
CHAPTER 7
Designing programs
From then on, when anything went wrong with a computer, we said it had bugs in it.
Admiral Grace Hopper
upon pulling a two-inch moth from the Harvard Mark I computer in 1945
Every hour of planning saves about a day of wasted time and effort.
Steve McConnell
Software Project Survival Guide (1988)
IT should go without saying that we want our programs to be correct. That is, we want our algorithms to produce the correct output for every possible input, and we want our implementations to be faithful to the design of our algorithms. Unfortunately however, in practice, perfectly correct programs are virtually nonexistent. Due to their complexity, virtually every significant piece of software has errors, or “bugs” in it. But there are techniques that we can use to increase the likelihood that our functions and programs are correct. First, we can make sure that we thoroughly understand the problem we are trying to solve and spend quality time designing a solution, well before we start typing any code. Second, we can think carefully about the requirements on our inputs and function parameters, and enforce these requirements to head off problems down the road. And third, we can adopt a thorough testing strategy to make sure that our programs work correctly. In this chapter, we will introduce the basics of these three practices, and encourage you to follow them hereafter. Following these more methodical practices can actually save time in the long run by preventing errors and more easily discovering those that do creep into your programs.
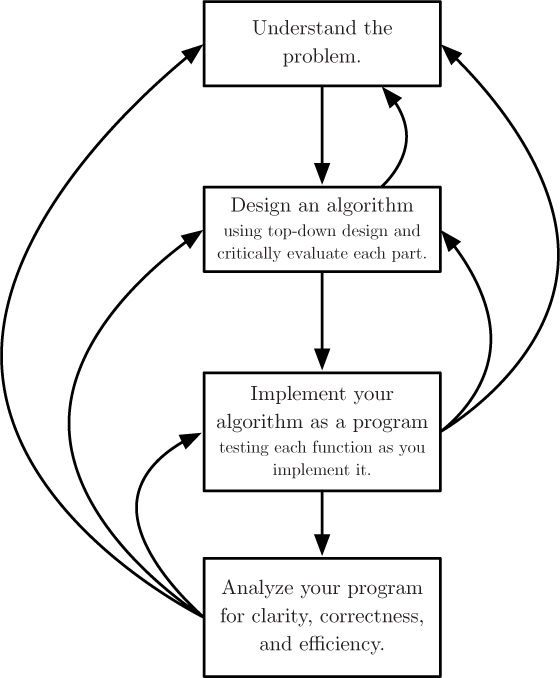
7.1 HOW TO SOLVE IT
Designing and implementing a computational solution to a problem is a multistep process requiring planning, reflection and revision, not unlike the writing process. This is especially true for large projects involving many people, for which there are established guidelines and formal processes, the primary concerns of a field called software engineering. In this book, we are working with relatively small problems, so less formality is necessary. However, it is still very important to develop good habits, represented by the process illustrated in Figure 7.1.
This process, and the title of this section, come from the book How to Solve It by mathematician George Polya [41]. Originally published in 1945, Polya’s problem solving framework has withstood the test of time. Polya outlined a four step process:
Understand the problem. What is the unknown [output]? What are the data [inputs]? What is the condition [linking the input to the output]?
Devise a plan to solve the problem.
Carry out the plan, checking each step.
Look back. Check the result. Can you derive the result differently?
These four steps, with some modifications, can be applied just as well to computational problem solving. In this section, we will outline these four steps, and illustrate the process with the following example problem.
Given a text, we would like to measure the distribution of a particular word by breaking the text into “windows” of some length and computing how many times the word appears in each window. The output will be a plot of these frequencies across all of the windows, as well as the average frequency per window.
Understand the problem
As we discussed in the first pages of this book, every useful computation solves a problem with an input and output. Therefore, the first step is to understand the inputs to the problem, the desired outputs, and the connections between them. In addition, we should ask whether there are any restrictions or special conditions relating to the inputs or outputs. If something is unclear, seek clarification right away; it is much better to do so immediately than to wait until you have spent a lot of time working on the wrong problem! It is a good idea at this point to re-explain the problem back to the poser, either orally or in writing. The feedback you get from this exercise might identify points of misunderstanding. You might include a picture, depending upon the type of problem. In addition, work out some examples by hand to make sure you understand all of the requirements and subtleties involved.
The inputs to our problem are a text, a word, and a window length. The outputs are a plot of the frequencies of the word in each window of the text and the average frequency across all of the windows.
Reflection 7.1 What more do we need to know about the input and output to better understand this problem?
Where should the text come from? Should we prompt for the word and window length? Should the windows overlap? What should the plot look like? Since we would like to be able to analyze large texts, let’s read the text in from a file. But we can prompt for the name of the file, the word and the window length. For simplicity, we will not have overlapping windows. Here is a sketch of the desired plot:


The windows over the text will be represented on the x-axis, perhaps by the starting index of each window. The y-axis will correspond to the number of times the word occurs in each window.
Design an algorithm
Once we think we understand the problem to be solved, the next step is to design an algorithm. An important part of this process is to identify smaller subproblems that can be solved individually, each with its own function. Once written, these functions can be used as functional abstractions to solve the overall problem. We saw an example of this in the flower-drawing program illustrated in Figure 3.7. This technique is called top-down design because it involves starting from the problem to be solved, and then breaking this problem into smaller pieces. Each of these pieces might also be broken down into yet smaller pieces, until we arrive at subproblems that are relatively straightforward to solve. A generic picture of a top-down design is shown in Figure 7.2. The generic program is broken into three main subproblems (i.e., functions). First, a function gets the input. Second, a function computes the output from the input. Third, another function displays the output. The dotted lines represent the flow of information through return values and parameters. The function that gets the input returns it to the main program, which then passes it into the function that computes the output. This function then returns the output to the main program, which passes it into the function that displays it. In Python, this generic program looks like the following:
def main():
input = getInput()
output = compute(input)
displayOutput(output)
main()
Moving on from this generic structure, the next step is to break these three subproblems into smaller subproblems, as needed, depending on the particular problem. Identifying these subproblems/functions can be as much an art as a science, but here are a few guidelines to keep in mind:

A subproblem/function should accomplish something relatively small, and make sense standing on its own.
Functions should be written for subproblems that may be called upon frequently, perhaps with different arguments.
A function should generally fit on a page or, in many cases, less.
The
mainfunction should be short, generally serving only to set up the program and call other functions that carry out the work.
You may find that, during this process, new questions arise about the problem, sending you briefly back to step one. This is fine; it is better to discover this immediately and not later in the process. The problem solving process, like the writing process, is inherently cyclic and fluid, as illustrated in Figure 7.1.
Reflection 7.2 What steps should an algorithm follow to solve our problem?
First, we can specialize the generic design by specifying what each of the three main subproblems should do.
Get inputs: prompt for a file name, a word, and a window length. Read the text from the file.
Compute: a list of word frequencies and the average word frequency.
Display outputs: plot the frequencies and print the average frequency.
Since each of these subproblems has multiple parts, we can break each subproblem down further:
Get inputs.
(a) Get the text.
Prompt for and get a file name.
Read the text from the file with that file name.
(b) Prompt for and get a word.
(c) Prompt for and get a window length.
Compute a list of word frequencies and the average word frequency.
- In each window, count the frequency of the word.
Display outputs:
- Plot the frequencies.
- Print the average frequency.
This outline is represented visually in Figure 7.3. We have broken the input subproblem into three parts, one for each input that we need. The text input part is further broken down into getting the file name and then reading the text from that file. Next, in the computation subproblem, we will need to count the words in each of the windows that we construct, so it will make sense to create another function that counts the words in each of those windows. Finally, we break the output subproblem into two parts, one for the plot and one for the average frequency.
Next, before we implement our top-down design as a program, we need to design an algorithm for each “non-trivial” subproblem. Each of the input and output subproblems is pretty straightforward, but the main computation subproblem is not. It is convenient at this stage to write our algorithm semi-formally in what is known as pseudocode. Pseudocode does not have an exact definition, but is somewhere between English and a programming language. When we write algorithms in pseudocode, we need to be guided by our understanding of what can and cannot be done in a programming language, but not necessarily write out every detail. For example, in the algorithm that will find the frequency of the word in every window, we know that we will have to somehow iterate over these windows using a loop, but we do not necessarily have to decide at this point the precise form of that loop. Here is one possible algorithm written in a Python-like pseudocode. We have colored it blue to remind you that it is not an actual Python function.
getWordCounts(text, word, window_length)
total_word_count = 0
total_window_count = 0
word_count_list = []
for each non-overlapping window:
increment total_window_count
count = instances of word in window
add count to total_word_count
append count to word_count_list
return (total_word_count / total_window_count) and word_count_list
In the algorithm, we are maintaining three main values. The total number of instances of the word that we have found (total_word_count) and the total number of windows that we have processed (total_window_count) are needed to compute the average count per window. The list of word counts (word_count_list), which stores one word count per window, is needed for the plot. The loop iterates over all of the windows and, for each one, finds the count of the word in that window and uses it to update the total word count and the word count list. At the end, we return the average word count and the list of word counts.
Although analyzing your algorithm is the last step in Polya’s four-step process, we really should not wait until then to consider the efficiency, clarity, and correctness of our algorithms. At each stage, we need to critically examine our work and look for ways to improve it. For example, if our windows overlapped, we could make the algorithm above more efficient by basing the count in each window on the count in the previous window, as we did in Section 1.3. Notice that this improvement could be made before we implement any code.
Implement your algorithm as a program
Only once your program and function designs are complete should you begin writing your program. This point cannot be emphasized enough. Beginning programmers often rush to the keyboard prematurely, only to find that, after many hours of work, they really do not understand the problem and/or how to solve it. Although it often appears as if getting right to the program will save time, in the long run, the very opposite tends to happen. Expert programmers will sometimes prototype specific pieces of code in very long programs earlier in the process to test whether new ideas are feasible. However, beginning programmers, writing smaller programs like the ones in this book, are always better off with a tentative solution on paper before they start writing any code.
When you do sit down to write your program, your first task should be to lay out your functions, including main, with their docstrings. Because the Python interpreter will complain if your function does not contain any statements, you can initially place the “dummy” statement pass in the body of your functions. In our design, we have decided to group all of the input in one function because it will be so little code. Also, we have not created a separate function for printing the average count per window because it will be just a single line.
def getInputs():
"""Prompt for the name of a text file, a word to analyze, and a
window length. Read and return the text, word, and window length.
Parameters: none
Return value: a text, word, and window length
"""
pass
def count(text, target):
"""Count the number of target strings in text.
Parameters:
text: a string object
target: a string object
Return value: the number of times target occurs in text
"""
pass
def getWordCounts(text, word, windowLength):
"""Find the number of times word occurs in each window in the text.
Parameters:
text: a string containing a text
word: a string
windowLength: the integer length of the windows
Return values: average count per window and list of window counts
"""
pass
def plotWordCounts(wordCounts):
"""Plot a list of word frequencies.
Parameter:
wordCounts: a list of word frequencies
Return value: None
"""
pass
def main():
pass
# call getInputs
# call getWordCounts
# call plotWordCounts
# print average count per window
main()
In Section 7.2, we will discuss a more formal method for thinking about and enforcing requirements for your parameters and return values. Requirements for parameters are called preconditions and requirements for return values (and side effects) are called postconditions. For example, in the getWordCounts function, we are assuming that text and target are strings, and that windowLength is a positive integer, but we do not check whether they actually are. If we mistakenly pass a negative number in for windowLength, an error is likely to ensue. A precondition would state formally that windowLength must be a positive integer and make sure that the function does not proceed if it is not.
Once your functions exist, you can begin to implement them, one at a time. Comment your code as you go. While you are working on a function, test it often by calling it from main and running the program. By doing so, you can ensure that you always have working code that is free of syntax errors. If you are running your program often, then finding syntax errors when they do crop up will be much easier because they must exist in the last few lines that you wrote.
Once you are pretty sure that a function works, you can initiate a more formal testing process. This is the subject of Section 7.3. You must make sure that each function is working properly in isolation before moving on to the next one. Once you are sure that it works, a function becomes a functional abstraction that you don’t need to think about any more, making your job easier! Once each of your functions is working properly, you can assemble your complete program.
For example, we might start by implementing the getInputs function:
def getInputs():
""" (docstring omitted) """
fileName = input('Text file name: ') # get file name
textFile = open(fileName, 'r', encoding = 'utf-8') # read file
text = textFile.read()
textFile.close()
word = input('Word: ') # get word
windowLength = int(input('Window length: ')) # get window length
return text, word, windowLength
Now we need to test this function on its own before continuing to the next one. Call the function from main and just print the results to make sure it is working correctly.
def main():
testText, testWord, testLength = getInputs()
print(testText, testWord, testLength)
main()
If there were syntax errors or something did not work the way you expected, it is important to fix it now. This process continues for each of the remaining three functions. Then the final main function ties them all together:
def main():
text, word, windowLength = getInputs()
average, wordCounts = getWordCounts(text, word, windowLength)
plotWordCounts(wordCounts)
print(word, 'occurs on average', average, 'times per window.')
You can find a finished version of the program on the book web site. An example of a plot generated by the program is shown in Figure 7.4.

Analyze your program for clarity, correctness, and efficiency
Once you are done with your program, it is time to reflect on your work as a whole.
Does your program work properly?
As you did for each function, test your program with many different inputs, especially ones that seem difficult or that you think might break your program. It is important to test with inputs that are representative of the entire range of possibilities. For example, if your input is a number, try both negative and positive integers and floating point numbers, and zero. If some inputs are not allowed, this should be stated explicitly in the docstring(s), as we will discuss further in the next section.
Is your program as efficient as it could be?
Is your program doing too much work? Is there a way to streamline it? As our programs get more complicated, we will see some examples of how to bring down the time complexity of algorithms.
Is your program easy to read? Is it commented properly? Is there anything extraneous that could be omitted?
Refer back to Section 3.4 for commenting and program structure guidelines.
Are there chunks of code that should be made into functions to improve readability?
You may very well decide in this process that revisions are necessary, sending you back up to an earlier step. Again, this is completely normal and encouraged. No one ever designs a perfect solution on a first try!
Keep these steps and Figure 7.1 in mind as we move forward. We will gradually begin to solve more complex problems in which these steps will be crucial to success.
*7.2 DESIGN BY CONTRACT
There are often subtleties in a problem definition that are easily overlooked, leading to serious problems later. In this section, we will follow a more rigorous and nuanced approach to thinking about the input and output of a problem, and where things might go awry in an algorithm. We will start by looking at some small functions from Section 6.3, and then revisit the program from the previous section.
Preconditions and postconditions
Part of understanding the input to a problem is understanding any restrictions on it. For example, consider the digit2String function from Section 6.3.
def digit2String(digit):
"""Converts an integer digit to its corresponding string
representation.
Parameter:
digit: an integer in 0, 1, ..., 9
Return value:
the corresponding character '0', '1', ..., '9'
or None if a non-digit is passed as an argument
"""
if (digit < 0) or (digit > 9):
return None
return chr(ord('0') + digit)
Recall that this function is meant to convert an integer digit between 0 and 9 to its associated character. For example, if the input were 4, the output should be the string '4'. We noted when we designed this function that inputs less than 0 or greater than 9 would not work, so we returned None in those cases. The requirement that digit must be integer between 0 and 9 is called a precondition. A precondition for a function is something that must be true when the function is called for it to behave correctly. Put another way, we do not guarantee that the function will give the correct output when the precondition is false.
On the other hand, the postcondition for a function is a statement of what must be true when the function finishes. A postcondition usually specifies what the function returns and what, if any, side effects it has. Recall that a side effect occurs when a global variable is modified or some other event in a function modifies a global resource. For example, calls to print and modifications of files can be considered side effects because they have impacts outside of the function itself.
Reflection 7.3 What is the postcondition of the digit2String function?
The postcondition for the digit2String function should state that the function returns a string representation of its input.
The use of preconditions and postconditions is called design by contract because the precondition and postcondition establish a contract between the function designer and the function caller. The function caller understands that the precondition must be met before the function is called and the function designer guarantees that, if the precondition is met, the postcondition will also be met.
Because they describe the input and output of a function, and therefore how the function can be used, preconditions and postconditions should be included in the docstring for a function. If they include information about the parameters and return value, they can replace those parts of the docstring. For example, a new docstring for digit2String would look like:
def digit2String(digit):
"""Converts an integer digit to its corresponding string
representation.
Precondition: digit is an integer between 0 and 9
Postcondition: returns the string representation of digit, or
None if digit is not an integer between 0 and 9
"""
Checking parameters
The digit2String function partially “enforces” the precondition by returning None if digit is not between 0 and 9. But there is another part of the precondition that we do not handle.
Reflection 7.4 What happens if the argument passed in for digit is not an integer?
Calling digit2String('cookies') results in the following error:
TypeError: unorderable types: str() < int()
This error happens in the if statement when the value of digit, in this case 'cookies', is compared to 0. To avoid this rather opaque error message, we should make sure that digit is an integer at the beginning of the function. We can do so using the isinstance function, which takes two arguments: a variable name (or value) and the name of a class. The function returns True if the variable or value refers to an object (i.e., instance) of the class, and False otherwise. For example,
>>> isinstance(5, int)
True
>>> isinstance(5, float)
False
>>> s = 'a string'
>>> isinstance(s, str)
True
>>> isinstance(s, float)
False
We can use isinstance in the if statement to make digit2String more robust:
def digit2String(digit):
""" (docstring omitted) """
if not isinstance(digit, int) or (digit < 0) or (digit > 9):
return None
return chr(ord('0') + digit)
Now let’s consider how we might use this function in a computation. For example, we might want to use digit2String in the solution to Exercise 6.3.10 to convert a positive integer named value to its corresponding string representation:
def int2String(value):
"""Convert an integer into its corresponding string representation.
Parameter:
value: an integer
Return value: the string representation of value
"""
intString = ''
while value > 0:
digit = value % 10
value = value // 10
intString = digit2String(digit) + intString
return intString
In each iteration of the while loop, the rightmost digit of value is extracted and value is divided by ten, the digit is converted to a string using digit2String, and the result is prepended to the beginning of a growing string representation.
Reflection 7.5 What happens if value is a floating point number, such as 123.4?
If value is 123.4, then the first value of digit will be 3.4. Because this is not an integer, digit2String(digit) will return None. This, in turn, will cause an error when we try to prepend None to the string:
TypeError: unsupported operand type(s) for +: 'NoneType' and 'str'
Because we clearly stated in the docstring of digit2String that the function would behave this way, by the principle of design by contract, the int2String function, as the caller of digit2String, is responsible for catching this possibility and handling it appropriately. In particular, it needs to check whether digit2String returns None and, if it does, do something appropriate. For example, we could just abort and return None:
def int2String(value):
""" (docstring omitted) """
intString = ''
while value > 0:
digit = value % 10
value = value // 10
digitStr = digit2String(digit)
if digitStr != None:
intString = digit2Str + intString
else:
return None
return intString
Reflection 7.6 What are some alternatives to this function returning None in the event that value is a floating point number?
Alternatively, we could return a string representing the integer portion of value. In other words, if value were assigned 123.4, it could return the string '123'. But this would need to be stated clearly in the postcondition of the function. Exercises 7.2.1 and 7.2.2 ask you to write a precondition and postcondition for this function, and then modify the function so that it works correctly for all inputs.
Assertions
A stricter alternative is to display an error and abort the entire program if a parameter violates a precondition. This is precisely what happened above when the Python interpreter displayed a TypeError and aborted when the + operator tried to concatenate None and a string. These now-familiar TypeError and ValueError messages are called exceptions. A built-in function “raises an exception” when something goes wrong and the function cannot continue. When a function raises an exception, it does not return normally. Instead, execution of the function ends at the moment the exception is raised and execution instead continues in part of the Python interpreter called an exception handler. By default, the exception handler prints an error message and aborts the entire program.
It is possible for our functions to also raise TypeError and ValueError exceptions, but the mechanics of how to do so are beyond the scope of this book. We will instead consider just one particularly simple type of exception called an AssertionError, which may be raised by an assert statement. An assert statement tests a Boolean condition, and raises an AssertionError if the condition is false. If the condition is true, the assert statement does nothing. For example,
>>> value = -1
>>> assert value < 0
>>> assert value > 0
AssertionError
>>> assert value > 0, 'value must be positive'
AssertionError: value must be positive
The first assert statement above does nothing because the condition being asserted is True. But the condition in the second assert statement is False, so an AssertionError exception is raised. The third assert statement demonstrates that we can also include an informative message to accompany an AssertionError.
We can replace the if statement in our digit2String function with assertions to catch both types of errors that we discussed previously:
def digit2String(digit):
""" (docstring omitted) """
assert isinstance(digit, int), 'digit must be an integer'
assert (digit >= 0) and (digit <= 9), 'digit must be in [0..9]'
return chr(ord('0') + digit)
If digit is not an integer, then the first assert statement will display
AssertionError: digit must be an integer
and abort the program. If digit is an integer (and therefore gets past the first assertion) but is not in the correct range, the second assert statement will display
AssertionError: digit must be in [0..9]
and abort the program.
Reflection 7.7 Call this modified version of digit2String from the int2String function. What happens now when you call int2String(123.4)?
Note that, since the assert statement aborts the entire program, it should only be used in circumstances in which there is no other reasonable course of action. But the definition of “reasonable” usually depends on the circumstances.
For another example, let’s look at the count and getWordCounts functions that we discussed in the previous section. We did not implement the functions there, so they are shown below. We have added to the count function a precondition and postcondition, and an assertion that tests the precondition.
def count(text, target):
"""Count the number of target strings in text.
Precondition: text and target are string objects
Postcondition: returns number of occurrences of target in text
"""
assert isinstance(text, str) and isinstance(target, str),
'arguments must be strings'
count = 0
for index in range(len(text) - len(target) + 1):
if text[index:index + len(target)] == target:
count = count + 1
return count
def getWordCounts(text, word, windowLength):
"""Find the number of times word occurs in each window in the text.
Parameters:
text: a string containing a text
word: a string
windowLength: the integer length of the windows
Return values: average count per window and list of window counts
"""
wordCount = 0
windowCount = 0
wordCounts = []
for index in range(0, len(text) - windowLength + 1, windowLength):
window = text[index:index + windowLength]
windowCount = windowCount + 1
wordsInWindow = count(window, word)
wordCount = wordCount + wordsInWindow
wordCounts.append(wordsInWindow)
return wordCount / windowCount, wordCounts
Reflection 7.8 What are a suitable precondition and postcondition for the getWordCounts function? Should the precondition state anything about the values of text or word? (What happens if text is too short?)
The precondition should state that both text and word are strings, and wordLength is a positive integer. In addition, special attention must be paid to the contents of text. If the length of text is smaller than windowLength, then there will be no iterations of the loop. In this case, windowCount will remain at zero and the division in the return statement will result in an error. Depending on the circumstances, we might also want to prescribe some restrictions on the value of word but, in general, this is not necessary for the function to work correctly. Incorporating these requirements, a suitable precondition might look like this:
Precondition: text and word are string objects and
windowLength is a positive integer and
text contains at least windowLength characters
Assuming the precondition is met, the postcondition is relatively simple:
Postcondition: returns a list of word frequencies and the
average number of occurrences of word per window
Not satisfying any one of the precondition requirements will break the getWordCounts function, so let’s check that the requirements are met with assert statements. First, we can check that text and word are strings with the following assert statement:
assert isinstance(text, str) and isinstance(word, str),
'first two arguments must be strings'
We can check that windowLength is a positive integer with:
assert isinstance(windowLength, int) and windowLength > 0,
'window length must be a positive integer'
To ensure that we avoid dividing by zero, we need to assert that the text is at least as long as windowLength:
assert len(text) >= windowLength,
'window length must be shorter than the text'
Finally, it is not a bad idea to add an extra assertion just before the division at the end of the function:
assert windowCount > 0, 'no windows were found'
Although our previous assertions should prevent this assertion from ever failing, being a defensive programmer is always a good idea. Incorporating these changes into the function looks like this:
def getWordCounts(text, word, windowLength):
"""Find the number of times word occurs in each window in the text.
Precondition: text and word are string objects and
windowLength is a positive integer and
text contains at least windowLength characters
Postcondition: returns a list of word frequencies and the
average number of occurrences of word per window
"""
assert isinstance(text, str) and isinstance(word, str),
'first two arguments must be strings'
assert isinstance(windowLength, int) and windowLength > 0,
'window length must be a positive integer'
assert len(text) >= windowLength,
'window length must be shorter than the text'
wordCount = 0
windowCount = 0
wordCounts = []
for index in range(0, len(text) - windowLength + 1, windowLength):
window = text[index:index + windowLength]
windowCount = windowCount + 1
wordsInWindow = count(window, word)
wordCount = wordCount + wordsInWindow
wordCounts.append(wordsInWindow)
assert windowCount > 0, 'no windows were found'
return wordCount / windowCount, wordCounts
In the next section, we will discuss a process for more thoroughly testing these functions once we think they are correct.
Exercises
7.2.1. Write a suitable precondition and postcondition for the int2String function.
7.2.2. Modify the int2String function with if statements so that it correctly satisfies the precondition and postcondition that you wrote in the previous exercise, and works correctly for all possible inputs.
7.2.3. Modify int2String function with assert statements so that it correctly satisfies the precondition and postcondition that you wrote in Exercise 7.2.1, and works correctly for all possible inputs.
For each of the following functions from earlier chapters, (a) write a suitable precondition and postcondition, and (b) add assert statements to enforce your precondition. Be sure to include an informative error message with each assert statement.
7.2.4. def volumeSphere(radius):
return (4 / 3) * math.pi * (radius ** 3)
7.2.5. def fair(employee, ceo, ratio):
return (ceo / employee <= ratio)
7.2.6. def windChill(temp, wind):
chill = 13.12 + 0.6215 * temp +
(0.3965 * temp - 11.37) * wind ** 0.16
return round(chill)
Note that wind chill is only defined for temperatures at or below 10° C and wind speeds above 4.8 km/h.
7.2.7. def plot(tortoise, n):
for x in range(-n, n + 1):
tortoise.goto(x, x * x)
7.2.8. def pond(years):
population = 12000
print('Year Population')
print('{0:<4} {1:>9.2f}'.format(0, population))
for year in range(1, years + 1):
population = 1.08 * population - 1500
print('{0:<4} {1:>9.2f}'.format(year, population))
return population
7.2.9. def decayC14(originalAmount, years, dt):
amount = originalAmount
k = -0.00012096809434
numIterations = int(years / dt) + 1
for i in range(1, numIterations):
amount = amount + k * amount * dt
return amount
7.2.10. def argh(n):
return 'A' + ('r' * n) + 'gh!'
7.2.11. def reverse(word):
newstring = ''
for index in range(len(word) - 1, -1, -1):
newstring = newstring + word[index]
return newstring
7.2.12. def find(text, target):
for index in range(len(text) - len(target) + 1):
if text[index:index + len(target)] == target:
return index
return -1
7.2.13. def lineNumbers(fileName):
textFile = open(fileName, 'r', encoding = 'utf-8')
lineCount = 1
for line in textFile:
print('{0:<5} {1}'.format(lineCount, line[:-1]))
lineCount = lineCount + 1
textFile.close()
To determine whether a file exists, you can use:
import os.path
assert os.path.isfile(fileName)
Then, to make sure you can read the file, you can use:
import os
assert os.access(fileName, os.R_OK)
The value os.R_OK is telling the function to determine whether reading the file is OK.
*7.3 TESTING
Once we have carefully defined and implemented a function, we need to test it thoroughly. You have surely been testing your functions all along, but now that we have written some more involved ones, it is time to start taking a more deliberate approach.
It is very important to test each function that we write before we move on to other functions. The process of writing a program should consist of multiple iterations of design—implement—test, as we illustrated in Figure 7.1 in Section 7.1. Once you come up with an overall design and identify what functions you need, you should follow this design—implement—test process for each function individually. If you do not follow this advice and instead test everything for the first time when you think you are done, it will likely be very hard to discern where your errors are.
The only way to really ensure that a function is correct is to either mathematically prove it is correct or test it with every possible input (i.e., every possible parameter value). But, since both of these strategies are virtually impossible in all but the most trivial situations, the best we can do is to test our functions with a variety of carefully chosen inputs that are representative of the entire range of possibilities. In large software companies, there are dedicated teams whose sole jobs are to design and carry out tests of individual functions, the interplay between functions, and the overall software project.
Unit testing
We will group our tests for each function in what is known as a unit test. The “unit” in our case will be an individual function, but in general it may be any block of code with a specific purpose. Each unit test will itself be a function, named test_ followed by the name of the function that we are testing. For example, our unit test function for the count function will be named test_count. Each unit test function will contain several individual tests, each of which will assert that calling the function with a particular set of parameters returns the correct answer.
To illustrate, we will design unit tests for the count and getWordCounts functions from the previous section, reproduced below in a simplified form. We have omitted docstrings and the messages attached to the assert statements, simplified getWordCounts slightly by removing the list of window frequencies, and simplified the main function by removing the plot.
def getInputs():
⋮ # code omitted
def count(text, target):
assert isinstance(text, str) and isinstance(target, str)
count = 0
for index in range(len(text) - len(target) + 1):
if text[index:index + len(target)] == target:
count = count + 1
return count
def getWordCounts(text, word, windowLength):
assert isinstance(text, str) and isinstance(word, str)
assert isinstance(windowLength, int) and windowLength > 0
assert len(text) >= windowLength
wordCount = 0
windowCount = 0
for index in range(0, len(text) - windowLength + 1, windowLength):
window = text[index:index + windowLength]
windowCount = windowCount + 1
wordsInWindow = count(window, word)
wordCount = wordCount + wordsInWindow
assert windowCount > 0
return wordCount / windowCount
def main():
text, word, windowLength = getInputs()
average = getWordCounts(text, word, windowLength)
print(word, 'occurs on average', average, 'times per window.')
main()
We will place all of the unit tests for a program in a separate file to reduce clutter in our program file. If the program above is saved in a file named wordcount.py, then the unit test file will be named test_wordcount.py, and have the following structure:
from wordcount import count, getWordCounts
def test_count():
"""Unit test for count"""
# tests of count here
print('Passed all tests of count!')
def test_getWordCounts():
"""Unit test for getWordCounts"""
# tests of getWordCounts here
print('Passed all tests of getWordCounts!')
def test():
test_count()
test_getWordCounts()
test()
The first line imports the two functions that we are testing from wordcount.py into the global namespace of the test program. Recall from Section 3.6 that a normal import statement creates a new namespace containing all of the functions from an imported module. Instead, the
from <module name> import <function names>
form of the import statement imports functions into the current namespace. The advantage is that we do not have to preface every call to count and getWordCounts with the name of the module. In other words, we can call
count('This is fun.', 'is')
instead of
wordcount.count('This is fun.', 'is')
The import statement in the program is followed by the unit test functions and a main test function that calls all of these unit tests.
Regression testing
When we test our program, we will call test() instead of individual unit test functions. Besides being convenient, this technique has the advantage that, when we test new functions, we also re-test previously tested functions. If we make changes to any one function in a program, we want to both make sure that this change worked and make sure that we have not inadvertently broken something that was working earlier. This idea is called regression testing because we are making sure that our program has not regressed to an earlier error state.
Before we design the actual unit tests, there is one more technical matter to deal with. Although we have not thought about it this way, the import statement both imports names from another file and executes the code in that file. Therefore, when test_wordcount.py imports the functions from wordcount.py into the global namespace, the code in wordcount.py is executed. This means that main will be called, and therefore the entire program in wordcount.py will be executed, before test() is called. But we only want to execute main() when we run wordcount.py as the main program, not when we import it for testing. To remedy this situation, we need to place the call to main() in wordcount.py inside the following conditional statement:
if __name__ == '__main__':
main()
You may recall from Section 3.6 that __name__ is the name of the current module, which is assigned the value '__main__' if the module is run as the main program. When wordcount.py is imported into another module instead, __name__ is set to 'wordcount'. So this statement executes main() only if the module is run as the main program.
Designing unit tests
Now that we have the infrastructure in place, let’s design the unit test for the count function. We will start with a few easy tests:
def test_count():
quote = 'Diligence is the mother of good luck.'
assert count(quote, 'the') == 2
assert count(quote, 'them') == 0
print('Passed all tests of count!')
Reflection 7.9 What is printed by the assert statements in the test_count function?
If the count function is working correctly, nothing should be printed by the assert statements. On the other hand, if the count function were to fail one of the tests, the program would abort at that point with an AssertionError exception. To see this, change the second assertion to (incorrectly) read assert count(quote, 'them') == 1 instead. Then rerun the program. You should see
Box 7.1: Unit testing frameworks
Python also provides two modules to specifically facilitate unit testing. The doctest module provides a way to incorporate tests directly into function docstrings. The unittest module provides a fully featured unit testing framework that automates the unit and regression testing process, and is more similar to the approach we are taking in this section. If you would like to learn more about these tools, visit
http://docs.python.org/3/library/development.html
Traceback (most recent call last):
⋮ (order of function calls displayed here)
assert count(quote, 'them') == 1
AssertionError
This error tells you which assertion failed so that you can track down the problem. (In this case, there is no problem; change the assertion back to the correct version.)
On their own, the results of these two tests do not provide enough evidence to show that the count function is correct. As we noted earlier, we need to choose a variety of tests that are representative of the entire range of possibilities. The input that we use for a particular test is called a test case. We can generally divide test cases into three categories:
Common cases. First, test the function on several straightforward inputs to make sure that its basic functionality is intact. Be sure to choose test cases that result in a range of different answers. For example, for the
countfunction, we might create the following tests (which include the two above):quote = 'Diligence is the mother of good luck.'
assert count(quote, 'the') == 2
assert count(quote, 'the ') == 1
assert count(quote, 'them') == 0
assert count(quote, ' ') == 6Notice that we have chosen inputs that result in a variety of results, including the case in which the target string is not found.
Boundary cases. A boundary case is an input that rests on a boundary of the range of legal inputs. In the case of the
countfunction, the input is two strings, so we want to test the function on strings with the minimum possible lengths and on strings with lengths that are close to the minimum. (If there were a maximum length, we would want to test that too.)The minimum length string is the empty string (
''). So we need to design test cases for thecountfunction in which either parameter is the empty string. We will start with cases in whichtargetis the empty string.Reflection 7.10 What should the correct answer be for
count(quote, '')? In other words, how many times does the empty string occur in a non-empty string?This question is similar to asking how many zeros there are in 10. In mathematics, this number (10/0) is undefined, and Python gives an error. Should counting the number of empty strings in a string also result in an error? Or perhaps the answer should be 0; in other words, there are no empty strings in a non-empty string.
Let’s suppose that we want the function to return zero if
targetis the empty string. So we add the following three test cases to thetest_countfunction:assert count(quote, '') == 0
assert count('a', '') == 0
assert count('', '') == 0Notice that we passed in strings with three different lengths for
text.Reflection 7.11 Does the
countfunction pass these tests? What doescount(quote, '')actually return? Look at the code and try to understand why. For comparison, what does the built-in string methodquote.count('')return?The return values of both
count(quote, '')andquote.count('')are38, which islen(quote) + 1, so the tests fail. This happens because, whentargetis the empty string, every test of theifcondition, which evaluates toif text[index:index] == '':
is true. Since the loop iterates
len(text) + 1times, each time incrementingcount,len(text) + 1is assigned tocountat the end.This is a situation in which testing has turned up a case that we might not have noticed otherwise. Since our expectation differs from the current behavior, we need to modify the
countfunction by inserting anifstatement before theforloop:def count(text, target):
assert isinstance(text, str) and isinstance(target, str)
if target == '':
return 0
count = 0
for index in range(len(text) - len(target) + 1):
if text[index:index + len(target)] == target:
count = count + 1
return countWith this change, all of the tests should pass.
Now what if
textis the empty string? It seems reasonable to expect that, iftextis empty, thencountshould always return zero. So we add two more test cases, one with a longtargetand the other with a shorttarget:assert count('', quote) == 0
assert count('', 'a') == 0Reflection 7.12 What does
count('', quote)actually return?In this case, both tests pass. If
textis the empty string andtargetcontains at least one character, then the range of theforloop is empty and the function returns zero.In addition to tests with the empty string, we should add a few tests in which both strings are close to the empty string:
assert count(quote, 'e') == 4
assert count('e', 'e') == 1
assert count('e', 'a') == 0Another kind of boundary case involves situations in which an algorithm is searching near the beginning or end of a string (or, in the next chapter, a list). For example, we should make sure that our function correctly counts substrings that appear at the beginning and end of
text:assert count(quote, 'D') == 1
assert count(quote, 'Di') == 1
assert count(quote, 'Dx') == 0
assert count(quote, '.') == 1
assert count(quote, 'k.') == 1
assert count(quote, '.x') == 0Notice that we have also included two cases in which the target is close to something at the beginning and end, but does not actually match.
Corner cases. A corner case is any other kind of rare input that might cause the function to break. For the
countfunction, our boundary cases took care of most of these. But two other unusual cases to check might be if thetextandtargetare the same, and iftextis shorter thantarget:assert count(quote, quote) == 1
assert count('the', quote) == 0Thinking up pathological corner cases is an acquired skill that comes with experience. Many companies pay top dollar for programmers whose sole job is to discover corner cases that break their software!
Putting all of these test cases together, our unit test for the count function looks like this:
def test_count():
quote = 'Diligence is the mother of good luck.'
assert count(quote, 'the') == 2 # common cases
assert count(quote, 'the ') == 1
assert count(quote, 'them') == 0
assert count(quote, ' ') == 6
assert count(quote, '') == 0 # boundary cases
assert count('a', '') == 0
assert count('', '') == 0
assert count('', quote) == 0
assert count('', 'a') == 0
assert count(quote, 'e') == 4
assert count('e', 'e') == 1
assert count('e', 'a') == 0
assert count(quote, 'D') == 1
assert count(quote, 'Di') == 1
assert count(quote, 'Dx') == 0
assert count(quote, '.') == 1
assert count(quote, 'k.') == 1
assert count(quote, '.x') == 0
assert count(quote, quote) == 1 # corner cases
assert count('the', quote) == 0
print('Passed all tests of count!')
Testing floating point values
Once we are sure that the count function works correctly, we can go on to implement and test the getWordCounts function. The beginning of a unit test for this function might look like the following. (We will leave the remaining tests as an exercise.)
def test_getWordCounts():
text = 'Call me Ishmael. Some years ago--never mind how long
precisely--having little or no money in my purse, and nothing
particular to interest me on shore, I thought I would sail about
a little and see the watery part of the world. It is a way I have
of driving off the spleen and regulating the circulation.'
assert getWordCounts(text, 'the', 20) == 4 / 15
assert getWordCounts(text, 'spleen', 20) == 1 / 15
print('Passed all tests of getWordCounts!')
Reflection 7.13 Why did we use 4 / 15 and 1 / 15 in the tests above instead of something like 0.267 and 0.067?
Using these floating point approximations of 4/15 and 1/15 would cause the assertions to fail. For example, try this:
>>> assert 4 / 15 == 0.267 # fails
In general, you should never test for equality between floating point numbers. There are two reasons for this. First, the value you use may not accurately represent the correct value that you are testing against. This was the case above. To get assert 4 / 15 == 0.267 to pass, you would have to add a lot more digits to the right of the decimal point (e.g., 0.26666 ··· 66). But, even then, the number of digits in the value of 4 / 15 may depend on your specific computer system, so even using more digits is a bad idea. Second, as we discussed in Sections 2.2 and 4.4, floating point numbers have finite precision and are therefore approximations. For example, consider the following example from Section 4.4.
sum = 0
for index in range(1000000):
sum = sum + 0.0001
assert sum == 100.0
This loop adds one ten-thousandths one million times, so the answer should be one hundred, as reflected in the assert statement. However, the assert fails because the value of sum is actually slightly greater than 100 due to rounding errors. To deal with this inconvenience, we should always test floating point values within a range instead. For example, the assert statement above should be replaced by
assert sum > 99.99 and sum < 100.01
or
assert sum > 99.99999 and sum < 100.00001
The size of the range that you test will depend on the accuracy that is necessary in your particular application.
Let’s apply this idea to the familiar volumeSphere function:
def volumeSphere(radius):
return (4 / 3) * math.pi * (radius ** 3)
To generate some test cases for this function, we would figure out what the answers should be for a variety of different values of radius and then write assert statements for each of these test cases. For example, the volume of a sphere with radius 10 is about 4188.79. So our assert statement should look something like
assert volumeSphere(10) > 4188.789 and volumeSphere(10) < 4188.791
Exercises
7.3.1. Finish the unit test for the getWordCounts function. Be sure to include both boundary and corner cases.
7.3.2. Design a thorough unit test for the digit2String function from Section 7.2.
7.3.3. Design a thorough unit test for the int2String function from Section 7.2.
7.3.4. Design a thorough unit test for the assignGP function below.
def assignGP(score):
if score >= 90:
return 4
if score >= 80:
return 3
if score >= 70:
return 2
if score >= 60:
return 1
return 0
7.3.5. Design a thorough unit test for the volumeSphere function in Exercise 7.2.4.
7.3.6. Design a thorough unit test for the windChill function in Exercise 7.2.6.
7.3.7. Design a thorough unit test for the decayC14 function in Exercise 7.2.9.
7.3.8. Design a thorough unit test for the reverse function in Exercise 7.2.11.
7.3.9. Design a thorough unit test for the find function in Exercise 7.2.12.
7.4 SUMMARY
Designing correct algorithms and programs requires following a careful, reflective process. We outlined an adaptation of Polya’s How to Solve It with four main steps:
Understand the problem.
Design an algorithm, starting from a top-down design.
Implement your algorithm as a program.
Analyze your program for clarity, correctness, and efficiency.
It is important to remember, however, that designing programs is not a linear process. For example, sometimes after we start programming (step 3), we notice a more efficient way to organize our functions and return to step 2. And, while testing a function (step 4), we commonly find errors that need to be corrected, returning us to step 3. So treat these four steps as guidelines, but always allow some flexibility.
In the last two sections, we formalized the process of designing and testing our functions. In the design process, we introduced design by contract using preconditions and postconditions, and the use of assert statements to enforce them. Finally, we introduced unit testing and regression testing as means for discovering errors in your functions and programs. In the remaining chapters, we encourage you to apply design by contract and unit testing to your projects. Although this practice requires more time up front, it virtually always ends up saving time overall because less time is wasted chasing down hard-to-find errors.
7.5 FURTHER DISCOVERY
The first epigraph is from an April 1984 Time magazine article titled “The Wizard inside the Machine” about Admiral Grace Hopper [55]. The second epigraph is from the Software Project Survival Guide by Steve McConnell [32] (p. 36).
Grace Hopper was an extraordinarily influential figure in the early development of programming languages and compilers. The original room-sized computers of the 1940’s and 1950’s had to be programmed directly in binary code by highly trained experts. But, by developing early compilers, Admiral Hopper demonstrated that programming could be made more user-friendly. Grace Hopper earned a Ph.D. in mathematics from Yale University in 1934, and taught at Vassar College until 1943, when she left to join the U.S. Naval Reserve. After World War II, she worked with early computers for both industry and the military. She retired from the Navy in 1986 with the rank of Rear Admiral. You can find a detailed biography at
http://www.history.navy.mil/bios/hopper_grace.htm.
A biographical video was also recently produced for the web site fivethirtyeight. com. You can watch it at