
CONTENTS
20.3 Human Motion Change Detection
20.3.1 Hierarchical Gaussian Process Dynamical Model
20.3.2 Human Motion Change Detection Based on HGPDM
20.3.2.2 Jointly Initializing Model Parameters
20.3.2.3 Initializing the Particle Filter Framework
20.3.2.4 Latent Space Motion Classification and Change Detection
20.3.2.5 Leaf Node Latent Space Particle Sampling and Predicting
20.3.2.6 Determining Probabilistic Mapping from the Latent Space to Observation Space
20.3.3 Human Motion Training in HGPDM
20.3.3.1 Extracting Human Motion Trajectory Data
20.3.3.2 Establishing Trajectory Learning Model on the Leaf Node
20.3.4 hgpdm with Particle Filter in Testing Phase
20.3.4.1 Initializing the Particle Filter Framework
20.3.4.2 Latent Space Motion Classification and Change Detection
20.3.4.3 Particle Filter Tracking and Update
20.3.5 Experimental Results on Human Motion Change Detection
20.4 Human Group Behavior Analysis
20.4.1 Group Human Behaviour Recognition Frame Work
20.4.1.1 Adaptive Mean-Shift Tracking
20.4.1.2 Small Group Clustering
20.4.1.3 Social Network-Based Feature Extraction
20.4.1.4 Human Group Behavior Modeling
20.4.2 Small Group Activity Recognition
20.4.2.2 Jointly Initializing Model Parameters
20.4.2.3 Training GPDM for Each Group Activity
20.4.2.4 Calculating the Conditional Probability with Each Trained GPDM
20.4.2.5 Selecting the GPDM with the Highest Conditional Probability
20.4.3 Experimental Results on Human Group Behavior Recognition
20.4.3.1 Results on BEHVAE Dataset
20.4.3.2 Results on IDIAP Dataset
20.5 Discussions and Future Directions
Multimedia content analysis is essential in a wide range of applications, including information retrieval, surveillance, robotics, automation, and so on. A general objective of such operation is to extract semantic meanings from multimedia content. Recent developments in image and video processing, audio signal processing, computer vision, and machine learning have all contributed to the advances in this field (Gong and Xiang, 2011).
As shown in Figure 20.1, the analysis of multimedia content is usually built on top of feature extraction, object/event detection, and recognition. A variety of visual features have been introduced and studied in the past, which include color, histogram, edge, shape, Haar-like feature, SIFT (scale-invariant feature transform), and HOG (histogram of oriented gradient). With the extracted features, object detection and recognition based on statistic modeling and machine learning methods are performed as middle-level analysis operations. Examples include target detection, human detection, face recognition, background modeling, and so on. The results of these operations will then be used to support high-level tasks, such as semantic abstraction, semantic description, and semantic query.
Since human objects are of most importance in a majority of multimedia content analysis applications, in the chapter, we will mainly focus on human behavior modeling. In particular, we will introduce two new methods for modeling human motion changes and small human group motions. Human motion modeling and motion change detection are important tasks in intelligent surveillance systems, and they have attracted significant amount of attentions in recent years. The major challenges in these tasks include complex scenes with a large number of targets and confusors, and complex motion behaviors of different human objects. In real-world applications, variant environmental conditions, such as illumination, reflection, and multiple human objects with occlusion, present further difficulties to human motion modeling. From the learning perspective, existing motion detection algorithms can be divided into two categories: model-based detection and signature-based detection. In model-based motion detection methods, human motions are frequently described by statistical methods (Stauffer and Grimson, 2000; Zhong et al., 2004), while in signature-based motion detection methods, human motions are specified by predefined patterns (Ivanov and Bobick, 1999).
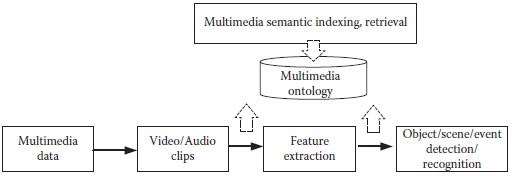
FIGURE 20.1 Multimedia content analysis process.
In addition to single person motion recognition, small human groups contain much richer interperson interactions among group members. Compared to dense crowd analysis, in which each person can be regarded as a point in a flow, small groups contain much detailed information about each individual in the group. The major challenges of small group activity analysis include mutual occlusions betweendifferent people, varying group size, and interactions within or between groups. Therefore, small group activity recognition demands a structural feature to bridge the local description of single human objects and global description for crowd analysis, as well as addressing both spatial dynamics (varying group size) and temporal dynamics (varying clip length). Unlike single person or dense crowd analysis, small group action recognition requires detection and tracking of each group member rather than extracting feature from the entire scene, as there may be several small groups with different actions in an individual scene.
The rest of this chapter is organized as follows. In Section 20.2, a set of most commonly used visual features for describing human objects will be reviewed, which include Haar-like feature, SIFT features, and HOG features. In Section 20.3, a hierarchical Gaussian process latent variable model (HGPLVM) is introduced for human motion change detection. In Section 20.4, a Gaussian process dynamical model (GPDM) based on a unique social network feature set is introduced for modeling small human group behavior. Selected experimental results are included in these discussions. Conclusions and discussions on future steps are provided in Section 20.5.
Feature selection plays a very crucial role in multimedia content analysis. Various features and feature extraction methods have been proposed for image and video processing. On on a low-dimensional feature space during feature extraction, which greatly reduces the computational cost in the later stages. On the other hand, a distinctive feature set can capture the characteristic of visual objects in both spatial domain and temporal domain, which is essential for multimedia semantic analysis. Several commonly used features are introduced in this section.
Besides the basic features, such as image pixel value, edges, and color histogram, more and more distinctive features have been proposed in large-scale machine learning algorithms. Among those features, SIFT (Lowe, 1999), Haar-like (Viola and Jones, 2001), and HOG (Dalal and Triggs 2005) are the most widely used features for human object detection and recognition in recent years. Here, we focus on the features for the behavior modeling with a small number of actors in a controlled environment, such as SIFT, HOG, optical flow, 3D-SIFT, and space—time interest points (STIP) features.
SIFT features were proposed by Lowe in 1999 (Lowe, 1999). Due to their translation, scale, and rotation-invariant properties, SIFT features have been widely applied for object detection and recognition. To characterize these invariant properties in SIFT features, the key points are first identified through different scales and locations of the image. For each key point, an array is sampled around the key point’s location and the array is transformed to the direction of the key point. The entire sampled array is then divided into grids of a certain size. In each grid, the gradient of each pixel is calculated and accumulated to different directions in a histogram. The normalized bin of the histogram will then form the final SIFT descriptor. For a 16 × 16 array with 4 × 4 grids, and 8 bins for each histogram, the dimension of the SIFT descriptor is 4 × 4 × 8 = 128.
HOG is derived from SIFT features, and it was introduced by Dalal and Triggs (2005). By implementing HOG features with support vector machine (SVM) classifier, it has shown impressive results on human detection. To extract HOG features, the whole detection window is first divided into grids of small cells. Similar to the cells for computing SIFT features, the gradient in each cell is also accumulated at different directions in a histogram and forms a normalized vector description. Usually, 2 × 2 cells are combined into a block. Different from SIFT calculation, blocks are allowed to overlap with each other in a sliding window fashion in HOG feature calculation. This approach connects all the feature descriptions in local regions. Zhu et al. (2006) showed that the combination of the cascade of rejecters approach and the HOG features led to a fast and accurate human detection system. They used AdaBoost for selecting the best blocks for human detection. They claimed that their system could achieve close to real-time performance.
While most aforementioned features are local image features in the spatial domain, which is naturally extended from images to frames in the video, to exploit the characteristic in the temporal domain as well as the spatial domain, many new features have been proposed for video analysis, such as optical flow, 3D-SIFT, and STIP features.
Optical flow is the most used feature for motion recognition (Barron et al., 1994). Optical flow describes the local motion difference between two or more consecutive frames. Based on the partial derivatives with respect to the spatial and temporal coordinates, optical flow shows the motion magnitude and direction at each pixel. By assuming the motion to be small and with an image constraint: I(x, y, t) = I(x + δx, + δy, t + δt), optical flow is computed by
(20.1) |
where Ix and Iy are the derivatives at location (x, y) of the frame at time t, and Vx and Vy are the velocities. As there are two unknowns in Equation 20.1, other constraints are needed to solve this equation. Many approaches have been proposed, such as Lucas–Kanade method (Lucas and Kanade, 1981), Horn–Schunck method (Horn and Schunck, 1981), and so on.
3D-SIFT extends the original SIFT features from 2D image domain to 3D video data cube (Cupillard et al., 2002). The gradient magnitudes in each small cube at different directions are accumulated to form a histogram. 3D-SIFT-based action recognition methods have been shown to outperform many other feature-based recognition methods.
Beyond the aforementioned features, recently, many middle-level features have been proposed for human group behavior analysis, as group behavior involves interactions among different group members, and requires the feature set that can capture local detailed information as well as global structure description. Middlelevel features characterize the global properties of low-level features rather than local description. Ni et al. (2009) proposed a middle-level feature set for group structure information above the general low-level feature, which has been developed for small group human action recognition. Yuan et al. (2010) also proposed a middlelevel representation for human activity recognition.
20.3 HUMAN MOTION CHANGE DETECTION
Motion change detection has been frequently used in human action recognition and suspicious behavior analysis (Rao and Sastry, 2003). Many existing works use segmentation and tracking for human motion detection (Haritaoglu et al., 2000; Medioni et al., 2001). Boiman and Irani (2005) proposed a probabilistic graphical model for detecting irregularities in the video. Kiryati et al. (2008) extracted the motion features from videos, and used a pretrained motion model to classify different human motions. The abnormal human motion patterns relied on the trained motion trajectories. Sherrah and Gong (2000) presented a platform (VIGOUR) for tracking and recognizing the activities of multiple people. The system can track up to three people and recognize their gestures. However, most of these methods cannot handle human motion change detection with multiple people, due to the increasing computational complexity in tracking multiple targets.
In the following sections, we will introduce a new human motion change detection method as an example for human behavior modeling in surveillance video.
20.3.1 HIERARCHICAL GAUSSIAN PROCESS DYNAMICAL MODEL
A hierarchical Gaussian process dynamical model (HGPDM) integrated with particle filter tracker is introduced for human motion change detection (Yin et al., 2010). First, the high-dimensional human motion trajectory training data are projected to a low-dimensional latent space with a two-layered hierarchy. The latent space of the leaf nodes at the bottom layer represents a typical human motion trajectory, while the root node at the upper layer controls the interaction and switching among the leaf nodes.
The HGPDM is inspired by the HGPLVM (Lawrence and Moore, 2007). Lawrence applied the HGPLVM for modeling the human interaction. The HGPDM approach is different from Lawrence’s work in two ways: first, it extends the GPLVM to GPDM in the leaf nodes, which gives a compact representation for the joint distribution of observed temporal data in the latent space. In addition, the latent space of the roo node is optimized after the optimizations of leaf nodes, instead of a joint optimization of all nodes simultaneously (Lawrence and Moore, 2007). In other words, the root node in this framework is a classifier controlling all the switching between the leaf nodes.
The trained HGPDM will then be used to classify test object trajectories which are captured by a particle filter tracker. If the motion trajectory is different from the motion in the previous frame, the root node will transfer the motion trajectory to the corresponding leaf node. In addition, HGPDM can be used to predict the next motion state, and provide Gaussian process dynamical samples for the particle filter framework, and this framework can accurately track and detect the human motion changes despite the complex motion and occlusion. Also, the sampling in the hierarchical latent space has greatly improved the efficiency of the particle filter framework. The assumpt similar motion trajectory in a specific location, while sudden motion change usually implies suspicious behaviors. If we can learn these similar trajectories in advance, they can be used for motion trajectory classification and motion change detection.
In contrast to the GPDM used in Urtasun (2006), Wang et al. (2008a), Raskin et al. (2008), and Wang et al. (2008b), HGPDM focuses on the global human motion rather than the local motion of human body parts. Therefore, instead of using 3D motion database, it high-dimensional training dataset, and trains HGPDM. In addition, this framework can address the switching between different motion patterns, which is very critical for change detection of human with complex motion.
20.3.2 HUMAN MOTION CHANGE DETECTION BASED ON HGPDM
The HGPDM method is aimed to learn a general human motion trajectory model for multiple human motion change detection. The pretrained model can robustly detect different human motion changes, and reduce the computational complexity as well as improve the robustness of particle-tracking framework. The flowchart of this motion change detection framework is shown in Figure 20.2.
The basic procedure of the particle filter with the HGPDM is described as follows.
The leaf node of HGPDM is created on the basis of the trajectory training datasets, that is, coordinate difference values, while the top node is created on the basis of dependence of leaf nodes. The learning model parameters include where YT is the training observation dataset, XT is the corresponding latent variable are hyperparameters, and W is a scale parameter.
20.3.2.2 Jointly Initializing Model Parameters
The three nodes of latent variable sets and parameters are obtained by minimizing the negative log-posterior function −lnp of the unknown parameters with scaled conjugate gradient (SCG) on the training datasets.

FIGURE 20.2 Human motion change detection and tracking framework
20.3.2.3 Initializing the Particle Filter Framework
The prior probability is derived from the basis of the created model. In this step, target templates are obtained from the previous frames as reference images for similarity calculation in the later stage.
After initializing the target’s position, each target will be tracked by the regular particle filter in the first five frames. Then, the test observation motion pattern data are calculated and projected to the latent coordinate system on the top node of HGPDM by using probabilistic principal component analysis (PPCA).
20.3.2.4 Latent Space Motion Classification and Change Detection
After projecting the current motion data into the latent space, the top node will determine which motion pattern in the leaf node the current motion belongs to. If the motion pattern is not consistent with the previous one, the motion change is reported and the latent space will switch to the new leaf node.
20.3.2.5 Leaf Node Latent Space Particle Sampling and Predicting
Particles are generated in the latent space of leaf node GPDM to infer the likely coordinate change value (Δxi, Δyi).
20.3.2.6 Determining Probabilistic Mapping from the Latent Space to Observation Space
The log-posterior probability of the coordinate difference values of the test data is maximized to find the best mapping in the training datasets of the observation space. In addition, the most likely coordinate change value (Δxi, Δyi) is used for predicting
the next motion.
In the next frame, the similarity between the template’s corresponding appearance model and the cropped region centered on the particle is calculated to determine the weights wi and the most likely location of the corresponding target, as well as to decide whether resampling is necessary or not.
The detailed training and test procedures are introduced in the following sections.
20.3.3 HUMAN MOTION TRAINING IN HGPDM
The reason for utilizing the HGPDM for change detection is that the root node can control all the interactions and switchings between each leaf node. Therefore, it can model more complex motion patterns. Its structure is described in Figure 20.3. all the interactions between the latent space of leaf nodes in X1, …, Xn. Y1, …, Yndenotes the observation data associated with X1, …, Xn.
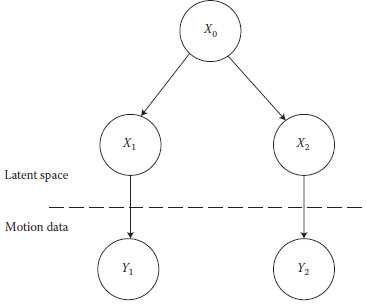
FIGURE 20.3 A hierarchical Gaussian process dynamical model. The root node X0 controls
20.3.3.1 Extracting Human Motion Trajectory Data
During the training phase, the motion data are manually extracted from the KTH motion database (KTH dataset, 2004). At each frame of a walking cycle, a point at the central location of the human body is selected. Then, coordinate difference between two consecutive frames forms a motion vector. Supposing that the total frame number is 30, the dimension of one person’s motion data is 30 by 2. In the training set, 20 different people are chosen and each person walks in a different direction. The total training data are then 30 by 40 dimensional. To demonstrate the performance of the HGPDM framework, two typical motion trajectories, walking and running, are selected from the KTH motion database. In the walking and running categories, different human motions at different directions are extracted as the training data.
20.3.3.2 Establishing Trajectory Learning Model on the Leaf Node
GPDM is applied to learn the specific trajectories of the moving human. The probability density function of latent variable X and the observation variable Y are defined by
(20.2) |
where W is the hyperparameter, N is the number of Y sequences, D is the data dimension of Y, and KY is the kernel function.
In this study, the radial basis function (RBF) kernel given by the following equation is used for the HGPDM model:
(20.3) |
where x and x′ are any latent variables in the latent space, γ controls the width of the kernel, and β–1 is the variance of the noise.
Given a specific surveillance environment, certain patterns may be observed and are worth exploring for future inferences. To initialize the latent coordinate, the d (dimensionality of the latent space) principal directions of the latent coordinates is determined by deploying PPCA on the mean-subtracted training dataset YT, that is, .
Given YT, the learning parameters are estimated by minimizing the negative-logposterior using SCG (Riedmiller and Braun, 1992).
As the structure described in Figure 20.2, Y1and Y2denote the high-dimensional multiple human walking and running data and X1 and X2 represent the corresponding latent space in the leaf nodes.
The joint probability distribution of Y1 and Y2 is given by
(20.4) |
where each conditional distribution is given by the Gaussian process. The major advantage of the GPDM is that each training datum is associated with likelihood in the latent space. Then, the maximum A-posteriori probability (MAP) method is applied to find all the values of latent variables. For this simple model, we are trying to optimize the parameters by maximizing
(20.5) |
The training process for optimizing the HGPDM is described as follows:
1. Initialize each leaf node: Project the walking and running training data to (X1, X2) through PPCA.
2. Initialize root node: Initialize the root’s latent variable through PPCA and its dependence of (X1, X2).
3. Jointly optimize the parameters of each GPDM.
Once the latent space has been optimized, supervised clustering is applied at the top latent space to group the training data to the leaf node. Supposing we have N leaf nodes, and Y = {yi, i = 1, 2, …, M}. Each leaf node is associated with mean μj and variance μj, and each training sample yi is assigned to the leaf node by
(20.6) |
One example of the learned running latent space in the leaf node is shown in Figure 20.4.
20.3.4 hgpdm WITH PARTICLE FILTER IN TESTING PHASE
After jointly optimizing the HGPDM, the trained HGPDM can be used to identify the human motion trajectories captured by particle filter tracker. In the meantime, the classified motion pattern provides the most similar motion trajectory for efficient particle sampling. The process of the HGPDM framework is described as follows.
20.3.4.1 Initializing the Particle Filter Framework
A particle filter is a Monte Carlo method for nonlinear, non-Gaussian models, which approximates the continuous probability density function by using a large number of samples. In the HGPDM framework, a histogram was used as appearance modeling for its simplicity and efficiency. The red, green, blue (RGB) histogram of the template and the image region under consideration are obtained, respectively. The likelihood is defined to be proportional to the similarity between the histogram of the template and the candidate, and is measured by the Bhattacharya distance.
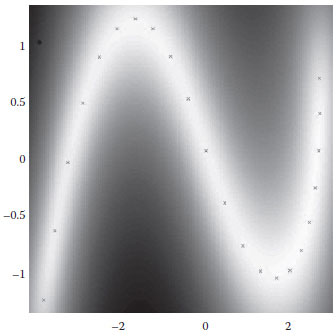
FIGURE 20.4 Trained running latent space.
At this step, target templates are obtained by using background subtraction. The obtained target templates will be used for similarity calculation in the testing stage. After initializing the target’s position for the first frame, each target will be tracked by using regular particle filter in the first five frames. This is based on the assumption that the human motion does not change at the very beginning. Then, the test observation motion data of the first five frames are calculated and projected to the latent coordinate system on the top node of HGPDM.
20.3.4.2 Latent Space Motion Classification and Change Detection
Since HGPDM was constructed in the latent space, at the beginning of the test process, the target observation data of the first five frames have to be projected to the same two-dimensional latent space in order to be compared to the upper level of trained HGPDM. The purpose of projecting the test data from the observation space to the latent space is to initialize the testing data in the latent space and obtain a compact representation of the similar motion patterns in the training dataset. This projection is achieved by using PPCA, same as the first stage in HGPDM learning. The feature vector of each frame contains the coordinate change values for every target being tracked in that frame. For n targets, the feature vector will contain n × 2 pairs of coordinate change values. The PPCA projection will reduce this n × 2-dimensional feature vector to a 1 × 2 latent space vector. After projecting test motion data from observation to latent space, the upper level of hierarchical GPDM will be used to identify the most similar motion patterns in the leaf node. The classification algorithm in the HGPDM is shown below:
1. Select the top K most likely latent variables xi in the root node by
(20.7) |
2. Compute the relative normalized probability as
3. Establish the latent variable
4. Determine the corresponding latent space in the leaf node as in
(20.8) |
At each frame, once the human motion pattern is classified to a different category by Equation 20.8, the system does not immediately transfer the latent space to the corresponding one. If the motion pattern continues to be identified as another category for five consecutive frames, then the sampling latent space is switched from one leaf node to the other, and the human motion change is reported to the system. Otherwise, the temporary human motion change is considered as noise and the particle filter framework will still perform sampling in the latent space which is determined in the last frame. The next possible position is predicted by determining the most similar trajectory pattern in the leaf node and using the corresponding position change value plus noise.
20.3.4.3 Particle Filter Tracking and Update
After determining the general categories of the human motion pattern in the root node of HGPDM, the particles are propagated in the latent space of the leaf node. The next possible position is predicted by determining the most similar trajectory pattern in the training database and using the corresponding position change value plus noise. The number of particles is reduced from over 100 to about 20 by deriving the posterior distribution over latent functions. Each point on this 2D latent space in Figure 20.4 is a projection of a feature vector representing 20 training targets, that is, 20 pairs of coordinate change values. The gray-scale intensity represents the precision of mapping from the observation space to the latent space, and the lighter the pixel appears, the higher the precision of mapping is.
Thereafter, the latent variables are mapped in a probabilistic way to the location difference data in the observation space. The estimation maximization (EM) approach is employed to determine the most likely observation coordinates in the observation space after the distribution is derived.
The nondecreasing log-posterior probability of the test data is given by P(Yk | Xk). KY is a kernel matrix defined by the RBF kernel function. The log-posterior probability is maximized to search for the most probable correspondence on the training datasets. The corresponding trajectory pattern is then selected for predicting the following motion.
The weights of the particles are updated in terms of the likelihood estimation based on the appearance model. The importance weight equation is given by
(20.9) |
where Ŷt denotes the estimation data, Zt denotes the observation data, kt represents the identity of the target, and wt represnts the weight of a particle.
20.3.5 EXPERIMENTAL RESULTS ON HUMAN MOTION CHANGE DETECTION
The HGPDM particle filter framework was implemented using MATLAB®. Lawrence’s Gaussian process software provides the related GPDM functions for conducting simulations (Lawrence, 2005).
During the training phase, the human motion data are extracted from the KTH action dataset (KTH dataset, 2004), which includes running and walking videos of different people. The walking and running motion trajectories are extracted manually and projected to the leaf nodes of hierarchical latent space GPDM. After joint optimization, the root node represents the interaction and switching of leaf nodes, while the leaf nodes denote different types of trajectory motion. The learned motion model are then used to classify test object trajectories, predict the next motion state, and provide Gaussian process dynamical samples for the particle filter framework.
The motion change detection framework is evaluated on the video dataset (Kiryati et al., 2008) and the IDIAP dataset (Smith et al., 2005). The first testing sequence extracted from the IDIAP dataset contains two targets and one of them runs after the other from left to right. The motion data are captured by the particle filter and classified in the HGPDM. Human motion change is reported at the 58th frame. Figure 20.5 shows the corresponding frames sampled from the tracking results and Figure 20.6 shows the posterior probability of left target motion belonging to the running GPDM latent space. According to Figure 20.6, the posterior probability is higher than 0.5 before the 58th frame, while lower than 0.5 after the 58th frame. This means that the motion trajectory is switched from running to walking in the HGPDM near the 58th frame. The sampling frames in Figure 20.5 verify that the human motion change is correctly detected. It needs to be noticed that there are several sparks in the posterior probability curve due to the noisy motion data captured by the particle filter.
The second sequence contains four people with occlusion and complex motion patterns. The person with blue bounding box first walked to the road center, and then circled around the bike ramp in the middle of the road. Both the direction and the velocity were varied at this circle motion. Motion changes are reported at the 42th and 129th frame. Figure 20.7 shows the posterior probability of motion change. The posterior probability is below 0.5 near the 42th and 129th frame, as the person made a turn near these two frames. The sampling frames in Figure 20.8 indicate that the motion change is correctly detected.

FIGURE 20.5 Sampling frames of 3, 19, 58, and 98 in the first testing sequence.
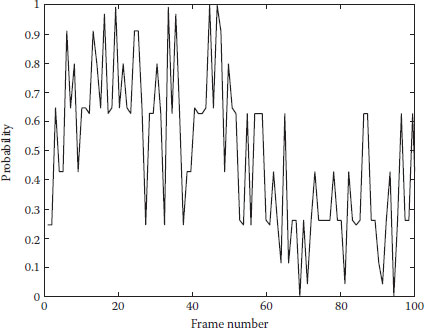
FIGURE 20.6 Posterior probability of running motion change.
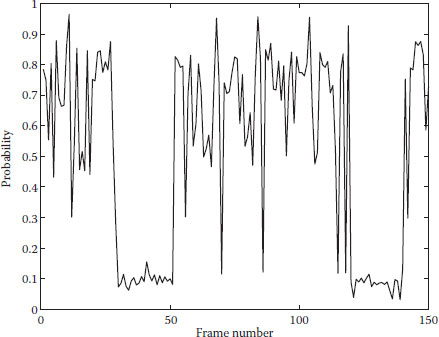
FIGURE 20.7 Posterior probability of circle motion.
The change detection framework is also evaluated on the dataset (Kiryati et al., 2008), and the human motion change detection results with the abnormal motion recognition are compared. The experimental results indicate that the HGPDM framework can detect all the motion change correctly, which are corresponding to the defined abnormal motions (Kiryati et al., 2008). One of the testing sequences shown in Figure 20.9 was defined as the jumping episode (Kiryati et al., 2008). The motion change detection of the left target is reported at the 18th and 60th frame. According to Figure 20.8, the woman stopped from running near frame 9 and began to walk after jumping toward the man near frame 60. The change detection system can capture the motion change successfully through the switching between different latent space nodes.
As all the abnormal motion patterns in Kiryati et al. (2008) were predefined, their system can only detect all the trained trajectories, while the HGPDM-based change detection framework can be used for general motion change detection of tracked targets over time.
These experimental results demonstrate the efficiency and accuracy of this motion change detection framework. They indicated that this method can correctly detect each motion change and robustly track multiple targets with complex motion at the same time. As the HGPDM is a general motion trajectory model, this framework can not only be used for suspicious behavior analysis and irregular motion detection, but can also be used for key frame detection and scene change detection in multimedia content analysis.

FIGURE 20.8 Sampling frames of 1, 42, 65, 87, 129, and 150 in the second testing sequence.
20.4 HUMAN GROUP BEHAVIOR ANALYSIS
Compared with single human action recognition and human crowd analysis, action recognition of small human group with <10 people has more practical applications in surveillance systems. Most public safety scenarios consist of small group activities. However, relatively few research works have been reported on this topic, due to the difficulties of describing varying number of participants and mutual occlusions among group members. Ni et al. (2009) introduced three types of localized causalities for human group activities with different numbers of people, and their experiment results showed that dynamic human interactions could be used to classify group actions. They provided feature vectors of different sizes to describe different group activities, which needed to train specific classifiers using different input samples with different lengths. Chang et al. (2010) proposed a bottom-up method to form a group and calculated the similarity of different groups. Ge et al. (2009) also developed a hierarchical clustering algorithm for small group detection in a crowded scene. Guimera et al. (2005) proposed a collaboration network structure to determine the team performance, and the experiment result indicated that team assembly mechanism could be used for predicting and describing the group dynamics.

FIGURE 20.9 Sample frames of 1, 18, 25, 33, 60, and 85 in the third testing sequence.
Most human activity recognition methods fall into two large categories, that is, non-target-oriented and target-oriented approaches. Non-target-oriented methods extract features on the entire image region regardless of each target’s position and the number of targets. Non-target-oriented methods are widely used in single human action recognition, as the background is often fixed and the individual’s actions dominate the entire scene. However, target-oriented methods require tracking of each target in the scene and then modeling targets’ behavior according to the motion flow. As the extracted features are much more accurate in the scene, object-oriented methods can be more effective for multiple human activities recognition and human group behavior analysis under a complex environment.
To exploit the property of human action, Hospedales et al. (2009) implemented the dynamic Bayesian network (DBN) or other models to drive the potential characteristic behind the simple features, which sought to connect the extracted features by probabilistic distribution. However, in the large-scale human action recognition, people always clustered to groups, which means there are intergroup interaction as well as intragroup interaction. Treating the entire scene as a whole may not be a good choice for such a recognition task. Therefore, target-oriented approaches are becomingmore popular in the large-scale video analysis.
Tracking plays an essential role in the target-oriented methods for human action recognition, as it can provide the central location information for each target in the video sequence. With the development of multiple-camera system, robust and accurate tracking of multiple human is not difficult. Two of the most widely used tracking algorithms are mean-shift- and particle filter-based tracking methods.
After targets tracking, many machine learning algorithms have been introduced for high-level human action understanding. Ryoo and Aggarwal (2008) proposed a hierarchical recognition algorithm for the recognition of high-level group activities, and each group activity is based on activities of individual members and group activity is represented with language-like description, while each representation need to be encoded by human experts. To handle recognition and understanding on video clips with variable length, a probabilistic model (GPDM) is built for each human behavior during the training phase, and the posterior probability is computed for each test sample.
Vaswani et al. (2003) utilized the statistical shape theory to detect abnormal group activity. Each person in a frame is modeled as a point and the shape is formed based on the connections of a fixed number of landmarks. The normal shape sequence was modeled as a stationary Gaussian Markov model, and abnormal activity was detected by comparing the tracking results with pretrained models. Cupillard et al. (2002) proposed a high-level group behavior recognition algorithm based on the hierarchy of operators; each operation was associated with a method to recognize human behaviors. Each group behavior was defined by different combination of operators. This provided the flexibility for different users. Also, the author fused the detected motion information from multiple cameras to form a global graph to improve long-term tracking for each target. Intille and Bobick (1999) introduced the belief networks for probabilistically representing and recognizing multiple-agent action based on temporal structure description. The experiment results had demonstrated their approach could find the logic connection of each agent during football play.
To recognize group human behaviors, the aforementioned approaches have exploited both the feature description and semantic understanding from different perspectives. However, due to the difficulty of understanding spatial dynamics as well as temporal dynamics, group human behavior recognition still remains a challenging problem in the image-processing field.
In the following sections, we will introduce a new group human behavior modeling method based upon social network features and probabilistic learning as an example for multimedia content analysis.
20.4.1 GROUP HUMAN BEHAVIOUR RECOGNITION FRAME WORK
We will demonstrate a multimedia content analysis system focusing on the group human action recognition, which includes feature extraction, human detection and tracking, and group human behavior classification. This system introduces a novel structural feature set to represent group activities as well as a probabilistic framework for small group activity learning and recognition.
As shown in Figure 20.10, the whole learning procedure of our system consists of four stages. First, a robust mean-shift-based tracker is applied to track each individual in a small group sequentially. Then, the output coordinates of each tracker will be clustered and allocated to different small human groups. Based on social network feature description, the structural features are extracted from each video clip in the third stage. The feature vectors from each frame will form a feature matrix for each video clip. To understand the group human behavior, a corresponding GPDM is trained for each group behavior. The group activity feature matrix for each video clip will be projected to a low-dimensional latent space and the posterior conditional probability is computed with each trained model to identify different human group behaviors.
The detailed procedure of social network features-based probabilistic framework is introduced below.
20.4.1.1 Adaptive Mean-Shift Tracking
One of the important factors for small group human activities analysis is the accuracy and robustness of tracking each individual in the human group. As multiple camera systems develop, the accurate tracking of each individual can be well addressed. In the social network features-based probabilistic framework, the adaptive mean-shift tracking (Collins et al., 2005) on two different datasets is applied
Compared to the general mean-shift tracking, online feature selection is applied during the adaptive mean-shift tracking. The feature set (Collins et al., 2005; Yin and Man, 2009) consisted of a linear combination of pixel valves at R, G, B channels: By pruning all redundant coefficients of ωi, the feature set was cut down to 49. Linear discriminative analysis (LDA) was then used to determine the most descriptive feature for target tracking.
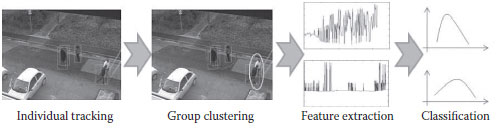
FIGURE 20.10 Overview of group activity recognition framework.
In order to reduce the computational complexity during tracking, the feature set is updated every 50 frames instead of being updated at each frame. In addition, the single mean-shift tracking algorithm is extended for multiple targets tracking. As the cameras were fixed in these two datasets, a simple motion detector is applied to detect each new person coming into the scene. Once a person comes in the scene, a new tracker will be allocated and track that person over time. Due to the difficulties in the reliable multiple targets tracking, each target will be reinitialized manually if the tracking algorithm fails for some reason.
20.4.1.2 Small Group Clustering
After obtaining all the positions of each target, a group clustering algorithm (Chang et al., 2010) will be applied to locate small groups. The closeness of each person is calculated and the minimum span tree (MST) clustering is used to obtain the distribution of each group. After that, the hierarchical clustering method (Chang et al., 2010) is applied to locate the mass center of each small group.
20.4.1.3 Social Network-Based Feature Extraction
Inspired by the social network analysis (SNA) (Wasserman and Faust, 1994), several structural features are extracted to capture the dynamic properties of a small group structure. It is believed that the dynamic structure and its theoretical framework can help us to model the group scenario in the real world. To our best knowledge, this is the first time that SNA-based feature is used to model group behavior in the surveillance videos. Similar to the original definitions of betweenness, closeness, and centrality(Krebs, 2000; Blunsden and Fisher, 2010) in SNA, several group structure features which are derived from SNA with modification in the group activity recognition are defined, including motion histograms, closeness histogram, and centrality histogram.
According to the previous section, suppose we have a group activity clip of m frames and the size of the feature matrix is 26 × m. Figure 20.11 shows the centrality feature of two different group activities. The assumption of this framework is that in the normal situation, the motion distribution of a group is prone to have a Gaussian distribution. If we treat the centrality feature in Figure 20.12 as a Gaussian process, then the centrality histogram at each frame is a sampling of this process. Different group activities can be seen as a set of Gaussian processes with different means and covariance matrices. Therefore, the Gaussian process can be used to model the dynamics in the temporal dimension. However, the size of covariance matrix will increase as the number of samples increases. In addition, since the Gaussian process just captures the general properties of the social network-based tructural feature, a more specific characteristic of human motion needs to be addressed.
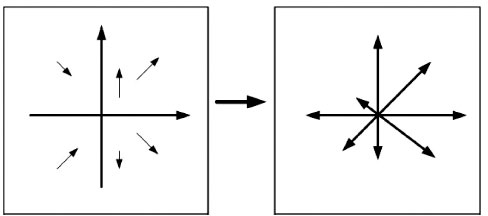
FIGURE 20.11 Motion histogram illustrations.
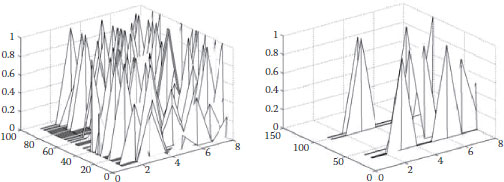
FIGURE 20.12 The overlapped central histogram of GroupFighting (left) and InGroup (right) from two video clips.
20.4.1.4 Human Group Behavior Modeling
In order to describe the dynamic property of the group behavior, the GPDM (Wang et al., 2008a) is adopted to represent different group activities.
As shown in Figure 20.10, the small group activity recognition framework consists of four stages: adaptive mean-shift tracking,
20.4.2 SMALL GROUP ACTIVITY RECOGNITION
The small group activity recognition can be divided into two phases: group activity training and group activity classification. In the training stage, for each small group activity {Ai, i = 1, …, n}, a GPDM {Λi, i = 1, …, n}will be trained. Suppose we have k samples of a group activity Ai, the length of each sample is m, then we have k feature matrices of size 26 × m. To learn a specific GPDM for Ai, the mean value of k feature matrices will first be computed, and will be used for activity model training.
GPDM is applied to learn the specific trajectories of a group activity. The probability density function of the latent variable X and the observation variable are defined by the following equations. The basic procedure of the GPDM training is described below.
GPDM is created on the basis of the trajectory training datasets, that is, extracted structural feature, where is the training observation data, XT is the corresponding latent variable sets, and are hyperparameters
20.4.2.2 Jointly Initializing Model Parameters
The latent variable sets and parameters are obtained by minimizing the negative log-posterior function −lnp of the unknown parameters with SCG on the training datasets.
20.4.2.3 Training GPDM for Each Group Activity
For each group activity {Ai, i = 1, …, n}, repeat procedure 1 and 2, and create a corresponding GPDM: {Λi, i = 1, …, n}. After training, we have a set of GPDMs: {Λi, i = 1, …, n}for the human group activities. When a new human group activity Z* comes in, the conditional probability will be computed with respect to each trained GPDM, and the one with the highest conditional probability will be selected.
20.4.2.4 Calculating the Conditional Probability with Each Trained GPDM
For each trained GPDM {Λi}, compute by using the learned parameters: This can be obtained by minimizing the negative log-posterior function −lnp with SCG on the training datasets. After that, the conditional probability is calculated.
20.4.2.5 Selecting the GPDM with the Highest Conditional Probability
The new group activity can be determined by
(20.10) |
As discussed in the previous section, the length of the new observation can be different from the size of the training data, which means that the number of frames in test clips can be different with training clips. Therefore, the trained model can address the dynamics in the temporal dimension. As the duration of an activity may change under different situations, it is important that the classifier can handle the testing sequences with varying lengths.
20.4.3 EXPERIMENTAL RESULTS ON HUMAN GROUP BEHAVIOR RECOGNITION
The social network-based group behavior modeling method was evaluated on two group activity datasets. The first one is the recently released BEHAVE dataset (Blunsden and Fisher, 2010), which contains the ground truth for each group activity. The second dataset is IDIAP dataset (Smith et al., 2005), which was originally captured for multiple target tracking.
20.4.3.1 Results on BEHVAE Dataset
The BEHVAE dataset consists of 76, 800 frames in total. This video dataset is recorded at 26 frames per second and has a resolution of 640 × 480. Different activities include InGroup, Approach, Walk Together, Split, Ignore, Following, Chase, Fight, RunTogether, and Meet. There are 174 samples of different group activities in this dataset.
To focus on the small group activity analysis, 118 samples from all the group activities dataset are selected, excluding those samples with less than three people in the scene. The selected group activities include InGroup (IG), WalkingTogether (WT), Split (S), and Fight (F) as the group activities for classification. For each activity, the samples are divided into 10 categories, nine for training and one for testing. The classification result is shown in Table 20.1. Two of the learned GPDMs are shown in Figure 20.13. Each point in the latent space corresponds to a feature vector in a single frame. The distribution of InGroup activity is prone to have some local clusters in the latent space, while the distribution of GroupFight activity is similar to a random distribution.
Some selected frames for InGroup and GroupFighting are shown in Figure 20.14. Although the number of group size is varying, the framework can still recognize the group activity correctly.
The result of social network features-based probabilistic method is also compared with the best recognition results (Blunsden and Fisher, 2010). The training and testing data are divided 50/50; the comparison results in Table 20.2 indicate the competitive performance of the social network features-based probabilistic framework. It should be noted that the recognition rate is the average rate for all activities. For the hidden Markov model (HMM)-based method (Blunsden and Fisher, 2010), the time window size is 100, which means that their method required at least 200 frames to recognize an action type, while the social network features-based probabilistic framework can handle small group action recognition regardless of time durations through the probabilistic recognition approach.
TABLE 20.1
Classification Results of the Social Network Features-Based Probabilistic Method
Small Group Action Type |
IG |
WT |
F |
S |
The social network features-based probabilistic approach |
94.3% |
92.1% |
95.1% |
93.1% |

FIGURE 20.13 Visualization of trained GPDMs, the left one is the InGroup and the right one is GroupFight.

FIGURE 20.14 Sampling frames of InGroup and GroupFight, the left column is the InGroup, the middle column is GroupFight, and the right column is WalkTogether.
TABLE 20.2
Comparison of Classification Results
HMM-Based Method (Blunsden and Fisher, 2010) |
Social Network Features-Based Probabilistic Approach |
93.67% |
93.12% |
20.4.3.2 Results on IDIAP Dataset
The IDIAP dataset is first used for multiple targets tracking (Smith et al., 2005). The dataset contains 37, 182 frames in a total of 46 clips that are manually selected with different lengths for human group activity recognition. As there is no Fight activity in the IDIAP dataset, only three other activities, InGroup, WalkTogether, and Split, are evaluated. To validate the robustness of the social network features-based probabilistic framework, the trained GPDMs from the BEHVAE dataset for activity recognition are directly applied on the IDIAP dataset for testing, and the overall average classification rate is 90.3%. The experiment results indicate that the social network features-based probabilistic framework is robust enough to identify human group activities under different scenarios. Some of the sample frames from IDIAP dataset are shown in Figure 20.15.

FIGURE 20.15 Sampling frames of InGroup, WalkTogether, and Split.
20.5 DISCUSSIONS AND FUTURE DIRECTIONS
Human behavior modeling is very challenging in intelligent surveillance systems. In this chapter, we introduced two new modeling methods for human motion change detection and small human group behavior modeling.
The HGPDM (Yin et al., 2010) extends the GPDM (Lawrence, 2005; Lawrence and Moore 2007) and incorporates particle filtering in general modeling of human motion patterns. The hierarchical structure in HGPDM can address complex human motions and model the changes of such motion patterns. On one hand, the particle filter is capable of tracking nonlinear and non-Gaussian human motions. This enables HGPDM to utilize the captured human motion data in classification and change detection over time. On the other hand, the hierarchical structure of GPDM ensures the finding of the most similar motion pattern in the leaf nodes. Therefore, the sampling in the prelearned HGPDM model improves the efficiency of the particle filter framework.
We also introduced a conditional GPDM based on a set of unique structural features for small human group activity recognition. The social network-based structural feature set is very effective in describing the interactions among multiple group members. The feature set can characterize both the global distribution of a group as well as local motion of each individual. In addition, this feature set can keep a fixed length while handling varying group size and group location, which is very important for recognition. Multiple GPDMs are pretrained for known group activities. The conditional probabilities on these GPDMs are computed for each test sequence, and the one with the highest probability is selected as the group activity type.
Experiment results have demonstrated the efficiency and accuracy of these models in human action change detection and group behavior modeling. Overall, these are examples of recent progresses toward semantic analysis of multimedia content. There are still many interesting research topics to be explored, including new features, modeling tools, and learning schemes. For example, social networking has become a popular network service with billions of users generating media-rich content every day. It becomes possible and desirable to automatically analyze these contents and recognize as well as understand the social behaviors of the users in each of their social groups. Video-based human action and group behavior modeling can be exploited for such purpose. In addition, multimodality modeling methods, which can effectively fuse video-based features and decisions with outputs from other modalities, such as geo-locations, social connections, wireless environment, and so on, will be able to provide a much more comprehensive understanding of the object of interest. Furthermore, semantic representations of visual concepts need to be further extended from attribute-oriented ontologies to rich behavioral descriptions.
Barron, J.L., Fleet, D. J., and Beauchemin, S. S. Performance of optical flow techniques, International Journal of Computer Vision, 12, 43–77, 1994
Blunsden, S., and Fisher, R. B. The BEHAVE video dataset: Ground truthed video for multiperson, Annals of the British Machine Vision Association, 2010(4), 1–11, 2010
Boiman, O., and Irani, M. Detecting irregularities in images and in video, Proceedings of the IEEE International Conference on Computer Vision, pp. 462–469, Beijing, China, October 2005
Chang, M. C., Krahnstoever, N., Lim, S. and Yu, T. Group level activity recognition in crowded environments across multiple cameras, in Workshop on Activity Monitoring by Multi-Camera Surveillance Systems, Boston, USA, September 2010
Collins, R.T., Liu, Y., and Leordeanu, M. Online selection of discriminative tracking features, IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(10), 1631–1643, 2005
Cupillard, F., Bremond, F., and Thonnat, M. Group behavior recognition with multiple cameras Proceedings of the IEEE Workshop on Applications of Computer Vision, pp. 177–183, Orlando, FL, USA, December 2002
Dalal, N., and Triggs, B. Histograms of oriented gradients for human detection Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol. 2, pp. 886–893, San Diego, CA, USA, June 2005
Ge, W., Collins, R. T., and Ruback, B. Automatically detecting the small group structure of a crowd, in Workshop on Applications of Computer Vision, pp. 1–8, Snowbird, UT, USA, 2009
Gong, S., and Xiang, T., Visual Analysis of Behaviour: From Pixels to Semantics, 376 pages Springer, London, 2011
Guimera, R., Uzzi, B., Spiro, J., and Amaral, L., Team assembly mechanisms determine collaboration network structure and team performance, Science, 308(5772) 697–702, 2005
Haritaoglu, I., Harwood, D., and David, L.S., Real-time surveillance of people and their activities, IEEE Transactions on Pattern Analysis and Machine Intelligence, 8(22) 809–830, 2000
Horn, B. K. P., and Schunck, B. G., Determining optical flow, Artificial Intelligence, 17 185–203, 1981
Hospedales, T., Gong, S. G., and Xiang, T., A Markov clustering topic model for mining behavior in videos, Proceedings of the International Conference on Computer Vision, pp. 1165–1172, Kyoto, Japan, September 2009
Intille, S. S., and Bobick, A. F., A framework for recognizing multi-agent action from visual evidence, Proceedings of the Conference of the Association for the Advancement of Artificial Intelligence, pp. 518–525, Orlando, Florida, July 1999
Ivanov, Y., and Bobick, A., A framework for recognizing multi-agent action from visual evidence, Proceedings of the International Conference on Computer Vision, pp. 169–176, Kerkyra, Greece, September 1999
Kiryati, N., Raviv, T., Ivanchenko, Y., and Rochel, S., Real time abnormal motion detection in surveillance video, Proceedings of the International Conference on Pattern Recognition, pp. 1–4, Tampa, FL, USA, December 2008
KTH action database, http://www.nada.kth.se/cvap/actions, 2004
Krebs, V., The social life of routers, Internet Protocol Journal, 3, 14–25, 2000
Lawrence, N.D.–s, Gaussian process software, http://www.cs.man.ac.uk/neill/software.html, 2005
Lawrence, N. D., and Moore, A.J., Hierarchical Gaussian process latent variable models, Proceedings of the International Conference on Machine Learning, pp. 481–488, Corvallis, OR, USA, June 2007
Lowe, D. G., Object recognition from local scale-invariant features, Proceedings of the International Conference on Computer Vision, vol, 2 pp. 1115–1150, Kerkyra, Greece, September 1999
Lucas, B. D., and Kanade, T., An iterative image registration technique with an application to stereo vision, Proceedings of the Imaging Understanding Workshop, pp. 121–130, Washington, USA, April, 1981
Medioni, G., Nevatia, R., and Cohen, I., Event detection and analysis from video streams, IEEE Transactions on Pattern Analysis and Machine Intelligence, 23, 873–889, 2001
Ni, B. B., Yan, S. C., and Kassim, A. A., Recognizing human group activities with localized causalities, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1470–1477, Miami, FL, USA, April 2009
Rao, S., and Sastry, P., Abnormal activity detection in video sequences using learnt probability densities, IEEE Convergent Technologies for the Asia-Pacific Region, vol 1, pp. 369–372, Bangalore, October 2003
Raskin, L., Rivlin, E., and Rudzsky, M., Using Gaussian process annealing particle filter for 3D human tracking, EURASIP Journal on Advances in Signal Processing,, vol 2008, 1–14, 2008.
Riedmiller, M., and Braun, H., RPROP—A fast adaptive learning algorithm, Proceedings of the International Symposium on Computer and Information Sciences (ISCIS VII), Antalya, Turkey, November 1992.
Ryoo, M.S., and Aggarwal, J. K., Recognition of high-level group activities based on activities of individual members, Proceedings of the IEEE Workshop on Motion and Video Computing, pp. 1–8, Copper Mountain, CO, USA, January 2008.
Sherrah, J., and Gong, s., A system for tracking and recognition of multiple people and their activities, Proceedings of the International Conference on Pattern Recognition, vol. 1, pp. 179–182, Barcelona, Spain, September, 2000.
Smith, K., Pérez, D. G., and Odobez, J., Using particles to track varying numbers of interacting people, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 962–969, San Diego, CA, USA, June, 2005.
Stauffer, C., and Grimson, W., Learning patterns of activity using real-time tracking, IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(8), 747–757, 2000.
Urtasun, R., 3D people tracking with Gaussian process dynamical models, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 238–245, New York, NY, USA, June, 2006.
Vaswani, N., Chowdhury, A.R., and Chellappa, R., Activity recognition using the dynamics of the configuration of interacting objects, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol II, pp. 633–640, Madison, WI, USA, June, 2003.
Viola, P.A., and Jones, M.J., Rapid object detection using a boosted cascade of simple features, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol I, pp.I 511–518, Kauai, HI, USA, September, 2001.
Wasserman, S., and Faust, K., Social Networks Analysis: Methods and Applications, Cambridge University Press, 1994.
Wang, J. M., Fleet, D., and Hertzmann, A., Gaussian process dynamical models for human motion, IEEE Transactions on Pattern Analysis and Machine Intelligence, 30(2), 283–298, Tampa, FL, USA, December 2008a.
Wang, J., Yin, Y., and Man, H., Multiple human tracking using particle filter with Gaussian process dynamic model, EURASIP Journal on Image and Video Processing, 2008, 1–11, 2008b.
Yin, Y., and Man, H., Adaptive mean shift for target-tracking in FLIR imagery, Proceedings of the International Conference on Wireless and Optical Communications Conference, Newark, NJ, USA, April 2009.
Yin, Y., Man, H., and Wang, J., Human motion change detection by hierarchical Gaussian process dynamical model with particle filter, Proceedings of the International Conference on Advanced Video and Signal-Based Surveillance, pp.304–317 Boston, USA, September 2010.
Yuan, F., Prinet, V., and Yuan, J., Middle-level representation for human activities recognition, The role of spatio-temporal relationships, In ECCV Workshop on Human Motion: Understanding, Modeling, Capture and Animation, Crete, Greece, September 2010.
Zhong, H., Shi, J., and Visontai, M., Detecting unusual activity in video, The role of spatio-temporal relationships, In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol. 2, pp.819–826 Los Alamitos, CA, USA, July 2010.
Zhu, Q. A., Yeh, M.C., Cheng, K. T. and Avidan, S., Fast human detection using a cascade of histograms of oriented gradients, In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. II, 1419–1498 New York, NY, USA, June 2006.