
CONTENTS
18.2 Some Video Forensics-Related Scenarios
18.3 Existing Technologies that Support Video Forensics
18.3.1 Blurred License Plate Image Recognition
18.3.2 Rotation-, Translation-, and Scaling-Invariant Object Recognition
18.3.3 Trajectory Analysis on Moving Objects
18.4 Some Required Techniques that May Help Promote Video Forensics
18.4.1 People Counting in Videos
18.4.2 Recognizing Video Objects Using Features Extracted from a Video Shot (Clip)
Computational forensics (Bijhold et al., 2007; Franke and Srihari, 2007, Franke and Srihari, 2008; Lambert et al., 2007) is an emerging research field. Franke and Srihari (2007) discussed the growing trend of using mathematical, statistical, and computer science methods to develop new procedures for the investigation and prosecution of crimes as well as for law enforcement. Computational methods are becoming increasingly popular and important in forensic science because they provide powerful tools for representing human knowledge as well as for realizing the recognition and reasoning capabilities of machines. Another reason is that forensic testimony presented in court is often criticized by defense lawyers because they argue that it lacks a scientific basis (Saks and Koehler, 2005). However, Franke and Srihari point out that computational methods can systematically help forensic practitioners to (1) analyze and identify traces in an objective and reproducible manner; (2) assess the quality of an examination method; (3) report and standardize investigative procedures; (4) search large volumes of data efficiently; (5) visualize and document the results of analysis; (6) assist in the interpretation and presentation of results; and (7) reveal previously unknown patterns/links, to derive new rules and contribute to the generation of new knowledge.
A survey of the literature shows that computational forensics has become a very popular research area in recent years because it provides crucial crime scene investigation tools. Indeed, recent advances in computational forensics could benefit a number of research fields that are closely related to criminal investigations, for example, DNA analysis, blood spatter analysis, bullet trajectory analysis, voiceprint matching, fingerprint recognition, and video surveillance. In this chapter, we focus on video forensics, which we define as follows: Techniques that utilize computers to process video content and then apply the results to crime investigations can be called video forensics. Sun et al. (2005), Sun et al. (2006) developed an on-road vehicle detection system that can be used to alert drivers about driving environments and possible collision with other vehicles. Robust and reliable computer vision-based detection is a critical component of the system. To utilize the system in crime investigations, it is only necessary to modify the original system slightly. In the field of video processing, the trajectory of moving objects is one of the most widely used features for data retrieval. The trajectory of a moving object can be exploited to perform a coarse video search when a video database is very large. Calderara et al. (2009) developed a system that performs video surveillance and multimedia forensics by using the underlying feature trajectory to solve problems. Su et al. (2007) proposed a motion flow-based video retrieval system that links continual motion vectors with similar orientations to form motion flows. They also designed an algorithm to convert a group of motion flows into a single trajectory based on their group tendency. With a slight modification, the technique can be applied in video forensics. For example, the command “search all vehicles driving east” becomes a simple event detection problem if the trajectories of all moving objects are calculated in advance.
Since the 9/11 attack on the United States, counterterrorism strategies have been given a high priority in many countries. Surveillance camcorders are now almost ubiquitous in modern cities. As a result, the amount of recorded data is enormous, and it is extremely difficult and time-consuming to search the digital video content manually. The problem was highlighted by Worring and Cucchiara (2009) who presented a paper titled “Multimedia in Forensics” at the 2009 ACM Multimedia Conference in Beijing. They observed that “traces used to be fingerprints, fibers, documents and the like, but with the proliferation of multimedia data on the Web, surveillance cameras in cities, and mobile phones in everyday life we see an enormous growth in multimedia data that needs to be analyzed by forensic investigators.” Clearly, the investigators should be highly trained. However, in a 2010 report, the United States Academy of Sciences observed that “much of forensic science is not rooted in solid science.” Meanwhile, Neufeld and Scheck (2010) reported that “unvalidated or improperly used forensic science contributed to approximately half of the 251 convictions in the United States that have been overturned after DNA testing since 1989.” In 2005, Saks and Koehler (2005) challenged the conventional forensic science training process. Specifically, they stated that “… in normal science, academically gifted students require four or more years of doctoral training. During the training process, methodological rigor, openness, and cautious interpretation of data form the major components of a training process.” However, they found that “96% of the positions in forensic science are held by persons with bachelor’s degrees, 3% with master’s degrees, and only 1% with PhD degrees.” For experts trained to to conduct research in the field of video forensics, an in-depth knowledge of image/ video processing is essential.
In video forensics, mining for criminal evidence in videos recorded by a heterogeneous collection of surveillance camcorders is a major challenge. This is a new interdisciplinary field, and people working in the field need video processing skills as well as an in-depth knowledge of forensic science; hence, the barrier for entering the field is high. Mining surveillance videos directly for criminal evidence is very different from conventional crime scene investigations. In the latter, detectives need to actually visit the crime scene, check all available details and collect as much physical evidence as possible, for example, blood samples, hair, fingerprints, DNA, and weapons. In contrast, to conduct crime scene investigations directly from surveillance videos, forensic experts need to develop software that facilitates the automatic detection, tracking, and recognition of objects in the videos. Since the videos are captured by heterogeneous camcorders, to perform evidence mining on these videos is more challenging.
In the remainder of this chapter, we consider some video forensics-related scenarios in Section 18.2, describe existing technologies needed by experts in the field of video forensics in Section 18.3, and discuss important technologies that need to be developed in Section 18.4.
18.2 SOME VIDEO FORENSICS-RELATED SCENARIOS
In this section, we consider some scenarios that are closely related to the field of video forensics. From these scenarios, it is possible to identify some image/video processing related techniques that are needed to facilitate the investigation of crime scenes.
Scenario 1
A group of thieves stole a car with an apple logo and used it in a bank robbery. The license plate number could not be seen in the video of the crime scene because of the viewing angle problem. Therefore, detectives used a rotation, scaling, and translation invariant object detection algorithm (RST-invariant) to search for the apple logo in videos recorded by the surveillance camcorders mounted in the neighborhood of the crime scene. If the detectives can identify the car in some of the video clips and see the license plate number clearly, then the search time can be reduced significantly.
Scenario 2
A lady was robbed and the surveillance camcorders in the vicinity recorded the whole incident. However, the camcorder mounted at the actual location of the robbery only captured a profile of the thief. Therefore, the police analyzed the gait of the suspect and compared it with the gaits of all pedestrians recorded by the camcorders in the vicinity. Then, the gaits that were closest to the suspect’s gait formed a candidate set. Since the search space could be reduced significantly by comparing the subject’s gaits, the police only needed to check the height of the subjects, the color of their clothes, and other features to identify the suspect. Of course, a frontal shot of the suspect’s face would be the ideal view.
The general manager of a high-tech company was killed on the fifth floor of the company’s building. The suspect took the elevator to the first floor and was picked up by a white van. The surveillance camcorder at the front door of the building captured an image of the side of the van, but did not provide any clue about the license plate number. Detectives checked the surveillance videos captured by neighboring camcorders and found a good shot of the license plate, but the characters were blurred due to the distance. The police contacted a famous image processing laboratory, which used a systematic method to distinguish the license plate number. The police then used the license plate number to identify the owner of the van and traced his/ her cellular phone record. Based on the communications between the suspect and the person who gave instructions, the police were able to solve the crime.
Scenario 4
In the early hours of July 3, 2010, an old lady was hit by a speeding car at the intersection of Brown Avenue and Jackson Road. The car then sped away westbound along Jackson Road. The police retrieved the surveillance videos captured by all eastbound buses that were in the neighborhood during that period. They used these videos to analyze potential escape paths that the suspects may take.
From the above scenarios, it is clear that a number of video processing-based technologies are definitely needed. In the following, we discuss some existing forensics-related video processing technologies and others that are under development.
18.3 EXISTING TECHNOLOGIES THAT SUPPORT VIDEO FORENSICS
In this section, we discuss blurred license plate image recognition, invariant object recognition, trajectory analysis of moving objects, and video inpainting. These technologies can assist forensics experts to perform evidence mining on videos.
18.3.1 BLURRED LICENSE PLATE IMAGE RECOGNITION
To control the size of a video, the resolution of a video frame should not be too high. Under the circumstance, a suspect car or a human subject grabbed from a video directly is usually blurred. In Anagnostopoulos et al. (2006), the authors presented a survey of license plate recognition methods. They divided the license plate recognition procedure into three steps: (1) license plate detection, (2) character segmentation, and (3) character recognition. Existing license plate recognition methods process or modify the content of an image or video to some extent. In forensic science, the content of a video clip or an image captured from a crime scene is regarded as evidence. Conventional video/image processing techniques may modify the content of a video or an image so that the data presented as evidence are not exactly the same as the original version. The techniques are not suitable for forensic investigations because, in a court case, the defense lawyer could argue that the original evidence has been modified, and the prosecutor would find it difficult to refute the argument. Therefore, an appropriate image/video processing technique must not modify the content (i.e., potential evidence) in any way. In other words, the technique should be passive rather than active.

FIGURE 18.1 1 Normalizing source character images into character template images.
In a previous work (Hsieh et al., 2010), we proposed a filter that satisfies the above design requirement. Our approach can recognize the characters in blurred license plate images. Only one license plate image is required and character segmentation is not necessary. First, we use single-character templates to identify the positions of the characters and estimate the corresponding character list. Second, we train the character set, which includes all digits (from 0 to 9) and all English characters (from A to Z) to obtain 36 single-character templates, as shown in Figure 18.1. The training process is adaptive so it takes the height and average intensity of an extracted license plate image into consideration. Then, we slide the 36 single-character templates over the blurred license plate image and calculate the distance of all intensity difference during the sliding operation. As shown on the left-hand side of Figure 18.2a, we calculate the minimum distance at each position and form a minimum distance curve (the bottom of Figure 18.2a). The local minima of a minimum distance curve indicate the potential positions of the characters (Figure 18.2b). However, the results obtained by sliding single-character templates are not reliable due to the blurred nature of the image; therefore, we need to expand the size of the sliding window to double-character templates and then multiple-character templates. We also have to consider special symbols, which are very common on license plates. The symbols may vary and may be located in different positions on license plates. We solved the special symbol problem in Hsieh et al. (2010) and refined the recognition results by expanding the single-character templates to multiple-character templates. Since a license plate image may be captured at a slanted angle, we also handle the perspective effect. Figure 18.3 shows the image of a car and its correct license plate number 5E-1340 (8th place out of more than 10 million combinations). This technique could help the police solve the problem described in Scenario 3.
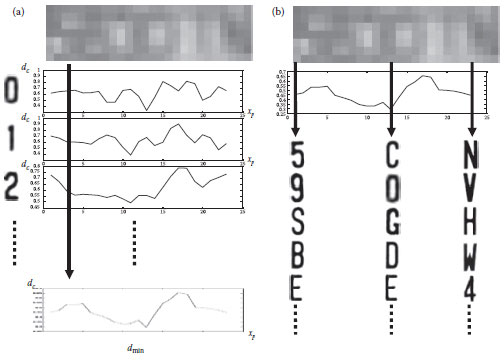
FIGURE 18.2 Candidate character positions and corresponding character estimation: (a) the calculated similarity curves and the minimum distance curve and (b) the estimated candidate positions and part of their corresponding characters.
18.3.2 ROTATION-, TRANSLATION-, AND SCALING-INVARIANT OBJECT RECOGNITION
Rotation-, translation-, and scaling-invariant (RST-invariant) object recognition is a very important technique in video forensics. In scenario 1, a group of thieves stole a car with an apple logo and used it to commit a crime and escape. The police retrieved all surveillance videos recorded in the vicinity of the crime scene and used the apple logo to automatically search for all video clips that contained the logo. The most difficult part of this type of problem is that the search involves videos recorded by a heterogeneous collection of camcorders. Therefore, the designed features should be independent of cameras. Lowe (1999) proposed a scale-invariant feature (SIFT) that is very effective in finding the corresponding points of two images. However, the requirement for high-dimensional feature input restricts its flexibility. For example, it is difficult to retrieve objects with similar structures but slightly different patterns. Compared to conventional interest points-based descriptors, shape descriptors are more powerful for general object detection because they extract more semantic information. Ferrari et al. (2006) introduced the kAS family of local contour features to demonstrate its power within a slide window-based object detector. Felzenszwalb and Schwartz (2007) proposed a hierarchical representation to capture shape information from multiple levels of resolution, while Zhu et al. (2008) extended the shape context of selected edges to represent contours on multiple scales.

FIGURE 18.3 An example of recognition performed on perspective projection distorted license plate images. The correct license plate number is ranked 8th in the top 10 list.

FIGURE 18.4 A hand-drawn query model.
In Su et al. (2010), we proposed an object detection method that does not need a learning mechanism. The method uses a local descriptor-based algorithm to detect objects in a cluttered image. Given a hand-drawn model as a query (as shown in Figure 18.4), we can detect and locate objects that are similar to the query model without learning. The algorithm matches partial shapes based on the local polar histogram of edge features and the histogram of gradient information, as shown in Figure 18.5. In contrast to conventional feature descriptors, which usually use more than one scale to perform matching, the scale of our descriptor is determined based on two random high-curvature points (HCPs) on edges. The two HCPs decide the pose and size of each polar histogram to ensure invariance with respect to rotation, scaling, and translation. Figure 18.5a shows a circular descriptor determined by two HCPs, P1 and P2, and Figure 18.5b shows the edge-based descriptor that partially represents the target shape. Figure 18.5c shows the gradient histogram, which can be used with the edge-based descriptor to describe a target object. Finally, we locate the target objects in real images by a voting process. Figure 18.6 shows some examples of how target objects are detected. This technique can be applied to perform object search in a large database.
18.3.3 TRAJECTORY ANALYSIS ON MOVING OBJECTS
In this section, we discuss how the trajectory of a moving object in a video can be used for event detection in a large surveillance video database. Since the amount of video content collected from a large number of surveillance camcorders is enormous, it is extremely difficult to examine the videos manually. A large number of motion-based video retrieval systems have been proposed in the last decade (Chang et al., 1998; Dagtas et al., 2000; Fablet et al., 2002; Ma and Zhang, 2002; Manjunath et al., 2002). The existing motion descriptors can be classified into two types: (1) statistics-based and (2) object-based. Fablet et al. (2002) used causal Gibbs models to represent the spatio-temporal distribution of the dynamic content in a video shot. In Ma and Zhang (2002), a multidimensional vector is generated by measuring the energy distribution of a motion vector field. In Manjunath et al. (2002), some fundamental bases of motion activity, such as intensity, direction, and spatial-temporal distribution, have been adopted to retrieve content from video databases. Chang et al. (1998) proposed object-based motion descriptors. They grouped regions that are similar in color, texture, shape, and motion together to form a video object. Then, the query-by-sketch mechanism is applied to retrieve video content from a database. The constituents of their database comprise a set of trajectories formed by linking the centroids of video objects across consecutive frames. Dagtas et al. (2000) proposed using a combination of trajectory—and trail-based models to characterize the motion of a video object. They adopted a Fourier transform-based similarity metric and a two-stage comparison strategy to search for similar trajectories.
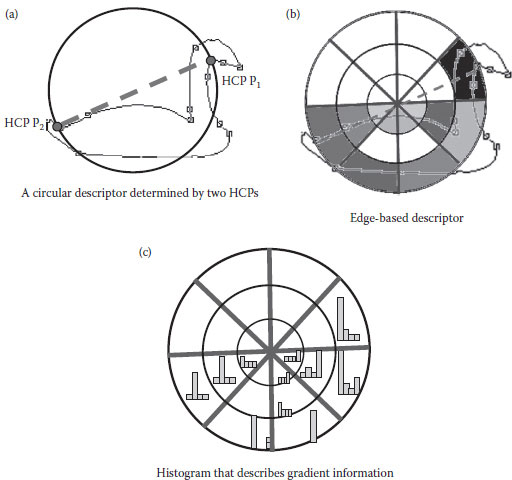
FIGURE 18.5 Figure 18.5 Our algorithm matches partial shapes based on the local polar histogram of edge features and the histogram of gradient information. (a) A circular descriptor determined by two HCPs, (b) local polar histogram of edge features, and (c) the histogram of gradient information.
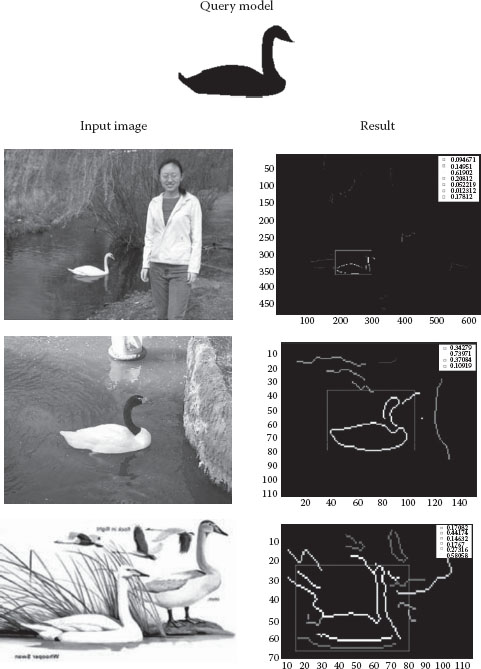
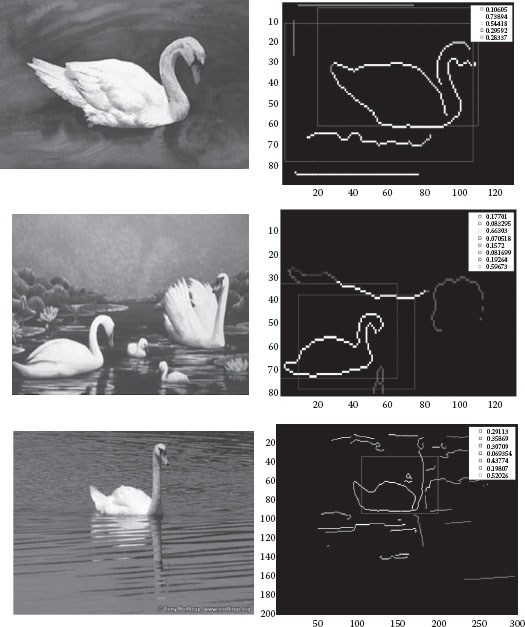
FIGURE 18.6 A query model and some retrieved results.
In Su et al. (2007), we proposed a motion flow-based video retrieval scheme that detects events in a video database based on the trajectories of moving objects. We exploit the motion vectors embedded in MPEG bitstreams to generate “motion flows,” which are then used to detect events. By using the motion vectors embedded in videos directly, we do not need to consider the shape of a moving object and its corresponding trajectory. Instead, we simply link the local motion vectors across consecutive video frames to form motion flows, which are recorded and stored in a video database. The event detection process can be executed by comparing the motion flow of a query video with all the motion flows in a video database. Figure 18.7 shows an event detection process using a trajectory summarized from motion flows. In this example, the user drew a climbing-wall trajectory with the help of a user interface. A total of 108 events were stored in trajectory format in the database. Among the top six retrieved events, only the second event occurred at another location. However, its corresponding trajectory was very close to the query sketch. This example demonstrates that the trajectory of a moving object in a video can be a good descriptor for searching for target events. In video forensics, we often encounter a scenario like “the suspect is heading west in a stolen car.” If we can record the trajectories of all moving objects in the surveillance videos, we can simply convert the query to “search all trajectories heading west.” In this way, we can save a lot of manpower during the event detection process

FIGURE 18.7 Event detection using trajectory information. A detected query trajectory (left) and some retrieved database events with similar trajectories (right).
Video inpainting has become a very popular research topic in recent years because of its powerful ability to fix/restore damaged videos and the flexibility it provides for editing home videos. Most inpainting techniques were developed to deal with images (Efros and Leung, 1999; Bertalmio et al., 2000; Criminisi et al., 2004). Conventional image inpainting techniques can be categorized into three groups: texture synthesis-based methods (Efros and Leung, 1999), partial differential equation-based (PDE-based) methods (Bertalmio et al., 2000), and patch-based methods (Criminisi et al., 2004). The concept of texture synthesis is derived from computer graphics. The idea is to insert a specific input texture into a damaged region. In contrast, PDE-based methods try to propagate information from the boundary of a missing region toward the center of that region. The above two methods are suitable for repairing damaged images that have thin missing regions. Patch-based methods, on the other hand, are much better for repairing damaged images because they yield high-quality visual results and maintain the consistency of local structures. Since patch-based methods are quite successful in image inpainting, Wexler et al. (2007) applied a similar concept to video inpainting. However, the issues that need to be dealt with in video inpainting are much more challenging. In Ling et al. (2011), we presented a framework for completing objects in a video. To complete an occluded object, we first sample a 3-D volume of the video into directional spatio-temporal slices. Then, we perform patch-based image inpainting to complete the partially damaged object trajectories in the 2-D slices. The completed slices are combined to obtain a sequence of virtual contours of the damaged object. Next, we apply a posture sequence retrieval technique to the virtual contours in order to retrieve the most similar sequence of object postures in the available nonoccluded postures. In video forensics, this technique can be used to restore moving object in the foreground if some consecutive frames that contain the moving object are missing or damaged.
In Tang et al. (2011), we proposed a video inpainting technique and used it as a video enhancement tool to repair digital videos. The quality of many surveillance videos is very poor due to the resolution of the camcorders used for recording. Therefore, some better video inpainting-related techniques are desperately needed. In recent years, researchers have extended some well-known image inpainting techniques to the repair of videos. An intuitive approach involves applying image inpainting techniques to each video frame so that the completed frames are visually pleasing when viewed individually. However, this approach neglects the issue of continuity across consecutive frames, so the quality of the resulting video is usually unsatisfactory. To resolve the problem, both spatial and temporal continuity must be considered in a video inpainting process. In Tang et al. (2011), we proposed two key techniques, namely, motion completion and frame completion, to perform better video inpainting job. Since accurate motion information is the key to achieving good video inpainting results, we begin by constructing a motion map to track the motion information in the background layer and then repair the missing motion information in the motion completion step. Motion completion recovers missing motion information in damaged areas to maintain good temporal continuity. Frame completion, on the other hand, repairs damaged frames to produce a visually pleasing video with good spatial continuity and stable luminance.
18.4 SOME REQUIRED TECHNIQUES THAT MAY HELP PROMOTE VIDEO FORENSICS
To deal with video forensics-related problems, forensic experts need to develop more useful software tools to facilitate forensics-related investigations. In this section, we shall mention a number of related techniques of this sort.
18.4.1 PEOPLE COUNTING IN VIDEOS
The number of human subjects in a short video clip provides a clue for conducting a coarse search of a large surveillance video database. In video forensics research, automating the video search process with the assistance of computers is a key objective. Among different types of features that can be used in searches, determining the existence of human subjects or counting the number of human subjects in videos are two very useful screening criteria. Knowing whether or not a video clip contains human subjects can reduce the search space significantly, while knowing the number of human subjects can improve the accuracy of annotating the video content. For example, if three suspects rob a bank and escape in a vehicle traveling east, the police can retrieve the videos captured by all surveillance camcorders along the escape route. Searching the videos manually would be extremely time-consuming. However, if the police use an annotation scheme that can determine the number of people in each video clip, they could easily select the clips that contain at least three people as fine search targets.
We proposed two people counting schemes in previous works (Chen et al., 2009; Su et al., 2009). In Chen et al. (2009), we introduced an online boosted people counting system for electronic advertising machines. The system can count the number of people that watch an advertisement on a large wall TV during a given period. More specifically, the system integrates face detection, face matching, dynamic face database management, and machine learning techniques to count people in real time. In Su et al. (2009), we proposed a vision-based people counting system that utilizes the symmetry feature to detect human subjects in a video clip. Since the symmetry feature is very easy to detect, the system can run in real time and achieve a high success rate. However, the above approaches can only partially assist a general-purpose people counting scheme, which must detect human subjects in a variety of postures, such as sitting, standing, running, walking, or lying down. In addition, the size of human subjects in the field of view may vary significantly. The people counting task may also be affected by the lighting conditions, the viewing angle, and the weather. Therefore, counting the number of people in a video is a challenging task. Recently, we propose a cross-camera people counting scheme which is able to deal with perspective effect as well as occlusion (Lin et al., 2011). Our scheme can adapt itself to a new environment without the need of manual inspection. The proposed counting model is composed of a pair of collaborative Gaussian processes, which are respectively designed to count people by taking the visible and occluded parts into account. The first Gaussian process exploits multiple visual features to result in better accuracy and the second Gaussian process instead investigates the conflicts among these features to recover the underestimate caused by occlusions. Our proposed system achieved promising performances.
18.4.2 RECOGNIZING VIDEO OBJECTS USING FEATURES EXTRACTED FROM a VIDEO SHOT (CLIP)
In video forensics, it is often necessary to retrieve every possible piece of evidence from the video clip of a crime scene. Since all the evidence that may help solve the crime is embedded in the video clip, it is necessary to extract features from the clip directly. Therefore, the problem becomes: “What features would be the most effective for solving the crime?” To efficiently manage video information, including proper indexing, efficient storage, and fast retrieval, it is required to develop better video indexing and fast search algorithms. In the last decade, many crucial algorithms, such as shot change detection (Su et al., 2005), shot representation (Chang et al., 1999), key frame/clip extraction (Lee and Kim, 2003), and video sequence matching (Cheung and Zakhor, 2003), have been developed to enhance video indexing and retrieval.
In Ho et al. (2006), we used motion vector statistics extracted directly from a shot to represent a video shot. The video retrieval scheme we proposed is a coarse-to-fine shot-based approach. The coarse search is to select a reasonably small number of video clips from a database, while avoiding nondetection of correct clips. We check the entropy of the motion vectors from every constituent shot and pick the one with the maximum entropy as the query shot. This shot usually has the most diverse object motions. The first step of the coarse search identifies a set of similar video clips by using shot-level spatio-temporal statistics. Then, in the second step, an adjacent shot to the first query shot is chosen, and the two shots are concatenated to form a two-shot query. A “causality” relation that defines the order of two consecutive shots is introduced to strengthen the discriminating capability. In the coarse search process, we extract object motions and then quantize them into 2-D probability distribution. The feature of this form is the temporal feature. In addition, the color histogram of key frames extracted from the same shot is used as the spatial feature. The joint distance, which sums up the distance of the motion statistics and that of the color histograms, is then used to measure the similarity between the two shots. Following the coarse search, a fine search is performed to enhance the retrieval accuracy. In the fine-search process, we extract color features from a set of selected key frames and use them to refine the ranks of the matched video clips obtained in the coarse search. Finally, we calculate the Bhattacharyya distance and use it to choose the closest shots from the coarse-search outcomes. Using similar strategies in video forensics, it is definitely helpful in a search-space reduction process.
Since the 9/11 attack on the United States, counterterrorism strategies have been given a high priority in many countries. Surveillance camcorders are now almost ubiquitous in modern cities. As a result, the amount of recorded data is enormous, and it is extremely difficult and time-consuming to search the digital video content manually. In this chapter, we consider some video forensics-related scenarios, describe existing technologies needed by experts in the field of video forensics, and discuss important technologies that need to be developed. We hope the initiation of video forensics can be a good start and we look forward to seeing the prosperity of its future.
Anagnostopoulos, C.N., Anagnostopoulos, I., Loumos, V., and Kavafas, E.,A license platerecognition algorithm for intelligent transportation system applications, IEEE Transactions on Intelligent Transportation Systems, 7(3), 377–392, 2006.
Bertalmio, M., Sapiro, G., Caselles, V., Ballester, C., Image inpainting, in Proceedings of ACM SIGGRAPH, pp. 417–424, 2000.
Bijhold, J. et.al., Forensic audio and visual evidence 2004–2007:, A review in Proceedings of the 15th INTERPOL Forensic Science Symposium, Lyon, France, October 2007.
Calderara, S., Prati, A., and Cucchiara, R., Video surveillance and multimedia forensics: An application to trajectory analysis, in Proceedings of First ACM Workshop on Multimedia in Forensics, Beijing, Chinapp. 13–18, October 2009.
Chang, H.S., Sull, S., andLee, S.U., Efficient video indexing scheme for content-based retrieval, IEEE Transactions on Circuits and Systems for Video Technology, 8(8), 1269–1279, 1999.
Chang, S.F., Chen, W., Meng, H.J., Sundaram, H., and Zhong, D., A fully automated contentbased video search engine supporting spatiotemporal queries, IEEE Transactions on Circuits and Systems for Video Technology, 8(5), 602–615, 1998.
Chen, D.Y., Su, C.W., Zeng, Y.C., Sun, S.W., Lai, W.R., and Liao, H.Y.M., An on-line boosted people counting system for electronic advertising machines, in Proceedings of IEEE International Conference on Multimedia and Expo, New York, June 2009.
Cheung, S., and Zakhor, A., Efficient video similarity measurement with video signature, IEEE Transactions on Circuits and Systems for Video Technology, 13(1), 59–74, 2003.
Criminisi, A., Pérez, P., and Toyama, K., Region filling and object removal by exemplar-based image inpainting, IEEE Transactions on Image Processing, 13(9), 1200–1212, 2004.
Dagtas, S., Al-Khatib, W., Ghafoor, A., and Kashyap, R.L., Models for motion-based video indexing and retrieval, IEEE Transactions on Image Processing, 9(1), 88–101, 2000.
Efros, A., and Leung, T., Texture synthesis by non-parametric sampling, in Proceedings of the IEEE Conference on Computer Vision, vol. 2, pp. 1033–1038, 1999.
Fablet, R., Bouthemy, p., and Pérez, p., Nonparametric motion characterization using causal probabilistic models for video indexing and retrieval, IEEE Transactions on Image Processing, 11(4), 393–407, 2002.
Felzenszwalb, P., and Schwartz, J., Hierarchical matching of deformable shapes, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1–8, 2007.
Ferrari, V., Tuytelaars, T., and Van Gool, I.J., Object detection by contour segment networks, in Proceedings of the European Conference on Computer Vision, vol. 3 pp. 14–28, 2006.
Franke, K., and Srihari, S.N., An overview, in Proceedings of the 3rd International Symposium on Information Assurance and Security, 2007.
Franke, K., and Srihari, S.N., An overview, in Proceedings of the International Workshop on Computational Forensics, Lecture Notes in Computer Science, vol. 5158 pp. 1–10, 2008.
Ho, Y.H., Lin, C.W., Chen, J.F., and Liao, H.Y.M., Fast coarse-to-fine video retrieval using shot-level spatio-temporal statistics, in IEEE Transactions on Circuits and Systems for Video Technology, 16(5) 642–648, 2006.
Hsieh, P.L., Liang, Y.M., and Liao, H.Y.M., Recognition of blurred license plate images, in Proceedings of the IEEE International Workshop on Information Forensics and Security, Seattle, Washington, USA, December, 2010.
Lambert, E., Hogan, N., Nerbonne, T., Barton, S., Watson, P., Buss, J., and Lambert, J., Differences in forensic science views and needs of law enforcement: A survey of Michigan law enforcement agencies, Police Practice and Research, 8(5), 415–430, 2007.
Lee, H.C., and Kim, S.D., Iterative key frame selection in the rate-constraint environment, Signal Processing: Image Communication, 18, 1–152003.
Lin, T.Y., Lin, Y.Y., Weng, M.F., Wang, Y.C., Hsu, Y.F., and Liao, H.Y.M., Cross camera people counting with perspective estimation and occlusion handling, in Proceedings of the IEEE International Workshop on Information Forensics and Security, Brazil, 2011.
Ling, C.H., Lin, C.W., Su, C.W., Liao, H.Y.M., and Chen, Y.S., Virtual contour guided video object inpainting using posture mapping and retrieval, IEEE Transactions on Multimedia, 13(2)292–302, 2011.
Lowe, D.G., Object recognition from local scale-invariant features, in Proceedings of the International Conference on Computer Vision, vol 2, pp 11150–11157, 1999.
Ma, Y.H., and Zhang, H.J., Motion texture: A new motion-based video representation, Proceedings of the 16th International Conference on Pattern Recognition, vol 2, pp. 548–551, August11–15, 2002.
Manjunath, B.S., Salembier, P., and Sikora, T., Introduction to MPEG-7:, Multimedia Content Description Interface, Wiley, Berlin, June 2002.
Neufeld, P., and Scheck, B., Making forensic science more scientific, Nature, 4643512010.
Saks, M.J., and Koehler, J.J., The coming paradigm shift in forensic identification science, Science, 309 892–8952005.
Su, C.W., Liang, Y.M., Tyan, H.R., and Liao, H.Y.M., An RST-tolerant shape descriptor for object detection, in Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, August 2010.
Su, C.W., Liao, H.Y.M., and Tyan, H.R., A vision-based people counting approach based on the symmetry measure, in Proceedings of the IEEE International Symposium on Circuits and Systems, May 2009.
Su, C.W., Liao, H.Y.M., Tyan, H.R. and Chen, L.H., A motion-tolerant dissolve detection algorithm, IEEE Transactions on Multimedia, 7(6), 1106–11132005.
Su, C.W., Liao, H.Y.M., Tyan, H.R., Lin, C.W., Chen, D.Y., and Fan, K.C., Motion flowbased video retrieval, IEEE Transactions on Multimedia, 9(6), 1193–12012007.
Sun, Z., Bebis, G., and Miller, R., On-road vehicle detection using evolutionary Gabor filter optimization, IEEE Transactions on Intelligent Transportation Systems, 6(2), 125–1372005.
Sun, Z., Bebis, G., and Miller, R., On-road vehicle detection: A review, IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(5), 694–7112006.
Tang, N.C., Hsu, C.T., Su, C.W., , Shih, T.K., and Liao, H.Y.M., Video inpainting on digitized vintage films via maintaining spatiotemporal continuity, IEEE Transactions on Multimedia, 13(4), 603–6142011.
Wexler, Y., Shechtman, E., and Irani, M., Space-time completion of video, IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(3), 1–142007.
Worring, M., and Cucchiara, R., Multimedia in forensics, in Proceedings of the ACM Conference on Multimedia, pp. 1153–1154, Beijing, China, October 19–24, 2009.
Zhu, Q., Wang, L., Wu, Y., and Shi, J., Contour context selection for object detection: A set-to-set contour matching approach, in Proceedings of the European Conference on Computer Vision, vol. 2, pp. 1153–1154, 774–787, 2008.