
Chaos-Based Hash Function with Both Modification Detection and Localization Capabilities |
CONTENTS
17.3.1.1 Padding, Division, and Preprocessing
17.3.1.2 Grouping and Processing in a Parallel Mode
17.3.1.3 Obtaining the Detection Hash and Localization Hash Values
17.3.2 Characteristics of the Algorithm Construction
17.3.2.1 Both Modification Detection and Localization Capabilities
17.3.2.3 Changeable-Parameter and Self-Synchronizing Keystream
17.4.1 Detection Hash Performance
17.4.1.1 Distribution of Hash Value
17.4.1.2 Sensitivity of Hash Value to the Message and the Secret Key
17.4.1.3 Statistic Analysis of Diffusion and Confusion
17.4.1.4 Analysis of Collision Resistance
17.4.2 Localization Hash Performance
17.4.5 Implementation and Flexibility
As one of the cores of Cryptography, hashing is a basic technique for information security (Schneier, 1996; Stinson, 1995). A cryptographic hash function is used to compress the message data to a fixed-size hash value in such a way that any alternation to the data will generate a different hash value. Chaos is a kind of deterministic random-like process provided by nonlinear dynamic systems. Chaotic systems are systems that are random-like, but in fact are not random. They are governed by physical laws to make the accurate prediction almost impossible. It is a promising direction to utilize the characteristics of chaos to design hash function.
Wong (2003) developed a combined encryption and hashing scheme based on the iteration of Logistic Map and the dynamical update of a look-up table, which is further improved by Xiao et al. (2006). Xiao et al. (2005) proposed an algorithm for one-way hash function construction based on a Piecewise Linear Chaotic Map (PWLCM) with changeable-parameter. Yi (2005) proposed a hash function algorithm based on Tent Maps. Zhang et al. (2007) proposed a novel chaotic keyed hash algorithm by using a Feedforward-Feedback Nonlinear Filter. Arumugam et al. (2007) studied the suitability of Logistic Map and Lorenz Map in generating Message Authentication Codes. However, the above algorithms have a common point that they are only able to verify whether there is modification, but unable to locate where the modification takes place. Besides, their iterative hash structures are all in a sequential mode. The processing of the current message unit, that is, a character as in Wong (2003) and Xiao et al. (2005), Xiao et al. (2006) or a block as in Yi (2005), Zhang et al. (2007), and Arumugam et al. (2007), cannot start until the previous one has been processed. These limitations restrict their applications.
In this chapter, we propose an algorithm for both modification detection and localization, whose structure can support parallel processing mode (Xiao et al., 2010). The mechanism of both changeable-parameter and self-synchronization is utilized to achieve all the performance requirements of hash function. The rest of this chapter is arranged as follows. Section 17.2 introduces the brief preliminaries about the chaotic maps used in the proposed algorithm. In Section 17.3, the hash function algorithm is described in detail. Performance analyses are given in Section 17.4. Finally, this chapter is concluded in Section 17.5.
The inherent merits of chaos, such as the sensitivity to tiny changes in initial conditions and parameters, mixing property, ergodicity, unstable periodic orbits with long periods, and one-way iteration, form the potential foundation for excellent hash function construction. In the proposed algorithm, PWLCM will be used.
PWLCM is defined as
(17.1) |
where Xt∈ [0,1] and P∈ (0,0.5) denote the iteration trajectory value and the parameter of PWLCM, respectively. According to Baranousky and Daems (1995), {Xt} is ergodic and uniformly distributed in [0,1], and the auto-correlation function of {Xt} is δ-like.
17.3.1.1 Padding, Division, and Preprocessing
In our algorithm, a lookup table with 16 × 16 blocks is built in advance, as shown in Figure 17.1. The original message M is padded such that its length is a multiple of 256 characters (2048 bits): let m be the length of the original message M; the padding bits (100…0)2 with length n (such that (m + n)mod2048 = 2048 – 64 = 1984, 1 ≤ n ≤ 2048) are appended. The left 64-bit is used to denote the length of the original message M. If m is greater than 264, then mmod264. After padding, M is constituted by s divisions with 256 characters (2048 bits), M = (M1, M2, …, Ms). For each division, its 256 characters are filled into the 256 blocks of the lookup table in turn. When all the divisions have been processed in this way, there will be s characters within each block of the lookup table. Without loss of generality, let i th block of the lookup table hold character array-c1, c2, …, cs. The detailed preprocessing of the ith block (i = 1, 2, …,256) in the lookup table is described in Figure 17.1.
1. Translates the pending character array-c1, c2, …, cs to the corresponding ASCII numbers, then maps these ASCII numbers into a number array-C1, C2, …, Cs by means of linear transform, in which the element is a number ∈[0,1] and the length is the character number s in the block of the lookup table.
2. The iteration process of PWLCM is as follows:
1st: P1 = (C1 + P0)/4 ∈ (0,0.5), X1 =Fp1(X0)∈(0,1),
2nd-sth: Pk = (Ck+ Xk-1)/4 ∈(0,0.5), Xk = Fpk(Xk-1) ∈(0,1),
(s + 1)th: Ps + 1 =(Cs+ Xs)/4 ∈ (0, 0.5), Xs + 1 = Fps + 1(Xs) ∈ (0,1),
(s+ 2)th–2sth: Pk = (C(2s-k+1)+ Xk-1)/4 ∈ (0,0.5), Xk = Fpk(Xk-1) ∈ (0,1).
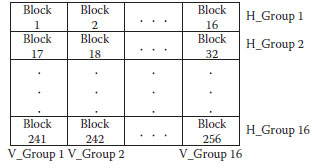
FIGURE 17.1 Look-up table.
Here, the initial condition X0∈ [0,1] and initial parameter P0∈ (0,1) of PWLCM are used as the secret key of the algorithm. If a certain iteration value Xk is equal to 0 or 1, then an extra iteration is carried out. The property of chaos can ensure that this kind of extra iteration time is very less.
3. X2s obtained in Step (ii) is the set as the representative value of the i th block (i = 1, 2,…,256) in the block of the lookup table.
17.3.1.2 Grouping and Processing in a Parallel Mode
The 256 blocks of the lookup table are assigned in turn into 16 horizontal groups and 16 vertical groups for further processing in a parallel mode, respectively. As shown in Figure 17.1, the groups are:
Horizontal Direction: H_Group 1-Block1, Block2, …, Block16; H_Group 2-Block17, Block18, …, Block32; …, H_Group 16-Block241, Block242, …, Block256; Vertical Direction: V_Group 1-Block1, Block17, …, Block241; V_Group 2-Block2, Block18, …, Block242; …, V_Group 16-Block16, Block32, …, Block256.
Without loss of generality, let CBi1, CBi2, …, CBil6 ∈ (0,1) be the corresponding representative values of the blocks in the ith horizontal group, the detailed processing of the ith horizontal group (i = 1, 2,…,16) is described as follows:
1. The iteration process of PWLCM is as follows:
1st: P1 = (CBi1+ P0+ i/16)/6 ∈(0,0.5), X1 = FP1(X0) ∈ [0,1], where the initial condition X0∈ [0,1] and intial parameter P0∈ (0, 1) of PWLCM are the secret key of the algorithm, and “i” is the order of each Horizontal Group.
2nd-16th: Pk = (CBik+ Xk-1)/4 ∈ (0,0.5), Xk = FPk(Xk-1) ∈[0,1],
17th: P17 = (CBi16+ X16)/4 ∈(0,0.5), X17 = FP17(X16) ∈ [0,1],
18th-32nd: Pk = (C(32-k+1)+ Xk-1)/4 ∈ (0,0.5), Xk = FPk(Xk-1) ∈ [0,1], 33rd ~ 34th: Xk = FP32(Xk-1) ∈ [0,1].
2. We transform the iteration values-X32, X33, X34to the corresponding binary format, extract 40, 40, 48 bits after the decimal point, respectively, and juxtapose them from left to right to get a 128-bit DHKi, the keystream of the ith horizontal group (i = 1, 2,…,16). At the same time, we extract 4 bits after the decimal point from the binary format of X32to get a 4-bit LHKi (i = 1, 2,…,16).
Similar operations have been performed on the j th vertical group (j = 1, 2,…,16). Then we will obtain a 128-bit DVKj, the keystream of the j th Vertical Group (j = 1, 2, …,16), and a 4-bit LVKj(j = 1, 2,…,16).
17.3.1.3 Obtaining the Detection Hash and Localization Hash Values
The final 256-bit hash value of the message Mis jointly composed of DHASH and LHASH, which are used to accomplish the detection and the localization, respectively. The 128-bit detection hash value can be obtained by DHASH = DHK1⊕ DHK2… ⊕ DHK16⊕ DVK1⊕ DVK2… ⊕ DVK16, where ⊕ denotes XOR (Exclusive-OR) operation. At the same time, all 4-bit LHKi (i = 1, 2, …, 16) and 4-bit LVKj (j = 1, 2, …, 16) are juxtaposed from left to right to get a 128-bit localization hash value-LHASH.
Note that the 16 horizontal groups and the 16 vertical groups of the lookup table can be processed in a parallel mode, respectively. Therefore, the efficiency of the proposed algorithm is promising. The most important point is that the generation of the keystream in each group must be under the control of the corresponding algorithm key as well as the order and the content of the current group, which can guarantee the security of the algorithm.
17.3.2 CHARACTERISTICS OF the ALGORITHM CONSTRUCTION
17.3.2.1 Both Modification Detection and Localization Capabilities
The proposed algorithm has the capabilities of both modification detection and localization. During the application of the hash function, we first verify whether there are modifications on the pending message by computing the new detection hash value and comparing it with the former one. If the comparison indicates some modifications, then we may further realize modification localization by using the localization hash value. This kind of function is very useful for information authentication or communications with resource constraints, which cannot be provided by most of other hash algorithms.
The parallel mode of the proposed algorithm is embodied in two aspects. One is that the preprocessing among 256 blocks of the lookup table can be performed in a parallel mode, and the other from the whole structural point of view, that the processing among 16 horizontal groups and 16 vertical groups can be performed in a parallel mode (see Figure 17.1). Actually, the processing of the 16 blocks within each horizontal or vertical group can also be adapted to a parallel mode if necessary.
17.3.2.3 Changeable-Parameter and Self-Synchronizing Keystream
In steps 1 and 2, the message unit at different positions will cause the parameter of chaotic maps to change dynamically during the iteration process of PWLCM. In step 2, the iteration process of PWLCM is also related to the order of each message group. On one hand, perturbation is introduced in a simple way to avoid the dynamical degradation of chaos, and on the other hand, self-synchronizing stream is realized, which ensures that the generated keystream is closely related to the algorithm key as well as the content and the order of each message group. The mechanism of both changeable-parameter and self-synchronization provides the foundation for the security of the proposed algorithm.
To implement the proposed algorithm for performance analyses, PWLCM given by Equation 17.1 is chosen. Its initial condition X0 = 0.232323 and initial parameter P0 = 0.858485 are set as the algorithm key. The randomly chosen original paragraph of a message is “As a ubiquitous phenomenon in nature, chaos is a kind of deterministic random-like process generated by nonlinear dynamic systems. The properties of chaotic cryptography includes: sensitivity to tiny changes in initial conditions and parameters, random like behavior, unstable periodic orbits with long periods and desired diffusion and confusion properties, etc. Furthermore, benefiting from the deterministic property, the chaotic system is easy to be simulated on the computer. Unique merits of chaos bring much promise of application in the information security field.”
17.4.1 DETECTION HASH PERFORMANCE
In this section, we focus on the performance of the 128-bit detection hash value.
17.4.1.1 Distribution of Hash Value
The uniform distribution of hash value is one of the most important requirements of hash functions related to security. Simulation experiment has been conducted on the above paragraph of message. Two-dimensional graphs are used to demonstrate the differences between the original message and the final detection hash value. In Figure 17.2, the ASCII codes of the original message are localized within a small area; while in Figure 17.3, the hexadecimal detection hash value spreads around very uniformly. This simulation result indicates that no information (including the statistic information) of the original message can be left over after the diffusion and confusion.
17.4.1.2 Sensitivity of Hash Value to the Message and the Secret Key
In order to evaluate the sensitivity of hash value to the message and the secret key, hash simulation experiments have been performed using the following seven conditions:
C1: The original message;
C2: Change the first character A in the original message into B;
C3: Change the word unstable in the original message into anstable;
C4: Change the full stop at the end of the original message into comma;
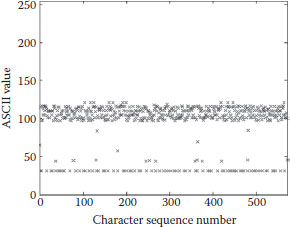
FIGURE 17.2 Distribution of the original message in ASCII.

FIGURE 17.3 Distribution of the hash values in hexadecimal format.
C5: Exchange the message blocks in the 1st message group M1 with the corresponding message blocks in the 2nd message group M2, respectively—“As a ubiquitous” with “phenomenon in na, ” “e behavior, unst” with “able periodic or, ” and “ch promise of ap” with “plication in the”;
C6: Change the secret key X0 from 0.232323 to 0.2323230000000001;
C7: Change the secret key P0 from 0.858485 to 0.8584850000000001.
The corresponding hash values in hexadecimal format are obtained as follows:
C1: 58196491612A7E56D6E7516B012D2529
C2: 580BDDEAE5730A88421E5A5375C16043
C3: 28BBDC5395CB941E90DC8448F6147A5F
C4: D1B7BC19F4D3AD0F6B01298EB687D797
C5: E62DF1C64672D8198154D35D1923B7CF
C6: E81515BD73C0097EB71A4FAF37279EE9
C7: 58196491612A7E56D6E7516B012D2529
The graphical display of binary sequences is shown in Figure 17.4.
The simulation result indicates that the sensitivity property of the proposed algorithm is so perfect that any least difference of the message or key will cause huge changes in the final detection hash value.
17.4.1.3 Statistic Analysis of Diffusion and Confusion
In order to hide message redundancy, Shannon (1949) introduced diffusion and confusion, which are two general principles to the practical cipher design, including hash functions. Since the hash value is in a binary format, that is, each bit is only 1 or 0, the ideal diffusion effect should be that any tiny changes in original conditions lead to the 50% changing probability for each bit of the hash value.
We have performed the following diffusion and confusion test. The detection hash value of the above paragraph of the original message is generated. Then a bit in the message is randomly selected and toggled, and a new detection hash value is generated. Two hash values are compared and the number of changed bits is counted as Bi. This kind of test is performed J-time, and the corresponding distribution of changed bit number is shown as Figure 17.5, where J = 2048. Obviously, the changed bit number corresponding to 1-bit changed message concentrates around the ideal changed bit number of 64 bits. It indicates that the algorithm has very strong capability for diffusion and confusion.
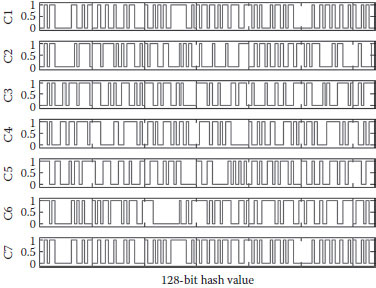
FIGURE 17.4 Hash values under different conditions.
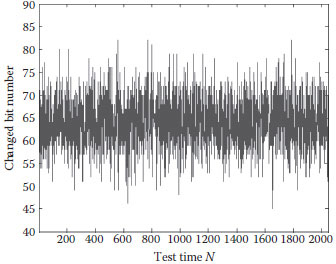
FIGURE 17.5 Distribution of changed bit number.
Usually, four statistics are defined as follows:
Mean changed bit number
Mean changed probability
Through the tests with J = 256, 512, 1024, 2048, respectively, the corresponding data are listed in Table 17.1.
Based on the analysis of the data in Table 17.1, we can draw the conclusion: the mean changed bit number and the mean changed probability P are both very close to the ideal value 64 bit and 50%. While ΔB and ΔB are very little, which indicates the capability for diffusion and confusion is very stable.
17.4.1.4 Analysis of Collision Resistance
The mechanism of both changeable-parameter and self-synchronization expedites the avalanche effect. We have performed the following test to conduct quantitative analysis on collision resistance (Wong, 2003; Xiao et al., 2005, Xiao et al., 2006; Zhang et al., 2007): First, the detection hash value of the above paragraph of original message is generated and stored in ASCII format. Then a bit in the message is selected randomly and toggled. A new detection hash value is then generated and stored in ASCII format. Two hash values are compared, and the number of ASCII character with the same value at the same location in the hash value, namely the number of hits, is counted. Moreover, the absolute difference of two hash values is calculated using the formula: , where ei and be the ith ASCII character of the original and the new hash value, respectively, and the function t( ) converts the entries to their equivalent decimal values. This kind of collision test has been performed 2048 times, with the secret key X0 = 0.232323 and P0 = 0.858485. Within them, the number of 0-hit is 1932, the number of 1-hit is 114, and the number of 2-hit is 2. The maximum, mean, minimum values of d, and the mean per character are listed in Table 17.2. A plot of the distribution of the number of hits is given in Figure 17.6. It should be noted that the maximum number of equal character is only 2 and the collision is very low.
TABLE 17.1
Statistics of Number of Changed Bit Bi
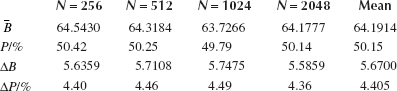
TABLE 17.2
Absolute Differences of Two Hash Values
Maximum |
Minimum |
Mean |
Mean/Character |
2224 |
573 |
1401.1 |
87.5625 |
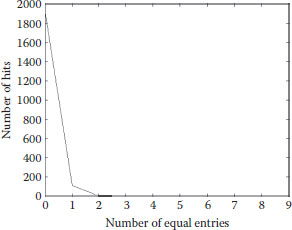
FIGURE 17.6 Distribution of the number of ASCII characters with the same value at the same location in the hash value.
17.4.2 LOCALIZATION HASH PERFORMANCE
In this section, we will focus on the performance of the 128-bit localization hash part. In the proposed algorithm, the 256 blocks of the lookup table are assigned into 16 horizontal groups and 16 vertical groups, respectively, as shown in Figure 17.1. The processing of each horizontal group or vertical group will generate the corresponding 4-bit LHKi (i = 1, 2, …,16) or LVKj (j = 1, 2, …,16), which constitute the final 128-bit localization hash value-LHASH. Note that each block belongs to a particular horizontal group and a particular vertical group at the same time. Therefore, any tiny modification in one block, actually in one character of the original message in a certain block from the lower level’s point of view, will very likely lead to the changes in the corresponding LHKi and LVKj. Theoretically, if a particular modification happens, the miss probability in one direction will be 1/24, and that in two directions will be 1/28, which are quite small.
We have performed the following modification localization test. The chosen original message is the same as above, with the length of 572 characters. The tiny modifications include: the 1st character-“A” to “B”; the 6th character-“u” to “v”; the 136th character-“p” to “q”; the 256th character-“k” to “l.” In the look-up table, the 1st character has been filled in Block 1, which belongs to H_Group 1 and V_Group 1; the 6th character has been filled in Block 6, which belongs to H_Group 1, and V_Group 6; the 136th character has been filled in Block 136, which belongs to H_Group 9 and V_Group 8; the 256th character has been filled in Block 256, which belongs to H_Group 16 and V_Group 16.
The comparison between the new localization hash value and the former one indicates that there are modifications within H_Group 1, H_Group 9, H_Group 16, V_Group 1, V_Group 6, V_Group 8, and V_Group 16. The possible modification blocks can be located within the intersection between the above groups, namely within 12 blocks (all the four modified blocks have been correctly located, but other eight innocent blocks have also been identified with false alarm), while the modification-free blocks are the rest 244 ones. From another perspective, it is more convenient to identify the modification-free area. On the condition that only a few modifications scatter in the message, this kind of localization is meaningful.
Theoretical analysis and simulation indicate that the proposed algorithm can realize modification localization, although some limitations still remain, such as miss probability, false alarm, and so on. It is our future work to find out more suitable solutions to overcome them, for example, by extending the length of 4-bit LHKi; and LVKj, increasing the grouping time, or introducing a random number to grouping, and so on.
The security of key includes two aspects. One is the key nonrecovery property. It must be computationally infeasible to recover key, given one or more message-hash value pairs. The other is the size of the key space, which characterizes the capability of resisting brute-force attack.
In the hashing process of our algorithm, the sensitivity to tiny changes in initial conditions and parameters as well as the mechanism of both changeable-parameter and self-synchronization are fully utilized. It makes the algorithm to possess strong one-way property, and there exist complicated nonlinear and sensitive dependence among message, hash value, and secret key. Therefore, it is immune from key recovery attack.
To investigate the key space size, the following evaluations are performed. Let the tiny change of the initial value X0 of PWLCM be larger than 10–16. For example, when X0 is changed from 0.232323 to 0.2323230000000001, the corresponding changed bit number of detection hash value obtained is around 64. Similarly, let the tiny change of the initial parameters P0of PWLCM be larger than 10–16. For example, when P0 is changed from 0.858485 to 0.8584850000000001, the corresponding changed bit number of hash value obtained is also around 64. Readers can refer to Section 3.1.1. However, if the tiny changes of X0and P0are set as 10–17, no corresponding bit of the hash value changes. Therefore, the sensitivities to X0and P0are both considered as 10–16. Considering the value ranges of components, X0∈[0,1] and P0∈(0,1), it can be derived that the size of the key space is approximately larger than 2106, which is large enough to resist the brute-force attack.
TABLE 17.3
Number of Required Multiplicative Operations for Each Character of Algorithms
Schneier (1996) |
Stinson (1995) |
Wong (2003) |
This Chapter |
|
Multiplication |
6 |
11.7 |
32 (by software)/8 (by hardware) |
4 + 33/(8 s) |
Source: Adapted from Schneier, B., Applied Cryptography: Protocols, Algorithms, and Source Code in C, 2nd ed., Wiley, New York, 1996; Stinson, D.R., Cryptography: Theory and Practice, CRC Press, Boca Raton, FL, 1995; Wong, K. W., Phys. Lett. A, 307, 292–298, 2003.
s represents the number of 256-character (2048-bit) divisions of message after padding, namely the number of characters within each block.
For speed comparison among different algorithms, the numbers of required multiplicative operations for each ASCII character (8-bit) message during the hash process are listed inTable 17.3. Since each multiplicative operation consumes much more time than each additive operation, this kind of comparison is objective, in spite of different implementing platforms. Obviously, our proposed algorithm is the fastest one.
The complexity calculation of our proposed algorithm is as follows. Each group has 16 blocks, and there ares characters within each block. First, step 1, in each block, the preprocessing of each character needs 4-time multiplicative operations. Therefore, all the 16 blocks in each group need 64 s-time multiplicative operations. Second, step 2, in each group, the processing of all the 16 blocks needs 4 × 16 + 2 = 66-time multiplicative operations. In all, the number of required multiplicative operations for each character in the proposed algorithm (64 s + 66)/ (16 s) = 4 + 33/(8 s). As the character number of message increases, the required multiplicative operation for each character becomes only slightly larger than 4.
Furthermore, since the proposed algorithm can support the parallel mode, its efficiency is predominant, especially compared to other hash algorithm in the sequential mode.
17.4.5 IMPLEMENTATION AND FLEXIBILITY
In the proposed hash algorithm, double precision floating-point arithmetic will be involved. Since IEEE 754 floating point standard is availabel on virtually almost all the computing platforms produced since 1980 (Goldberg and Priest, 1991), the proposed algorithm is suggested to implement with IEEE 754 double-precision floating-point arithmetic. Clearly, two hash values of a message with the same secret key produced on two computing platforms will be the same as long as IEEE 754 floatingpoint standard and the same operation order are implemented on both platforms, in spite of different O.S. or different program languages.
Through simply modifying the way to process X32, X33, and X34 in step 2 of the proposed algorithm, the length of the final hash value can be extended. Compared to the conventional hash algorithm such as MD5 with fixed 128-bit length, the proposed algorithm can adapt to the actual demand better.
In this chapter, a new hash function is proposed for both modification detection and localization. Its structure can also support the parallel processing mode. By means of the mechanism of both changeable-parameter and self-synchronization, the keystream establishes a close relation with the algorithm key, the content, and the order of each message unit. The proposed algorithm fulfills the performance requirements of hash functions. It is simple, efficient, practicable, and reliable.
Arumugam, G., Praba, V.L., and Radhakrishnan, S., Study of chaos functions for their suitability in generating message authentication codes, Appl. Soft Comput., 71064–10712007.
Baranousky, A., and Daems, D., Design of one-dimensional chaotic maps with prescribed statistical properties, Int. J. Bifurcation Chaos, 561585–15981995
Goldberg, D., and Priest, D., What every computer scientist should know about floating-point arithmetic, ACM Comput. Surv., 23(1),5–481991.
Schneier, B., Applied Cryptography: Protocols, Algorithms, and Source Code in C, 2nd ed., Wiley, New York, 1996.
Shannon, C.E., Communication theory of secrecy systems, Bell Syst. Tech. J. 28(4),656–715, 1949.
Stinson, D.R., Cryptography: Theory and Practice, CRC Press, Boca Raton, FL, 1995.
Wong, K. W., A combined chaotic cryptographic and hashing scheme, Phys. Lett. A, 307, 292–298, 2003.
Xiao, D., Liao, X. F., and Deng, S. J., One-way hash function construction based on the chaotic map with changeable-parameter, Chaos Solitons Fractals, 24(1),65–712005.
Xiao, D., Liao, X. F., and Wong, K. W., Improving the security of a dynamic look-up table based chaotic cryptosystem, IEEE Trans. Circuits Syst. II, 53(6)502–5062006.
Xiao D., F. Y.Shih, and Liao X., A chaos-based hash function with both modification detection and localization, Commun. Nonlinear Sci. Numer. Simul., 15(9), 2254–2261, 2010.
Yi, X., Hash function based on chaotic tent maps, IEEE Trans. Circuits Syst. II, 52(6), 354–357, 2005.
Zhang, J. S., Wang, X. M., Zhang, W. F., Chaotic keyed hash function based on feedforward feedback nonlinear digital filter, Phys. Lett. A, 362439–448, 2007.