
Selecting the Clusters menu option provides a list of your current Databricks clusters and their status. Of course, currently you have none. Selecting the Add Cluster option allows you to create one. Note that the amount of memory you specify determines the size of your cluster. There is a minimum of 54 GB required to create a cluster with a single master and worker. For each additional 54 GB specified, another worker is added.

The following screenshot is a concatenated image, showing a new cluster called semclust1 being created and in a Pending state. While Pending, the cluster has no dashboard, and the cluster nodes are not accessible.
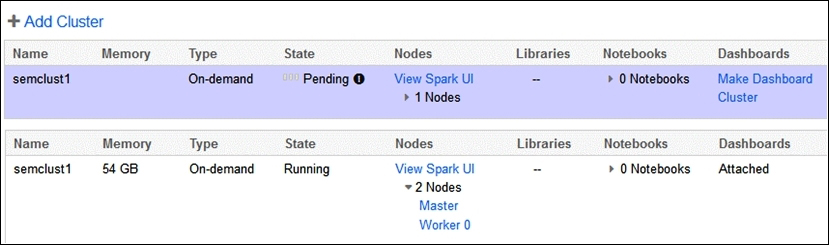
Once created the cluster memory is listed and it's status changes from Pending to Running. A default dashboard has automatically been attached, and the Spark master and worker user interfaces can be accessed. It is important to note here that Databricks automatically starts and manages the cluster processes. There is also an Option column to the right of this display that offers the ability to Configure, Restart, or Terminate a cluster as shown in the following screenshot:

By reconfiguring a cluster, you can change its size. By adding more memory, you can add more workers. The following screenshot shows a cluster, created at the default size of 54 GB, having its memory extended to 108 GB.

Terminating a cluster removes it, and it cannot be recovered. So, you need to be sure that deletion is the correct course of action. Databricks prompts you to confirm your action before the termination actually takes place.

It takes time for a cluster to be both, created and terminated. During termination, the cluster is marked with an orange banner, and a state of Terminating, as shown in the following screenshot:

Note that the cluster type in the previous screenshot is shown to be On-demand. When creating a cluster, it is possible to select a check box called Use spot instances to create a spot cluster. These clusters are cheaper than the on-demand clusters, as they bid for a cheaper AWS spot price. However, they can be slower to start than the on-demand clusters.
The Spark user interfaces are the same as those you would expect on a non-Databricks Spark cluster. You can examine workers, executors, configuration, and log files. As you create clusters, they will be added to your cluster list. One of the clusters will be used as the cluster where the dashboards are run. This can be changed by using the Make Dashboard Cluster option. As you add libraries and Notebooks to your cluster, the cluster details entry will be updated with a count of the numbers added.
The only thing that I would say about the Databricks Spark user interface option at this time, because it is familiar, is that it displays the Spark version that is used. The following screenshot, extracted from the master user interface, shows that the Spark version being used (1.3.0) is very up-to-date. At the time of writing, the latest Apache Spark release was 1.3.1, dated 17 April, 2015.

The next section will examine Databricks Notebooks and folders—how to create them, and how they can be used.