
We are now ready to add web support to our working sensor, which we prepared in the previous chapter, and publish its data using the HTTP protocol. The following are the three basic strategies that one can use when publishing data using HTTP:
- In the first strategy the sensor is a client who publishes information to a server on the Internet. The server acts as a broker and informs the interested parties about sensor values. This pattern is called publish/subscribe, and it will be discussed later in this book. It has the advantage of simplifying handling events, but it makes it more difficult to get momentary values. Sensors can also be placed behind firewalls, as long as the server is publically available on the Internet.
- Another way is to let all entities in the network be both clients and servers, depending on what they need to do. This pattern will be discussed in Chapter 3, The UPnP Protocol. This reduces latency in communication, but requires all participants to be on the same side of any firewalls.
- The method we will employ in this chapter is to let the sensor become an HTTP server, and anybody who is interested in knowing the status of the sensor become the clients. This is advantageous as getting momentary values is easy but sending events is more difficult. It also allows easy access to the sensor from the parties behind firewalls if the sensor is publically available on the Internet.
Setting up an HTTP server on the sensor is simple if you are using the Clayster libraries. In the following sections, we will demonstrate with images how to set up an HTTP server and publish different kinds of data such as XML, JavaScript Object Notation (JSON), Resource Description Framework (RDF), Terse RDF Triple Language (TURTLE), and HTML. However, before we begin, we need to add references to namespaces in our application. Add the following code at the top, since it is needed to be able to work with XML, text, and images:
using System.Xml; using System.Text; using System.IO; using System.Drawing;
Then, add references to the following Clayster namespaces, which will help us to work with HTTP and the different content types mentioned earlier:
using Clayster.Library.Internet; using Clayster.Library.Internet.HTTP; using Clayster.Library.Internet.HTML; using Clayster.Library.Internet.MIME; using Clayster.Library.Internet.JSON; using Clayster.Library.Internet.Semantic.Turtle; using Clayster.Library.Internet.Semantic.Rdf; using Clayster.Library.IoT; using Clayster.Library.IoT.SensorData; using Clayster.Library.Math;
The Internet library helps us with communication and encoding, the IoT library with interoperability, and the Math library with graphs.
During application initialization, we will first tell the libraries that we do not want the system to search for and use proxy servers (first parameter), and that we don't lock these settings (second parameter). Proxy servers force HTTP communication to pass through them. This makes them useful network tools and allows an added layer of security and monitoring. However. unless you have one in your network, it can be annoying during application development if the application has to always look for proxy servers in the network when none exist. This also causes a delay during application initialization, because other HTTP communication is paused until the search times out. Application initialization is done using the following code:
HttpSocketClient.RegisterHttpProxyUse (false, false);
To instantiate an HTTP server, we add the following code before application initialization ends and the main loop begins:
HttpServer HttpServer = new HttpServer (80, 10, true, true, 1);
Log.Information ("HTTP Server receiving requests on port " + HttpServer.Port.ToString ());This opens a small HTTP server on port 80, which requires the application to be run with superuser privileges, which maintains a connection backlog of 10 simultaneous connection attempts, allows both GET and POST methods, and allocates one working thread to handle synchronous web requests. The HTTP server can process both synchronous and asynchronous web resources:
- A synchronous web resource responds within the HTTP handler we register for each resource. These are executed within the context of a working thread.
- An asynchronous web resource handles processing outside the context of the actual request and is responsible for responding by itself. This is not executed within the context of a working thread.
Now we are ready to register web resources on the server. We will create the following web resources:
HttpServer.Register ("/", HttpGetRoot, false);
HttpServer.Register ("/html", HttpGetHtml, false);
HttpServer.Register ("/historygraph", HttpGetHistoryGraph, false);
HttpServer.Register ("/xml", HttpGetXml, false);
HttpServer.Register ("/json", HttpGetJson, false);
HttpServer.Register ("/turtle", HttpGetTurtle, false);
HttpServer.Register ("/rdf", HttpGetRdf, false);These are all registered as synchronous web resources that do not require authentication (the third parameter in each call). We will handle authentication later in this chapter. Here, we have registered the path of each resource and connected that path with an HTTP handler method, which will process each corresponding request.
In the previous example, we chose to register web resources using methods that will return the corresponding information dynamically. It is also possible to register web resources based on the HttpServerSynchronousResource and HttpServerAsynchronousResource classes and implement the functionality as an override of the existing methods. In addition, it is also possible to register static content, either in the form of embedded resources using the HttpServerEmbeddedResource class or in the form of files in the filesystem using the HttpServerResourceFolder class. In our examples, however, we've chosen to only register resources that generate dynamic content.
We also need to correctly dispose of our server when the application ends, or the application will not be terminated correctly. This is done by adding the following disposal method call in the termination section of the main application:
HttpServer.Dispose ();
If we want to add an HTTPS support to the application, we will need an X.509Certificate with a valid private key. First, we will have to load this certificate to the server's memory. For this, we will need its password, which can be obtained through the following code:
X509Certificate2 Certificate = new X509Certificate2 ("Certificate.pfx", "PASSWORD");We then create the HTTPS server in a way similar to the HTTP server that we just created, except we will now also tell the server to use SSL/TLS (sixth parameter) and not the client certificates (seventh parameter) and provide the server certificate to use in HTTPS:
HttpServer HttpsServer = new HttpServer (443, 10, true, true, 1, true, false, Certificate);
Log.Information ("HTTPS Server receiving requests on port " + HttpsServer.Port.ToString ());We will then make sure that the same resources that are registered on the HTTP server are also registered on the HTTPS server:
foreach (IHttpServerResource Resource in HttpServer.GetResources())
HttpsServer.Register (Resource);We will also need to correctly dispose of the HTTPS server when the application ends, just as we did in the case of the HTTP server. As usual, we will do this in the termination section of the main application, as follows:
HttpsServer.Dispose ();
The first web resource we will add is a root menu, which is accessible through the path /. It will return an HTML page with links to what can be seen on the device. We will add the root menu method as follows:
private static void HttpGetRoot (HttpServerResponse resp, HttpServerRequest req)
{
networkLed.High ();
try
{
resp.ContentType = "text/html";
resp.Encoding = System.Text.Encoding.UTF8;
resp.ReturnCode = HttpStatusCode.Successful_OK;
} finally
{
networkLed.Low ();
}
}This preceding method still does not return any page.
This is because the method header contains the HTTP response object resp, and the response should be written to this parameter. The original request can be found in the req parameter. Notice the use of the networkLed digital output in a try-finally block to signal web access to one of our resources. This pattern will be used throughout this book.
Before responding to the query, the method has to inform the recipient what kind of response it will receive. This is done by setting the ContentType parameter of the response object. If we return an HTML page, we use the Internet media type text/html here. Since we send text back, we also have to choose a text encoding. We choose the UTF8 encoding, which is common on the Web. We also make sure to inform the client, that the operation was successful, and that the OK status code (200) is returned.
We will now return the actual HTML page, a very crude one, having the following code:
resp.Write ("<html><head><title>Sensor</title></head>");
resp.Write ("<body><h1>Welcome to Sensor</h1>");
resp.Write ("<p>Below, choose what you want to do.</p><ul>");
resp.Write ("<li>View Data</li><ul>");
resp.Write ("<li><a href='/xml?Momentary=1'>");
resp.Write ("View data as XML using REST</a></li>");
resp.Write ("<li><a href='/json?Momentary=1'>");
resp.Write ("View data as JSON using REST</a></li>");
resp.Write ("<li><a href='/turtle?Momentary=1'>");
resp.Write ("View data as TURTLE using REST</a></li>");
resp.Write ("<li><a href='/rdf?Momentary=1'>");
resp.Write ("View data as RDF using REST</a></li>");
resp.Write ("<li><a href='/html'>");
resp.Write ("Data in a HTML page with graphs</a></li></ul>");
resp.Write ("</body></html>");And then we are done! The previous code will show the following view in a browser when navigating to the root:
We are now ready to display our measured information to anybody through a web page (or HTML page). We've registered the path /html to an HTTP handler method named HttpGetHtml. We will now start implementing it, as follows:
private static void HttpGetHtml (HttpServerResponse resp,
HttpServerRequest req)
{
networkLed.High ();
try
{
resp.ContentType = "text/html";
resp.Encoding = System.Text.Encoding.UTF8;
resp.Expires = DateTime.Now;
resp.ReturnCode = HttpStatusCode.Successful_OK;
lock (synchObject)
{
}
}
finally
{
networkLed.Low ();
}
}The only difference here, compared to the previous method, is that we have added a property to the response: an expiry date and time. Since our values are momentary and are updated every second, we will tell the client that the page expires immediately. This ensures the page is not cached on the client side, and it is reloaded properly when the user wants to see the page again. We also added a lock statement, using our synchronization object, to make sure that access to the momentary values are only available from one thread at a time.
We can now start to return our momentary values, from within the lock statement:
resp.Write ("<html><head>");
resp.Write ("<meta http-equiv='refresh' content='60'/>");
resp.Write ("<title>Sensor Readout</title></head>");
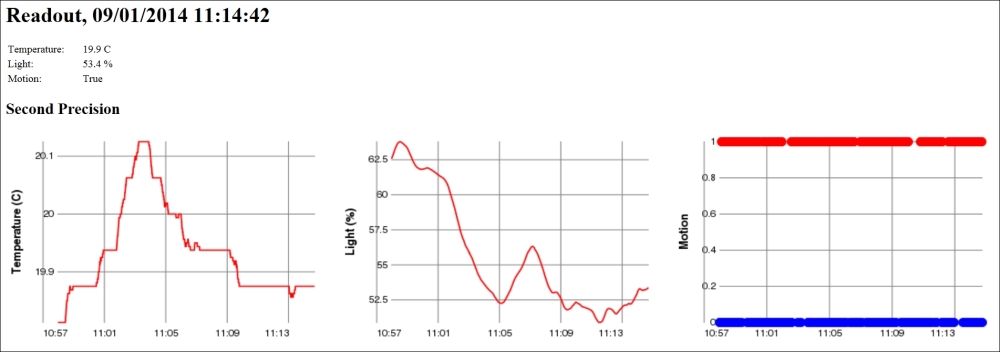
resp.Write ("<body><h1>Readout, ");
resp.Write (DateTime.Now.ToString ());
resp.Write ("</h1><table><tr><td>Temperature:</td>");
resp.Write ("<td style='width:20px'/><td>");
resp.Write (HtmlUtilities.Escape (temperatureC.ToString ("F1")));
resp.Write (" C</td></tr><tr><td>Light:</td><td/><td>");
resp.Write (HtmlUtilities.Escape (lightPercent.ToString ("F1")));
resp.Write (" %</td></tr><tr><td>Motion:</td><td/><td>");
resp.Write (motionDetected.ToString ());
resp.Write ("</td></tr></table>");We would like to draw your attention to the meta tag at the top of an HTML document. This tag tells the client to refresh the page every 60 seconds. So, by using this meta tag, the page automatically updates itself every minute when it is kept open.
Historical data is best displayed using graphs. To do this, we will output image tags with references to our historygraph web resource, as follows:
if (perSecond.Count > 1)
{
resp.Write ("<h2>Second Precision</h2>");
resp.Write ("<table><tr><td>");
resp.Write ("<img src='historygraph?p=temp&base=sec&");
resp.Write ("w=350&h=250' width='480' height='320'/></td>");
resp.Write ("<td style='width:20px'/><td>");
resp.Write ("<img src='historygraph?p=light&base=sec&");
resp.Write ("w=350&h=250' width='480' height='320'/></td>");
resp.Write ("<td style='width:20px'/><td>");
resp.Write ("<img src='historygraph?p=motion&base=sec&");
resp.Write ("w=350&h=250' width='480' height='320'/></td>");
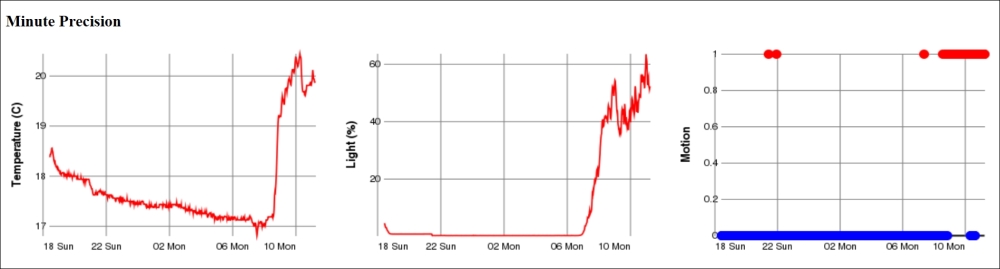
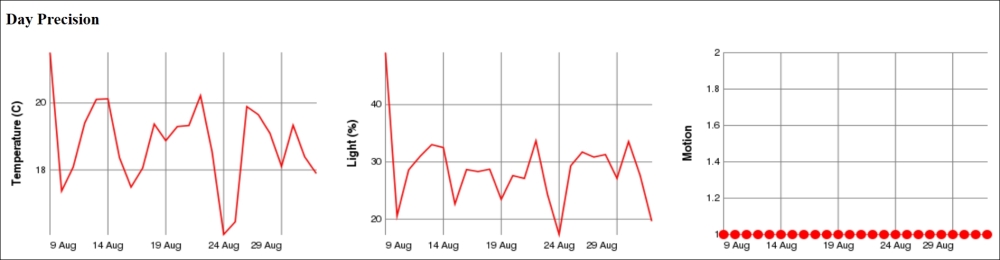
resp.Write ("</tr></table>");Here, we have used query parameters to inform the historygraph resource what we want it to draw. The p parameter defines the parameter, the base parameter the time base, and the w and h parameters the width and height respectively of the resulting graph. We will now do the same for minutes, hours, days, and months by assigning the base query parameter the values min, h, day and month respectively.
We will then close all if statements and terminate the HTML page before we send it to the client:
}
resp.Write ("</body><html>");Before we can view the page, we also need to create our historygraph resource that will generate the graph images referenced from the HTML page. We will start by defining the method in our usual way:
private static void HttpGetHistoryGraph (HttpServerResponse resp,
HttpServerRequest req)
{
networkLed.High ();
try
{
}
finally
{
networkLed.Low ();
}
}Within the try section of our method, we start by parsing the query parameters of the request. If we find any errors in the request that cannot be mended or ignored, we make sure to throw an HttpException exception by taking the HTTPStatusCode value and illustrating the error as a parameter. This causes the correct error response to be returned to the client. We start by parsing the width and height of the image to be generated:
int Width, Height;
if (!req.Query.TryGetValue ("w", out s) || !int.TryParse (s, out Width) || Width <= 0 || Width > 2048)
throw new HttpException (HttpStatusCode.ClientError_BadRequest);
if (!req.Query.TryGetValue ("h", out s) || !int.TryParse (s, out Height) || Height <= 0 || Height > 2048)
throw new HttpException (HttpStatusCode.ClientError_BadRequest);Then we extract the parameter to plot the graph. The parameter is stored in the p query parameter. From this value, we will extract the property name corresponding to the parameter in our Record class and the ValueAxis title in the graph. To do this, we will first define some variables:
string ValueAxis; string ParameterName; string s;
We will then extract the value of the p parameter:
if (!req.Query.TryGetValue ("p", out s))
throw new HttpException (HttpStatusCode.ClientError_BadRequest);We will then look at the value of this parameter to deduce the Record property name and the ValueAxis title:
switch (s)
{
case "temp":
ParameterName = "TemperatureC";
ValueAxis = "Temperature (C)";
break;
case "light":
ParameterName = "LightPercent";
ValueAxis = "Light (%)";
break;
case "motion":
ParameterName = "Motion";
ValueAxis = "Motion";
break;
default:
throw new HttpException (HttpStatusCode.ClientError_BadRequest);
}We will need to extract the value of the base query parameter to know what time base should be graphed:
if (!req.Query.TryGetValue ("base", out s))
throw new HttpException (HttpStatusCode.ClientError_BadRequest);In the Clayster.Library.Math library, there are tools to generate graphs. These tools can, of course, be accessed programmatically if desired. However, since we already use the library, we can also use its scripting capabilities, which make it easier to create graphs. Variables accessed by script are defined in a Variables collection. So, we need to create one of these:
Variables v = new Variables();
We also need to tell the client for how long the graph will be valid or when the graph will expire. So, we will need the current date and time:
DateTime Now = DateTime.Now;
Access to any historical information must be done within a thread-safe critical section of the code. To achieve this, we will use our synchronization object again:
lock (synchObject)
{
}Within this critical section, we can now safely access our historical data. It is only the List<T> objects that we need to protect and not the Records objects. So, as soon as we've populated the Variables collection with the arrays returned using the ToArray() method, we can unlock our synchronization object again. The following switch statement needs to be executed in the critical section:
switch (s)
{
case "sec":
v ["Records"] = perSecond.ToArray ();
resp.Expires = Now;
break;
case "min":
v ["Records"] = perMinute.ToArray ();
resp.Expires = new DateTime (Now.Year, Now.Month, Now.Day, Now.Hour, Now.Minute, 0).AddMinutes (1);
break;The hour, day, and month cases (h, day, and month respectively) will be handled analogously. We will also make sure to include a default statement that returns an HTTP error, making sure bad requests are handled properly:
default:
throw new HttpException (
HttpStatusCode.ClientError_BadRequest);
}Now, the Variables collection contains a variable called Records that contains an array of Record objects to draw. Furthermore, the ParameterName variable contains the name of the value property to draw. The Timestamp property of each Record object contains values for the time axis. Now we have everything we need to plot the graph. We only need to choose the type of graph to plot.
The motion detector reports Boolean values. Plotting the motion values using lines or curves may just cause a mess if it regularly reports motion and non-motion. A better option is perhaps the use of a scatter graph, where each value is displayed using a small colored disc (say, of radius 5 pixels). We interpret false values to be equal to 0 and paint them Blue, and true values to be equal to 1 and paint them Red.
The Clayster script to accomplish this would be as follows:
scatter2d(Records.Timestamp, if (Values:=Records.Motion) then 1 else 0,5, if Values then 'Red' else 'Blue','','Motion')
The other two properties are easier to draw since they can be drawn as simple line graphs:
line2d(Records.Timestamp,Records.Property,'Value Axis')
The Expression class handles parsing and evaluation of Clayster script expressions. This class has two static methods for parsing an expression: Parse() and ParseCached(). If the expressions are from a limited set of expressions, ParseCached() can be used. It only parses an expression once and remembers it. If expressions contain a random component, Parse() should be used since caching does not fulfill any purpose except exhausting the server memory.
The parsed expression has an Evaluate() method that can be used to evaluate the expression. The method takes a Variables collection, which represents the variables available to the expression when evaluating it. All graphical functions return an object of the Graph class. This object can be used to generate the image we want to return. First, we need a Graph variable to store our script evaluation result:
Graph Result;
We will then generate, parse, and evaluate our script, as follows:
if (ParameterName == "Motion")
Result = Expression.ParseCached ("scatter2d("+
"Records.Timestamp, "+
"if (Values:=Records.Motion) then 1 else 0,5, "+
"if Values then 'Red' else 'Blue','','Motion')").
Evaluate (v) as Graph;
else
Result = Expression.ParseCached ("line2d("+
"Records.Timestamp,Records." + ParameterName +
",'','" + ValueAxis + "')").Evaluate (v)as Graph;We now have our graph. All that is left to do is to generate a bitmapped image from it, to return to the client. We will first get the bitmapped image, as follows:
Image Img = Result.GetImage (Width, Height);

Then we need to encode it so that it can be sent to the client. This is done using
Multi-Purpose Internet Mail Extensions (MIME) encoding of the image. We can use MimeUtilities to encode the image, as follows:
byte[] Data = MimeUtilities.Encode (Img, out s);
The Encode() method on MimeUtilities returns a byte array of the encoded object. It also returns the Internet media type or content type that is used to describe how the object was encoded. We tell the client the content type that was used, and that the operation was performed successfully. We then return the binary block of data representing our image, as follows:
resp.ContentType = s; resp.ReturnCode = HttpStatusCode.Successful_OK; resp.WriteBinary (Data);
We can now view our /html page and see not only our momentary values at the top but also graphs displaying values per second, per minute, per hour, per day, and per month, depending on how long we let the sensor work and collect data. At this point, data is not persisted, so as soon as the data is reset, the sensor will lose all the history.
We have now created interfaces to display sensor data to humans, and are now ready to export the same sensor data to machines. We have registered four web resources to export sensor data to four different formats with the same names: /xml, /json, /turtle, and /rdf. Luckily, we don't have to write these export methods explicitly as long as we export the sensor data. Clayster.Library.IoT helps us to export sensor data to these different formats through the use of an interface named ISensorDataExport.
We will create our four web resources, one for each data format. We will begin with the resource that exports XML data:
private static void HttpGetXml (HttpServerResponse resp,
HttpServerRequest req)
{
HttpGetSensorData (resp, req, "text/xml",
new SensorDataXmlExport (resp.TextWriter));
}We can use the same code to export data to different formats by replacing the key arguments, as shown in the following table:
|
Format |
Method |
Content Type |
Export class |
|---|---|---|---|
|
XML |
|
|
|
|
JSON |
|
|
|
|
TURTLE |
|
|
|
|
RDF |
|
|
|
Clayster.Library.IoT can also help the application to interpret query parameters for sensor data queries in an interoperable manner. This is done by using objects of the ReadoutRequest class, as follows:
private static void HttpGetSensorData (HttpServerResponse resp, HttpServerRequest req,string ContentType, ISensorDataExport ExportModule)
{
ReadoutRequest Request = new ReadoutRequest (req);
HttpGetSensorData (resp, ContentType, ExportModule, Request);
}Often, as in our case, a sensor or a meter has a lot of data. It is definitely not desirable to return all the data to everybody who requests information. In our case, the sensor can store up to 5000 records of historical information. So, why should we export all this information to somebody who only wants to see the momentary values? We shouldn't. The ReadoutRequest class in the Clayster.Library.IoT.SensorData namespace helps us to parse a sensor data request query in an interoperable fashion and lets us know the type of data that is requested. It helps us determine which field names to report on which nodes. It also helps us to limit the output to specific readout types or a specific time interval. In addition, it provides all external credentials used in distributed transactions. Appendix F, Sensor Data Query Parameters, provides a detailed explanation of the query parameters that are used by the ReadoutRequest class.
Data export is now complete, and so the next step is to test the different data formats and see what they look like. First, we will test our XML data export using an URL similar to the following:
http://192.168.0.29/xml?Momentary=1&HistoricalDay=1&Temperature=1
This will only read momentary and daily historical-temperature values. Data will come in an unformatted manner, but viewing the data in a browser provides some form of formatting. If we want JSON instead of XML, we must call the /json resource instead:
http://192.168.0.29/json?Momentary=1&HistoricalDay=1&Temperature=1
The data that is returned can be formatted using online JSON formatting tools to get a better overview of its structure. To test the TURTLE and RDF versions of the data export, we just need to use the URLs similar to the following:
http://192.168.0.29/turtle?Momentary=1&HistoricalDay=1&Temperature=1
http://192.168.0.29/rdf?Momentary=1&HistoricalDay=1&Temperature=1
Publishing things on the Internet is risky. Anybody with access to the thing might also try to use it with malicious intent. For this reason, it is important to protect all public interfaces with some form of user authentication mechanism to make sure only approved users with correct privileges are given access to the device.
Tip
As discussed in the introduction to HTTP, there are several types of user authentication mechanisms to choose from. High-value entities are best protected using both server-side and client-side certificates over an encrypted connection (HTTPS). Although this book does not necessarily deal with things of high individual value, some form of protection is still needed.
We have two types of authentication:
- The first is the www authentication mechanism provided by the HTTP protocol itself. This mechanism is suitable for automation
- The second is a login process embedded into the web application itself, and it uses sessions to maintain user login credentials
Both of these will be explained in Appendix G, Security in HTTP.
Earlier we had a discussion about the positive and negative aspects of letting the sensor be an HTTP server. One of the positive aspects is that it is very easy for others to get current information when they want. However, it is difficult for the sensor to inform interested parties when something happens. If we would have let the sensor act as a HTTP client instead, the roles would have been reversed. It would have been easy to inform others when something happens, but it would have been difficult for interested parties to get current information when they wanted it.
Since we have chosen to let the sensor be an HTTP server, Appendix H, Delayed Responses in HTTP, is dedicated to show how we can inform interested parties of events that occur on the device and when they occur, without the need for constant polling of the device. This architecture will lend itself naturally to a subscription pattern, where different parties can subscribe to different types of events in a natural fashion. These event resources will be used later by the controller to receive information when critical events occur, without the need to constantly poll the sensor.