
Knowledge and Information: The Framework
This is a book about organizations and understanding how they work. A fundamental idea that we are going to use is that of a “process” because everything that organizations do, in one way or another, can be described as a process. In organizations, we design processes to accomplish specific goals, and I find it useful to think of these designed processes as “workflows,” the term in the title of this book.
Organizations and workflows are both critically dependent on information; in fact, I am going to argue that organizations themselves are information processors, in a very fundamental way. The information they process consists of two main types—information about what we are producing, whether tangible goods or intangible products like services, and information about how we do that. The latter can be thought of as information necessary for coordination, which is an absolute requirement in organizations because their reason for existing is to do work that is beyond the capability of a single individual. Coordination requires both formal and tacit knowledge, two other key terms we will hear much of in this book.
The “workflow” used by an artisan to craft an item of jewelry is entirely up to that artisan; as soon as the artisan hires help for that flow of work, however, it becomes necessary to think about who does what, in what order, what happens when things do not go as planned, and much more. That is what we mean by coordination, and there is no escaping it. Some of this information may be formal rules and policies, but a great deal of it is individual and worked out on the basis of day to day interaction, the way that masters and their apprentices did it for centuries. For every person added to the organization, the coordination requirements go up geometrically—coordinating four people takes much more than twice the information processing needed for two.
Organizations do not “just happen,” and therefore neither do workflows—they are designed. Neither one is static nor unchanging over time, so what was designed at one time will need to be modified in the future. We are constantly changing organization structures for one reason or another. One consequence is that the workflow designs that made good sense at one time no longer do, but they persist and often become seriously out of whack with the goals of the organization.
So, if there isn’t a “Second Law of Organizational Thermodynamics,” there should be. In physics, the Second Law of Thermodynamics says that everything eventually winds down until energy is evenly distributed throughout the universe and everything comes to a stop. Entropy rules! My experience with organizations suggests they follow this law, and this chapter is going to present some underlying reasons why this is the case. We build on this in chapter 2 to set the stage for the tools and techniques we will see in chapters 3 and 4, tools that not only help us to manage some of the chaos but actually change and improve processes and performance.
Understanding workflows also requires some fundamental understanding of information and knowledge, and in this way KM is related to workflow mapping. Given this relationship, one payoff is that mapping by the Kmetz method becomes a valuable way of capturing both formal and tacit knowledge in the workflow. We will discuss KM in more detail in chapter 5—our immediate concern is to know more about “information” and “knowledge,” two words that we use all the time but seldom appreciate for their richness and complexity.
Knowledge Is Information Is Knowledge
I want to begin with an idea that in some ways is the entire point of this introductory chapter. In the perspective of this book, information is “knowledge,” in the sense that it is a product of human intellect; it is structured, rather than random; and it is communicable to others.1 This is a utilitarian perspective on the definition of knowledge, in the sense that if you do not know you have information, then you do not have it. Two simple models help explain this perspective.
The first model posits that all information (and thus all knowledge) can be represented by a simple 2×2 framework, shown in Figure 1.1. This simple model categorizes all information into one of four cells. Known knowns (KK) are those items of information we consider to be “facts,” or to which we attach so little uncertainty as to make them effectively factual; known unknowns (KU) are essentially questions we know to be unanswered. Unknown knowns (UK) are information which we may have but cannot unambiguously interpret—a classic illustration is the problem faced by intelligence analysts, who are confronted with myriad facts that cannot be easily evaluated for truth or accuracy, or what they collectively mean. The final cell comprises unknown unknowns (UU), effectively an undefined area of information, the existence of which might be surmised but cannot be forced to yield to analysis—for example, what is the likelihood that a specific person will break his or her left leg in exactly 27 days; the probability that the Yellowstone volcano will erupt with the same force as its last eruption (and on a historical basis, it is due) and potentially end advanced civilization; the odds that we are actually on a surface in 11-dimension space-time, and that none of the universe we see can even begin to be understood in the four dimensions of space and time? All of these are serious questions, but with the exception of theoretical physics we have no way to frame a serious question in terms that we can comprehend, let alone a meaningful answer.
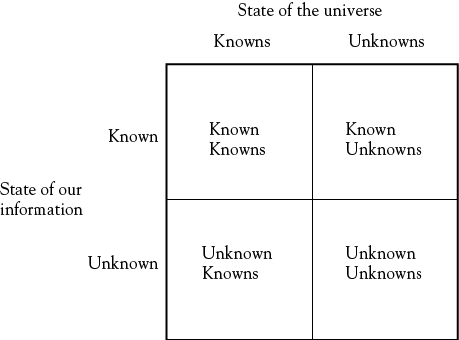
Figure 1.1 provides a way of characterizing the overall state of the information we have in terms of both knowns and unknowns. The contents of these cells are not the same for different observers, however, because information is a product of human intellect and dependent on the observer. One aspect of this content is that for each observer, any item of information may be described as a “vector,” which is our second model. In the terminology of linear algebra a vector may be thought of as an expression of a single path through a multidimensional matrix. In terms of human experience, at least seven properties of any item of information might define a vector, as shown in Figure 1.2.
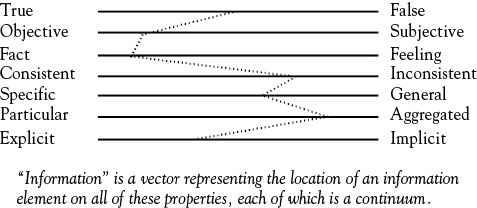
Figure 1.2. Properties of information.
Source: Adapted by permission of the publishers, in The Information Processing Theory of Organization by John L. Kmetz (Farnham: Gower, 1998), p. 16. Copyright © 1998.
The “vector” in Figure 1.2 is the dotted line connecting each scale or continuum for seven properties of information. Each of the seven properties is an opposite pair (true–false, consistent–inconsistent, and so on.), where the extreme end of each scale might be defined by the associated word—for example, only statements at the extreme left of the first continuum are really “true.” Where the dotted line intersects each of the scales defines the value of the vector for a specific item of information as seen by one observer.
How could information have a vector like that shown in Figure 1.2—in particular, how can information be partly true and partly false, as shown on the first continuum? Consider the following statement: “I don’t know whether to believe them entirely or not, but the numbers coming out of the rare-earth explorations we’ve been doing at Site X, even though they don’t agree with a number of other prospectors who’ve looked around the same area, seem to make a strong case for spending some serious development money.” Going from top to bottom of Figure 1.2, all seven vector properties are embodied in this statement. This is the way information usually comes to us—it is a bundle of qualities that are not necessarily reconcilable with each other, let alone the basis for a firm conclusion or immediate action. We literally need time and thought to figure out what we consider to be a KK.
Moreover, it is highly unlikely that any two individuals will perceive an item of information in identical terms for each of these vector properties; that is, the meaning of information (“knowledge”) to one person will inevitably not be the same as for another. Depending on where one person considers an item of information to fall on each vector, a bit of information may be considered highly credible and be placed in cell KK in Figure 1.1; another observer who evaluates the vector properties for that item differently places that item in cell KU. For example, “source credibility” will strongly affect where one places information on these continua, as any follower of marketing or political science can easily attest.
The idea of “known knowns” may ultimately be an oversimplification. Very few things are truly “known” in the sense of being fixed and final—courts review verdicts, analysts recalculate the books for businesses, research outcomes are reviewed, and so on. Because information is a function of both inherent content and human perception and processing, everything is subject to reinterpretation. Much of the tacit knowledge in organizations is derived from these kinds of highly individual processes.
What both of the models in Figures 1.1 and 1.2 emphasize is the importance of thinking about what we know, and also about how much confidence we have in that knowledge. In his highly recommended book, The Black Swan, Taleb points out a number of very important characteristics of human information processing which may lead to error in our conclusions about things.2 We have a tendency to “tunnel,” as he terms it, to look at one or more sources of information and disregard others. An immediate implication is that we need to be as receptive to information as we can, perhaps especially to that we do not really want to hear. The absence of information itself may have value—absence of evidence on a subject is not the same as evidence of absence. We are also strongly persuaded by stories, or “narratives,” which often have the property of making rough knowledge appear to be more smooth and complete than it really is if we look at it closely. These two figures give us some simple ways to think about what we think we know. In terms of Figure 1.1, categorizing important information on a performance problem into three of the four cells of that model can be a high-payoff application of it, as may evaluating arguments on the basis of relevant vectors in Figure 1.2.
So does this mean we never really know anything? Perhaps in the philosophical sense it does, but in the world of working organizations we deal with the complexities of information differently. Much of what we “know” is a social reality, meaning that through usage, experimentation, and learning, we come to agree on what something “means” to the extent that we can use it as if it were a KK. Working knowledge evolves. Most formal policies and procedures develop in response to a perceived need, to fill a vacuum when it becomes evident; they are changed and replaced in the same way. Tacit knowledge does the same thing, only on the part of individuals and small groups. Tacit workflow knowledge develops in the environment of formal organizational knowledge, which has many implications (one of them being the old bromide that “we get things done around here not because of the rules, but in spite of them”). So we may not have final answers to anything, but we agree on the information we need to make progress, and that information always includes tacit knowledge.
All Information Is Imperfect
What constitutes KU or UK in Figure 1.1 depends considerably on the individual making the judgment about the contents of these cells. As a commitment to faith, one observer may reject the entire construct of Figure 1.1, since it rejects the potential for all unknowns to rest in the hands of a higher power. Over time, each of the cells with known elements is a “fuzzy set,” in that the content and classification system may change. A humble example of this is the definition of “dishwasher safe” kitchen equipment and cutlery. As a wooden-handled knife (located in the KK cell as not “dishwasher safe” when acquired) becomes older, duller, and less prized, it is less likely to be hand-washed and more likely to be put in the dishwasher; “dishwasher safe” is partly a matter of who makes the determination as well as the physical properties of the item. Therefore, “information imperfection” can be summarized as either a problem of incompleteness, where at a minimum the UU cell in Figure 1.1 can never be eliminated, or as a function of the fuzzy set problems induced by vector properties shown in Figure 1.2.
Either of these two forms of information imperfection may be the product of active or passive sources, as summarized in Table 1.1. These may result in simply incomplete information or differing vector properties.
Table 1.1. Forms of Information Imperfection

Source: Reprinted by permission of the publishers, in The Information Processing Theory of Organization by John L. Kmetz (Farnham: Gower, 1998), p. 17. Copyright © 1998.
Active processes are shown in cells 1 and 3. In cell 1, active distortion of information or misleading information may be provided by a competitor as a deliberate method for concealment of strategy or intentions; in cell 3, various kinds of analytical error may result in imperfect information—these could include incorrect weighting of information content, misinterpretation of vector properties, and simple mathematical error. Passive forms of imperfection are shown in the other two cells, and are relatively straightforward—the lack or loss of information in cell 2, rendering what we think we know to be incomplete, and the unconscious filtering of vector properties or addition of unintended vector properties to information in cell 4. These four archetypal processes are interdependent for any observer; for example, jamming information about a source (person) may create emotional filters that affect the vector properties of all information from that source. Examples of such interactions can easily be imagined for all four sources of imperfection, and these interact over time.
We hear all the time that knowledge is often the most critical asset any organization possesses. The lengths taken to protect the formula of Coca-Cola, to protect innumerable trademarks, and the global concern over protection of intellectual property are abundant testimony to that fact. Thus, the cells in Table 1.1 where information is incomplete may be the product of active processes on the part of external agents who do not want knowledge to be full or complete, in addition to imperfections from our internal thought processes.
It is also important to recognize that actively derived imperfections do not necessarily imply bad intent. Businesses keep at least three sets of books—one to report to shareholders, one to use for internal decision making, and one for tax collectors. While we might view this cynically and suggest that each is intended to keep information away from people, it is equally true that compliance with a hugely complex tax code may not always tell the most accurate story of how the business is doing for the shareholders, and that neither of these is what a manager needs for day-to-day operations. Changing the way we keep accounts changes the properties of the knowledge we have to work with, and we need to actively create different versions of a single “truth.” In the wrong hands, of course, this same need opens the door for the kinds of abuses we have seen with the Enrons and WorldComs of the business community.
Information imperfection is a major issue in the mapping of workflows, as we will see in chapter 3. Much of the tacit knowledge in a workflow becomes so deeply embedded in individualized behavior that it becomes difficult to extract. Everyone has experienced the startling realization of having driven a long distance without really being aware of it until some point near the end. We overlearn a familiar route to the extent that conscious attention to driving it is not necessary, and we navigate by using waypoints and landmarks; if we are asked how we travel, we suddenly realize we no longer know route numbers or street names, but these landmarks. The same thing happens in our work, and a type of “uncertainty” is the inevitable result. But we should be aware that in cases where people feel threatened by a new workflow-mapping project in their company, they may respond by engaging in “jamming” and providing disinformation.
Organizations Are Information Processors
When we talk about “organizations,” the type of social creation we will be focusing on in this book, that word conjures up many images. The one that I personally prefer is that an organization is an information processor. Organizations, small or large, are groups of people using various technologies to accomplish something that cannot be done through individual effort alone. Because we have multiple players, different materials, different objectives, different constituencies, and all the myriad things that come with an organization, it is necessary to process information to coordinate everything that has to be done.
This need is easy to understand. A small team of people can coordinate their actions for a small project relatively easily (especially since they are likely to be self-selected members for the job at hand). They simply ask questions and make suggestions to each other as circumstances require, and with everyone in contact with each other, processing information to coordinate the team is easily managed. But when a job gets bigger, takes more people and more specialized skills, extends over a long time, and so on, the capacity for information processing activity sufficient to coordinate a small team will simply not be adequate.
The solution to this problem is also easy to understand—we break the big organization down into smaller groups (typically by the type of skills people have or the type of output they produce), and have a specialist in charge of each group, so that the amount of information that has to be processed within each group will be dramatically reduced relative to the whole organization. Each small team will only have to coordinate its actions within the group, and between-group coordination can be done by the team leaders. They may need a higher-level team leader, and if so, we have just created a three-level hierarchy.
This spontaneous hierarchy is hardly new, and the discovery of the information processing efficiency and effectiveness of the hierarchy is as old as organization itself. The Romans are often credited with invention of the hierarchy (a “centurion” was the leader of 10 groups of 10), but hierarchical military organization was used by the early Assyrians, Genghis Khan, and the Mongols, among others. This efficiency is also why the hierarchy is durable, despite the efforts of many thinkers and advocates of alternative forms of organization to discredit it—it persists because it works.
When we design an organization, we have a significant impact on the way the organization will be able to process information, and how much and what kind of processing it will have to do. There are significant tradeoffs. If we organize our basic units by skill or type of work, as opposed to grouping people and skills around production of a particular type of output, we create specialist units that tend to pay most attention to their specialization, and often lose touch with the customer; organizing by product may keep us closer to the customer, but at the cost of losing our skill (and innovative) edge. If we make the hierarchy tall and keep all the decision power at the top, it makes it easier for the whole organization to adapt its overall goals over time, but at the cost of “buy-in” and much valuable knowledge that stays at lower levels; if we reverse that and keep decision making at lower levels, we risk having the overall goal lost in the cracks between goals of the individual business units. These are never-ending problems, and they are a constant challenge to large organizations because the tradeoffs between them are important.
As an example, Gore Associates, the maker of Gore-Tex and many other nonconsumer products, decided to commit to an organizational form that reflected William Gore’s experience and preferences from his early career in a large company. His decision was to form production units of 200 or fewer people, and when a site grew beyond that size, he opened a new physical unit—a new plant at a new site. The reason was that in his early experience, large organizations always lost touch with individuals and were simply not much fun; he wanted plants small enough to let everyone get to know everyone else. He also abolished hierarchy and status differentiation, so that everyone who works with Gore is an “Associate.” As a result, this global company now has small units in roughly similarlysized buildings scattered around the globe. They have their own unique problems in trying to coordinate this kind of operation, but have learned how to do it successfully through several long-term business cycles and the end of patent protection for a major product line.
The scattering of task-related information through an organization thus induces a new type of information imperfection. Anyone who has been in an organization knows that keeping both the left and right hands informed of what the other is doing is an endless job; moreover, what is “important” at any given time depends considerably on the point of view of both the individuals and the unit they represent. It requires time and money to process information to achieve functional consistency, where goals can be met with enough success to keep the wolf from the door over the long term.
Figure 1.3 illustrates the problem in general terms. Knowing what we know is not free. From the vertical axis, two organizations (A and B) might start from much the same level of internal information consistency, and both might agree that this level of consistency is inadequate for their needs—they need to “get on the same page.” Doing that requires time and money, and as they move through time to the right, they improve their consistency, but at increasing cost. (It is also worth noting that the problem they are working on is less and less current.)

Figure 1.3. Functional consistency lag and cost.
Source: Adapted by permission of the publishers, in The Information Processing Theory of Organization by John L. Kmetz (Farnham: Gower, 1998), p. 352. Copyright © 1998.
The two organizations may start in a similar position with respect to their internal degree of functional consistency, which might be thought of as increasing the relative size of the KK cell in Figure 1.1. To increase the size of the KK cell requires effort and expense, as does further resolution of the UK and KU cells. How much processing toward these outcomes is justified, and how do we know? To what extent is acquiring the nth item of information worthwhile? What is the cost of the time to do this, and what is the time value of money relative to all of these tasks? These are questions that are fundamental to any organization design. The existence of the UU cell means that there is also an irreducible system-level cost, where spending infinite amounts of money will not gain much by way of new information.
Several decades ago, Aaron Wildavsky coined the term “uncertainty absorption” to describe what happens when information in raw or nearly raw form enters the organization, and decision makers have to deal with the unknowns and imperfections in it.3 Raw data and information at any level of an organization is partially a mess, and what to do in the face of a problem is frequently not clear. Wildavsky argues that managers acquire much of their information as summaries of it from the level below (an interesting process in its own right), and use this to make decisions that are hopefully consistent with the organization’s goals. From the subordinates’ point of view, once the management has made a decision and passed it down, uncertainty about what to do has been absorbed by the manager for the subordinate—I may or may not agree with management’s decision, for example, but my job is to comply with it. This pattern is repeated through all levels, with all the potential for organizational politicking and infighting one could imagine. Such battles need not originate from an outside problem—having been through several wars over technical design in the aerospace industry, I can personally attest that the technical battles in the labs and engineering divisions are as bloody as they come.
Against this backdrop, it should come as no surprise that organizations are destined to constantly struggle with the problem of internally getting their act together. Testament to the difficulty of this job is provided by the popularity of the Dilbert comic strip, which parodies the role of managers and the problems of running a company (a former MBA student, an engineer by training like Dilbert, once told me in all sincerity that all he needed to know about management in the real world could be learned by regular reading of the strip; the strip author, Scott Adams, has often noted that most ideas for his strips are sent to him by readers in the working world). The challenge to managers is that no matter how hard they try, there will always be some things that slip through the cracks.
Even in the world of international spying and intelligence, the fundamental need for effective information processing cannot be escaped. The “how did we miss that?” or “how could we not have known?” investigations that often follow intelligence failures are as predictable as rain.
Even attempts to resolve the problem by restricting information access fail—they only create different types of performance and coordination problems. Harold Wilensky made an observation in his 1967 book that is as true today as ever:4
The more secrecy, the smaller the intelligent audience, the less systematic the distribution and indexing of research, the greater the anonymity of authorship, and the more intolerant the attitude toward deviant views.
Organizations must constantly struggle to “get everyone on the same page,” and it is a never-ending battle. Organizations are constantly restructuring, and by some accounts the average time between reorganizations is at a record low. All of this is driven by the need to process the right information in the right place at the right time, and stay competitive in a rapidly changing world. From basic hierarchies with a decision maker at the head of each group, we experiment with pre-made decisions in the form of rules, policies, and procedures; we add staff specialists to take some of the processing burden off line managers; we add information technology; we split up by region or customer group or on some other basis that makes sense in our industry. Every one of these changes has an impact on our processes, and it is not uncommon to find that a large part of the body of tacit knowledge is directed toward patching the cracks in the workflow left by the last reorganization. Most of these “patches,” actually, are taken care of through voluntary action on the part of employees, who use their tacit knowledge of customers and situations to fix things when they get out of whack.
Organizations Are Systems
The next of the fundamentals to discuss is that organizations are “systems.” On one hand this will seem intuitively obvious when explained, but on the other, it is a powerful and useful way to think about organizational processes and the critical roles of formal knowledge and tacit knowledge in them.
The idea of a “system” that I am using here is based on the everyday observation of complex, organized, often self-regulating entities in the world around us. “Systems” are the subject of a body of knowledge known as General Systems Theory, and they are formally defined in several ways, but they all built on the idea that a system is a whole made of component parts, and which is relatively stable and is both recognized and functions as a whole. There are four properties associated with “systems” as they are defined in General Systems Theory: (1) the whole is greater than the sum of its parts; (2) the whole determines nature of the parts; (3) the parts cannot be understood in isolation from the whole; and (4) the parts of the system are dynamically interrelated—they are interdependent and interact with each other over time.
Much of this sounds theoretical, but the essence of these definitions is captured in my own somewhat tongue-in-cheek definition: “A system is a thing made up of other things, all connected to each other and all other things.” Examples are everywhere. A person is a system; so is a town or city, on a larger scale, or a gut bacterium, on a much smaller scale. What is evident from consideration of these three systems is that any system is on one hand a “subsystem” of a larger entity, while at the same time a “supersystem” for smaller entities within it. Bacteria in the human gut are independent organisms on their own right, but as subsystems of a human body they are essential, and without them the survival of the human would be impossible. A political entity like a town or city has specific governing bodies which give the entity of “town” the ability to regulate behavior, repair itself, protect itself from hazards, and so on, even as its human subsystems come and go.
In one respect, I tend to prefer my informal definition because it forces one relationship to the forefront—the relationship between the system and its environment. Is the human body the environment for the bacterium; the town for the citizen? Each system we examine has this relationship to larger and smaller entities, internally and externally. Where “the system” ends and “the environment” begins is a matter of both scientific and philosophical debate. This is something we will not attempt to resolve here, but it has significant implications for the way we define any system we want to examine through workflow mapping.
Figure 1.4 shows the basic relationship a system maintains with its environment, and this will be discussed in more detail in chapter 2, particularly what goes on inside the system. All systems have a permeable “boundary” with their environments, and take inputs, transform these using internal processes into outputs, and return these outputs to the environment. As I suggested above, the boundary is not fixed or impermeable, and how we define that boundary may have significant implications for workflow characteristics.
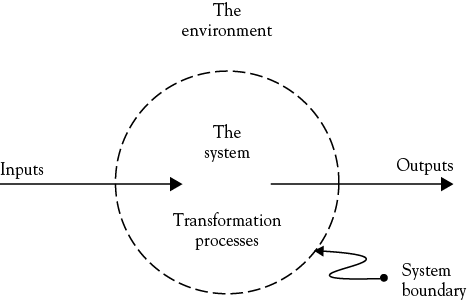
Examples of the importance of these boundary relationships can be found in modern supply-chain or just in time (JIT) management. In order to make these methods work, companies must share information with “outsiders” on a level that a few years ago would have been considered an unacceptable breach of corporate confidence. What was “the organizational environment” a few years ago is now part of “the operating system,” and cannot work any other way.
Understanding organizations as systems has a number of important implications for understanding what goes on inside them. First, the inputs to one system are the outputs from one or more other systems. We sometimes think of knowledge as an economic “stock” of information, to be categorized and accounted for as a bakery would with different flours being prepared to make bread and pastries, or in other cases, knowledge is treated more as an input variable, without regard to its source(s). My approach to capturing knowledge does not treat it as only a stock or an input flow—rather, knowledge takes on both roles in different times and circumstances in a workflow.
What differentiates the system and its environment is often worth careful consideration. Most companies (and perhaps most organizations in general) want to be as selectively open to the outside world as they can, while at the same time protecting the intellectual property (“knowledge base”) that makes them successful at what they do. This creates interesting problems and interesting opportunities. A few years ago many companies that used telephone back-office customer support felt that it was a no-brainer to take those functions offshore; what was once considered a necessary “internal” part of the business had become redefined as a routine function that could be done by contract employees on another continent. Since then, many of those firms have had to rethink that decision insofar as critical functions and customers are concerned. What constitutes a core body of knowledge, how porous the boundary should be, and how a company manages the relationships between them is quite important to workflow design and performance.
The environment is not static. Companies and organizations must adjust to shocks and environmental disturbances all the time, and many of them show remarkable resilience. In addition, there are things that go wrong internally for all manner of reasons (we often refer to these as “exceptions,” since they were not what we planned), and we have to adjust to these as well. Both types of adjustments require improvisation, jerry-rigging, and the like; they are heavily dependent on the expertise of people at the scene, at the time. These adjustments often become institutionalized because they worked, and they are both an important form and important source of tacit knowledge. From the perspective of the system, however, these tacit-knowledge adjustments are often nearly invisible, simply because they worked.
Another property to recognize is that complex systems, like companies and organizations, exhibit a high degree of self-regulation and adaptability. These properties are critically dependent on the knowledge base within the organization, which itself has to change and adapt as both internal and environmental forces require. Every individual and every group or unit within an organization possesses bodies of formal and tacit knowledge, the latter often a large body. These not only enable the organization to meet its immediate objectives, but to regulate its processes to do that and to react to problems in its workflow and change as necessary. Indeed, Senge and his colleagues argue that mastery of these knowledge bases and the ability to learn over time is a major competitive advantage and a requirement for long-term survival.5
Both the self-regulation and adaptability of complex systems depends on what may be thought of as the economic “stocks” of information mentioned earlier, and also “flows” of information. Every part of an organization depends on a knowledge base of formal knowledge, which is principally focused on the technical aspects of work; this knowledge base consists of many components, each of which is closely associated with the differentiated units that make up the organization. Each of these units applies its knowledge to the material in the flow of work, transforming raw inputs into final outputs. But much of this is heavily dependent on the tacit knowledge base, which is partly brought to the organization by its members, and partly created within it as the members interact with each other. It is primarily in this tacit knowledge base where we find “flows” of information, in the broadest sense meaning any information mobilized or used in a way that the formal knowledge base could not anticipate. Much tacit knowledge is also associated with units of the organization, but much is not, and it is free to “move” and be applied when and where it is needed to make the organization flexible and adaptable.
There is a good bit more to say about organizations as systems, but for the present time we should appreciate that “internal” processes are part of the “connected things” that make up a system. The inputs we bring into the organization from its environment not only include information about suppliers, markets, and so on, but the people who process it; they bring with them many other information inputs, along with a body of skills and interests. Some of these are unknown when we hire them and have unanticipated impact on the organization’s information processing—they are both an input to carry out formal processes, and a stock of their own knowledge which will influence how they do these processes. To fully understand an organization requires recognition of the openness of the system to its external environment as well as the full extent to which formal and tacit knowledge are necessary to meeting its goals. We will expand on this idea in chapter 2.
Information, Processes, and Performance
To pull the previous four points about organizational processes and information together, we need to consider the relationship of these to performance. Performance or goal attainment is not a foregone conclusion in a world of imperfect information, and this is one of the reasons that we often discuss performance in terms of the degree of goal attainment. The linkage between what an organization plans and projects on the one hand, and what actually happens on the other, is neither a sure thing nor a straight path. Thus, any discussion of performance must take factors that cause performance variations into account; these variations and deviations in the path to the future necessitate information processing, just as elements of other organizational processes do.
At the same time, the variability of process outcomes and the fact that we are always dealing with imperfect information makes it difficult to rigorously link performance to information. For example, the ability to demonstrate the payoff of investments in information technology has been a major challenge for decades. Strassmann argued that much of the early investment in information technology failed because it simply automated obsolete methods of doing work.6 Since then, information technology has been argued by some to be a key to the rapid increases in productivity of the U.S. economy during the late 1980s and early 1990s.7,8 But the time lags and lack of one-for-one correspondence between variables in a complex system always make such relationships difficult to identify or measure.
The desired or planned level of performance for a company or organization might be thought of as the outcome that would be attained under conditions of perfect information—but we know that is impossible because we have only imperfect information. Imperfect information causes deviations from the outcomes that we would obtain with perfect information, in the form of both gains and benefits on one hand, or as costs and losses, on the other. Considering both positive and negative outcomes caused by imperfect information, the performance of an organization may be described in terms of the following relationships:

What is that last term on the right—the “net payoff of outcomes resulting from imperfect information”? As shown in Table 1.2, this payoff is the net value of all benefits or gains, and costs or losses, resulting from both proactive and reactive organizational responses to imperfect information. Companies cannot simply sit and wait for everything to be known, so we take both proactive and reactive steps to deal with risks and unknowns. Costs or losses may be incurred whether the organization attempts to deal with imperfect information through proactive steps, such as planning, market research, and forecasting; or they may be incurred through reactive steps, such as missing market share or having to correct or compensate for the costs of delay. In either case, there are planned costs for coordinating organizational activities in the face of this imperfect information, and there are unforeseen costs and losses. Similarly, benefits may be gained from both proactive and reactive approaches to dealing with imperfect information, either through gains from anticipation and exploitation of new opportunities and competitive advantages, or through the avoidance of costs for unnecessary information and information-processing activities. An organization of any size usually does most of these things, and obtains many individual payoffs. The sum of all outcomes in cells 1–4 makes up the net “payoff” of imperfect information.
Table 1.2. Positive and Negative Outcomes as a Function of Imperfect Information
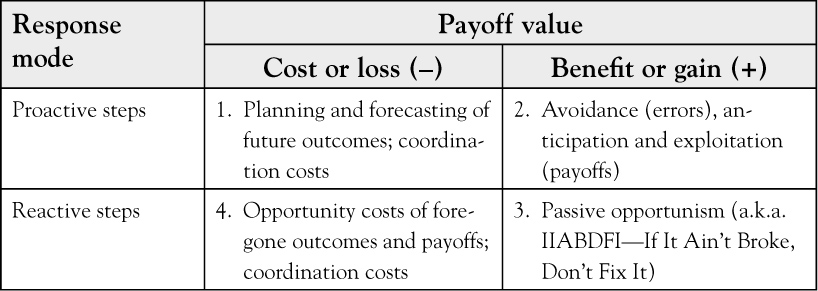
Source: Adapted by permission of the publishers, in The Information Processing Theory of Organization by John L. Kmetz (Farnham: Gower, 1998), p. 43. Copyright © 1998.
Consider the payoff of what I refer to as “coordination costs.” These costs may be to acquire information for decision making, or may be the costs of tightly coordinating activities within and between organizations. Again, an excellent example of the latter is JIT vendor–customer relationships, where considerable initial cost is borne by both parties to tightly coordinate their production and logistics flows across company boundaries. The net payoff of that investment in JIT, however, is so great that for many manufacturers any other approach to doing business is inconceivable.
But imperfect information often pays off in terms of benefits. For those companies able to find a competitive advantage in their technology or market niche, returns far above those obtained by competitors may be earned. For those who adopt a wait-and-see approach to dealing with unknowns, problems often go away and the unnecessary costs of coordination and attempted mastery of new technologies and new markets are avoided—“if it ain’t broke, don’t fix it.” Of course, many firms using either approach guess wrong, and fail—neither proacting nor reacting are totally free of risk.
An interesting implication of all of this is that companies can adjust to the challenges of imperfect information through lowered performance, that is, that if an organization lacks the information processing capacity to cope with all its knowns and unknowns, then an adjustive reaction is to reduce the level of output relative to what it might have been with adequate capacity. The hard question in this is “what might have been,” either in terms of opportunity costs or foregone benefits. Most organizations would not choose to lower performance levels, but many do so by not knowing how formal and tacit knowledge interact in their workflows.
The obverse, of course, also holds—if information processing capacity is increased in a system, then at a later time there should be a measurable increase in performance, which has clearly been the argument of both the information technology and business process consulting industries over the years.
The bottom line to this is that organizations are systems that function through information processing, and what we know about the formal and tacit aspects of this in our workflows has both direct and indirect effects on performance. If this seems obvious at this point, that is excellent; if not, we need to be clear about this fundamental point, which we will expand on in chapter 2. For now it is necessary to recognize that information is both the stuff of much organizational work, and the “glue” that holds the organization together so that it can work.
Summary and Implications
In some ways, it might be appropriate to return to Figure 1.1 and use that as the summary of this entire chapter, since the real issue is, as the chapter title says, “knowing what we know.” By now it should be clear that this is a more complicated question than it might first seem, and that realization is a good thing.
It is a good thing for two major reasons. First, a fundamental assumption of this entire book is that as organizations change and evolve over time, their internal processes need to do the same. Much experience has shown that this evolutionary change affects not only the overall structure of the organization, but has many subtle and frequently unknown effects on the workflows within it. Indeed, in later chapters we will hear about a number of these effects from many different kinds of companies and organizations. The information we do have about processes is seldom complete since part of that evolution is because people bring outside knowledge into the organization with them, and use it in creative, but often unexpected and unknown ways, to get their work done. Unless we understand the role of this tacit knowledge in our processes, we never really know what those processes are. So in short, it is quite reasonable to find that in many organizations, we really do not know how we do things, even though we may think we do before we take a careful look.
Second, much of the information we use for making decisions and controlling the day-to-day activities of a productive enterprise, the kind we consider to be in the KK cell of Figure 1.1, is seldom really examined or questioned as to whether that designation is accurate. Who has not left a meeting wondering what the whole thing was about? Who has not had the experience of being told to manage a financial decision on the basis of a policy that, with little analysis, can be shown to be less cost-effective than an easy alternative? One does not have to look very hard to find examples of companies that spent millions of dollars on an Enterprise Resource Planning (ERP) system, entirely on faith that it will work, only to find that in some respects it never really did. In reality, we do a lot of things in organizations on the basis of “because.” As long as our cash flow enables us to absorb the costs of “because,” we can get away with it, but that may not work over the long term, and we will hear some stories in this book about that, too.
Knowledge is information, and information is always partly incomplete and in some ways imperfect, so it can only be rendered useful through processing. One of the major functions of organizations is to process information and knowledge, so that coordinated progress toward goals is enabled despite the limits to the information we face. Organizations are also systems, and are therefore open to all manner of inside and outside shocks and internal changes, all of which require them to be adaptable. Many organizations do this rather well over the long term, while many others have short, if interesting, lives. How well an organization performs depends on all the outcomes of its actions, whether proactive “offensive” behaviors or reactive “defensive” behaviors. Both of these may result in costs or benefits, and it is the net payoff of these that determines how we do in the long term. I generally dislike sports analogies for their oversimplification of complex issues, but the idea of batting averages in baseball applies here. A batter can strike out whether he swings or not, and for the batter who produces a respectable average of hits in his at-bats, along with the occasional home run, there is a realistic chance of making the World Series.
This chapter has focused on some basic propositions about knowledge, information, and organizations. In some ways I have stressed the limits to our knowledge and our ability to cope with them. This does not mean that useful management of knowledge is beyond our reach, however—quite the opposite. I have focused on limitations and boundaries because it is important to know what we know as well as what we do not know. We may have to give up on the idea of a full and comprehensive database or boundless wellspring of innovation based on an open organization structure, but there are tools and methods that can be very helpful in increasing the extent to which we know what we know. We will always have to deal with the reality of unknown unknowns, and the conundrum that we cannot know what these are; there will always be questions about the value of information and the value of obtaining more of it, without fully knowing what the payoff of additional information might be. Nevertheless, there is also the potential to capture more of what we have discovered and learned, and to use what is frequently an “unknown known” to much greater advantage. One of the key functions of workflow mapping is to help the organization know what it knows.
Tacit knowledge is always a key to how organizations cope with their limits to knowledge. Consider three types of organizations—a glass products company, a software developer, and a hospital. At the beginning of this chapter I pointed out that organizations have to process information to achieve both technical and coordinative functions, and Figure 1.5 shows how formal and tacit knowledge both contribute to these objectives. First, formal knowledge is the basis of technical performance. The properties of materials that make various glasses, the programming rules and syntax for computer code, and sources of infection, are all among the many elements of the formal knowledge base that technical performance depends on; at the same time, coordination depends on related formal knowledge of how glass behaves in its molten state, so that a successful production line can be designed; how (and to whom) to assign code modules for new programs; and on the steps and procedures medical staff follow to keep sterile zones sterile, since hospital-derived infections are a major medical problem.
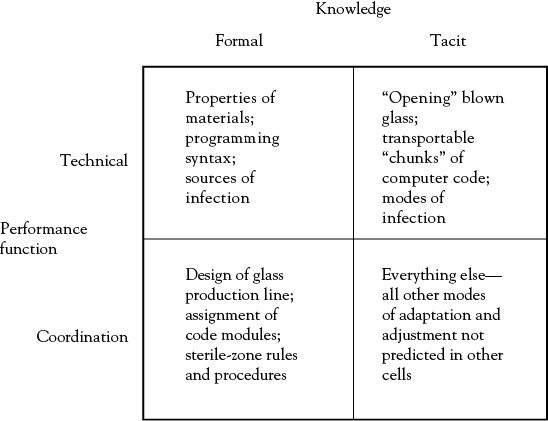
Tacit knowledge, shown in the right column of Figure 1.5, is equally important to organizational capabilities. Much of the technical success of organizations is entirely dependent on what people learn in what might be thought of as “apprenticeships.” One learns to “open” blown glass through trial and error; knowing how to apply transportable “chunks” of computer code is often a matter of deeply knowing how a piece of code works, by the programmer; and how and where infections get started is often as important as the bug that causes it, and sometimes more so.
What is most important to realize about tacit knowledge, however, is the bottom-right coordination cell—this is literally “everything else” we know how to do. It is where individual and group learning and knowledge give the organization response capabilities it never could have anticipated needing, let alone designed. In a universe where we can never have complete and perfect information, an absolute necessity is the ability to compensate and adjust when the UUs and other unknowns in Figure 1.1 reveal themselves. In many situations this cell defines how organizations survive.
The next chapter provides an expanded framework for understanding how organizations function, and that understanding is the basis for the simple, robust, and widely applicable method of graphically describing workflow processes, in a form that can quickly be mastered and applied to a wide variety of organizations, which is the subject of chapter 3. The combination of conceptual tools in this chapter and chapter 2, and applied tools in Chapters 3 and 4, will enable managers and analysts to comprehensively describe all that is done with material and information in a process. The ability to accurately capture both formal and tacit knowledge in our workflows has a big payoff. While it will never solve the fundamental limitations to full and complete information, WFMA will certainly go a long way toward letting us know what we know, and experience clearly shows that improvements in the quality of information from that increase our ability to improve performance.