
Chapter 2. Mastering modularity
- Understanding modularity and why it’s desirable
- Using metadata to describe OSGi bundles (aka modules)
- Explaining how bundle metadata is used to manage code visibility
- Illustrating how bundles are used to create an application
In the previous chapter, we took a whistle-stop tour of the OSGi landscape. We made a number of observations about how standard Java is broken with respect to modularity and gave you examples where OSGi can help. We also introduced you to some OSGi concepts, including the core layers of the OSGi framework: module, life-cycle, and service.
In this chapter, we’ll deal specifically with the module layer, because its features are the initial attraction for most Java developers to OSGi. The module layer is the foundation on which everything else rests in the OSGi world. We’ll provide you with a full understanding of what OSGi modularity is, why modularity is important in a general sense, and how it can help you in designing, building, and maintaining Java applications in the future.
The goal of this chapter is to get you thinking in terms of modules rather than JAR files. We’ll teach you about OSGi module metadata, and you’ll learn how to describe your application’s modularity characteristics with it. To illustrate these concepts, we’ll continue the simple paint program example that we introduced in chapter 1; you’ll convert it from a monolithic application into a modular one. Let’s get started with modularity.
2.1. What is modularity?
Modularity encompasses so many aspects of programming that we often take it for granted. The more experience you have with system design, the more you know good designs tend to be modular—but what precisely does that mean? In short, it means designing a complete system from a set of logically independent pieces; these logically independent pieces are called modules. You may be thinking, “Is that it?” In the abstract, yes, that is it; but of course there are a lot of details underneath these simple concepts.
A module defines an enforceable logical boundary: code either is part of a module (it’s on the inside) or it isn’t part of a module (it’s on the outside). The internal (implementation) details of a module are visible only to code that is part of a module. For all other code, the only visible details of a module are those that it explicitly exposes (the public API), as depicted in figure 2.1. This aspect of modules makes them an integral part of designing the logical structure of an application.
Figure 2.1. A module defines a logical boundary. The module itself is explicitly in control of which classes are completely encapsulated and which are exposed for external use.

2.1.1. Modularity vs. object orientation
You may wonder, “Hey, doesn’t object orientation give you these things?” That’s correct: object orientation is intended to address these issues too. You’ll find that modularity provides many of the same benefits as object orientation. One reason these two programming concepts are similar is because both are forms of separation of concerns. The idea behind separation of concerns is you should break down a system into minimally overlapping functionality or concerns, so that each concern can be independently reasoned about, designed, implemented, and used. Modularity is one of the earliest forms of separation of concerns. It gained popularity in the early 1970s, whereas object orientation gained popularity in the early 1980s.
With that said, you may now be wondering, “If I already have object orientation in Java, why do I need modularity too?” Another good question. The need for both arises due to granularity.
Assume you need some functionality for your application. You sit down and start writing Java classes to implement the desired functionality. Do you typically implement all your functionality in a single class? No. If the functionality is even remotely complicated, you implement it as a set of classes. You may also use existing classes from other parts of your project or from the JRE. When you’re done, a logical relationship exists among the classes you created—but where is this relationship captured? Certainly it’s captured in the low-level details of the code, because there are compilation dependencies that won’t be satisfied if all classes aren’t available at compilation time. Likewise, at execution time, these dependencies will fail if all classes aren’t present on the class path when you try to execute your application.
Unfortunately, these relationships among classes can only be known through low-level source code inspection or trial and error. Classes allow you to encapsulate the state and behavior of a single, logical concept. But numerous classes are generally necessary to create a well-designed application. Modules encapsulate classes, allowing you to express the logical relationship among the classes—or concepts—in your application. Figure 2.2 illustrates how modules encapsulate classes, and the resulting inter-module relationships. You may think that Java packages allow you to capture such logical code relationships. Well, you’re right. Packages are a form of built-in modularity provided by Java, but they have some limitations, as discussed in section 1.1.1. So packages are a good starting point in understanding how modularity helps you encapsulate code, but you need a mechanism that goes further. In the end, object orientation and modularity serve different but complementary purposes (see figure 2.3).
Figure 2.2. Classes have explicit dependencies due to the references contained in the code. Modules have implicit dependencies due to the code they contain.

Figure 2.3. Even though object orientation and modularity provide similar capabilities, they address them at different levels of granularity.

When you’re developing in Java, you can view object orientation as the implementation approach for modules. As such, when you’re developing classes, you’re programming in the small, which means you aren’t thinking about the overall structure of your application, but instead are thinking in terms of specific functionality. After you begin to logically organize related classes into modules, then you start to concern yourself with programming in the large, which means you’re focusing on the larger logical pieces of your system and the relationships among those pieces.
In addition to capturing relationships among classes via module membership, modules also capture logical system structure by explicitly declaring dependencies on external code. With this in mind, we now have all the pieces in place to more concretely define what we mean by the term module in the context of this book.
Module
A set of logically encapsulated implementation classes, an optional public API based on a subset of the implementation classes, and a set of dependencies on external code.
Although this definition implies that modules contain classes, at this point this sense of containment is purely logical. Another aspect of modularity worth understanding is physical modularity, which refers to the container of module code.
A module defines a logical boundary in your application, which impacts code visibility in a fashion similar to access modifiers in object-oriented programming. Logical modularity refers to this form of code visibility. Physical modularity refers to how code is packaged and/or made available for deployment.
In OSGi, these two concepts are largely conflated; a logical module is referred to as a bundle, and so is the physical module (that is, the JAR file). Even though these two concepts are nearly synonymous in OSGi, for modularity in general they aren’t, because it’s possible to have logical modularity without physical modularity or to package multiple logical modules into a single physical module. Physical modules are sometimes also referred to as deployment modules or deployment units.
The OSGi module layer allows you to properly express the modularity characteristics of applications, but it’s not free. Let’s look in more depth at why you should modularize your applications, so you can make up your own mind.
2.2. Why modularize?
We’ve talked about what modularity is, but we haven’t gone into great depth about why you might want to modularize your own applications. In fact, you may be thinking, “If modularity has been around for almost 40 years and it’s so important, why isn’t everyone already doing it?” That’s a great question, and one that probably doesn’t have any single answer. The computer industry is driven by the next best thing, so we tend to throw out the old when the new comes along. And in fairness, as we discussed in the last section, the new technologies and approaches (such as object orientation and component orientation) do provide some of the same benefits that modularity was intended to address.
Java also provides another important reason why modularity is once again an important concern. Traditionally, programming languages were the domain of logical modularity mechanisms, and operating systems and/or deployment packaging systems were the domain of physical modularity. Java blurs this distinction because it’s both a language and a platform. To compare to a similar situation, look at the .NET platform. Microsoft, given its history of operating system development and the pain of DLL hell, recognized this connection early in .NET, which is why it has a module concept called an assembly. Finally, the size of applications continues to grow, which makes modularity an important part of managing their complexity—divide and conquer!
This discussion provides some potential explanations for why modularity is coming back in vogue, but it doesn’t answer this section’s original question: Why should you modularize your applications? Modularity allows you to reason about the logical structure of applications. Two key concepts arose from modularity decades ago:
- Cohesion measures how closely aligned a module’s classes are with each other and with achieving the module’s intended functionality. You should strive for high cohesion in your modules. For example, a module shouldn’t address many different concerns (network communication, persistence, XML parsing, and so on): it should focus on a single concern.
- Coupling, on the other hand, refers to how tightly bound or dependent different modules are on each other. You should strive for low coupling among your modules. For example, you don’t want every module to depend on all other modules.
As you start to use OSGi to modularize your applications, you can’t avoid these issues. Modularizing your application will help you see your application in a way that you couldn’t before.
By keeping these principles of cohesion and coupling in mind, you’ll create more reusable code, because it’s easier to reuse a module that performs a single function and doesn’t have a lot of dependencies on other code.
More specifically, by using OSGi to modularize your applications, you’ll be able to address the Java limitations discussed in section 1.1.1. Additionally, because the modules you’ll create will explicitly declare their external code dependencies, reuse is further simplified because you’ll no longer have to scrounge documentation or resort to trial and error to figure out what to put on the class path. This results in code that more readily fits into collaborative, independent development approaches, such as in multiteam, multilocation projects or in large-scale open source projects.
Now you know what modularity is and why you want it, so let’s begin to focus on how OSGi provides it and what you need to do to use it in your own applications. The example paint program will help you understand the concepts.
2.3. Modularizing a simple paint program
The functionality provided by OSGi’s module layer is sophisticated and can seem overwhelming when taken in total. You’ll use a simple paint program, as discussed in chapter 1, to learn how to use OSGi’s module layer. You’ll start from an existing paint program, rather than creating one from scratch. The existing implementation follows an interfaced-based approach with logical package structuring, so it’s amenable to modularization, but it’s currently packaged as a single JAR file. The following listing shows the contents of the paint program’s JAR file.
Listing 2.1. Contents of existing paint program’s JAR file
META-INF/ META-INF/MANIFEST.MF org/ org/foo/ org/foo/paint/ org/foo/paint/PaintFrame$1$1.class org/foo/paint/PaintFrame$1.class org/foo/paint/PaintFrame$ShapeActionListener.class org/foo/paint/PaintFrame.class org/foo/paint/SimpleShape.class org/foo/paint/ShapeComponent.class org/foo/shape/ org/foo/shape/Circle.class org/foo/shape/circle.png org/foo/shape/Square.class org/foo/shape/square.png org/foo/shape/Triangle.class org/foo/shape/triangle.png
The listing begins with a standard manifest file. Then come the application classes, followed by various shape implementations.
The main classes composing the paint program are described in table 2.1.
Table 2.1. Overview of the classes in the paint program
|
Class |
Description |
|---|---|
| org.foo.paint.PaintFrame | The main window of the paint program, which contains the toolbar and drawing canvas. It also has a static main() method to launch the program. |
| org.foo.paint.SimpleShape | An interface representing an abstract shape for painting. |
| org.foo.paint.ShapeComponent | A GUI component responsible for drawing shapes onto the drawing canvas. |
| org.foo.shape.Circle | An implementation of SimpleShape for drawing circles. |
| org.foo.shape.Square | An implementation of SimpleShape for drawing squares. |
| org.foo.shape.Triangle | An implementation of SimpleShape for drawing triangles. |
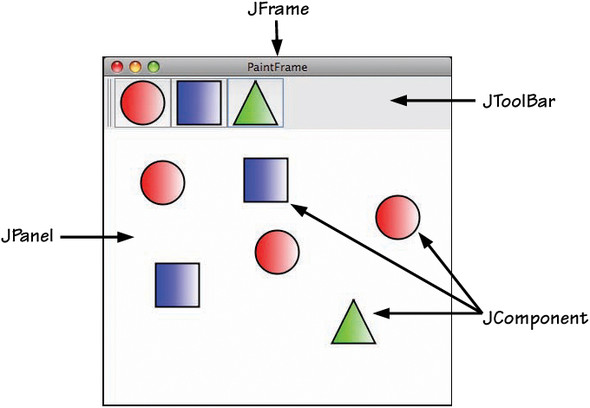
For those familiar with Swing, PaintFrame extends JFrame and contains a JToolBar and a JPanel canvas. PaintFrame maintains a list of available SimpleShape implementations, which it displays in the toolbar. When the user selects a shape in the toolbar and clicks in the canvas to draw the shape, a ShapeComponent (which extends JComponent) is added to the canvas at the location where the user clicked. A ShapeComponent is associated with a specific SimpleShape implementation by name, which it retrieves from a reference to its PaintFrame. Figure 2.4 highlights some of the UI elements in the paint program GUI.
Figure 2.4. The paint program is a simple Swing application.
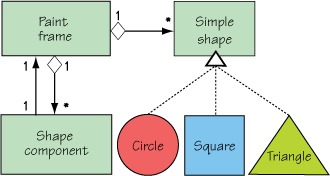
A static main() method on PaintFrame launches the paint program, which creates an instance of the PaintFrame and each shape implementation, adding each shape instance to the created PaintFrame instance. For further explanation, figure 2.5 captures the paint program classes and their interrelationships.
Figure 2.5. Paint program class relationships
To run this nonmodular version of the paint program, go into the chapter02/ paint-nonmodular/ directory of the companion code. Type ant to build the program, and then type java -jar main.jar to run it. Feel free to click around and see how it works; we won’t go into any more details of the program’s implementation, because GUI programming is beyond the scope of this book. The important point is to understand the structure of the program. Using this understanding, you’ll divide the program into bundles so you can enhance and enforce its modularity.
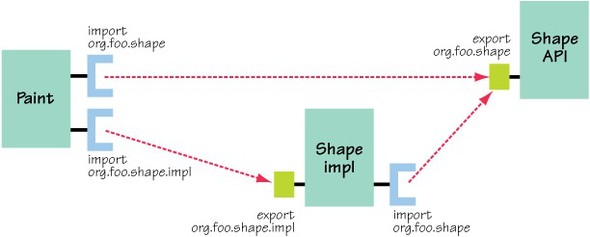
Currently, the paint program is packaged as a single JAR file, which we’ll call version 1.0.0 of the program. Because everything is in a single JAR file, this implies that the program isn’t already modularized. Of course, single-JAR-file applications can still be implemented in a modular way—just because an application is composed of multiple JAR files, that doesn’t mean it’s modular. The paint program example could have both its logical and physical modularity improved. First, we’ll examine the program’s logical structure and define modules to enhance this structure. Where do you start?
One low-hanging fruit you can look for is public APIs. It’s good practice in OSGi (you’ll see why later) to separate your public APIs into packages so they can be easily shared without worrying about exposing implementation details. The paint program has a good example of a public API: its SimpleShape interface. This interface makes it easy to implement new, possibly third-party shapes for use with the program. Unfortunately, SimpleShape is in the same package as the program’s implementation classes. To remedy this situation, you’ll shuffle the package structure slightly. You’ll move SimpleShape into the org.foo.shape package and move all shape implementations into a new package called org.foo.shape.impl. These changes divide the paint program into three logical pieces according to the package structure:
- org.foo.shape—The public API for creating shapes
- org.foo.shape.impl—Various shape implementations
- org.foo.paint—The application implementation
Given this structure (logical modularity), you could package each of these packages as separate JAR files (physical modularity). To have OSGi verify and enforce the modularity, it isn’t sufficient to package the code as JAR files: you must package them as bundles. To do this, you need to understand OSGi’s bundle concept, which is its logical and physical unit of modularity. Let’s introduce bundles.
2.4. Introducing bundles
If you’re going to use OSGi technology, you may as well start getting familiar with the term bundle, because you’ll hear and say it a lot. Bundle is how OSGi refers to its specific realization of the module concept.
Throughout the remainder of this book, the terms module and bundle will be used interchangeably; but in most cases we’re specifically referring to bundles and not modularity in general, unless otherwise noted. Enough fuss about how we’ll use the term bundle—let’s define it.
Bundle
A physical unit of modularity in the form of a JAR file containing code, resources, and metadata, where the boundary of the JAR file also serves as the encapsulation boundary for logical modularity at execution time.
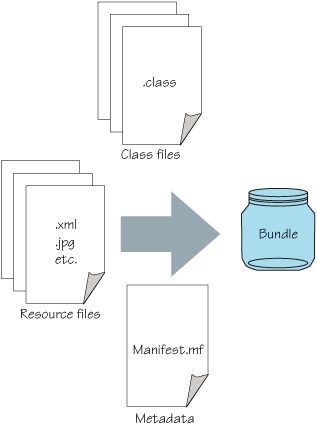
The contents of a bundle are graphically depicted in figure 2.6. The main thing that makes a bundle JAR file different than a normal JAR file is its module metadata, which is used by the OSGi framework to manage its modularity characteristics. All JAR files, even if they aren’t bundles, have a place for metadata, which is in their manifest file or, more specifically, in the META-INF/MANIFEST.MF entry of the JAR file. This is where OSGi places its module metadata. Whenever we refer to a bundle’s manifest file, we’re specifically referring to the module-related metadata in this standard JAR manifest file.
Figure 2.6. A bundle can contain all the usual artifacts you expect in a standard JAR file. The only major difference is that the manifest file contains information describing the bundle’s modular characteristics.
Note that this definition of a bundle is similar to the definition of a module, except that it combines both the physical and logical aspects of modularity into one concept. So before we get into the meat of this chapter, which is defining bundle metadata, let’s discuss the bundle’s role in physical and logical modularity in more detail.
2.4.1. The bundle’s role in physical modularity
The main function of a bundle with respect to physical modularity is to determine module membership. No metadata is associated with making a class a member of a bundle. A given class is a member of a bundle if it’s contained in the bundle JAR file. The benefit for you is that you don’t need to do anything special to make a class a member of a bundle: just put it in the bundle JAR file.
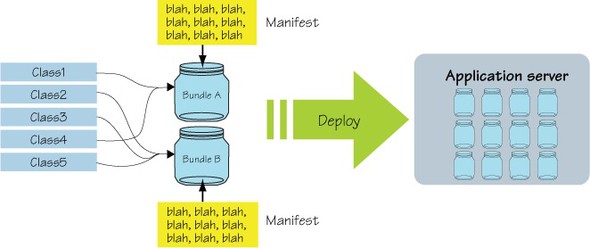
This physical containment of classes leads to another important function of bundle JAR files as a deployment unit. The bundle JAR file is tangible, and it’s the artifact you share, deploy, and use when working with OSGi. The final important role of the bundle JAR file is as the container of bundle metadata, because, as we mentioned, the JAR manifest file is used to store it. These aspects of the bundle are shown in figure 2.7. The issue of metadata placement is part of an ongoing debate, which we address in the sidebar for those interested in the issue.
Figure 2.7. A class is a member of a bundle if it’s packaged in it, the bundle carries its module metadata inside it as part of its manifest data, and the bundle can be deployed as a unit into a runtime environment.
Is it a good thing to store the module metadata in the physical module and not in the classes themselves? There are two schools of thought on this subject. One says it’s better to include the metadata alongside the code it’s describing (in the source file itself), rather than in a separate file where it’s more difficult to see the connection to the code. This approach is possible with various techniques, such as doclets or the annotations mechanism introduced in Java 5.
Annotations are the choice du jour today. Unfortunately, when OSGi work started back in 1999, annotations weren’t an option because they didn’t exist yet. Besides, there are some good reasons to keep the metadata in a separate file, which brings us to the second school of thought.
This school of thought argues that it’s better to not bake metadata into the source code, because it becomes harder to change. Having metadata in a separate file offers you greater flexibility. Consider the following benefits of having separate module metadata:
- You don’t need to recompile your bundle to make changes to its metadata.
- You don’t need access to the source code to add or modify metadata, which is sometimes necessary when dealing with legacy or third-party libraries.
- You don’t need to load classes into the JVM to access the associated metadata.
- Your code doesn’t get a compile-time dependency on OSGi API.
- You can use the same code in multiple modules, which is convenient or even necessary in some situations when packaging your modules.
- You can easily use your code on older or smaller JVMs that don’t support annotations.
Regardless of whether your preferred approach is annotations, you can see that you gain a good deal of flexibility by maintaining the module metadata in the manifest file.
2.4.2. The bundle’s role in logical modularity
Similar to how the bundle JAR file physically encapsulates the member classes, the bundle’s role in logical modularity is to logically encapsulate member classes. What precisely does this mean? It specifically relates to code visibility. Imagine that you have a utility class in a util package that isn’t part of your project’s public API. To use this utility class from different packages in your project, it must be public. Unfortunately, this means anyone can use the utility class, even though it’s not part of your public API.
The logical boundary created by a bundle changes this, giving classes inside the bundle different visibility rules to external code, as shown in figure 2.8. This means public classes inside your bundle JAR file aren’t necessarily externally visible. You may be thinking, “What?” This isn’t a misstatement: it’s a major differentiator between bundles and standard JAR files. Only code explicitly exposed via bundle metadata is visible externally. This logical boundary effectively extends standard Java access modifiers (public, private, protected, and package private) with module private visibility (only visible in the module). If you’re familiar with .NET, this is similar to the internal access modifier, which marks something as being visible in an assembly but private from other assemblies.
Figure 2.8. Packages (and therefore the classes in them) contained in a bundle are private to that bundle unless explicitly exposed, allowing them to be shared with other bundles.
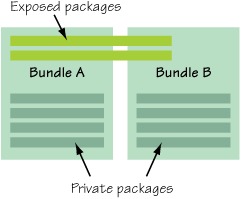
As you can see, the bundle concept plays important roles in both physical and logical modularity. Now we can start to examine how you use metadata to describe bundles.
2.5. Defining bundles with metadata
In this section, we’ll discuss OSGi bundle metadata in detail, and you’ll use the paint program as a use case to understand the theory. The main purpose of bundle metadata is to precisely describe the modularity-related characteristics of a bundle so the OSGi framework can handle it appropriately, such as resolving dependencies and enforcing encapsulation. The module-related metadata captures the following pieces of information about the bundle:
- Human-readable information —Optional information intended purely as an aid to humans who are using the bundle
- Bundle identification —Required information to identify a bundle
- Code visibility —Required information for defining which code is internally visible and which internal code is externally visible
We’ll look at each of these areas in the following subsections. But because OSGi relies on the manifest file, we’ve included a sidebar to explain its persnickety syntax details and OSGi’s extended manifest value syntax. Luckily, there are tools for editing and generating bundle metadata, so you don’t have to create it manually, but it’s still worthwhile to understand the syntax details.
The JAR file manifest is composed of groups of name-value pairs (attributes). The general format for an attribute declaration is
name: value
The name isn’t case sensitive and can contain alphanumeric, underscore, and hyphen characters. Values can contain any character information except carriage returns and line feeds. The name and the value must be separated by a colon and a space. A single line can’t exceed 72 characters. If a line must exceed this length, you must continue it on the next line, which you do by starting the next line with a single space character followed by the continuation of the value. Manifest lines in OSGi can grow quite long, so it’s useful to know this.
You define an attribute group by placing attribute declarations on successive lines (one line after the other) in the manifest file. An empty or blank line between attribute declarations signifies different attribute groups. OSGi uses the first group of attributes, called the main attributes, for module metadata. The order of attributes in a group isn’t important. If you look in a manifest file, you may see something like this:
Manifest-Version: 1.0 Created-By: 1.4 (Sun Microsystems Inc.) Bundle-ManifestVersion: 2 Bundle-SymbolicName: org.foo.api Bundle-Version: 1.0.0.SNAPSHOT Bundle-Name: Simple Paint API Export-Package: org.foo.api Import-Package: javax.swing,org.foo.api Bundle-License: http://www.opensource.org/licenses/apache2.0.php
We’ll get into the exact meaning of most of these attributes throughout the remainder of this section. But for now, we’ll focus on the syntax. Whereas the standard Java manifest syntax is a name-value pair, OSGi defines a common structure for OSGi-specified attribute values. Most OSGi manifest attribute values are a list of clauses separated by commas, such as
Property-Name: clause, clause, clause
Each clause is further broken down into a target and a list of name-value pair parameters separated by semicolons:
Property-Name: target1; parameter1=value1; parameter2=value2, target2; parameter1=value1; parameter2=value2, target3; parameter1=value1; parameter2=value2
Parameters are divided into two types, called attributes and directives. Directives alter framework handling of the associated information and are explicitly defined by the OSGi specification. Attributes are arbitrary name-value pairs. You’ll see how to use directives and attributes later. Slightly different syntax is used to differentiate directives (:=) from attributes (=), which looks something like this:
Property-Name: target1; dir1:=value1; attr1=value2, target2; dir1:=value1; attr1=value2, target3; dir1:=value1; attr1=value2
Keep in mind that you can have any number of directives and attributes assigned to each target, all with different values. Values containing whitespace or separator characters should be quoted to avoid parsing errors. Sometimes you’ll have lots of targets with the same set of directives and attributes. In such a situation, OSGi provides a shorthand way to avoid repeating all the duplicated directives and attributes, as follows:
Property-Name: target1; target2; dir1:=value1; attr1=value2
This is equivalent to listing the targets separately with their own directives and attributes. This is pretty much everything you need to understand the structure of OSGi manifest attributes. Not all OSGi manifest values conform to this common structure, but the majority do, so it makes sense for you to become familiar with it.
2.5.1. Human-readable information
Most bundle metadata is intended to be read and interpreted by the OSGi framework in its effort to provide a general module layer for Java. But some bundle metadata serves no purpose other than helping humans understand what a bundle does and from where it comes. The OSGi specification defines several pieces of metadata for this purpose, but none of it is required, nor does it have any impact on modularity. The OSGi framework completely ignores it.
The following code snippet shows human-readable bundle metadata for the paint program’s org.foo.shape bundle (the other program bundles are described similarly):
Bundle-Name: Simple Paint API Bundle-Description: Public API for a simple paint program. Bundle-DocURL: http://www.manning.com/osgi-in-action/ Bundle-Category: example, library Bundle-Vendor: OSGi in Action Bundle-ContactAddress: 1234 Main Street, USA Bundle-Copyright: OSGi in Action
The Bundle-Name attribute is intended to be a short name for the bundle. You’re free to name your bundle anything you want. Even though it’s supposed to be a short name, there’s no enforcement of this; just use your best judgment. The Bundle-Description attribute lets you be a little more long-winded in describing the purpose of your bundle. To provide even more documentation about your bundle, Bundle-DocURL allows you to specify a URL to refer to documentation. Bundle-Category defines a comma-separated list of category names. OSGi doesn’t define any standard category names, so you’re free to choose your own. The remaining attributes, Bundle-Vendor, Bundle-ContactAddress, and Bundle-Copyright, provide information about the bundle vendor.
Human-readable metadata is reasonably straightforward. The fact that the OSGi framework ignores it means you can pretty much do what you want to with it. But don’t fall into a laissez-faire approach just yet—the remaining metadata requires more precision. Next, we’ll look at how you use metadata to uniquely identify bundles.
2.5.2. Bundle identification
The human-readable metadata from the previous subsection helps you understand what a bundle does and where it comes from. Some of this human-readable metadata also appears to play a role in identifying a bundle. For example, Bundle-Name seems like it could be a form of bundle identification. It isn’t. The reason is somewhat historical. Earlier versions of the OSGi specification didn’t provide any means to uniquely identify a given bundle. Bundle-Name was purely informational, and therefore no constraints were placed on its value. As part of the OSGi R4 specification process, the idea of a unique bundle identifier was proposed. For backward-compatibility reasons, Bundle-Name couldn’t be commandeered for this purpose because it wouldn’t be possible to place new constraints on it and maintain backward compatibility. Instead, a new manifest entry was introduced: Bundle-SymbolicName.
In contrast to Bundle-Name, which is only intended for users, Bundle-SymbolicName is only intended for the OSGi framework to help uniquely identify a bundle. The value of the symbolic name follows rules similar to Java package naming: it’s a series of dot-separated strings, where reverse domain naming is recommended to avoid name clashes. Although the dot-separated construction is enforced by the framework, there’s no way to enforce the reverse-domain-name recommendation. You’re free to choose a different scheme; but if you do, keep in mind that the main purpose is to provide unique identification, so try to choose a scheme that won’t lead to name clashes.
Identifying the Paint Program (Part 1)
The paint program is divided into bundles based on packages, so you can use each package as the symbolic name, because they already follow a reverse-domain-name scheme. For the public API bundle, you declare the symbolic name in manifest file as
Bundle-SymbolicName: org.foo.shape
Although it would be possible to solely use Bundle-SymbolicName to uniquely identify a bundle, it would be awkward to do so over time. Consider what would happen when you released a second version of your bundle: you’d need to change the symbolic name to keep it unique, such as org.foo.shapeV2. This is possible, but it’s cumbersome; and worse, this versioning information would be opaque to the OSGi framework, which means the modularity layer couldn’t take advantage of it. To remedy this situation, a bundle is uniquely identified not only by its Bundle-SymbolicName but also by its Bundle-Version, whose value conforms to the OSGi version number format (see the sidebar “OSGi version number format”). This pair of attributes not only forms an identifier, it also allows the framework to capture the time-ordered relationship among versions of the same bundle.
Identifying the Paint Program (Part 2)
For example, the following metadata uniquely identifies the paint program’s public API bundle:
Bundle-SymbolicName: org.foo.shape Bundle-Version: 2.0.0
Although technically only Bundle-SymbolicName and Bundle-Version are related to bundle identification, the Bundle-ManifestVersion attribute also plays a role. Starting with the R4 specification, it became mandatory for bundles to specify Bundle-SymbolicName. This was a substantial change in philosophy. To maintain backward compatibility with legacy bundles created before the R4 specification, OSGi introduced the Bundle-ManifestVersion attribute. Currently, the only valid value for this attribute is 2, which is the value for bundles created for the R4 specification or later. Any bundles without Bundle-ManifestVersion aren’t required to be uniquely identified, but bundles with it must be.
Identifying the Paint Program (Part 3)
The following example shows the complete OSGi R4 metadata to identify the shape bundle:
Bundle-ManifestVersion: 2 Bundle-SymbolicName: org.foo.shape Bundle-Version: 2.0.0
This is the complete identification metadata for the public API bundle. The identification metadata for the other paint program bundles are defined in a similar fashion. Now that bundle identification is out of the way, we’re ready to look at code visibility, which is perhaps the most important area of metadata.
One important concept you’ll visit over and over again in OSGi is a version number, which appears here in the bundle-identification metadata. The OSGi specification defines a common version number format that’s used in a number of places throughout the specification. For this reason, it’s worth spending a few paragraphs exploring exactly what a version number is in the OSGi world.
A version number is composed of three separate numerical component values separated by dots; for example, 1.0.0 is a valid OSGi version number. The first value is referred to as the major number, the second value as the minor number, and the third value as the micro number. These names reflect the relative precedence of each component value and are similar to other version-numbering schemes, where version-number ordering is based on numerical comparison of version-number components in decreasing order of precedence: in other words, 2.0.0 is newer than 1.2.0, and 1.10.0 is newer than 1.9.9.
A fourth version component is possible, which is called a qualifier. The qualifier can contain alphanumeric characters; for example, 1.0.0.alpha is a valid OSGi version number with a qualifier. When comparing version numbers, the qualifier is compared using string comparison. As the following figure shows, this doesn’t always lead to intuitive results; for example, although 1.0.0.beta is newer than 1.0.0.alpha, 1.0.0 is older than both.

OSGi versioning semantics can sometimes lead to non-intuitive results.
In places in the metadata where a version is expected, if it’s omitted, it defaults to 0.0.0. If a numeric component of the version number is omitted, it defaults to 0, and the qualifier defaults to an empty string. For example, 1.2 is equivalent to 1.2.0. One tricky aspect is that it isn’t possible to have a qualifier without specifying all the numeric components of the version. So you can’t specify 1.2.build-59; you must specify 1.2.0.build-59.
OSGi uses this common version-number format for versioning both bundles and Java packages. In chapter 9, we’ll discuss high-level approaches for managing version numbers for your packages, bundles, and applications.
2.5.3. Code visibility
Human-readable and bundle-identification metadata are valuable, but they don’t go far in allowing you to describe your bundle’s modularity characteristics. The OSGi specification defines metadata for comprehensively describing which code is visible internally in a bundle and which internal code is visible externally. OSGi metadata for code visibility captures the following information:
- Internal bundle class path —The code forming the bundle
- Exported internal code —Explicitly exposed code from the bundle class path for sharing with other bundles
- Imported external code —External code on which the bundle class path code depends
Each of these areas captures separate but related information about which Java classes are reachable in your bundle and by your bundle. We’ll cover each in detail; but before we do that, let’s step back and dissect how you use JAR files and the Java class path in traditional Java programming. This will give you a basis for comparison to OSGi’s approach to code visibility.
Important!
Standard JAR files typically fail as bundles since they were written under the assumption of global type visibility (i.e., if it’s on the class path, you can use it). If you’re going to create effective bundles, you have to free yourself from this old assumption and fully understand and accept that type visibility for bundles is based purely on the primitives we describe in this section. To make this point very clear, we’ll go into intricate details about type visibility rules for standard JAR files versus bundle JAR files. Although this may appear to be a lesson in the arcane, it’s critical to understand these differences.
Code Visibility in Standard Jar Files and the Class Path
Generally speaking, you compile Java source files into classes and then use the jar tool to create a JAR file from the generated classes. If the JAR file has a Main-Class attribute in the manifest file, you can run the application like this:
java -jar app.jar
If not, you add it to the class path and start the application something like this:
java -cp app.jar org.foo.Main
Figure 2.9 shows the stages the JVM goes through. First it searches for the class specified in the Main-Class attribute or the one specified on the command line. If it finds the class, it searches it for a static public void main(String[]) method. If such a method is found, it invokes it to start the application. As the application executes, any additional classes needed by the application are found by searching the class path, which is composed of the application classes in the JAR file and the standard JRE classes (and anything you may have added to the class path). Classes are loaded as they’re needed.
Figure 2.9. Flow diagram showing the steps the JVM goes through to execute a Java program from the class path
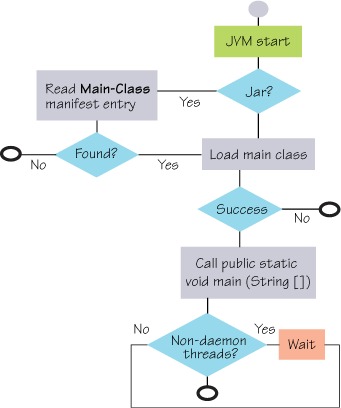
This represents a high-level understanding of how Java executes an application from a JAR file. But this high-level view conceals a few implicit decisions made by standard JAR file handling, such as these:
- Where to search inside the JAR file for a requested class
- Which internal classes should be externally exposed
With respect to the first decision, a JAR file has an implicit policy of searching all directories relative to the root of the JAR file as if they were package names corresponding to the requested class (for example, the class org.foo.Bar is in org/foo/Bar.class inside the JAR file). With respect to the second decision, JAR files have an implicit policy of exposing all classes in root-relative packages to all requesters. This is a highly deconstructed view of the behavior of JAR files, but it helps to illustrate the implicit modularity decisions of standard JAR files. These implicit code-visibility decisions are put into effect when you place a JAR file on the class path for execution.
While executing, the JVM finds all needed classes by searching the class path, as shown in figure 2.10. But what is the exact purpose of the class path with respect to modularity? The class path defines which external classes are visible to the JAR file’s internal classes. Every class reachable on the class path is visible to the application classes, even if they aren’t needed.
Figure 2.10. Flow diagram showing the steps the JVM goes through to load a class from the class path
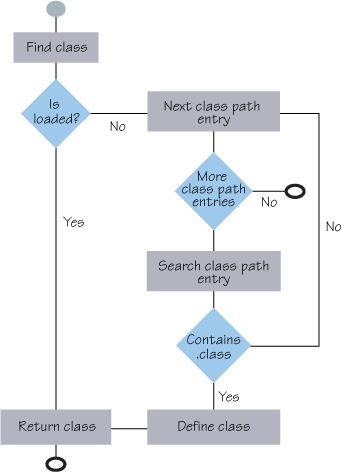
With this view of how standard JAR files and the class path mechanism work, let’s look into the details of how OSGi handles these same code-visibility concepts, which is quite a bit different. We’ll start with how OSGi searches bundles internally for code, followed by how OSGi externally exposes internal code, and finally how external code is made visible to internal bundle code. Let’s get started.
Internal Bundle Class Path
Whereas standard JAR files are implicitly searched for internal classes in all directories from the root of the JAR file as if they were package names, OSGi uses a more explicit approach called the bundle class path. Like the standard Java class path concept, the bundle class path is a list of locations to search for classes. The difference is the bundle class path refers to locations inside the bundle JAR file.
Bundle-Classpath
An ordered, comma-separated list of relative bundle JAR file locations to be searched for class and resource requests.
When a given bundle class needs another class in the same bundle, the entire bundle class path of the containing bundle is searched to find the class. Classes in the same bundle have access to all code reachable on their bundle class path. Let’s examine the syntax for declaring it.
Bundles declare their internal class path using the Bundle-ClassPath manifest header. The bundle class path behaves in the same way as the global class path in terms of the search algorithm, so you can refer to figure 2.10 to see how this behaves; but in this case, the scope is limited to classes contained in the bundle. With Bundle-ClassPath, you can specify a list of paths in the bundle where the class loader should look for classes or resources. For example:
Bundle-ClassPath: .,other-classes/,embedded.jar
This tells the OSGi framework where to search inside the bundle for classes. The period (.) signifies the bundle JAR file. For this example, the bundle is searched first for root-relative packages, then in the folder called other-classes, and finally in the embedded JAR in the bundle. The ordering is important, because the bundle class path entries are searched in the declared order.
Bundle-ClassPath is somewhat unique, because OSGi manifest headers don’t normally have default values. If you don’t specify a value, the framework supplies a default value of period (.). Why does Bundle-ClassPath have a default value? The answer is related to how standard JAR files are searched for classes. The bundle class path value of . corresponds to the internal search policy of standard JAR files. Putting . on your bundle class path likewise treats all root-relative directories as if they were packages when searching for classes. Making . the default gives both standard and bundle JAR files the same default internal search policy.
Note
It’s important to understand that the default value of Bundle-Class-Path is . if and only if there is no specified value, which isn’t the same as saying the value . is included on the bundle class path by default. In other words, if you specify a value for Bundle-ClassPath, then . is included only if you explicitly specify it in your comma-separated list of locations. If you specify a value and don’t include ., then root-relative directories aren’t searched when looking for classes in the bundle JAR file.
As you can see, the internal bundle class path concept is powerful and flexible when it comes to defining the contents and internal search order of bundles; refer to the sidebar “Bundle class path flexibility” for some examples of when this flexibility is useful. Next, you’ll learn how to expose internal code for sharing with other bundles.
You may wonder why you’d want to package classes in different directories or embed JAR files in the bundle JAR file. First, the bundle class path mechanism doesn’t apply only to classes, but also to resources. A common use case is to place images in an image/ directory to make it explicit in the JAR file where certain content can be found. Also, in web applications, nested JAR files are embedded in the JAR file under the WEB-INF/lib/ directory and classes can be placed in the WEB-INF/classes/ directory.
In other situations, you may have a legacy or proprietary JAR file that you can’t change. By embedding the JAR file into your bundle and adding bundle metadata, you can use it without changing the original JAR. It may also be convenient to embed a JAR file when you want your bundle to have a private copy of some library; this is especially useful when you want to avoid sharing static library members with other bundles.
Embedding JAR files isn’t strictly necessary, because you can also unpack a standard JAR file into your bundle to achieve the same effect. As an aside, you can also see a performance improvement by not embedding JAR files, because OSGi framework implementations must extract the embedded JAR files to access them.
Exporting Internal Code
Bundle-ClassPath affects the visibility of classes in a bundle, but how do you share classes among bundles? The first stage is to export the packages you wish to share with others.
Externally useful classes are those composing the public API of the code contained in the JAR file, whereas non-useful classes form the implementation details. Standard JAR files don’t provide any mechanism to differentiate externally useful classes from non-useful ones, but OSGi does. A standard JAR file exposes everything relative to the root by default, but an OSGi bundle exposes nothing by default. A bundle must use the Export-Package manifest header to explicitly expose internal classes it wishes to share with other bundles.
Export-Package
A comma-separated list of internal bundle packages to expose for sharing with other bundles.
Instead of exposing individual classes, OSGi defines sharing among bundles at the package level. Although this makes the task of exporting code a little simpler, it can still be a major undertaking for large projects; we’ll discuss some tools to simplify this in appendix A. When you include a package in an Export-Package declaration, every public class contained in the package is exposed to other bundles. A simple example for the paint program shape API bundle is as follows (figure 2.11 shows how we’ll graphically represent exported module packages):
Figure 2.11. Graphical depiction of an exported package
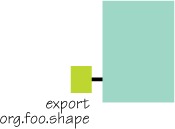
Export-Package: org.foo.shape
Here, you’re exporting every class in the org.foo.shape package. You’ll likely want to export more than one package at a time from your bundles. You can export multiple packages by separating them with commas:
Export-Package: org.foo.shape,org.foo.other
You can also attach attributes to exported packages. Because it’s possible for different bundles to export the same packages, a given bundle can use attributes to differentiate its exports from other bundles. For example:
Export-Package: org.foo.shape; vendor="Manning", org.foo.other; vendor="Manning"
This attaches the vendor attribute with the value "Manning" to the exported packages. In this particular example, vendor is an arbitrary attribute because it has no special meaning to the framework—it’s something we made up. When we talk about importing code, you’ll get a better idea of how arbitrary attributes are used in package sharing to differentiate among exported packages. As we mentioned previously in the sidebar “JAR file manifest syntax,” OSGi also supports a shorthand format when you want to attach the same attributes to a set of target packages, like this:
Export-Package: org.foo.shape; org.foo.other; vendor="Manning"
This is equivalent to the previous example. This shorthand comes in handy, but it can be applied only if all attached attributes are the same for all packages. Using arbitrary attributes allows a bundle to differentiate its exported packages, but there’s a more meaningful reason to use an attribute for differentiation: version management.
Code is constantly evolving. Packages contain classes that change over time. It’s important to document such changes using version numbers. Version management isn’t a part of standard Java development, but it’s inherent in OSGi-based Java development. In particular, OSGi supports not only bundle versioning, as discussed previously, but also package versioning, which means every shared package has a version number. Attributes are used to associate a version number with a package:
Export-Package: org.foo.shape; org.foo.other; version="2.0.0"
Here, you attach the version attribute with the value "2.0.0" to the exported packages, using OSGi’s common version-number format. In this case, the attribute isn’t arbitrary, because this attribute name and value format is defined by the OSGi specification. You may have noticed that some of the earlier Export-Package examples don’t specify a version. In that case, the version defaults to "0.0.0", but it isn’t a good idea to use this version number. We’ll discuss versioning in more detail in chapter 9.
With Bundle-ClassPath and Export-Package, you have a pretty good idea how to define and control the visibility of the bundle’s internal classes; but not all the code you need will be contained in the bundle JAR file. Next, you’ll learn how to specify the bundle’s dependencies on external code.
Importing External Code
Both Bundle-ClassPath and Export-Package deal with the visibility of internal bundle code. Normally, a bundle is also dependent on external code. You need some way to declare which external classes are needed by the bundle so the OSGi framework can make them visible to it. Typically, the standard Java class path is used to specify which external code is visible to classes in your JAR files, but OSGi doesn’t use this mechanism. OSGi requires all bundles to include metadata explicitly declaring their dependencies on external code, referred to as importing.
Importing external code is straightforward, if not tedious. You must declare imports for all packages required by your bundle but not contained in your bundle. The only exception to this rule is for classes in the java.* packages, which are automatically made visible to all bundles by the OSGi framework. The manifest header you use for importing external code is appropriately named Import-Package.
Import-Package
A comma-separated list of packages needed by internal bundle code from other bundles.
You may be thinking that you already do imports in your source code with the import keyword. Conceptually, the import keyword and declaring OSGi imports are similar, but they serve different purposes. The import keyword in Java is for namespace management; it allows you to use the short name of the imported classes instead of using its fully qualified class name (for example, you can refer to SimpleShape rather than org.foo.shape.SimpleShape). You can import classes from any other package to use their short name, but it doesn’t grant any visibility. In fact, you never need to use import, because you can use the fully qualified class name instead. For OSGi, the metadata for importing external code is important, because it’s how the framework knows what your bundle needs.
The value of the Import-Package header follows the common OSGi manifest header syntax. First, let’s start with the simplest form. Consider the main paint program bundle, which has a dependency on the org.foo.shape package.
It needs to declare an import for this package as follows (figure 2.12 shows how we’ll graphically represent imported module packages):
Figure 2.12. Graphical depiction of an imported package
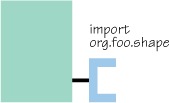
Import-Package: org.foo.shape
This specifically tells the OSGi framework that the bundle requires access to org.foo.shape in addition to the internal code visible to it from its bundle class path. Be aware that importing a package doesn’t import its subpackages; remember, there’s no relationship among nested packages. If your bundle needs access to org.foo.shape and org.foo.shape.other, it must import both packages as comma-separated targets, like this:
Import-Package: org.foo.shape,org.foo.shape.other
Your bundles can import any number of packages by listing them on Import-Package and separating them using commas. It’s not uncommon in larger projects for the Import-Package declaration to grow large (although you should strive to minimize this).
Sometimes, you’ll want to narrow your bundle’s package dependencies. Recall how Export-Package declarations can include attributes to differentiate a bundle’s exported packages. You can use these export attributes as matching attributes when importing packages. For example, we previously discussed the following export and associated attribute:
Export-Package: org.foo.shape; org.foo.other; vendor="Manning"
A bundle with this metadata exports the two packages with the associated vendor attribute and value. It’s possible to narrow your bundle’s imported packages using the same matching attribute:
Import-Package: org.foo.shape; vendor="Manning"
The bundle with this metadata is declaring a dependency on the package org.foo.shape with a vendor attribute matching the "Manning" value. The attributes attached to Export-Package declarations define the attribute’s value, whereas attributes attached to Import-Package declarations define the value to match; essentially, they act like a filter. The details of how imports and exports are matched and filtered is something we’ll defer until section 2.7. For now, it’s sufficient to understand that attributes attached to imported packages are matched against the attributes attached to exported packages.
For arbitrary attributes, OSGi only supports equality matching. In other words, it either matches the specified value or it doesn’t. You learned about one non-arbitrary attribute when we discussed Export-Package and the version attribute. Because this attribute is defined by the OSGi specification, more flexible matching is supported. This is an area where OSGi excels. In the simple case, it treats a value as an infinite range starting from the specified version number. For example:
Import-Package: org.osgi.framework; version="1.3.0"
This statement declares an import for package org.osgi.framework for the version range of 1.3.0 to infinity, inclusive. This simple form of specifying an imported package version range implies an expectation that future versions of org.osgi.framework will always be backward compatible with the lower version. In some cases, such as specification packages, it’s reasonable to expect backward compatibility. In situations where you wish to limit your assumptions about backward compatibility, OSGi allows you to specify an explicit version range using interval notation, where the characters [ and ] indicate inclusive values and the characters ( and ) indicate exclusive values. Consider the following example:
Import-Package: org.osgi.framework; version="[1.3.0,2.0.0)"
This statement declares an import for package org.osgi.framework for the version range including 1.3.0 and up to but excluding 2.0.0 and beyond. Table 2.2 illustrates the meaning of the various combinations of the version range syntax.
Table 2.2. Version range syntax and meaning
|
Syntax |
Meaning |
|---|---|
| "[min,max)" | min <_ x < max |
| "[min,max]" | min <_ x <_ max |
| "(min,max)" | min < x < max |
| "(min,max]" | min < x <_ max |
| "min" | min <_ x |
If you want to specify a precise version range, you must use a version range like "[1.0.1,1.0.1]". You may wonder why a single value like "1.0.1" is an infinite range rather than a precise version. The reason is partly historical. In the OSGi specifications prior to R4, all packages were assumed to be specification packages where backward compatibility was guaranteed. Because backward compatibility was assumed, it was only necessary to specify a minimum version. When the R4 specification added support for sharing implementation packages, it also needed to add support for arbitrary version ranges. It would have been possible at this time to redefine a single version to be a precise version, but that would have been unintuitive for existing OSGi programmers. Also, the specification would have had to define syntax to represent infinity. In the end, the OSGi Alliance decided it made the most sense to define versions ranges as presented here.
You may have noticed that some of the earlier Import-Package examples didn’t specify a version range. When no version range is specified, it defaults to the value "0.0.0", which you may expect from past examples. Of course, the difference here is that the value "0.0.0" is interpreted as a version range from 0.0.0 to infinity.
Now you understand how to use Import-Package to express dependencies on external packages and Export-Package to expose internal packages for sharing. The decision to use packages as the basis for interbundle sharing isn’t an obvious choice to everyone, so we discuss some arguments for doing so in the sidebar “Depending on packages, not bundles.”
We’ve now covered the major constituents of the OSGi module layer: Bundle-ClassPath, Export-Package, and Import-Package. We’ve discussed these in the context of the paint program you’ll see running in the next section, but the final piece of the puzzle we need to look at is how these various code-visibility mechanisms fit together in a running application.
Importing packages seems fairly normal for most Java programmers, because you import the classes and packages you use in the source files. But the import statements in the source files are for managing namespaces, not dependencies. OSGi’s choice of using package-level granularity for expressing dependencies among bundles is novel, if not controversial, for Java-based module-oriented technologies. Other approaches typically adopt module-level dependencies, meaning dependencies are expressed in terms of one module depending on another. The OSGi choice of package-level dependencies has created some debate about which approach is better.
The main criticisms leveled against package-level dependencies is that they’re too complicated or fine-grained. Some people believe it’s easier for developers to think in terms of requiring a whole JAR file rather than individual packages. This argument doesn’t hold water, because a Java developer using any given technology must know something about its package naming. For example, if you know enough to realize you want to use the Servlet class in the first place, you probably have some idea about which package it’s in, too.
Package-level dependencies are more fine-grained, which does result in more metadata. For example, if a bundle exports 10 packages, only 1 module-level dependency is needed to express a dependency on all of them, whereas package-level dependencies require 10. But bundles rarely depend on all exported packages of a given bundle, and this is more of a condemnation of tooling support. Remember how much of a nuisance it was to maintain import declarations before IDEs started doing it for you? This is starting to change for bundles, too; in appendix A, we describe tools for generating bundle metadata. Let’s look at some of the benefits of package-level dependencies.
The difference between module- and package-level dependencies is one of who versus what. Module-level dependencies express which specific module you depend on (who), whereas package-level dependencies express which specific packages you depend on (what). Module-level dependencies are brittle, because they can only be satisfied by a specific bundle even if another bundle offers the same packages. Some people argue that this isn’t an issue, because they want the specific bundle they’ve tested against, or because the packages are implementation packages and won’t be provided by another bundle. Although these arguments are reasonable, they usually break down over time.
For example, if your bundle grows too large over time, you may wish to refactor it by splitting its various exported packages into multiple bundles. If you use module-level dependencies, such a refactoring will break existing clients, which tends to be a real bummer when the clients are from third parties and you can’t easily change them. This issue goes away when you use package-level dependencies. Also, a bundle doesn’t usually depend on everything in another bundle, only a subset. As a result, module-level dependencies are too broad and cause transitive fanout. You end up needing to deploy a lot of extra bundles you don’t use, just to satisfy all the dependencies.
Package-level dependencies represent a higher-level view of the code’s real class dependencies. It’s possible to analyze a bundle’s code and generate its set of imported packages, similar to how IDEs maintain import declarations in source files. Module-level dependencies can’t be discovered in such a fashion, because they don’t exist in the code. Package-level dependencies sound great, right? You may now wonder if they have any issues.
The main issue is that OSGi must treat a package as an atomic unit. If this assumption weren’t made, then the OSGi framework wouldn’t be free to substitute a package from one bundle for the same package from another bundle. This means you can’t split a package across bundles; a single package must be contained in a single bundle. If packages were split across bundles, there would be no easy way for the OSGi framework to know when a package was complete. Typically, this isn’t a major limitation. Other than this, you can do anything with package-level dependencies that you can with module-level dependencies. And truth be told, the OSGi specification does support module-level dependencies and some forms of split packages, but we won’t discuss those until chapter 5.
2.5.4. Class-search order
We’ve talked a lot about code visibility, but in the end all the metadata we’ve discussed allows the OSGi framework to perform sophisticated searching on behalf of bundles for their contained and needed classes. Under the covers, when an importing bundle needs a class from an exported package, it asks the exporting bundle for it. The framework uses class loaders to do this, but the exact details of how it asks are unimportant. Still, it’s important to understand the ordering of this class-search process.
When a bundle needs a class at execution time, the framework searches for the class in the following order:
- If the class is from a package starting with java., the parent class loader is asked for the class. If the class is found, it’s used. If there is no such class, the search ends with an exception.
- If the class is from a package imported by the bundle, the framework asks the exporting bundle for the class. If the class is found, it’s used. If there is no such class, the search ends with an exception.
- The bundle class path is searched for the class. If it’s found, it’s used. If there is no such class, the search ends with an exception.
These steps are important because they also help the framework ensure consistency. Specifically, step 1 ensures that all bundles use the same core Java classes, and step 2 ensures that imported packages aren’t split across the exporting and importing bundles.
That’s it! We’ve finished the introduction to bundle metadata. We haven’t covered everything you can possibly do, but we’ve discussed the most important bundle metadata for getting started creating bundles; we’ll cover additional modularity issues in chapter 5. Next, you’ll put all the metadata in place for the paint program and then step back to review the current design. Before moving on, if you’re wondering if it’s possible to have a JAR file that is both a bundle and an ordinary JAR file, see the sidebar “Is a bundle a JAR file or a JAR file a bundle?”
Maybe you’re interested in adding OSGi metadata to your existing JAR files or you want to create bundles from scratch, but you’d still like to use them in non-OSGi situations too. We’ve said before that a bundle is just a JAR file with additional module-related metadata in its manifest file, but how accurate is this statement? Does it mean you can use any OSGi bundle as a standard JAR file? What about using a standard JAR file as a bundle? Let’s answer the second question first, because it’s easier.
A standard JAR file can be installed into an OSGi framework unchanged. Unfortunately, it doesn’t do anything useful. Why? The main reason is that a standard JAR file doesn’t expose any of its content; in OSGi terms, it doesn’t export any packages. The default Bundle-ClassPath for a JAR file is ., but the default for Export-Package is nothing. So even though a standard JAR file is a bundle, it isn’t a useful bundle. At a minimum, you need to add an Export-Package declaration to its manifest file to explicitly expose some (or all) of its internal content.
What about bundle JAR files? Can they be used as a standard JAR file outside of an OSGi environment? The answer is, it depends. It’s possible to create bundles that function equally well in or out of an OSGi environment, but not all bundles can be used as standard JAR files. It comes down to which features of OSGi your bundle uses. Of the metadata features you’ve learned about so far, only one can cause issues: Bundle-ClassPath. Recall that the internal bundle class path is a comma-separated list of locations inside the bundle JAR file and may contain
- A . representing the root of the bundle JAR file
- A relative path to an embedded JAR file
- A relative path to an embedded directory
Only bundles with a class path entry of . can be used as standard JAR files. Why? The OSGi notion of . on the bundle class path is equivalent to standard JAR file class searching, which is to search from the root of the JAR file as if all relative directories are package names. If a bundle specifies an embedded JAR file or directory, it requires special handling that’s available only in an OSGi environment. Luckily, it isn’t too difficult to avoid using embedded JAR files and directories.
It’s a good idea to try to keep your bundle JAR files compatible with standard JAR files if you can, but it’s still best to use them in an OSGi environment. Without OSGi, you lose dependency checking, consistency checking, and boundary enforcement, not to mention all the cool lifecycle and service stuff we’ll discuss in the coming chapters.
2.6. Finalizing the paint program design
So far, you’ve defined three bundles for the paint program: a shape API bundle, a shape implementation bundle, and a main paint program bundle. Let’s look at the complete metadata for each. The shape API bundle is described by the following manifest metadata:
Bundle-ManifestVersion: 2 Bundle-SymbolicName: org.foo.shape Bundle-Version: 2.0.0 Bundle-Name: Paint API Import-Package: javax.swing Export-Package: org.foo.shape; version="2.0.0"
The bundle containing the shape implementations is described by the following manifest metadata:
Bundle-ManifestVersion: 2 Bundle-SymbolicName: org.foo.shape.impl Bundle-Version: 2.0.0 Bundle-Name: Simple Shape Implementations Import-Package: javax.swing, org.foo.shape; version="2.0.0" Export-Package: org.foo.shape.impl; version="2.0.0"
And the main paint program bundle is described by the following manifest metadata:
Bundle-ManifestVersion: 2 Bundle-SymbolicName: org.foo.paint Bundle-Version: 2.0.0 Bundle-Name: Simple Paint Program Import-Package: javax.swing, org.foo.shape; org.foo.shape.impl; version="2.0.0"
As you can see in figure 2.13, these three bundles directly mirror the logical package structure of the paint program.
Figure 2.13. Structure of the paint program’s bundles
This approach is reasonable, but can it be improved? To some degree, you can answer this question only if you know more about the intended uses of the paint program; but let’s look more closely at it anyway.
2.6.1. Improving the paint program’s modularization
In the current design, one aspect that sticks out is the shape-implementation bundle. Is there a downside to keeping all shape implementations in a single package and a single bundle? Perhaps it’s better to reverse the question. Is there any advantage to separating the shape implementations into separate bundles? Imagine use cases where not all shapes are necessary; for example, small devices may not have enough resources to support all shape implementations. If you separate the shape implementations into separate packages and separate bundles, you have more flexibility when it comes to creating different configurations of the application.
This is a good issue to keep in mind when you’re modularizing applications. Optional components or components with the potential to have multiple alternative implementations are good candidates to be in separate bundles. Breaking your application into multiple bundles gives you more flexibility, because you’re limited to deploying configurations of your application based on the granularity of your defined bundles. Sounds good, right? You may then wonder why you don’t divide your applications into as many bundles as you can.
You pay a price for the flexibility afforded by dividing an application into multiple bundles. Lots of bundles mean you have lots of artifacts that are versioning independently, creating lots of dependencies and configurations to manage. So it’s probably not a good idea to create a bundle out of each of your project’s packages, for example. You need to analyze and understand your needs for flexibility when deciding how best to divide an application. There is no single rule for every situation.
Returning to the paint program, let’s assume the ultimate goal is to enable the possibility for creating different configurations of the application with different sets of shapes. To accomplish this, you move each shape implementation into its own package (org.foo.shape.circle, org.foo.shape.square, and org.foo.shape.triangle). You can now bundle each of these shapes separately. The following metadata captures the circle bundle:
Bundle-ManifestVersion: 2 Bundle-SymbolicName: org.foo.shape.circle Bundle-Version: 2.0.0 Bundle-Name: Circle Implementation Import-Package: javax.swing, org.foo.shape; version="2.0.0" Export-Package: org.foo.shape.circle; version="2.0.0"
The metadata for the square and triangle bundles is nearly identical, except with the correct shape name substituted where appropriate. The shape-implementation bundles have dependencies on Swing and the public API and export their implementation-specific shape package. These changes also require changes to the program’s metadata implementation bundle; you modify its metadata as follows:
Bundle-ManifestVersion: 2 Bundle-SymbolicName: org.foo.paint Bundle-Version: 2.0.0 Bundle-Name: Simple Paint Program Import-Package: javax.swing, org.foo.shape; org.foo.shape.circle; org.foo.shape.square; org.foo.shape.triangle; version="2.0.0"
The paint program implementation bundle depends on Swing, the public API bundle, and all three shape bundles. Figure 2.14 depicts the new structure of the paint program.
Figure 2.14. Logical structure of the paint program with separate modules for each shape implementation
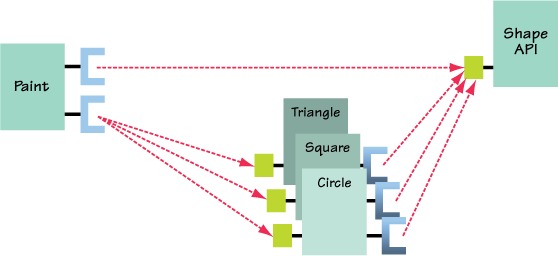
Now you have five bundles (shape API, circle, square, triangle, and paint). Great. But what do you do with these bundles? The initial version of the paint program had a static main() method on PaintFrame to launch it; do you still use it to launch the program? You could use it by putting all the bundle JAR files on the class path, because all the example bundles can function as standard JAR files, but this would defeat the purpose of modularizing the application. There’d be no enforcement of modular boundaries or consistency checking. To get these benefits, you must launch the paint program using the OSGi framework. Let’s look at what you need to do.
2.6.2. Launching the new paint program
The focus of this chapter is on using the module layer, but you can’t launch the application without a little help from the lifecycle layer. Instead of putting the cart before the horse and talking about the lifecycle layer now, we created a generic OSGi bundle launcher to launch the paint program for you. This launcher is simple: you execute it from the command line and specify a path to a directory containing bundles; it creates an OSGi framework and deploys all bundles in the specified directory. The cool part is that this generic launcher hides all the details and OSGi-specific API from you. We’ll discuss the launcher in detail in chapter 13.
Just deploying the paint bundles into an OSGi framework isn’t sufficient to start the paint program; you still need some way to kick-start it. You can reuse the paint program’s original static main() method to launch the new modular version. To get this to work with the bundle launcher, you need to add the following metadata from the original paint program to the paint program bundle manifest:
Main-Class: org.foo.paint.PaintFrame
As in the original paint program, this is standard JAR file metadata for specifying the class containing the application’s static main() method. Note that this feature isn’t defined by the OSGi specification but is a feature of the bundle launcher. To build and launch the newly modularized paint program, go into the chapter02/paint-modular/ directory in the companion code and type ant. Doing so compiles all the code and packages the modules. Typing java -jar launcher.jar bundles/ starts the paint program.
The program starts up as it apparently always has; but underneath, the OSGi framework is resolving the bundles’ dependencies, verifying their consistency, and enforcing their logical boundaries. That’s all there is to it. You’ve now used the OSGi module layer to create a nicely modular application. OSGi’s metadata-based approach didn’t require any code changes to the application, although you did move some classes around to different packages to improve logical and physical modularity.
The goal of the OSGi framework is to shield you from a lot of the complexities; but sometimes it’s beneficial to peek behind the curtain, such as to help you debug the OSGi-based applications when things go wrong. In the next section, we’ll look at some of the work the OSGi framework does for you, to give you a deeper understanding of how everything fits together. Afterward, we’ll close out the chapter by summarizing the benefits of modularizing the paint program.
2.7. OSGi dependency resolution
You’ve learned how to describe the internal code composing the bundles with Bundle-ClassPath, expose internal code for sharing with Export-Package, and declare dependencies on external code with Import-Package. Although we hinted at how the OSGi framework uses the exports from one bundle to satisfy the imports of another, we didn’t go into detail. The Export-Package and Import-Package metadata declarations included in bundle manifests form the backbone of the OSGi bundle dependency model, which is predicated on package sharing among bundles.
In this section, we’ll explain how OSGi resolves bundle package dependencies and ensures package consistency among bundles. After this section, you’ll have a clear understanding of how bundle modularity metadata is used by the OSGi framework. You may wonder why this is necessary, because bundle resolution seems like an OSGi framework implementation detail. Admittedly, this section covers some of the more complex details of the OSGi specification; but it’s helpful when defining bundle metadata if you understand a little of what’s going on behind the scenes. Further, this information can come in handy when you’re debugging OSGi-based applications. Let’s get started.
2.7.1. Resolving dependencies automatically
Adding OSGi metadata to your JAR files represents extra work for you as a developer, so why do it? The main reason is so you can use the OSGi framework to support and enforce the bundles’ inherent modularity. One of the most important tasks performed by the OSGi framework is automating dependency management, which is called bundle dependency resolution.
A bundle’s dependencies must be resolved by the framework before the bundle can be used, as shown in figure 2.15. The framework’s dependency resolution algorithm is sophisticated; we’ll get into its gory details, but let’s start with a simple definition.
Figure 2.15. Transitive dependencies occur when bundle A depends on packages from bundle B and bundle B in turn depends on packages from bundle C. To use bundle A, you need to resolve the dependencies of both bundle B and bundle C.

Resolving
The process of matching a given bundle’s imported packages to exported packages from other bundles and doing so in a consistent way so any given bundle only has access to a single version of any type.
Resolving a bundle may cause the framework to resolve other bundles transitively, if exporting bundles themselves haven’t yet been resolved. The resulting set of resolved bundles are conceptually wired together in such a fashion that any given imported package from a bundle is wired to a matching exported package from another bundle, where a wire implies having access to the exported package. The final result is a graph of all bundles wired together, where all imported package dependencies are satisfied. If any dependency can’t be satisfied, then the resolve fails, and the instigating bundle can’t be used until its dependencies are satisfied.
This description likely makes you want to ask three questions:
- When does the framework resolve a bundle’s dependencies?
- How does the framework gain access to bundles to resolve them in the first place?
- What does it mean to wire an importing bundle to an exporting bundle?
The first two questions are related, because they both involve the lifecycle layer, which we’ll discuss in the next chapter. For the first question, it’s sufficient to say that the framework resolves a bundle automatically when another bundle attempts to use it. To answer the second question, we’ll say that all bundles must be installed into the framework in order to be resolved (we’ll discuss bundle installation in more depth in chapter 3). For the discussion in this section, we’ll always be talking about installed bundles. As for the third question, we won’t answer it fully because the technical details of wiring bundles together isn’t important; but for the curious, we’ll explain it briefly before looking into the resolution process in more detail.
At execution time, each OSGi bundle has a class loader associated with it, which is how the bundle gains access to all the classes to which it should have access (the ones determined by the resolution process). When an importing bundle is wired to an exporting bundle, the importing class loader is given a reference to the exporting class loader so it can delegate requests for classes in the exported package to it. You don’t need to worry about how this happens—relax and let OSGi worry about it for you. Now, let’s look at the resolution process in more detail.
Simple Cases
At first blush, resolving dependencies is fairly straightforward; the framework just needs to match exports to imports. Let’s consider a snippet from the paint program example:
Bundle-Name: Simple Paint Program Import-Package: org.foo.shape
From this, you know that the paint program has a single dependency on the org.foo.shape package. If only this bundle were installed in the framework, it wouldn’t be usable, because its dependency wouldn’t be satisfiable. To use the paint program bundle, you must install the shape API bundle, which contains the following metadata:
Bundle-Name: Paint API Export-Package: org.foo.shape
When the framework tries to resolve the paint program bundle, it knows it must find a matching export for org.foo.shape. In this case, it finds a candidate in the shape API bundle. When the framework finds a matching candidate, it must determine whether the candidate is resolved. If the candidate is already resolved, the candidate can be chosen to satisfy the dependency. If the candidate isn’t yet resolved, the framework must resolve it first before it can select it; this is the transitive nature of resolving dependencies. If the shape API bundle has no dependencies, it can always be successfully resolved. But you know from the example that it does have some dependencies, namely javax.swing:
Bundle-Name: Paint API Import-Package: javax.swing Export-Package: org.foo.shape
What happens when the framework tries to resolve the paint program? By default, in OSGi it wouldn’t succeed, which means the paint program can’t be used. Why? Because even though the org.foo.shape package from the API bundle satisfies the main program’s import, there’s no bundle to satisfy the shape API’s import of javax.swing. In general, to resolve this situation, you can conceptually install another bundle exporting the required package:
Bundle-Name: Swing Export-Package: javax.swing
Now, when the framework tries to resolve the paint program, it succeeds. The main paint program bundle’s dependency is satisfied by the shape API bundle, and its dependency is satisfied by the Swing bundle, which has no dependencies. After resolving the main paint program bundle, all three bundles are marked as resolved, and the framework won’t try to resolve them again (until certain conditions require it, as we’ll describe in the next chapter). The framework ends up wiring the bundles together, as shown in figure 2.16.
Figure 2.16. Transitive bundle-resolution wiring
What does the wiring in figure 2.16 tell you? It says that when the main bundle needs a class in package org.foo.shape, it gets it from the shape API bundle. It also says when the shape API bundle needs a class in package javax.swing, it gets it from the Swing bundle. Even though this example is simple, it’s largely what the framework tries to do when it resolves bundle dependencies.
In actuality, the javax.swing case in the previous example is a little misleading if you’re running your OSGi framework with a JRE that includes javax.swing. In such a case, you may want bundles to use Swing from the JRE. The framework can provide access using system class path delegation. We’ll look at this area a little in chapter 13, but this highlights a deficiency with the heavyweight JRE approach. If it’s possible to install a bundle to satisfy the Swing dependencies, why are they packaged in the JVM by default? Adoption of OSGi patterns could massively trim the footprint of future JVM implementations.
You’ve learned that you can have attributes attached to exported and imported packages. At the time, we said it was sufficient to understand that attributes attached to imported packages are matched against attributes attached to exported packages. Now you can more fully understand what this means. Let’s modify the bundle metadata snippets to get a deeper understanding of how attributes factor into the resolution process. Assume you modify the Swing bundle to look like this:
Bundle-Name: Swing Export-Package: javax.swing; vendor="Sun"
Here, you modify the Swing bundle to export javax.swing with an attribute vendor with value "Sun". If the other bundles’ metadata aren’t modified and you perform the resolve process from scratch, what impact does this change have? This minor change has no impact at all. Everything resolves as it did before, and the vendor attribute never comes into play. Depending on your perspective, this may or may not seem confusing. As we previously described attributes, imported attributes are matched against exported attributes. In this case, no import declarations mention the vendor attribute, so it’s ignored. Let’s revert the change to the Swing bundle and instead change the API bundle to look like this:
Bundle-Name: Paint API Export-Package: org.foo.shape Import-Package: javax.swing; vendor="Sun"
Attempting to resolve the paint program bundle now fails because no bundle is exporting the package with a matching vendor attribute for the API bundle. Putting the vendor attribute back on the Swing bundle export allows the main paint program bundle to successfully resolve again with the same wiring, as shown earlier in figure 2.16. Attributes on exported packages have an impact only if imported packages specify them, in which case the values must match or the resolve fails.
Recall that we also talked about the version attribute. Other than the more expressive interval notation for specifying ranges, it works the same way as arbitrary attributes. For example, you can modify the shape API bundle as follows:
Bundle-Name: Paint API Export-Package: org.foo.shape; vendor="Manning"; version="2.0.0" Import-Package: javax.swing; vendor="Sun"
And you can modify the paint program bundle as follows:
Bundle-Name: Simple Paint Program Import-Package: org.foo.shape; vendor="Manning"; version="[2.0.0,3.0.0)"
In this case, the framework can still resolve everything because the shape API bundle’s export matches the paint program bundle’s import; the vendor attributes match, and 2.0.0 is in the range of 2.0.0 inclusive to 3.0.0 exclusive. This particular example has multiple matching attributes on the import declaration, which is treated like a logical AND by the framework. Therefore, if any of the matching attributes on an import declaration don’t match a given export, the export doesn’t match at all.
Overall, attributes don’t add much complexity to the resolution process, because they add additional constraints to the matching of imported and exported package names already taking place. Next, we’ll look into slightly more complicated bundle-resolution scenarios.
Multiple Matching Package Providers
In the previous section, dependency resolution is fairly straightforward because there’s only one candidate to resolve each dependency. The OSGi framework doesn’t restrict bundles from exporting the same package. Actually, one of the benefits of the OSGi framework is its support for side-by-side versions, meaning it’s possible to use different versions of the same package in the same running JVM. In highly collaborative environments of independently developed bundles, it’s difficult to limit which versions of packages are used. Likewise, in large systems, it’s possible for different teams to use different versions of libraries in their subsystems; the use of different XML parser versions is a prime example.
Let’s consider what happens when multiple candidates are available to resolve the same dependency. Consider a case in which a web application needs to import the javax.servlet package and both a servlet API bundle and a Tomcat bundle provide the package (see figure 2.17).
Figure 2.17. How does the framework choose between multiple exporters of a package?
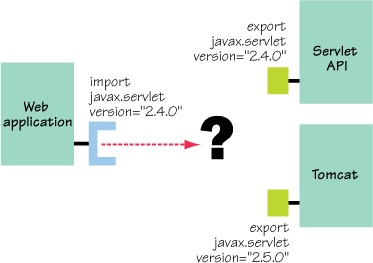
When the framework tries to resolve the dependencies of the web application, it sees that the web application requires javax.servlet with a minimum version of 2.4.0 and both the servlet API and Tomcat bundles meet this requirement. Because the web application can be wired to only one version of the package, how does the framework choose between the candidates? As you may intuitively expect, the framework favors the highest matching version, so in this case it selects Tomcat to resolve the web application’s dependency. Sounds simple enough. What happens if both bundles export the same version, say 2.4.0?
In this case, the framework chooses between candidates based on the order in which they’re installed in the framework. Bundles installed earlier are given priority over bundles installed later; as we mentioned, the next chapter will show you what it means to install a bundle in the framework. If you assume the servlet API was installed before Tomcat, the servlet API will be selected to resolve the web application’s dependency. The framework makes one more consideration when prioritizing matching candidates: maximizing collaboration.
So far, you’ve been working under the assumption that you start the resolve process on a cleanly installed set of bundles. But the OSGi framework allows bundles to be dynamically installed at any time during execution. In other words, the framework doesn’t always start from a clean slate. It’s possible for some bundles to be installed, resolved, and already in use when new bundles are installed. This creates another means to differentiate among exporters: already-resolved exporters and not-yet-resolved exporters. The framework gives priority to already-resolved exporters, so if it must choose between two matching candidates where one is resolved and one isn’t, it chooses the resolved candidate. Consider again the example with the servlet API exporting version 2.4.0 of the javax.servlet package and Tomcat exporting version 2.5.0. If the servlet API is already resolved, the framework will choose it to resolve the web application’s dependency, even though it isn’t exporting the highest version, as shown in figure 2.18. Why?
Figure 2.18. If a bundle is already resolved because it’s in use by another bundle, this bundle is preferred to bundles that are only installed.
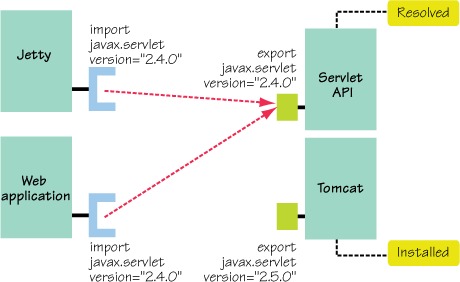
It has to do with maximizing the potential for collaboration. Bundles can only collaborate if they’re using the same version of a shared package. When resolving, the framework favors already-resolved packages as a means to minimize the number of different versions of the same package being used. Let’s summarize the priority of dependency resolution candidate selection:
- Highest priority is given to already-resolved candidates, where multiple matches of resolved candidates are sorted according to version and then installation order.
- Next priority is given to unresolved candidates, where multiple matches of unresolved candidates are sorted according to version and then installation order.
It looks like we have all the bases covered, right? Not quite. Next, we’ll look at how an additional level of constraint checking is necessary to ensure that bundle dependency resolution is consistent.
2.7.2. Ensuring consistency with uses constraints
From the perspective of any given bundle, a set of packages is visible to it, which we’ll call its class space. Given your current understanding, you can define a bundle’s class space as its imported packages combined with the packages accessible from its bundle class path, as shown in figure 2.19.
Figure 2.19. Bundle A’s class space is defined as the union of its bundle class path with its imported packages, which are provided by bundle B’s exports.
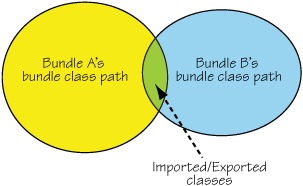
A bundle’s class space must be consistent, which means only a single instance of a given package must be visible to the bundle. Here, we define instances of a package as those with the same name, but from different providers. For example, consider the previous example, where both the servlet API and Tomcat bundles exported the javax.servlet package. The OSGi framework strives to ensure that the class spaces of all bundles remain consistent. Prioritizing how exported packages are selected for imported packages, as described in the last section, isn’t sufficient. Why not? Let’s consider the simple API in the following code snippet:
package org.osgi.service.http;
import javax.servlet.Servlet;
public interface HttpService {
void registerServlet(Sting alias, Servlet servlet, HttpContext ctx);
}
This is a snippet from an API you’ll meet in chapter 15. The details of what it does are unimportant at the moment; for now, you just need to know its method signature. Let’s assume the implementation of this API is packaged as a bundle containing the org.osgi.service.http package but not javax.servlet. This means it has some metadata in its manifest like this:
Export-Package: org.osgi.service.http; version="1.0.0" Import-Package: javax.servlet; version="2.3.0"
Let’s assume the framework has the HTTP service bundle and a servlet library bundle installed, as shown in figure 2.20. Given these two bundles, the framework makes the only choice available, which is to select the version of javax.servlet provided by the Servlet API bundle.
Figure 2.20. HTTP service-dependency resolution
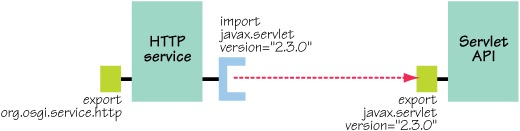
Now, assume you install two more bundles into the framework: the Tomcat bundle exporting version 2.4.0 of javax.servlet and a bundle containing a client for the HTTP service importing version 2.4.0 of javax.servlet. When the framework resolves these two new bundles, it does so as shown in figure 2.21.
Figure 2.21. Subsequent HTTP client-dependency resolution

The HTTP client bundle imports org.osgi.service.http and version 2.4.0 of javax.servlet, which the framework resolves to the HTTP service bundle and the Tomcat bundle, respectively. It seems that everything is fine: all bundles have their dependencies resolved, right? Not quite. There’s an issue with these choices for dependency resolution—can you see what it is?
Consider the servlet parameter in the HTTPService.registerServlet() method. Which version of javax.servlet is it? Because the HTTP service bundle is wired to the Servlet API bundle, its parameter type is version 2.3.0 of javax.servlet.Servlet. When the HTTP client bundle tries to invoke HTTPService.registerServlet(), which version of javax.servlet.Servlet is the instance it passes? Because it’s wired to the Tomcat bundle, it creates a 2.4.0 instance of javax.servlet.Servlet. The class spaces of the HTTP service and client bundles aren’t consistent; two different versions of javax.servlet are reachable from both. At execution time, this results in class cast exceptions when the HTTP service and client bundles interact. What went wrong?
The framework made the best choices at the time it resolved the bundle dependencies; but due to the incremental nature of the resolve process, it couldn’t make the best overall choice. If you install all four bundles together, the framework resolves the dependencies in a consistent way using its existing rules. Figure 2.22 shows the dependency resolution when all four bundles are resolved together.
Figure 2.22. Consistent dependency resolution of HTTP service and client bundles
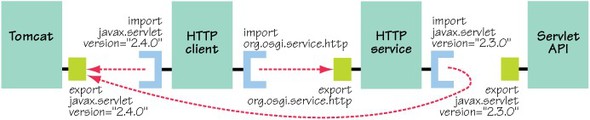
Because only one version of javax.servlet is in use, you know the class spaces of the HTTP service and client bundles are consistent, allowing them to interact without issue. But is this a general remedy to class-space inconsistencies? Unfortunately, it isn’t, as you’ll see in chapter 3, because OSGi allows you to dynamically install and uninstall bundles at any time. Moreover, inconsistent class spaces don’t only result from incremental resolving of dependencies. It’s also possible to resolve a static set of bundles into inconsistent class spaces due to inconsistent constraints. For example, imagine that the HTTP service bundle requires precisely version 2.3.0 of javax. servlet, whereas the client bundle requires precisely version 2.4.0. These constraints are clearly inconsistent, but the framework will happily resolve the example bundles given the current set of dependency resolution rules. Why doesn’t it detect this inconsistency?
Inter- VS. Intra-Bundle Dependencies
The difficulty is that Export-Package and Import-Package only capture inter-bundle dependencies, but class-space consistency conflicts result from intra-bundle dependencies. Recall the org.osgi.service.http.HttpService interface; its register-Servlet() method takes a parameter of type javax.servlet.Servlet, which means org.osgi.service.http uses javax.servlet. Figure 2.23 shows this intra-bundle uses relationship between the HTTP service bundle’s exported and imported packages.
Figure 2.23. Bundle export uses import
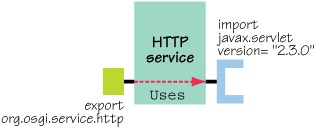
How do these uses relationships arise? The example shows the typical way, which is when the method signatures of classes in an exported package expose classes from other packages. This seems obvious, because the used types are visible, but it isn’t always the case. You can also expose a type via a base class that’s downcast by the consumer. Because these types of uses relationships are important, how do you capture them in the bundle metadata?
Uses Directive
A directive attached to exported packages whose value is a comma-delimited list of packages exposed by the associated exported package.
The sidebar “JAR file manifest syntax” in section 2.5 introduced the concept of a directive, but this is the first example of using one. Directives are additional metadata to alter how the framework interprets the metadata to which the directives are attached. The syntax for capturing directives is similar to arbitrary attributes. For example, the following modified metadata for the HTTP service example shows how to use the uses directive:
Export-Package: org.osgi.service.http; uses:="javax.servlet"; version="1.0.0" Import-Package: javax.servlet; version="2.3.0"
Notice that directives use the := assignment syntax, but the ordering of the directives and the attributes isn’t important. This particular example indicates that org.osgi. service.http uses javax.servlet. How exactly does the framework use this information? uses relationships among packages act like grouping constraints for the packages. In this example, the framework ensures that importers of org.osgi.service.http also use the same javax.servlet used by the HTTP service implementation.
This captures the previously missing intra-bundle package dependency. In this specific case, the exported package expresses a uses relationship with an imported package, but it could use other exported packages. These sorts of uses relationships constrain which choices the framework can make when resolving dependencies, which is why they’re also referred to as constraints. Abstractly, if package foo uses package bar, importers of foo are constrained to the same bar if they use bar at all. Figure 2.24 depicts how this would impact the original incremental dependency resolutions.
Figure 2.24. Uses constraints detect class-space inconsistencies, so the framework can determine that it isn’t possible to resolve the HTTP client bundle.
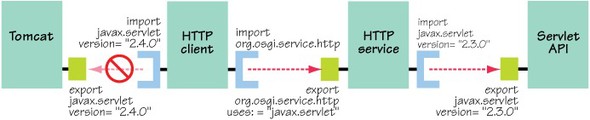
For the incremental case, the framework can now detect inconsistencies in the class spaces, and resolution fails when you try to use the client bundle. Early detection is better than errors at execution time, because it alerts you to inconsistencies in the deployed set of bundles. In the next chapter, you’ll learn how to cause the framework to re-resolve the bundle dependencies to remedy this situation.
You can further modify the example, to illustrate how uses constraints help find proper dependency resolutions. Assume the HTTP service bundle imports precisely version 2.3.0 of javax.servlet, but the client imports version 2.3.0 or greater. Typically, the framework tries to select the highest version of a package to resolve a dependency; but due to the uses constraint, the framework ends up selecting a lower version instead, as shown in figure 2.25.
Figure 2.25. Uses constraints guide dependency resolution.
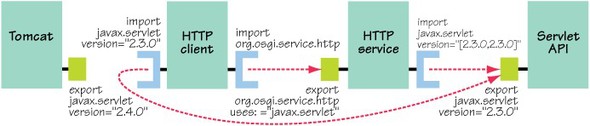
If you look at the class space of the HTTP client, you can see how the framework ends up with this solution. The HTTP client’s class space contains both javax.servlet and org.osgi.service.http, because it imports these packages. From the perspective of the HTTP client bundle, it can use either version 2.4.0 or 2.3.0 of javax.servlet, but the framework has only one choice for org.osgi.service.http. Because org.osgi. service.http from the HTTP service bundle uses javax.servlet, the framework must choose the same javax.servlet package for any clients. Because the HTTP service bundle can only use version 2.3.0 of javax.servlet, this eliminates the Tomcat bundle as a possibility for the client bundle. The end result is a consistent class space where a lower version of a needed package is correctly selected even though a higher version is available.
Odds and Ends of Uses Constraints
Let’s finish the discussion of uses constraints by touching on some final points. First, uses constraints are transitive, which means that if a given bundle exports package foo that uses imported package bar, and the selected exporter of bar uses package baz, then the associated class space for a bundle importing foo is constrained to have the same providers for both bar and baz, if they’re used at all.
Also, even though uses constraints are important to capture, you don’t want to create blanket uses constraints, because doing so overly constrains dependency resolution. The framework has more leeway when resolving dependency on packages not listed in uses constraints, which is necessary to support side-by-side versions. For example, in larger applications, it isn’t uncommon for independently developed subsystems to use different versions of the same XML parser. If you specify uses constraints too broadly, this isn’t possible. Accurate uses constraints are important, but luckily tools exist for generating them for exported packages.
OK! You made it through the most difficult part and survived. Don’t worry if you didn’t understand every detail, because some of it may make more sense after you have more experience creating and using bundles. Let’s turn our attention back to the paint program to review why you did all this in the first place.
2.8. Reviewing the benefits of the modular paint program
Even though the amount of work required to create the modular version of the paint program wasn’t great, it was still more effort than if you left the paint program as it was. Why did you create this modular version? Table 2.3 lists some of the benefits.
Table 2.3. Benefits of modularization in the paint program
|
Benefit |
Description |
|---|---|
| Logical boundary enforcement | You can keep the implementation details private, because you’re only exposing what you want to expose in the org.foo.shape public API package. |
| Reuse improvement | The code is more reusable because you explicitly declare what each bundle depends on via Import-Package statements. This means you know what you need when using the code in different projects. |
| Configuration verification | You no longer have to guess if you’ve deployed the application properly, because OSGi verifies whether all needed pieces are present when launching the application. |
| Version verification | Similar to configuration verification, OSGi also verifies whether you have the correct versions of all the application pieces when launching the application. |
| Configuration flexibility | You can more easily tailor the application to different scenarios by creating new configurations. Think of this as paint program a la carte. |
Some of these benefits are more obvious than others. Some you can demonstrate easily. For example, assume you forgot to deploy the shape API bundle in the launcher, which you can simulate by deleting bundles/shape-2.0.jar before launching the paint program. If you do this, you’ll see an exception like this:
org.osgi.framework.BundleException: Unresolved constraint in bundle 1:
package; (&(package=org.foo.shape)(version>=2.0.0)(!(version>=3.0.0)))
The exact syntax of this message will become familiar to you when you read chapter 4; but ignoring the syntax, it tells you the application is missing the org.foo.shape package, which is provided by the API bundle. Due to the on-demand nature of Java class loading, such errors are typically only discovered during application execution when the missing classes are used. With OSGi, you can immediately discover such issues with missing bundles or incorrect versions. In addition to detecting errors, let’s look at how OSGi modularity helps you create different configurations of the application.
Creating a different configuration of the paint program is as simple as creating a new static main() method for the launcher to invoke. Currently, you’re using the original static main() method provided by PaintFrame. In truth, it isn’t modular to have the static main() on the implementation class; it’s better to create a separate class so you don’t need to recompile the implementation classes when you want to change the application’s configuration. The following listing shows the existing static main() method from the PaintFrame class.
Listing 2.2. Existing PaintFrame.main() method implementation

The existing static main() is simple. You create a PaintFrame instance ![]() and add a listener
and add a listener ![]() to cause the VM to exit when the PaintFrame window is closed. You inject the various shape implementations into the paint frame
to cause the VM to exit when the PaintFrame window is closed. You inject the various shape implementations into the paint frame ![]() and make the application window visible. The important aspect from the point of view of modularity is at
and make the application window visible. The important aspect from the point of view of modularity is at ![]() . Because the configuration decision of which shapes to inject is hardcoded into the method, if you want to create a different
configuration, you must recompile the implementation bundle.
. Because the configuration decision of which shapes to inject is hardcoded into the method, if you want to create a different
configuration, you must recompile the implementation bundle.
For example, assume you want to run the paint program on a small device only capable of supporting a single shape. To do so, you could modify Paint-Frame.main() to only inject a single shape, but this wouldn’t be sufficient. You’d also need to modify the metadata for the bundle so it would no longer depend on the other shapes. Of course, after making these changes, you’d lose the first configuration. These types of issues are arguments why the static main() method should be in a separate bundle.
Let’s correct this situation in the current implementation. First, delete the Paint-Frame.main() method and modify its bundle metadata as follows:
Bundle-ManifestVersion: 2 Bundle-SymbolicName: org.foo.paint Bundle-Version: 2.0.0 Bundle-Name: Simple Paint Program Import-Package: javax.swing, org.foo.shape; version="2.0.0" Export-Package: org.foo.paint; version="2.0.0"
The main paint program bundle no longer has any dependencies on the various shape implementations, but it now needs to export the package containing the paint frame. You can take the existing static main() method body and put it inside a new class called org.foo.fullpaint.FullPaint, with the following bundle metadata:
Bundle-ManifestVersion: 2 Bundle-SymbolicName: org.foo.fullpaint Bundle-Version: 1.0.0 Bundle-Name: Full Paint Program Configuration Import-Package: javax.swing, org.foo.shape; org.foo.paint; org.foo.shape.circle; org.foo.shape.square; org.foo.shape.triangle; version="2.0.0" Main-Class: org.foo.fullpaint.FullPaint
To launch this full version of the paint program, use the bundle launcher to deploy all the associated bundles, including this FullPaint bundle. Likewise, you can create a different bundle containing the org.foo.smallpaint.SmallPaint class in this listing to launch a small configuration of the paint program containing only the circle shape.
Listing 2.3. New launcher for smaller paint program configuration

The metadata for the bundle containing the small paint program configuration is as follows:
Bundle-ManifestVersion: 2 Bundle-SymbolicName: org.foo.smallpaint Bundle-Version: 1.0.0 Bundle-Name: Reduced Paint Program Configuration Import-Package: javax.swing, org.foo.shape; org.foo.paint; org.foo.shape.circle; version="2.0.0" Main-Class: org.foo.smallpaint.SmallPaint
This small configuration only depends on Swing, the public API, the paint program implementation, and the circle implementation. When you launch the full configuration, all shape implementations are required; but for the small configuration, only the circle implementation is required. Now you can deploy the appropriate configuration of the application based on the target device and have OSGi verify the correctness of it all. Pretty sweet. For completeness, figure 2.26 shows the before and after views of the paint program.
Figure 2.26. Modular and nonmodular versions of the paint program
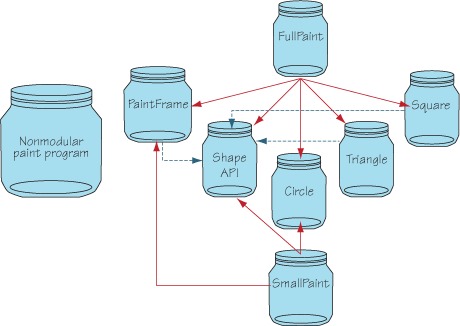
2.9. Summary
We’ve covered a lot of ground in this chapter. Some of the highlights include the following:
- Modularity is a form of separation of concerns that provides both logical and physical encapsulation of classes.
- Modularity is desirable because it allows you to break applications into logically independent pieces that can be independently changed and reasoned about.
- Bundle is the name for a module in OSGi. It’s a JAR file containing code, resources, and modularity metadata.
- Modularity metadata details human-readable information, bundle identification, and code visibility.
- Bundle code visibility is composed of an internal class path, exported packages, and imported packages, which differs significantly from the global type assumption of standard JAR files.
- The OSGi framework uses the metadata about imported and exported packages to automatically resolve bundle dependencies and ensure type consistency before a bundle can be used.
- Imported and exported packages capture inter-bundle package dependencies, but uses constraints are necessary to capture intra-bundle package dependencies to ensure complete type consistency.
From here, we’ll move on to the lifecycle layer, where we enter execution time aspects of OSGi modularity. This chapter was all about describing bundles to the OSGi framework; the lifecycle layer is all about using bundles and the facilities provided by the OSGi framework at execution time.