CF sequences can be mapped to the same fingerprint or neighboring ones. The second fingerprint corresponds to the temporal interval between the two fragments, the resolution of which is set to a given set of seconds. As shown in Figure 1.3, all the recurring fragment pairs derived from the stream are inserted into a 2-dimensional hash table based on the two fingerprints. By doing so, the recurring fragment pairs with high-temporal consistency can be automatically assembled into the same bin. These fragments, the assembly of which corresponds to a pair of long and complete CF sequences, can thus be easily detected by searching for the hash collisions from the hash table. More details about this algorithm can be found in Wu and Satoh (2011).

FIGURE 1.2 Recurring fragment pairs derived from two CF sequences of the same CF cluster.
This temporal recurrence hashing algorithm was tested by using a 10-h broadcast video stream with a manually annotated ground truth for the accuracy evaluation. The sequence-level accuracy was 98.1%, which is enough to evaluate how precisely the algorithm can detect and identify recurring CF sequences. The frame-level accuracy was 97.4%, which evaluates how precisely the algorithm can localize the start and end positions of the CF sequences in the stream. Three state-of-the-art studies were implemented for comparison, including two video-based techniques (Berrani et al., 2008; Dohring and Lienhart, 2009) and one audio-based one (Haitsma and Kalker, 2002). The temporal recurrence hashing algorithm outperformed the related studies in terms of both the sequence- and the frame-level accuracy. The algorithm mined the CFs from the 10-h stream in <4 s, and was more than 10 times faster than those in the related studies.
1.3.3 KNOWLEDGE DISCOVERY BASED ON CF MINING
CF mining is an important and valuable task for competitive marketing analysis and is used as a barometer for advertising planning. We discuss a promising application of CF mining in this section that visualizes the chronological distribution of a massive amount of CFs and enables the discovery of hidden knowledge in the advertising market. This application is illustrated in Figure 1.4. It visualizes nine types of chronological distributions involving five types of information including broadcast frequency, date, hour of the day, day of the week, and channel. The CFs were mined from a 4-month and 5-channel broadcast video archive, the total length of which was 20 months. The algorithm mined CFs from this 20-month stream in around 5 h.
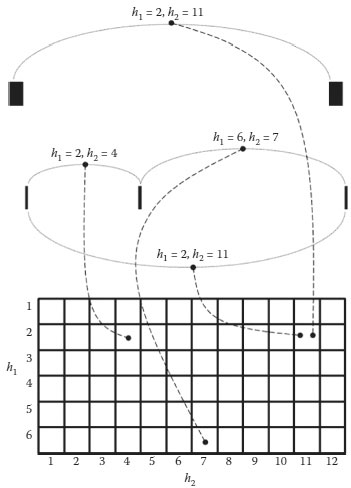
FIGURE 1.3 Temporal recurrence hashing.
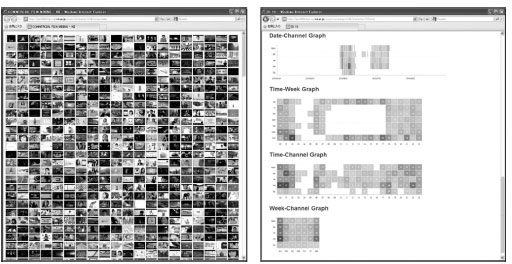
FIGURE 1.4 Application of knowledge discovery based on CF mining.

FIGURE 1.5 Asahi Breweries CF chronological distribution.
Figure 1.5 visualizes the chronological distribution of a beer CF. The horizontal axis indicates the hour of the day, and the vertical one indicates the day of the week. The darker-shaded blocks indicate the time zones with a higher broadcast frequency. A well-regulated distribution can be observed from this graph. The distributions with the same figuration were also found in the graphs of other alcohol-related CFs. This is because there is a voluntary restriction in Japan, which prohibits the broadcast of alcohol CFs from 5 a.m. to 5 p.m. on weekdays and from 5 a.m. to 11 a.m. on weekends.
Figure 1.6 shows an example of a car CF. Three time zones with higher broadcast frequencies can be seen in Figure 1.6a. The first time zone is from 6 a.m. to 8 a.m., which is when most salaried employees are having breakfast. The second one is around 12 a.m., which is lunch time. The third one is after 6 p.m., which is when most salaried employees have finished their work and are watching TV. This observation can also be found in Figure 1.6b. One explanation of this observation could be that this car targets toward male rather than female drivers. Another explanation could be that in most Japanese families, the fathers rather than the mothers manage the money, so the car dealer prefers the most popular TV slots for male viewers rather than those for female viewers.
By analyzing these statistics derived from CF mining, the actual conditions of the business management, which could not be efficiently grasped by using conventional technology, can be determined in a business-like atmosphere. Furthermore, the influences that the information sent from producers, distributors, and advertisers had on the audiences and consumers can be circumstantially analyzed by analyzing the relationship between the statistics from the TV commercials and those from the Web sources, including blogs, and Twitter. We believe that this kind of knowledge can be transformed into business intelligence for producers, distributors, and advertisers.
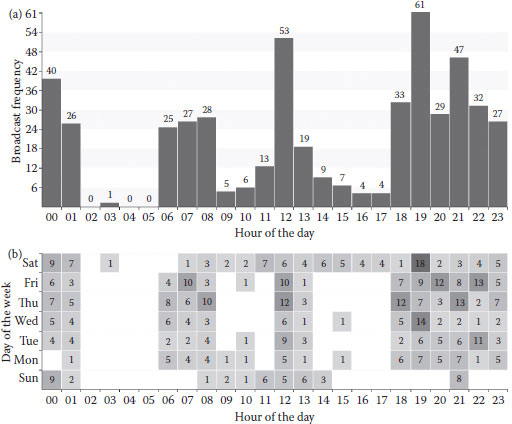
FIGURE 1.6 Daihatsu Tanto Exe CF chronological distribution. (a) Hour–frequency histogram. (b) Hour–day frequency diagram.
1.4 NEWS STORY RETRIEVAL AND THREADING
The spread of digital multimedia content and services in the field of broadcasting and on the Internet has made data retrieval and its reuse an important methodology for helping a user to more easily grasp the availability of these sources. A recent research domain known as news story retrieval has emerged largely in response to this methodological trend, and it is a fundamental step toward semantic-based video summarization and browsing. It tracks the development of evolving and historical news stories originating from a specific news topic, mines their dependencies from different sources, and represents their temporal flow in a semantic way.
News story retrieval is normally studied as a Query-By-Example (QBE) topic with textual information as the underlying cues. A QBE parser parses the query, for example, the text of a full document obtained from the given Web pages or the closed captions of a news story, and looks for keywords on the basis of which similar documents are searched for (Chieu and Lee, 2004; Ide et al., 2004; Kumar et al., 2004;Kumar et al., 2010). The main limitation of this research domain is that the textual information is normally not discriminating enough to distinguish between the documents of similar but irrelevant topics. For example, a news story on the “Trial of Saddam Hussein” was broadcast on November 6, 2006 during the Japanese news program “FNN SPEAK.” The keywords parsed from this story included “sentence” (8), “this go-round” (4), “former president Hussein” (3), “President Bush” (3), “United States” (3), and “November 5th” (3), with the parenthetic numbers being the frequencies of the keywords. By using these keywords as the query and Ide et al.’s work (Ide et al., 2004) as the search engine, the news stories on irrelevant topics were output as the results, including the “Sentence of Homicidal Criminal Yasunori Suzuki,” “United States Midterm Election,” “Sentence of Criminal Miyoko Kawahara,” and “Sentence of Homicidal Criminal Shizue Tamura.” The reason for this is because the keywords parsed from the query were limited and not informative enough to represent the characteristics of the corresponding news topic. In addition to the textual transcripts, news videos provide a rich source of visual information. In broadcast videos, there are also a number of visual near duplicates, which appear at different times and dates and across various broadcast sources. These near duplicates basically form pairwise equivalent constraints that are useful for bridging evolving news stories across time and sources.
The aim of this research is news story retrieval and reranking using visual nearduplicate constraints. A news story is formally defined as a semantic segment within a news program that contains a report depicting a specific news topic. A news topic is a significant event or incident that is occurring in the contemporary time frame. A news story can be described in the form of multiple video segments, for example, shots, and closed captions. Each of the segments and sentences in a news story must be semantically identical with respect to its news topic. For instance, a news program can typically be regarded as an assembly of individual news stories that are presented by one or more anchors and collectively cover the entire duration of the program. Adjacent stories within a news program must be significantly different in topic. Figure 1.7 shows an example of two news stories reported by different TV stations and on different days.
The first task of the proposed news story retrieval and reranking approach involves a news story retrieval process based on the textual information. Given a news story as the query, the objective is to return a set of candidate news stories satisfying the following criterion:
(1.1) |
Sim denotes the textual similarity between and , σqa threshold, and ns the number of candidate stories. The second task involves a news story reranking process based on the pseudo-relevance feedback, which is the main emphasis of this approach. The objective of this task is to find a subset , then to assume that all are semantically identical to in the topic, and finally, to do a query expansion under this assumption to perform a second-round retrieval. The problems that need to be solved here include: (1) how to automatically find a proper subset out of S satisfying the assumption described above, and (2) how to expand the query so that the relevant stories low-ranked in the initial round can then be retrieved at a higher rank to improve the overall performance.

FIGURE 1.7 Two news stories originating from “Lewinsky Scandal” and “UNSCOM” news topics. (From LDC, TRECVID 2004 Development Data. With permission.)
We propose a novel approach called StoryRank in this study, which solves the first problem by exploiting the visual near-duplicate constraints. After retrieving news stories based on the textual information, near duplicates are mined from the set of candidate news stories. A one-to-one symmetric algorithm with a local interest point index structure (Ngo et al., 2006) is used because of its robustness to any variations in translation and scaling due to video editing and different camerawork. Figure 1.8 shows some examples of visual near duplicates within the set of candidate news stories depicting the “Lewinsky Scandal.” Note that some of these examples are derived from news stories reported by different TV stations or on different days.
Visual near-duplicate constraints are integrated with textual constraints so that the news story reranking approach can guarantee a high-relevance quality for pseudo-relevance feedback. As shown in Figure 1.9, two news stories are linked together if they share at least one pair of near duplicates. This pair of stories can be regarded as having a must-link constraint, which indicates that they discuss the same topic. News stories are then clustered into groups called feedback sets by applying transitive closure to these links. One of the characteristics of these feedback sets is that the visual near-duplicate constraints within each feedback set usually form a strongly connected network so that the news stories that are identical to the query in topic comprise a majority of all the stories in this network. Another characteristic is that the dominant feedback set is usually identical in topic to the query. Therefore, the dominant feedback set is chosen as the pseudo-relevance feedback and used for performing the second-round news story retrieval.

FIGURE 1.8 Visual near duplicates existing across multiple news stories for same topic. (From LDC, TRECVID 2004 Development Data. With permission.)
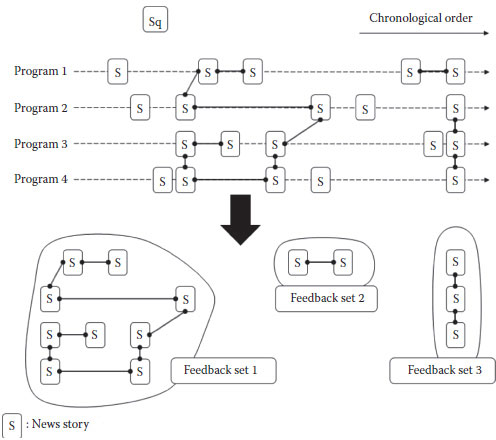
FIGURE 1.9 Exploit must-link near-duplicate constraints between news stories.
Within graph theory and network analysis, there are various measures for the centrality of a vertex within a graph that determines the relative importance of a vertex within the graph, for example, how important a person is within a social network, or in the theory of space syntax, how important a room is within a building or how well used a road is within an urban network. One of these measures is called the Eigenvector centrality. It assigns relative scores to all the nodes in a network based on the principle as follows: connections to high-scoring nodes contribute more, to the score of the node in question, than equal connections to low-scoring nodes. PageRank (Brin and Page, 1998) is a variant of the Eigenvector centrality measure, the most famous application of which is the Google Internet search engine. In this study, PageRank is used as a pseudo-relevance feedback algorithm and integrated with visual near-duplicate constraints. Each news story is regarded as a node and the whole candidate story set a node-connected network. The news stories in the dominant feedback set are regarded as high-quality nodes, which are different from the classic PageRank, and for each node in the entire network, only the connections between the node and the high-quality nodes are used as votes of support to iteratively define the overall relevancy of the story.
1.4.3 EXPERIMENTATION EVALUATION
The approach was tested by using a very-large-scale broadcast video database comprised of videos broadcast from April 1, 2005 to March 31, 2009. These videos were broadcast from eight news programs produced by four Japanese TV stations. The database was comprised of 100,573 news stories, and 20 queries were selected for experimentation, as listed in Table 1.1, including 11 Japanese and nine foreign news stories. The design of these queries is based on the most important topics from both domestic and international news stories during these 4 years. The duration within which the search was conducted varied from 1 to 15 months. The average precision (Turpin and Scholer, 2006) was computed to evaluate the performance of the news story reranking.
TABLE 1.1
Twenty Queries Selected for Experimentation
ID |
Topic |
Start Date |
Duration |
|
T01 |
7 July 2005 London Bombings |
July 7, 2005 |
1 |
Foreign |
T02 |
Trial of Saddam Hussein |
October 19, 2005 |
15 |
Foreign |
T03 |
Architectural Forgery in Japan |
November 17, 2005 |
2 |
Domestic |
T04 |
Murder of Airi Kinoshita |
December 1, 2005 |
1 |
Domestic |
T05 |
Murder of Yuki Yoshida |
December 2, 2005 |
1 |
Domestic |
T06 |
Fraud Allegations of Livedoor |
January 16, 2006 |
2 |
Domestic |
T07 |
Murder of Goken Yaneyama |
May 18, 2006 |
1 |
Domestic |
T08 |
2006 North Korean Missile Test |
July 6, 2006 |
1 |
Foreign |
T09 |
2006 North Korean Nuclear Test |
October 4, 2006 |
1 |
Foreign |
T10 |
Trial of Saddam Hussein |
November 5, 2006 |
2 |
Foreign |
T11 |
2007 Chuetsu Offshore Earthquake |
July 16, 2007 |
1 |
Domestic |
T12 |
2007 Burmese Anti-Government Protests |
September 23, 2007 |
1 |
Foreign |
T13 |
Tainted Chinese Dumplings |
January 30, 2008 |
2 |
Domestic |
T14 |
Tokitsukaze Stable Hazing Scandal |
February 7, 2008 |
1 |
Domestic |
T15 |
2008 Sichuan Earthquake |
May 20, 2008 |
1 |
Foreign |
T16 |
Akihabara Massacre |
June 8, 2008 |
1 |
Domestic |
T17 |
Wakanoho Toshinori |
August 18, 2008 |
1 |
Domestic |
T18 |
2008 Chinese Milk Scandal |
September 22, 2008 |
1 |
Foreign |
T19 |
Murder of Former MHLW Minister |
November 18, 2008 |
1 |
Domestic |
T20 |
2008 Mumbai Attacks |
November 27, 2008 |
1 |
Foreign |
The Mean Average Precision of the news story reranking approach was 96.9%, which was higher than all the related studies based on textual information. An intuitive reason for this is that the reranking approach based on PageRank improves the informativeness and representativeness of the original query, and the visual near-duplicate constraints guarantee a higher relevance quality than the textual constraints used in pseudo-relevance feedback algorithms. Additionally, evolving news stories usually repeatedly use the same representative videos even if the airdates and consequently the subtopics of these stories are distant from each other. Therefore, the feedback set formulated from visual near duplicates can guarantee a larger coverage of subtopics than those derived from textual constraints, so the news reranking approach is more robust against the potential variation of the subtopics of the evolving news stories.
1.5 INDEXING FOR SCALING UP VIDEO MININGI
A major and common issue of works focused on videos and images is to deal with some very large amounts of data. Millions of hours of video and billions of images are now available on the Internet and in the archives. Various research domains share the necessity of finding some similarities in datasets in order to highlight the links for categorization, classification, and so on. Performing a rough similarity comparison is a basic quadratic operation. Consequently, applying such a brute force approach on a very large pool may become hopeless. Some subsets can and must be predefined, but, even in very specialized domains, the accumulation of data and knowledge pushes the time consumption of algorithms beyond an acceptable limit. On the other hand, parallelism can also be performed, but this usually induces a massive expenditure of money and energy. Moreover, it is a linear solution, and some other bottlenecks may appear. One solution more than the others has been found to quickly perform a similarity search. The core of the proposition is to perform an approximative similarity search, which, for a low loss of quality in the results, may offer a tremendous reduction of time consumption, which is better than for an exact similarity search. A large part of these approximative approaches use an index structure (Datar et al., 2004; Joly et al., 2007; Lv et al., 2007). This type of structure is used to filter out the database, and thus shrinks the pool of candidates.
Different approaches must be investigated depending on resources and requirements in order to organize a video database. The similarities between videos can be computed between their annotations, their audio component, or their image component.
A textual search engine can be set up if some annotations are available. The main advantage of such an approach is the powerful scalability. It can also deal with the semantic aspect provided by the users. The drawbacks are the sparsity and low resolution of the annotations. The audio part of a video can also be processed (Haitsma and Kalker, 2002); lots of speech-to-text applications are gaining popularity, and a more accurate extraction of the meaning and knowledge is being attained. Videos sharing the same sound line, or even subject, but different visual contents can be gathered. However, when the sound line is changed between a copy and an original, it becomes harder to gather similar ones. In this case, the image part is processed (Ke et al., 2004; Joly et al., 2007; Law-To et al., 2007; Poullot et al., 2008). The advantages and drawbacks of audio and image approaches are somehow opposite to the textual ones: a potential tight resolution, but a lack of scalability. The following part of this section is dedicated to one of the possible image-based solutions.
In this proposition, the goal is to find videos with a very strong similarity: copies, that is, near duplicates. Digging out copies can be useful in many automatic processes for organizing and preserving the contents: merge annotations, clustering, cleaning (by deleting some duplicates), and classifying (using nodes and links attributes). Moreover, once links are found, some mining works can be done to characterize them and the videos. Now, given the massive amount of video available contents, a scalable approach is mandatory for finding the links between videos.
A cross-dimensional index structure (Poullot et al., 2008, Poullot et al., 2009) based on the local description and image plane is introduced here. It is designed for images but can be used for video (an image stream) by extension. The structure can easily be generalized to many applications; here, it is applied to a content-based video copy detection framework.
The Glocal description relies on a binary quantization of the local description space. This space is considered a cell, and each step of the quantization splits the cell(s) of the previous step along one dimension. The number of cell is Nc= 2h, where h is the quantization step. Figure 1.10 shows three possible quantizations of a description space (symbolized in 2D here, and should be 128D for a SIFT case) containing six local descriptors. The resulting Glocal vector is binary, the presence or absence of descriptors in the cells is quoted. It is not a histogram, so it is not influenced by the textures and repeated patterns, which is the inverse to standard BoW features.
The Dice coefficient is used to measure the similarity between Glocal signatures, SDice (g1,g2) = 2 × (G1⋂ G2)/(|G1| + |G2|), where Gi is a set of bits set to one in the signature giand |Gi| denotes the set cardinality.
There must be a balance between the number of local features used and the quantization in order to obtain discriminant vectors. Therefore, sparsity is needed, for example, in Figure 1.10, Nc = 16 at minimum is needed. For the case of a copy detection, using Na ∈ [100, 200] local descriptors per keyframe and Nc= 1024 has shown good results. However, for an object search application, a lot more local descriptors must be picked up in the frames, hundreds (or more) of them, and thus Nc must be increased to more than a thousand in order to preserve the sparsity and discriminating power of the vectors.
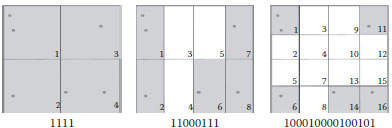
FIGURE 1.10 Three different quantizations of six local descriptors at Nc= 4, 8, 16.
Two types of descriptors were used in our experiments, a local jet spatio-temporal descriptor, which is a 20-dimensional vector (see Gouet and Boujemaa, 2001 for details) and SIFT. The first one is computed at the Point of Interest (PoI) detected by the Harris Corner Detector. SIFT is computed at PoI detected by using the Difference of Gaussian. However, using raw SIFTs for building the Glocal descriptors is not a good option, because of the sparsity of the SIFT description space itself. So, the SIFTs are first randomly projected in a subspace of 32 dimensions that maintains the intrinsic dimensionality of the SIFTs.
Then, for the rough local jet and projected SIFT descriptors, the components are ordered by decreasing uniformity (computed on a set of random descriptors). Indeed, as only the 10th or so first dimensions are used for the quantization, it is better to work on the ones that offer the best balance and separability.
Only the keyframes are exploited to create the descriptors to improve the scalability of the system. They are automatically detected in the videos using the global luminance variation, and the appearance rate is 3000 per hour (a little <1 keyframe per second, very much less than the usual 25-fps rate).
1.5.3 CROSS-DIMENSIONAL INDEXING
Once the Glocal descriptors have been computed for the entire video set, the indexing is performed. The mining task has a quadratic complexity (Θ(n2) where n is the number of items). Only the keyframes and a Glocal description are used to reduce n and the complexity of the task. Indexing aims at further reducing the final complexity. The idea is to construct buckets based on the N-grams of a bit set to one in the binary descriptor. This scheme was already tested before by picking the bits set to one depending on their position in the binary vector itself. For instance, take the positions of the three following bits set to one to build a triplet. This triplet is associated to the bucket where the Glocal descriptor is inserted. In that way, the triplets 1-6-11, 6-11-14, and 11-14-16 from Figure 1.10 can be obtained, and four buckets in which the Glocal descriptor of the keyframe is inserted.
In the case of strong occlusions (half picture for example), this generally leads to a loss of detection. That is not surprising as the local descriptors are not associated considering their position in the keyframe but in the description space for indexing. A dual space indexing which uses both the position in the keyframe and in the description space is then more likely to be relevant, that is, stronger to many postproduction transformations observed on copies, as occlusion, crop, subtitles, inlays, and so on. The recall gets better, and, crossing two types of information for indexing precision does as well. Note also that in the case of an object search, this solution will also be much more relevant, and will be able to focus on only a small part of the image.
The local descriptors in a keyframe may describe the background, a moving object, a standing character, and so on. Linking the local descriptors to objects is very difficult, and thus, the community for this issue has not yet been determined. It would require perfect segmentation and good tracking. Moreover, these tasks are likely to have higher computational costs, and so, are not suitable for the scalability issue. However, using these relations between the local descriptors would be very powerful. In order to exploit this relation, a simple assumption can be made: if the positions of the Pol are close to each other the local descriptors computed around are more likely to describe the same object in the keyframe. Consequently, descriptors that are close must be associated, and we propose using these associations in the indexing scheme. The quantizations of the local features (the bits set to one in the binary vector) are thus associated depending on the positions of their PoI in the keyframe for building the N-grams. The indexing relies on a 2-fold association that crosses the description and keyframe spaces.
Let say N = 3, the 3-grams are built this way: take a PoI, find its nearest neighbor in the keyframe (using L2 distance in the image plane), then associate it with 1-NN and 2-NN, and with 3-NN and 4-NN, and so on. The resulting 3-grams are the quantizations of these local descriptors associations. Of course N can be increased, but the higher it is, the stronger the constraints are: N PoI neighbors must be preserved and the descriptors computed at these positions must be quantized in the same way.
As PoI or SIFT matching can be lost between two versions of a video, creating only one N-gram per local descriptor is still quite risky and unstable for retrieval purposes. Some more redundancy can be injected in the index for improving the recall. For each descriptor, an unlimited number of N-grams can be set up using more or less neighbors. The more N-grams that are chosen, the better the recall is and the lower the scalability is. In Figure 1.11, on the left is a set of PoI, and three N-grams from two of them, and on the right the N-grams resulting from the deletion of one PoI and the insertion of another one (quoted with *). It can be seen that at the top one out of three combinations is kept, and at the bottom, two out of three are kept.
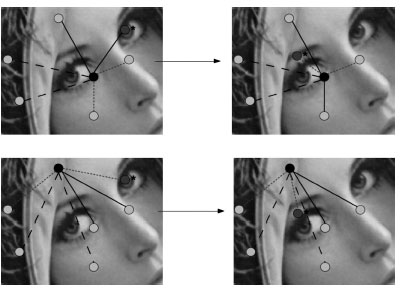
FIGURE 1.11 Set of points with three triplet associations, centered on two different PoI. The original associations are on the left, and the deletions and insertions of one point are on the right.
It was also quite interesting to find that depending on the PoI, the N-grams are not redundant between each other, offering a widespread of the keyframes in the index.
The sparseness of the database can be evaluated along with the cost of a query in such a system. Let us assume that 150 PoI are extracted per keyframe, and 3 grams are built for each, then the Glocal descriptor is then inserted in a maximum of 450 buckets. For Nc = 2048, there are Nb = (2048!/3!) ≈ 1.42 × 109 possible buckets. For a 15,000-h video database, about 4.5 × 107 keyframes are extracted, so about 2 × 109 Glocal descriptors are stored in the buckets. If equiprobability of the quantization is respected, each bucket on an average contains about 15 Glocal descriptors. Now, for a picture query, under the same conditions, 450 buckets, and 6750 comparisons will be performed to find similar keyframes. If we compare this to the number of keyframes in the database, and so to the number of necessary comparisons in the case of a sequential search, we have a computation ratio of rc = 1.5 × 10-4 (0.015% of the computations are performed compared to the sequential scan).
Some statistics were computed on a real 15,000-h database in order to get the true distribution of the bucket population. It contains 5.2 × 107 KF and 1.2 × 1010 Glocal descriptors. Gathering the population of the 450 hundred most populated buckets (the worst scenario) leads to a set of 4 × 107 Glocal descriptors. In the worst case, 77% of the exhaustive comparisons are performed for an image query. In particular, when performing a set of 600 queries, we have an average of 73,000 comparisons per picture, which is far below the extreme value: 0.14% of the comparisons that are performed for each picture. However, this value is still 10 times larger than the expected theoretical one due to the imbalance in the number of buckets.
However, we can apply a cut in the database by removing the bigger buckets. They can actually be seen as “stop words,” very noisy, and not informative. If 99.9% of the information (population of the database) is kept, the 450 most populated buckets contain 1.6 × 106Glocal descriptors. Then, in the worst case, only 3.5% of the sequential comparisons are computed.
A shape descriptor is embedded during the indexing to more precisely improve our results. The shape descriptor aims at characterizing the spatial conformation in the keyframe of the associated local descriptors used for defining an N-gram. A fuzzy comparison of two shape descriptors can then be used to discard some false-positive matching, and thus, improving the precision. Moreover, this test can be done before the similarity computation, as a filtering step, and, so, reduces the processing time.
We propose using rij = (sizeOfLongerSide/sizeOfSmallerSide), where sizeOfSmallerSide is the smaller length between the PoI used for building the N-gram and sizeOfLongerSide is the longer one. Currently, 3 grams are mainly used, so this corresponds to the ratio between the smaller on the longer edges of the triangle. It must be noted that this shape descriptor is robust to scale changes, rotations, and small affine transformations. This descriptor is then a metadata associated with a Glocal descriptor for a given N-gram. For indexing, the Glocal descriptor is inserted in the bucket corresponding to this N-gram along with this shape descriptor. Figure 1.12 sums up the indexing process.
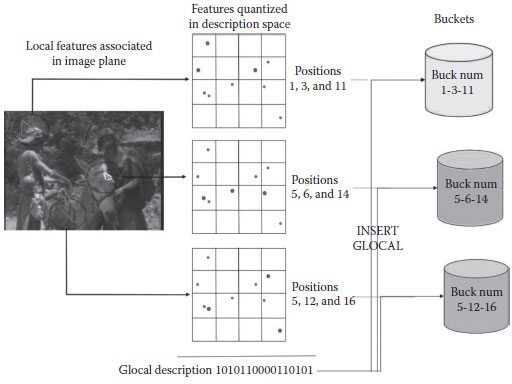
FIGURE 1.12 Indexing of the Glocal description of a keyframe in three different buckets along with three different shape codes. (From NISV, Sound and Vision Video Collection 2008. With permission.)
In the mining stage, or query stage, when comparing two Glocal descriptors lying in the same bucket, a fuzzy comparison between their shape descriptors is performed first. Basically, the test is to see if |(s1 – s2)| ≤ θ returns true, where s1 is the shape descriptor of Glocal descriptor 1 and s2 the shape descriptor of Glocal descriptor 2. If the test is successful (if the shape descriptors are more or less equal), then the similarity between the two Glocal descriptors is computed. The fuzzy test adds some robustness to the shape descriptor. It also can be adjusted for more or less tolerance. Typically θ = 0.5 is used for our test on the CBCD TRECVID task. For object search, it should be lower than for video copy detection.
In the 15,000-h database, the number of avoided distance computations between the Glocal descriptors was counted in the real case of 600 query pictures. Using all the buckets, 75% of the computations were skipped, and 47% were skipped when removing the “stop words” bucket. These statistics show that the matchings due to “stop words” can also be discarded by using the shape description.
Finally, if a similarity between two Glocal descriptors is computed, in order to limit the number of results, a threshold Th is used, and the pair of frame (F1, F2) is kept if SDice(GF1,GF2) ≥ Th where GFi is the Glocal descriptor of frame Fi.
The connections identified between individual keyframes are used to delimit and link together the video sequences that are transformed versions of the same content. Starting from the two connected keyframes, two adjoined sequences are built by using the stepwise addition of the other connected keyframes (with increasing time codes) that verify the temporal consistency conditions. These conditions make the detection more robust to the absence of a few connected keyframes and to the presence of some false-positive detections.
The first requirement is that the temporal gap between the last keyframe in a sequence (with time code Tcx,l) and a candidate keyframe to be added to the same sequence (with time code Tcx,c) should be lower than a given threshold g:Tcx,c) – Tcx,l < g. The gaps are due to the absence of several connected keyframes, as a result of the postprocessing operations (addition or removal of several frames), of any instabilities of the keyframe detector, or of any false negatives in the detection of connected keyframes.
The second requirement bounds the variation of the temporal offset (jitter) between the connected keyframes of two different sequences of IDx and IDy. Jitter is caused by postprocessing operations or by instabilities in the keyframe detector. If Tcx,l is the time code of the last keyframe in IDx, Tcy,l is the time code of the last keyframe in IDy, Tcx,c and Tcy,c are the time codes of the candidate keyframes, then the condition for upper bounding the jitter by using τj is: |(Tcx,c – Tcx,l) – (Tcy,c – Tcy,l)| < τj.
The candidate keyframes are added at the end of the current sequences only if both the gap and the jitter conditions are satisfied. And, finally, the third condition is that the sequences should be longer than a minimal value τj to be considered valid; this removes the very short detections, which are typically false positives.
Since the scalability is our main focus in this work, the tests were mainly driven on a laptop PC, a Samsung Q310, processor dual core Q8600 at 2.6 GHz with 4 Gb of RAM. No parallel version of the methods for using both of the cores was used.
We used the TRECVID 2008 CBCD benchmark to experiment with the proposed description and indexing approach. This benchmark is composed of a 207-h video reference database and 2010 artificially generated query video segments (or 43 h), 1340 of which contain copies. One query can only correspond to one segment of one video from the reference database. A query not only can contain a copied part of a reference video, but also the video segments that are not related to the reference database. The queries are divided into 10 groups of 134 queries each, each group corresponding to one type of transformation (“attack”): camcording (group 1), picture-in-picture type 1 (group 2), insertion of pattern (group 3), strong reencoding (group 4), change of gamma (group 5), three combined basic transformations (group 6), five combined basic transformations (group 7), three combined postproduction transformations (group 8), five combined postproduction transformations (group 9), and a combination of all the transformations (group 10). The “basic” transformations are: blur, gamma, frame dropping, contrast, compression, scaling, and noise. The postproduction transformations are: crop, shift, contrast, caption, flip, insertion of pattern, and picture in picture (insertion of a shrunk version of an original video in a larger one). Since many queries include a left-right flip to which the local features used here are not robust, the features were detected and described on both the initial queries and a flipped version of the queries (so there are 4020 queries and a total of 293 h of video).
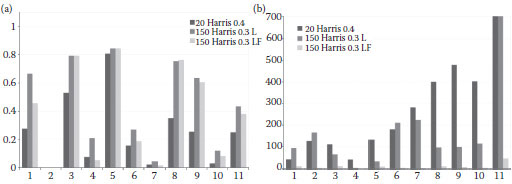
FIGURE 1.13 Comparison of recall on TV2008 CBCD benchmark (a); comparison of absolute number of false alarms (b). The 10 first sets of columns correspond to the attack groups, and the 11th one is the average (a) and absolute sum (b).
Three different methods were used for testing our proposals. The first one is the reference method described by Poullot et al. (2008) with the following settings: Na = 20, Nc = 256, Th = 0.4. The other two methods use the following settings: Na = 150, Nc = 1024, Th = 0.3, and cross-space indexing. However, one uses shape embedding (denoted as “locality and shape”) while the other does not (denoted as “locality”). These settings were chosen because they offered the best compromises between precision and recall (a study was first driven and Na ∈ [20, 200], Nc ∈ [256, 512, 1024], Th ∈ [0.2, 0.5] were tested). The feature used was the local jet spatio-temporal descriptor computed at Harris Corner positions.
Figure 1.13 shows the recall and number of false alarms for each method. It can be seen that the recall is improved by using more local features and the locality-based bucket selection (L); the addition of local geometric information (distance ratios in LF) has a weak impact on the recall, lowering it for some specific transformations (especially camcording and strong reencoding). The most important contribution of the geometric information was the significant reduction in the number of false positives, despite a lower decision threshold.
The examples in Figure 1.14 were not detected if cross-dimensional hashing was not used; we should note that large inlays were inserted in these examples, and thus we found that using the locality information is indeed very relevant.
A comparison between two features (Section 1.5.2) is shown in Figure 1.15, for the method using both the locality and distance ratios (LF). We set Na = 150 and, since the precision was high, the decision threshold was reduced to Th = 0.2. With these parameter values, the SIFT features provided on average a slightly lower overall recall and equivalent precision.

FIGURE 1.14 Three examples of detected copies (original image is on right). (From NISV, Sound and Vision Video Collection 2008. With permission.)
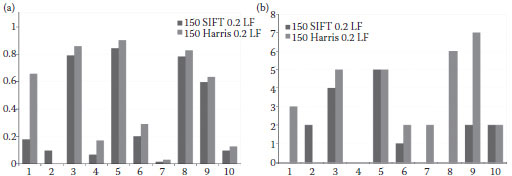
FIGURE 1.15 (a) comparison of recall using SIFT and Local Jets. (b) comparison of absolute number of false alarms. The 10 groups correspond to the attack groups.
We used two larger datasets, which were some continuous recordings of five different Japanese TV channels over several days for experimenting scalability of the approach. Overall, the databases, respectively, contained 1000 and 3000 h of video. In this set, we found a lot of redundancy (jingles, advertising, credits, weather forecast, reporting, and so on), but most of the transformations were light and corresponded to the insertion of logos or design changes and also to time-line editing. For performing a real large-scale test, a self-join of the database was performed: use all the videos inserted in the database as a query. Once the database is built, the Glocal descriptors in each bucket, according to the shape descriptor condition, are compared to the lying ones. Then, the time consistency step (Section 1.5.5) is applied.
Concerning some main memory issues, the 3000-h database was built on a computer with an X7460 single core CPU at 2.66 GHz and 8 Gb of RAM. For the time comparison with the building step, the self-join was also performed on the same computer. Table 1.2 shows the computation time for these operations. The time required to build the database depends only on the number of features selected on the frames and the number of frames, and this is a linear dependency. The self-join similarity is supposed to have a quadratic complexity, but when using an index structure, the real complexity is far below this limit. Using the locality for indexing does not change this complexity; it just improves the recall, as seen in the previous quality part. On the other hand, using the shape description, the complexity is drastically reduced, and thus, so is the required time. In this case, many of the distance computations between Glocal Descriptors are cut off (Section 1.5.4).
TABLE 1.2
Building and Self-Join Operation on Large Video Databases
Database Size |
|||
Method |
Operation |
1000 h |
3000 h |
20_Harris_0.4 |
Build |
15 min |
21 min |
Self-join |
2 h 01 min |
12 h 00 min |
|
100_Harris_0.3 |
Build |
1 h 57 min |
3 h 04 min |
Locality |
Self-join |
7 h 30 min |
40 h 00 min |
Locality and shape |
Self-join |
1 h 17 min |
0 h 54 min |
150_Harris_0.3 |
Build |
3 h 11 min |
5 h 01 min |
Locality |
Self-join |
8 h 48 min |
41 h 10 min |
Locality and shape |
Self-join |
2 h 21 min |
1 h 34 min |
Content-based video copy detection can provide useful information for browsing and structuring video databases, for large institutional archives as well as for video-sharing websites. The challenge is to be both fast and reliable even when the transformations between original videos and copies are strong.
On the basis of the local descriptions of the video frames and a BoF approach, information regarding the geometric configuration of these features in the image plane is also exploited in order to obtain a sufficient level of reliability and scalability, resulting in a cross-dimensional hashing process. Since many transformations like strong cropping and video inlays alter the longer-range structure of the frames but maintain part of the short-range structure, we suggest taking into account the locality in the image plane (nearest neighbors of a feature) when indexing the video frames. Moreover, some simple local geometric data can be used to further discriminate the frames hashed in the same bucket and accelerate the matching computations. These data are selected to be as robust as possible to the most common types of image transformations.
An experimental evaluation of the detection quality of our proposal was conducted on the TRECVID 2008 copy-detection benchmark, using two different types of features, and we found that there was a significant improvement over the previous method. The scalability was then assessed on larger databases of up to 3000 h of video and the fact that the computation time was greatly reduced by the filtering operation exploiting the local geometric information was highlighted.
1.6 CONCLUSIONS AND FUTURE ISSUES
The main elements of an MDM system include the sampling and description of videos, the indexing structure, and the retrieval process, which depend on the application purposes. On the basis of these claims, this chapter discusses the requirements and selection criteria of MDM approaches in terms of the robustness, discriminative power, scalability, and so on. It also provided a review of three promising MDM systems and their applications to knowledge discovery. The experimental evaluations and the application cases of these systems demonstrated the high applicability and potential of this research domain. Future research is expected to contribute toward achieving a good tradeoff between the robustness and discriminative power, reducing the storage space and memory usage required for video sampling and indexing, and getting a good trade-off between the effectiveness and efficiency. It will be also interesting to see what will happen if we combine the watermarking and MDM strategies in the rich area of digital rights management and copyright violation detection. Although MDM is still in its early stages, the urgent need for practical applications in this area as well as in market research and broadcast media research makes it a hot topic, and numerous innovations are expected in the near future. We hope this chapter will provide some useful information to readers interested in this research field.
Sound and Vision video is copyrighted. The Sound and Vision video used in this work is provided solely for research purposes through the TREC Video Information Retrieval Evaluation Project Collection.
Commercial film
Cross dimensional indexing
Data mining
Duplicate detection
Fast quantization
Fingerprinting
Hashing algorithm
News story reranking
News story tracking
PageRank
Shape embedding
Albiol, A., Ch, M. J., Albiol, F. A., and Torres, L., Detection of TV commercials, IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, Qeubec, Canada, Vol. 3, pp. 541–544, May 2004.
Berrani, S.-A., Manson, G., and Lechat, P., A non-supervised approach for repeated sequence detection in TV broadcast streams, Image Commun., 23(7), 525–537, 2008.
Brin, S. and Page, L., The anatomy of a large-scale hypertextual Web search engine, Comput. Netw. ISDN Syst., 30(1–7), 107–117, 1998.
Cano, P., Batlle, E., Kalker, T., and Haitsma, J., A review of audio fingerprinting, J. VLSI Signal Process. Syst., 41(3), 271–284, 2005.
Chieu, H. L. and Lee, Y. K., Query based event extraction along a timeline, Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, pp. 425–432, July 2004.
Datar, M., Immorlica, N., Indyk, P., and Mirrokni, V. S., Locality-sensitive hashing scheme based on p-stable distributions, Proceedings of the Twentieth Annual Symposium on Computational Geometry, Brooklyn, NY, USA, pp. 253–262, June 2004.
Dohring, I. and Lienhart, R., Mining TV broadcasts for recurring video sequences, Proceedings of the ACM International Conference on Image and Video Retrieval, Santorini, Fira, Greece, pp. 1–8, July 2009.
Duan, L.-Y., Wang, J., Zheng, Y., Jin, J. S., Lu, H., and Xu, C., Segmentation, categorization, and identification of commercial clips from TV streams using multimodal analysis, Proceedings of the 14th Annual ACM International Conference on Multimedia, Santa Barbara, CA, USA, pp.201–210, October 2006.
Duygulu, P., Pan, J.-Y., and Forsyth, D. A., Towards auto-documentary: Tracking the evolution of news stories, Proceedings of the 12th Annual ACM International Conference on Multimedia, New York, NY, USA, pp. 820–827, October 2004.
Fischler, M. A. and Bolles, R. C., Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography, Commun. ACM, 24(6), 381–395, 1981.
Gauch, J. M. and Shivadas, A., Finding and identifying unknown commercials using repeated video sequence detection, Comput. Vis. Image Underst., 103(1), 80–88, July 2006.
Gouet, V. and Boujemaa, N., Object-based queries using color points of interest, Proceedings of the IEEE Workshop on Content-based Access of Image and Video Libraries, Kauai, Hawaii, pp. 30–36, December 2001.
Haitsma, J. and Kalker, T., A highly Robust audio fingerprinting system, Third International Conference on Music Information Retrieval, Paris, France, October 2002.
Hampapur, A., Hyun, K., and Bolle, R. M., Comparison of sequence matching techniques for video copy detection, Storage and Retrieval for Media Databases, San Jose, CA, USA, pp. 194–201, January 2002.
Herley, C., ARGOS: Automatically extracting repeating objects from multimedia streams, IEEE Trans. Multimed., 8(1), 115–129, 2006.
Hua, X.-S., Lu, L., and Zhang, H.-J., Robust learning-based TV commercial detection, IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, pp. 149–152, July 2005.
Ide, I., Mo, H., Katayama, N., and Satoh, S., Topic threading for structuring a large—scale news video archive, Image and Video Retrieval, Lecture Notes in Computer Science, Springer, Berlin, Vol. 3115, pp. 123–131, 2004.
Jegou, H., Douze, M., and Schmid, C., Hamming embedding and weak geometric consistency for large scale image search, Proceedings of the 10th European Conference on Computer Vision: Part I, Marseille, France, pp.304–317, October 2008.
Joly, A., Buisson, O., and Frelicot, C., Content-based copy retrieval using distortion-based probabilistic similarity search, IEEE Trans. Multimed., 9(2), 293–306, February 2007.
Ke, Y., Sukthankar, R., and Huston, L., An efficient parts-based near-duplicate and sub-image retrieval system, Proceedings of the 12th Annual ACM International Conference on Multimedia, New York, NY, USA, pp. 869–876, October 2004.
Kumar, R., Mahadevan, U., and Sivakumar, D., A graph-theoretic approach to extract storylines from search results, Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, pp. 216–225, August 2004.
Law-To, J., Chen, L., Joly, A., Laptev, I., Buisson, O., Gouet-Brunet, V., Boujemaa, N., and Stentiford, F., Video copy detection: A comparative study, Proceedings of the 6th ACM International Conference on Image and Video Retrieval, Amsterdam, The Netherlands, pp. 371–378, July 2007.
Lee, Y., Jung, H., Song, W., and Lee, J.-H., Mining the blogosphere for top news stories identification, Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, pp. 395–402, July 2010.
Li, Y., Jin, J. S., and Zhou, X., Matching commercial clips from TV streams using a unique, robust and compact signature, Proceedings of the Digital Image Computing on Techniques and Applications, Cairns, Australia, pp.355–362, December 2005.
Li, Y., Zhang, D., Zhou, X., and Jin, J. S., A confidence based recognition system for TV commercial extraction, Proceedings of the Nineteenth Conference on AustralasianDatabase—Volume 75, Gold Coast, Australia, pp. 57–64, January 2007.
Lowe, D. G., Distinctive image features from scale-invariant keypoints, Int. J. Comput. Vis., 60(2), pp. 91–110, November 2004.
Lv, Q., Josephson, W., Wang, Z., Charikar, M., and Li, K., Multi-probe LSH: Efficient indexing for high-dimensional similarity search, Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, pp.950–961, September 2007.
Matas, J. and Chum, O., Randomized RANSAC with sequential probability ratio test, Proceedings of the Tenth IEEE International Conference on Computer Vision—Volume 2, Rio de Janeiro, Brazil, pp.1727–1732, October 2005.
Mikolajczyk, K., Tuytelaars, T., Schmid, C., Zisserman, A., Matas, J., Schaffalitzky, F., Kadir, T., and Gool, L. V., A comparison of affine region detectors, Int. J. Comput. Vis., 65(1–2), pp. 43–72, November 2005.
Ngo, C.-W., Zhao, W.-L., and Jiang, Y.-G., Fast tracking of near-duplicate keyframes in broadcast domain with transitivity propagation, Proceedings of the 14th Annual ACM International Conference on Multimedia, Santa Barbara, CA, USA, pp. 845–854, October 2006.
Philbin, J., Chum, O., Isard, M., Sivic, J., and Zisserman, A., Object retrieval with large vocabularies and fast spatial matching, IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, Minnesota, USA, pp. 1–8, June 2007.
Poullot, S., Crucianu, M., and Buisson, O., Scalable mining of large video databases using copy detection, Proceedings of the 16th ACM International Conference on Multimedia, Vancouver, British Columbia, Canada, pp. 61–70, October 2008.
Poullot, S., Crucianu, M., and Satoh, S., Indexing local configurations of features for scalable content-based video copy detection, Proceedings of the First ACM Workshop on Large-Scale Multimedia Retrieval and Mining, Beijing, China, pp. 43–50, October 2009.
Putpuek, N., Cooharojananone, N., Lursinsap, C., and Satoh, S., Unified approach to detection and identification of commercial films by temporal occurrence pattern, Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, pp. 3288–3291, August 2010.
Satoh, S., News video analysis based on identical shot detection, 2002 IEEE International Conference on Multimedia and Expo, Lausanne, Switzerland, Vol. 1, pp. 69–72, August 2002.
Turpin, A. and Scholer, F., User performance versus precision measures for simple search tasks, Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, Washington, USA, pp. 11–18, August 2006.
Wu, X., Hauptmann, A. G., and Ngo, C.-W., Novelty detection for cross-lingual news stories with visual duplicates and speech transcripts, Proceedings of the 15th International Conference on Multimedia, Augsburg, Germany, pp. 168–177, September 2007a.
Wu, X., Hauptmann, A. G., and Ngo, C.-W., Practical elimination of near-duplicates from web video search, Proceedings of the 15th International Conference on Multimedia, Augsburg, Germany, pp. 218–227, September 2007b.
Wu, X., Ngo C.-W., and Hauptmann, A.G., Multimodal news story clustering with pairwise visual near-duplicate constraint, IEEE Trans. Multimed., 10(2), pp. 188–199, February 2008a.
Wu, X., Hauptmann, A. G., and Ngo, C.-W., Measuring novelty and redundancy with multiple modalities in cross-lingual broadcast news, Comput. Vis. Image Underst., 110(3), pp. 418–431, June 2008b.
Wu, X., Ide, I., and Satoh, S., PageRank with text similarity and video near-duplicate constraints for news story re-ranking, Advances in Multimedia Modeling, Lecture Notes in Computer Science, Springer, Berlin, Vol. 5916, pp. 533–544, 2010.
Wu, X. and Satoh, S., Temporal recurrence hashing algorithm for mining commercials from multimedia streams, 2011 IEEE International Conference on Acoustics Speech and Signal Processing, Prague, Czech Republic, pp. 2324–2327, May 2011.
Yuan, J., Wu, Y., and Yang M., Discovery of collocation patterns: From visual words to visual phrases, IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, pp. 1–8, June 2007.
Zhai, Y. and Shah, M., Tracking news stories across different sources, Proceedings of the 13th Annual ACM International Conference on Multimedia, Hilton, Singapore, pp. 2–10, November 2005.