
Chapter 6. Block Return Values: How Should I Handle This?

You’ve seen only a fraction of the power of blocks. Up until now, the methods have just been handing data off to a block, and expecting the block to handle everything. But a block can also return data to the method. This feature lets the method get directions from the block, allowing it to do more of the work.
In this chapter, we’ll show you some methods that will let you take a big, complicated collection, and use block return values to cut it down to size.
A big collection of words to search through
Word got out on the great work you did on the invoicing program, and your next client has already come in—a movie studio. They release a lot of films each year, and the task of making commercials for all of them is enormous. They want you to write a program that will go through the text of movie reviews, find adjectives that describe a given movie, and generate a collage of those adjectives:
The critics agree, Hindenburg is:
“Romantic”
“Thrilling”
“Explosive”

They’ve given you a sample text file to work off of, and they want you to see if you can make a collage for their new release, Truncated.
Looking at the file, though, you can see your work is cut out for you:

It’s true, this job is a bit complex. But don’t worry: arrays and blocks can help!
Let’s break our tasks down into a checklist:
Five tasks to accomplish. Sounds simple enough. Let’s get to it!
Opening the file
Our first task is to open the text file with the review contents. This is easier than it sounds—Ruby has a built-in class named File that represents files on disk. To open a file named reviews.txt in the current directory (folder) so you can read data from it, call the open method on the File class:
review_file = File.open("reviews.txt")The open method returns a new File object. (It actually calls File.new for you, and returns the result of that.)
There are many different methods that you can call on this File instance, but the most useful one for our current purpose is the readlines method, which returns all the lines in the file as an array.

Safely closing the file
We’ve opened the file and read its contents. Your next step should be to close the file. Closing the file tells the operating system, “I’m done with this file; others can use it now.”
review_file.close
Why are we so emphatic about doing this? Because bad things happen when you forget to close files.
You can get errors if your operating system detects that you have too many files open at once. If you try to read all the contents of the same file multiple times without closing it, it will appear to be empty on subsequent attempts (because you’ve already read to the end of the file, and there’s nothing after that). If you’re writing to a file, no other program can see the changes you made until you close the file. It is very important not to forget.
Are we making you nervous? Don’t be. As usual, Ruby has a developer-friendly solution to this problem.
Safely closing the file, with a block
Ruby offers a way to open a file, do whatever you need with it, and automatically close it again when you’re done with it. The secret is to call File.open...with a block!
We just change our code from this:

...to this!

Why does File.open use a block for this purpose? Well, the first and last steps in the process are pretty well defined...

...but the creators of File.open have no idea what you intend to do with that file while it’s open. Will you read it one line at a time? All at once? That’s why they let you decide what to do, by passing in a block.

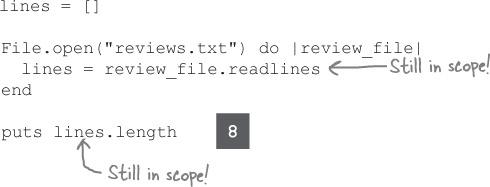
Don’t forget about variable scope!
When we’re not using a block, we can access the array of lines from the

Switching to the block form of File.open has introduced a problem, however. We store the array returned by readlines in a variable within the block, but we can’t access it after the block.

The problem is that we’re creating the lines variable within the block. As we learned back in Chapter 5, any variable created within a block has a scope that’s limited to the body of that block. Those variables can’t be “seen” from outside the block.
But, as we also learned in Chapter 5, local variables declared before a block can be seen within the block body (and are still visible after the block, of course). So the simplest solution is to create the lines variable before declaring the block.
Okay, we’ve safely closed the file, and we’ve got our review contents. What do we do with them? We’ll be tackling that problem next.

Finding array elements we want, with a block
We’ve opened the file and used the readlines method to get an array with every line from the file in its own element. The first feature from our checklist is complete!
Let’s see what remains:
It seems we can’t expect the text file to contain only reviews for the movie we want. Reviews for other movies are mixed in there, too:

Fortunately, it also looks like every review mentions the name of the movie at least once. We can use that fact to find only the reviews for our target movie.

The verbose way to find array elements, using “each”
You can call the include? method on any instance of the String class to determine if it includes a substring (which you pass as an argument). Remember, by convention, methods that end in ? return a Boolean value. The include? method will return true if the string contains the specified substring, and false if it doesn’t.

It doesn’t matter if the substring you’re looking for is at the beginning of the string, at the end, or somewhere in the middle; include? will find it.
So here’s one way you could select only the relevant reviews, using the include? method and the other techniques we’ve learned so far...

Introducing a faster method...
But actually, Ruby offers a much quicker way to do this. The find_all method uses a block to run a test against each element in an array. It returns a new array that contains only the elements for which the test returned a true value.
We can use the find_all method to achieve the same result, by calling include? in its block:
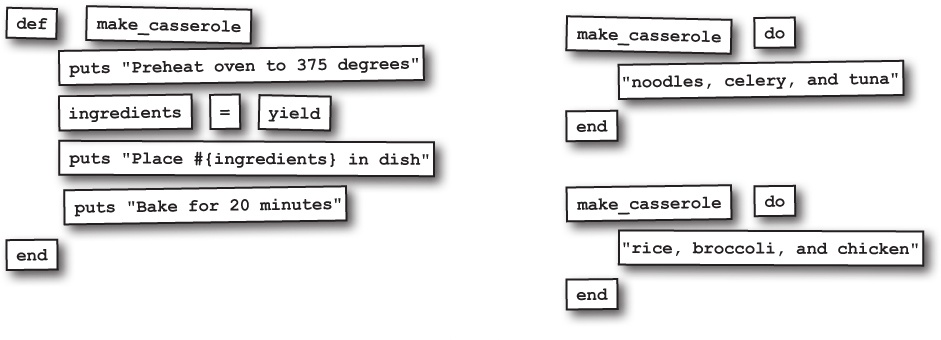
lines = []
File.open("reviews.txt") do |review_file|
lines = review_file.readlines
end
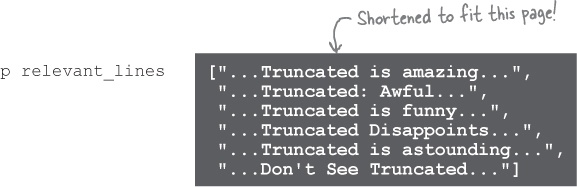
relevant_lines = lines.find_all { |line| line.include?("Truncated") }This shortened code works just as well: only lines that include the substring "Truncated" are copied to the new array!
puts relevant_lines

Replacing six lines of code with a single line...not bad, huh?
Uh, oh. Did we just blow your mind again?
Blocks have a return value
We just saw the find_all method. You pass it a block with selection logic, and find_all finds only the elements in an array that match the block’s criteria.
lines.find_all { |line| line.include?("Truncated") }By “elements that match the block’s criteria,” we mean elements for which the block returns a true value. The find_all method uses the return value of the block to determine which elements to keep, and which to discard.
As we’ve progressed, you’ve probably noticed a few similarities between blocks and methods...
Methods:
Accept parameters
Have a body that holds Ruby expressions
Return a value
Blocks:
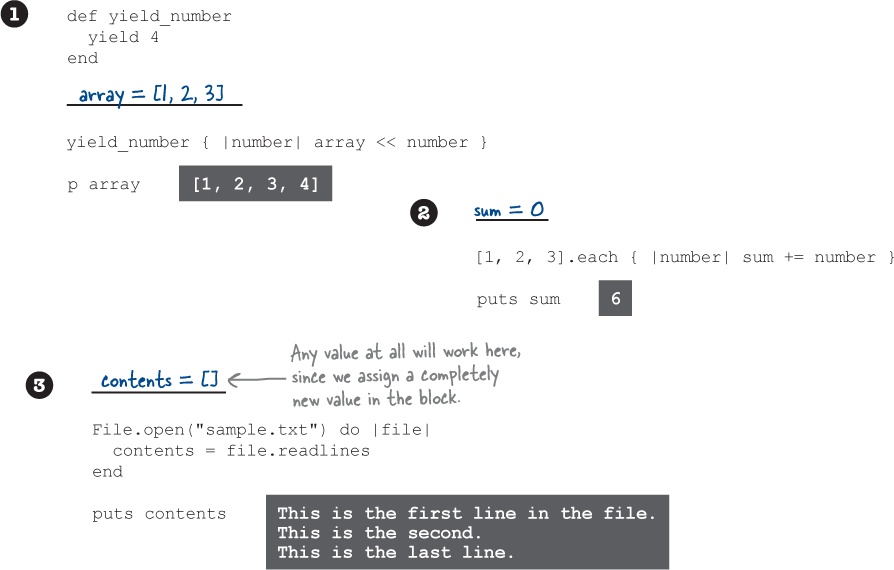
That’s right, just like methods, Ruby blocks return the value of the last expression they contain! It’s returned to the method as the result of the yield keyword.
We can create a simple method that shows this in action, and then call it with different blocks to see their return values:
The value of the last expression in a block gets returned to the method.

The method isn’t limited to printing the block return value, of course. It can also do math with it:
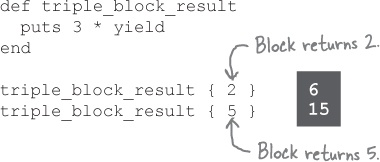
Or use it in a string:
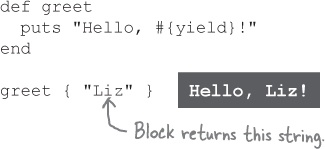
Or use it in a conditional:

Up next, we’ll take a detailed look at how find_all uses the block’s return value to give you just the array elements you want.
Watch it!
We say that blocks have a “return value,” but that doesn’t mean you should use the return keyword.
Using the return keyword within a block isn’t a syntax error, but we don’t recommend it. Within a block body, the return keyword returns from the method where the block is being defined, not the block itself. It’s very unlikely that this is what you want to do.
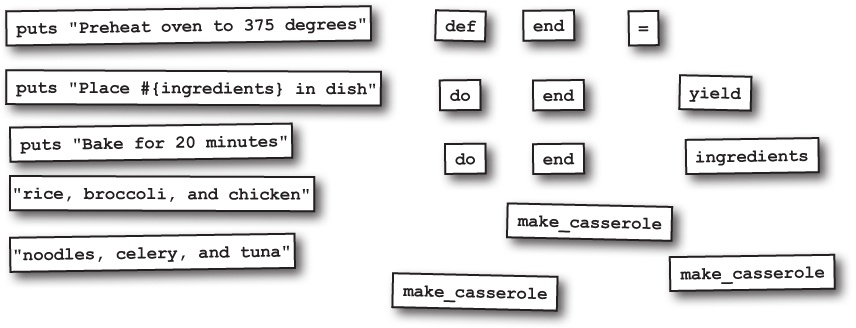
def print_block_value
puts yield
end
def other_method
print_block_value { return 1 + 1 }
end
other_methodThe above code won’t print anything, because other_method exits as the block is being defined.
If you change the block to simply use its last expression as a return value, then everything works as expected:


How the method uses a block return value
We’re close to deciphering how this snippet of code works:
lines.find_all { |line| line.include?("Truncated") }The last step is understanding the find_all method. It passes each element in an array to a block, and builds a new array including only the elements for which the block returns a true value.
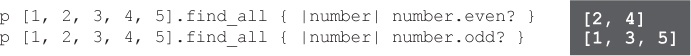
You can think of the values the block returns as a set of instructions for the method. The find_all method’s job is to keep some array elements and discard others. But it relies on the block’s return value to tell it which elements to keep.
Think of block return values as instructions from the block to the method.
All that matters in this selection process is the block’s return value. The block body doesn’t even have to use the parameter with the current array element (although in most practical programs, it will). If the block returns true for everything, all the array elements will be included...
...but if it returns false for everything, none of them will be.
If we were to write our own version of find_all, it might look like this:
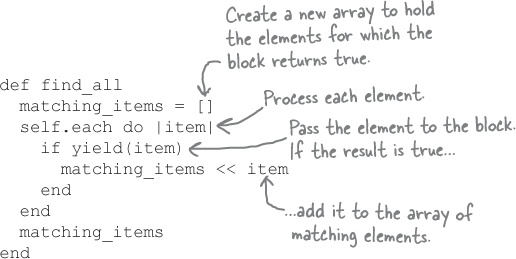
If this code looks familiar, it should. It’s a more generalized version of our earlier code to find lines that were relevant to our target movie!
relevant_lines = []
lines.each do |line|
if line.include?("Truncated")
relevant_lines < < line
end
end
puts relevant_linesPutting it all together
Now that we know how the find_all method works, we’re really close to understanding this code.

Here’s what we’ve learned (not necessarily in order):
The last expression in a block becomes its return value.
The
include?method returnstrueif the string contains the specified substring, andfalseif it doesn’t.The
find_allmethod passes each element in an array to a block, and builds a new array including only the elements for which the block returns a true value.



Let’s look inside the find_all method and the block as they process the first few lines of the file, to see what they’re doing...
A closer look at the block return values
The
find_allmethod passes the first line from the file to the block, which receives it in thelineparameter. The block tests whetherlineincludes the string"Truncated". It does, so the return value of the block istrue. Back in the method, the line gets added to the array of matching items.The
find_allmethod passes the second line from the file to the block. Again, thelineblock parameter includes the string"Truncated", so the return value of the block is againtrue. Back in the method, this line also gets added to the array of matching items.The third line from the file doesn’t include the string
"Truncated", so the return value of the block isfalse. This line is not added to the array.
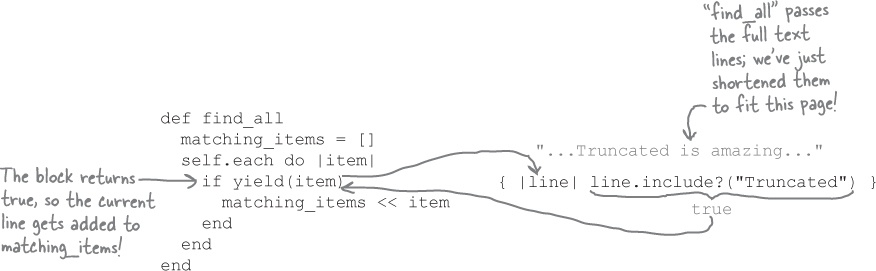


...and so on, through the rest of the lines in the file. The find_all method adds the current element to a new array if the block returns a true value, and skips it if the block returns a false value. The result is an array that contains only the lines that mention the movie we want!
Eliminating elements we don’t want, with a block
Using the find_all method, we’ve successfully found all the reviews for our target movie and placed them in the relevant_lines array. We can check another requirement off our list!
Our next requirement is to discard the reviewer bylines, because we’re only interested in retrieving adjectives from the main text of each review.

Fortunately, they’re clearly marked. Each one starts with the characters --, so it should be easy to use the include? method to determine if a string contains a byline.
Before, we used the find_all method to keep lines that included a particular string. The reject method is basically the opposite of find_all—it passes elements from an array to a block, and rejects an element if the block returns a true value. If find_all relies on the block to tell it which items to keep, reject relies on the block to tell it which items to discard.
If we were to implement our own version of reject, it would look very similar to find_all:
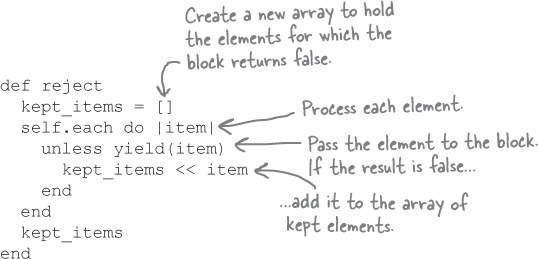
The return values for “reject”
So reject works just like find_all, except that instead of keeping elements that the block returns a true value for, it rejects them. If we use reject, it should be easy to get rid of the bylines!
reviews = relevant_lines.reject { |line| line.include?("--") }The
rejectmethod passes the first line from the file to the block. Thelineblock parameter does not include the string"--", so the return value of the block isfalse. Back in the method, this line gets added to the array of items we’re keeping.The
rejectmethod passes the second line to the block. Thelineparameter does include the string"--", so the return value of the block istrue, and the method discards (rejects) this line.The third line doesn’t include
"--", so the return value of the block isfalse, and the method keeps this line.
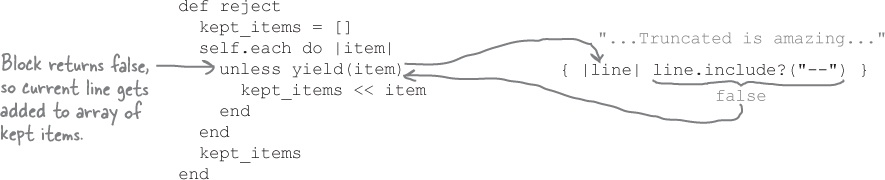
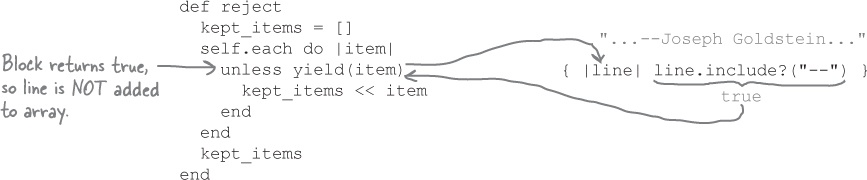
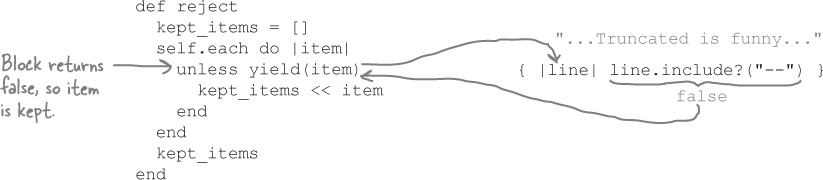
...and so on, for the rest of the lines in the file. The reject method skips adding a line to the new array if it includes "--". The result is a new array that omits the bylines and includes only the reviews!

Breaking a string into an array of words
We’ve discarded the reviewer bylines, leaving us with an array containing only the text of each review. That’s another requirement down! Two to go...
For our next requirement, we’re going to need a couple of new methods. They don’t take blocks at all, but they are super-useful.
We need to find an adjective in each review:

If you look above, you’ll notice a pattern... The adjective we want always seems to follow the word is.
So we need to get one word that follows another word... What we have right now are strings. How can we convert those to words?
Strings have a split instance method that you can call to split them into an array of substrings.
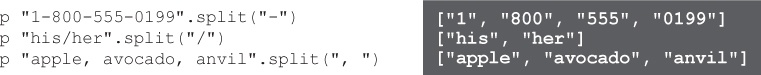
The argument to split is the separator: one or more characters that separate the string into sections.
What separates words in the English language? A space! If we pass " " (a space character) to split, we’ll get an array back. Let’s try it with our first review.

There you have it—an array of words!
Finding the index of an array element
The split method converted our review string into an array of words. Now, we need to find the word is within that array. Again, Ruby has a method ready to go for us. If you pass an argument to the find_index method, it will find us the first index where that element occurs in the array.

Using find_index, let’s write a method that will split a string into an array of words, find the index of the word is, and return the word that comes after that.
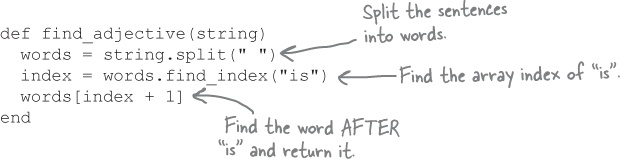
We can easily test our method on one of our reviews...
There’s our adjective! That only takes care of one review, though. Next, we need to process all the reviews and create an array of the adjectives we find. With the each method, that’s easy enough to do.

Now we have an array of adjectives, one for each review!
Would you believe there’s an even easier way to create an array of adjectives based on the array of reviews, though?
Making one array that’s based on another, the hard way
We had no problem looping through our array of reviews to build up an array of adjectives using each and our new find_adjective method.
But creating a new array based on the contents of another array is a really common operation, one that requires similar code each time. Some examples:

In each of these examples, we have to set up a new array to hold the results, loop through the original array and apply some logic to each of its members, and add the result to the new array. (Just like in our adjective finder code.) It’s a bit repetitive...
Wouldn’t it be great if there were some sort of magic processor for arrays? You drop in your array, it runs some (interchangeable) logic on its elements, and out pops a new array with the elements you need!

Making one array based on another, using “map”
Ruby has just the magic array processor we’re looking for: the map method. The map method takes each element of an array, passes it to a block, and builds a new array out of the values the block returns.

The map method is similar to find_all and reject, in that it processes each element in an array. But find_all and reject use the block’s return value to decide whether to copy the original element from the old array to the new one. The map method adds the block’s return value itself to the new array.
If we were to code our own version of map, it might look like this:
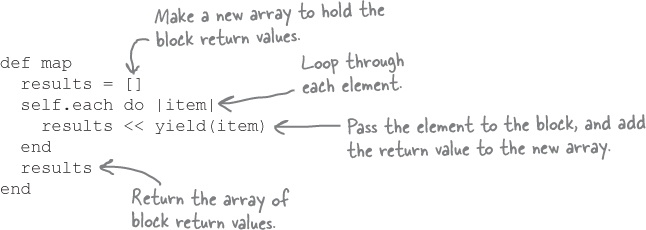
The map method can shorten our code to gather adjectives down to a single line!

The return value of map is an array with all the values the block returned:
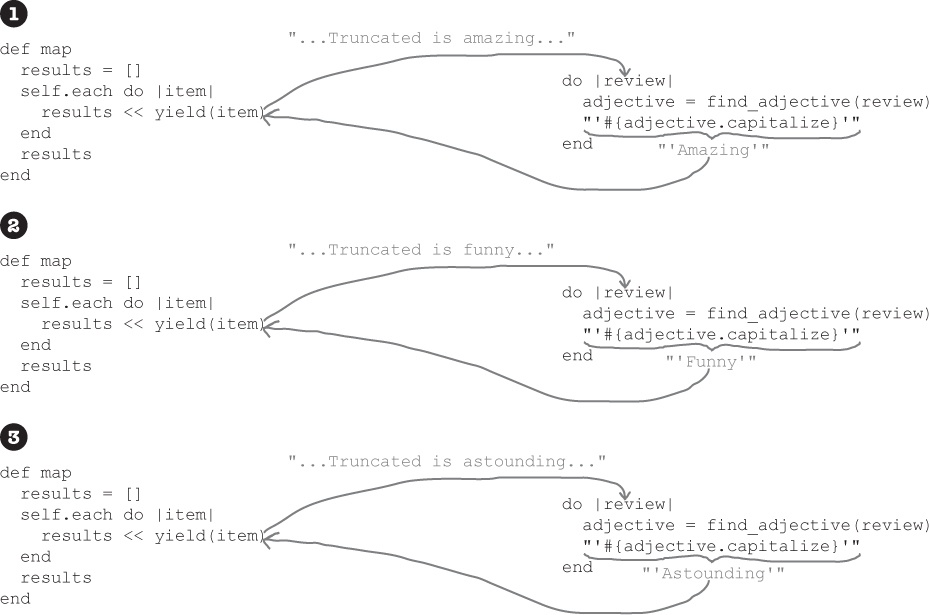
Let’s look at how the map method and our block process the array of reviews, step by step...

The
mapmethod passes our first review to the block. The block, in turn, passes the review tofind_adjective, which returns"amazing". The return value offind_adjectivealso becomes the return value of the block. Back in themapmethod,"amazing"is added to the results array.The second review is passed to the block, and
find_adjectivereturns"funny". Back in the method, the new adjective is added to the results array.For the third review,
find_adjectivereturns"astounding", which gets added to the array with the others.



Another requirement finished! We have just one more, and this one will be easy!
Some additional logic in the “map” block body
We’re already using map to find the adjectives for each review:
adjectives = reviews.map { |review| find_adjective(review) }Lastly, we need to capitalize the adjective and enclose it in quotation marks. We can do this in the block, right after the call to our find_adjective method.
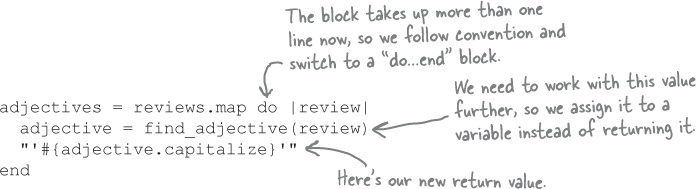
Here are the new return values that this updated code produces:
The finished product
That’s our last requirement. Congratulations, we’re done!
You’ve successfully learned to use block return values to find elements you want within an array, to reject elements you don’t want, and even to use an algorithm to create an entirely new array!
Processing a complex text file like this would take dozens of lines of code in other languages, with lots of repetition. The find_all, reject, and map methods handled all of that for you! They can be difficult to learn to use, but now that you’ve mastered them, you’ve got powerful new tools at your disposal!
Here’s our complete code listing:



Up Next...
Arrays have their limitations. If you need to find a particular value within an array, you have to start at the beginning and search through the items one by one. In the next chapter, we’ll show you another kind of collection that will help you find things much more quickly: hashes.