
9.4 Object-Relational Databases
Given the wide-spread use of relational database management systems on the one hand and the predominance of object-oriented programming languages on the other hand, most RDBMSs now include some object-oriented functionality. At the heart of this, the SQL standard also includes some object-oriented extensions; the basic unit of storage however is still a tuple inside a relation. RDBMSs supporting (part of) the object-oriented extensions of the SQL standard have been termed object-relational database management systems (ORDBMSs). Note however that (equivalent to the purely relational SQL standard) no ORDBMS implements this standard to its full extent. We now briefly discuss some of these SQL extensions. The presented SQL notation is just meant as an illustrative example: the specific object-relational syntax differs very much between different object-relational database systems.
SQL Objects and Object Identifiers (OIDs): In the purely relational model, a relation is a set of tuples (that is, rows). In the object-oriented extension, a relation can also be a set of SQL objects. A SQL object is a tuple with an additional object identifier; a SQL object is constructed by inserting values into a typed table (cf. the description of user-defined types below). A tuple ranges as usual over a set of attributes (that is, columns). Attribute domains can still be the usual SQL primitive (single-valued) types such as CHAR(18), INTEGER, DECIMAL, BOOLEAN; in addition, more complex types are allowed as detailed below.
Tuple Values: With tuples values, SQL can support composite attributes. Inside a tuple, an attribute can have another tuple as its value. A tuple groups together several attributes of (possibly) different domains. An example for a tuple value is an address tuple inside a person tuple: While each person has first name, last name and address as its attributes; the address itself consists of street, house number, city and ZIP code. In SQL, a subtuple can be constructed with the ROW constructor:
CREATE TABLE Person (
Firstname CHAR(20),
Lastname CHAR(20),
Street CHAR(20),
Number INTEGER,
ZIP CHAR(5),
City CHAR(20)
)
)
In queries, components of a tuple value can be accessed using path expressions with the dot operator multiple times. For example, the ZIP code in the address can be accessed via the address of a person:
exttt{SELECT P.Name FROM Person P WHERE P.Address.ZIP=31141}.
Insertion of new values can also be done using the ROW constructor:
INSERT INTO Person(Firstname,Lastname,Address)
VALUES (’Alice’,’Smith’,ROW(’Main Street’,1,31134,’Newtown’) )
Updating values can either be done using path expressions:
UPDATE Person SET Address.ZIP = 31134 WHERE Address.ZIP = 31141
or using the ROW constructor:
UPDATE Person SET Address=ROW(’Long Street’,5,31134,’Newtown’)
WHERE Address=ROW(’Main Street’,1,31134,’Newtown’)
AND Lastname=’Smith’
Collection Attributes: Collection attributes group values of the same type. In Section 9.2.1 we saw that one complication that the object-relational mappings involve are collection attributes (hence, multi-valued attributes in the conceptual model). Such collections are now supported by the object-oriented extensions of SQL; in particular, multisets (called “bag” in the ODMG standard; see Section 9.1.4), and arrays. As multisets are a generalization of sets, we can simulate the conventional sets by checking for and disallowing duplication in multisets. With collection types we can indeed avoid redundancy and normalization efforts for multi-valued attributes. For example, the Person table in Section 9.2.1 suffers from duplications of values due to multiple hobbies and multiple children. Turning the Hobby and Child attributes into collection attributes avoids this duplication. More precisely, we let Person be a relation schema with attributes ID, Name, Hobby, Child; and the attribute domains dom(ID): Integer, dom(Name): String, dom(Child): set of Integers, dom(Hobby): set of Strings. The resulting table (equivalent to the one from Section 9.2.1) is shown in Table 9.3.

There are two operations that can be executed on tables with (multi-)set-valued columns: nesting and unnesting. Nesting is the process of grouping values of a column from several rows into a single set in a single row. For example, converting the Person table in Section 9.2.1 into Table 9.3 is done by nesting the Hobby attribute and nesting the Child attribute. The reverse operation of unnesting write values from a set-valued attribute into separate rows.
Let us have a closer look at another collection: the array. As it is a collection, an array combines several values of the same type. However, an array has a fixed length (that is, a maximum amount of values that can be stored in the array), and its values can be accessed by an index number. The ARRAY constructor can be used to build an array of elements by writing a pair of square brackets [ and ] and separating the individual elements by commas. For example, an array of four String elements can be constructed as ARRAY[’Alice’,’Bob’,’Charlene’,’David’]. Moreover, the ARRAY constructor can build an array from a single column of a table. For example, an array containing all names currently stored in the Person table: ARRAY(SELECT Name FROM Person). When declaring an attribute in a table, we can set the length of the array by writing the length value into square brackets. Let us assume that each person can have up to three telephone numbers that are stored in an array:
CREATE TABLE Person(
Telephone VARCHAR(13) [3],
Name CHAR(20)
)
Insertion of values can be done using the ARRAY constructor:
INSERT INTO Person VALUES
(ARRAY[’935279’,’908077’,’278784’], Alice’)
The selection of one of the telephone numbers can than be done by specifying the index of the telephone number; for example:
SELECT Telephone[2] FROM Person WHERE Name=’Alice’
User-Defined Types (UDTs): Close to the object-oriented concept of a class, SQL offers user-defined types to structure data into reusable definitions. For example, we can create a type for persons as follows:
CREATE TYPE PersonType AS (
Firstname CHAR(20),
Lastname CHAR(20),
Address ROW(Street CHAR(20), Number INTEGER, ZIP CHAR(5), City CHAR(20))
)
SQL also supports inheritance for UDTs. For example, a new type StudentType inherits first and last name and address information from PersonType if derived from Person-Type with the key word UNDER:
CREATE TYPE StudentType UNDER PersonType AS (
University CHAR(20),
StudentID INTEGER
)
As another object-oriented concept, SQL support methods for UDTs. The method signature (for example, the return value type) is declared independently from the actual implementation. For example, we may declare the signature of a method called study:
METHOD study() RETURNS BOOLEAN
Later on we define the method explicitly to apply to the StudentType with a link to an external implementation (for example in the language C):
CREATE METHOD study() FOR StudentType
LANGUAGE C
EXTERNAL NAME ‘file:/home/admin/study’
Method definitions can also directly contain the method implementation written in SQL. UDTs have two main application contexts in a SQL database:
1.A UDT can be used as a type for an attribute inside a table.
2.A UDT can be used as a type for a table.
As an example for the first application context, we create a new type for names and use this NameType for the name attribute in the person table:
Firstname CHAR(20),
Lastname CHAR(20)
)
CREATE TABLE Person (
Name NameType,
Age INTEGER
)
We can then use path expressions to query for typed attributes. For example, querying the Person table for all firstnames of people with lastname Smith by descending into the NameType object:
SELECT (P.Name).Firstname FROM Person P
WHERE (P.Name).Lastname=’Smith’
As an example for the second application context, with the key word OF we can create a table of type StudentType. That is, the table has the attributes defined by the type (without the need to declare them again):
CREATE TABLE Student OF StudentType
Tables of a UDT are called typed tables; only rows (tuples) inside a typed table are SQL objects and hence have an OID. Only tuples of typed tables can hence be referenced by a reference attribute (see description of reference types below). Tuples in the following untyped table Student1 are not SQL objects and hence do not have an OID:
CREATE TABLE Student1 (
Firstname CHAR(20),
Lastname CHAR(20),
Address ROW(Street CHAR(20),
Number INTEGER, ZIP CHAR(5), City CHAR(20)) University CHAR(20),
StudentID INTEGER
)
In a similar vein, values for typed attributes (for example, the Name attribute of the Person table) are not SQL objects.
References: Another feature of SQL objects is that they can be referenced by their OID from other tables. Here it is important to note that every typed table has a so-called self-referencing column that stores the OIDs of the tuples. When creating a table, we can give the self-referencing column an explicit name (with the expression REF IS) and also declare the OID values to be system-generated when creating a tuple. For example, in the typed student table, we can call the self-referencing column studoid.
CREATE TABLE Student OF StudentType
REF IS studoid SYSTEM GENERATED
Otherwise the self-referencing column exists but is unnamed. When declaring a reference attribute in another table, we can reference a typed table by declaring the referenced type and – as the scope – the table from which referenced tuples can be chosen.
CREATE TABLE StudentRecord (
Course CHAR(20),
Mark DECIMAL(1,1),
Testee REF(StudentType) SCOPE Student )
The reference attribute hence stores the OID of a SQL object in a typed table; it is used as a direct reference to a specific tuple in the typed table. To access attributes inside the referenced tuple, a special dereference operator -> has to be used. For example, to access the student ID of some student taking a database course referenced in a student record:
SELECT R.Testee->StudentID FROM StudentRecord R WHERE R.Course=’Databases’
There are also other ways of dereferencing reference attributes specific to each object-relational DBMS.
In summary, object-relational database systems support major object-oriented features on top of conventional relational technology. The data model on disk is still the relational table format and hence different from the object models used in object-oriented programming languages. However, not all ORDMBSs support all the object-oriented SQL extension and they each use a different syntax. Hence, code portability is is only limited when using object-oriented extensions of SQL.
9.5 Object Databases
Pure object database managements systems (ODBMSs) use the same data model (that is, a particular “object model”) as object-oriented programming languages (OOPL). There is no need to map the objects into a different format – be it relational or something different; there might however be the need to map objects written in a particular OOPL into the object model used by the ODBMS. Nevertheless, there is no object-relational impedance mismatch (see Section 9.1): due to a uniform data and storage model an object database combines features of OOPLs and DBMSs.
| An object database has to meet both object-oriented requirements (like complex objects, object identity, encapsulation, classes and UDTs, inheritance and polymorphism) and database requirements (like persistence, disk-storage organization, concurrent transactions, recovery mechanisms, query languages and database operations). |
In this section we survey some strategies relevant for object storage.
9.5.1 Object Persistence
Different options to persistently storing objects could be used; some of them depend on the object-oriented programming language (OOPL) used or even the system an object-oriented application is run on. For one, a snapshot (or checkpoint) of the part of the main memory that is occupied by the application can be stored to disk. The main memory organization is however highly system-dependent and a checkpointed application could then only be restarted by the system that created the snapshot. Hence, checkpointing an application does not offer data independence: how the stored object is accessed highly depends on the physical internal storage format; moreover, from a logical point of view, a stored application can only be accessed in its entirety and not be filtered to access only the relevant subset of objects inside the application. Neither schema evolution nor versioning can be easily achieved with checkpointing, and we cannot differentiate between transient attributes (which should not be stored) and persistent attributes (which should be stored).
Serialization is the process of converting objects into a reusable and transportable format. When serializing complex objects, the closure of the complex object is serialized: a serialized deep copy of the object is created with all references followed and serialized; for large objects with lots of deep references, (de-)serialization is a time-consuming process. Object identity however is usually lost when objects are serialized. This means when two objects are serialized that reference the same object, the referenced object will appear in the two different deep copies; upon deserialization, the referenced object will be instantiated twice with different identities. Ensuring object identity with serialization can only be achieved by influencing the serialization and deserialization process and hence requires extra effort by the application programmer. Class information is usually not part of the serialization – only the object state is serialized; for deserialization the class definition must be made available to the deserialization process. Moreover, serialization exposes private attributes of an object because they are fully accessible in the serialized object. Serialization has no support for schema evolution as the process of deserialization will fail when class definition used for deserialization differs from the one used for serialization. As serialization usually is OOPL-specific, using a serialized object with a different OOPL requires transforming the serialized object into the required format by hand.
In contrast to the above, pure object databases store objects together with their class definition (and hence together with their methods). Object identity and relationships between objects are preserved and, when objects are retrieved from the database, the correct object graph is reconstructed.
There are roughly three different options to indicate that a particular object should be persisted in the object database – some ODBMSs allow a combination of these strategies:
Persistence by reachability: Some objects are denoted as root objects. All objects that are referenced by a root object (directly and indirectly) will be automatically stored whenever the root object is stored. Restricting the level of references followed up to a certain depth in the object graph is possible in some ODMBSs for an improved storage performance.
Persistence by type: All objects of a user-defined class will automatically be persisted. The class can be denoted as a persistent class by either inheriting from a system-defined class (for example, a marker interface) or by using annotations (as in JPA; see Section 9.3).
Persistence by instantiation: When an object is created it can be marked as persistent.
ODBMSs handle objects very efficiently: for example, a query can navigate in the object graph (that is, follow references between objects) until the relevant information is reached and without actually loading unnecessary objects along the navigation path; moreover, updated objects can be stored back to disk without actually persisting unmodified objects in the object graphs – some ODBMSs allow the application programmer to mark updated objects as “dirty” to notify the ODMS that this particular object must be written to disk.
9.5.2 Single-Level Storage
While the object-relational mapping follows a two-level storage approach described in Section 9.2.4 (the OOPL object model in main memory, and relational table model on disk), an ODBMS follows a single-level storage approach, with a similar representation of objects in main memory as well as on disk. In contrast to the conventional file manager and buffer manager presented in Section 1.2, an ODBMS has a component called object manager that loads or stores objects: given some OID, the object manager returns the address (a pointer) to the object in main memory (possibly after loading it into main memory from the disk); or the object manager persists an object from the main memory to disk.
Objects and references between objects can be seen as a directed graph: Objects are vertices (nodes) and references are directed edges (from the referencing to the referenced object). This graph of the objects in an application and references between them is often called the virtual heap of the application. During execution of the application the heap is traversed along the references by going from one object to the next via method calls. Not the entire heap of an application is loaded into main memory: hence, inside the virtual heap we make a distinction between resident objects (the one loaded into main memory) and non-resident objects (the ones not in the main memory but only stored on disk). When traversing the virtual heap at runtime, the application may use a reference attribute inside a resident object to access the contents or execute a method of a non-resident object. This leads to an object fault (a notification that the referenced object is not yet in the main memory) which causes the object manager to make the referenced object resident; that is, the object manager loads the required object into main memory from disk, and returns a pointer to the referencing object to the newly resident object. More precisely, inside the main memory we can usually again distinguish between the ODMBS page buffer (which is directly managed by the object manager) and an application’s local object cache; hence, the ODMBS will first load the object into the DBMS page buffer and then copy the object to the local object cache of the application for further processing. Because in the single-level storage the ODBMS can handle objects directly, the steps to load an object differ from the steps required in the two-level storage (see Section 9.2.4):
1.The application needs to access some object stored in an ODBMS; the application hence produces some query to access the object in the database (for example, by telling the DBMS the OID of the object, or specifying search conditions for finding relevant objects);
2.the DBMS locates a page containing the demanded object on disk (possibly using indexes that help find matching objects);
3.the DBMS copies this page into its page buffer;
4.the DBMS locates the object’s representation inside the page;
5.the DBMS copies the object representation into the application’s local object cache (potentially conversions the DBMS object representation into the OOPL-specific representation are necessary);
6.the application can access and update the object’s attribute values in its local object cache;
7.When the application wants to store an updated object, the DBMS transfers the modified object representation into the DBMS page buffer (possibly converting it from the OOPL-specific representation into the DBMS object representation);
8.the DBMS eventually writes pages containing modified objects back from the DBMS page buffer onto disk.
9.5.3 Reference Management
As mentioned above, the objects inside a virtual heap are connected by references. We discuss three basic options for reference management: direct referencing, indirect referencing and OID-based referencing.
As a first option, pointer-based direct referencing uses direct addressing with physical memory addresses. The main memory address (that is, a pointer the referenced object in main memory) is stored in the reference attribute. This pointer corresponds to the actual physical address which a resident object currently occupies in main memory. When a non-resident object is loaded into main memory, it must be loaded exactly into the physical address which is contained in the reference attribute referencing this loaded object; this hence requires hence a sophisticated main memory management to avoid that the same pointer is used to reference different objects.
As a second option for implementing references, with indirect referencing reference attributes contain virtual memory addresses (see Section 1.2). Using virtual addresses introduces a level of indirection because it requires a mapping from virtual to the actual physical address; it requires appropriate management of pointers in an indirection table. The virtual (and also the physical) address space is usually a lot smaller than the persistent OID space; this could lead to difficulties with long-term storage of objects (because after some time, different objects may be located at the same address).
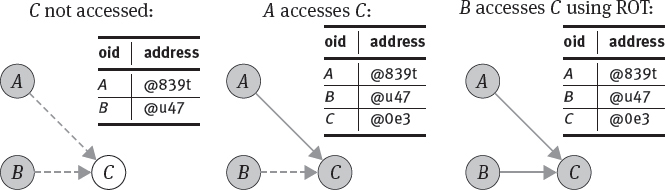
Another option is use OID-based referencing: The OID of the referenced object is stored in the reference attribute. Applications have to make sure that the OIDs are permanent and persistent (see the discussion on OID permanence in Section 9.1.1). When following an OID-based reference, the DBMS has to map the OID to a main memory address. This task requires to look up the OID in the Resident Object Table: When an object is loaded into main memory, it may reside on an arbitrary physical address in the ODMBS page buffer (or application’s local object cache). A lookup mechanism must map the OID of a resident object to its current physical memory address. This mapping can be stored in a lookup-table called Resident Object Table (ROT) maintained by the ODBMS. Whenever an OID-based reference is followed, the object manager first looks for the OID in the ROT. If the OID is present in the ROT, the object is already resident and the object manager can return the memory address as recorded in the ROT; when the OID cannot be found in the ROT, the object has to be loaded from disk and its OID has to be stored in the ROT together with the current memory address of the object.
9.5.4 Pointer Swizzling
When the same OID-based reference is followed very often, the table lookup in the ROT might be inefficient. To achieve a better performance the process of pointer swizzling can be applied: an OID inside a resident objects is temporarily replaced by the current memory pointer of the referenced object; when such an object is stored back to disk, the swizzled pointers have to be replaced by the original OIDs (“unswizzled”). Hence, for swizzled OIDs, the lookup in the ROT can be avoided but instead the referenced object can be accessed directly. Two forms of pointer swizzling have been analyzed:
Edge Marking: Each reference attribute (representing an edge in the object graph) is accompanied with a tag bit. If the tag bit is set to 1, the object is already resident (that is, loaded into main memory) and the value of the reference attribute is the appropriate main memory pointer. If otherwise the tag bit is set to 0, the object is non-resident (has not been loaded into main memory) and the value of the reference attribute is an OID; in this case an object fault is generated, the object is loaded, the referencing OID is changed to the appropriate memory pointer, and finally the tag bit is set to 1. In other words, only references that are followed (“dereferenced”) are swizzled. It might hence happen that a resident object references the same object that already has been loaded by dereferencing an attribute in another attribute. In this case, the former object is unaware that the referenced object has been dereferenced by another object. To illustrate this (see Figure 9.9), assume that two resident objects A and B both reference a non-resident object C; at first, both A and B have the tag bit on their C-reference set to 0. When object A accesses object C, object C becomes resident, the pointer from A to C is swizzled (set to C’s current main memory address), and the tag bit on this pointer is set to 1. The tag bit of reference from B to C is still 0: object B still assumes that object C is non-resident as long as the reference inside object B has not been dereferenced. Hence, object B will only notice that C is resident by looking up C in the ROT, after which B swizzles the C-pointer and sets the tag bit to 1. When an object is stored back to disk, first of all the pointers inside the object have to be unswizzled (converted back to OIDs). Secondly, references to this object have to be unswizzled, too, as otherwise these references would be dangling pointers. Inverse references have to be maintained to unswizzle these references, or a counter for these references has to be maintained and removing the object out of main memory can only be done when this counter is 0.


Fig. 9.10. Node Marking (grey: resident, white: non-resident)
Node Marking: For node marking, artificial fault blocks are created in the main memory that serve as placeholders for non-resident objects (see Figure 9.10). When an object is loaded, all references are immediately replaced by memory pointers: References to resident objects are replaced by a direct memory pointer to the resident object (using the ROT); references to non-resident objects are replaced by memory pointer to a fault block. The fault block hence stands initially for a non-resident object. If another resident object references the same non-resident object, this reference is swizzled into a memory pointer to the same fault block; that is, a fault block may be referenced by many resident objects. When the non-resident object is loaded into main memory, the fault block caches its memory pointer: later traversals towards the object retrieve its memory pointer from the fault block and the ROT need not be used. Unnecessary fault blocks may be removed by a garbage collector, so that pointers to the fault block are replaced by direct links to the now resident object. When an object is stored back to disk, however, these direct pointers must then again be replaced by pointers to a fault block to avoid dangling references. While node marking reduces the need to access the ROT, it has the disadvantage of increased storage capacity and time for creation of fault blocks. The indirection introduced by fault block also takes extra time every time a resident object is accessed by retrieving the object’s address from the fault block.
9.6 Implementations and Systems
We briefly survey some implementations for object persistence: DataNucleus as one reference implementation for JDO and JPA; as well as ZooDB as an academic project developing an open source object database. In addition, OrientDB is described as a multi-model database including an object-oriented storage engine in Section 15.4.3.
9.6.1 DataNucleus
An implementation of JDO as well as JPA is DataNucleus which supports a variety of query languages as well as a variety of databases – not only RDBMSs but also graph databases or JSON documents.
| Web resources: –DataNucleus: http://www.datanucleus.org/ –documentation page: http://www.datanucleus.org/documentation/ –GitHub repository: https://github.com/datanucleus |
Plugins of DataNucleus for widely used data stores are the following:
HBase plugin: In general, each field of an object is mapped to a column in an HBase table. A name for the column family and a name for the qualifier (column name) can be set by an appropriate annotation:
@Column(name=“{familyName}:{qualifierName}”)
@Extension annotations can be used to modify some settings specific to HBase like BloomFilter configuration, maximum number of stored versions, and compression. For example, the bloom filter can be configured to consider the row key as follows:
@Extension
(key = “hbase.columnFamily.meta.bloomFilter”, value = “ROWKEY”)
MongoDB plugin: An object is mapped to a document, and a field of the object is mapped to a field in the document. References between objects are implemented by storing the IDs of referenced objects in the referencing (owning) object; such references can also be bidirectional. In some cases instead of ID-based referencing, embedding of a referenced object (annotated with @Embedded) can be a viable alternative; embedding can either be nested or flat. In a nested embedding, the referenced object is stored as a JSON object (sub-document) in a field of the owning object – and it can itself be nested. A flat embedding maps each field of the referenced object to a field in the owning object.
Neo4J plugin: Each object will be mapped to a node in the Neo4J graph; references between objects are mapped to edges in the Neo4J graph between the appropriate nodes.
Several other datastores and output formats (including REST commands) are supported and new plugins can be added by extending the AbstractStoreManager class.
9.6.2 ZooDB
ZooDB is a Java-based object database coming from an academic background which is currently under development.
| Web resources: | –– ZooDB: http://www.zoodb.org/ |
–– GitHub repository: https://github.com/tzaeschke/zoodb |
It supports parts of JDO and relies on a persistence manager and the ZooJdoHelper class to interact with the database. A persistence manager can be obtained for each database:
PersistenceManager pm = ZooJdoHelper.openOrCreateDB(“dbfile”);
Each object to be stored in ZooDB has to extend the ZooPC class. The ZooPC class manages the persistence states of objects during their lifetime (as described in Section 9.3.2); the ZooPC class executions the transitions between the different states – for example, from detached clean to detached dirty. Before writing or reading fields of an object they have to be activated for the write or read operation to enable this state management; it is hence decisive to call the appropriate activate method of the ZooPC class before the actual write or read operation (for example, in the getter and setter methods). Each object needs an empty constructor (to be able to use the Java reflection mechanism) but can also have other constructors with parameters. A simple Person class hence looks like this:
public class Person extends ZooPC {
private String firstname;
private String lastname;
private int age;
private Person() { } // empty constructor necessary
public Person(String firstname, String lastname, int age) { this.firstname = firstname;
this.lastname = lastname;
this.age = age;
}
public void setFirstname(String name) { zooActivateWrite();
this.firstname = name;
}
public String getFirstname() { zooActivateRead(); return this.firstname;
public void setLastname(String name) { zooActivateWrite();
this.lastname = name;
}
public String getLastname() { zooActivateRead(); return this.lastname;
public void setAge(int age) { zooActivateWrite();
this.age = age;
}
public String getAge() { zooActivateRead(); return this.age;
}
In the main class, new Person objects can then be created and stored to the database file:
Person alice = new Person(“Alice”,“Smith”,34); pm.makePersistent(alice);
From the database, the entire extent can be retrieved:
Extent<Person> extent = pm.getExtent(Person.class);
for (Person p: extent) {
System.out.println(p.getFirstname()+” “+p.getLastname());
}
extent.closeAll();
A query object can be created and executed as follows:
Query query = pm.newQuery(Person.class, “age == 34”);
Collection<Person> persons = (Collection<Person>) query.execute();
for (Person p: persons) {
System.out.println(p.getFirstname()+” “+p.getLastname());
}
query.closeAll();
9.7 Bibliographic Notes
The database books by Ricardo [Ric11] and Connolly and Begg [CB09] both contain chapters on the object-oriented and the object-relational paradigm and provide examples. The textbook by Dietrich and Urban [DU11] contains an in-depth coverage of object-oriented and object-relational databases and also contains case studies with db4o. Object-relational mapping technology was analyzed in the articles [O’N08, LG07]. [MK13] discuss the generic data access object and introduce the DAO dispatcher pattern. A Java implementation of the Data Access Object can be found at the Perfect JPattern repository.
As for storage management, the basic ideas of node marking and edge marking were established by Hosking, Moss and Bliss [HMB90]. Moss [Mos92] also analyzed whether swizzling results in performance improvements. Normalization for objects has been recently studied in [MT13]; previous approaches (like [TSS97, ME98]) focused on the definition of object dependencies.
Development of ODBMSs started together with the emergence of the object-oriented programming paradigms. [KZK11] compared several object databases regarding some of their decisive features like supported query languages. There are some mature commercial systems on the market; the open source field is however a bit reduced in particular since db4o has been discontinued.