
CONTENTS
16.2 Watermarking for im Age Authentication
16.4 copy–cover Image Forgery Detection
16.4.4 Statistical Domain Method
16.5.1 Robustness to JPEG Compression
16.5.2 Robustness to Gaussian Blurring
It was a very difficult task in old times without digital cameras and computers to create a good splicing photograph, which requires sophisticated skill of darkroom masking. Due to rapid advances in powerful image-processing software, digital images are easy to manipulate and modify. This makes it more difficult for humans to check the authenticity of a digital image. Nowadays, modifying the content of digital images becomes much easier with the help of sophisticated software such as Adobe PhotoshopTM. It was reported that there were five million registered users of Adobe Photoshop up to the year 2004 (Hafner, 2004). Image editing software is generally availabel, and some of them are even free, such as GIMPTM (the GNU Image Manipulation Program) and Paint.NetTM (the free image editing and photo manipulation software were designed to be used in computers that run Microsoft WindowsTM). The ease of creating fake digital images with a realistic quality makes us think twice before accepting an image as authentic. For the news photographs and the electronic check clearing systems, image authenticity becomes extremely critical.
As an example of image forgery after the U.S. Civil War, a photograph of Lincoln’s head was superimposed onto a portrait of the southern leader John Calhoun, as shown in Figure 16.1. Another example of image forgery appeared in a video of Osama bin Laden issued on Friday, September 7, 2007 before the sixth anniversary of 9/11. According to Neal Krawetz of Hactor Factor, an expert on digital image forensics, this video contained many visual and audio splices, and all of the modifications were of very low quality.
Checking the internal consistencies within an image, such as whether the shadow is consistent with the lighting or the objects in an image are in a correct perspective view, is one method to examine the authenticity of images. Minor details of fake images are likely to be overlooked by forgers, and thus it can be used to locate possible inconsistency. However, minor or ambiguous inconsistencies can be easily argued unless there are major and obvious inconsistencies. Moreover, it is not difficult for a professional to create a digital photomontage without major inconsistencies.
In this chapter, we describe and compare the techniques of copy–cover image forgery detection (Shih and Yuan, 2010). It is organized as follows. Section 16.2 reviews watermarking technique for image authentication. Section 16.3 introduces image splicing detection. Section 16.4 presents four copy–cover detection methods, including principal component analysis (PCA), discrete cosine transform (DCT), spatial domain, and statistical domain. Section 16.5 compares the four copy–cover detection methods, and provides the effectiveness and sensitivity under variant additive noises and lossy Joint Photographic Experts Group (JPEG) compressions. Finally, we draw conclusions in Section 16.6.

FIGURE 16.1 The 1860 portrait of (a) President Abraham Lincoln and (b) Southern politician John Calhoun. (Courtesy of Hoax Photo Gallery.)
16.2 WATERMARKING FOR IM AGE AUTHENTICATION
Watermarking is not a brand new phenomenon. For nearly 1000 years, watermarks on papers have been often used to visibly indicate a particular publisher and to discourage counterfeiting in currency. A watermark is a design impressed on a piece of paper during production and used for copyright identification. The design may be a pattern, a logo, or an image. In the modern era, as most of the data and information are stored and communicated in a digital form, proving authenticity plays an increasingly important role. As a result, digital watermarking is a process whereby arbitrary information is encoded into an image in such a way that the additional payload is imperceptible to image observers. Figure 16.2 shows the general procedure of watermarking.
Digital watermarking has been proposed as a tool to identify the source, creator, owner, distributor, or authorized consumer of a document or an image. It can also be used to detect a document or an image that has been illegally distributed or modified. In a digital world, a watermark is a pattern of bits inserted into a digital media that can identify the creator or authorized users. The digital watermark, unlike the printed visible stamp watermark, is designed to be invisible to viewers. The bits embedded into an image are scattered all around to avoid identification or modification. Therefore, a digital watermark must be robust enough to survive the detection, compression, and operations that are applied.
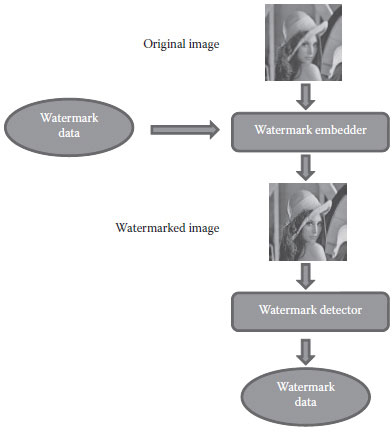
FIGURE 16.2 The general procedure of watermarking.
In general, watermarking techniques, such as fragile watermarking (Shih, 2007), semifragile watermarking (Wu and Shih, 2007), or content-based watermarking (Bas et al., 2002), are often used for the image authentication application. However, watermarking techniques have some drawbacks. Fragile watermark is not suitable for such applications involving compression of images, which is a common practice before sharing images on the Internet. Even though the compression operation is content preserving, fragile watermarking techniques would probably declare a compressed image as unauthentic. Although semifragile watermark can be designed to tolerate a specific set of content-preserving operations such as JPEG compression (Lin and Chang, 1998), designing such a watermark that can meet the complex requirements of real-life applications is very challenging. It is indeed not easy to develop a watermarking algorithm that can resist such errors produced from scanning and transmission, as well as can tolerate the intensity and size adjustments.
Several watermarking methods have been proposed. Yuan et al. (2006) and Huang et al. (2006) put forward integer wavelet-based multiple logo-watermarking schemes, in which a visual meaningful logo is embedded in the wavelet domain. The watermark is inserted in different bands of wavelet coefficients to make it robust to different attacks. Wu and Cheung (2010) presented a reversible watermarking algorithm, which exploits the redundancy in the watermarked object to save the recovery information. Kalantari et al. (2010) proposed a robust watermarking algorithm in the ridgelet domain by modifying the amplitude of the ridgelet coefficients to resist additive white noise and JPEG compression. Luo et al. (2010) developed a watermarking algorithm using interpolation techniques to restore the original image without any distortion after the hidden data are extracted. Kang et al. (2010) proposed a watermarking algorithm which is resilient to both print—scan process and geometric distortion by adopting a log-polar mapping.
Since the watermark generation and embedding techniques are closely coordinated in the process of watermarking, the overall success of detection relies upon the security of the watermark generation and embedding. There are several issues to be considered: (1) how easy it is to disable the embedding of watermark, (2) how easy it is to hack the embedding procedure, and (3) how easy it is to generate a valid watermark or embed a valid watermark into a manipulated image. Unfortunately, the embedded watermark can be removed by exploiting the weak points of a watermarking scheme. When a sufficient number of images with the same secret watermark key are obtained, a watermarking scheme can be hacked. There is still not a fully secure watermarking scheme available till date.
Image splicing is a fundamental step in digital photomontage, which makes a paste-up image by editing images using digital tools such as Adobe Photoshop. Ng et al. (2004) investigated the prospect of using bicoherence features for blind image splicing detection. Image splicing is an essential operation for digital photomontaging, which in turn is a technique for creating image forgery. They fed bicoherence features of images to support vector machine for classification, and the detection accuracy reaches 70%.
Based on the observation that digitally processed image forgery makes the digital image data highly correlated, Gopi et al. (2006) exploited this property by using autoregressive (AR) coefficients as the feature vector for identifying the location of digital forgery in an image. There are 300 feature vectors extracted from different images to train an artificial neural network (ANN). The accuracy rate of identifying digital forgery is 77.67%.
Although image splicing is a very powerful technique, one still can detect the trace of splicing. Image splicing generally introduces a step-jump transition that does not usually happen at crossing boundaries of two objects in a natural scene image. Figure 16.3 shows the difference between the boundaries introduced by image splicing and natural boundary.
In general, the camera-captured images do not usually contain step-like edge transitions based upon the following reasons that make edges blurred:
1. Most output images from digital cameras are in the JPEG compressed format, which could cause loss of fine details.
2. Noise is usually unavoidable.
3. When people take a picture, the hand shaking is unavoidable.
4. Digital cameras often use a color filter array interpolation to produce RGB images.
5. The output image is often resized or resampled for application purposes.
Based on the above observations, we present an algorithm to detect the trace of image splicing:
1. Let Z2 and Z3 denote the horizontal and vertical neighbors of Z1, respectively. We calculate the first-order derivative of the input image by
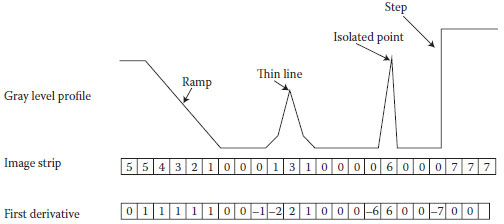
FIGURE 16.3 In a camera-captured image, there are ramp, isolated point, flat segment, and thin line. On the other hand, “step” is produced by image splicing.

FIGURE 16.4 Some examples, where the left-hand images are spliced images and the righthand images are our resulting images, in which the lines indicate the traces of splicing. (a1), (b1), and (c1) are spliced images and (a2), (b2), and (c2) are the respectively resulting images, in which the lines indicate the traces of splicing.
(16.1) |
2. Perform thresholding on the first-order derivatives to obtain the binary image BW1.
3. Apply a binary morphological erosion with a 2 × 2 structuring element on BW1 to obtain a new binary image BW2.
4. Calculate the difference image, that is, BW3 = BW1 – BW2.
5. Obtain the connected components in BW3. The noisy components whose sizes are less than a given threshold are removed. The components in BW3 are the traces of image splicing.
We apply this algorithm on the image splicing dataset images from Columbia University (Columbia, 2010). Figure 16.4 shows some examples, where the left-hand images are spliced images and the right-hand images are the resulting images, in which the lines indicate the traces of splicing.
16.4 COPY–COVER IMAGE FORGERY DETECTION
The copy–cover technique is the most popular technique for making image forgery. copy–cover means that one portion of a given image is copied and then used to cover some object in the given image. If the processing is properly done, most people would not notice that there are identical (or nearly identical) regions in an image. Figure 16.5 shows an example of copy–cover image forgery, where a region of wall background in the left image is copied and then used to cover two boxes on the wall.
Several researchers have explored the copy–cover image forgery detection. Mahdian and Saic (2007) proposed a method to automatically detect and localize duplicated regions in digital images. Their method is based on blur moment invariants, allowing the successful detection of copy–cover forgery even when blur degradation, additional noise, or arbitrary contrast changes are present in the duplicated regions. These modifications are commonly used techniques to conceal traces of copy–cover forgery.
Fridrich et al. (2003) presented an effective copy–cover forgery detection algorithm using DCT and quantization techniques. Popescu and Farid (2004) used the PCA domain representation to detect the forged part, even when the copied area is corrupted by noise. Ju et al. (2007) adopted PCA for small image blocks with fixed sizes, and generates the degraded dimensions representation for copy–cover detection.
Although both DCT and PCA representation methods are claimed to be successful in copy–cover forgery detection, there is a lack of performance comparisons. We evaluate the two methods in terms of time complexity, efficiency, and robustness, as well as evaluate two other methods—one based on spatial-domain representation and the other on statistical domain representation.
Given an image of N pixels, our goal is to identify the location and shape of duplicated regions resulting from copy–cover forgery. The general copy–cover detection method is described below. First, a given image is split into small overlapping blocks; each block is transformed into another domain, such as DCT or PCA domain. A twodimensional matrix is constructed in the way that the pixels in a block are placed in a row by a raster scan and the total number of rows corresponds to the total number of blocks in the given image. By lexicographically sorting all the rows, identical or nearly identical blocks can be detected since they are adjacent to each other. The computational cost of this method is the lexicographic sorting (with time complexity O(N log N)) and domain transformation.

FIGURE 16.5 The image on the left is original, and the image on the right is forged, in which a region of wall background is copied and then used to cover two boxes on the wall.
We use four different domain representations for copy–cover detection. The first method is based on PCA domain. The dimension of each block is reduced, and only a number of principal coefficients are preserved. The second method is based on the DCT domain. Only a number of most significant DCT coefficients are preserved. Both PCA and DCT methods are in general robust to noise introduced in the process of forgery and can reduce the time consumption in the lexicographical sorting.
The third method is based on the spatial domain. All the small blocks are sorted directly according to their pixel values. It saves time since no transformation is involved. However, the lexicographical sorting consumes much more time. The fourth method is based on statistical domain, which uses the mean value and standard deviation of each block for sorting. These four methods are described in more detail below.
Before describing the four methods, we need to define the parameter notations. Let N be the total number of pixels in a square grayscale or color image (i.e., the image has pixels in dimensions). Let b denote the number of pixels in a square block (i.e., the block has pixels in dimensions); there are totally blocks. Let Nc be the number of principal components preserved in the PCA domain, and let Nt be the number of significant DCT coefficients preserved in the DCT domain. Let Nn denote the number of neighboring rows to search for in the lexicographically sorted matrix. Let Nd be the minimum offset threshold.
PCA is known as the best data representation in the least-square sense for classical recognition (Jolliffe, 2002). It is commonly used to reduce the dimensionality of images and retain most information. The idea is to find the orthogonal basis vectors or the eigenvectors of the covariance matrix of a set of images, with each image being treated as a single point in a high-dimensional space. Since each image contributes to each of the eigenvectors, the eigenvectors resemble ghost-like images when displayed. The PCA domain method for copy–cover detection is described below.
1. Using PCA, we can compute the new Nb × NC matrix representation, in which each row is composed of the first Nc principal components in each block. If a color image is used, we convert the color image into a grayscale image or analyze each color channel separately.
2. Sort the rows of the above matrix in a lexicographic order to yield a matrix S. Let denote the rows of S, and let (xi, yi) denote the position of the block’s image coordinates (top-left corner) that corresponds to .
3. For every pair of rows and from S such that , place the pair of coordinates (xi, yi) and (xj, yj) in a list.
4. For all elements in this list, compute their offset, as defined by (xi – xj, yi – yj).
5. Discard all the pairs whose offset magnitude is less than Nd.
6. Find out the pairs of coordinates with highest offset frequency.
7. From the remaining pairs of blocks, build a duplication map by constructing a zero image, whose size is the same as the original, and coloring all pixels in a duplicated region by a unique grayscale intensity value.
Many video and image compression algorithms apply the DCT to transform an image to the frequency domain and perform quantization for data compression (Yip and Rao, 1990). One of its advantages is the energy compaction property, that is, the signal energy is concentrated on a few components while most other components are zero or negligibly small. This helps separate an image into parts (or spectral subbands) of hierarchical importance (with respect to the image’s visual quality). The popular JPEG compression technology uses the DCT to compress an image.
We replace step 1 of the aforementioned PCA domain method by DCT to compute the newNb × Nt matrix representation, where each row of the matrix is composed of Nt significant coefficients by zigzag ordering of DCT coefficients in each block.
We replace step 1 of the PCA domain method by the Nb × b matrix representation, where each row is the column-wise concatenation of the b pixels in each block.
16.4.4 STATISTICAL DOMAIN METHOD
We replace step 1 of the PCA domain method by an Nb × 2 matrix, where each row contains the mean value and the standard deviation of each block.
To compare the performance of the aforementioned four methods, we create an image database composed of 500 images for use in our experiment. The image resolution is of size 256 × 256. The content of those images includes landscape, buildings, flowers, human, animals, and so on. For each image, we randomly copy a region of size 81 × 81 and paste it to another location to form a tempered image. Since the detection results depend somewhat on the content of image and the region selected, we conduct the experiment for all the images and use the average value for comparisons. The following parameters are preset: b = 256, Nn = 1, Nd = 10, Nc = 26, and Nt = 26.
To compare the robustness of the four methods with respect to JPEG compression and Gaussian blurring, we use XNview (a software for viewing and converting graphic files, which is a freeware available at http://www.xnview.com), to accomplish the JPEG compression and Gaussian blurring. When conducting the JPEG compression, XNview allows us to choose the compression ratio between 0 and 100. The smaller the number, the smaller the output file will be. When conducting the Gaussian blurring, XNview allows us to choose the Gaussian blurring filter size. The larger the size, the more the given image will become blurred.

FIGURE 16.6 (a) The original image and (b) the copy–cover forgery image.

FIGURE 16.7 Output of copy–cover forgery detection by (a) PCA, (b) DCT, (c) spatial domain, and (d) statistical domain detection methods. Note that the matched blocks are displayed in light and dark gray.

FIGURE 16.8 Output of copy–cover forgery detection by (a) PCA, (b) DCT, (c) spatial domain, and (d) statistical domain detection methods when the given image is corrupted by Gaussian blurring with block size 7.
Figure 16.6 shows an example of a copy–cover forgery, in which the tampering consists of copying and pasting a region to cover a significant content. Figure 16.7 shows the output images of copy–cover forgery detection when the given image is compressed with JPEG quality 50, where Figures a–d are respectively obtained by PCA, DCT, spatial domain, and statistical domain detection methods. Figure 16.8 shows the output copy–cover forgery detection when the given image is corrupted by Gaussian blurring of block size 7.
16.5.1 ROBUSTNESS TO JPEG COMPRESSION
Since most images availabel are JPEG compressed, we apply JPEG compression ratios from 50 to 100 to compress the test images for comparing the robustness of the four methods under JPEG compression. The obtained true positive rates related to JPEG quality are shown in Figure 16.9. We observe that the performances of DCT domain and PCA domain methods are very similar, and are better than those of spatial domain and statistical domain methods. Moreover, the statistical domain method is slightly better than the spatial-domain method.
The true negative rates with respect to JPEG quality are shown in Figure 16.10. We observe that the performance of DCT domain, PCA domain, and statistical domain methods are very similar. However, the performance of spatial domain is worse than the other three.
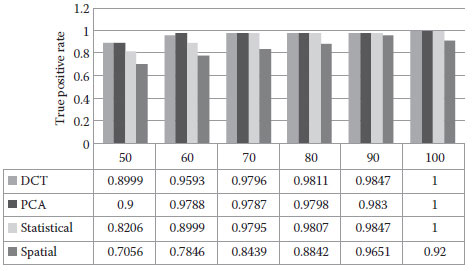
FIGURE 16.9 True positive rates with respect to JPEG compression ratio.
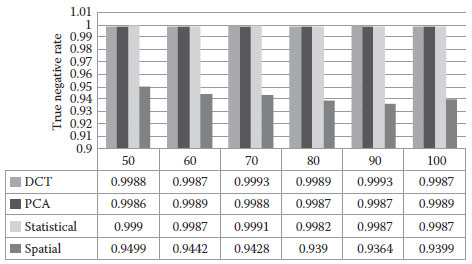
FIGURE 16.10 True negative rates with respect to JPEG compression ratio.
16.5.2 ROBUSTNESS TO GAUSSIAN BLURRING
Since copy–cover image forgery will produce two identical regions in an image, one method to conceal the forgery is to apply Gaussian blurring on the composite image to conceal the forgery. We apply Gaussian blurring with different block sizes from 1 × 1 to 11 × 11 on the test images and then perform the detection. Note that the image using 1 × 1 Gaussian blurring is the same as the original image.
The true positive rates with respect to Gaussian blurring are shown in Figure 16.11. We observe that the performances of DCT, PCA, and statistical domain methods are similar, which are slightly better than that of the spatial–domain method.
The true negative rates with respect to PSNR are shown in Figure 16.12. We observe that the true negative rate of the spatial domain method is the lowest. The true negative rates of DCT, PCA, and statistical domain methods are similar.
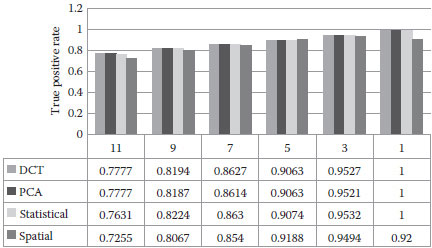
FIGURE 16.11 True positive rates with respect to Gaussian blurring.
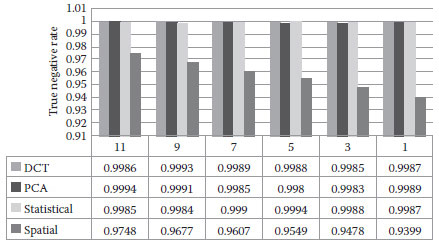
FIGURE 16.12 True negative rates with respect to Gaussian blurring.
TABLE 16.1
Running Time of the Four Detection Methods
Method |
Running Time (s) |
DCT domain |
29.8594 |
PCA domain |
20.5313 |
Spatial domain |
17.0156 |
Statistical domain |
20.8281 |
The experiment is performed on a Dell notebook computer with a 1.70 GHz Intel Pentium Mobile Processor and 512 MB of RAM running Windows XPTM. The program is coded in MATLAB®. For a given image of size 256 × 256, the average running time of the four methods is shown in Table 16.1.
In this chapter, we discuss the techniques of watermarking for authentication and the four methods for copy–cover identification, including PCA, DCT, spatial domain, and statistical domain. We evaluate their effectiveness and sensitivity under the influences of Gaussian blurring and lossy JPEG compressions. We conclude that the PCA domain method outperforms the other methods in terms of time complexity and detection accuracy. Our future work is to extend the capability of copy-and-paste modification from different images. Furthermore, we will explore more complicated spatially distributed copy-and-paste modification; that is, instead of copying a consecutive area, one may copy one pixel here and another pixel there in a random-like distribution.
Bas, P., Chassery, J. M., and Macq, B., Image watermarking: An evolution to content based approaches, Pattern Recognition, 35, 545–561, 2002.
Columbia Image Splicing Detection Evaluation Dataset, The DVMM Laboratory of Columbia University, 2010.
Fridrich, J., Soukal, D., and Lukáš. J., Detection of copy-move forgery in digital images, in Digital Forensic Research Workshop, 2003.
Gopi, E. S., Lakshmanan, N., Gokul, T., Ganesh, S., and Shah, P. R., Digital image forgery detection using artificial neural network and auto regressive coefficients, Proceedings of the Canadian Conference on Electrical and Computer Engineering, pp.194–197, May 2006.
Hafner, K., The camera never lies, but the software can, New York Times, 2004.
Huang, D., Yuan, Y., and Lu, Y., Novel multiple logo-watermarking algorithm based on integer wavelet, Chinese Journal of Electronics, 15, 857–860, 2006.
Jolliffe, I. T., Principal Component Analysis, Springer, New York, 2002.
Ju, S., Zhou, J., and He, K., An authentication method for copy areas of images, in International Conference on Image and Graphics, pp. 303–306, 2007.
Kalantari, N. K., Ahadi, S. M., and Vafadust, M., A robust image watermarking in the ridgelet domain using universally optimum decoder, IEEE Transactions on Circuits and Systems for Video Technology, 20, 396–406, 2010.
Kang, X., Jiwu, H., and Wenjun, Z., Efficient general print-scanning resilient data hiding based on uniform log-polar mapping, IEEE Transactions on Information Forensics and Security, 5, 1–12, 2010.
Lin, C. Y. and Chang, S. F., A robust image authentication method surviving JPEG lossy compression, in SPIE Conference on Storage and Retrieval of Image/Video Database, pp.296–307, 1998.
Luo, L., Chen, Z., Chen, M., Zeng, X.n, and Xiong, Z., Reversible image watermarking using interpolation technique, IEEE Transactions on Information Forensics and Security, 5,187–193, 2010.
Mahdian, B. and Saic, S., Detection of copy-move forgery using a method based on blur moment invariants, International Journal of Forensic Science, 171, 180–189, 2007.
Ng, T.-T., and Chang, S.-F., Sun, Q., Blind detection of photomontage using higher order statistics, Proceedings of the IEEE International Symposium on Circuits and Systems, Vancouver, Canada pp, 23–26, May 2004.
Popescu, A. C. and Farid, H., Exposing digital forgeries by detecting duplicated image regions, Technical Report, TR2004-515, Dartmouth College, 2004.
Shih, F. Y., Digital Watermarking and Steganography: Fundamentals and Techniques, CRC Press, Boca Raton, FL, 2007.
Shih, F. Y. and Yuan, Y., A comparison study on copy–cover image forgery detection, The Open Artificial Intelligence Journal, 4, 49–54, 2010.
Wu, H. T. and Cheung, Y. M., Reversible watermarking by modulation and security enhancement, IEEE Transactions on Instrumentation and Measurement, 59, 221–228, 2010.
Wu, Y., and Shih, F. Y., Digital watermarking based on chaotic map and reference register, Pattern Recognition, 40, 3753–3763, 2007.
Yip, P. and Rao, K., Discrete Cosine Transform: Algorithms, Advantages, and Applications, Academic Press, San Diego, CA, 1990.
Yuan, Y., Decai, H., and Duanyang, L., An integer wavelet based multiple logo-watermarking scheme, First International Multi-Symposiums on Computer and Computational Sciences, 2, 175–179, 2006.